Download as PDF, PPTX







![What are we deploying?
13
def predict(data):
data[‘is_good’] = data[‘rating’] > 3
return model.predict(data)
Advantages
• Flexibility: No need for complicated abstractions.
• Software deployment is a very mature field.
• Rapid model updating with continuous deployments.
Treat model deployment the same was as code deployment!](https://image.slidesharecdn.com/machinelearninginproduction-150928004829-lva1-app6891/75/Machine-learning-in-production-13-2048.jpg)
![What are we deploying?
def predict(data):
data[‘is_good’] = data[‘rating’] > 3
return model.predict(data)
def predict(data) : double = {
data[‘is_good’] = data[‘rating’] > 3
return model.predict(data)
}
predict <- function(data):
data$is_good = data$rating > 3
return predict(model, data)
14](https://image.slidesharecdn.com/machinelearninginproduction-150928004829-lva1-app6891/75/Machine-learning-in-production-14-2048.jpg)



















![What are we deploying?
def predict(data):
data[‘is_good’] = data[‘rating’] > 3
return model.predict(data)
def predict(data) : double = {
data[‘is_good’] = data[‘rating’] > 3
return model.predict(data)
}
predict <- function(data):
data$is_good = data$rating > 3
return predict(model, data)
49](https://image.slidesharecdn.com/machinelearninginproduction-150928004829-lva1-app6891/75/Machine-learning-in-production-49-2048.jpg)












![What are we deploying?
13
def predict(data):
data[‘is_good’] = data[‘rating’] > 3
return model.predict(data)
Advantages
• Flexibility: No need for complicated abstractions.
• Software deployment is a very mature field.
• Rapid model updating with continuous deployments.
Treat model deployment the same was as code deployment!](https://crownmelresort.com/image.slidesharecdn.com/machinelearninginproduction-150928004829-lva1-app6891/75/Machine-learning-in-production-13-2048.jpg)
![What are we deploying?
def predict(data):
data[‘is_good’] = data[‘rating’] > 3
return model.predict(data)
def predict(data) : double = {
data[‘is_good’] = data[‘rating’] > 3
return model.predict(data)
}
predict <- function(data):
data$is_good = data$rating > 3
return predict(model, data)
14](https://crownmelresort.com/image.slidesharecdn.com/machinelearninginproduction-150928004829-lva1-app6891/75/Machine-learning-in-production-14-2048.jpg)


































![What are we deploying?
def predict(data):
data[‘is_good’] = data[‘rating’] > 3
return model.predict(data)
def predict(data) : double = {
data[‘is_good’] = data[‘rating’] > 3
return model.predict(data)
}
predict <- function(data):
data$is_good = data$rating > 3
return predict(model, data)
49](https://crownmelresort.com/image.slidesharecdn.com/machinelearninginproduction-150928004829-lva1-app6891/75/Machine-learning-in-production-49-2048.jpg)


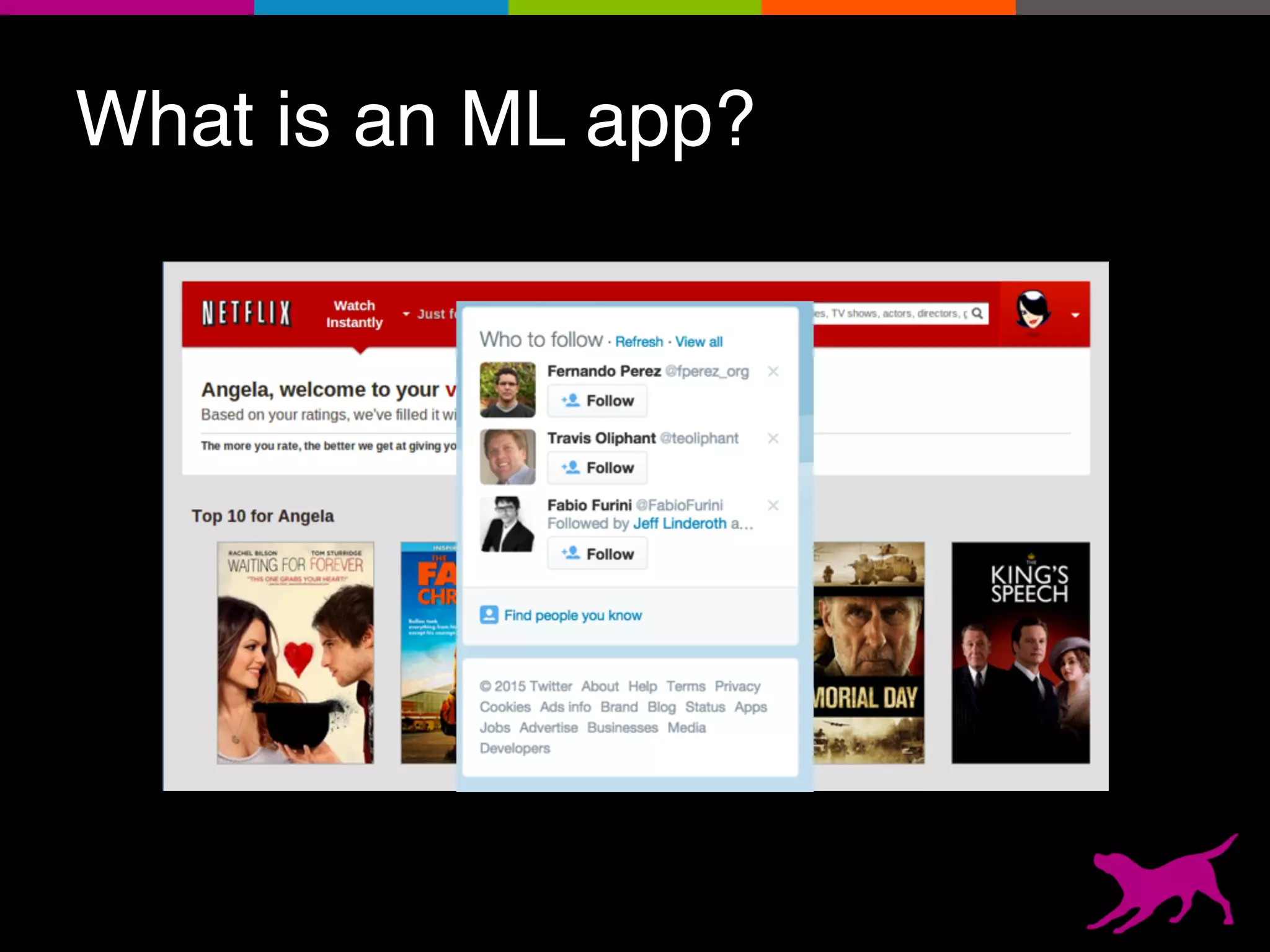
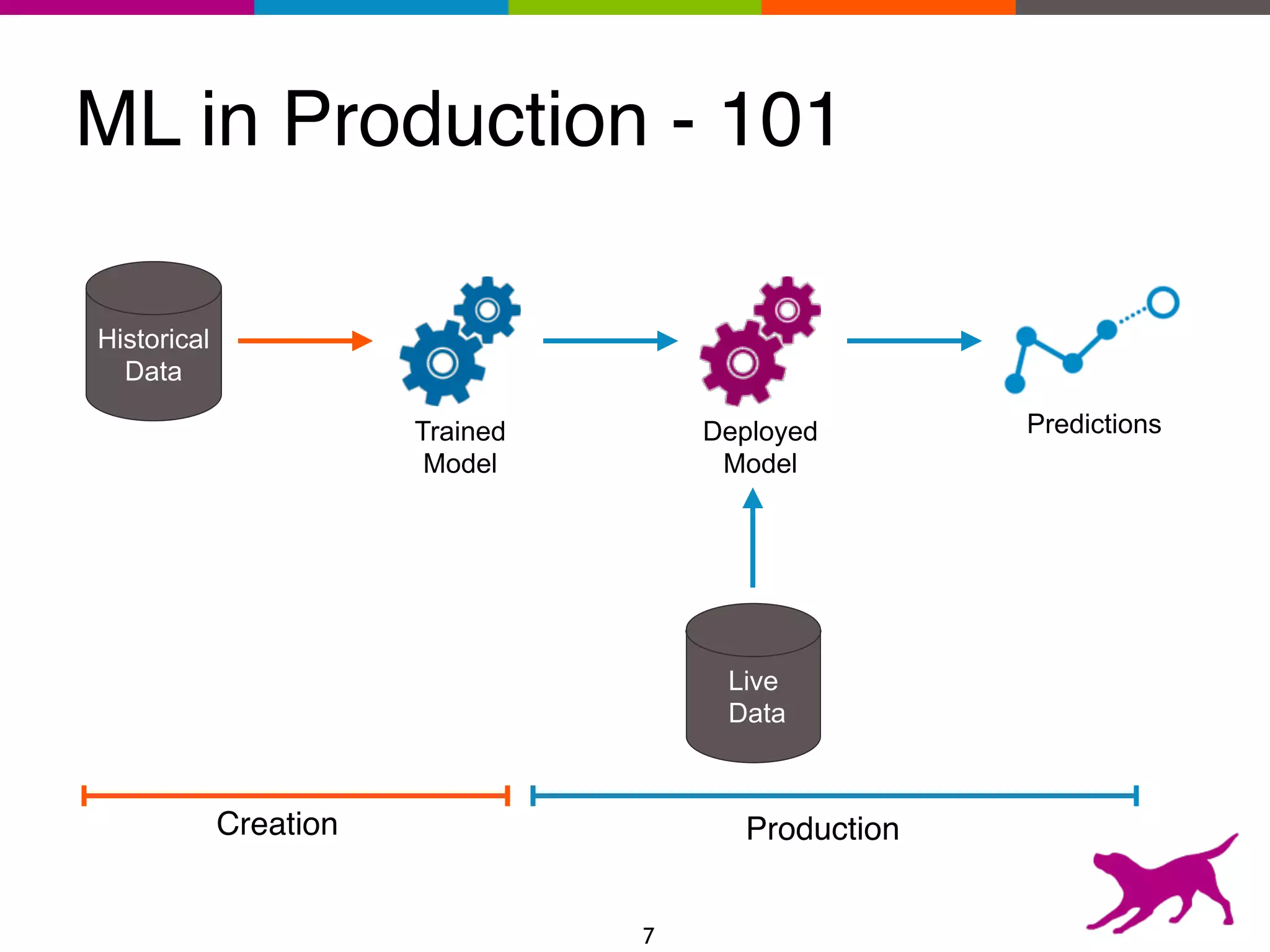
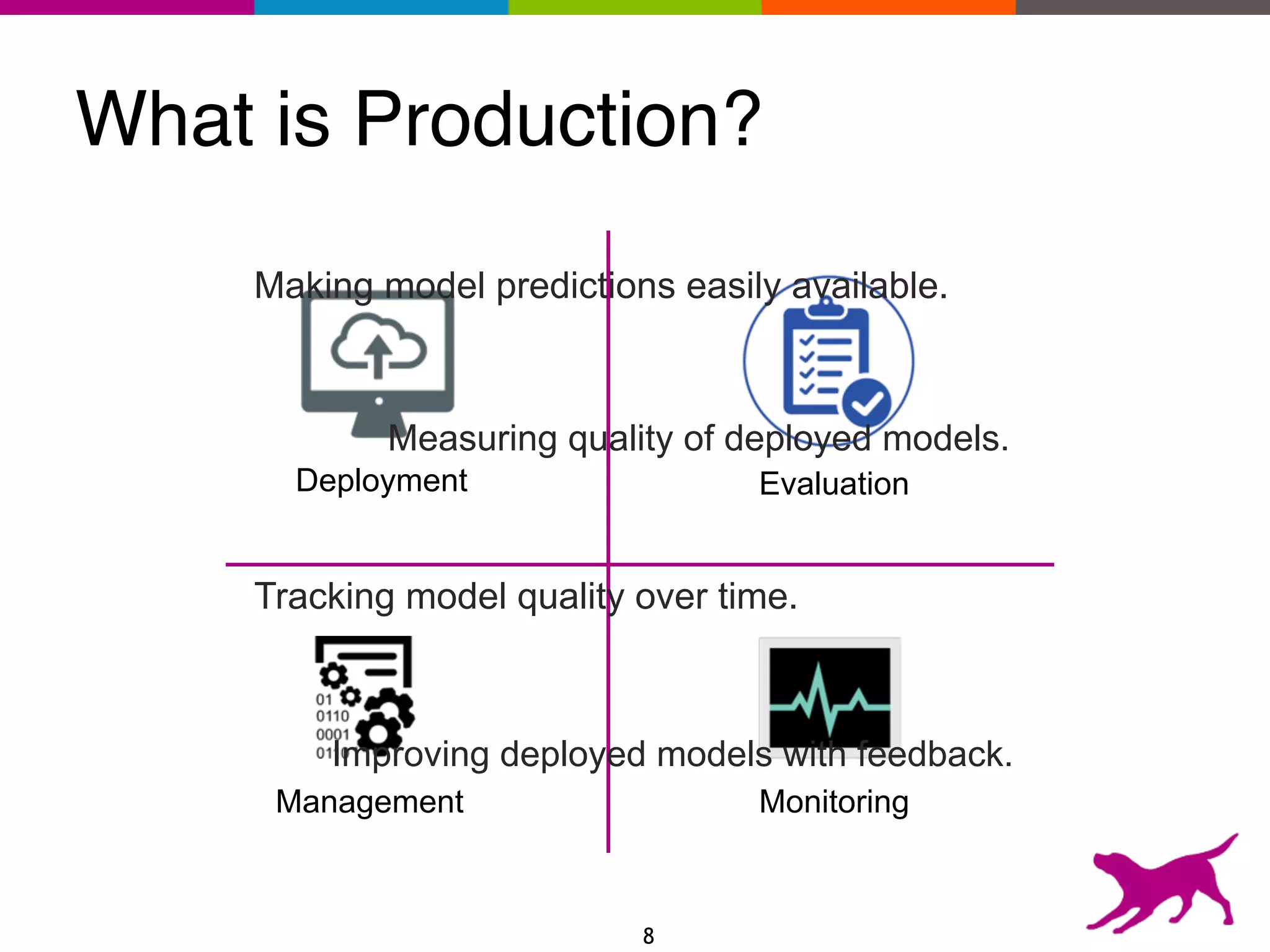
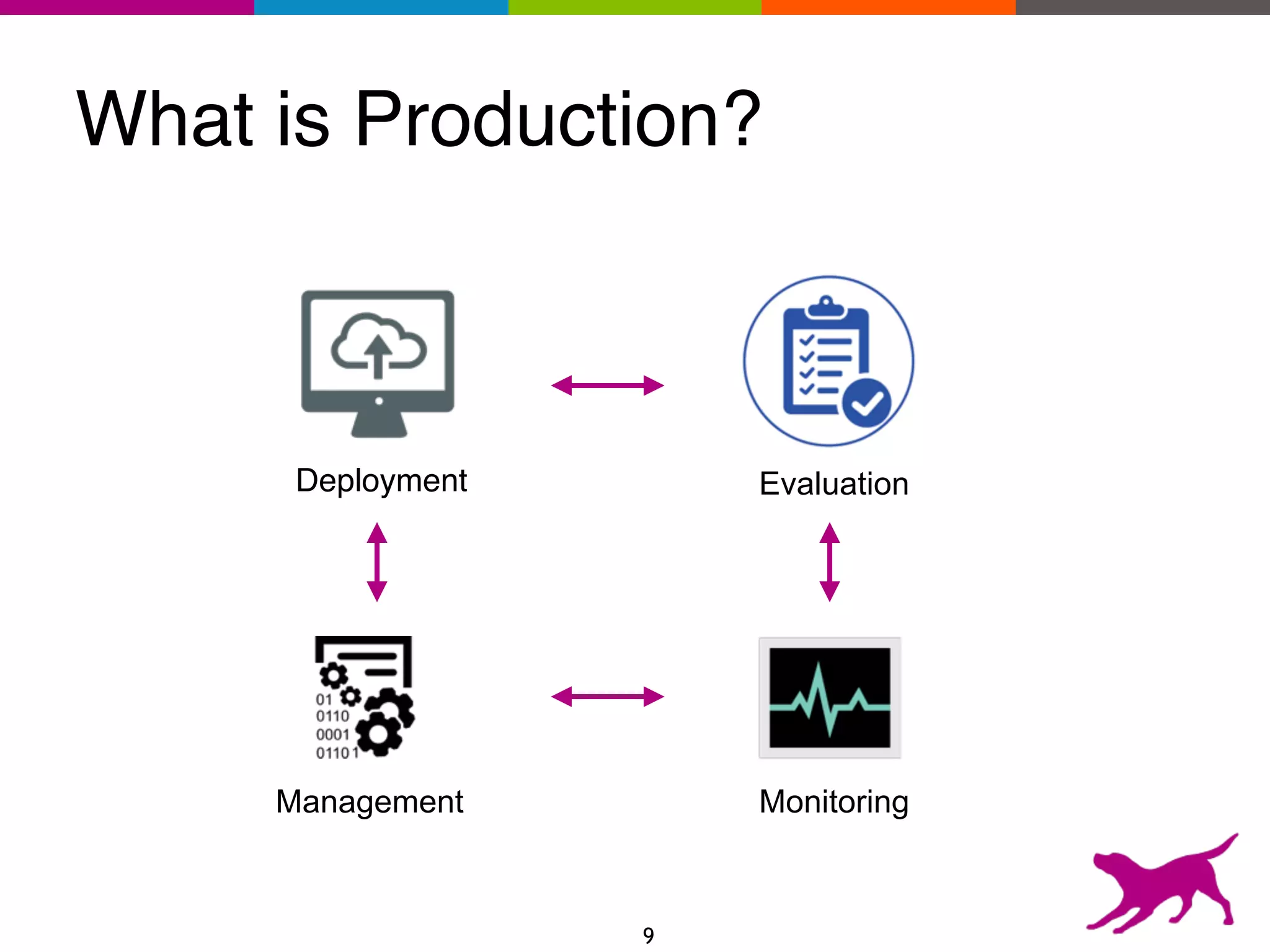
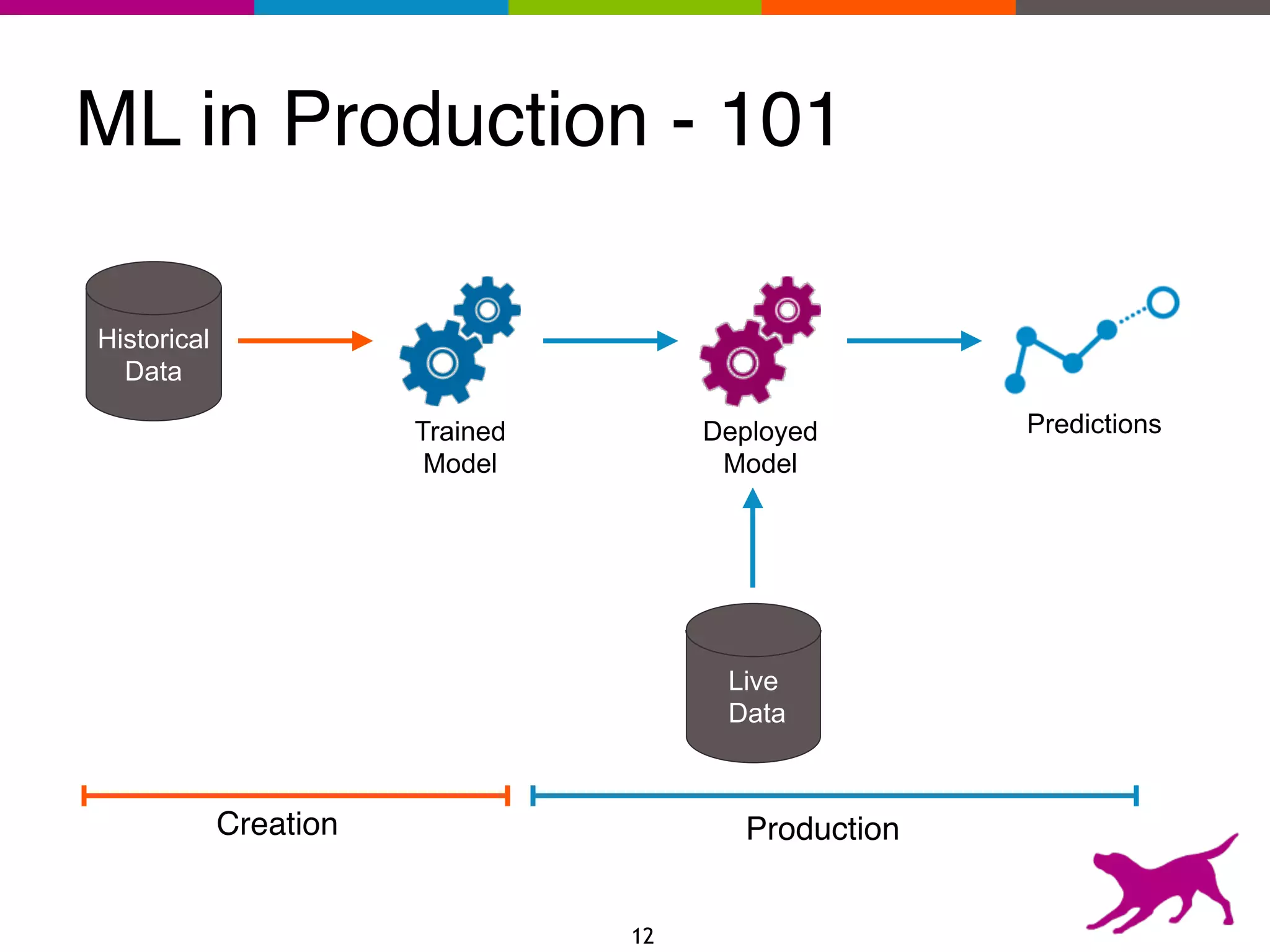
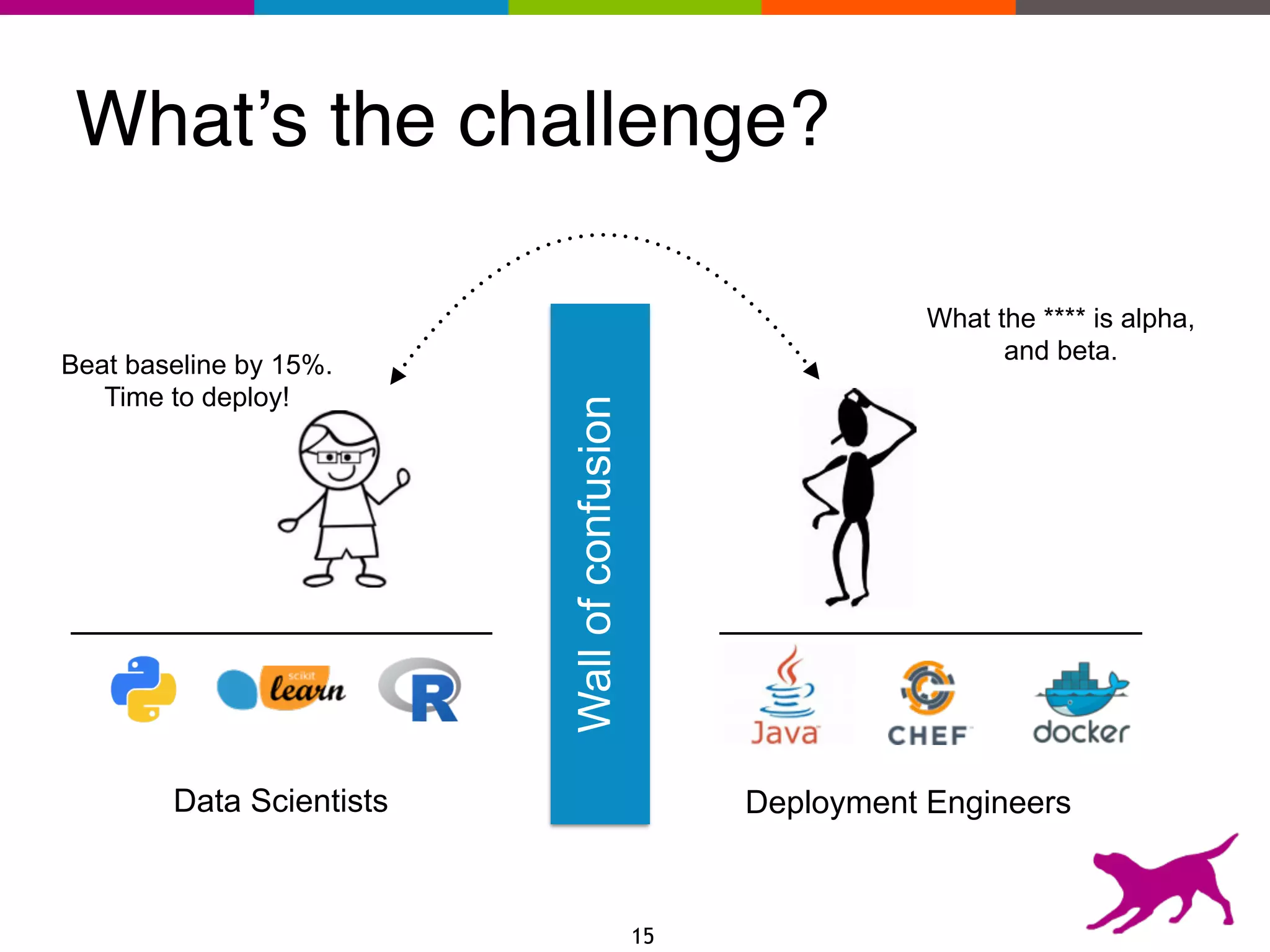
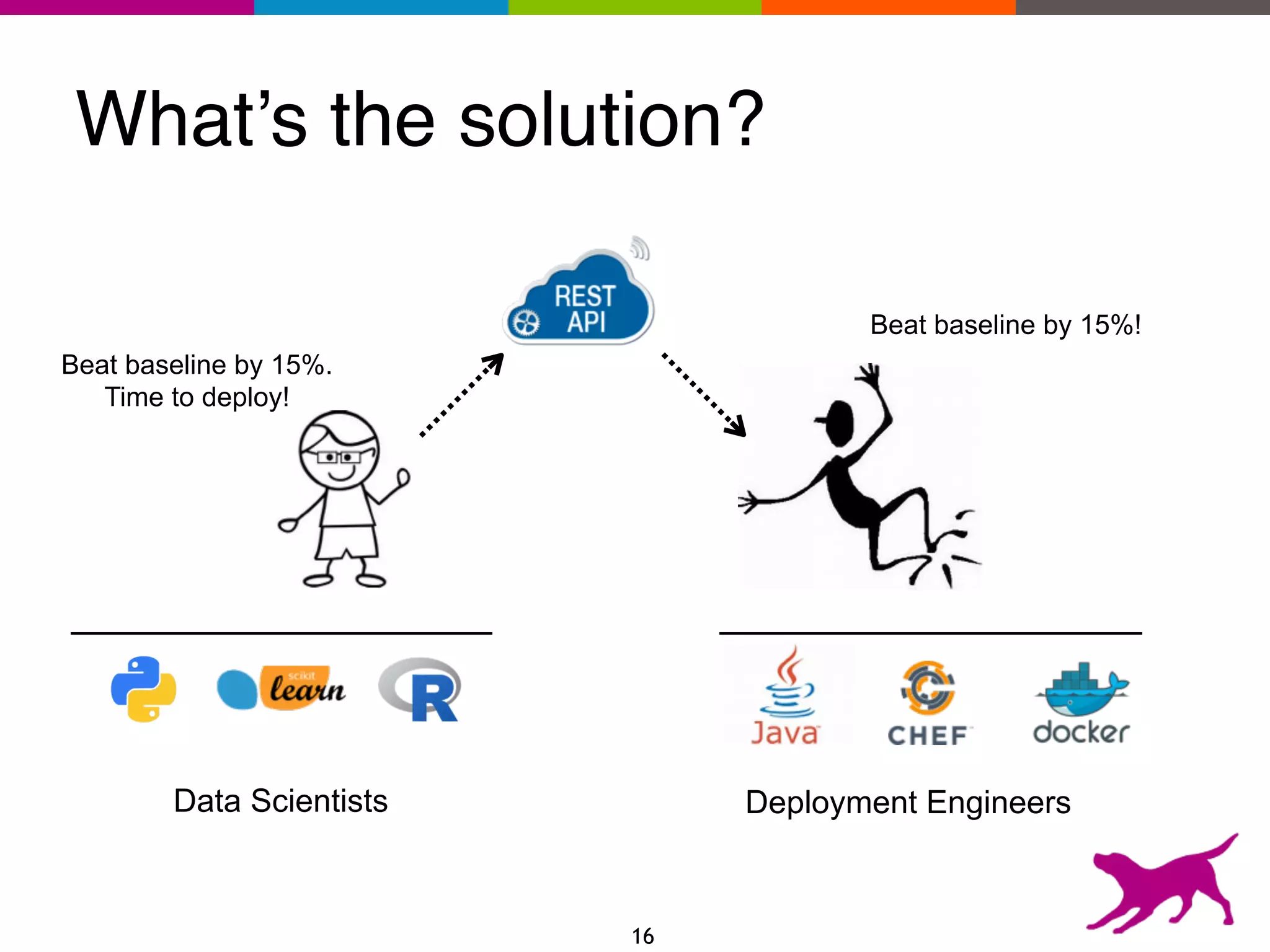
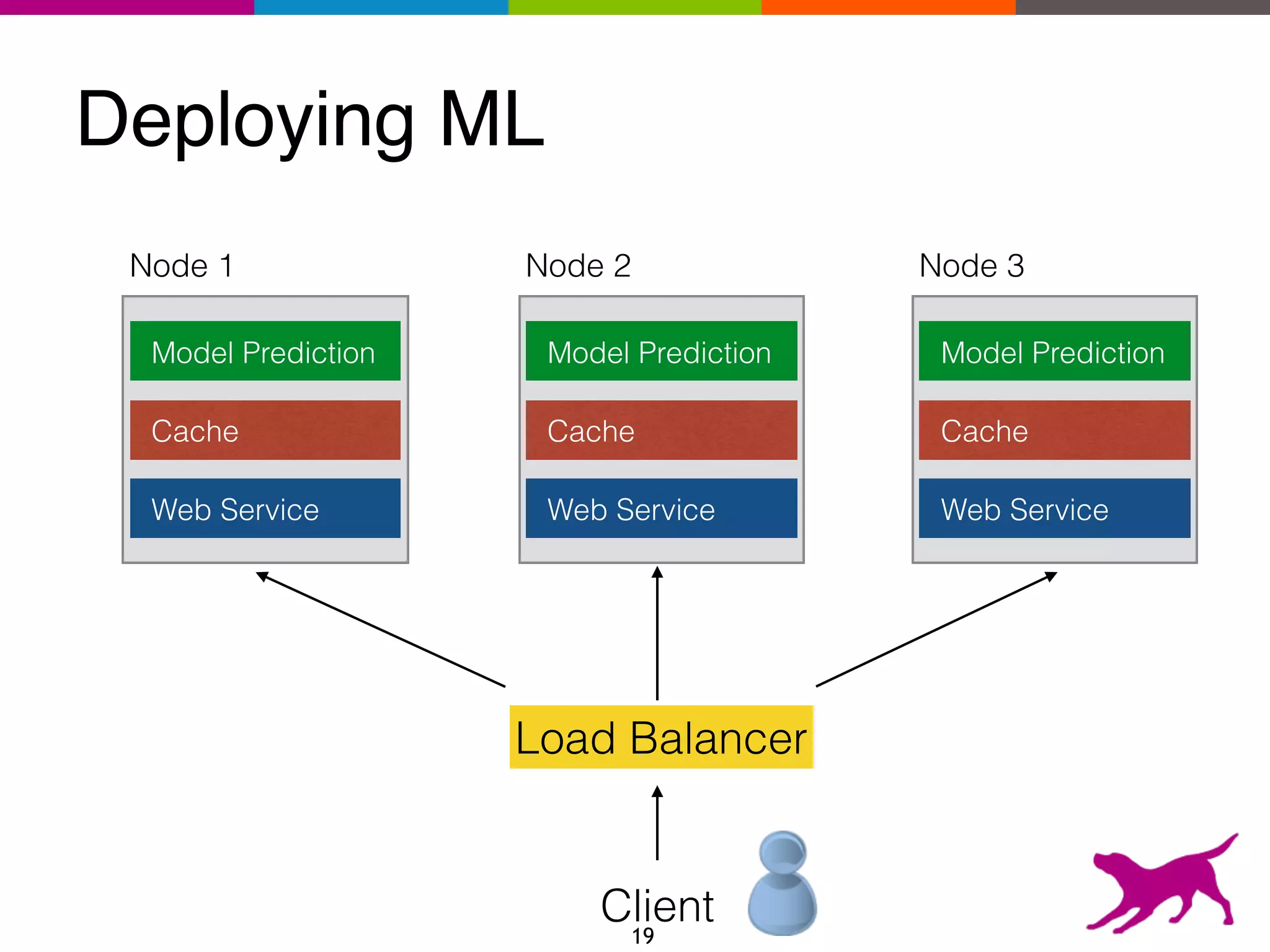
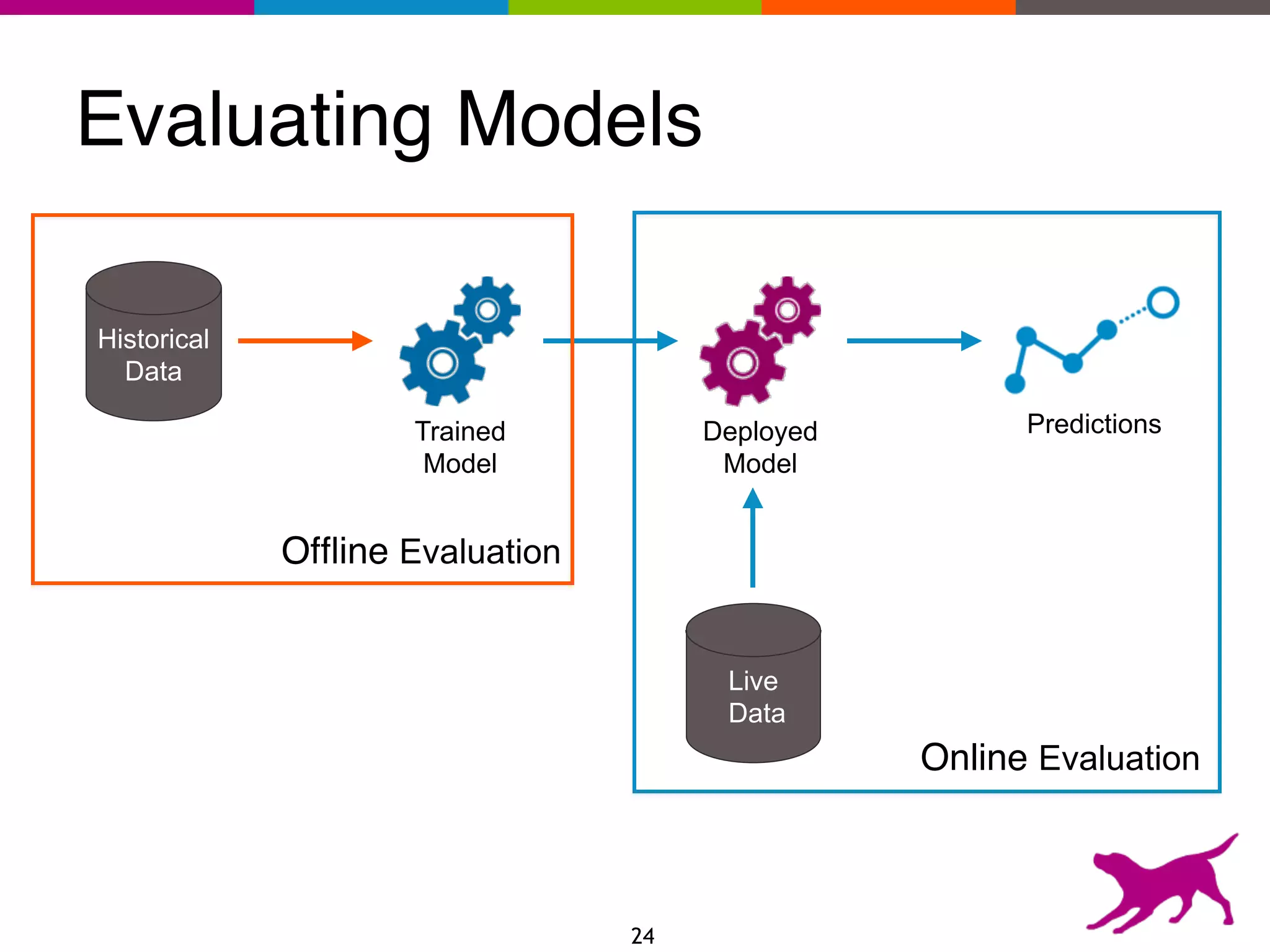
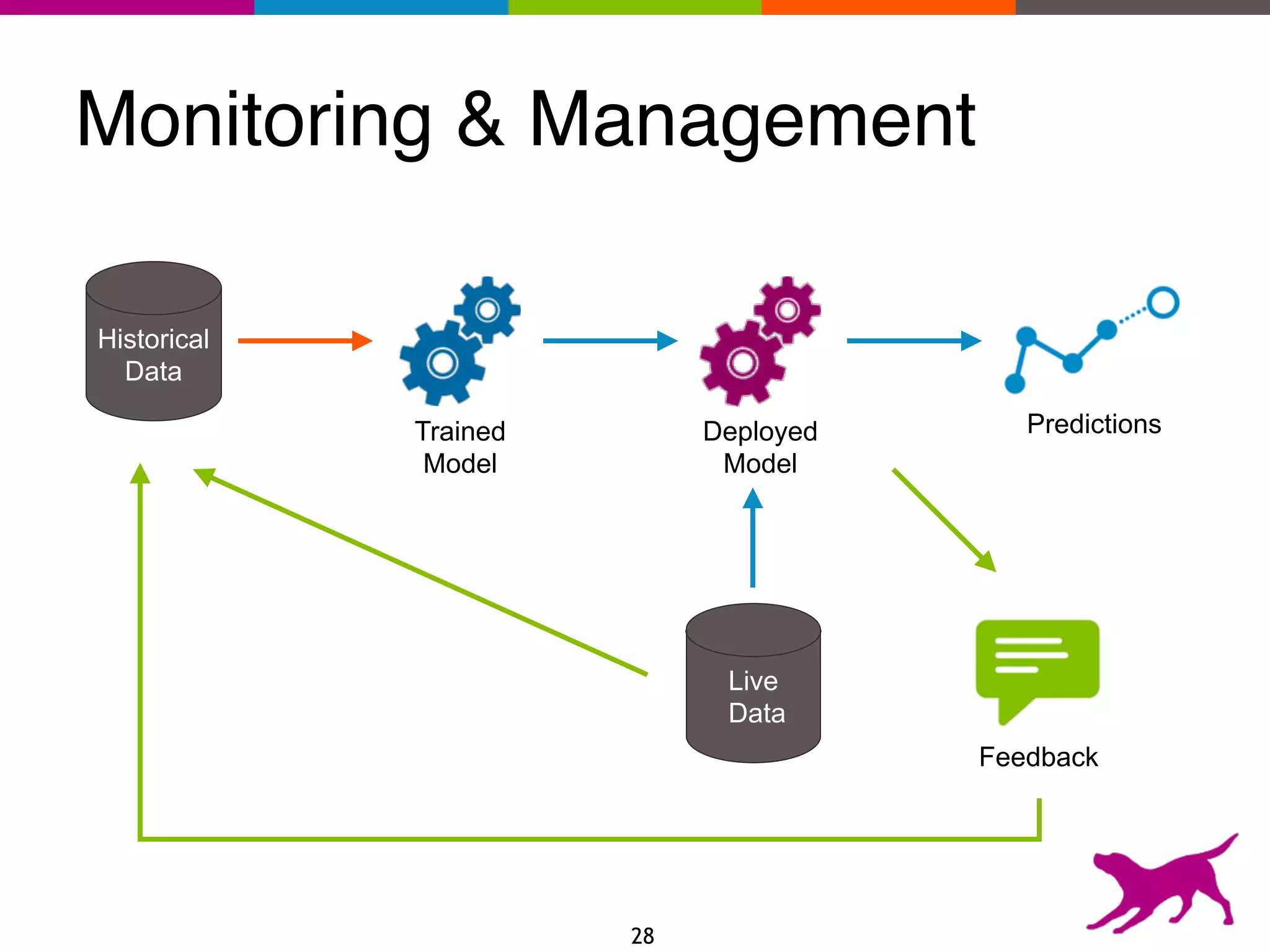
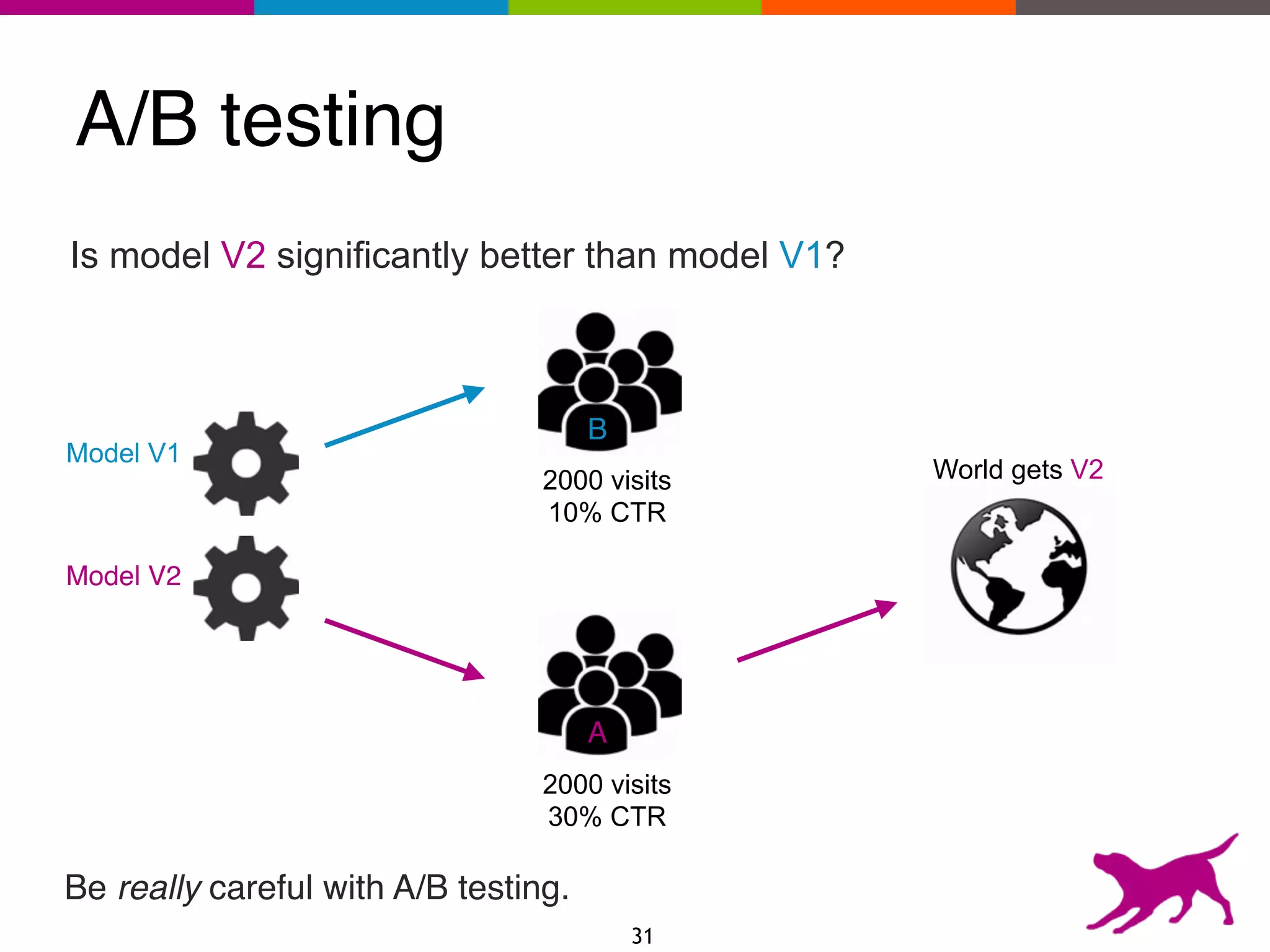
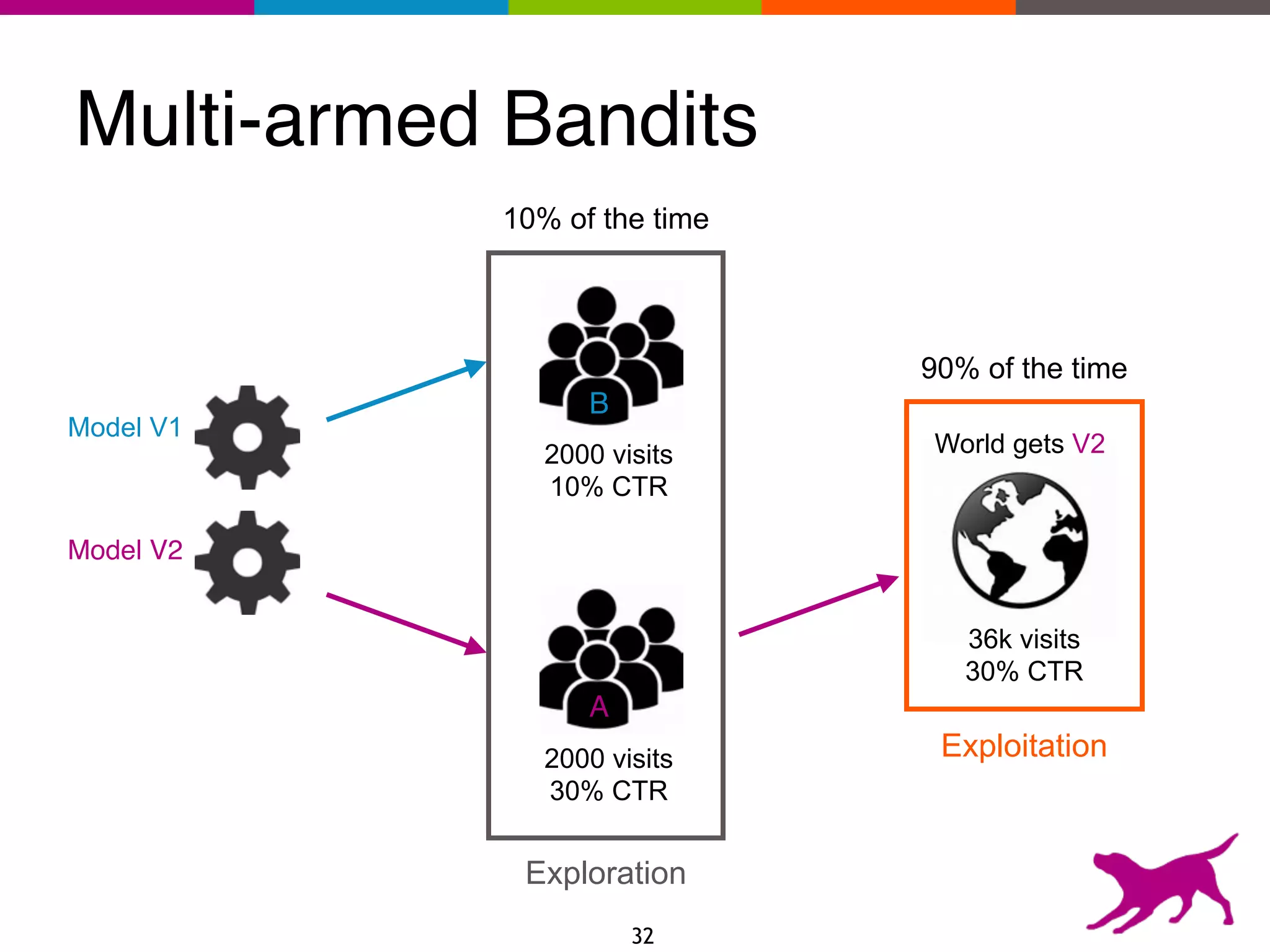
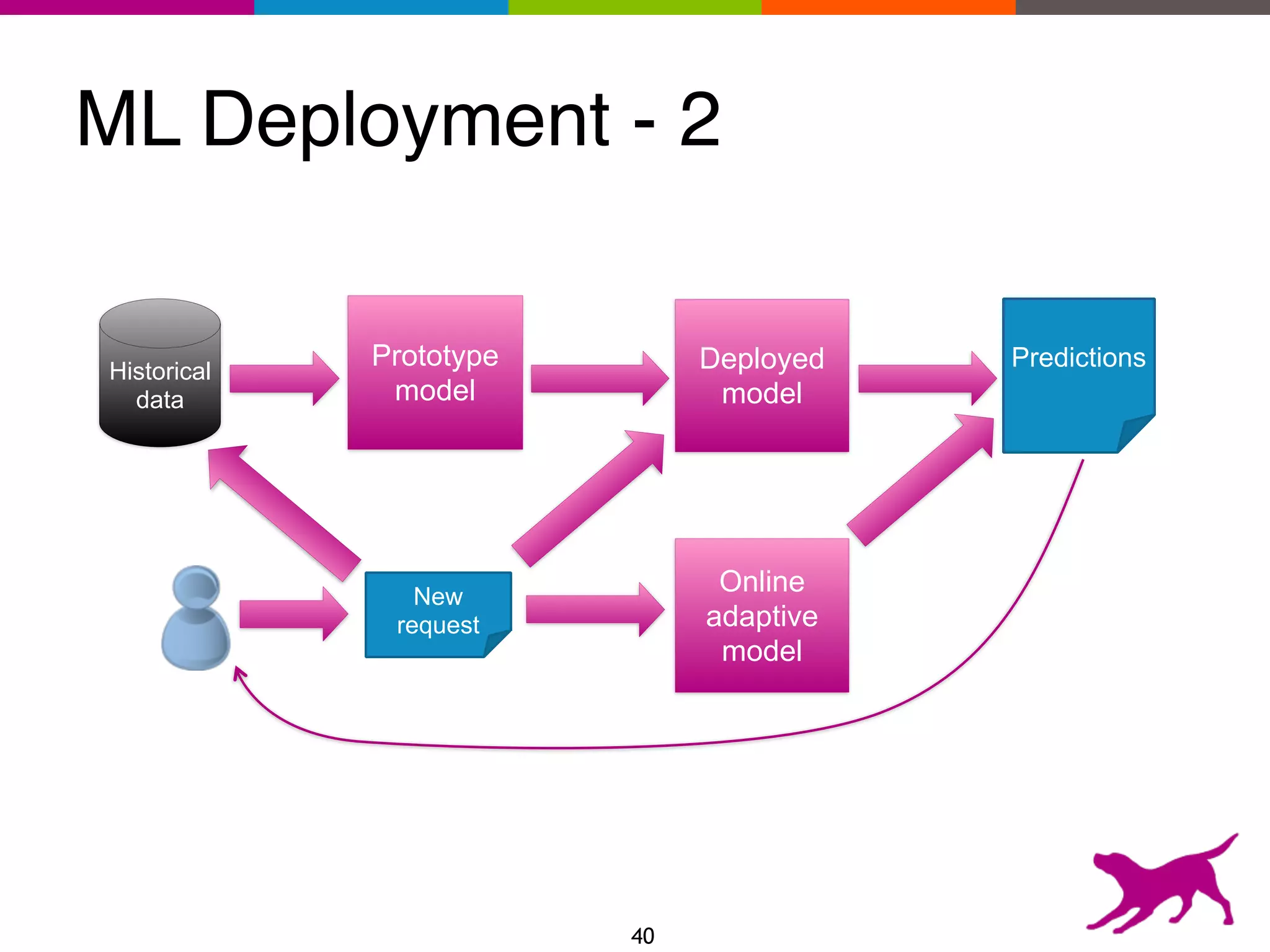
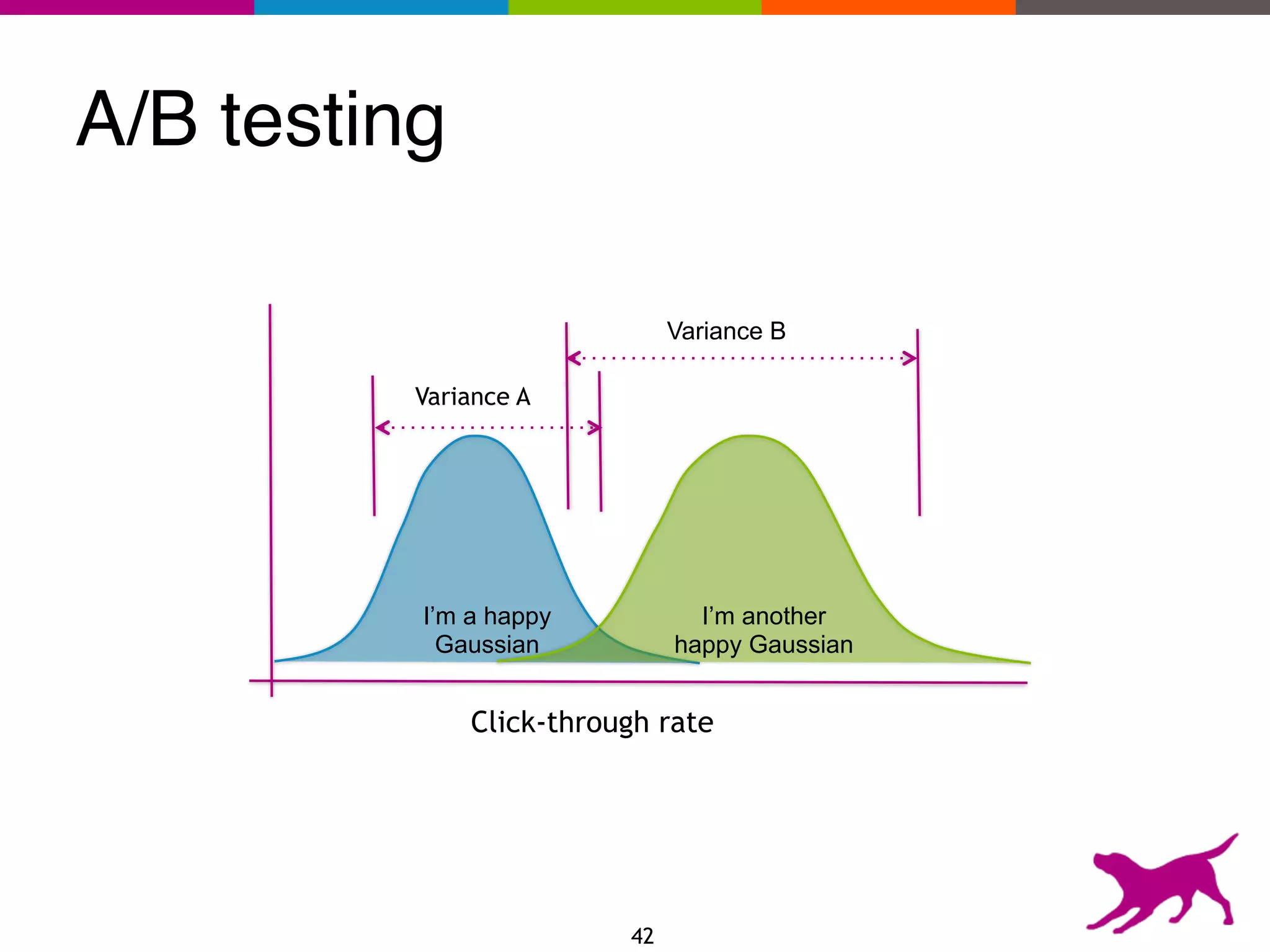
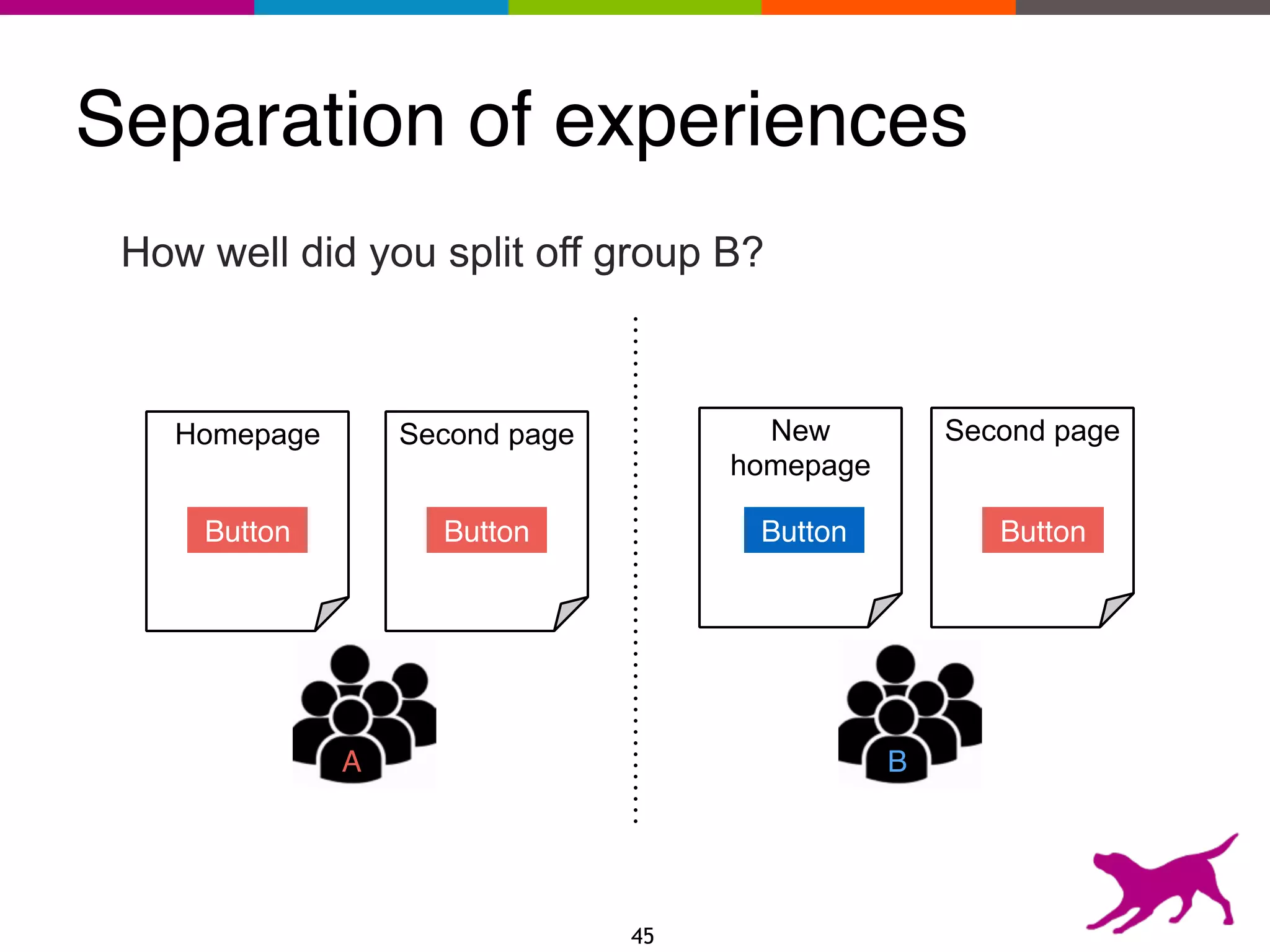
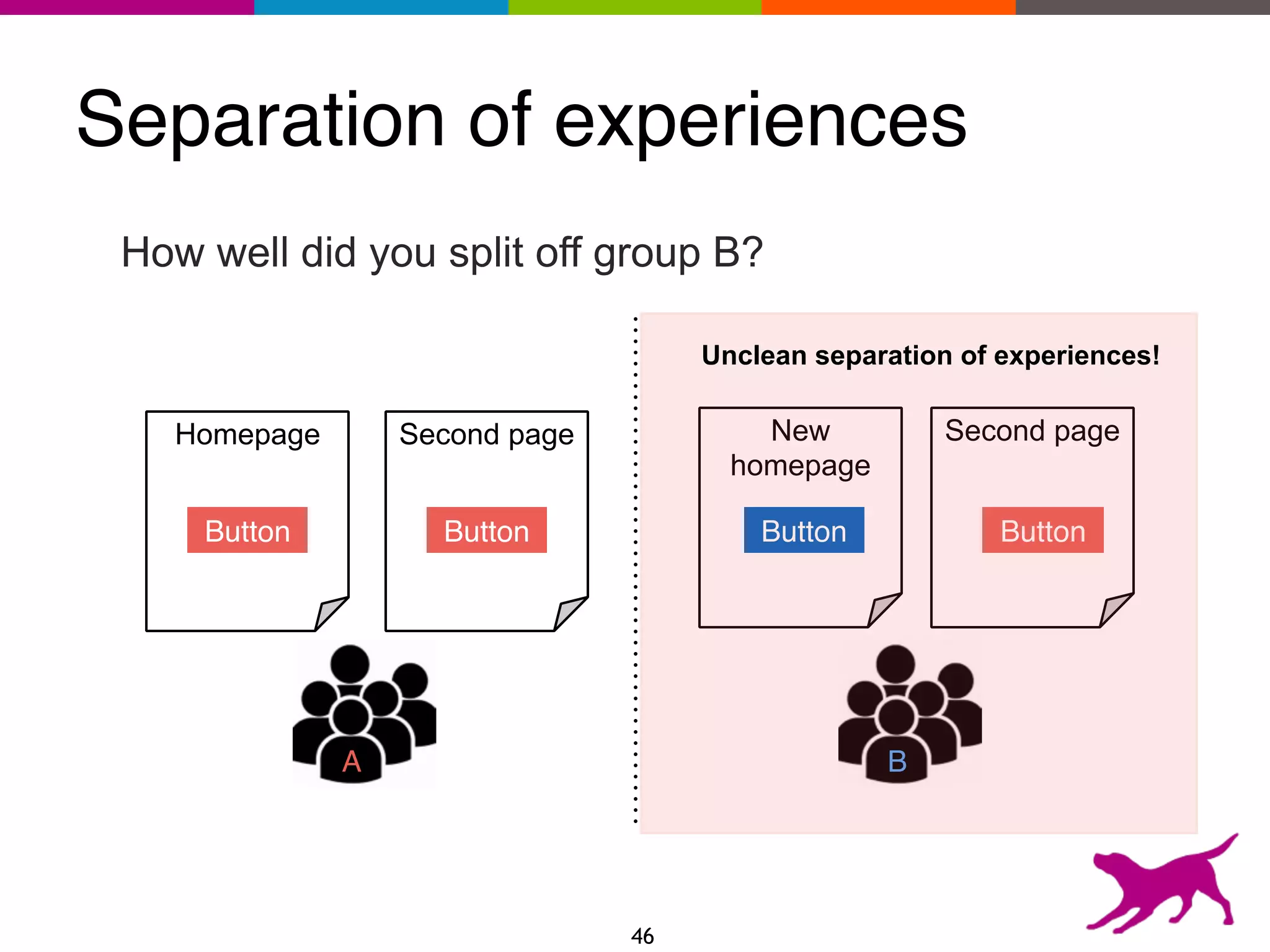
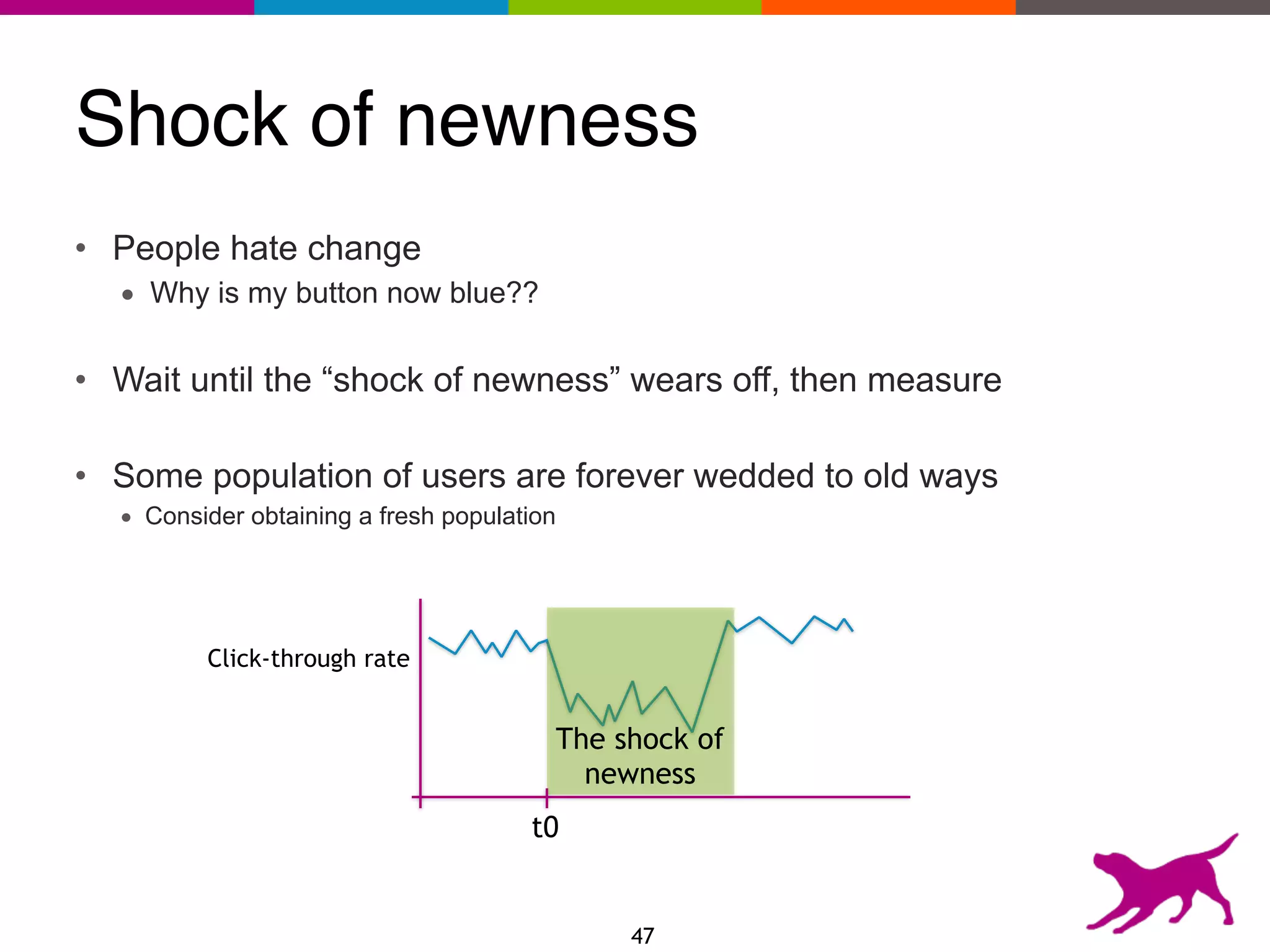
The document provides an overview of the challenges and strategies involved in deploying machine learning models in production environments, emphasizing the importance of evaluation, monitoring, and continuous model improvement. It discusses the required features for successful deployment, such as ease of integration, low latency, fault tolerance, scalability, and maintainability, while also highlighting evaluation metrics and the differences between business and model performance metrics. The conclusion stresses the need for careful testing methods like A/B testing and multi-armed bandits to track model effectiveness over time.










![[QCon.ai 2019] People You May Know: Fast Recommendations Over Massive Data](https://cdn.slidesharecdn.com/ss_thumbnails/qconaisf2019-pymk-190424130904-thumbnail.jpg?width=640&height=640&fit=bounds)
























































































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)

