Download as PDF, PPTX




















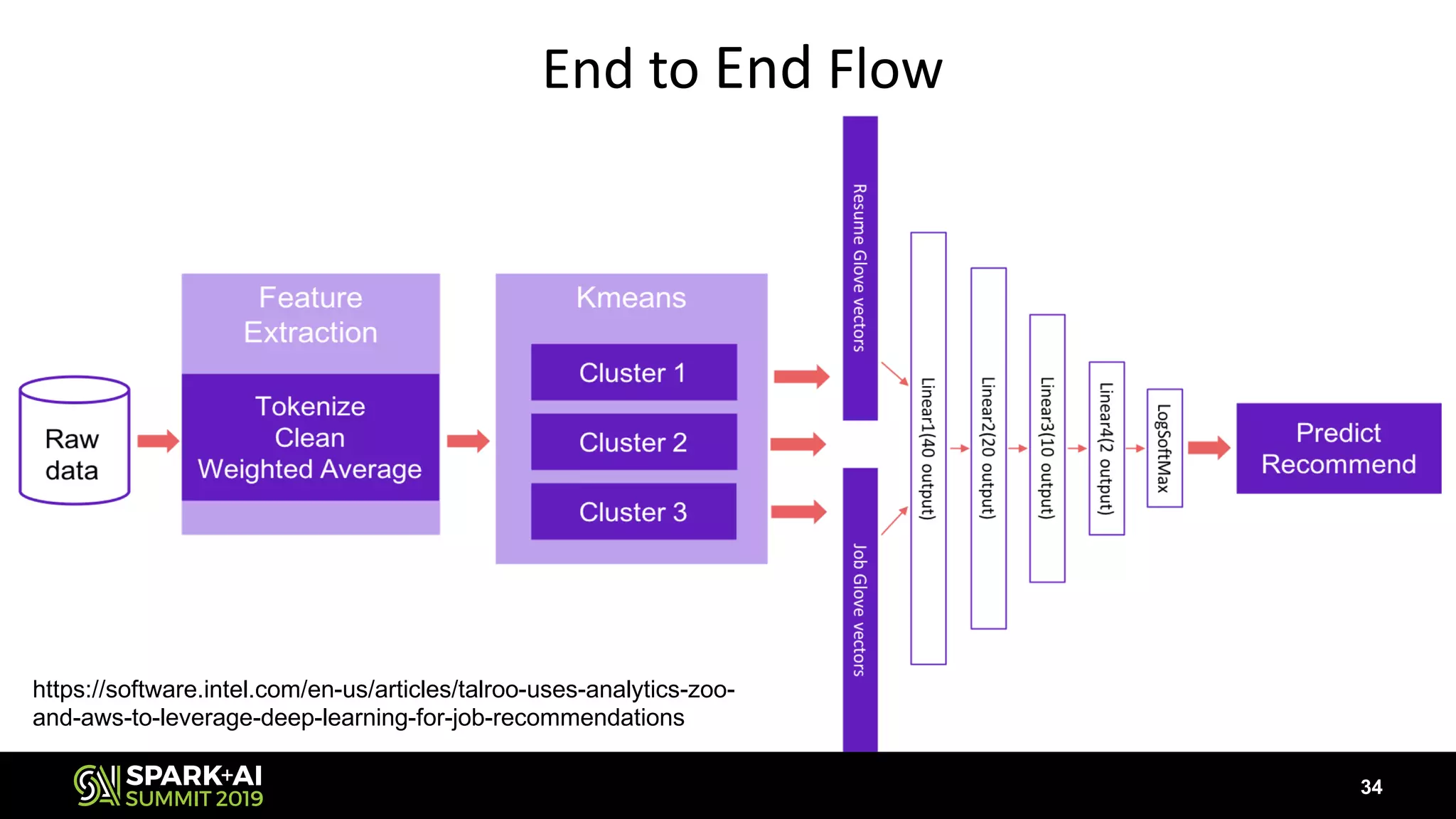
![Recommender model
33
val model = Sequential[Float]()
model.add(Linear(100, 40)).add(ReLU())
.add(Linear(40, 20)).add(ReLU())
.add(Linear(20, 10)).add(ReLU())
.add(Linear(10, 2)).add(ReLU())
.add(LogSoftMax())
Resume Glove vectors
Linear1(40 output)
Linear2(20 output)
Linear3(10 output)
LogSoftMax
Job Glove vectors
Linear4(2 output)](https://image.slidesharecdn.com/072002guoqiongsong-190506222558/75/Leveraging-NLP-and-Deep-Learning-for-Document-Recommendations-in-the-Cloud-33-2048.jpg)



































![Recommender model
33
val model = Sequential[Float]()
model.add(Linear(100, 40)).add(ReLU())
.add(Linear(40, 20)).add(ReLU())
.add(Linear(20, 10)).add(ReLU())
.add(Linear(10, 2)).add(ReLU())
.add(LogSoftMax())
Resume Glove vectors
Linear1(40 output)
Linear2(20 output)
Linear3(10 output)
LogSoftMax
Job Glove vectors
Linear4(2 output)](https://crownmelresort.com/image.slidesharecdn.com/072002guoqiongsong-190506222558/75/Leveraging-NLP-and-Deep-Learning-for-Document-Recommendations-in-the-Cloud-33-2048.jpg)






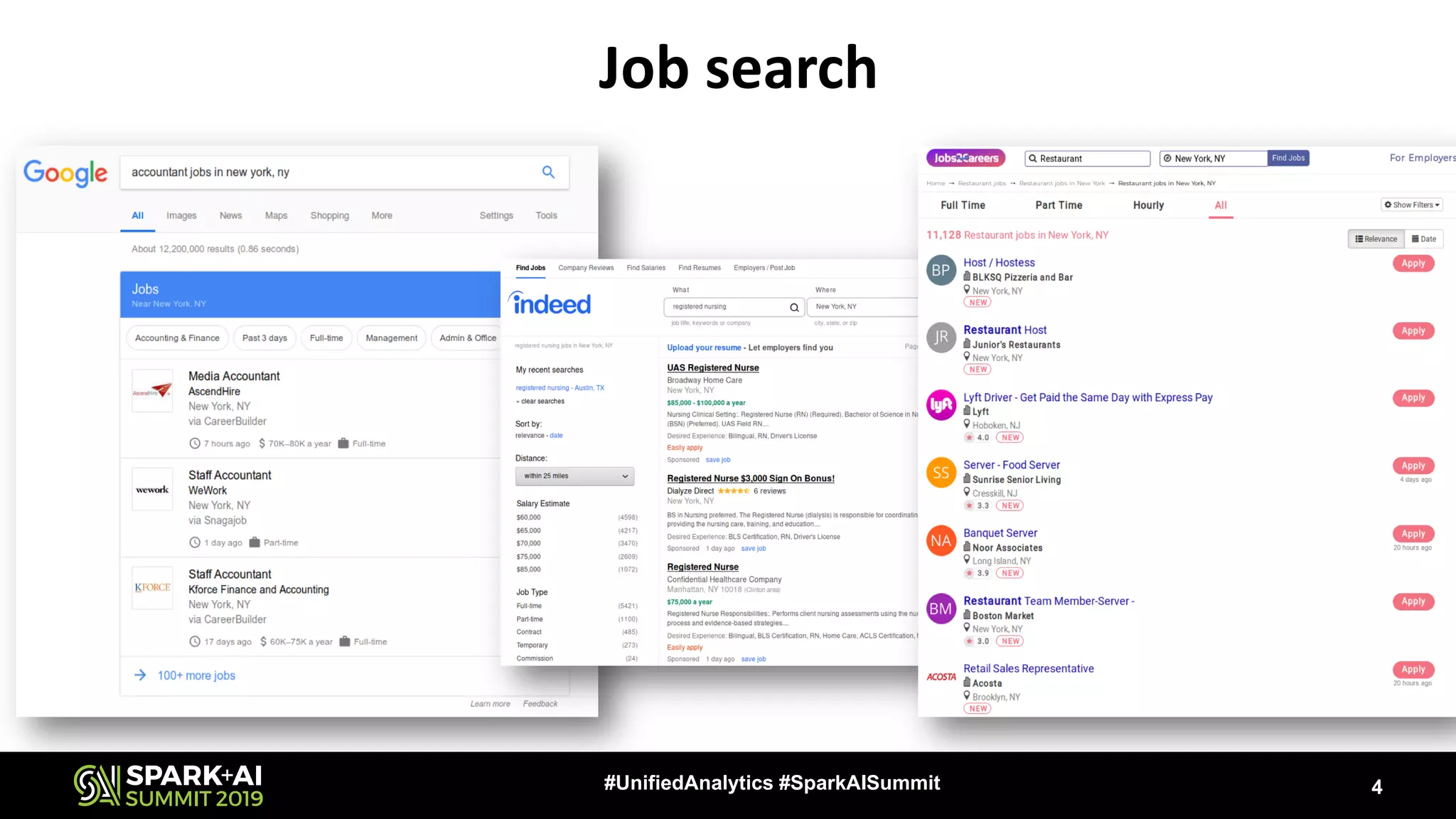
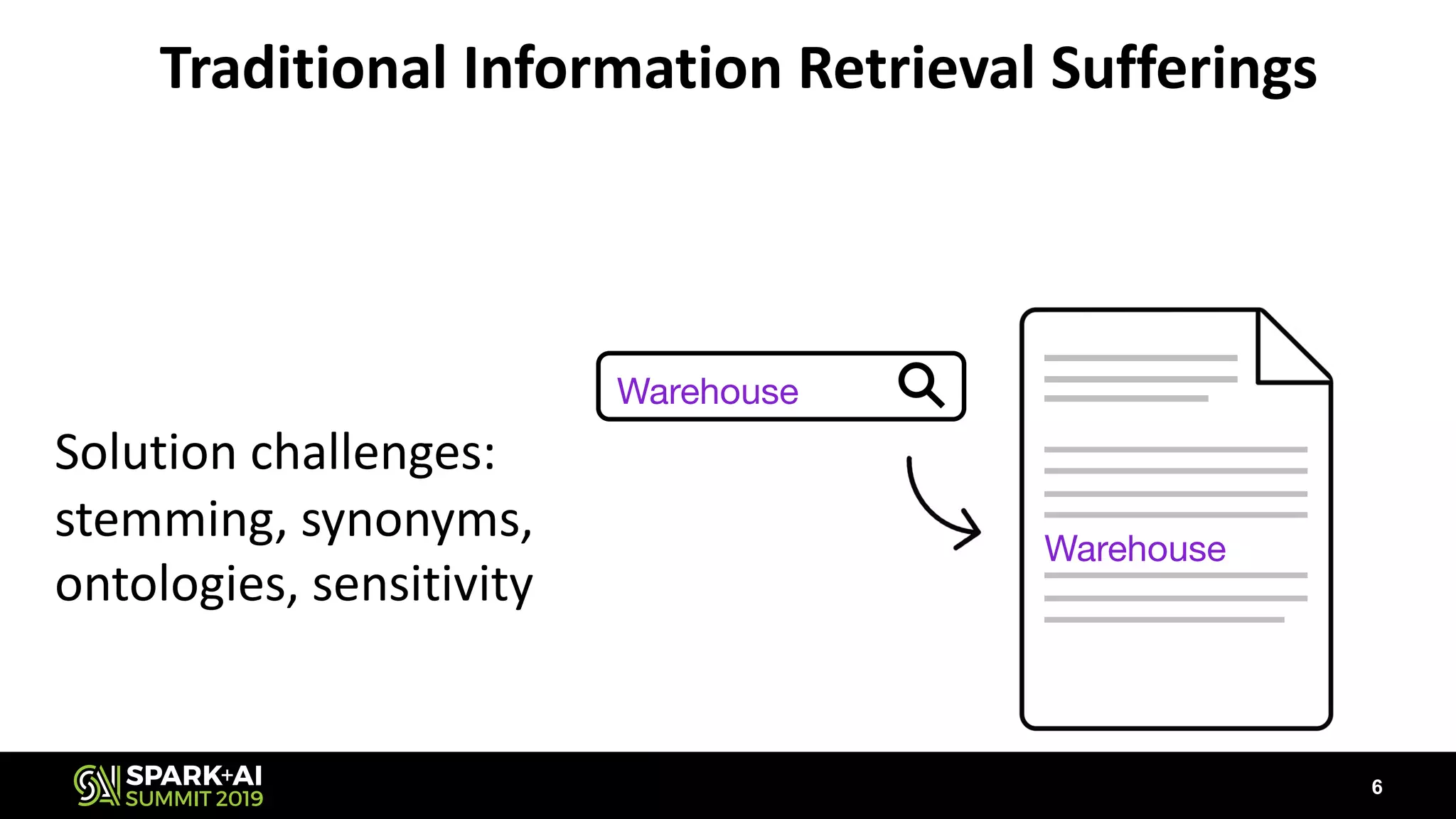
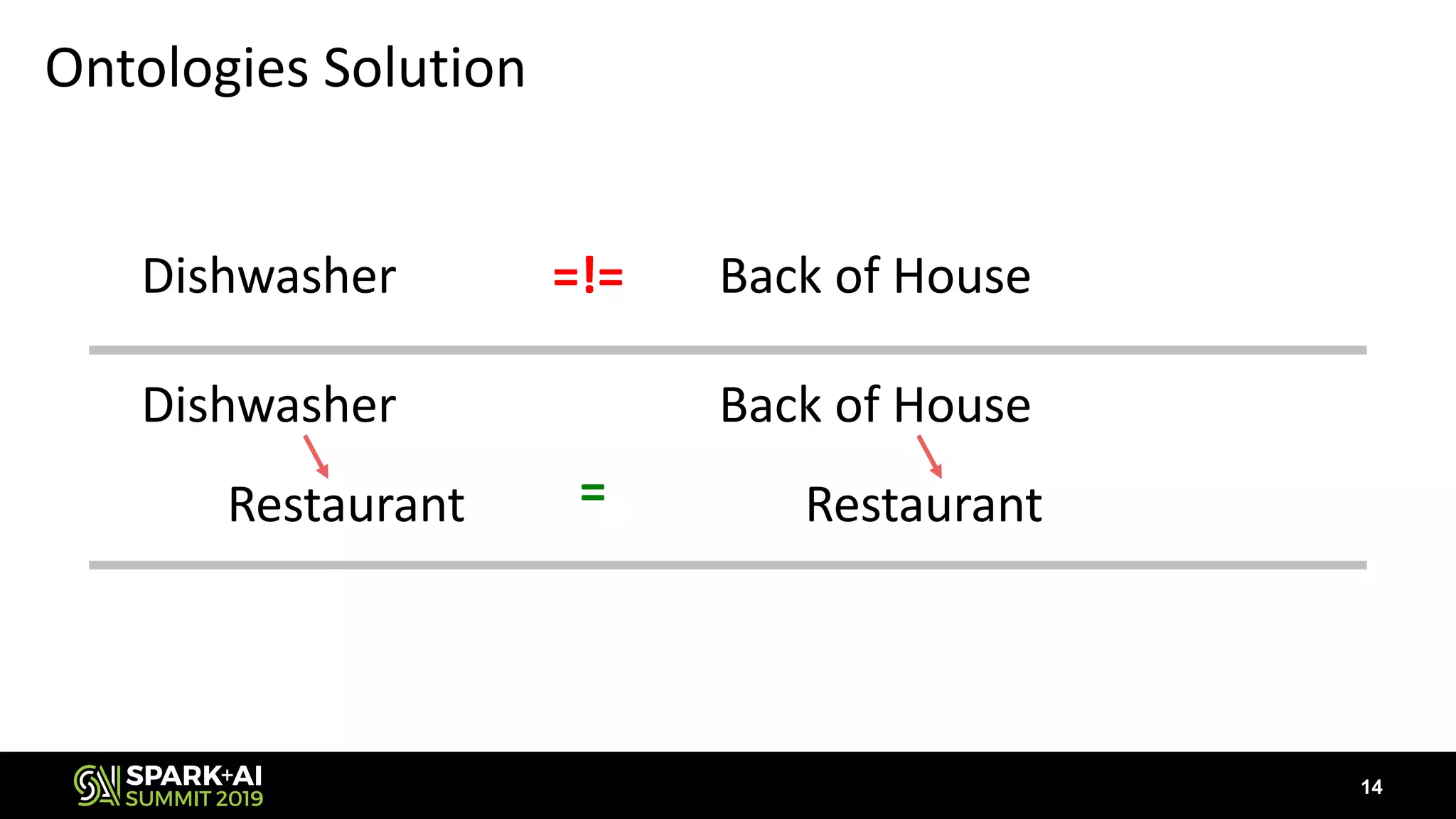
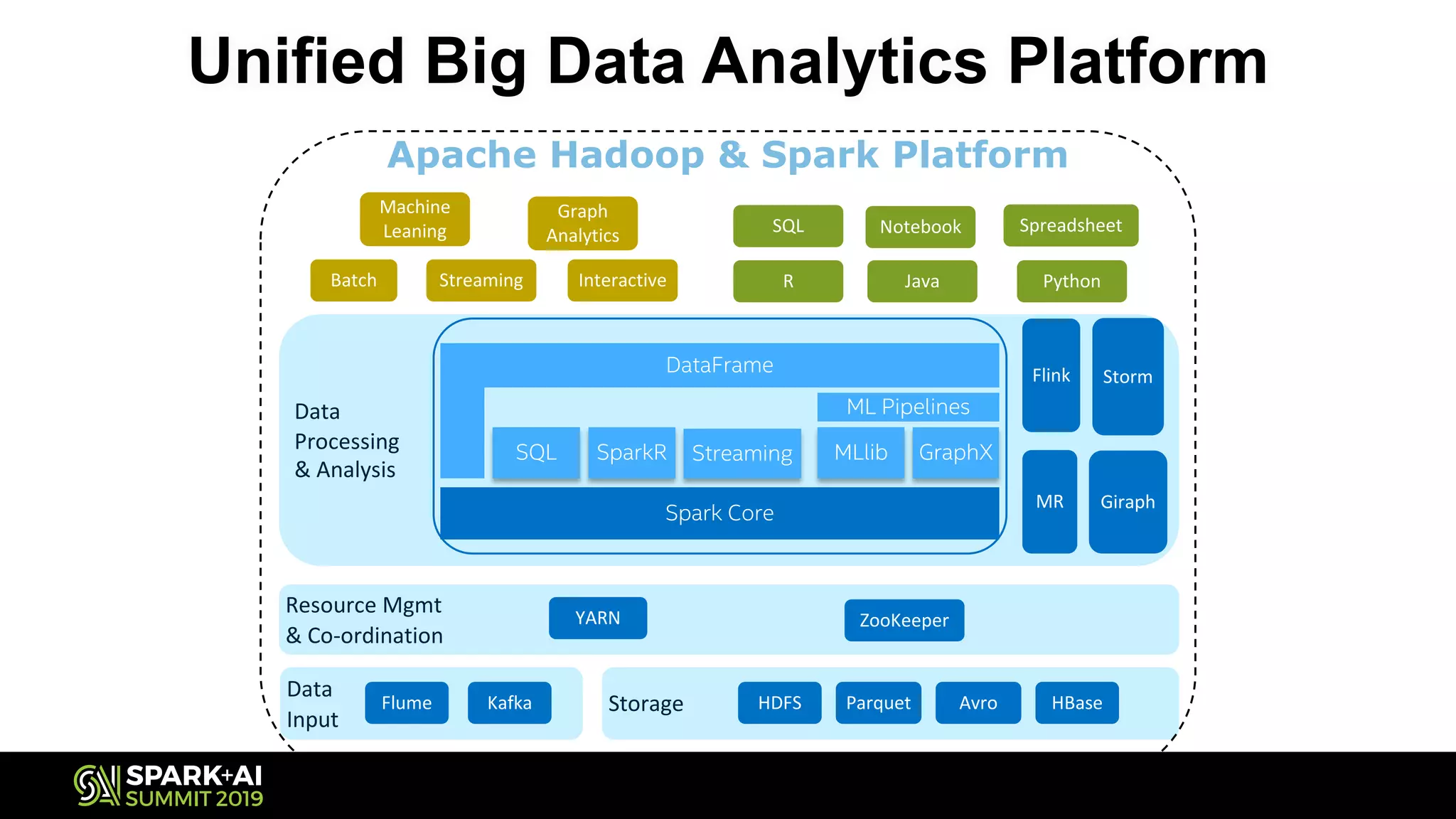
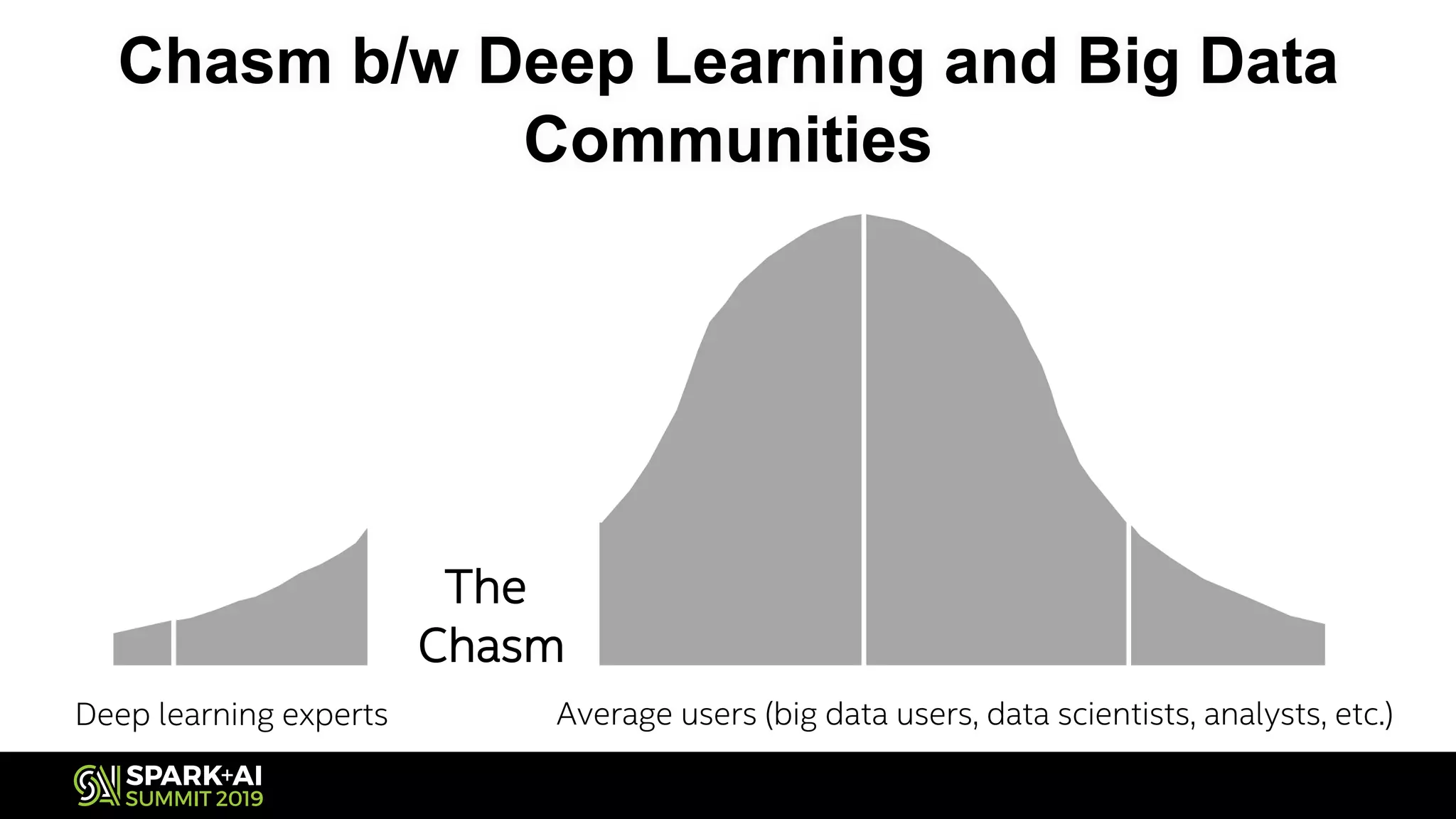
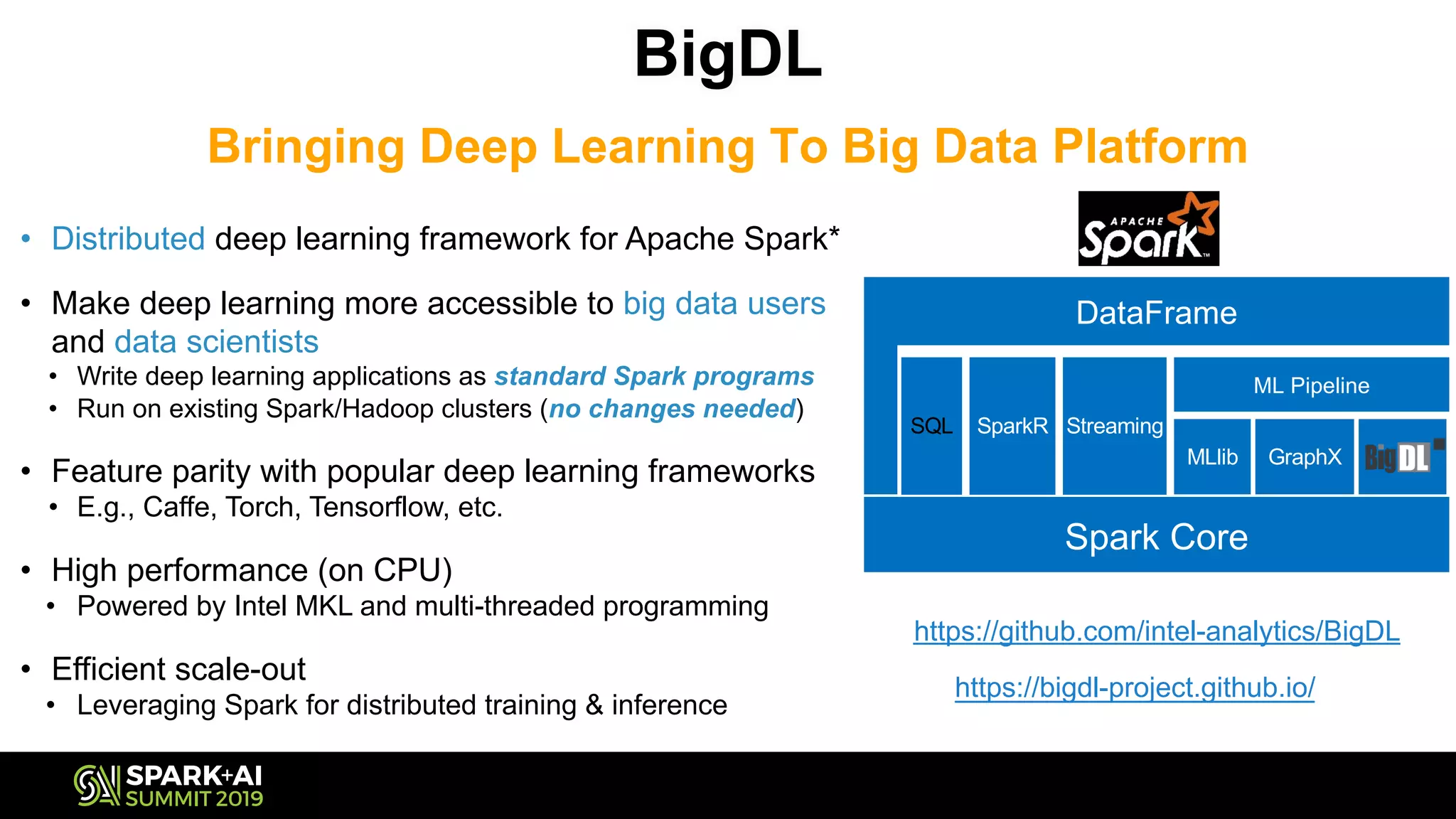
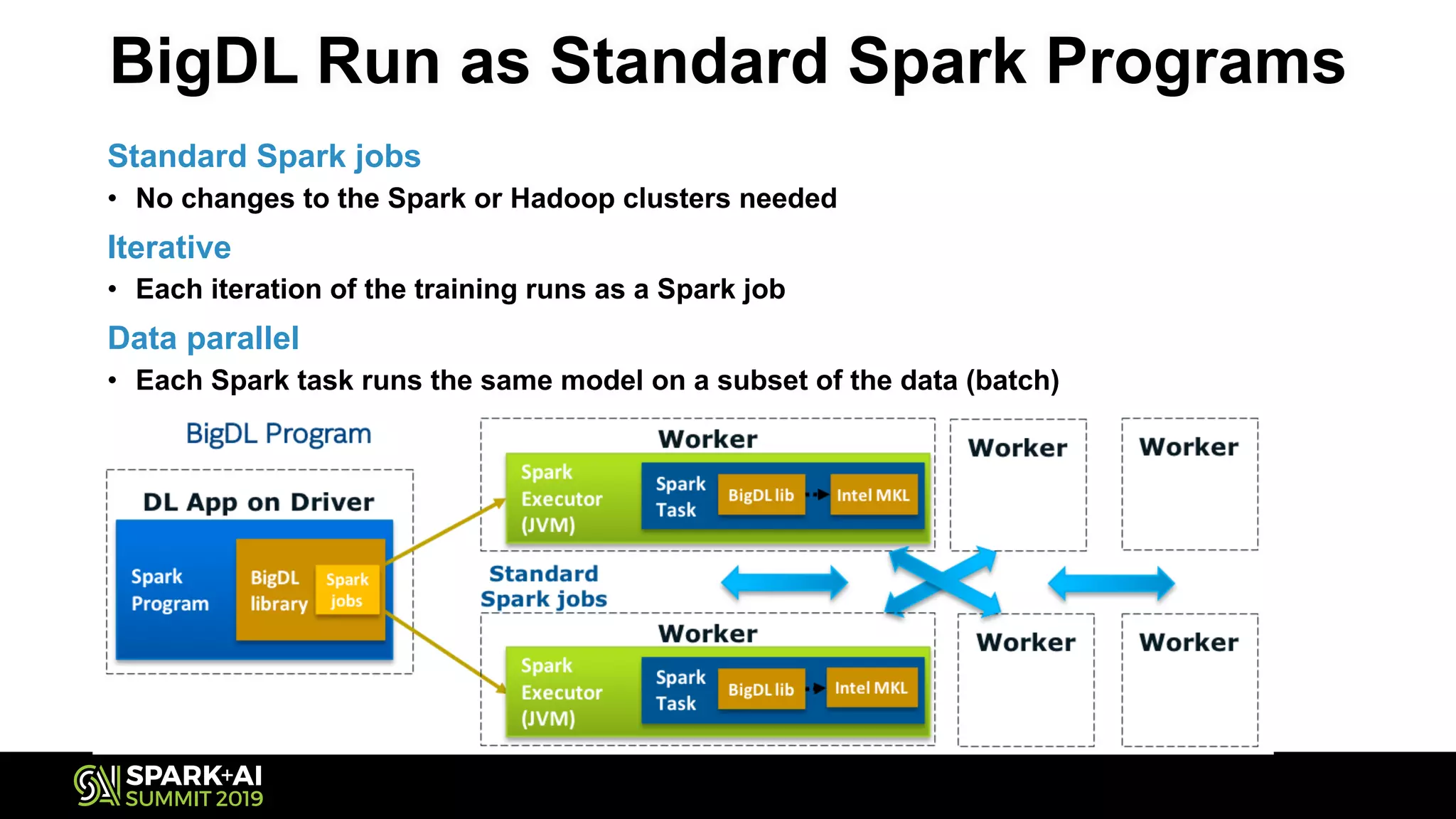
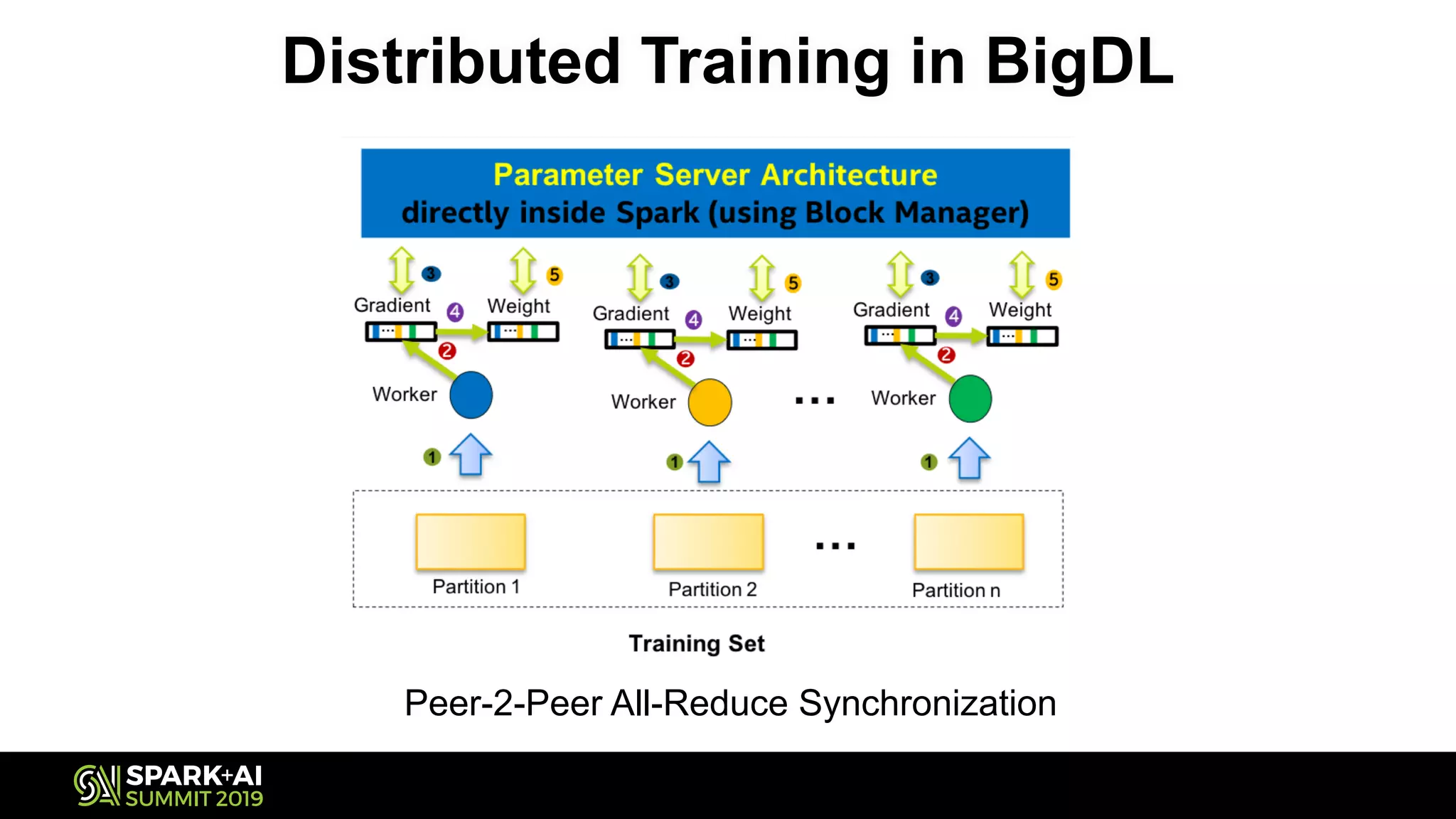
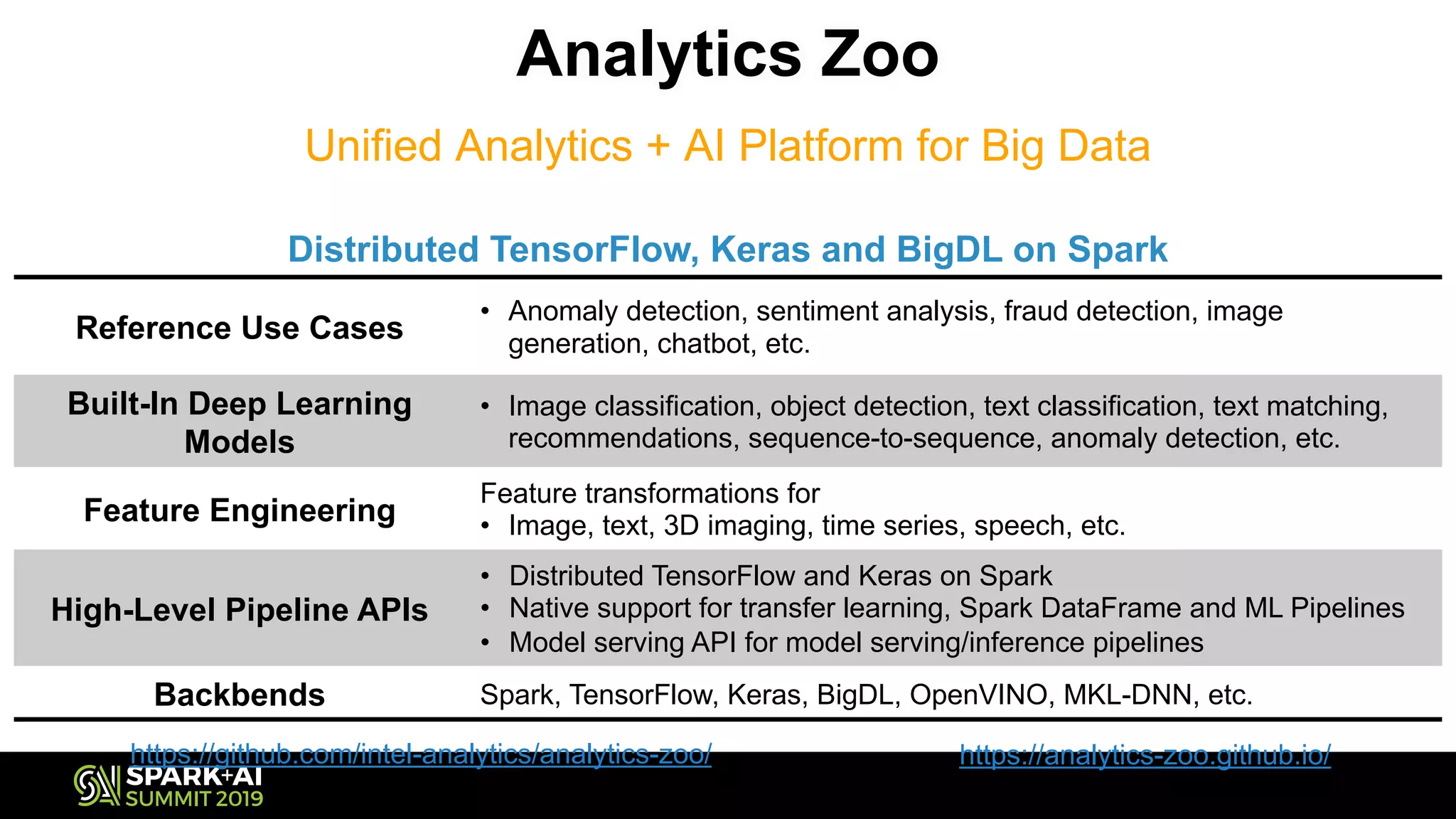
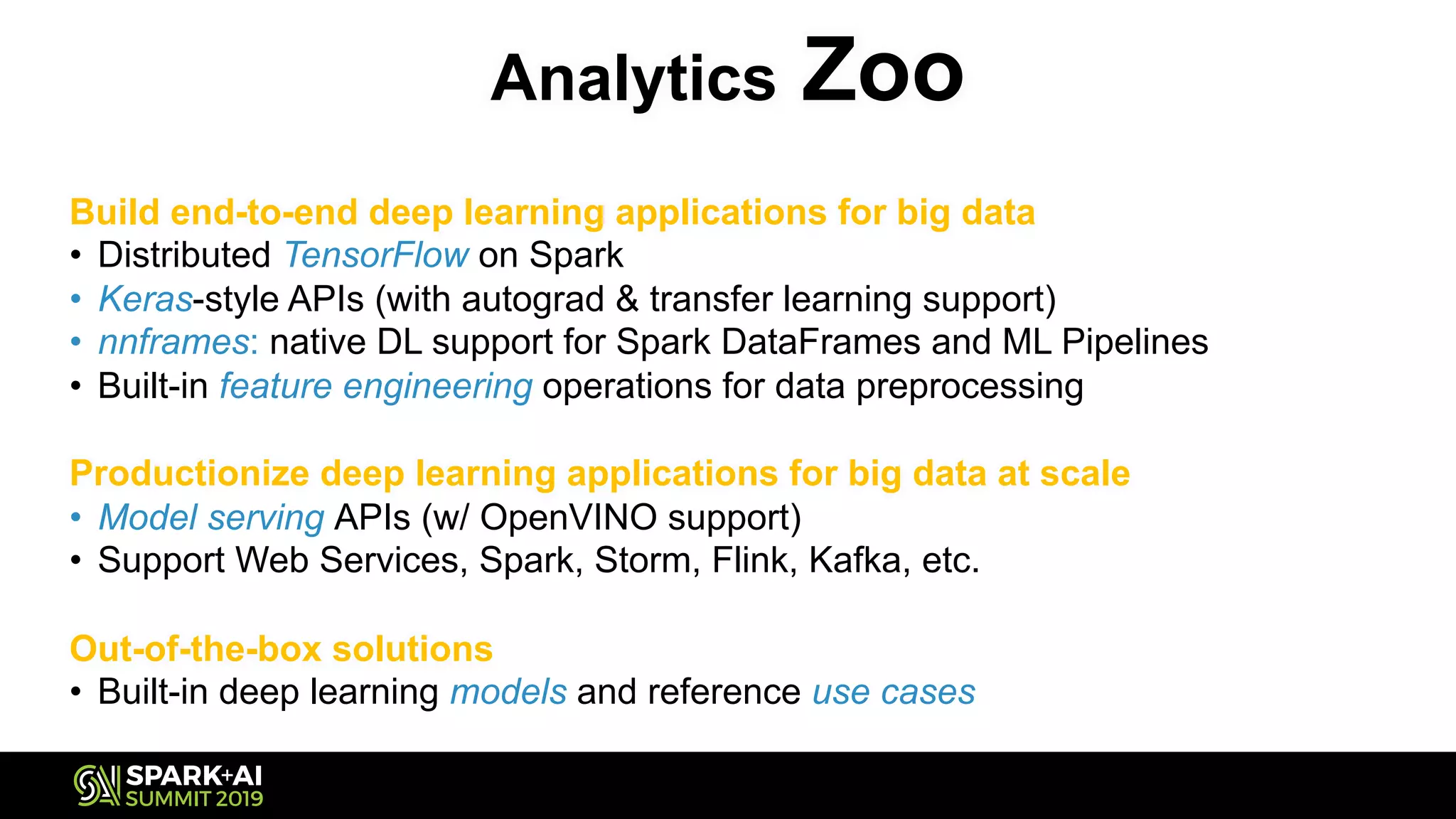
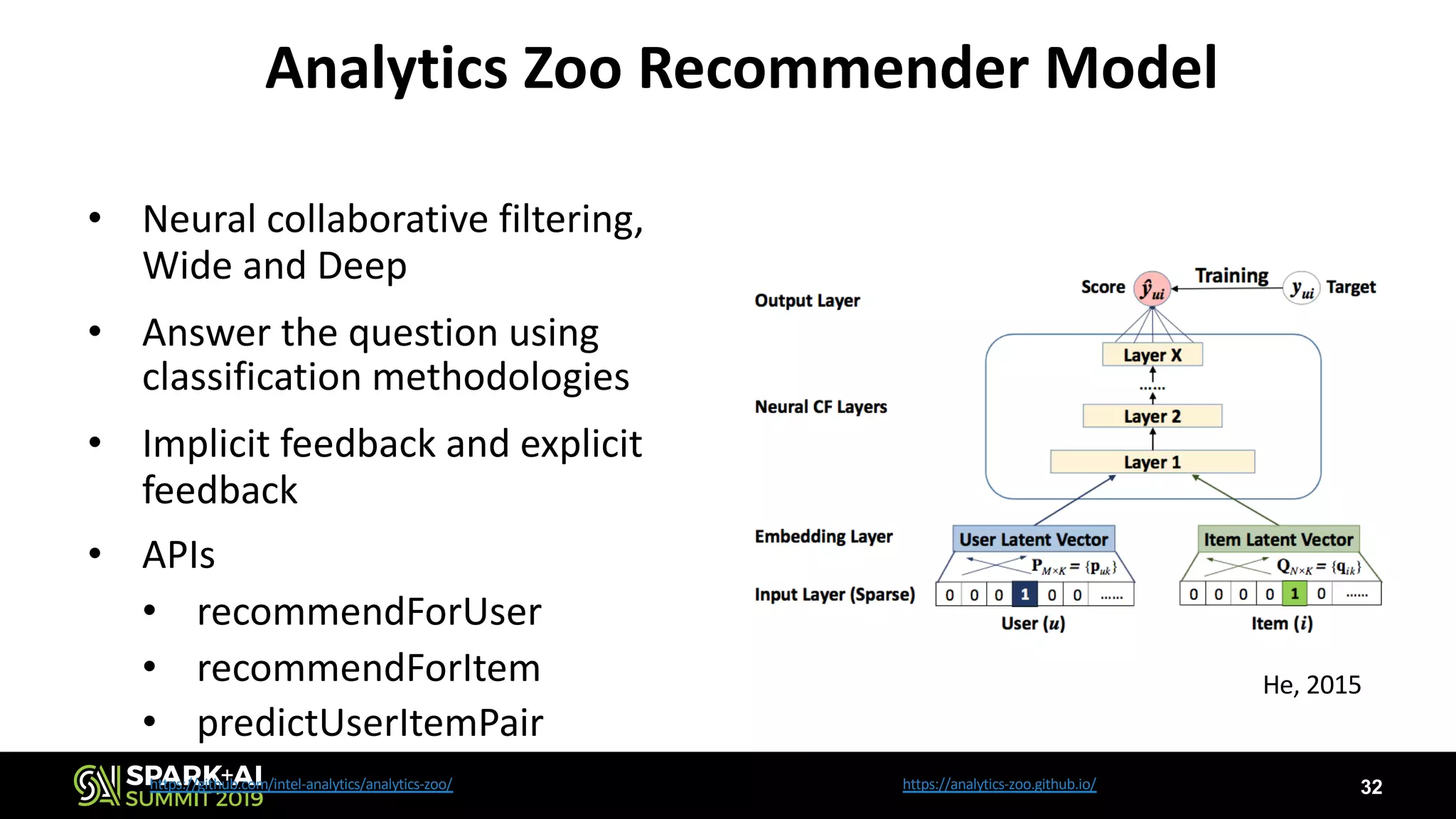
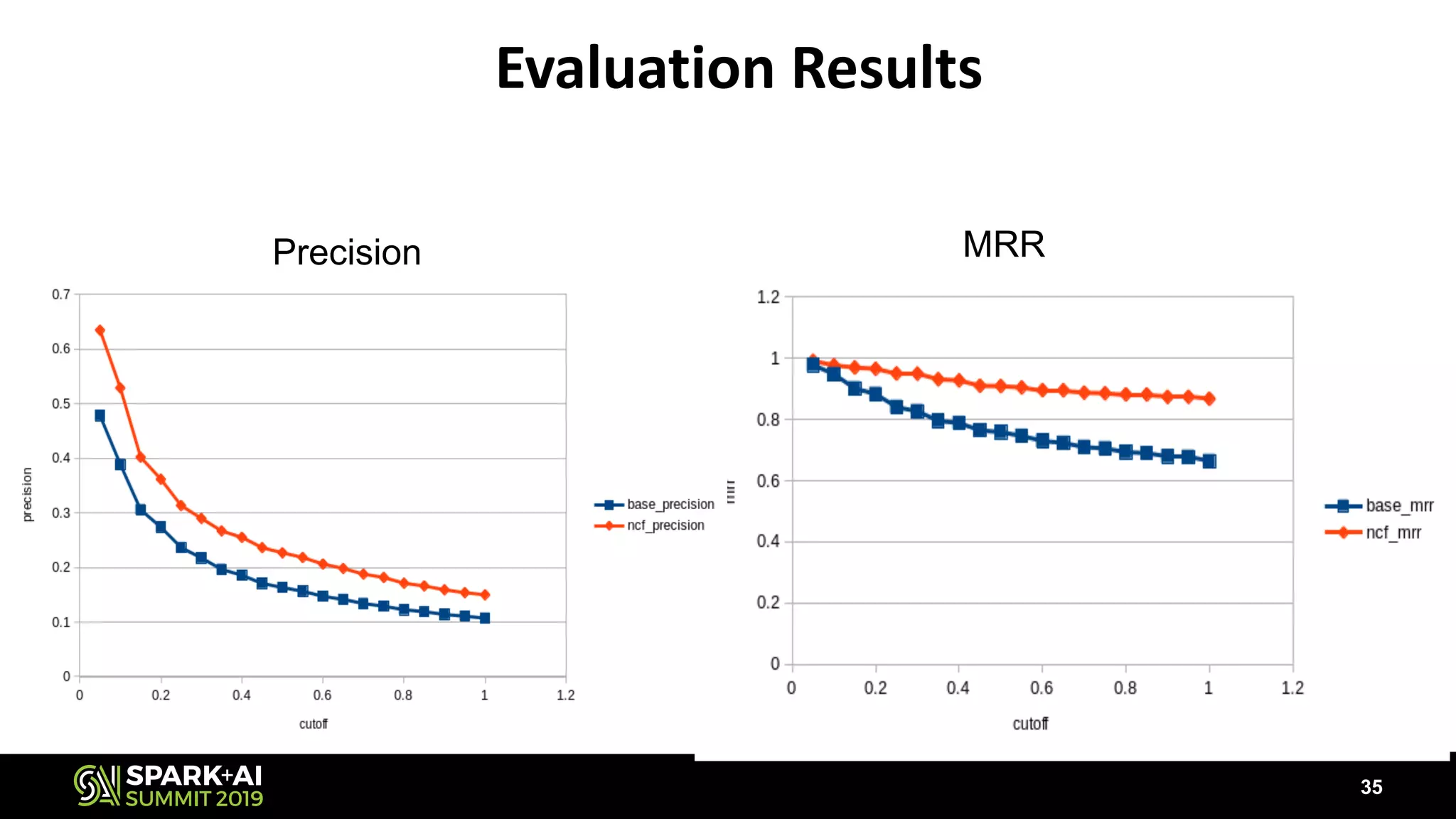
The document discusses the challenges and opportunities in job and resume search analytics, emphasizing the integration of NLP and deep learning through Intel's Analytics Zoo and BigDL for enhanced document recommendation. It highlights the importance of personalized results for job seekers and employers, addressing issues related to traditional information retrieval methods such as stemming and synonyms. The document also outlines practical applications of deep learning in big data analytics and showcases reference use cases including anomaly detection and sentiment analysis.
















































































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)





