Download as PDF, PPTX


























![Example 2 - Quora’s feed
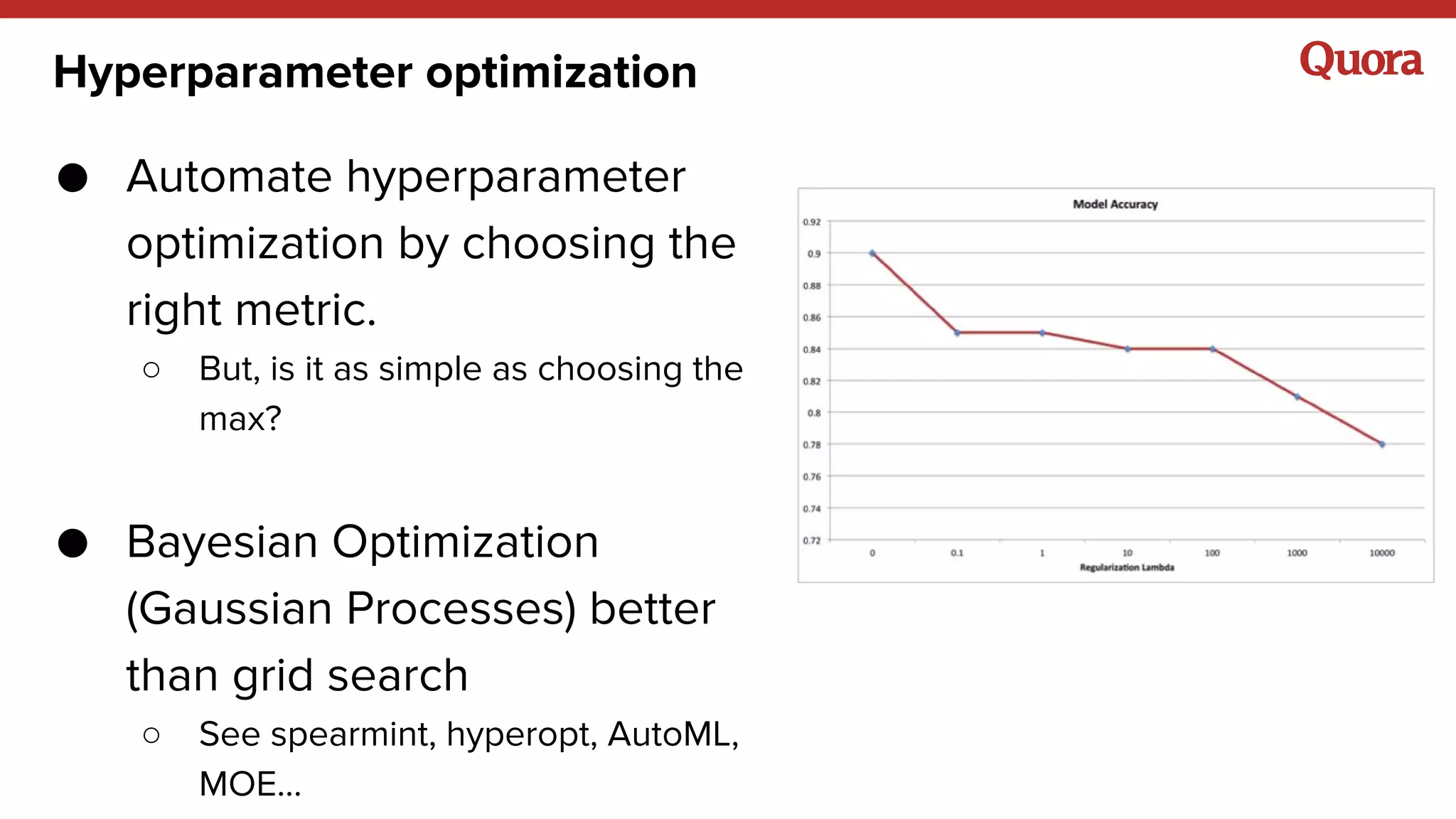
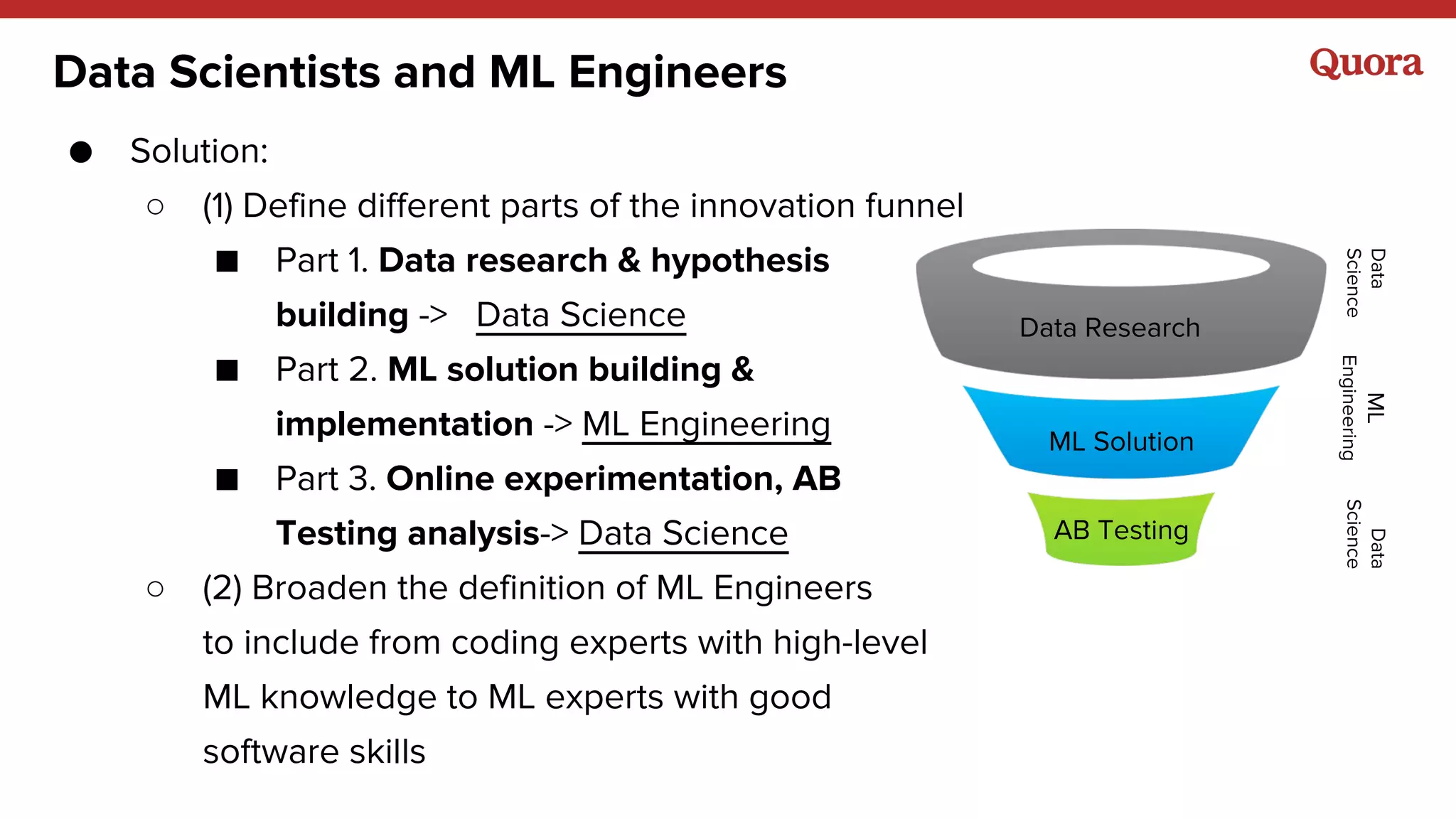
● Training data = implicit + explicit
● Target function: Value of showing a story to a
user ~ weighted sum of actions: v = ∑a
va
1{ya
= 1}
○ predict probabilities for each action, then compute expected
value: v_pred = E[ V | x ] = ∑a
va
p(a | x)
● Metric: any ranking metric](https://image.slidesharecdn.com/strata-lessonslearned-160329172556/75/Strata-2016-Lessons-Learned-from-building-real-life-Machine-Learning-Systems-36-2048.jpg)













































![Example 2 - Quora’s feed
● Training data = implicit + explicit
● Target function: Value of showing a story to a
user ~ weighted sum of actions: v = ∑a
va
1{ya
= 1}
○ predict probabilities for each action, then compute expected
value: v_pred = E[ V | x ] = ∑a
va
p(a | x)
● Metric: any ranking metric](https://crownmelresort.com/image.slidesharecdn.com/strata-lessonslearned-160329172556/75/Strata-2016-Lessons-Learned-from-building-real-life-Machine-Learning-Systems-36-2048.jpg)
















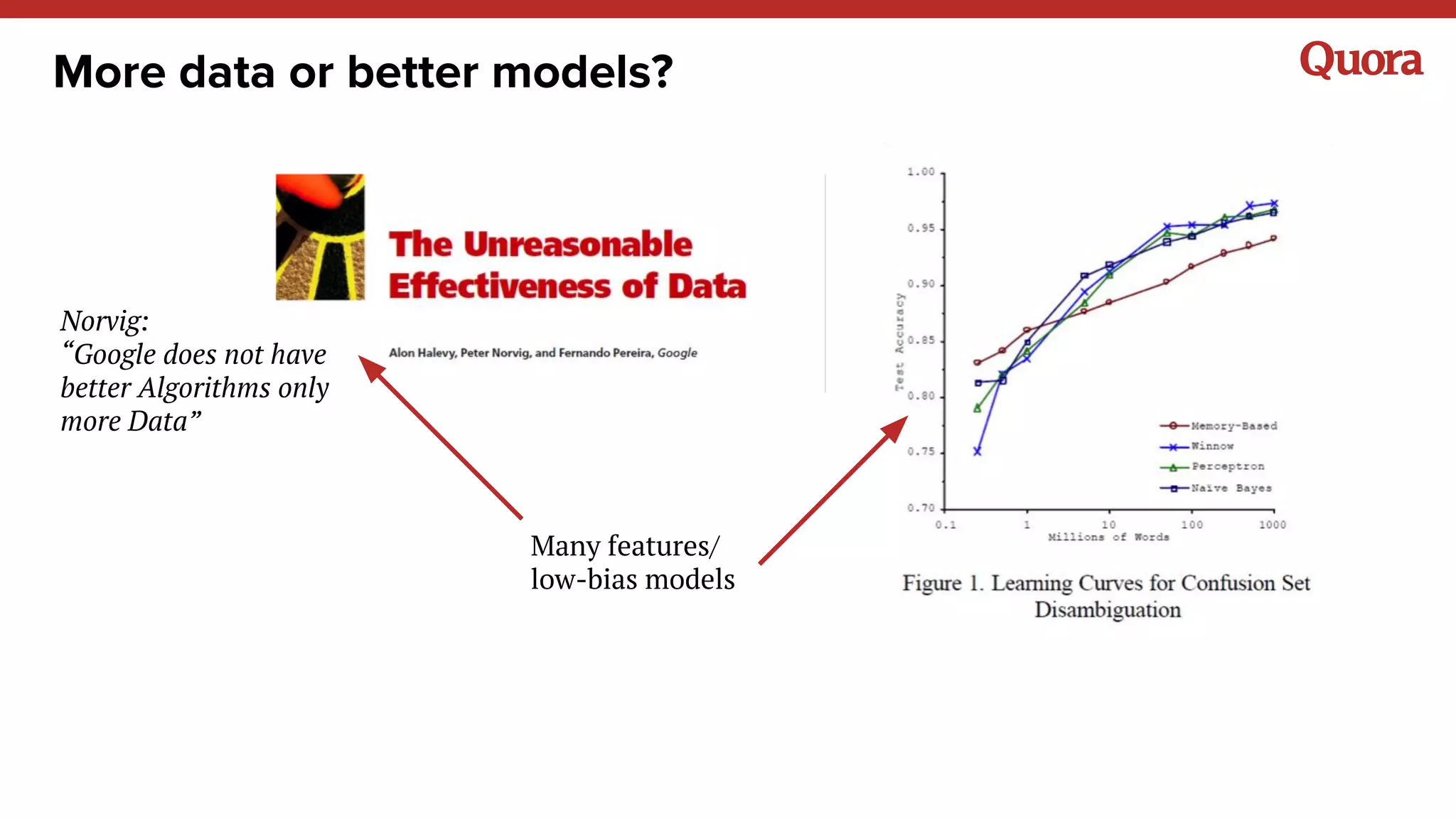
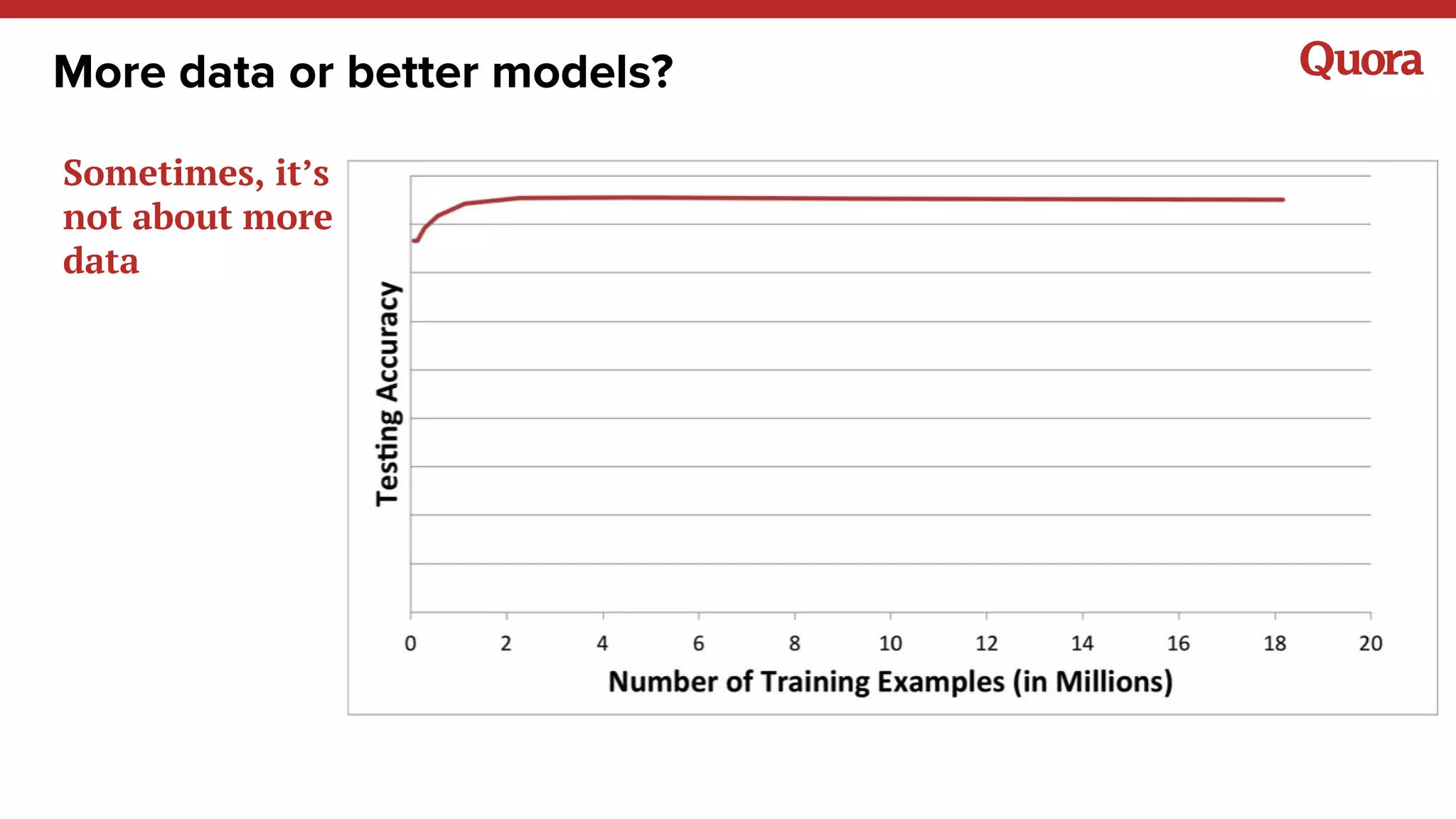
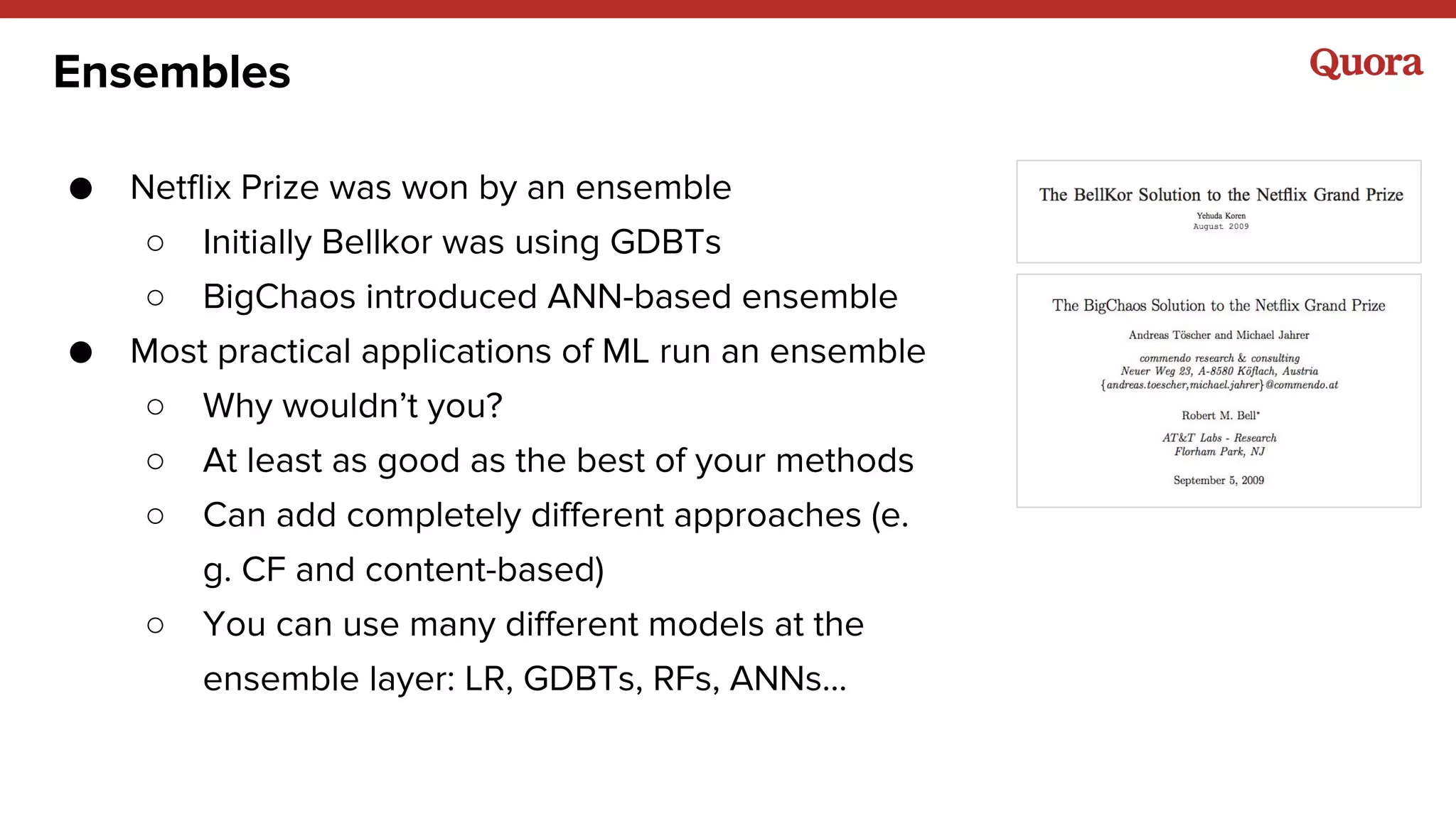
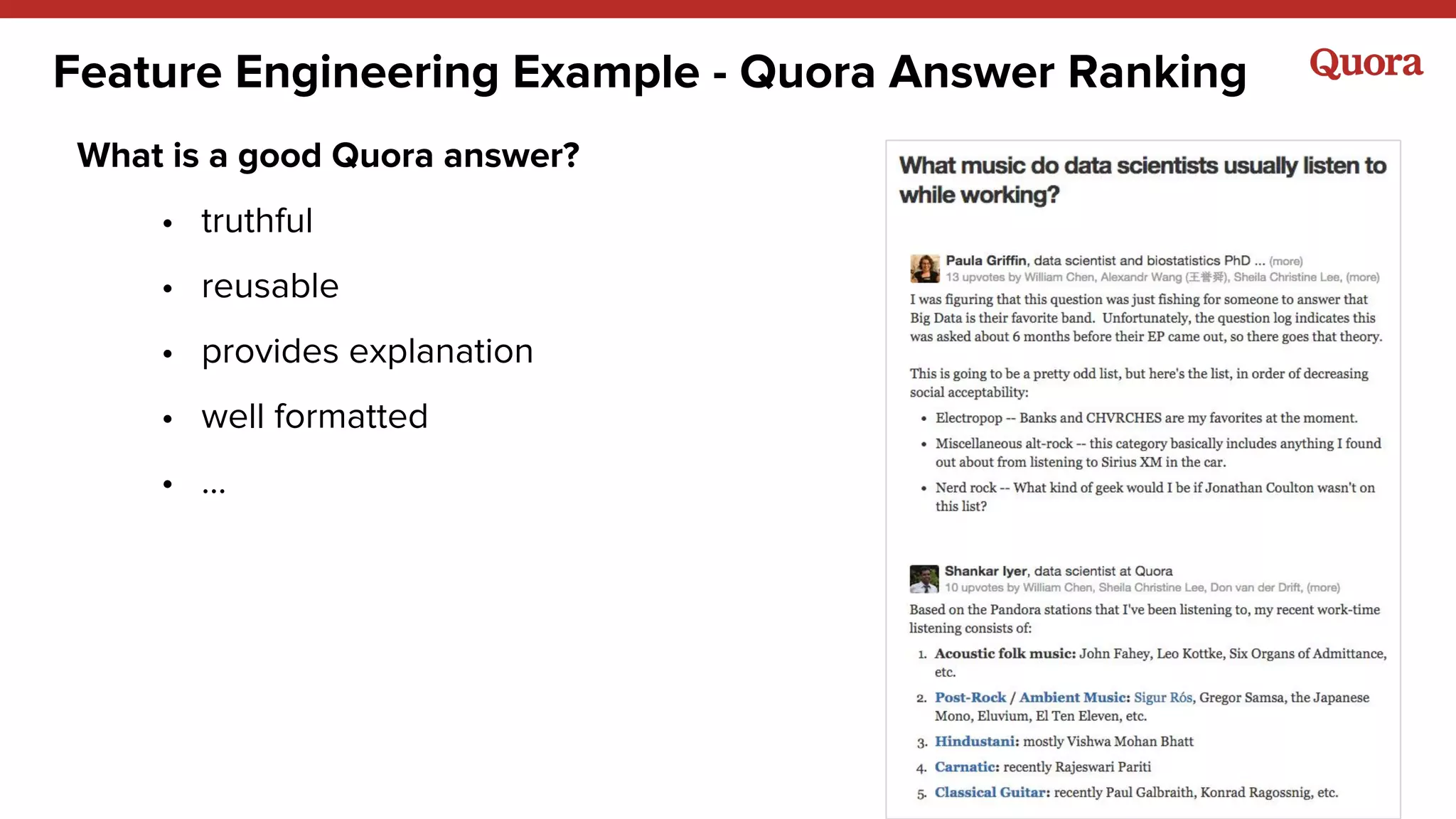
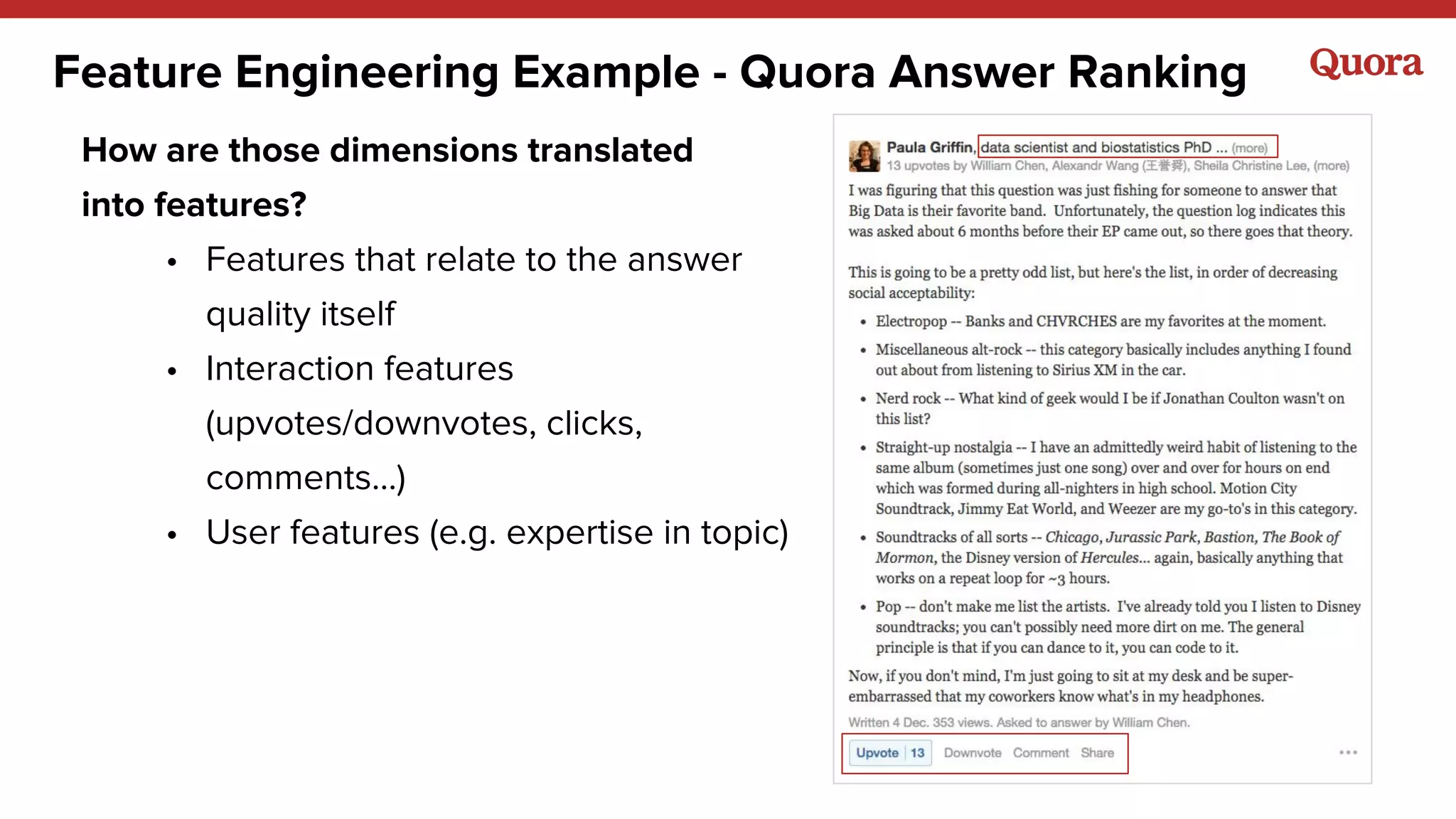
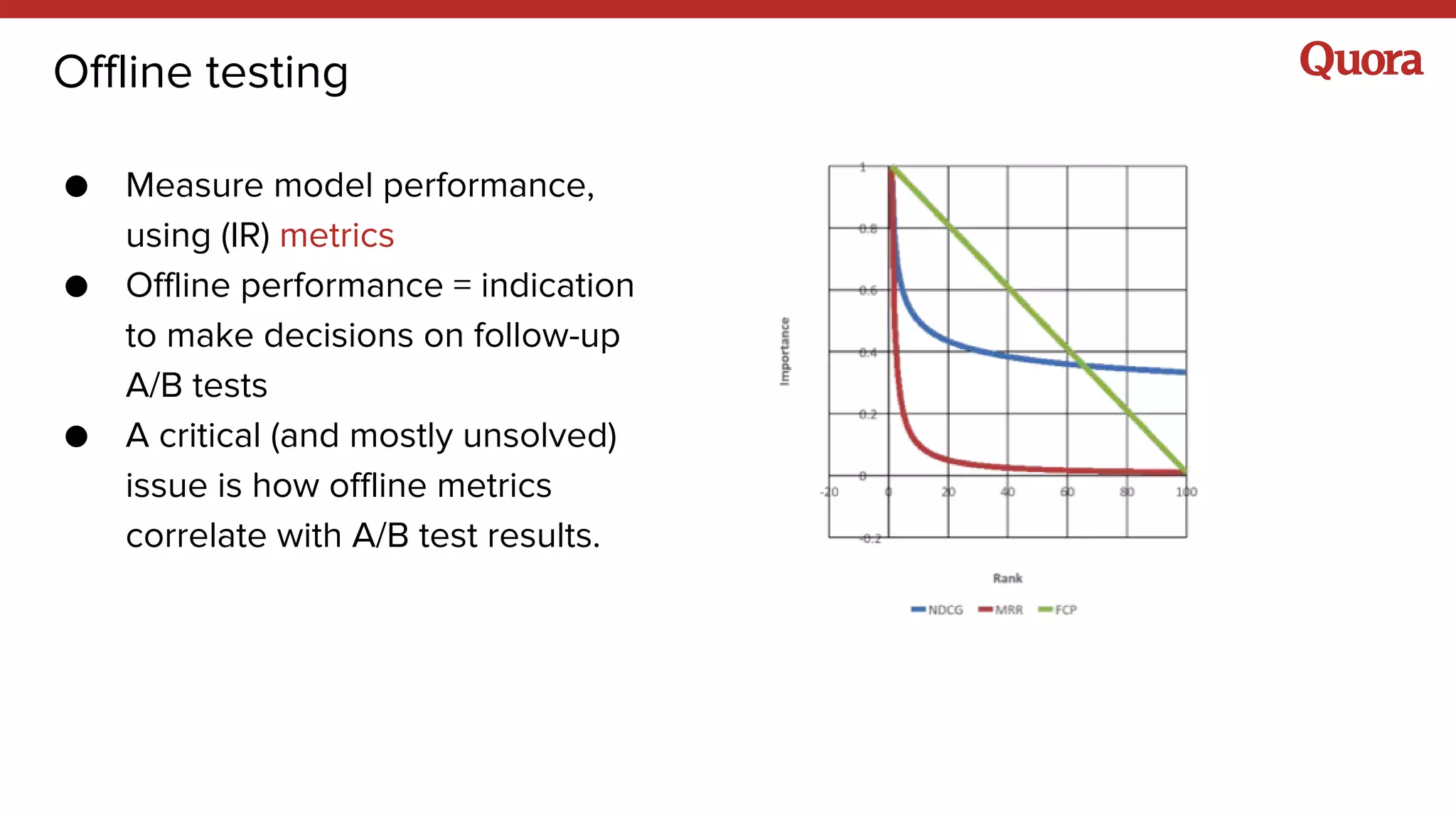
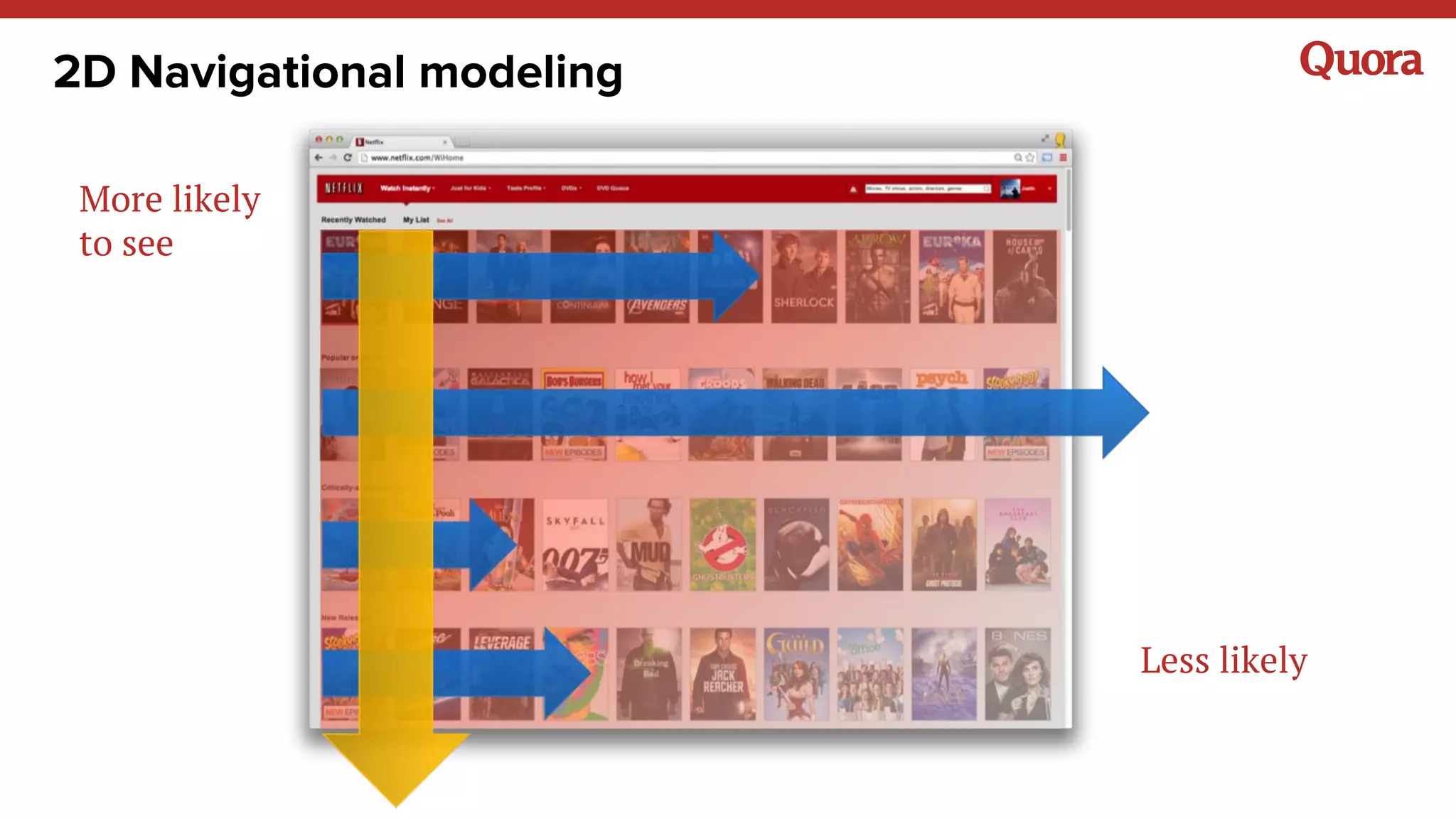
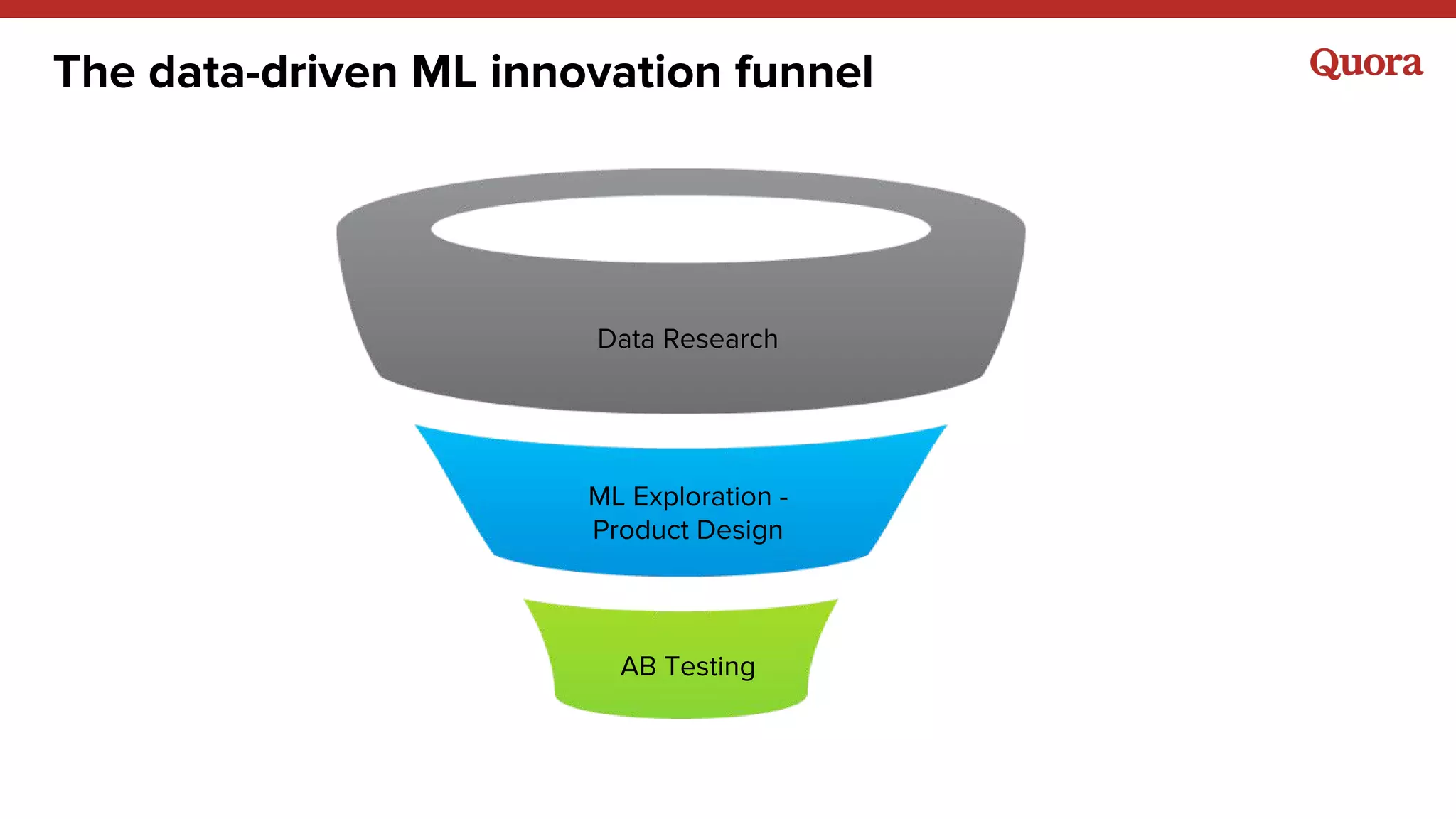
The document discusses various lessons learned from building machine learning systems, highlighting the balance between using more data versus better models, the importance of hyperparameter optimization, and the need for effective feature engineering. It emphasizes the utility of ensembles in model performance, the significance of implicit feedback, and the complexities of defining training data. Furthermore, it outlines the roles of data scientists and ML engineers in the innovation funnel, stressing the importance of collaboration in data-driven ML projects.






![Machine learning the high interest credit card of technical debt [PWL]](https://cdn.slidesharecdn.com/ss_thumbnails/machinelearning-thehighinterestcardoftechnicaldebtmeetup1-160911083514-thumbnail.jpg?width=640&height=640&fit=bounds)












































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)

