Download as PDF, PPTX








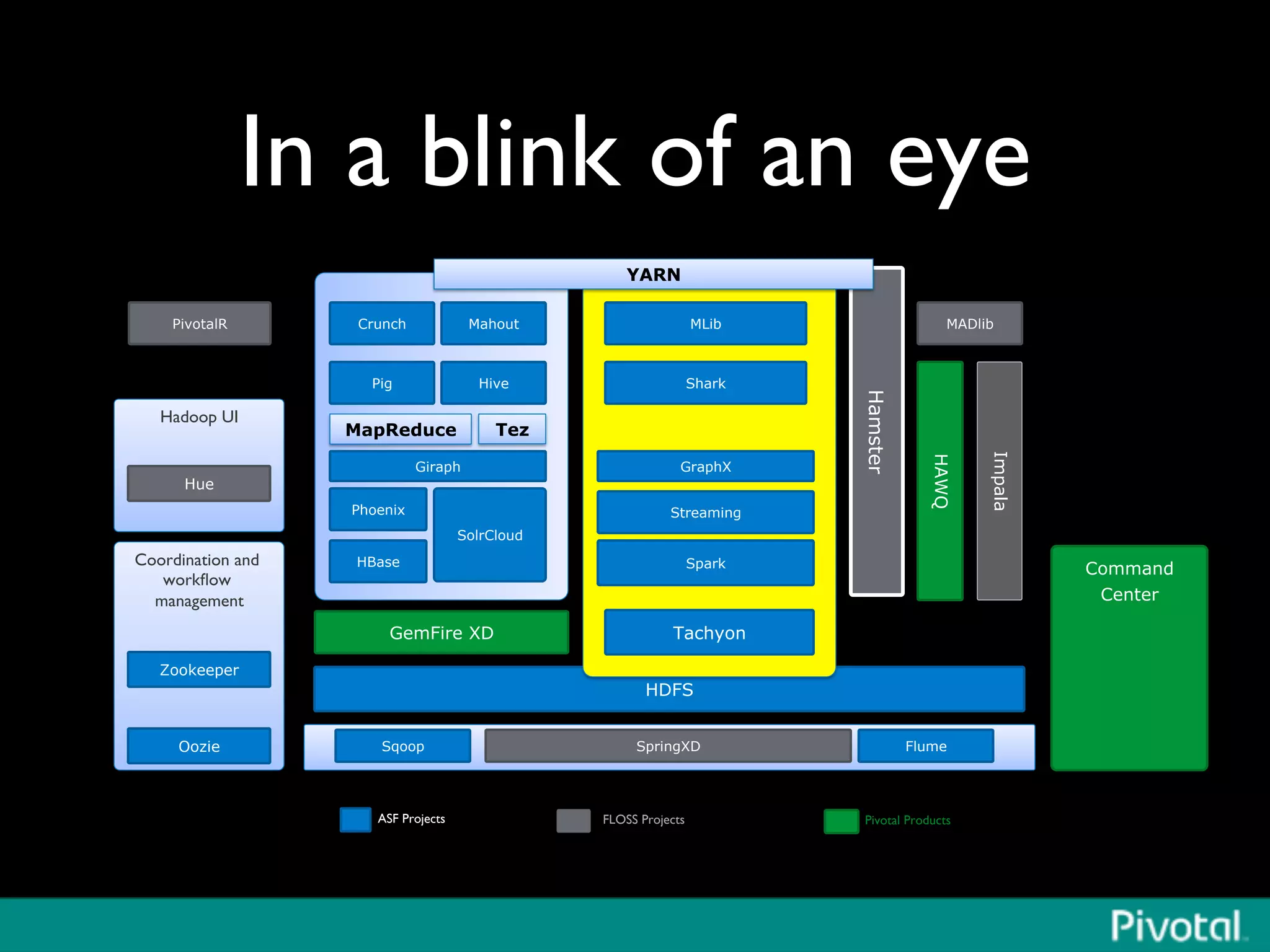
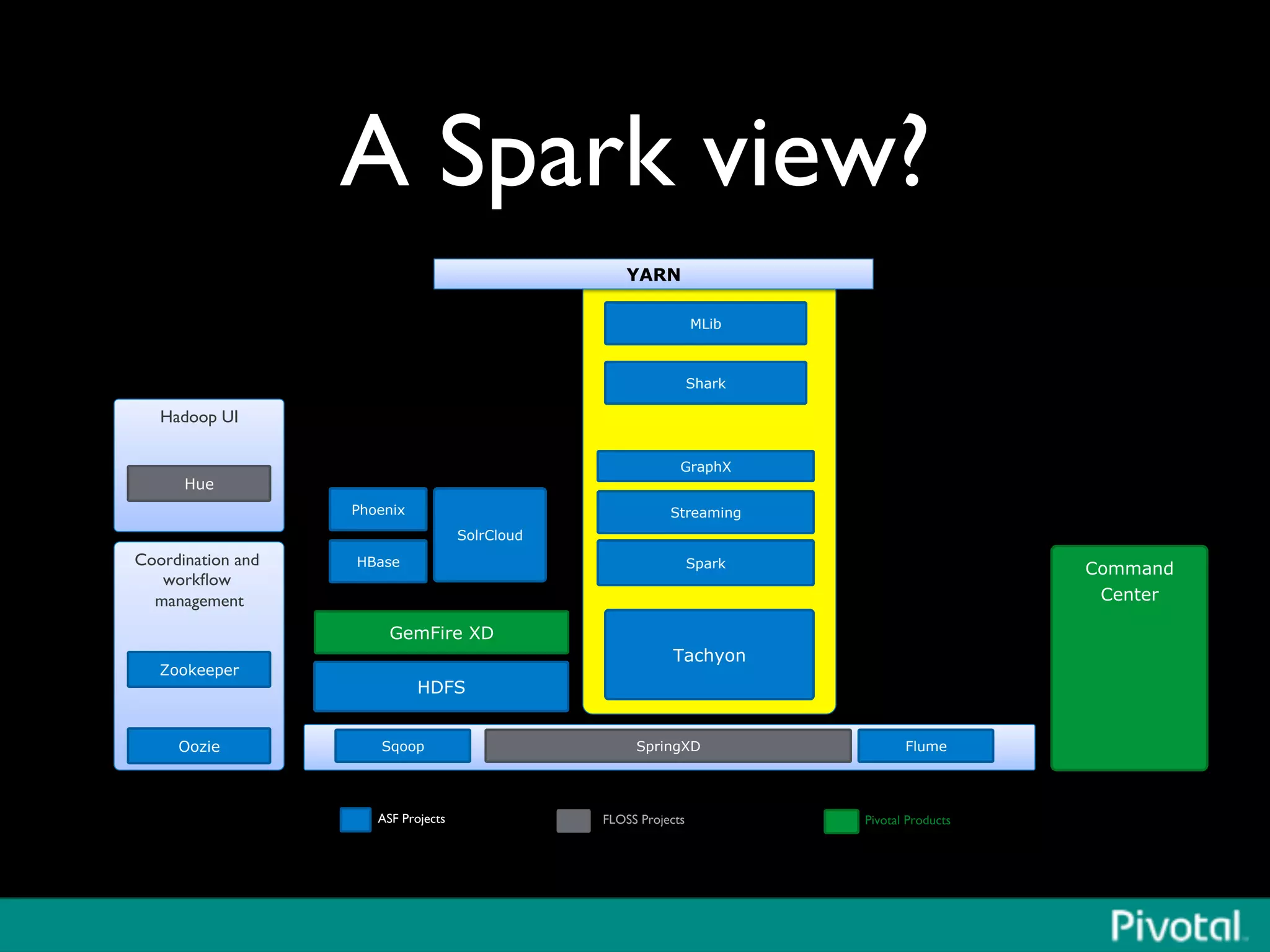
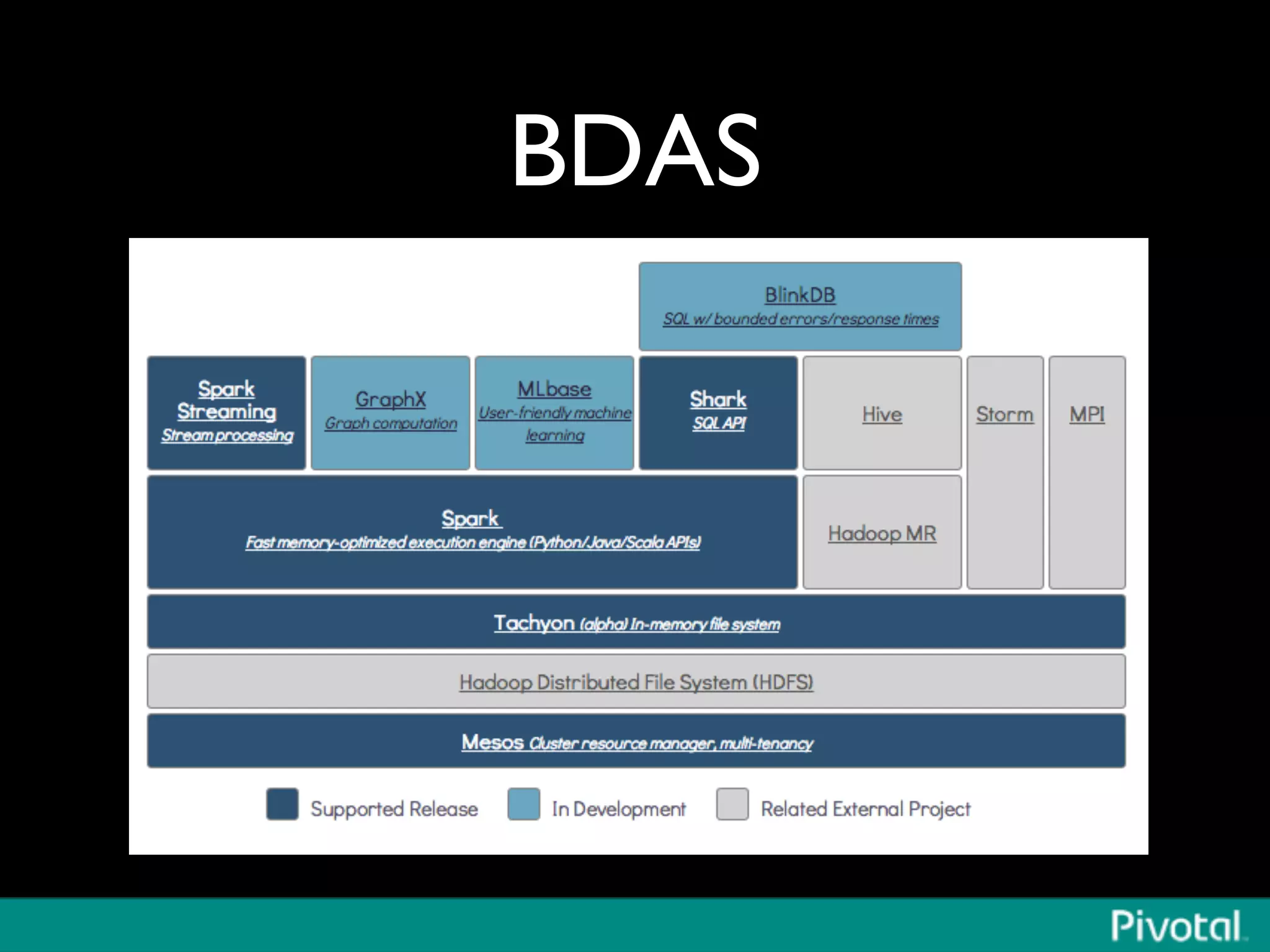

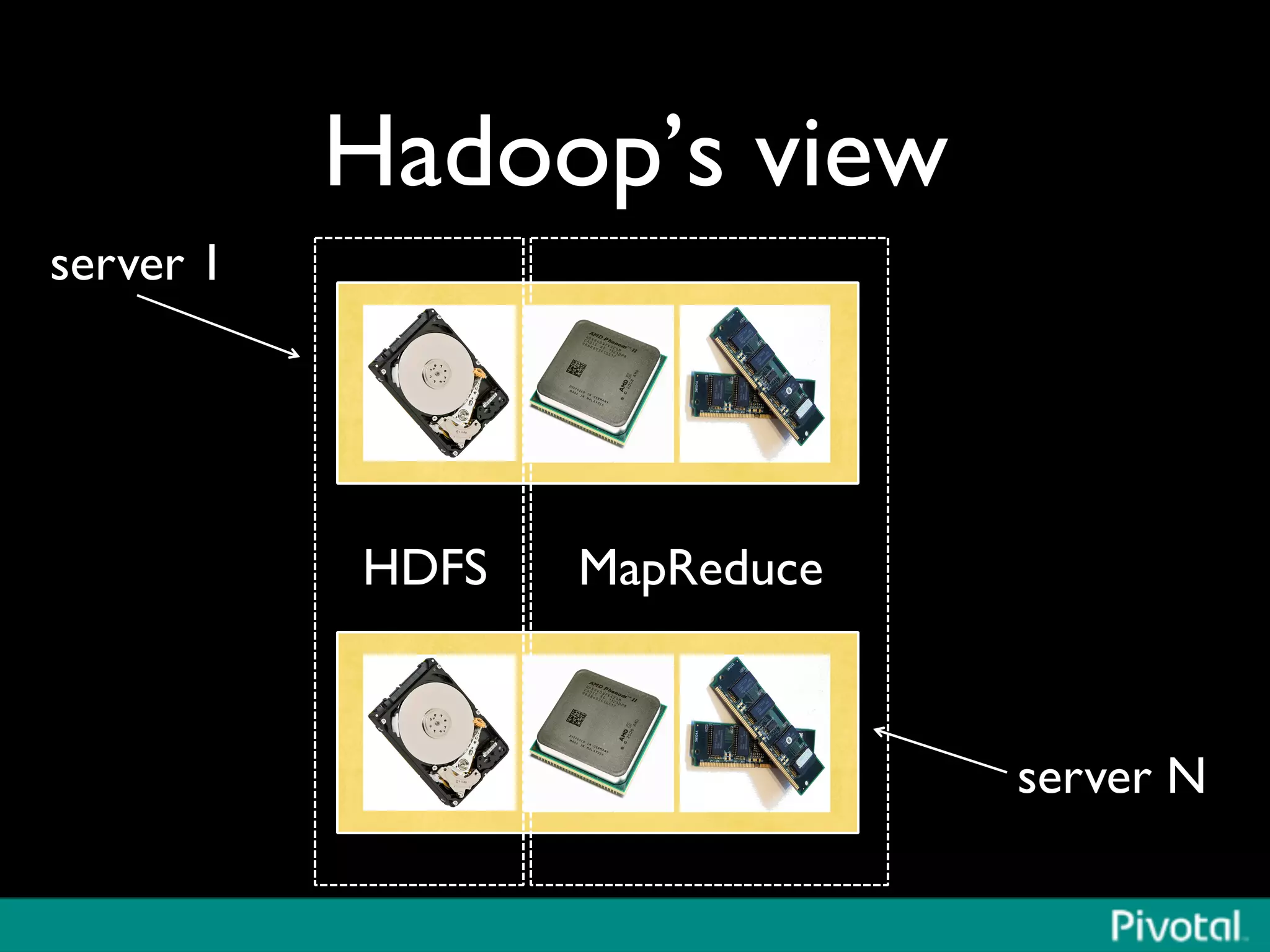
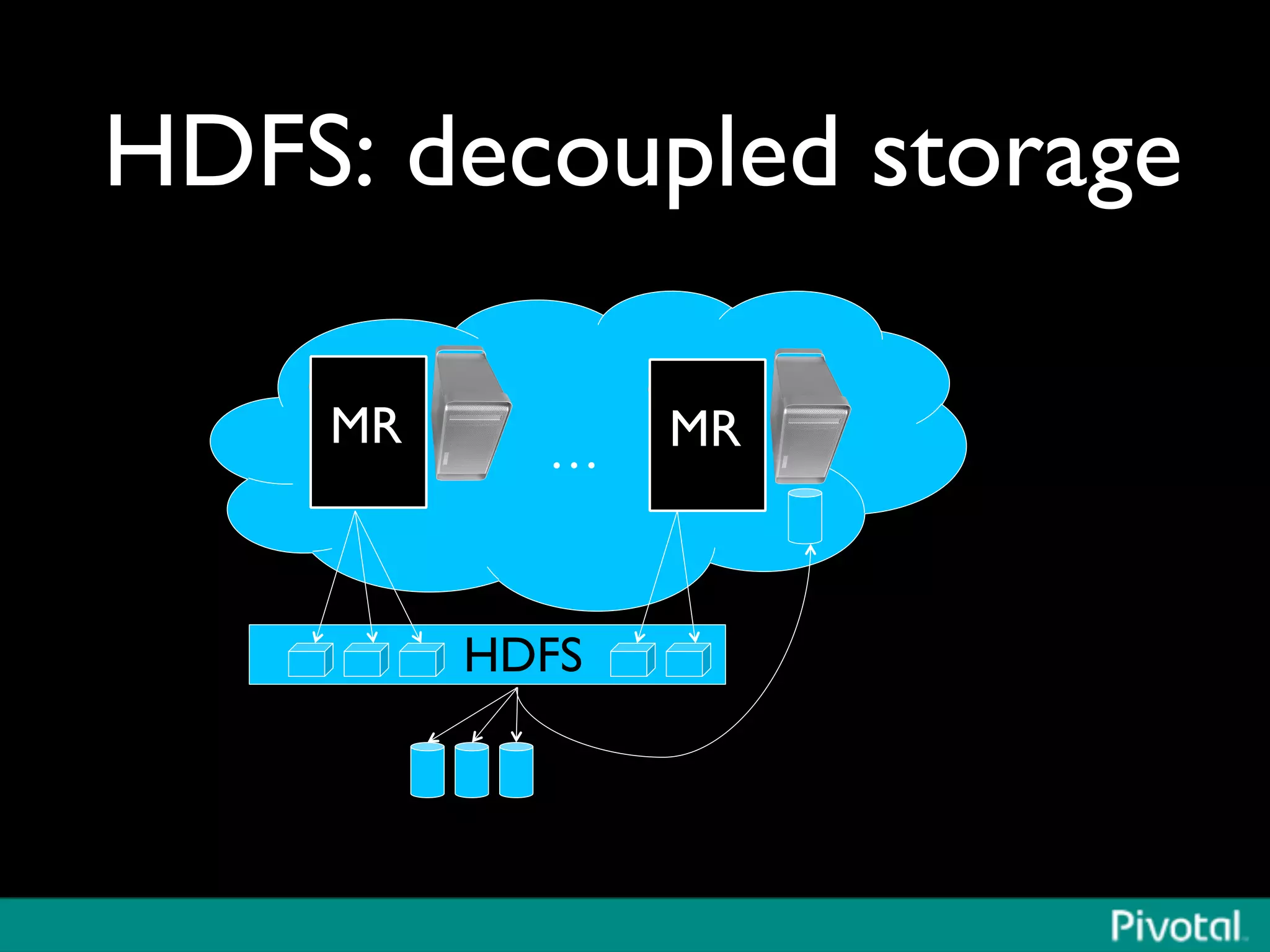

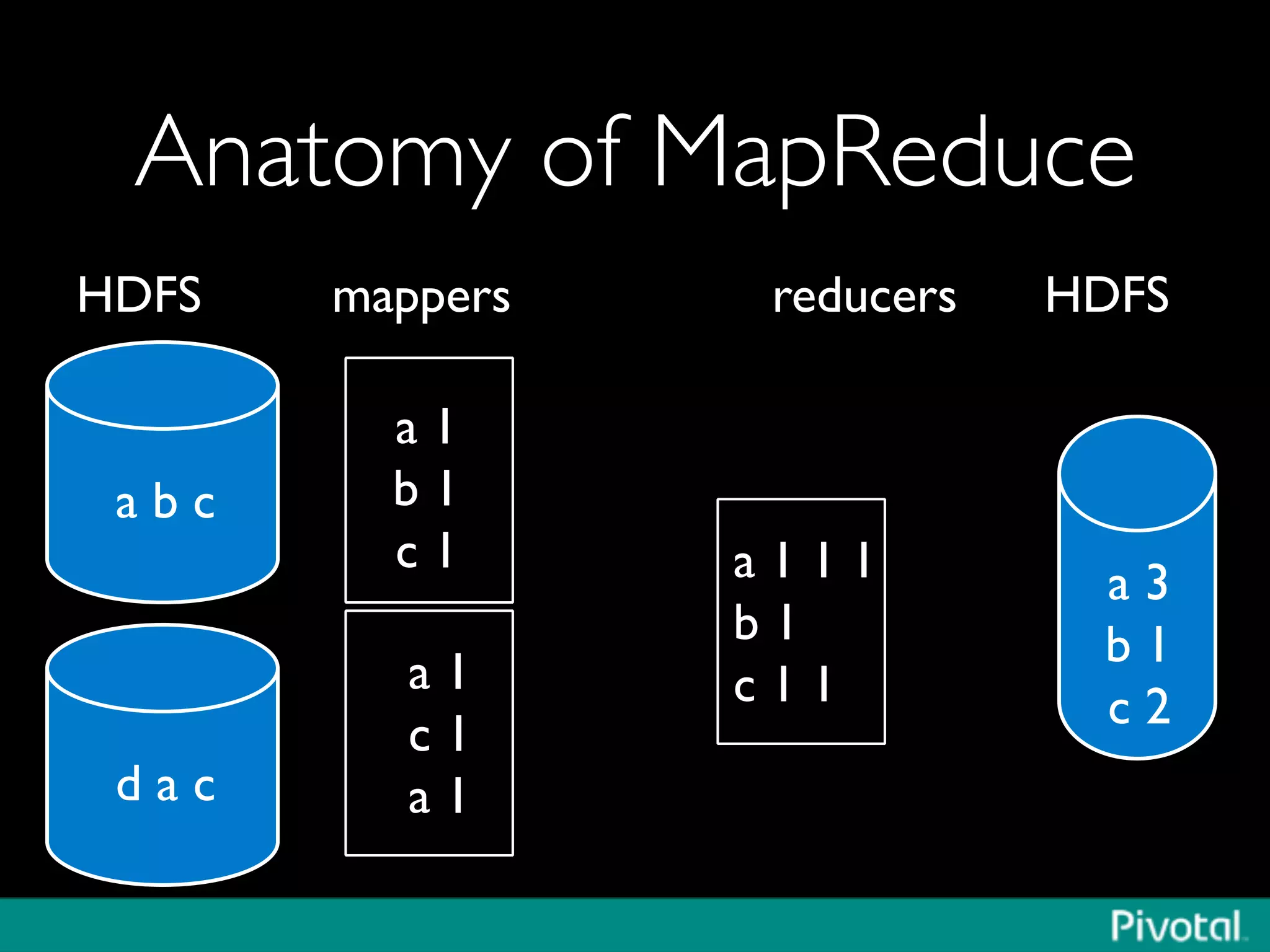

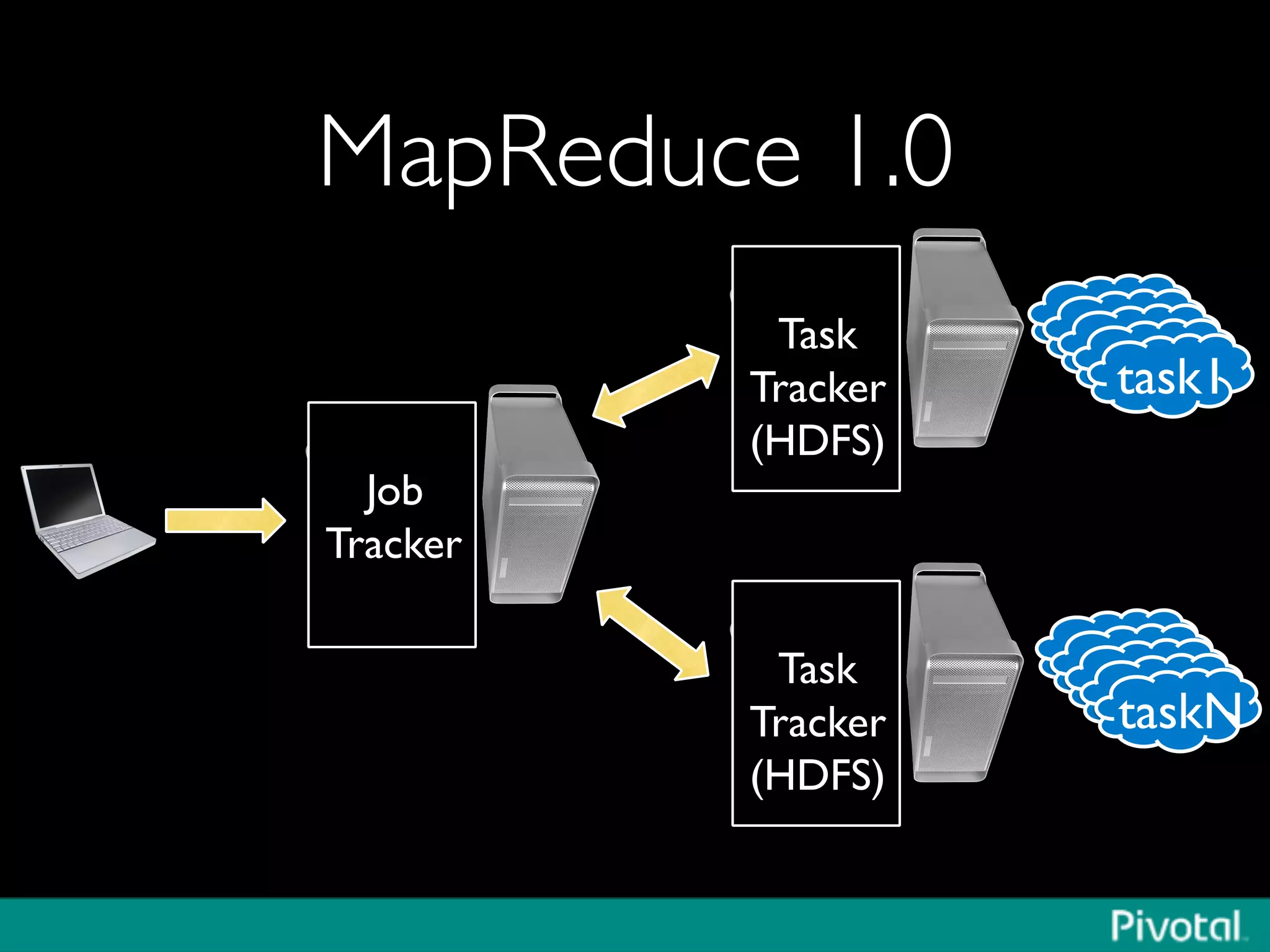
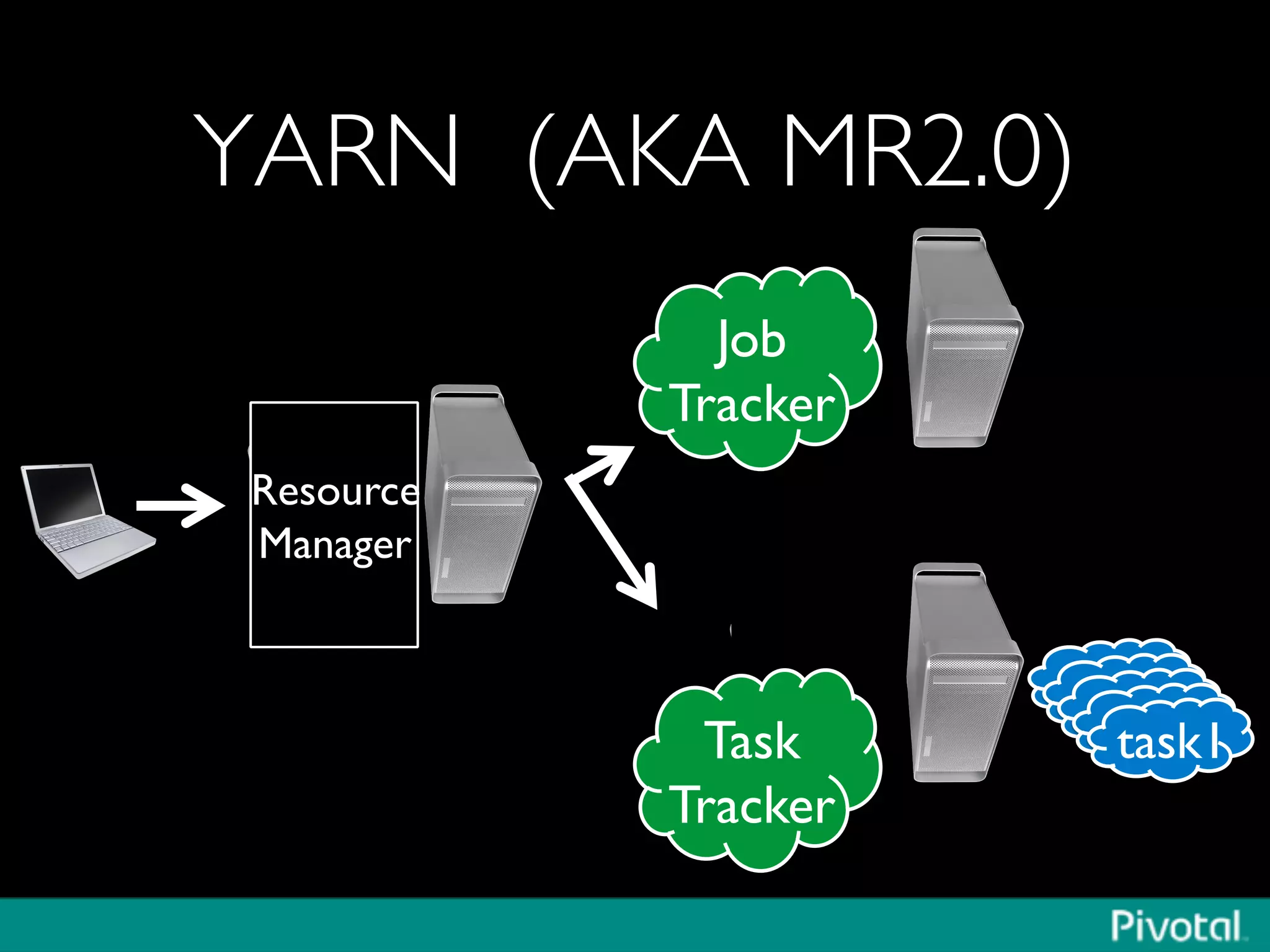
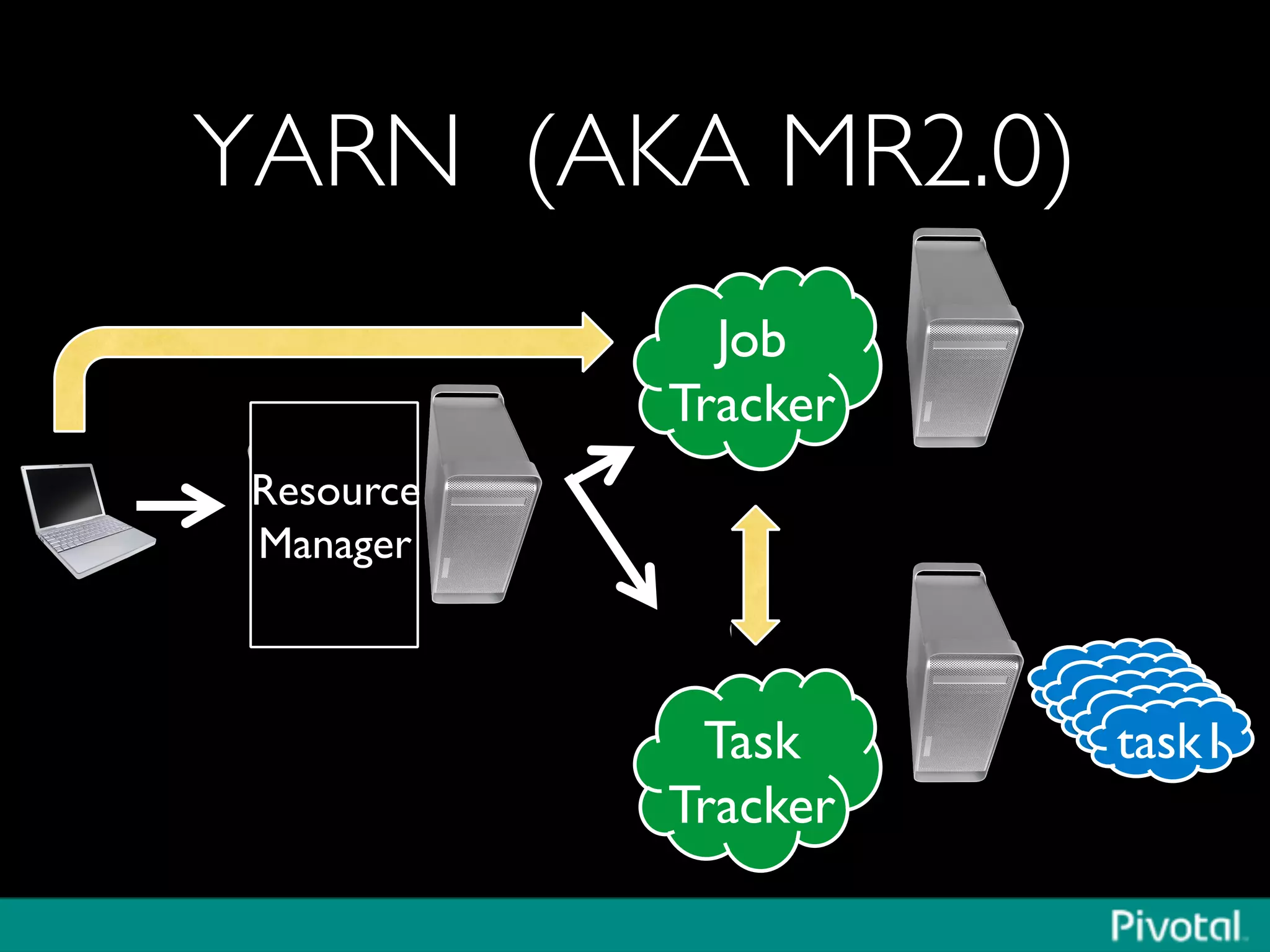

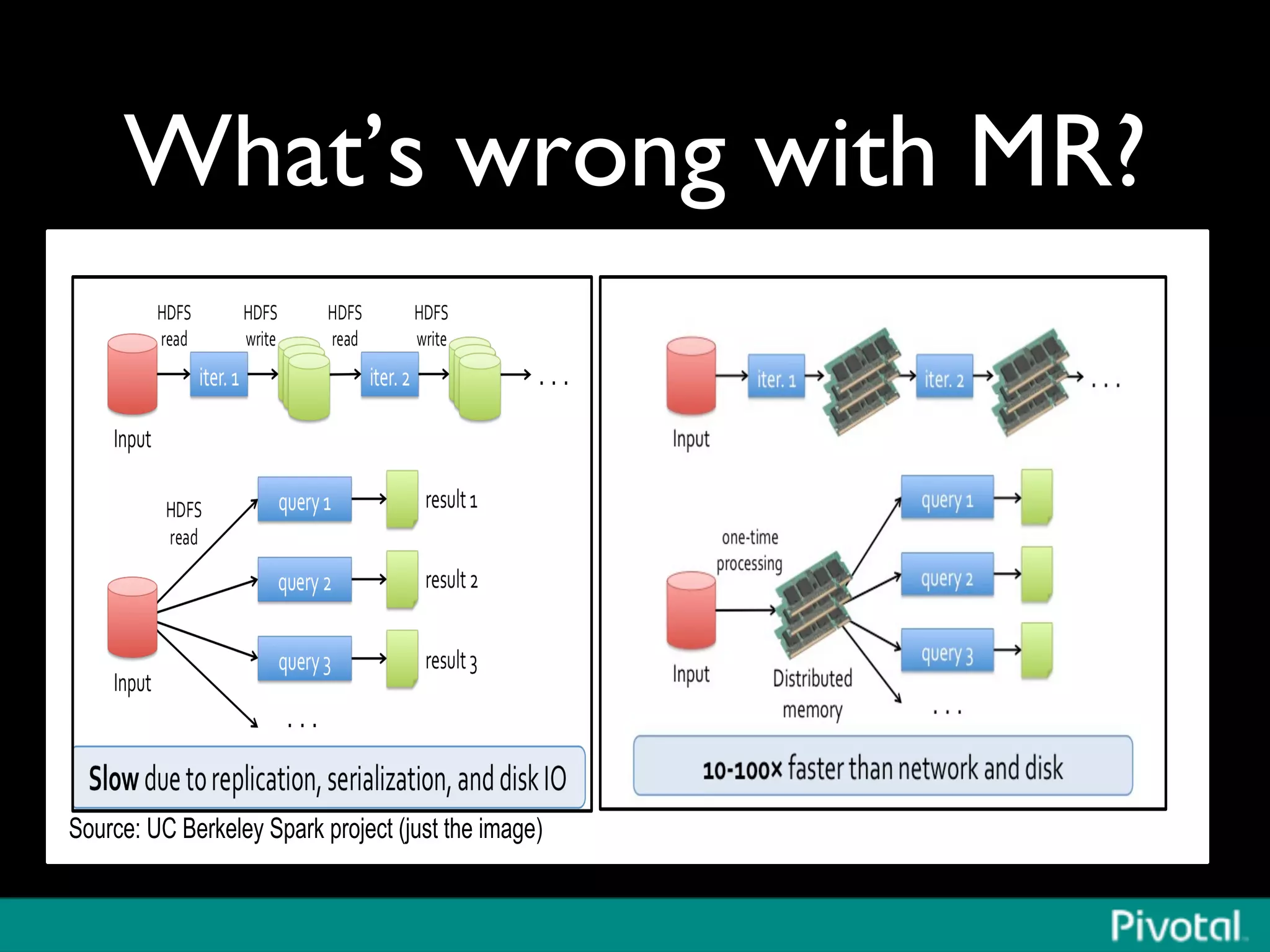



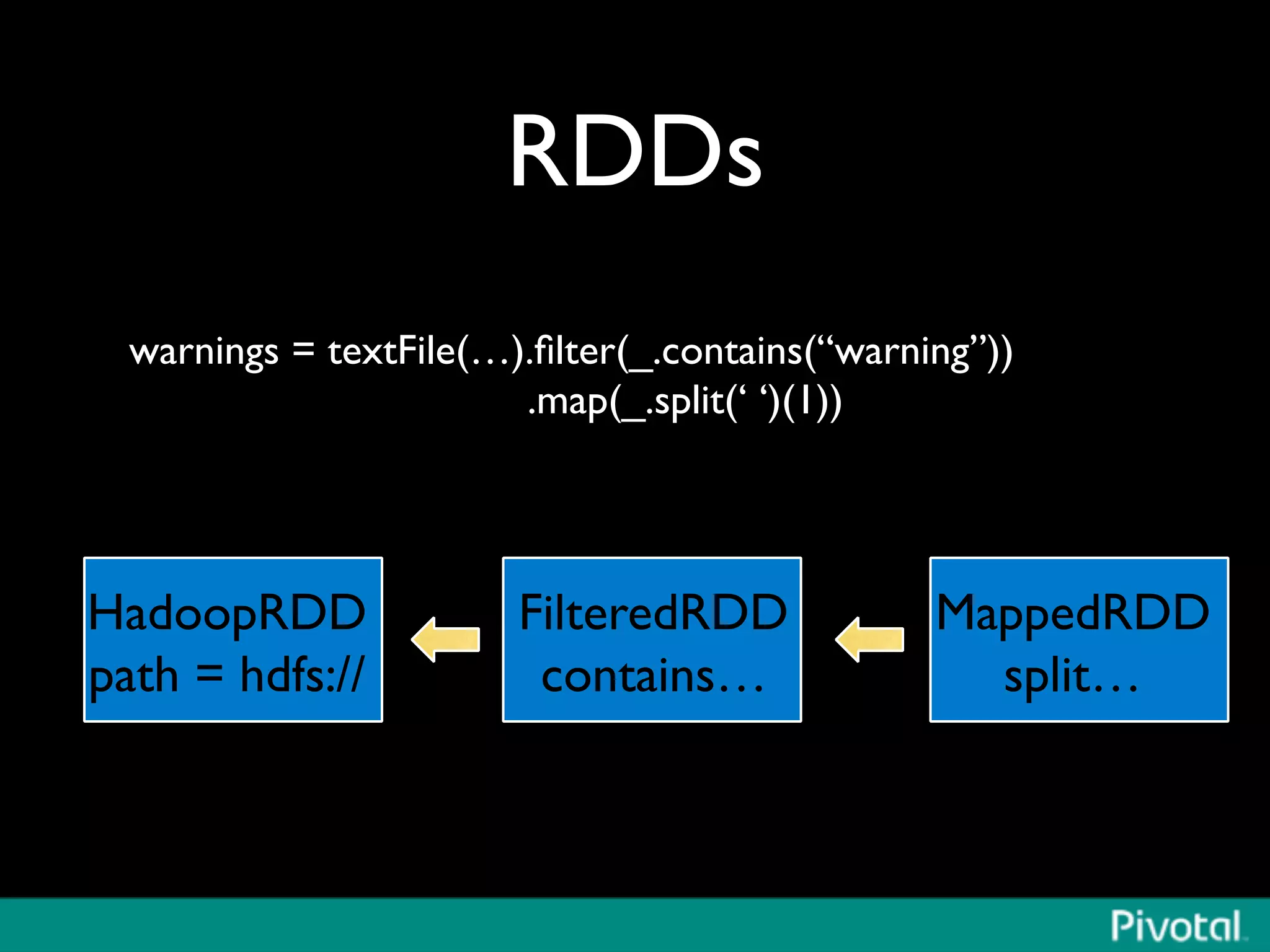


















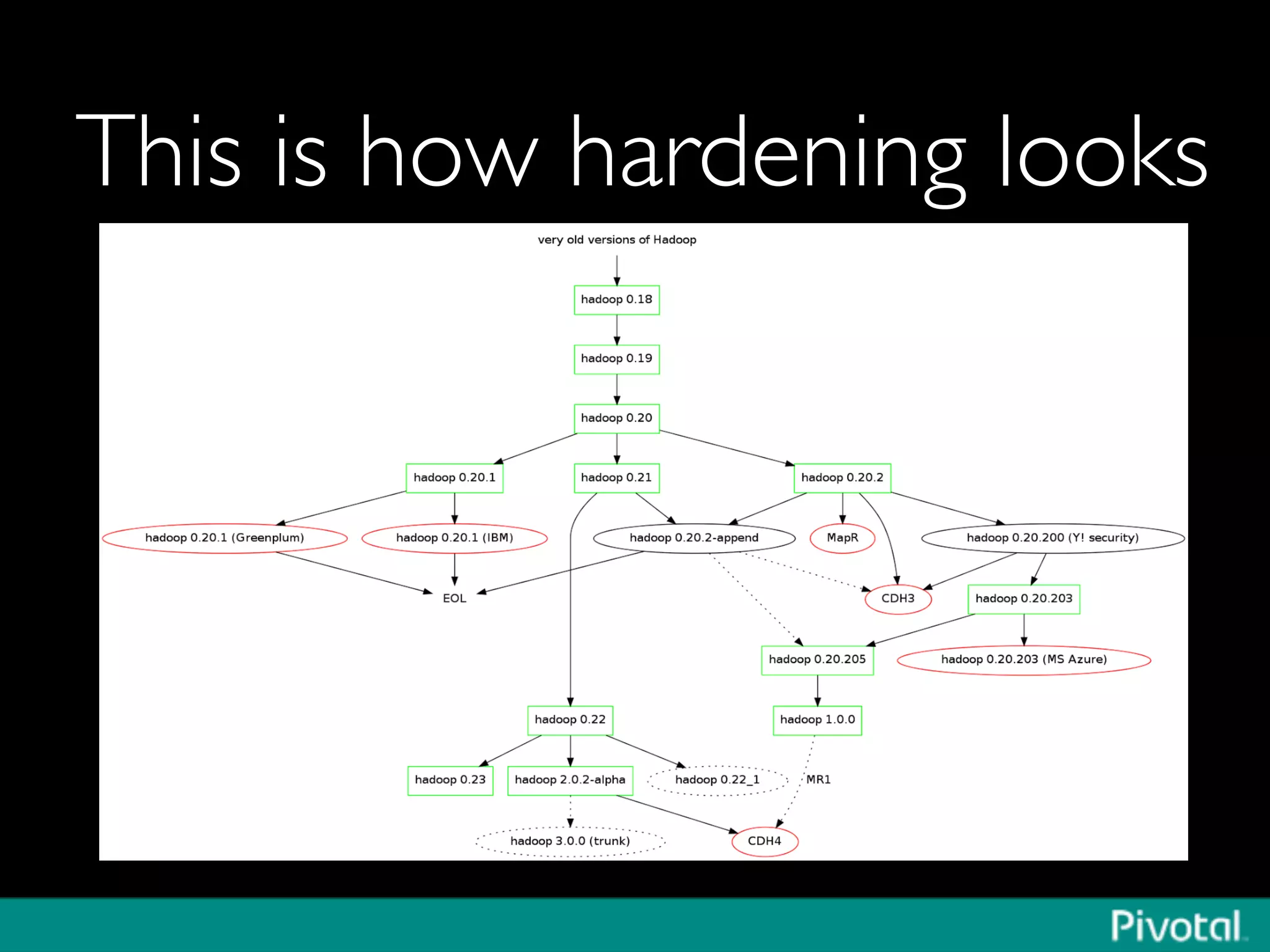






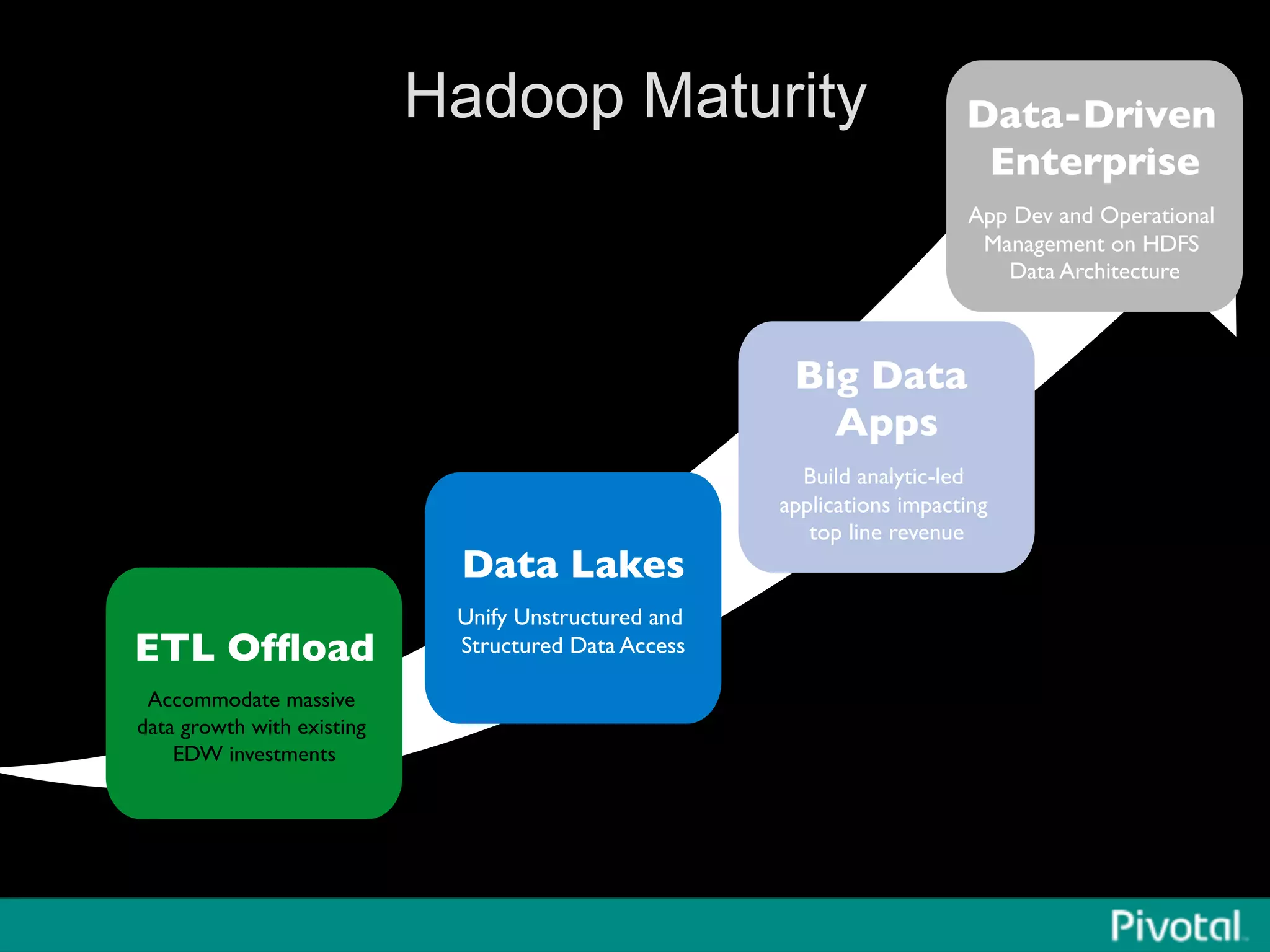

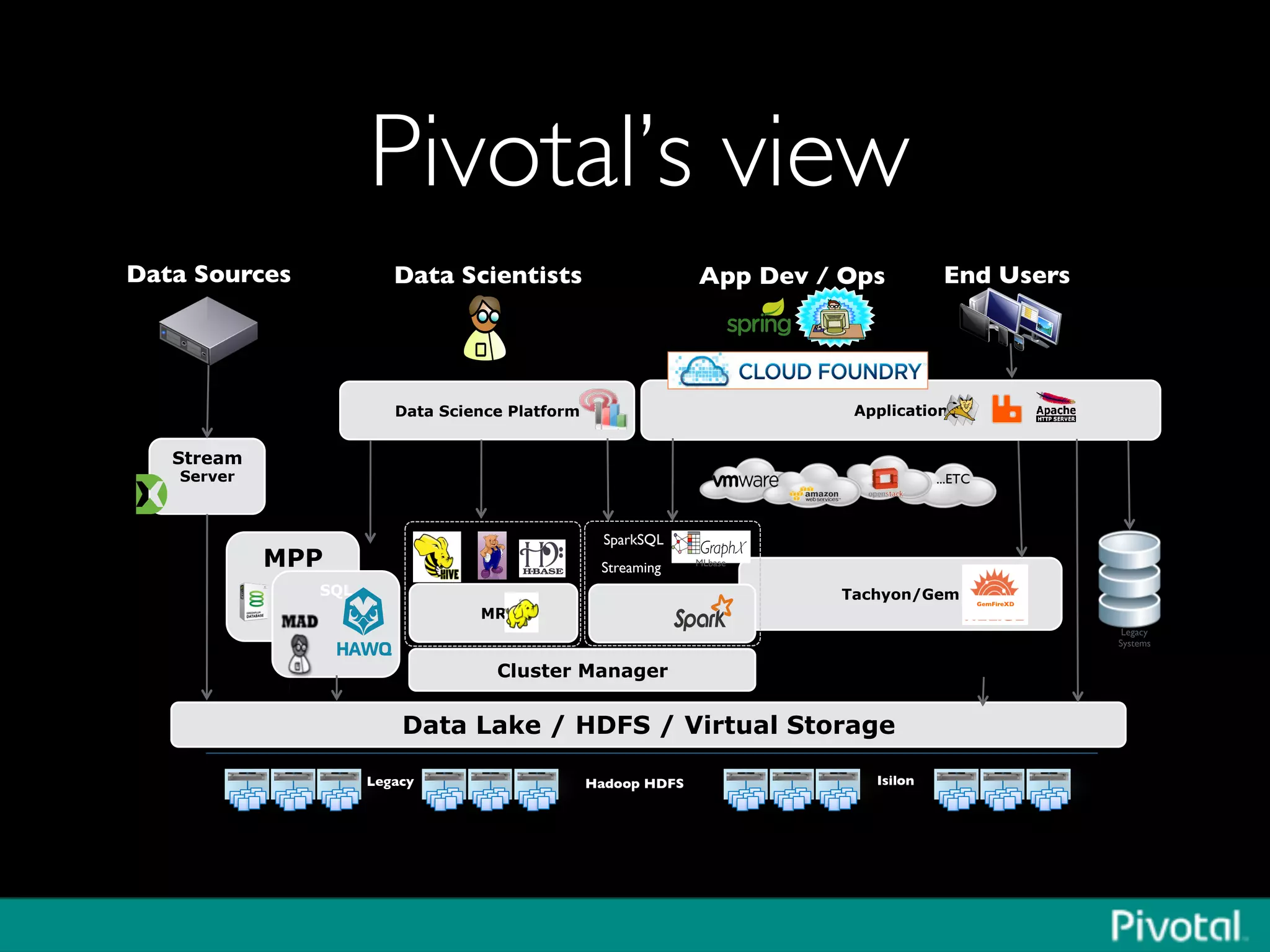

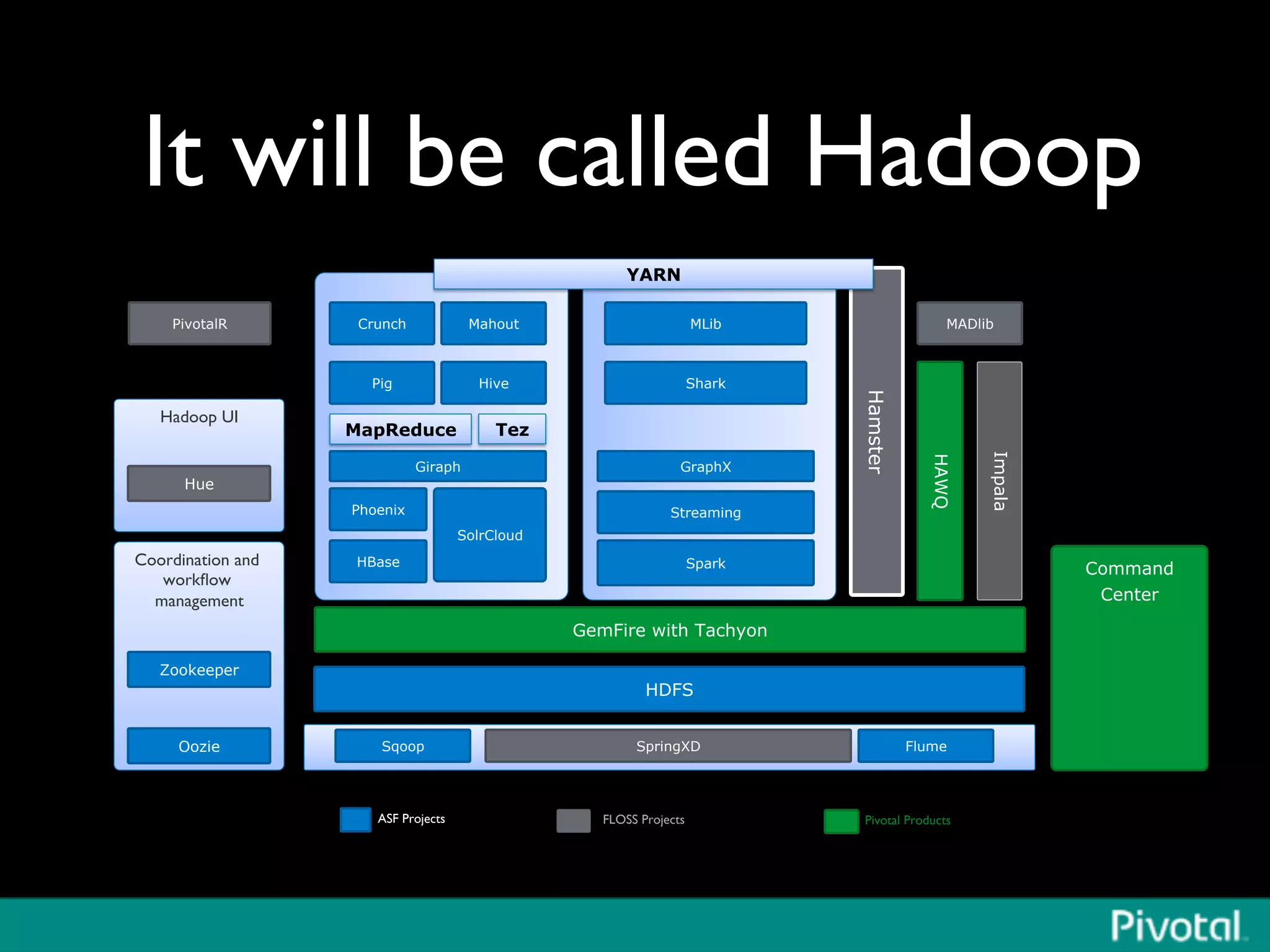



































































The document discusses Apache Spark's relationship with Hadoop, analyzing its functionalities and innovations, particularly how Spark simplifies data processing for data scientists. It highlights Spark's features, including resilient distributed datasets (RDDs), capabilities for stream processing, and machine learning integration, contrasting them with traditional MapReduce methods. Additionally, the document provides insights into the evolving ecosystem of big data technologies, emphasizing Spark's advantages and its emergence as a significant tool in modern data architectures.