Downloaded 378 times


















![ML Workflow
24
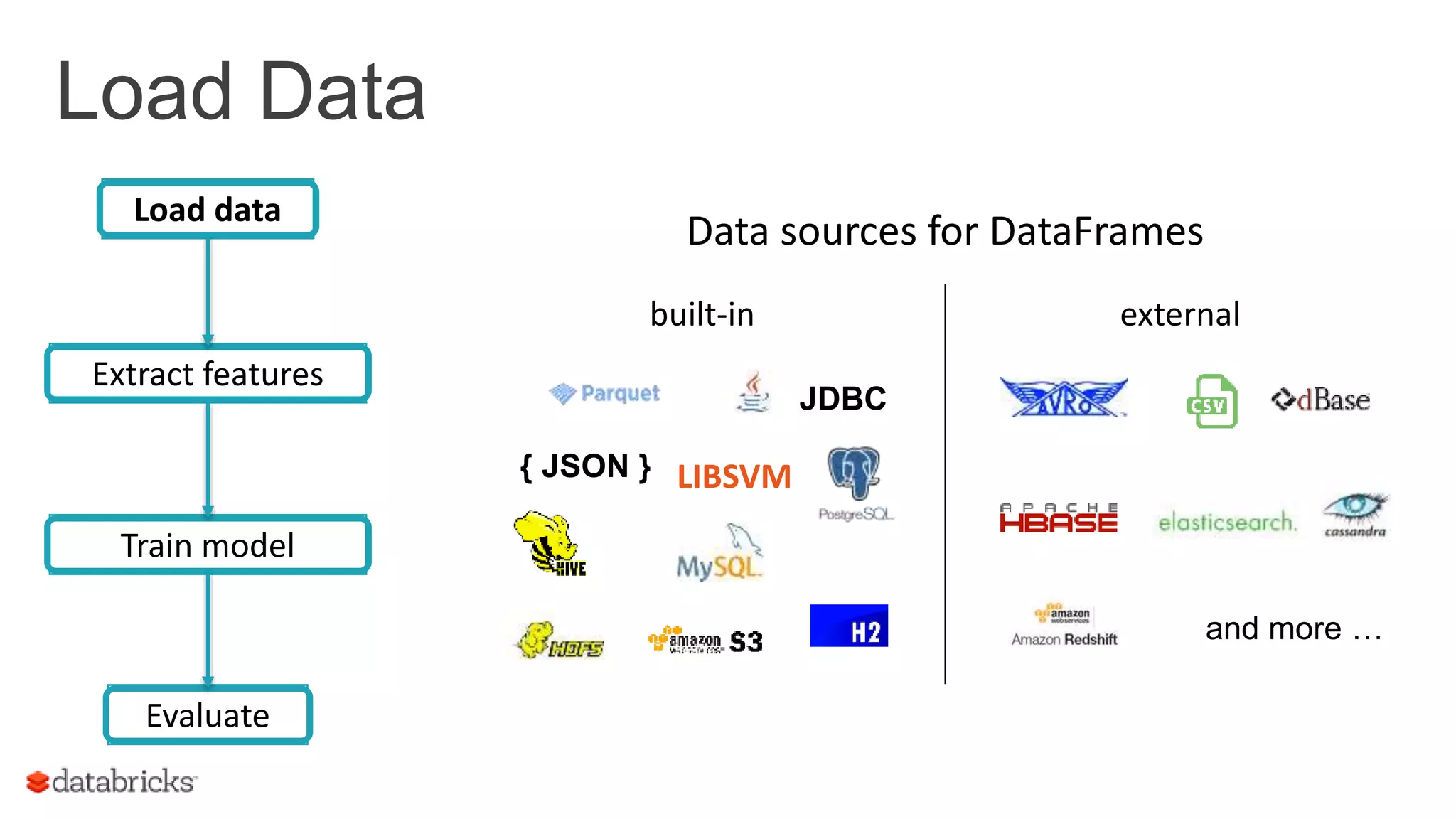
Train model
Evaluate
Load data
Extract features
Review: This product doesn't seem to be made to last… Rating: 2
feature_vector: [0.1 -1.3 0.23 … -0.74] rating: 2.0
Regression: (review: String) => Double](https://image.slidesharecdn.com/16-06-24hadoopsummit-160708174831/75/Combining-Machine-Learning-Frameworks-with-Apache-Spark-24-2048.jpg)
![Extract Features
words: [this, product, doesn't, seem, to, …]
feature_vector: [0.1 -1.3 0.23 … -0.74]
Review: This product doesn't seem to be made to last… Rating: 2
Prediction: 3.0
Train model
Evaluate
Load data
Tokenizer
Hashed Term Frequ.](https://image.slidesharecdn.com/16-06-24hadoopsummit-160708174831/75/Combining-Machine-Learning-Frameworks-with-Apache-Spark-26-2048.jpg)
![Extract Features
words: [this, product, doesn't, seem, to, …]
feature_vector: [0.1 -1.3 0.23 … -0.74]
Review: This product doesn't seem to be made to last… Rating: 2
Prediction: 3.0
Linear regression
Evaluate
Load data
Tokenizer
Hashed Term Frequ.](https://image.slidesharecdn.com/16-06-24hadoopsummit-160708174831/75/Combining-Machine-Learning-Frameworks-with-Apache-Spark-27-2048.jpg)































![ML Workflow
24
Train model
Evaluate
Load data
Extract features
Review: This product doesn't seem to be made to last… Rating: 2
feature_vector: [0.1 -1.3 0.23 … -0.74] rating: 2.0
Regression: (review: String) => Double](https://crownmelresort.com/image.slidesharecdn.com/16-06-24hadoopsummit-160708174831/75/Combining-Machine-Learning-Frameworks-with-Apache-Spark-24-2048.jpg)

![Extract Features
words: [this, product, doesn't, seem, to, …]
feature_vector: [0.1 -1.3 0.23 … -0.74]
Review: This product doesn't seem to be made to last… Rating: 2
Prediction: 3.0
Train model
Evaluate
Load data
Tokenizer
Hashed Term Frequ.](https://crownmelresort.com/image.slidesharecdn.com/16-06-24hadoopsummit-160708174831/75/Combining-Machine-Learning-Frameworks-with-Apache-Spark-26-2048.jpg)
![Extract Features
words: [this, product, doesn't, seem, to, …]
feature_vector: [0.1 -1.3 0.23 … -0.74]
Review: This product doesn't seem to be made to last… Rating: 2
Prediction: 3.0
Linear regression
Evaluate
Load data
Tokenizer
Hashed Term Frequ.](https://crownmelresort.com/image.slidesharecdn.com/16-06-24hadoopsummit-160708174831/75/Combining-Machine-Learning-Frameworks-with-Apache-Spark-27-2048.jpg)
















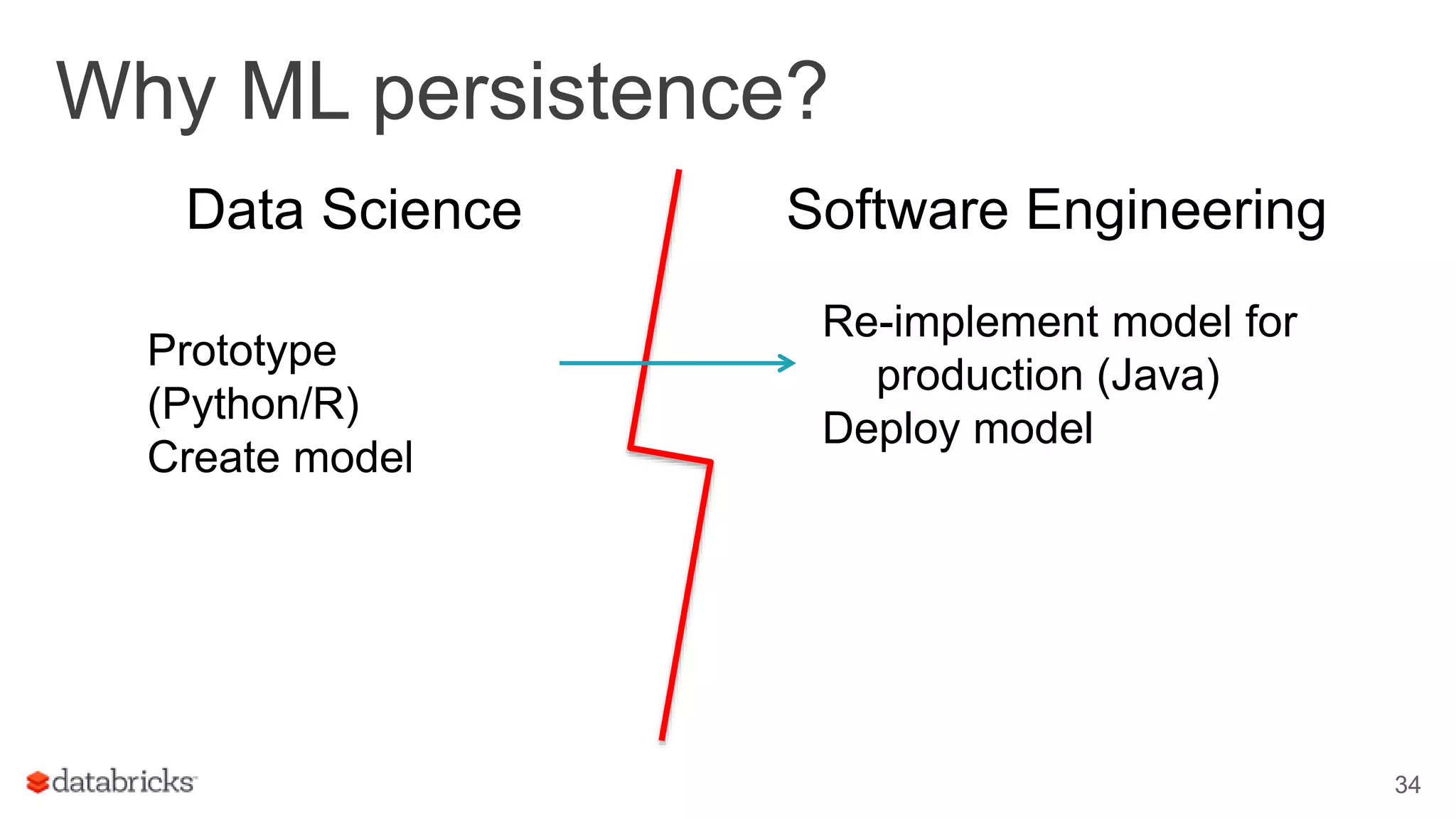
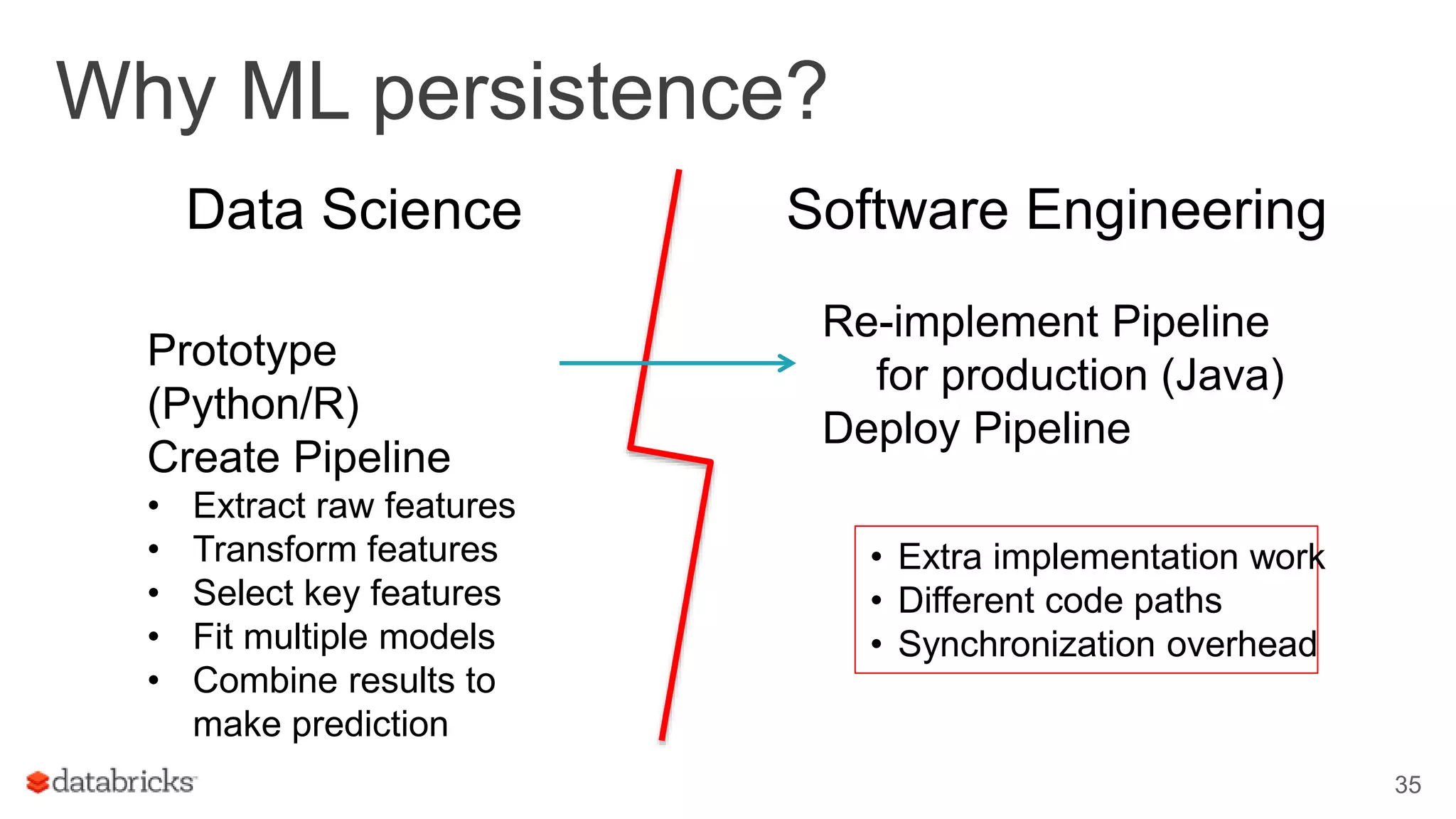
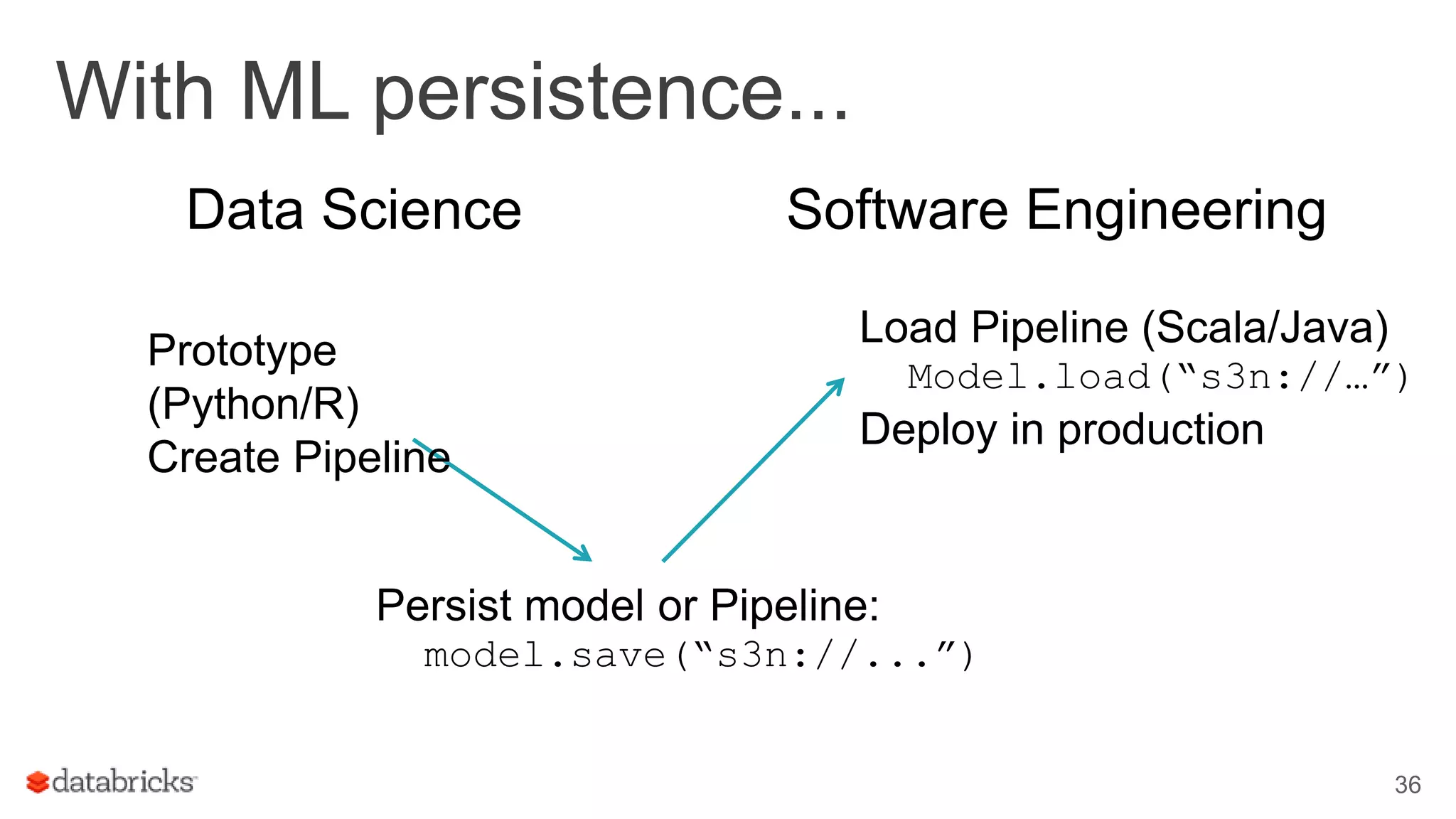
This document discusses combining machine learning frameworks with Apache Spark. It provides an overview of Apache Spark and MLlib, describes how to distribute TensorFlow computations using Spark, and discusses managing machine learning workflows with Spark through features like cross validation, persistence, and distributed data sources. The goal is to make machine learning easy, scalable, and integrate with existing workflows.
Introduces Apache Spark's role in big data, contributions by Tim Hunter, and Spark's significance as an open-source project.
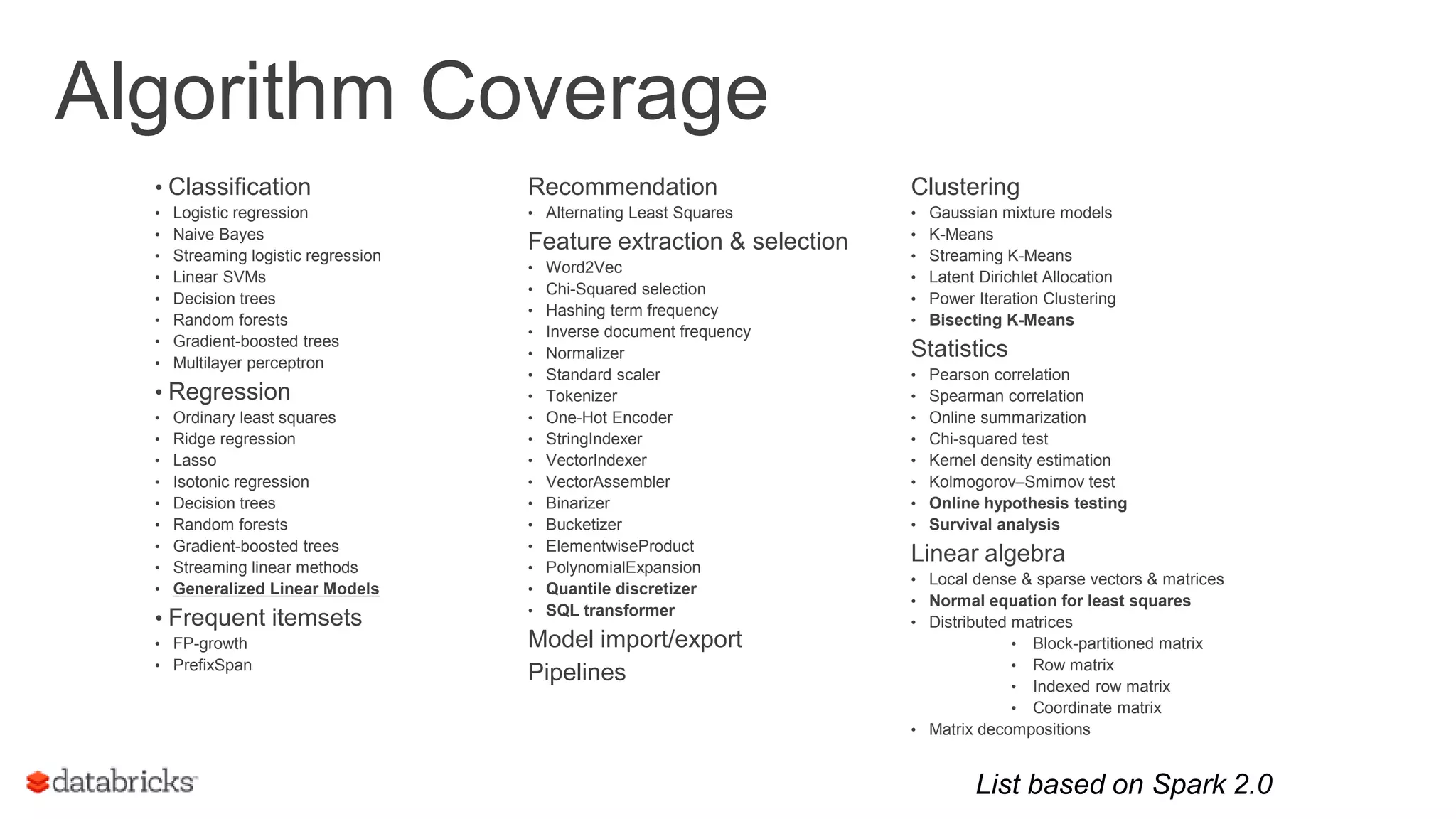
Discusses the MLlib library for large-scale machine learning in Spark, covering algorithms and mission to simplify scalable ML.
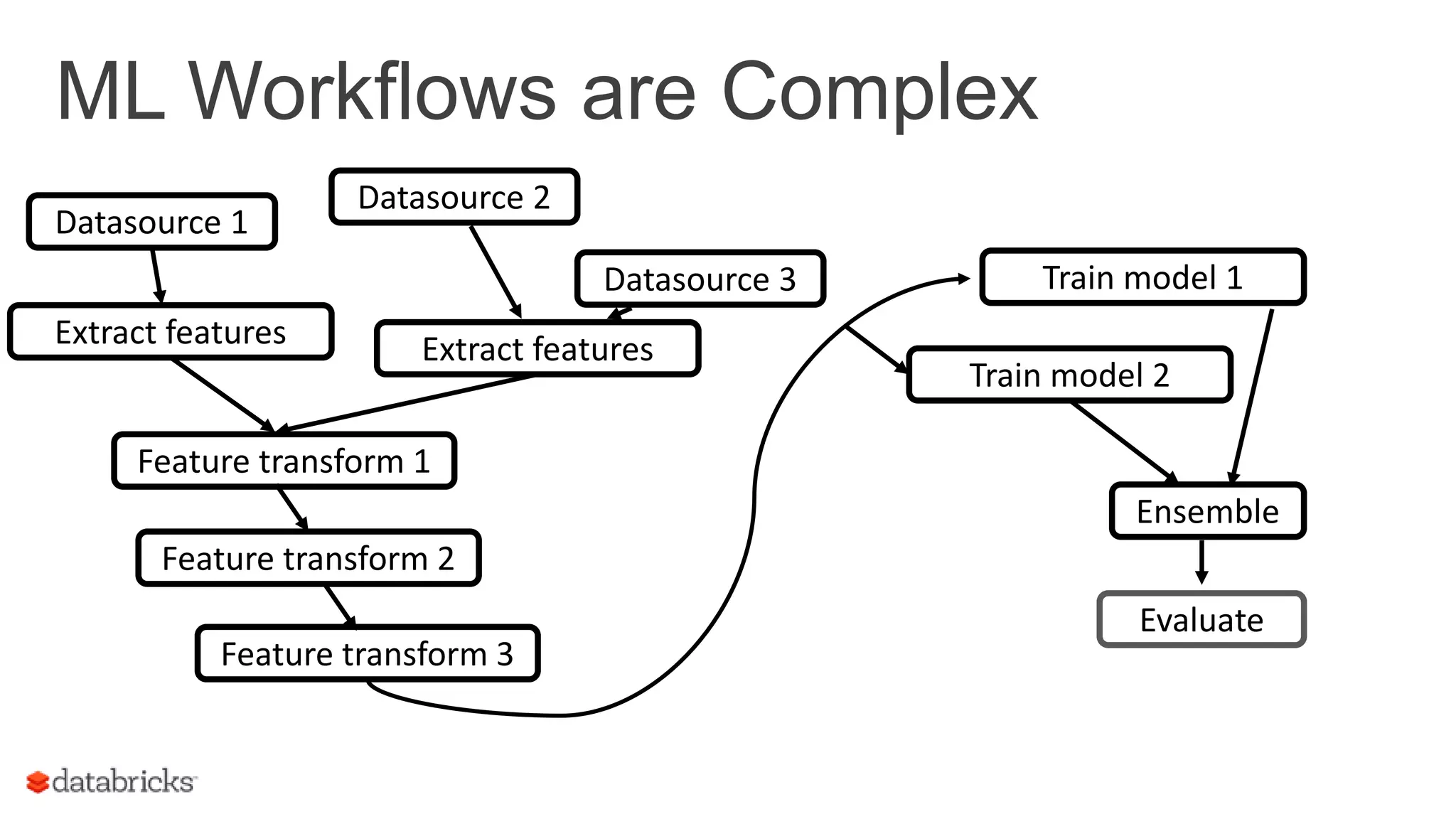
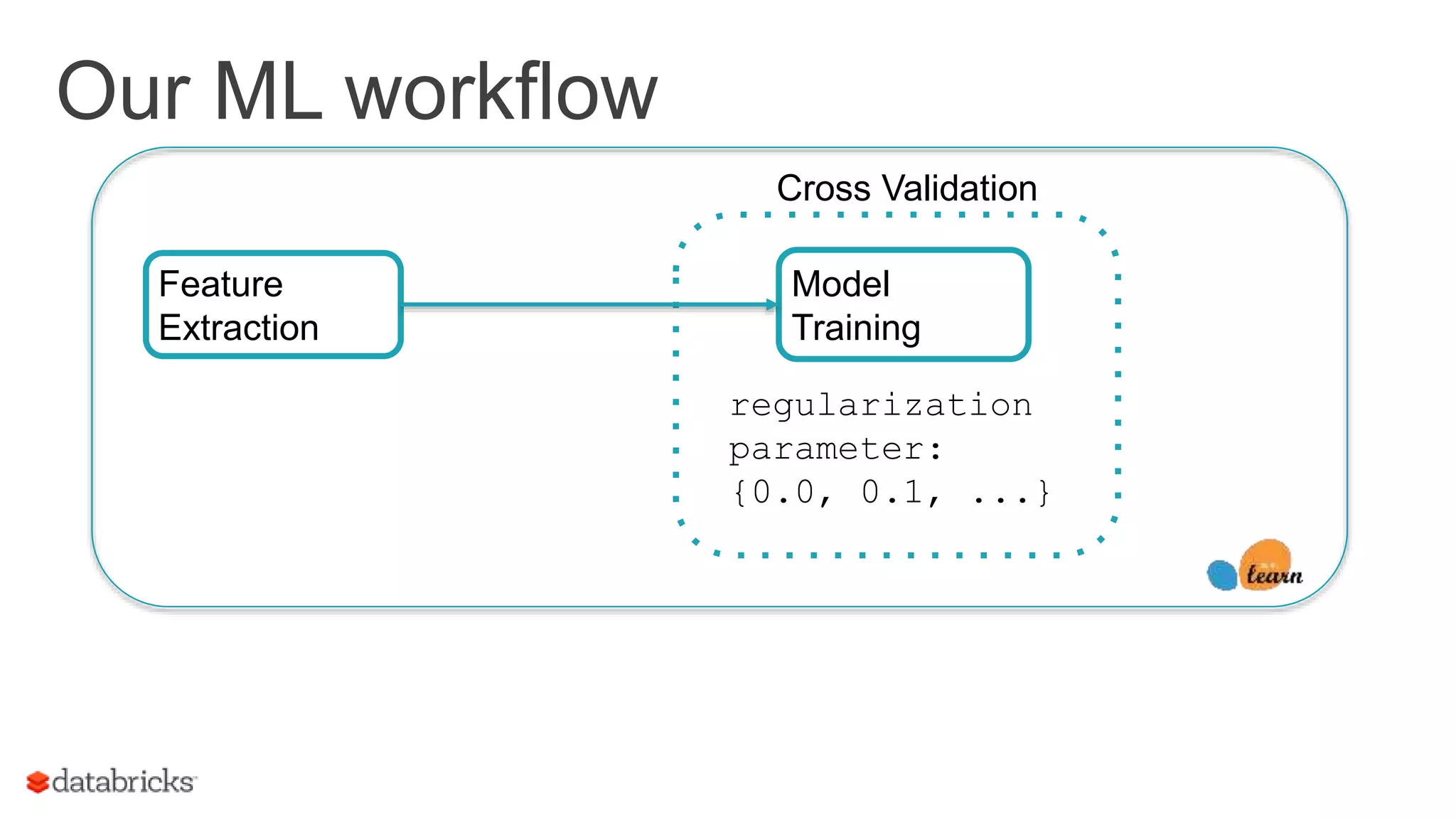
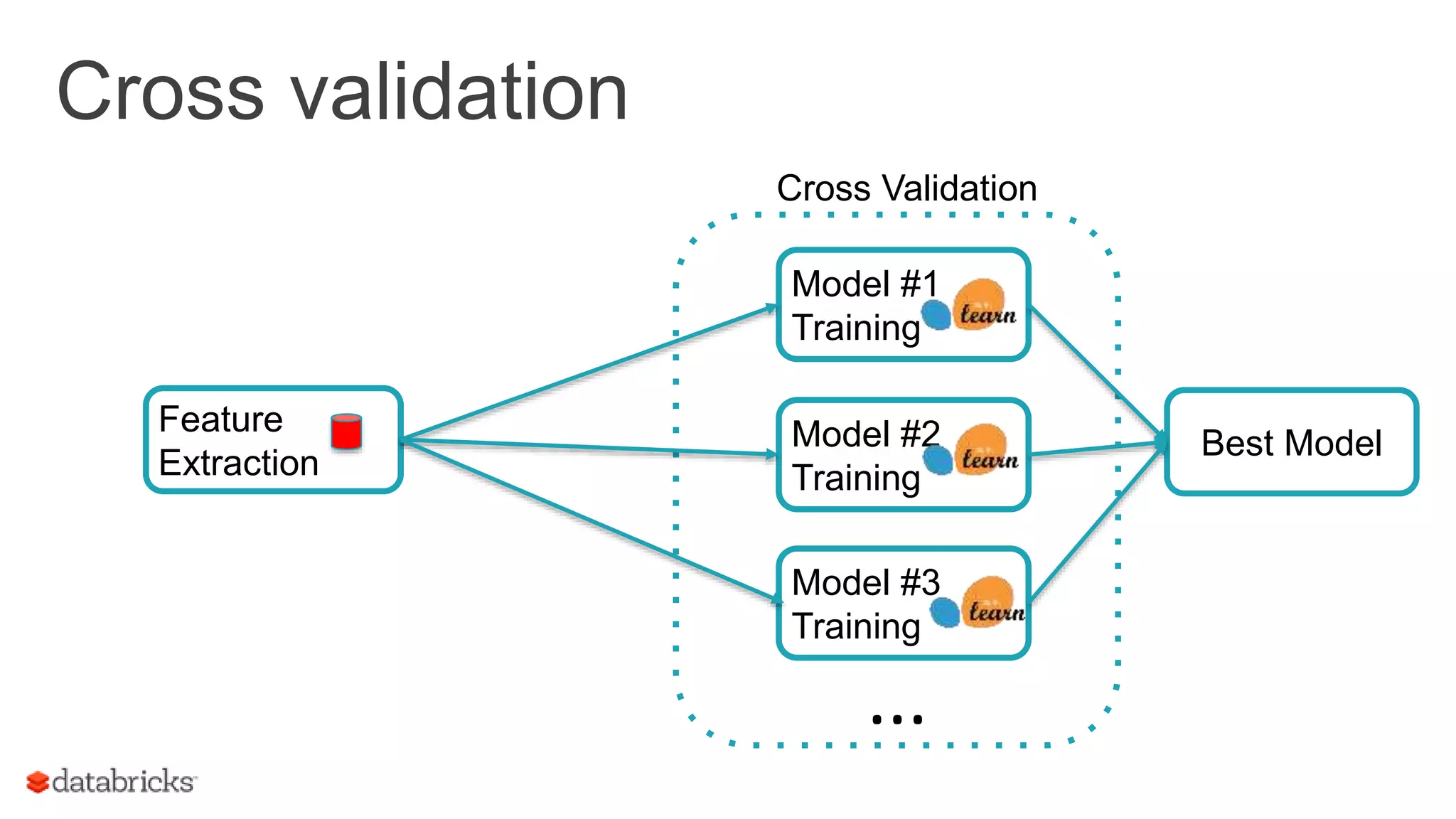
Outlines complex ML workflows, emphasizing pipeline specifications, data re-runs, and evaluation processes.
Explores existing tools like Scikit-Learn and R, clarifying common misconceptions about Spark's capabilities.
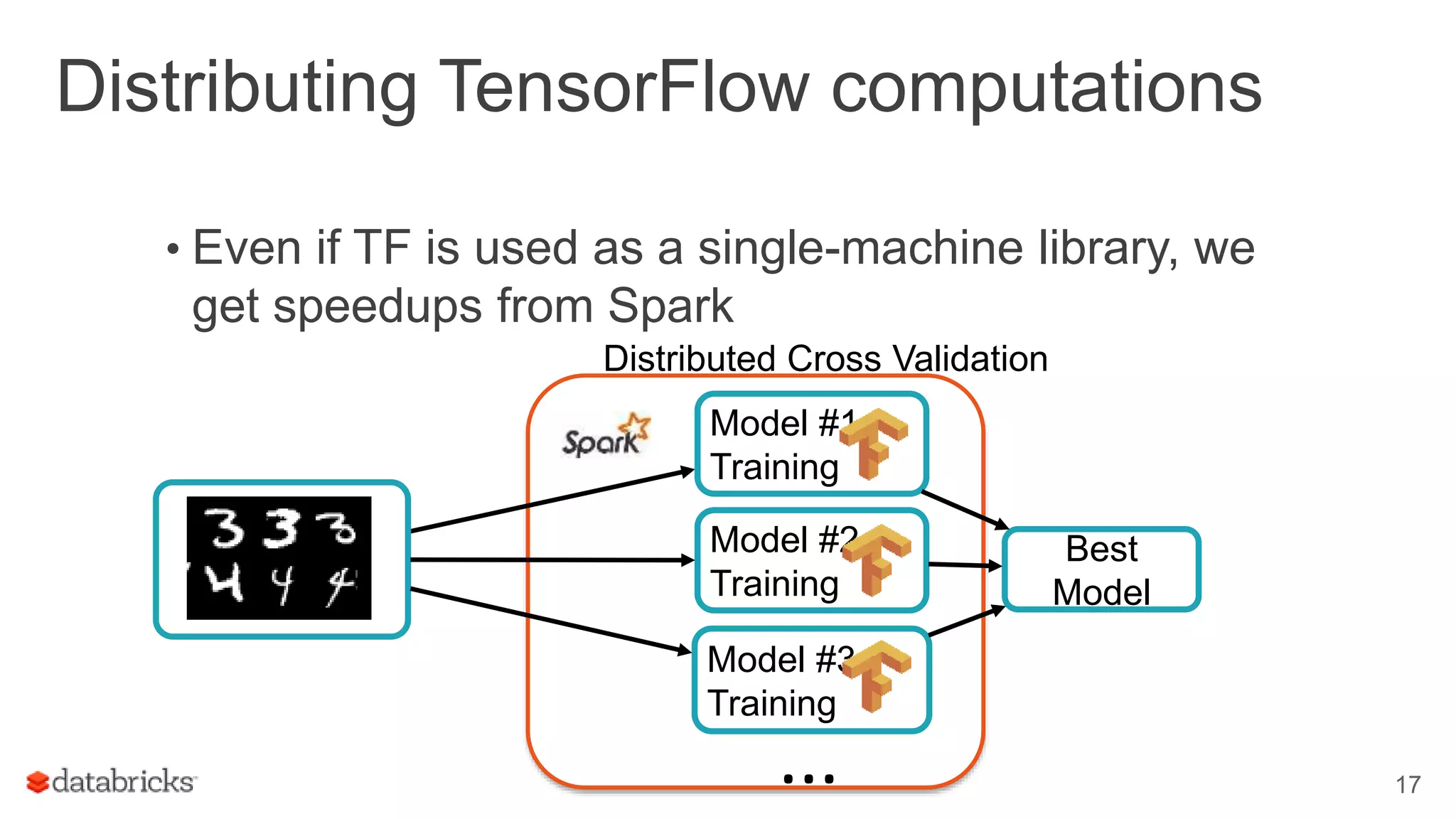
Describes using Spark for scheduling 'embarrassingly parallel' ML tasks and provides an example of digit learning.
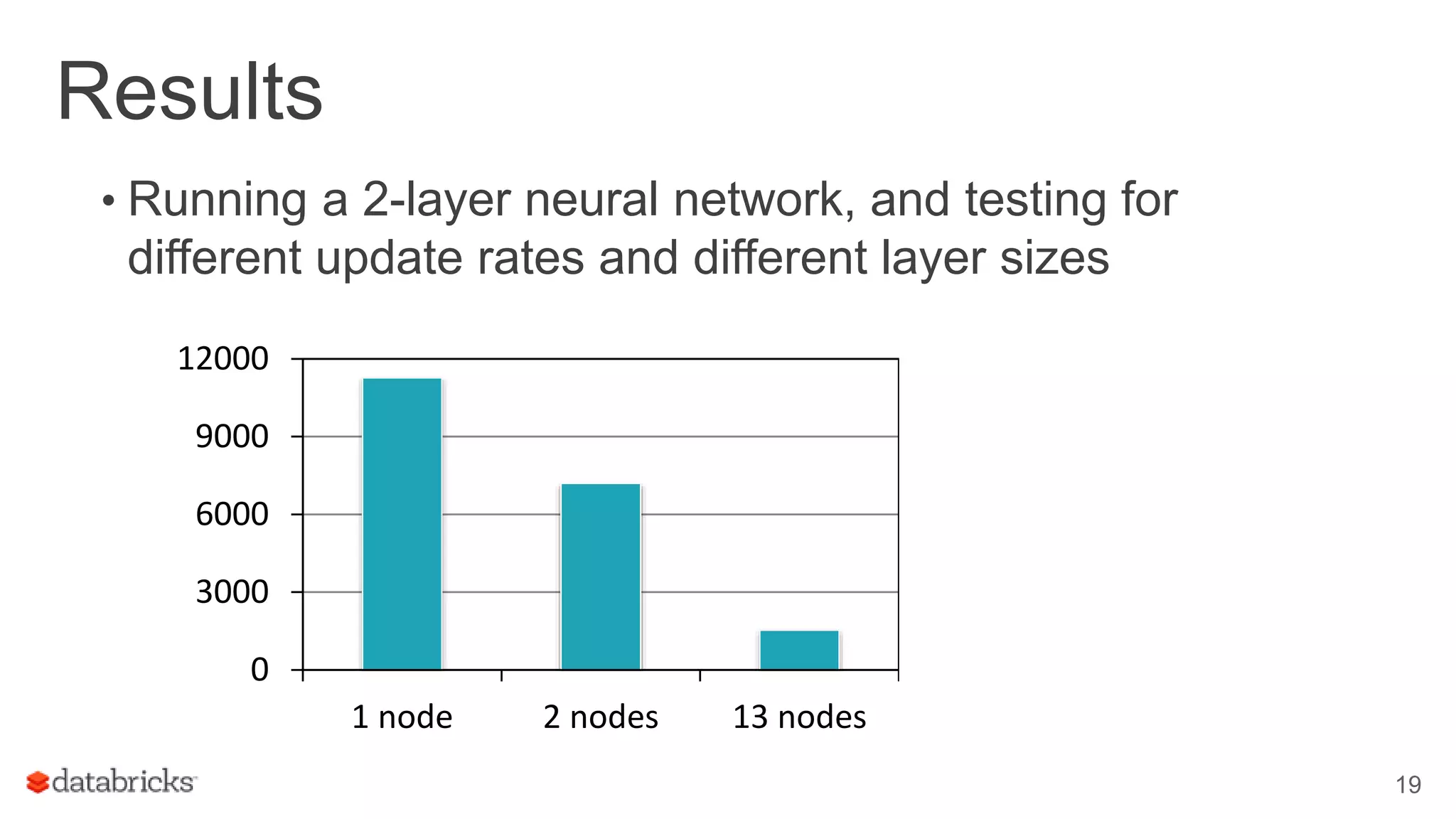
Highlights the challenges of training neural networks, including the use of TensorFlow for its ease of integration with Spark.
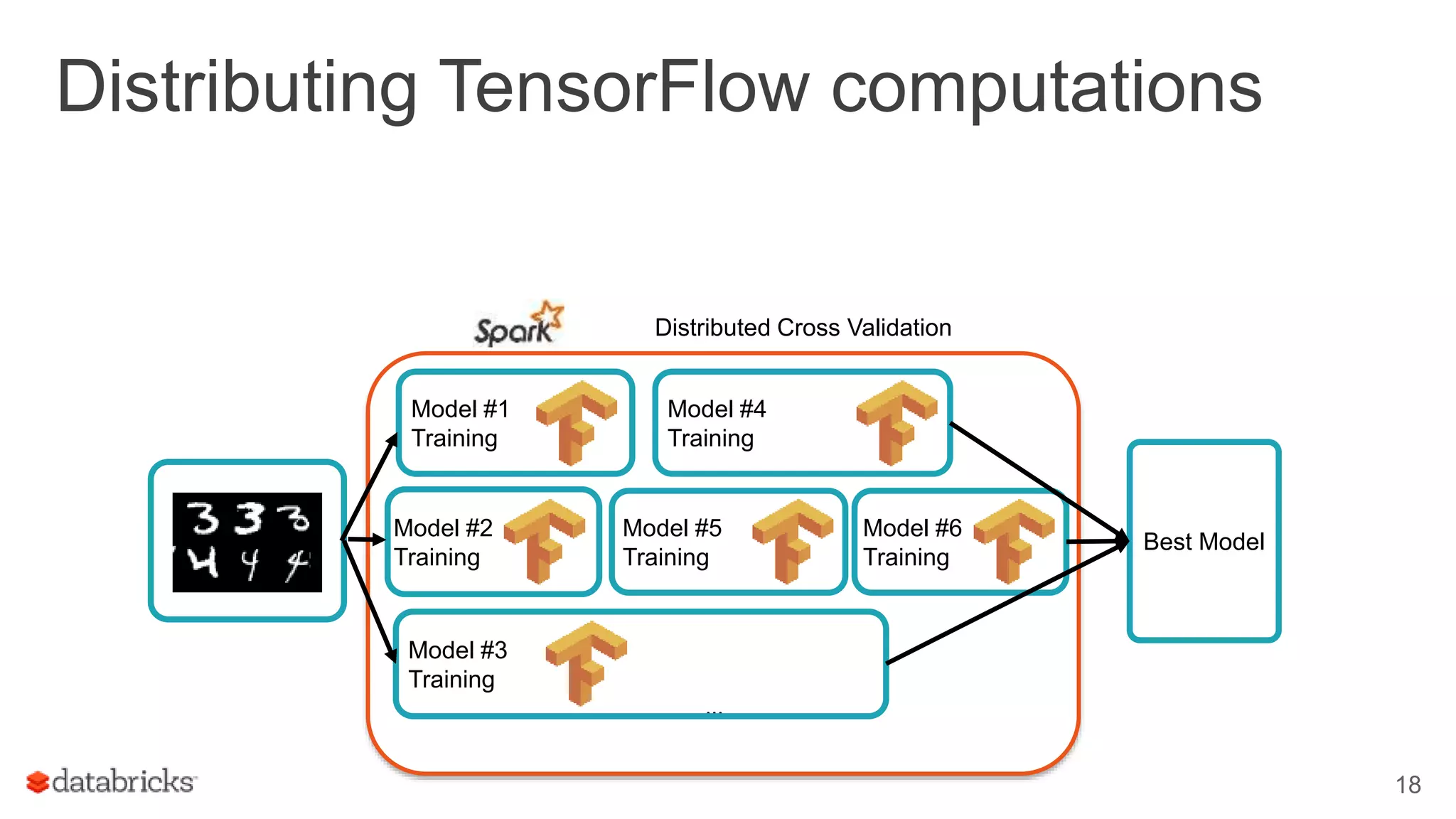
Details the distribution of TensorFlow computations using Spark to achieve speedups in model training.
Reports on results from training a 2-layer neural network, emphasizing the importance of parameter selection.
Discusses managing ML workflows in Spark, focusing on a data scientist's requirements for production environments.
Presents a sentiment analysis example that predicts user ratings from text reviews using feature extraction.
Describes loading data from various sources and extracting meaningful features for ML model training.
Explains the workflow for executing ML tasks and the importance of cross-validation in model training.
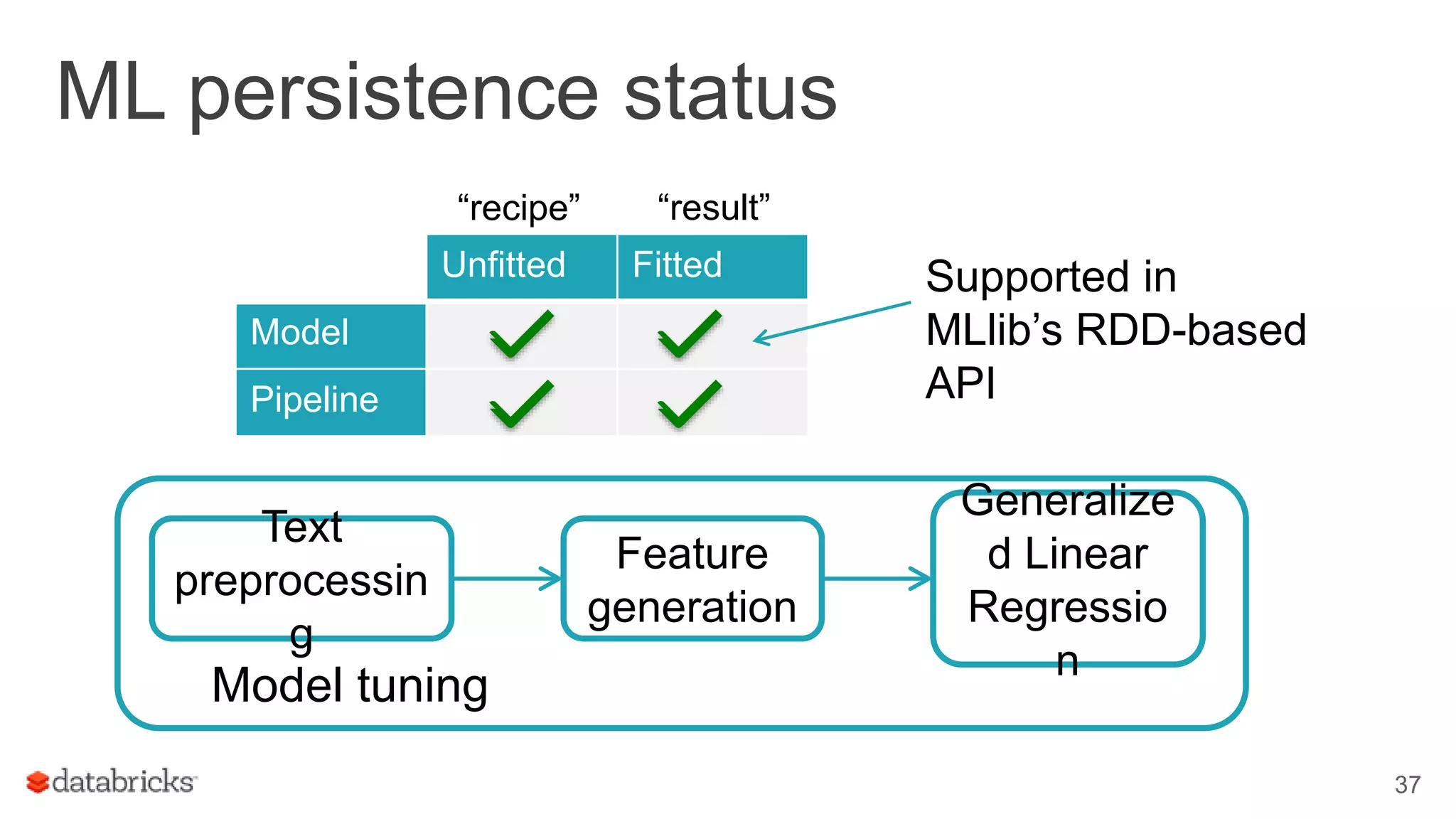
Covers production readiness of MLlib, emphasizing model persistence and transition from prototype to production.
Highlights upcoming features in Spark MLlib, promoting community involvement and providing resources to get started.
Concludes the presentation and provides links to resources for further exploration of Apache Spark.






















































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)
