Download as PDF, PPTX

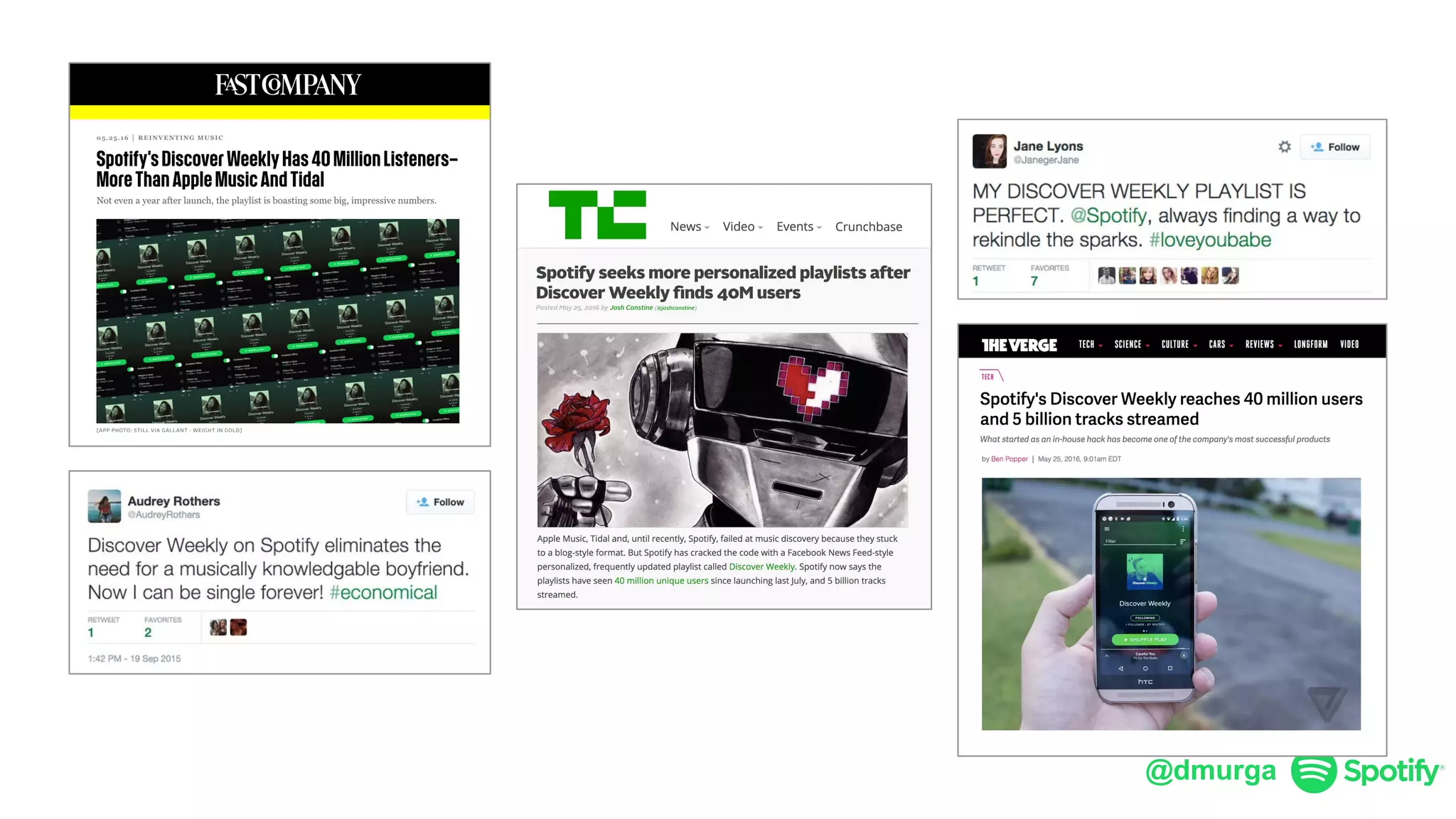
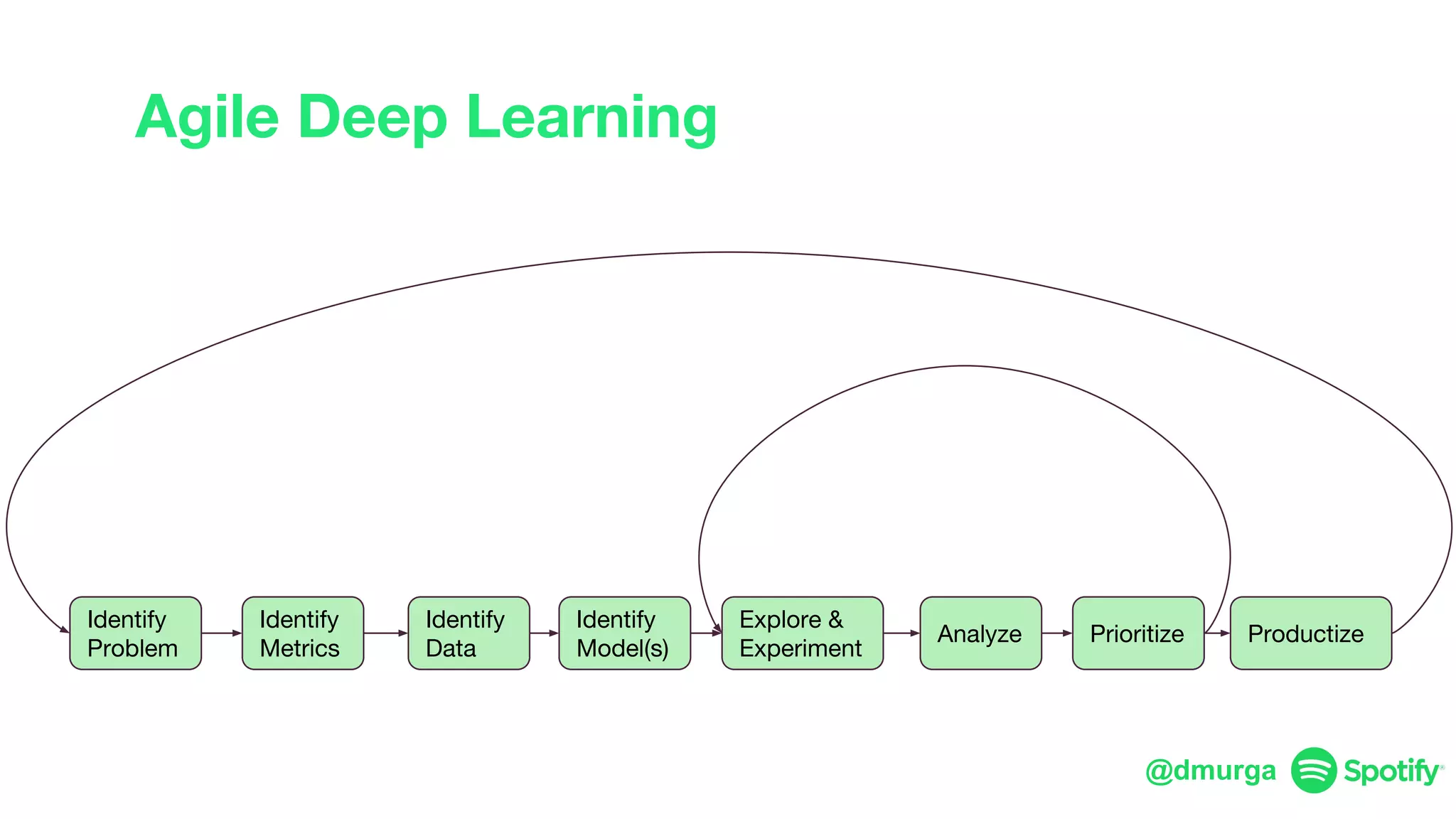
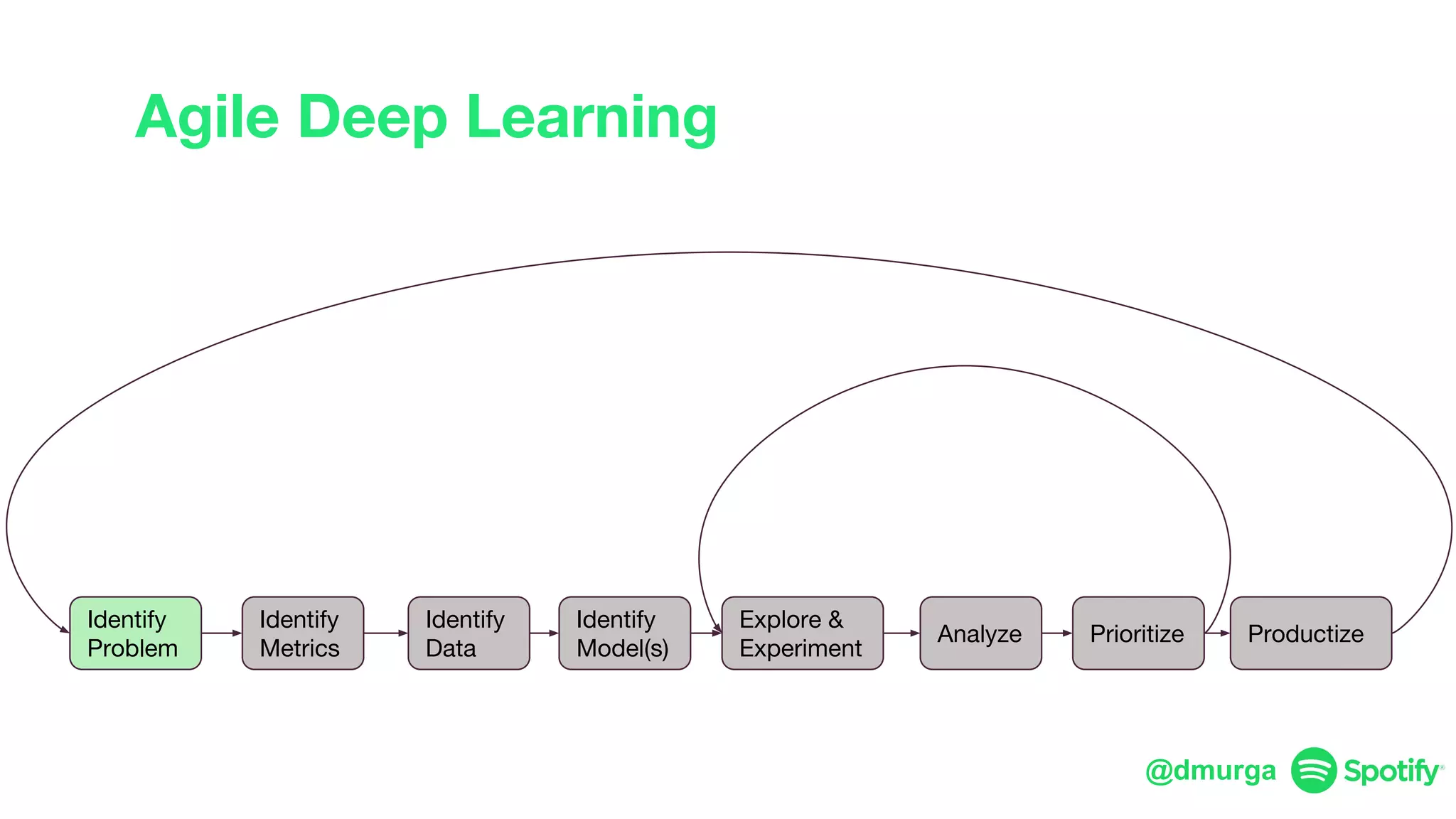



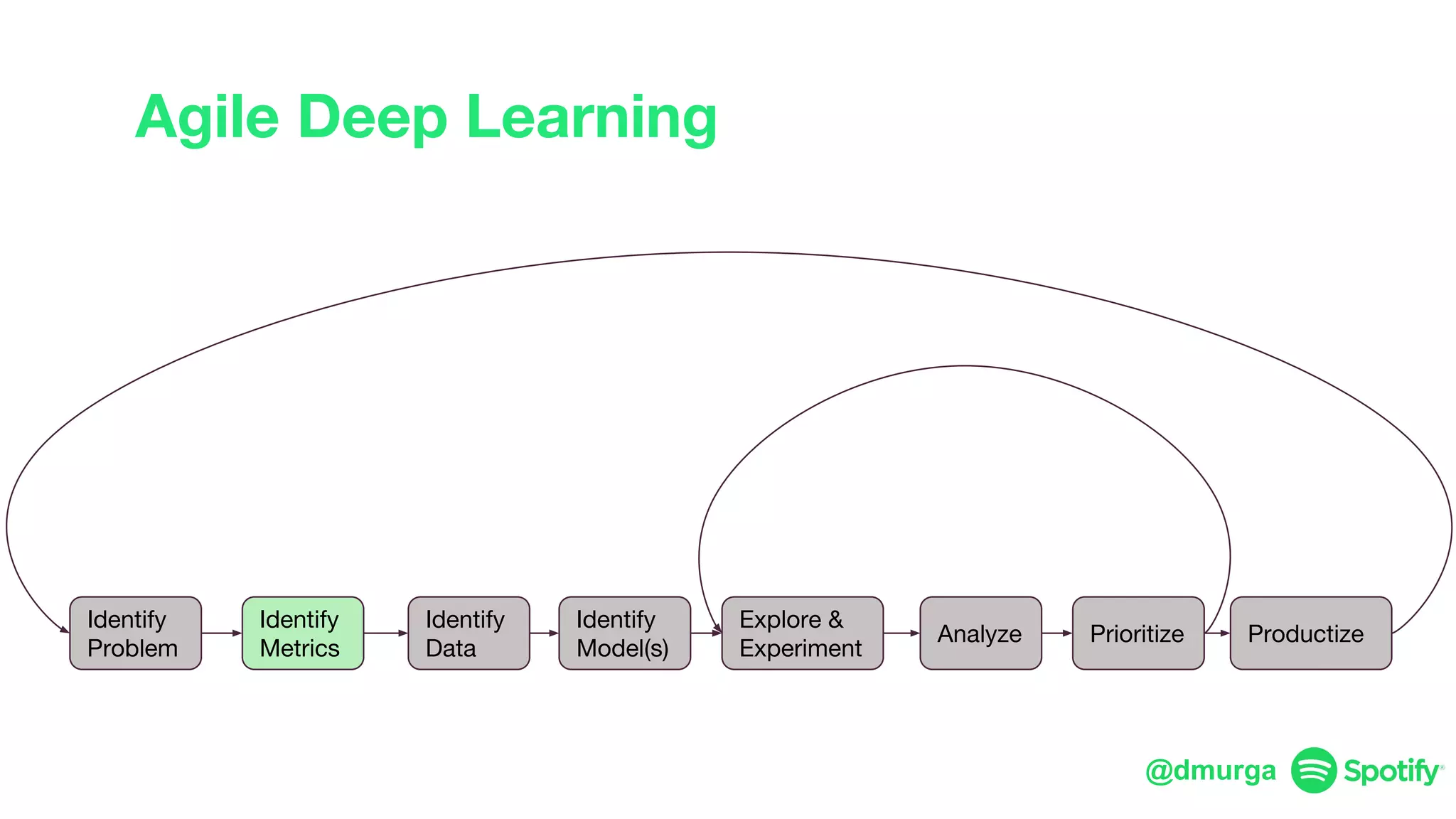



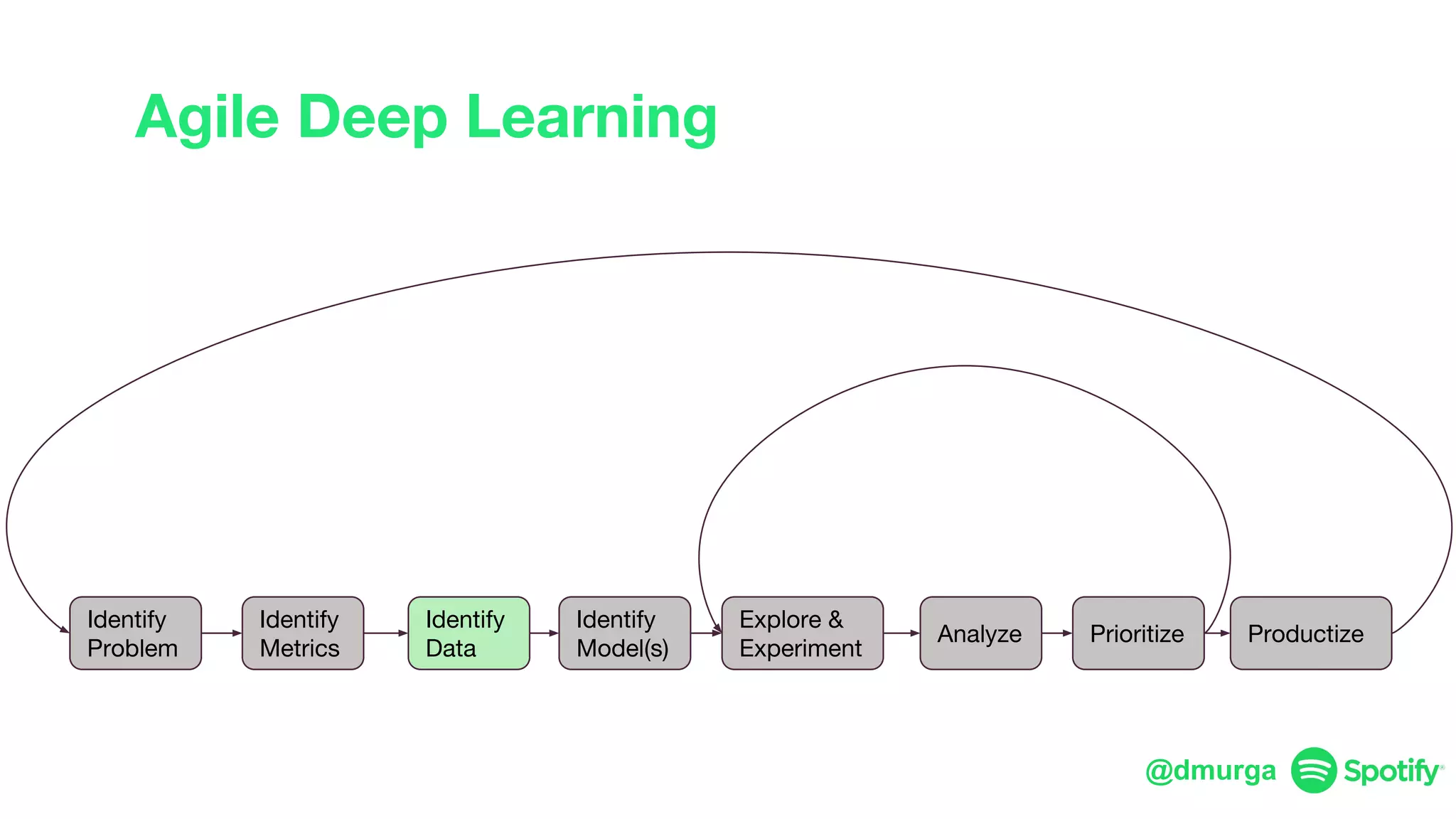




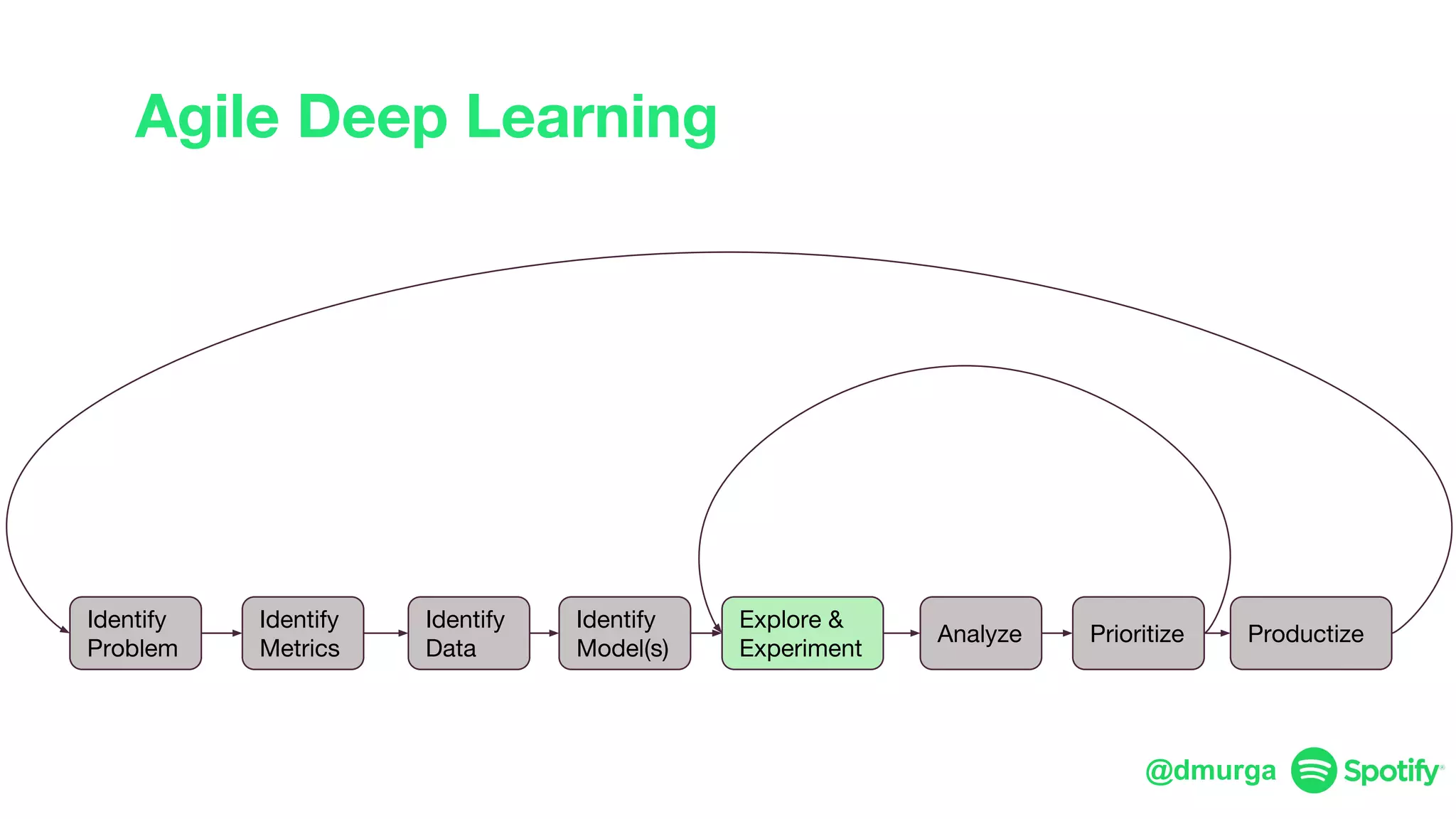



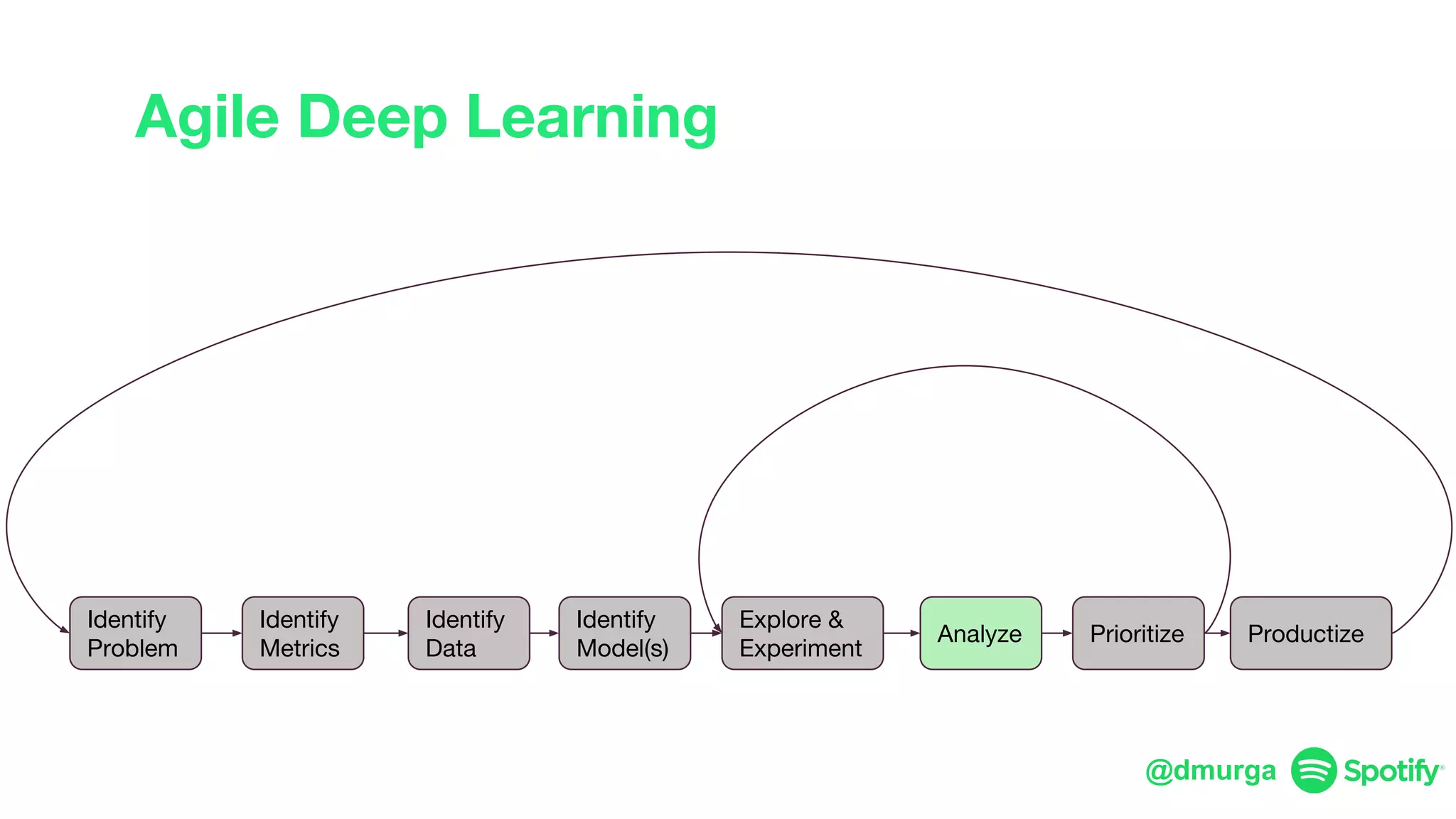


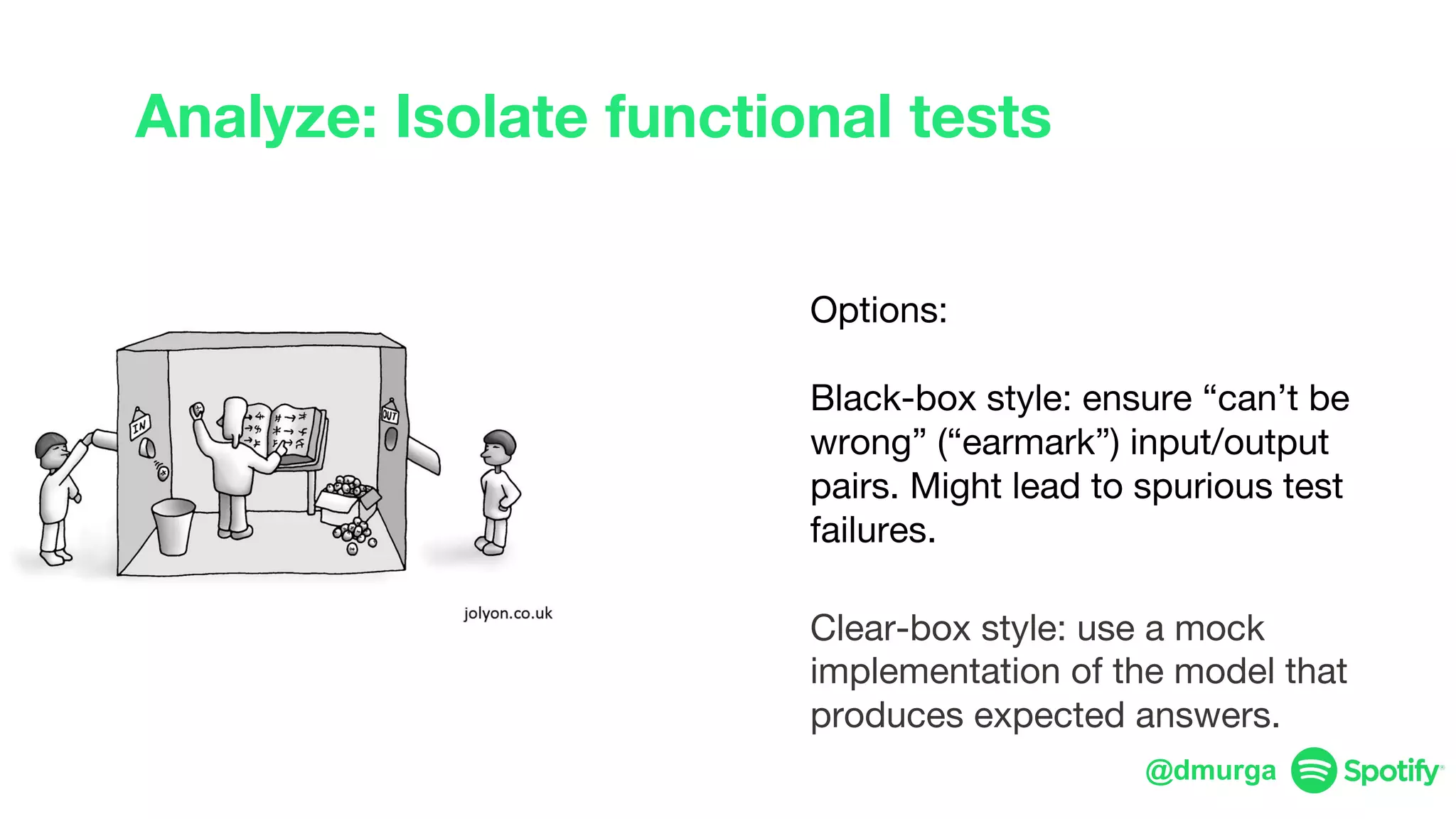

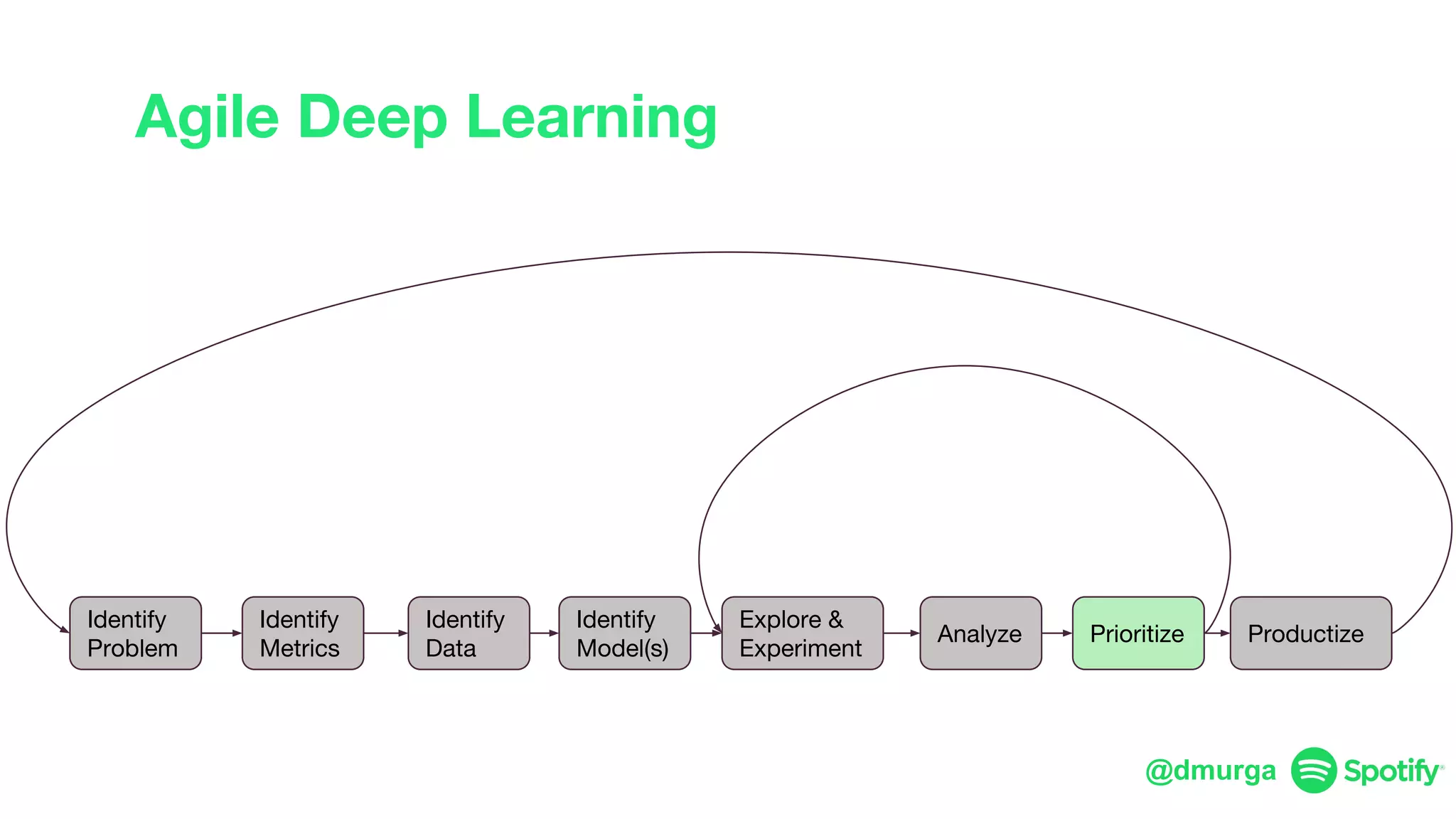
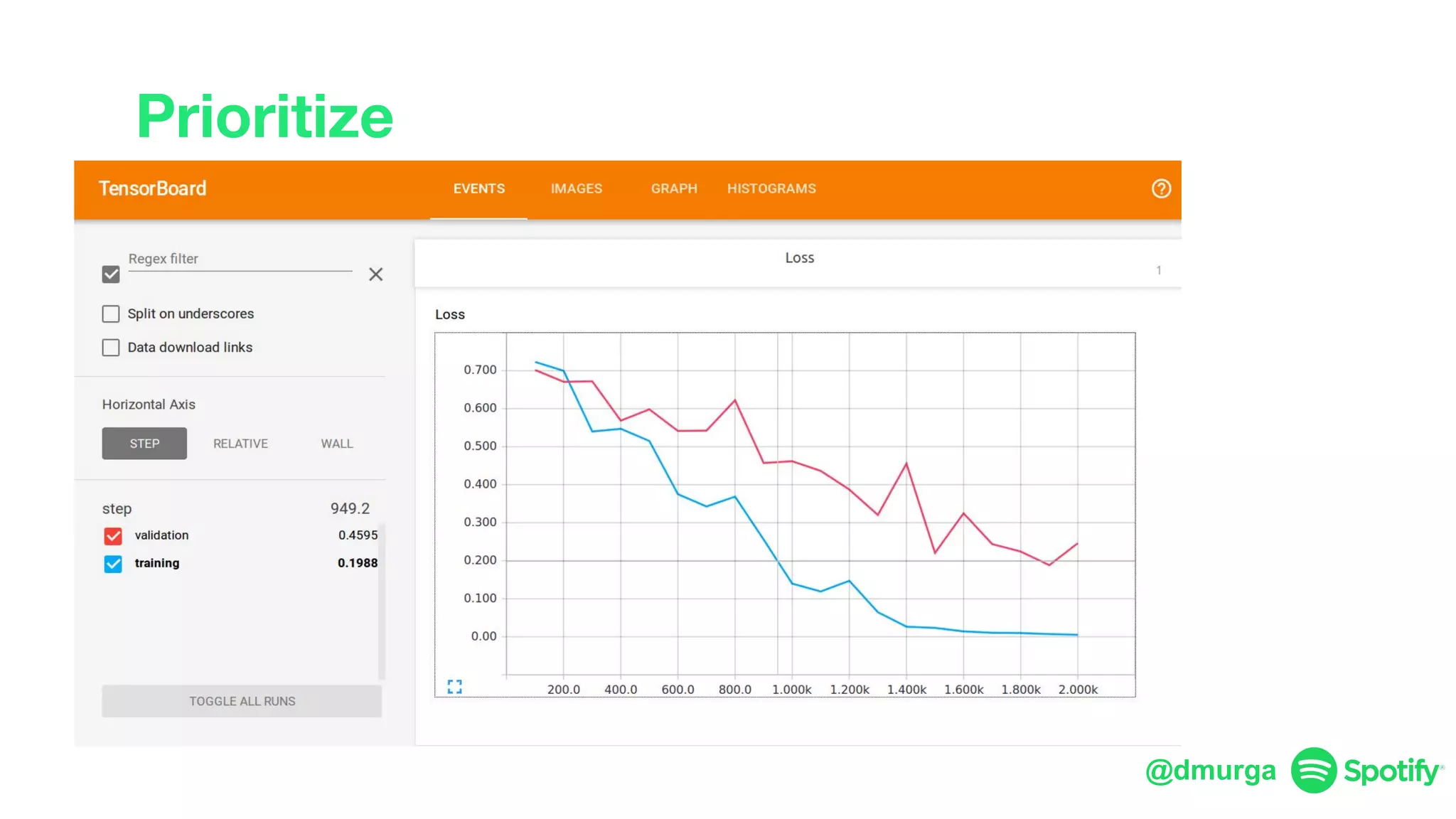
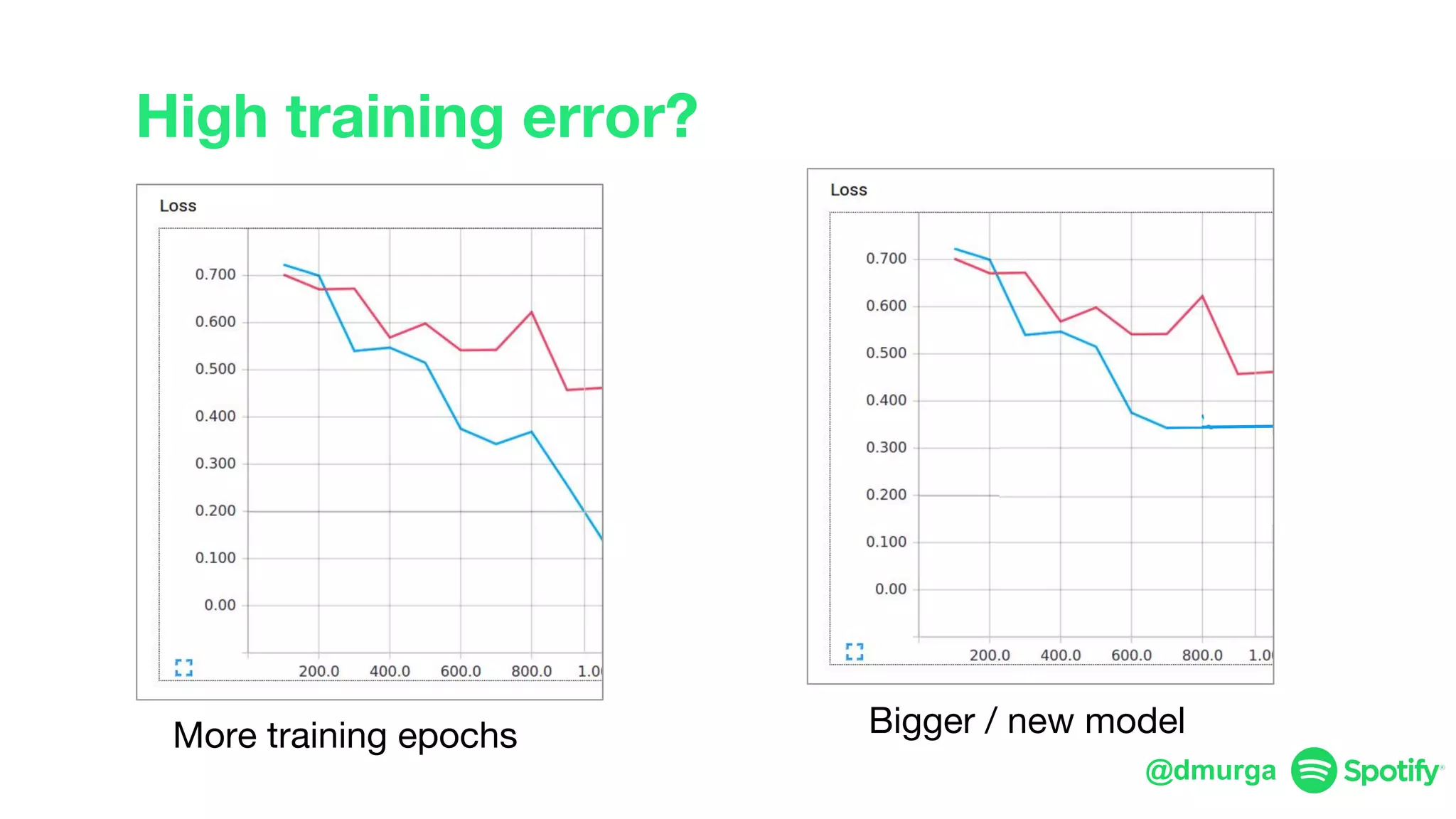
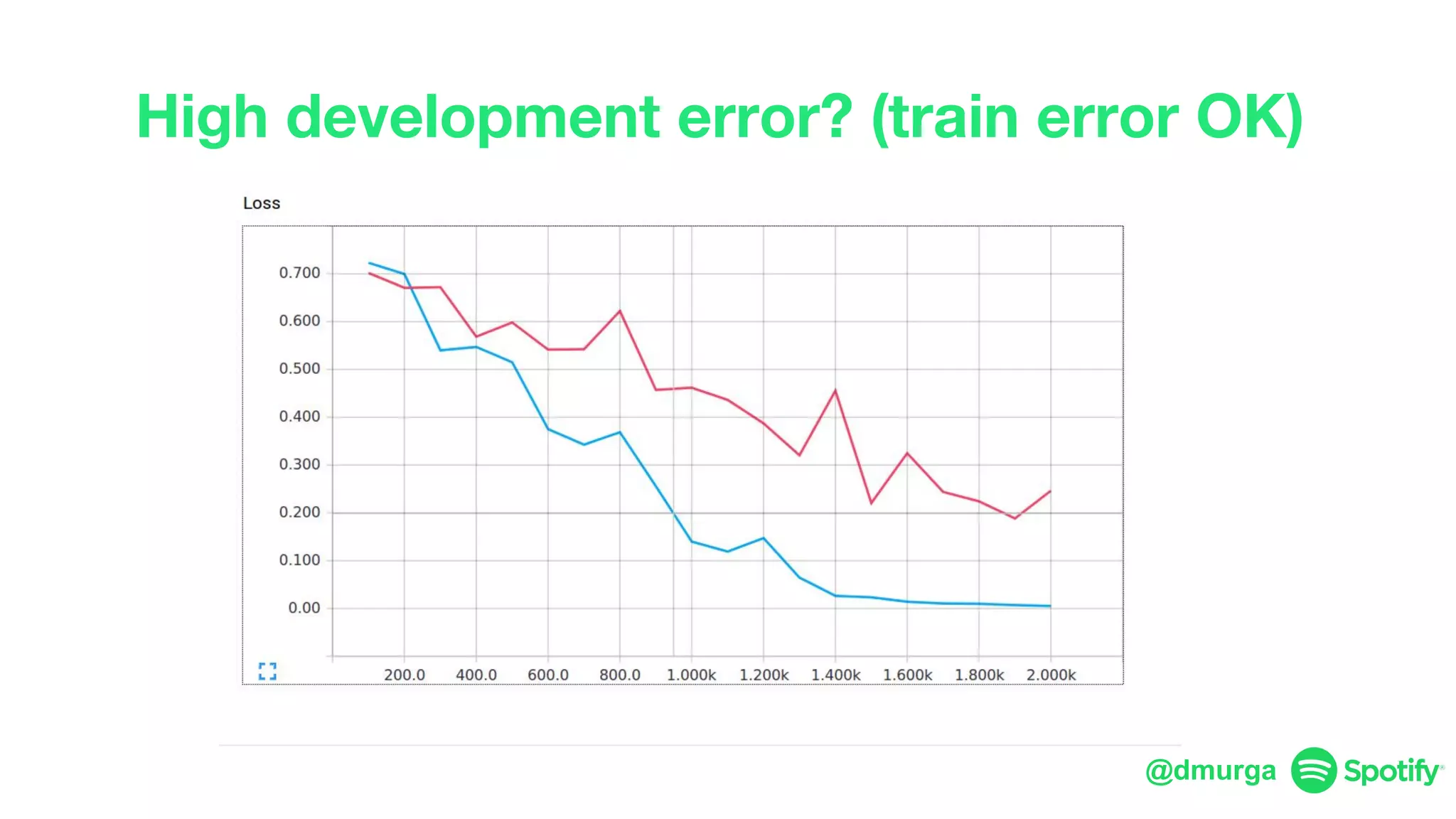


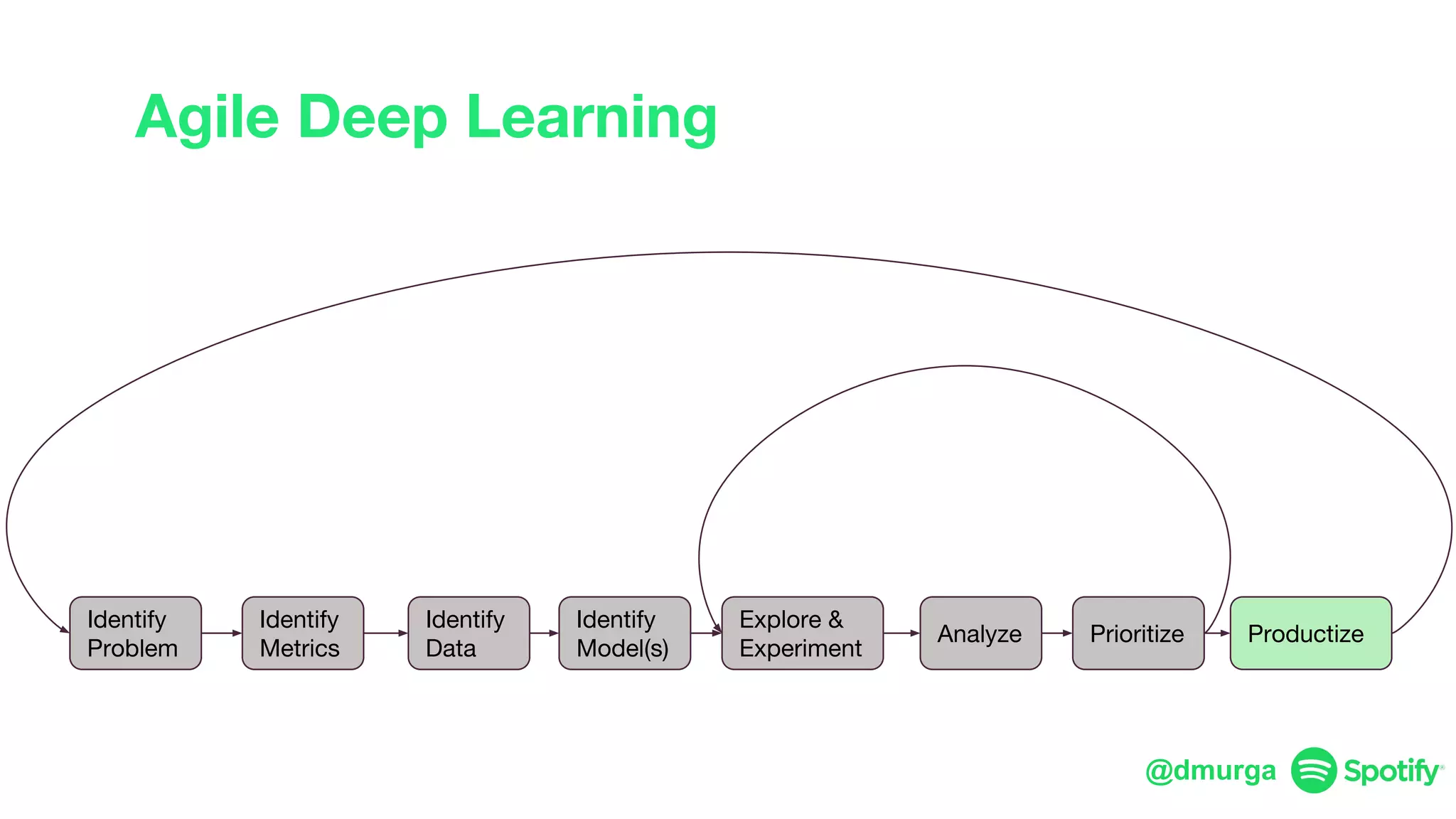



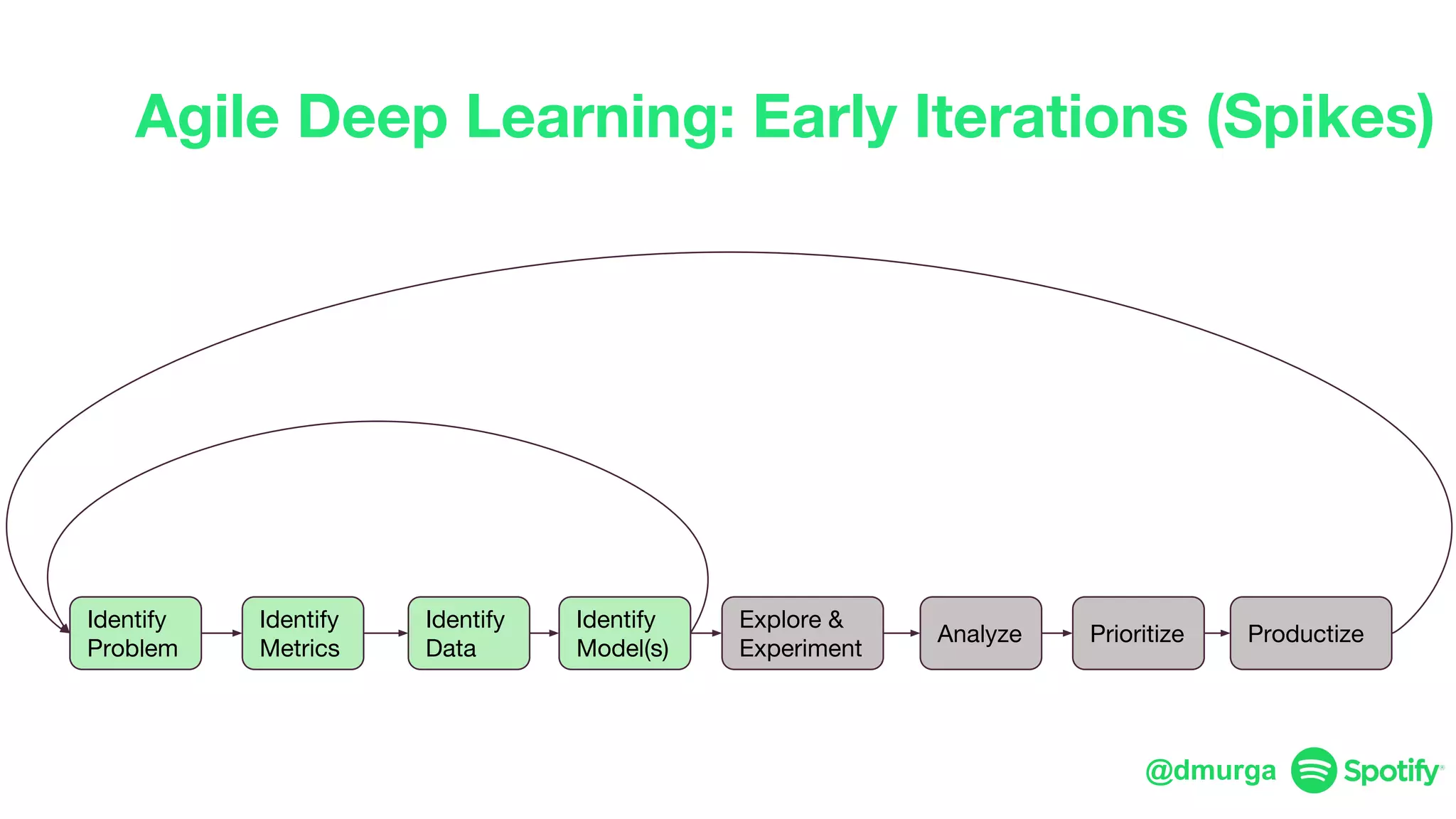
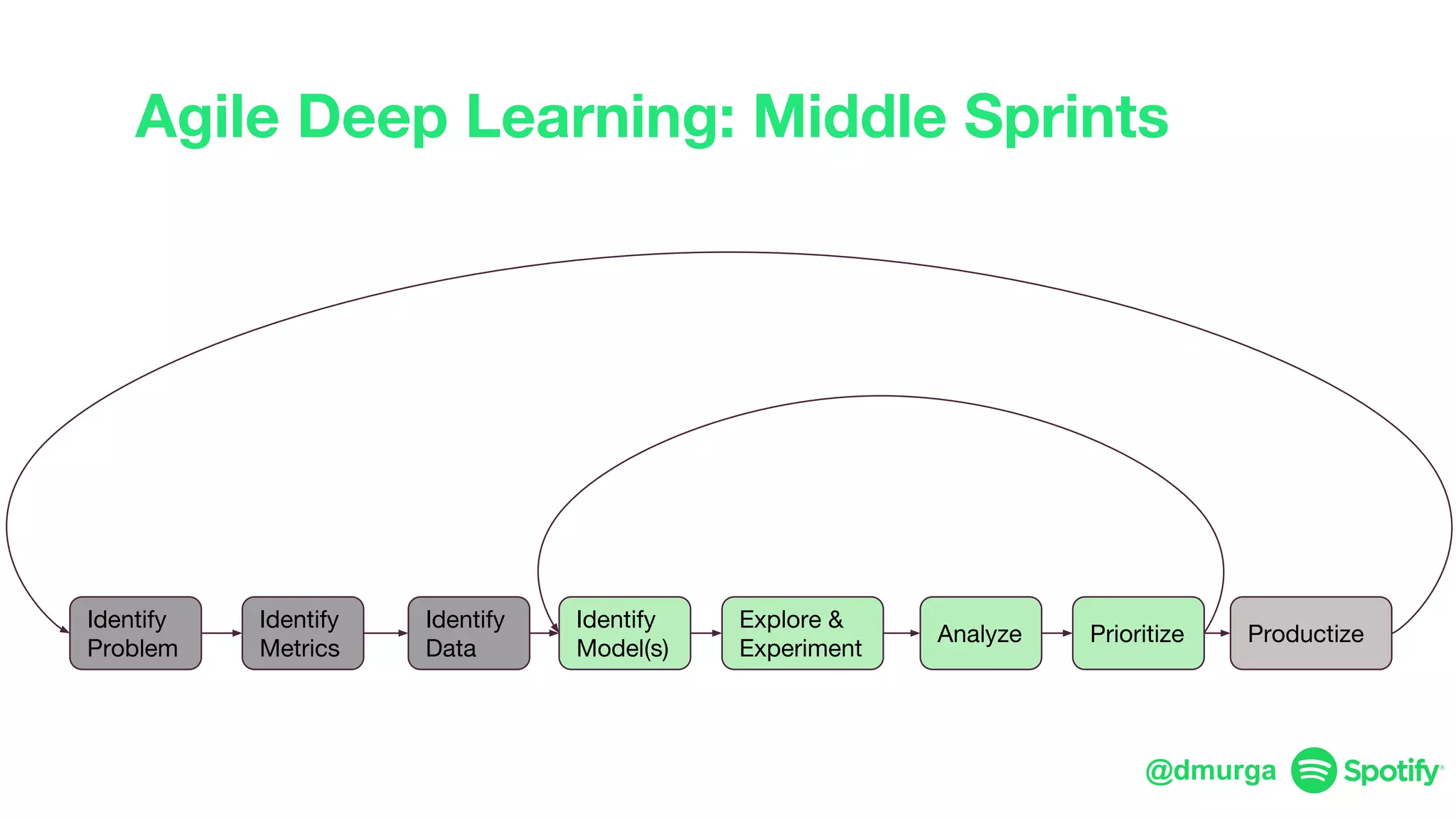
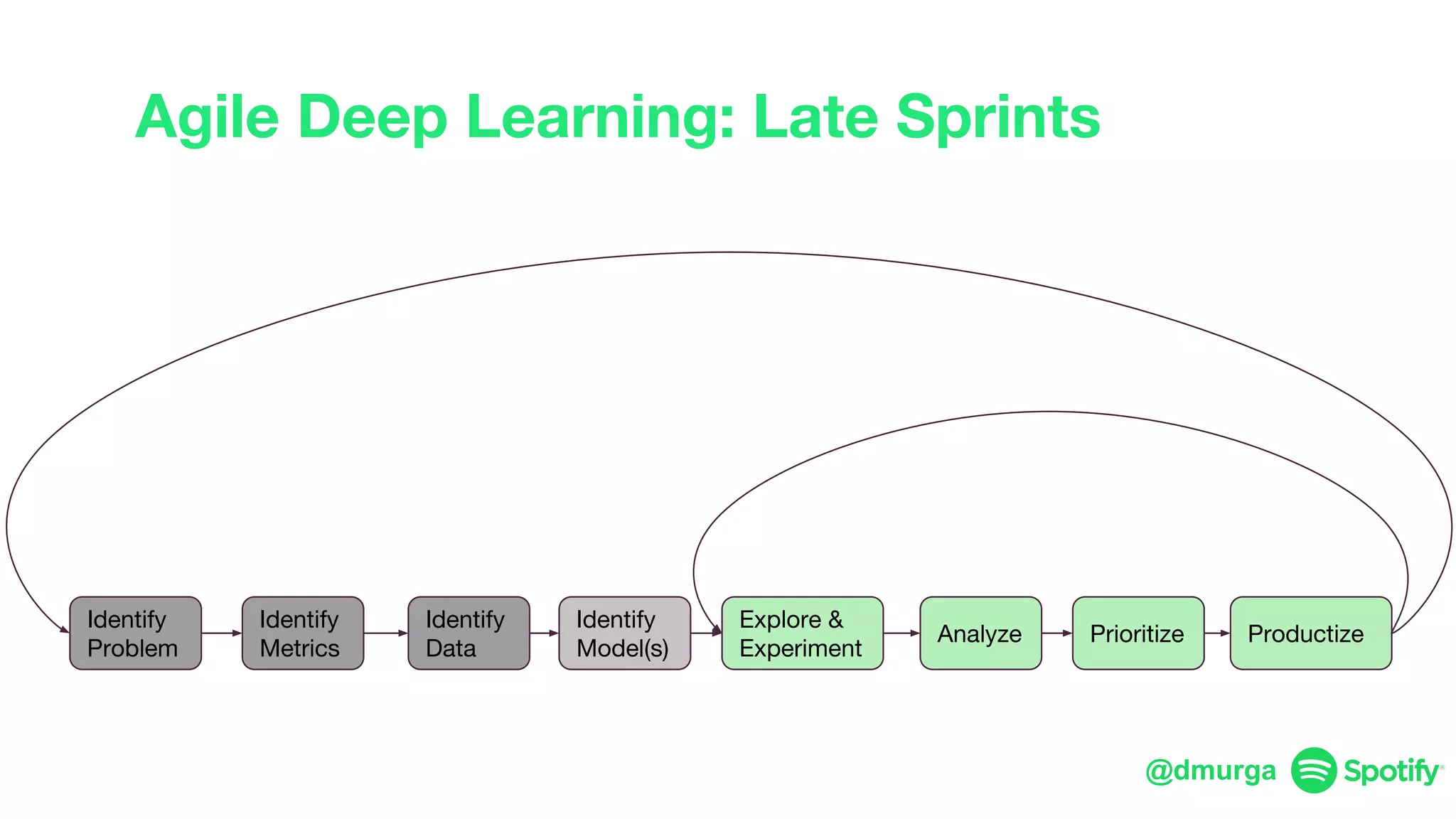
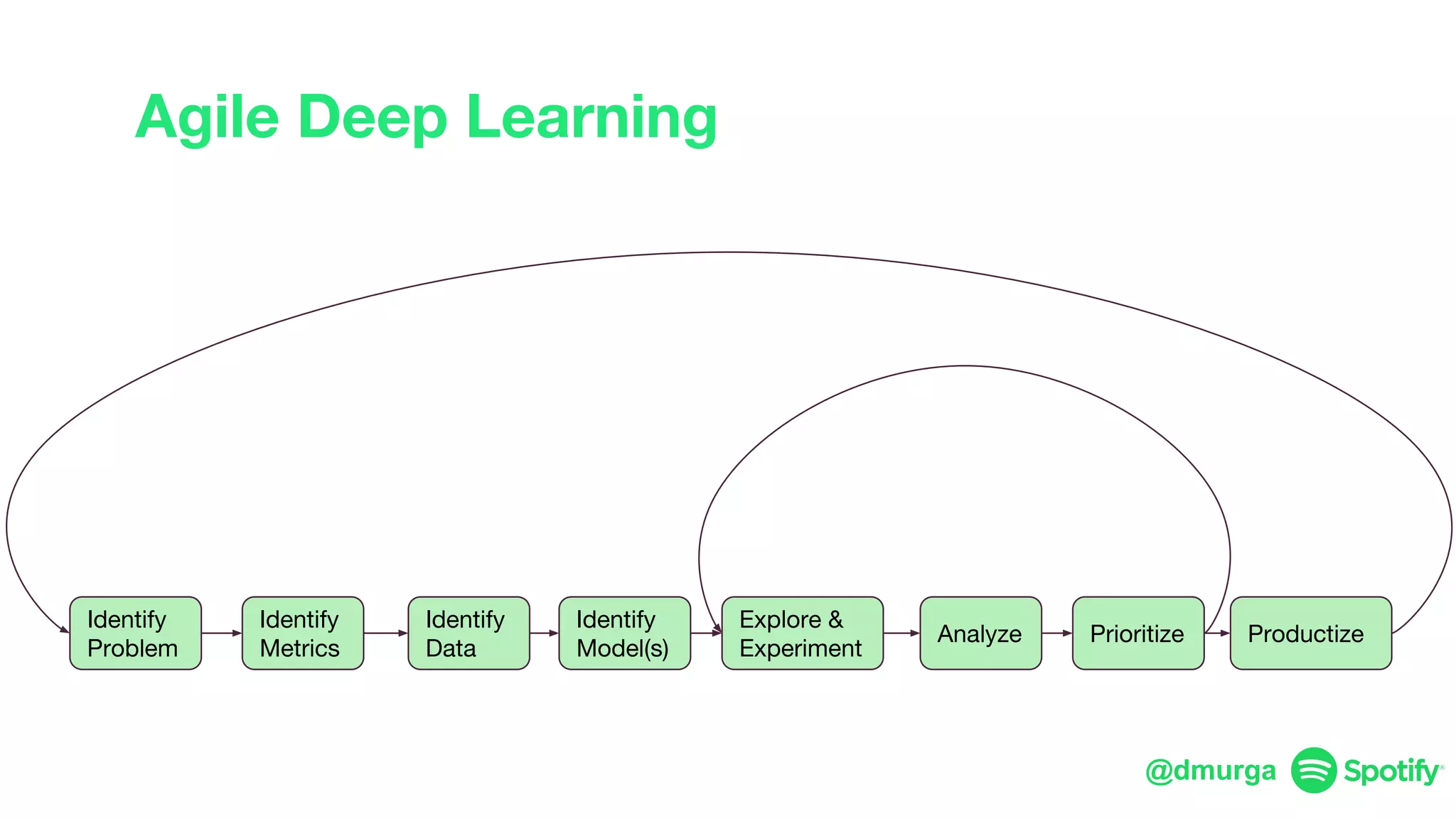



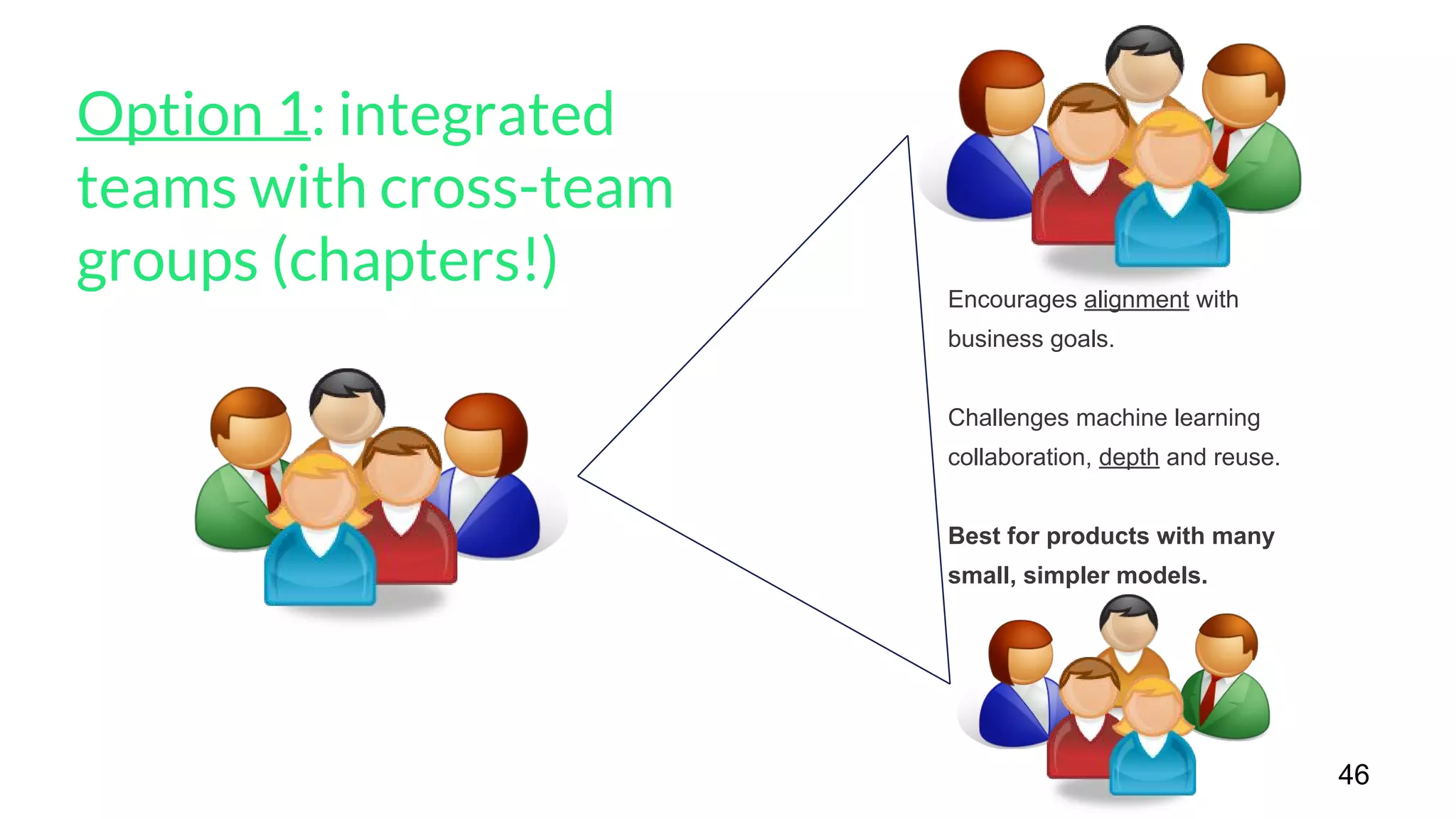
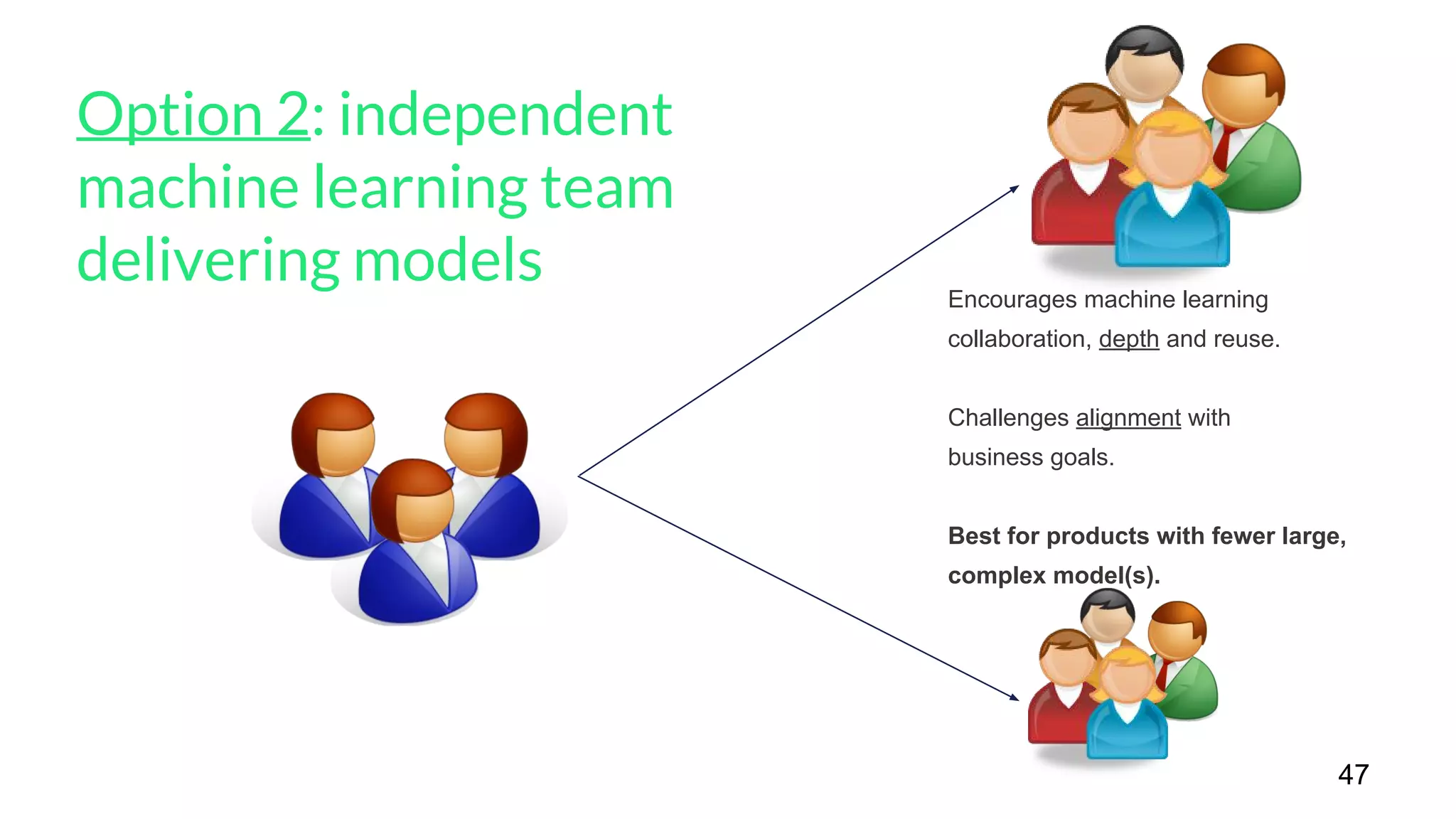


































































The document outlines a framework for agile deep learning that includes identifying problems, metrics, data, models, exploring, experimenting, analyzing, and productizing solutions. It emphasizes the importance of automation in tasks that can be completed by a human in under a second and provides strategies for data management and model training. Additionally, it discusses team organization in machine learning, suggesting different configurations based on the complexity of models and alignment with business goals.












































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)



