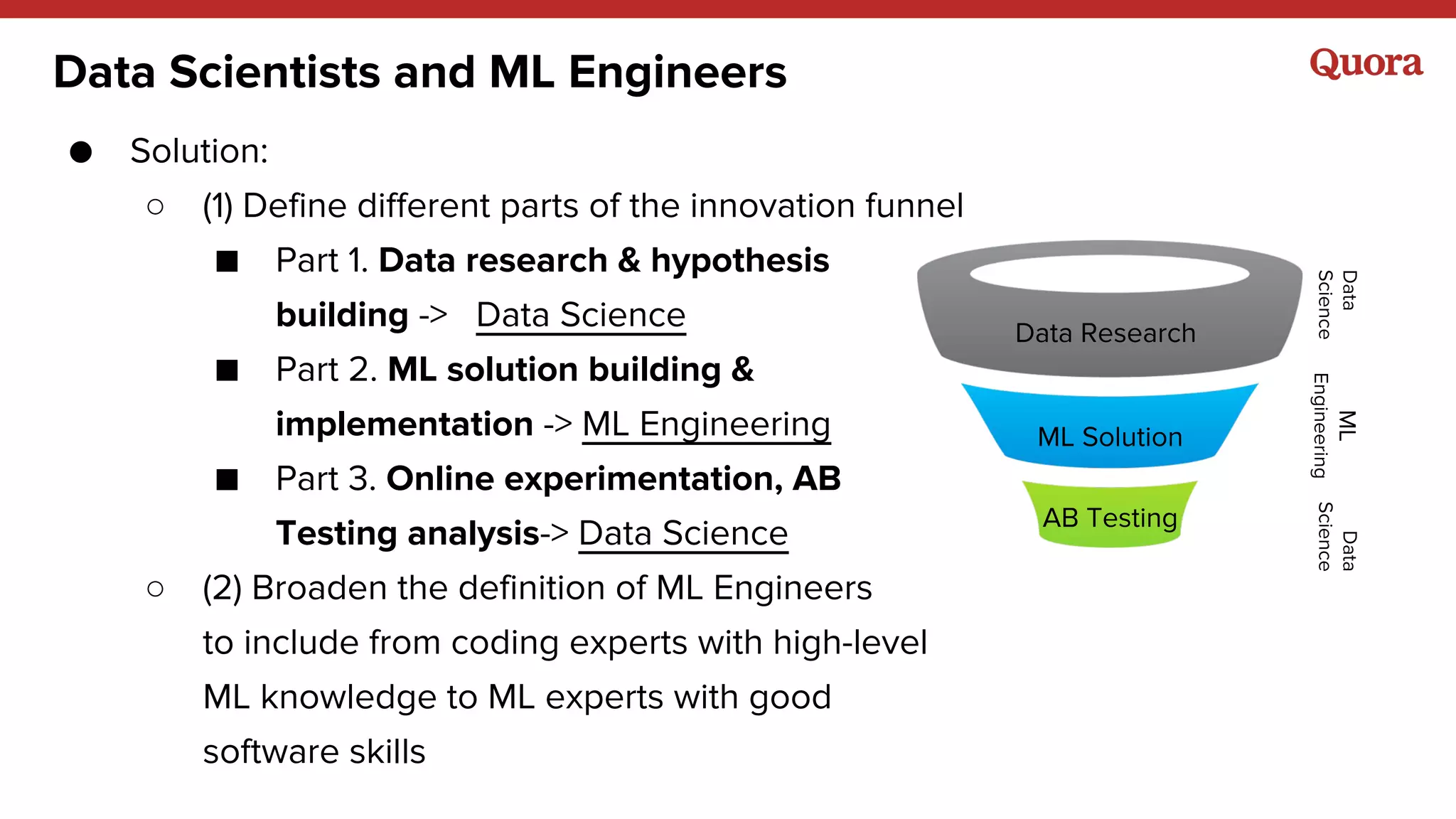
Download as PDF, PPTX








![Example 2 - Quora’s feed
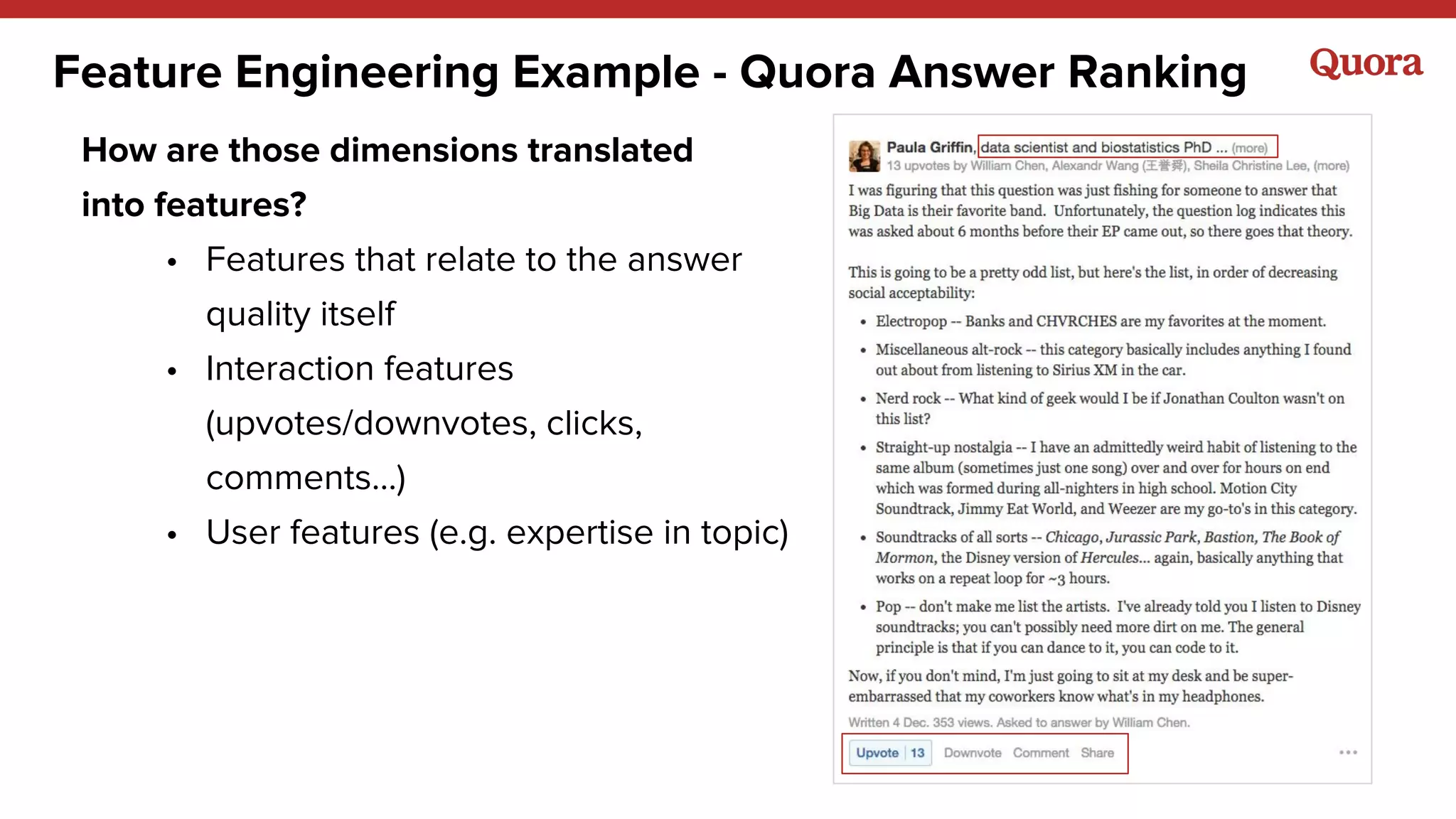
● Training data = implicit + explicit
● Target function: Value of showing a story to a
user ~ weighted sum of actions: v = ∑a
va
1{ya
= 1}
○ predict probabilities for each action, then compute expected
value: v_pred = E[ V | x ] = ∑a
va
p(a | x)
● Metric: any ranking metric](https://image.slidesharecdn.com/qrtifmhshqoti4gyaina-signature-3f25559444b0ec3e66afc518788fe7492fab403f8041db4d301093802a261eaa-poli-151114063712-lva1-app6891/75/10-more-lessons-learned-from-building-Machine-Learning-systems-15-2048.jpg)








































![Example 2 - Quora’s feed
● Training data = implicit + explicit
● Target function: Value of showing a story to a
user ~ weighted sum of actions: v = ∑a
va
1{ya
= 1}
○ predict probabilities for each action, then compute expected
value: v_pred = E[ V | x ] = ∑a
va
p(a | x)
● Metric: any ranking metric](https://crownmelresort.com/image.slidesharecdn.com/qrtifmhshqoti4gyaina-signature-3f25559444b0ec3e66afc518788fe7492fab403f8041db4d301093802a261eaa-poli-151114063712-lva1-app6891/75/10-more-lessons-learned-from-building-Machine-Learning-systems-15-2048.jpg)


































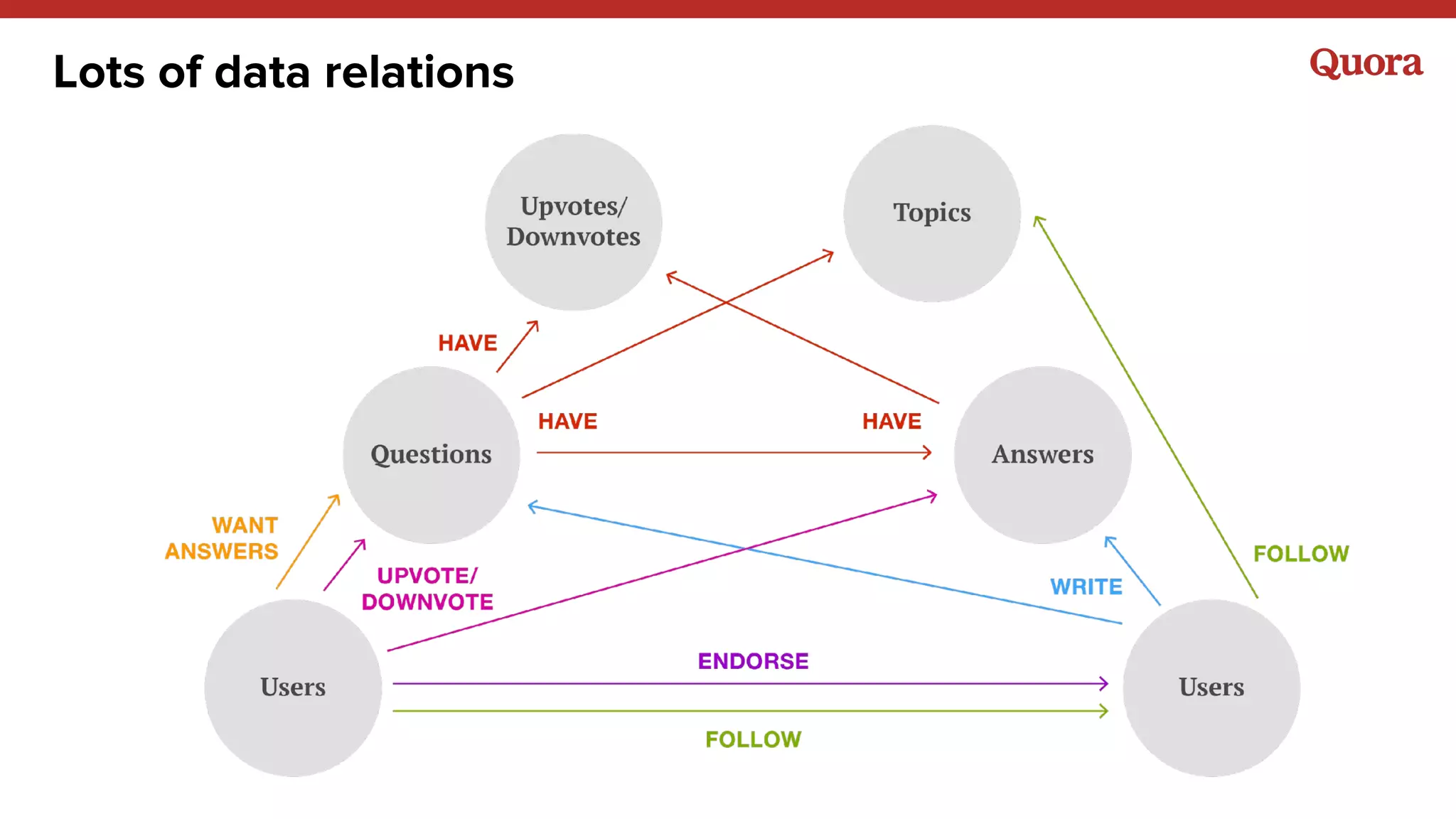
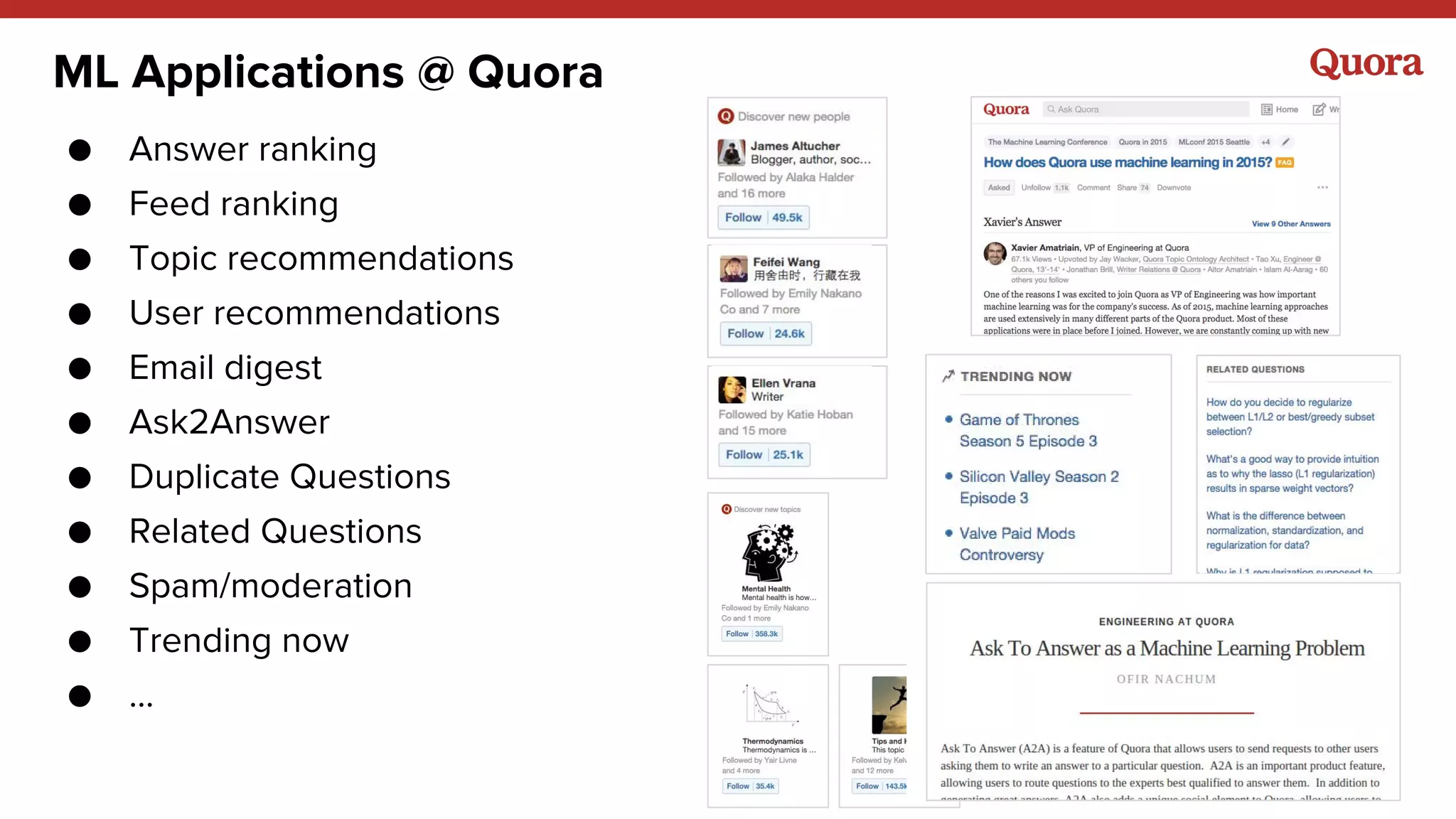
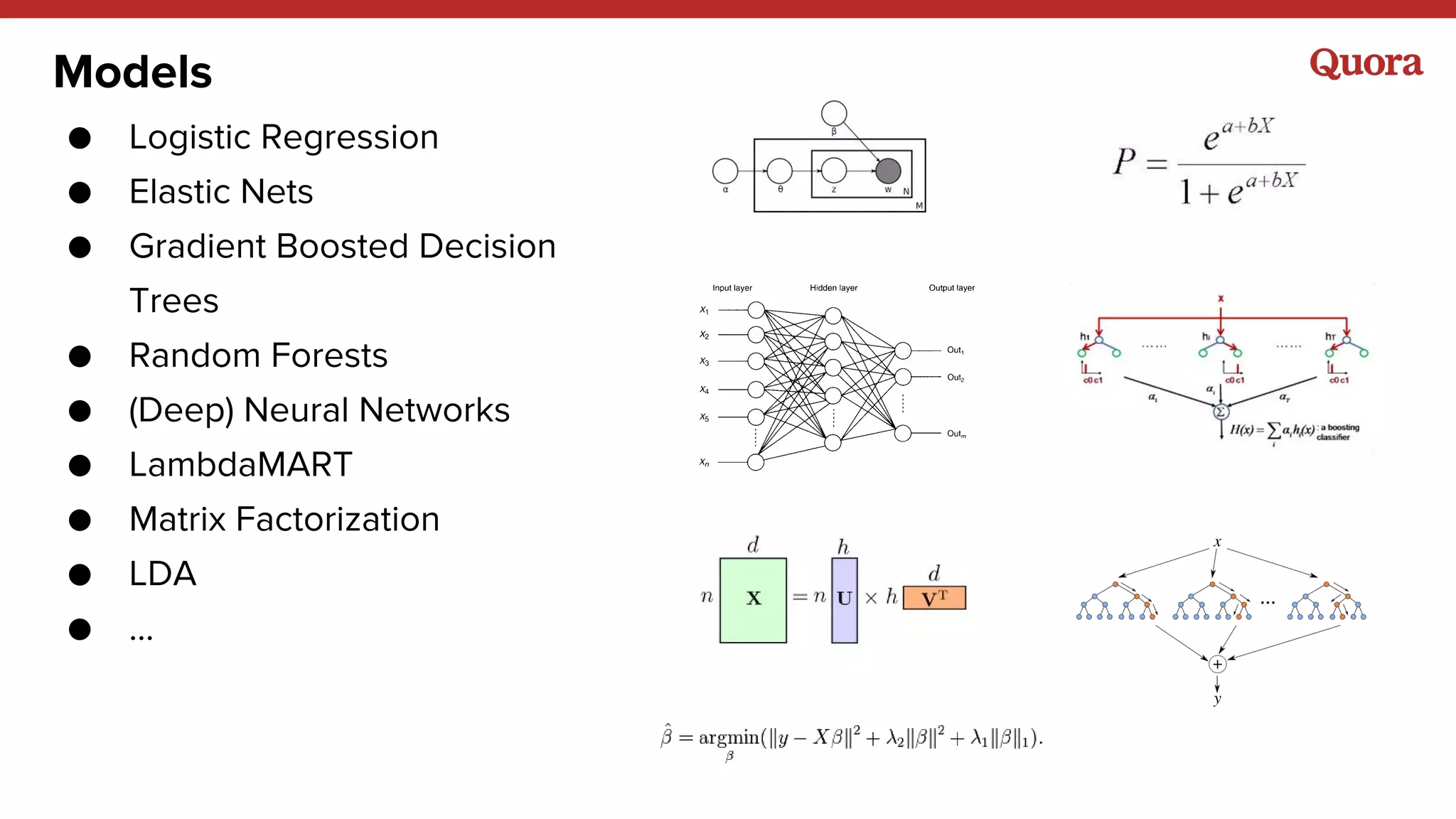
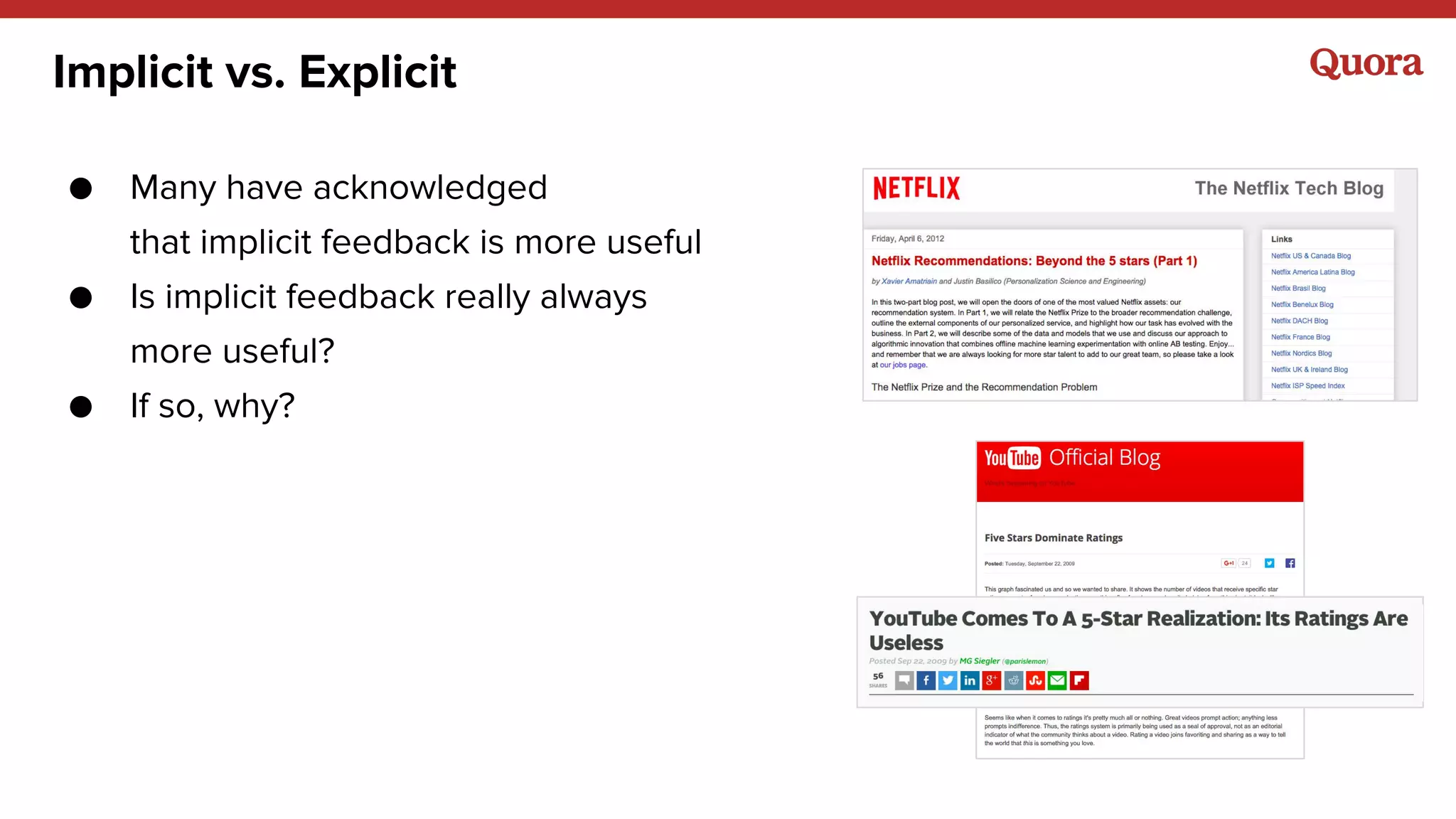
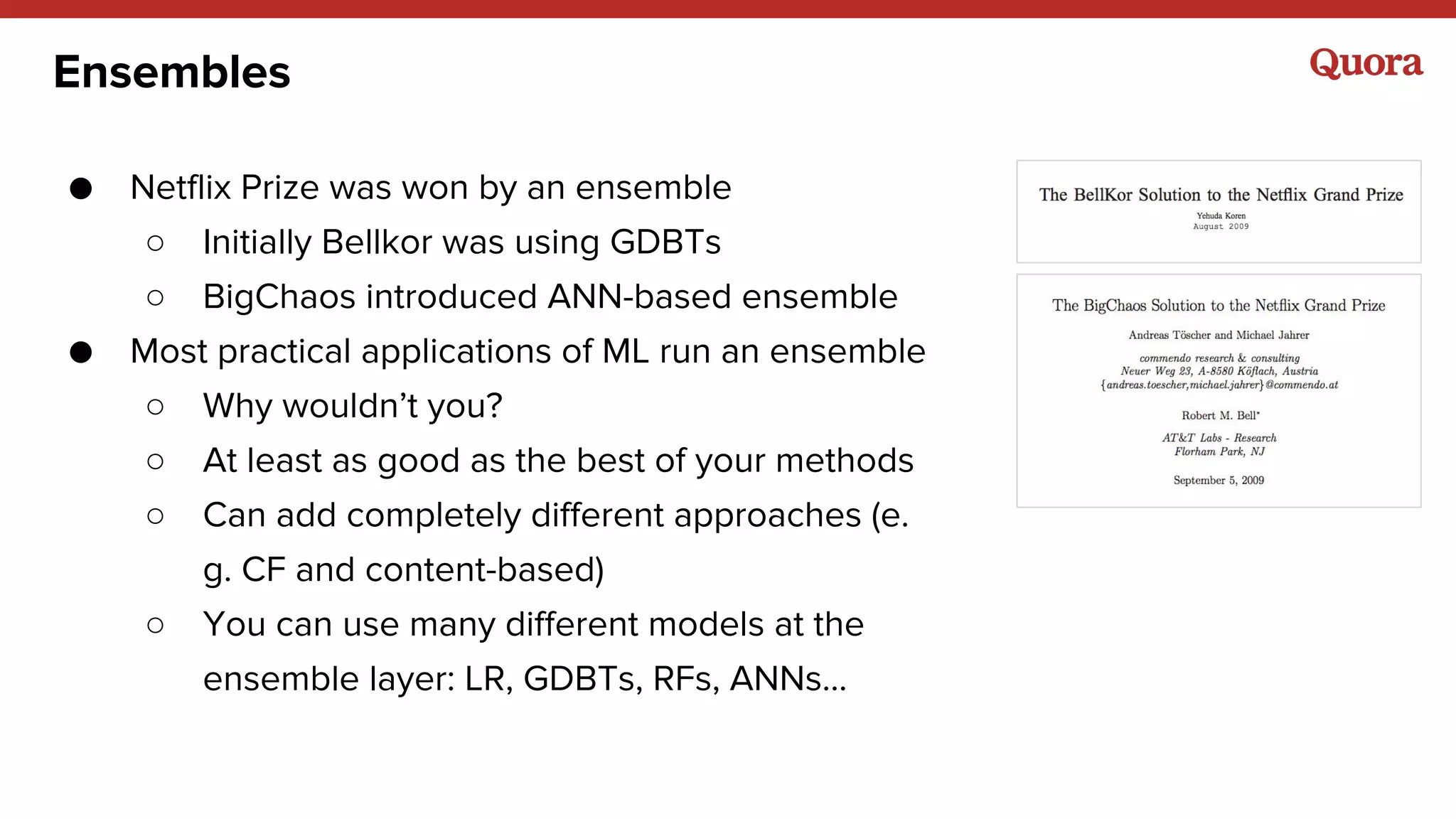
1. Machine learning applications at Quora include answer ranking, feed ranking, topic recommendations, user recommendations, and more. A variety of models are used including logistic regression, gradient boosted decision trees, neural networks, and matrix factorization. 2. Implicit signals like watching and clicking tend to be more useful than explicit signals like ratings. However, both implicit and explicit signals combined can better represent long-term goals. 3. The outputs of machine learning models will often become inputs to other models, so models need to be designed with this in mind to avoid issues like feedback loops.






















































































