Download as PDF, PPTX





































































The document discusses the limitations of correlational recommender systems, emphasizing the need for causal models to improve recommendations based on temporal context. It outlines various approaches, including epsilon-greedy methods and instrumental variable models, each with their pros and cons in handling unobserved confounders and scaling issues. Ultimately, it concludes that effective recommendation algorithms must consider the immediate context and the causal nature of user interactions.
Overview of the topic on time, context, and causality within recommender systems presented by Yves Raimond.
Discusses the need for quick content discovery and the importance of personalization for customer satisfaction.
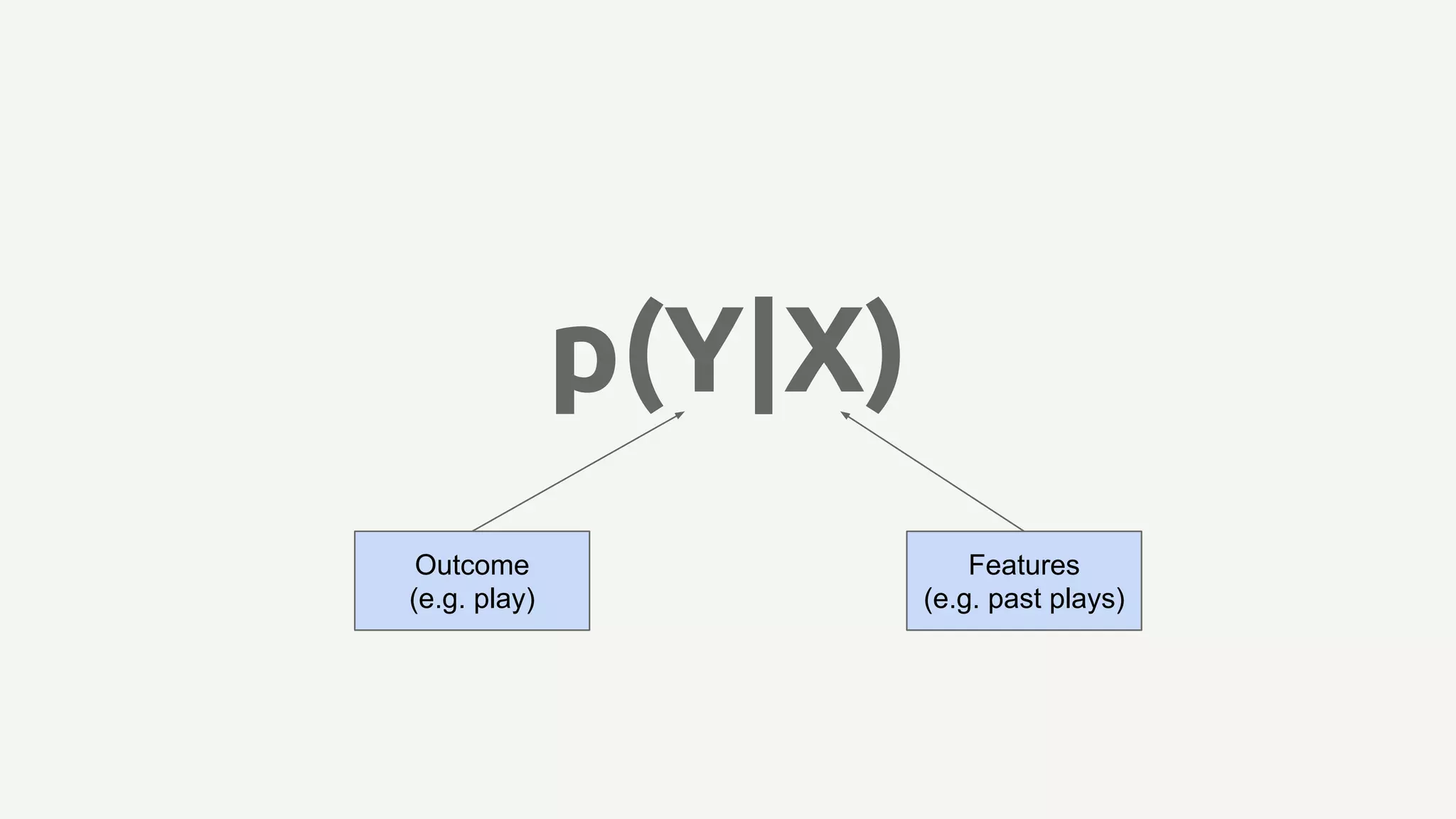
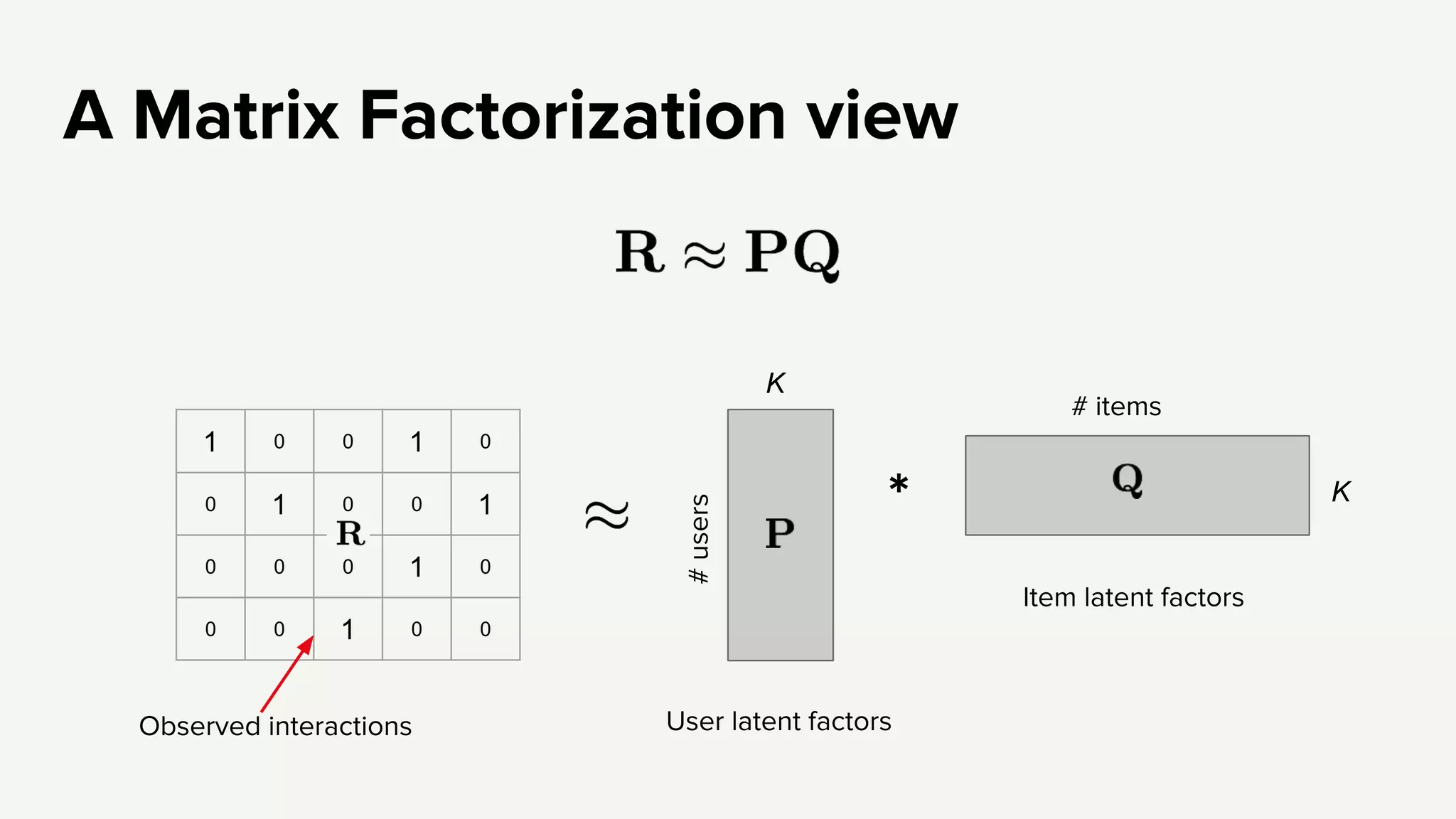
Introduces the concept of correlational recommender systems using statistical models with features and outcomes.
Highlights the shortcomings of traditional models by emphasizing the importance of time and predictive accuracy.
Explains the need to incorporate time and context for better predictions in recommendation systems.
Defines causal recommender systems, emphasizing the need for causal modeling and its benefits over correlational approaches.
Outlines strategies like Epsilon-Greedy for selecting recommendations, discussing their advantages and disadvantages.
Presents approaches to tackle biases in recommendations, including the propensity model and instrumental variables.
Summarizes various recommendation strategies, their benefits, and drawbacks, highlighting the need for causal models.
Final thoughts on the necessity of understanding context, time, and causality in recommendation systems for effective outcomes.
Opens the floor for questions, inviting dialogue regarding the discussed recommender system strategies.












































































