Downloaded 32 times



















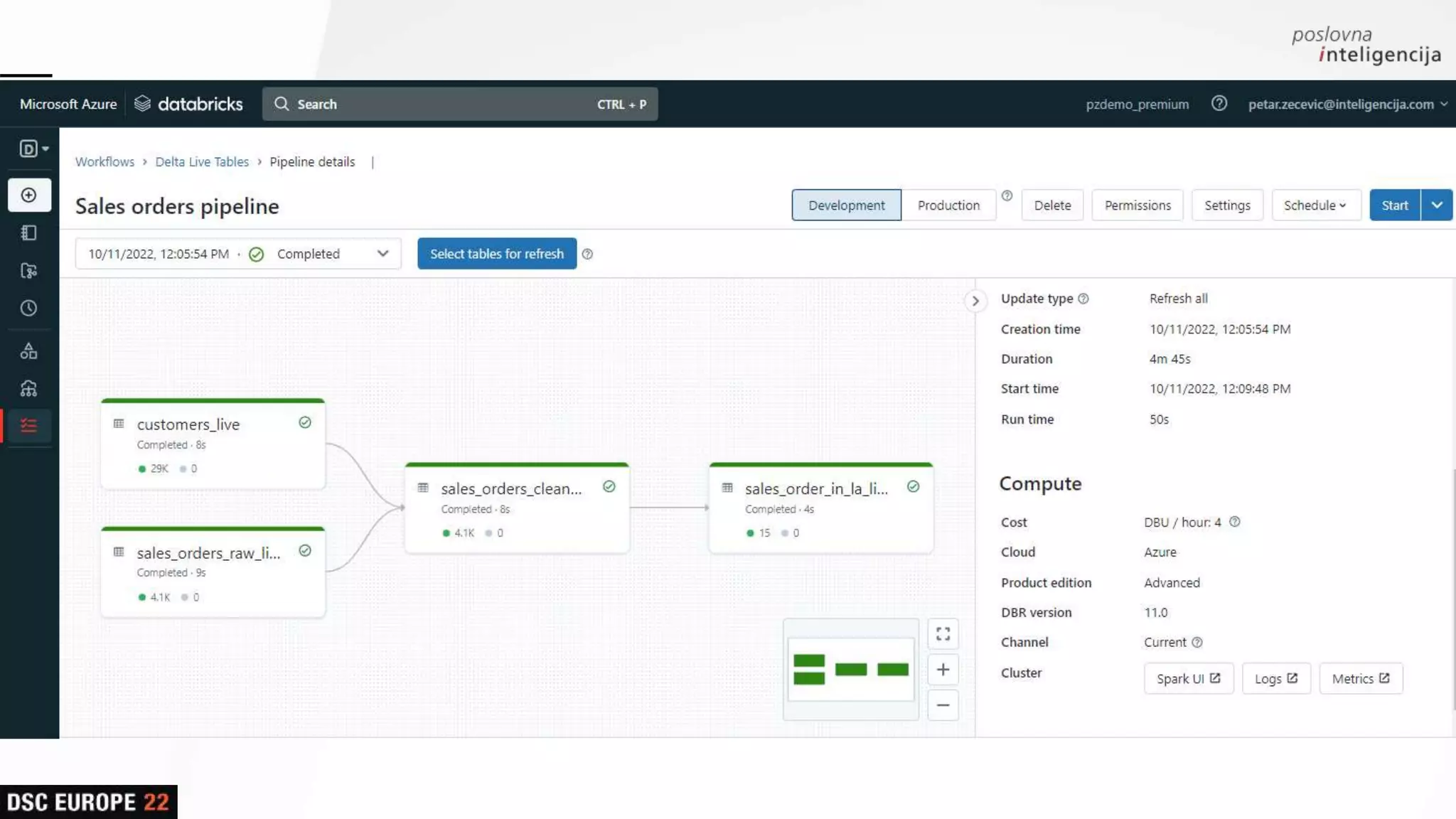
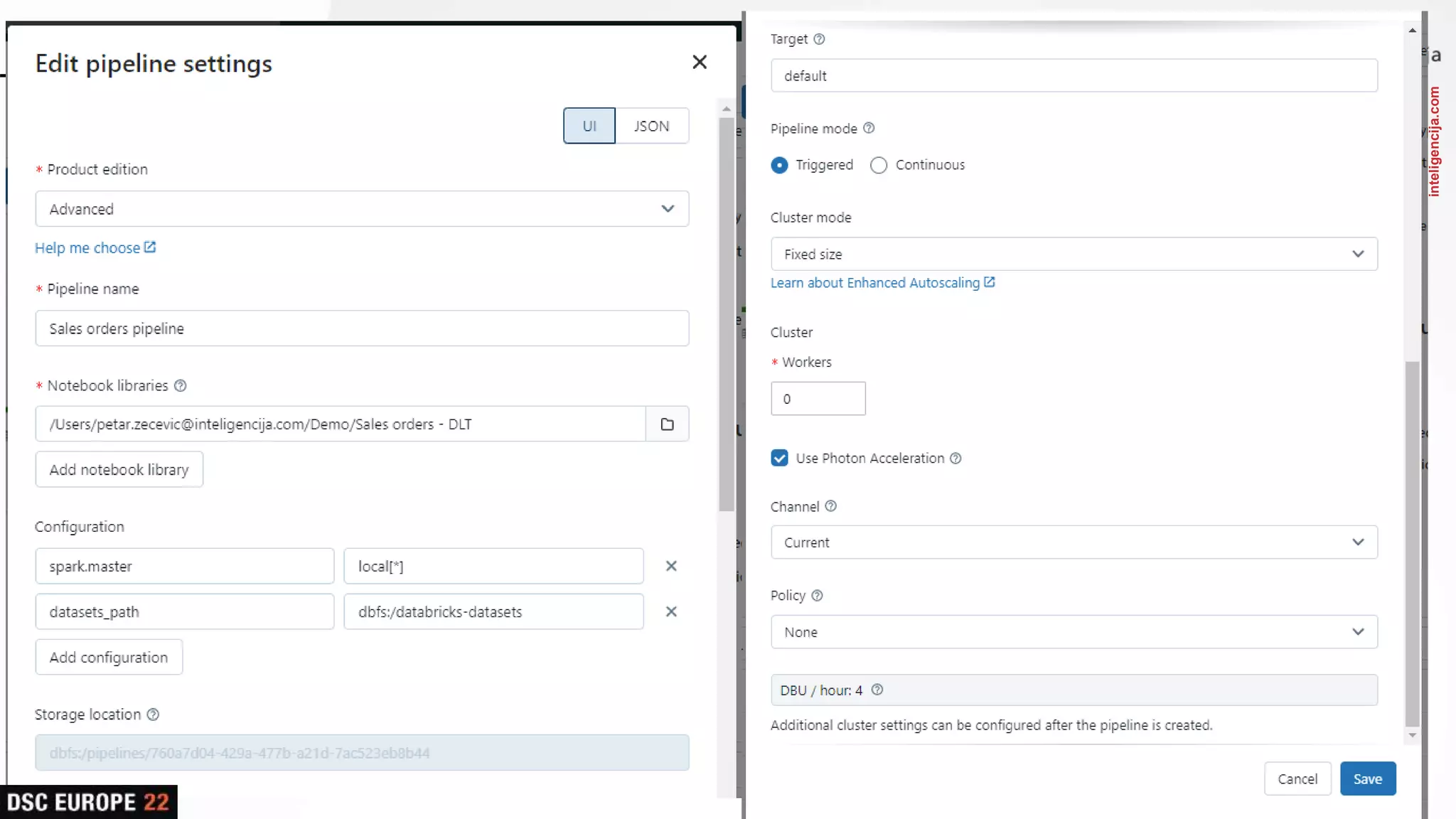












































This document provides an overview of the Databricks platform. It discusses how Databricks combines features of data warehouses and data lakes to create a "data lakehouse" that supports both business intelligence/reporting and data science/machine learning use cases. Key components of the Databricks platform include Apache Spark, Delta Lake, MLFlow, Jupyter notebooks, and Delta Live Tables. The platform aims to unify data engineering, data warehousing, streaming, and data science tasks on a single open-source platform.
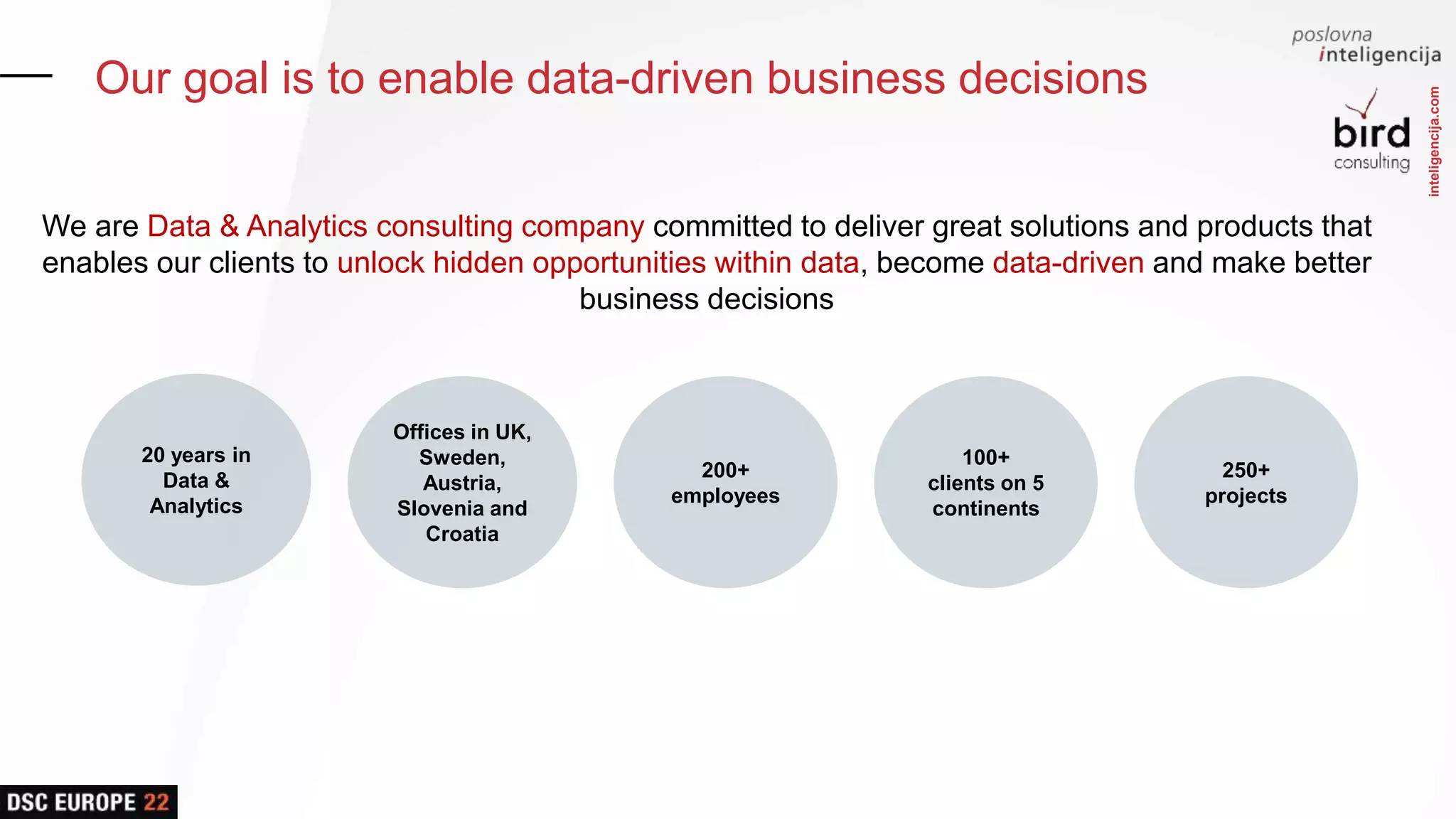
Overview of the company and its mission focused on data-driven business decisions, highlighting global reach and experience in data and analytics.
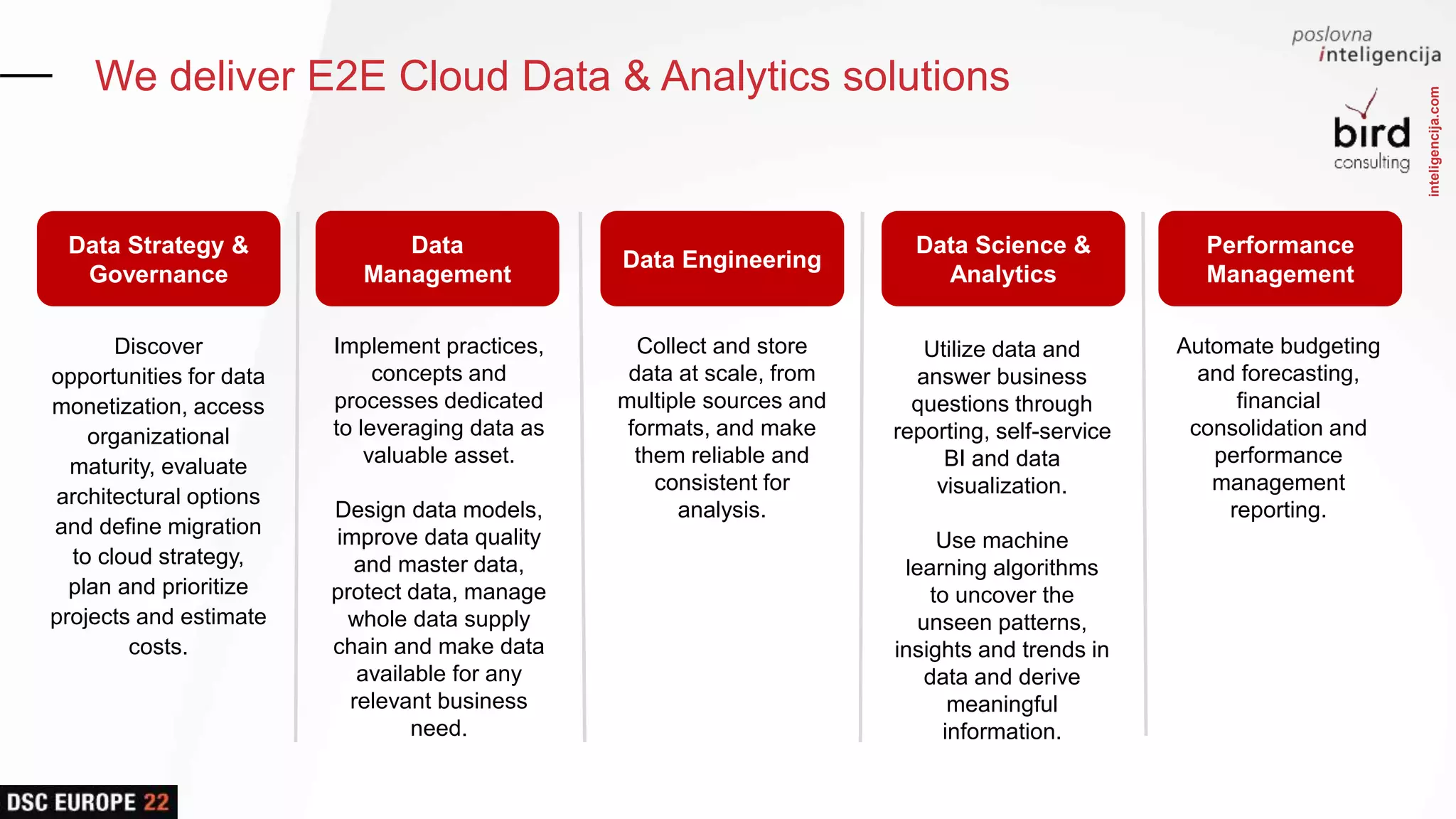
Presentation of comprehensive cloud data and analytics solutions, including data management, governance, and engineering.
Overview of Databricks and its foundation, emphasizing its historical significance and leadership in the data lakehouse concept.
Databricks' expanding customer base and workforce, highlighting its significant funding and market presence.
Fundamentals of the data lakehouse, merging strengths of data warehouses and lakes while addressing shortcomings.
Stats highlighting failure rates in data projects and issues related to governance, silos, and data access.
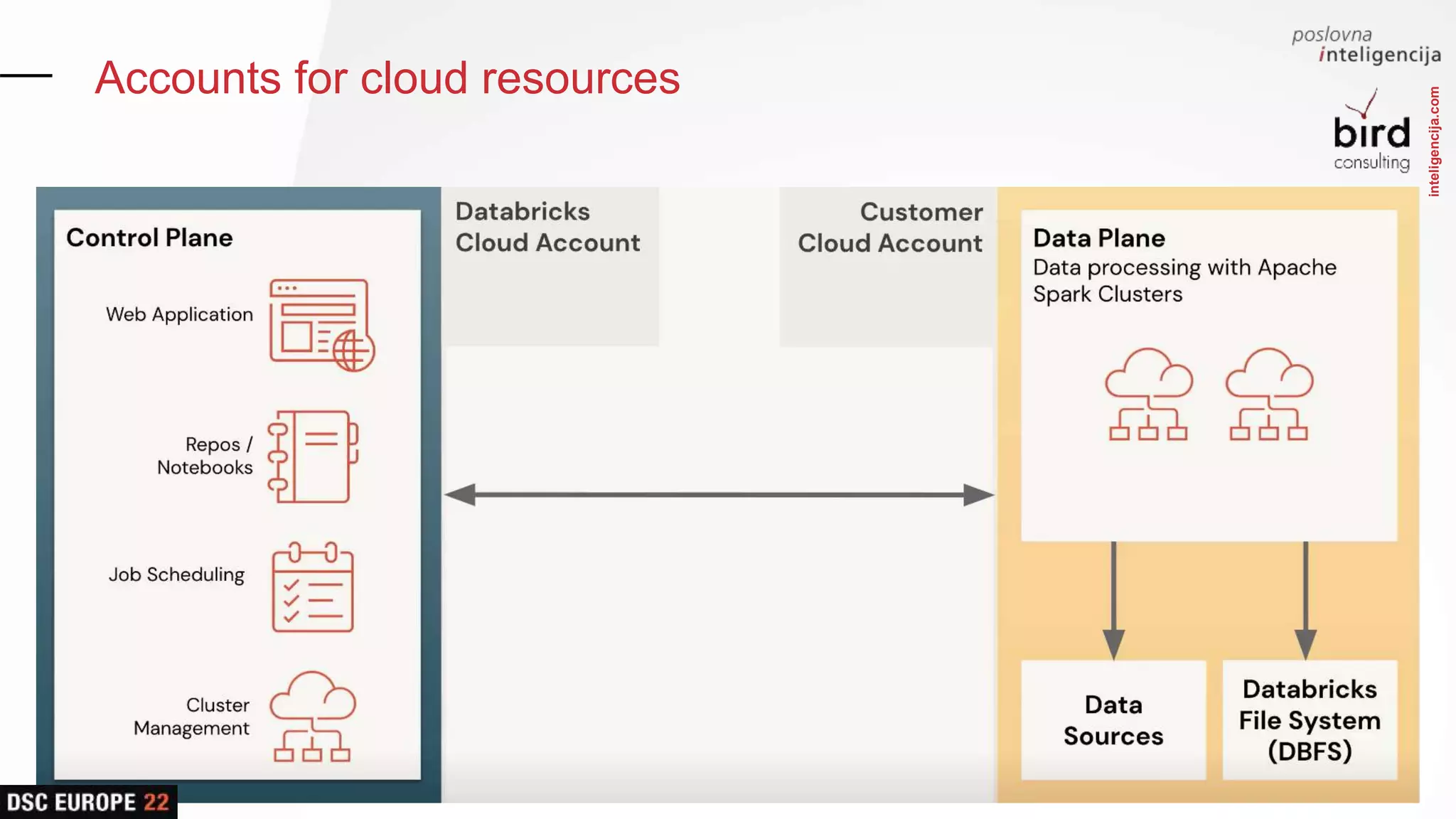
Advantages of the Databricks Lakehouse, focusing on unifying data usage and ensuring consistent performance across platforms.
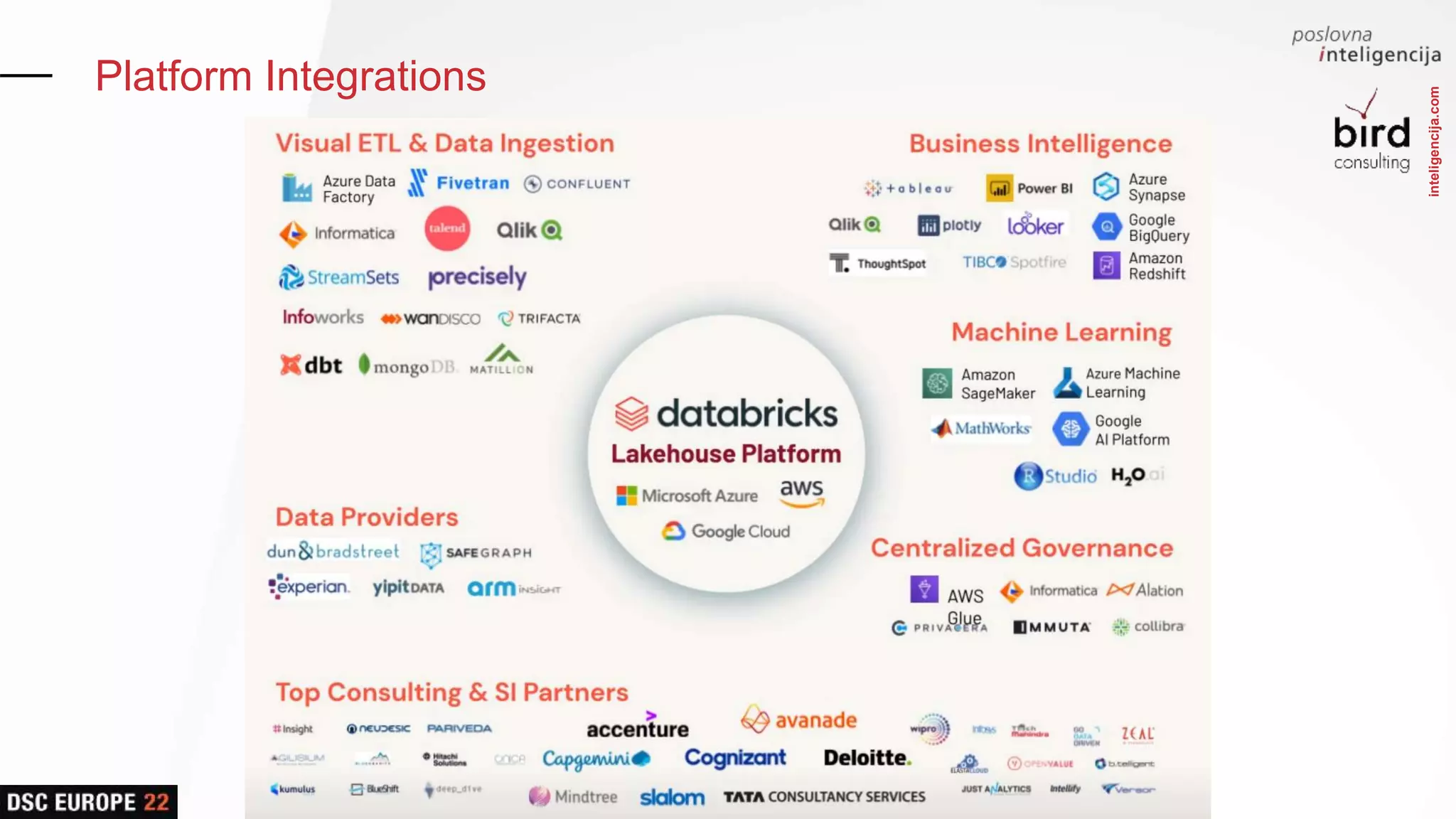
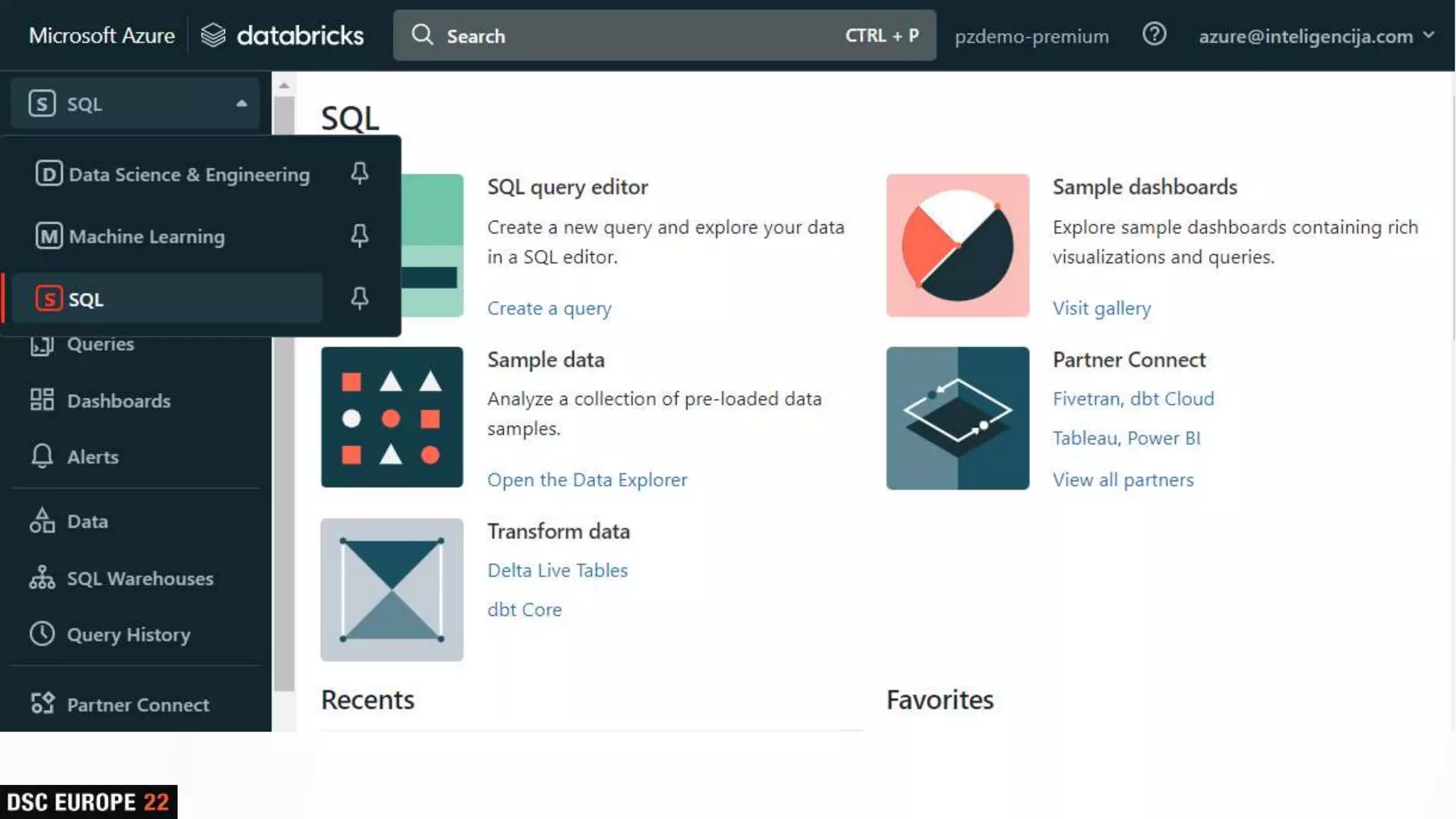
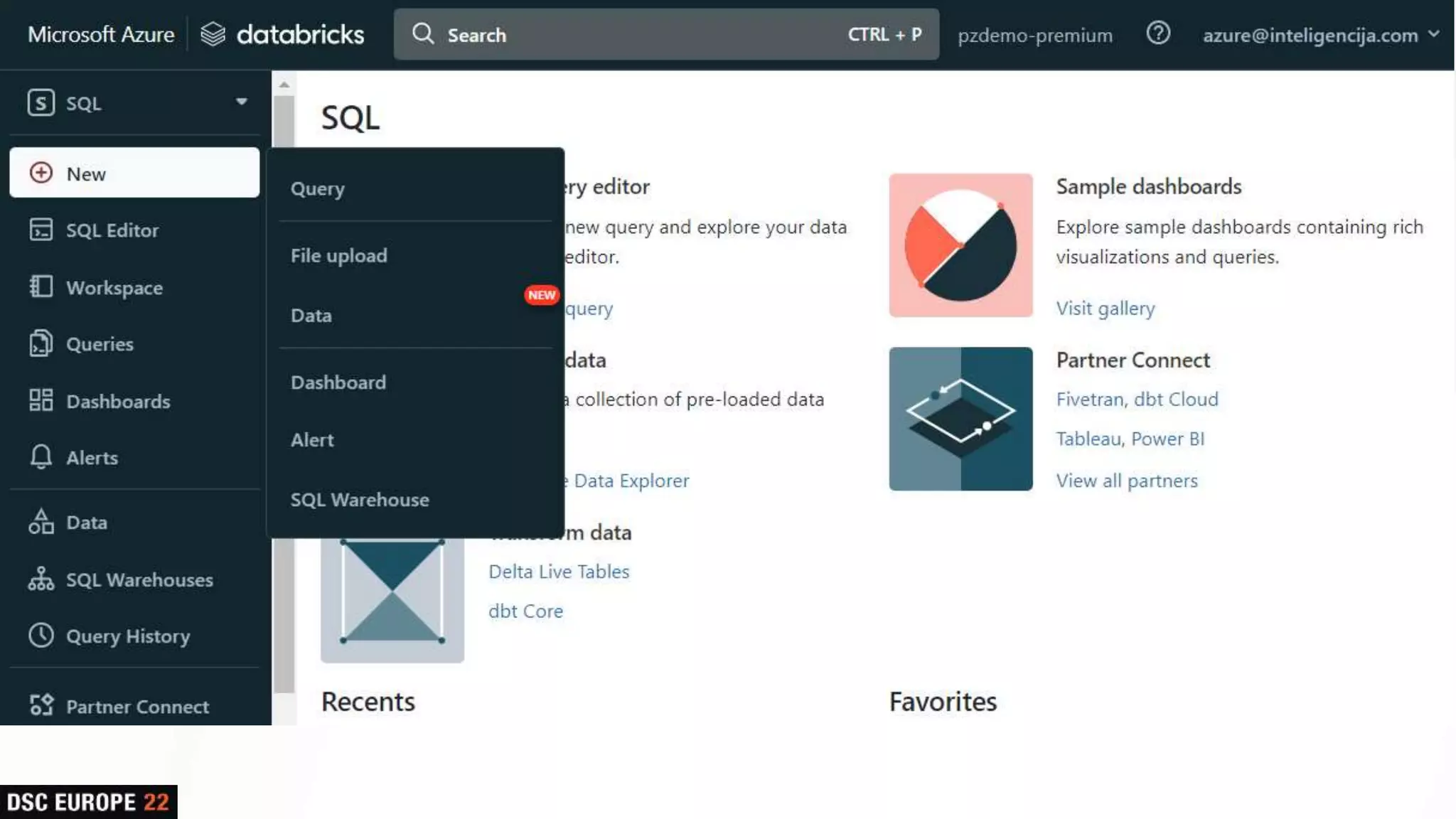
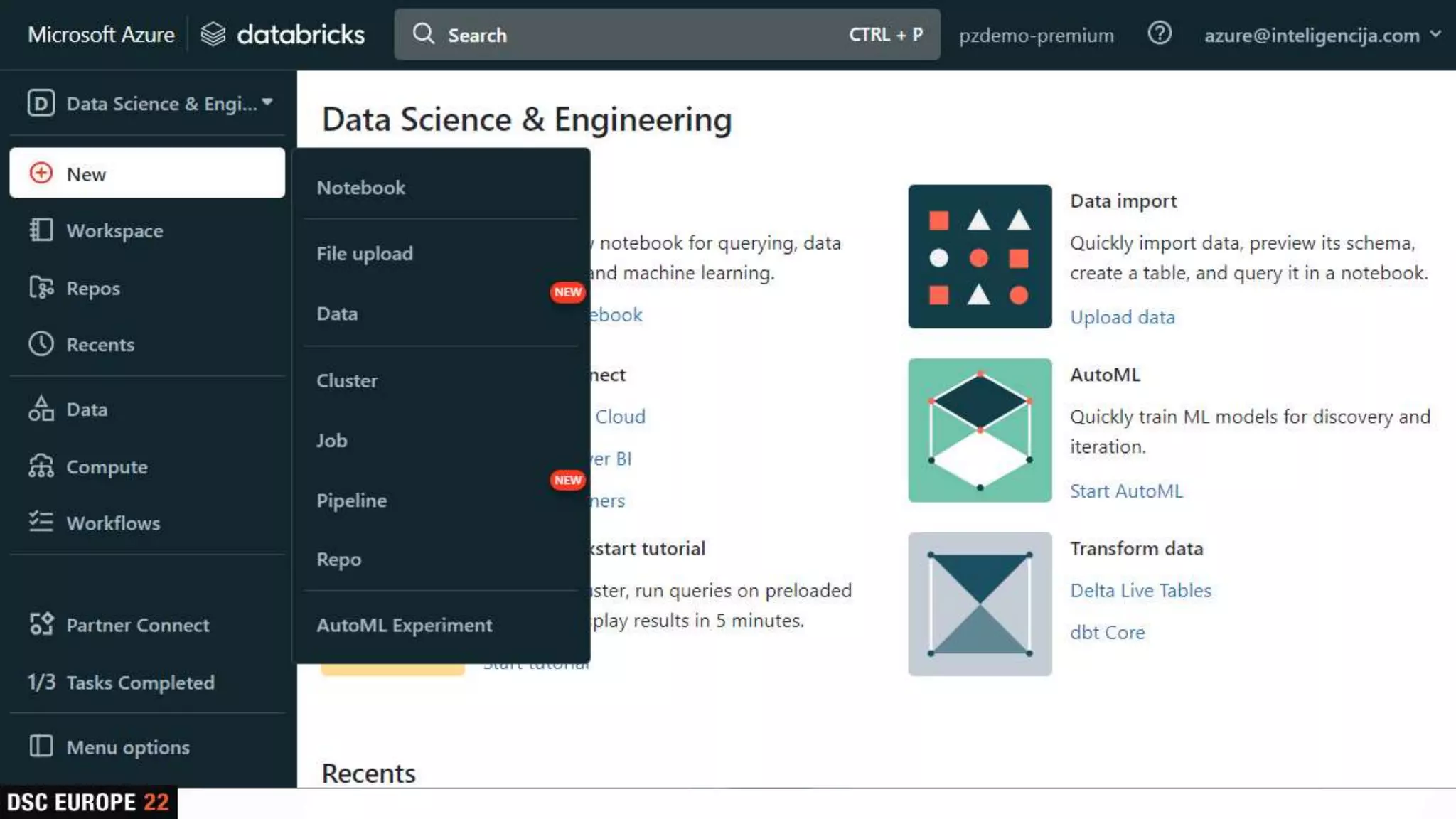
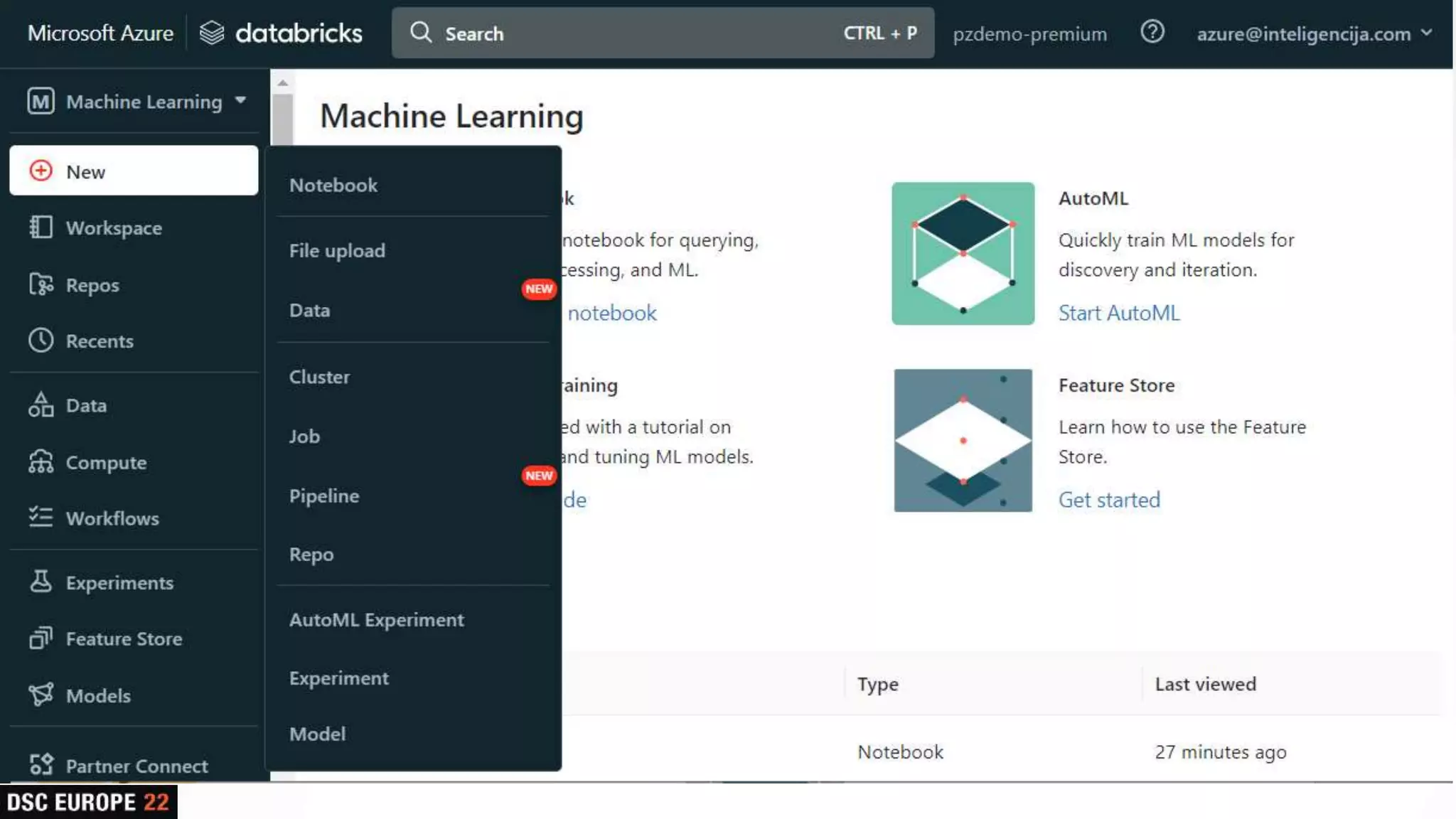
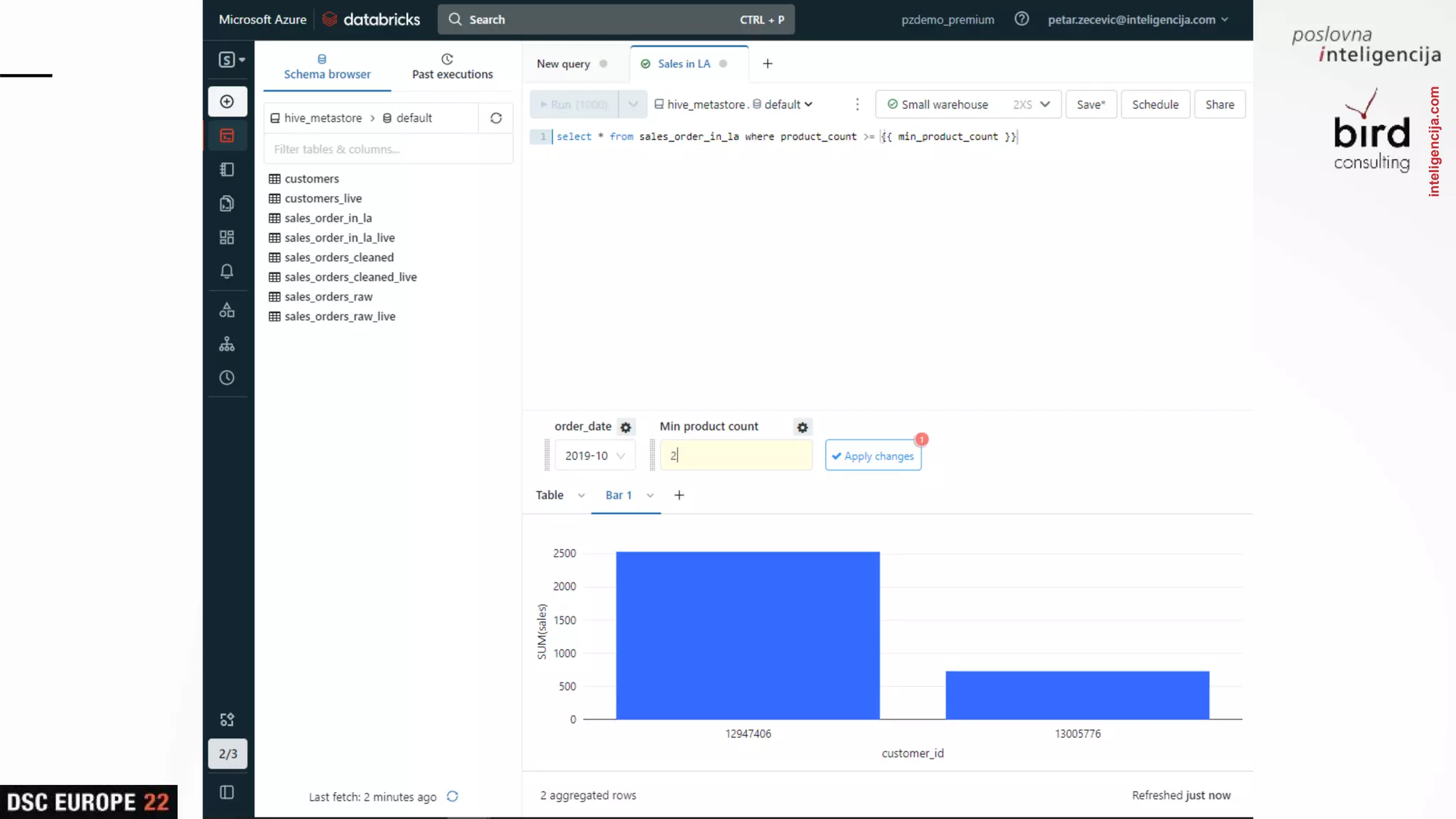
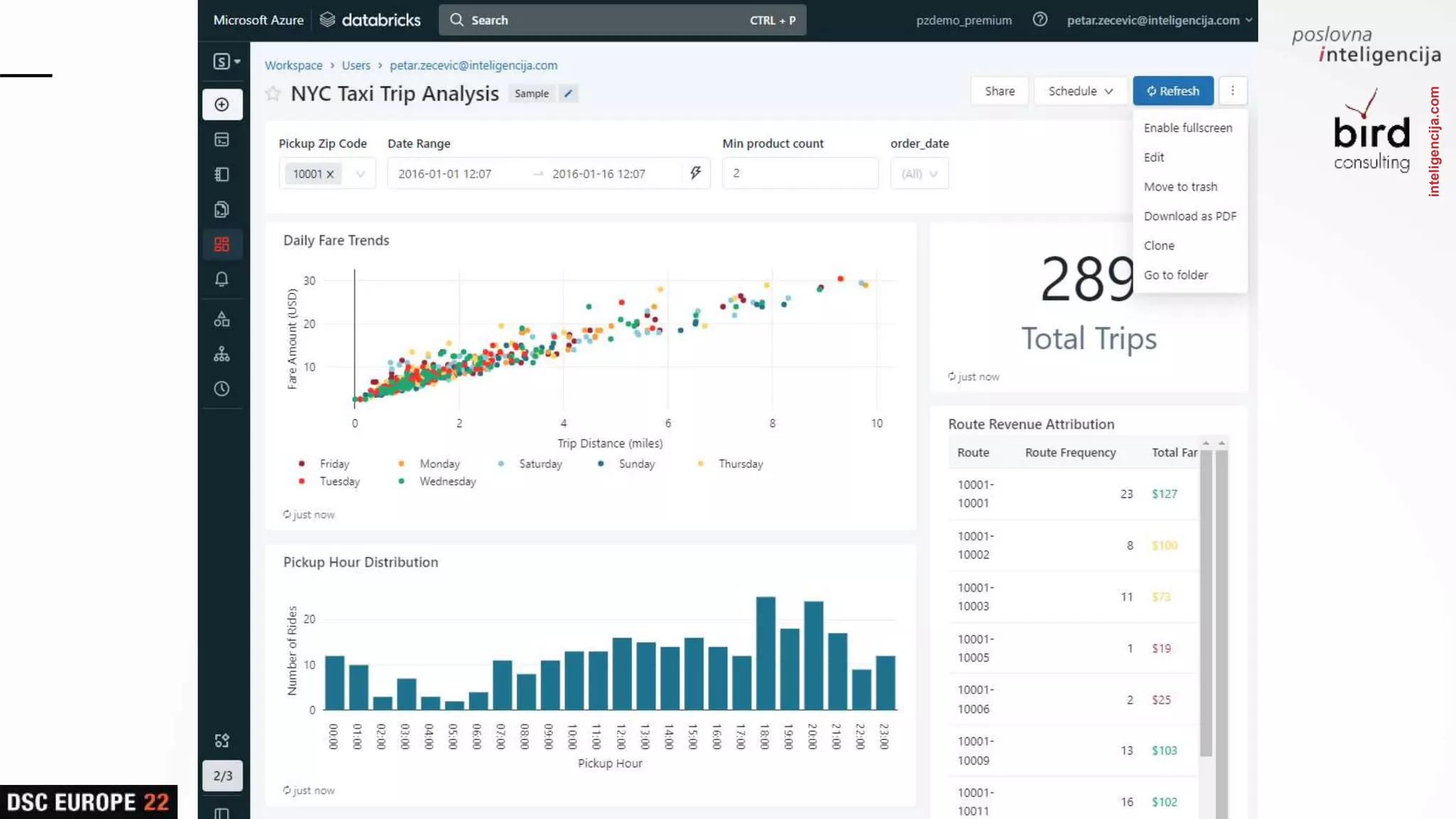
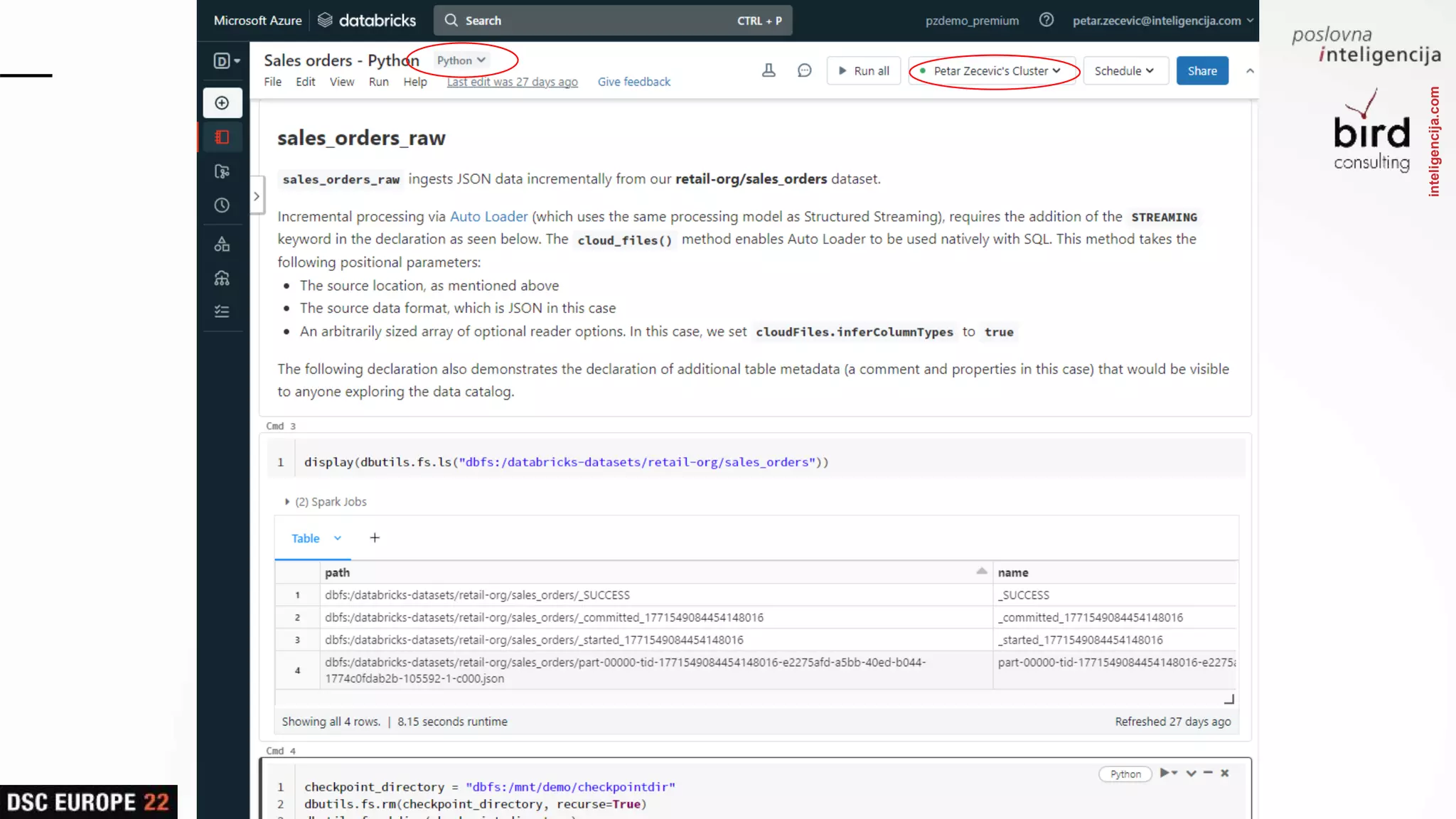
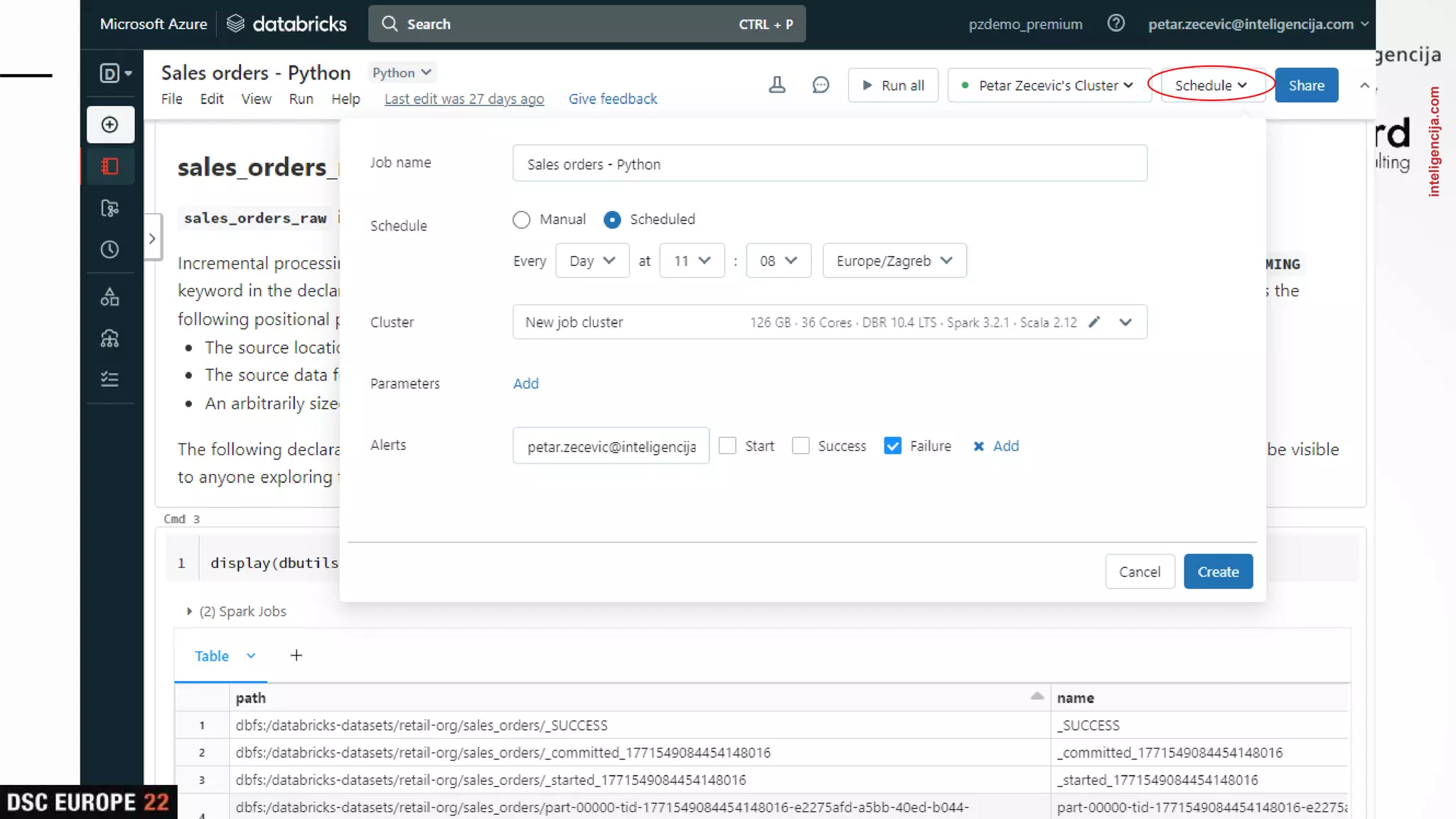
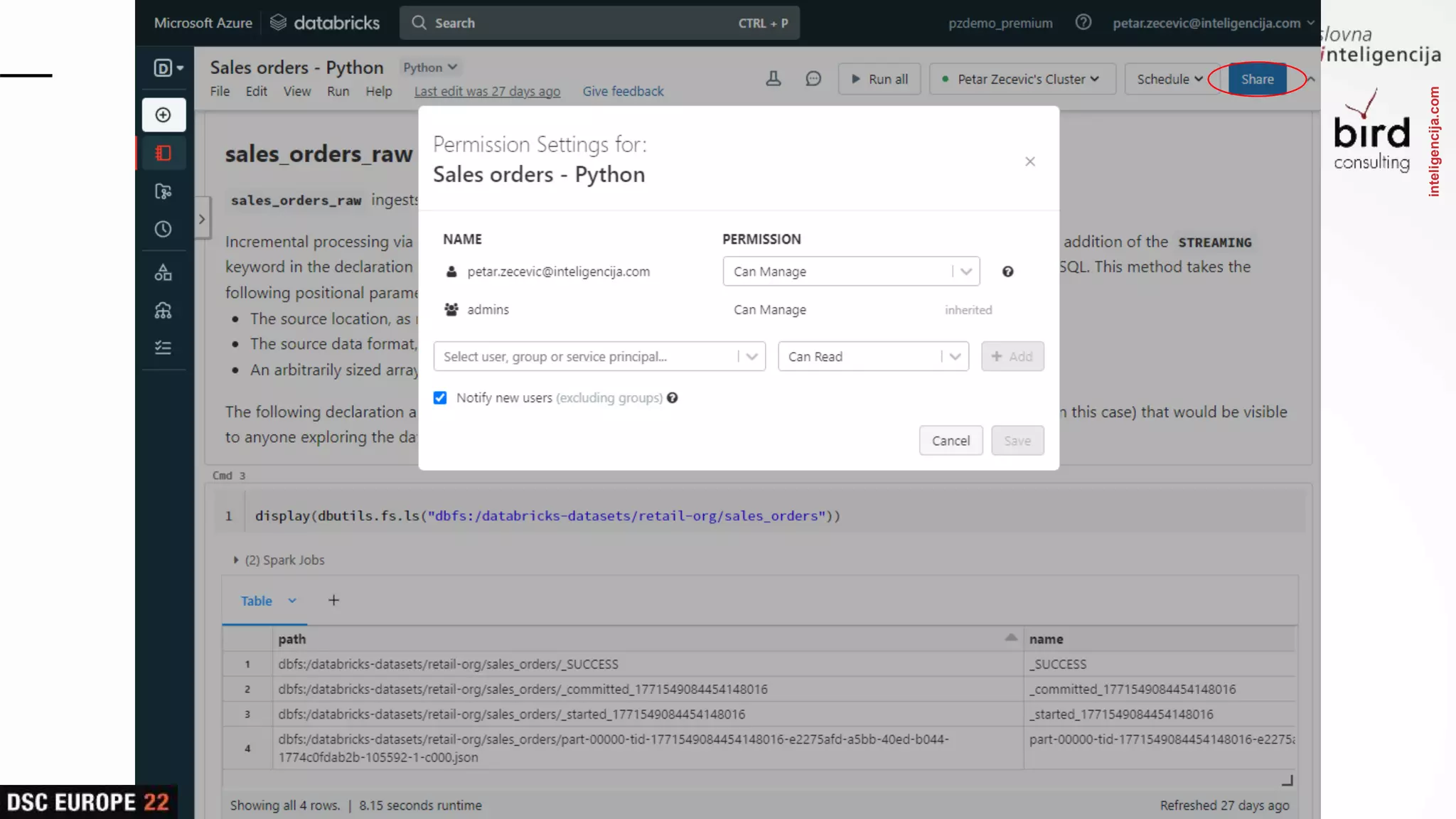
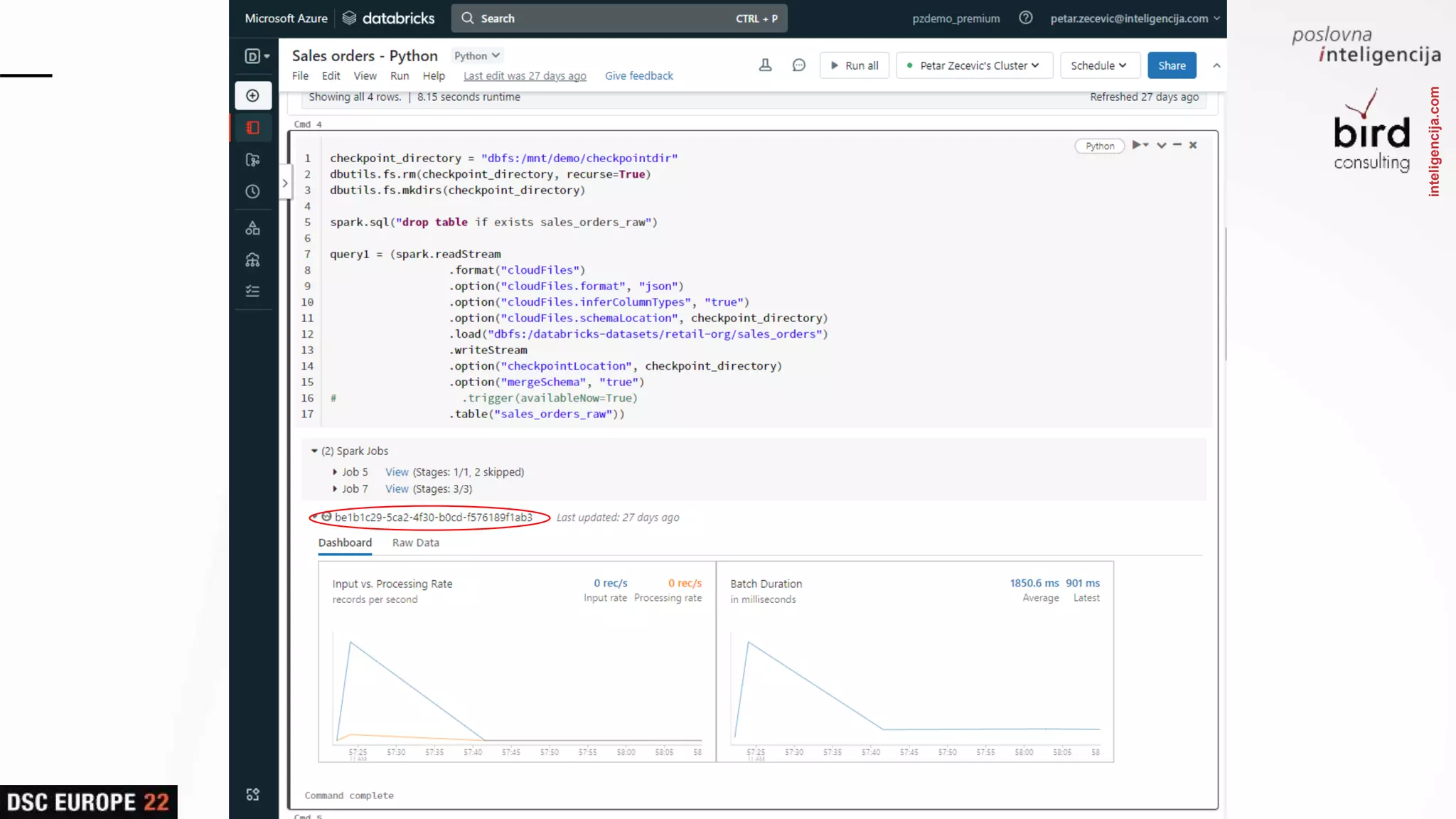
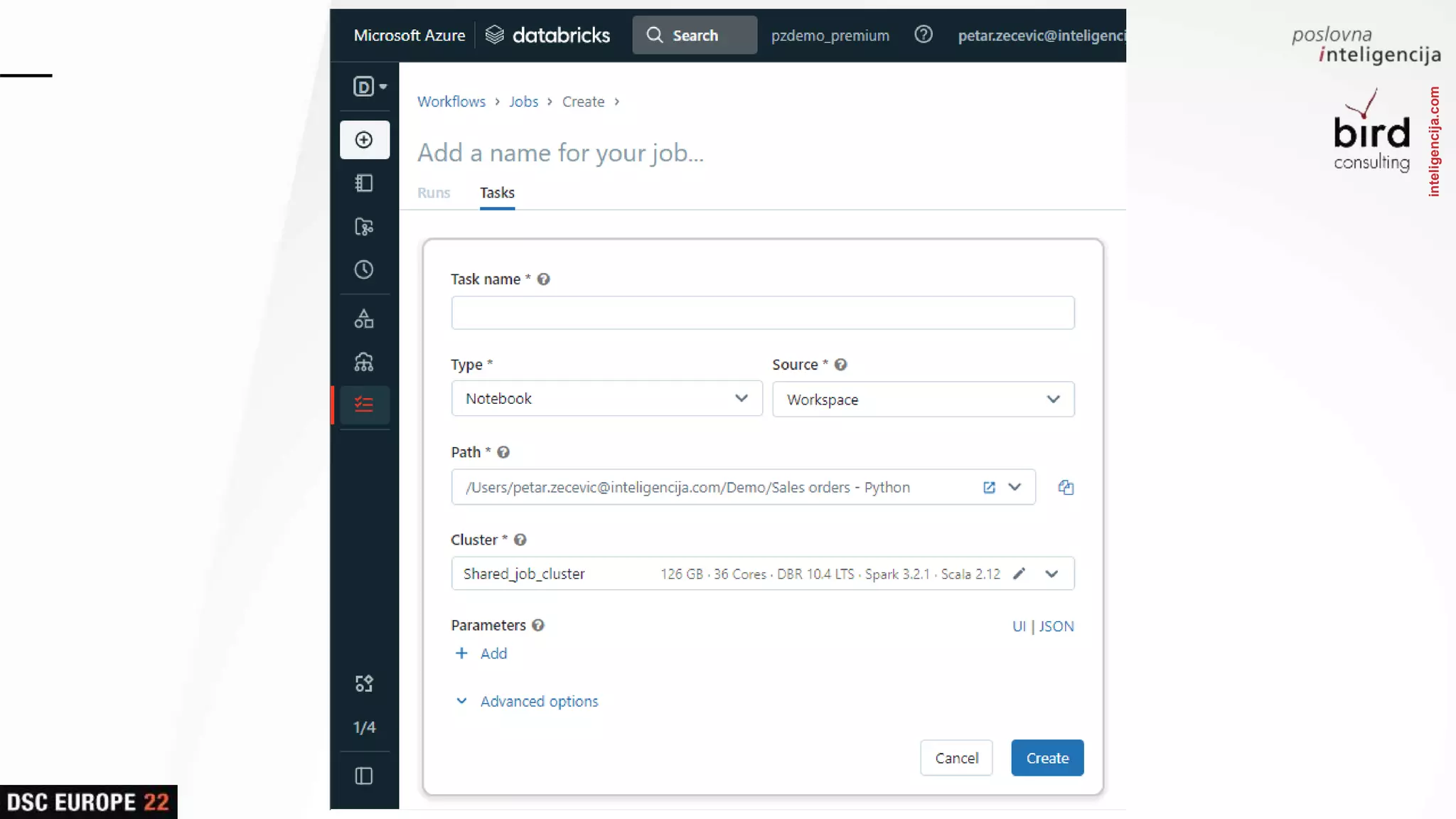
Insights into platform integrations, computing resources, and technical foundations of Databricks, including key components like Apache Spark and Delta Lake.
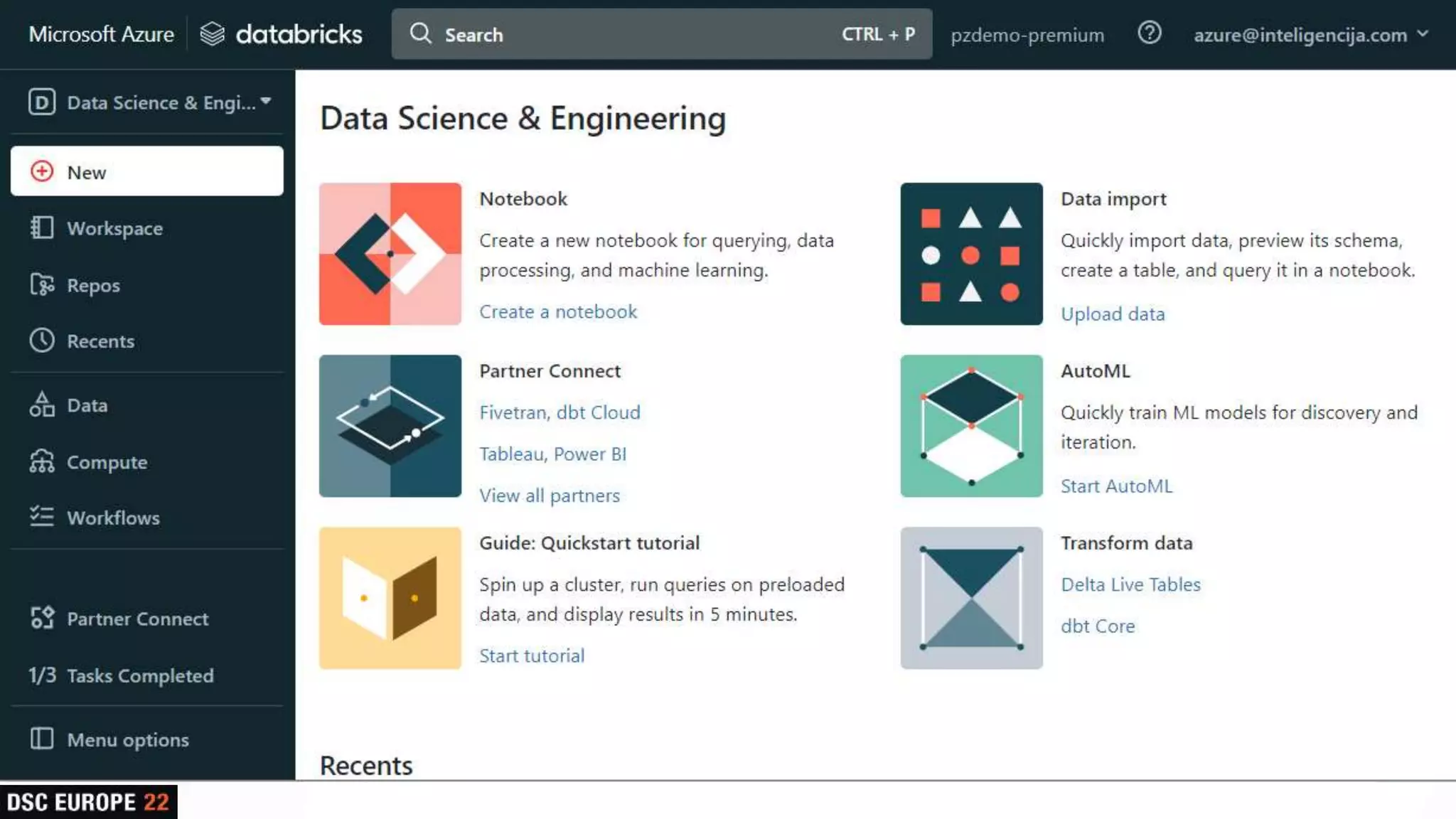
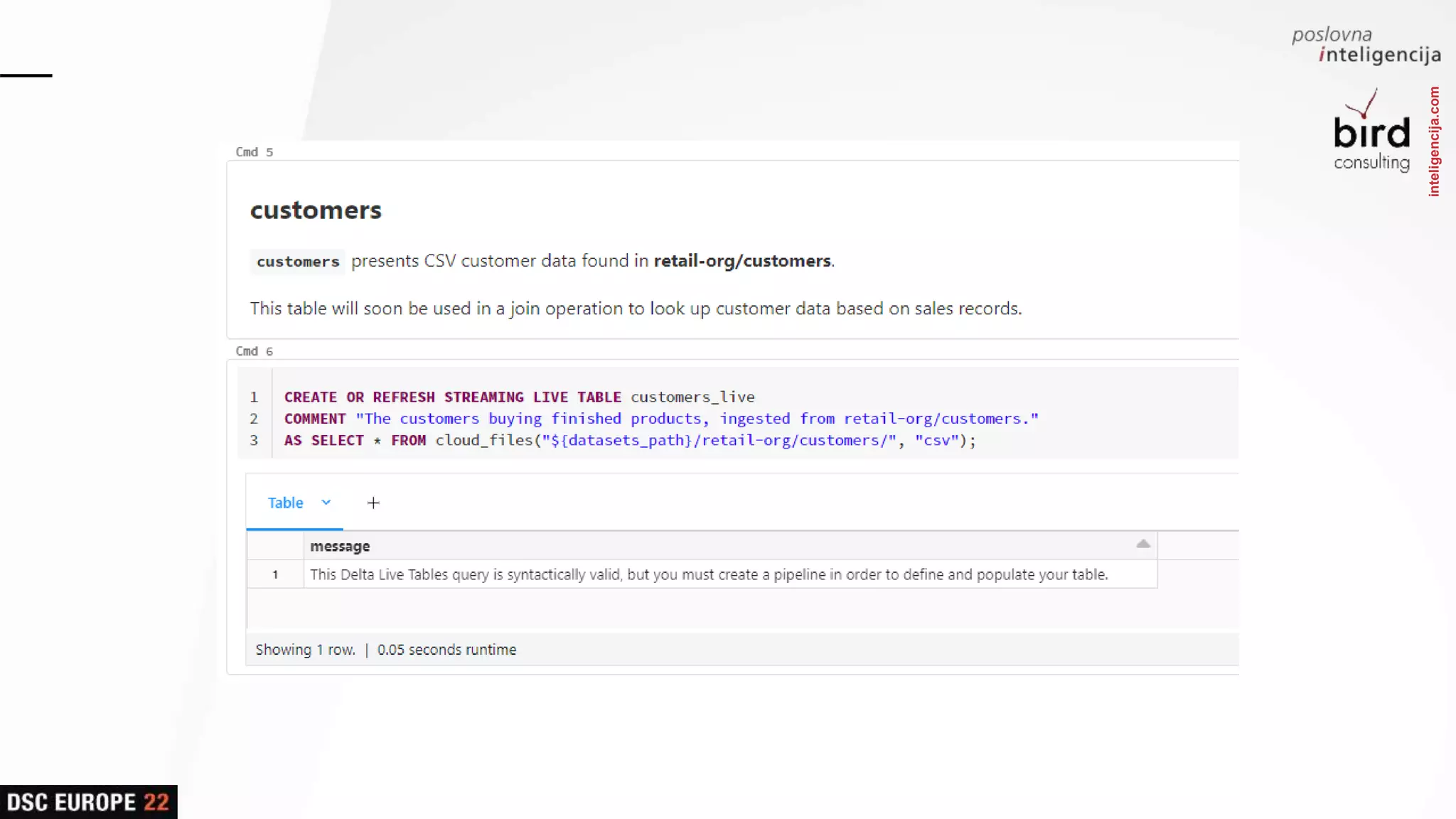
Detailed overview of essential tools like Apache Spark, Jupyter Notebooks, Delta Lake, and MLflow, explaining their functionality and purpose.
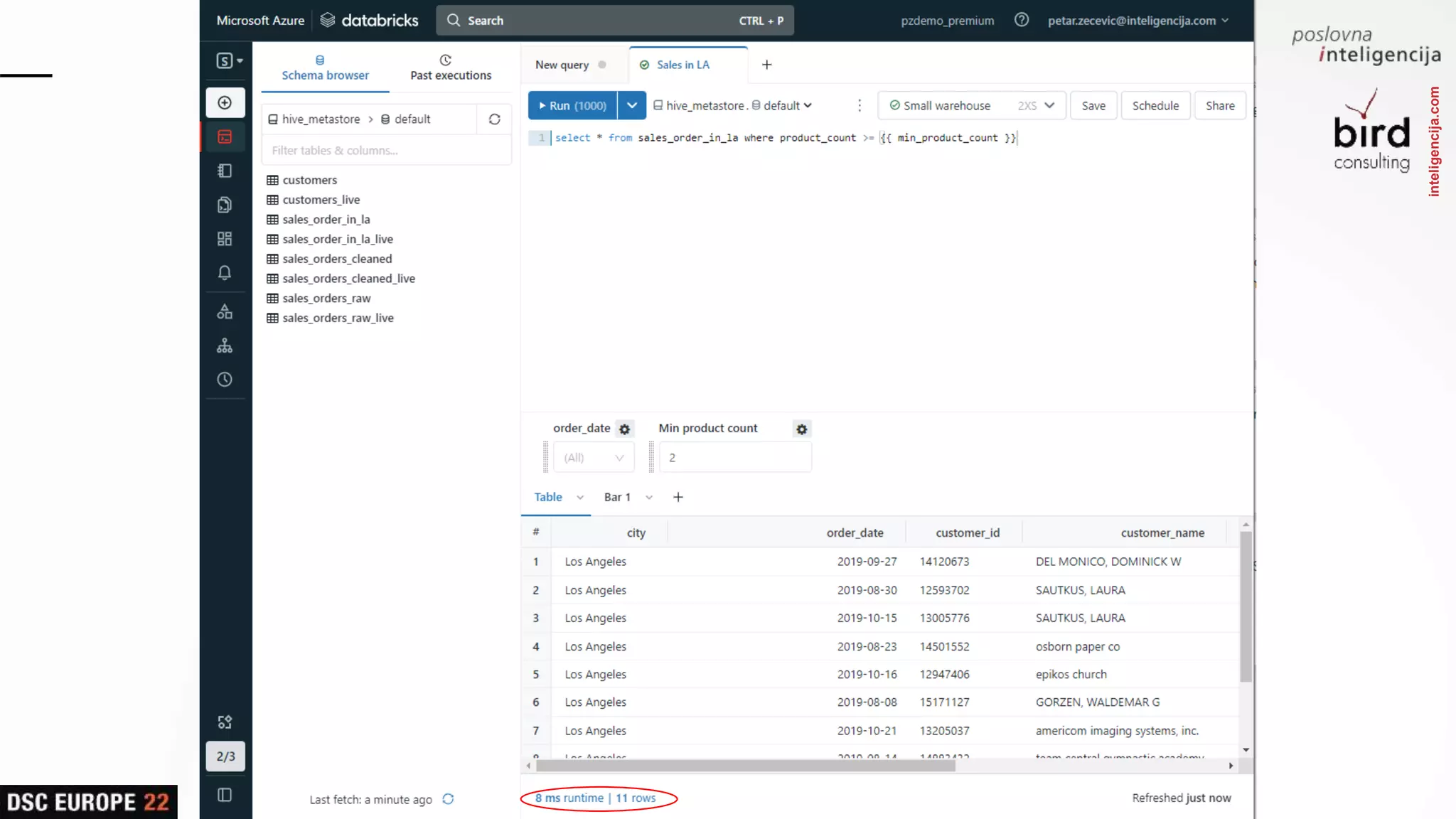
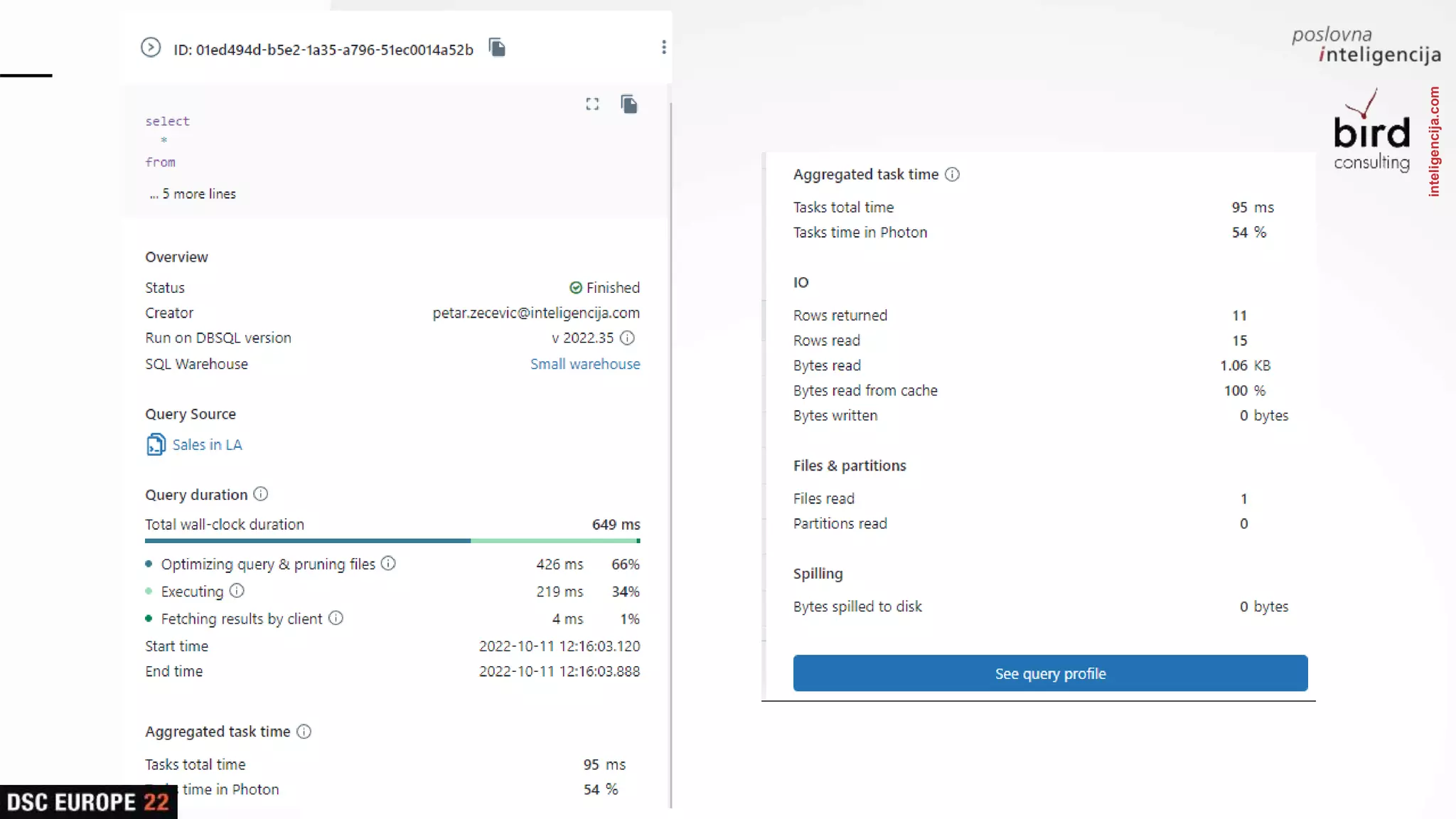
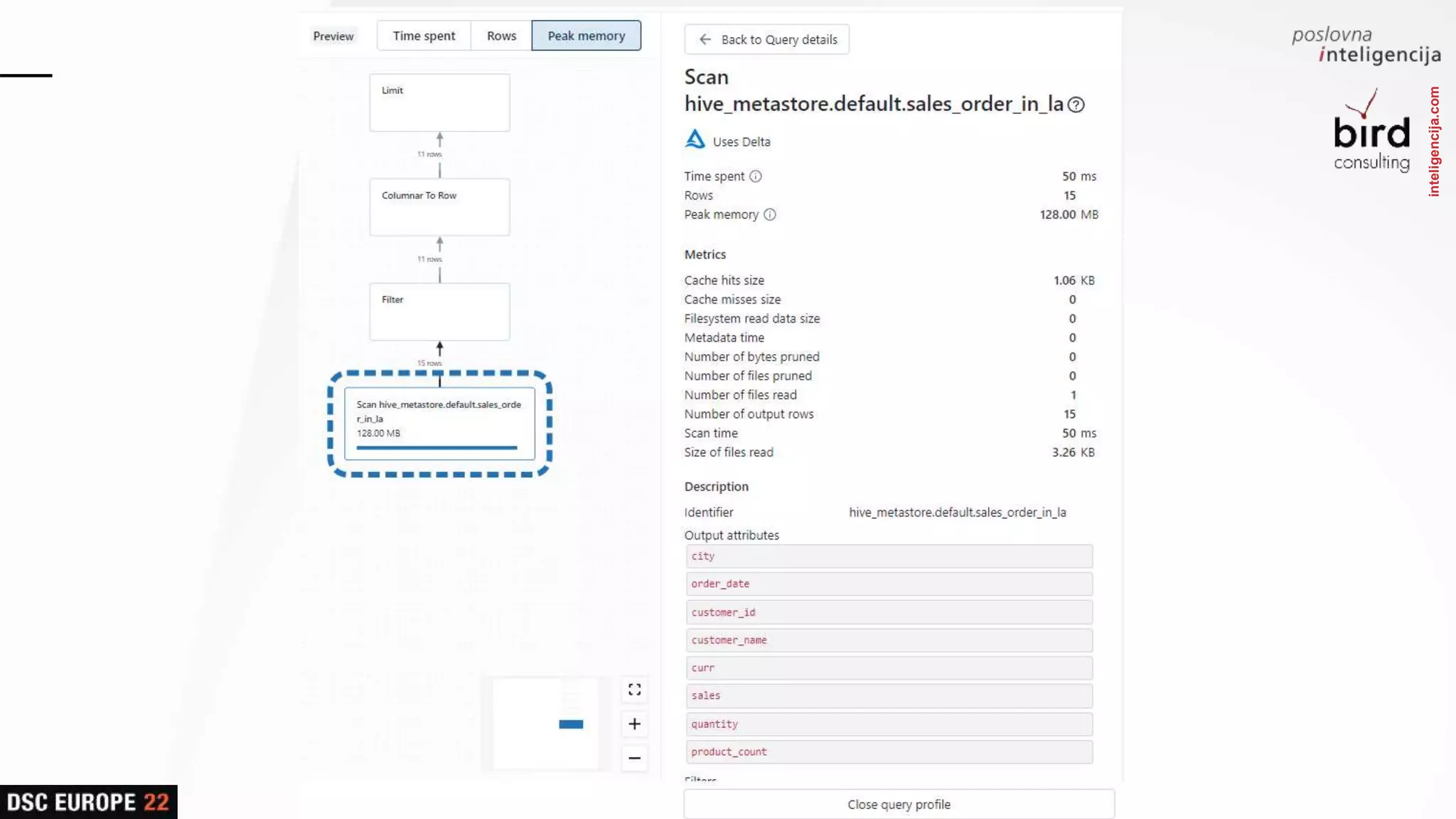
Presentation on SQL capabilities and various Databricks functions, concluding with an interactive Q&A session.
Final remarks and opening the floor for audience questions, allowing for engagement and clarification on topics discussed.




























![[DSC Europe 23] Petar Zecevic - ML in Production on Databricks](https://cdn.slidesharecdn.com/ss_thumbnails/petarzecevic-mlinproductionondatabricks-231129095155-959d35fe-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[DSC DACH 25] Verena Pietsch & Ioan Toma - Intent-Driven Automation for Machi...](https://cdn.slidesharecdn.com/ss_thumbnails/dscdach25verenapietschioantoma-intent-drivenautomationformachinedata-251104140916-80fa643c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC DACH 25] Ved Prakash - Talk to Your Data - Implementing Natural Language...](https://cdn.slidesharecdn.com/ss_thumbnails/dscdach25vedprakash-talktoyourdata-implementingnaturallanguageanalyticswithsnowflakecortex-251104140916-b7707859-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC DACH 25] Christian Casari - Augmented Intelligence - The future of GenAI...](https://cdn.slidesharecdn.com/ss_thumbnails/dscdach25christiancasari-augmentedintelligence-thefutureofgenai-251104140916-8110db6a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC DACH 25] Ali Mokh - Symbolic Reasoning in telecom oriented LLMs.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/dscdach25alimokh-symbolicreasoningintelecomorientedllms-251027100200-99093bc8-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC DACH 25] Brinnae Bent - Hacking the Blackbox.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/brinnaebenthackingtheblackbox1-251024080947-002ebd1f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC DACH 25] Zrinka Puljiz - Importance of data at the time of LLMs.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/importanceofdataatthetimeofllms2-251024080620-db0b03b5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC DACH 25] Jacqueline Berger - Beyond the Hype: The Real Story of Building...](https://cdn.slidesharecdn.com/ss_thumbnails/dsc-dach-2025jacquelineberger-251024080522-7625155a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC DACH 25] Yudan Lin_The Human - AI Paradox and Effective Fix.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/dscdach2025yudanlinthehuman-aiparadoxandeffectivefix-251024080438-f3a7a9e1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC DACH 25] Emmanuel Goffi - Moving from Compliance to Post-Compliance Ethi...](https://cdn.slidesharecdn.com/ss_thumbnails/goffi2025-movingfromcompliancetopost-complianceethicsakeychangeforcompanies-251024080222-644893cc-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC DACH 25] AI in Action_ From Industrial Data to Sustainable Impact_Ashraf...](https://cdn.slidesharecdn.com/ss_thumbnails/aiinactionfromindustrialdatatosustainableimpactashrafabushady20251016-251024080148-05e79a02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC DACH 25] Uros Miletic - Common pitfalls in AI adoption.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/commonpitfallsinaiadoption-251024075719-4a9d71ea-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 24] Sofija Pervulov - Building up the Bosch Semantic Data Lake.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/dscsofijapervulovboschupdated-251023082520-942d23c1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC DACH 25] Dr. Jochen Kokemueller.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251015dsckokemueller-251022092212-44cf2599-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC DACH 25] Mario Meir-Huber Demystifying Data Products: From Buzzword to P...](https://cdn.slidesharecdn.com/ss_thumbnails/demdapro-251022092046-55c8d73b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC DACH 25] Stefan Stricker-Agentic_BI.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/stefanstricker-agenticbi-251022091858-f3944612-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC DACH 25] Governance of Agentic AI - Nescho Topalov.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/governanceofagenticai-neschotopalov-251022091803-3be2a1fe-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC DACH 25] Nuno Antonio_BigDataDrivenStrategies.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/nunoantoniobigdatadrivenstrategies-251022091406-23769848-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC DACH 25] Ivan Vukasinovic $20M Datapipeline Built by AI in 48 hours.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/ivanvukasinovic20mdatapipelinebuiltbyaiin48hours-251022090438-b9651e46-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC DACH 25] Davor Gasparac - Unscrewing Agile.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/gasparac-unscrewingagile-251022090222-a69d34b8-thumbnail.jpg?width=640&height=640&fit=bounds)



















