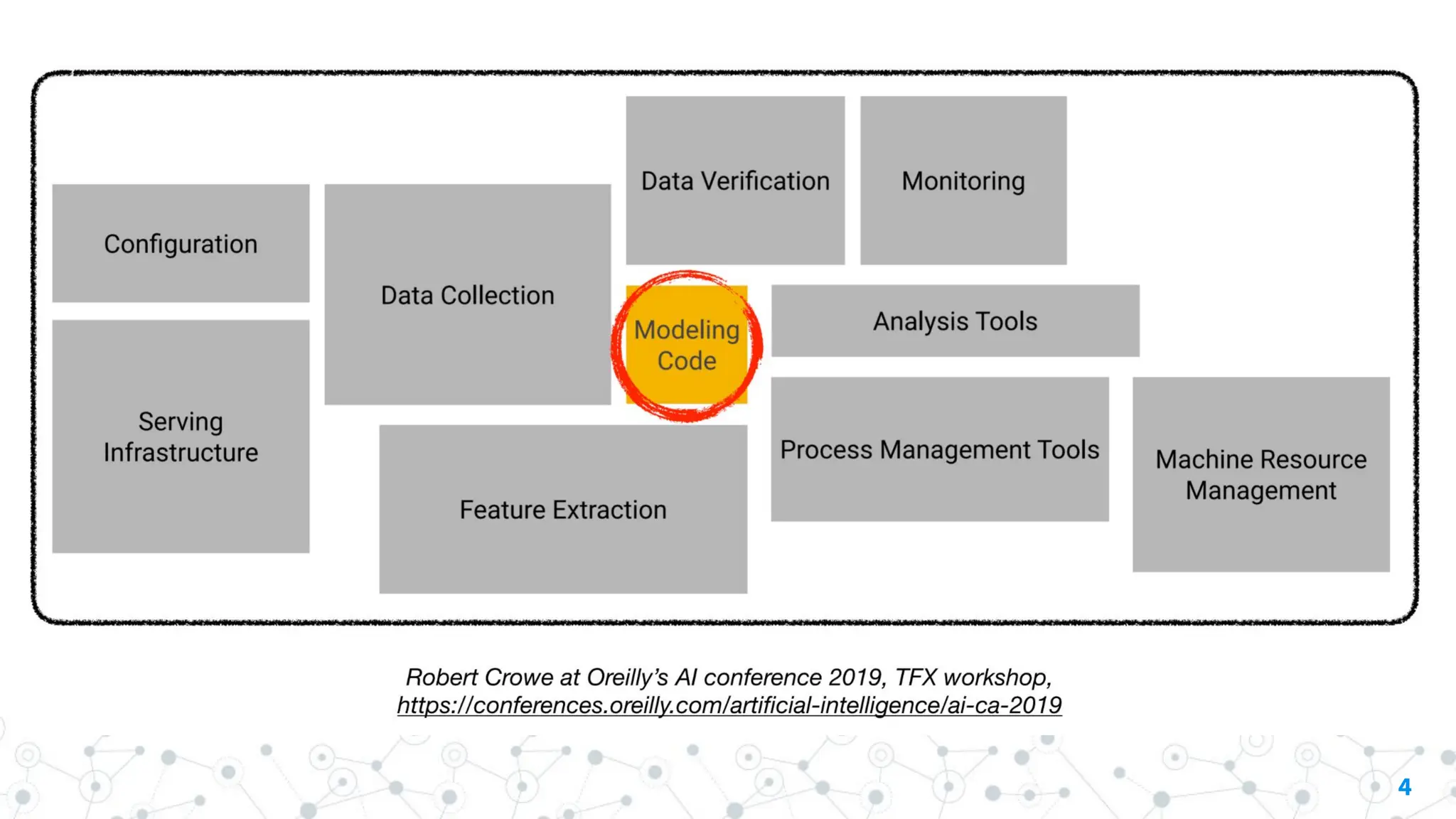
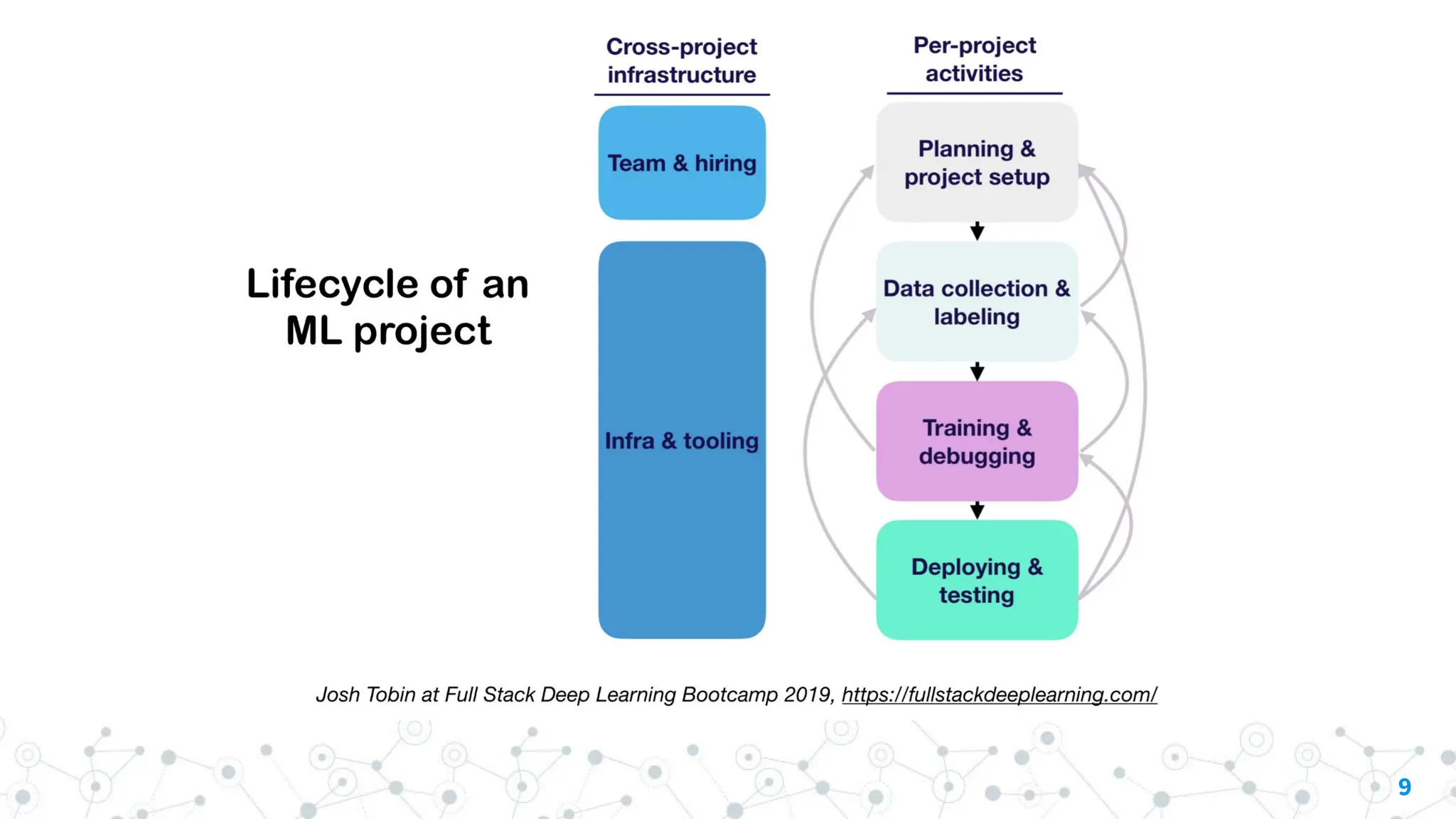
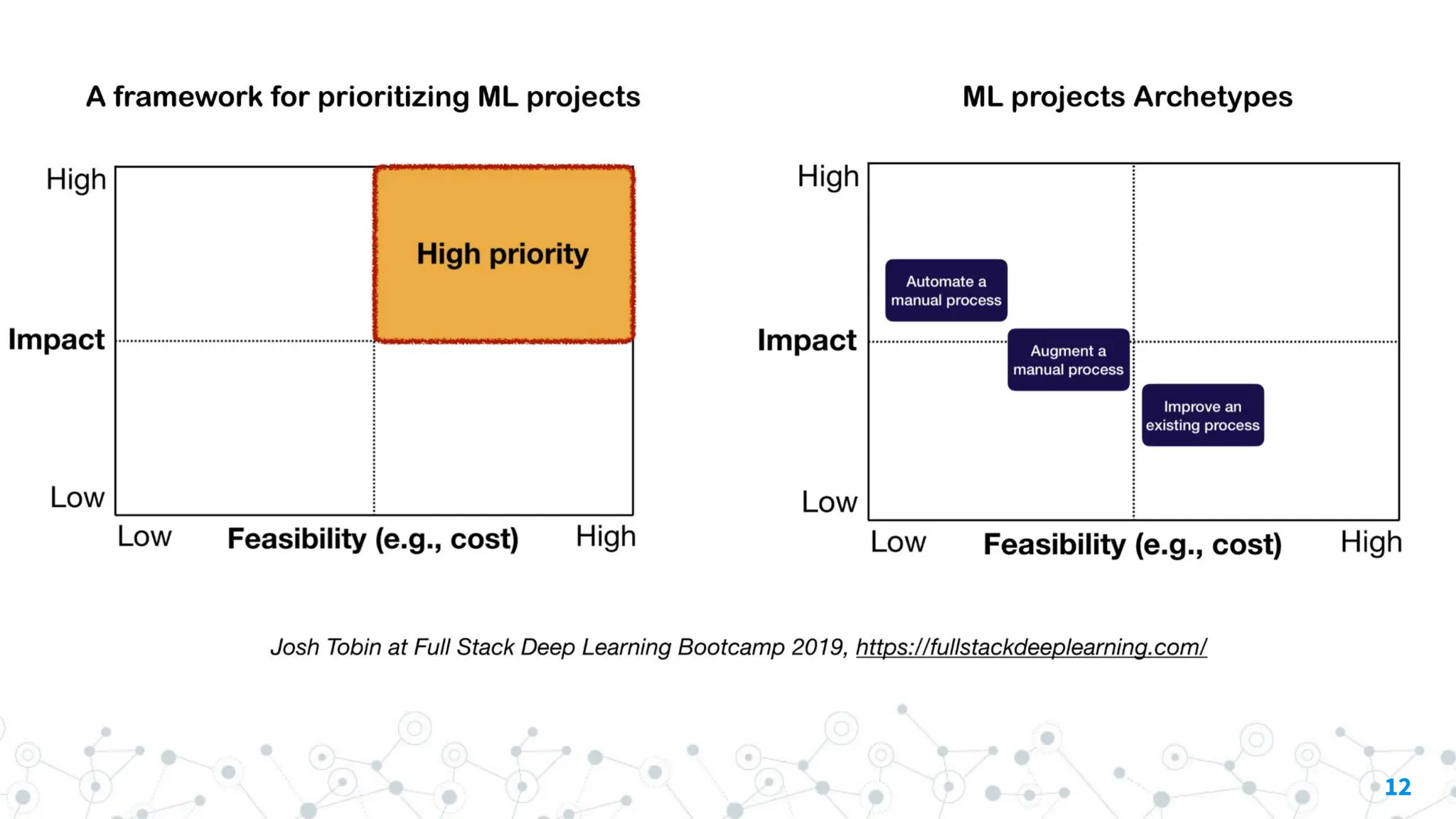
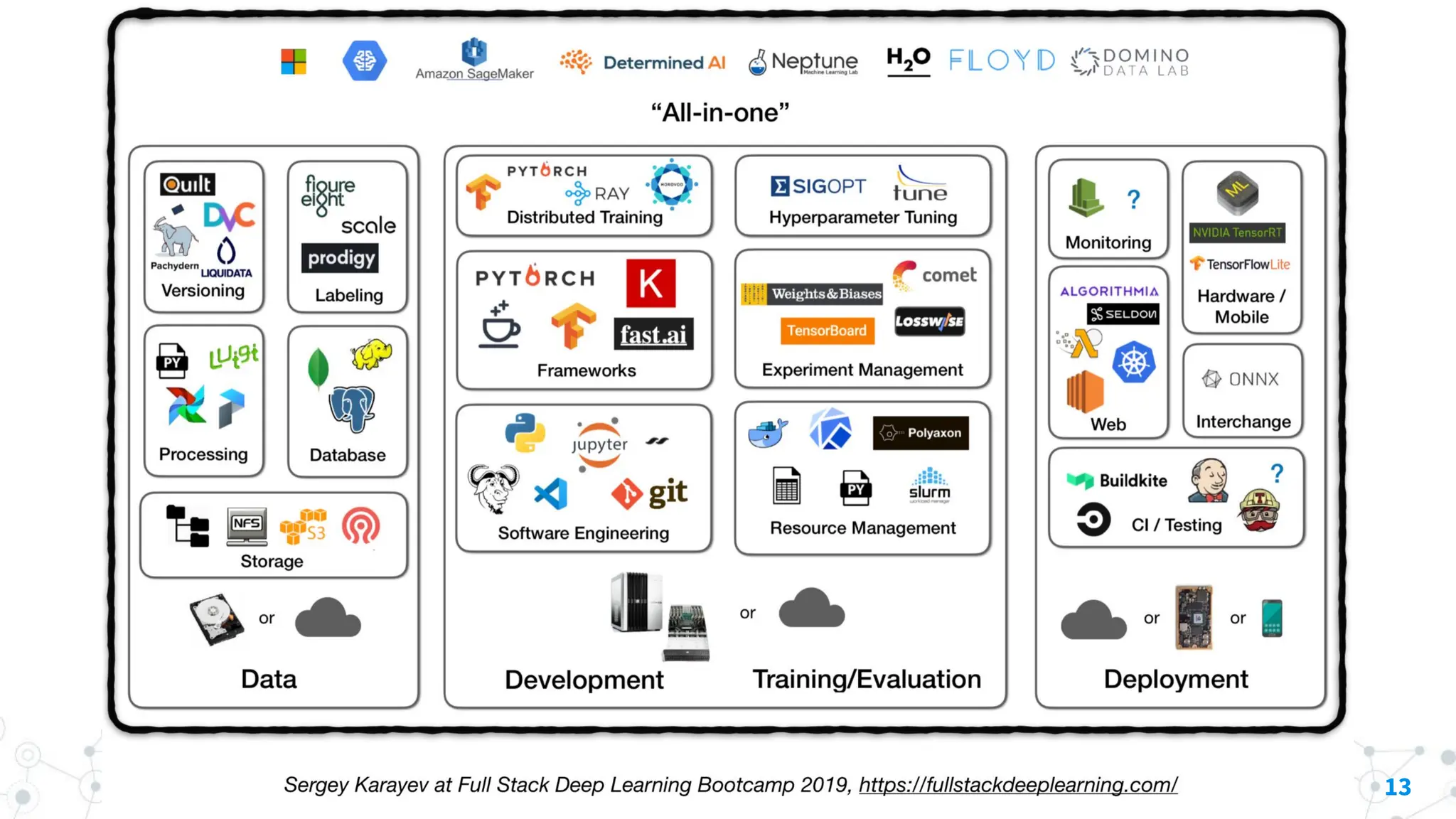
Potential reasons include:
◎Technically infeasible or poorly scoped
◎ Never make the leap to production
◎ Unclear success criteria (metrics)
◎ Poor team management
6
7.
“
This talk aimsto be an engineering
guideline for building
production-level machine learning
systems which will be deployed in
real world applications.
7
Important Note:
It isimportant to understand state of the art in your
domain:
Why?
◎ Helps to understand what is possible
◎ Helps to know what to try next
10
11.
Important factors toconsider when defining and
prioritizing ML projects:
High Impact
◎ Complex parts of your pipeline
◎ Where "cheap prediction" is
valuable
◎ Where automating complicated
manual process is valuable
Low Cost
◎ Cost is driven by:
○ Data availability
○ Performance requirements:
costs tend to scale super-linearly
in the accuracy requirement
○ Problem difficulty
11
2.1 Data Sources
◎Supervised deep learning requires a lot of labeled data
◎ Labeling own data is costly!
◎ Here are some resources for data:
○ Open source data (good to start with, but not an
advantage)
○ Data augmentation (a MUST for computer vision, an
option for NLP)
○ Synthetic data (almost always worth starting with, esp.
in NLP)
○
○ 15
16.
2.2 Data Labeling
◎Requires: separate software stack (labeling platforms),
temporary labor, and QC
◎ Sources of labor for labeling:
○ Crowdsourcing (Mechanical Turk): cheap and scalable,
less reliable, needs QC
○ Hiring own annotators: less QC needed, expensive,
slow to scale
○ Data labeling service companies
◎ Labeling platforms
16
17.
2.3 Data Storage
◎Data storage options
○ Object store: Store binary data (images, sound files,
compressed texts)
○ Database: Store metadata (file paths, labels, user
activity, etc).
○ Data Lake: to aggregate features which are not
obtainable from database (e.g. logs)
○ Feature Store: store, access, and share machine
learning features
◎ Suggestion: At training time, copy data into a local or
networked filesystem (NFS)
17
18.
2.4 Data Versioning
◎It's a "MUST" for deployed ML models:
Deployed ML models are part code, part data. No data
versioning means no model versioning.
◎ Data versioning platforms
18
19.
2.5 Data Processing
◎Training data for production models may come from
different sources.
◎ There are dependencies between tasks, each needs to be
kicked off after its dependencies are finished.
◎ Makefiles are not scalable. ʻWorkflow managerʼs become
pretty essential in this regard.
◎ Workflow orchestration
19
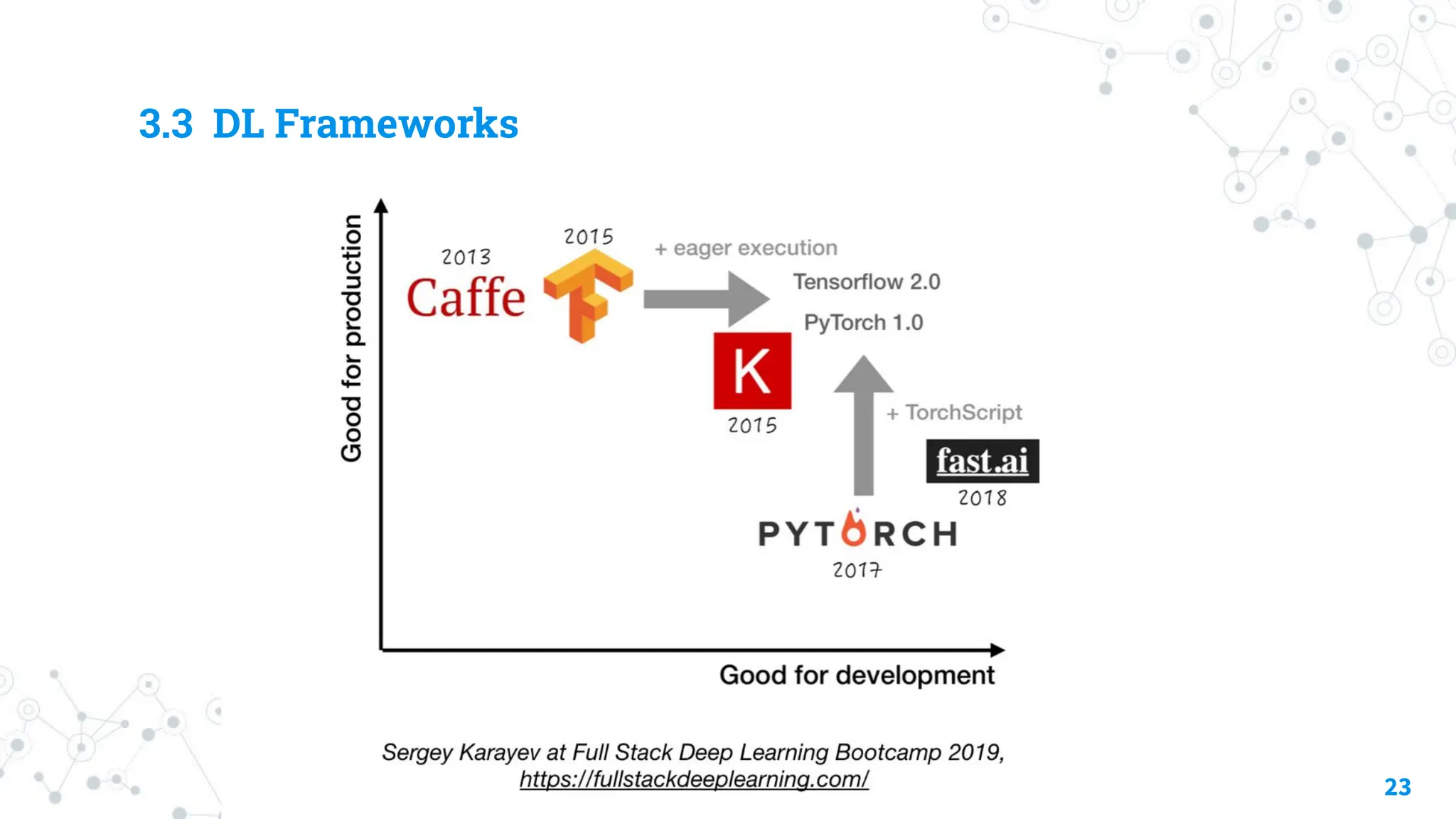
3.1 Software Engineering
◎Winner language: Python
◎ Editors:
○ VS Code, Pycharm
○ Notebooks -> Jupyter notebook, JupyterLab, nteract
○ Streamlit: Interactive data science tool with applets
◎ Compute recommendations
○ For individuals or startups: Use GPU PC or buy shared
servers or use cloud instances
○ For large companies: Use cloud instances with proper
provisioning and handling of failures
21
22.
3.2 Resource Management
◎Allocating free resources to programs
◎ Resources management options:
○ Old school cluster job scheduler
○ Docker + Kubernetes
○ Kubeflow
○ Polyaxon (paid features)
22
3.6 Distributed Training
◎Data parallelism: Use it when iteration time is too long
(both tensorflow and PyTorch support)
◎ Model parallelism: when model does not fit on a single GPU
◎ Solutions
○ Horovod
26
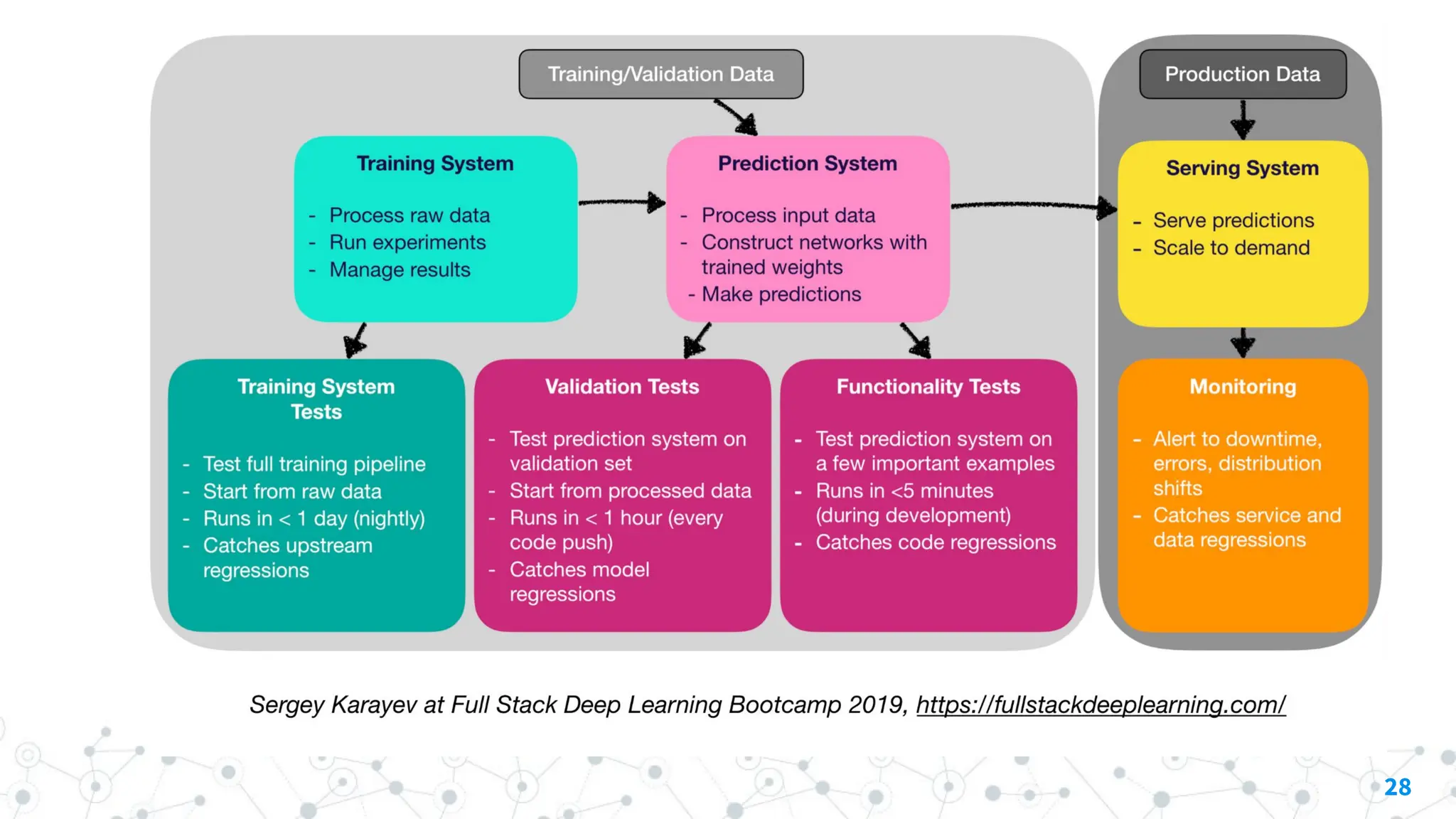
4.2 Web Deployment
◎Consists of a Prediction System and a Serving System
◎ Serving options:
○ Deploy to VMs, scale by adding instances
○ Deploy as containers, scale via orchestration
◎ Model serving:
○ Specialized web deployment for ML models
○ Frameworks:
◉ Tensorflow serving, Clipper (Berkeley), Seldon
◎ Decision making: CPU or GPU?
◎ (Bonus) Deploying Jupyter Notebooks: Use Kubeflow
Fairing
29
30.
4.3 Service Meshand Traffic Routing
◎ Transition from monolithic applications towards a
distributed microservice architecture could be challenging.
◎ A Service mesh (consisting of a network of microservices)
reduces the complexity of such deployments, and eases the
strain on development teams.
○ Istio: a service mesh to ease creation of a network of
deployed services with load balancing,
service-to-service authentication, monitoring, with few
or no code changes in service code.
30
31.
4.4 Monitoring
◎ Purposeof monitoring:
○ Alerts for downtime, errors, and distribution shifts
○ Catching service and data regressions
◎ Kiali: an observability console for Istio with service mesh
configuration capabilities. It answers these questions: How
are the microservices connected? How are they
performing?
31
32.
4.5 Deploying onEmbedded and Mobile Devices
◎ Main challenge: memory footprint and compute constraints
◎ Solutions:
○ Quantization
○ Reduced model size (MobileNets)
○ Knowledge Distillation
◎ Embedded and Mobile Frameworks:
○ Tensorflow Lite, PyTorch Mobile, Core ML, FRITZ, ML Kit
◎ Model Conversion:
○ Open Neural Network Exchange (ONNX): open-source
format for deep learning models
○
○ 32
33.
4.6 All-in-one solutions
◎Tensorflow Extended (TFX)
◎ Michelangelo (Uber)
◎ Google Cloud AI Platform
◎ Amazon SageMaker
◎ Neptune
◎ FLOYD
◎ Paperspace
◎ Determined AI
◎ Domino data lab
33