This document provides an overview and comparison of Apache Hadoop and Apache Spark for big data analytics. It discusses the architectures and functionality of Hadoop MapReduce and HDFS, as well as Spark's RDDs, transformations, and actions. The document demonstrates K-means clustering in both Spark and Hadoop MapReduce and shows that Spark outperforms Hadoop MapReduce, especially for iterative algorithms. While Hadoop remains useful for its features, the combination of Spark and HDFS can achieve high performance for both batch and interactive analytics.


![Source: [1]
The World of Big Data
Apache Hadoop and Spark within the context of big data analytics:](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-3-2048.jpg)


![What is Hadoop?
The Hadoop project’s open-source software for reliable, scalable, distributed computing
Source: [7], [8]
](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-6-2048.jpg)
![HDFS and YARN Architecture
A Hadoop cluster is characterized by a master – slave architecture, which utilizes the
“shared-nothing” principle for effective data processing.
Source: [11]](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-7-2048.jpg)
![Map Reduce: an example
MapReduce means breaking the processing into two phases: the map phase and the
reduce phase, both performed in a distributed, parallel way on a cluster of computers.
Source: [11]](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-8-2048.jpg)
![MapReduce within Hadoop Framework
…represents a scalable solution, which can be extended to several reduce tasks…
Source: [18]](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-9-2048.jpg)
![Limitations of Hadoop MapReduce
…however not necessarily a universally suitable solution especially for the tasks with growing
importance.
Source: [2]
](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-10-2048.jpg)
![Shuffle and Sort
Slow due to replication, serialization, I/O. Inefficient for iterative algorithms and interactive
data mining:
Source: [4]](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-11-2048.jpg)

![What is Spark ?
“Effective, fast, general-purpose cluster computing framework with high level APIs in Java,
Scala, Python and R”:
Source: [9]](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-13-2048.jpg)
![Spark‘s buildup
In addition to the benefits of HDFS Spark relies on DAG* pattern for complex, multi-step data
pipelines and in-memory data sharing across DAG.
Source: [12]
*DAG: Directed Acyclic Graph](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-14-2048.jpg)
![Anatomy of RDD
Distributed collections of objects that can be cached in memory across cluster nodes.
Source: [5]
*RDD: Resilient Distributed Datasets
Some of RDD Characteristics
immutable
resilient,
distributed,
lazily evaluated,
cacheable/persistent and
fault-tolerant](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-15-2048.jpg)
![Actions and Transformations
Spark enables lazy evaluation due to a dependency chain of RDDs. DAG allows for
running consistently more complex operations.
Source: [14], [8]
Transformations
Return pointers to new RDD
Transformations are lazy (Not computed
immediately)
Transformed RDDs gets recomputed when
actions run on it
RDD can be persisted in memory or disk
Actions
Return Values
Actions result into a DAG of operations
DAG is compiled into stages where each stage is
executed as series of tasks
Tasks : Fundamental units of work](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-16-2048.jpg)

![The Map Side
Spark does not merge or partition spill files, the output of map phase is written to OS buffer
cache, each map task outputs as many spill files as number of reducers.
Source: [6]
vs
Hadoop MapReduce Spark](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-18-2048.jpg)
![The Reduce Side
The map phase pushes the data in the form of intermediate (shuffle) files to the reducers.
These files are written to reducer’s memory and reduce functionality is invoked.
Source: [6]
Hadoop MapReduce Spark
vs](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-19-2048.jpg)
![Better for Iterative Computations
Data sharing in Hadoop is slow due to replication, serialization and disk I/O.
Source: [16]
vs
Hadoop MapReduce
Spark](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-20-2048.jpg)
![Better for Interactive Computations
By the same reason Hadoop underperforms for interactive (low-latency) computations.
Source: [16]
Hadoop MapReduce
Spark
vs](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-21-2048.jpg)

![The combination of Hadoop and Spark
Operational applications augmented by in-memory performance:
Source: [14]
Hadoop features
Spark features](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-23-2048.jpg)

![The Algorithm
K-Means works by forming clusters of data points by minimizing the sum of squared distances
between the data points and their centroids.
Source: [6]](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-25-2048.jpg)
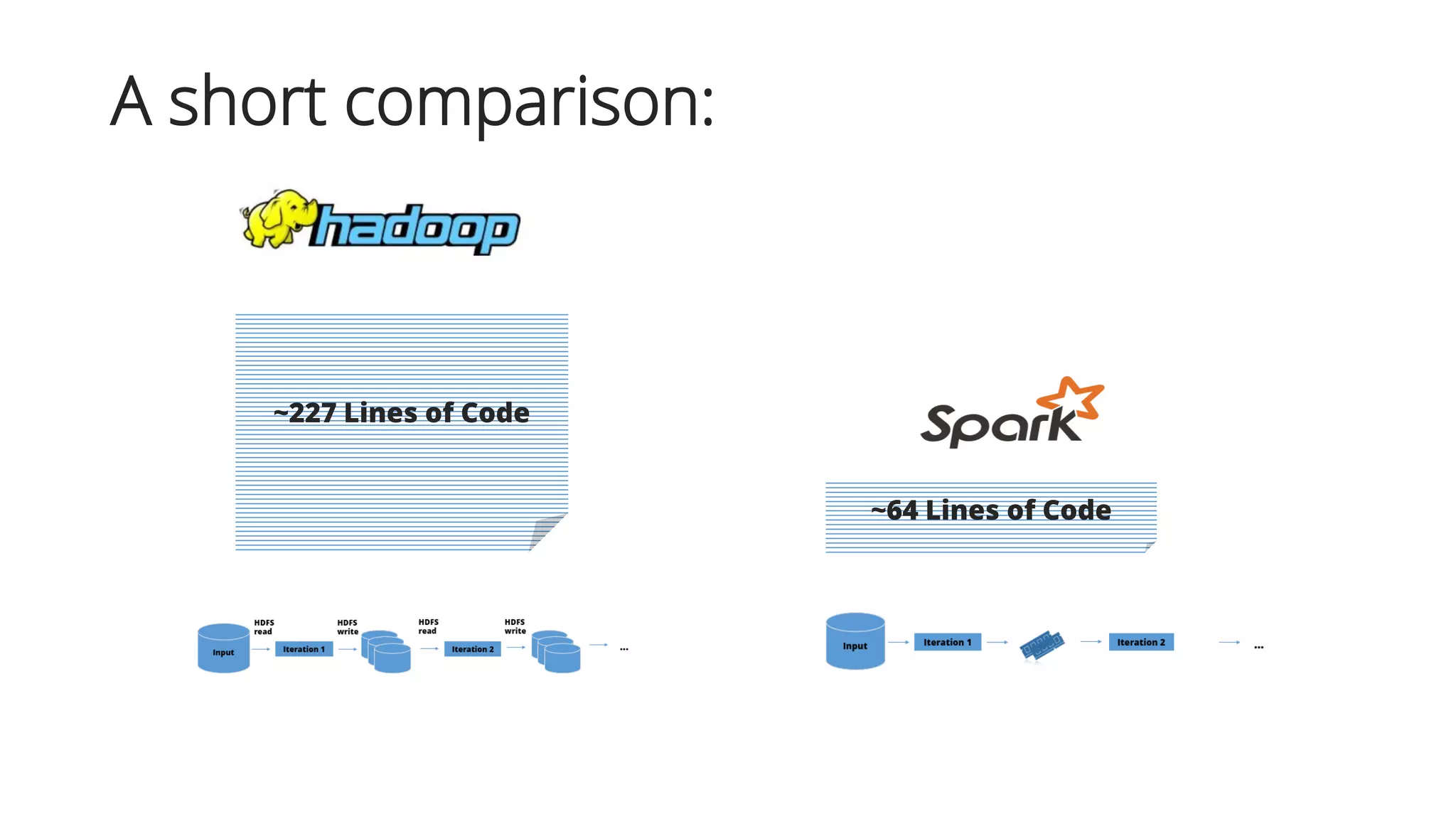
![Results by S. Gopalani, R. Arora
The results clearly showed that the performance of Spark turn out to be considerably higher
in terms of time.
Source: [6]
Experimental Environment
64MB, 1240 MB with a single node and 1240MB with
two nodes
monitored the performance in terms of the time
taken for clustering as per the requirements
The machines used had a configuration as follows: •
4GB RAM • Linux Ubuntu • 500 GB Hard Drive](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-27-2048.jpg)
![Results by M. Zacharia et. al.
Spark outperforms Hadoop by up to 20x in iterative machine learning and graph applications.
Source: [13]](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-28-2048.jpg)
![Source: [1]
High Performance Computing
… Apache Hadoop and Spark within the context of the big data analytics:](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-29-2048.jpg)
![MPI and HARP Performance
HPC* tools perform better Hadoop and Spark , but can be boosted using a hybrid approach
of other technologies that blend HPC and big data, including Spark and HARP.
Source: [17]
*HPC: High Performance Computing](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-30-2048.jpg)

![Literature
Resources used for this presentation:
[1] B. Zhang. A Brief Introduction of Existing Big Data Tools - A Presentation, Retrieved August 2015,
URL: http://scholarwiki.indiana.edu/Z604/slides/big%20data%20tools%20v2.pdf
[2] G. Fox. Multi-faceted Classification of Big Data Uses and Proposed Architecture Integrating High
Performance Computing and the Apache Stack – A Presentation for the Sixth Interantional Workshop
on Cloud Data Management, Cloud DB 2014, Chicago March 2014.
[3] S. Jha, J. Qiu, A. Luckow, P. Mantha, G. C.Fox. A Tale of Two Data-Intensive Paradigms:
Applications, Abstractions, and Architectures. Big Data (BigData Congress), 2014 IEEE International
Congress on. IEEE, 2014.
[4] T. White. Hadoop. The Denite Guide. O'Reilly Media, Inc., 2010.
[5] T. Duarte. Anatomy of RDD - An Explanatory Video Illustration, Retrieved in June 2015.
URL:http://www.sparkinternals.com/](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-33-2048.jpg)
![Literature
Resources used for this presentation:
[6] A. R. Gopalani, S. Comparing apache spark and map reduce with performance analysis using k-
means. International Journal of Computer Applications (0975 - 8887), 113(1), March 2015.
[7] Apache, Inc. Apache™ Hadoop® Documetation, Retreived in July 2015.URL:
http://www.apache.org/
[8] Hortonworks, Inc. Hortonworks Data Platform: Getting Started Guide – A Whitepaper, May 2014
[9] Apache, Inc . Apache ™ SparkDocumetation, Retreived in July 2015.URL:
http://www.apache.org/
[10] A.Murthy, Hortonworks, Inc. Apache Hadoop 2 is now GA! – A Blog Entry, October 2013,
Retrieved August 2015. URL: http://hortonworks.com/blog/apache-hadoop-2-is-ga/](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-34-2048.jpg)
![[11] Edureka!. Apache Hadoop 2.0 and YARN – Instruction, October 2013, Retrieved in August
2015, URL: http://www.edureka.co/blog/apache-hadoop-2-0-and-yarn/
[12] V. Shukla, R. Venkatesh. Hortonworks, Inc. Spark Webinar Presentation, October 2014
[13] e. a. M. Zacharía Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster
computing. University of California, Berkeley, 2012.
[14] MC Srivas, MapR Technologies, Inc. Why Spark on Hadoop Matters – A Presentation, July 2014.
[15] Y Wang, R Goldstone, W Yu, T Wang. Characterization and optimization of memory-resident
mapreduce on HPC systems . - 2014 IEEE 28th International Parallel & Distributed Processing
Symposium
Literature
Resources used for this presentation:](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-35-2048.jpg)
![[16] Databricks, Inc. Intro to Apache Spark – A Workshop Presentation, Retrieved in August 2015.
URL: http://training.databricks.com/workshop/itas_workshop.pdf
[17] S. Jha, J. Qiu, A.Luckow, P. Mantha, G. C. Fox. A tale of two data-intensive paradigms: AppliBig
Data (BigData Congress), 2014 IEEE International Congress on (pp. 645-652). IEEE. June 2014
cations, abstractions, and architectures.
[18] IBM, Inc. What is MapReduce? – An Explanatory Article, Retreived in August 2015. URL:
http://www-01.ibm.com/software/data/infosphere/hadoop/mapreduce/
Literature
Resources used for this presentation:](https://image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-36-2048.jpg)


![Source: [1]
The World of Big Data
Apache Hadoop and Spark within the context of big data analytics:](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-3-2048.jpg)


![What is Hadoop?
The Hadoop project’s open-source software for reliable, scalable, distributed computing
Source: [7], [8]
](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-6-2048.jpg)
![HDFS and YARN Architecture
A Hadoop cluster is characterized by a master – slave architecture, which utilizes the
“shared-nothing” principle for effective data processing.
Source: [11]](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-7-2048.jpg)
![Map Reduce: an example
MapReduce means breaking the processing into two phases: the map phase and the
reduce phase, both performed in a distributed, parallel way on a cluster of computers.
Source: [11]](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-8-2048.jpg)
![MapReduce within Hadoop Framework
…represents a scalable solution, which can be extended to several reduce tasks…
Source: [18]](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-9-2048.jpg)
![Limitations of Hadoop MapReduce
…however not necessarily a universally suitable solution especially for the tasks with growing
importance.
Source: [2]
](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-10-2048.jpg)
![Shuffle and Sort
Slow due to replication, serialization, I/O. Inefficient for iterative algorithms and interactive
data mining:
Source: [4]](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-11-2048.jpg)

![What is Spark ?
“Effective, fast, general-purpose cluster computing framework with high level APIs in Java,
Scala, Python and R”:
Source: [9]](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-13-2048.jpg)
![Spark‘s buildup
In addition to the benefits of HDFS Spark relies on DAG* pattern for complex, multi-step data
pipelines and in-memory data sharing across DAG.
Source: [12]
*DAG: Directed Acyclic Graph](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-14-2048.jpg)
![Anatomy of RDD
Distributed collections of objects that can be cached in memory across cluster nodes.
Source: [5]
*RDD: Resilient Distributed Datasets
Some of RDD Characteristics
immutable
resilient,
distributed,
lazily evaluated,
cacheable/persistent and
fault-tolerant](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-15-2048.jpg)
![Actions and Transformations
Spark enables lazy evaluation due to a dependency chain of RDDs. DAG allows for
running consistently more complex operations.
Source: [14], [8]
Transformations
Return pointers to new RDD
Transformations are lazy (Not computed
immediately)
Transformed RDDs gets recomputed when
actions run on it
RDD can be persisted in memory or disk
Actions
Return Values
Actions result into a DAG of operations
DAG is compiled into stages where each stage is
executed as series of tasks
Tasks : Fundamental units of work](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-16-2048.jpg)

![The Map Side
Spark does not merge or partition spill files, the output of map phase is written to OS buffer
cache, each map task outputs as many spill files as number of reducers.
Source: [6]
vs
Hadoop MapReduce Spark](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-18-2048.jpg)
![The Reduce Side
The map phase pushes the data in the form of intermediate (shuffle) files to the reducers.
These files are written to reducer’s memory and reduce functionality is invoked.
Source: [6]
Hadoop MapReduce Spark
vs](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-19-2048.jpg)
![Better for Iterative Computations
Data sharing in Hadoop is slow due to replication, serialization and disk I/O.
Source: [16]
vs
Hadoop MapReduce
Spark](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-20-2048.jpg)
![Better for Interactive Computations
By the same reason Hadoop underperforms for interactive (low-latency) computations.
Source: [16]
Hadoop MapReduce
Spark
vs](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-21-2048.jpg)

![The combination of Hadoop and Spark
Operational applications augmented by in-memory performance:
Source: [14]
Hadoop features
Spark features](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-23-2048.jpg)

![The Algorithm
K-Means works by forming clusters of data points by minimizing the sum of squared distances
between the data points and their centroids.
Source: [6]](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-25-2048.jpg)

![Results by S. Gopalani, R. Arora
The results clearly showed that the performance of Spark turn out to be considerably higher
in terms of time.
Source: [6]
Experimental Environment
64MB, 1240 MB with a single node and 1240MB with
two nodes
monitored the performance in terms of the time
taken for clustering as per the requirements
The machines used had a configuration as follows: •
4GB RAM • Linux Ubuntu • 500 GB Hard Drive](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-27-2048.jpg)
![Results by M. Zacharia et. al.
Spark outperforms Hadoop by up to 20x in iterative machine learning and graph applications.
Source: [13]](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-28-2048.jpg)
![Source: [1]
High Performance Computing
… Apache Hadoop and Spark within the context of the big data analytics:](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-29-2048.jpg)
![MPI and HARP Performance
HPC* tools perform better Hadoop and Spark , but can be boosted using a hybrid approach
of other technologies that blend HPC and big data, including Spark and HARP.
Source: [17]
*HPC: High Performance Computing](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-30-2048.jpg)


![Literature
Resources used for this presentation:
[1] B. Zhang. A Brief Introduction of Existing Big Data Tools - A Presentation, Retrieved August 2015,
URL: http://scholarwiki.indiana.edu/Z604/slides/big%20data%20tools%20v2.pdf
[2] G. Fox. Multi-faceted Classification of Big Data Uses and Proposed Architecture Integrating High
Performance Computing and the Apache Stack – A Presentation for the Sixth Interantional Workshop
on Cloud Data Management, Cloud DB 2014, Chicago March 2014.
[3] S. Jha, J. Qiu, A. Luckow, P. Mantha, G. C.Fox. A Tale of Two Data-Intensive Paradigms:
Applications, Abstractions, and Architectures. Big Data (BigData Congress), 2014 IEEE International
Congress on. IEEE, 2014.
[4] T. White. Hadoop. The Denite Guide. O'Reilly Media, Inc., 2010.
[5] T. Duarte. Anatomy of RDD - An Explanatory Video Illustration, Retrieved in June 2015.
URL:http://www.sparkinternals.com/](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-33-2048.jpg)
![Literature
Resources used for this presentation:
[6] A. R. Gopalani, S. Comparing apache spark and map reduce with performance analysis using k-
means. International Journal of Computer Applications (0975 - 8887), 113(1), March 2015.
[7] Apache, Inc. Apache™ Hadoop® Documetation, Retreived in July 2015.URL:
http://www.apache.org/
[8] Hortonworks, Inc. Hortonworks Data Platform: Getting Started Guide – A Whitepaper, May 2014
[9] Apache, Inc . Apache ™ SparkDocumetation, Retreived in July 2015.URL:
http://www.apache.org/
[10] A.Murthy, Hortonworks, Inc. Apache Hadoop 2 is now GA! – A Blog Entry, October 2013,
Retrieved August 2015. URL: http://hortonworks.com/blog/apache-hadoop-2-is-ga/](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-34-2048.jpg)
![[11] Edureka!. Apache Hadoop 2.0 and YARN – Instruction, October 2013, Retrieved in August
2015, URL: http://www.edureka.co/blog/apache-hadoop-2-0-and-yarn/
[12] V. Shukla, R. Venkatesh. Hortonworks, Inc. Spark Webinar Presentation, October 2014
[13] e. a. M. Zacharía Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster
computing. University of California, Berkeley, 2012.
[14] MC Srivas, MapR Technologies, Inc. Why Spark on Hadoop Matters – A Presentation, July 2014.
[15] Y Wang, R Goldstone, W Yu, T Wang. Characterization and optimization of memory-resident
mapreduce on HPC systems . - 2014 IEEE 28th International Parallel & Distributed Processing
Symposium
Literature
Resources used for this presentation:](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-35-2048.jpg)
![[16] Databricks, Inc. Intro to Apache Spark – A Workshop Presentation, Retrieved in August 2015.
URL: http://training.databricks.com/workshop/itas_workshop.pdf
[17] S. Jha, J. Qiu, A.Luckow, P. Mantha, G. C. Fox. A tale of two data-intensive paradigms: AppliBig
Data (BigData Congress), 2014 IEEE International Congress on (pp. 645-652). IEEE. June 2014
cations, abstractions, and architectures.
[18] IBM, Inc. What is MapReduce? – An Explanatory Article, Retreived in August 2015. URL:
http://www-01.ibm.com/software/data/infosphere/hadoop/mapreduce/
Literature
Resources used for this presentation:](https://crownmelresort.com/image.slidesharecdn.com/presentationeidamolesya130815-160917173722/75/Spark-vs-Hadoop-36-2048.jpg)



























































![Apache spark installation [autosaved]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkinstallationautosaved-171023151151-thumbnail.jpg?width=640&height=640&fit=bounds)




![[@NaukriEngineering] Apache Spark](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkppt-170105054406-thumbnail.jpg?width=640&height=640&fit=bounds)



















