
















![28
Example: Simple ranking system
High-level API: List<Video> rank(User u, List<Video> videos)
Example model description file:
{
“type”: “ScoringRanker”,
“scorer”: {
“type”: “FeatureScorer”,
“features”: [
{“type”: “Popularity”, “days”: 10},
{“type”: “PredictedRating”}
],
“function”: {
“type”: “Linear”,
“bias”: -0.5,
“weights”: {
“popularity”: 0.2,
“predictedRating”: 1.2,
“predictedRating*popularity”:
3.5
}
}
}
}
Ranker
Scorer
Features
Linear function
Feature transformations](https://image.slidesharecdn.com/lessonslearnedpublic-141213213559-conversion-gate02/75/Lessons-Learned-from-Building-Machine-Learning-Software-at-Netflix-28-2048.jpg)































![28
Example: Simple ranking system
High-level API: List<Video> rank(User u, List<Video> videos)
Example model description file:
{
“type”: “ScoringRanker”,
“scorer”: {
“type”: “FeatureScorer”,
“features”: [
{“type”: “Popularity”, “days”: 10},
{“type”: “PredictedRating”}
],
“function”: {
“type”: “Linear”,
“bias”: -0.5,
“weights”: {
“popularity”: 0.2,
“predictedRating”: 1.2,
“predictedRating*popularity”:
3.5
}
}
}
}
Ranker
Scorer
Features
Linear function
Feature transformations](https://crownmelresort.com/image.slidesharecdn.com/lessonslearnedpublic-141213213559-conversion-gate02/75/Lessons-Learned-from-Building-Machine-Learning-Software-at-Netflix-28-2048.jpg)







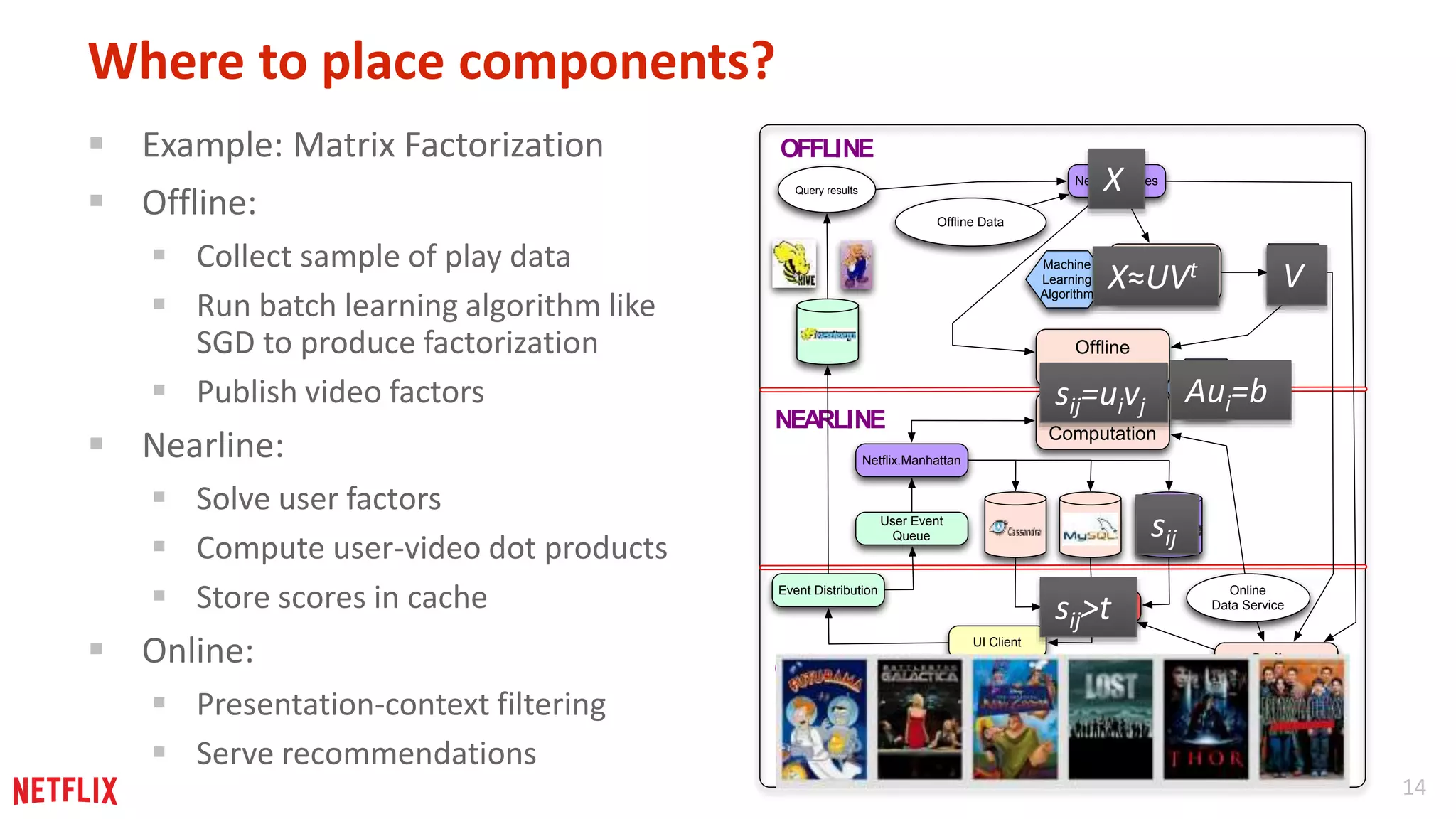
The document outlines key lessons learned from building machine learning software at Netflix, emphasizing flexibility in computation, the importance of distribution and modular algorithms, and the necessity for thorough testing beyond just metrics. It discusses techniques for improving recommendations through various machine learning models and the design considerations necessary for scalability and responsiveness. Additionally, it highlights the iterative nature of machine learning development and the significance of experimentation in software design.
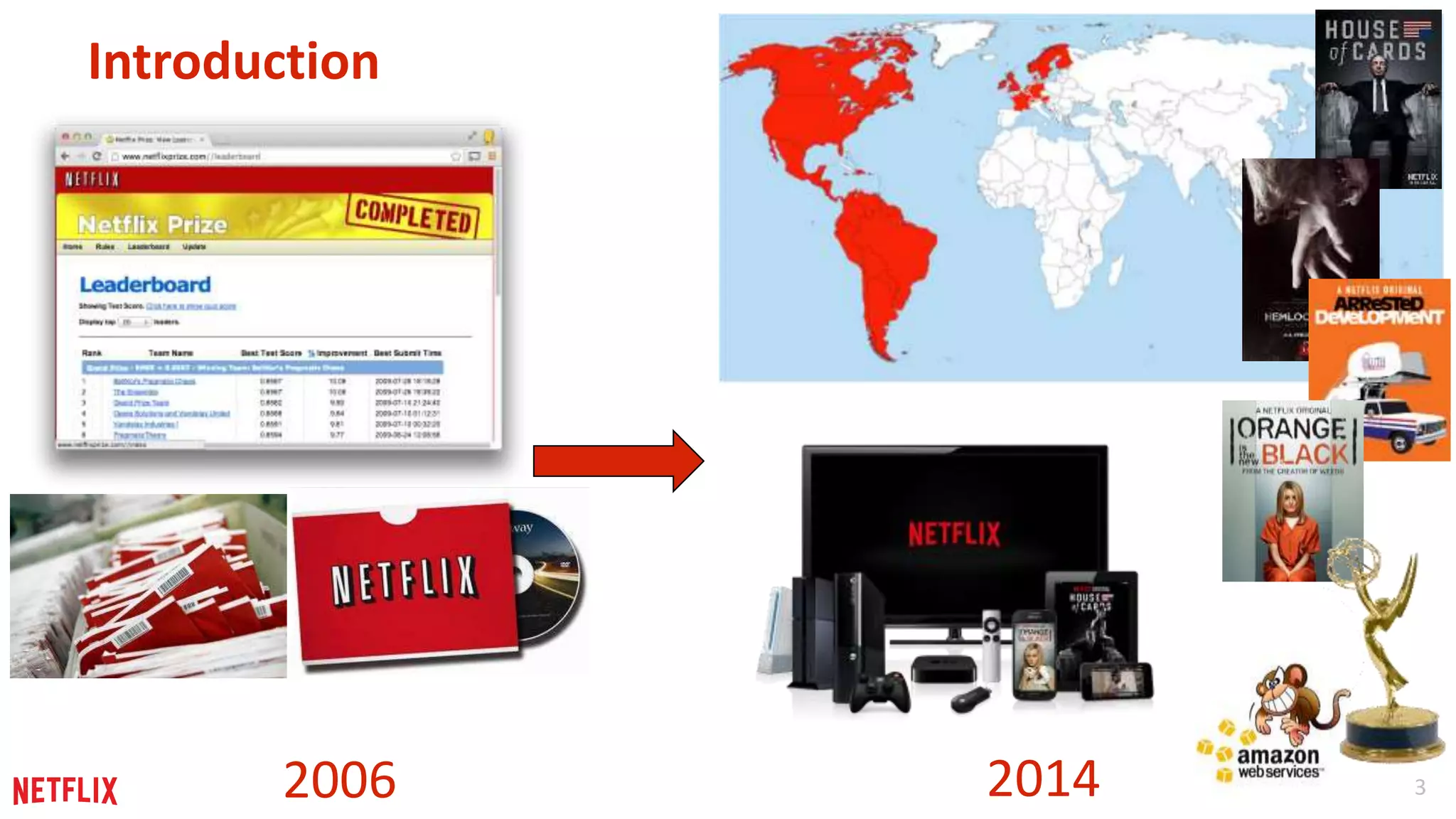
Overview of lessons learned in building ML software at Netflix, including the context of development from 2006 to 2014.
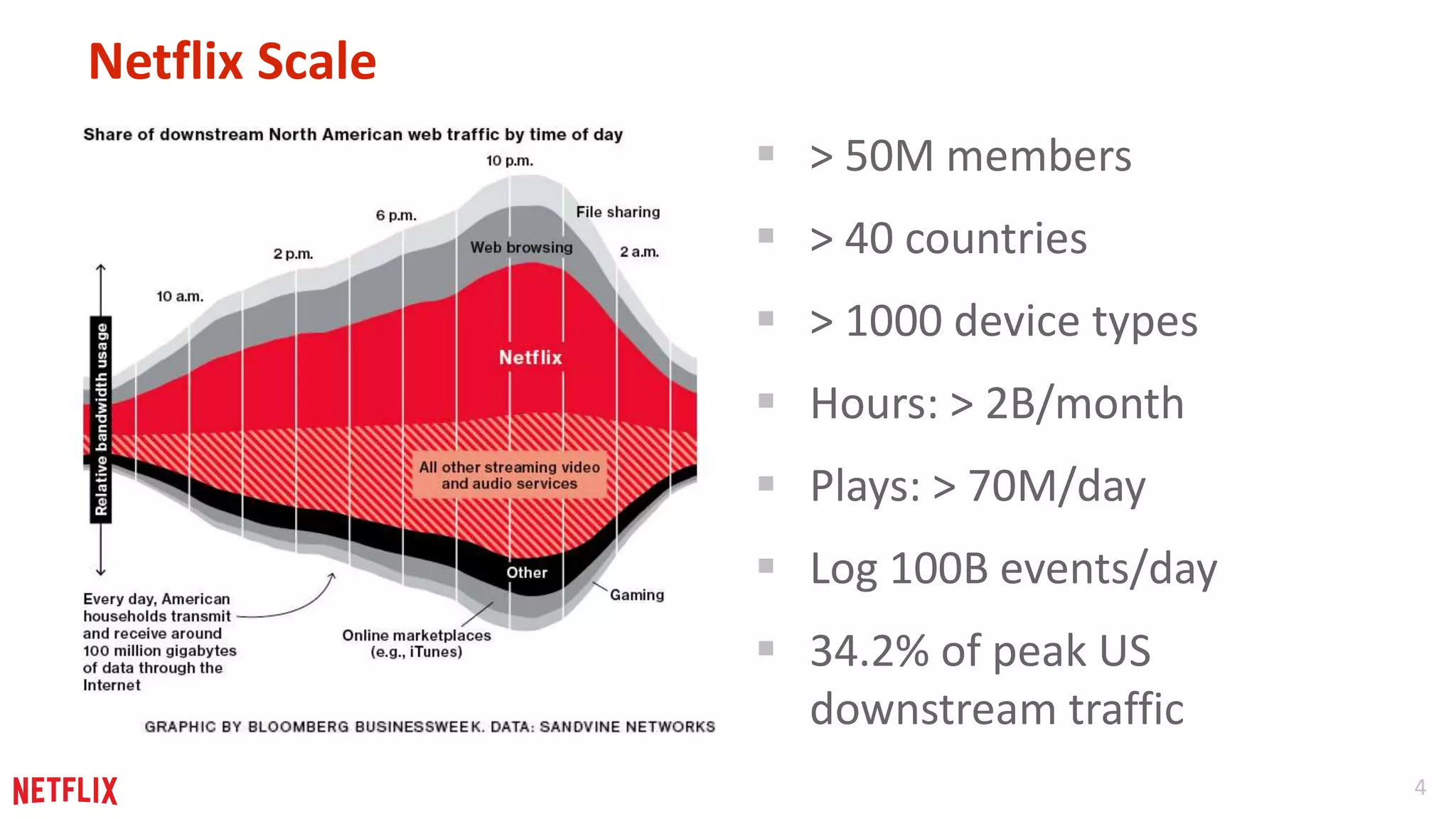
Netflix's massive scale with over 50M members and its goal to enhance user experience and retention through personalized content recommendations.
The significance of machine learning in content recommendations, with over 75% of selections influenced by suggestions.
Diverse ML approaches at Netflix, employing various algorithms like Neural Networks, Matrix Factorization, and Clustering.
Key design principles for recommendations, ensuring they are personal, accurate, diverse, and that the software is scalable and resilient.
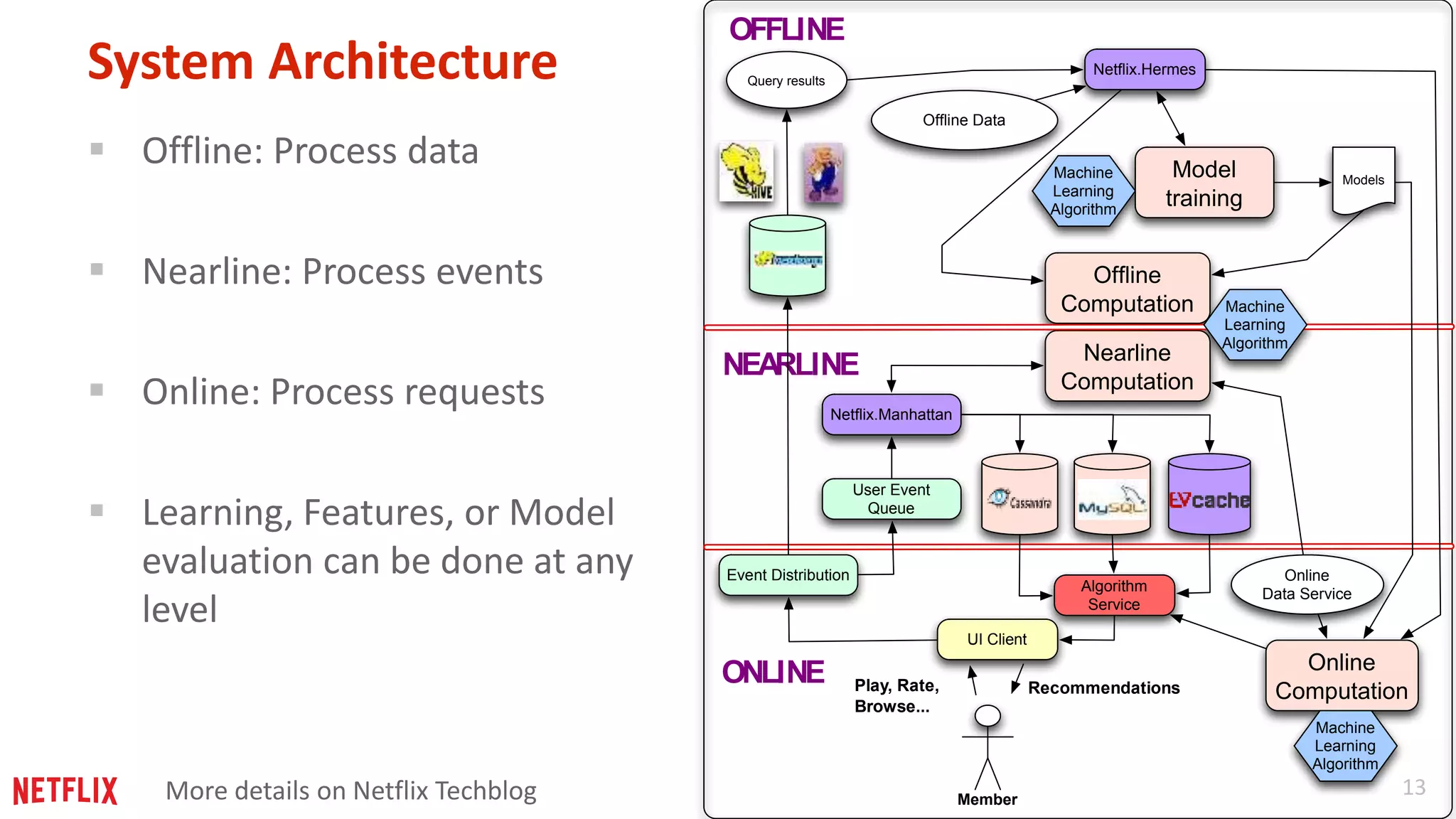
Introduction to the Netflix tech stack as relevant for building machine learning applications.
Insightful lessons regarding flexibility in computation location and timing in building machine learning systems.
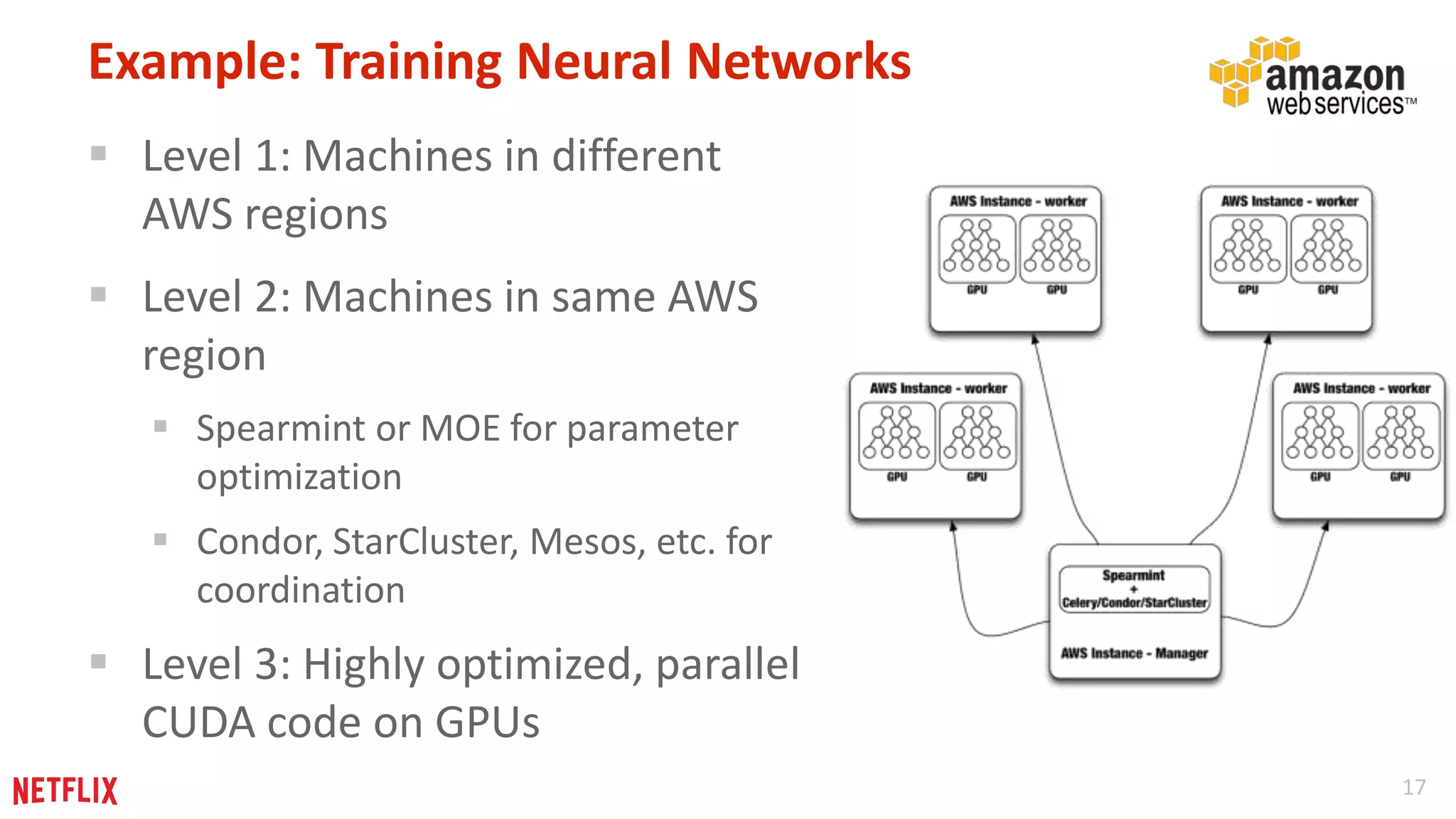
Approaches for distributing learning processes at different levels, allowing for efficient training across multiple parameters and data subsets.
Summary of distributed training for neural networks across different AWS regions, employing varied optimization strategies.
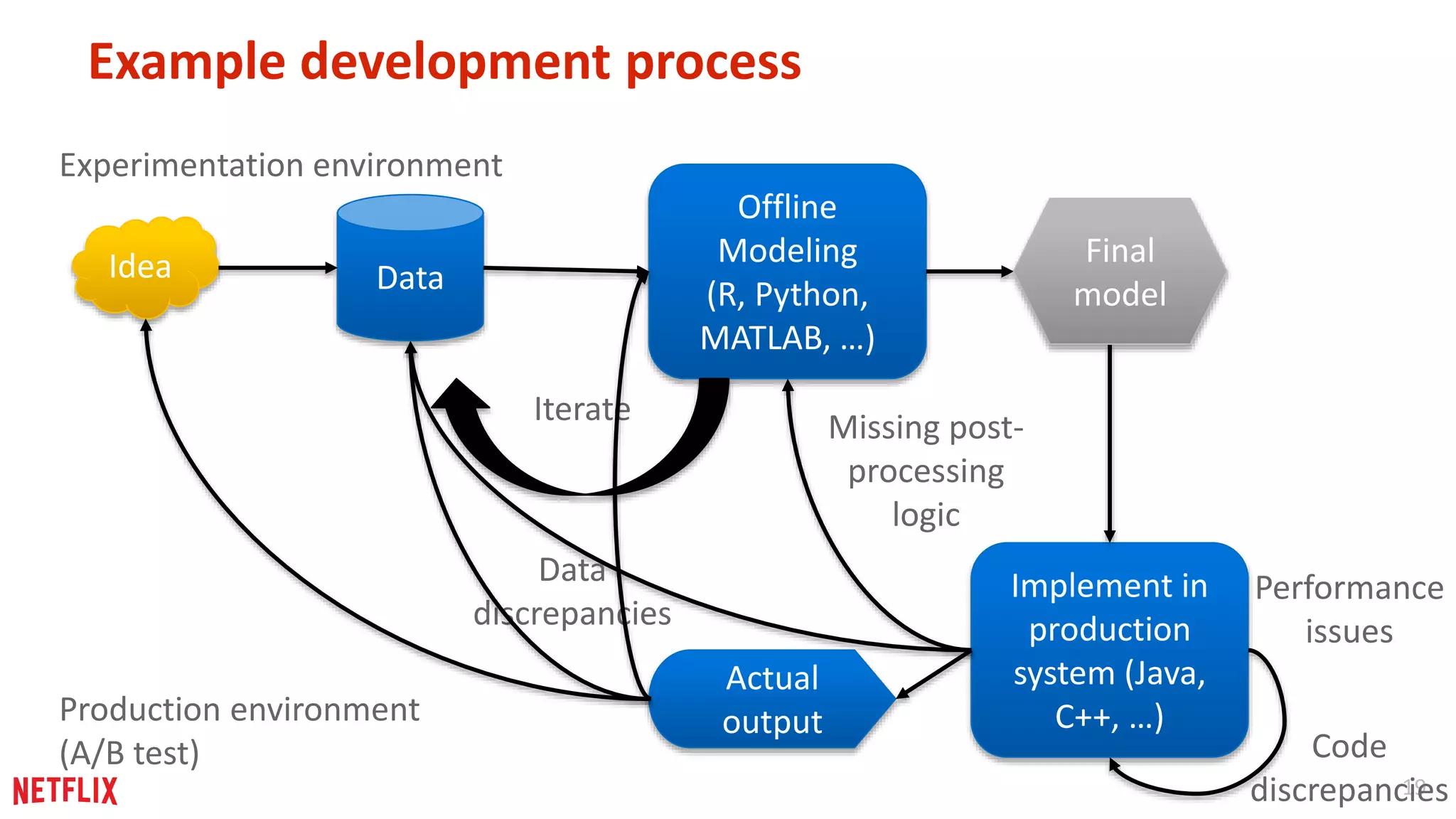
The necessity for adaptable application design to support continuous experimentation and iteration during the development process.
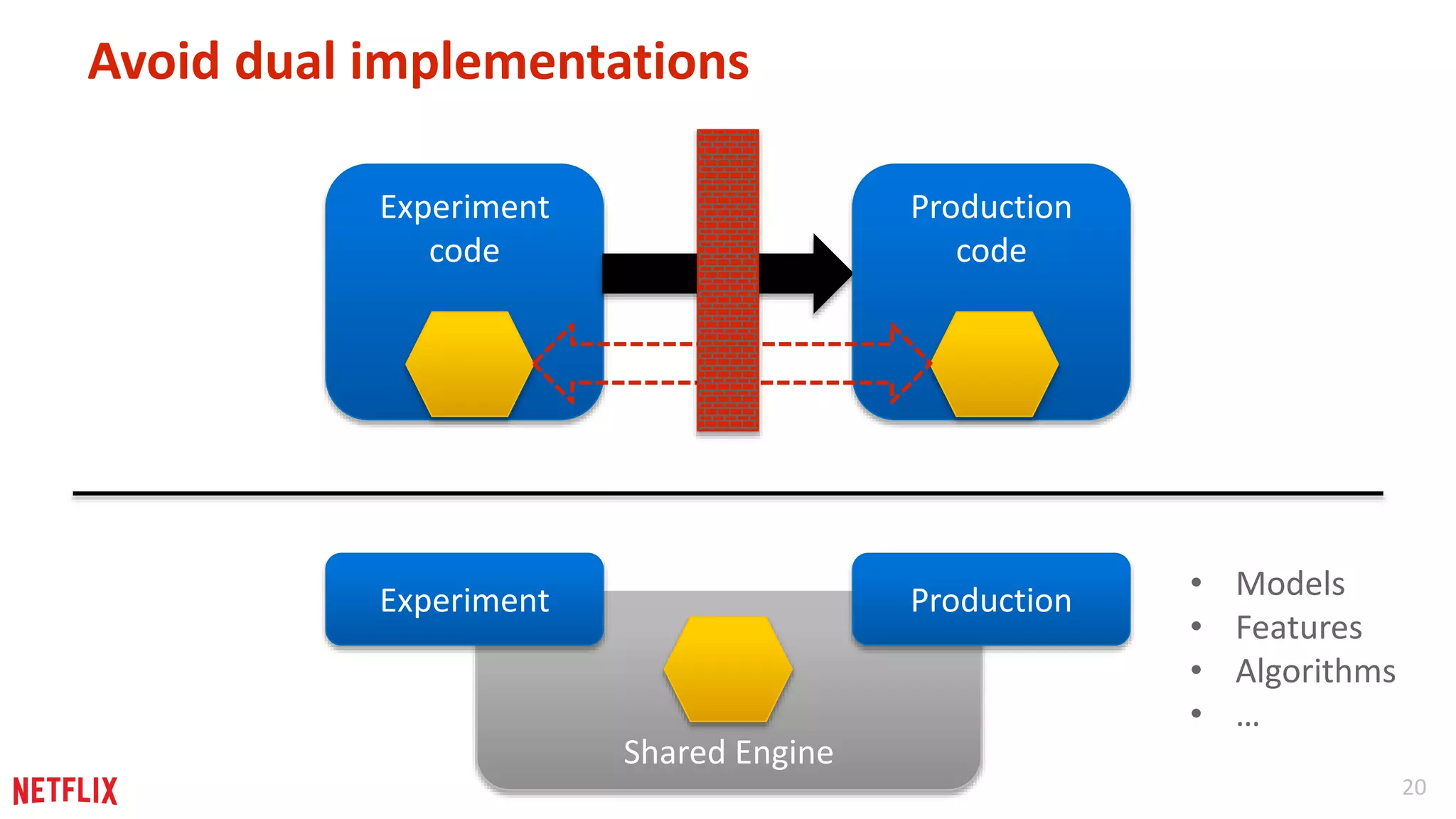
The importance of designing algorithms that allow customization and modularity, emphasizing reusability and parameter flexibility.
Illustration of customizing Random Forest algorithms for specific metrics and runtime optimizations.
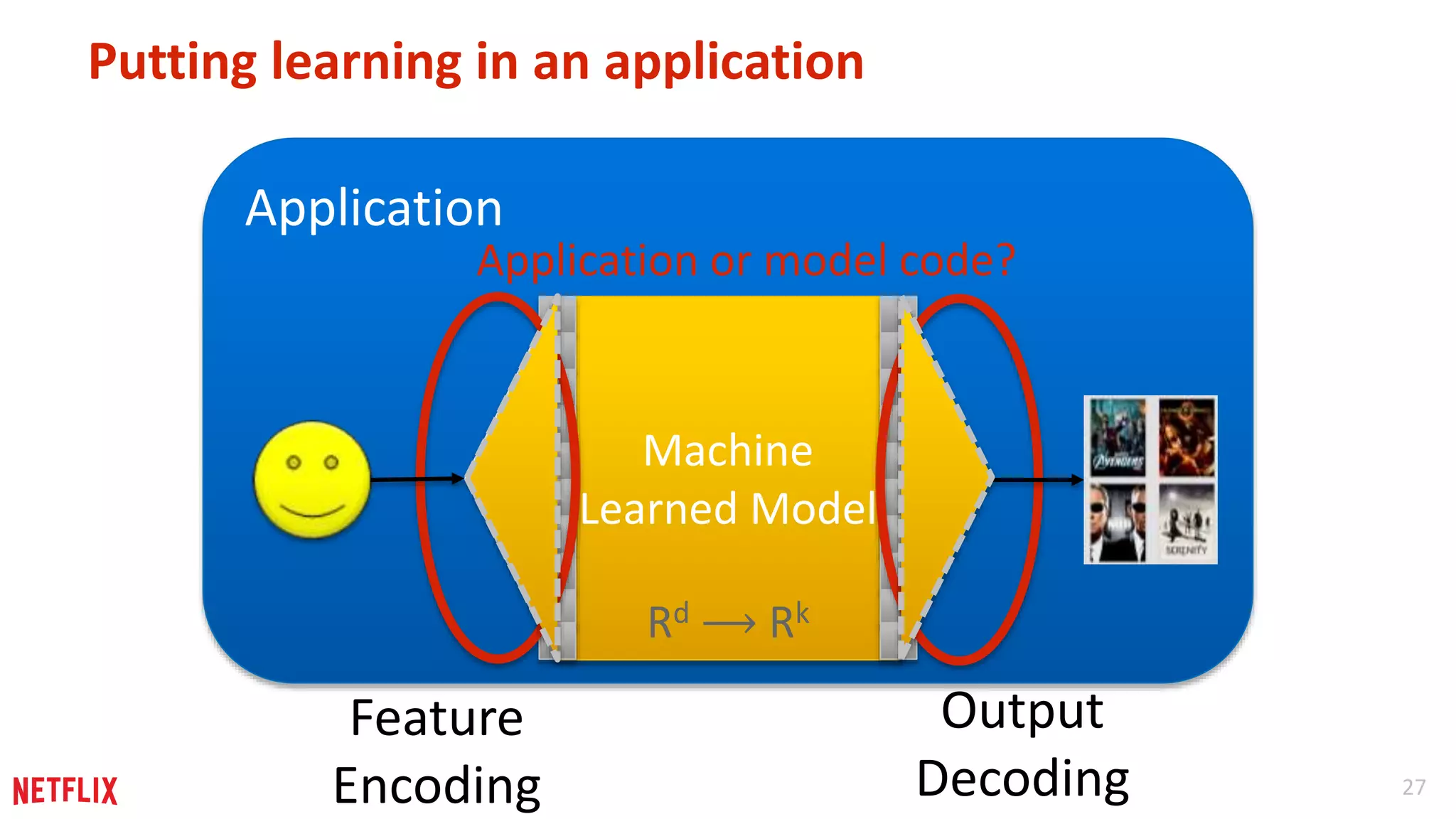
Explains the need to clearly define input and output transformations in machine learning applications with practical examples.
Discussion on the necessity of rigorous testing beyond metrics to validate machine learning models and code integrity.
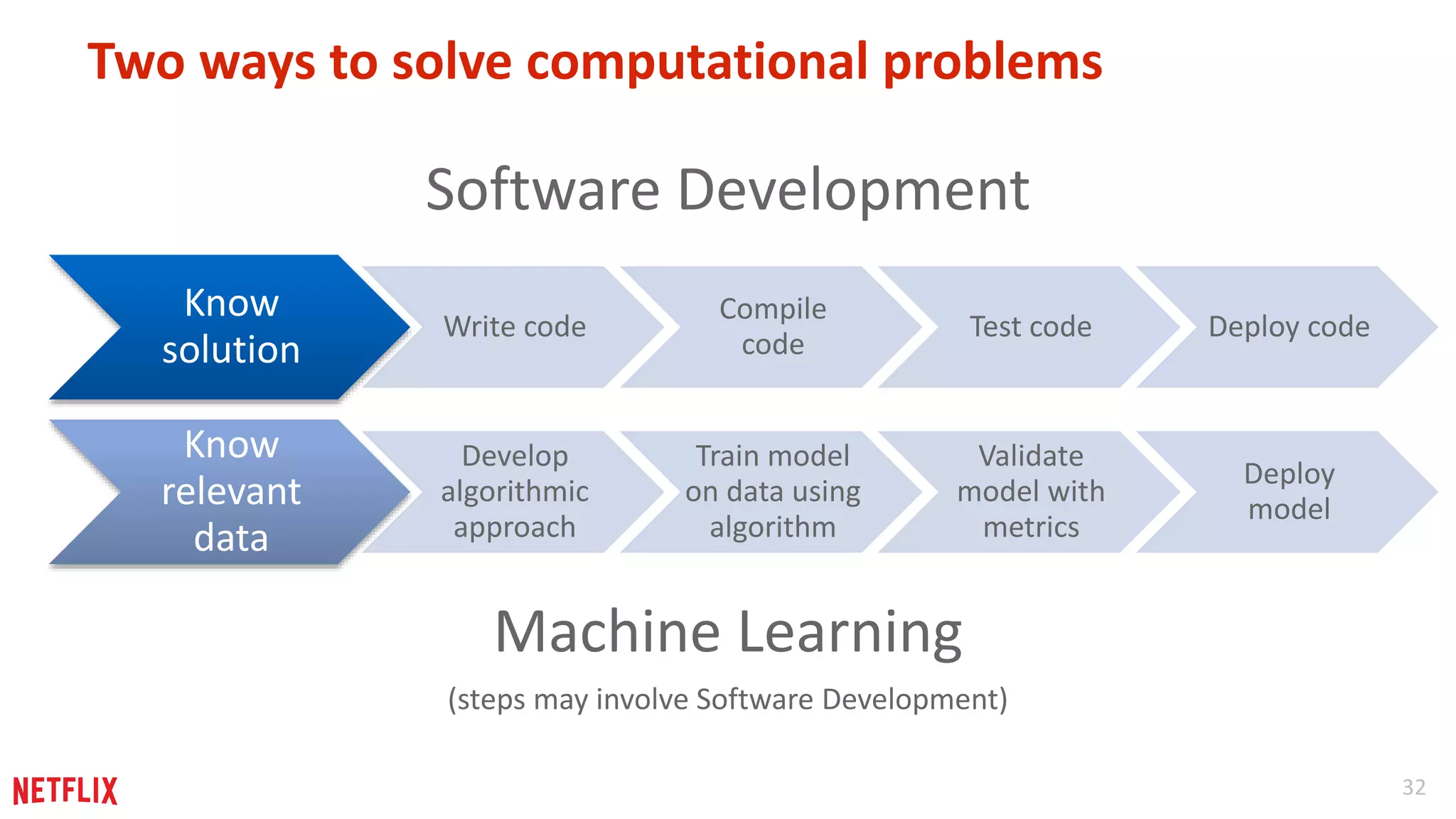
Summary of contrasting software development with machine learning processes, highlighting systematic approaches for success.
Key insights on iterative development, experimentation, holistic views of systems, and the value of thorough testing.



































































