Downloaded 135 times






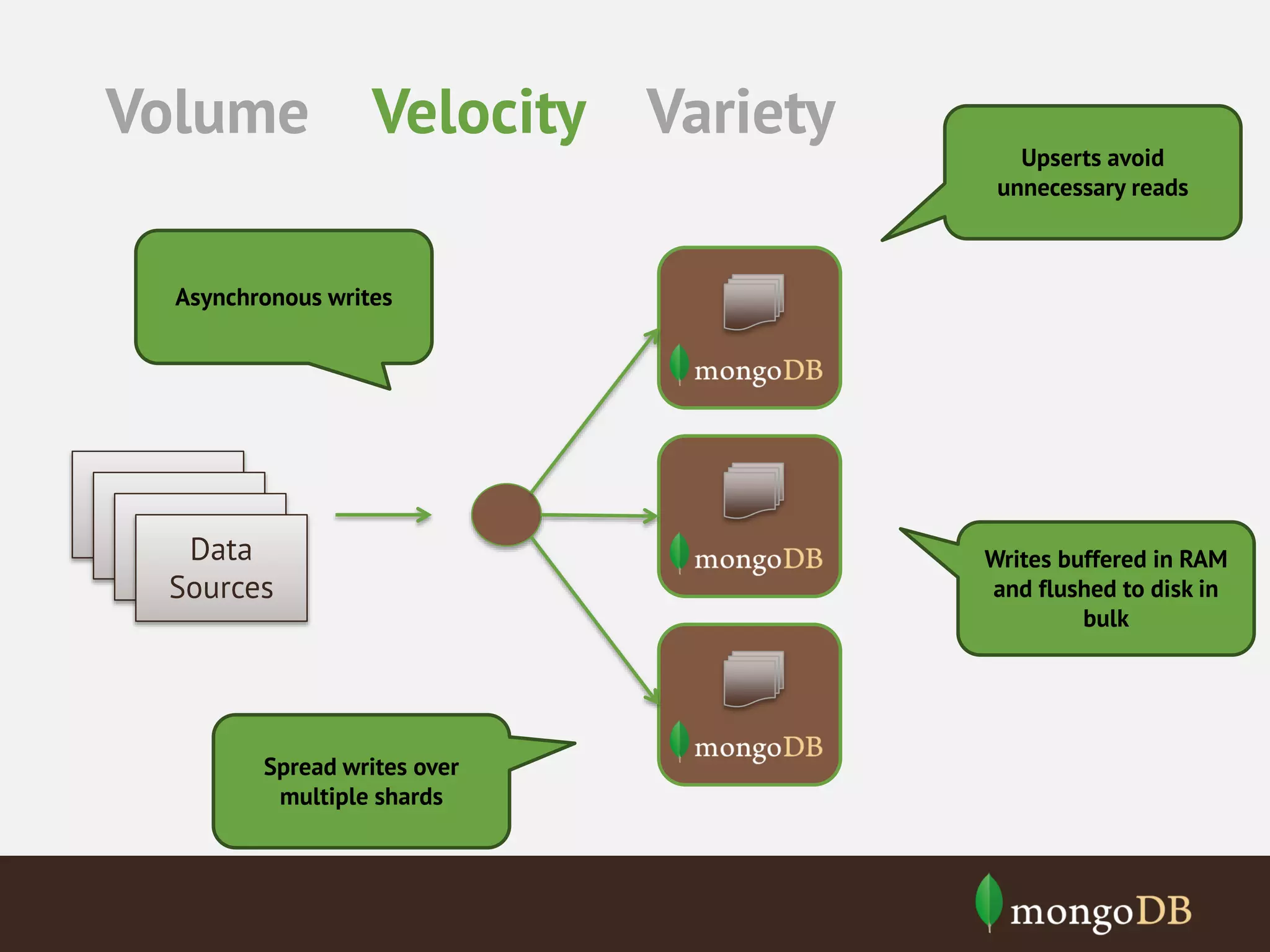
![Volume Velocity Variety
MongoDB
RDBMS
{
_id : ObjectId("4c4ba5e5e8aabf3"),
employee_name: "Dunham, Justin",
department : "Marketing",
title : "Product Manager, Web",
report_up: "Neray, Graham",
pay_band: “C",
benefits : [
{
type :
"Health",
plan : "PPO Plus" },
{
type :
"Dental",
plan : "Standard" }
]
}](https://image.slidesharecdn.com/mongodbandanalytics-aggregationandhadoopconnector-140306044120-phpapp02/75/Analytics-with-MongoDB-Aggregation-Framework-and-Hadoop-Connector-11-2048.jpg)








![Aggregation Framework
Requests db.logs.aggregate( [
{ '$match': {
per day by
'time': {
URL
'$gte': new Date(2013, 0),
'$lt': new Date(2013, 1) } } },
{ '$project': {
'path': 1,
'date': {
'y': { '$year':
'$time' },
'm': { '$month':
'$time' },
'd': { '$dayOfMonth': '$time' } } } },
{ '$group': {
'_id': {
'p': '$path',
'y': '$date.y',
'm': '$date.m',
'd': '$date.d' },
'hits': { '$sum': 1 } } },
])](https://image.slidesharecdn.com/mongodbandanalytics-aggregationandhadoopconnector-140306044120-phpapp02/75/Analytics-with-MongoDB-Aggregation-Framework-and-Hadoop-Connector-21-2048.jpg)
![Aggregation Framework
{
‘ok’: 1,
‘result’: [
{ '_id': {'p':’/index.html’,'y':
{ '_id': {'p':’/index.html’,'y':
{ '_id': {'p':’/index.html’,'y':
{ '_id': {'p':’/index.html’,'y':
{ '_id': {'p':’/index.html’,'y':
]
}
2013,'m':
2013,'m':
2013,'m':
2013,'m':
2013,'m':
1,'d':
1,'d':
1,'d':
1,'d':
1,'d':
1
2
3
4
5
},
},
},
},
},
'hits’:
'hits’:
'hits’:
'hits’:
'hits’:
124 },
245 },
322 },
175 },
94 }](https://image.slidesharecdn.com/mongodbandanalytics-aggregationandhadoopconnector-140306044120-phpapp02/75/Analytics-with-MongoDB-Aggregation-Framework-and-Hadoop-Connector-22-2048.jpg)









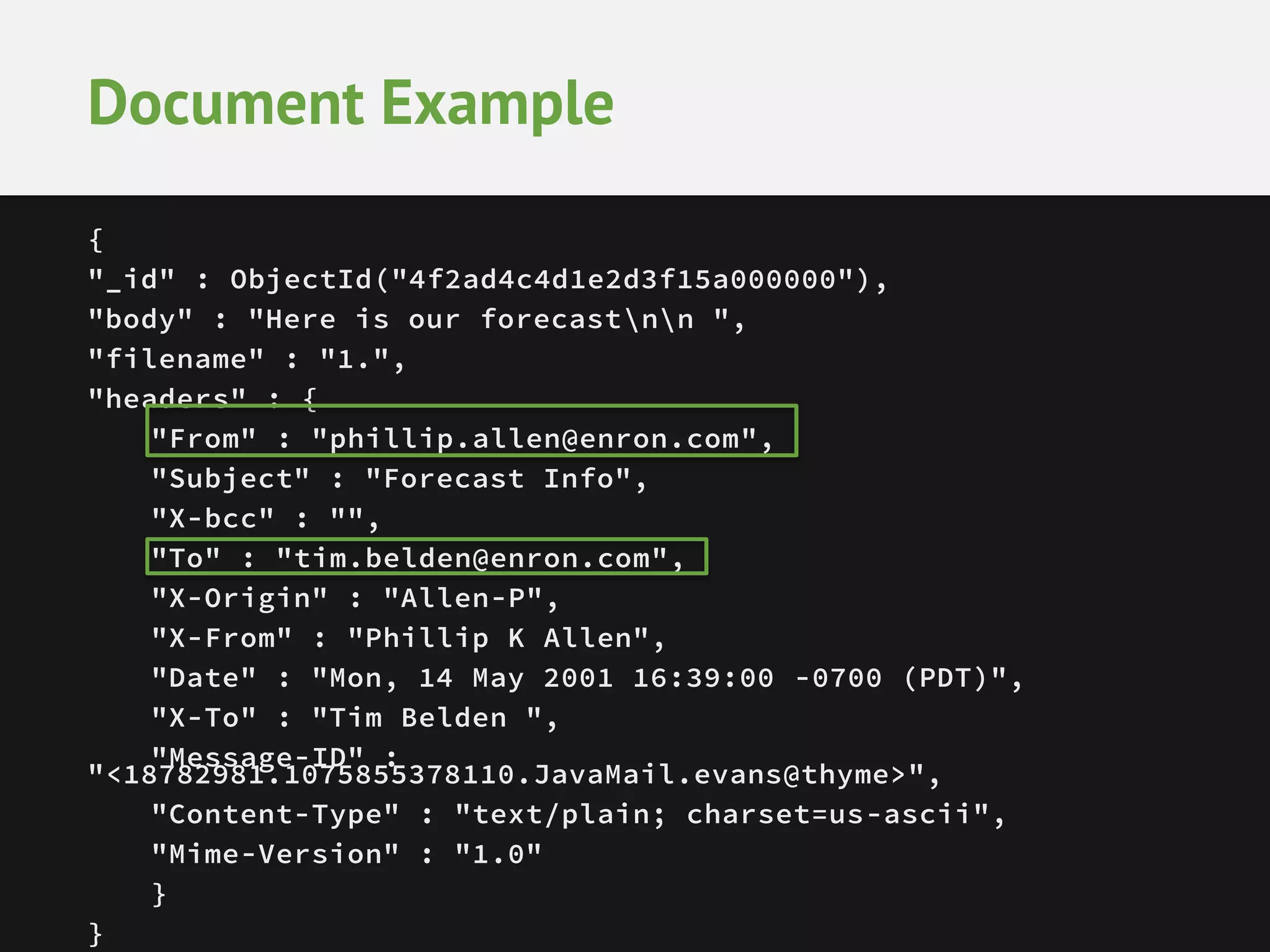

![Map Phase – each document get’s
through mapper function
@Override
public void map(NullWritable key, BSONObject val,
final Context context){
BSONObject headers = (BSONObject)val.get("headers");
if(headers.containsKey("From") && headers.containsKey("To")){
String from = (String)headers.get("From"); String to =
(String) headers.get("To"); String[] recips = to.split(",");
for(int i=0;i<recips.length;i++){
String recip = recips[i].trim();
context.write(new MailPair(from, recip), new
IntWritable(1));
}
}
}](https://image.slidesharecdn.com/mongodbandanalytics-aggregationandhadoopconnector-140306044120-phpapp02/75/Analytics-with-MongoDB-Aggregation-Framework-and-Hadoop-Connector-40-2048.jpg)

















![Volume Velocity Variety
MongoDB
RDBMS
{
_id : ObjectId("4c4ba5e5e8aabf3"),
employee_name: "Dunham, Justin",
department : "Marketing",
title : "Product Manager, Web",
report_up: "Neray, Graham",
pay_band: “C",
benefits : [
{
type :
"Health",
plan : "PPO Plus" },
{
type :
"Dental",
plan : "Standard" }
]
}](https://crownmelresort.com/image.slidesharecdn.com/mongodbandanalytics-aggregationandhadoopconnector-140306044120-phpapp02/75/Analytics-with-MongoDB-Aggregation-Framework-and-Hadoop-Connector-11-2048.jpg)









![Aggregation Framework
Requests db.logs.aggregate( [
{ '$match': {
per day by
'time': {
URL
'$gte': new Date(2013, 0),
'$lt': new Date(2013, 1) } } },
{ '$project': {
'path': 1,
'date': {
'y': { '$year':
'$time' },
'm': { '$month':
'$time' },
'd': { '$dayOfMonth': '$time' } } } },
{ '$group': {
'_id': {
'p': '$path',
'y': '$date.y',
'm': '$date.m',
'd': '$date.d' },
'hits': { '$sum': 1 } } },
])](https://crownmelresort.com/image.slidesharecdn.com/mongodbandanalytics-aggregationandhadoopconnector-140306044120-phpapp02/75/Analytics-with-MongoDB-Aggregation-Framework-and-Hadoop-Connector-21-2048.jpg)
![Aggregation Framework
{
‘ok’: 1,
‘result’: [
{ '_id': {'p':’/index.html’,'y':
{ '_id': {'p':’/index.html’,'y':
{ '_id': {'p':’/index.html’,'y':
{ '_id': {'p':’/index.html’,'y':
{ '_id': {'p':’/index.html’,'y':
]
}
2013,'m':
2013,'m':
2013,'m':
2013,'m':
2013,'m':
1,'d':
1,'d':
1,'d':
1,'d':
1,'d':
1
2
3
4
5
},
},
},
},
},
'hits’:
'hits’:
'hits’:
'hits’:
'hits’:
124 },
245 },
322 },
175 },
94 }](https://crownmelresort.com/image.slidesharecdn.com/mongodbandanalytics-aggregationandhadoopconnector-140306044120-phpapp02/75/Analytics-with-MongoDB-Aggregation-Framework-and-Hadoop-Connector-22-2048.jpg)

















![Map Phase – each document get’s
through mapper function
@Override
public void map(NullWritable key, BSONObject val,
final Context context){
BSONObject headers = (BSONObject)val.get("headers");
if(headers.containsKey("From") && headers.containsKey("To")){
String from = (String)headers.get("From"); String to =
(String) headers.get("To"); String[] recips = to.split(",");
for(int i=0;i<recips.length;i++){
String recip = recips[i].trim();
context.write(new MailPair(from, recip), new
IntWritable(1));
}
}
}](https://crownmelresort.com/image.slidesharecdn.com/mongodbandanalytics-aggregationandhadoopconnector-140306044120-phpapp02/75/Analytics-with-MongoDB-Aggregation-Framework-and-Hadoop-Connector-40-2048.jpg)









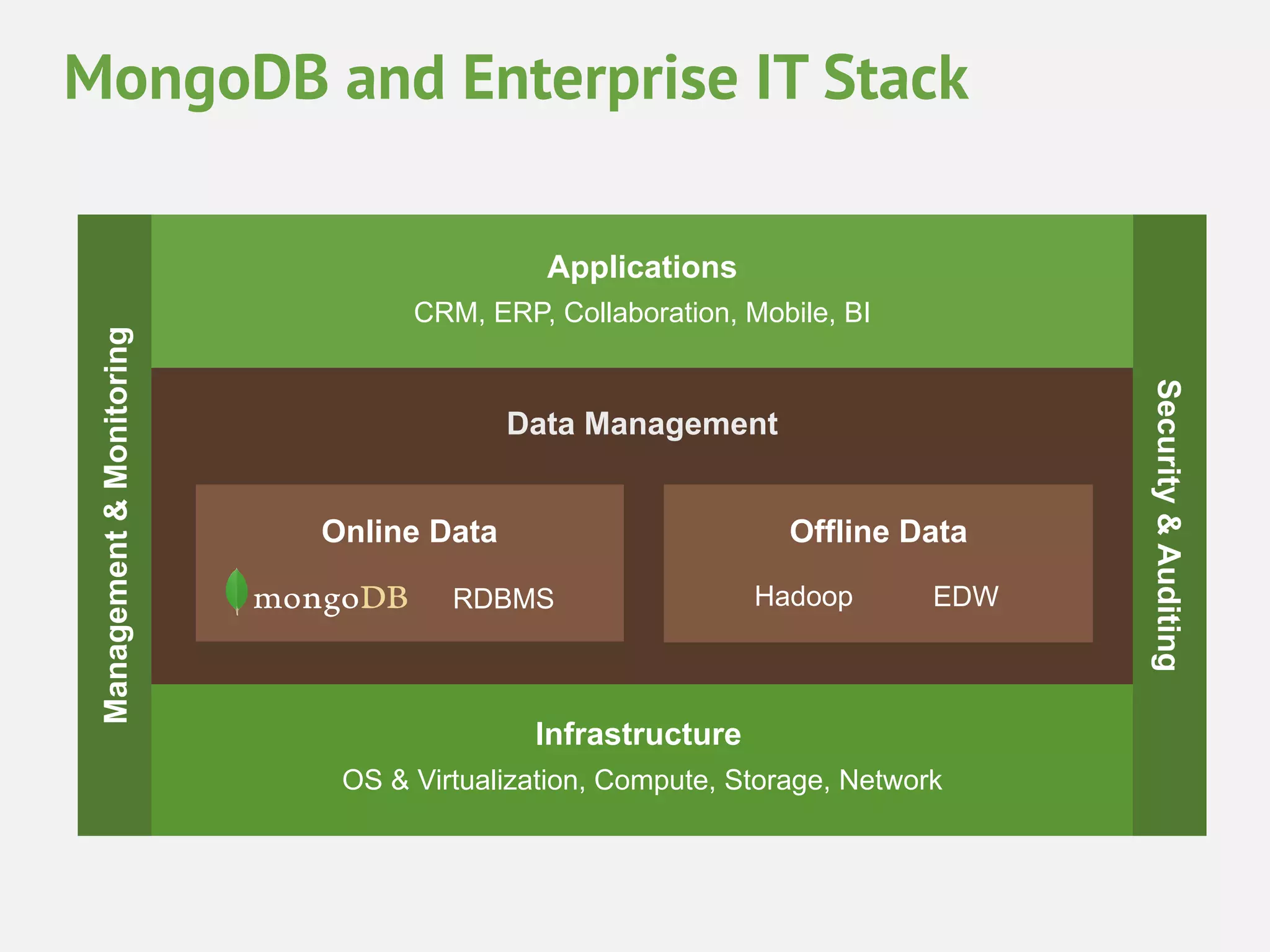
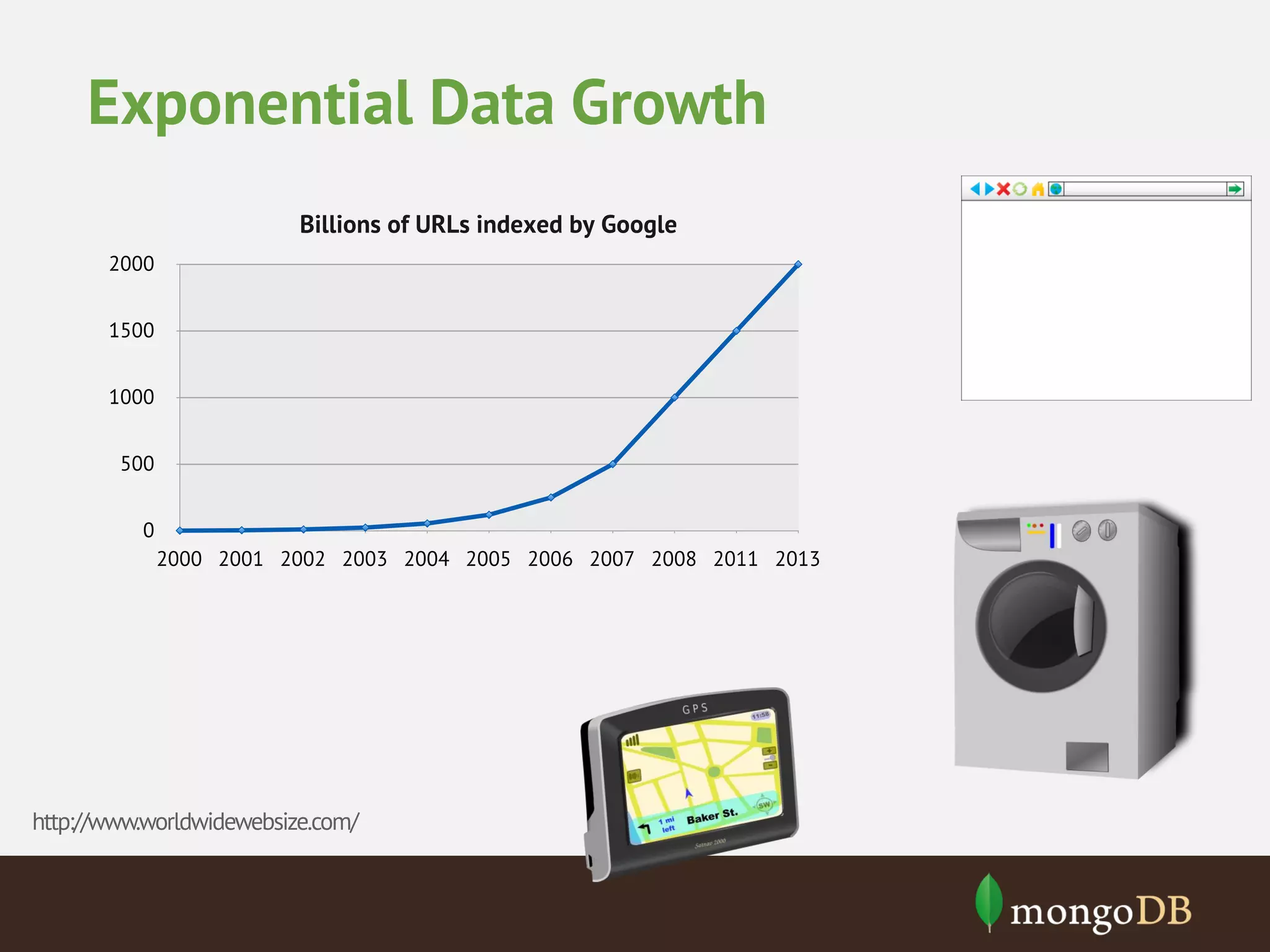
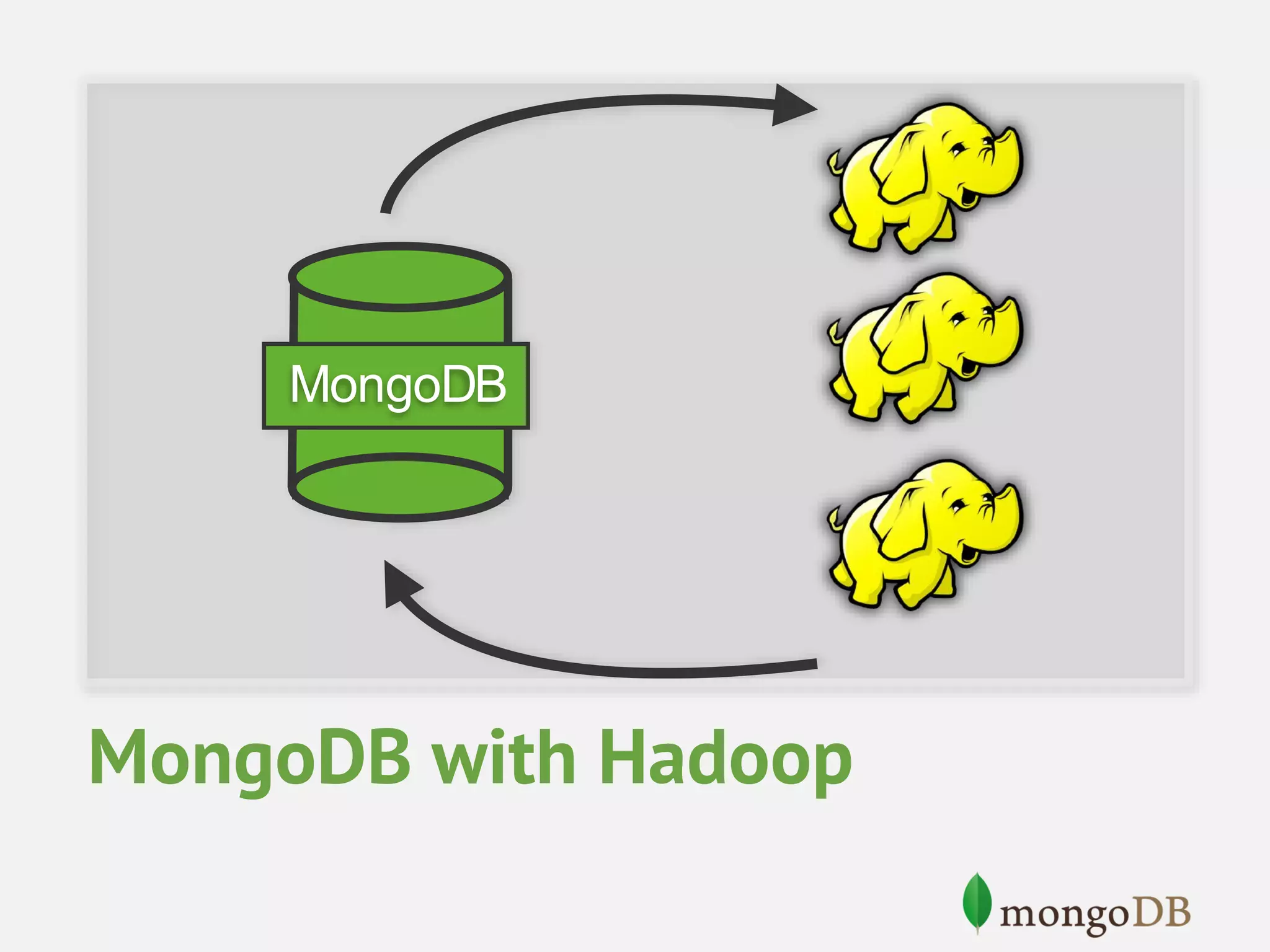
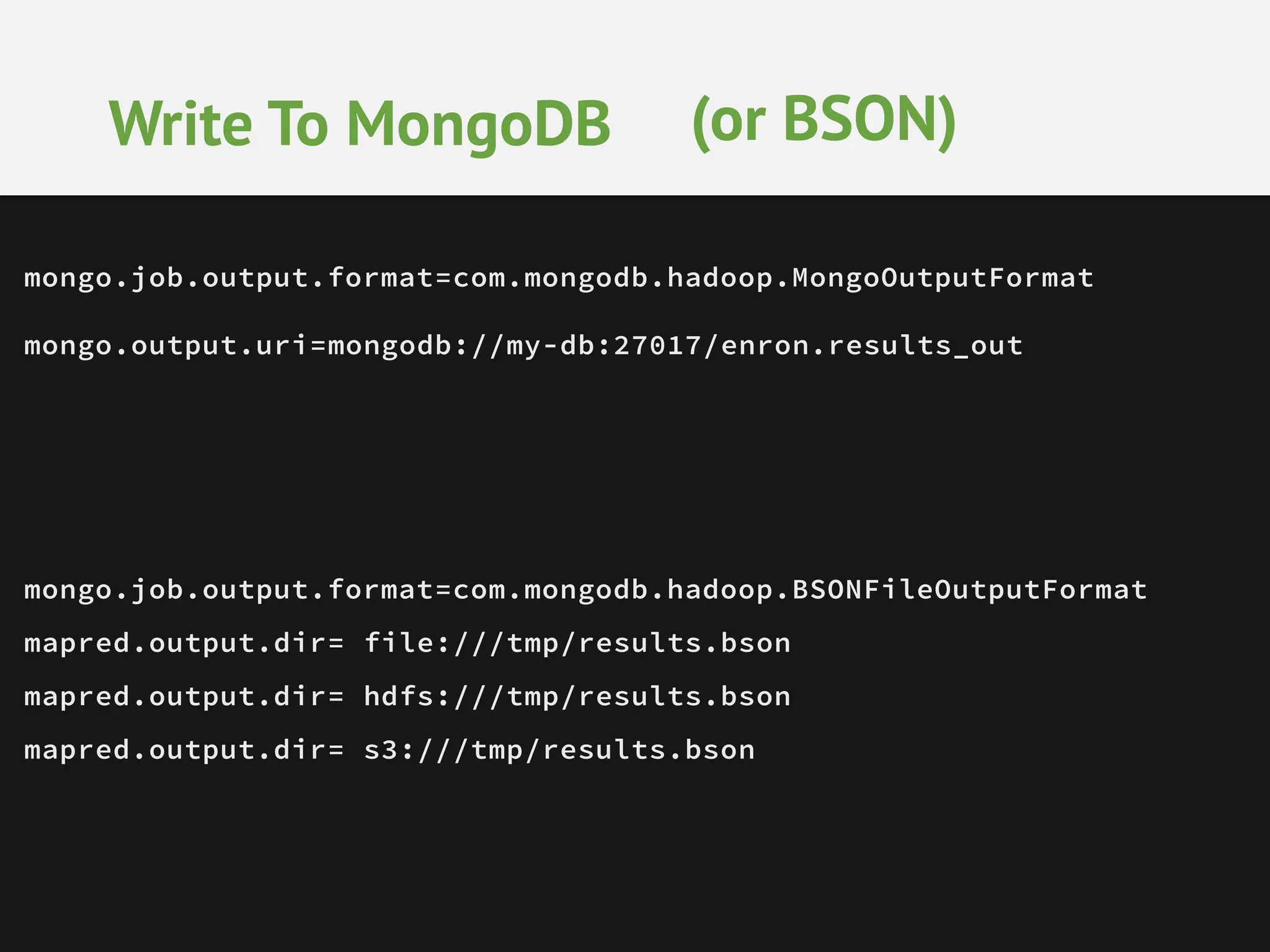
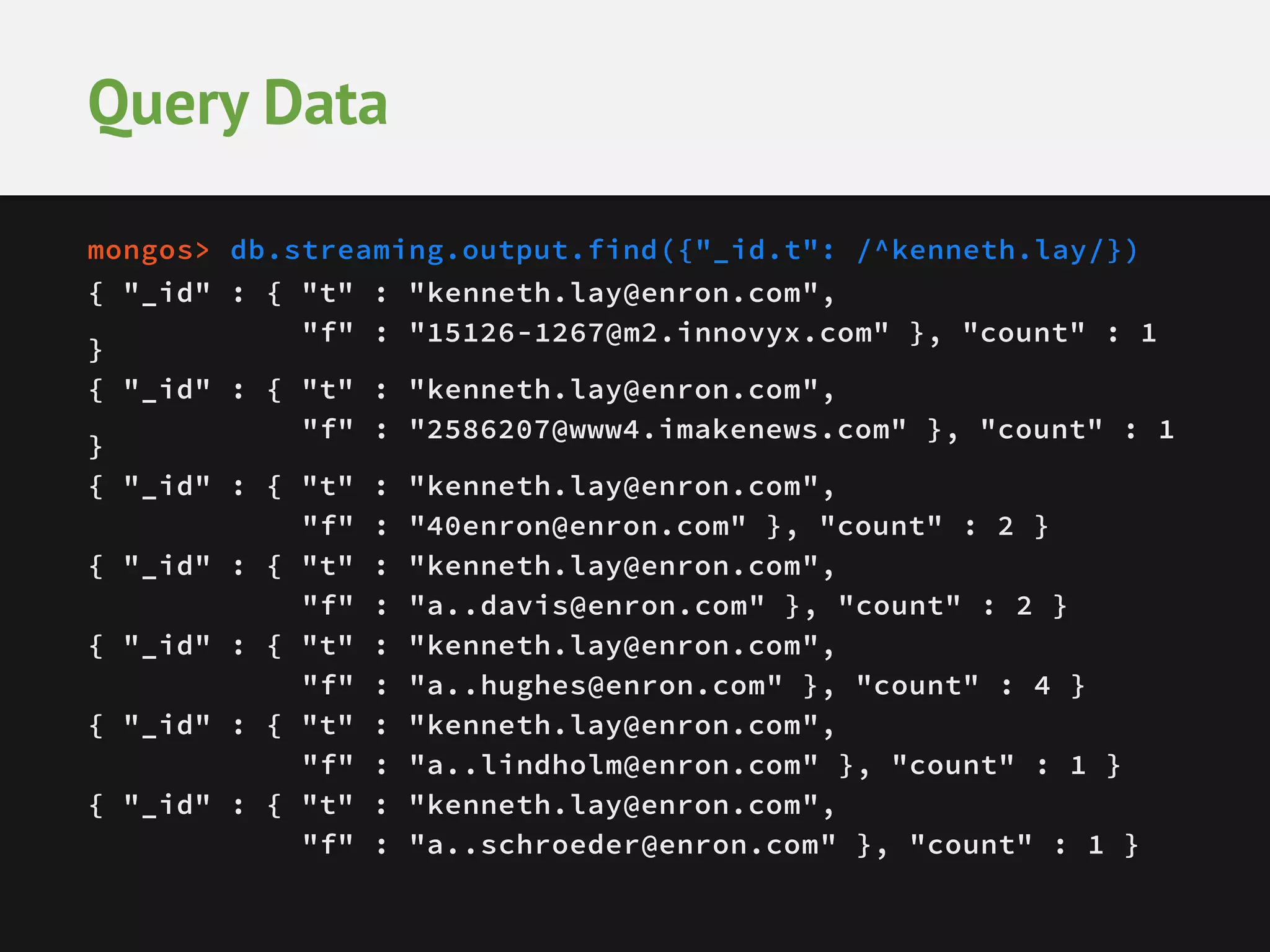
This document provides an overview of analytics with MongoDB and Hadoop Connector. It discusses how to collect and explore data, use visualization and aggregation, and make predictions. It describes how MongoDB can be used for data collection, pre-aggregation, and real-time queries. The Aggregation Framework and MapReduce in MongoDB are explained. It also covers using the Hadoop Connector to process large amounts of MongoDB data in Hadoop and writing results back to MongoDB. Examples of analytics use cases like recommendations, A/B testing, and personalization are briefly outlined.





















































































