Downloaded 11 times



![5
“…autonomous vehicles would have
to be driven hundreds of millions of
miles and sometimes hundreds of
billions of miles to demonstrate their
reliability in terms of fatalities and
injuries.” [1]
[1] Driving to Safety, Rand Corporation
https://www.rand.org/content/dam/rand/pubs/research_reports/RR1400/RR1478/RAND_RR1478.pdf](https://image.slidesharecdn.com/292arvindhosagrahara-210616155254/75/Processing-Large-Datasets-for-ADAS-Applications-using-Apache-Spark-5-2048.jpg)











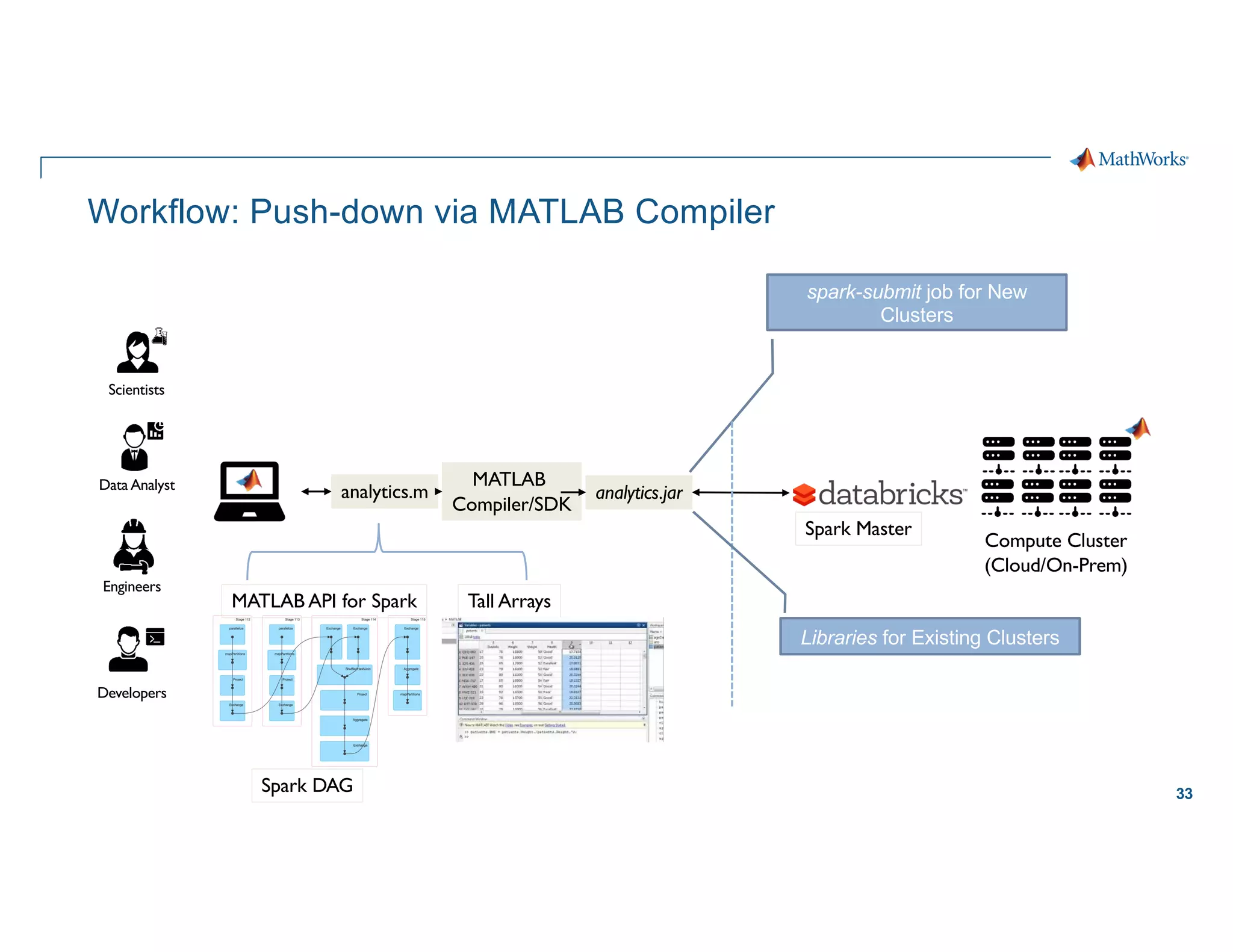




![48
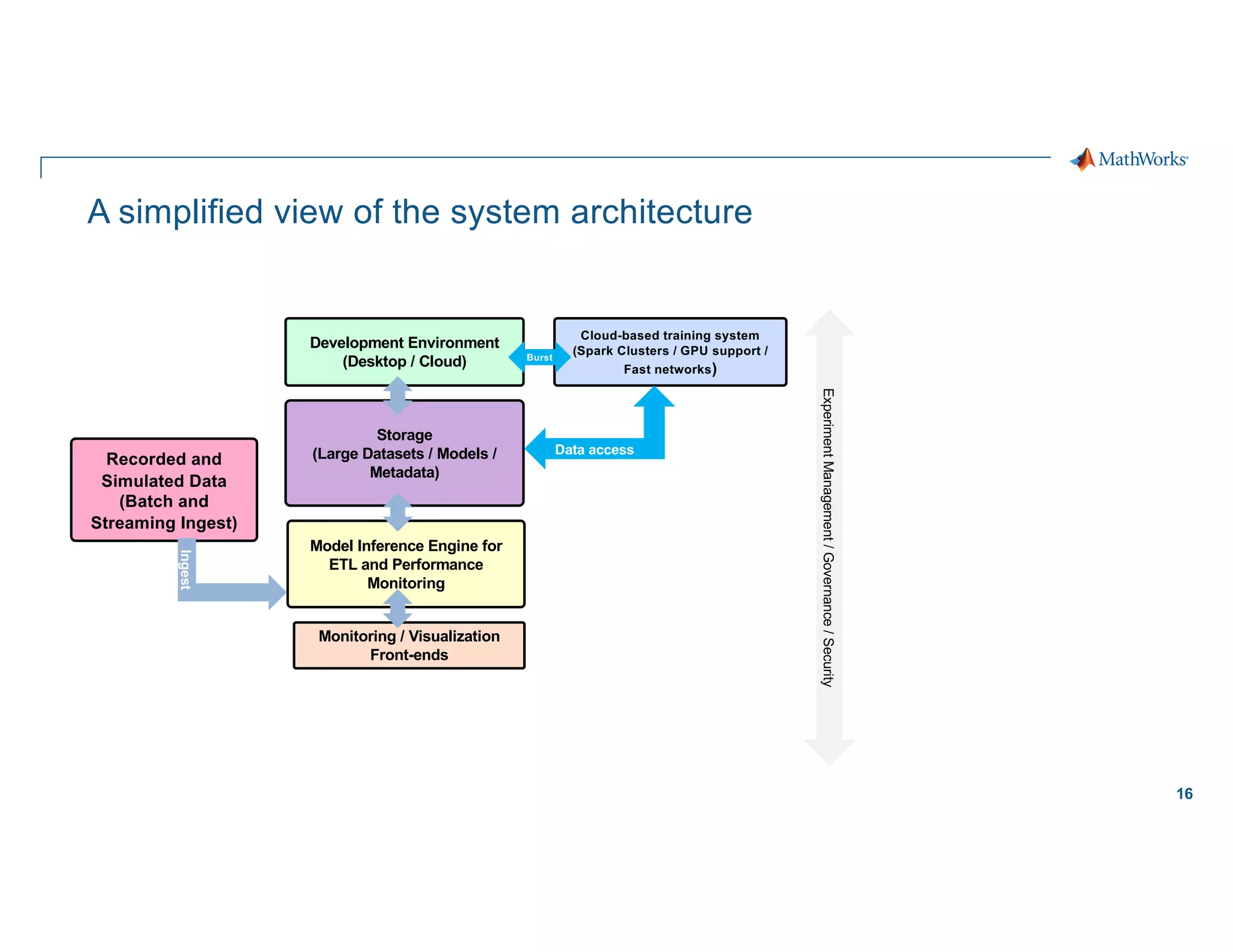
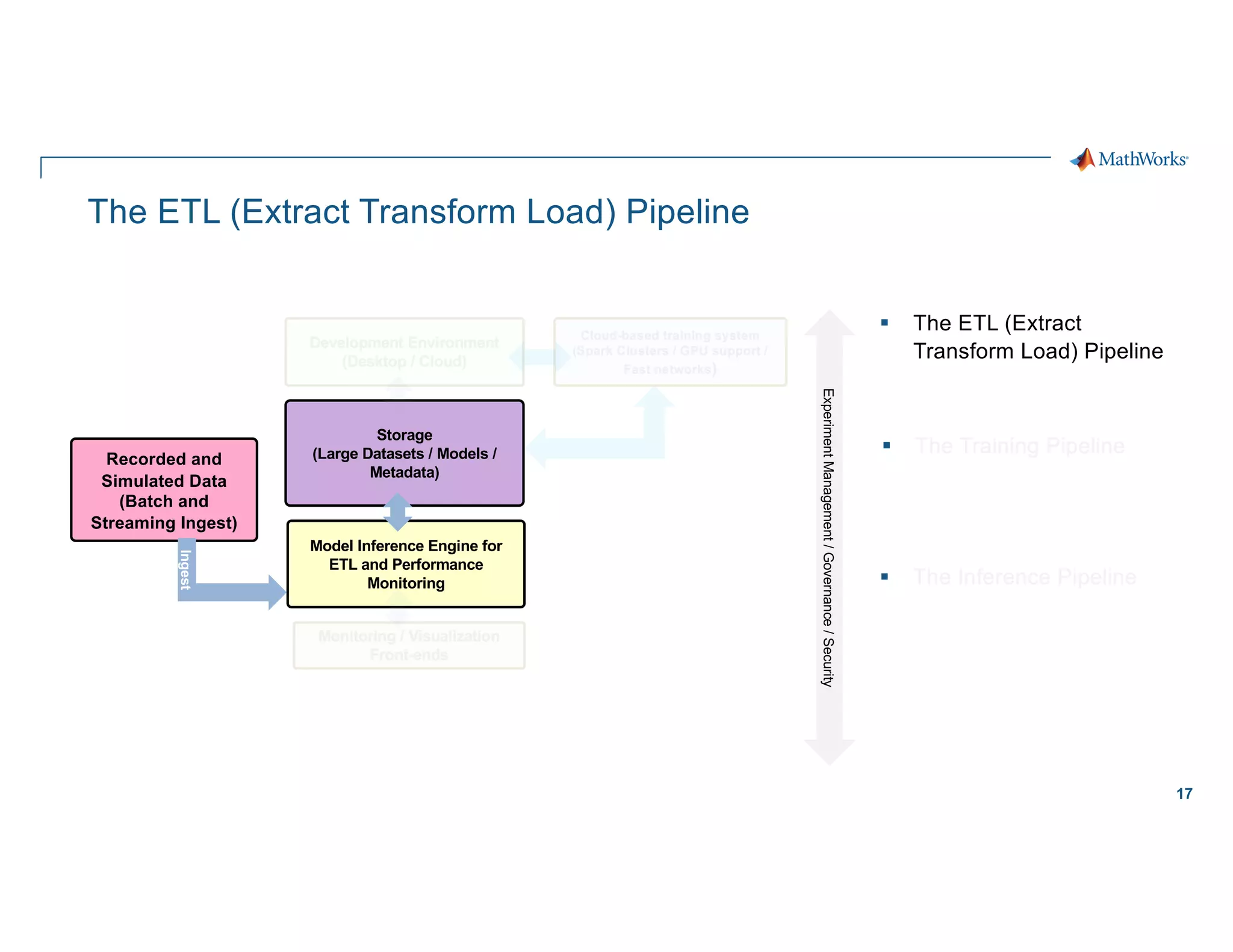
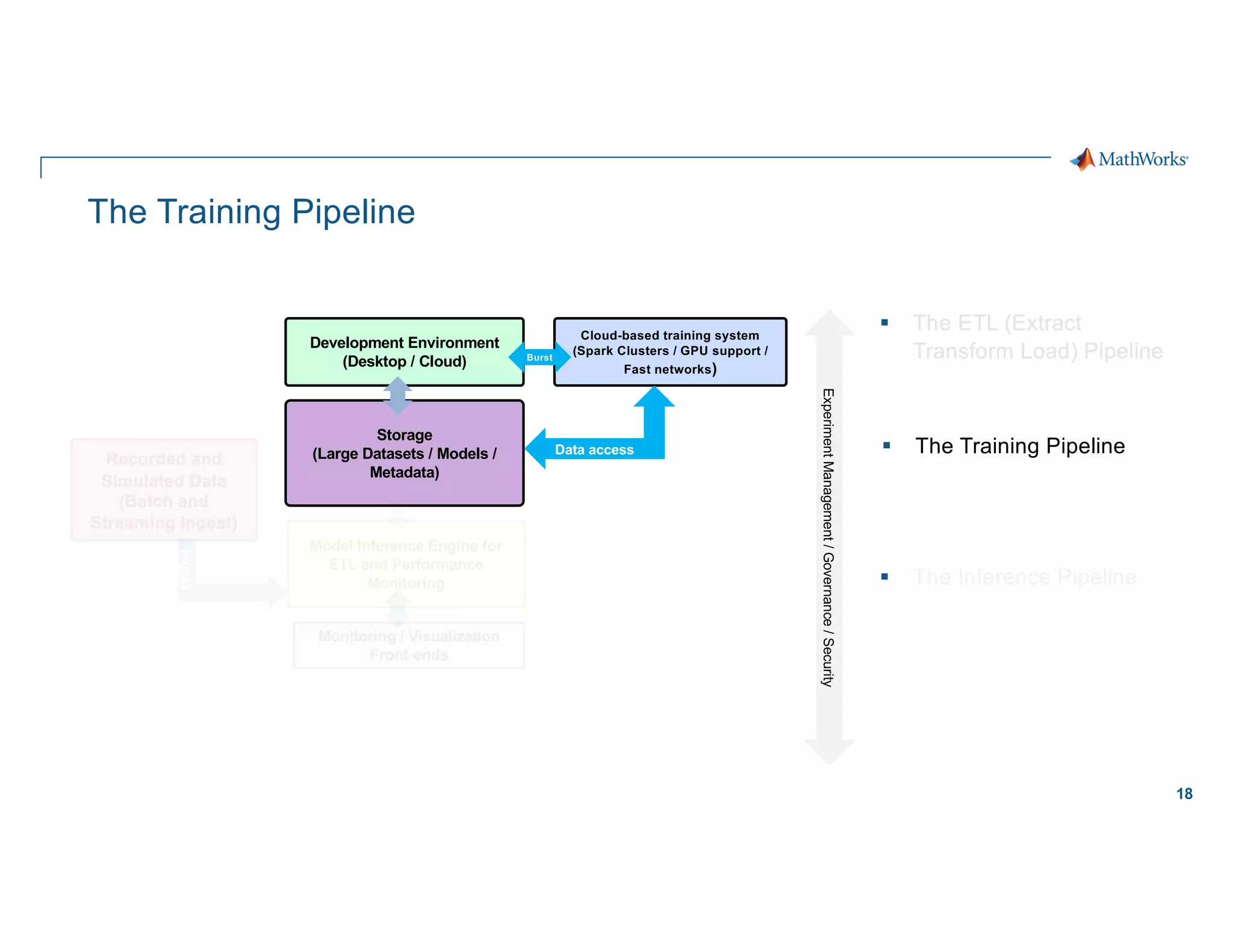
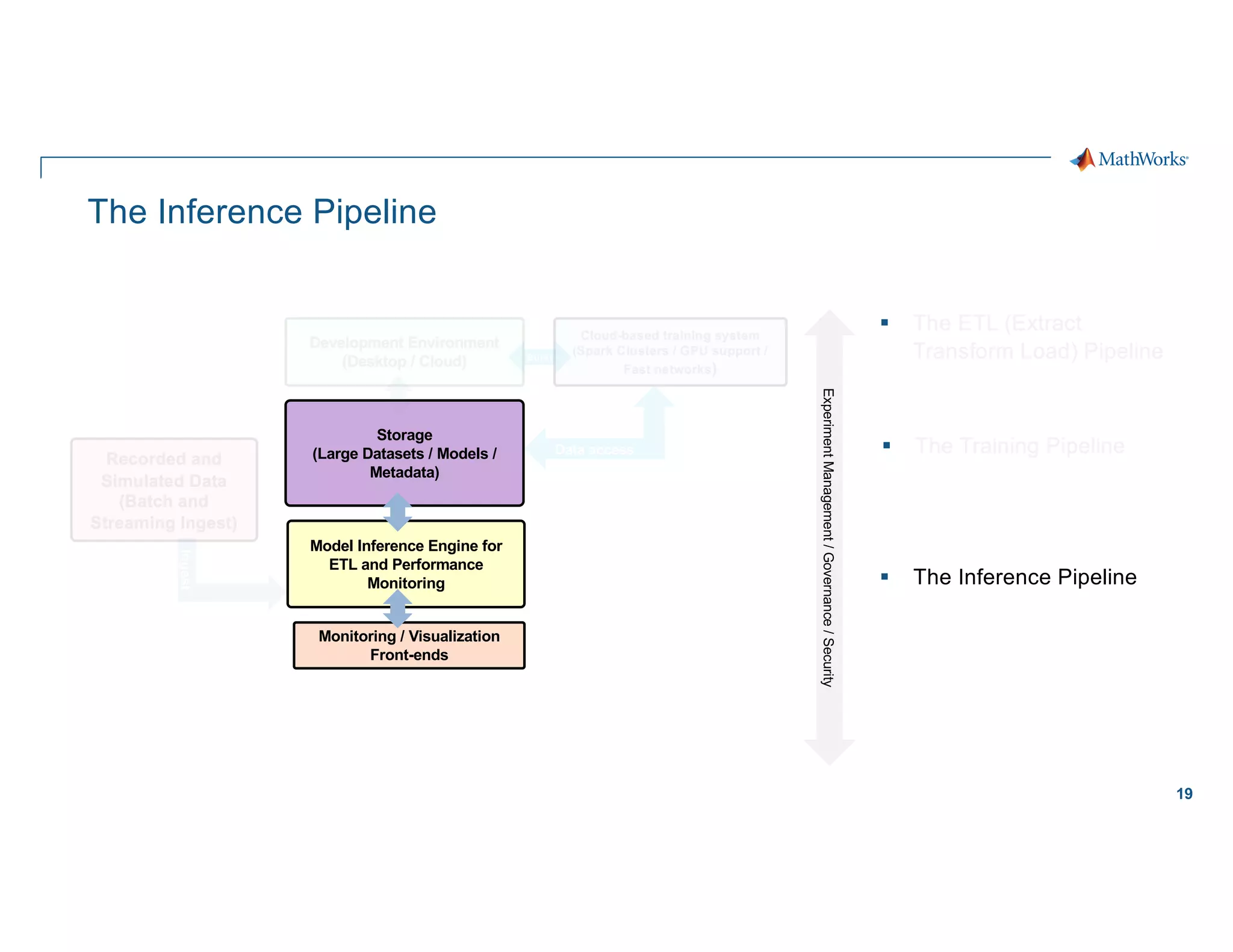
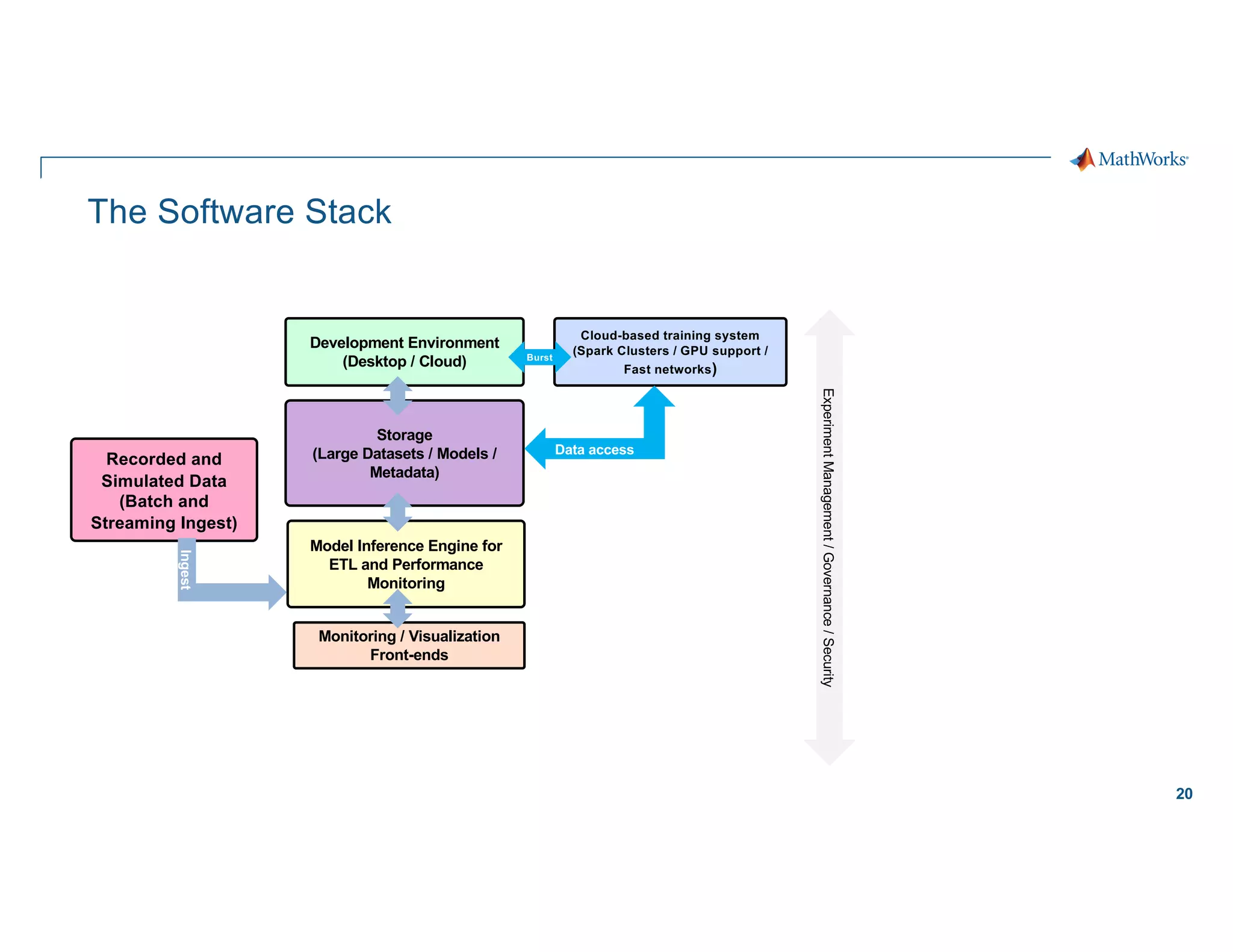
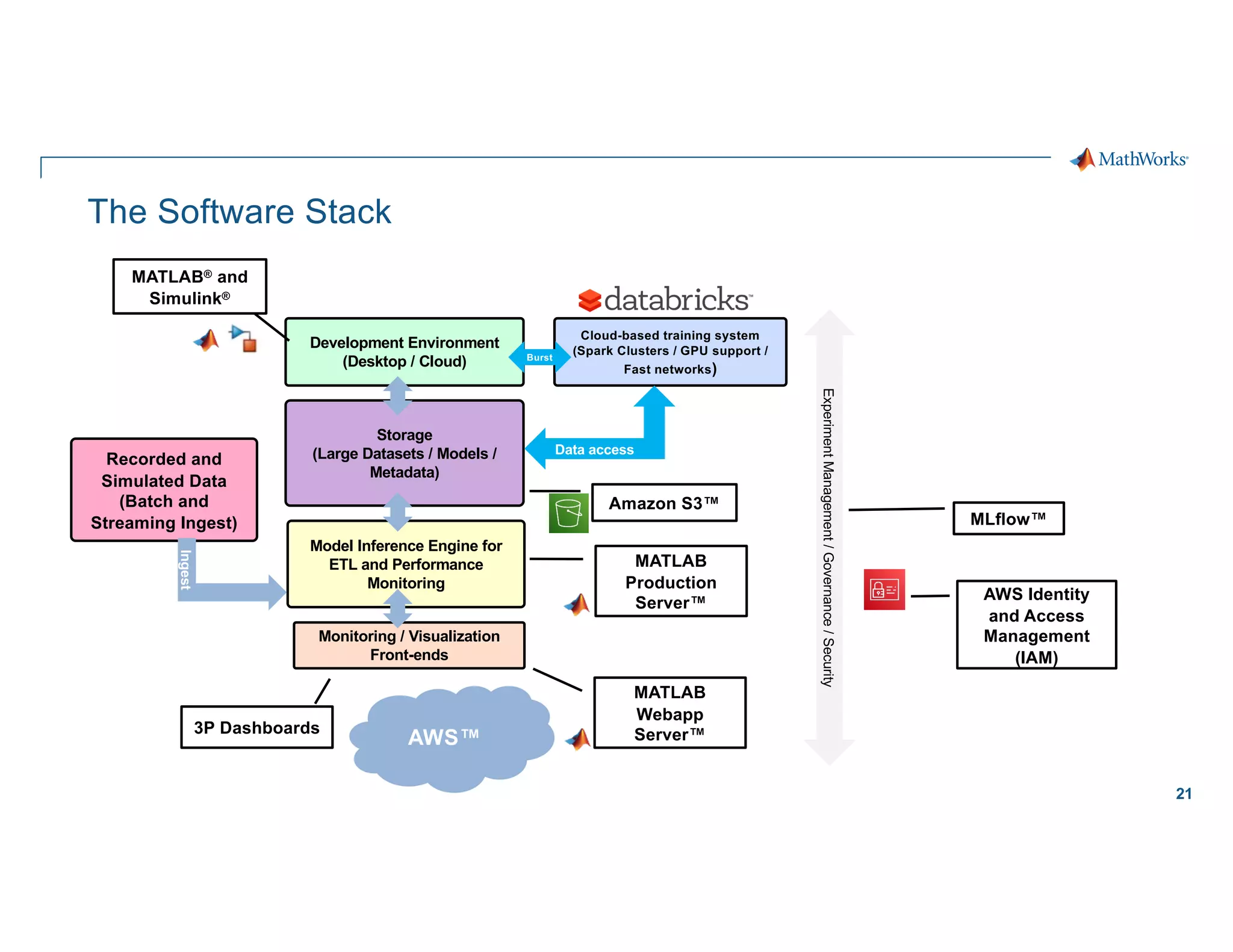
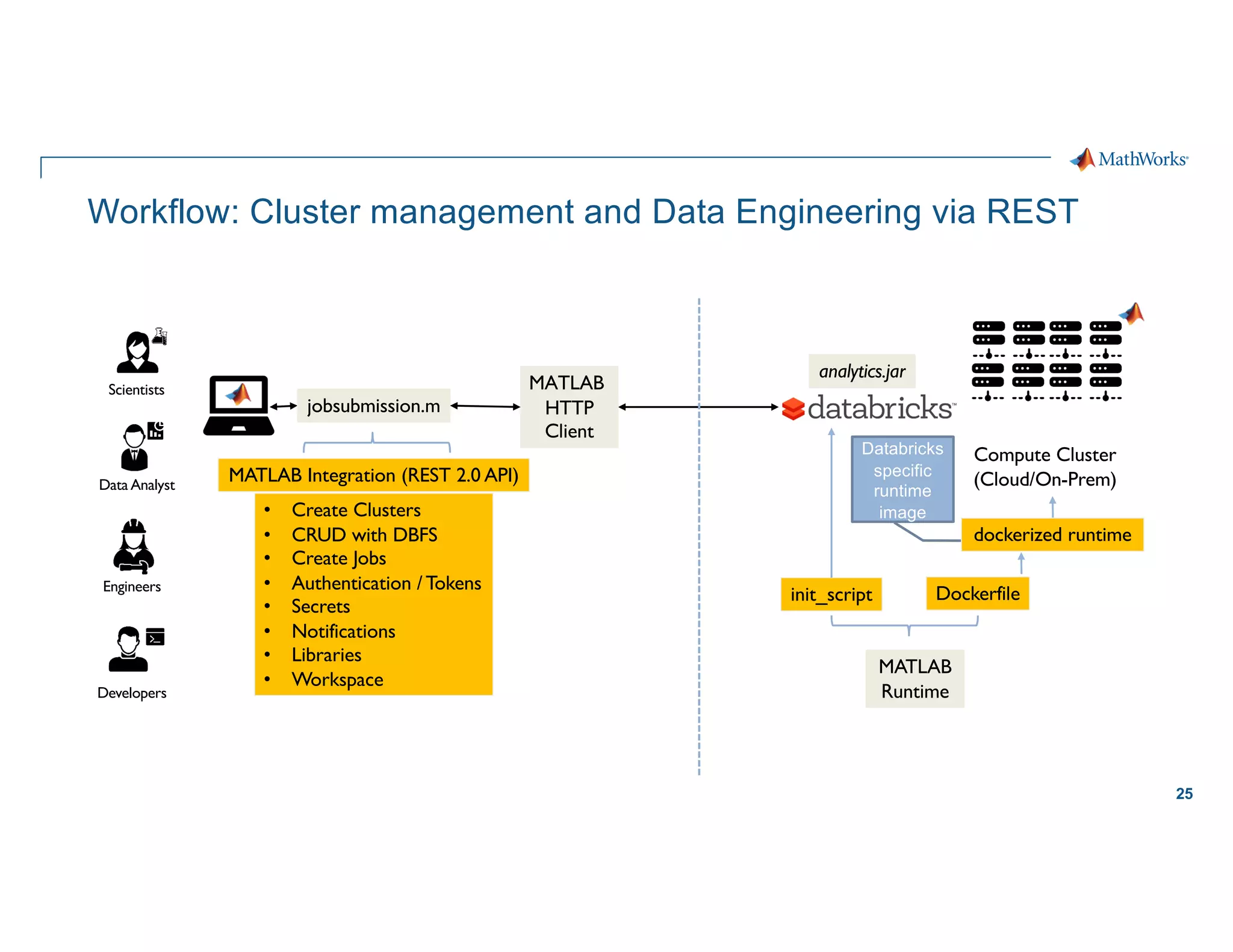
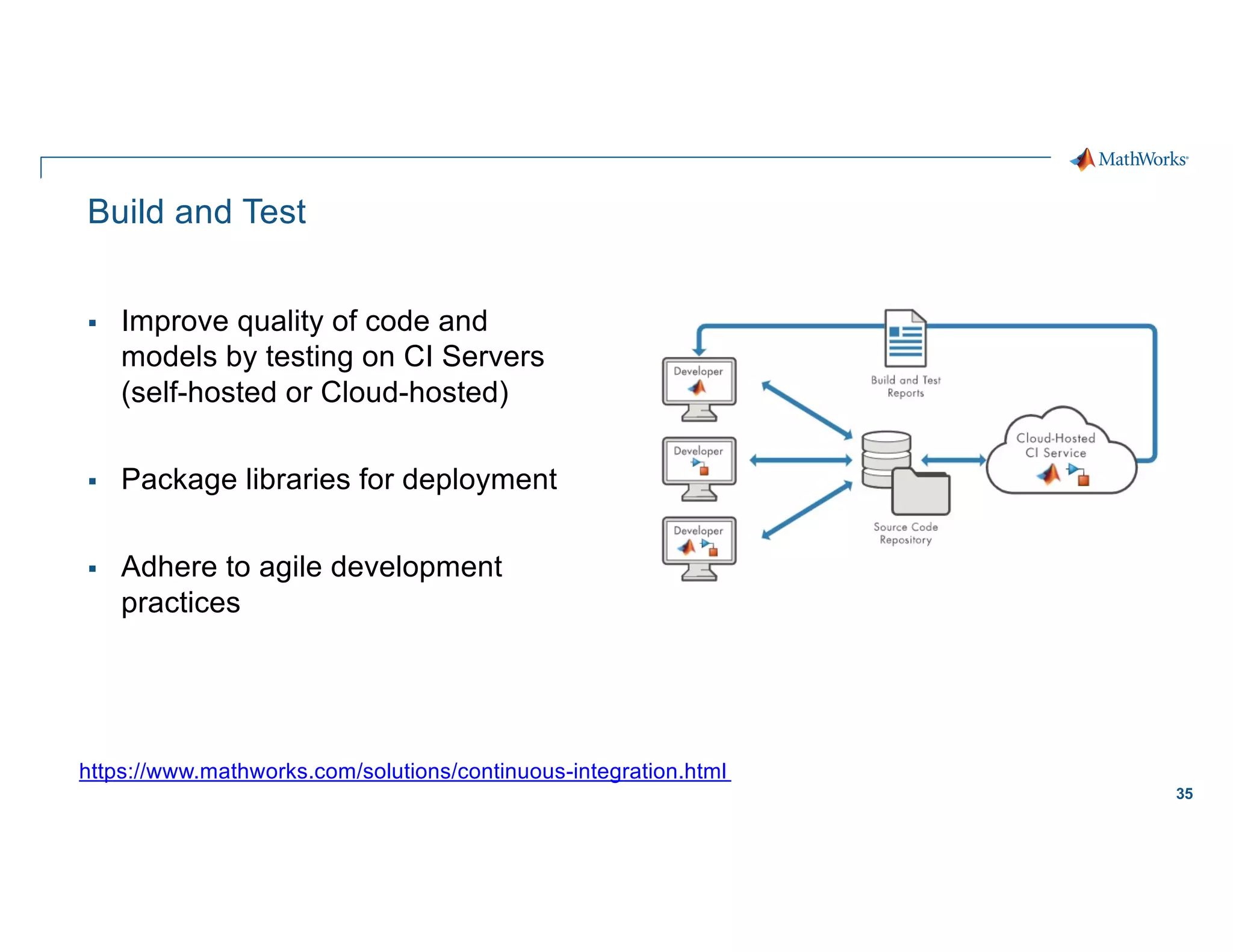
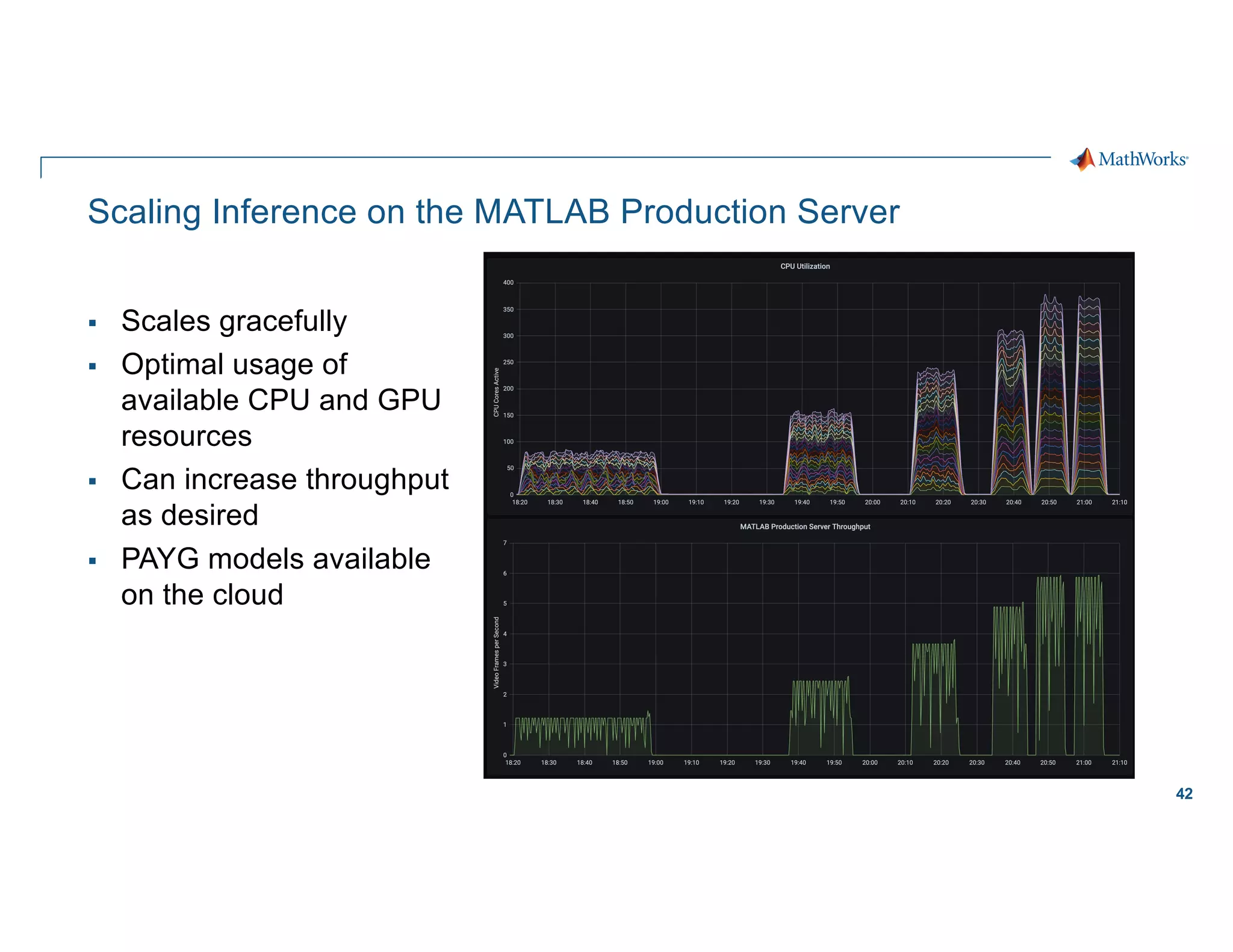
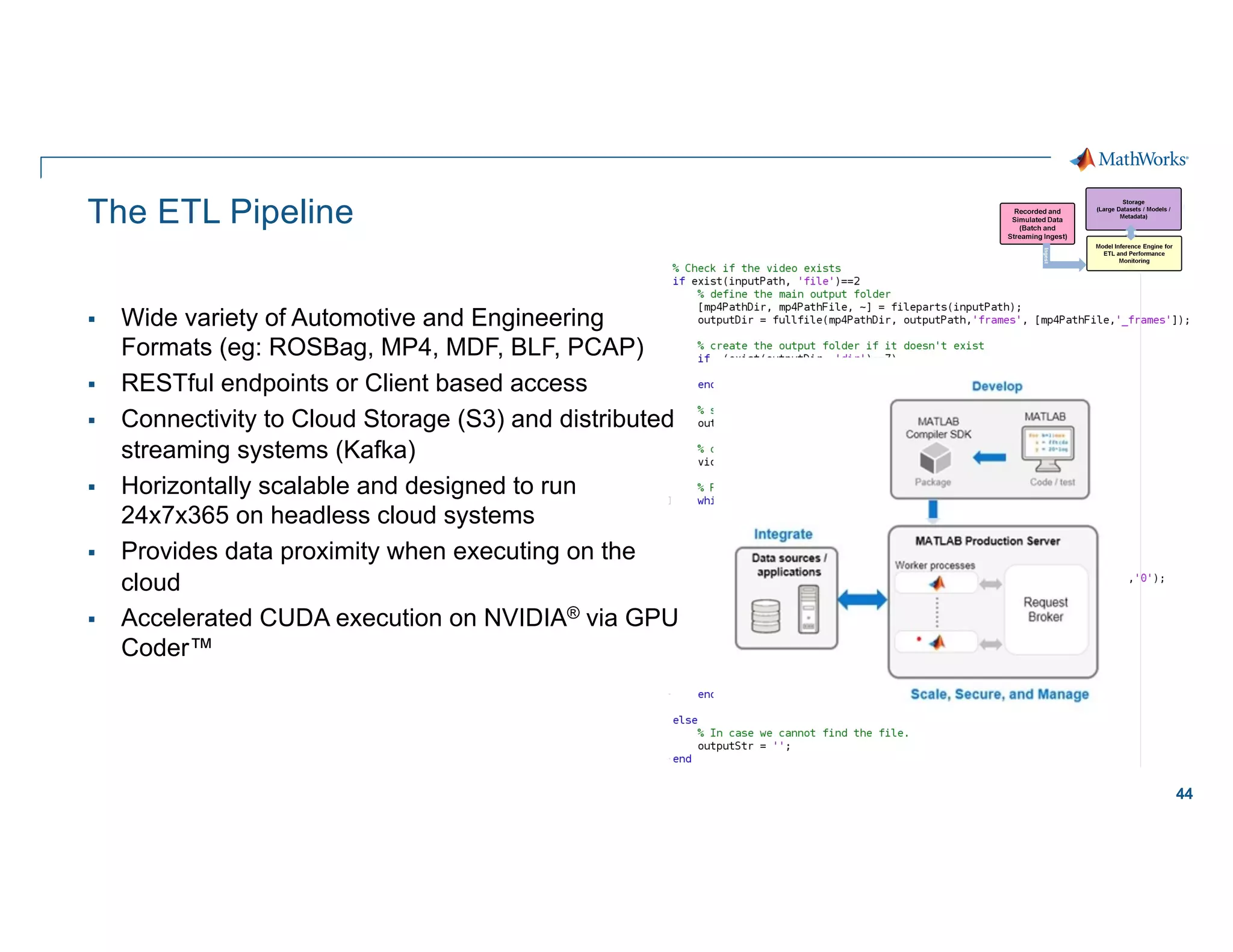
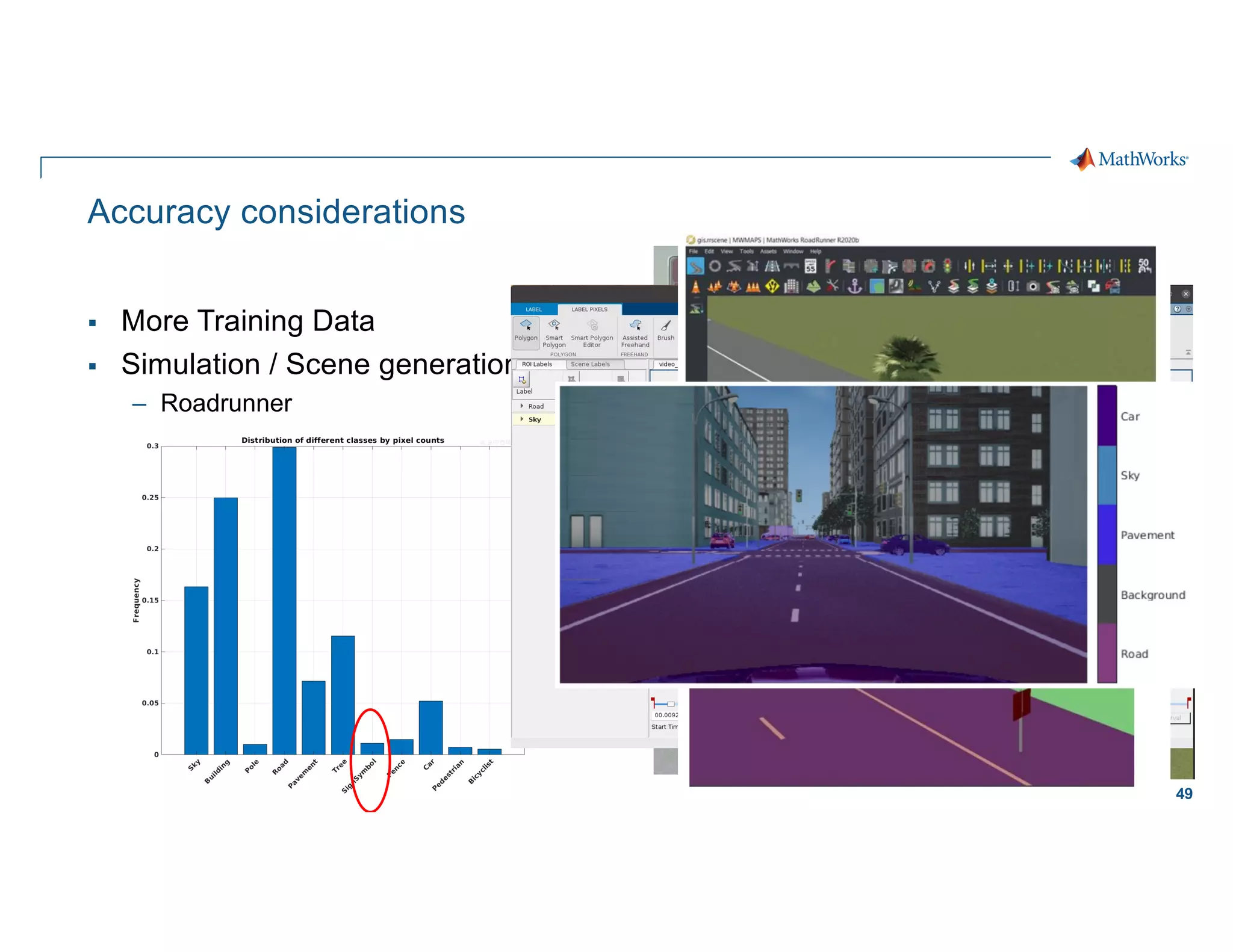
Scaling considerations
Storage
§ Cloud based storage allows
ingestion of larger datasets
Compute
§ Quicker training iterations both
locally and on the cloud
§ Faster inference pipeline
Cost
§ CapEx è OpEx
Workflows
§ Self-serve analytics optimized for
agility along a maturity framework
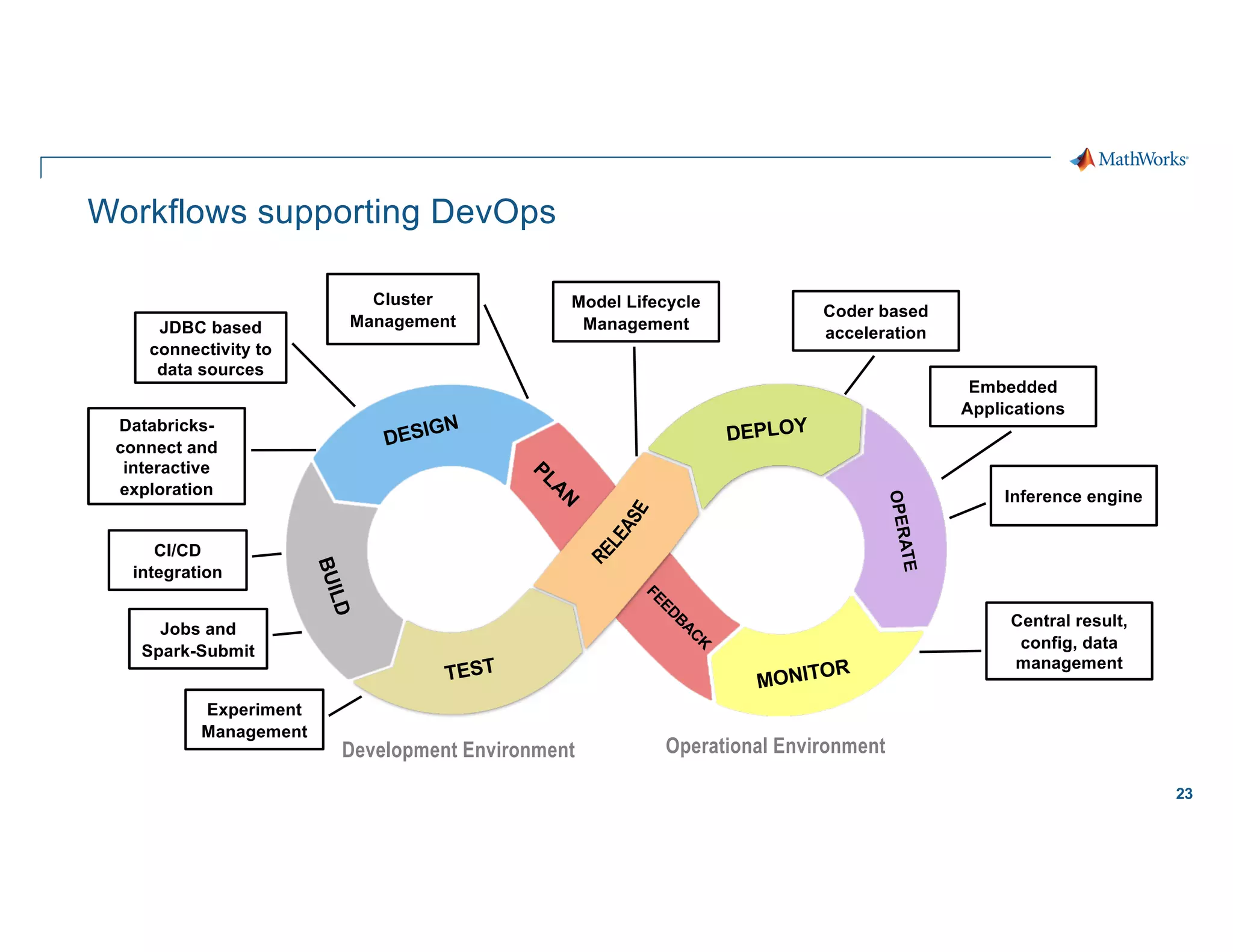
"Glue code and pipeline jungles are symptomatic of
integration issues that may have a root cause in
overly separated “research” and “engineering”
roles…
… engineers and researchers are embedded together
on the same teams (and indeed, are often the same
people) can help reduce this source of friction
significantly [1].
[1] The Hidden Technical Debt of Machine Learning Systems
https://proceedings.neurips.cc/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf](https://image.slidesharecdn.com/292arvindhosagrahara-210616155254/75/Processing-Large-Datasets-for-ADAS-Applications-using-Apache-Spark-48-2048.jpg)



![54
Conclusions
§ Well-architected systems [1] accelerate development of automated
semantic segmentation against large datasets
§ Local development provides smooth workflows for the development and
refinement of deep learning models
§ Cloud-based scaling of compute and storage can be leveraged on
Databricks to enable self-service analytics
§ Techniques that are relevant for ADAS development are equally applicable
across other domains such as medical, geo-exploration, etc.
[1] AWS Well-Architected
https://aws.amazon.com/architecture/well-architected/](https://image.slidesharecdn.com/292arvindhosagrahara-210616155254/75/Processing-Large-Datasets-for-ADAS-Applications-using-Apache-Spark-54-2048.jpg)







![5
“…autonomous vehicles would have
to be driven hundreds of millions of
miles and sometimes hundreds of
billions of miles to demonstrate their
reliability in terms of fatalities and
injuries.” [1]
[1] Driving to Safety, Rand Corporation
https://www.rand.org/content/dam/rand/pubs/research_reports/RR1400/RR1478/RAND_RR1478.pdf](https://crownmelresort.com/image.slidesharecdn.com/292arvindhosagrahara-210616155254/75/Processing-Large-Datasets-for-ADAS-Applications-using-Apache-Spark-5-2048.jpg)










































![48
Scaling considerations
Storage
§ Cloud based storage allows
ingestion of larger datasets
Compute
§ Quicker training iterations both
locally and on the cloud
§ Faster inference pipeline
Cost
§ CapEx è OpEx
Workflows
§ Self-serve analytics optimized for
agility along a maturity framework
"Glue code and pipeline jungles are symptomatic of
integration issues that may have a root cause in
overly separated “research” and “engineering”
roles…
… engineers and researchers are embedded together
on the same teams (and indeed, are often the same
people) can help reduce this source of friction
significantly [1].
[1] The Hidden Technical Debt of Machine Learning Systems
https://proceedings.neurips.cc/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf](https://crownmelresort.com/image.slidesharecdn.com/292arvindhosagrahara-210616155254/75/Processing-Large-Datasets-for-ADAS-Applications-using-Apache-Spark-48-2048.jpg)





![54
Conclusions
§ Well-architected systems [1] accelerate development of automated
semantic segmentation against large datasets
§ Local development provides smooth workflows for the development and
refinement of deep learning models
§ Cloud-based scaling of compute and storage can be leveraged on
Databricks to enable self-service analytics
§ Techniques that are relevant for ADAS development are equally applicable
across other domains such as medical, geo-exploration, etc.
[1] AWS Well-Architected
https://aws.amazon.com/architecture/well-architected/](https://crownmelresort.com/image.slidesharecdn.com/292arvindhosagrahara-210616155254/75/Processing-Large-Datasets-for-ADAS-Applications-using-Apache-Spark-54-2048.jpg)




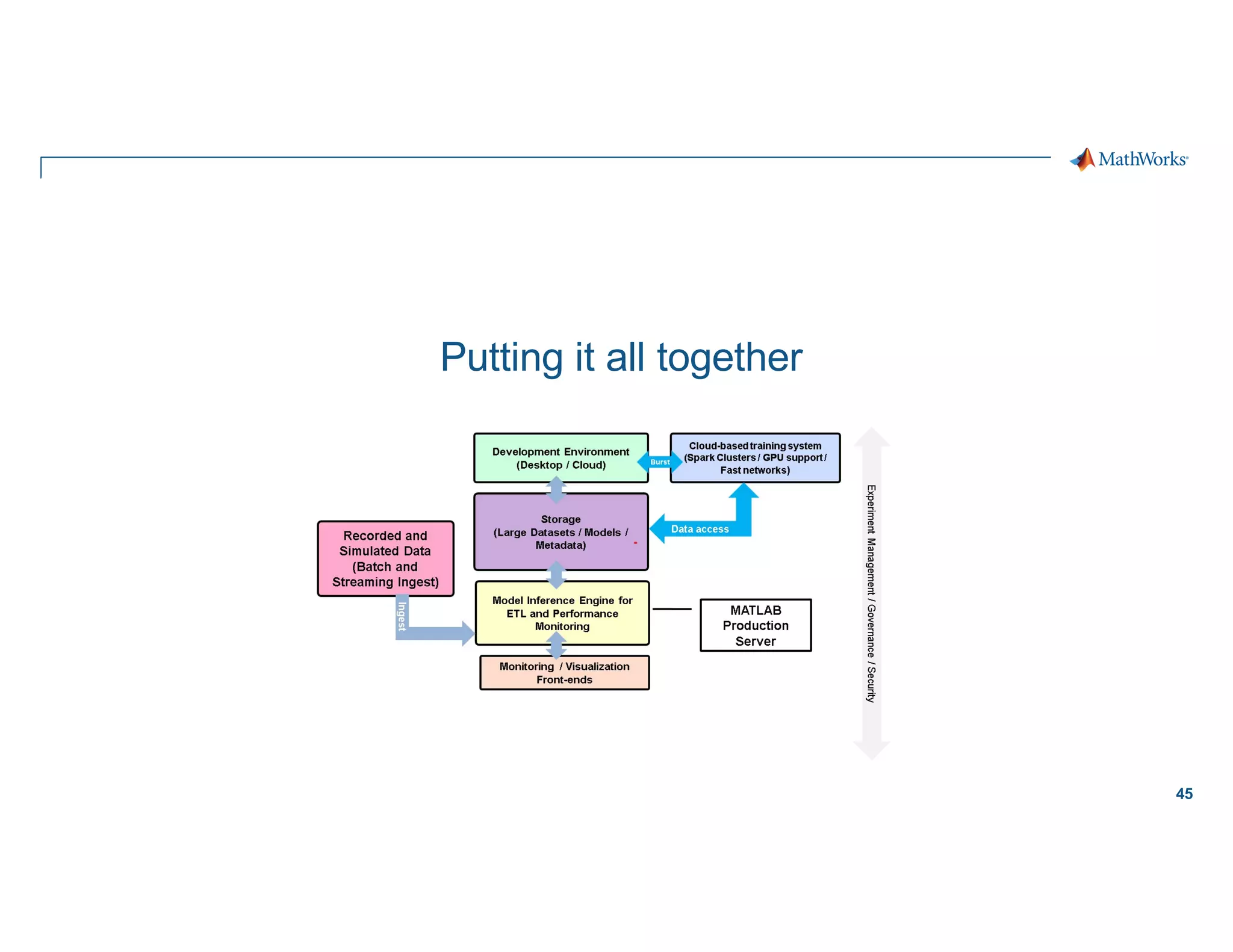
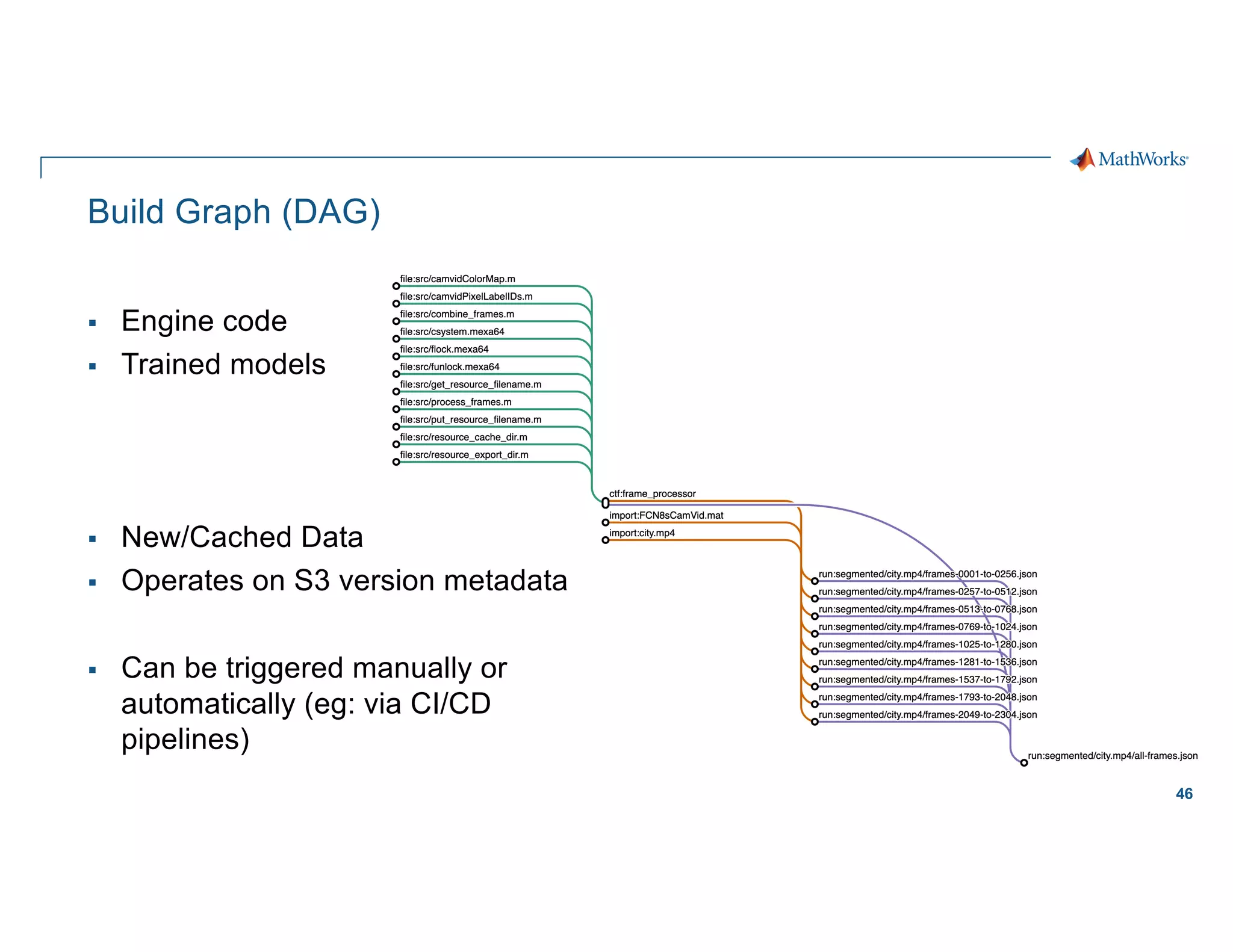
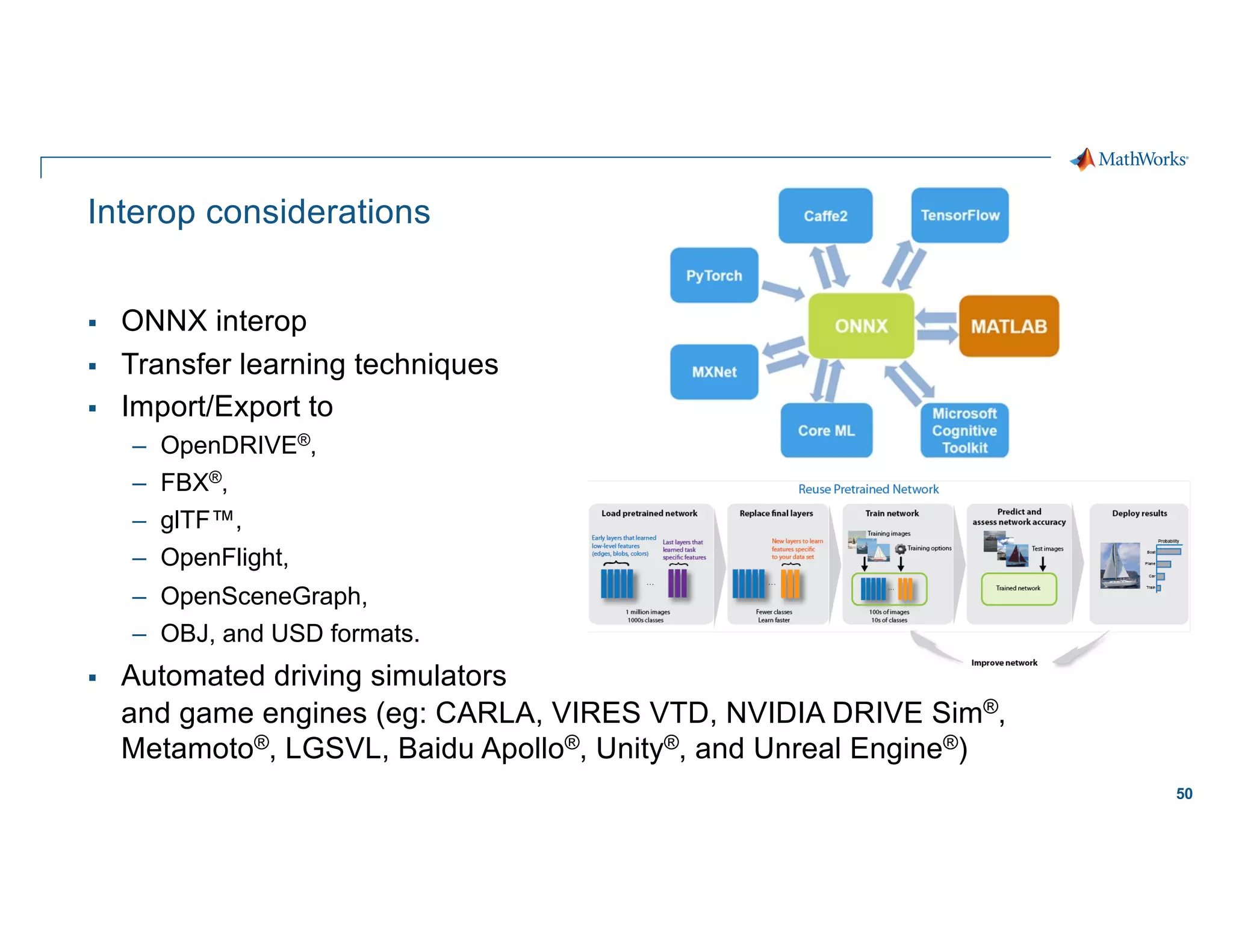
The document outlines the use of Spark for processing large datasets in automated driving applications, focusing on semantic segmentation and the challenges of moving from prototype to production. It presents the architecture of the system, covering ETL processes, model training, and inference, while addressing design considerations like scaling, security, and governance. Key takeaways emphasize the importance of leveraging cloud-based solutions and effective workflow management to enhance the development of perception software for autonomous vehicles.




![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 22] Overview of the Databricks Platform - Petar Zecevic](https://cdn.slidesharecdn.com/ss_thumbnails/petarzecevic-databricksoverview-221130080703-c60d93de-thumbnail.jpg?width=640&height=640&fit=bounds)





































































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)









