Download to read offline








![Methodology
Log-Based Anomaly Detection System
Log parsing:
Transforms unstructured log messages into a structured format.
Produces an event template (constant part) + parameters (variable
parts).
Example:
Raw: sendmail[17795]: j0170NVv017795: from=root,
size=117, class=0, nrcpts=1,
msgid=<200501010700.j0170NVv017795@sn209>,
relay=#2#@localhost
Template: <*> <*> from=root, <*> class=0, nrcpts=1, <*>
relay=#2#@localhost
In our work: a pre-parsed version of the Spirit dataset is used, with
fields such as:
Timestamp, Event ID, Event Template, Anomaly Label
Bekkouche Mohammed (ESI-SBA) Log-based anomaly detection TACC 2025 9 / 24](https://image.slidesharecdn.com/presentation-tacc2025-251119111740-3ad8ab26/75/Supervised-Machine-Learning-Approaches-for-Log-Based-Anomaly-Detection-A-Case-Study-on-the-Spirit-Dataset-9-2048.jpg)

![Methodology
Log-Based Anomaly Detection System
Feature Engineering:
Algorithm 1: Time Window Log Grouping
Input : log dataset: list of log entries with timestamp, event ID,
event template, and anomaly label (True or False)
time window: fixed time interval (e.g., 15 minutes)
Output: log sequences: list of log sequences grouped by time window
1 Sort log dataset by timestamp in ascending order; Initialize
log sequences ← [ ];
2 Initialize current sequence ← [ ]; Set window start ← timestamp of
first log entry;
3 Set window end ← window start + time window;
4 label seq ← True; // True means the sequence is normal
5 foreach log entry in log dataset do
6 if log entry.timestamp < window end then
7 Append log entry.event ID or event template to
current sequence;
8 current sequence.label ← label seq ∧ log entry.label;
9 end
10 else
11 Append current sequence to log sequences;
12 current sequence ← [log entry.event ID] or
[log entry.event template];
13 current sequence.label ← log entry.label;
14 window start ← log entry.timestamp;
15 window end ← window start + time window;
16 end
17 end
18 if current sequence is not empty then
19 Append current sequence to log sequences;
20 end
21 return log sequences;
Bekkouche Mohammed (ESI-SBA) Log-based anomaly detection TACC 2025 11 / 24](https://image.slidesharecdn.com/presentation-tacc2025-251119111740-3ad8ab26/75/Supervised-Machine-Learning-Approaches-for-Log-Based-Anomaly-Detection-A-Case-Study-on-the-Spirit-Dataset-11-2048.jpg)


















![Methodology
Log-Based Anomaly Detection System
Log parsing:
Transforms unstructured log messages into a structured format.
Produces an event template (constant part) + parameters (variable
parts).
Example:
Raw: sendmail[17795]: j0170NVv017795: from=root,
size=117, class=0, nrcpts=1,
msgid=<200501010700.j0170NVv017795@sn209>,
relay=#2#@localhost
Template: <*> <*> from=root, <*> class=0, nrcpts=1, <*>
relay=#2#@localhost
In our work: a pre-parsed version of the Spirit dataset is used, with
fields such as:
Timestamp, Event ID, Event Template, Anomaly Label
Bekkouche Mohammed (ESI-SBA) Log-based anomaly detection TACC 2025 9 / 24](https://crownmelresort.com/image.slidesharecdn.com/presentation-tacc2025-251119111740-3ad8ab26/75/Supervised-Machine-Learning-Approaches-for-Log-Based-Anomaly-Detection-A-Case-Study-on-the-Spirit-Dataset-9-2048.jpg)

![Methodology
Log-Based Anomaly Detection System
Feature Engineering:
Algorithm 1: Time Window Log Grouping
Input : log dataset: list of log entries with timestamp, event ID,
event template, and anomaly label (True or False)
time window: fixed time interval (e.g., 15 minutes)
Output: log sequences: list of log sequences grouped by time window
1 Sort log dataset by timestamp in ascending order; Initialize
log sequences ← [ ];
2 Initialize current sequence ← [ ]; Set window start ← timestamp of
first log entry;
3 Set window end ← window start + time window;
4 label seq ← True; // True means the sequence is normal
5 foreach log entry in log dataset do
6 if log entry.timestamp < window end then
7 Append log entry.event ID or event template to
current sequence;
8 current sequence.label ← label seq ∧ log entry.label;
9 end
10 else
11 Append current sequence to log sequences;
12 current sequence ← [log entry.event ID] or
[log entry.event template];
13 current sequence.label ← log entry.label;
14 window start ← log entry.timestamp;
15 window end ← window start + time window;
16 end
17 end
18 if current sequence is not empty then
19 Append current sequence to log sequences;
20 end
21 return log sequences;
Bekkouche Mohammed (ESI-SBA) Log-based anomaly detection TACC 2025 11 / 24](https://crownmelresort.com/image.slidesharecdn.com/presentation-tacc2025-251119111740-3ad8ab26/75/Supervised-Machine-Learning-Approaches-for-Log-Based-Anomaly-Detection-A-Case-Study-on-the-Spirit-Dataset-11-2048.jpg)














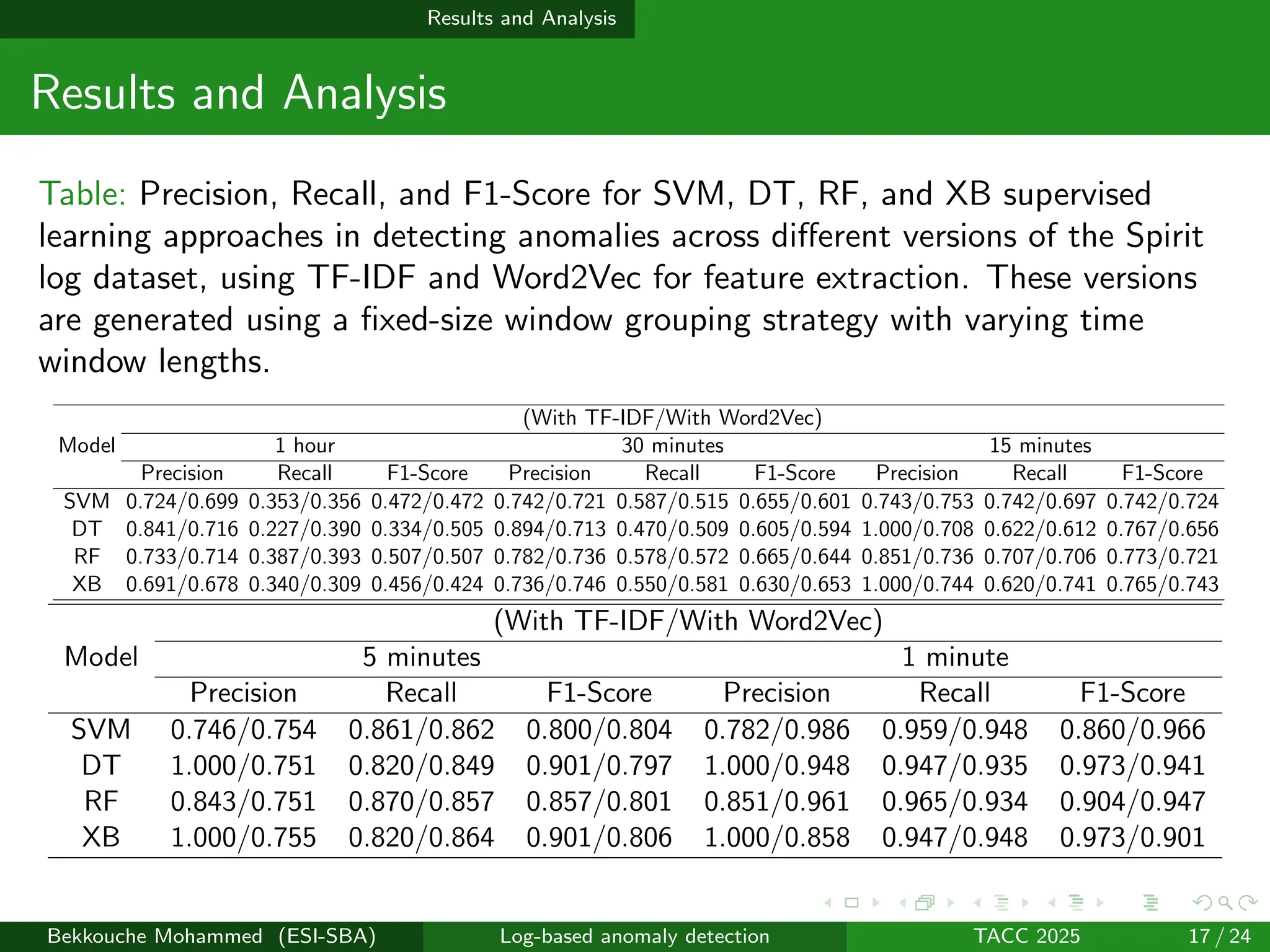
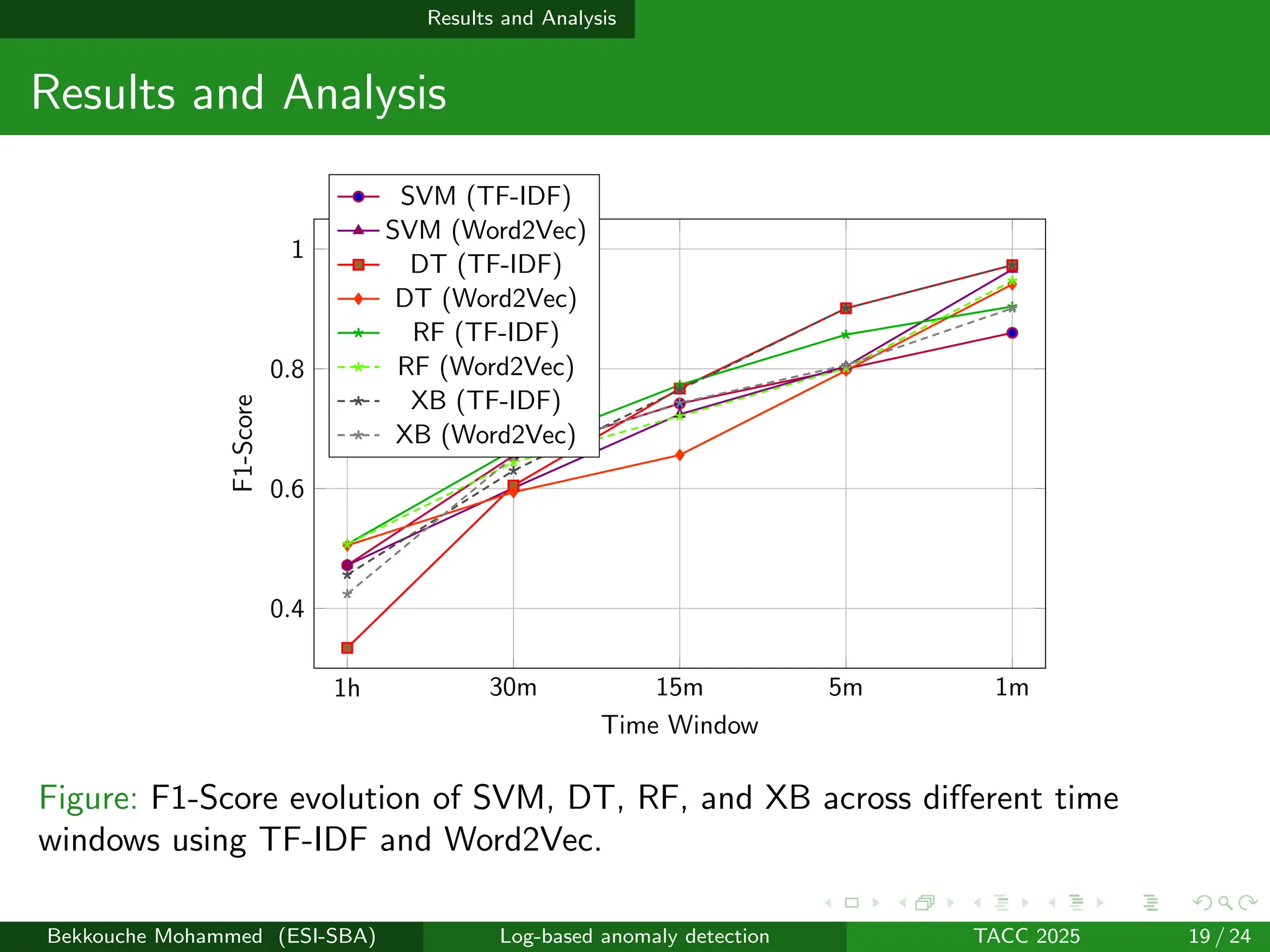
System logs provide important insights into the behavior and reliability of computing systems. Detecting anomalies through log analysis is essential for identifying failures and security issues. However, manual inspection is time-consuming and prone to error, particularly in large-scale environments. Machine learning techniques aim to automate anomaly detection and improve its accuracy. While most existing approaches are unsupervised due to the lack of labeled data, supervised methods can achieve higher accuracy when labeled logs are available by learning from both normal and abnormal examples. The Spirit dataset is a real-world labeled log dataset that enables the evaluation of supervised learning approaches. In this work, we present a comparative evaluation of four supervised models: Support Vector Machine (SVM), Decision Tree (DT), Random Forest (RF), and XGBoost (XB), applied to the Spirit dataset. We examine the effect of varying time-based fixed window sizes used to group log messages and compare two feature extraction techniques: TF-IDF (Term Frequency–Inverse Document Frequency) and Word2Vec. Results show that smaller window sizes improve detection performance by producing more sequences and enabling better identification of anomalous behavior. Tree-based models (DT, RF, XB) generally achieve better performance than SVM, especially when using TF-IDF features. SVM performs well with Word2Vec when short time windows are used. The 1-minute window configuration yields the best results across all models and feature types. These findings demonstrate the effectiveness of supervised models for log-based anomaly detection and highlight the importance of selecting appropriate log grouping strategies and feature representations.















































