Download to read offline


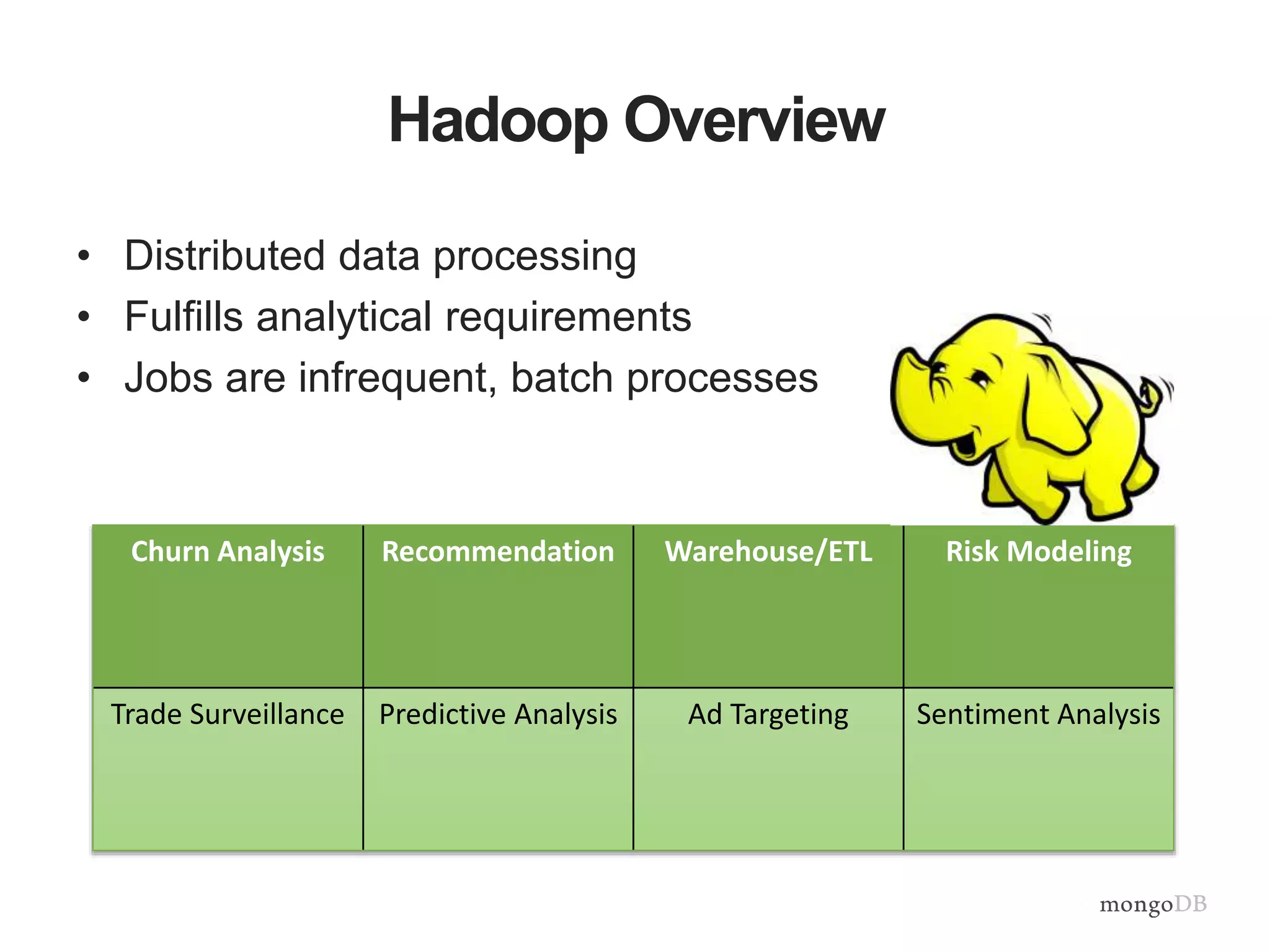
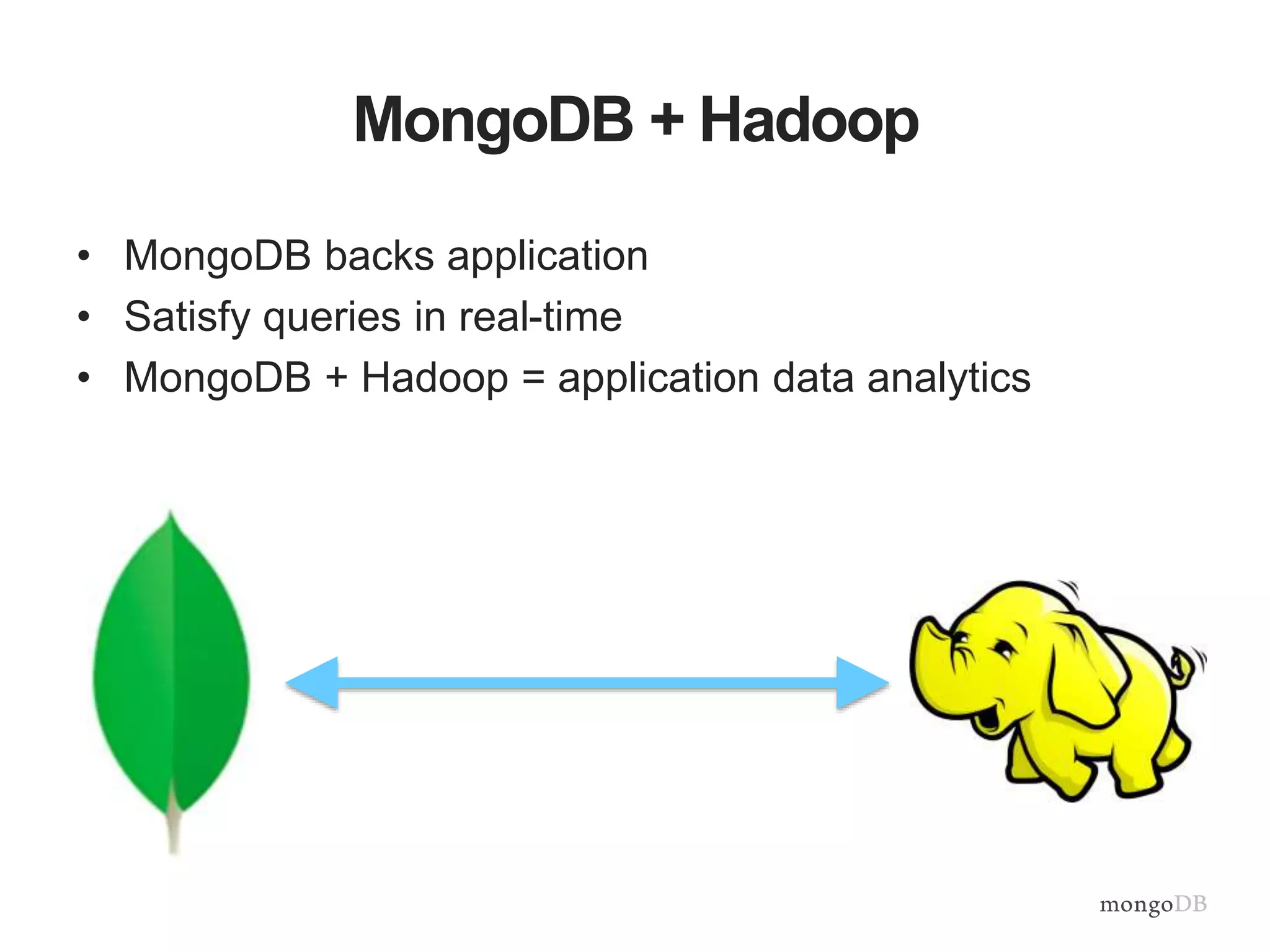





















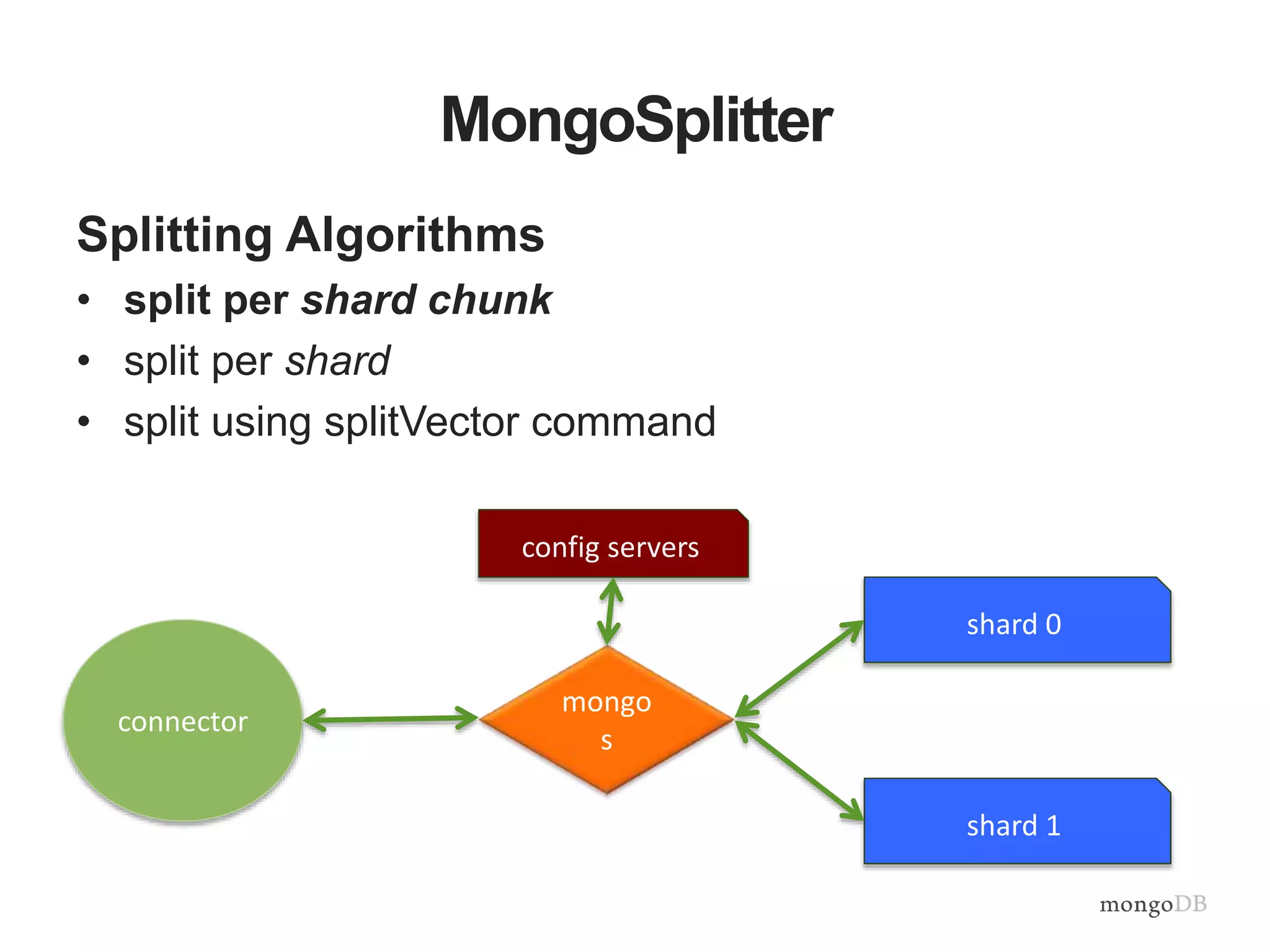

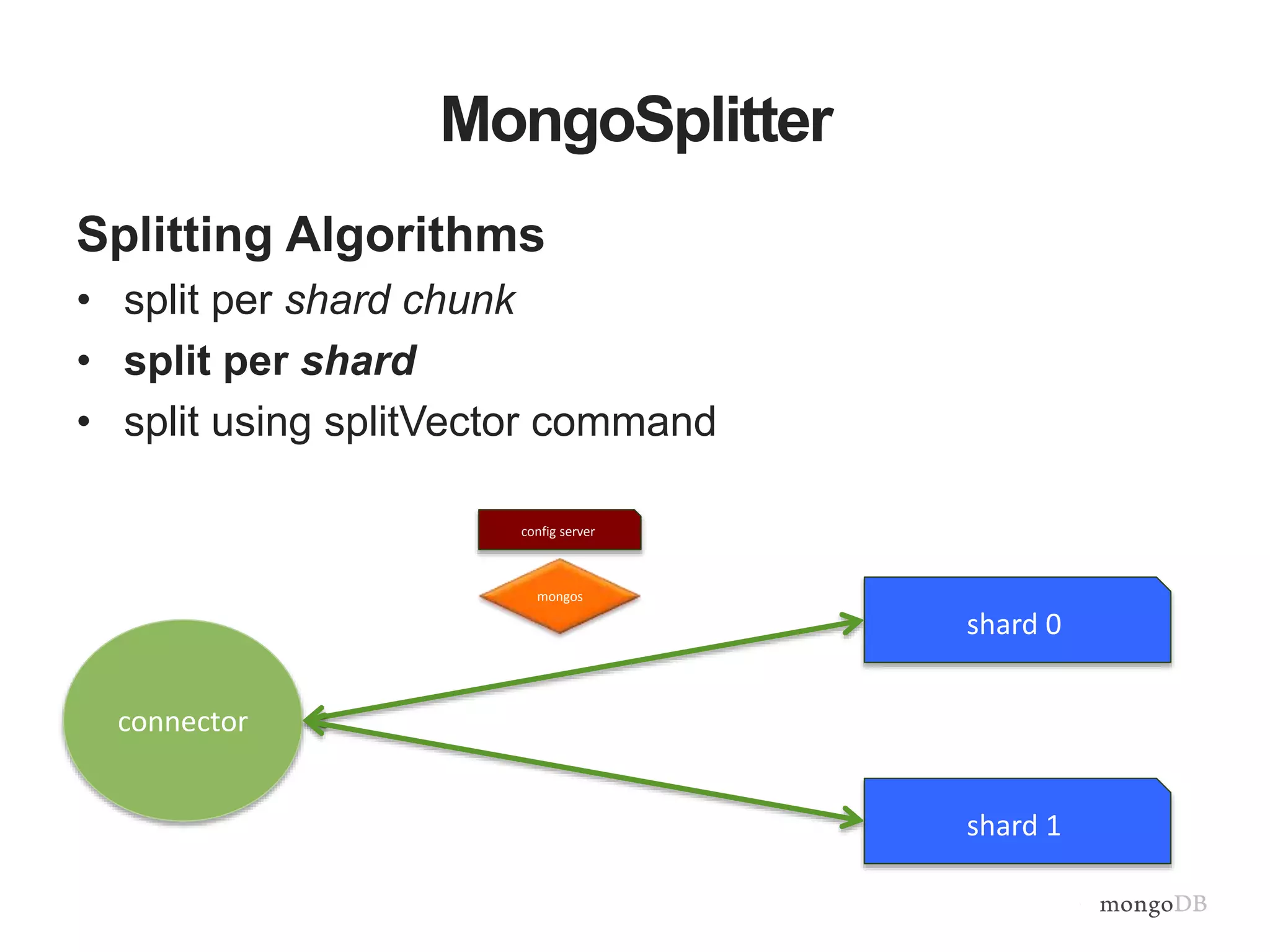
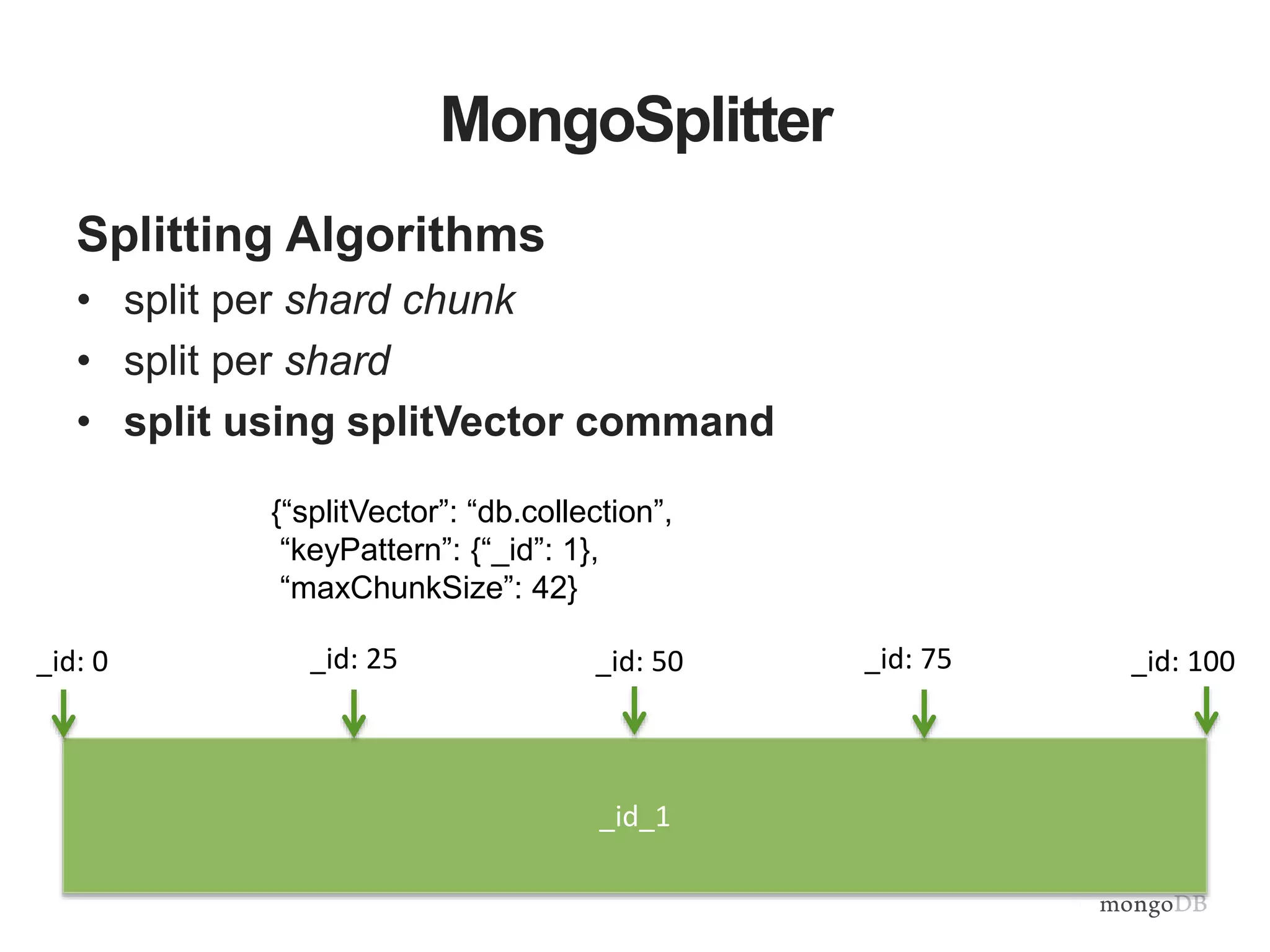






















































The document provides an overview of the MongoDB-Hadoop connector, detailing its integration with Hadoop for analytical processes and features like hive predicate pushdown and pyspark support. It discusses splitting algorithms used for optimal data distribution and the future work aimed at enhancing data locality. Additionally, it emphasizes the seamless interaction between MongoDB and various data processing frameworks within the Hadoop ecosystem.
































































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)





















![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)









