Download as PDF, PPTX




















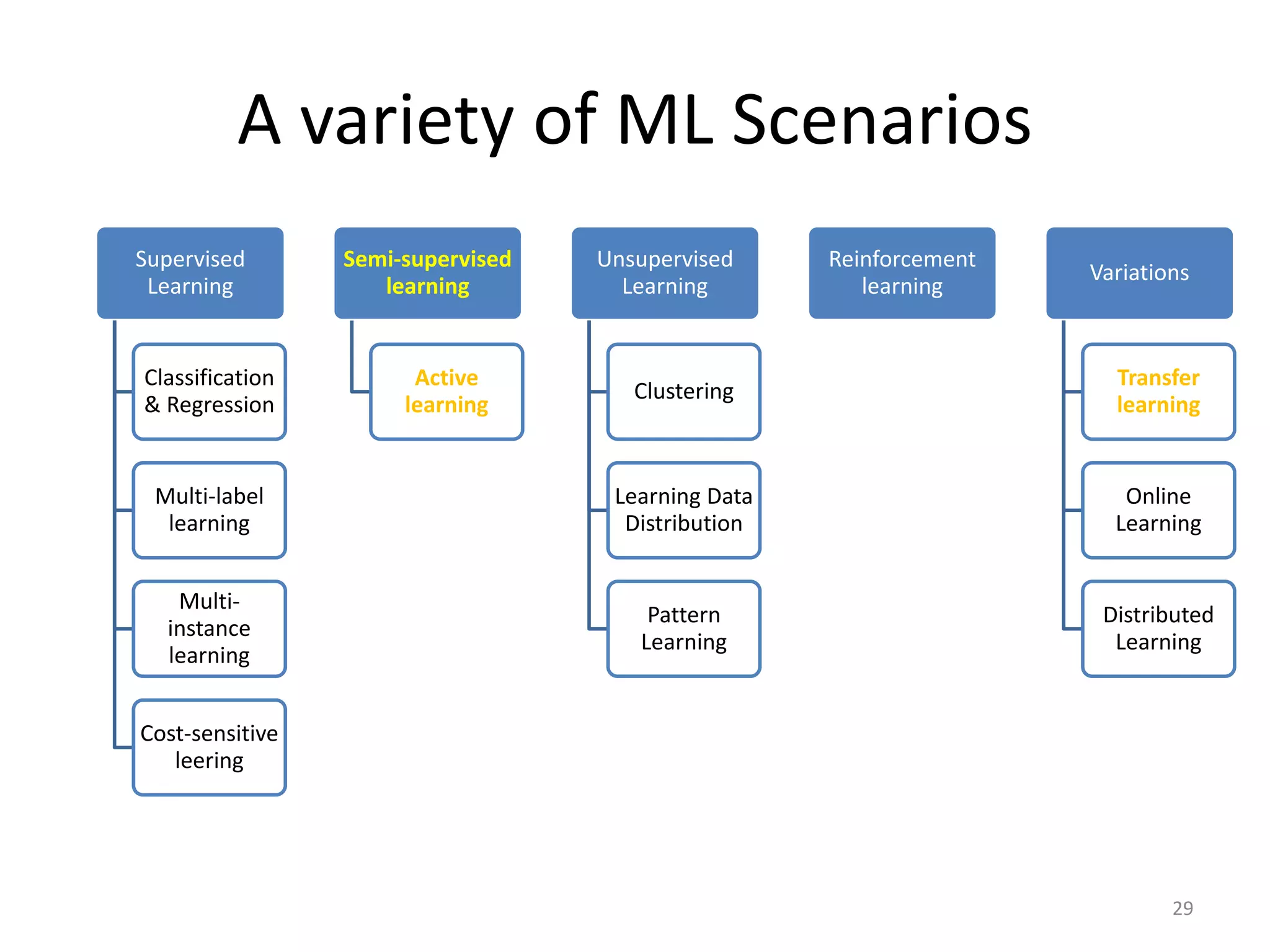
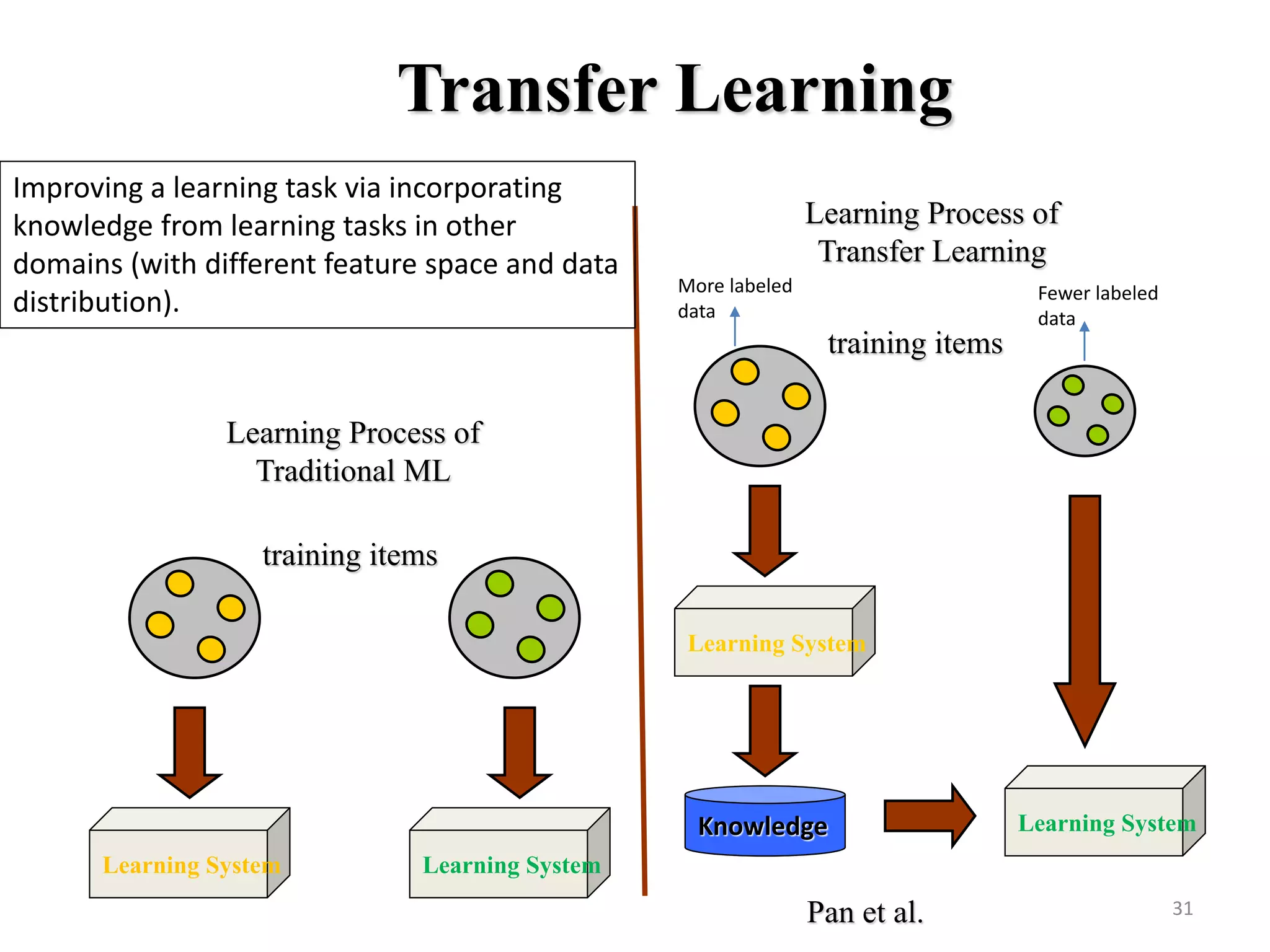
![Semi-supervised Learning
• Only a small
portion of data
are annotated
(usually due to
high annotation
cost)
• Leverage the
unlabeled data
for better
performance
[Zhu2008]
30](https://image.slidesharecdn.com/random-160717040825/75/Practical-Issues-in-Machine-Learning-29-2048.jpg)













































![Semi-supervised Learning
• Only a small
portion of data
are annotated
(usually due to
high annotation
cost)
• Leverage the
unlabeled data
for better
performance
[Zhu2008]
30](https://crownmelresort.com/image.slidesharecdn.com/random-160717040825/75/Practical-Issues-in-Machine-Learning-29-2048.jpg)



























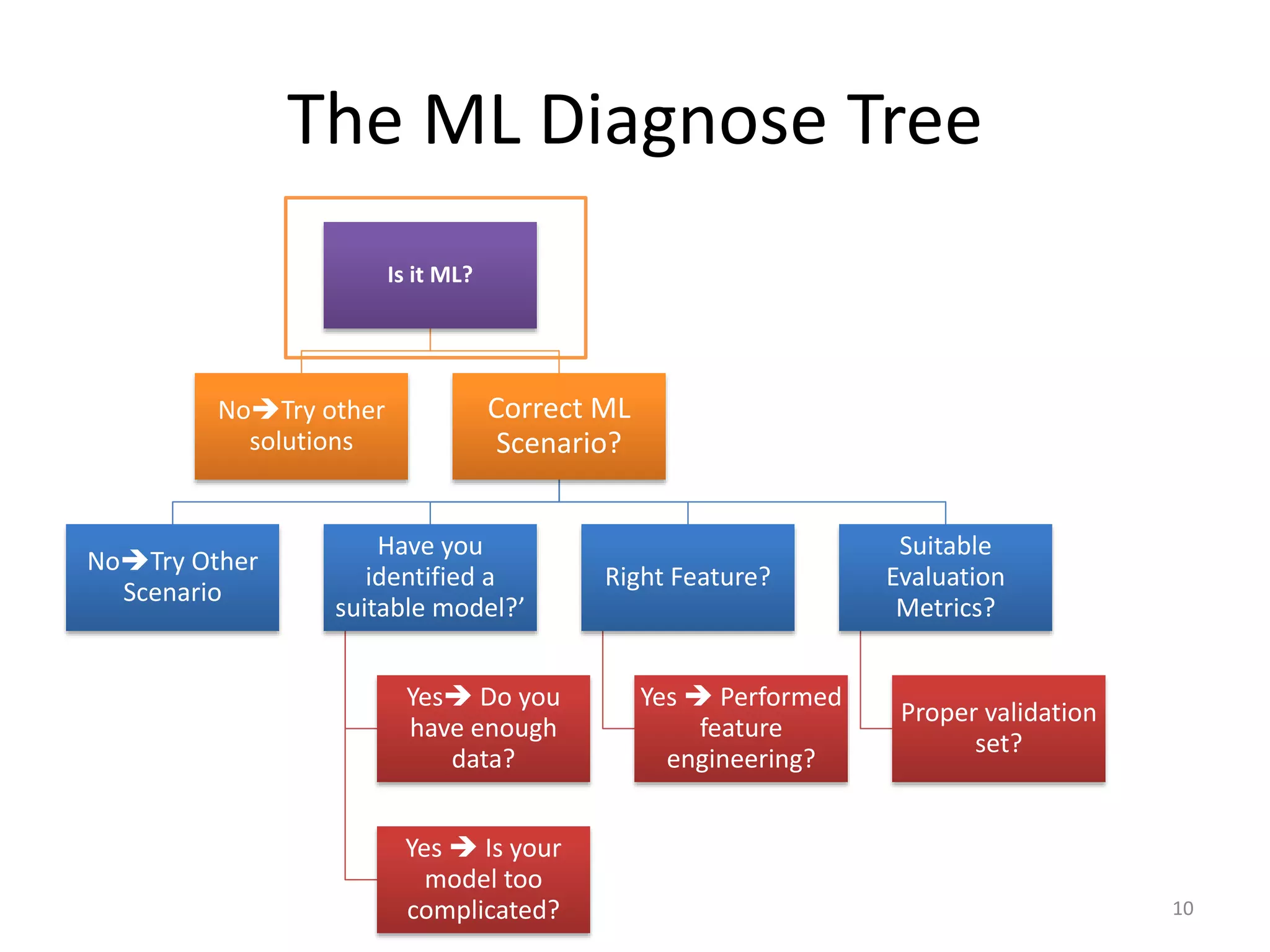
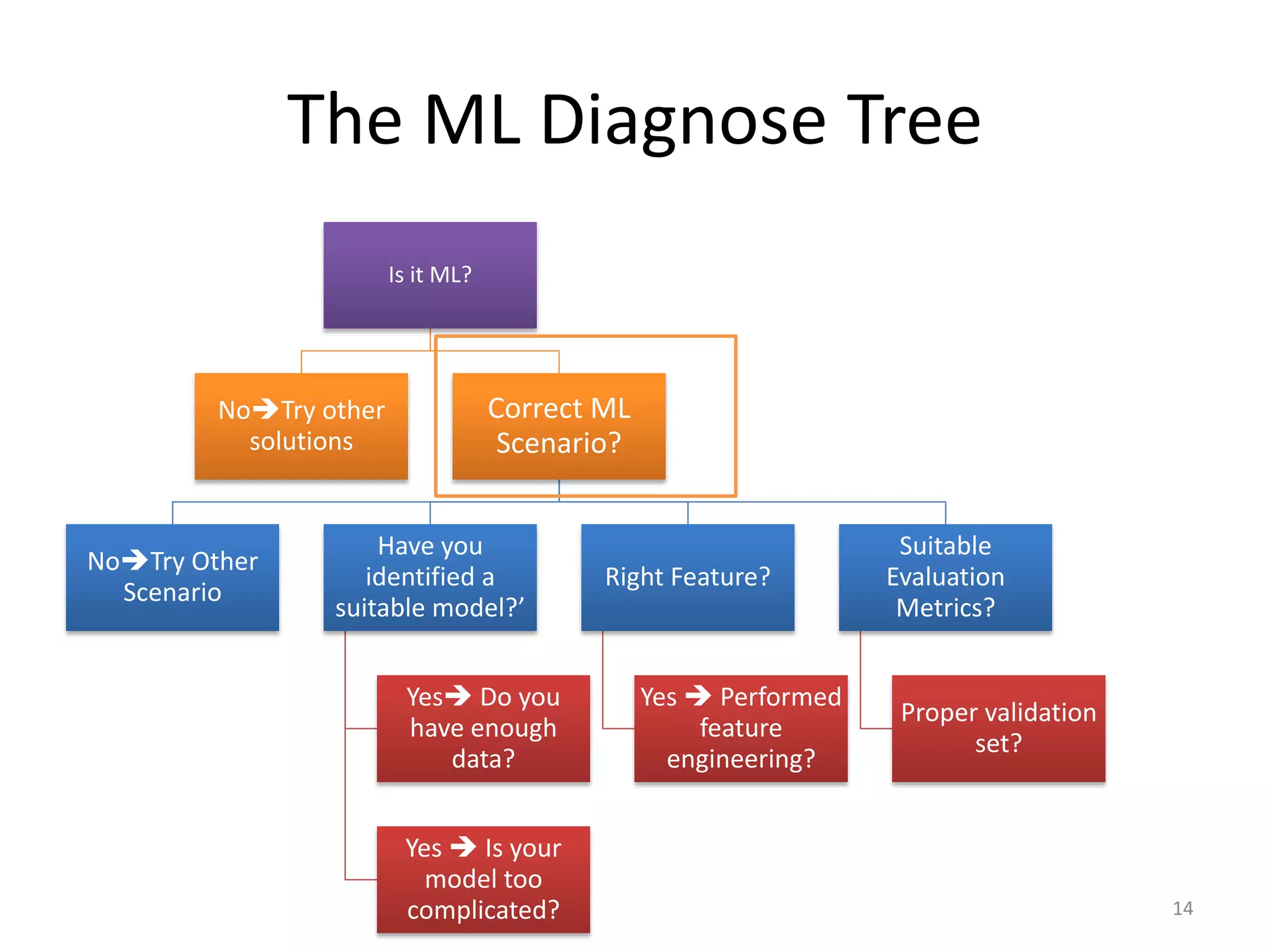
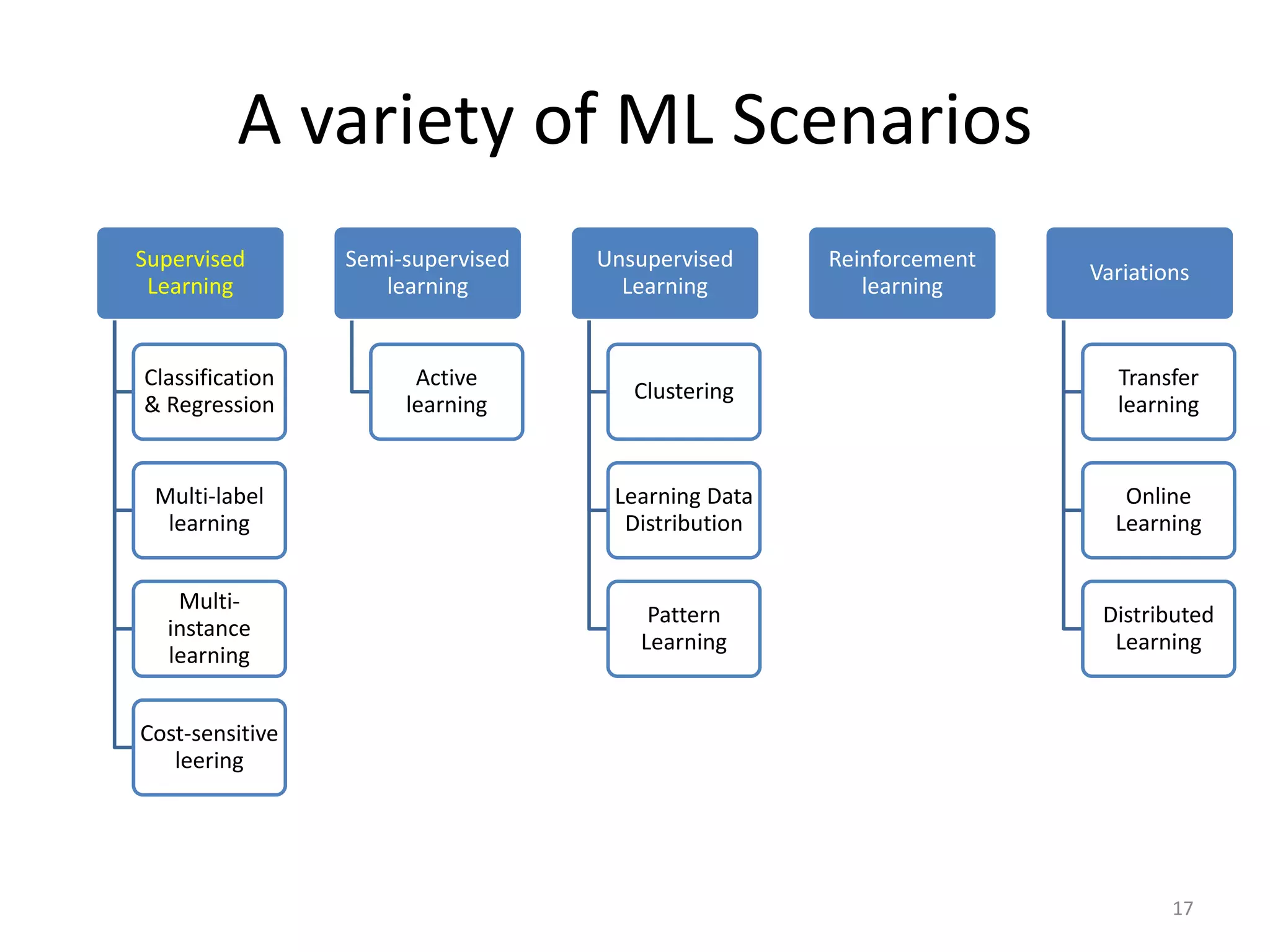
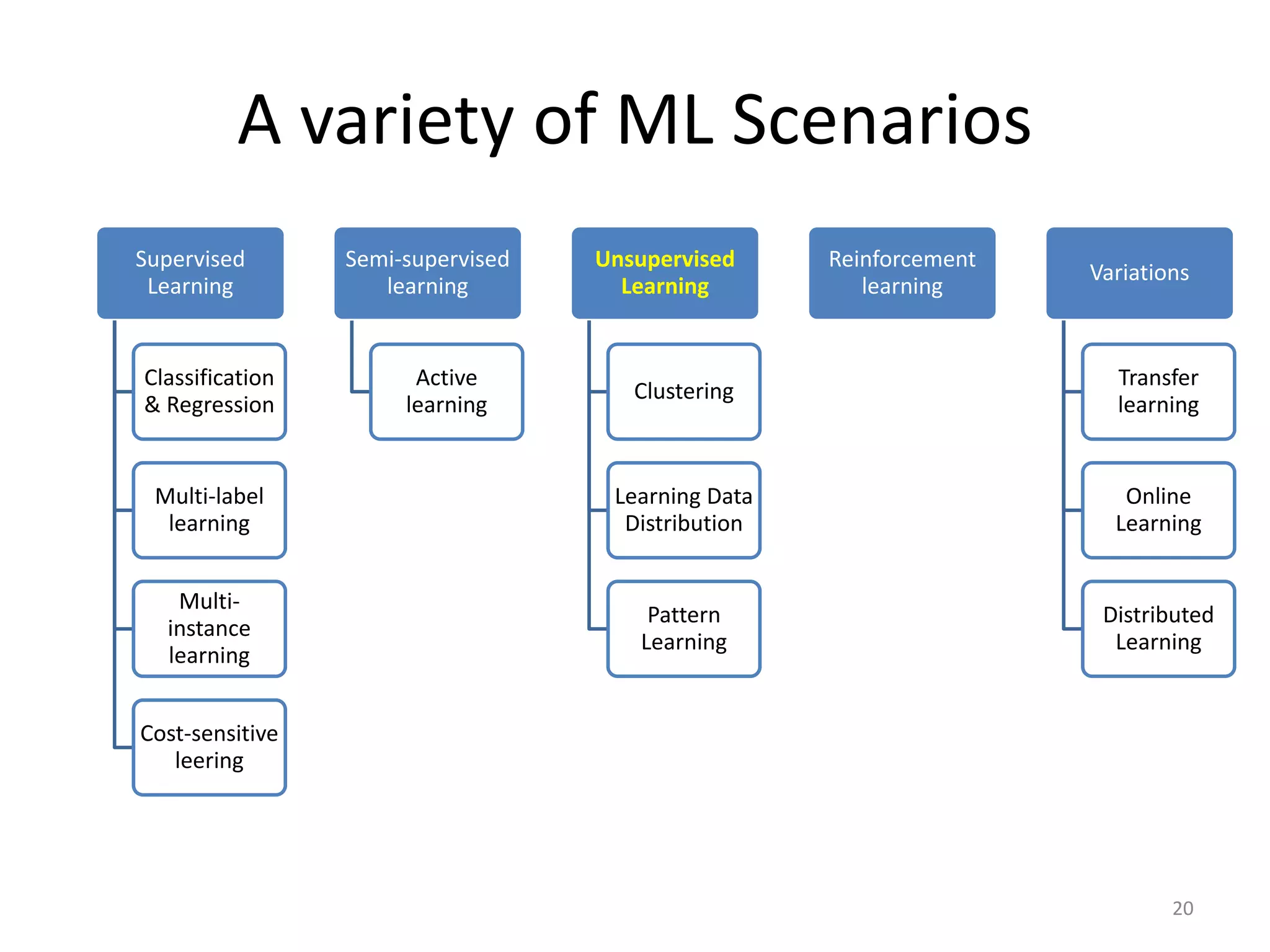
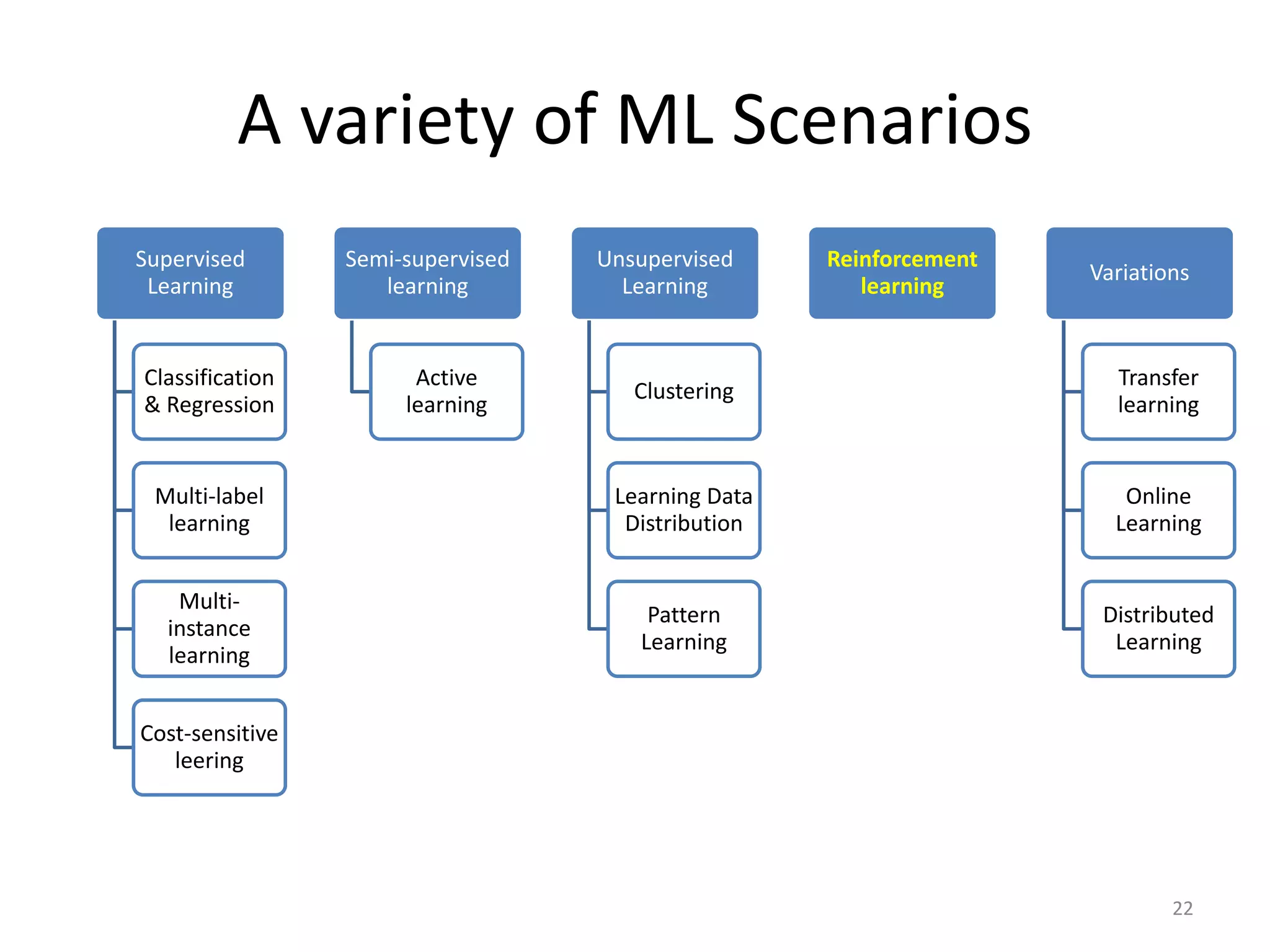
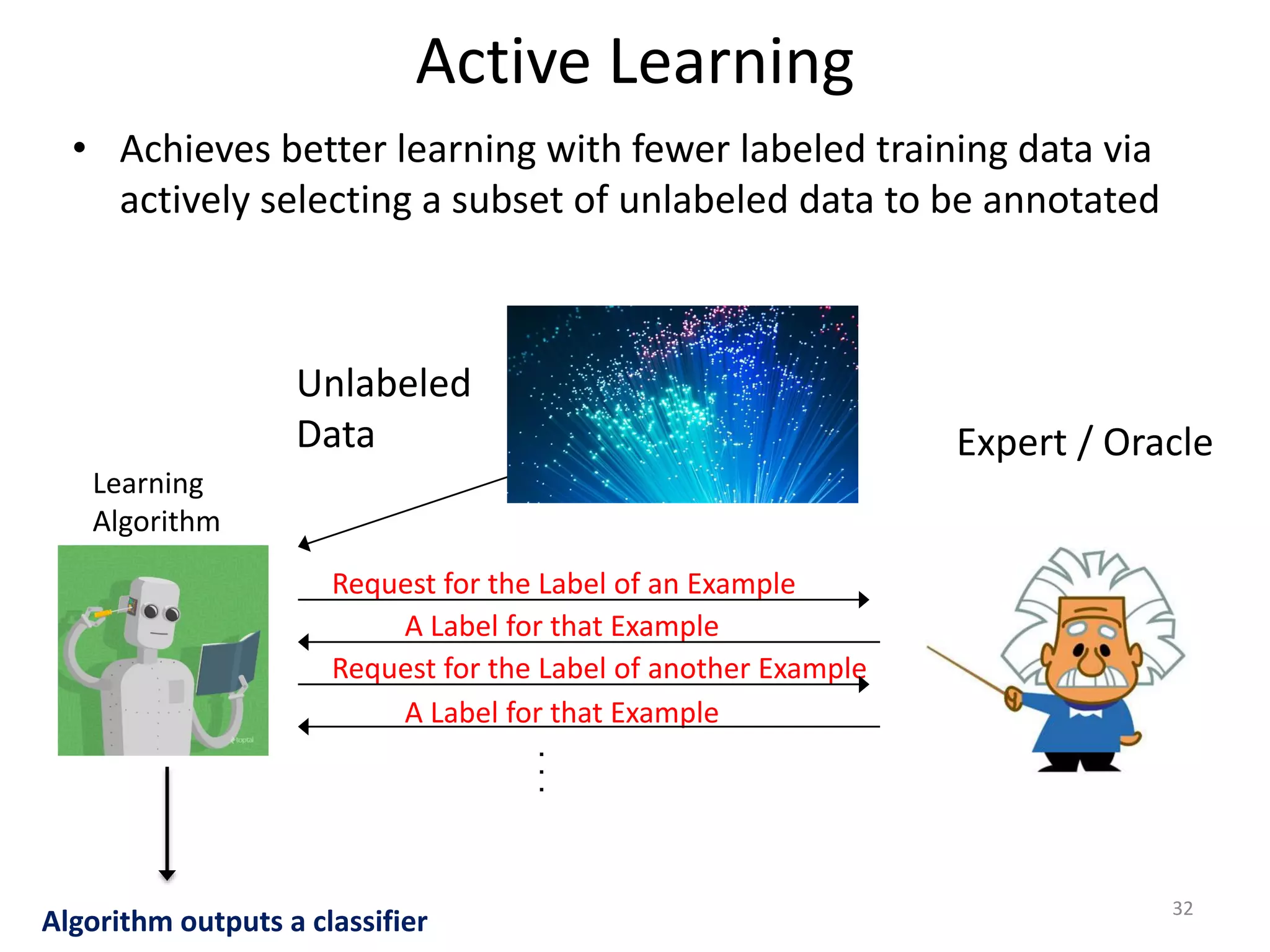
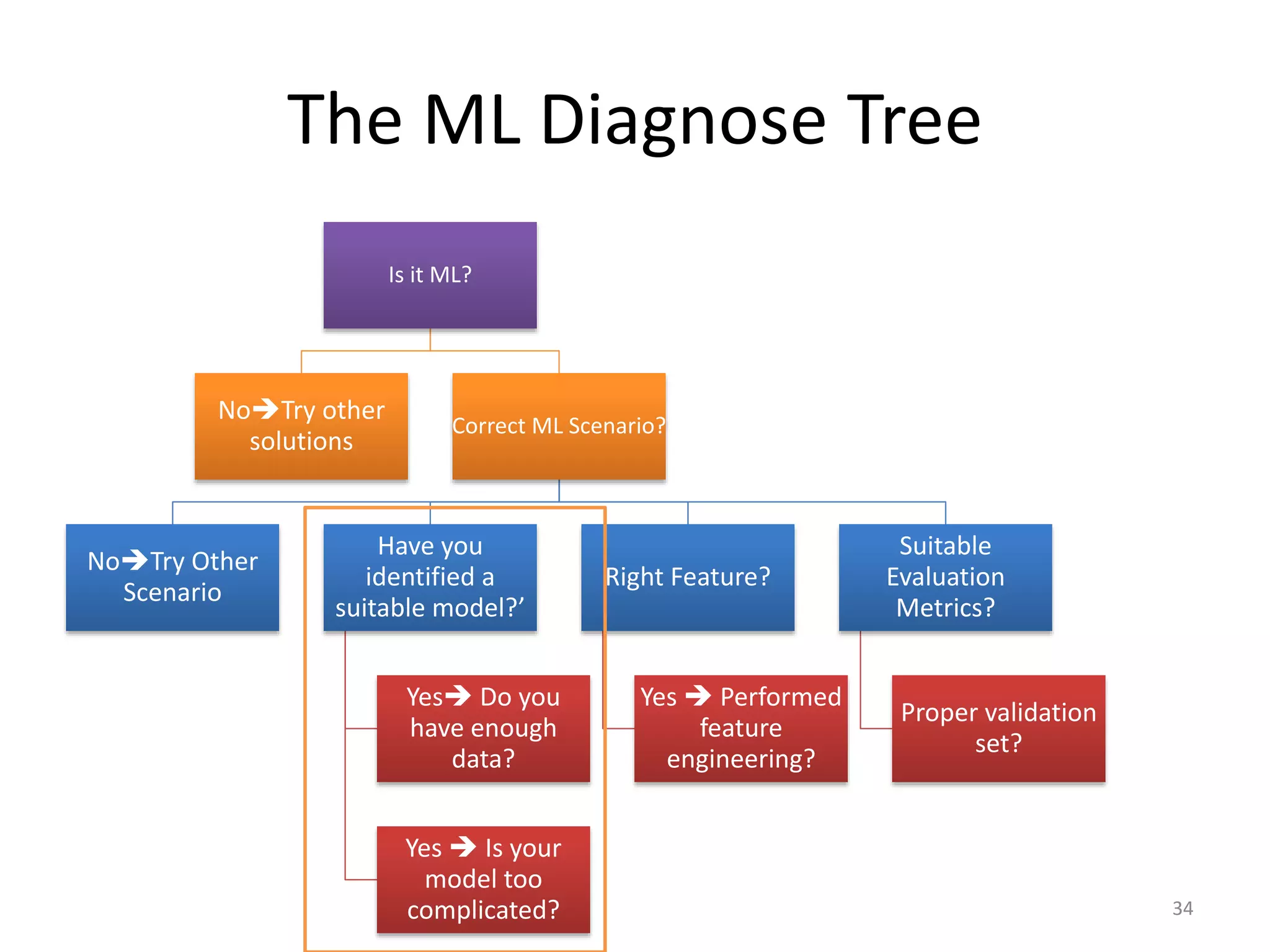
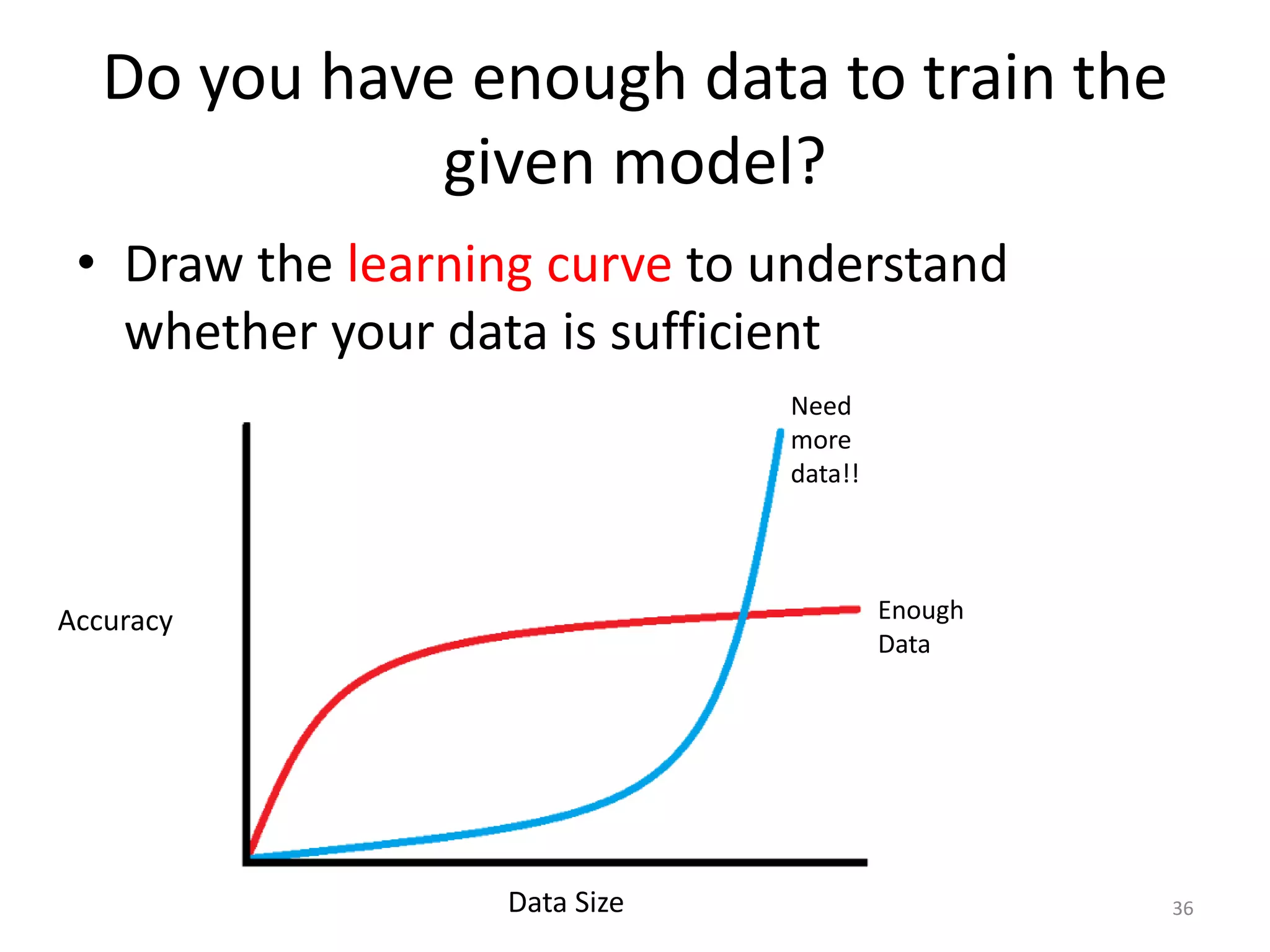
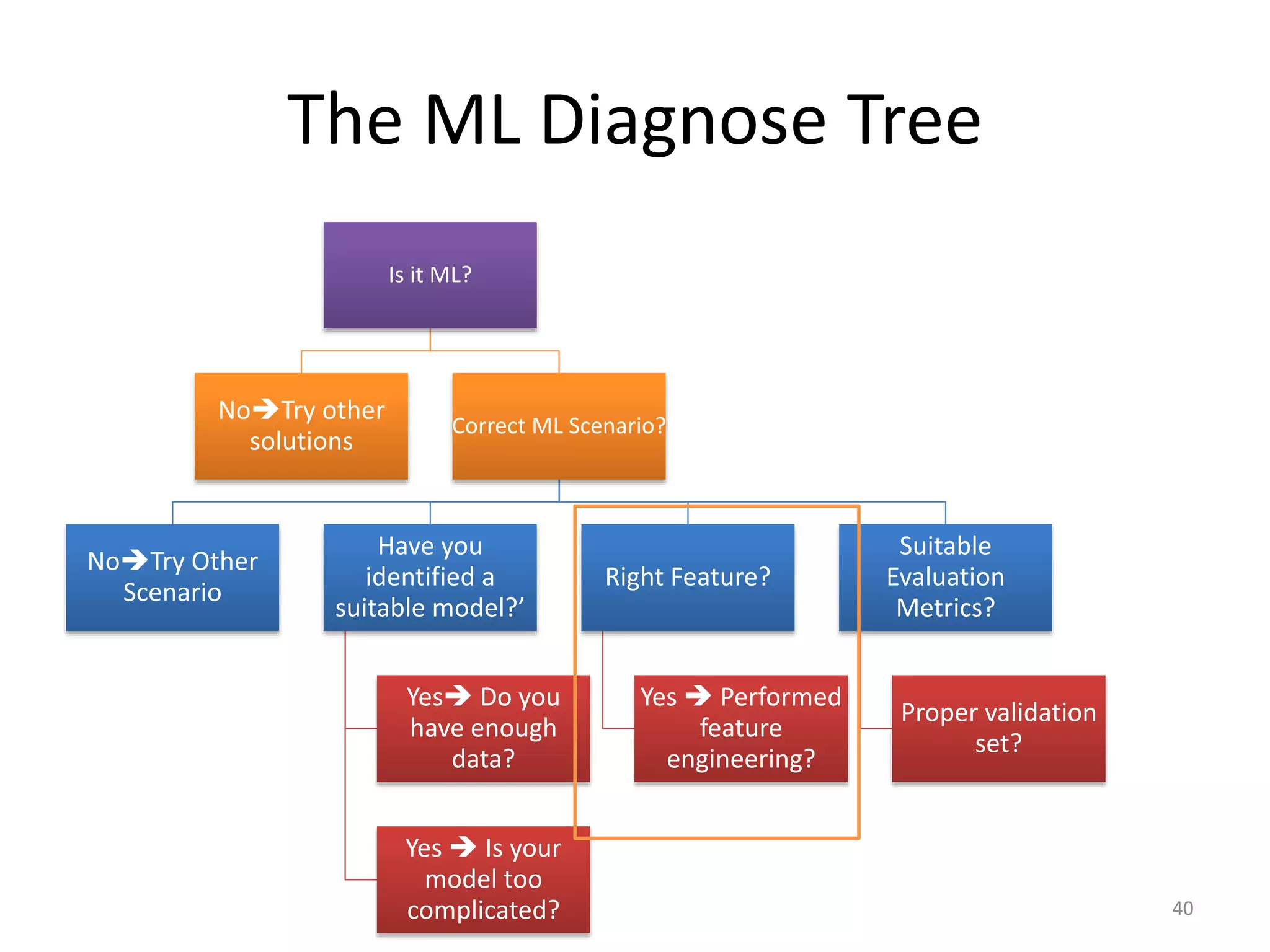
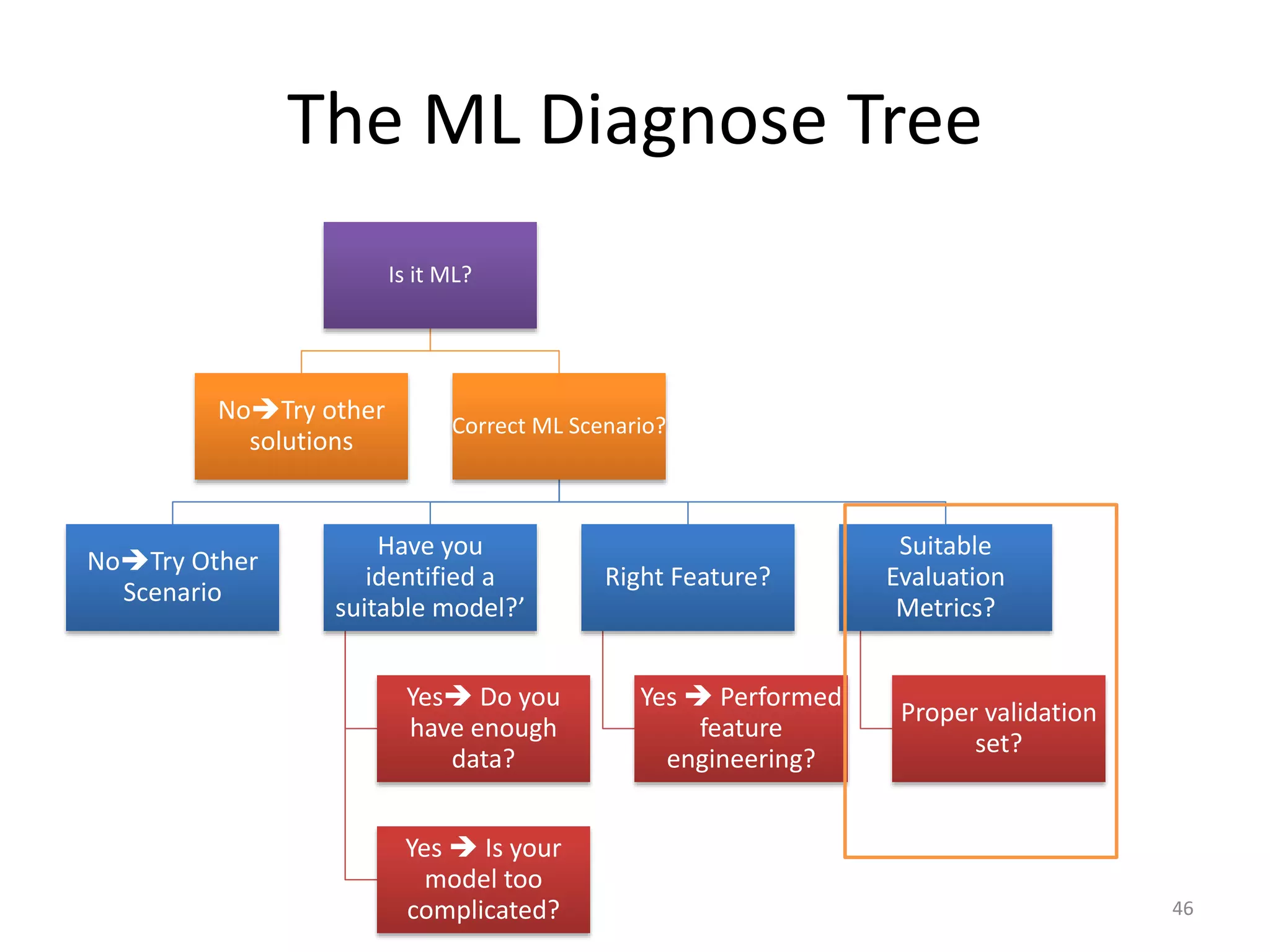
This document summarizes a talk on practical machine learning issues. It discusses identifying the right machine learning scenario for a given task, such as classification, regression, clustering, or reinforcement learning. It also addresses common reasons why machine learning models may fail, such as using the wrong evaluation metrics, not having enough labeled training data, or not performing proper feature engineering. The document emphasizes the importance of choosing the appropriate machine learning model, having sufficient high-quality data, and selecting useful features.

![[系列活動] 機器學習速遊](https://cdn.slidesharecdn.com/ss_thumbnails/mltourhandout-170310083857-thumbnail.jpg?width=640&height=640&fit=bounds)

![[系列活動] Machine Learning 機器學習課程](https://cdn.slidesharecdn.com/ss_thumbnails/ml4ds02122017-170212005829-thumbnail.jpg?width=640&height=640&fit=bounds)












































![[台灣人工智慧學校] 人工智慧技術發展與應用](https://cdn.slidesharecdn.com/ss_thumbnails/version5-final-190319060225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 執行長報告](https://cdn.slidesharecdn.com/ss_thumbnails/openingsw-190315170512-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 工業 4.0 與智慧製造的發展趨勢與挑戰](https://cdn.slidesharecdn.com/ss_thumbnails/20190316jyh-horngchou-190315170336-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 開創台灣產業智慧轉型的新契機](https://cdn.slidesharecdn.com/ss_thumbnails/aiotforaiabytedchangho-190227081005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 開創台灣產業智慧轉型的新契機](https://cdn.slidesharecdn.com/ss_thumbnails/aiinhealthcare-20190216victoria-v6-190227081004-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 台北總校第三期結業典禮 - 執行長談話](https://cdn.slidesharecdn.com/ss_thumbnails/tp3closingsw-190126030359-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA台中分校] AI 引爆新工業革命,智慧機械首都台中轉型論壇](https://cdn.slidesharecdn.com/ss_thumbnails/aia-chen-190116063635-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA台中分校] 2019 台灣數位轉型 與產業升級趨勢觀察](https://cdn.slidesharecdn.com/ss_thumbnails/to-sheng-190116063620-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA台中分校] 智慧製造成真! 產線導入AI的致勝關鍵](https://cdn.slidesharecdn.com/ss_thumbnails/thu-hsu-190116063619-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 從經濟學看人工智慧產業應用](https://cdn.slidesharecdn.com/ss_thumbnails/1-the-application-of-ai-industry-from-economics-190108064940-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 台中分校第二期開學典禮 - 執行長報告](https://cdn.slidesharecdn.com/ss_thumbnails/tc2-opening1-compressed-190107034100-thumbnail.jpg?width=640&height=640&fit=bounds)

![[台中分校] 第一期結業典禮 - 執行長談話](https://cdn.slidesharecdn.com/ss_thumbnails/sw-ppt-181217031715-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] 工業4.0潛力新應用! 多模式對話機器人](https://cdn.slidesharecdn.com/ss_thumbnails/20181206004-181210031031-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] AI整合是重點! 竹科的關鍵轉型思維](https://cdn.slidesharecdn.com/ss_thumbnails/20181206002-181210031031-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] 2019 台灣數位轉型與產業升級趨勢觀察](https://cdn.slidesharecdn.com/ss_thumbnails/20181206-001-181210031002-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] 深度學習與Kaggle實戰](https://cdn.slidesharecdn.com/ss_thumbnails/20181206003-181210031001-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] Bridging AI to Precision Agriculture through IoT](https://cdn.slidesharecdn.com/ss_thumbnails/hc-2nd-openingai-school-181206104858-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 台灣人工智慧學校校友年會] 產業經驗分享: 如何用最少的訓練樣本,得到最好的深度學習影像分析結果,減少一半人力,提升一倍品質 / 李明達](https://cdn.slidesharecdn.com/ss_thumbnails/lee-181130104127-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 台灣人工智慧學校校友年會] 啟動物聯網新關鍵 - 未來由你「喚」醒 / 沈品勳](https://cdn.slidesharecdn.com/ss_thumbnails/20181117shengfn-181130083931-thumbnail.jpg?width=640&height=640&fit=bounds)



















