Downloaded 32 times






















![Two Main Algorithms
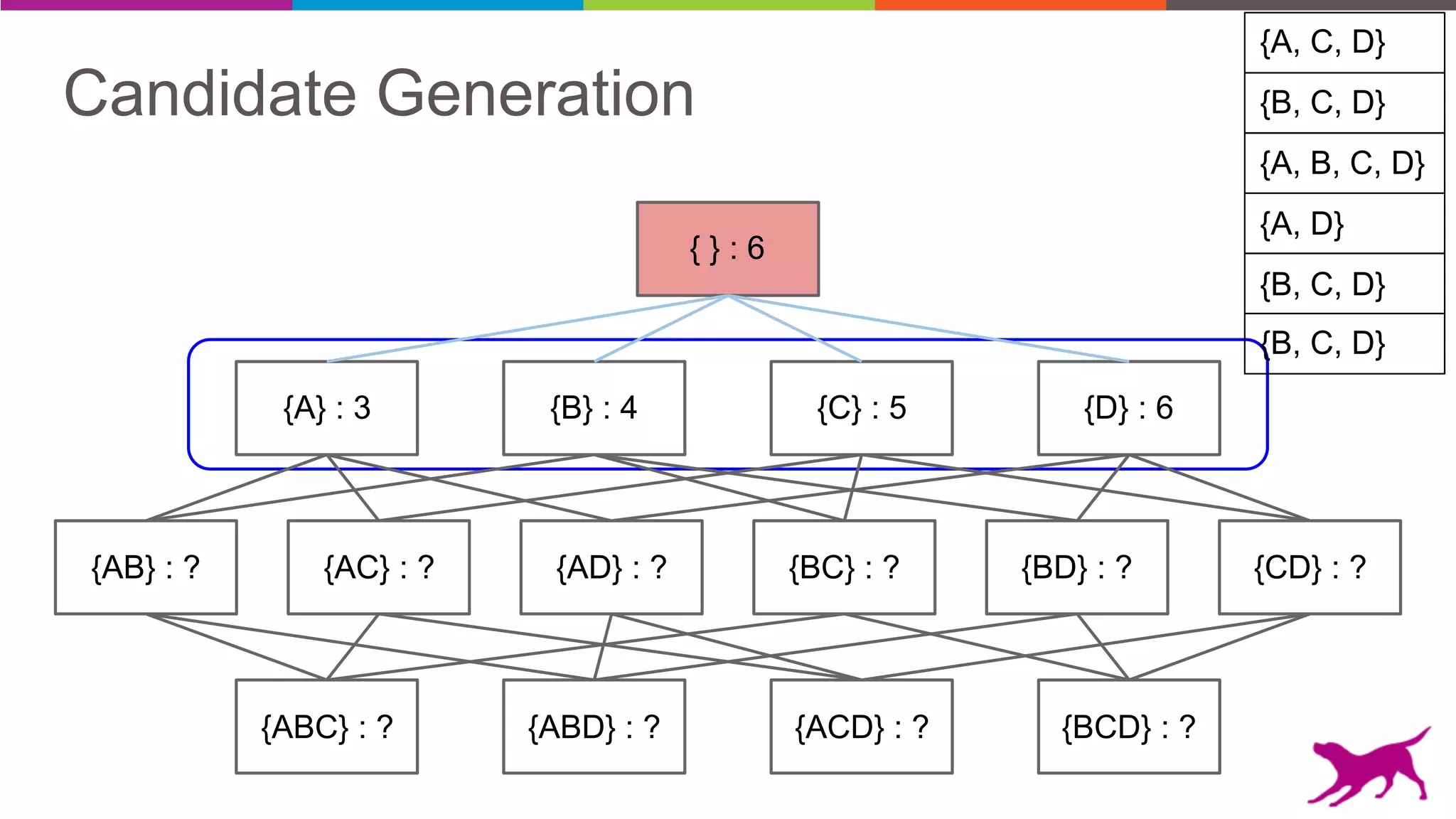
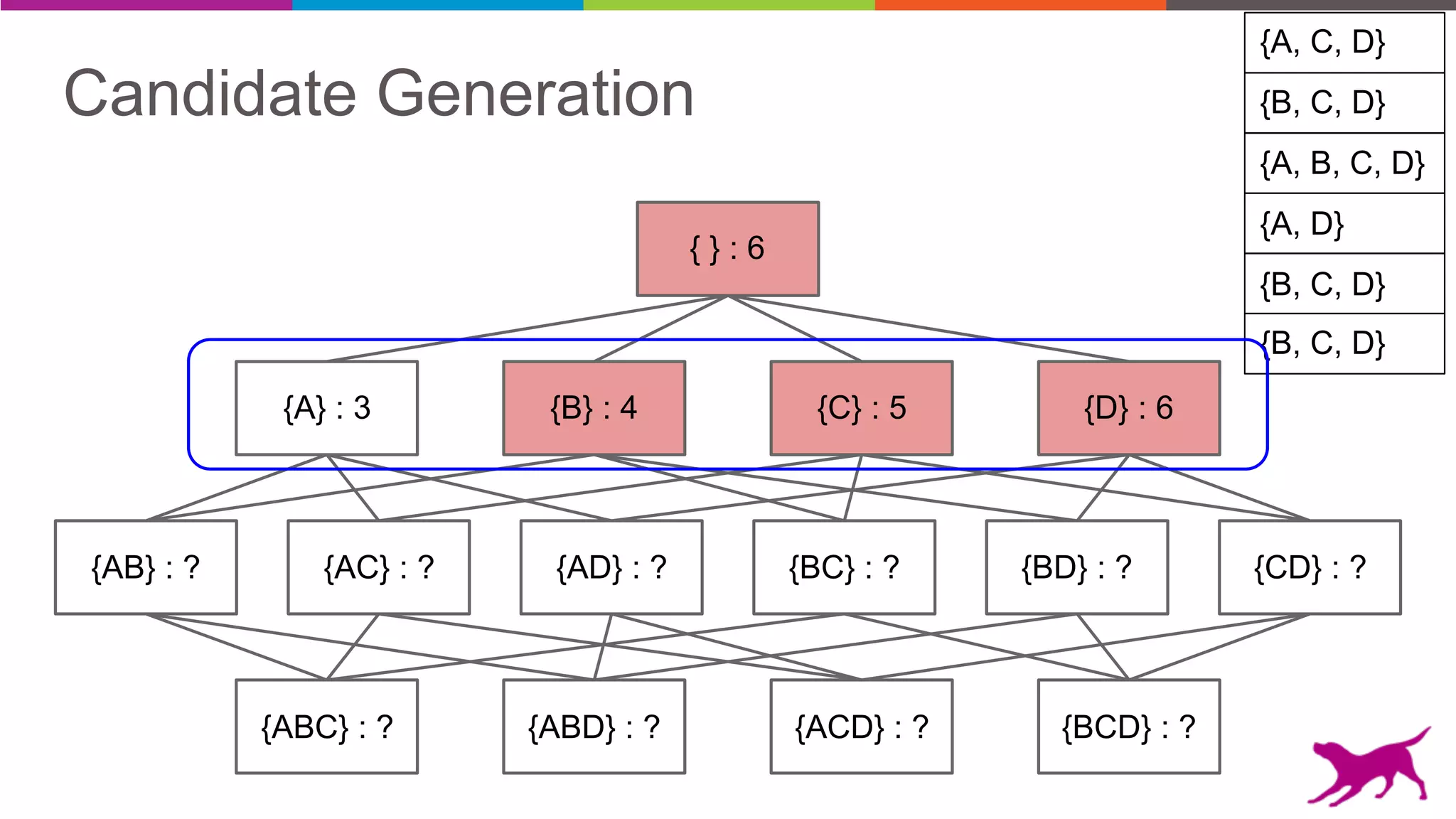
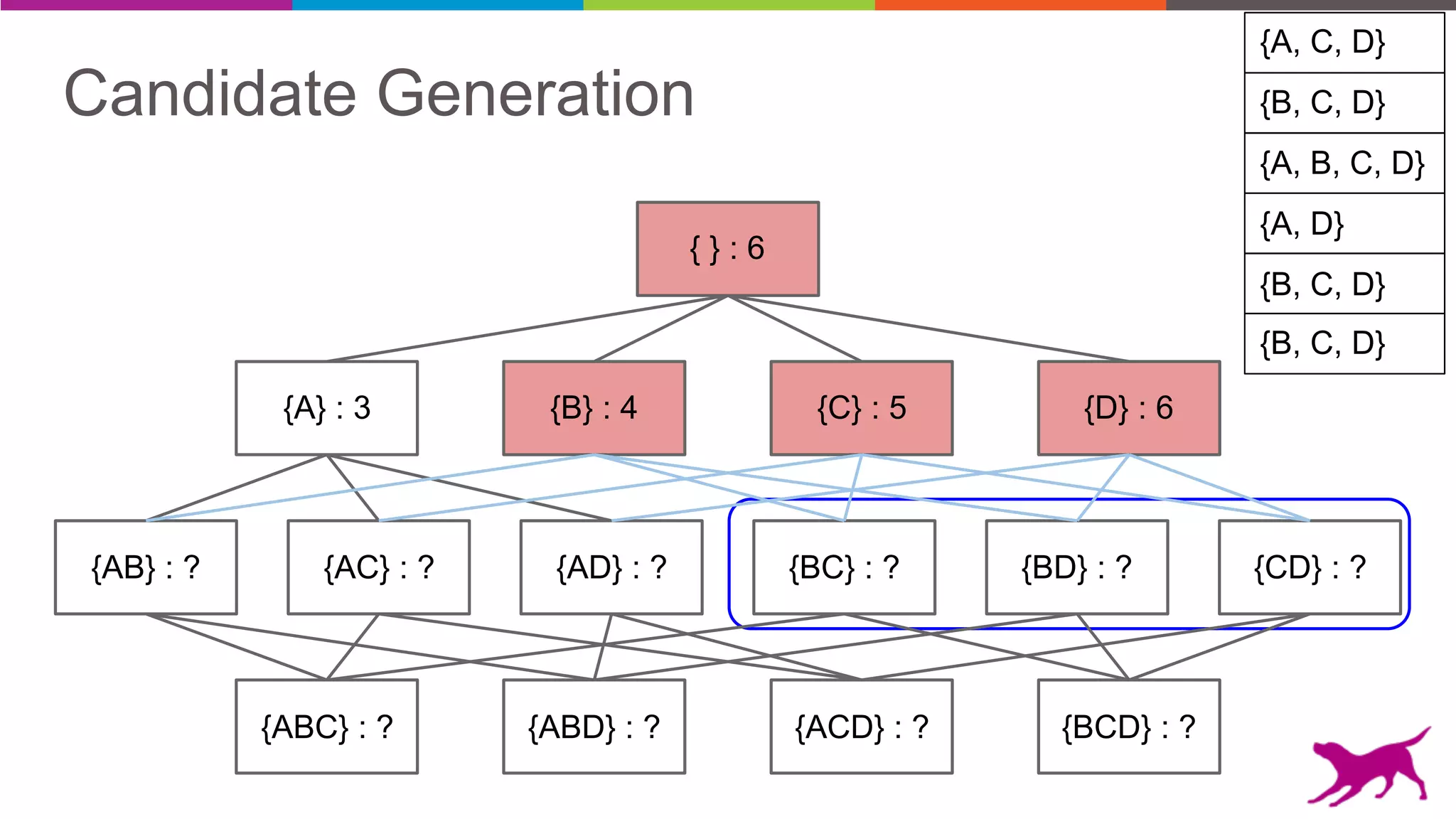
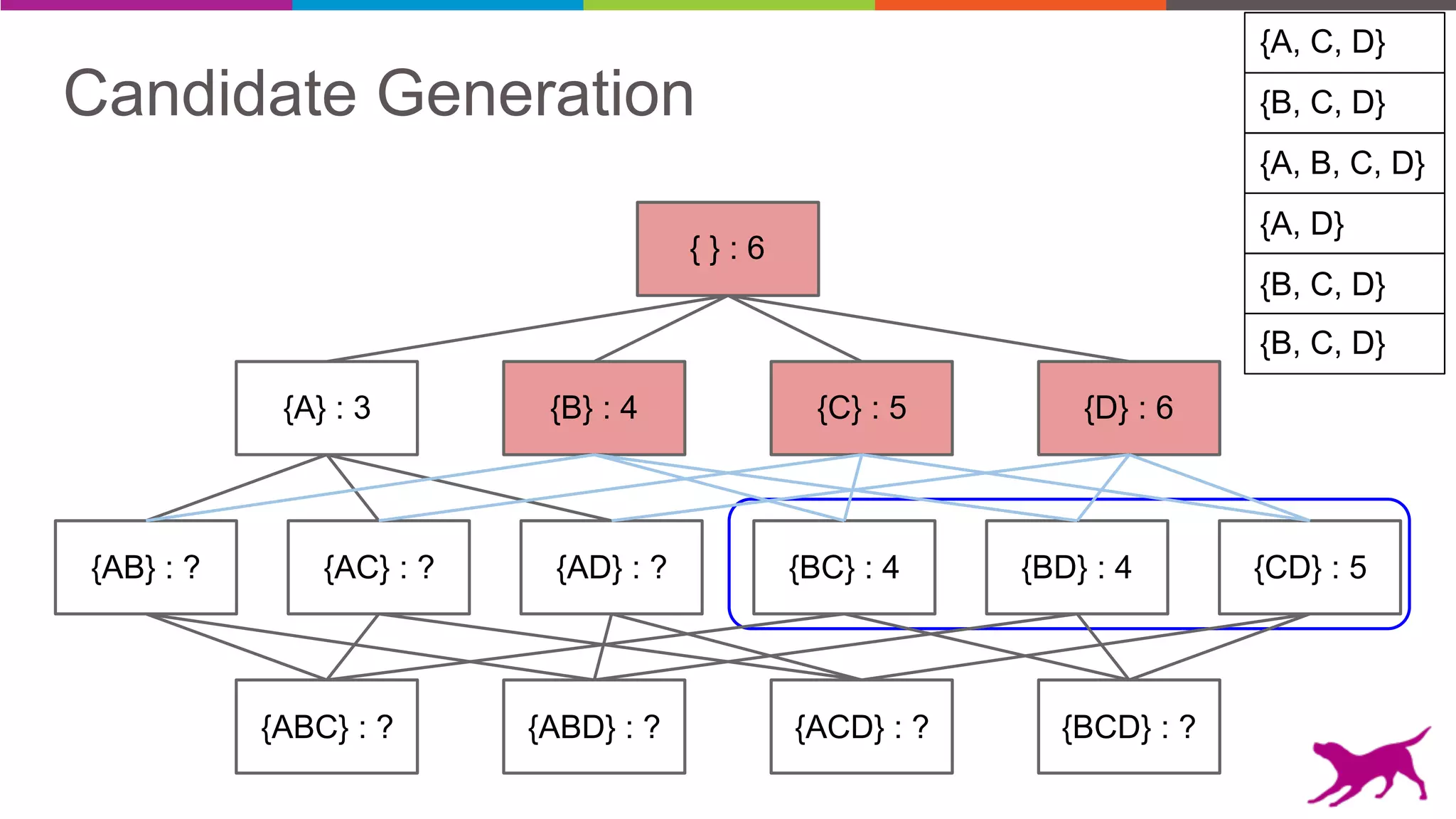
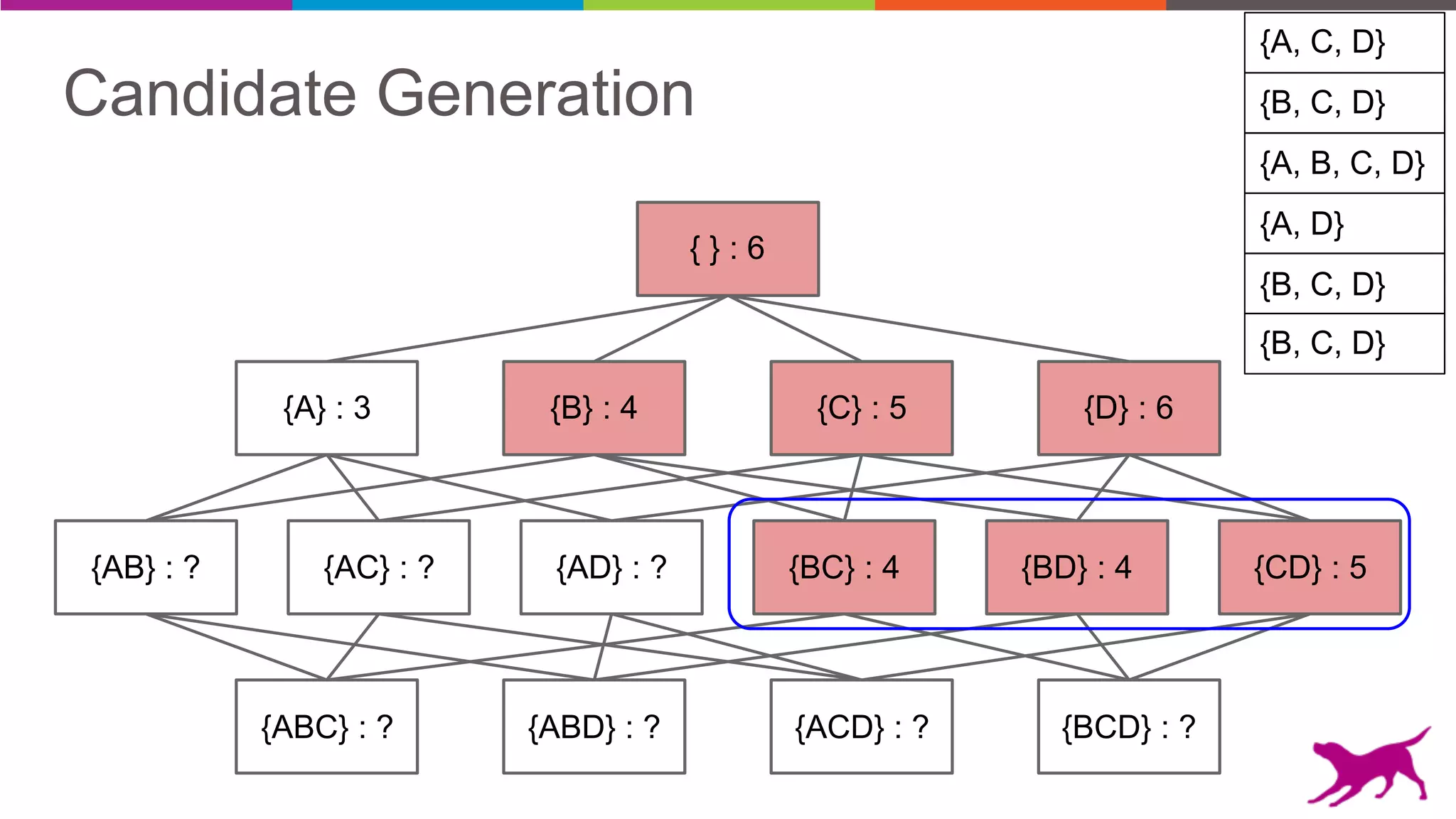
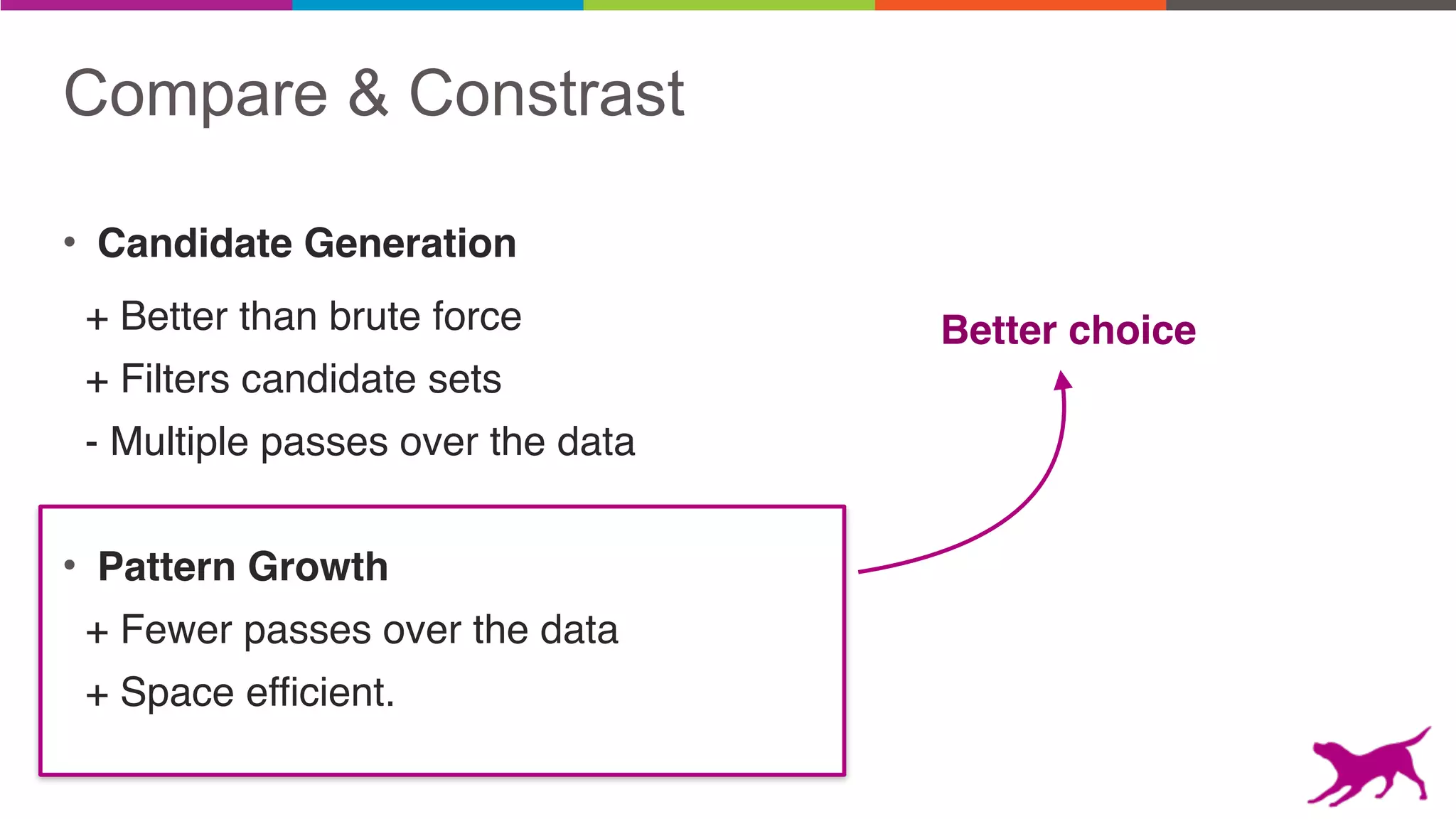
• Candidate Generation
- Apriori
- Eclat
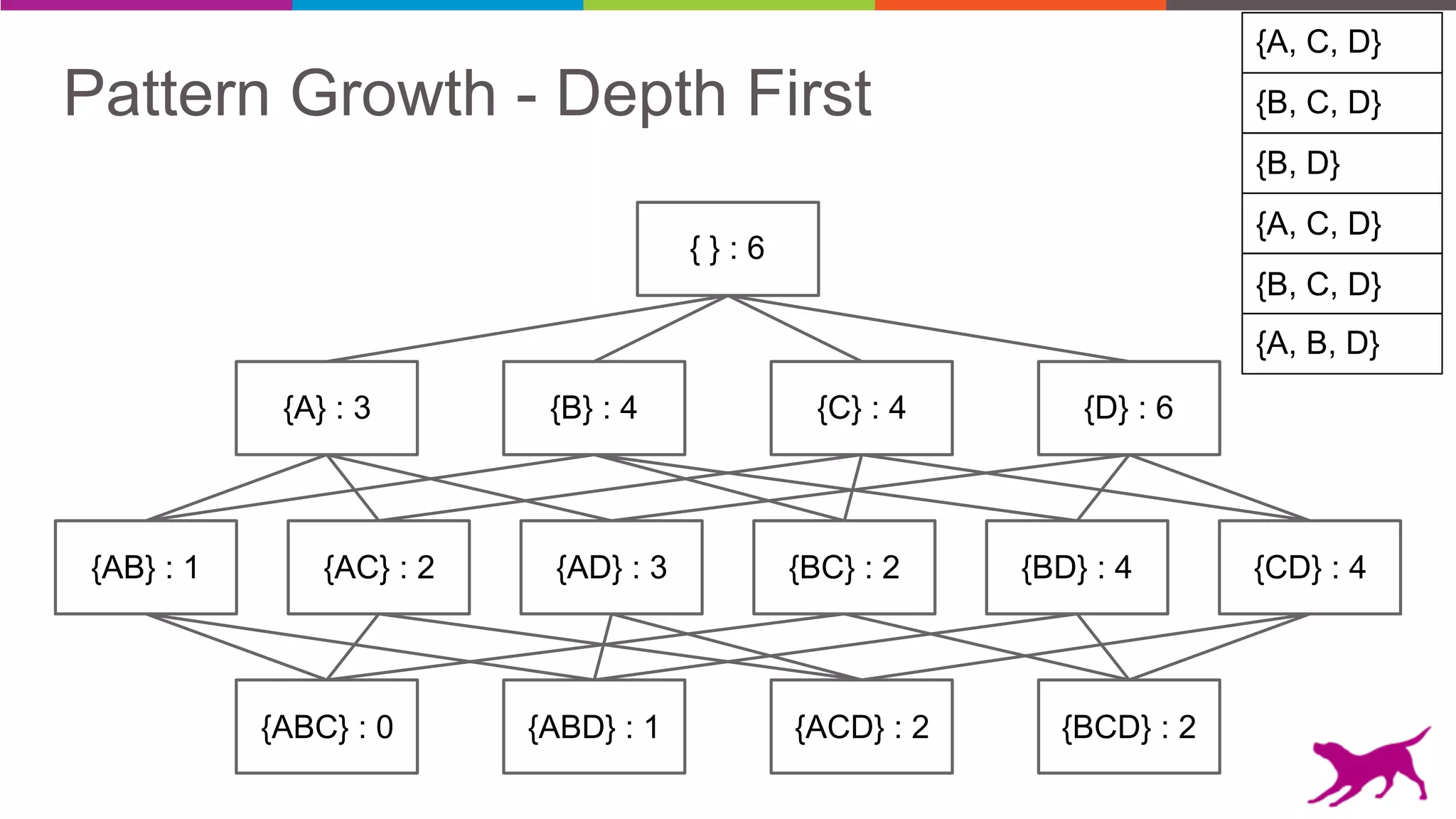
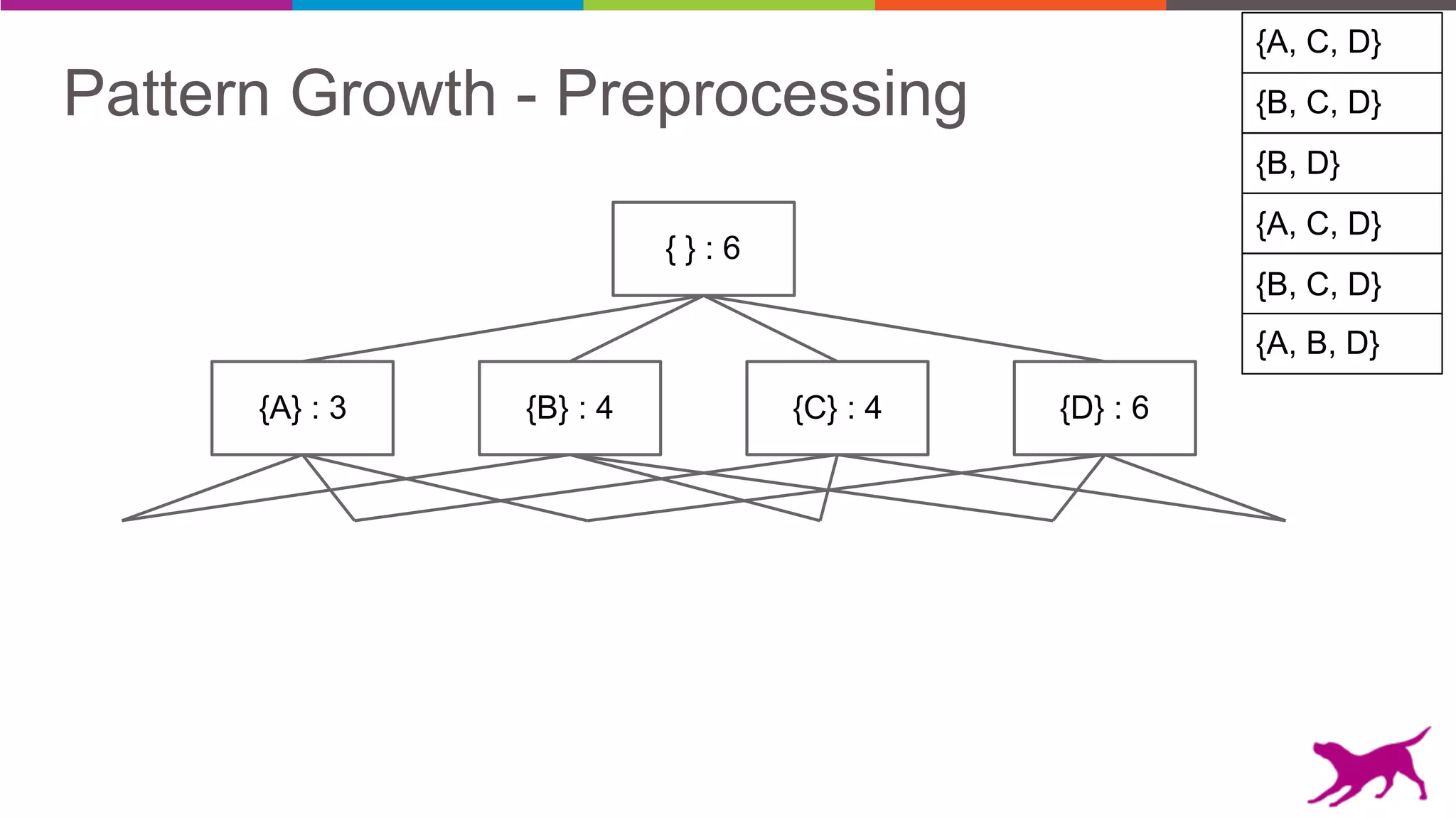
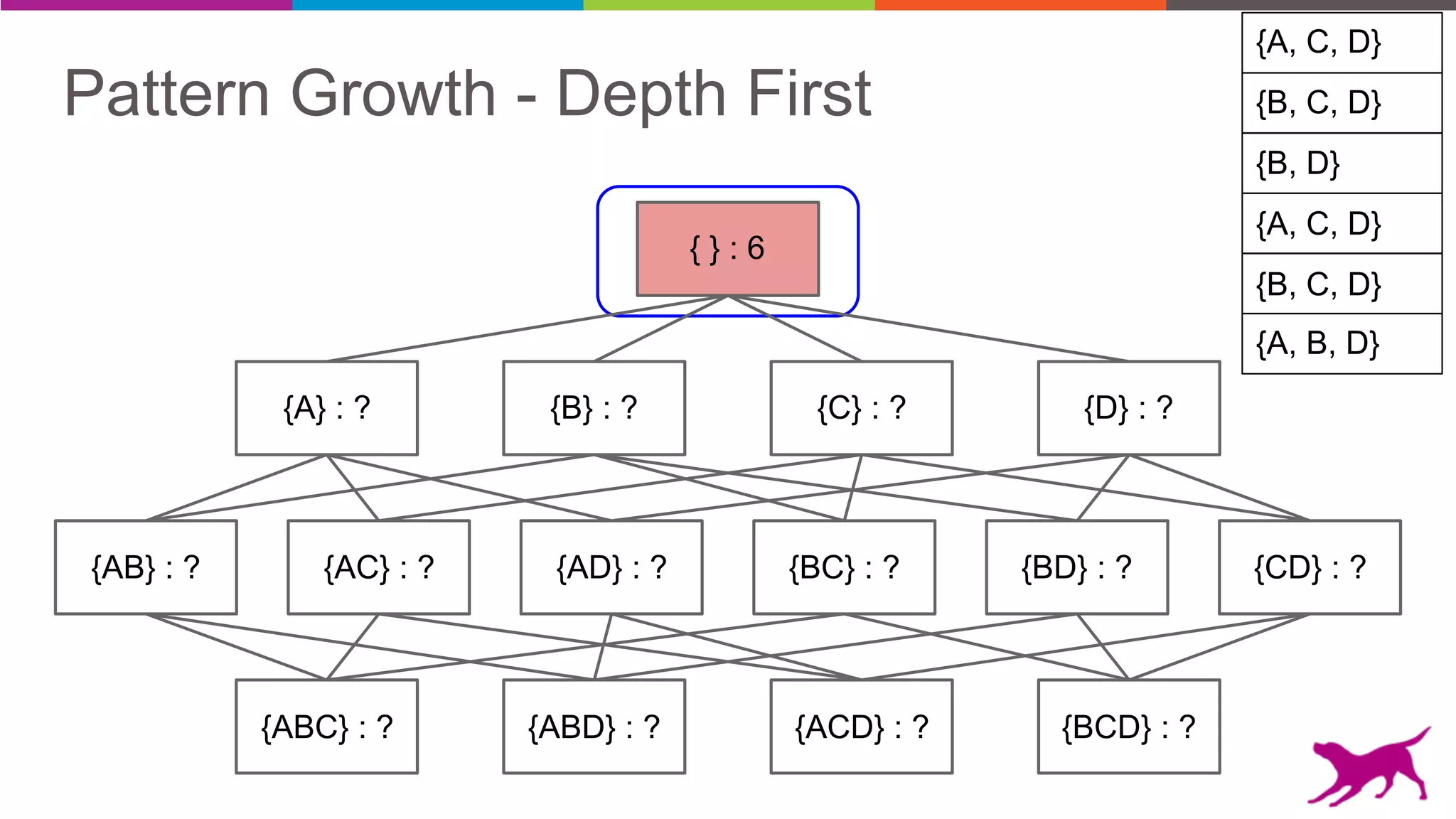
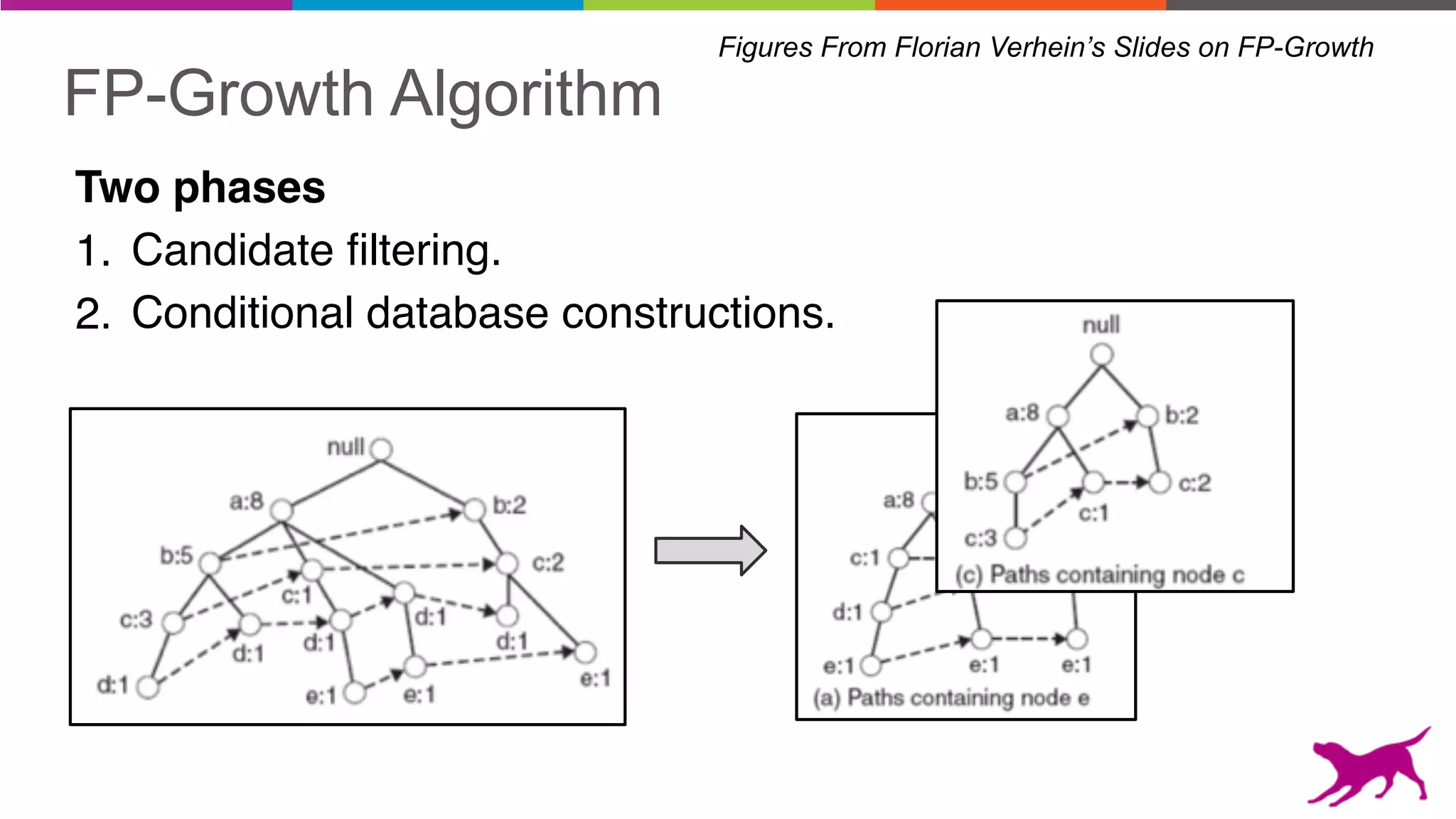
• Pattern Growth
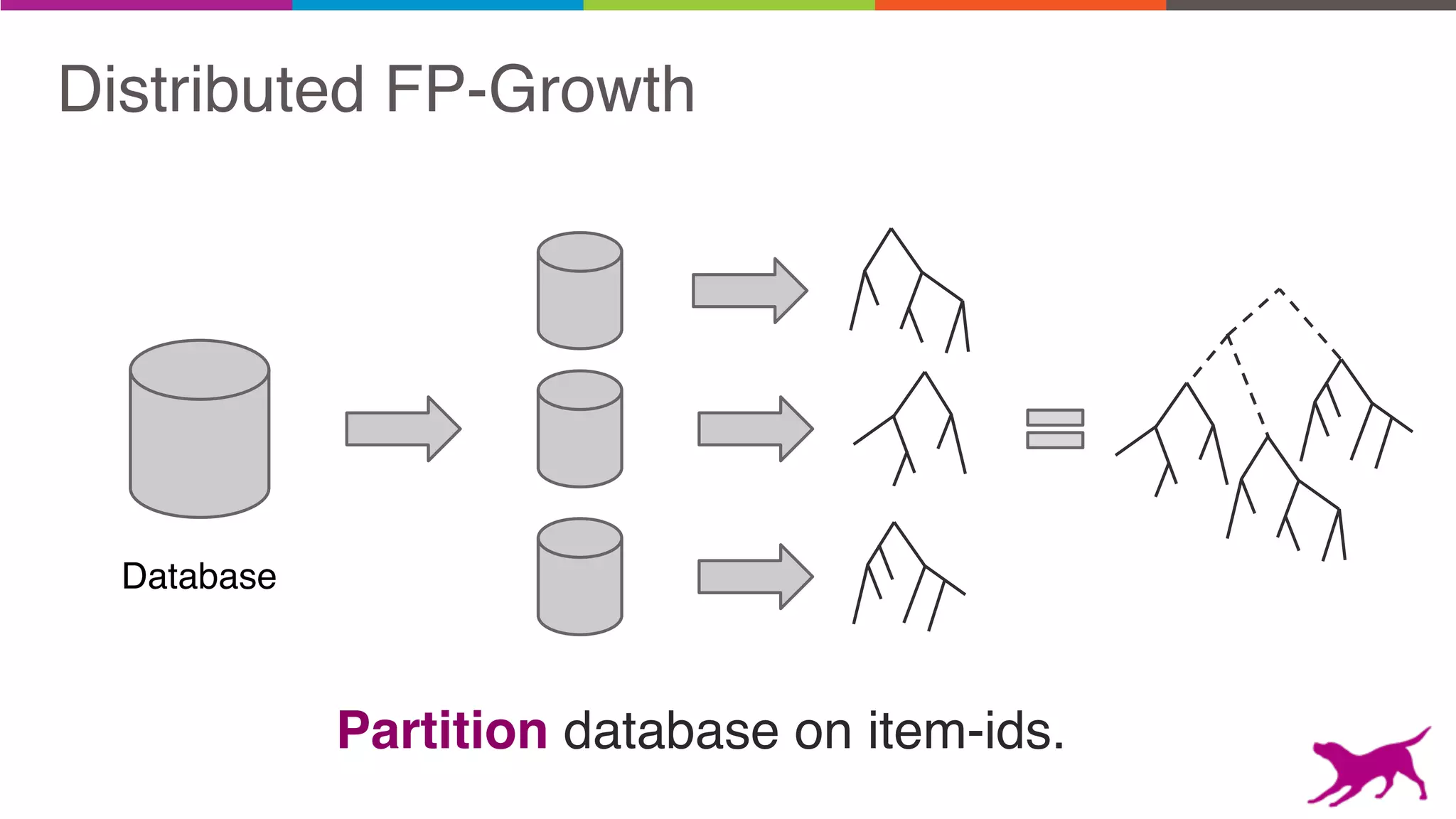
- FP-Growth
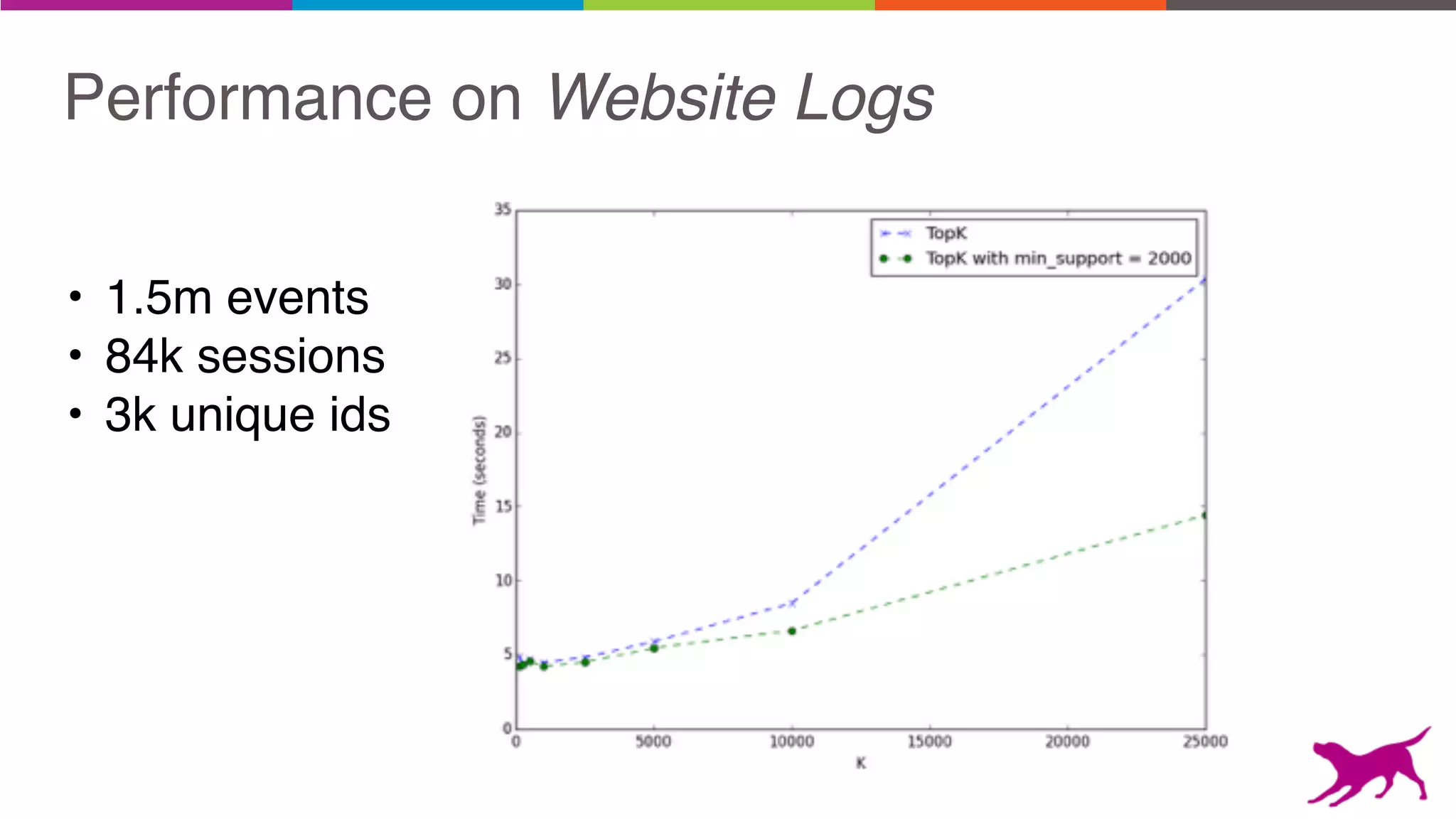
- TopK FP-Growth [GLC 1.6]](https://image.slidesharecdn.com/webinar-patternmining-krishna20160421-160422164640/75/Pattern-Mining-Extracting-Value-from-Log-Data-36-2048.jpg)
















































![Two Main Algorithms
• Candidate Generation
- Apriori
- Eclat
• Pattern Growth
- FP-Growth
- TopK FP-Growth [GLC 1.6]](https://crownmelresort.com/image.slidesharecdn.com/webinar-patternmining-krishna20160421-160422164640/75/Pattern-Mining-Extracting-Value-from-Log-Data-36-2048.jpg)






































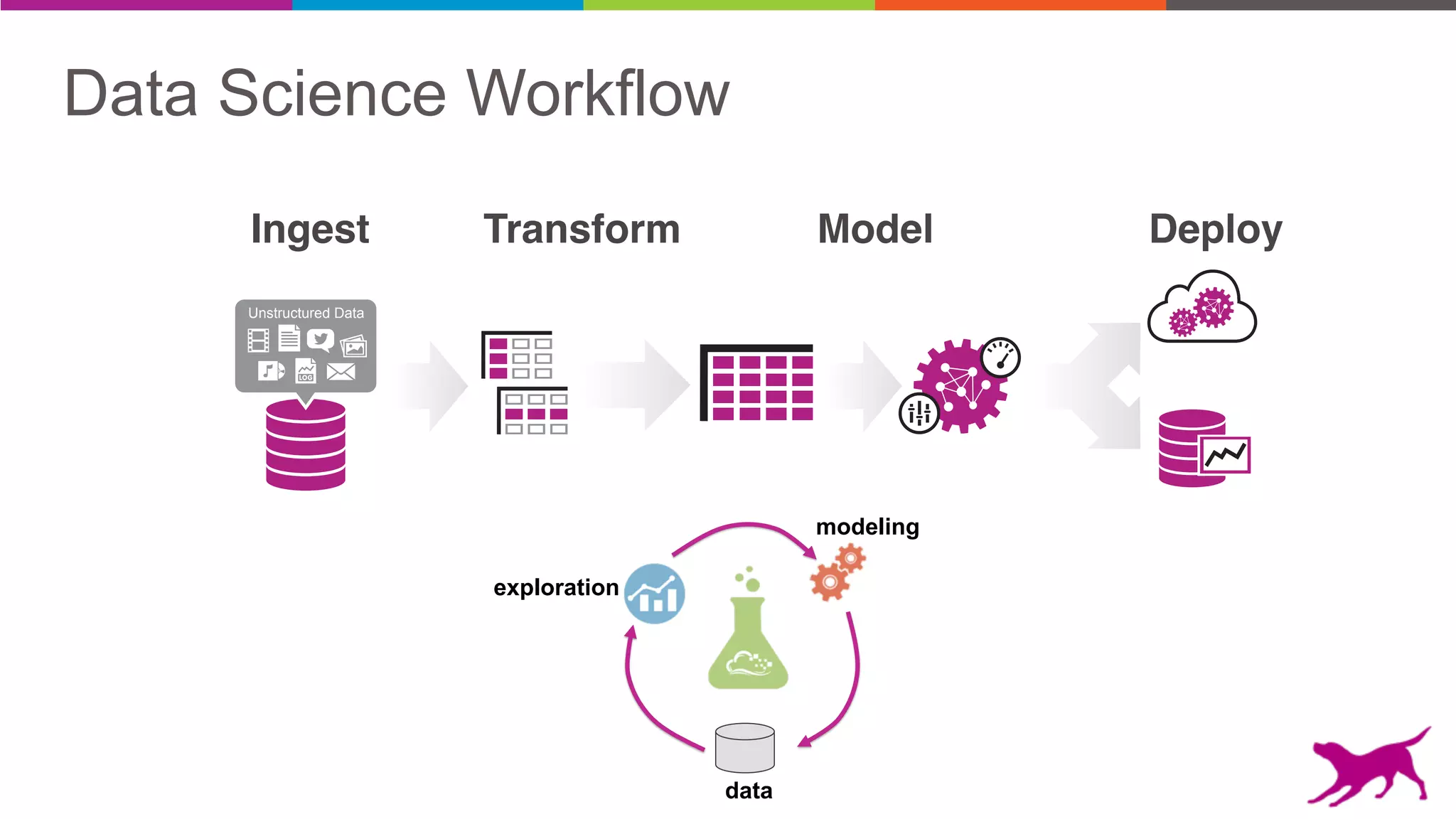
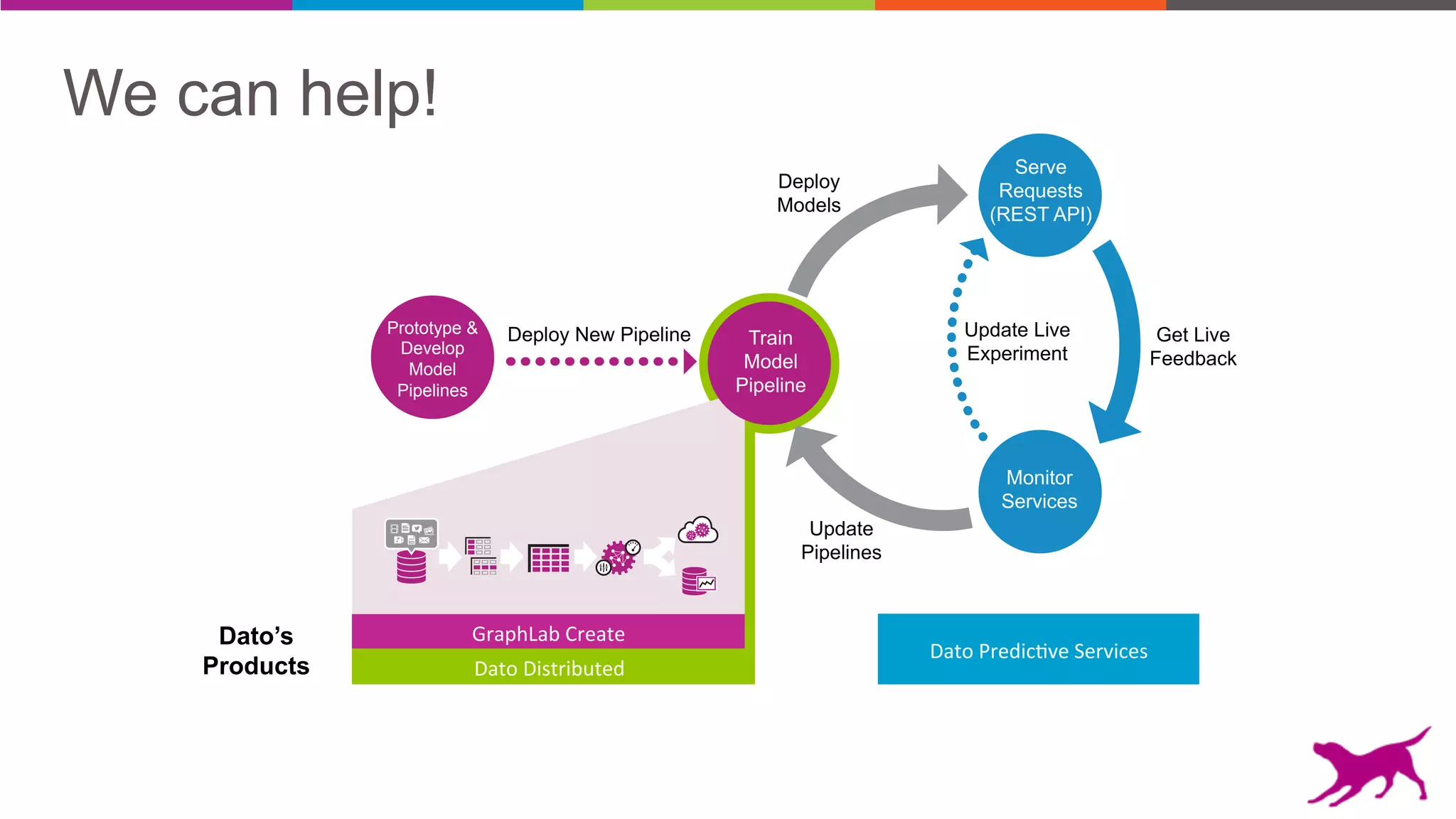
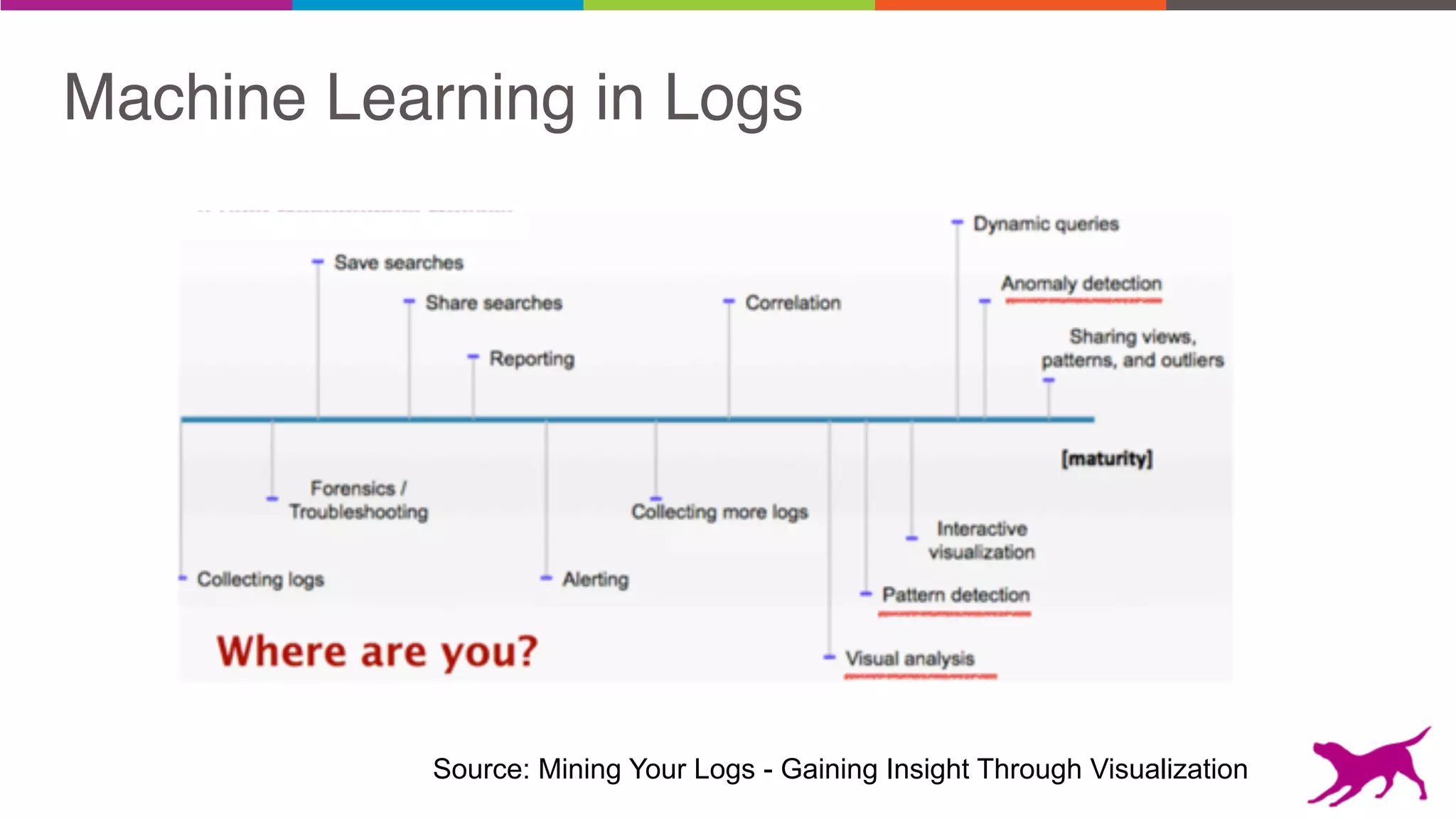
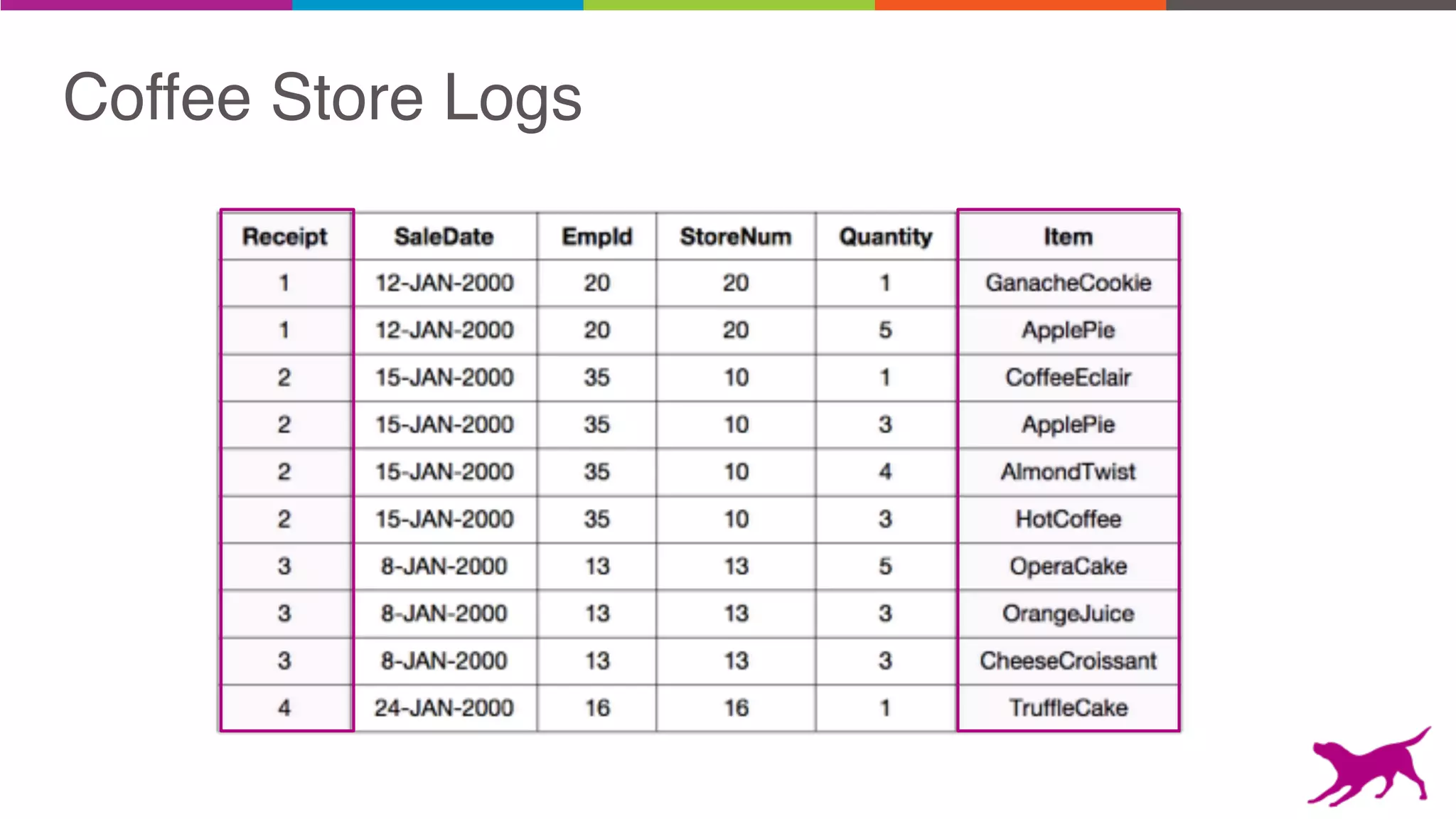
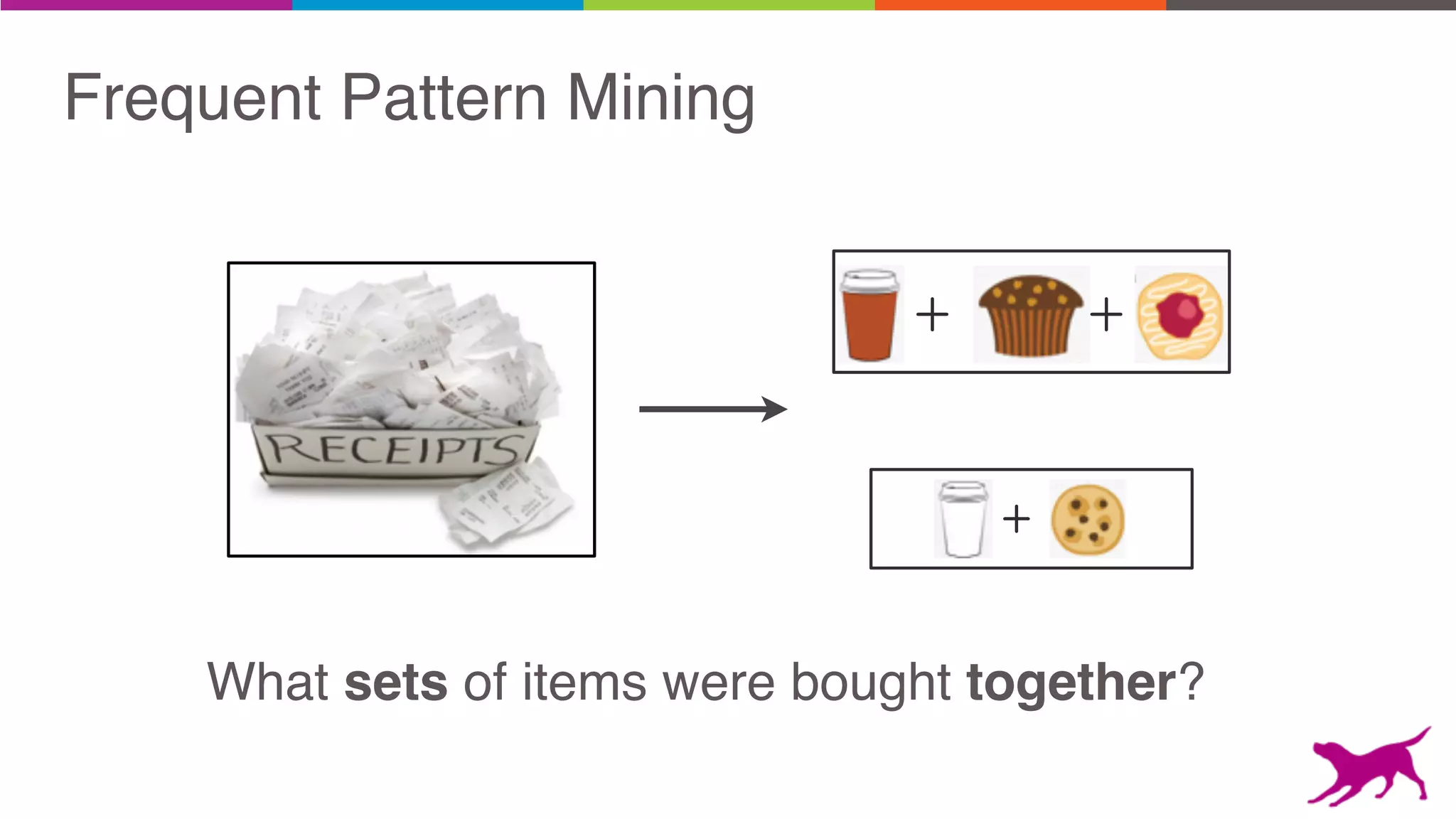
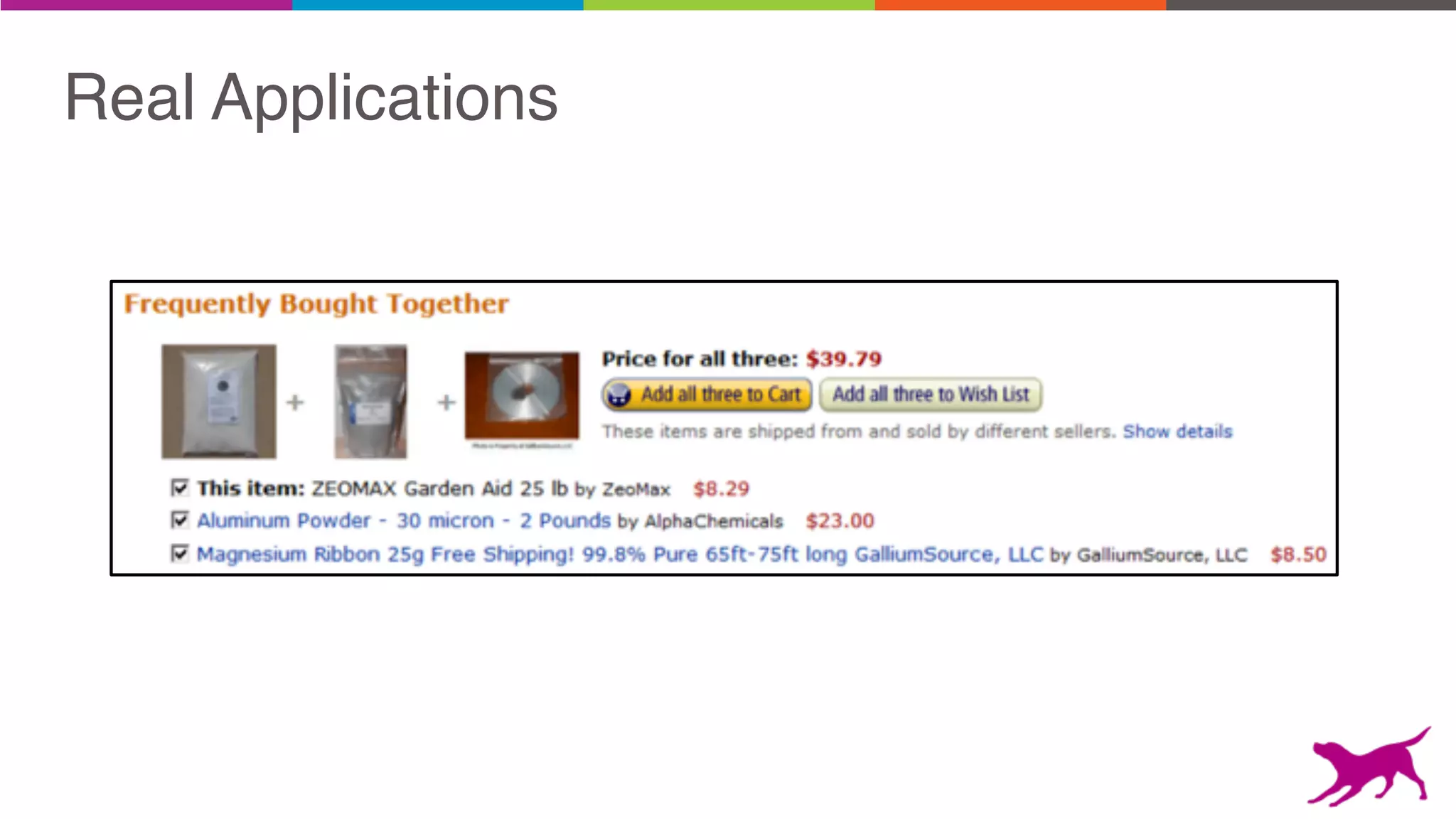
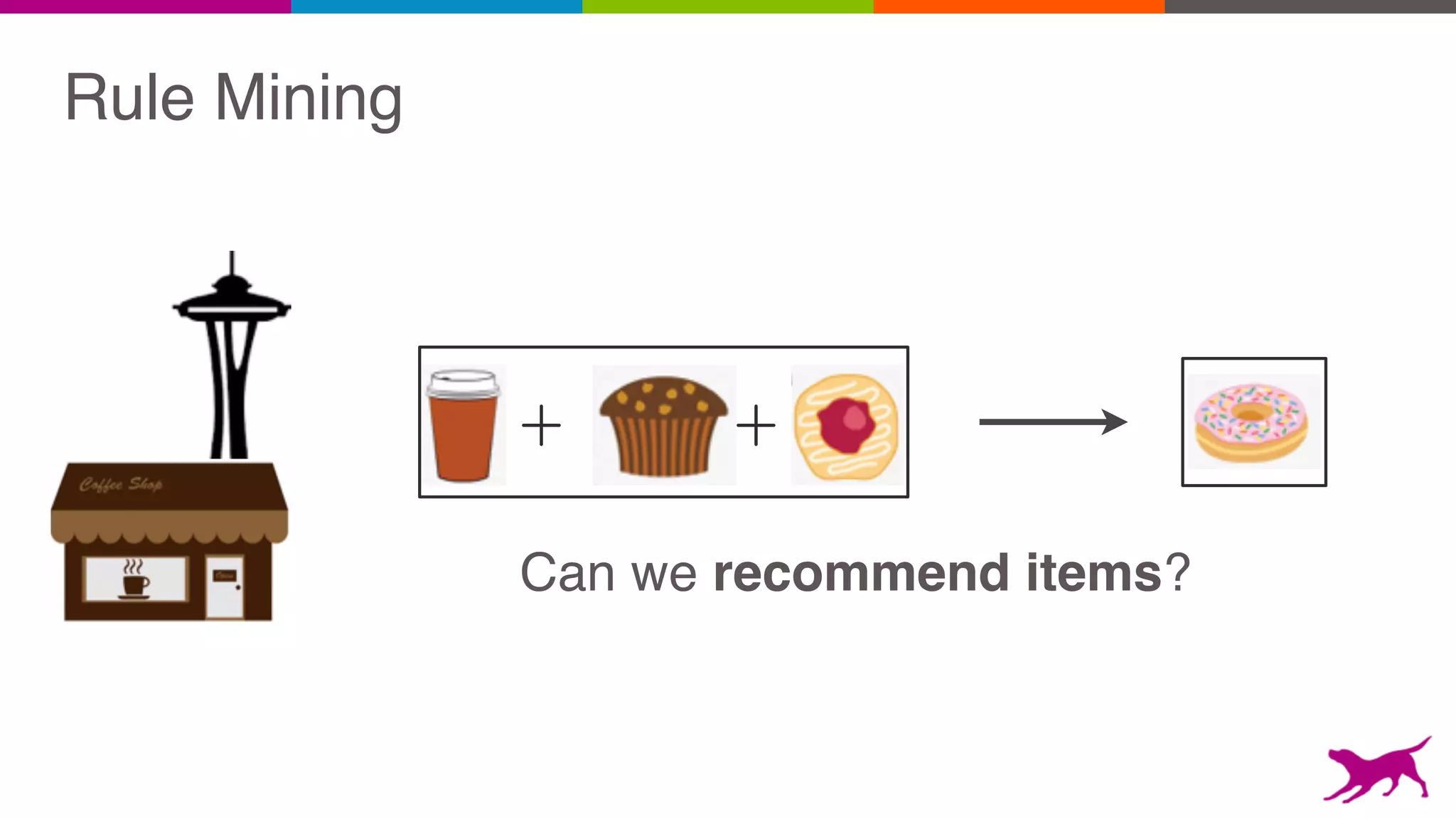
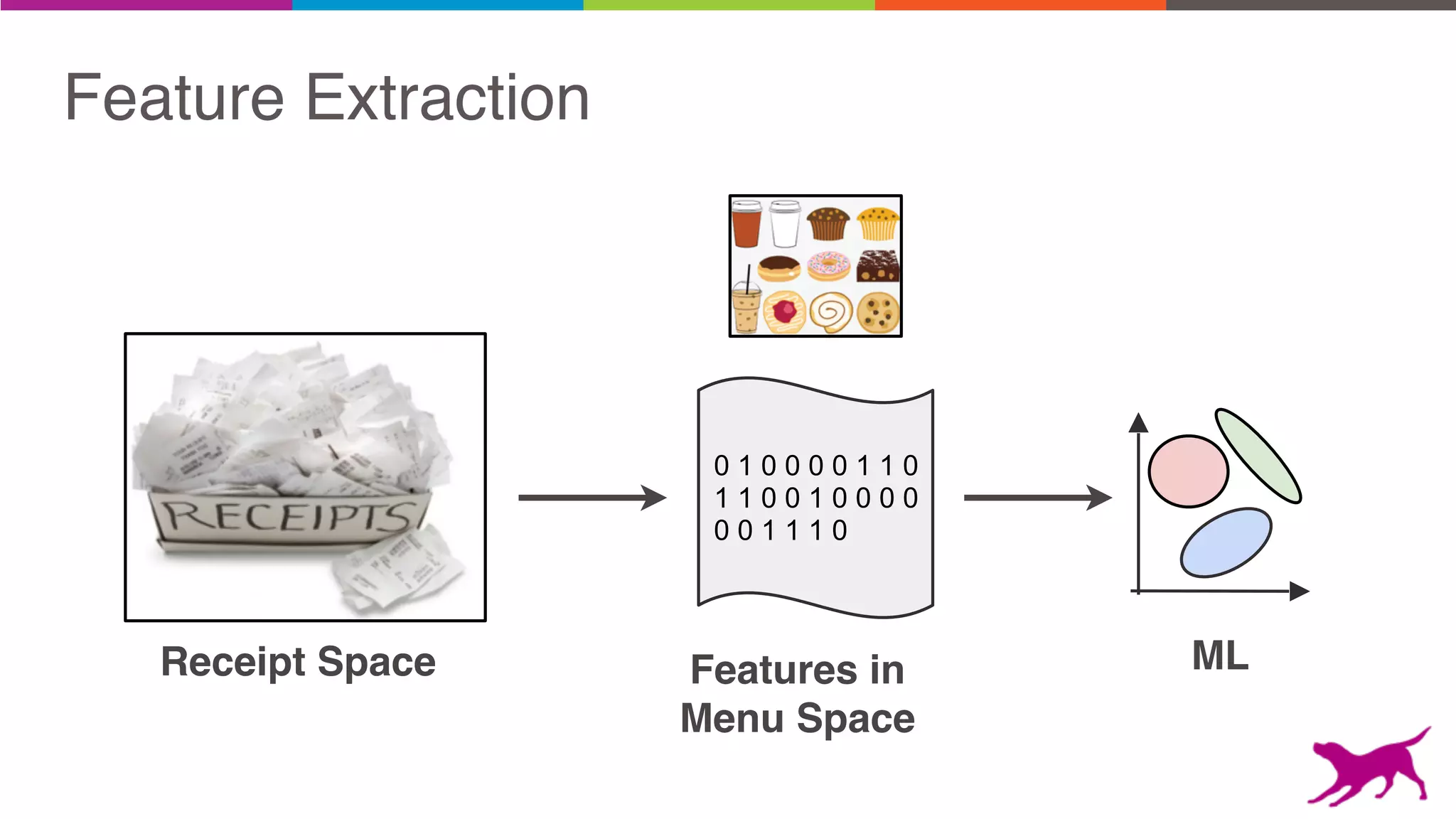
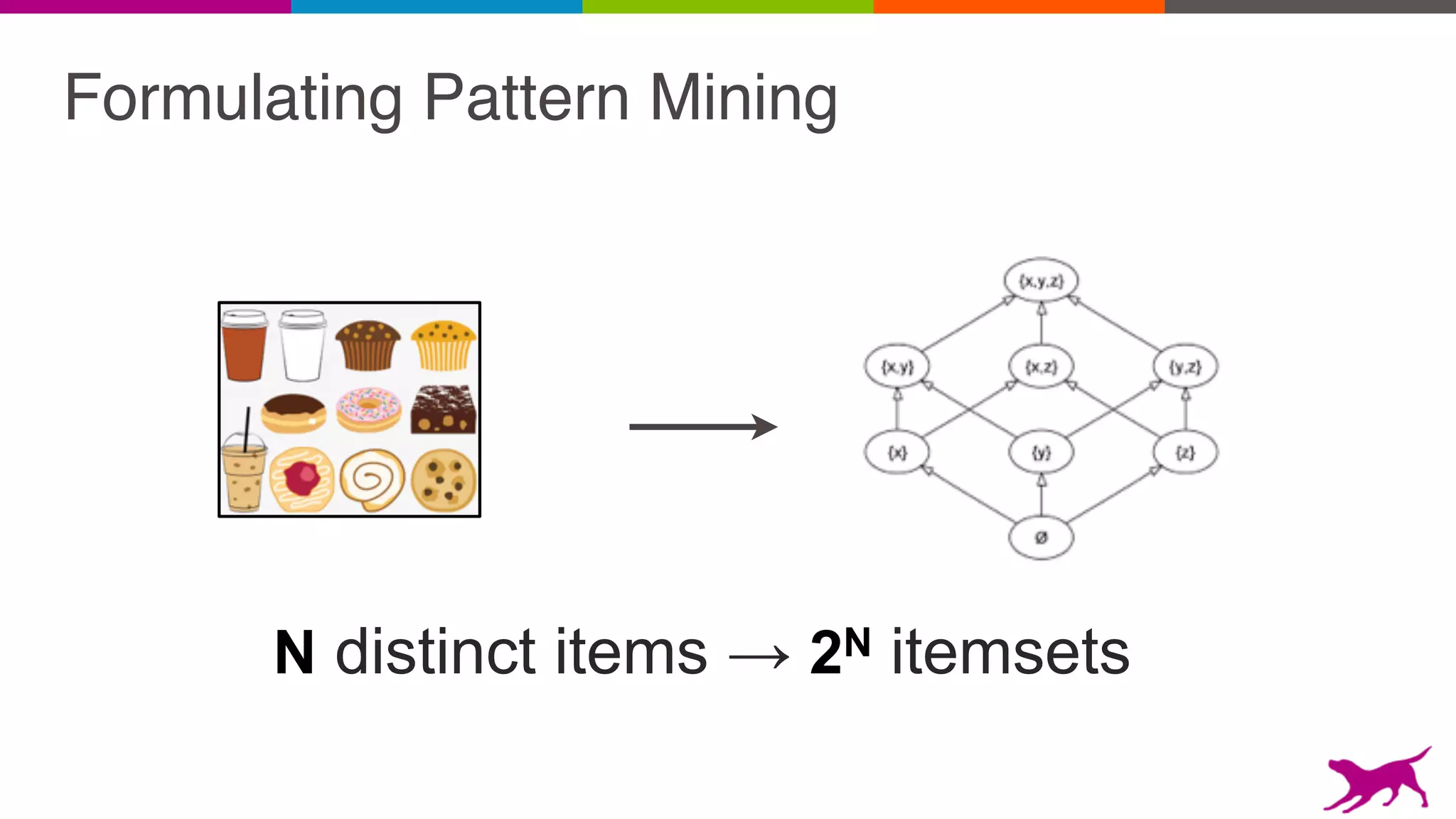
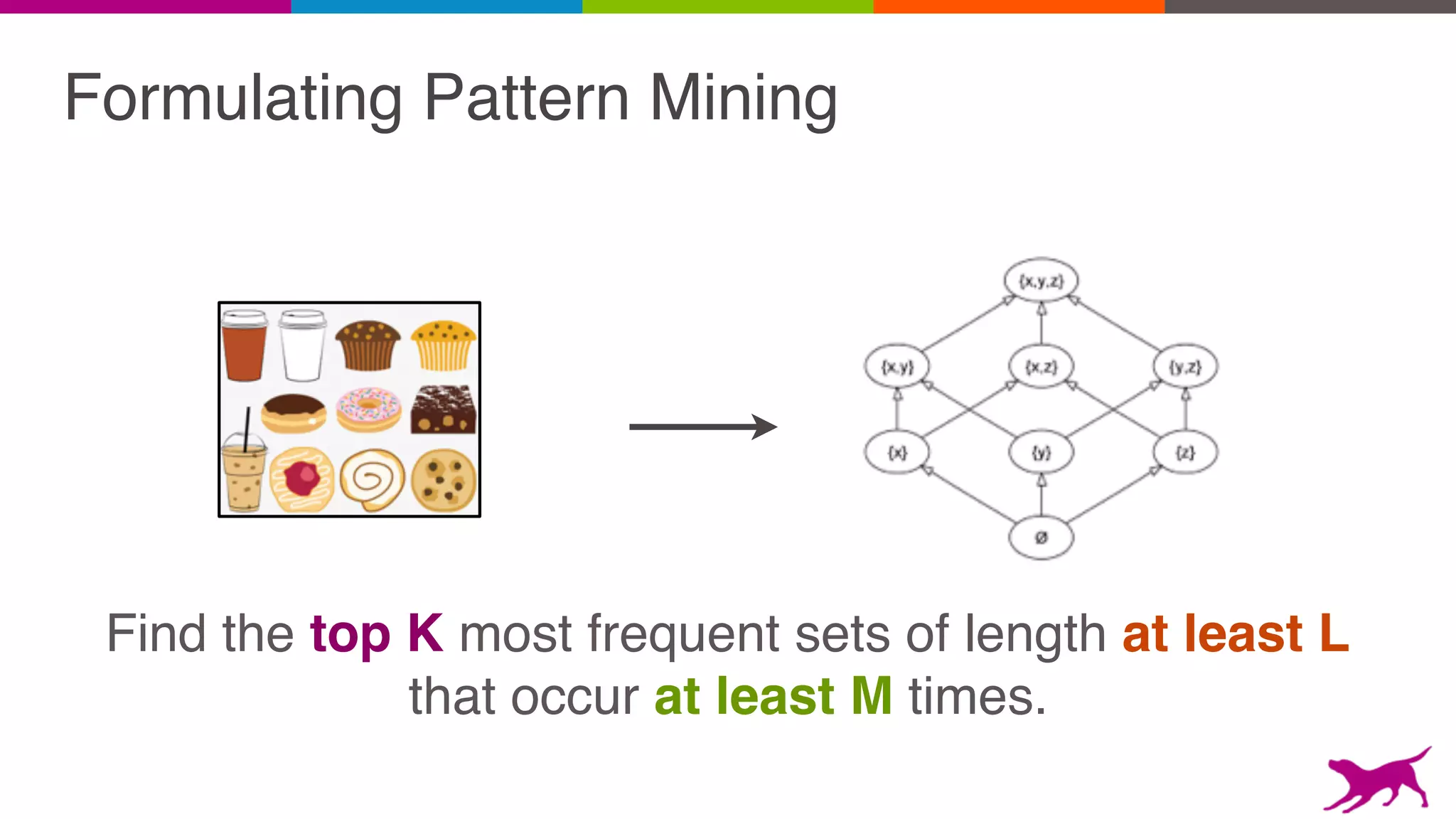
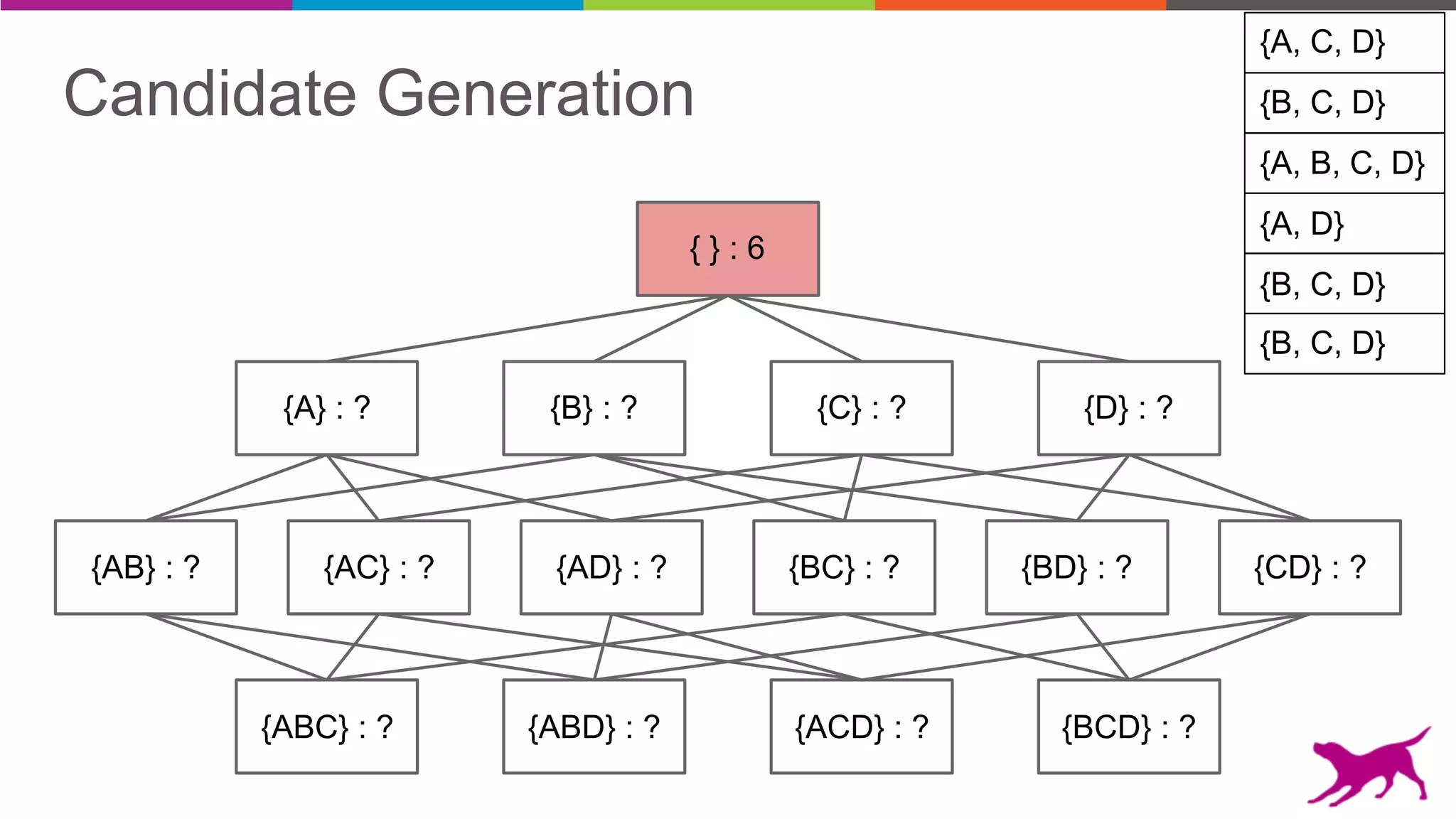
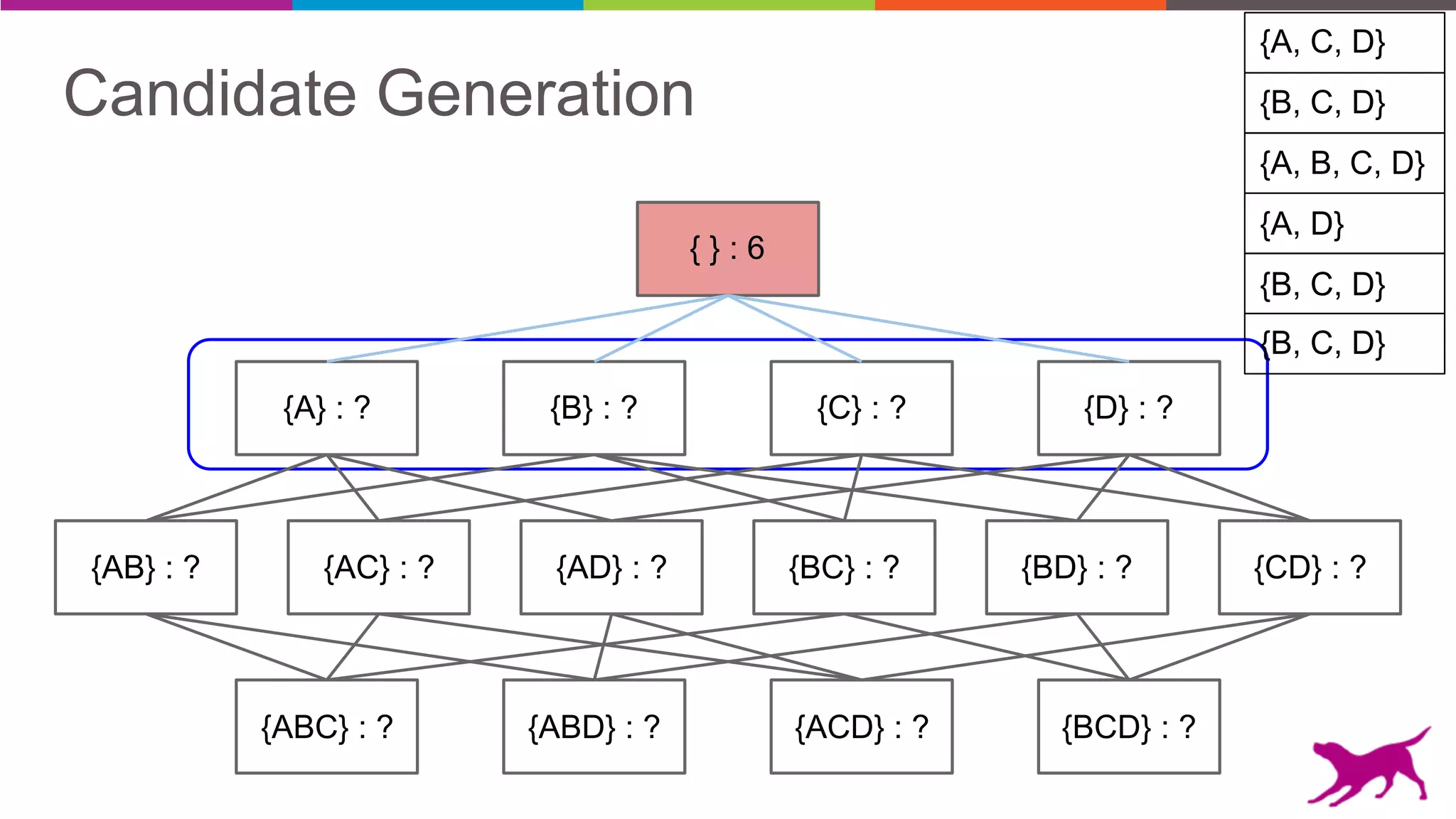
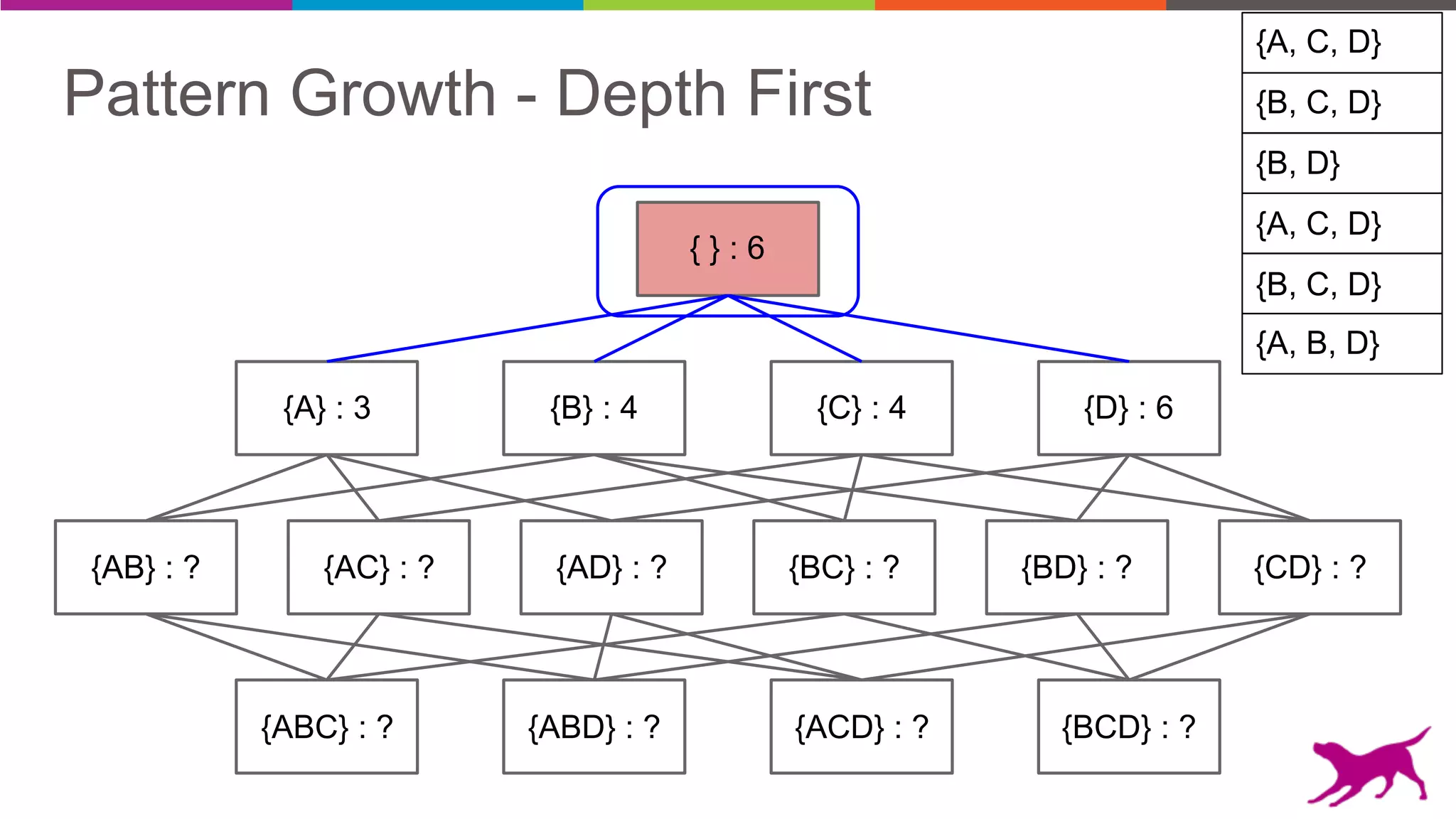
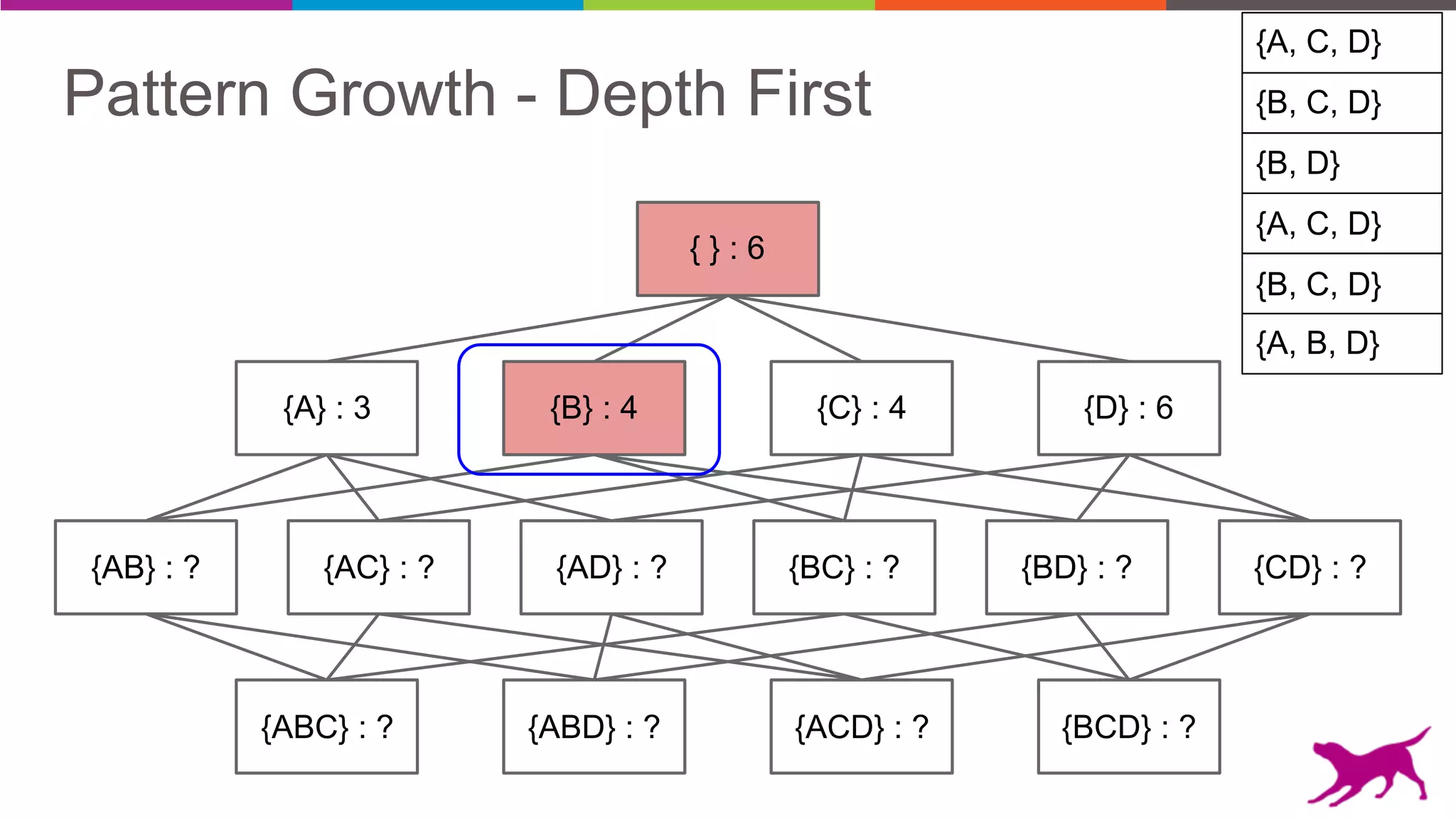
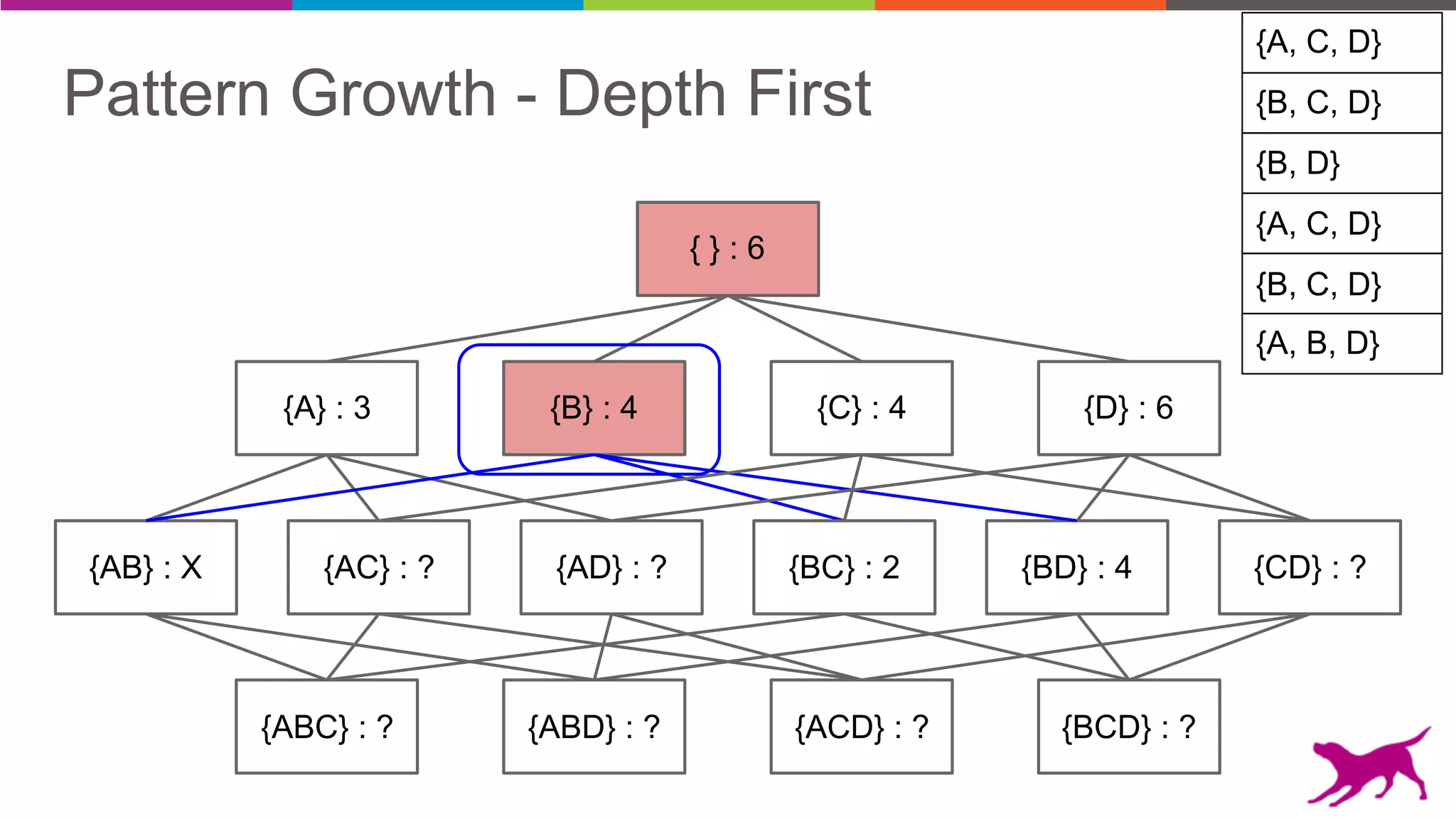
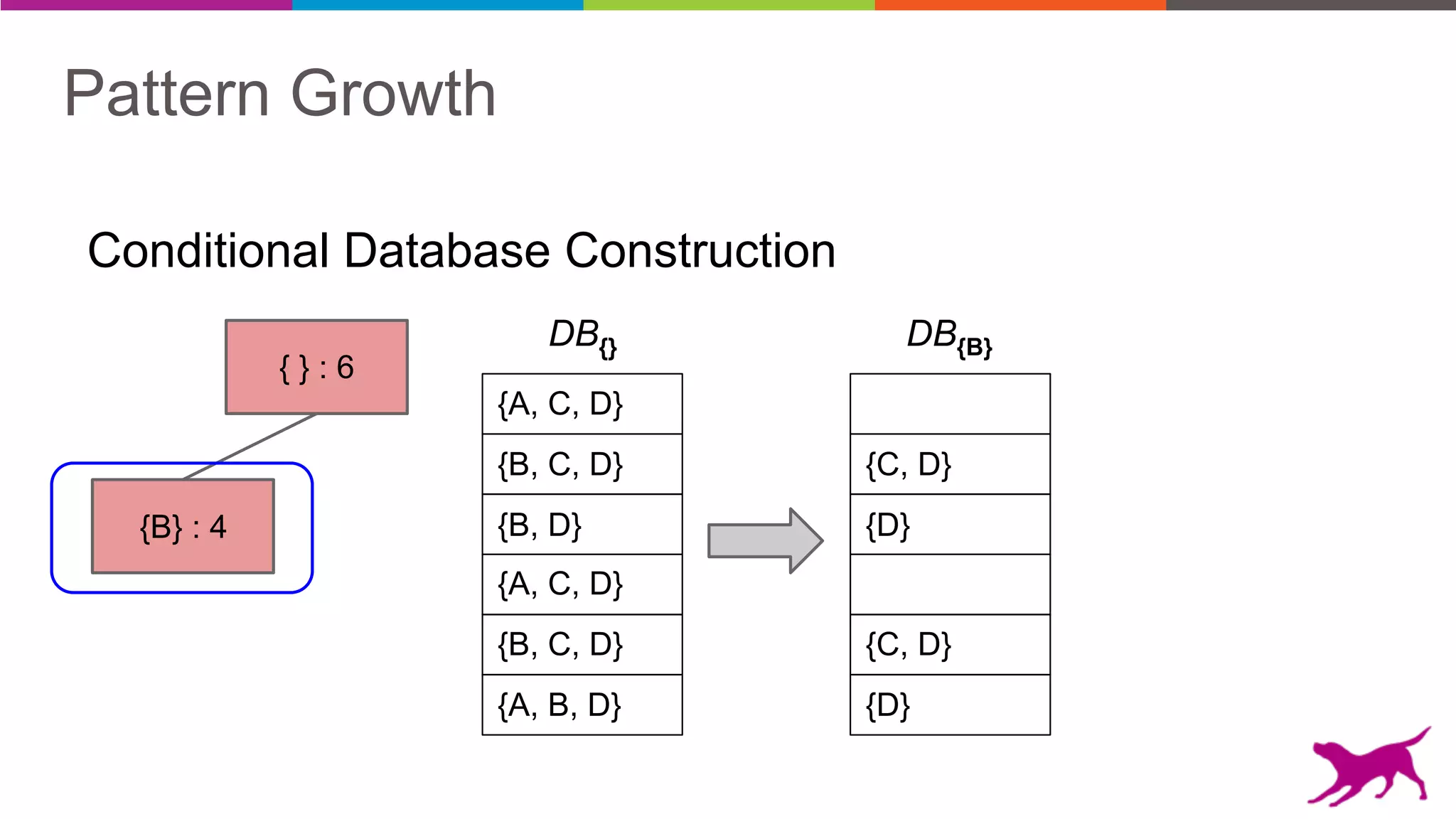
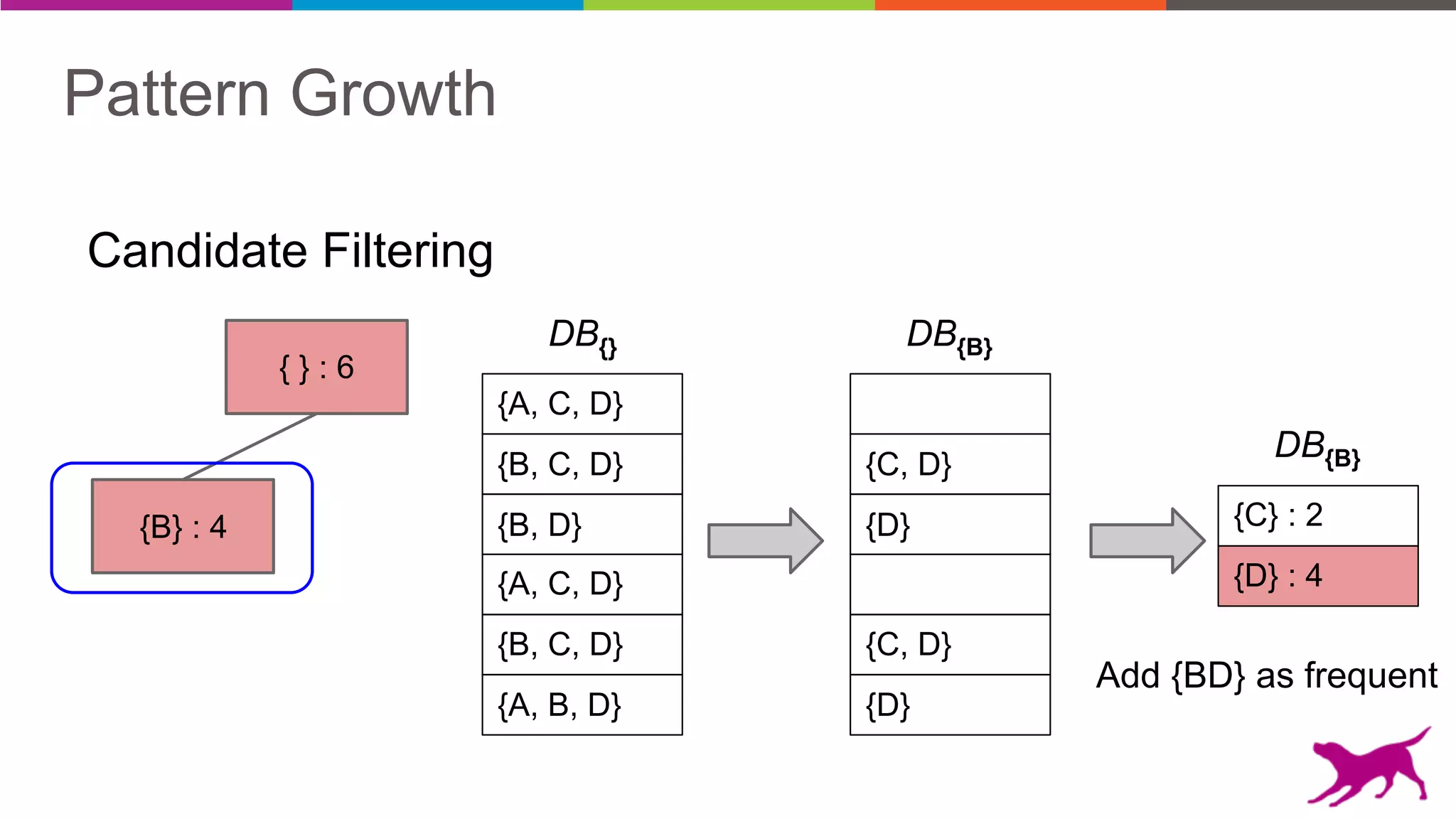
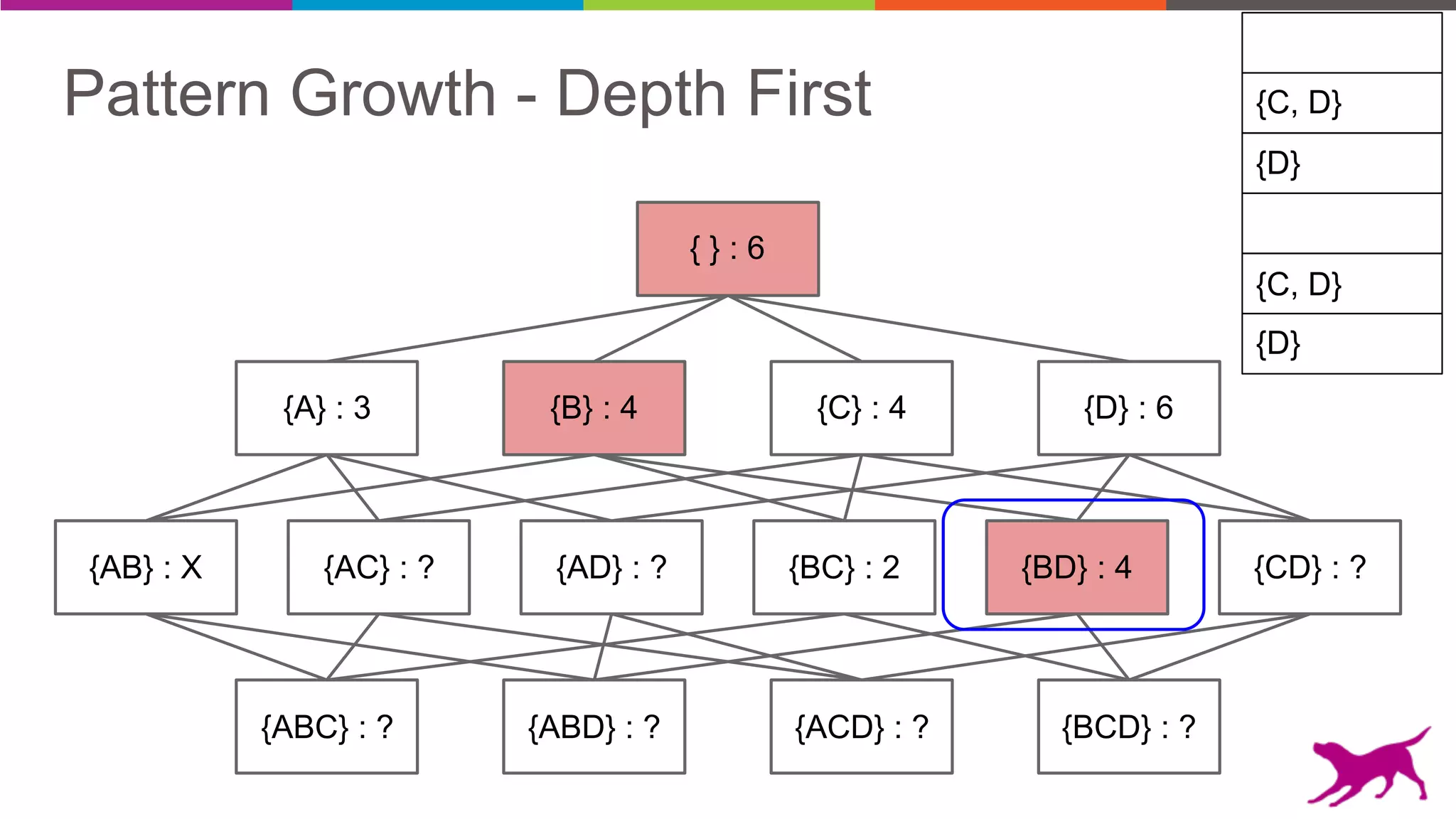
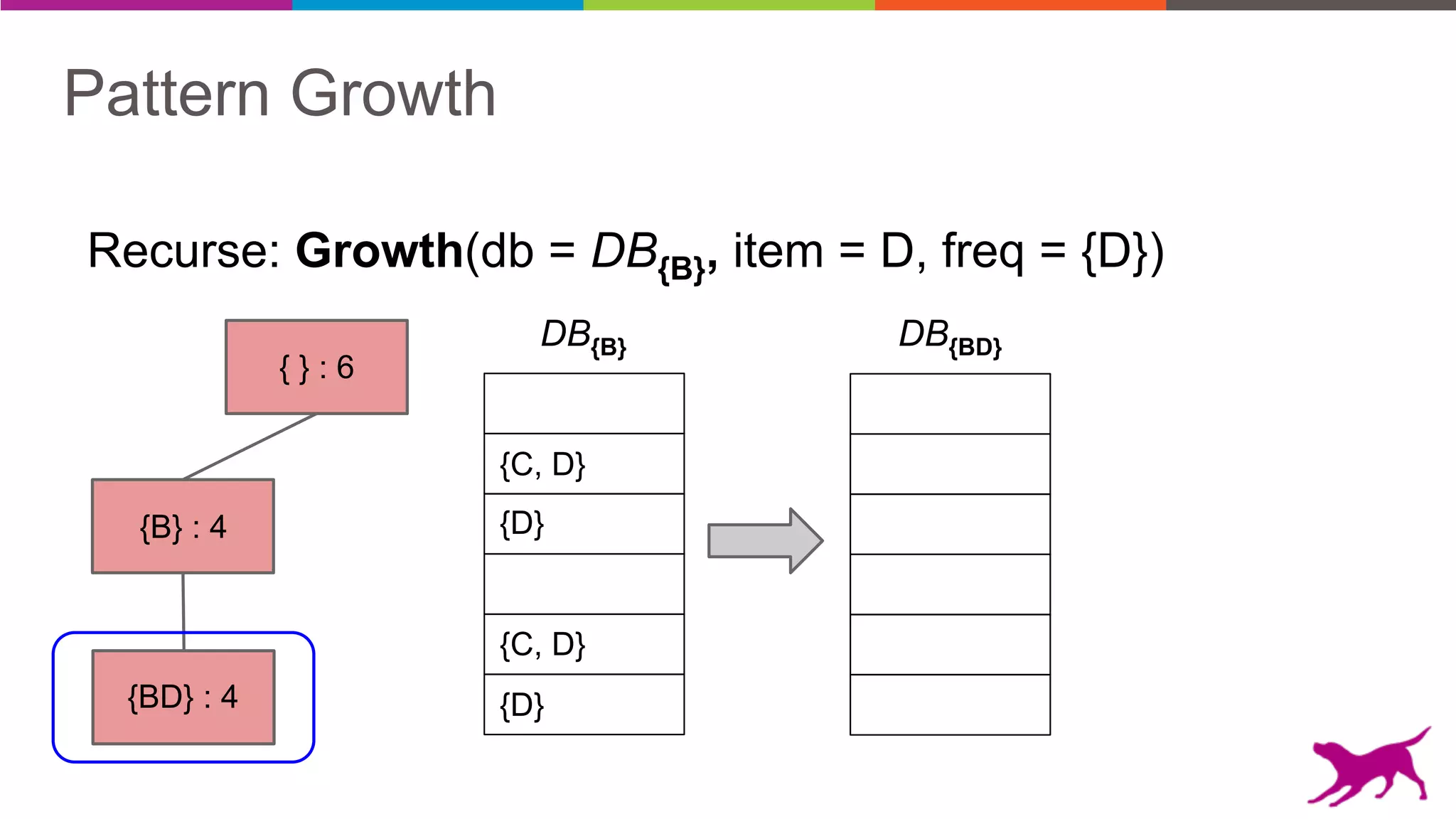
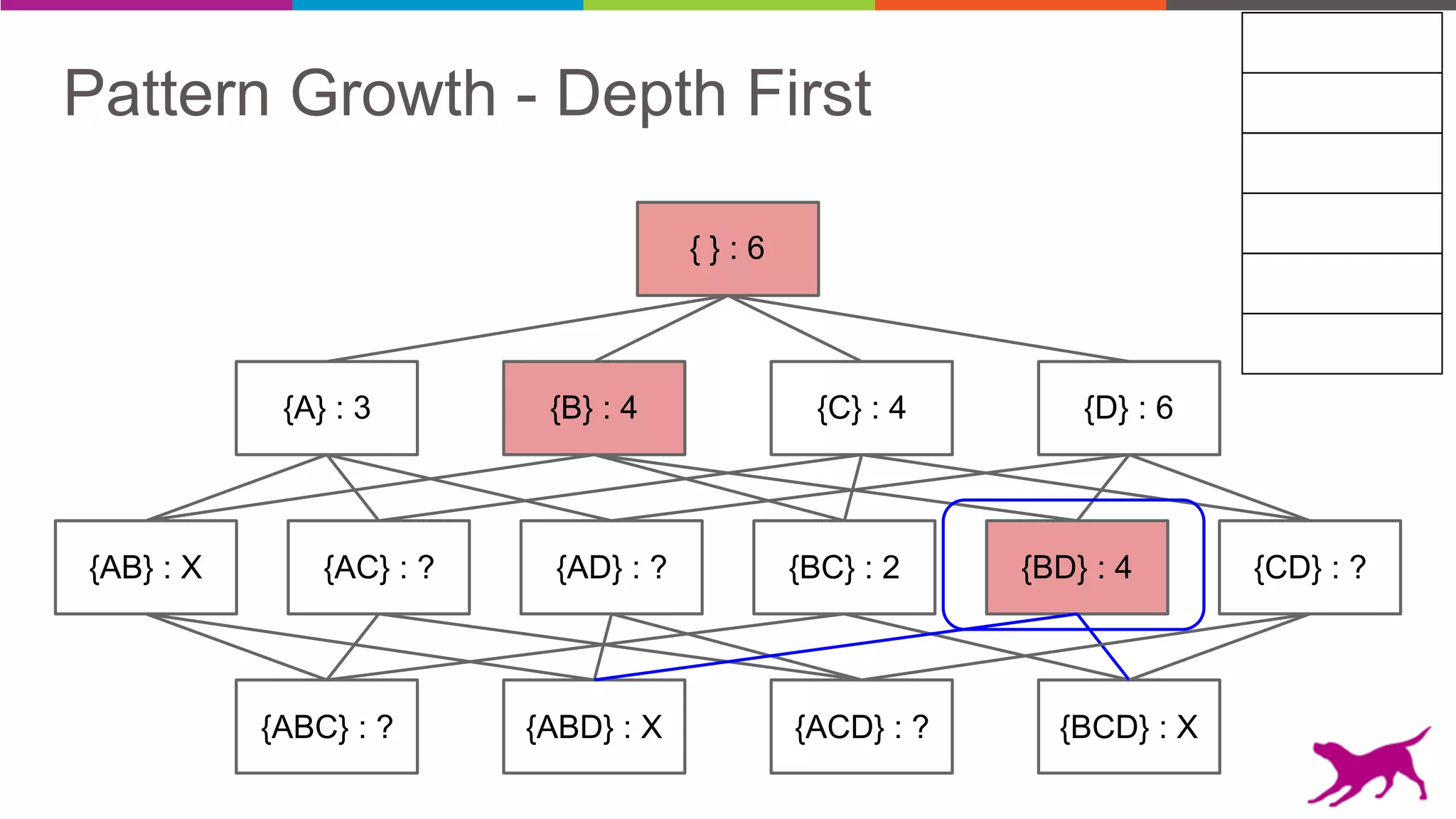
Pattern mining is an unsupervised machine learning technique used to discover frequent patterns and relationships in log data. It involves finding the top frequent sets of items that occur together in the data at least a minimum number of times. There are two main approaches - candidate generation which generates and filters candidate patterns in multiple passes over the data, and pattern growth which constructs conditional databases to avoid multiple full scans. Pattern mining can be used to find commonly purchased itemsets, extract features from log data, and derive rules for recommendations.






































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)















