Download as PDF, PPTX



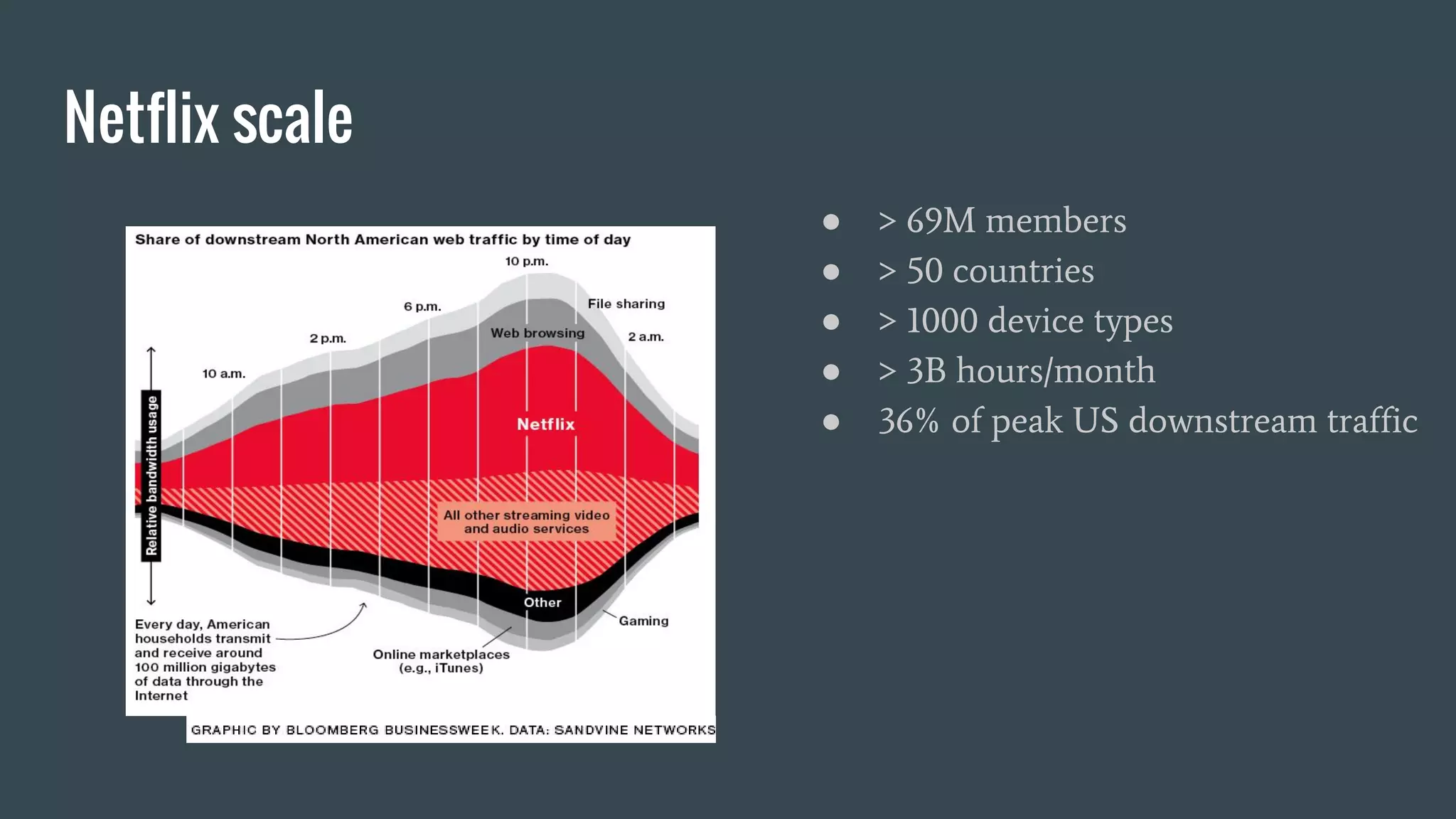









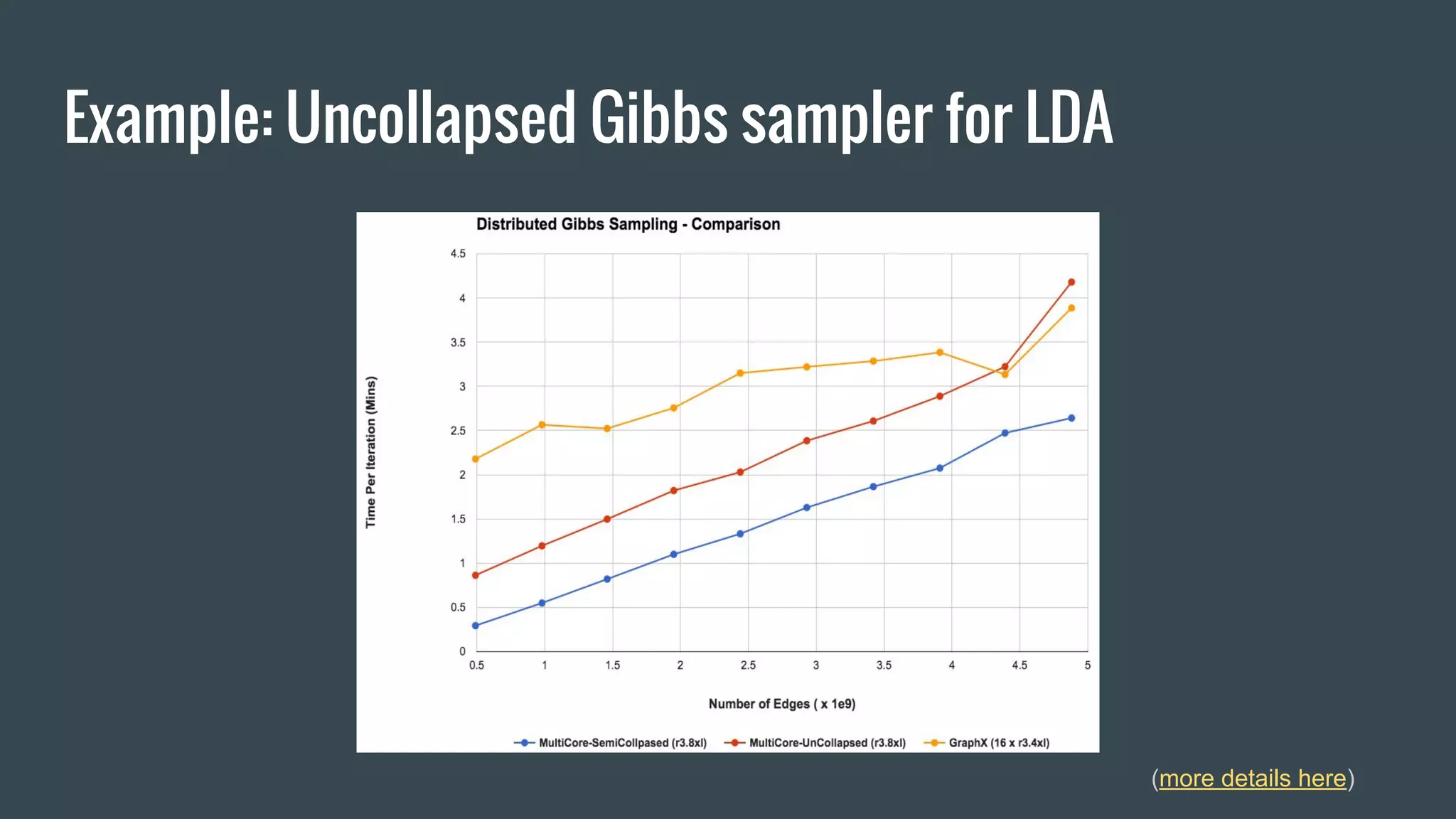

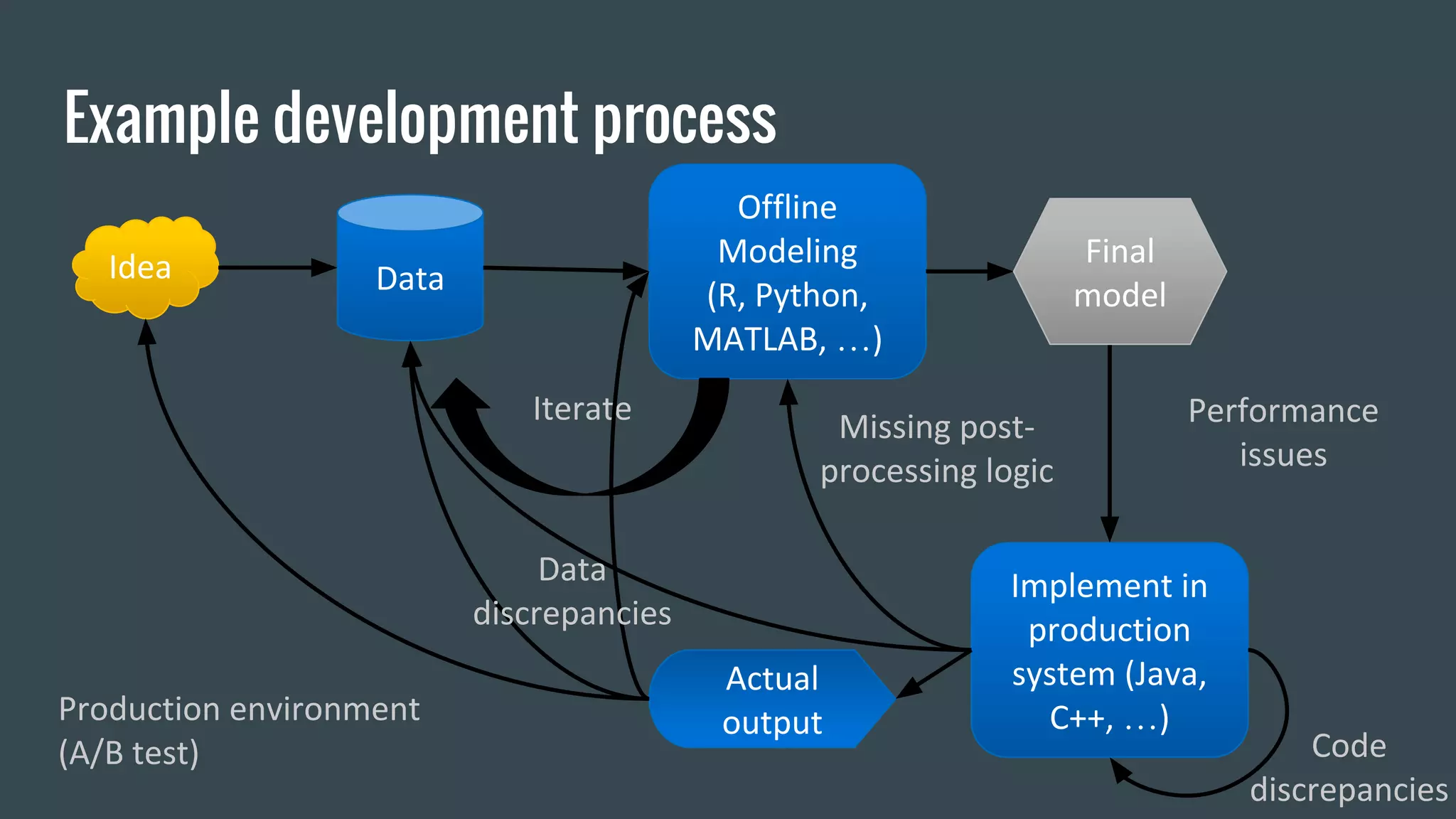
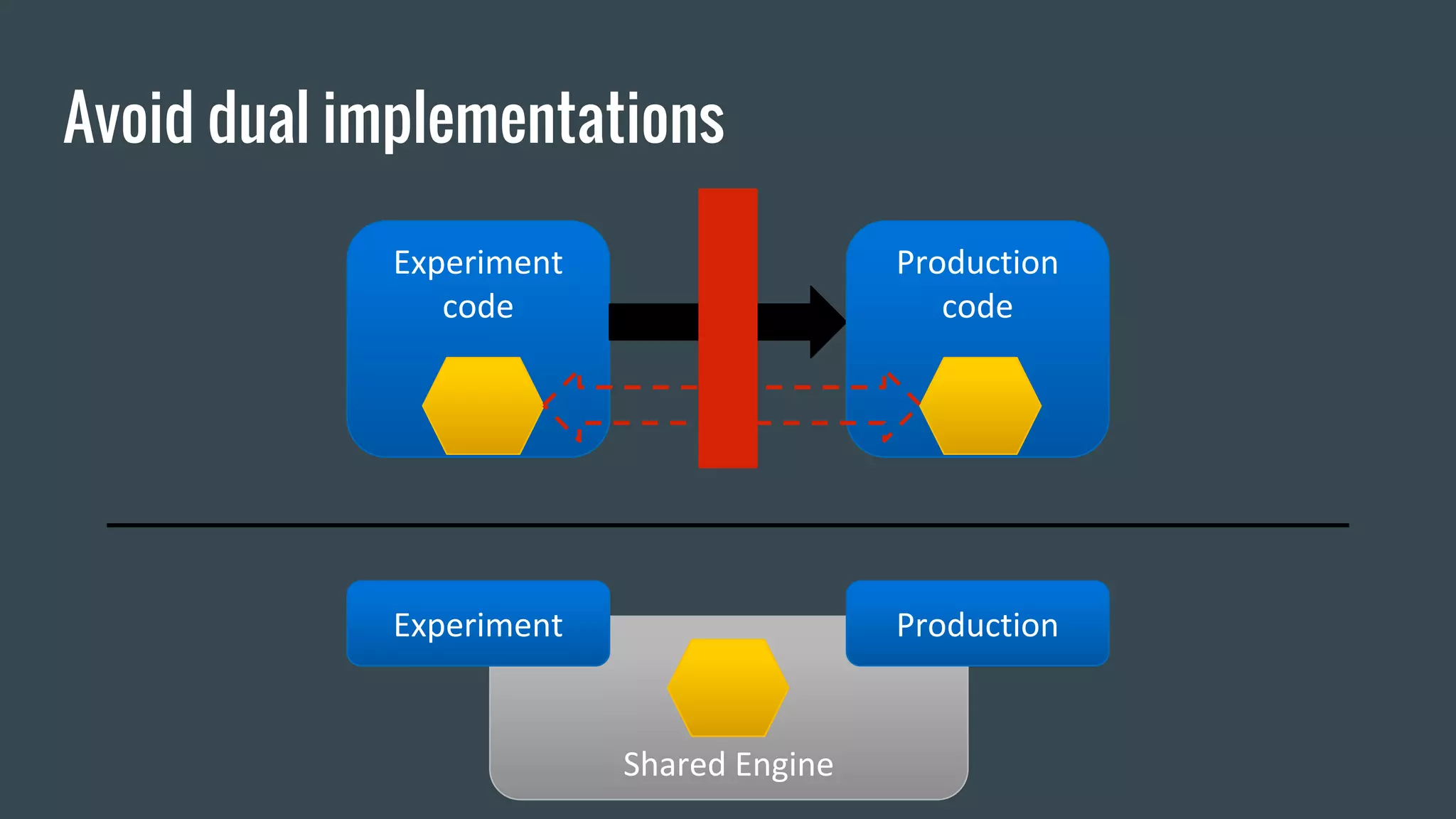






















Netflix uses machine learning and algorithms to power recommendations for over 69 million members across more than 50 countries. They experiment with a wide range of algorithms including regression, matrix factorization, deep neural networks, and more. Some lessons learned are to first build an offline experimentation framework with clear metrics, consider distribution from the start, and design production code to also support experimentation. The goal is to efficiently iterate experiments and smoothly implement successful models in production.


































































































