Downloaded 96 times























![RDDs
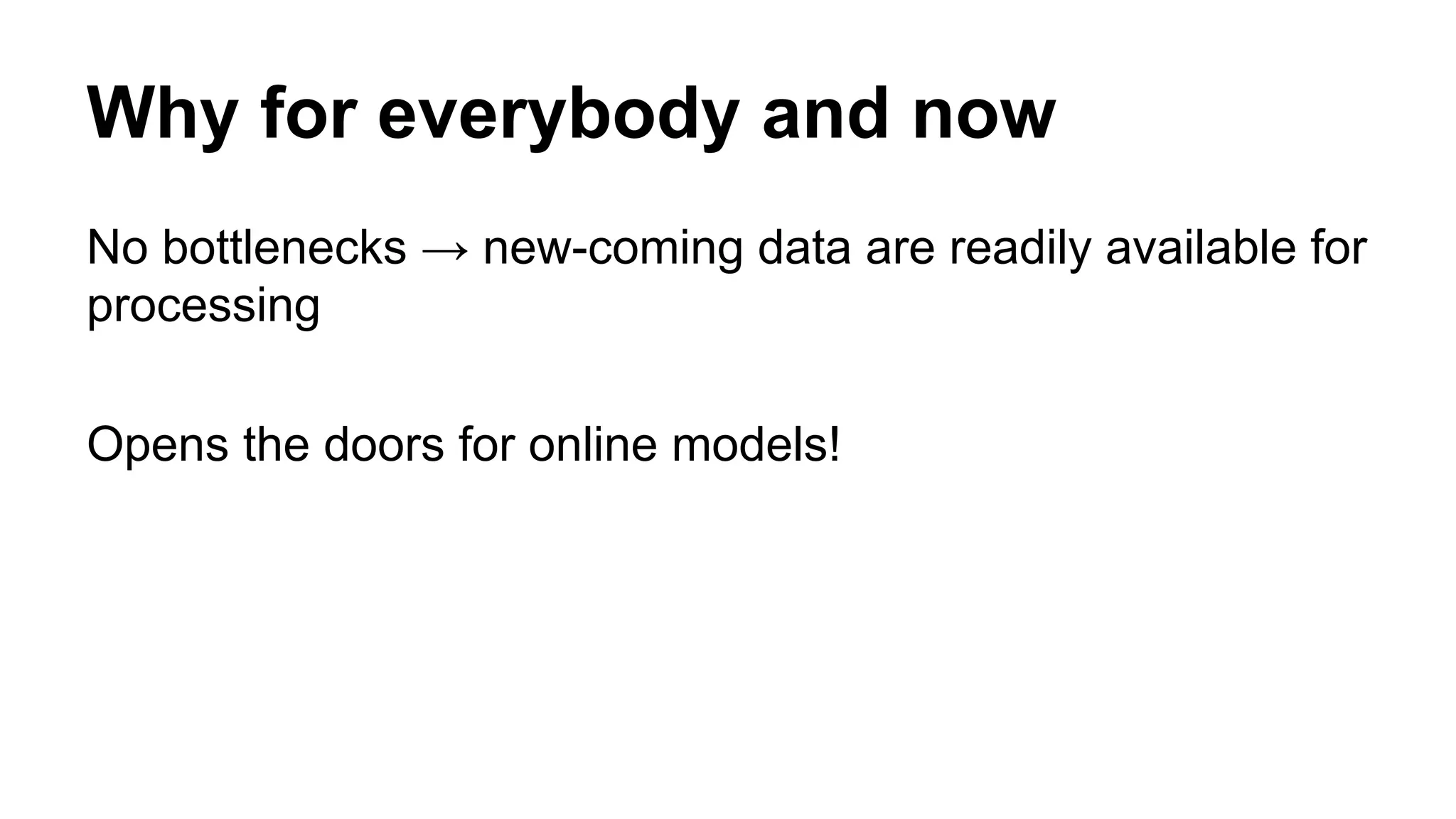
Think of an RDD[T] as an immutable, distributed collection
of objects of type T
• Resilient => Can be reconstructed in case of failure
• Distributed => Transformations are parallelizable
operations
• Dataset => Data loaded and partitioned across cluster
nodes (executors)](https://image.slidesharecdn.com/geeksa-150130082242-conversion-gate02/75/What-is-Distributed-Computing-Why-we-use-Apache-Spark-26-2048.jpg)
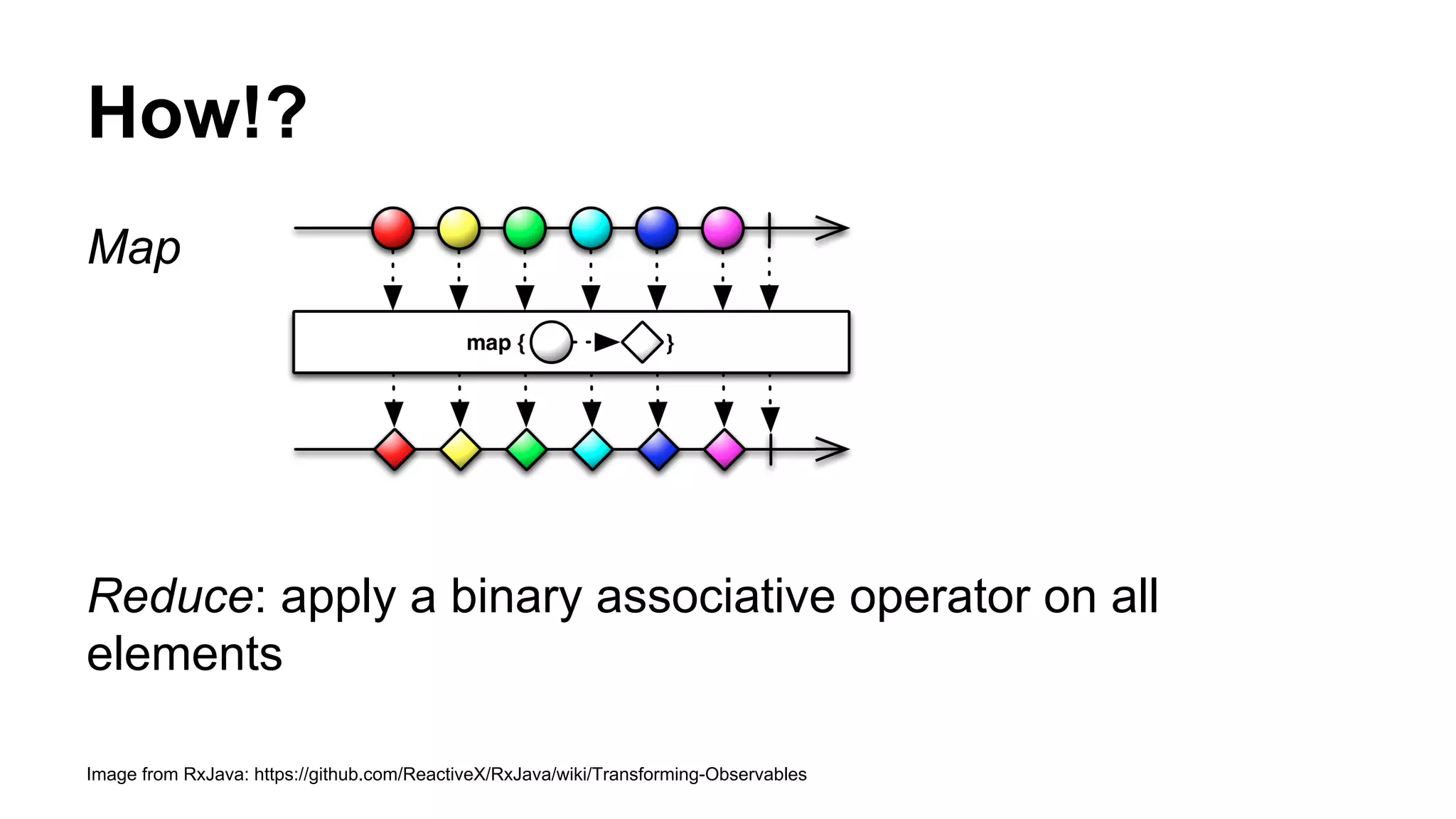
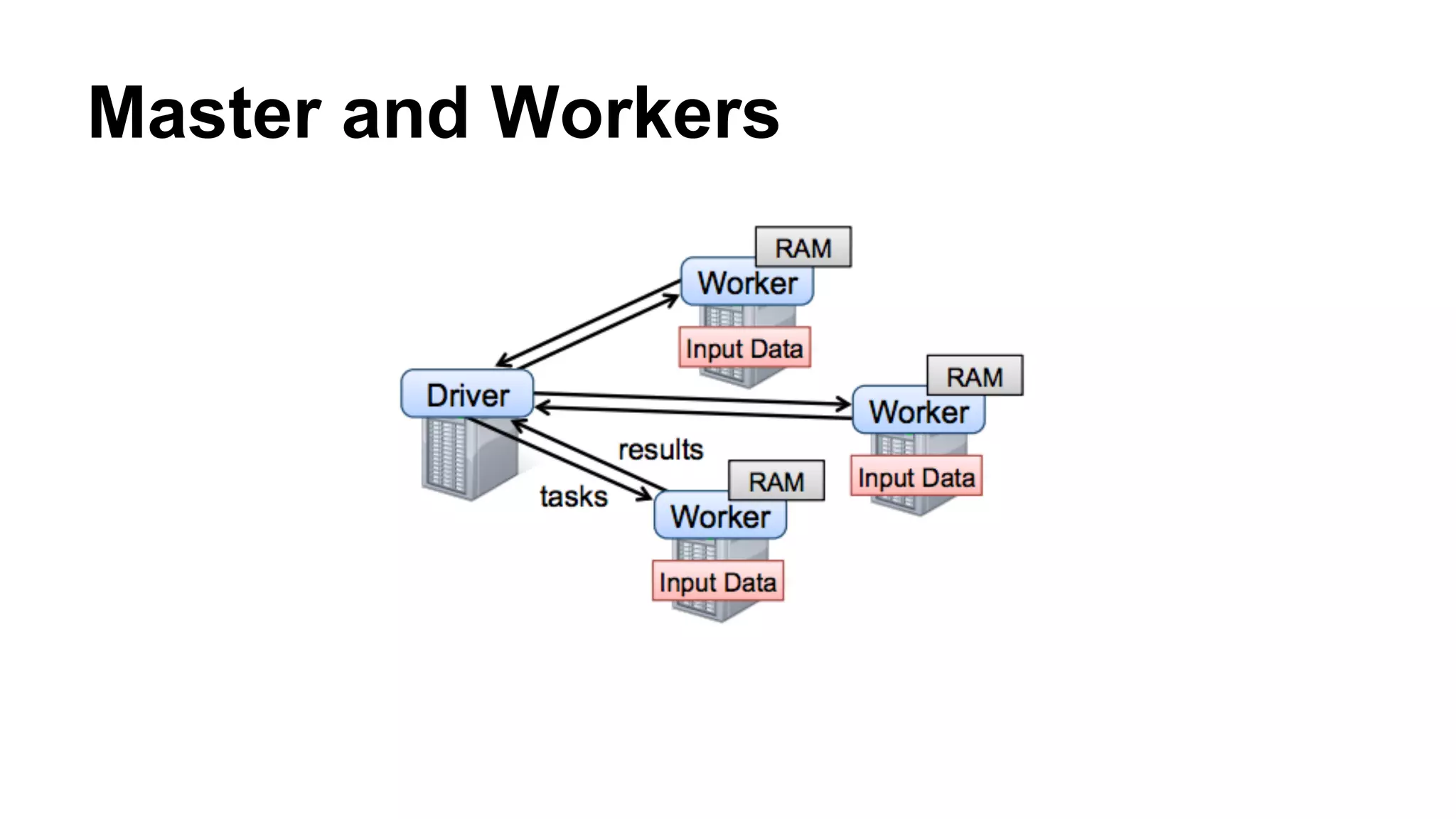
![RDD[T]
Data distribution hierarchy:
- RDD[T]
- Elements
[ x1, x2 ]
[ x10 ]
[ x8,x5,x6 ]
[ x11 ]
[ x14,x13 ]
[ x9,x16 ]
[ x3 ]
[ x7,x12 ]
[ x15 ]
[ x17,x4 ]
Executor 1
- Executors
- Partitions
Executor 2 Executor 3 Executor 4](https://image.slidesharecdn.com/geeksa-150130082242-conversion-gate02/75/What-is-Distributed-Computing-Why-we-use-Apache-Spark-27-2048.jpg)

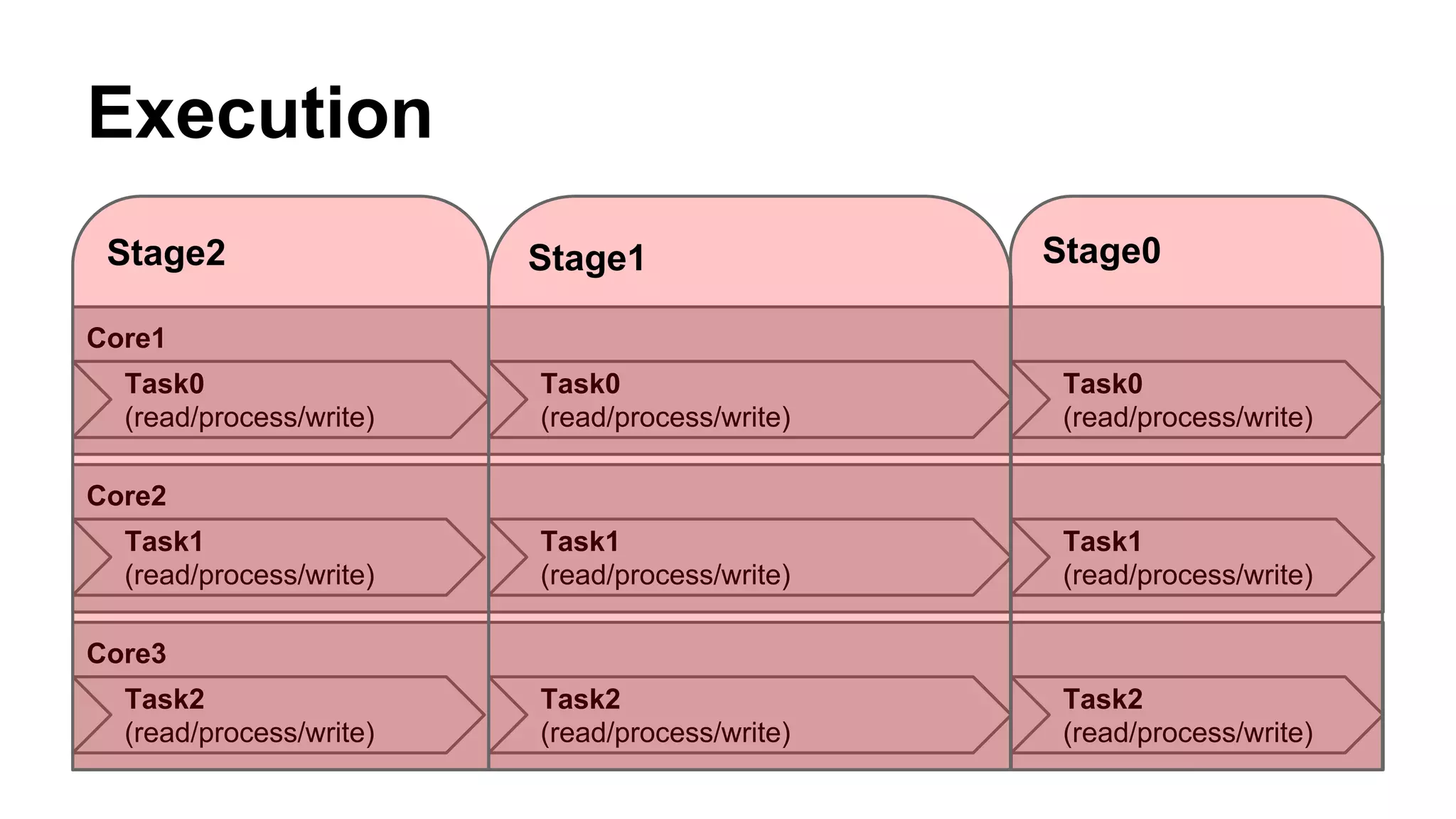
![Spark Streaming
When you have big fat streams behaving as one single
collection
t
DStream[T]
RDD[T] RDD[T] RDD[T] RDD[T] RDD[T]
DStreams: Discretized Streams (= Sequence of RDDs)](https://image.slidesharecdn.com/geeksa-150130082242-conversion-gate02/75/What-is-Distributed-Computing-Why-we-use-Apache-Spark-31-2048.jpg)







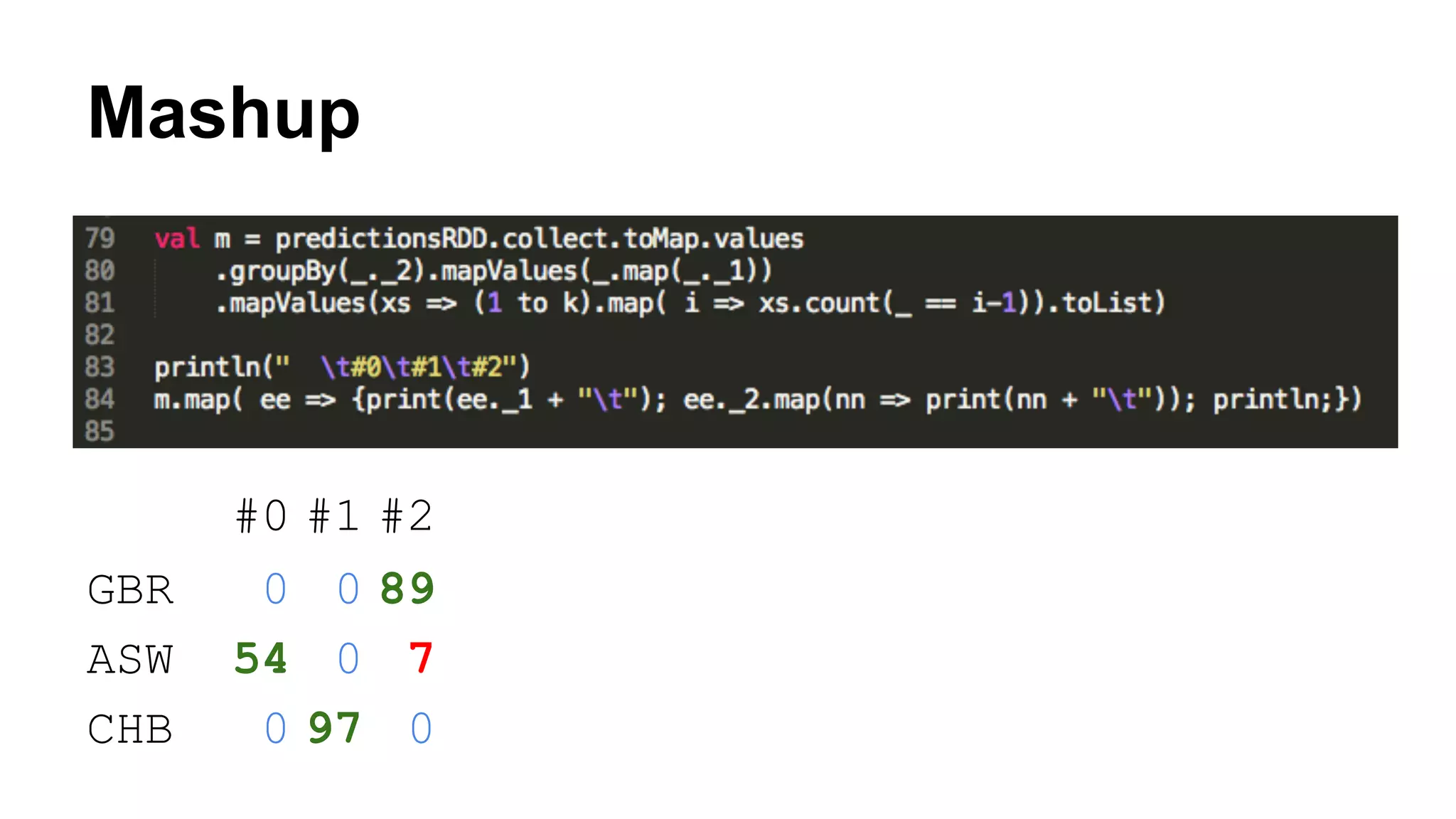
![Mashup
prediction
Sample [NA20332] is in cluster #0 for population Some( ASW)
Sample [NA20334] is in cluster # 2 for population Some( ASW)
Sample [HG00120] is in cluster # 2 for population Some( GBR)
Sample [NA18560] is in cluster # 1 for population Some( CHB)](https://image.slidesharecdn.com/geeksa-150130082242-conversion-gate02/75/What-is-Distributed-Computing-Why-we-use-Apache-Spark-41-2048.jpg)
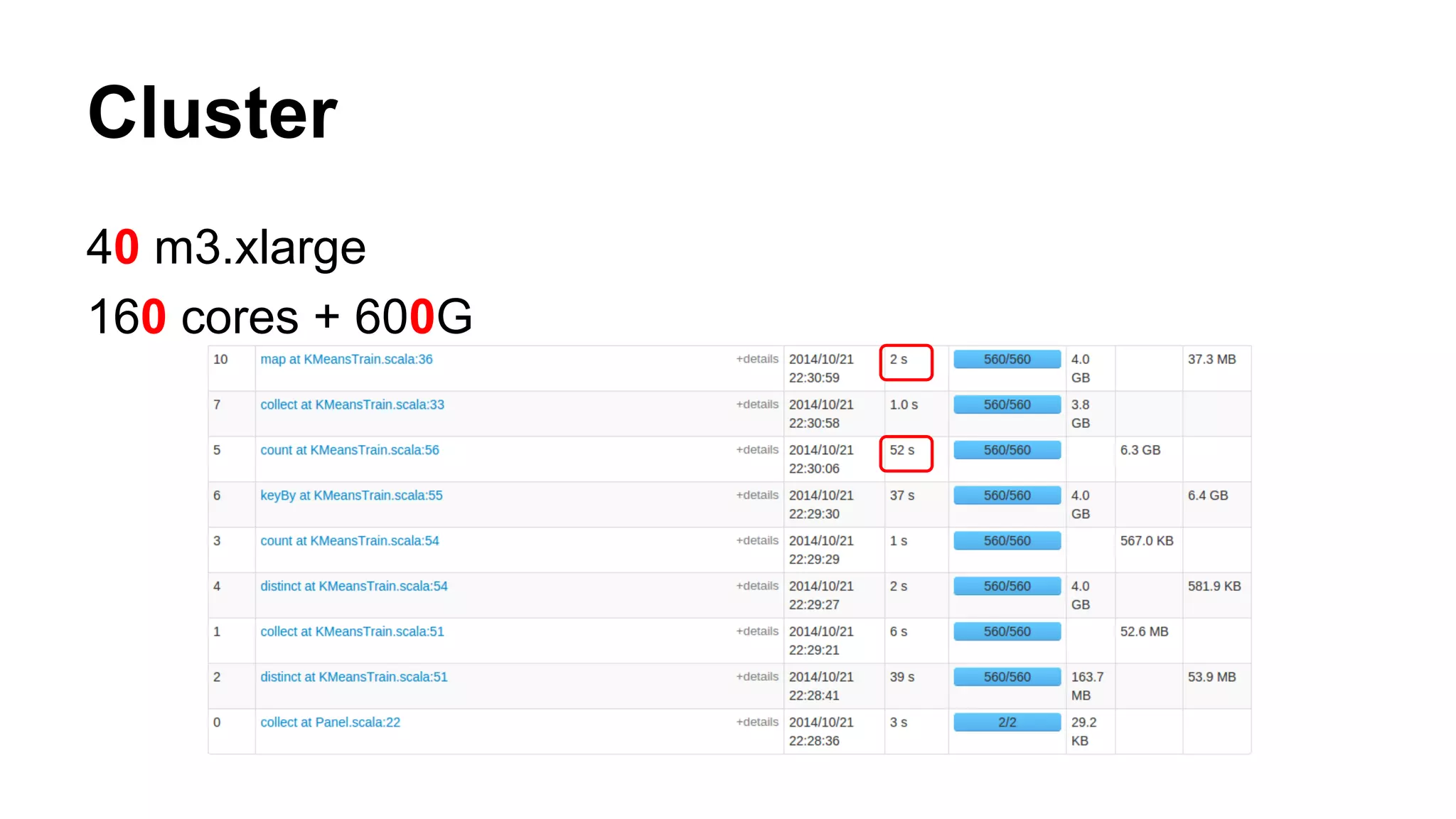



























![RDDs
Think of an RDD[T] as an immutable, distributed collection
of objects of type T
• Resilient => Can be reconstructed in case of failure
• Distributed => Transformations are parallelizable
operations
• Dataset => Data loaded and partitioned across cluster
nodes (executors)](https://crownmelresort.com/image.slidesharecdn.com/geeksa-150130082242-conversion-gate02/75/What-is-Distributed-Computing-Why-we-use-Apache-Spark-26-2048.jpg)
![RDD[T]
Data distribution hierarchy:
- RDD[T]
- Elements
[ x1, x2 ]
[ x10 ]
[ x8,x5,x6 ]
[ x11 ]
[ x14,x13 ]
[ x9,x16 ]
[ x3 ]
[ x7,x12 ]
[ x15 ]
[ x17,x4 ]
Executor 1
- Executors
- Partitions
Executor 2 Executor 3 Executor 4](https://crownmelresort.com/image.slidesharecdn.com/geeksa-150130082242-conversion-gate02/75/What-is-Distributed-Computing-Why-we-use-Apache-Spark-27-2048.jpg)



![Spark Streaming
When you have big fat streams behaving as one single
collection
t
DStream[T]
RDD[T] RDD[T] RDD[T] RDD[T] RDD[T]
DStreams: Discretized Streams (= Sequence of RDDs)](https://crownmelresort.com/image.slidesharecdn.com/geeksa-150130082242-conversion-gate02/75/What-is-Distributed-Computing-Why-we-use-Apache-Spark-31-2048.jpg)









![Mashup
prediction
Sample [NA20332] is in cluster #0 for population Some( ASW)
Sample [NA20334] is in cluster # 2 for population Some( ASW)
Sample [HG00120] is in cluster # 2 for population Some( GBR)
Sample [NA18560] is in cluster # 1 for population Some( CHB)](https://crownmelresort.com/image.slidesharecdn.com/geeksa-150130082242-conversion-gate02/75/What-is-Distributed-Computing-Why-we-use-Apache-Spark-41-2048.jpg)





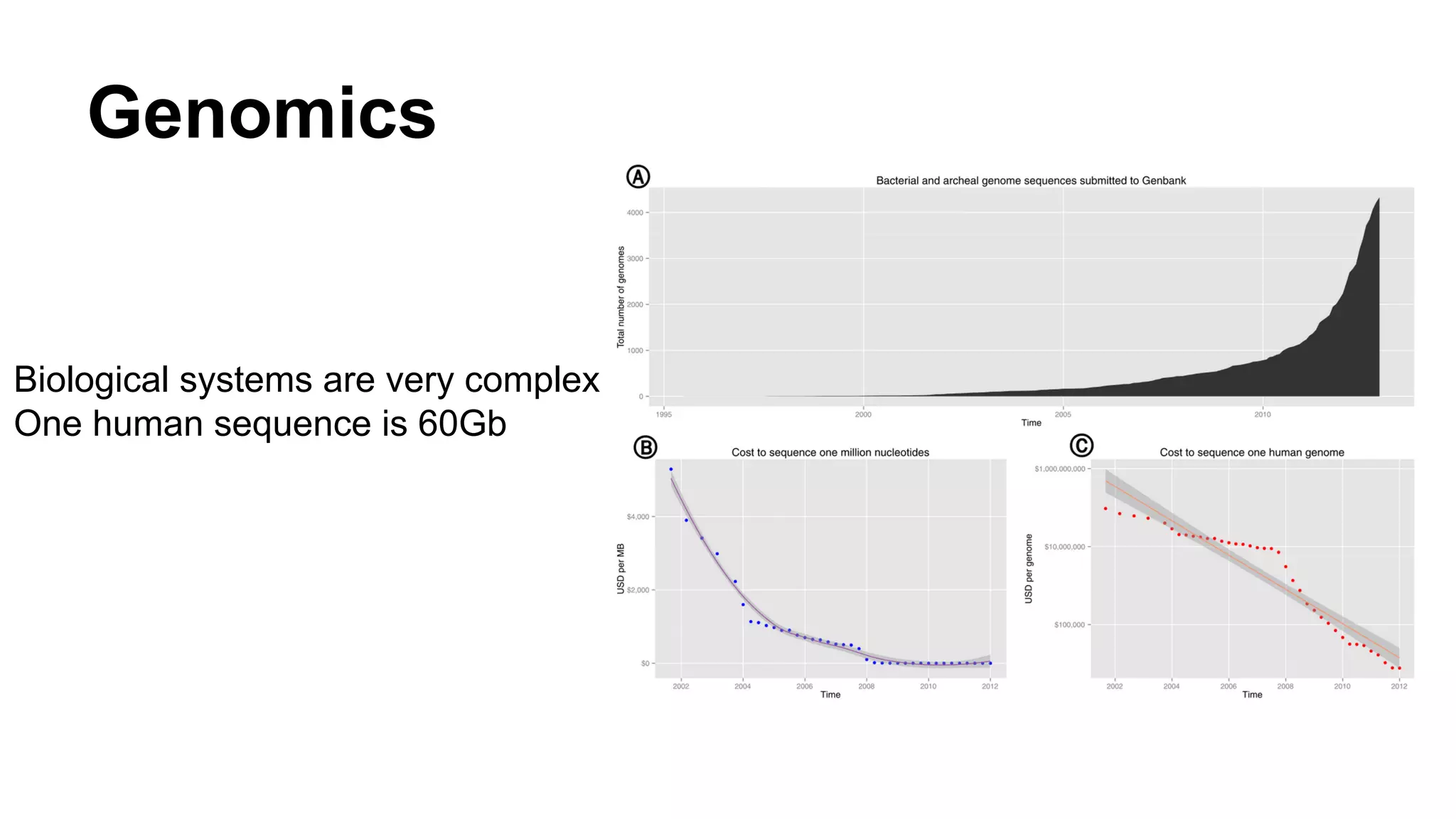
The document discusses the advancements in big data technologies, particularly focusing on Apache Spark and its advantages over Hadoop. It highlights the importance of distributed environments and how Spark's features, such as resilient distributed datasets (RDDs) and in-memory caching, enable faster and smarter data processing for various use cases, including machine learning and genomics. The authors emphasize Spark's efficiency in handling large datasets and its capabilities in real-time processing and complex model training.












































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)









