Downloaded 25 times




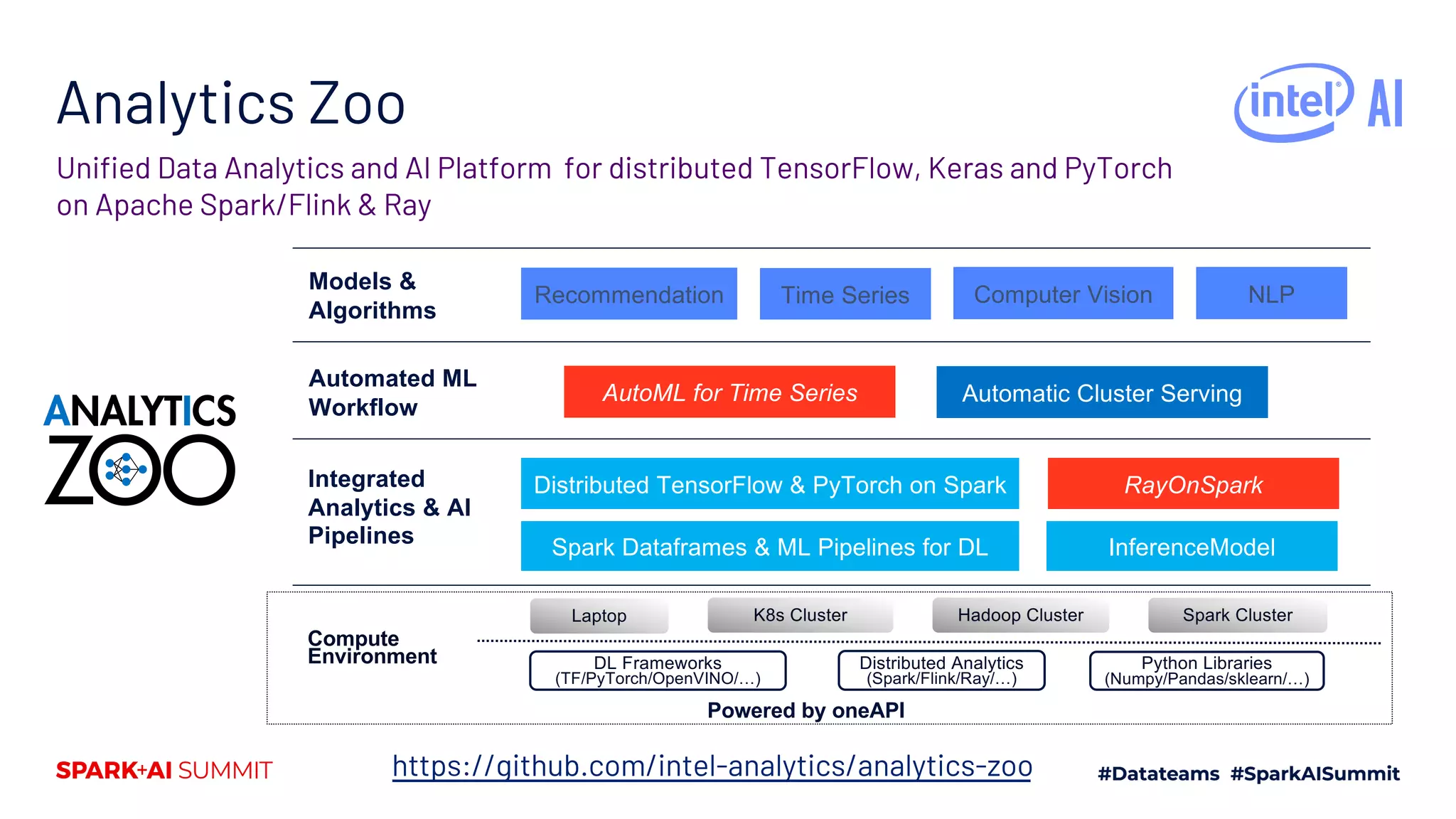
![Ray
Ray Core provides easy Python interface for parallelism by using remote functions
and actors.
Ray is a fast and simple framework for building and running distributed applications.
import ray
ray.init()
@ray.remote(num_cpus, …)
def f(x):
return x * x
# Executed in parallel
ray.get([f.remote(i) for i in range(5)])
@ray.remote(num_cpus, …)
class Counter(object):
def __init__(self):
self.n = 0
def increment(self):
self.n += 1
return self.n
counters = [Counter.remote() for i in range(5)]
# Executed in parallel
ray.get([c.increment.remote() for c in counters])](https://image.slidesharecdn.com/235kaihuangjasondai-200707200514/75/Running-Emerging-AI-Applications-on-Big-Data-Platforms-with-Ray-On-Apache-Spark-7-2048.jpg)


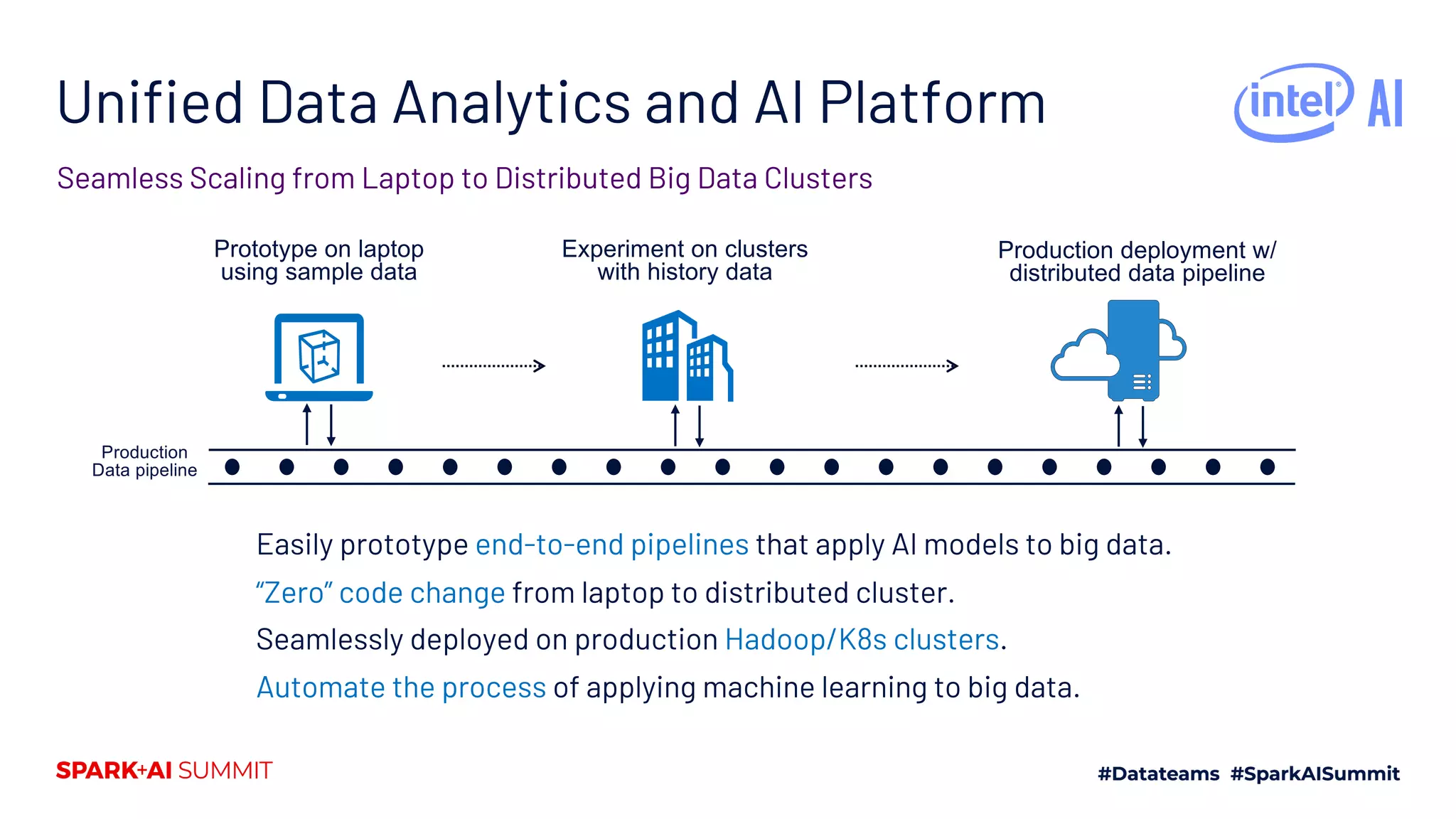
![Interface of RayOnSpark
Three-step programming with minimum code
changes:
Initiate or use an existing SparkContext.
Initiate RayContext.
Shut down SparkContext and RayContext
after tasks finish.
More instructions at: https://analytics-
zoo.github.io/master/#ProgrammingGuide/r
ayonspark/
import ray
from zoo import init_spark_on_yarn
from zoo.ray import RayContext
sc = init_spark_on_yarn(hadoop_conf, conda_name,
num_executors, executor_cores,…)
ray_ctx = RayContext(sc, object_store_memory,…)
ray_ctx.init()
@ray.remote
class Counter(object):
def __init__(self):
self.n = 0
def increment(self):
self.n += 1
return self.n
counters = [Counter.remote() for i in range(5)]
ray.get([c.increment.remote() for c in counters])
ray_ctx.stop()
sc.stop()
RayOnSpark code
Pure Ray code](https://image.slidesharecdn.com/235kaihuangjasondai-200707200514/75/Running-Emerging-AI-Applications-on-Big-Data-Platforms-with-Ray-On-Apache-Spark-11-2048.jpg)










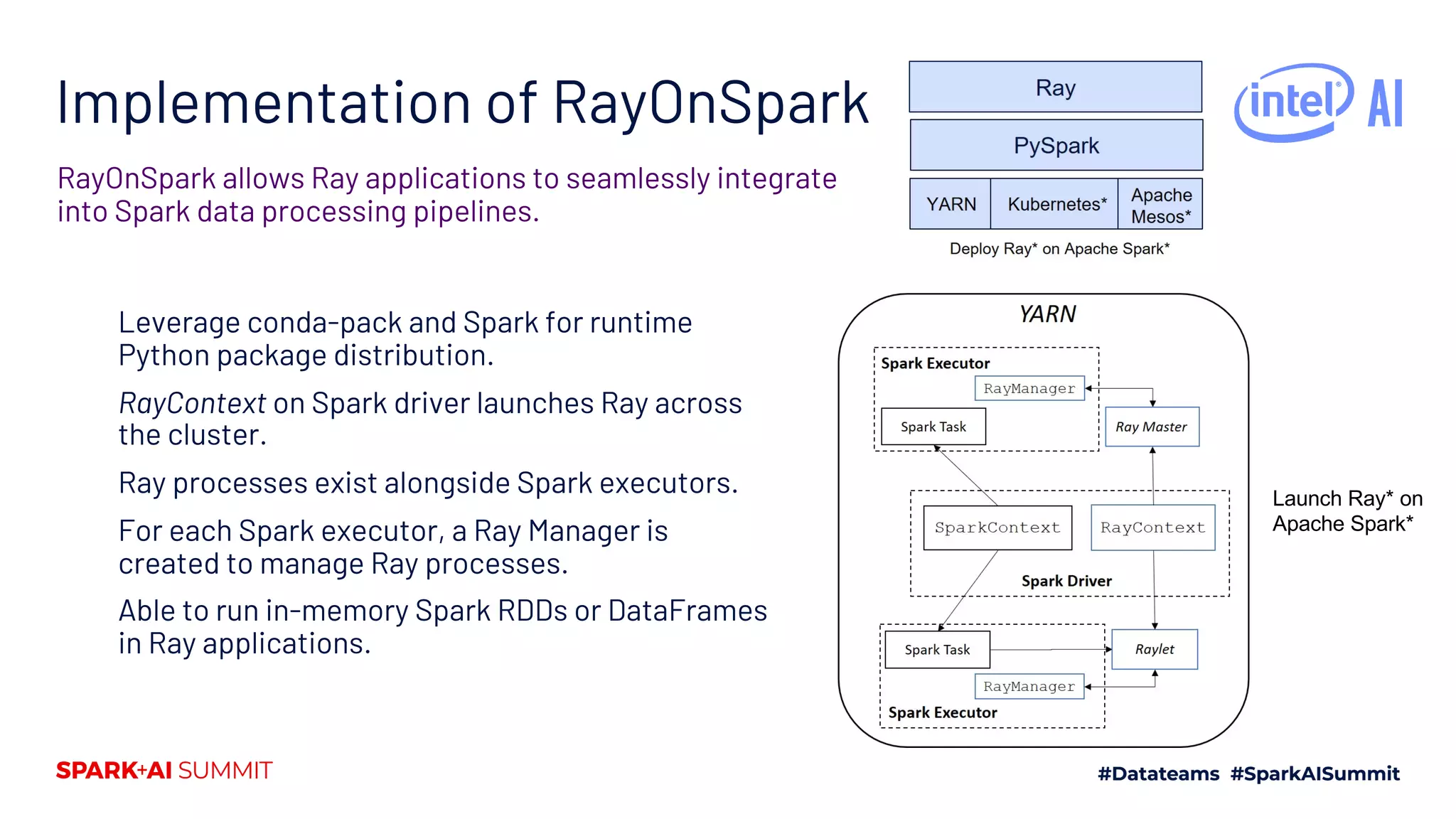
![Ray
Ray Core provides easy Python interface for parallelism by using remote functions
and actors.
Ray is a fast and simple framework for building and running distributed applications.
import ray
ray.init()
@ray.remote(num_cpus, …)
def f(x):
return x * x
# Executed in parallel
ray.get([f.remote(i) for i in range(5)])
@ray.remote(num_cpus, …)
class Counter(object):
def __init__(self):
self.n = 0
def increment(self):
self.n += 1
return self.n
counters = [Counter.remote() for i in range(5)]
# Executed in parallel
ray.get([c.increment.remote() for c in counters])](https://crownmelresort.com/image.slidesharecdn.com/235kaihuangjasondai-200707200514/75/Running-Emerging-AI-Applications-on-Big-Data-Platforms-with-Ray-On-Apache-Spark-7-2048.jpg)



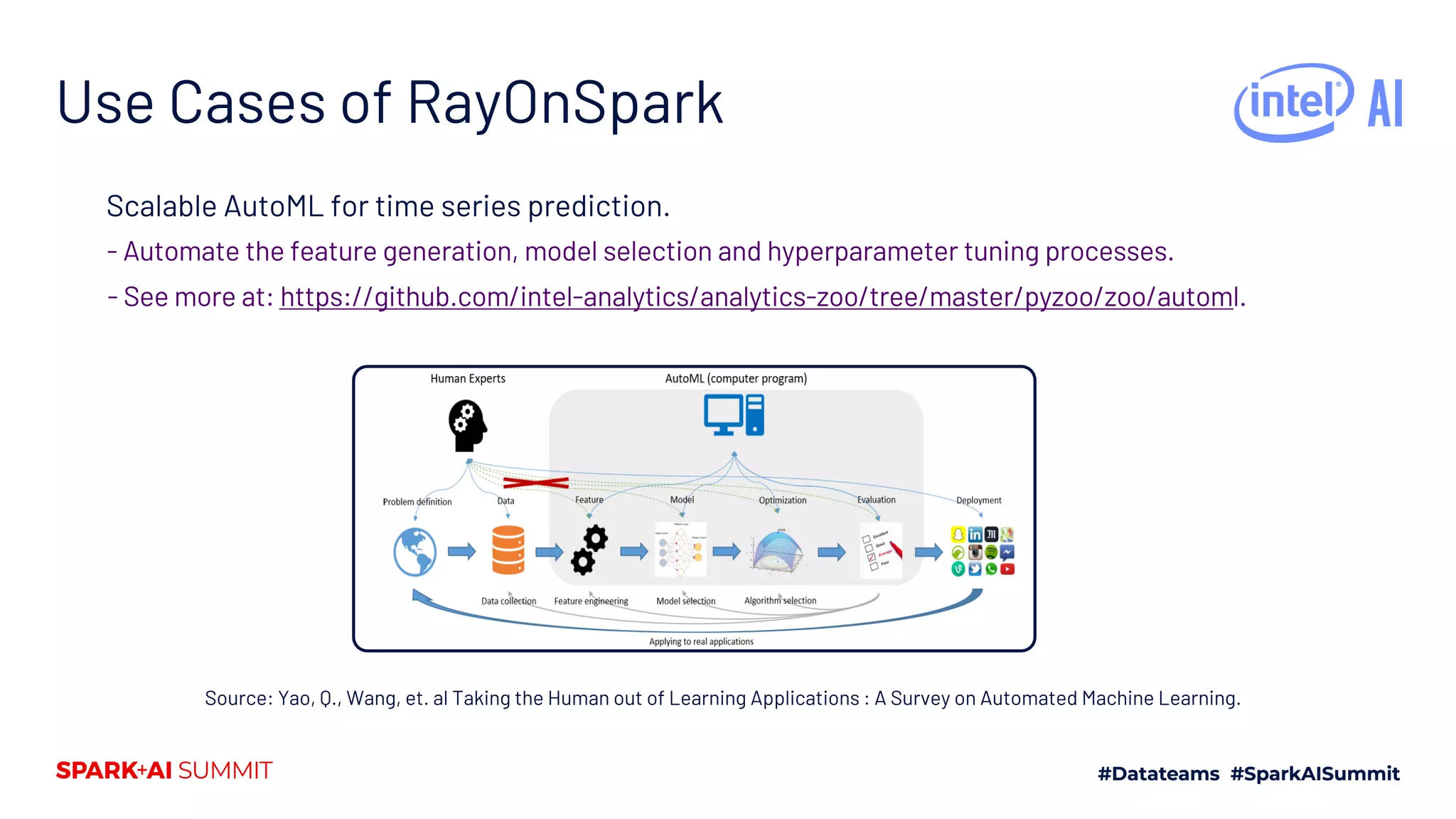
![Interface of RayOnSpark
Three-step programming with minimum code
changes:
Initiate or use an existing SparkContext.
Initiate RayContext.
Shut down SparkContext and RayContext
after tasks finish.
More instructions at: https://analytics-
zoo.github.io/master/#ProgrammingGuide/r
ayonspark/
import ray
from zoo import init_spark_on_yarn
from zoo.ray import RayContext
sc = init_spark_on_yarn(hadoop_conf, conda_name,
num_executors, executor_cores,…)
ray_ctx = RayContext(sc, object_store_memory,…)
ray_ctx.init()
@ray.remote
class Counter(object):
def __init__(self):
self.n = 0
def increment(self):
self.n += 1
return self.n
counters = [Counter.remote() for i in range(5)]
ray.get([c.increment.remote() for c in counters])
ray_ctx.stop()
sc.stop()
RayOnSpark code
Pure Ray code](https://crownmelresort.com/image.slidesharecdn.com/235kaihuangjasondai-200707200514/75/Running-Emerging-AI-Applications-on-Big-Data-Platforms-with-Ray-On-Apache-Spark-11-2048.jpg)








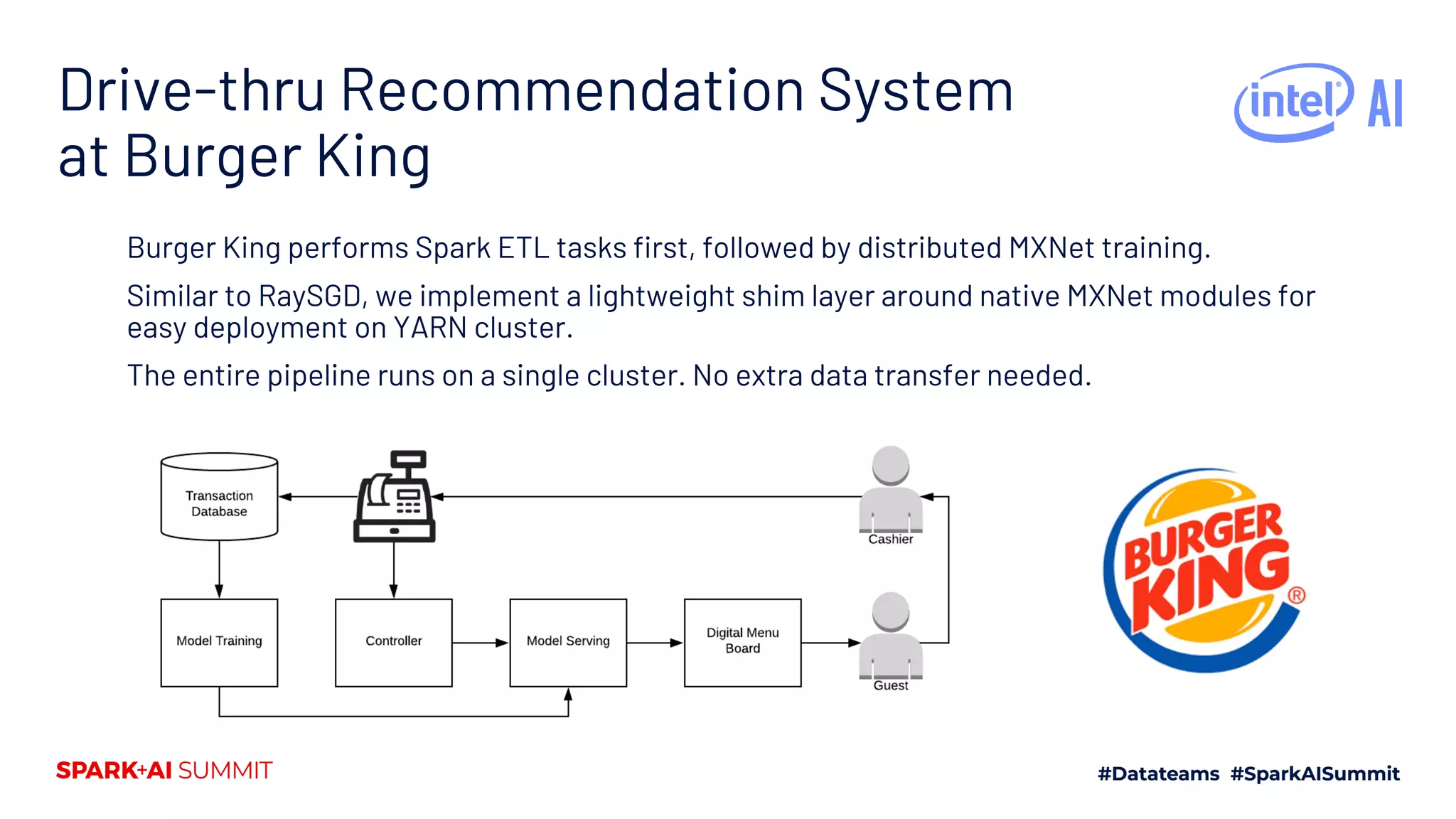
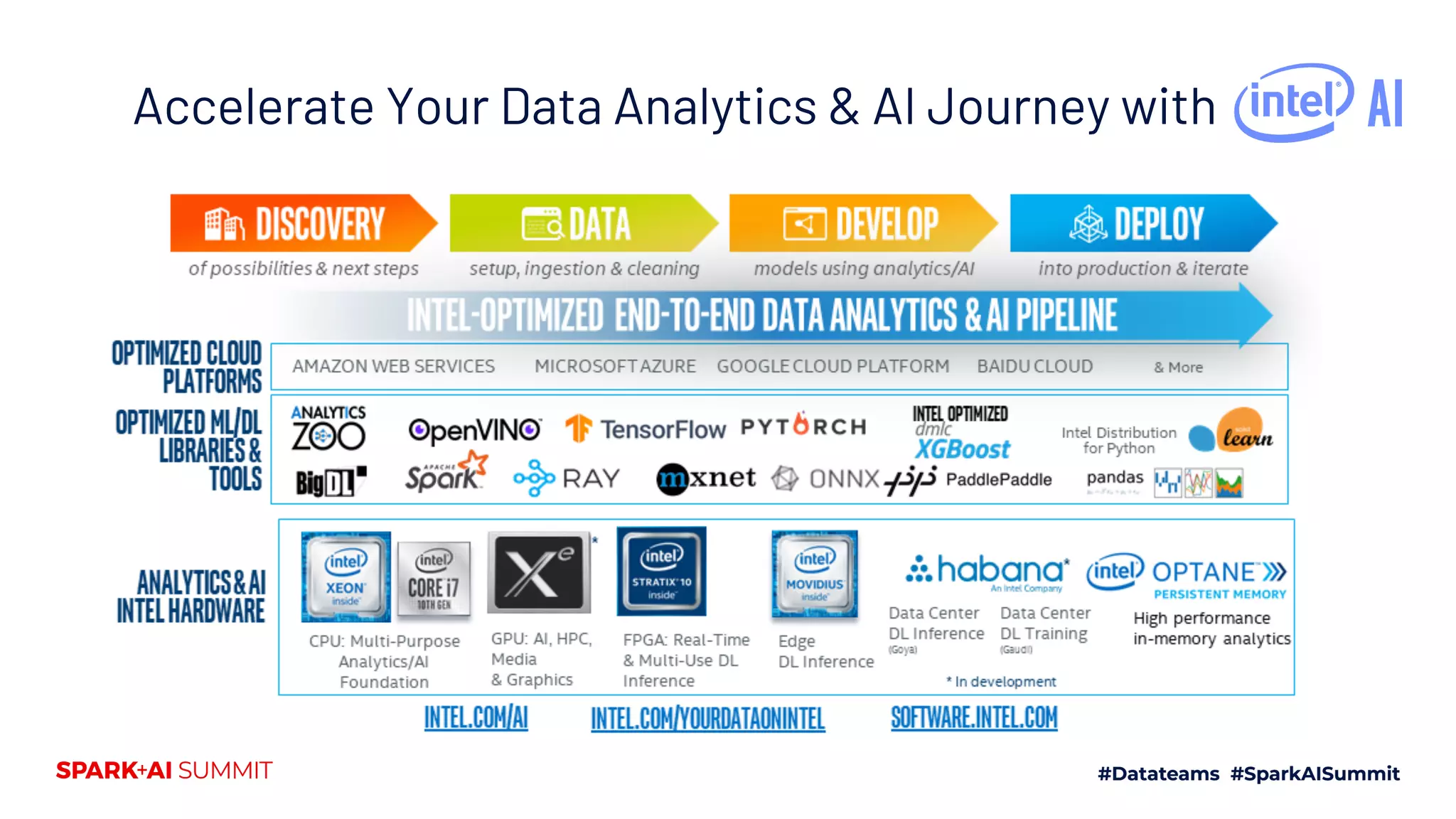
The document discusses the integration of Ray with Apache Spark for deploying AI applications on big data platforms, highlighting its capabilities in distributed deep learning and automated machine learning workflows. It outlines the implementation details, including a seamless environment setup and use cases like time series prediction and deep neural network training. The document emphasizes the ease of transitioning from local to cluster environments with minimal code changes, backed by examples such as Burger King's recommendation system.























































































