Download as PDF, PPTX













![Traditional methods for representing word vectors
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 … ]
[0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 … ]
[government debt problems turning into banking crisis as has happened]
[saying that Europe needs unified banking regulation to replace the old]
Motel Say Good Cat Main
Snake Award Business Cola Twitter
Google Save Money Florida Post
Great Success Today Amazon Hotel
…. …. …. …. ….
Keep word by its context](https://image.slidesharecdn.com/mymastersthesis-170110033545/75/Spark-Based-Distributed-Deep-Learning-Framework-For-Big-Data-Applications-21-2048.jpg)







![Traditional methods for representing word vectors
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 … ]
[0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 … ]
[government debt problems turning into banking crisis as has happened]
[saying that Europe needs unified banking regulation to replace the old]
Motel Say Good Cat Main
Snake Award Business Cola Twitter
Google Save Money Florida Post
Great Success Today Amazon Hotel
…. …. …. …. ….
Keep word by its context](https://image.slidesharecdn.com/mymastersthesis-170110033545/75/Spark-Based-Distributed-Deep-Learning-Framework-For-Big-Data-Applications-43-2048.jpg)

























![Traditional methods for representing word vectors
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 … ]
[0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 … ]
[government debt problems turning into banking crisis as has happened]
[saying that Europe needs unified banking regulation to replace the old]
Motel Say Good Cat Main
Snake Award Business Cola Twitter
Google Save Money Florida Post
Great Success Today Amazon Hotel
…. …. …. …. ….
Keep word by its context](https://crownmelresort.com/image.slidesharecdn.com/mymastersthesis-170110033545/75/Spark-Based-Distributed-Deep-Learning-Framework-For-Big-Data-Applications-21-2048.jpg)





















![Traditional methods for representing word vectors
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 … ]
[0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 … ]
[government debt problems turning into banking crisis as has happened]
[saying that Europe needs unified banking regulation to replace the old]
Motel Say Good Cat Main
Snake Award Business Cola Twitter
Google Save Money Florida Post
Great Success Today Amazon Hotel
…. …. …. …. ….
Keep word by its context](https://crownmelresort.com/image.slidesharecdn.com/mymastersthesis-170110033545/75/Spark-Based-Distributed-Deep-Learning-Framework-For-Big-Data-Applications-43-2048.jpg)













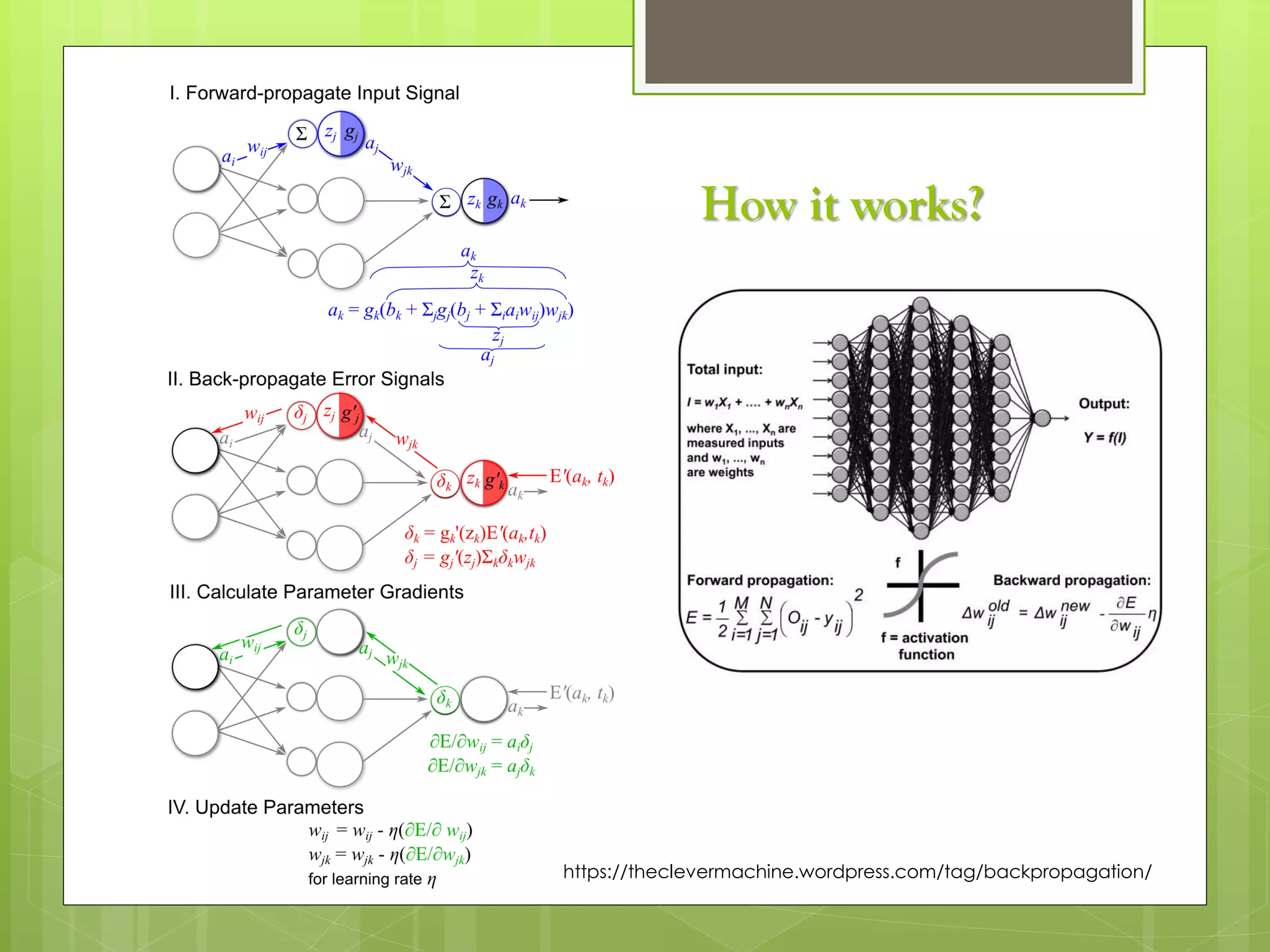
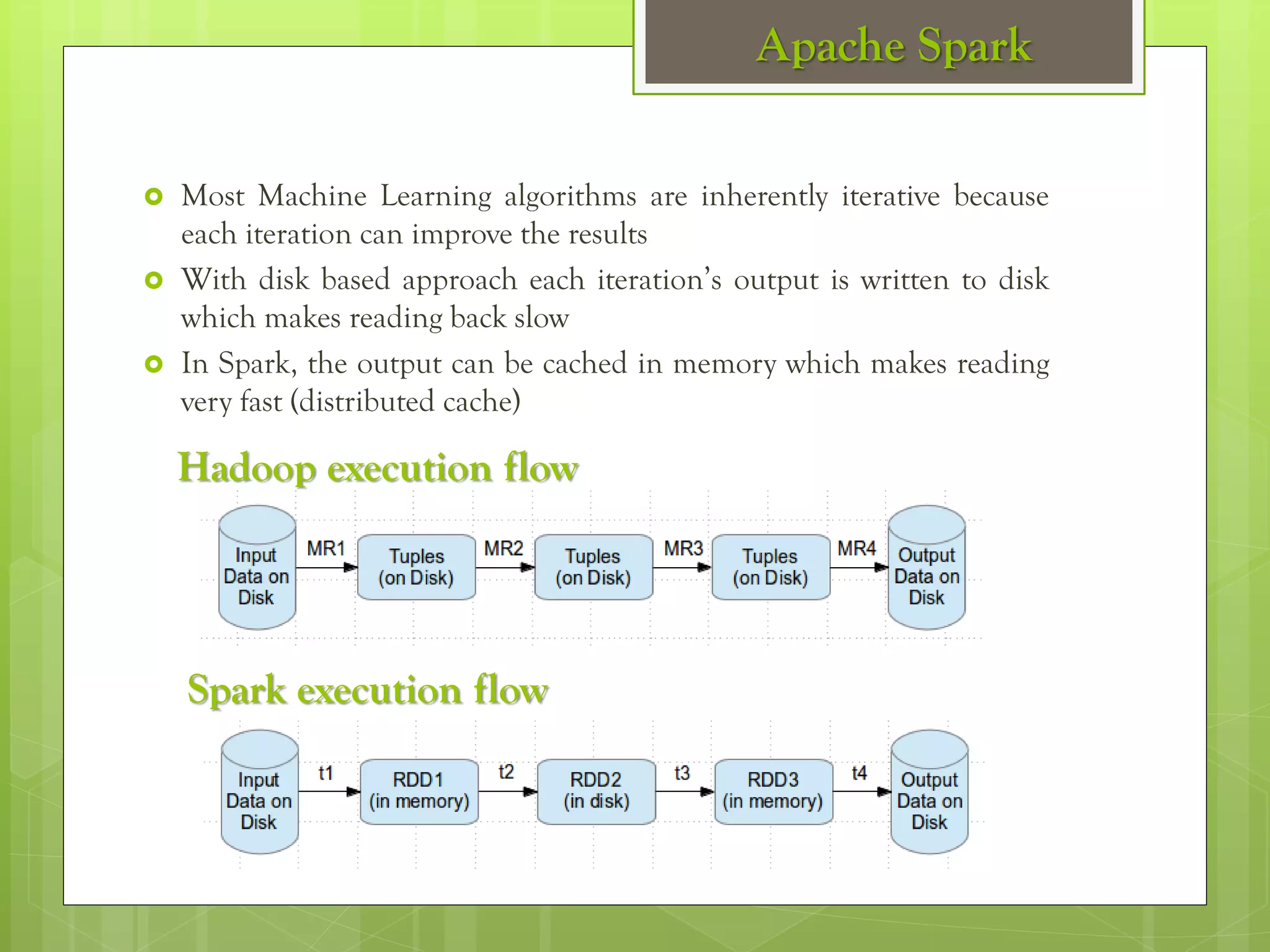
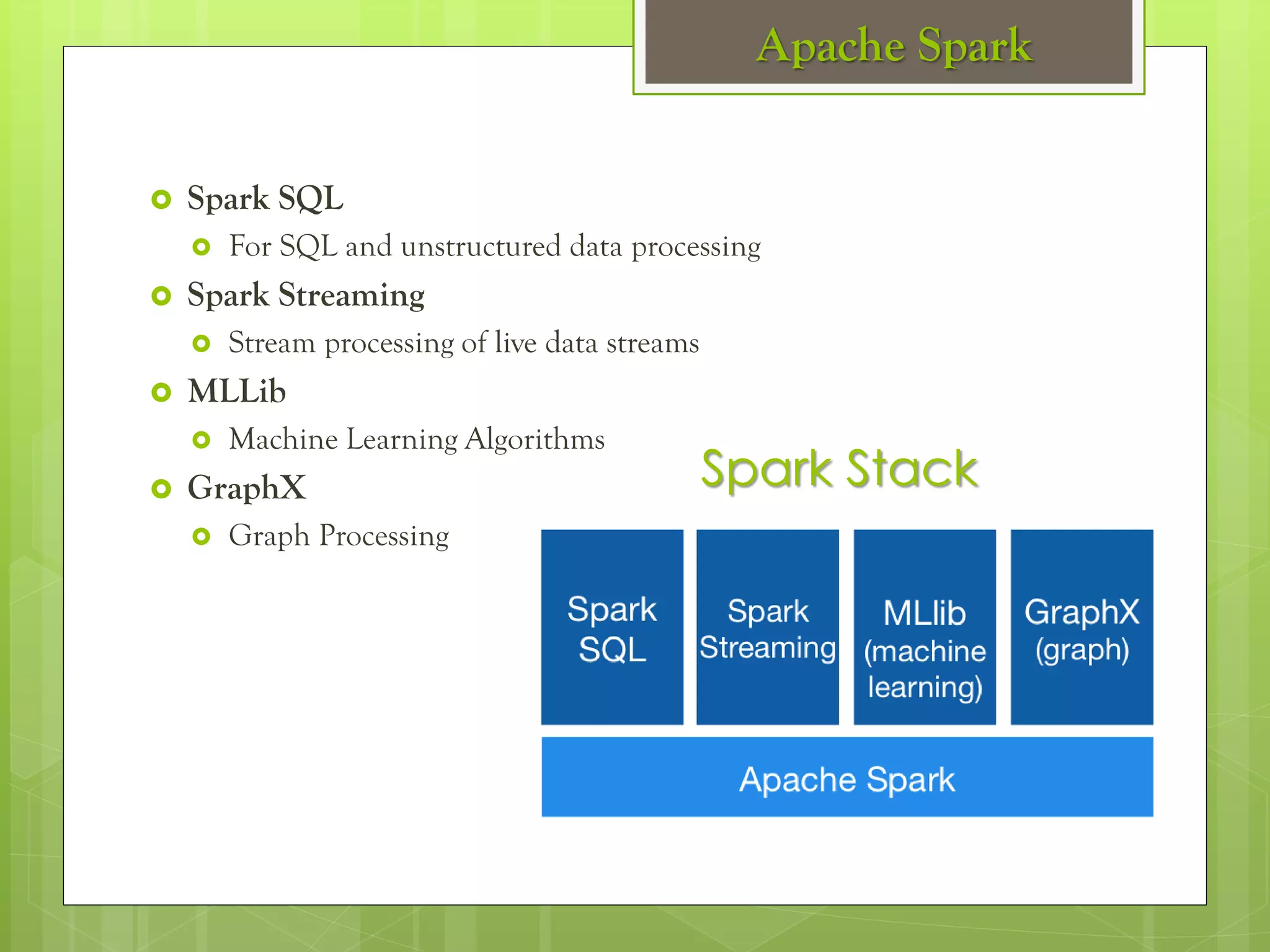
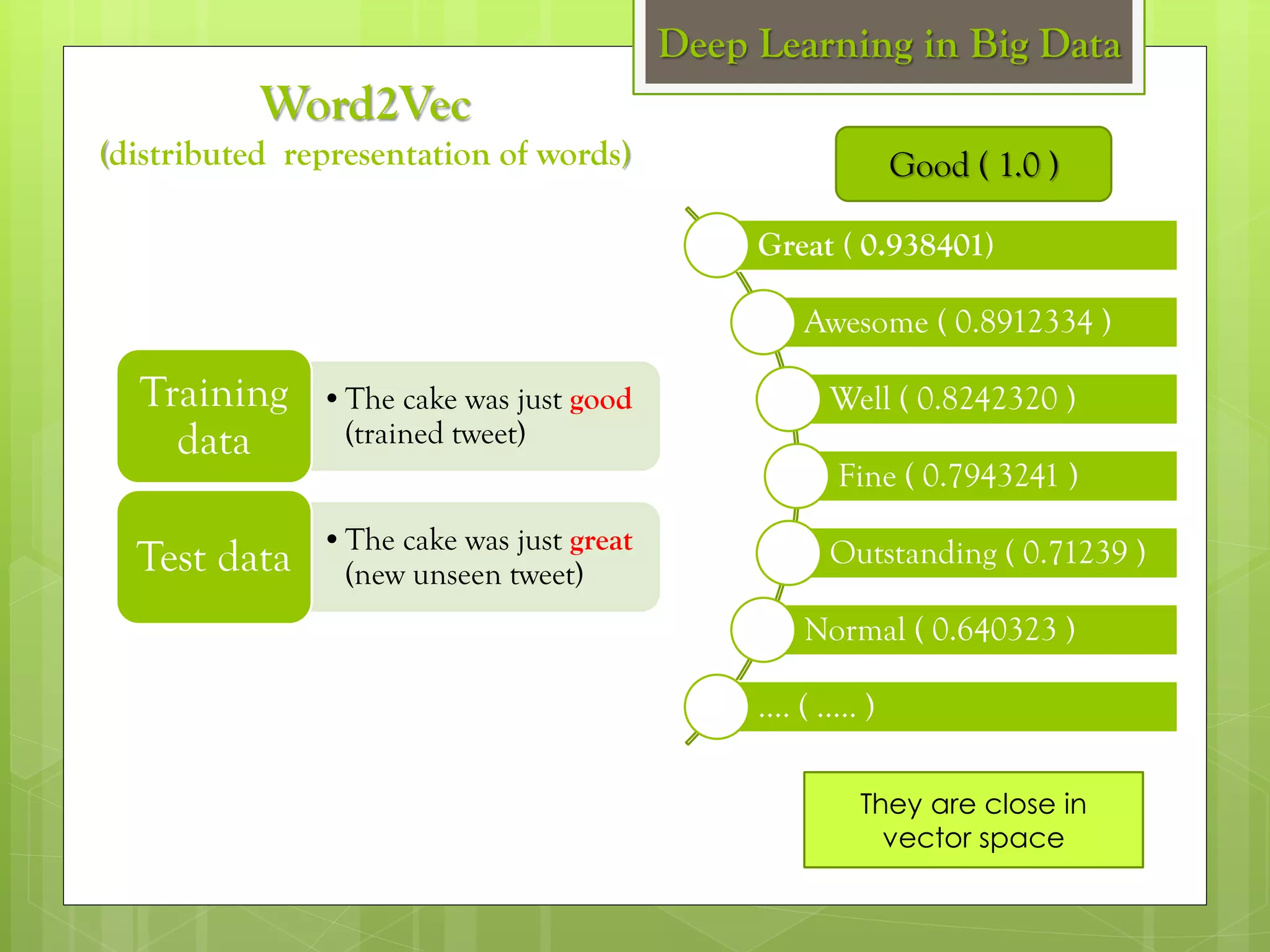
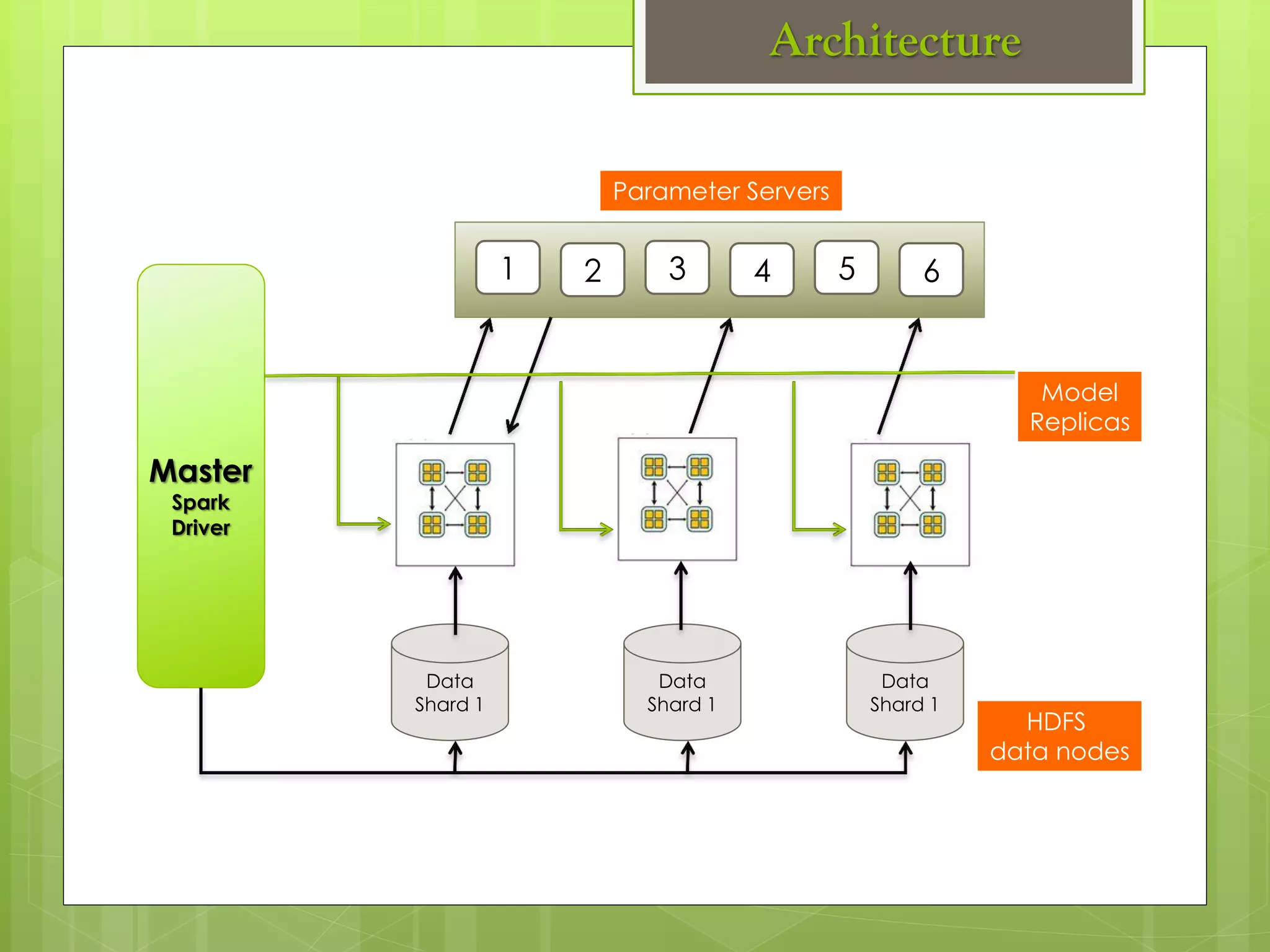
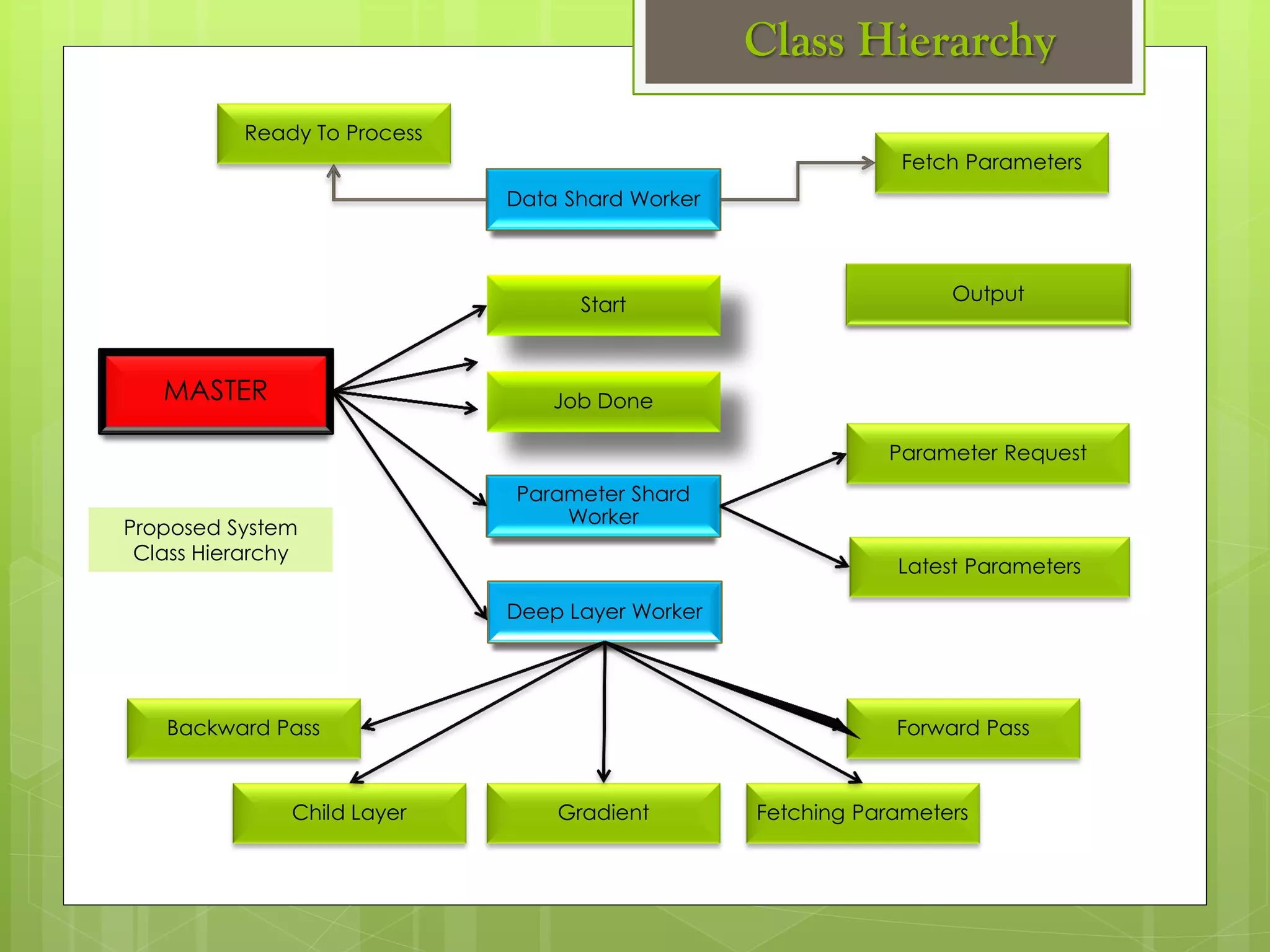
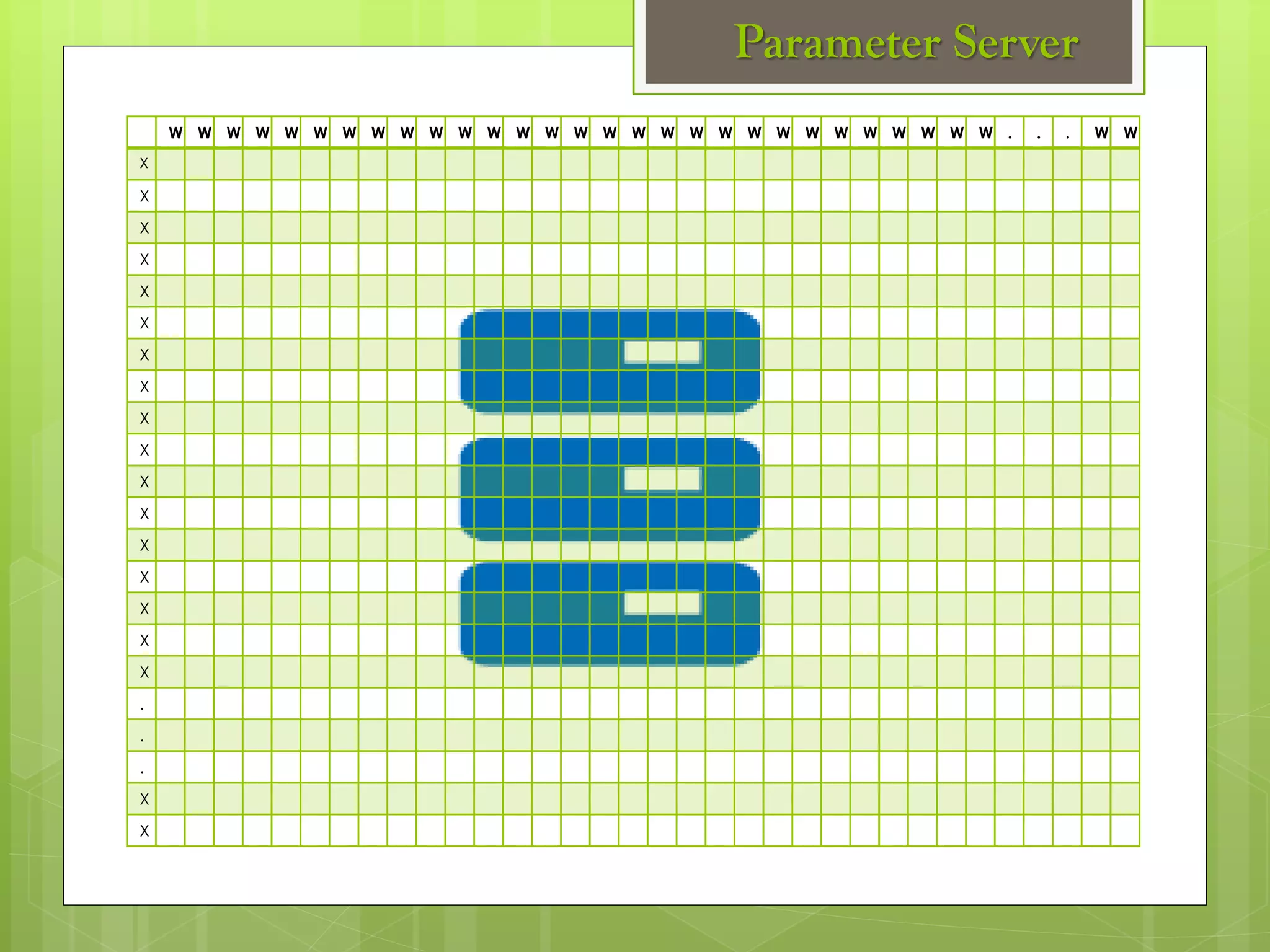
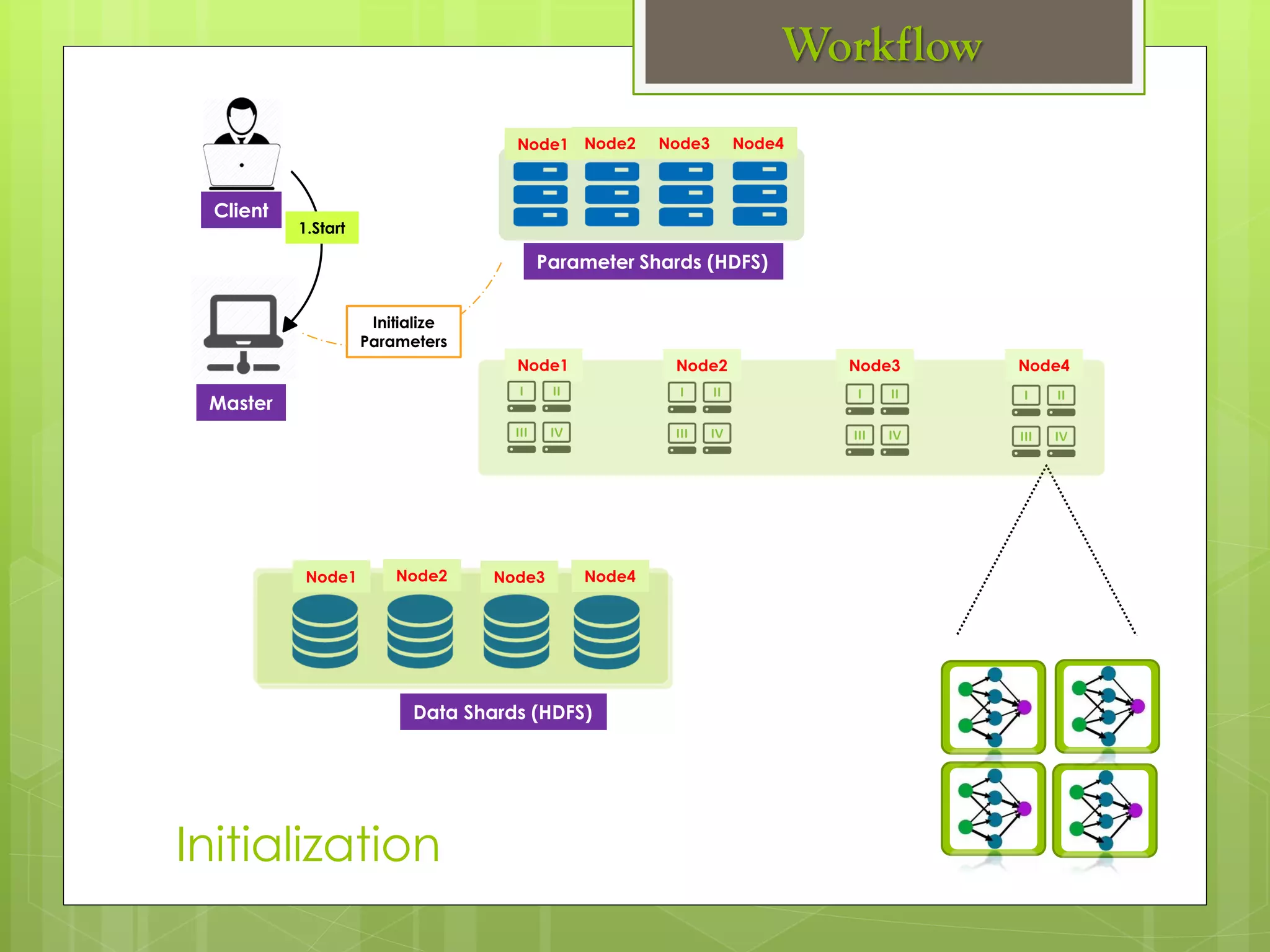
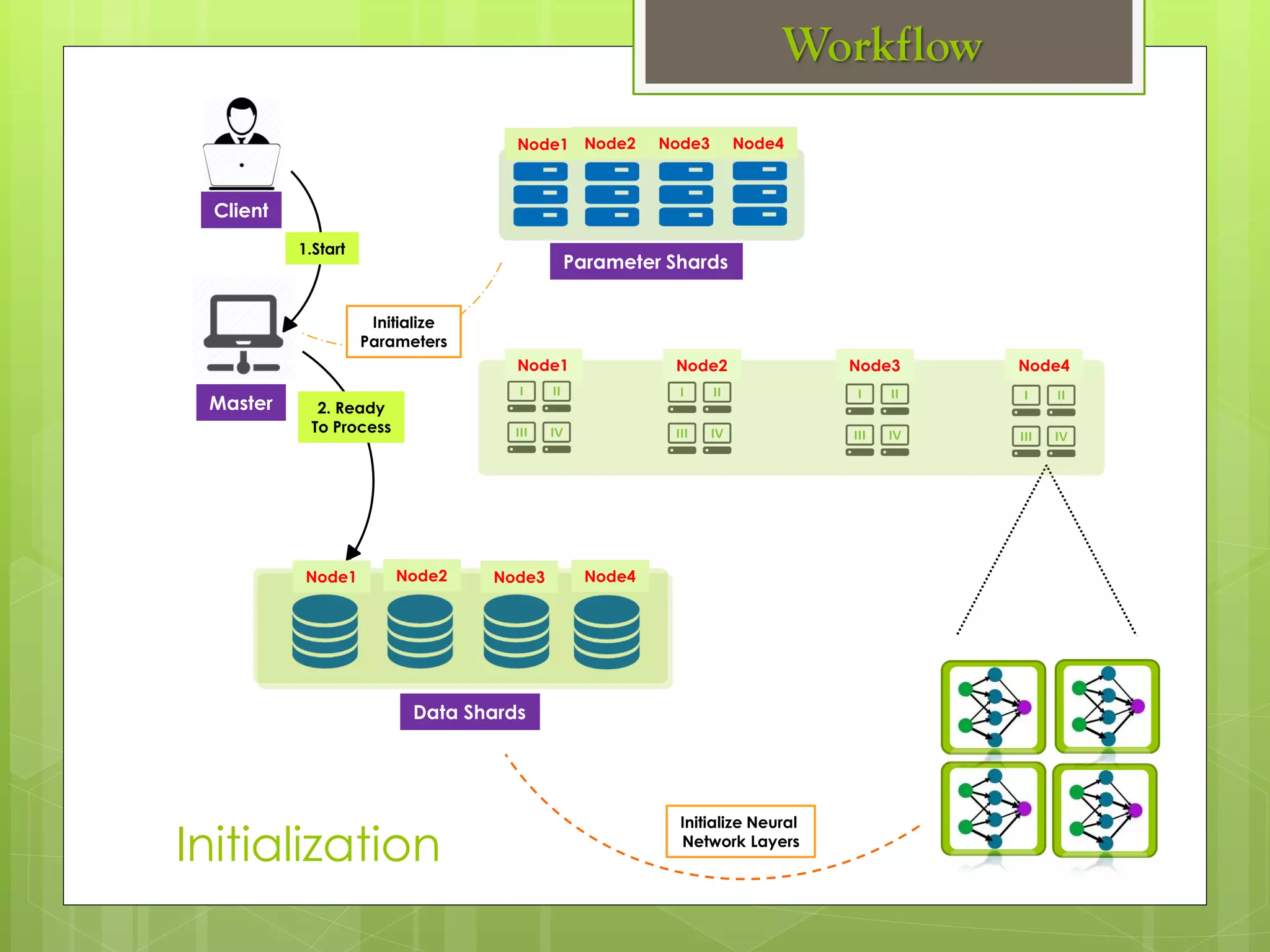
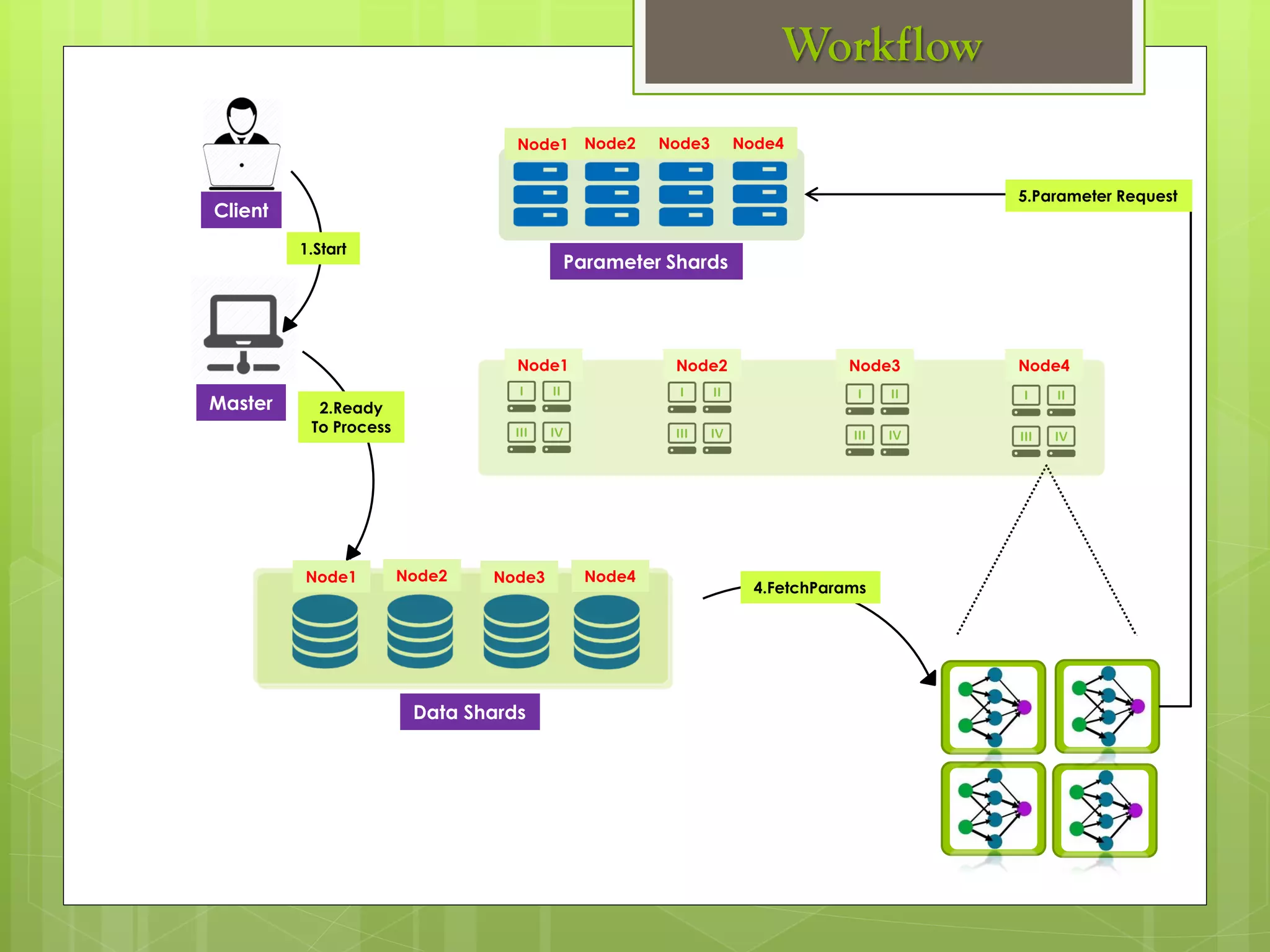
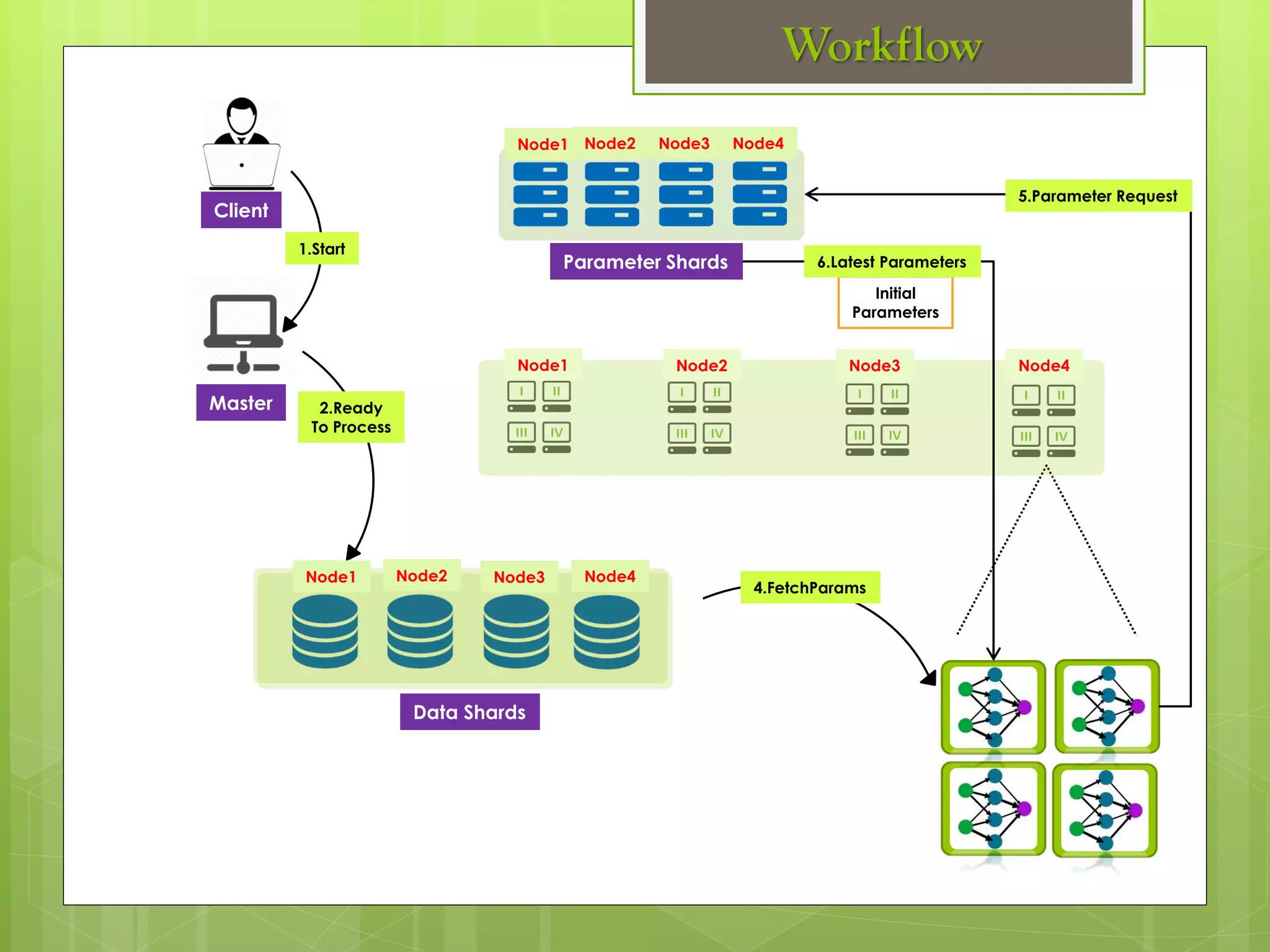
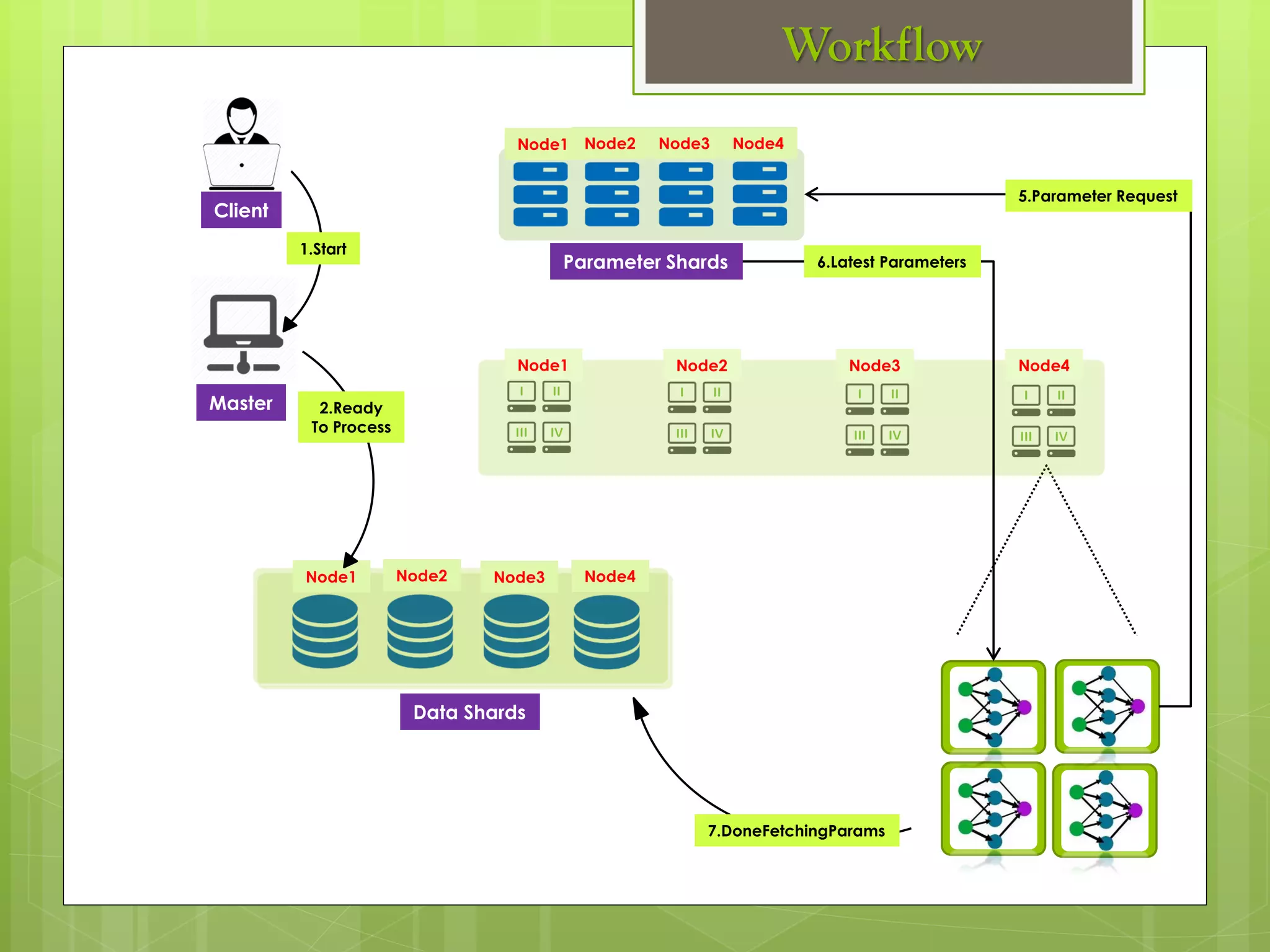
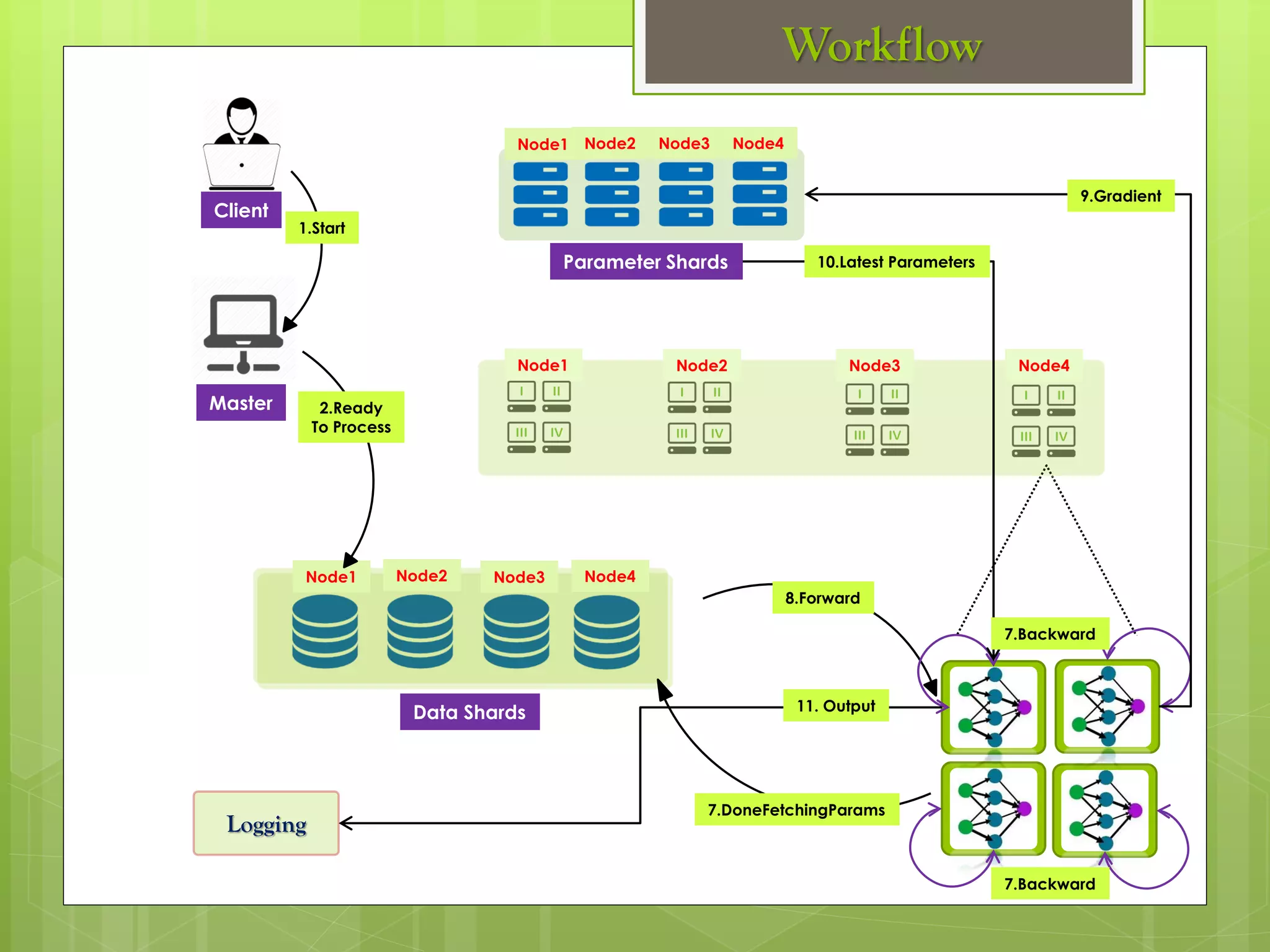
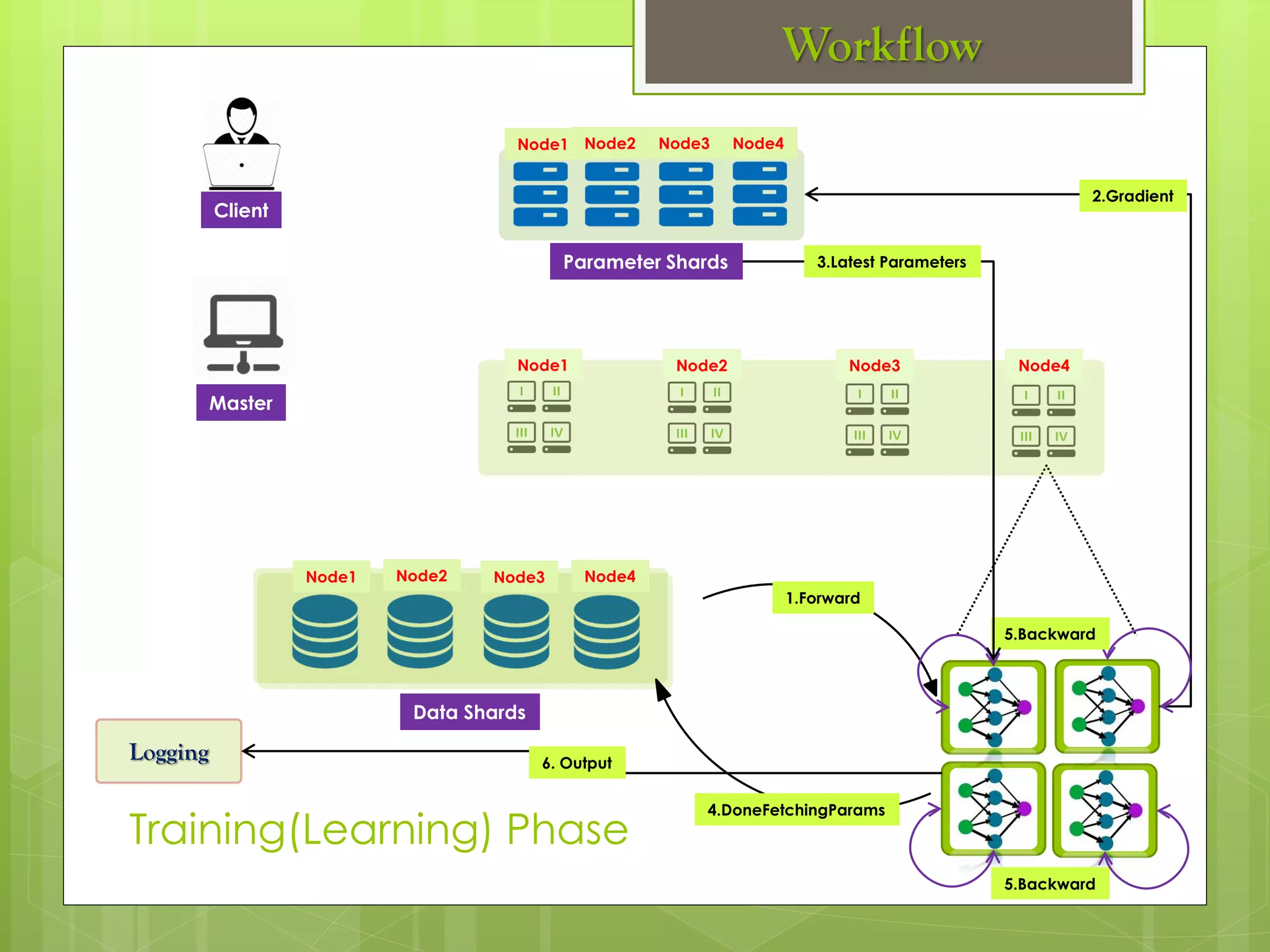
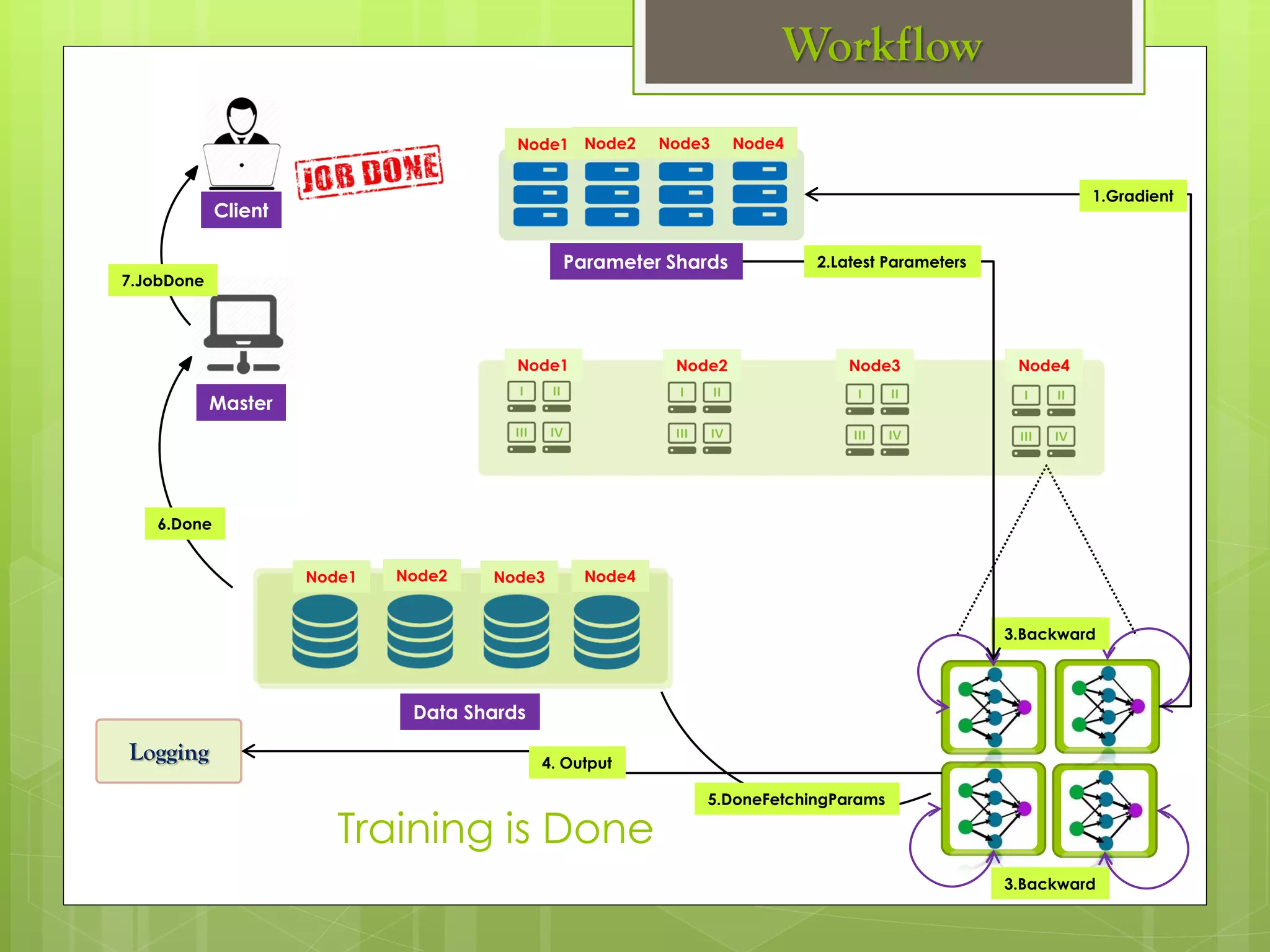
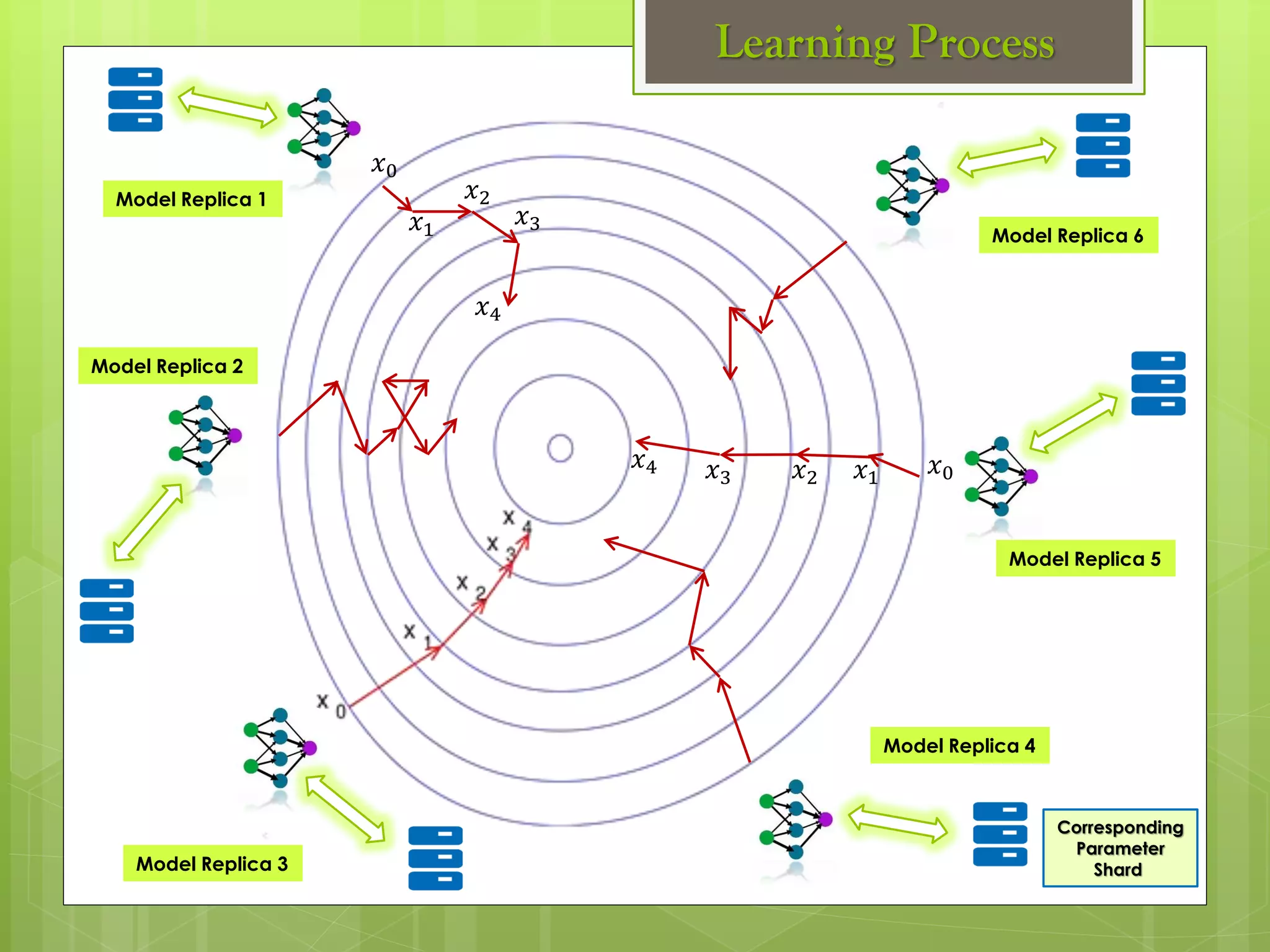
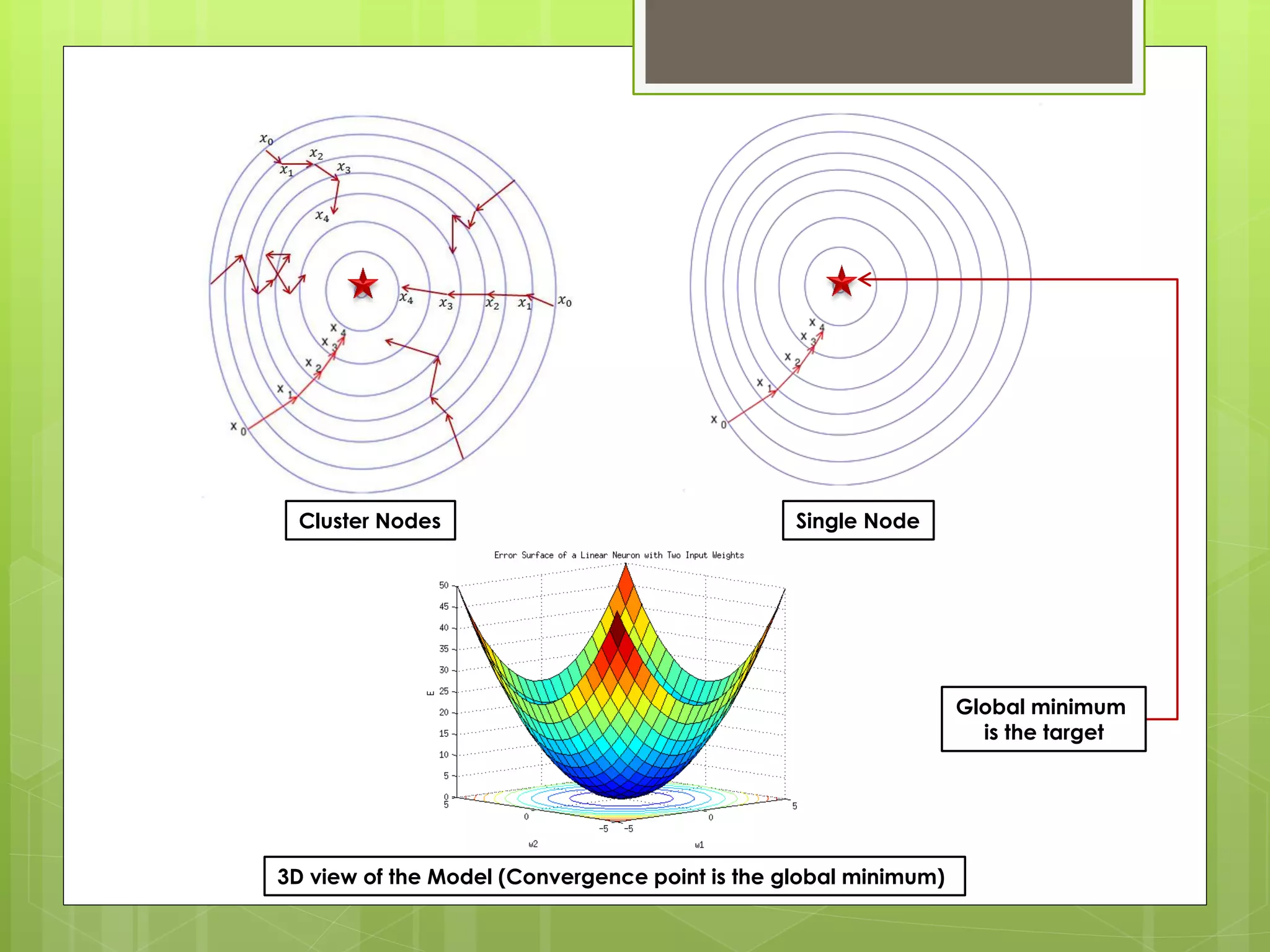
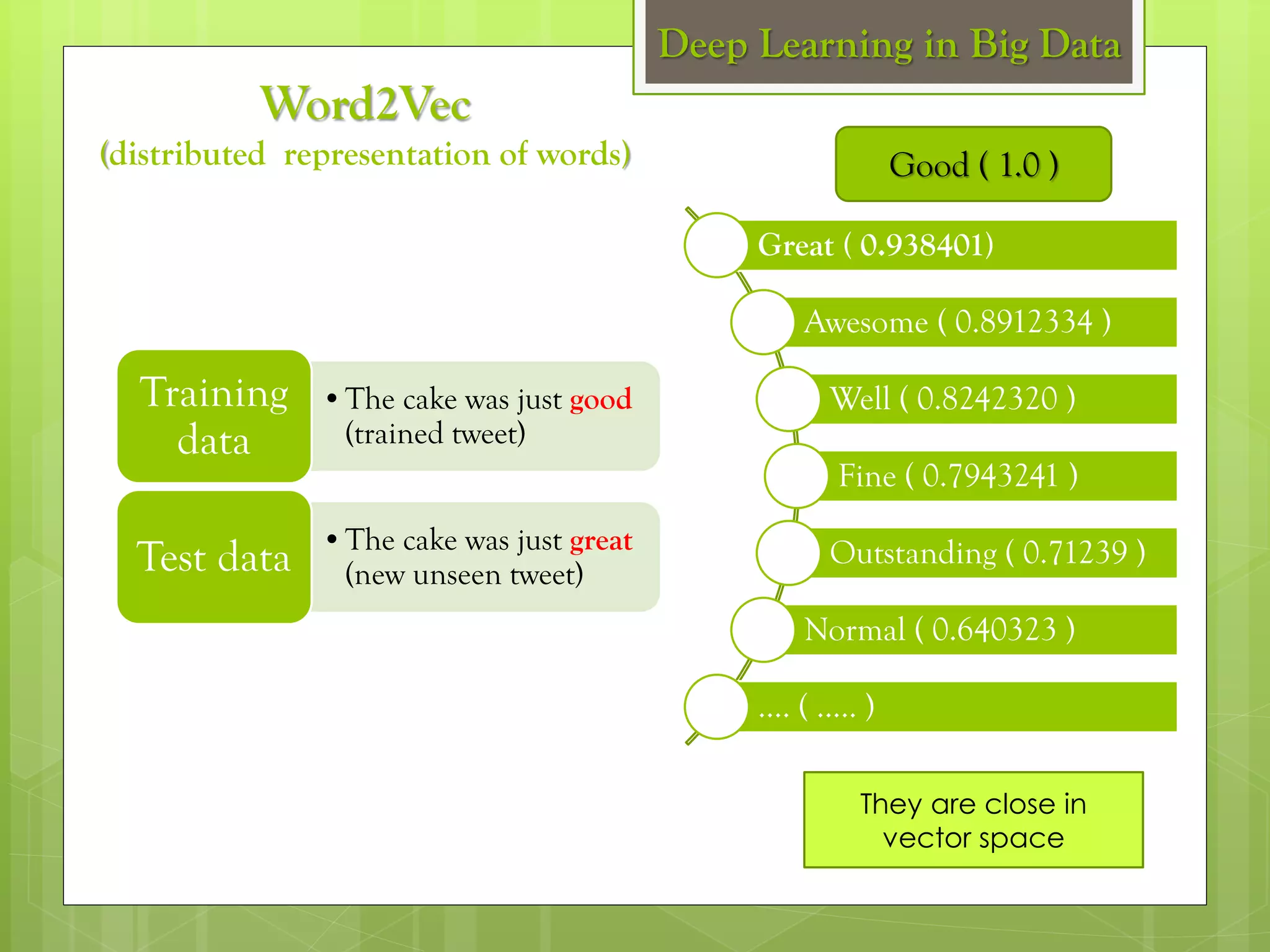
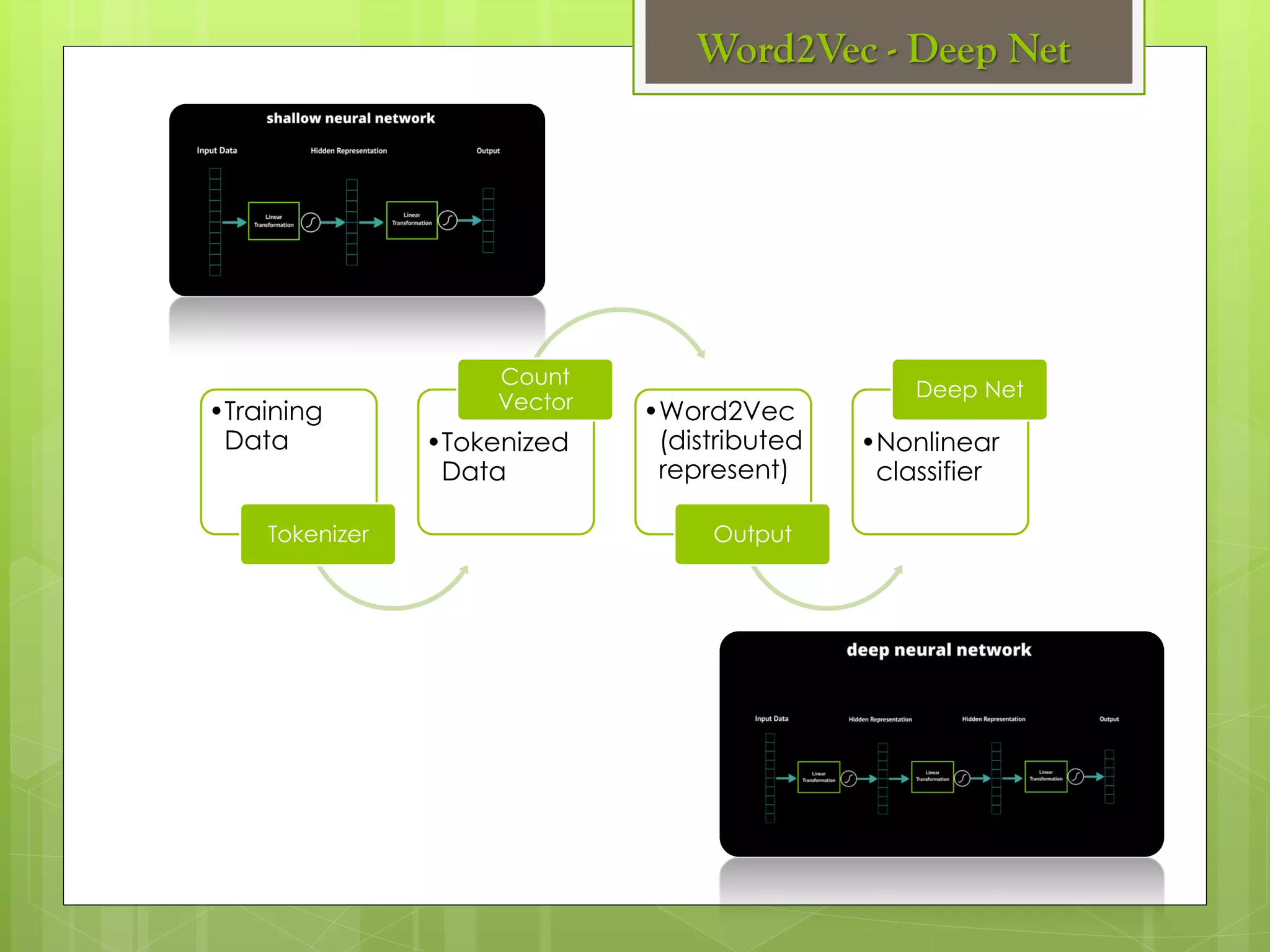
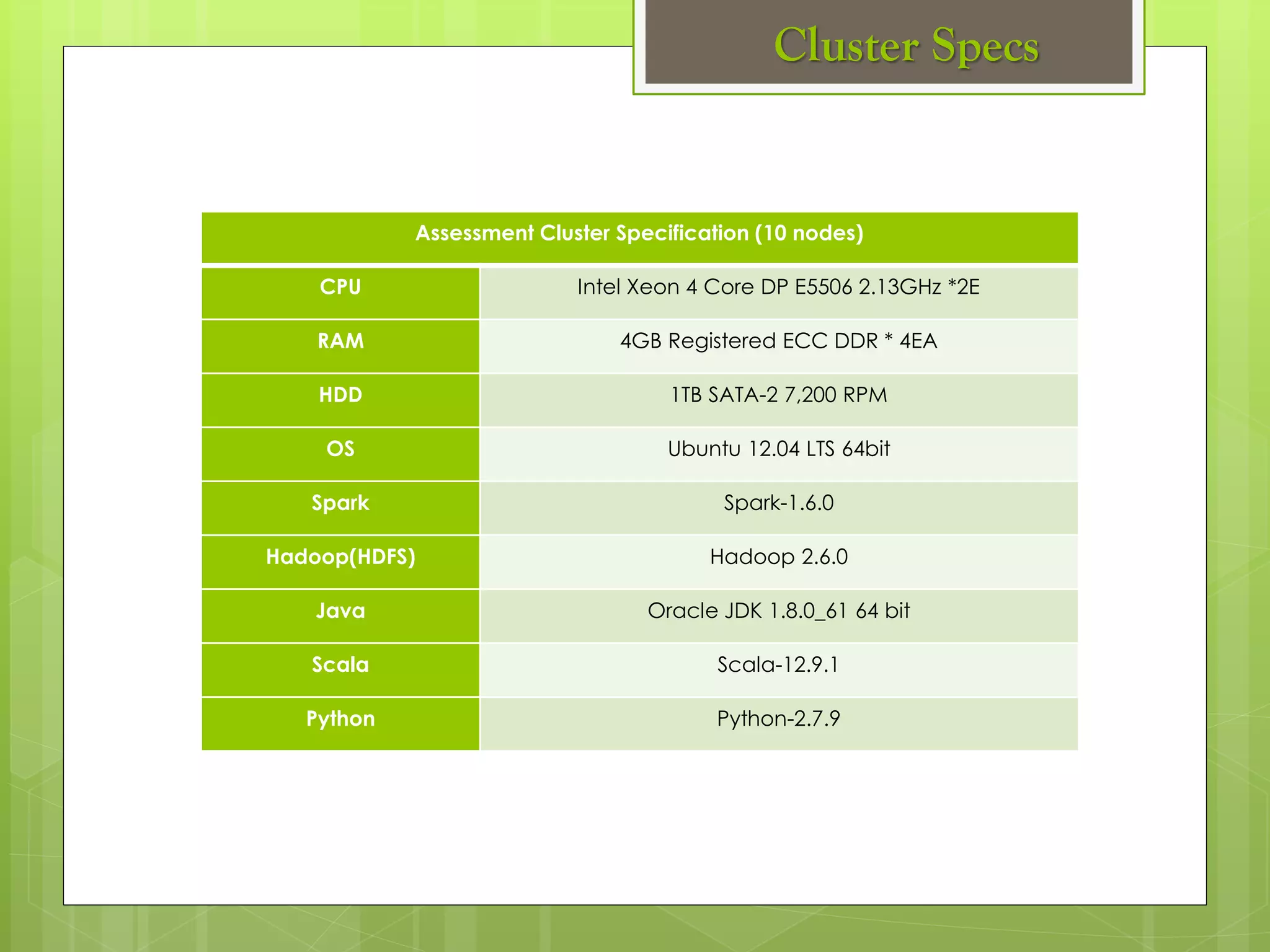
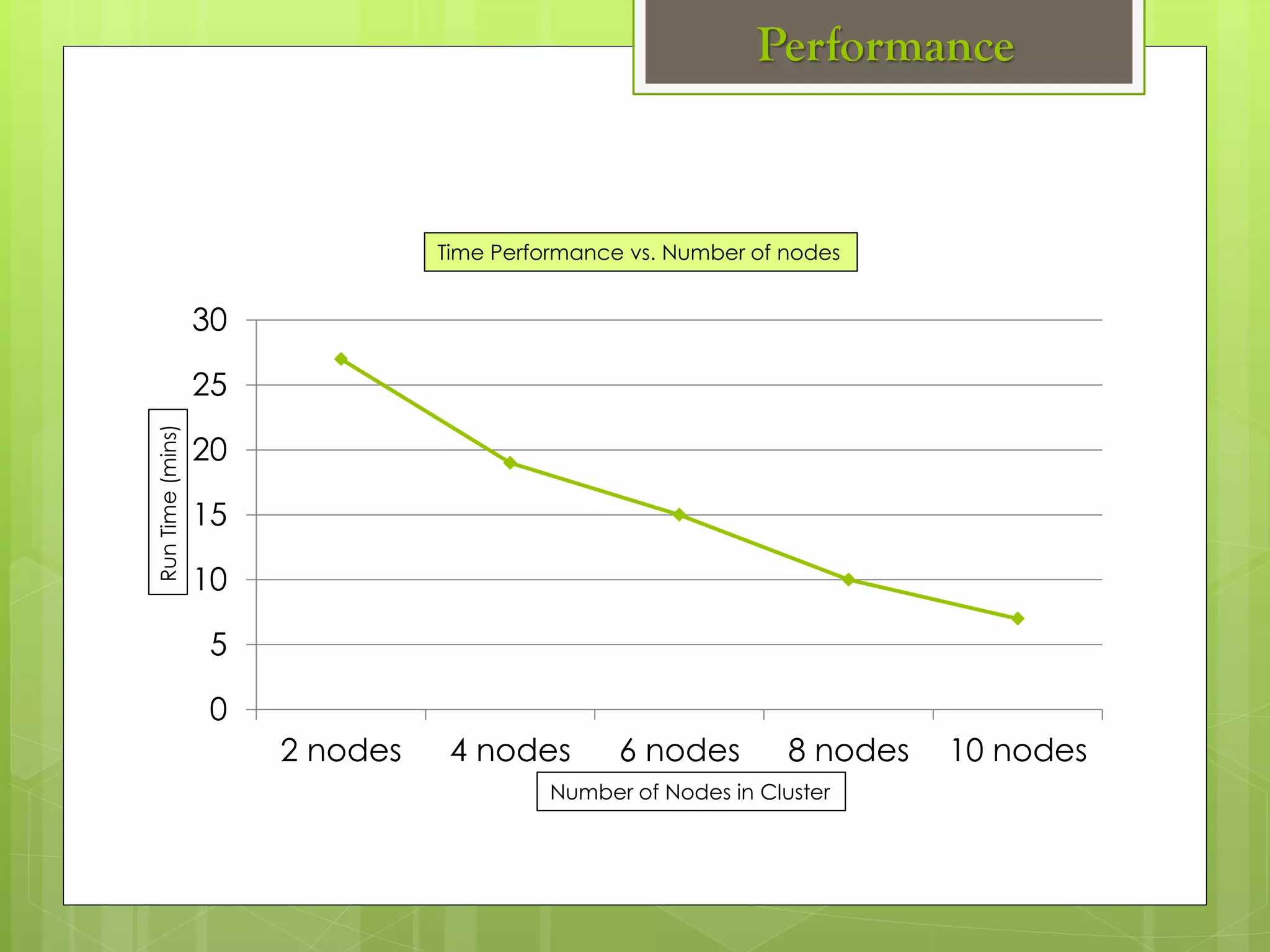
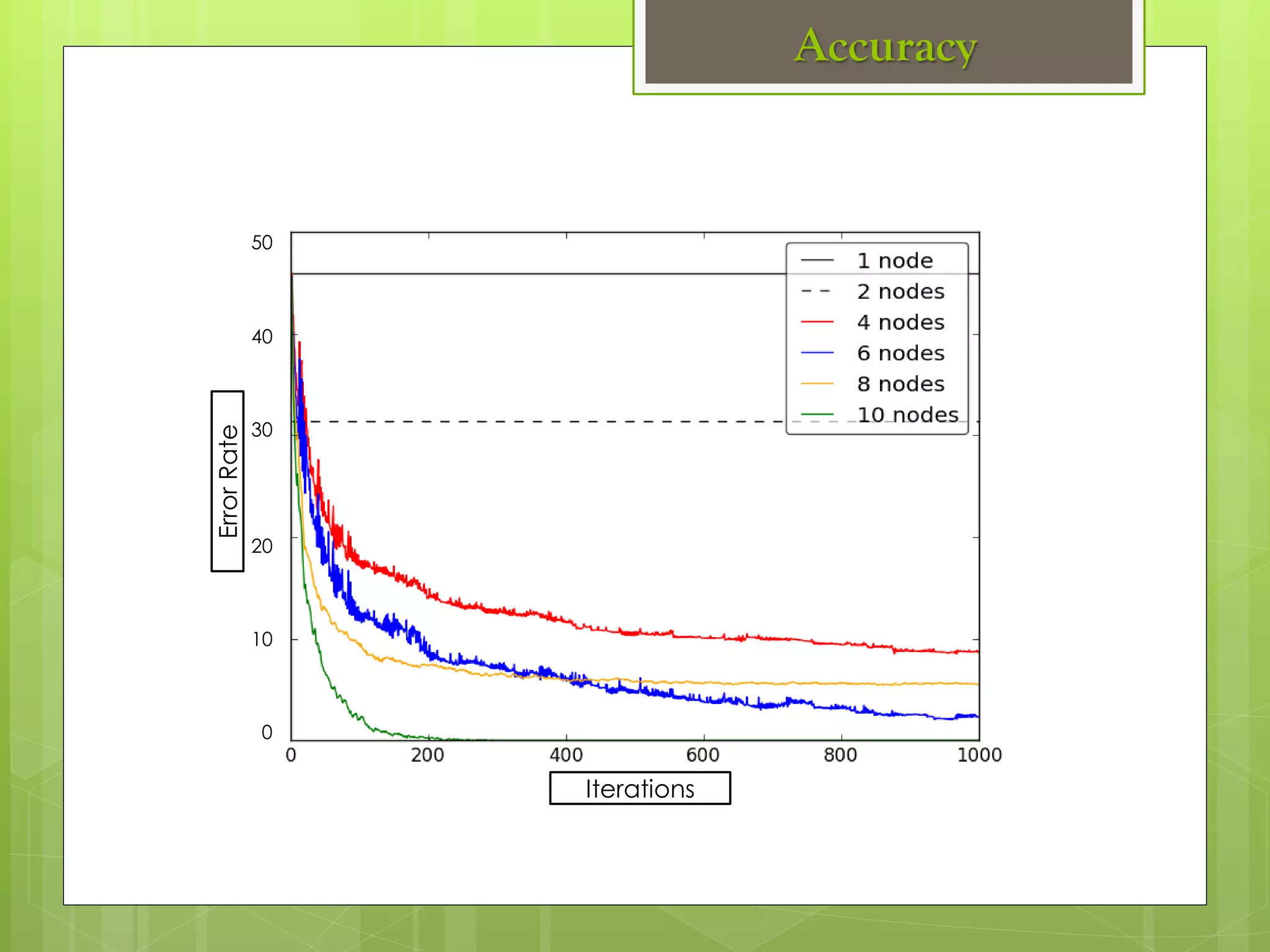
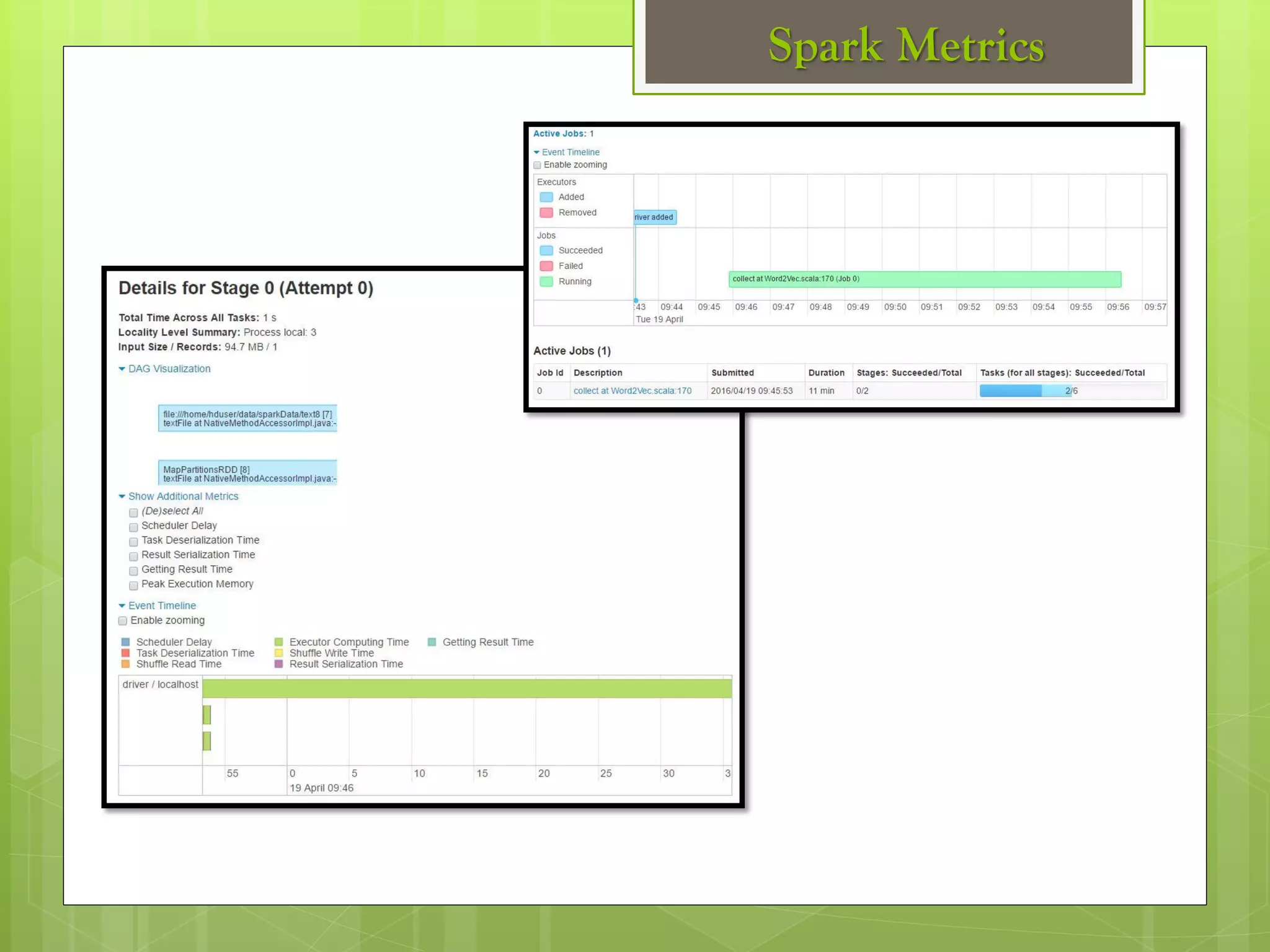
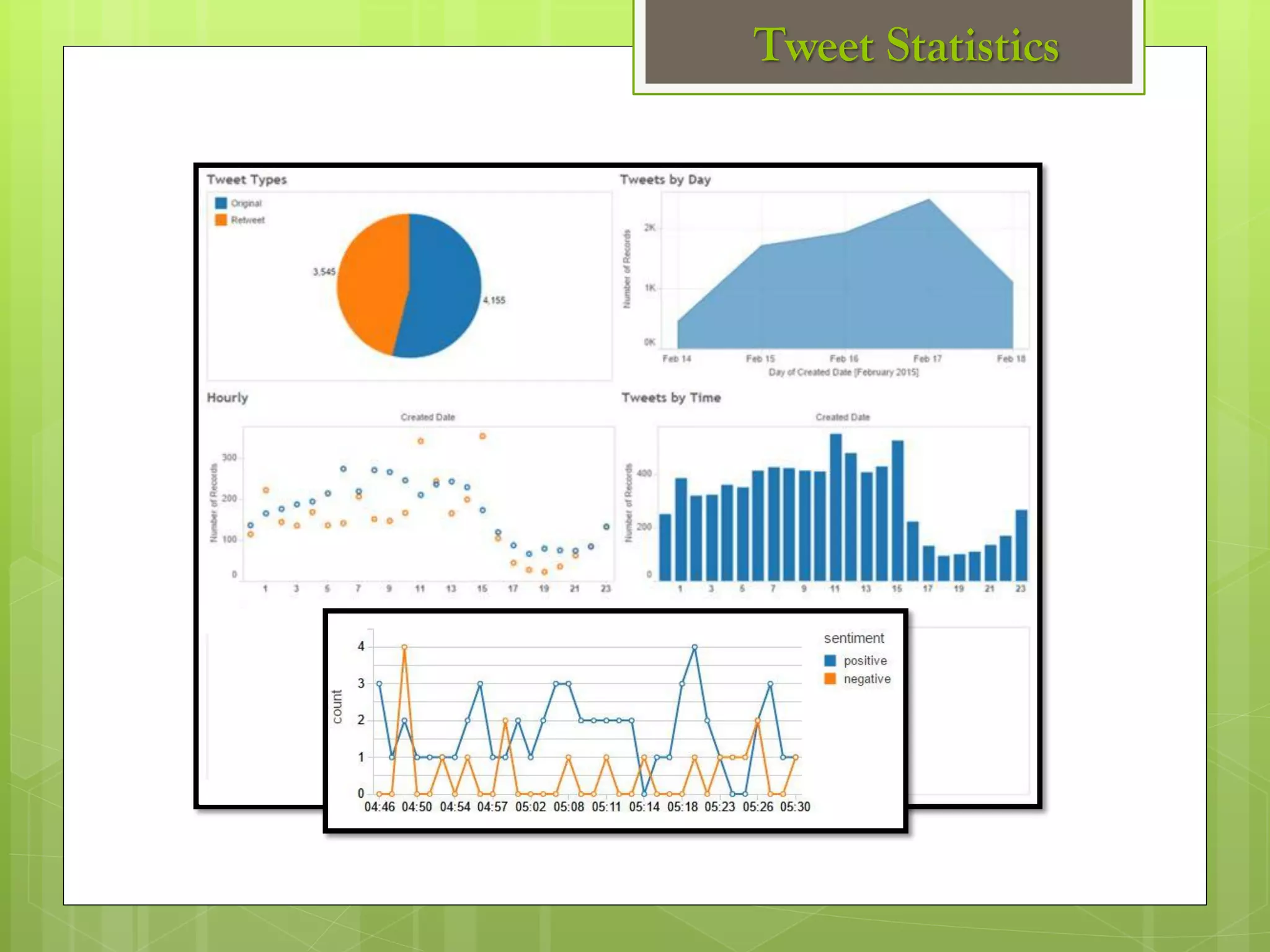
The document outlines a proposed spark-based distributed deep learning framework aimed at big data applications, detailing the challenges in distributed computing and the advantages of using Apache Spark for machine learning tasks. It highlights the importance of deep learning in big data for semantic indexing and efficient information retrieval, and describes the implementation of the system utilizing distributed stochastic gradient descent. Results indicate satisfactory performance in time and accuracy, with potential for future enhancements.


































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)
