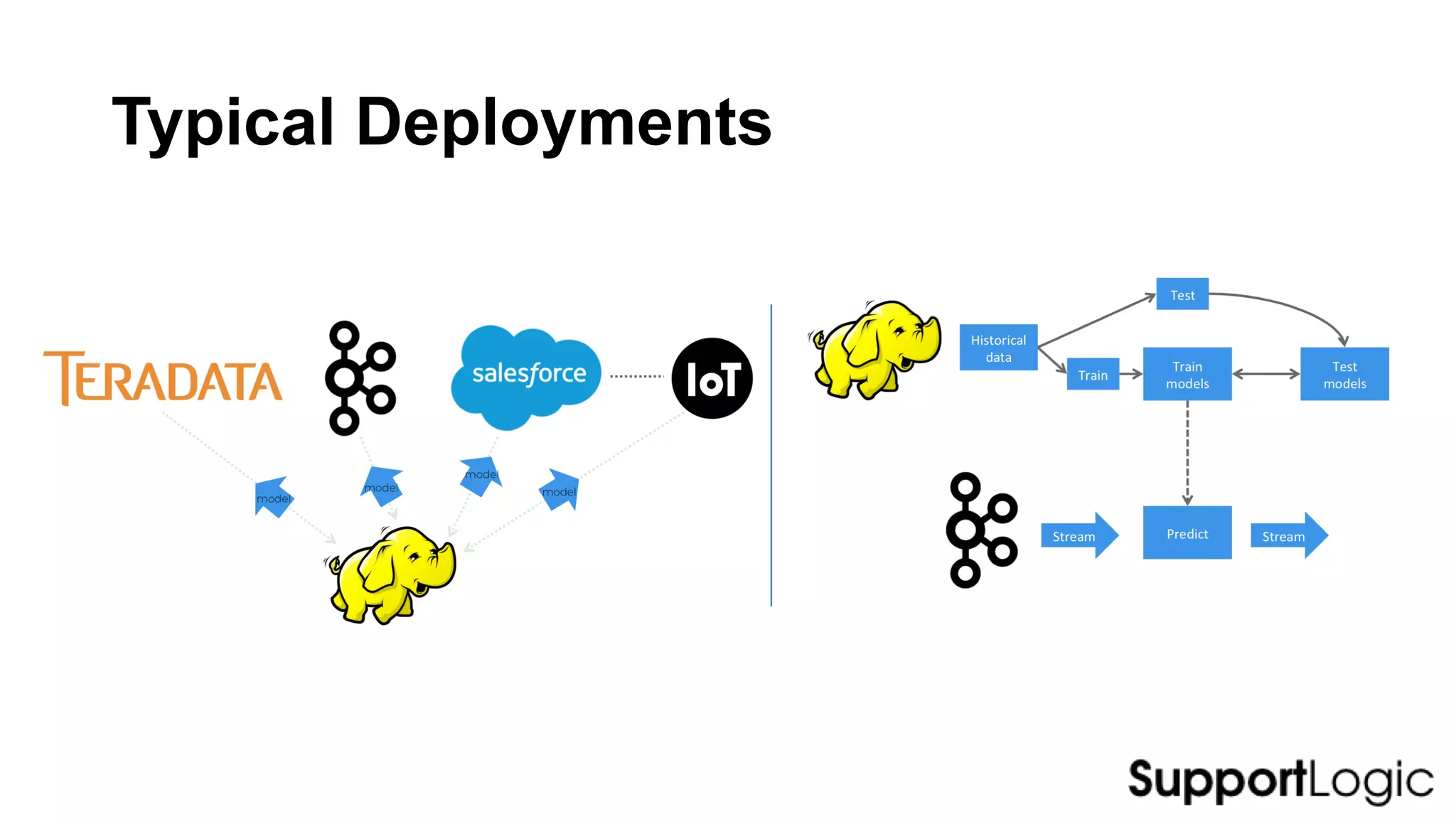
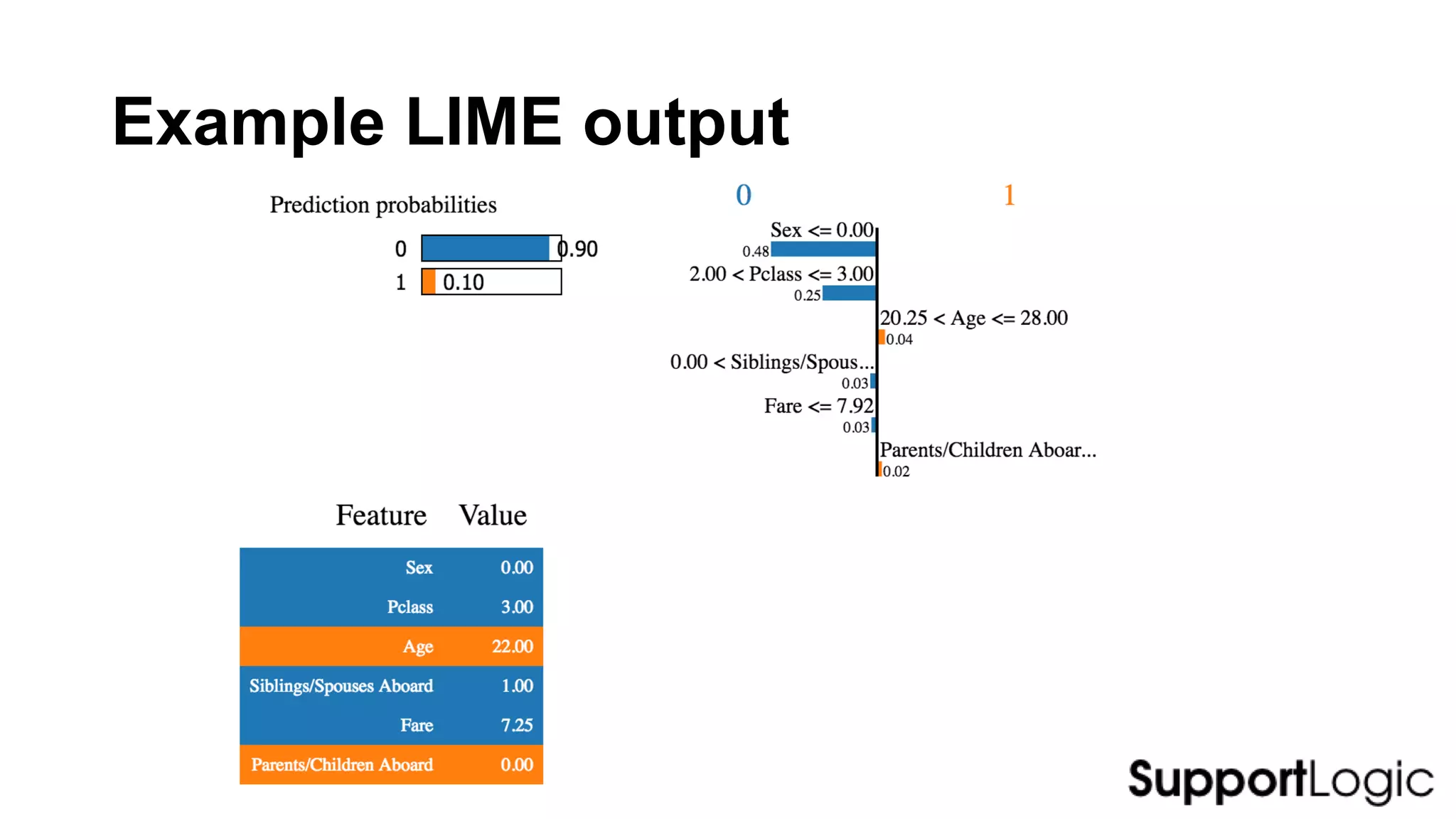
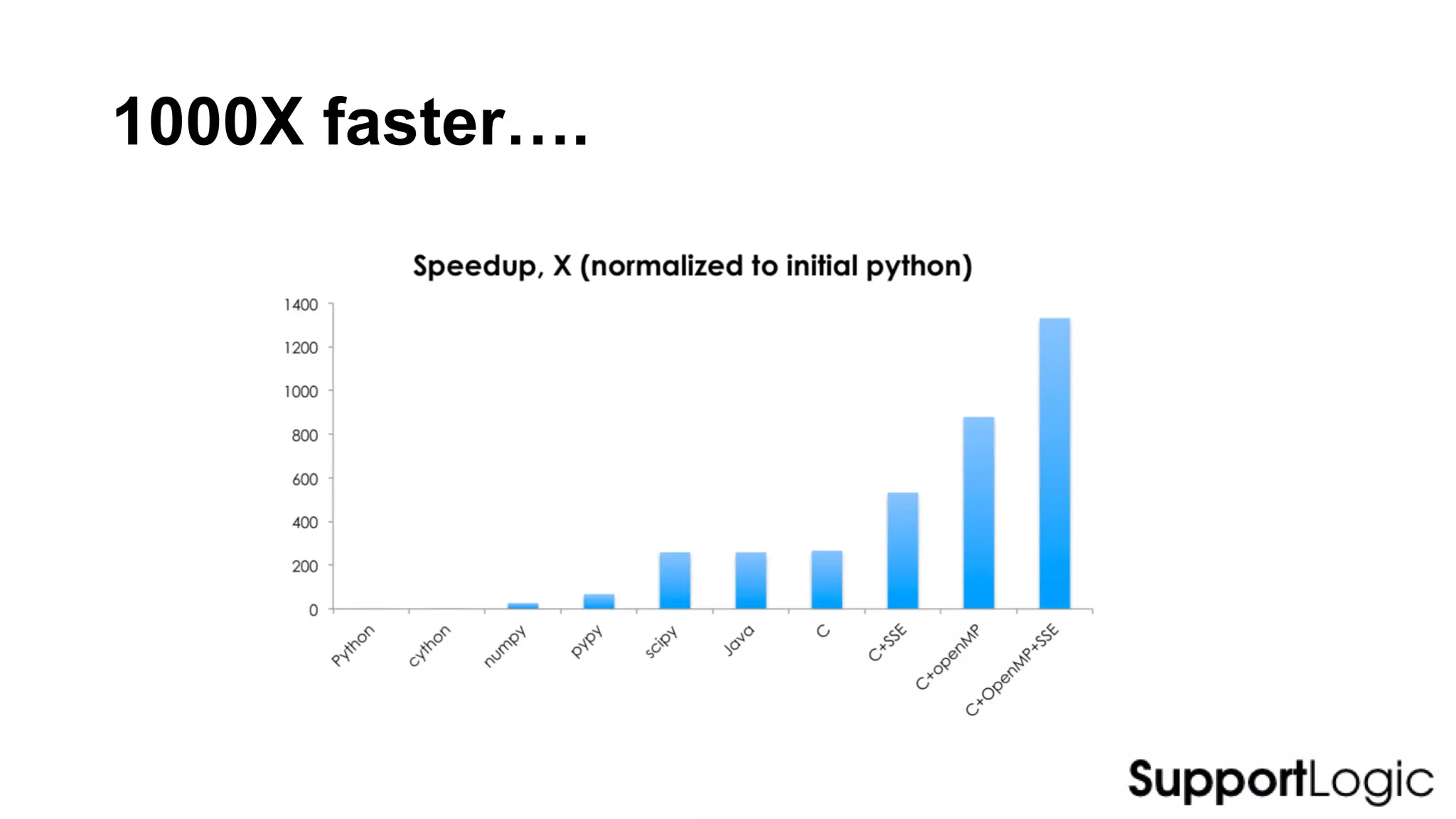
This document discusses challenges and considerations for leveraging machine learning and big data. It covers the full machine learning lifecycle from data acquisition and cleaning to model deployment and monitoring. Key points include the importance of feature engineering, selecting the right frameworks, addressing barriers to operationalizing models, and deciding between single node versus distributed solutions based on data and algorithm characteristics. Python is presented as a flexible tool for prototyping solutions.