Downloaded 139 times





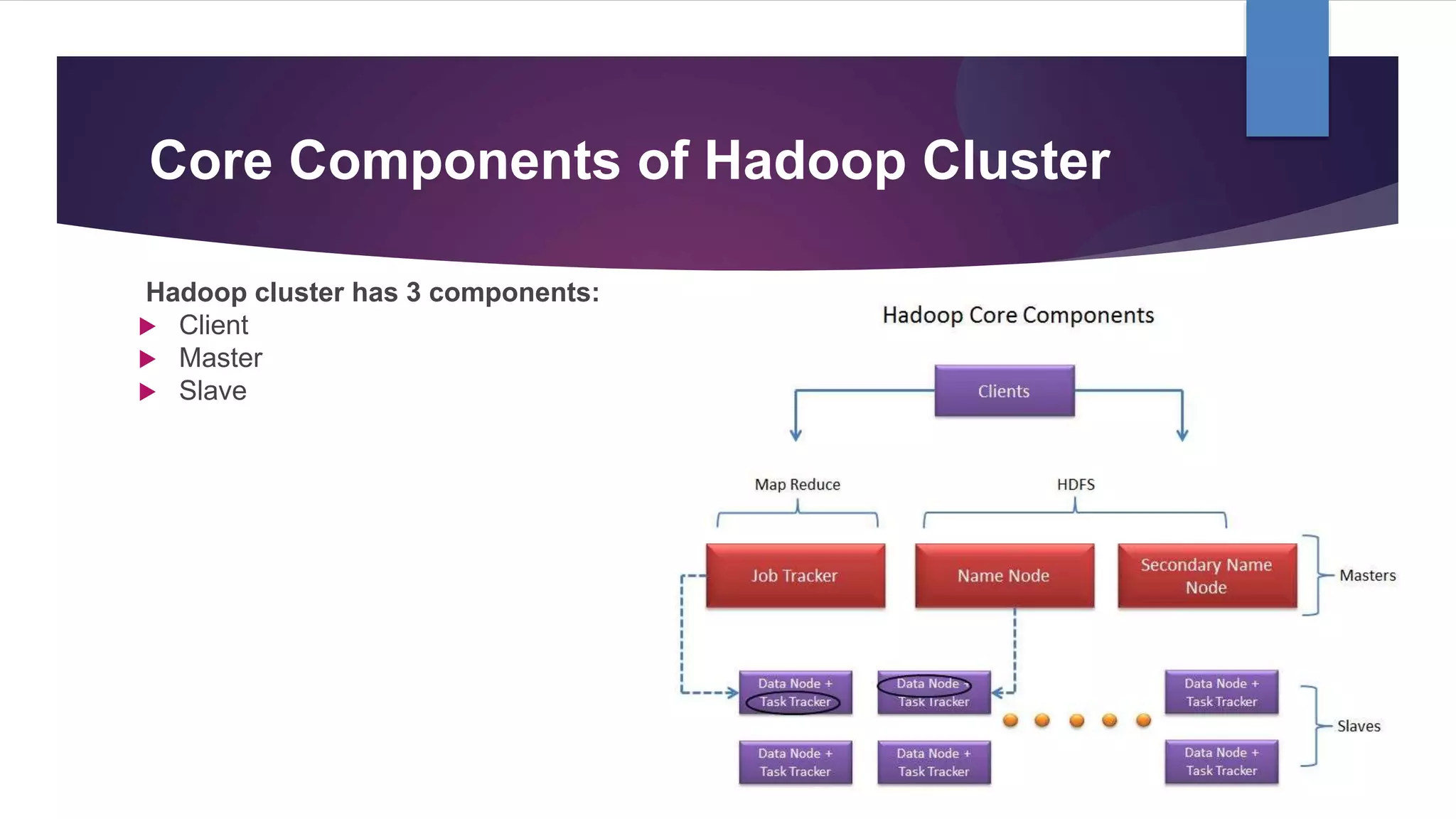

























This document provides an introduction to Apache Hadoop, which is an open-source software framework for distributed storage and processing of large datasets. It discusses Hadoop's main components of MapReduce and HDFS. MapReduce is a programming model for processing large datasets in a distributed manner, while HDFS provides distributed, fault-tolerant storage. Hadoop runs on commodity computer clusters and can scale to thousands of nodes.

















































































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)





