Download to read offline



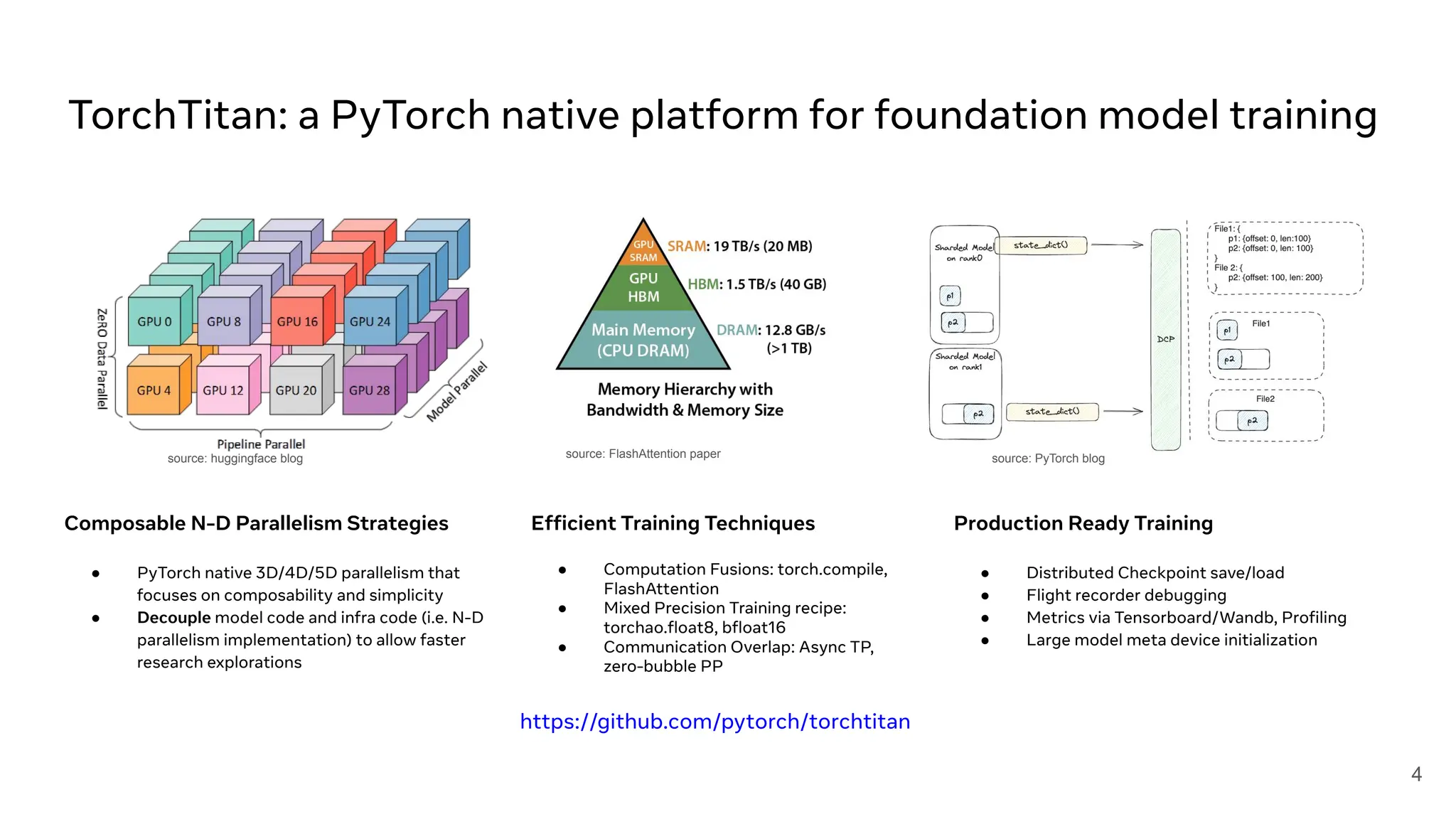
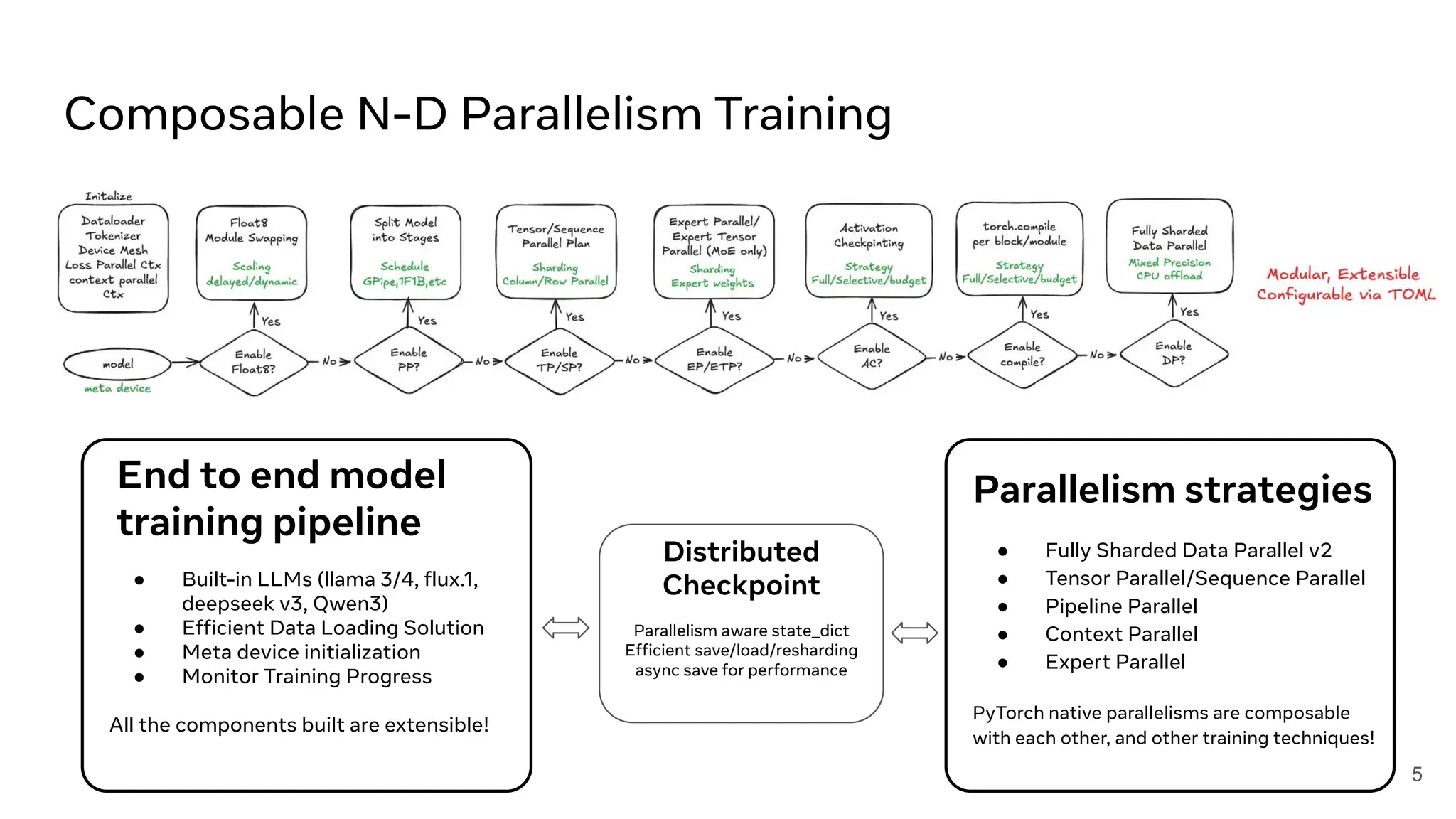
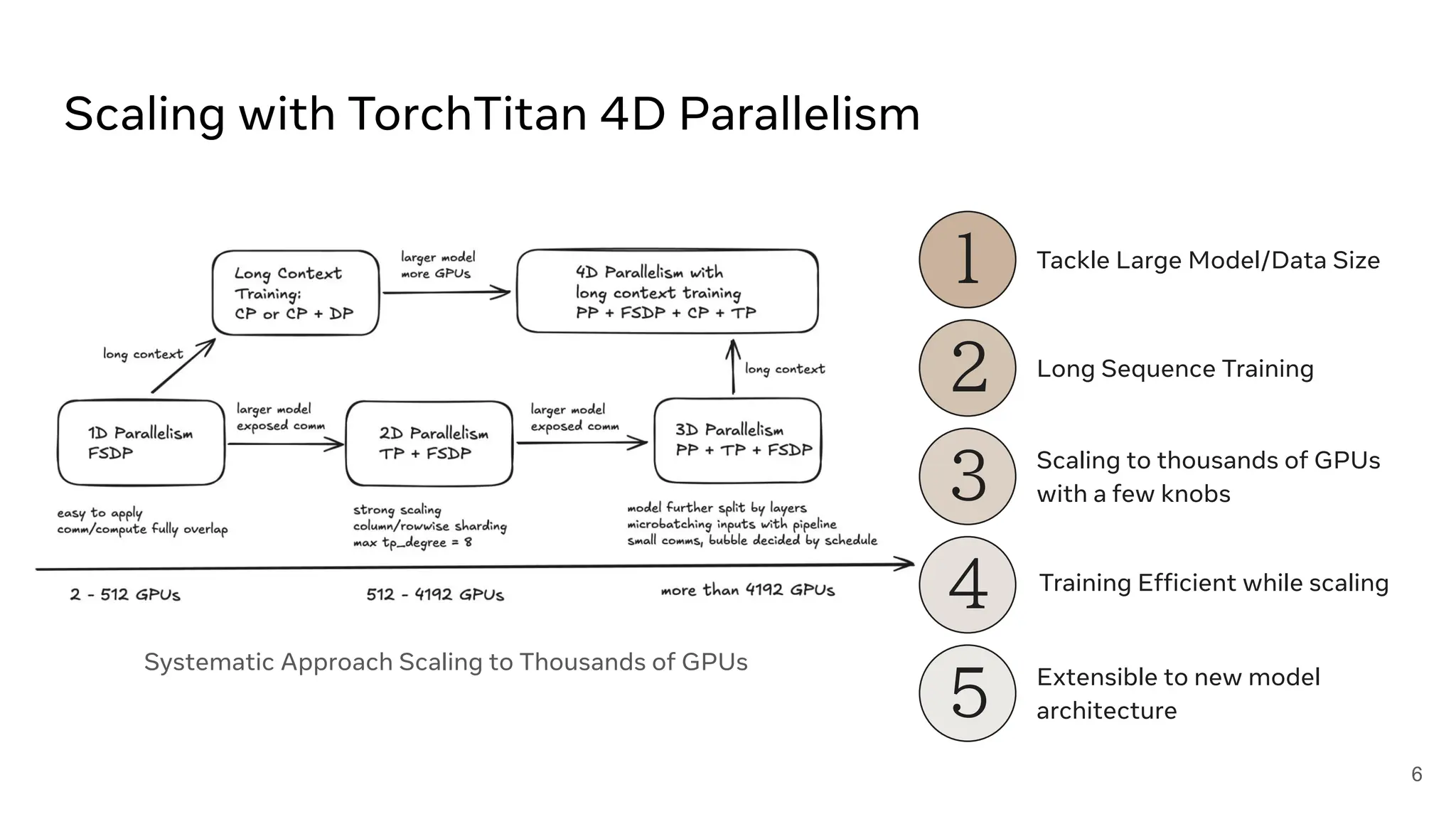



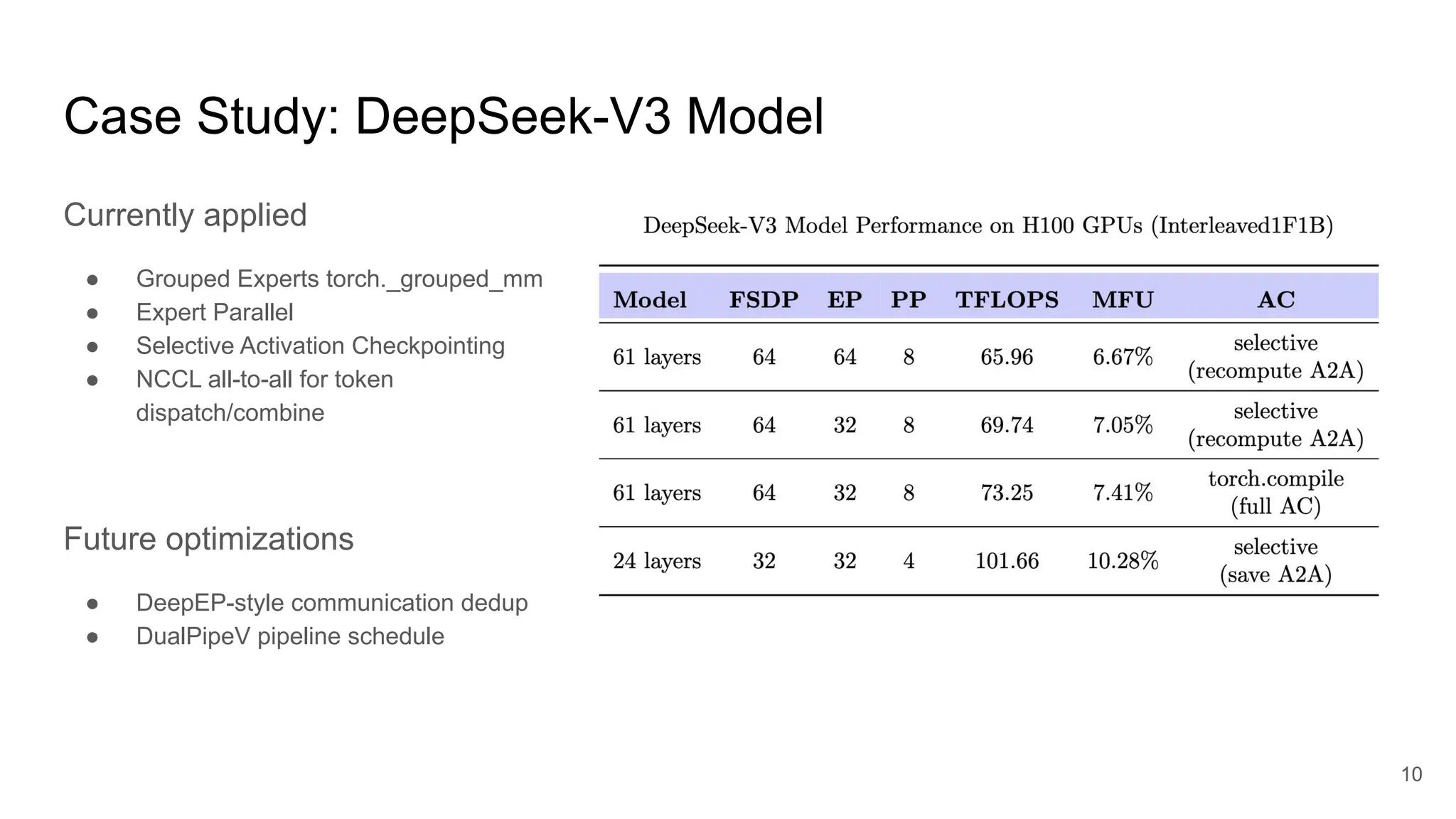

















AI/ML Infra Meetup Nov. 13, 2025 Organized by Alluxio For more Alluxio Events: https://www.alluxio.io/events/ Speaker: - Jiani Wang (Software Engineer @ Meta's PyTorch Team) Hear from Jiani Wang, Software Engineer Meta's Pytorch Team, on the overview and the latest advancements in TorchTitan.


































































