

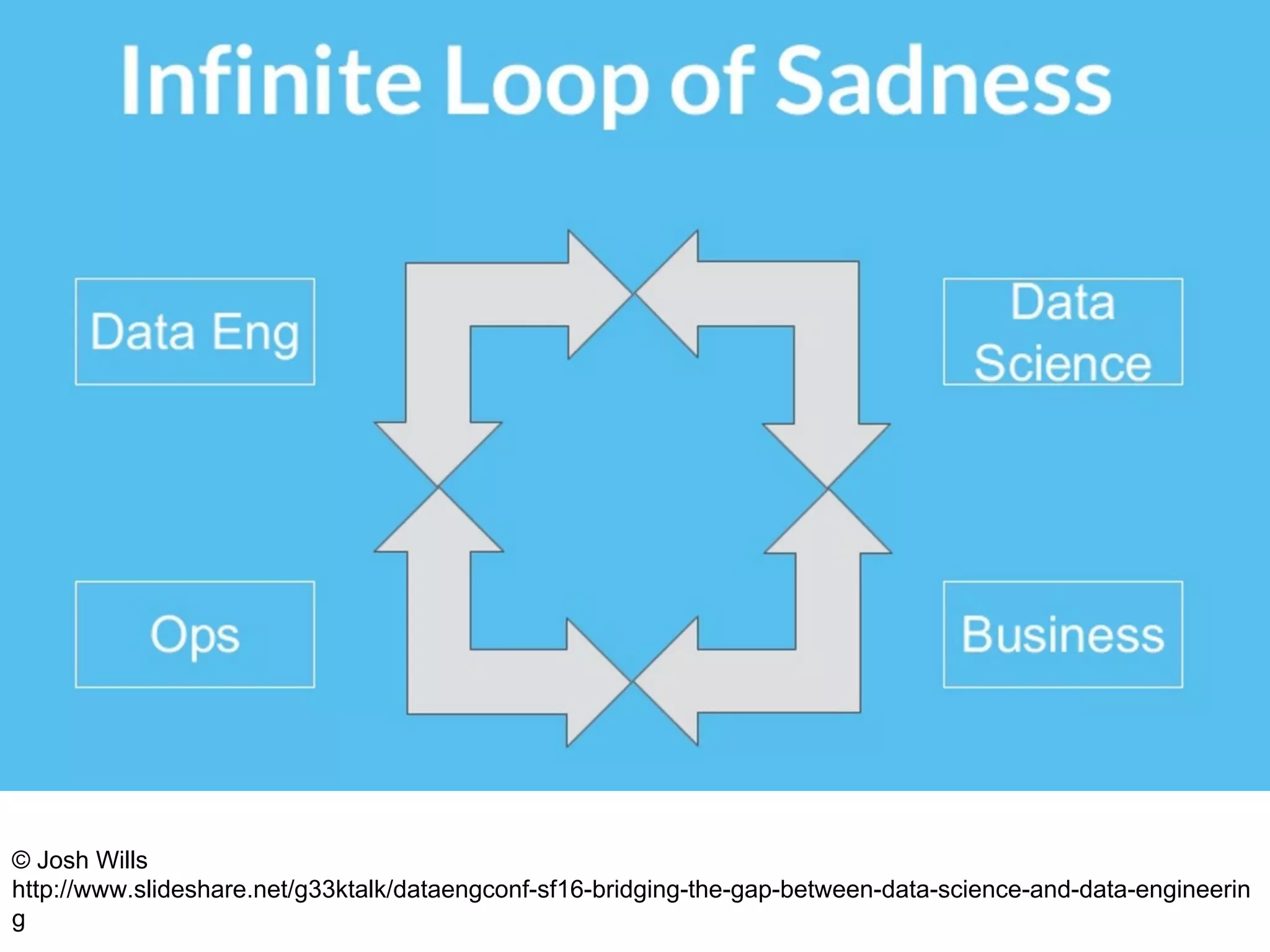








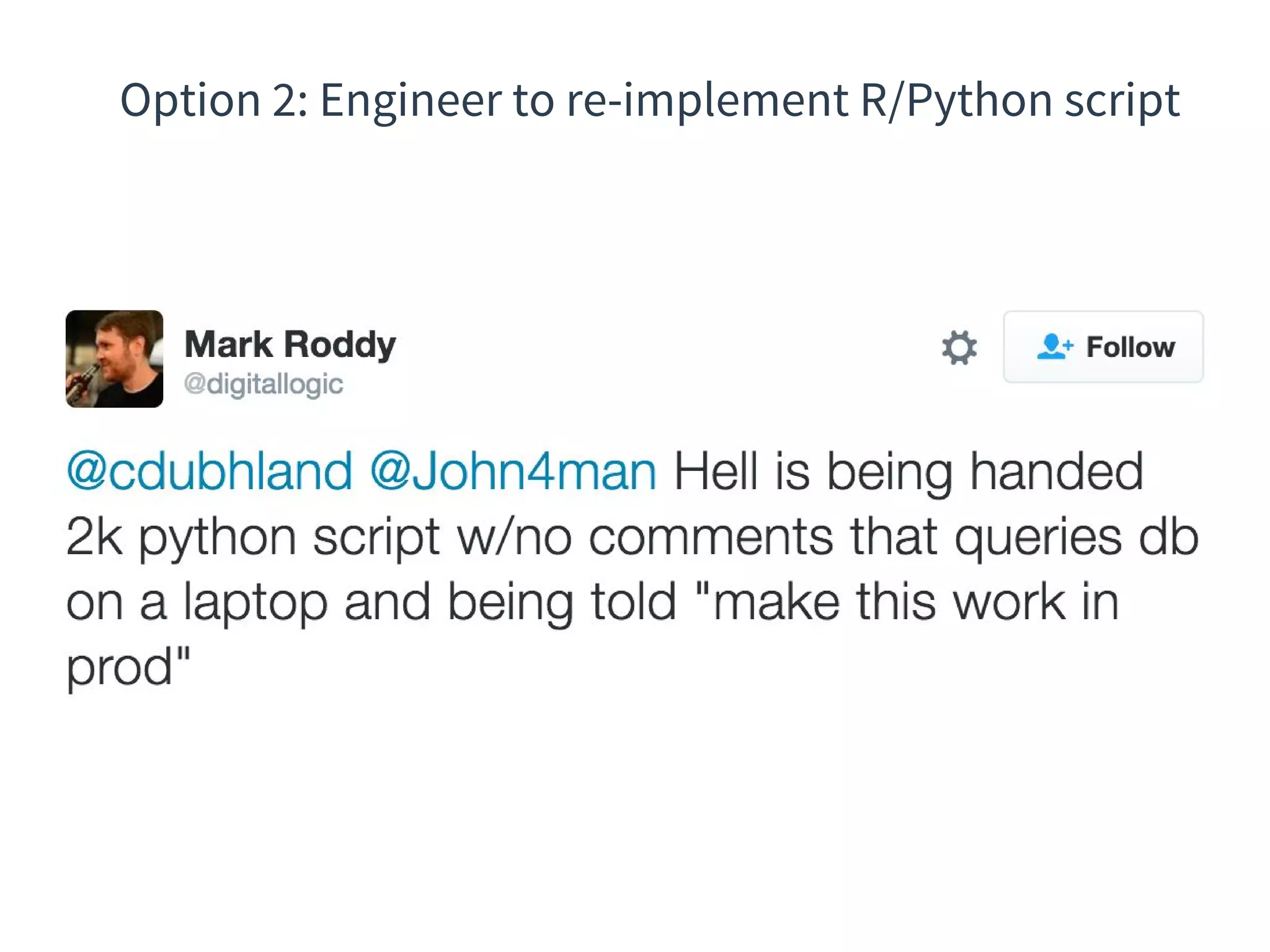





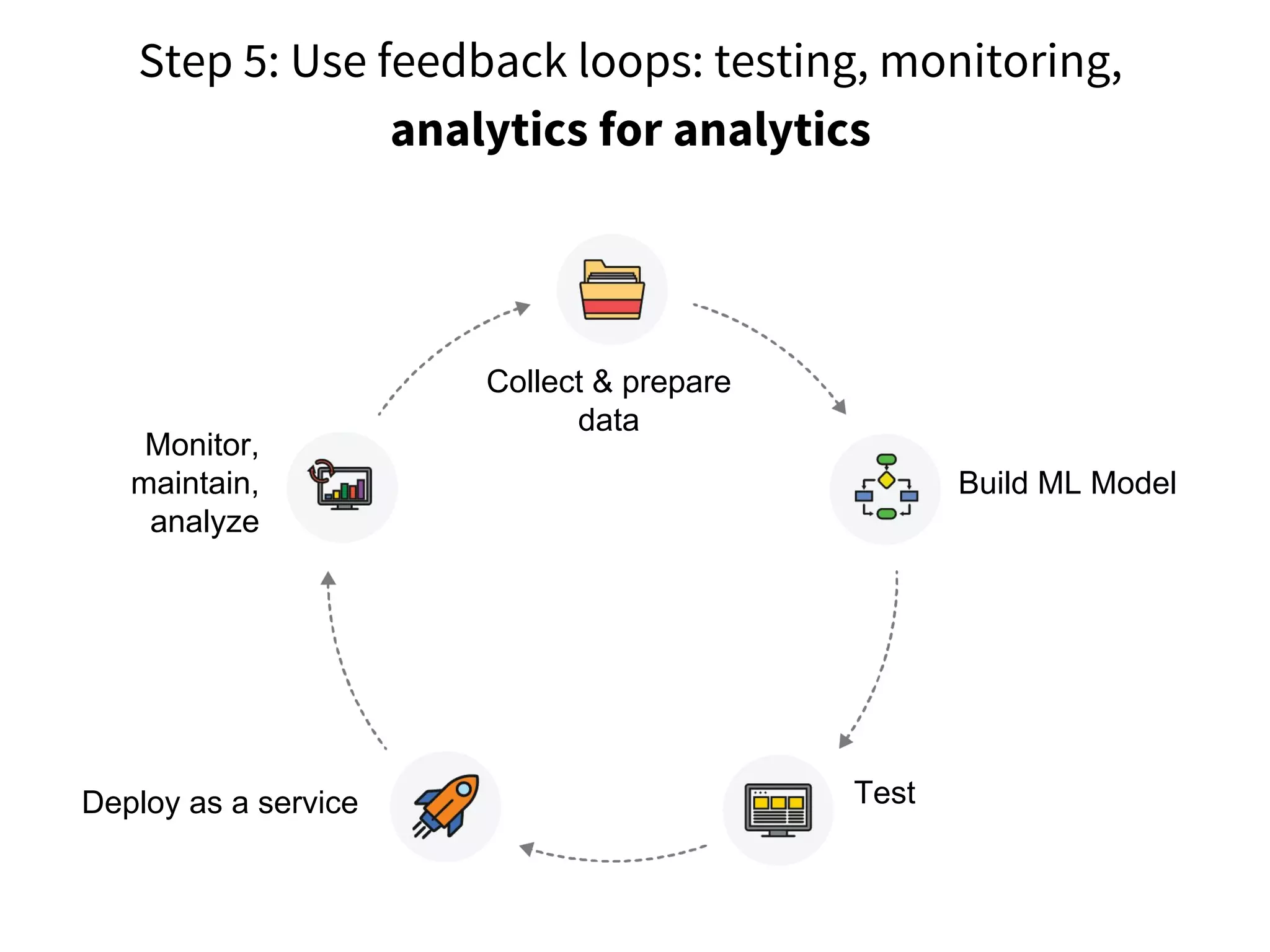



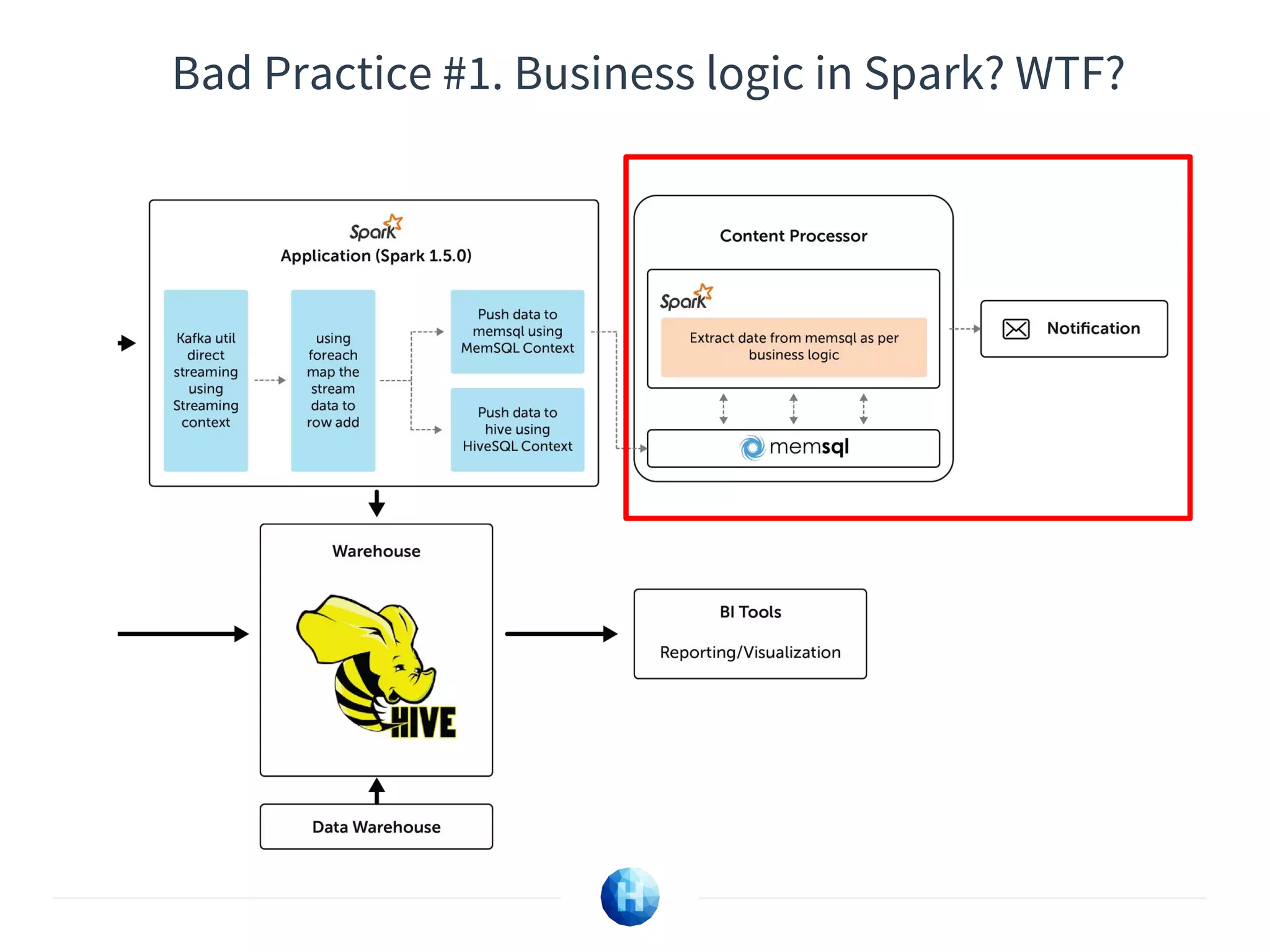


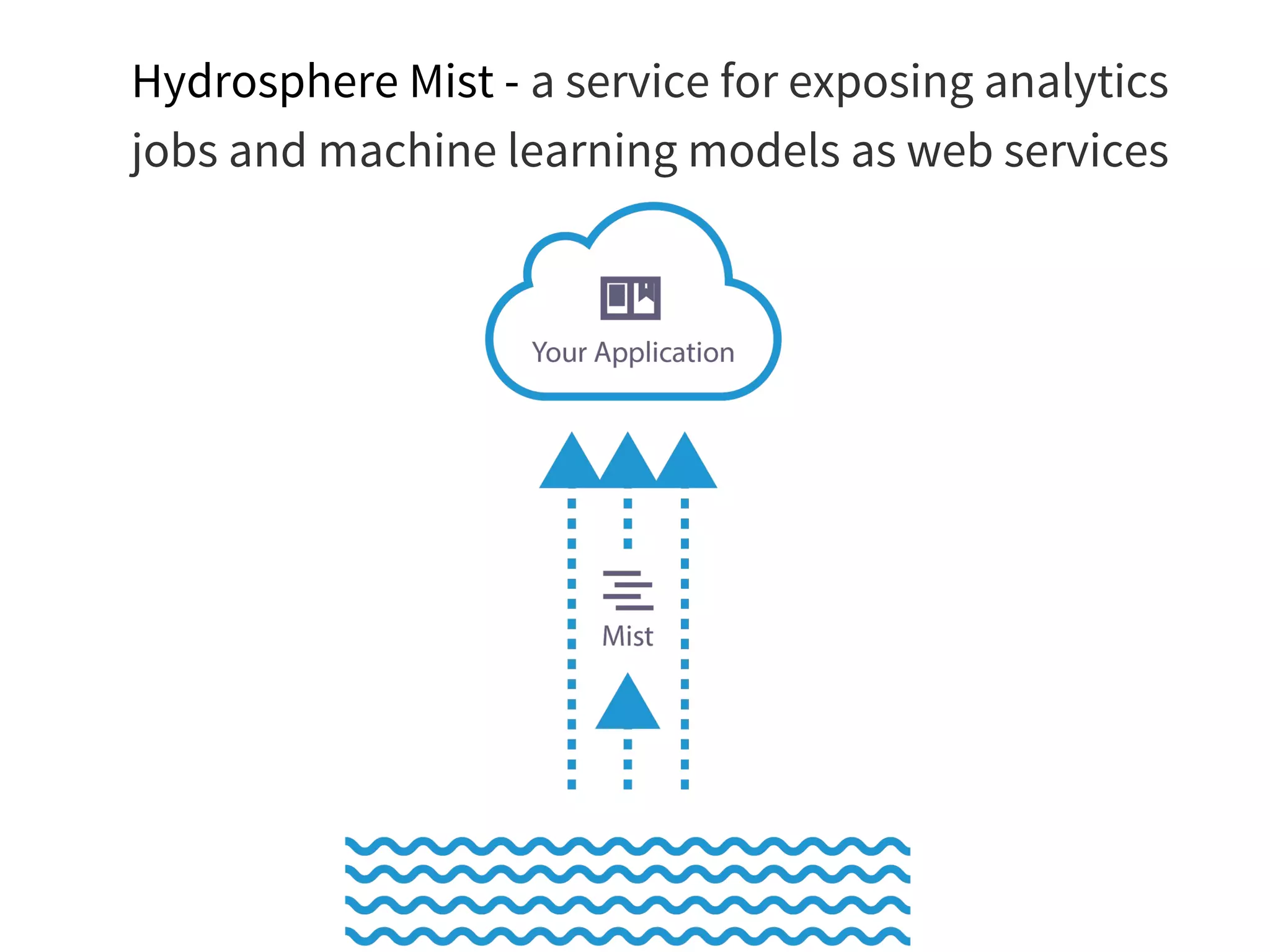

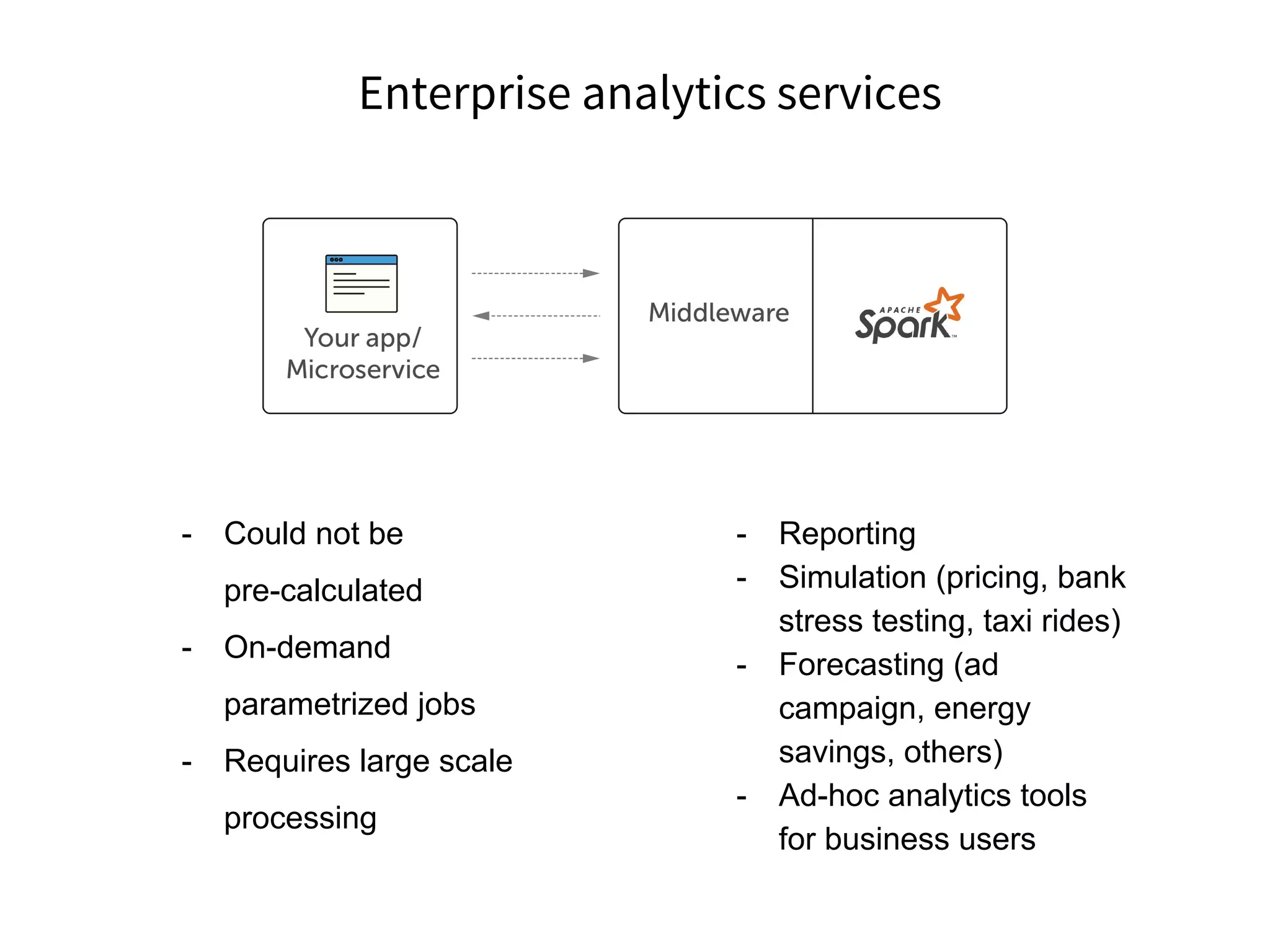

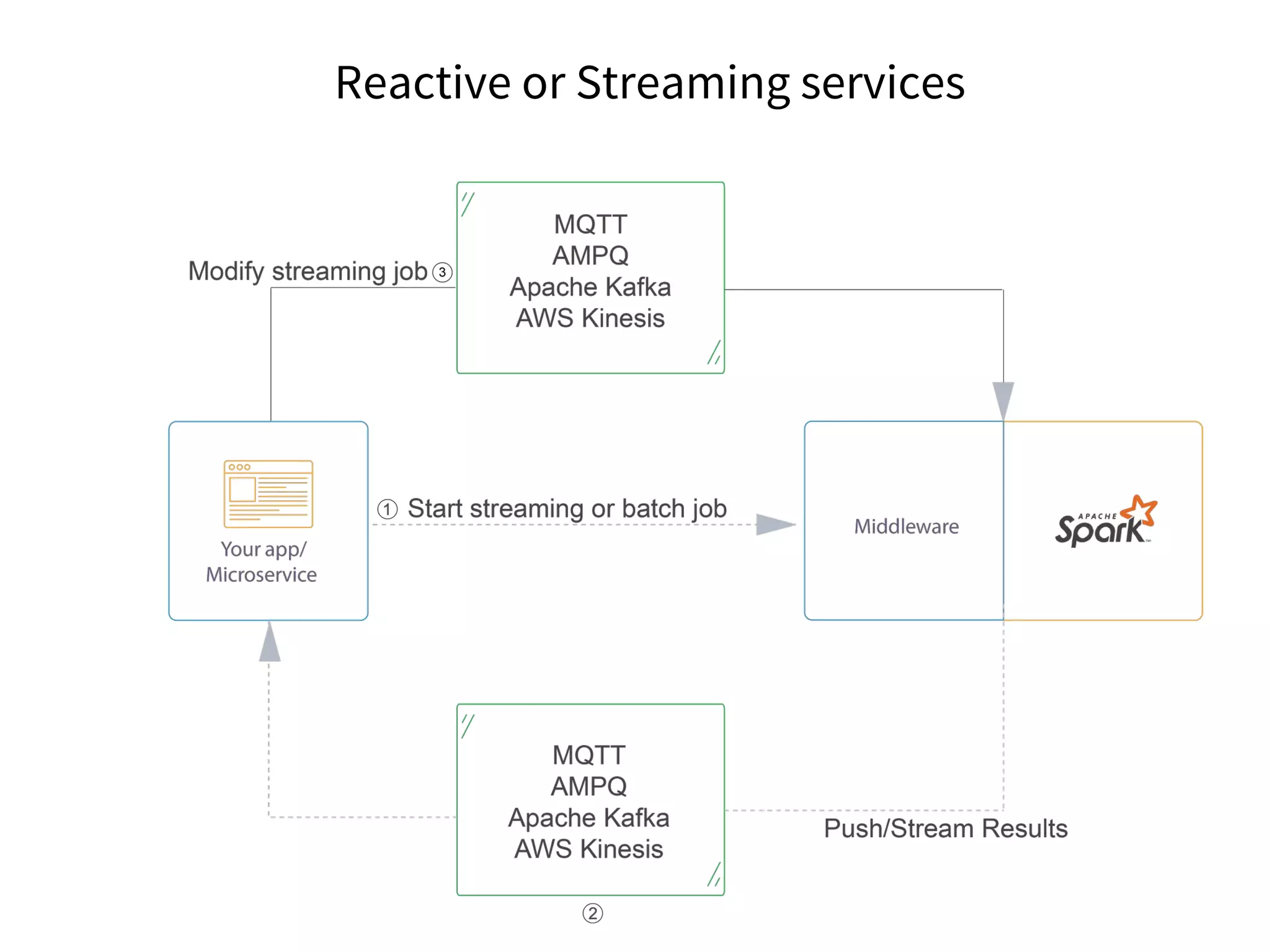
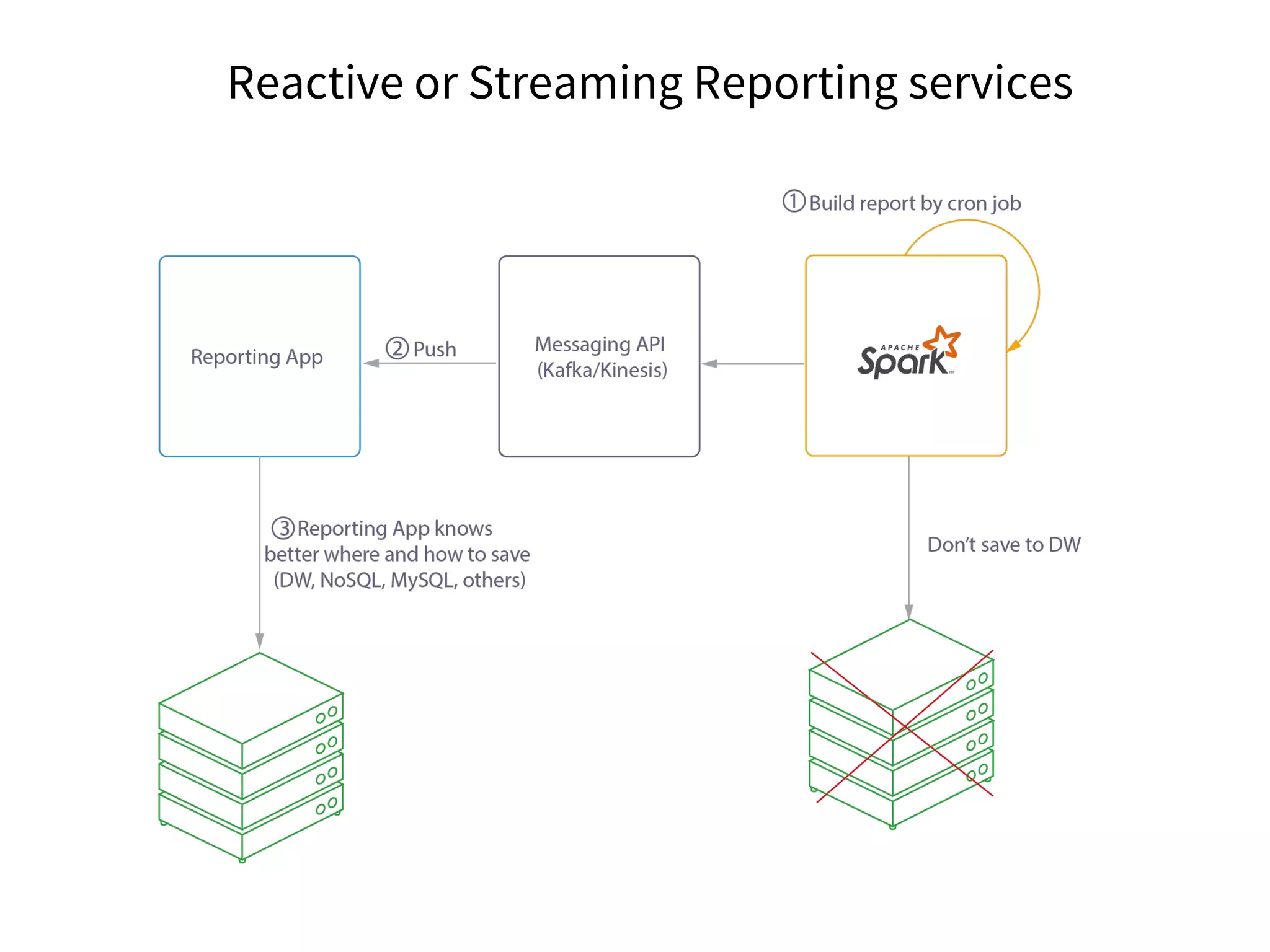

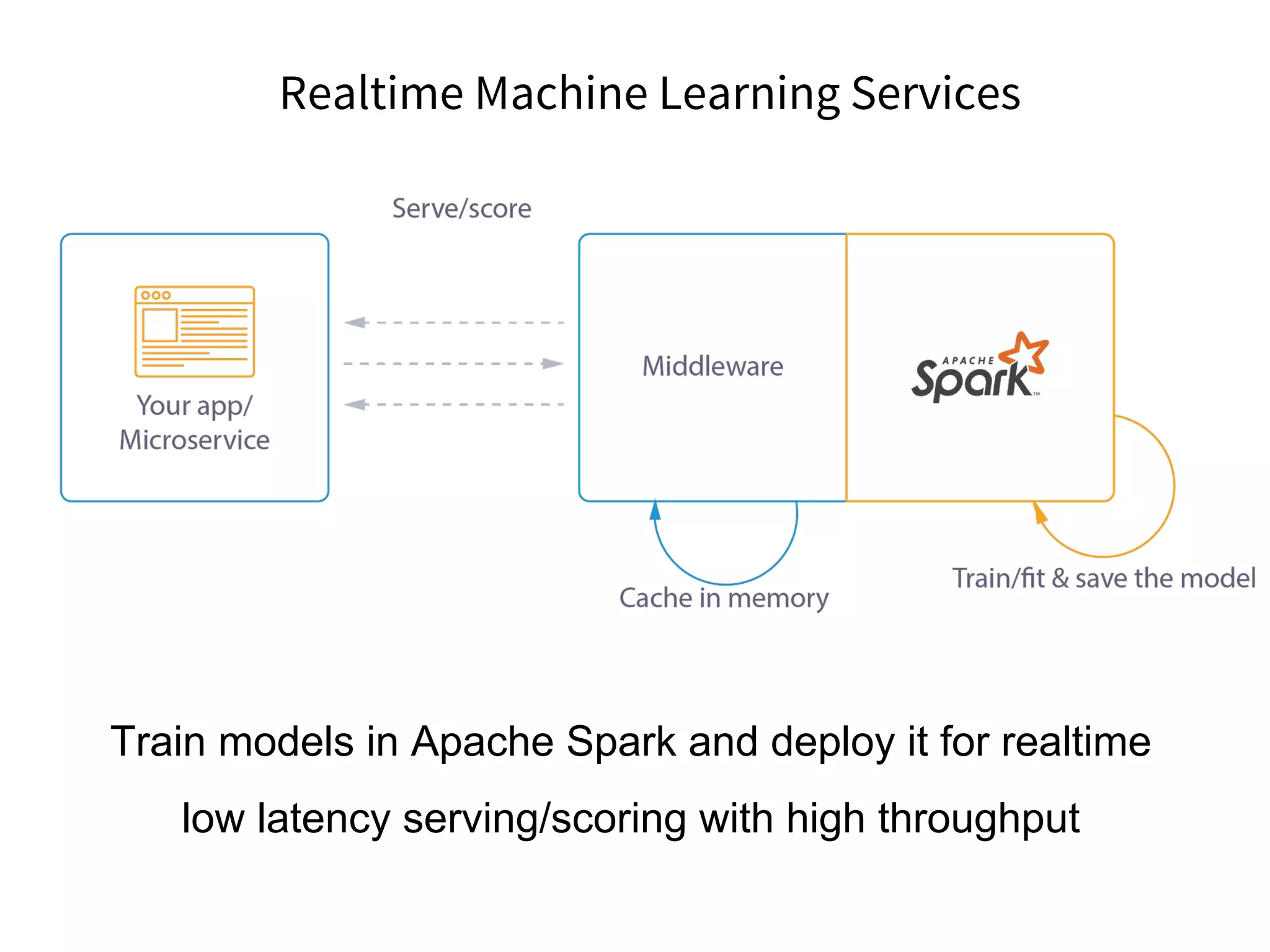


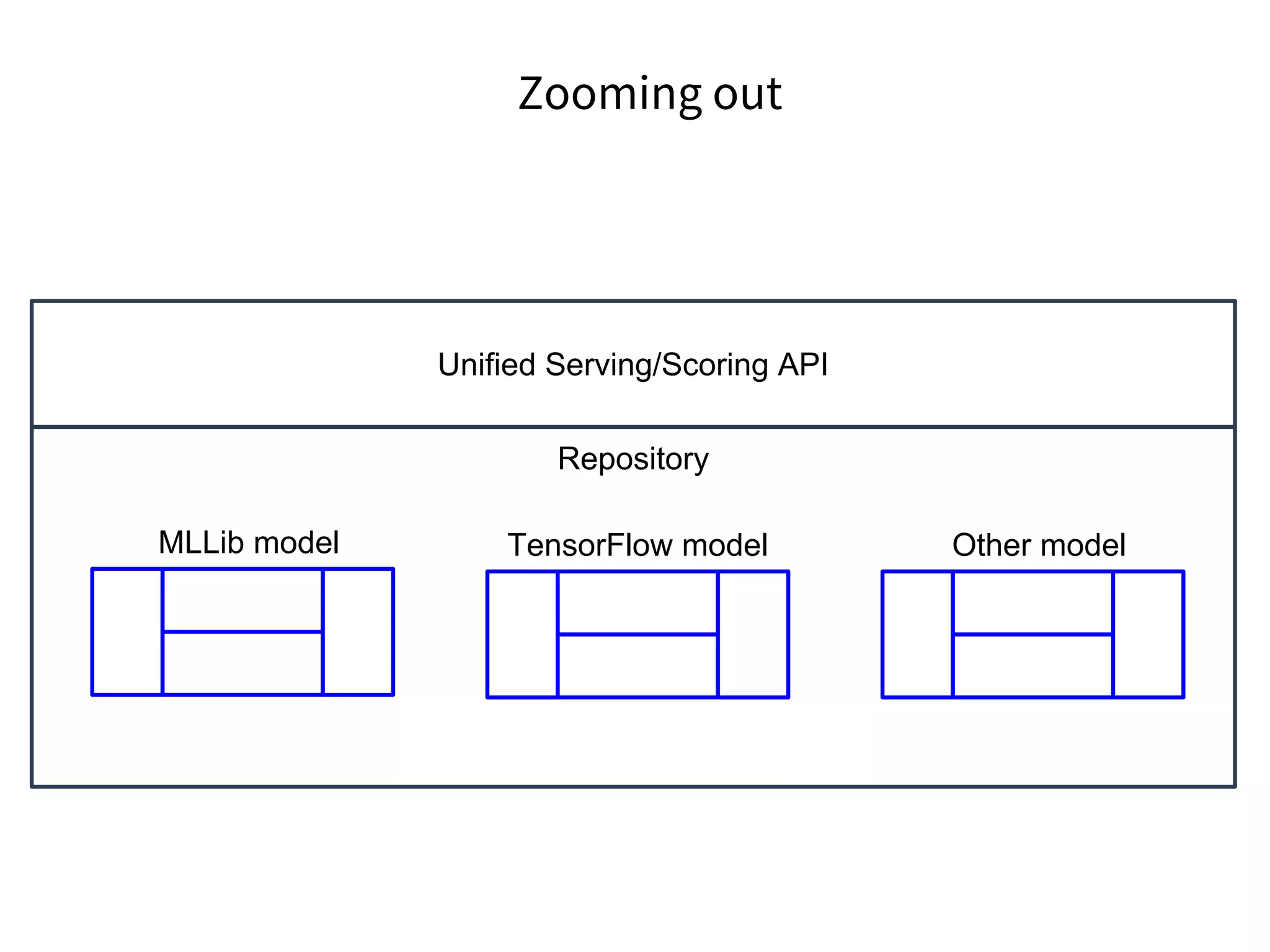












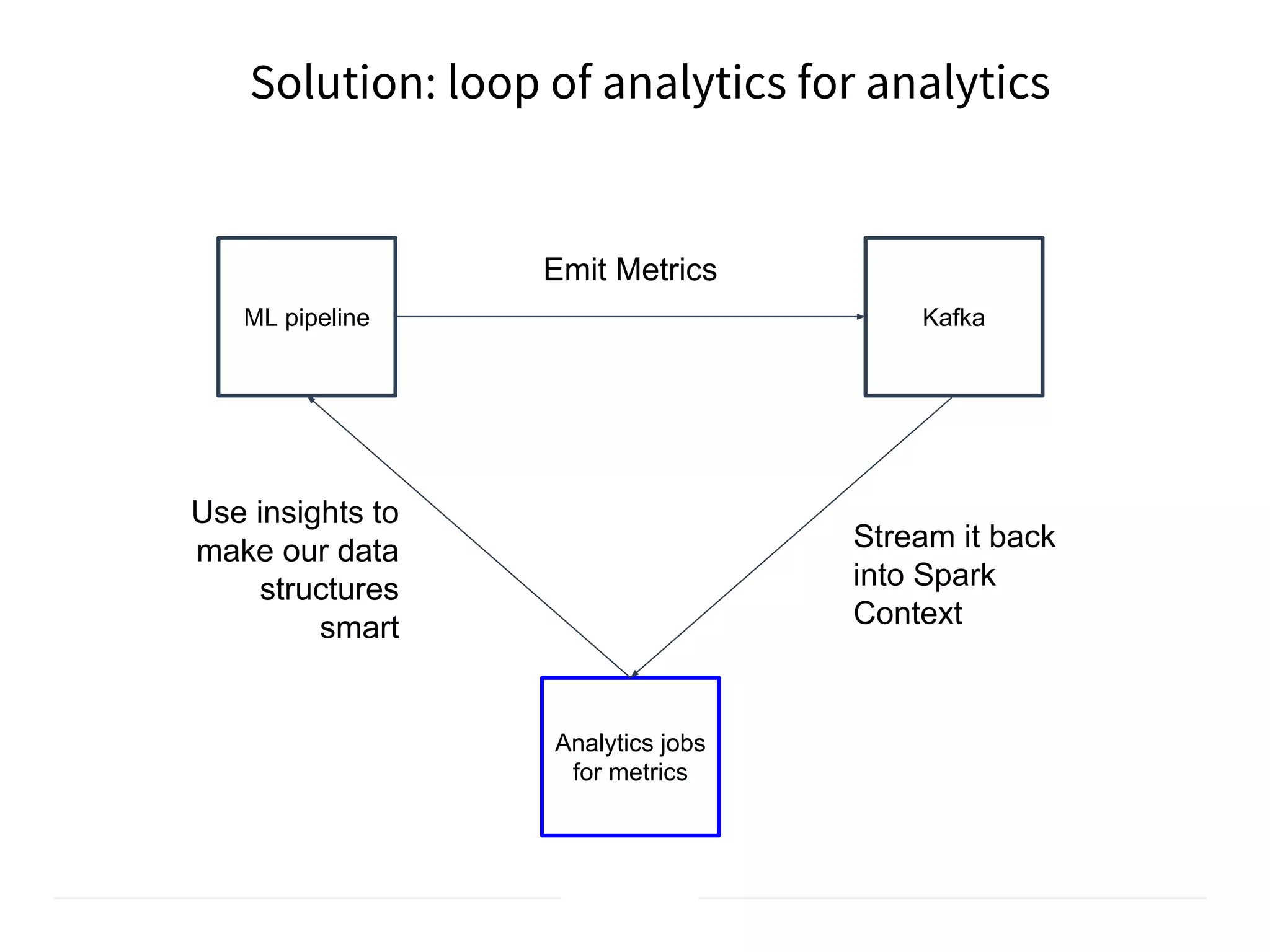


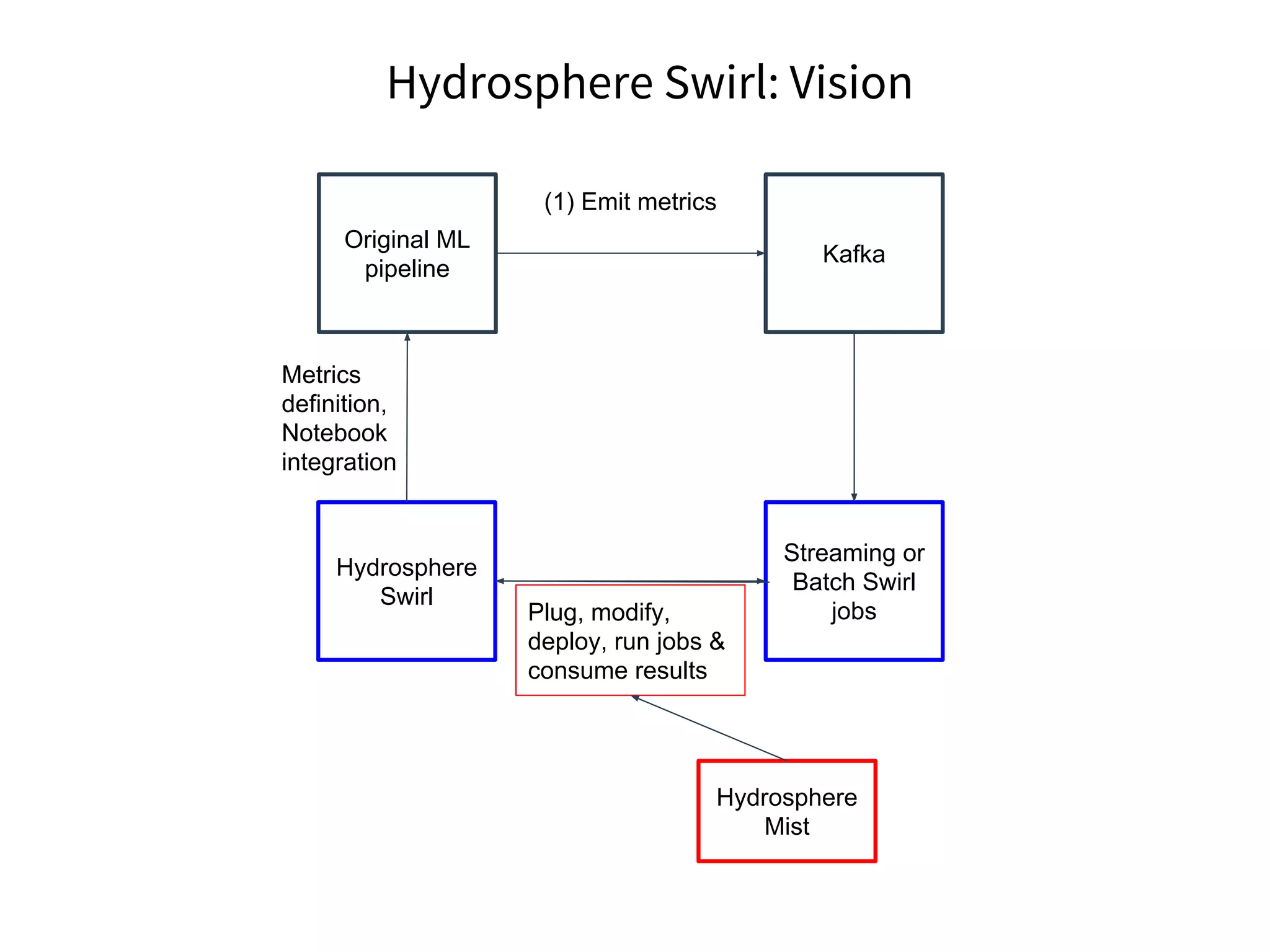

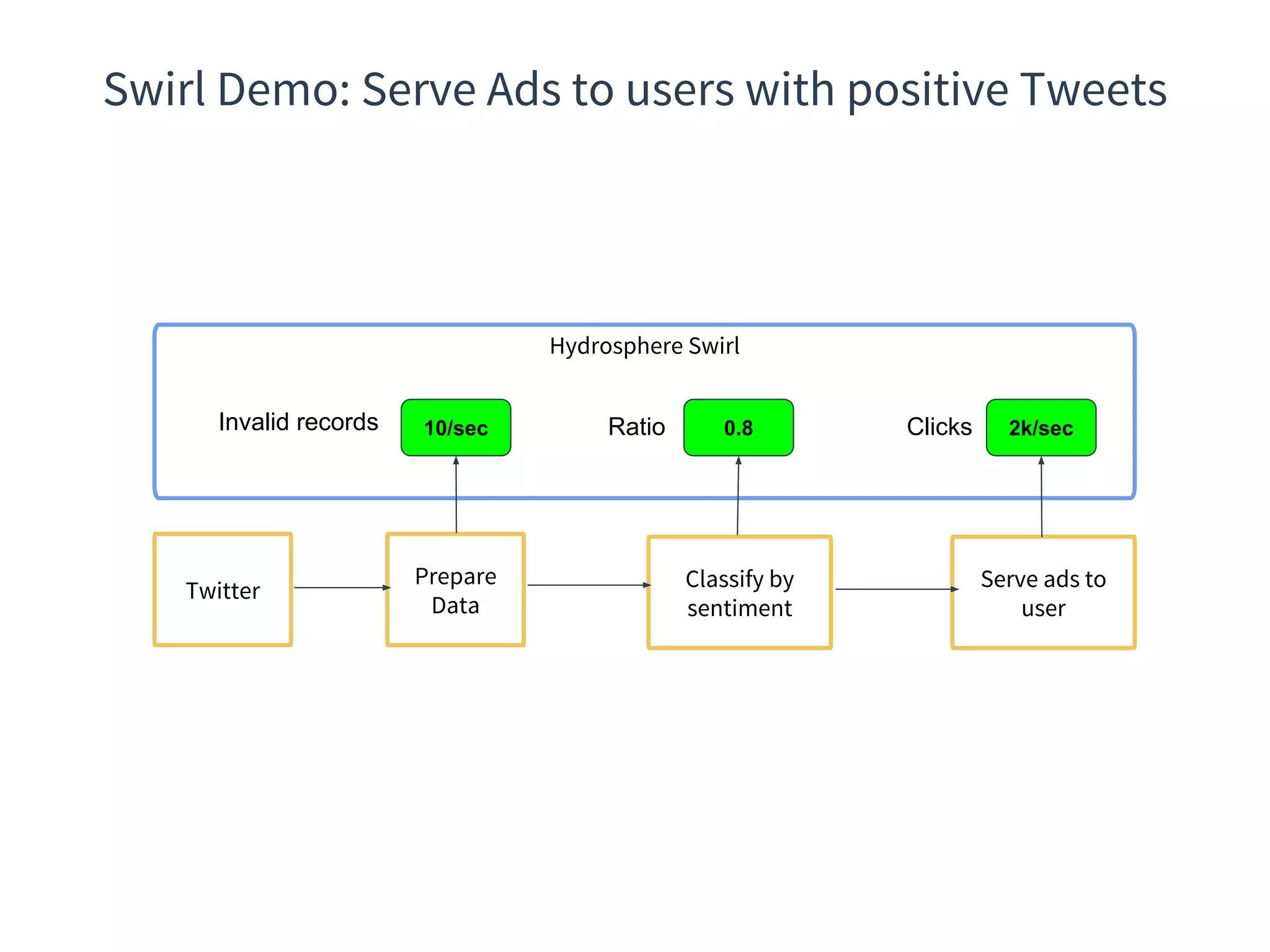
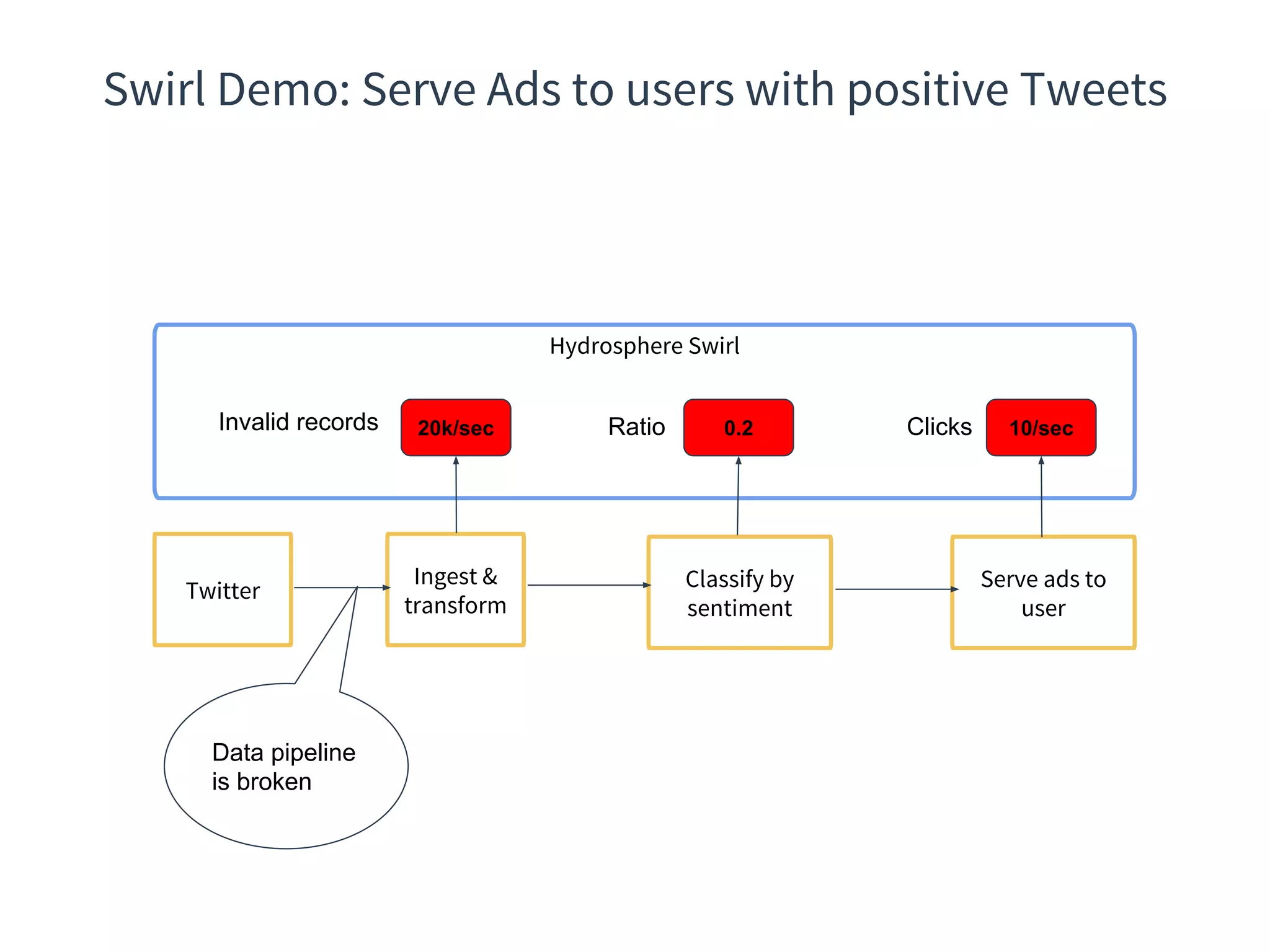
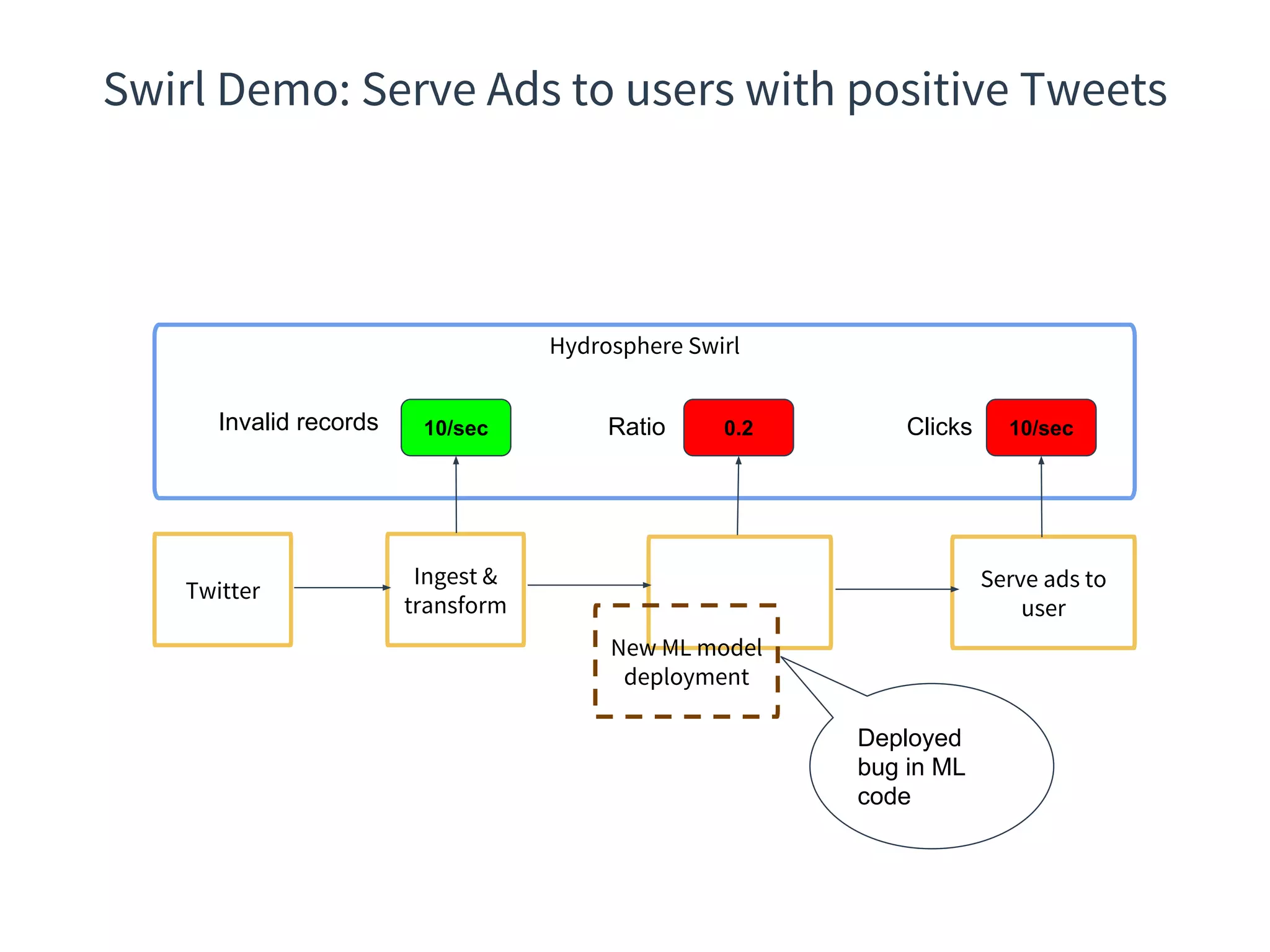































































The document discusses the integration of DevOps practices into data science, focusing on deploying analytics into production and the responsibilities of data scientists and data engineers. It outlines the importance of feedback loops, testing, and monitoring in the deployment process, as well as the challenges faced in ensuring analytics reliability. The presentation also introduces Hydrosphere's tools, like Mist and Swirl, for managing machine learning models and analytics services efficiently.









































































