TOPICS COVERED
Data
Collection of Data
Organization of Data
Presentation of Data
Hypothesis testing
Types of errors
3.
DATA
Data isa collection of raw, unprocessed facts and figures
that can be used as a basis for calculation, reasoning, or
discussion. It can include abstract ideas, concrete
measurements, statistics, and more. Data is often collected
through experiments, observations, or measurements, and
it lacks context and interpretation.
4.
EXAMPLES
The amountof Food that goes waste in India every year
was more than 40% valued at 58,000 core.
In India, 96.5% kids got to School: Survey
1. There is a lot food that goes waste in India every
year
2. The Population of India is Growing Rapidly
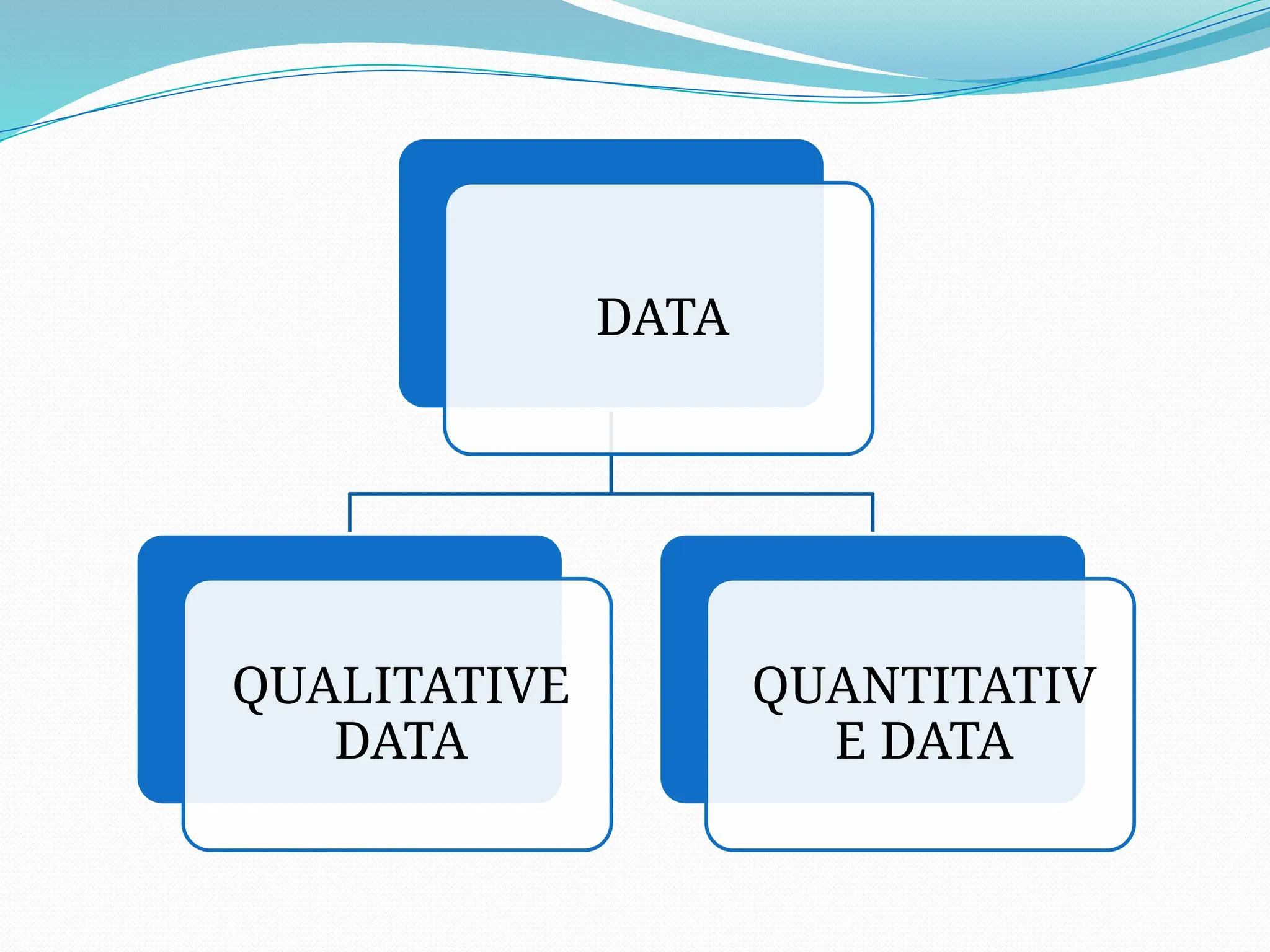
is interpretation-based,descriptive, and relating to language.
can help us to understand why, how, or what happened behind certain
behaviors.
subjective and unique.
methods are interviewing and observing.
is analyzed by grouping the data into categories and themes.
is numbers-based, countable, or measurable.
tells us how many, how much, or how often in calculations.
is fixed and universal.
is subjective and unique.
methods are measuring and counting.
is analyzed using statistical analysis.
QUALITATIVE DATA
QUANTITATIVE DATA
DATA COLLECTION
It’s theprocess of gathering and measuring information on
variables of interest, in an established systematic fashion
that enables one to answer stated research questions, test
hypotheses, and evaluate outcomes
10.
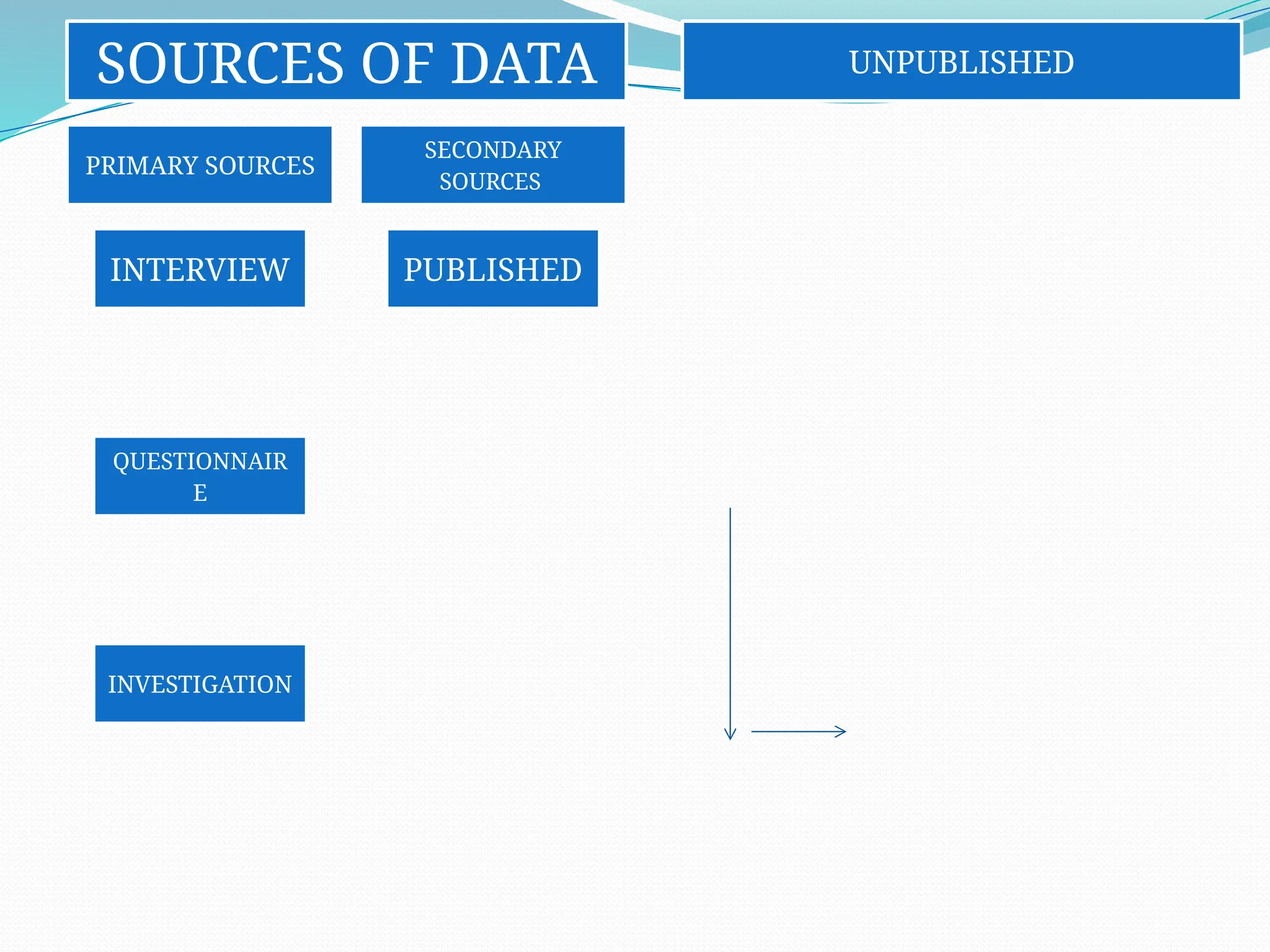
SOURCES OF DATA
PRIMARYSOURCES
INTERVIEW
QUESTIONNAIR
E
INVESTIGATION
SECONDARY
SOURCES
PUBLISHED
UNPUBLISHED
11.
PRIMARY DATA
Primarydata is a type of information that is obtained from
first – hand sources by means of surveys, observation or
experimentation. It is data that has not been previously
published and is derived from a new or original research
study and collected at the source such as in marketing.
12.
SOURCES OF COLLECTIONOF
PRIMARY DATA
Direct Personal Interview:
Data is personally collected by the interviewer.
Telephonic Interviews:
Data is collected through an interview over the
telephone with the interviewer.
13.
SOURCES OF COLLECTIONOF
PRIMARY DATA
Indirect Oral Investigation:
Data is collected from third parties who have
information about subject of enquiry.
Information from Correspondents:
Data is collected from agents appointed in
the area of investigation.
14.
SOURCES OF COLLECTIONOF
PRIMARY DATA
Mailed Questionnaire:
Data is collected through questionnaire mailed to
the information.
Questionnaire filled by enumerators:
Data is collected by trained enumerators
who fill questionnaires.
15.
ESSENTIALS OF AGOOD
QUESTIONNAIRE
A covering letter with objectives and
scope of survey.
Minimum number of questions.
Avoid personal questions.
Questions should be clear and simple.
Questions should be logically arranged.
16.
HOW TO COLLECTPRIMARY DATA?
These are the ways to collect primary data:
1. Sampling: It is a process through which we choose
a smaller group to collect data that can be the best
representative of the population.
2. Survey: it can be done in face to face
mode(interviews) or indirect mode(Telephone,
internet etc.,)
3. Census: It is method in which data is collected
from every unit of population.
17.
CENSUS METHOD SAMPLING
METHOD
1.Everyunit of
population studied
2.Reliable and
accurate results
3.Expensive method
4.Suitable when
population is of
homogenous
nature.
1.Few unit of
population are
studied
2.Less Reliable and
accurate results
3.Less expensive
method
4. Suitable when
population is
18.
SECONDARY DATA
Secondary datais data that is not collected by the
person who is doing research. An example of
secondary data is a community assessment done
by another organization but used to substantiate
another organizations research.
19.
SOURCES OF SECONDARYDATA
Published Source
Government publications, Semi-government
publications etc.,
Unpublished Source
Census of India, National Sample Survey organization
[They are collected by the organizations for their own
record]
20.
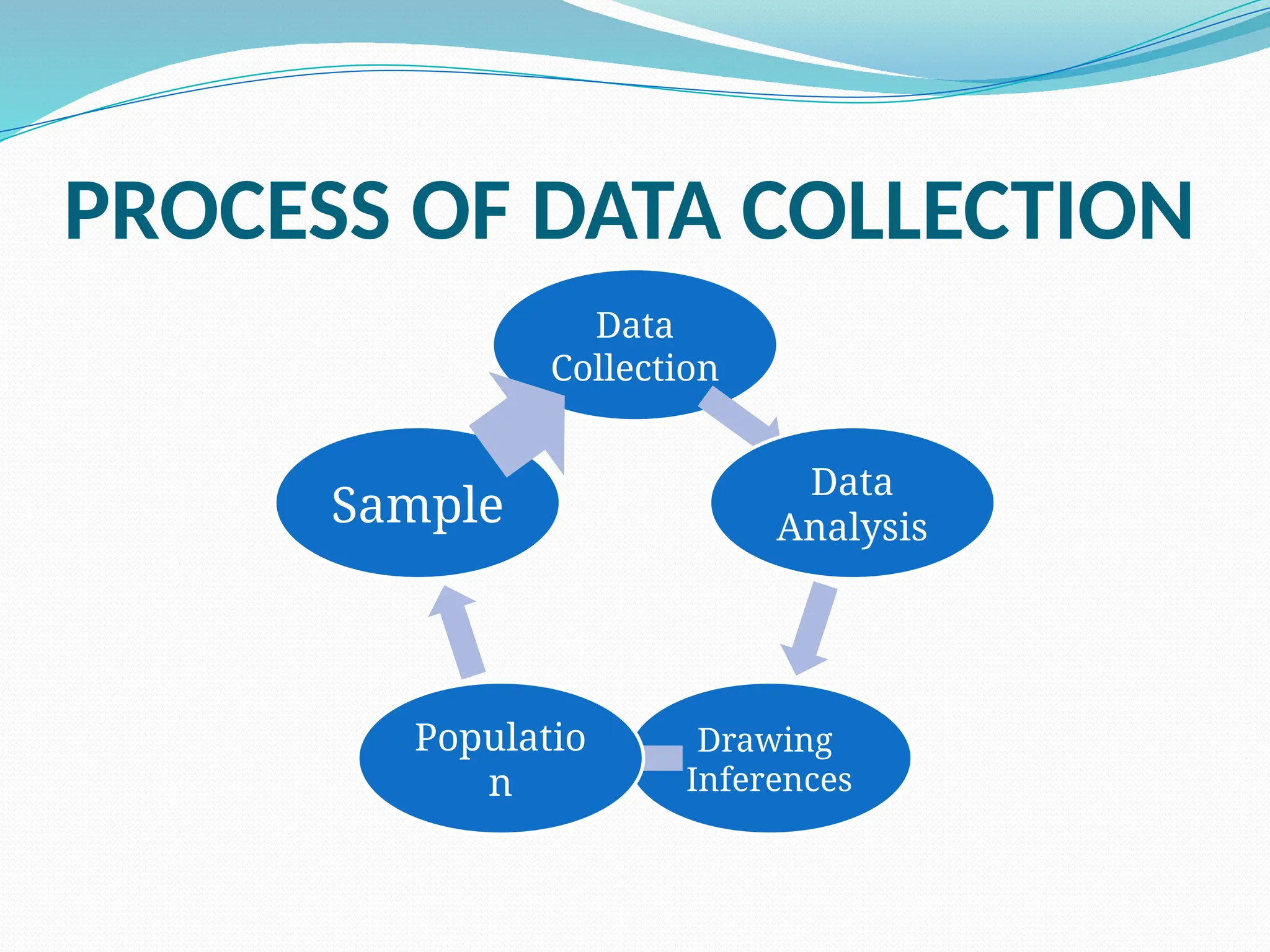
PROCESS OF DATACOLLECTION
Data
Collection
Data
Analysis
Drawing
Inferences
Populatio
n
Sample
Data organization isthe way to arrange the raw data in an
understandable order. Organizing data include classification,
frequency distribution table.
Example: The marks scored out of 50 in a Maths
exam taken by 15 students are as follows:
26,15, 40, 18, 26, 24, 48, 40, 39, 26, 23, 37, 38, 40, 45, 48.
The data collectedshould be presented in a
suitable, concise form for further analysis. The
collected data may be presented in the form of
tabular or diagrammatic or graphical form.
WHAT IS AHYPOTHESIS?
A hypothesis is an assumption about the
population parameter.
A parameter is characteristic of the population,
like its mean or variance.
The parameter must be identified before
analysis.
27.
TESTING OF HYPOTHESIS
Ahypothesis is an assumption about the population parameter (say
population mean) which is to be tested.
For that we collect sample data, then we calculate sample
statistics(say sample mean) and then use this information to
judge/decide whether hypothesized value of population parameter
is correct or not.
28.
To testthe validity of assumed or hypothetical value of
population, we gather sample data and determine the
difference between hypothesized value and actual value of
the sample mean.
Then we judge whether the difference is significant or not.
The smaller the difference, the greater the likelihood that
our hypothesized value for the mean is correct. The larger
the difference, the smaller the likelihood.
29.
In hypothesistesting the first step is to state the assumed
or hypothesized (numerical) value of the population
parameter.
The assumption we wish/ want to test is called the null
hypothesis. It is denoted with
30.
THE NULL HYPOTHESIS,
State the Assumption to be tested.
The average marks of the second year
students( in sem3) is 75
Begin with the assumption that the null
hypothesis is true.
31.
The Alternative Hypothesis,
The Alternate Hypothesis is the logical opposite
of the null hypothesis.
The average marks of the second year
students( in sem3) is not 75. (:µ≠75)
32.
PROCEDURE OF HYPOTHESIS
TESTING
TheHypothesis Testing comprises the following steps:
Step 1:
Set up a hypothesis.
Step 2:
Set up a suitable significance level.
The confidence with which an experimenter rejects or
accepts Null hypothesis depends on the significance level
adopted.
Level of significance is the rejection region. It is denoted
with α.
33.
SELECTING A SIGNIFICANCELEVEL
Level of significance can be adopted either 5% or 1%.
5% level of significance ie., α=0.05, then there are about 5
chances out of 100 that we would reject the null
hypothesis.
There is 95% chance to accept the null hypothesis.
It means that there is about 95% confidence that the
decision taken is right.
34.
If the samplestatistic(calculated value) falls in non shaded
region( acceptance region), then it simply means that there
is no evidence to reject the null hypothesis.
It proves that null hypothesis is true. Otherwise it will be
rejected.
35.
Step 3: Determinationof suitable test statistics
Step 4: Determine the critical value from the table.
Step 5: After doing computation , check the sample result.
Compare the calculated value(sample result) with the value obtained
from the table(tabulated or critical value)
Step 6: Making decisions either accepting or rejecting the null
hypothesis. If the computed value is more than the tabulated or
critical value, then it falls in the critical region. In that case, reject
null hypothesis, otherwise accept.
TYPE I ANDII ERRORS
When a statistical hypothesis is tested, there are 4 possible
results:
1. The hypothesis is true but our test accepts it.
2. The hypothesis is false but our test rejects it.
3. The hypothesis is true but our test rejects it.
4. The hypothesis is false but our test accept it.
Rejecting a null hypothesis when it is true is called Type I
error.
Accepting a null hypothesis when it is false is called Type II
error.
38.
Example:
In a courtroom, a defendant is considered not guilty as
long as his guilt is not proven. The prosecutor tries to prove
the guilt of the defendant. Only when there is enough
charging evidence the defendant is condemned. In the start
of the procedure, there are two hypotheses
















![SOURCES OF SECONDARY DATA
Published Source
Government publications, Semi-government
publications etc.,
Unpublished Source
Census of India, National Sample Survey organization
[They are collected by the organizations for their own
record]](https://image.slidesharecdn.com/presentation-251117160033-d7a87af8/75/WIELD-OF-STATISTICS-IN-DECISION-MAKING-19-2048.jpg)







































![SOURCES OF SECONDARY DATA
Published Source
Government publications, Semi-government
publications etc.,
Unpublished Source
Census of India, National Sample Survey organization
[They are collected by the organizations for their own
record]](https://crownmelresort.com/image.slidesharecdn.com/presentation-251117160033-d7a87af8/75/WIELD-OF-STATISTICS-IN-DECISION-MAKING-19-2048.jpg)






















































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)














