Downloaded 245 times



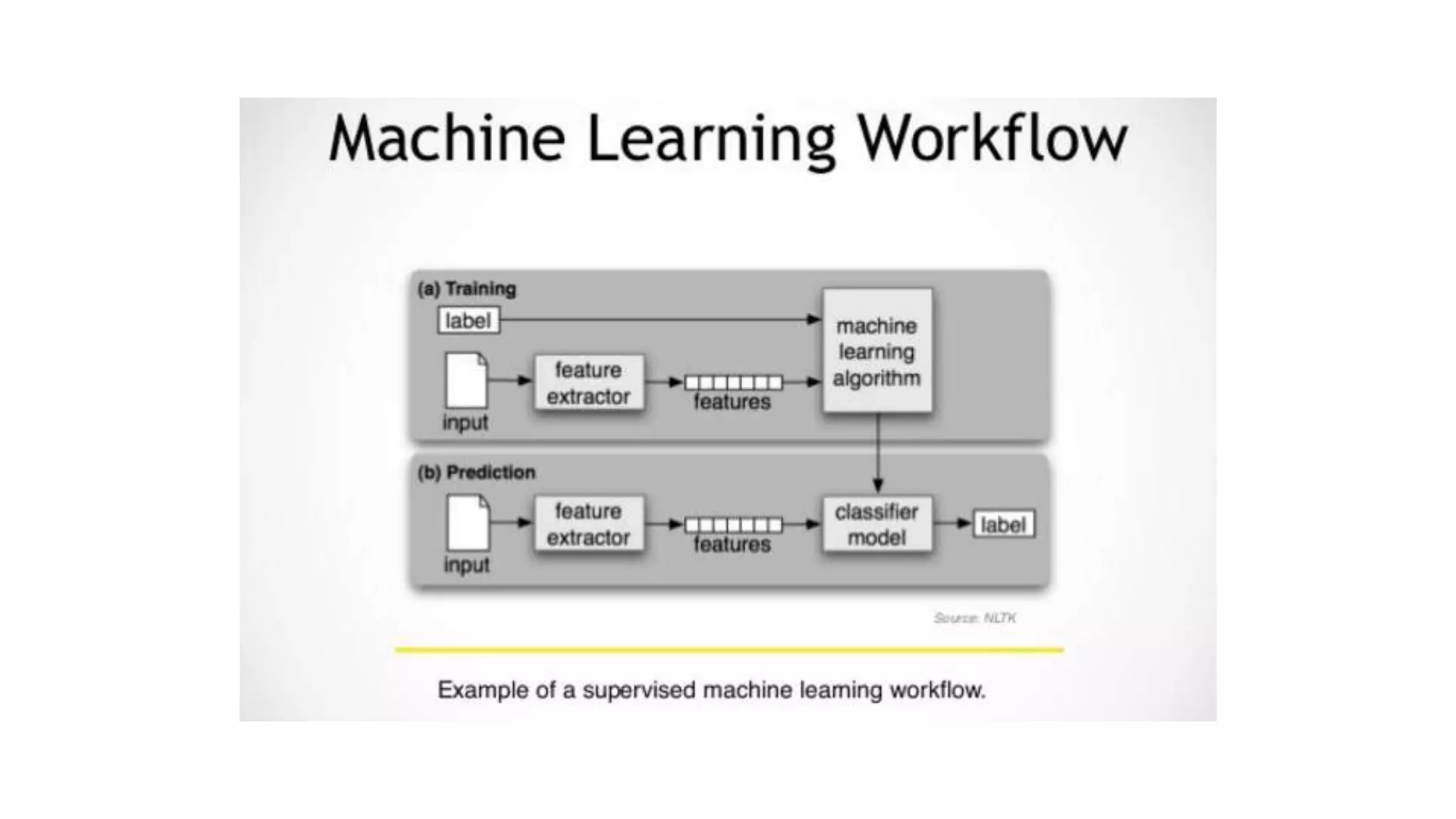


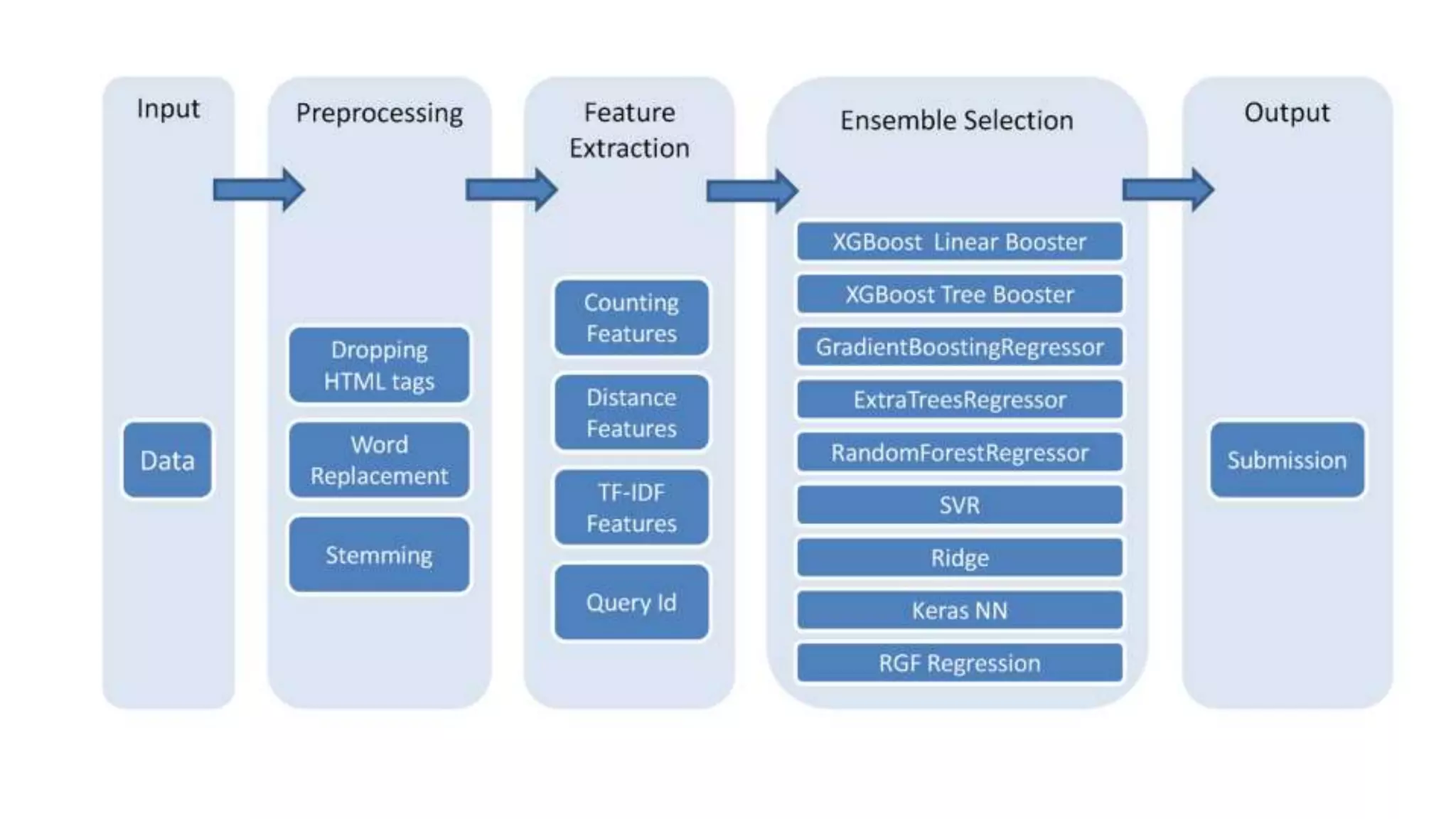



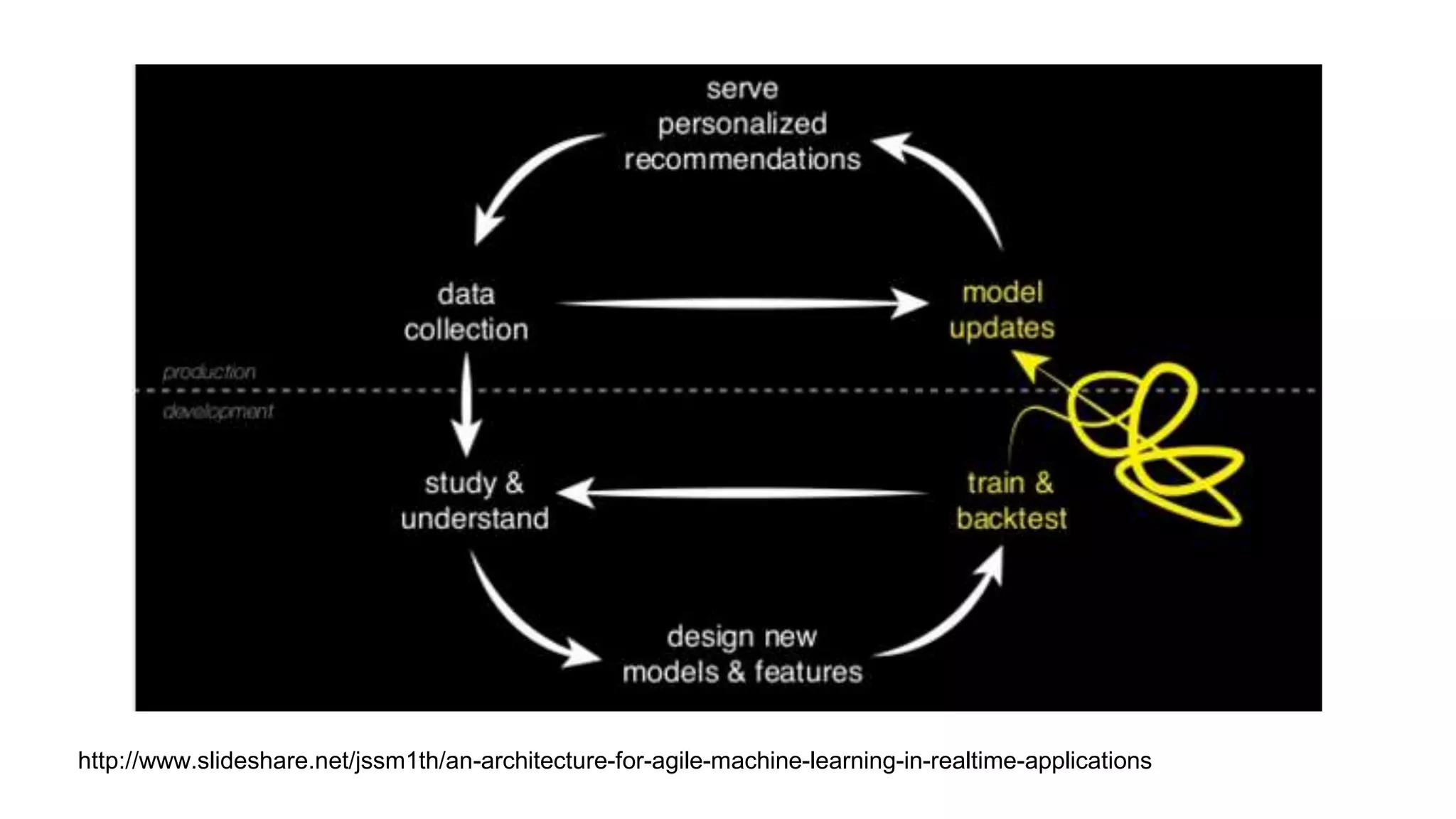
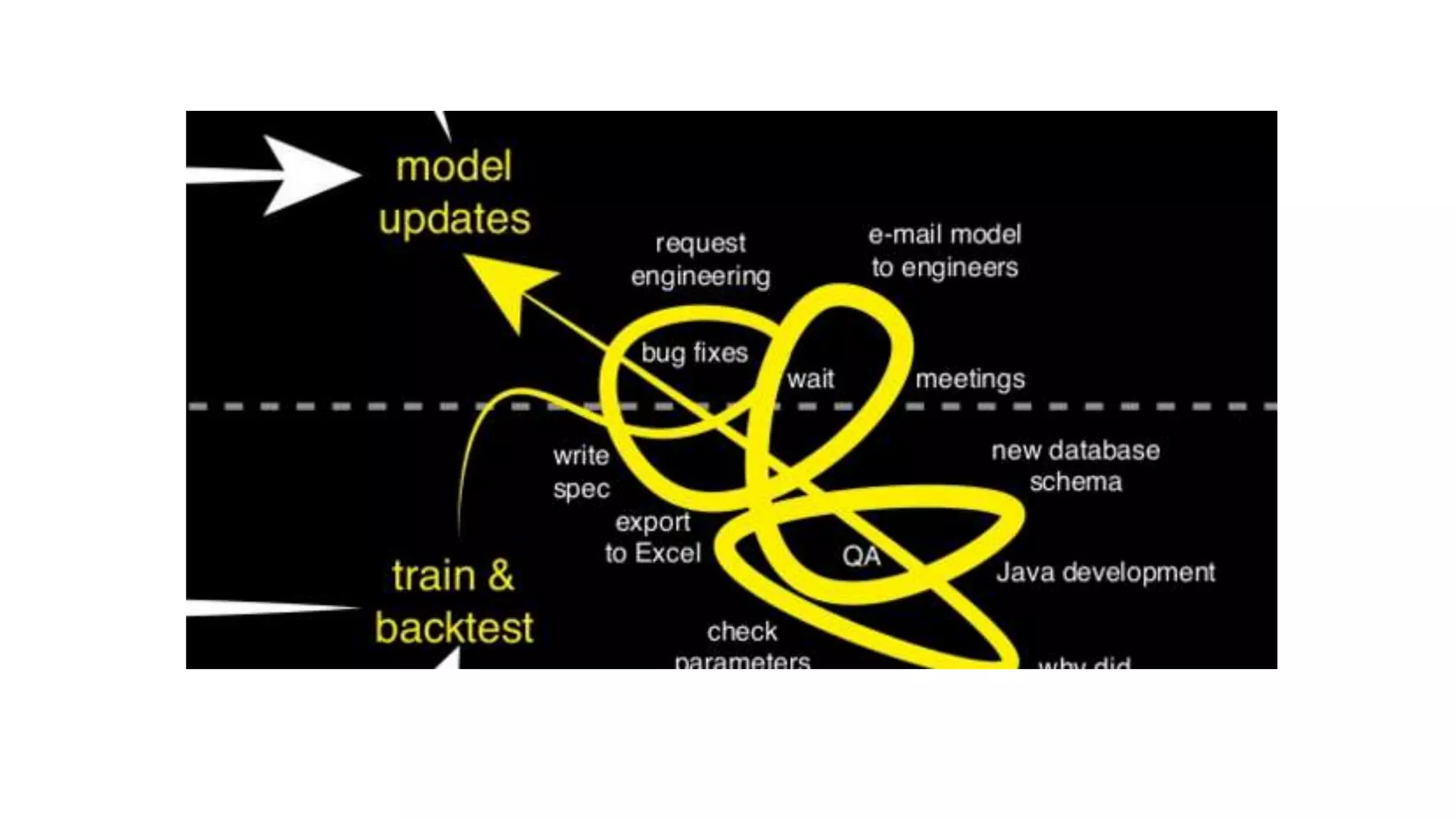


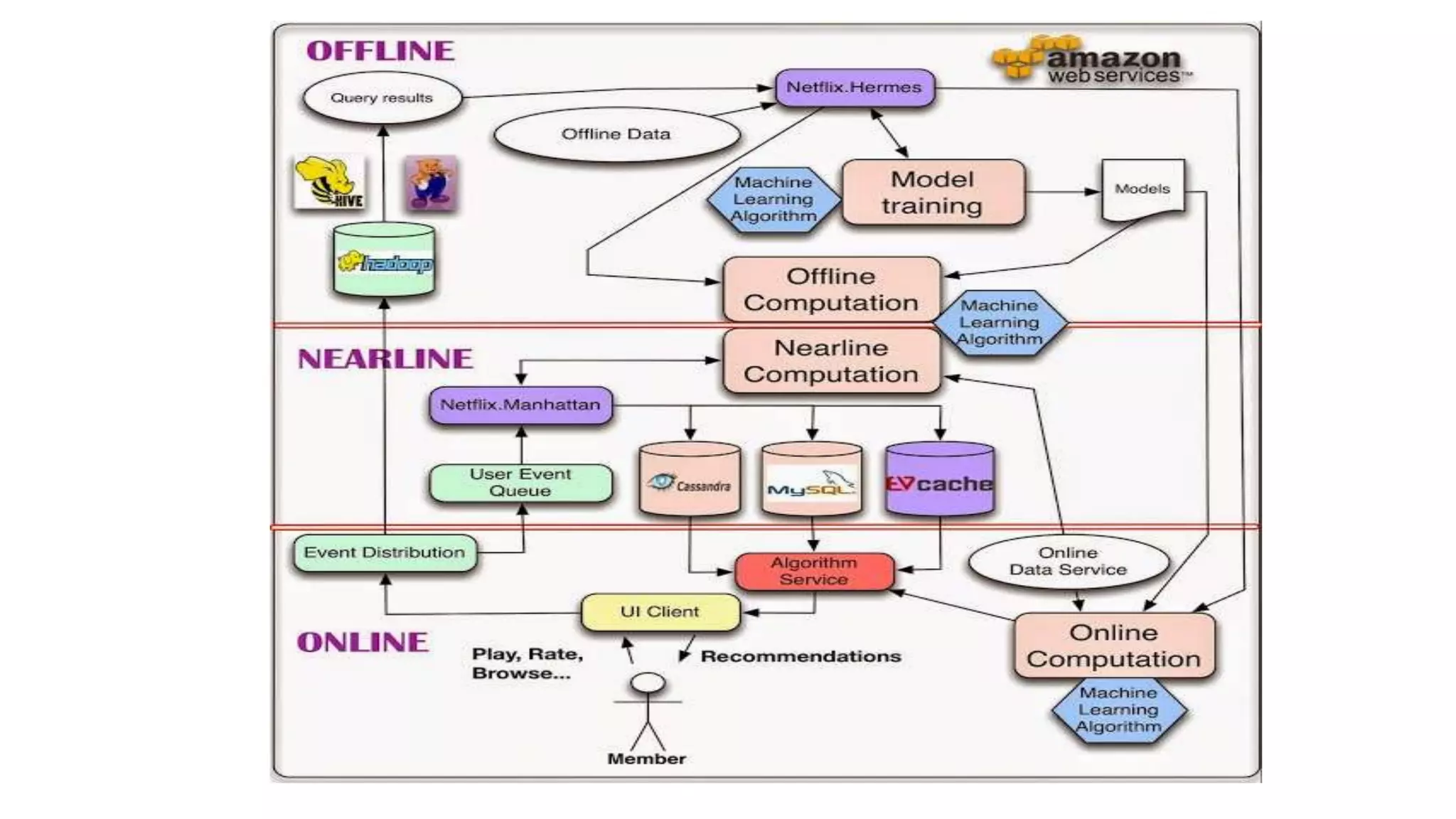

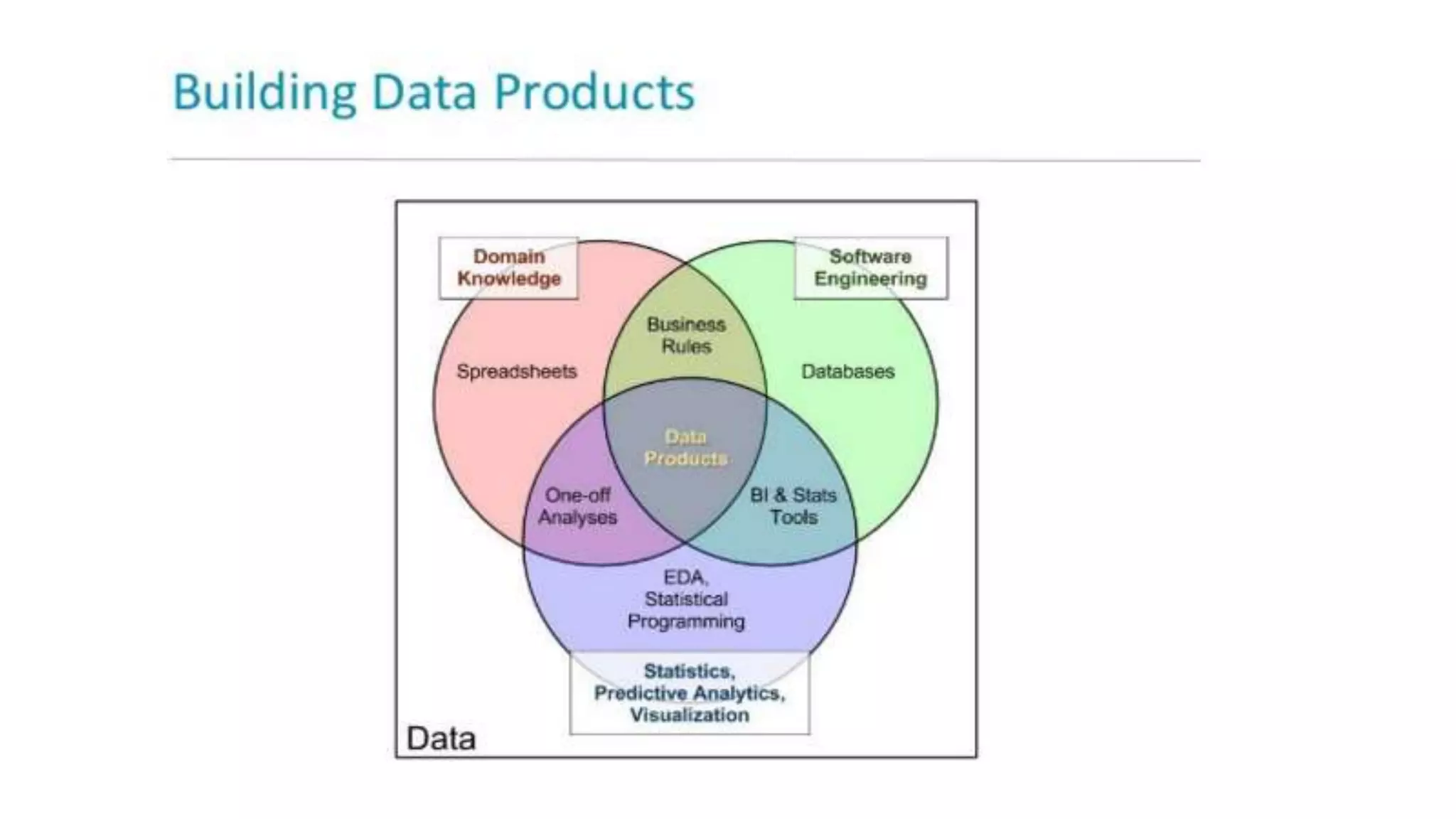
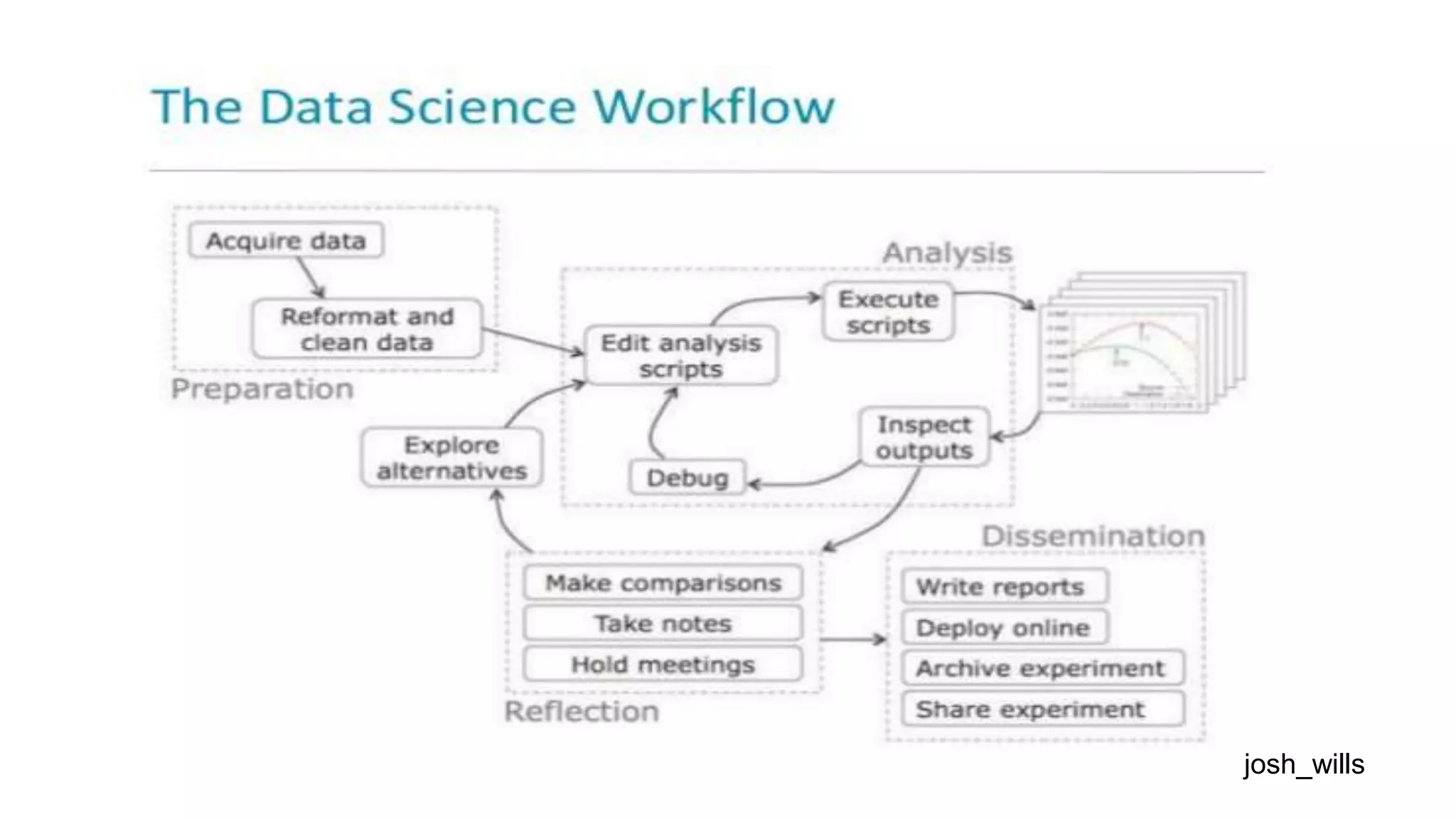



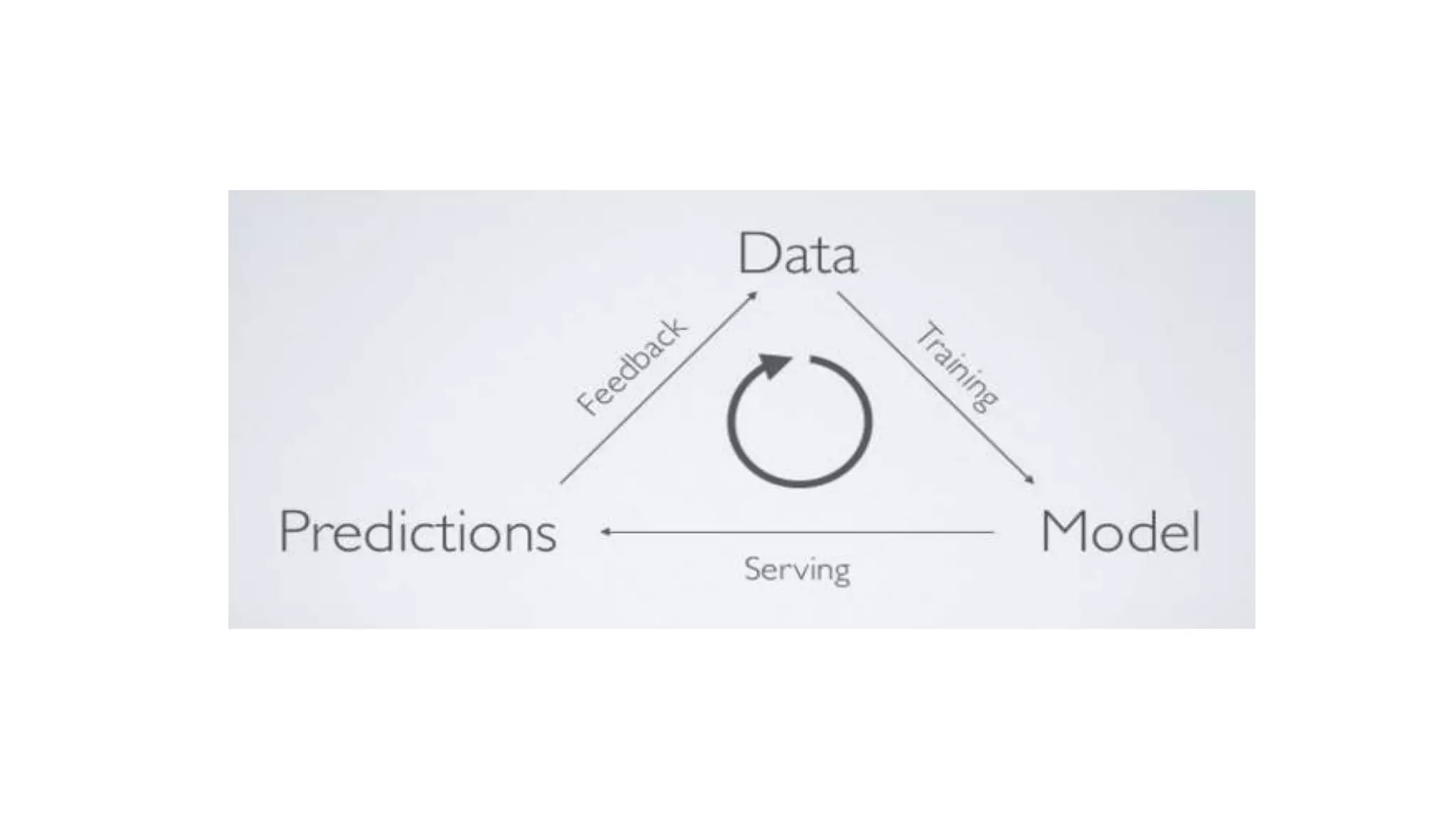
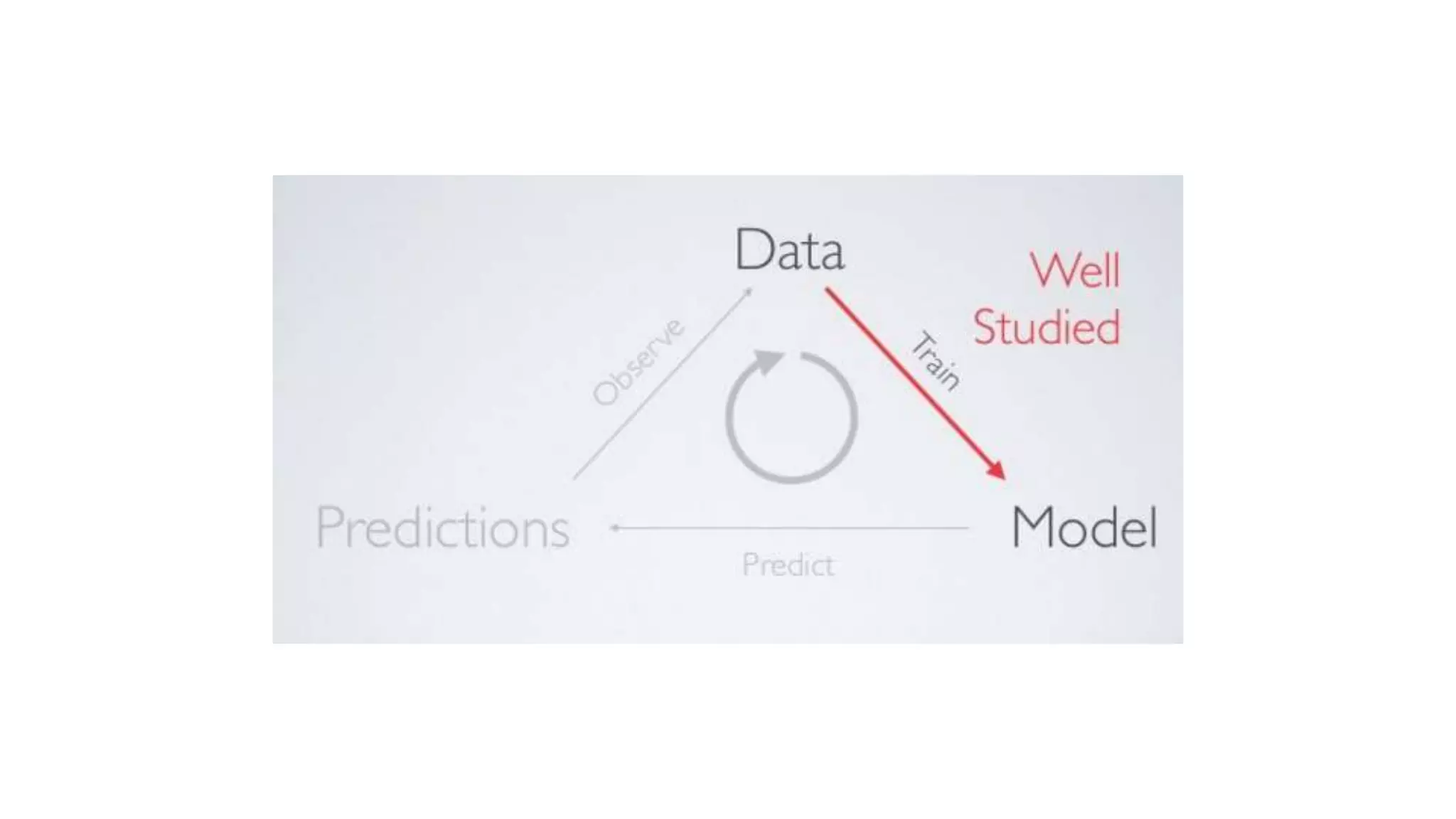
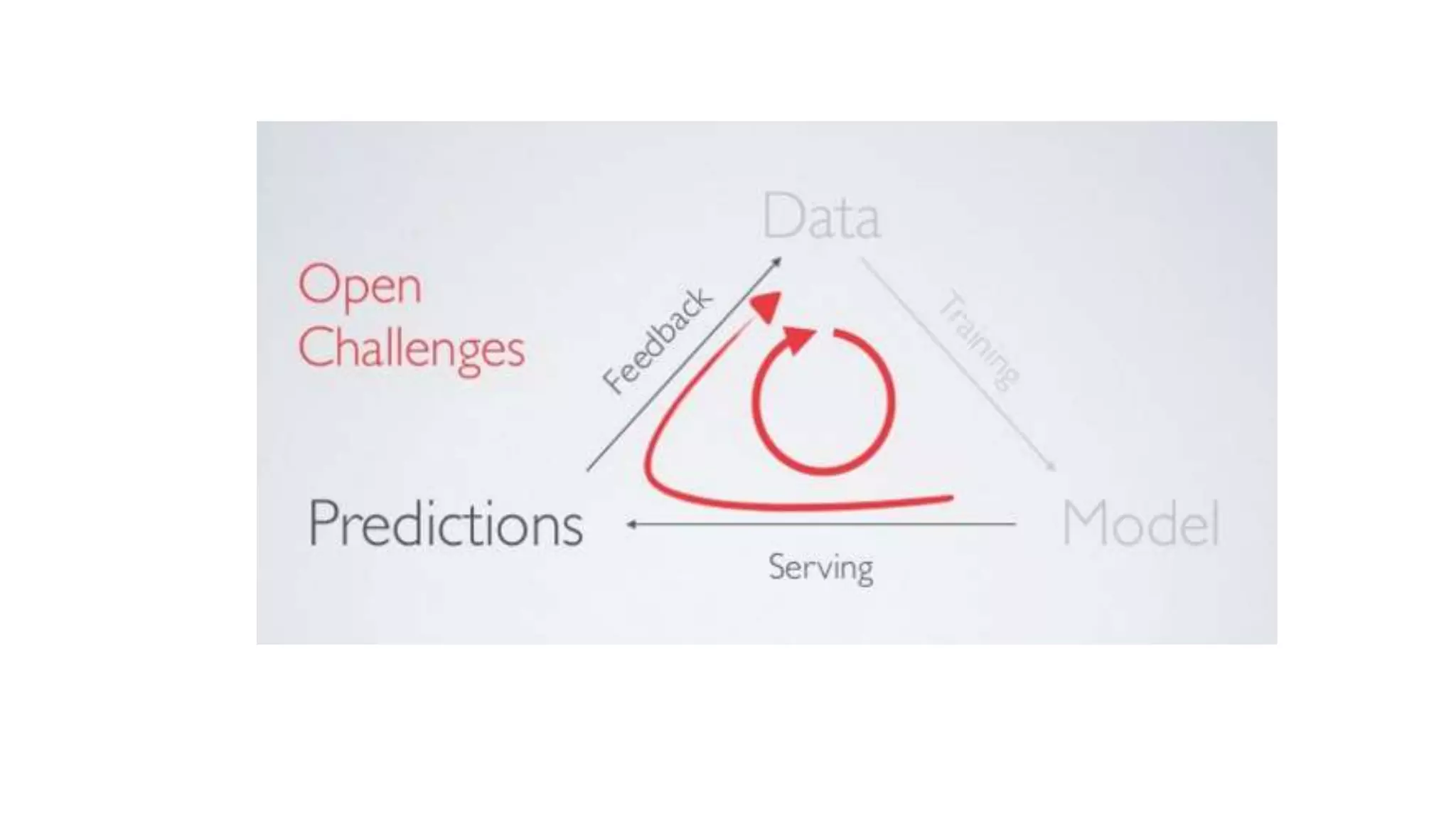



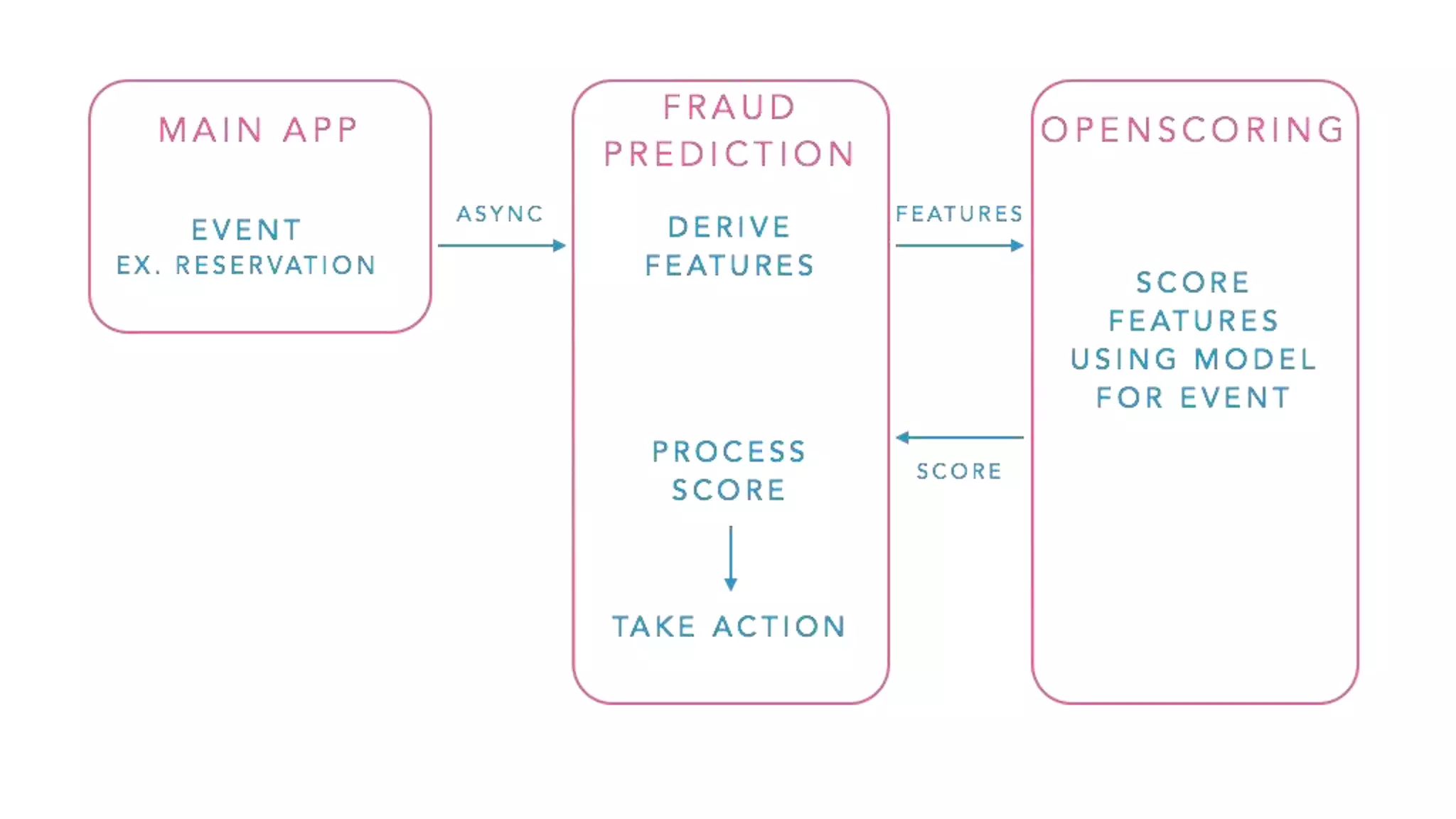
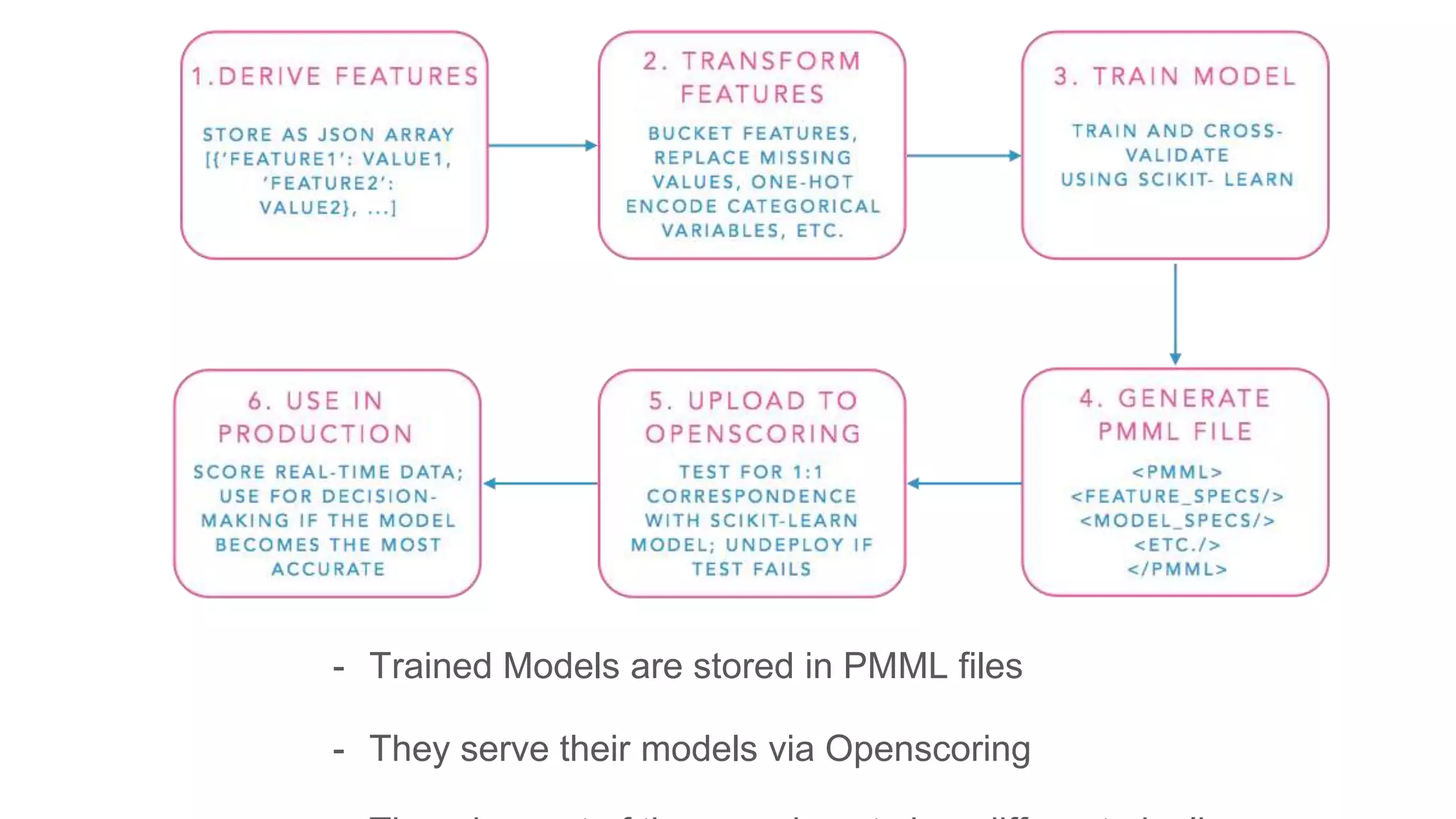



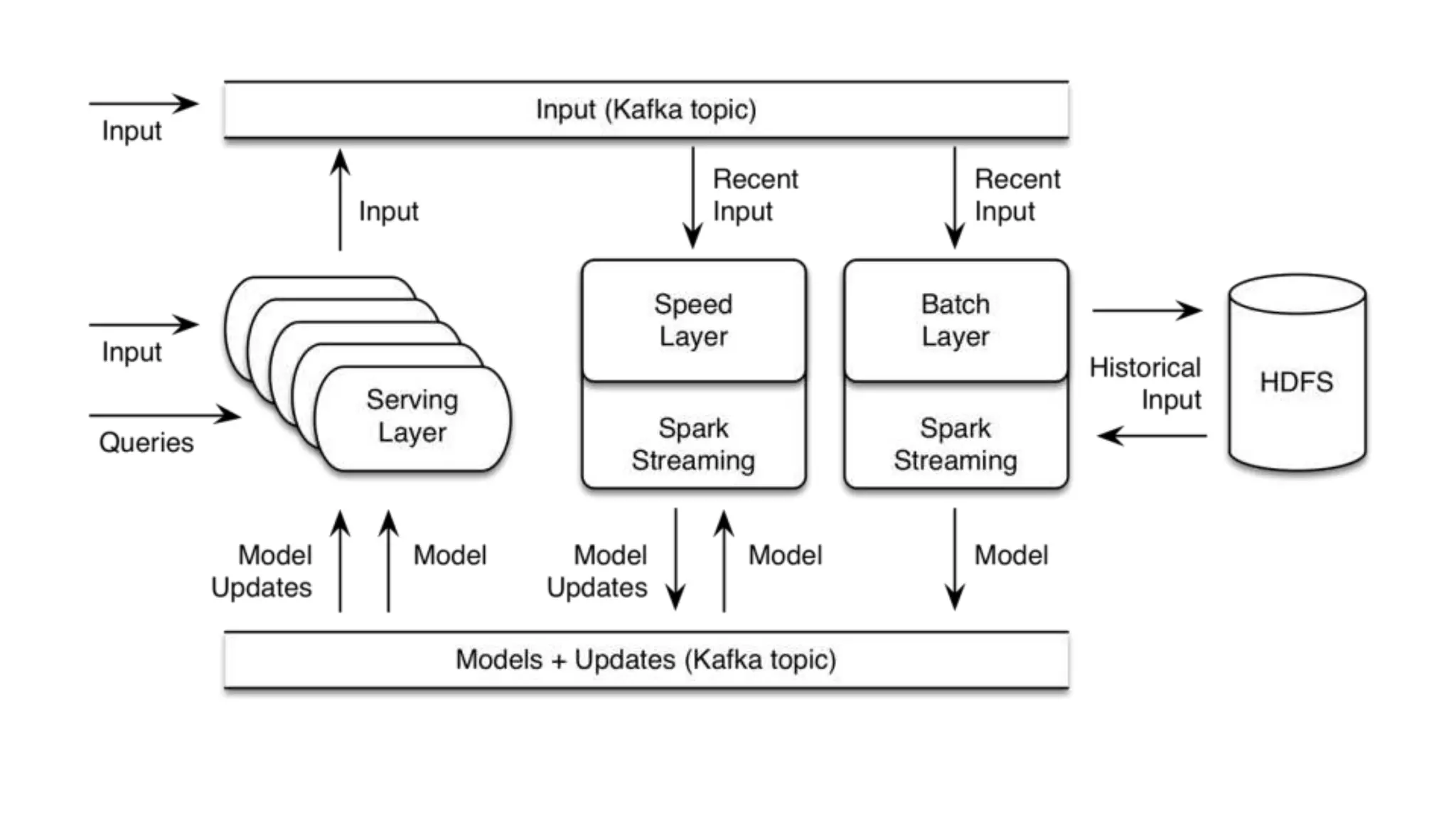


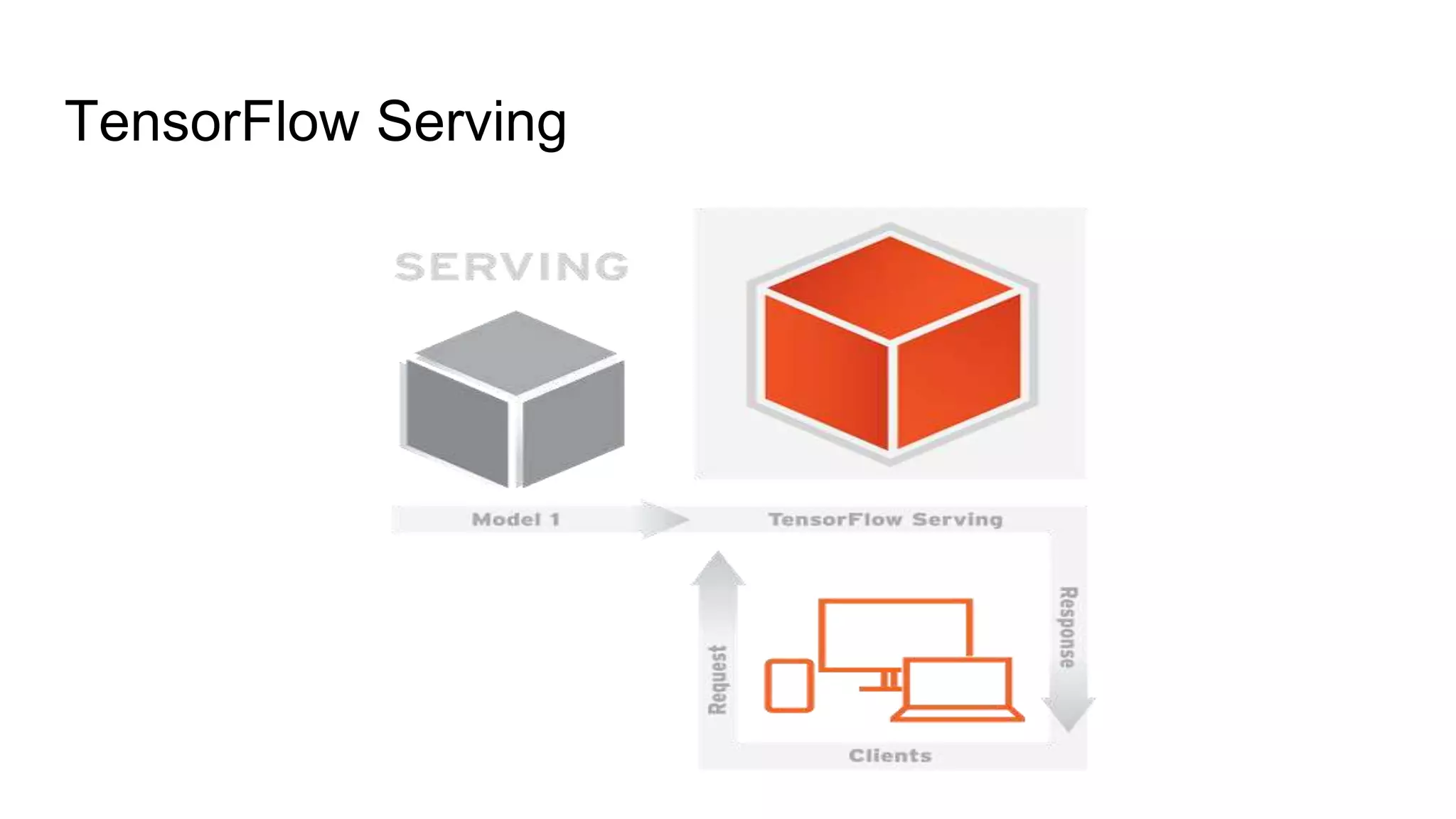
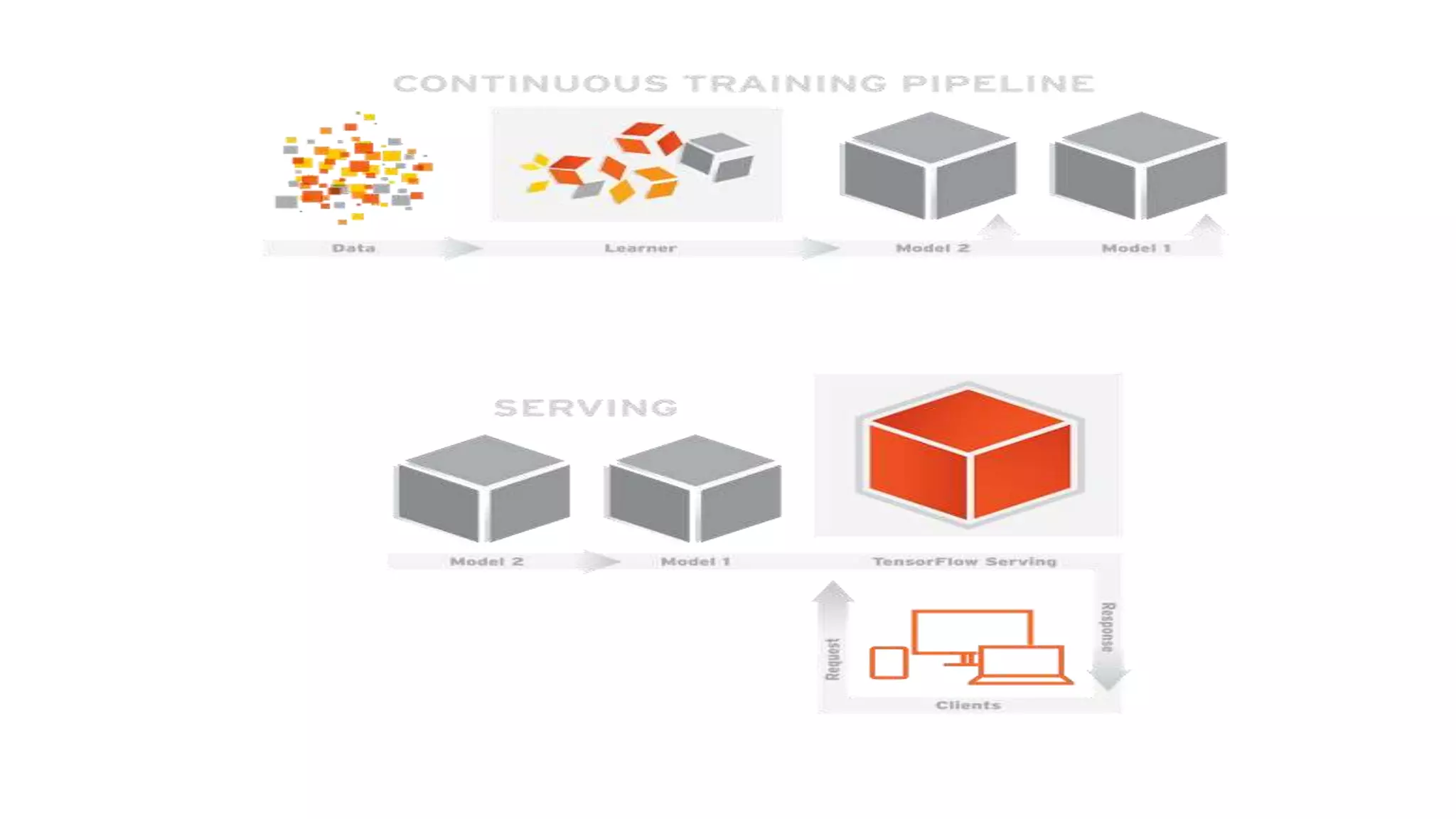
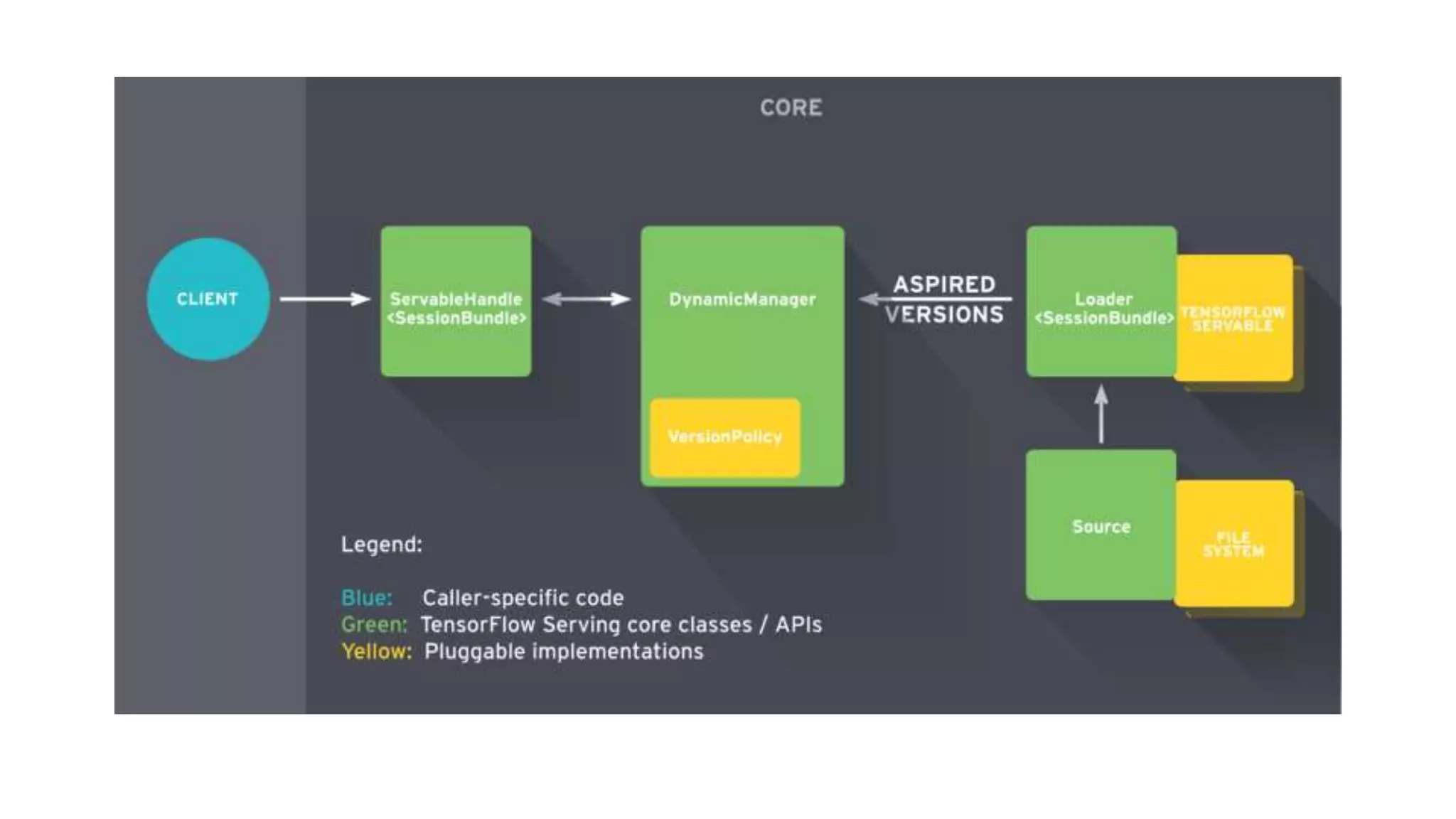


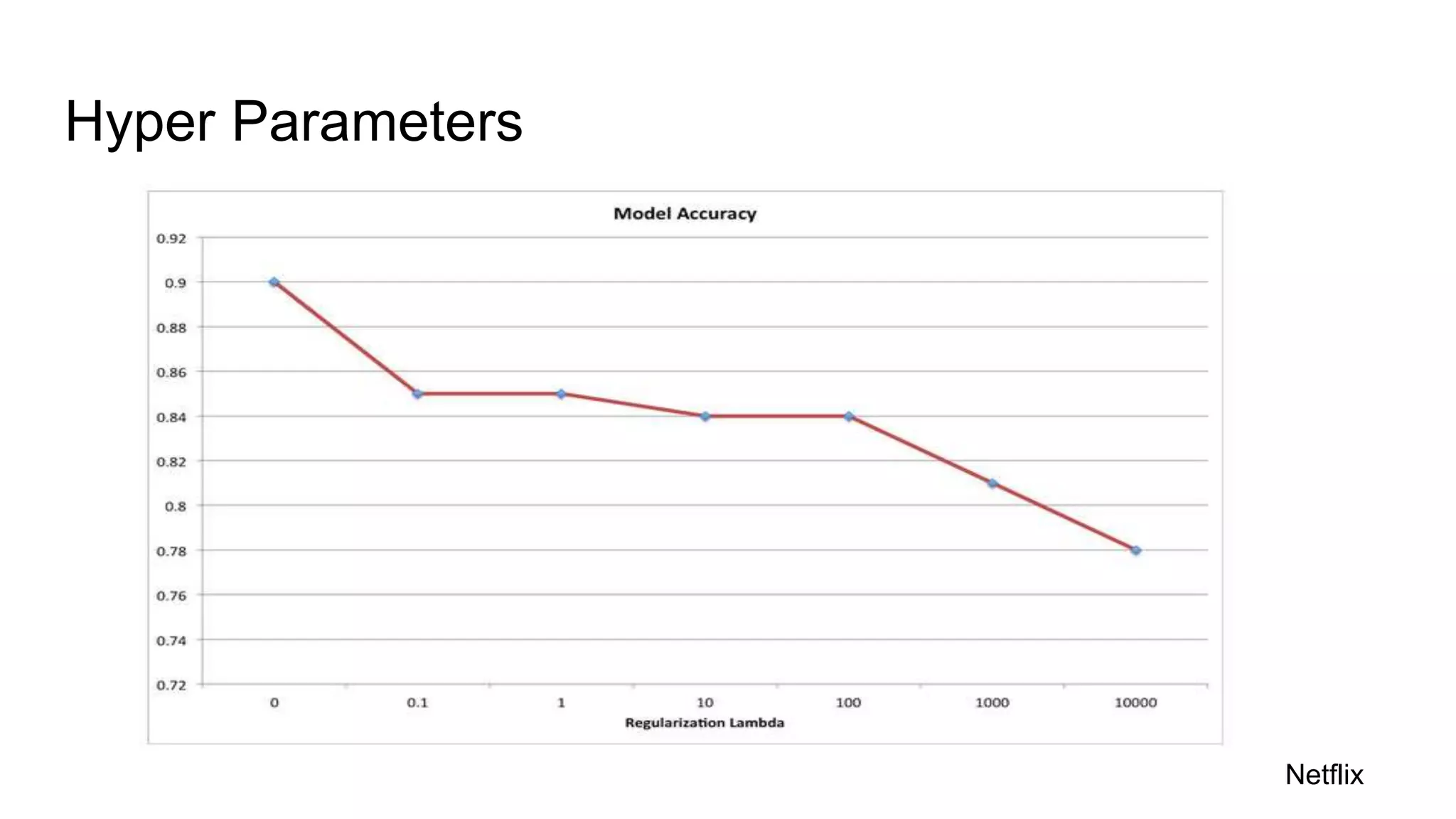
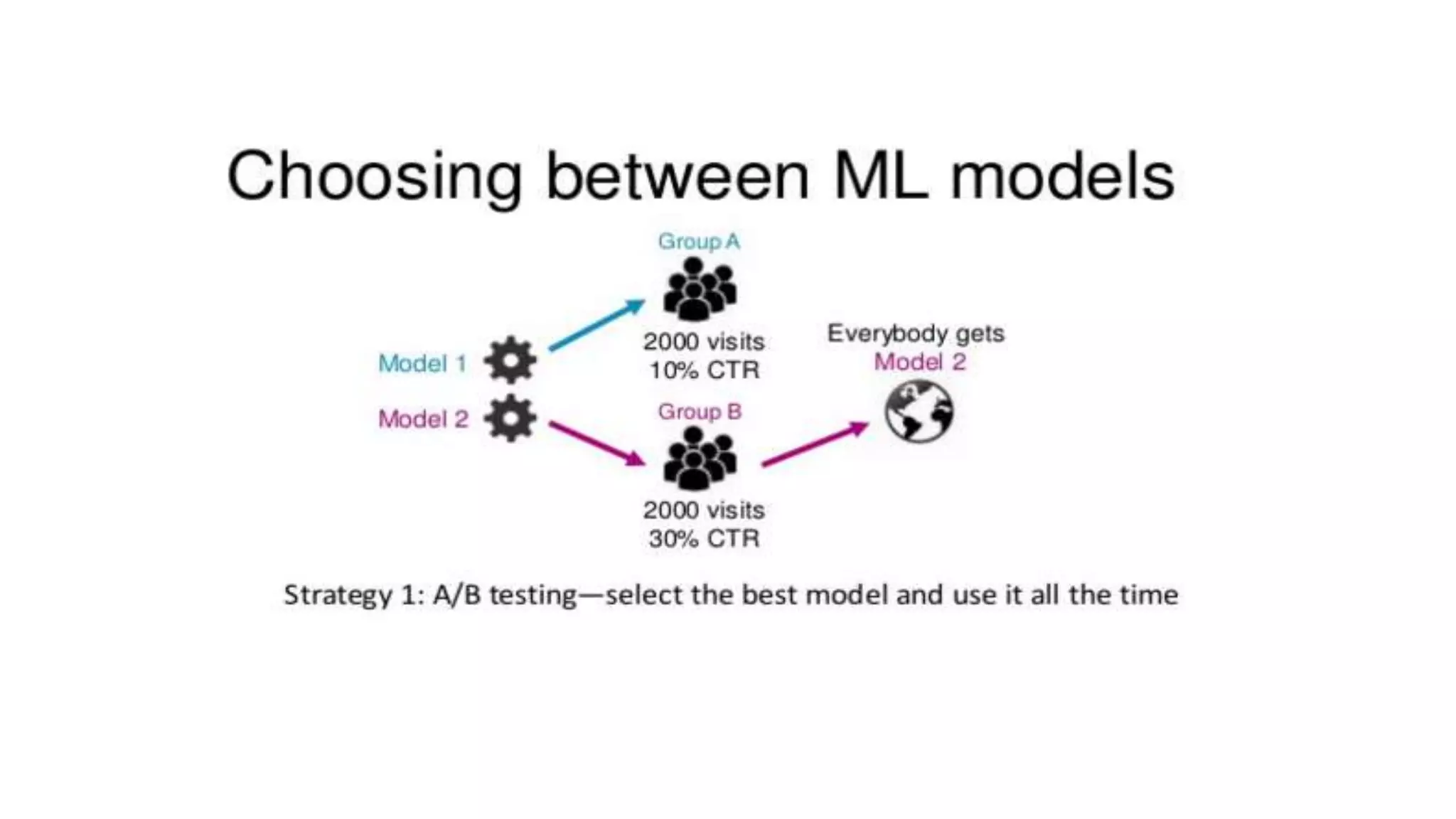
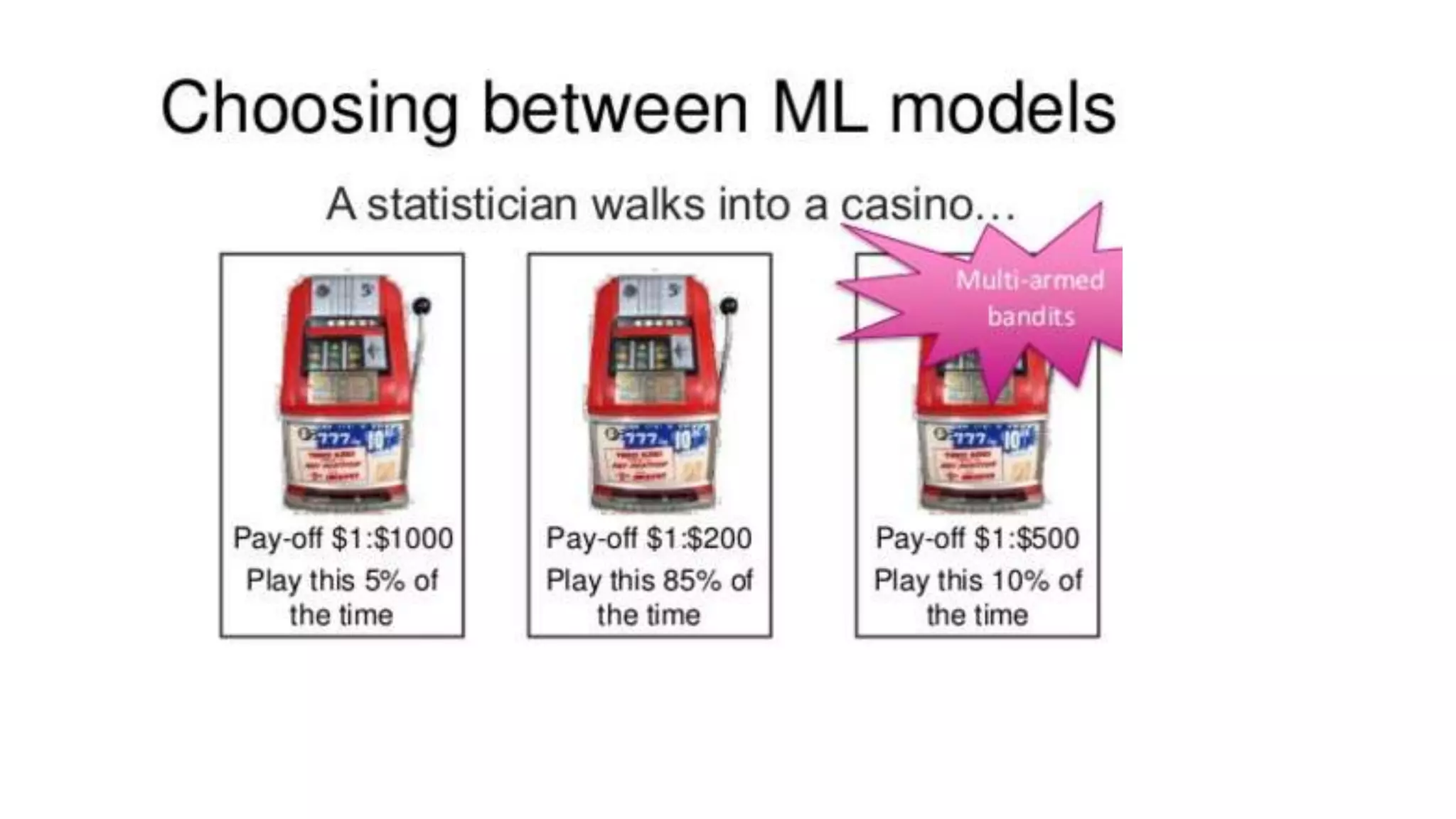
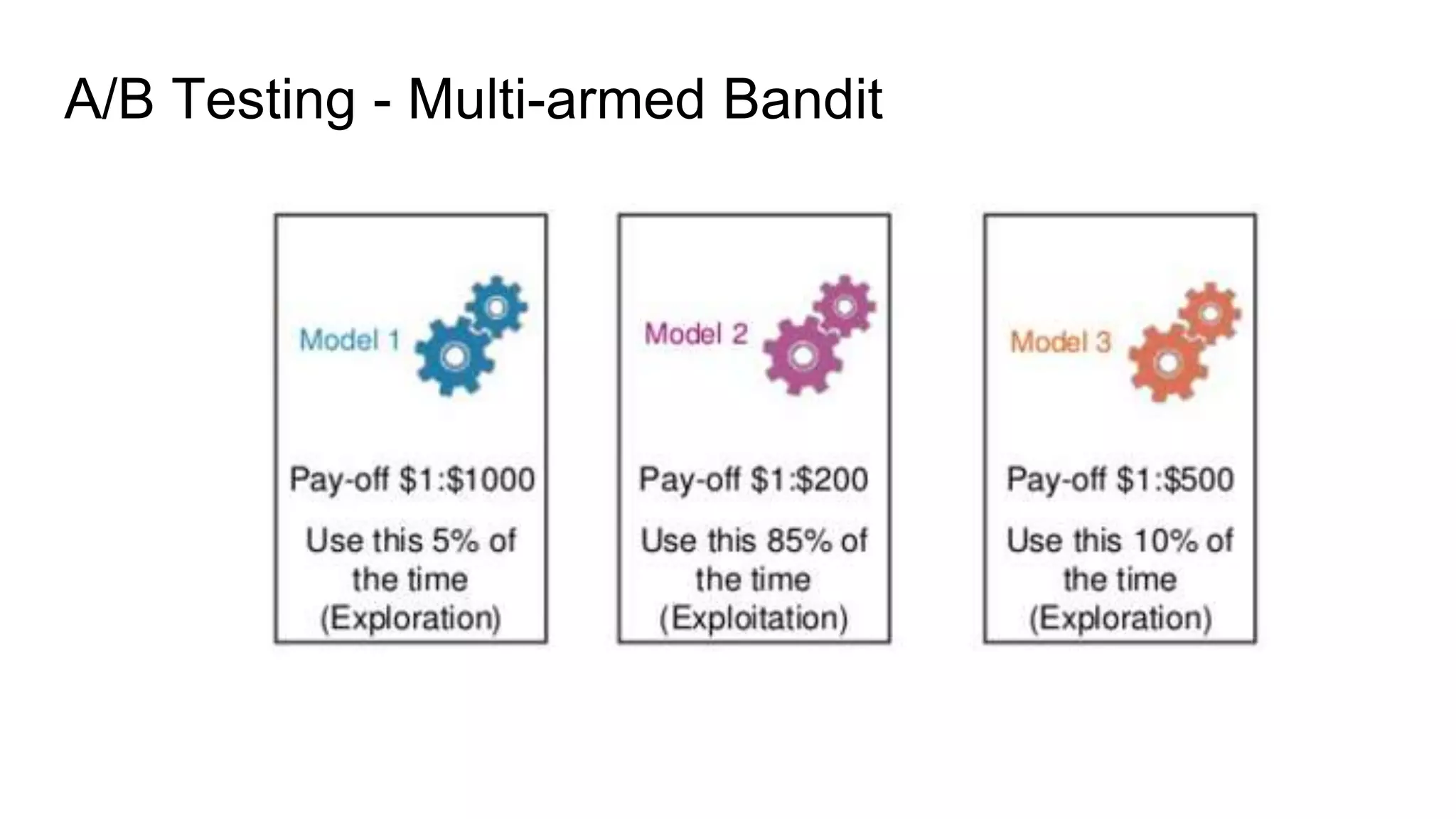
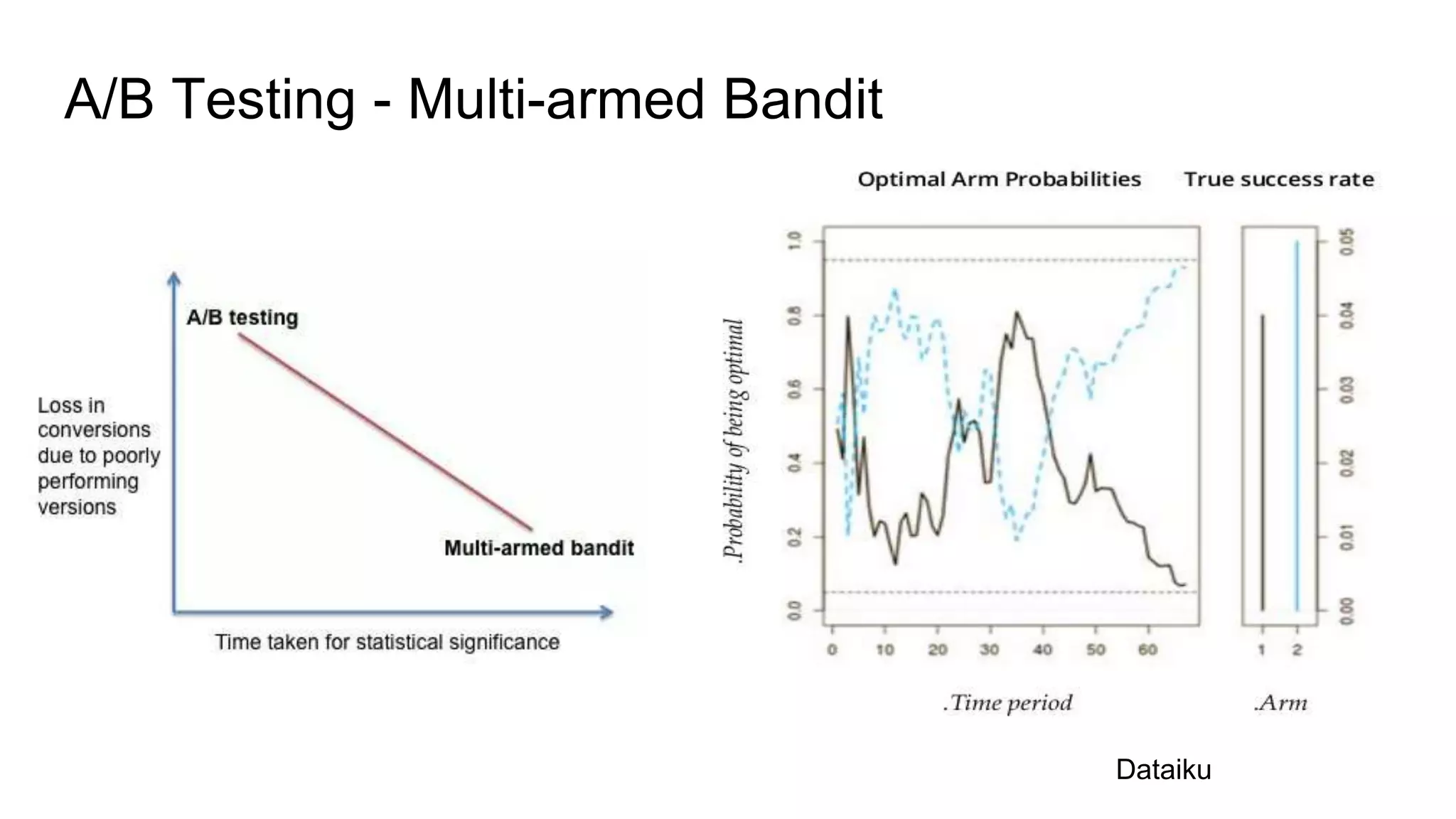
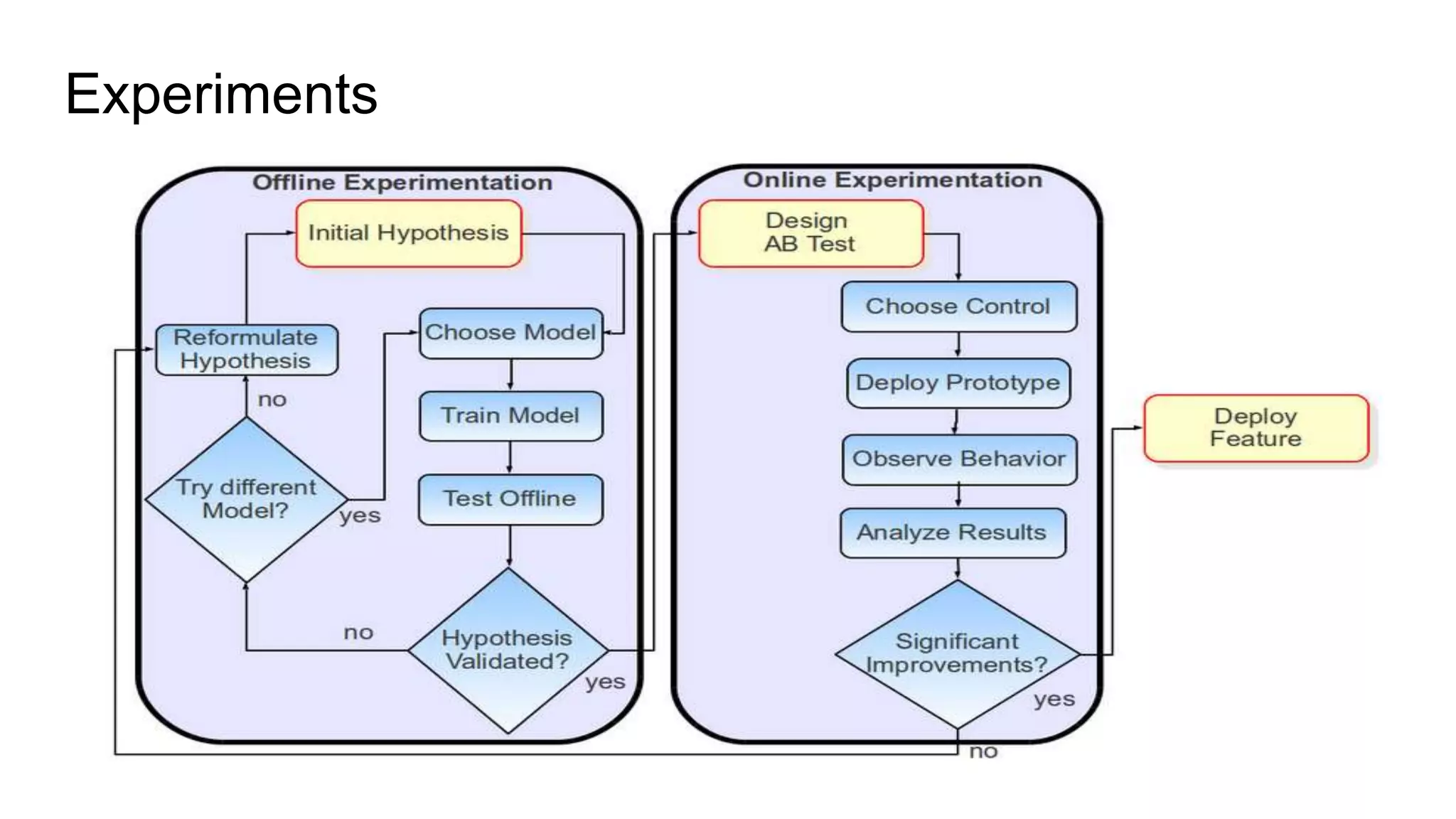
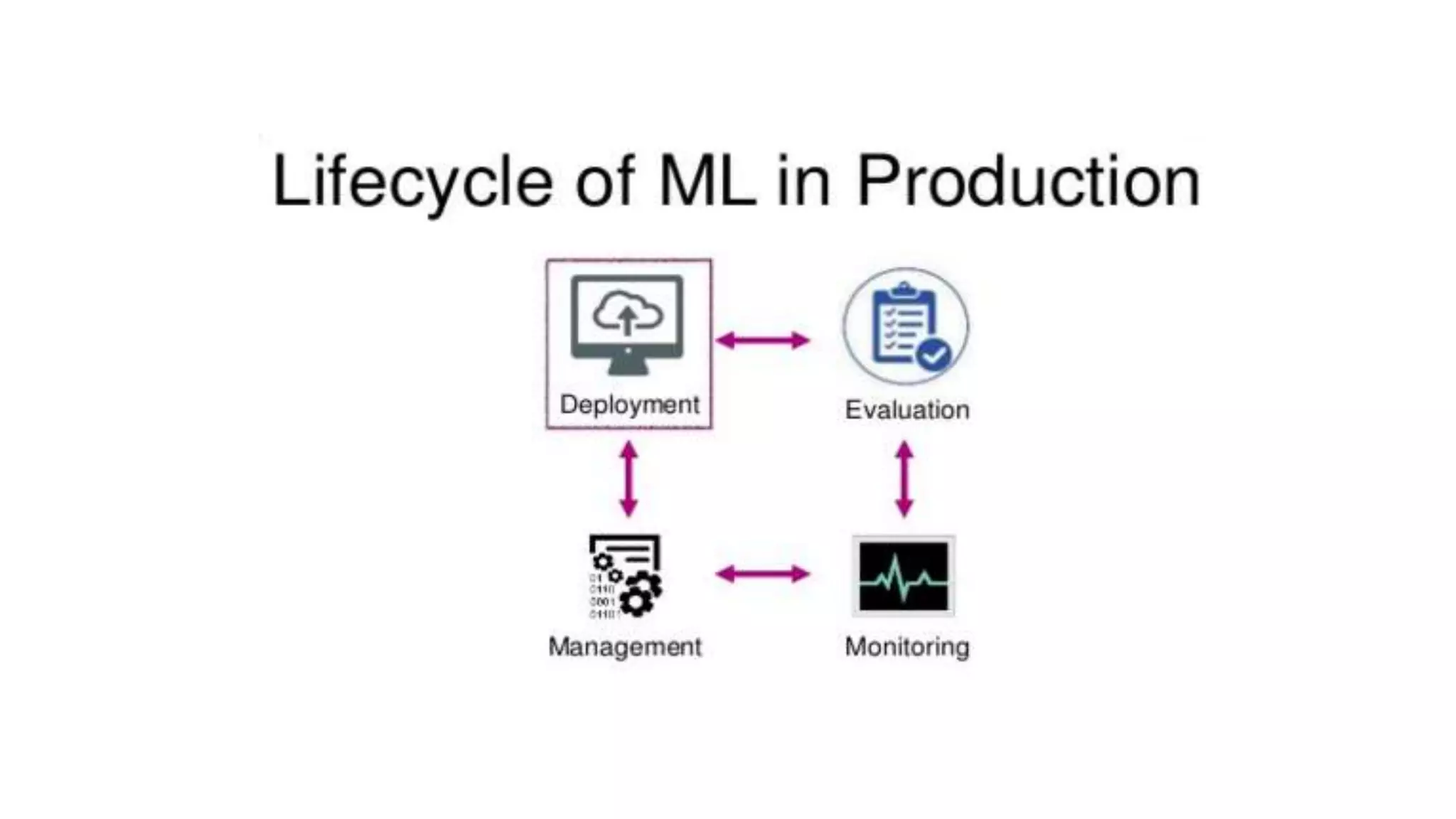


























































This document discusses challenges in running machine learning applications in production environments. It notes that while Kaggle competitions focus on accuracy, real-world applications require balancing accuracy with interpretability, speed and infrastructure constraints. It also emphasizes that machine learning in production is as much a software and systems problem as a modeling problem. Key aspects that are discussed include flexible and scalable deployment architectures, model versioning, packaging and serving, online evaluation and experiments, and ensuring reproducibility of results.



























































![[DSC Europe 22] Engineers guide for shepherding models in to production - Mar...](https://cdn.slidesharecdn.com/ss_thumbnails/markodimitrijevic-engineersguideforshepherdingmodelsintoproduction2-221130080720-6e979b6f-thumbnail.jpg?width=640&height=640&fit=bounds)

































