Download as PDF, PPTX


















![Submitting Applications
Once a user application is bundled, it can be launched using the
bin/spark-submit script.
./bin/spark-submit
--class <main-class>
--master <master-url>
--deploy-mode <deploy-mode>
--conf <key>=<value>
... # other options
<application-jar>
[application-arguments]
See next page for detailed descriptions for each argument
This is the only way to submit jobs to Spark!](https://image.slidesharecdn.com/20150130-sparkintroduction-150130015658-conversion-gate01/75/Hadoop-Spark-Introduction-20150130-31-2048.jpg)









































![Submitting Applications
Once a user application is bundled, it can be launched using the
bin/spark-submit script.
./bin/spark-submit
--class <main-class>
--master <master-url>
--deploy-mode <deploy-mode>
--conf <key>=<value>
... # other options
<application-jar>
[application-arguments]
See next page for detailed descriptions for each argument
This is the only way to submit jobs to Spark!](https://crownmelresort.com/image.slidesharecdn.com/20150130-sparkintroduction-150130015658-conversion-gate01/75/Hadoop-Spark-Introduction-20150130-31-2048.jpg)












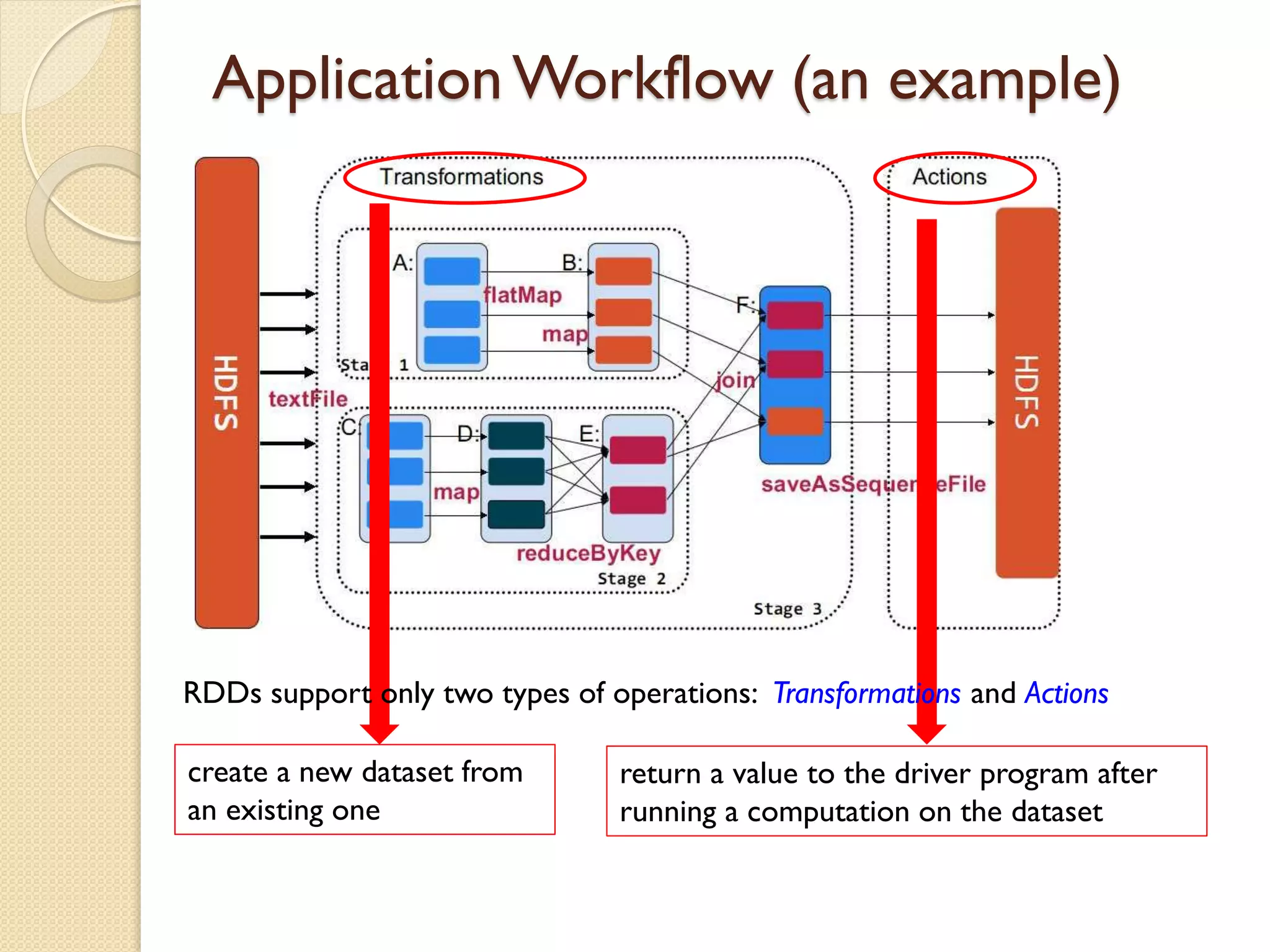
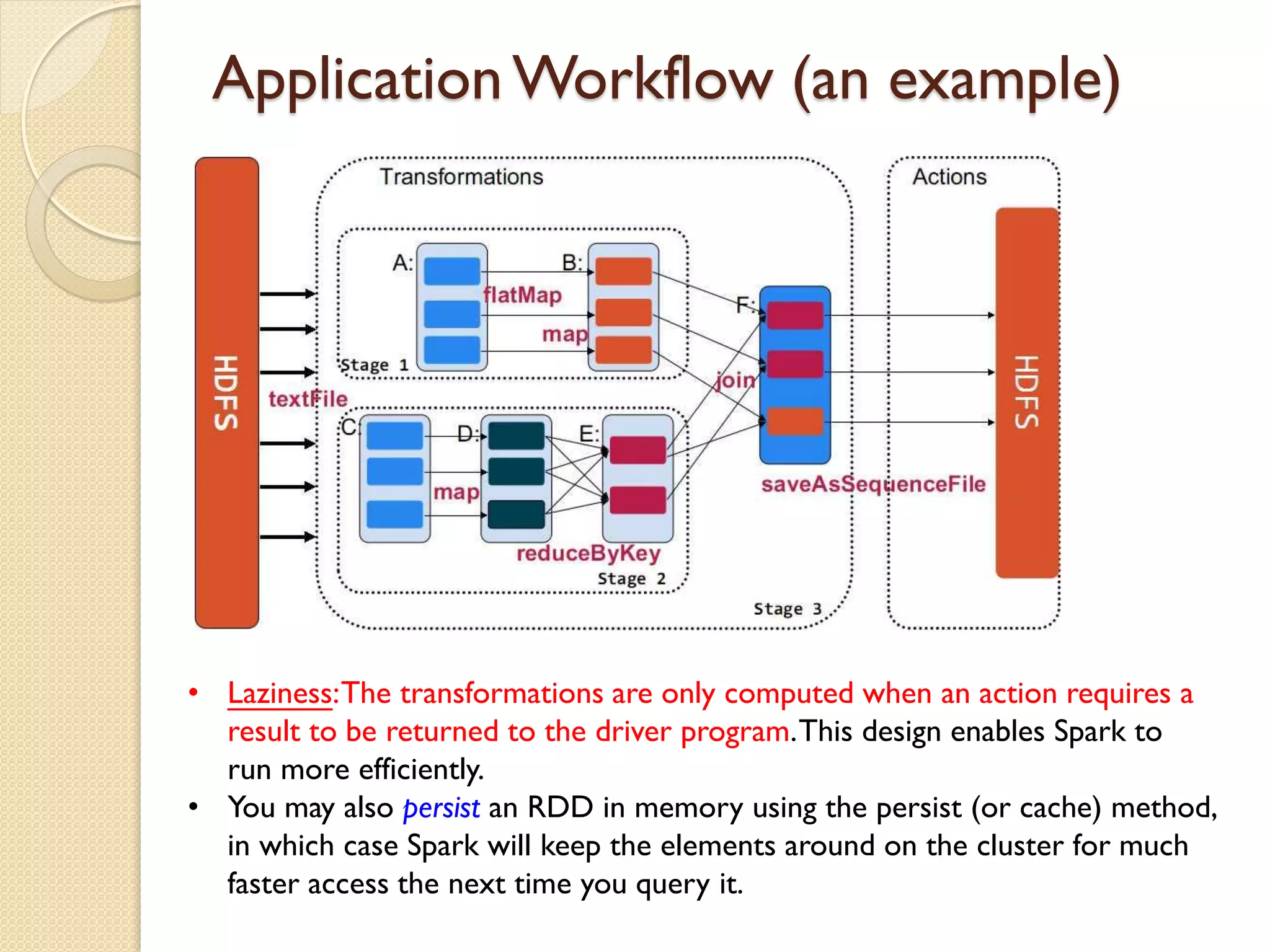
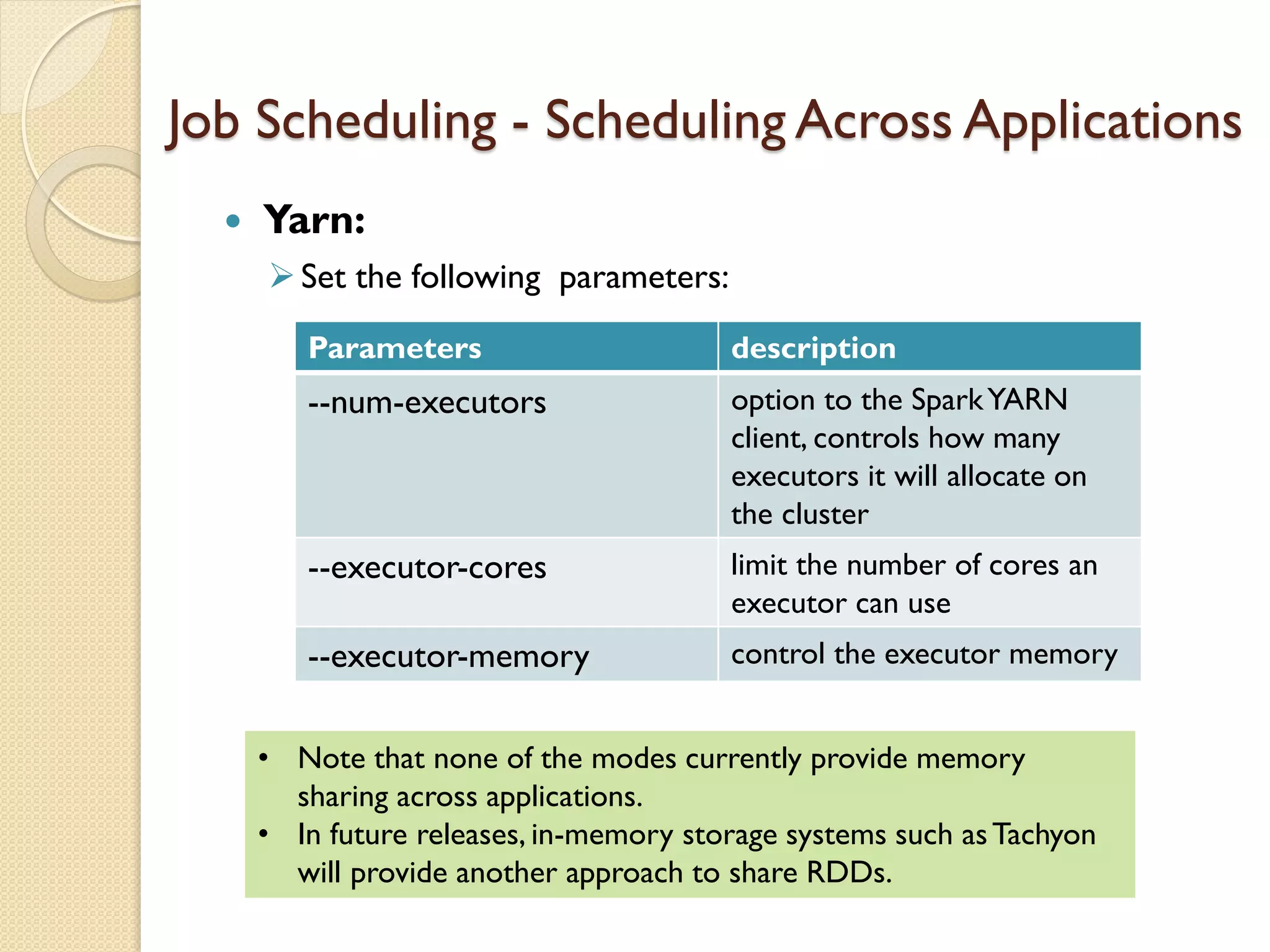
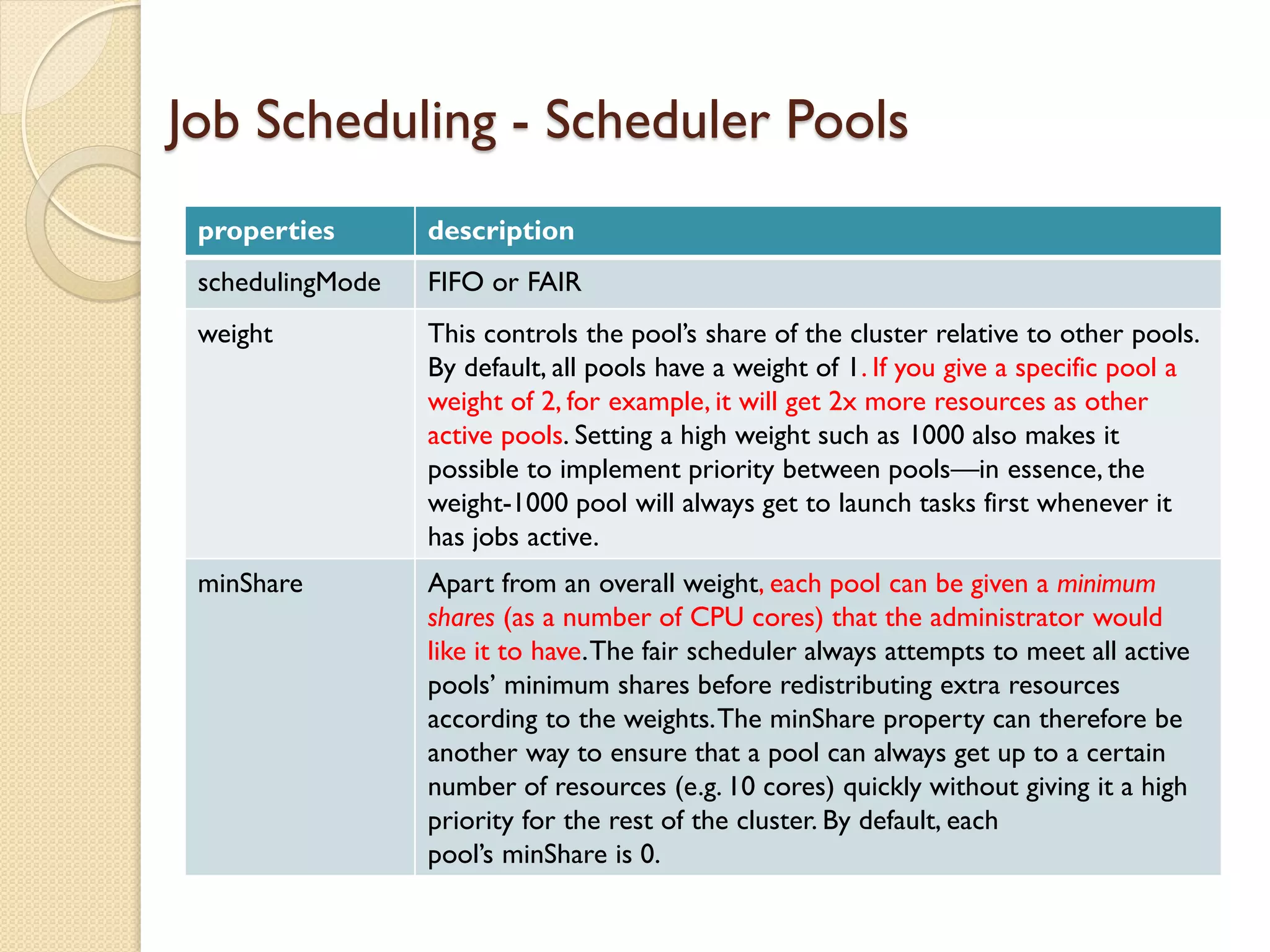
This document serves as an introduction to Apache Spark, covering its architecture, data processing capabilities, job scheduling, and application submission. Spark is a fast, general engine for large-scale data processing that can run programs significantly faster than Hadoop MapReduce, with a focus on in-memory computing and support for multiple programming languages. Additionally, it discusses the architecture involving cluster managers, resilient distributed datasets (RDDs), and provides a programming guide for creating Spark applications.























































































