Downloaded 149 times






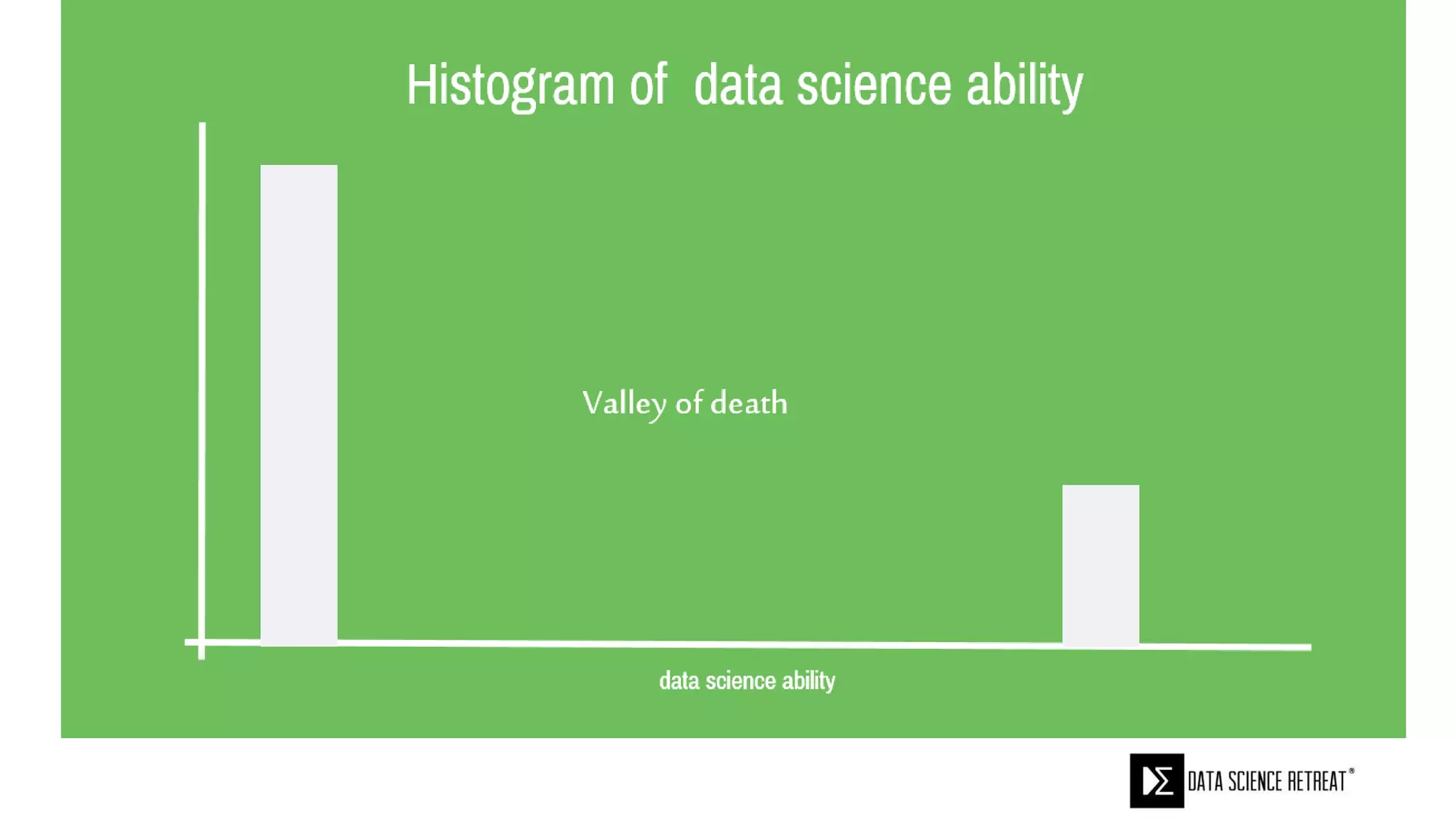








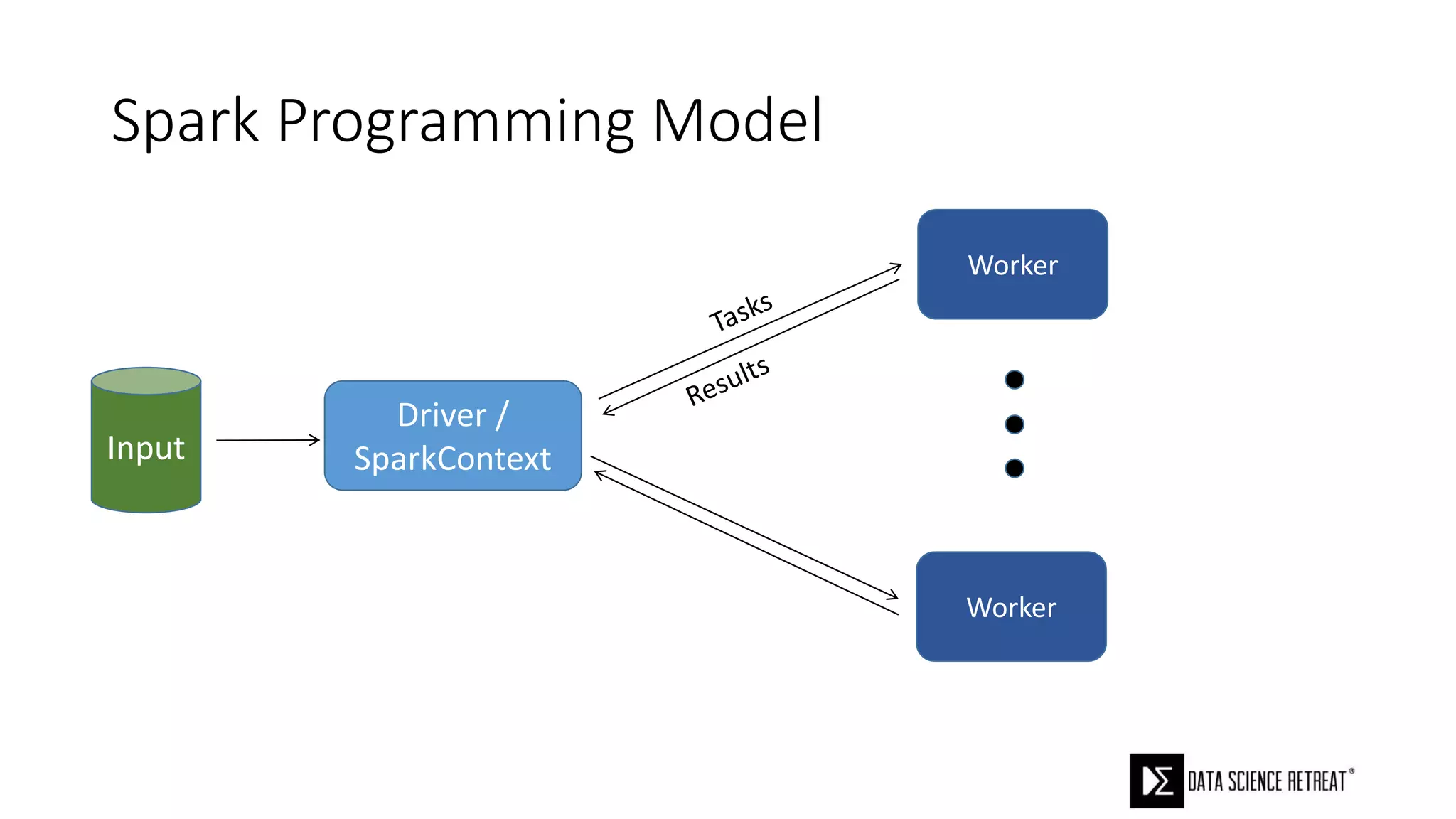
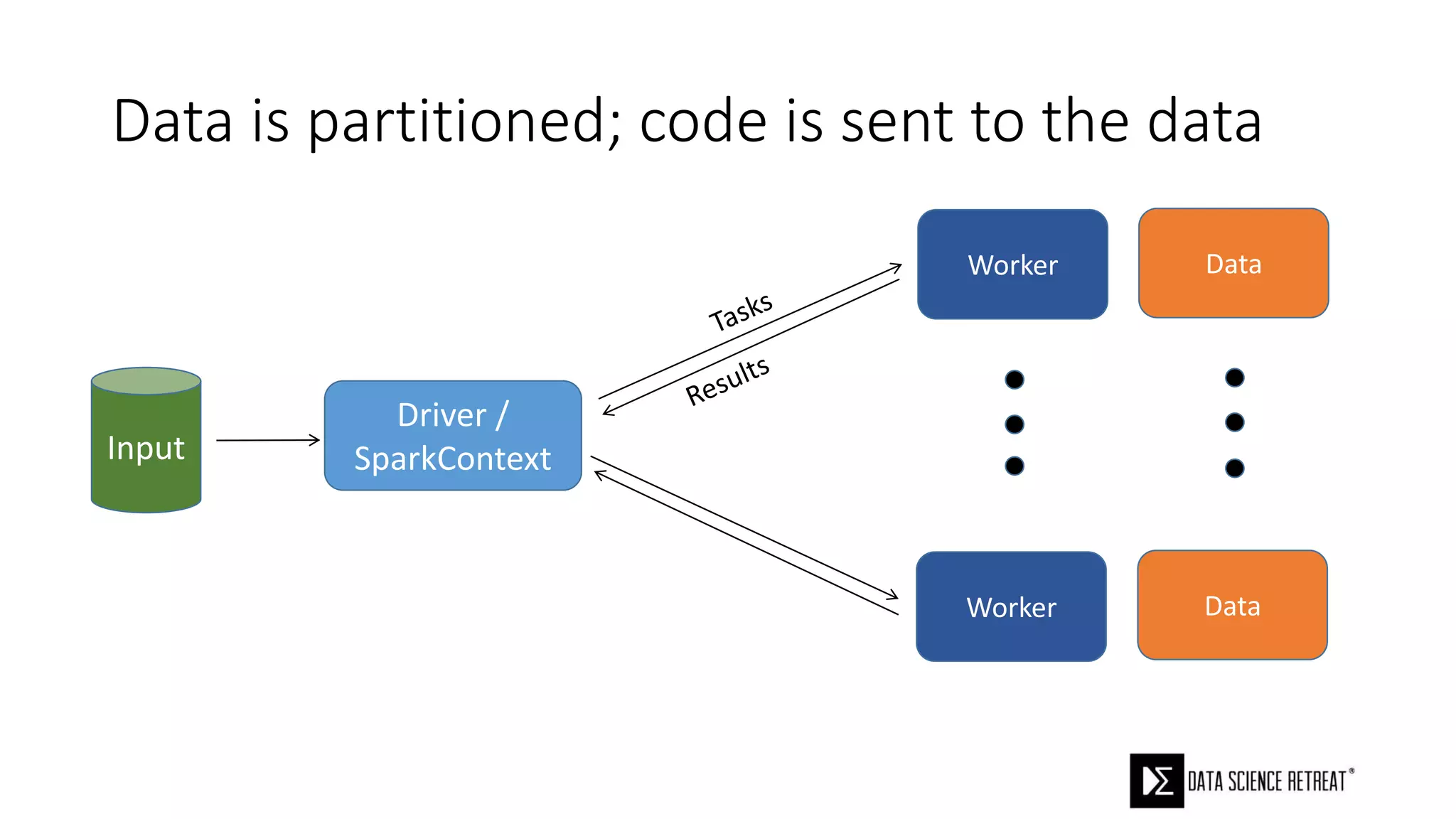

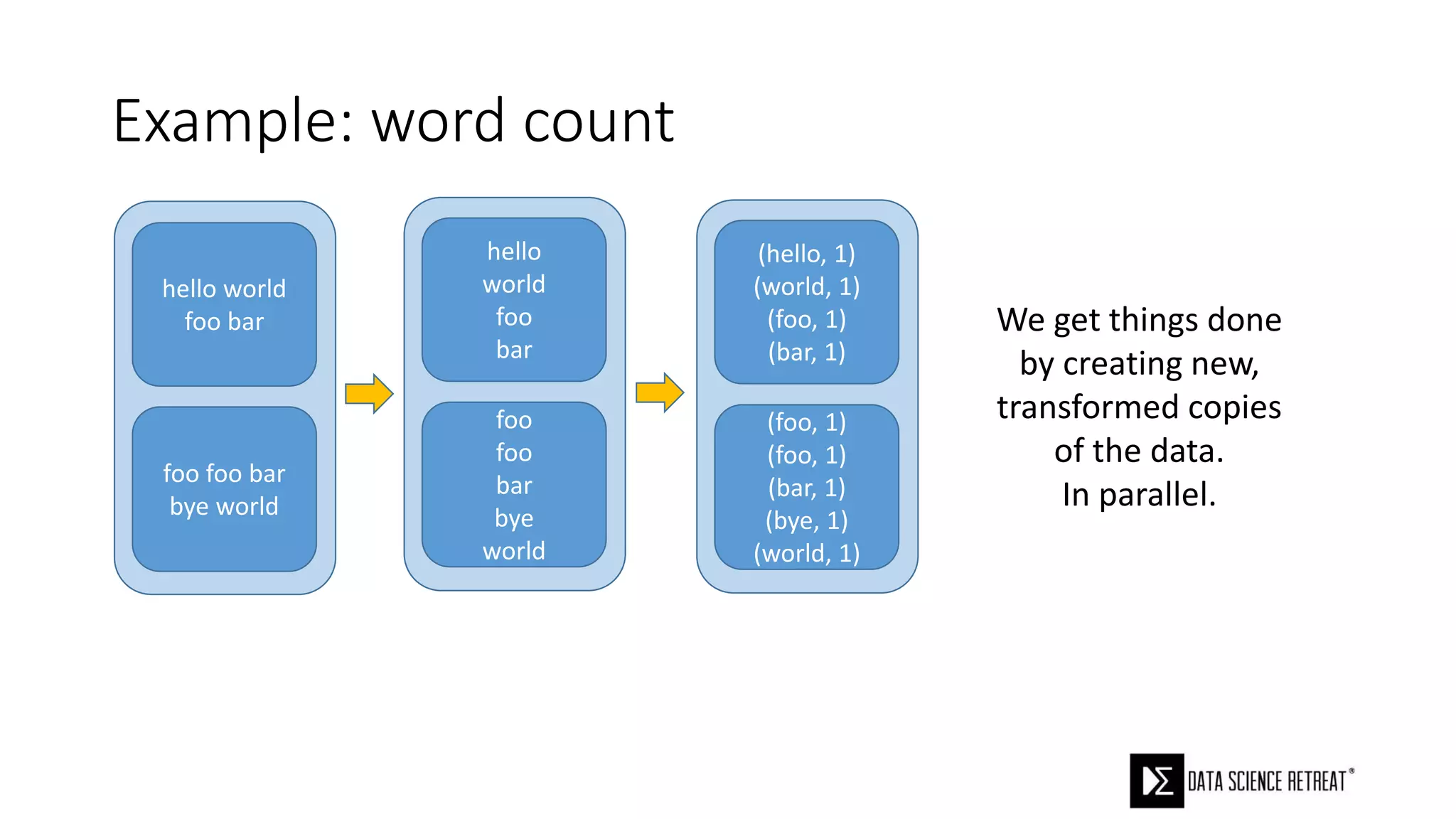
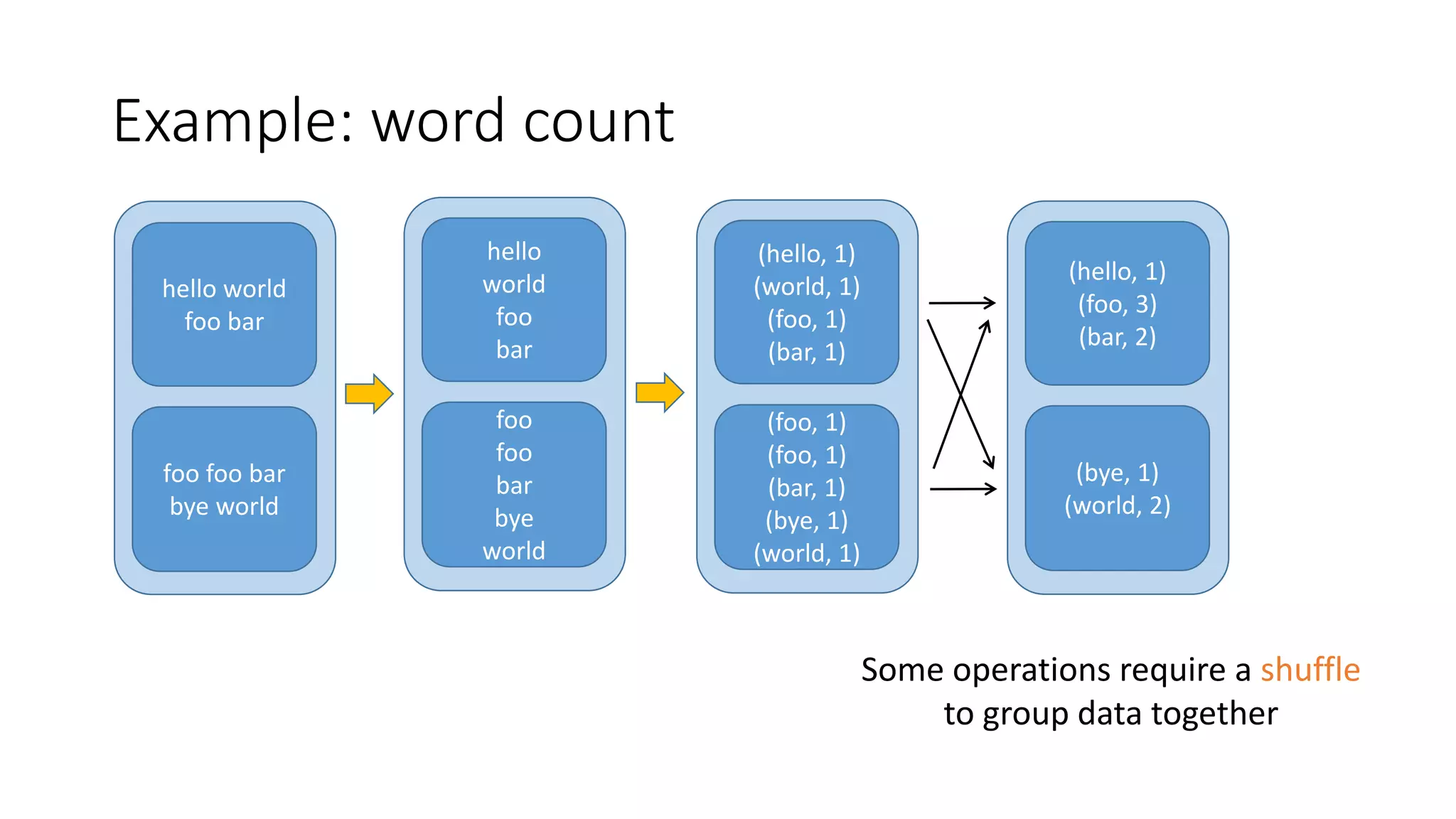


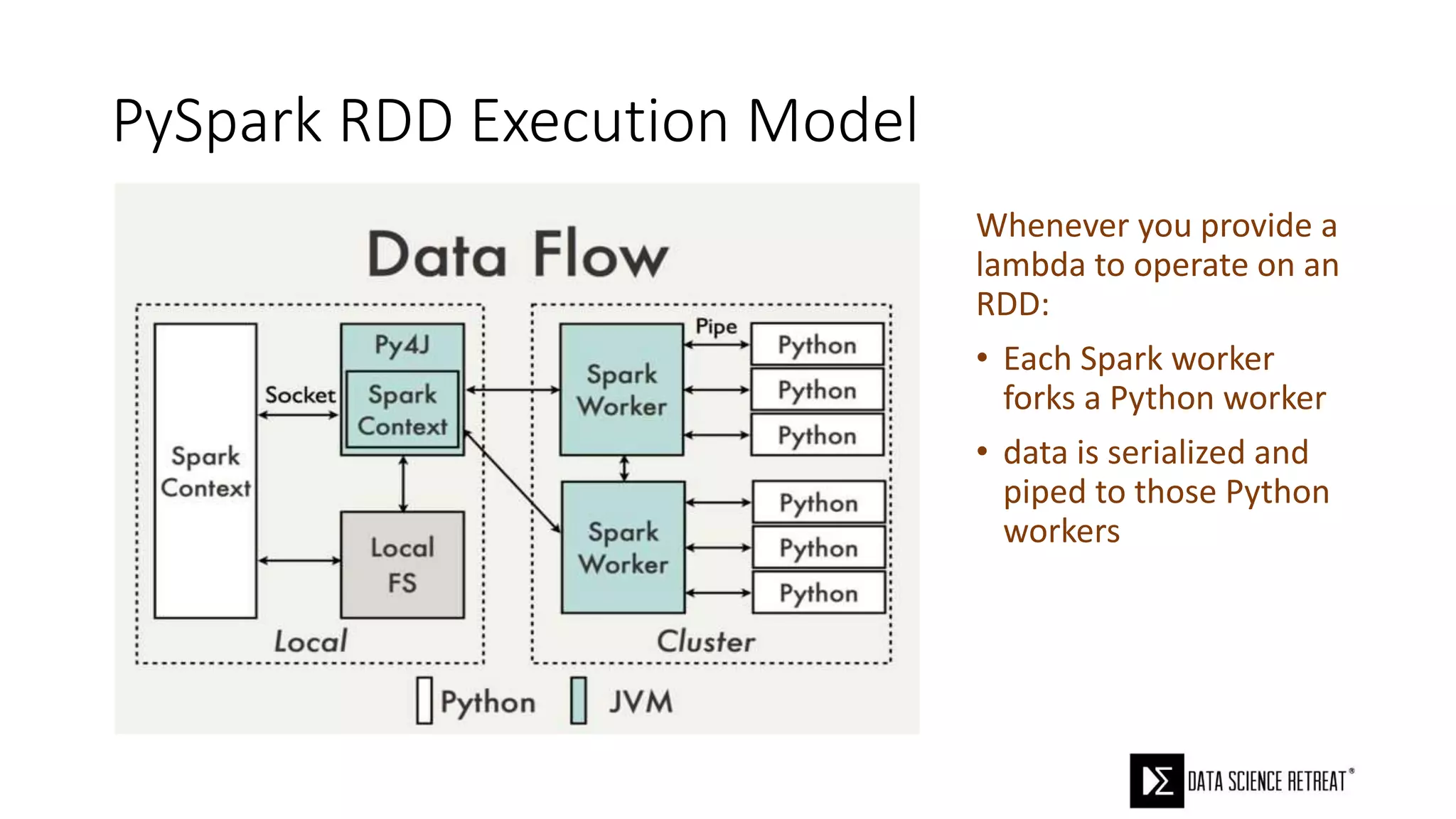


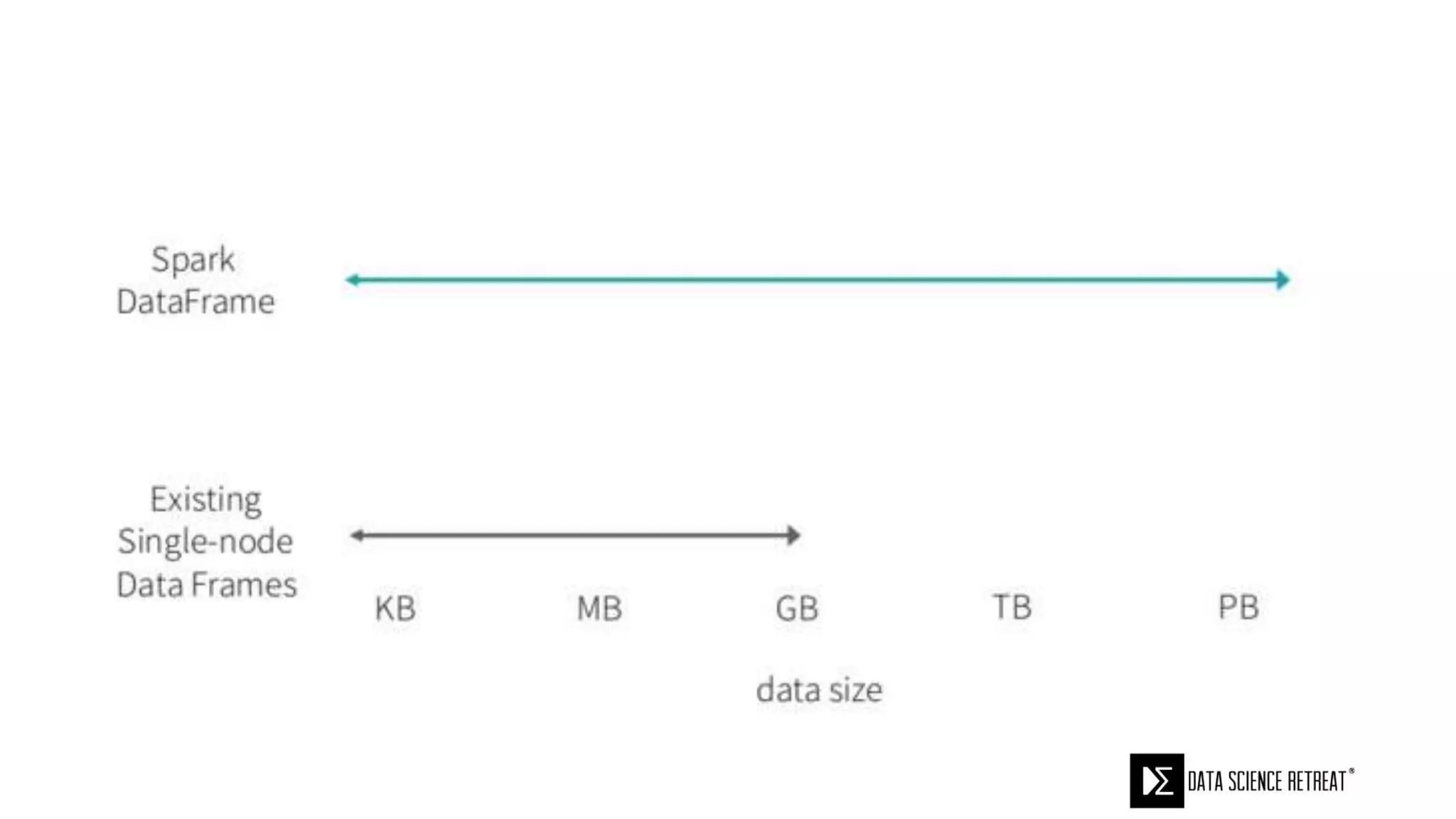
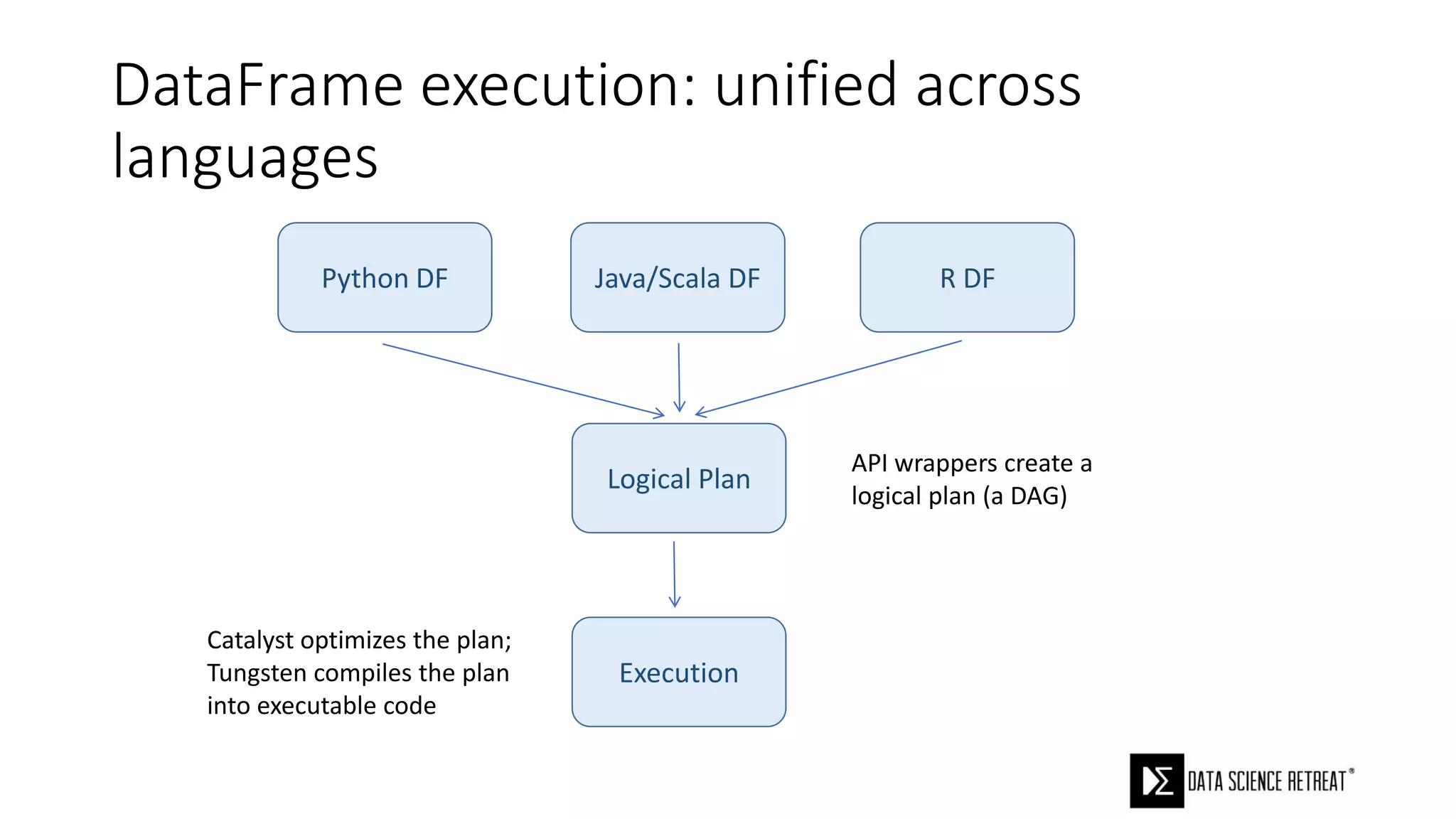
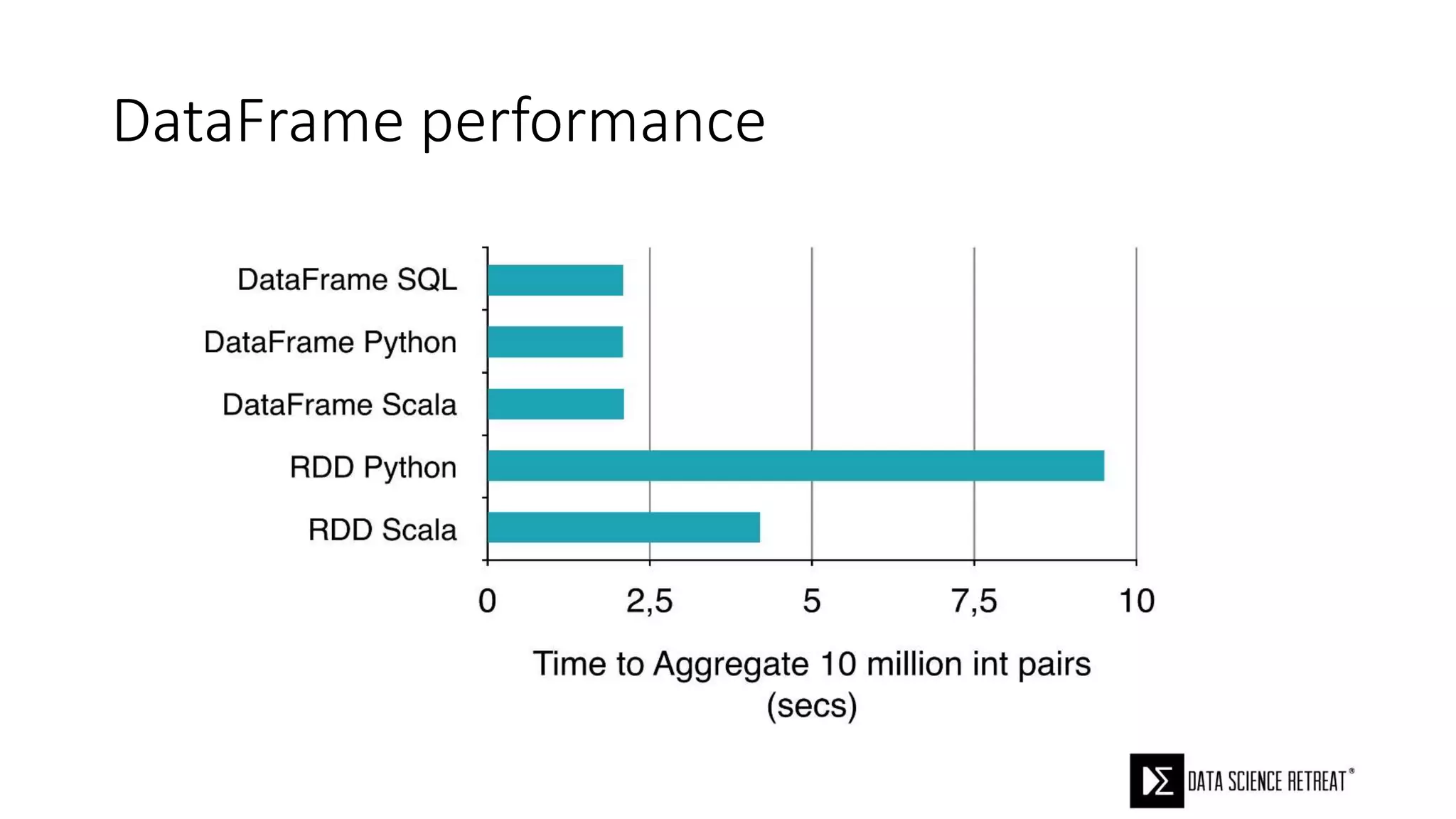
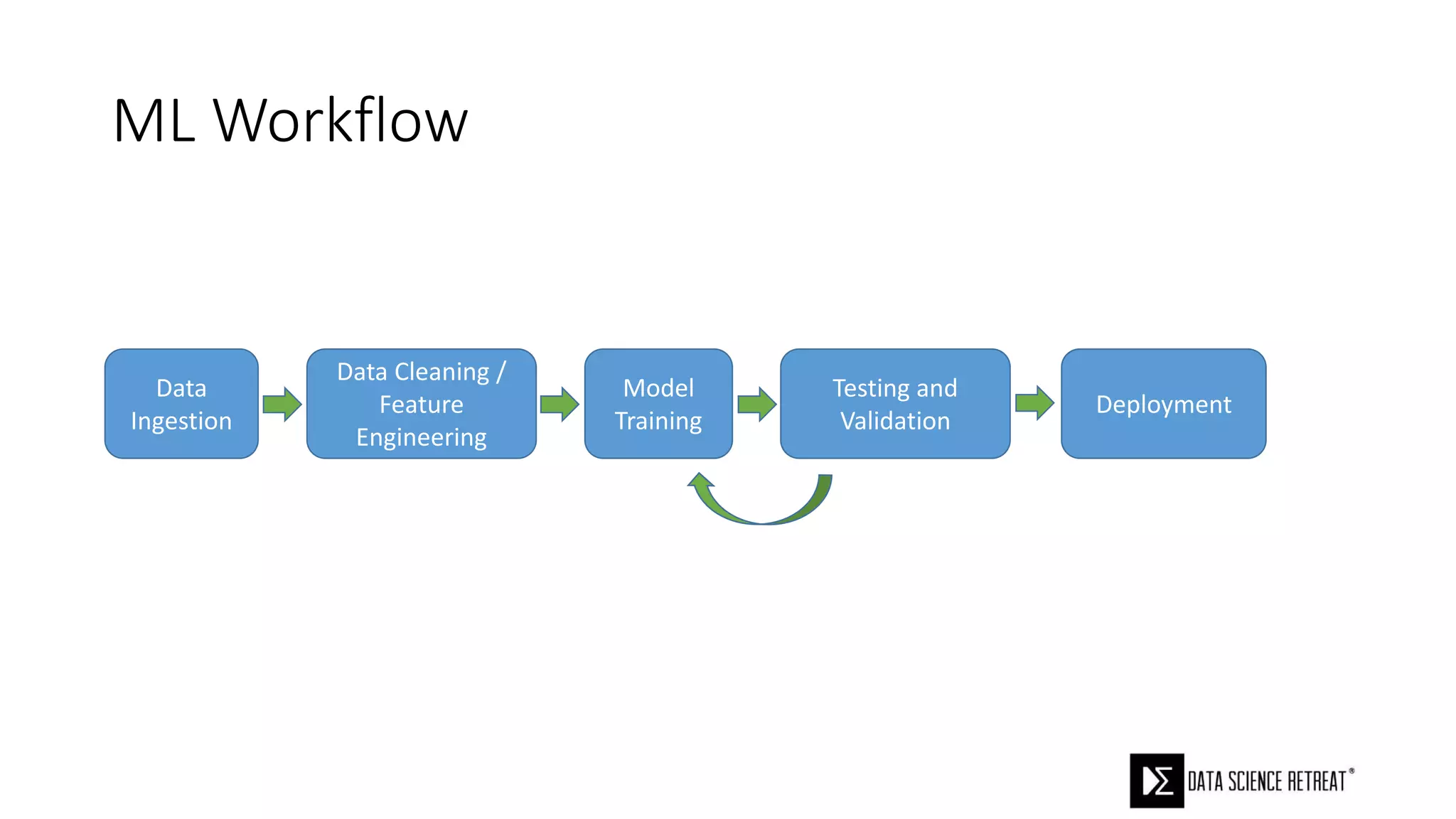


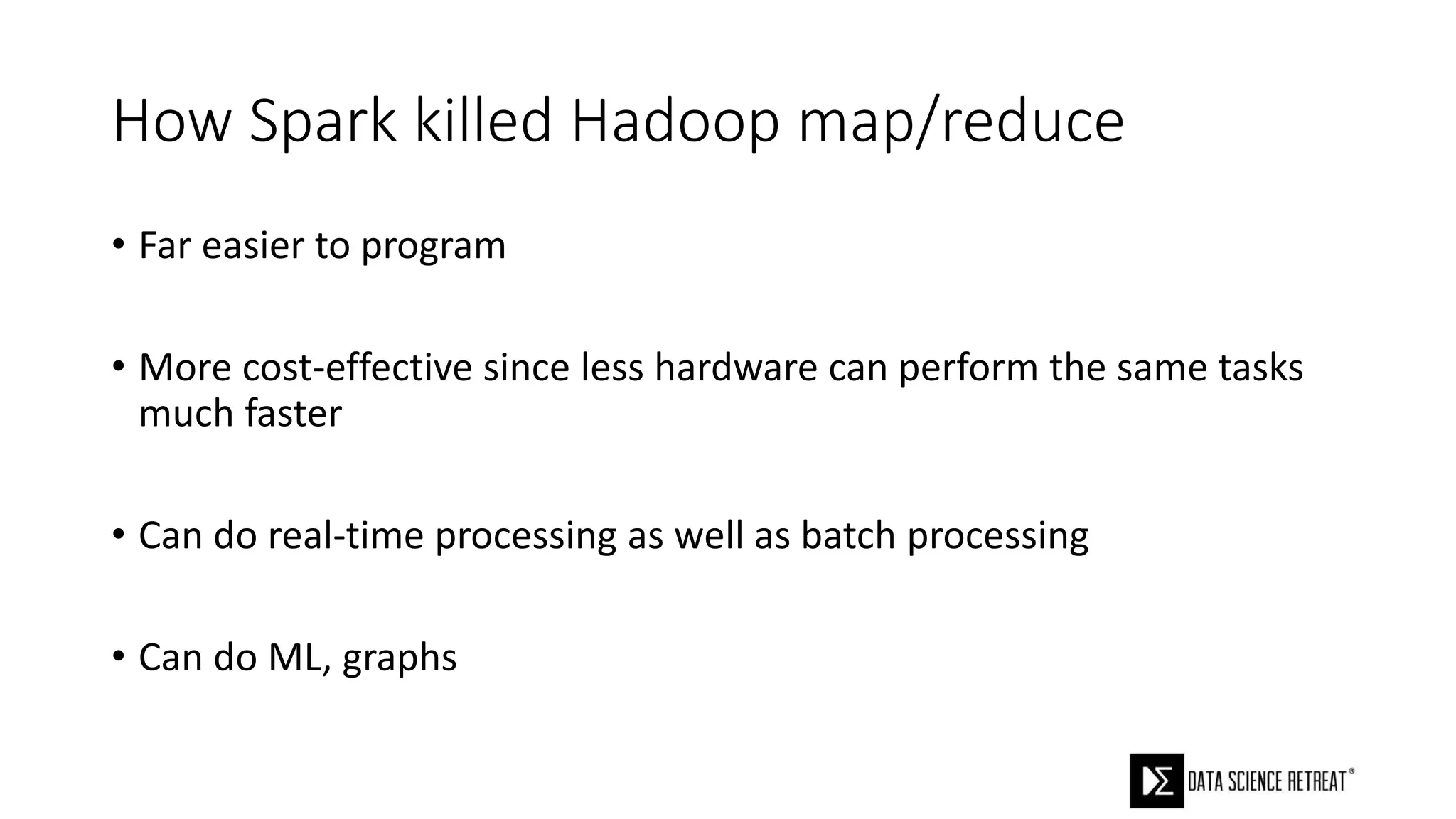





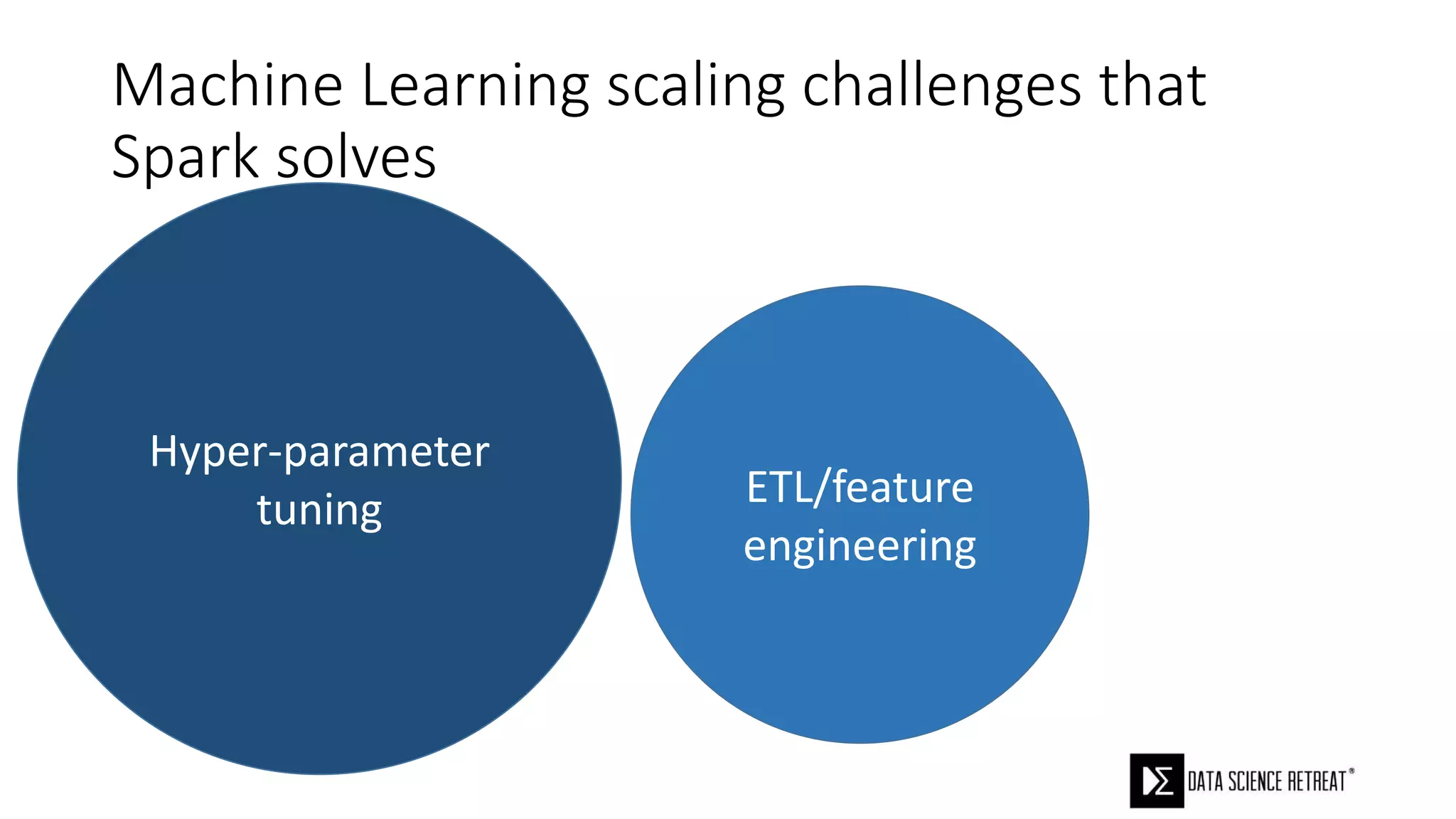
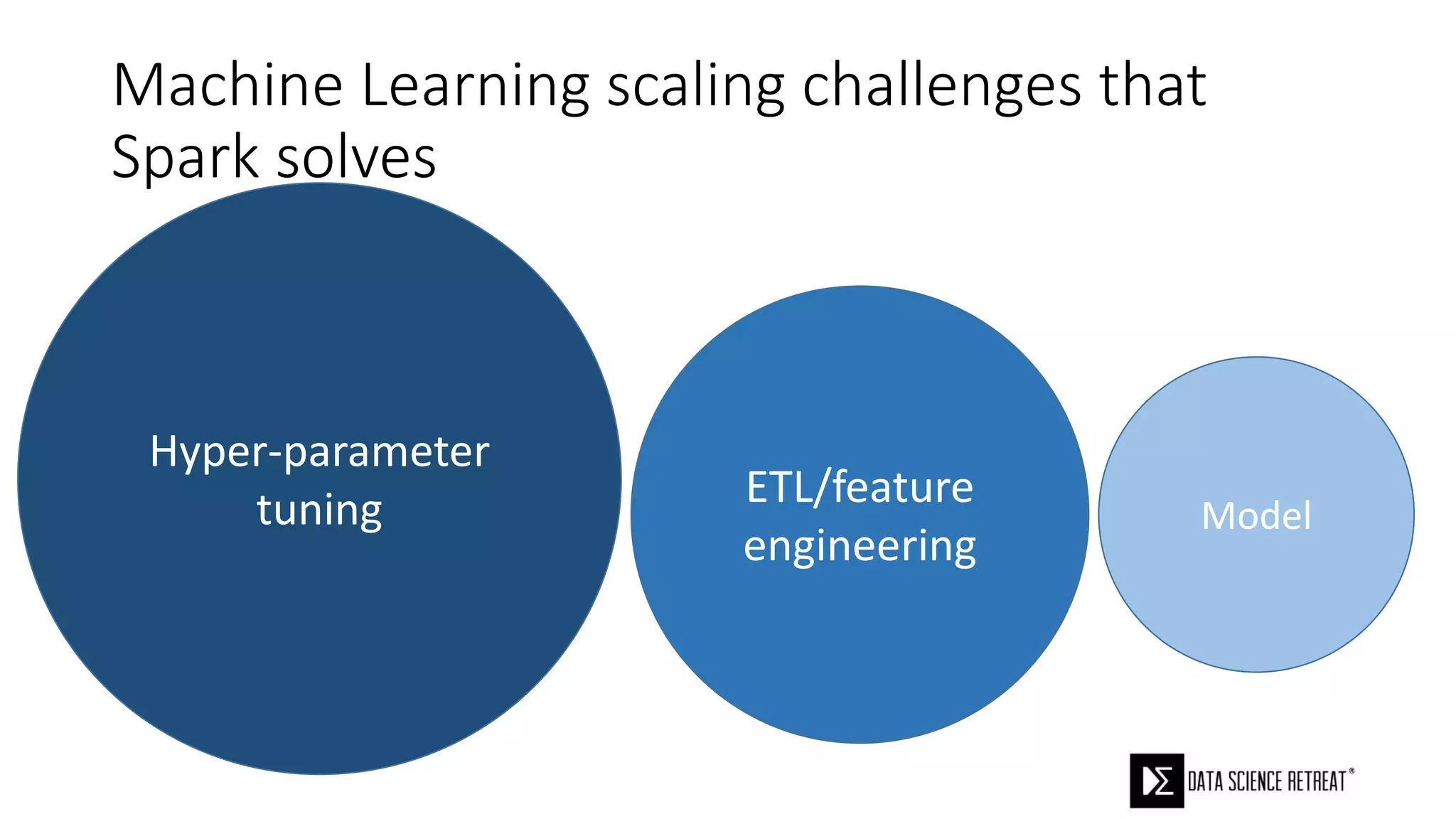

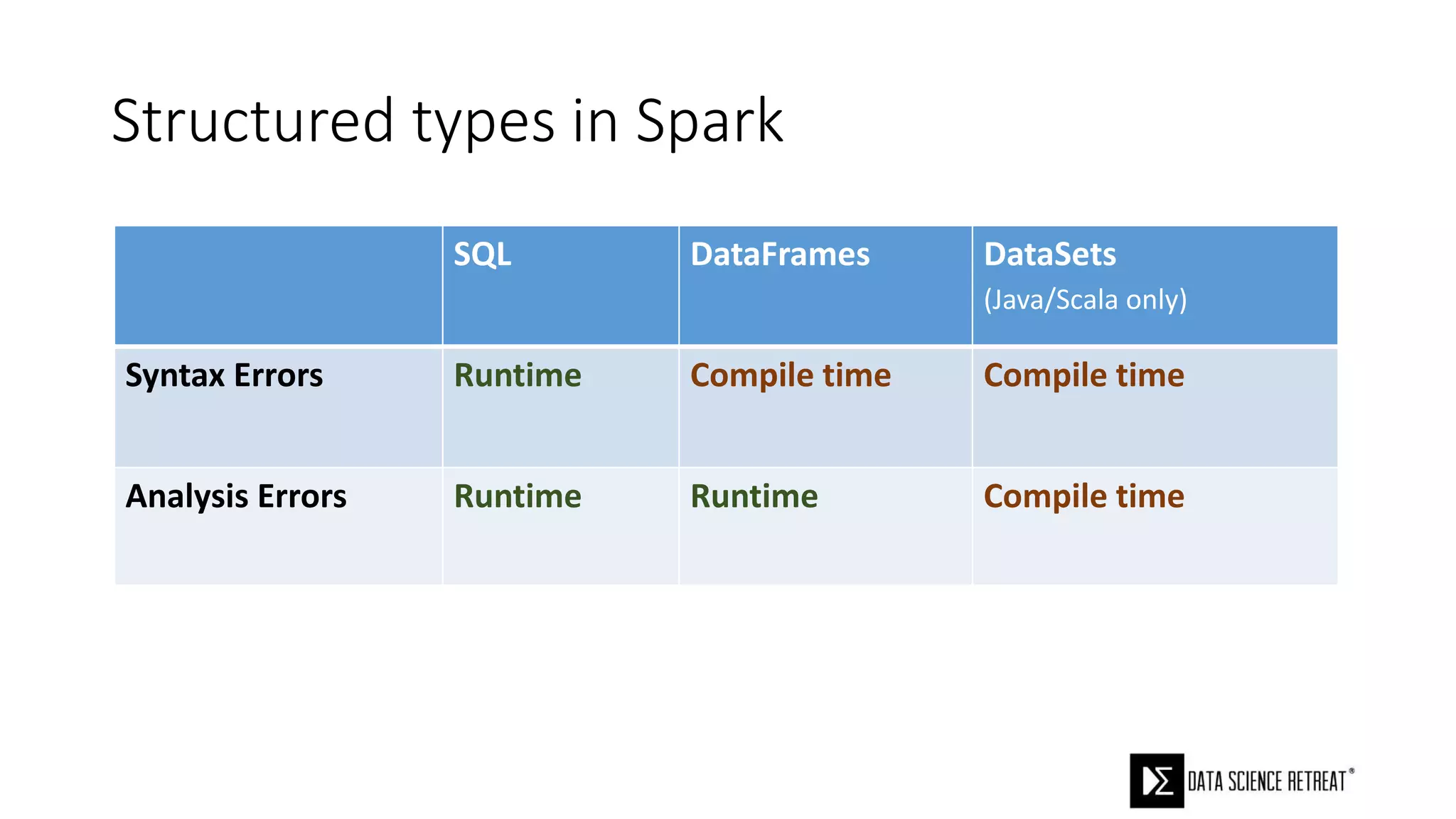


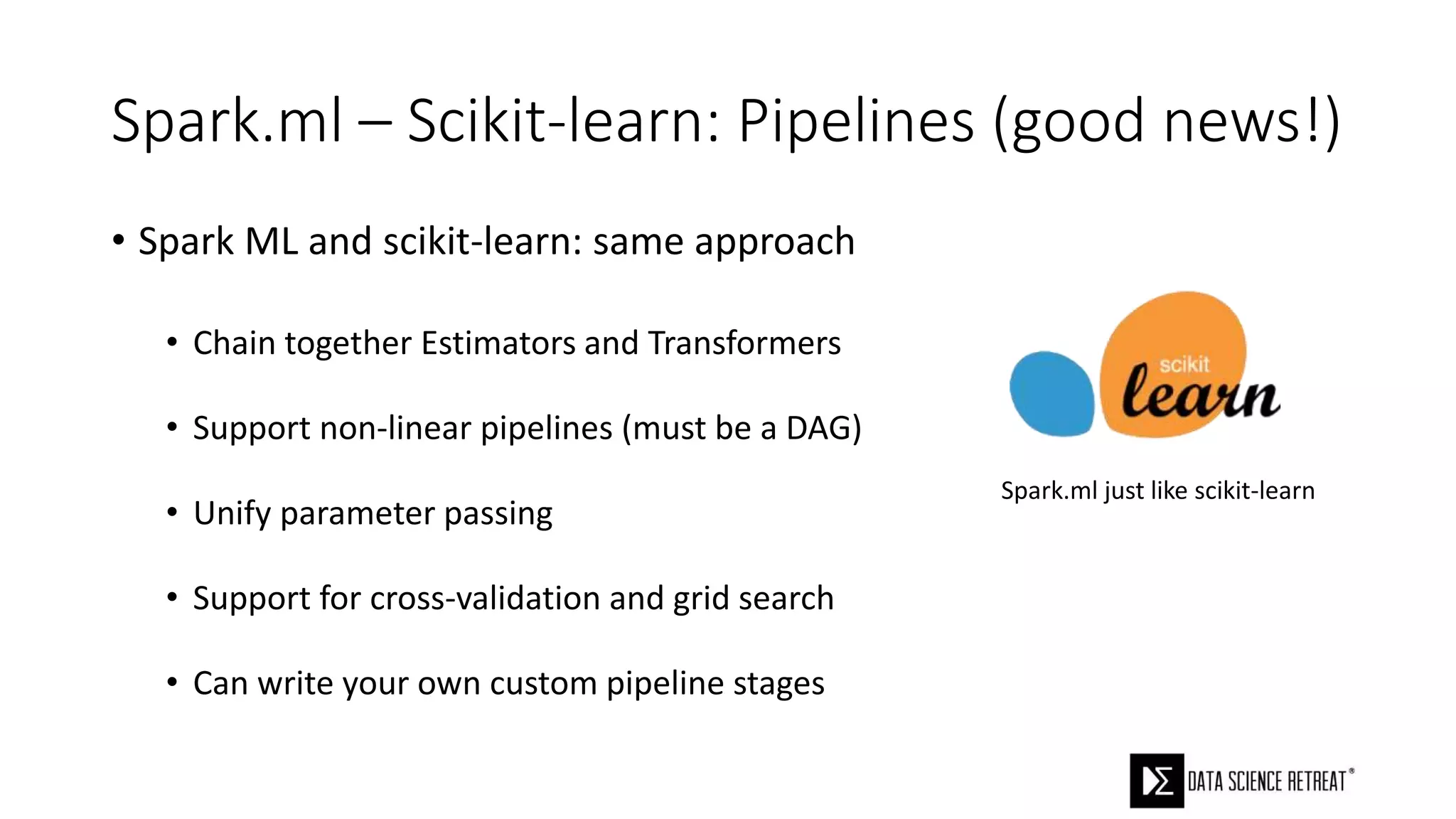
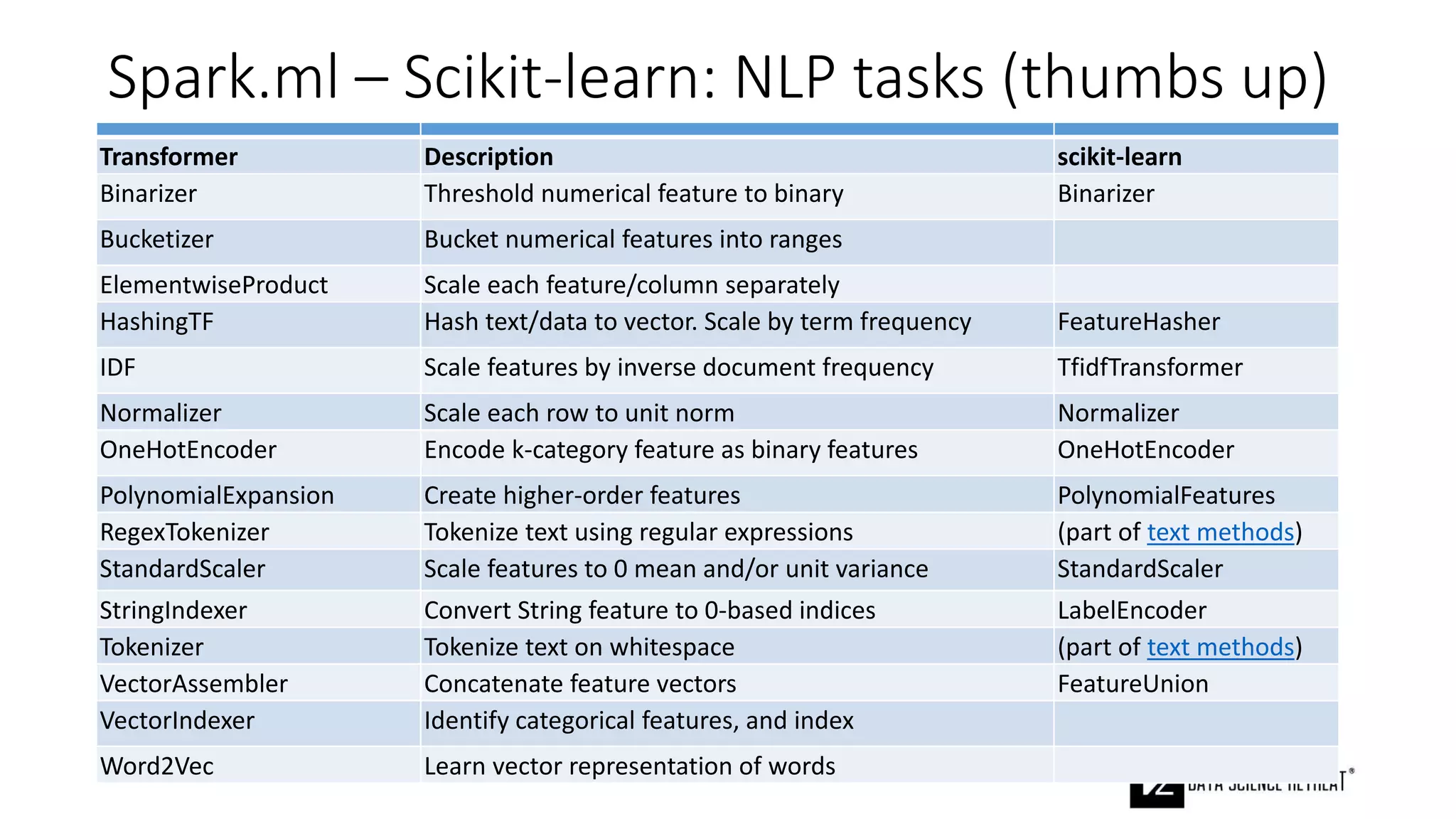




































































The document compares machine learning pipelines in scikit-learn and Scala-Spark, discussing the advantages of Spark for distributed machine learning workloads. It emphasizes Spark's capacity for real-time processing, ease of programming, and its unified DataFrame-based API in Spark 2.0, while also pointing out the potential challenges within Spark ML, such as feature indexing and the maximum depth limit for trees. Overall, it highlights Spark's evolution and its significant improvements over Hadoop in the context of machine learning.




















































































