Download as PDF, PPTX





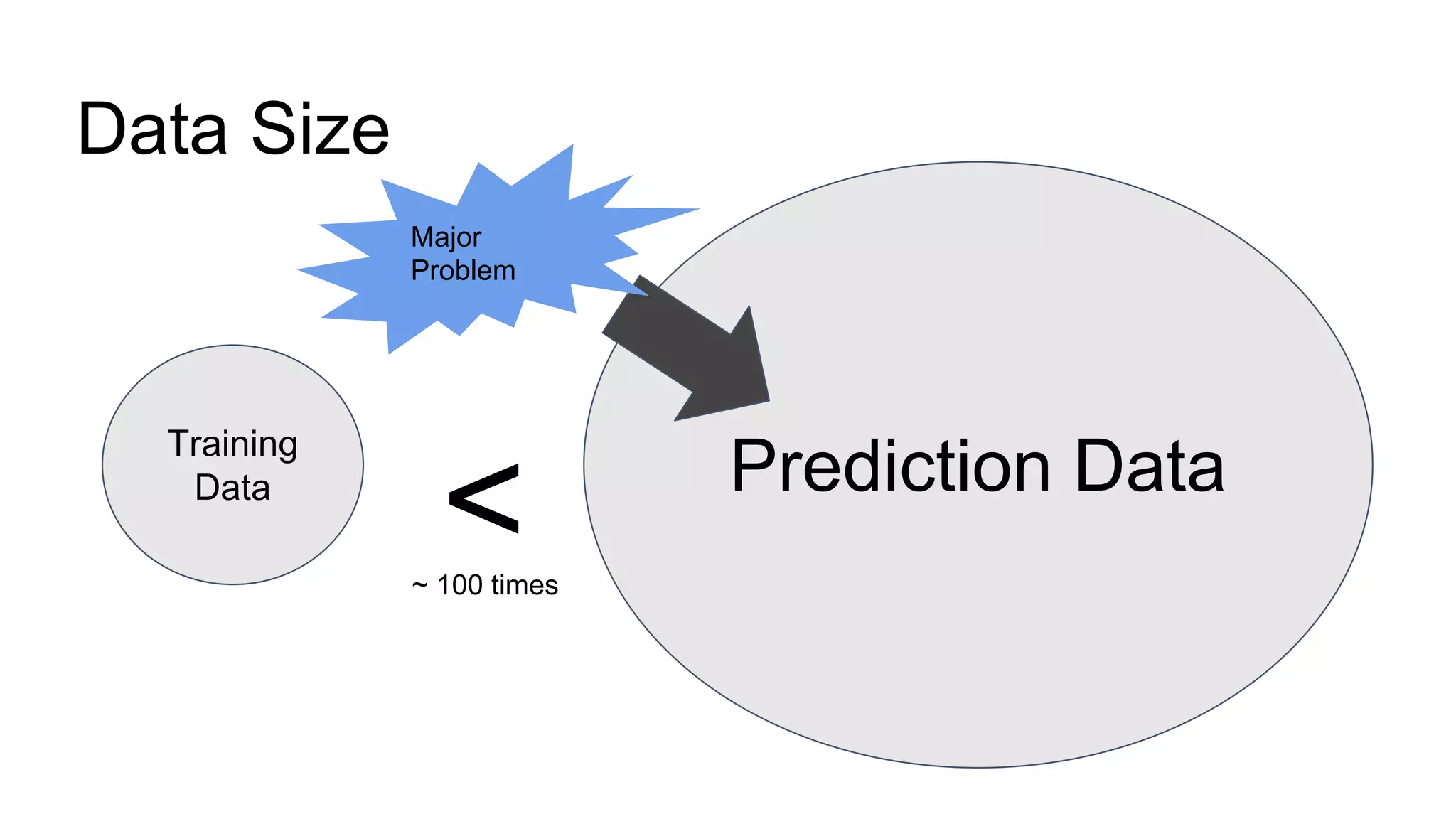
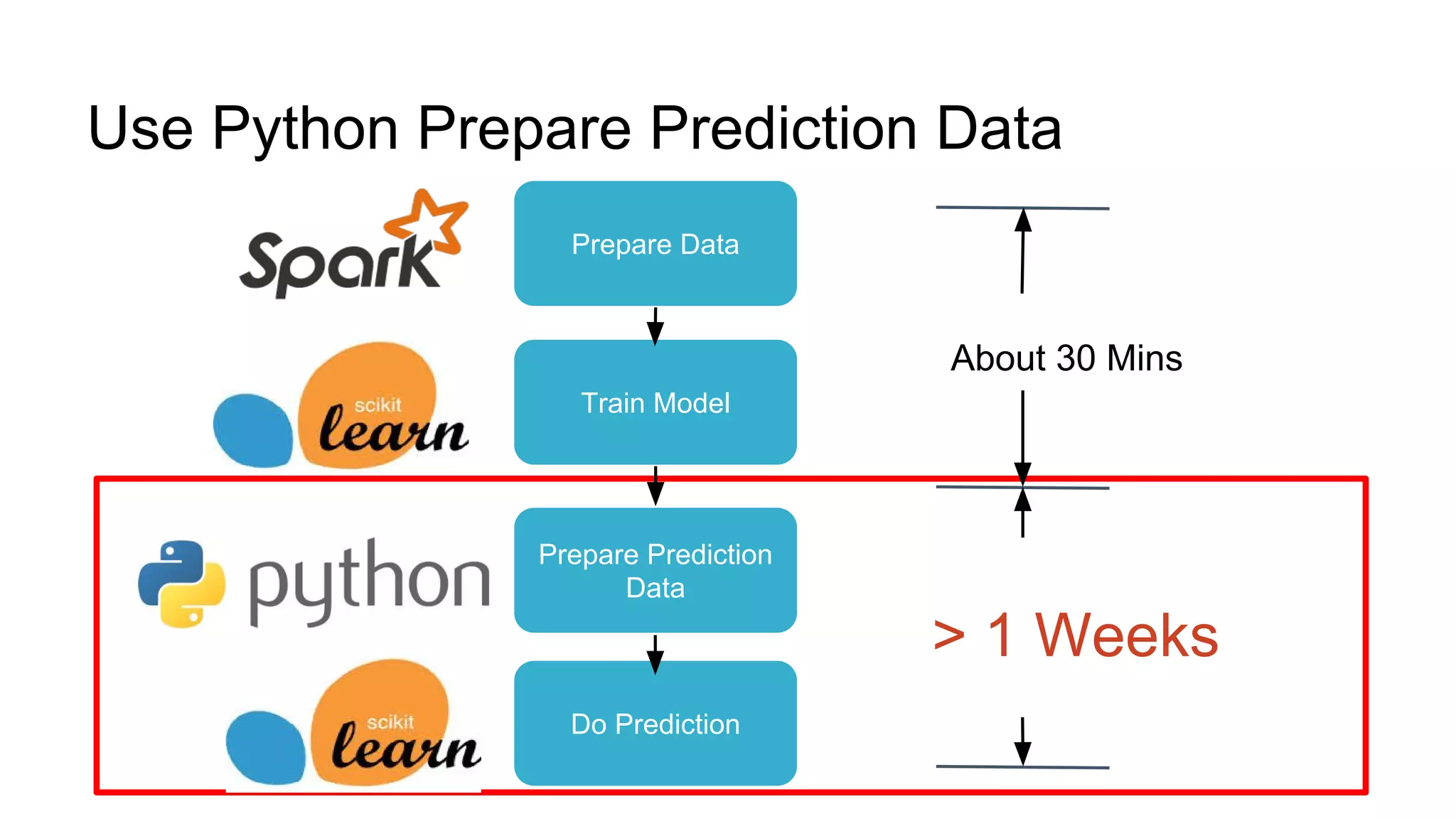


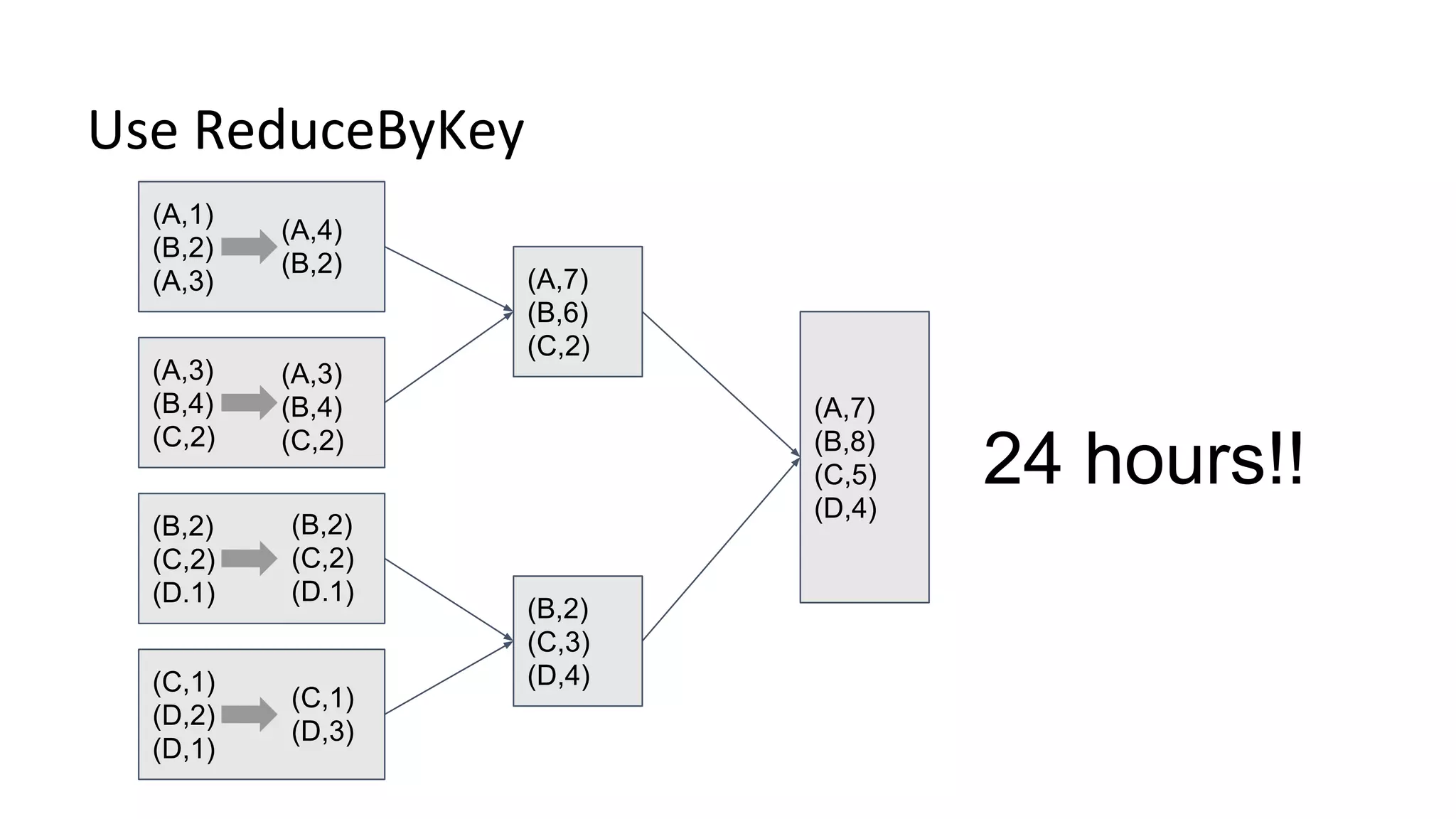

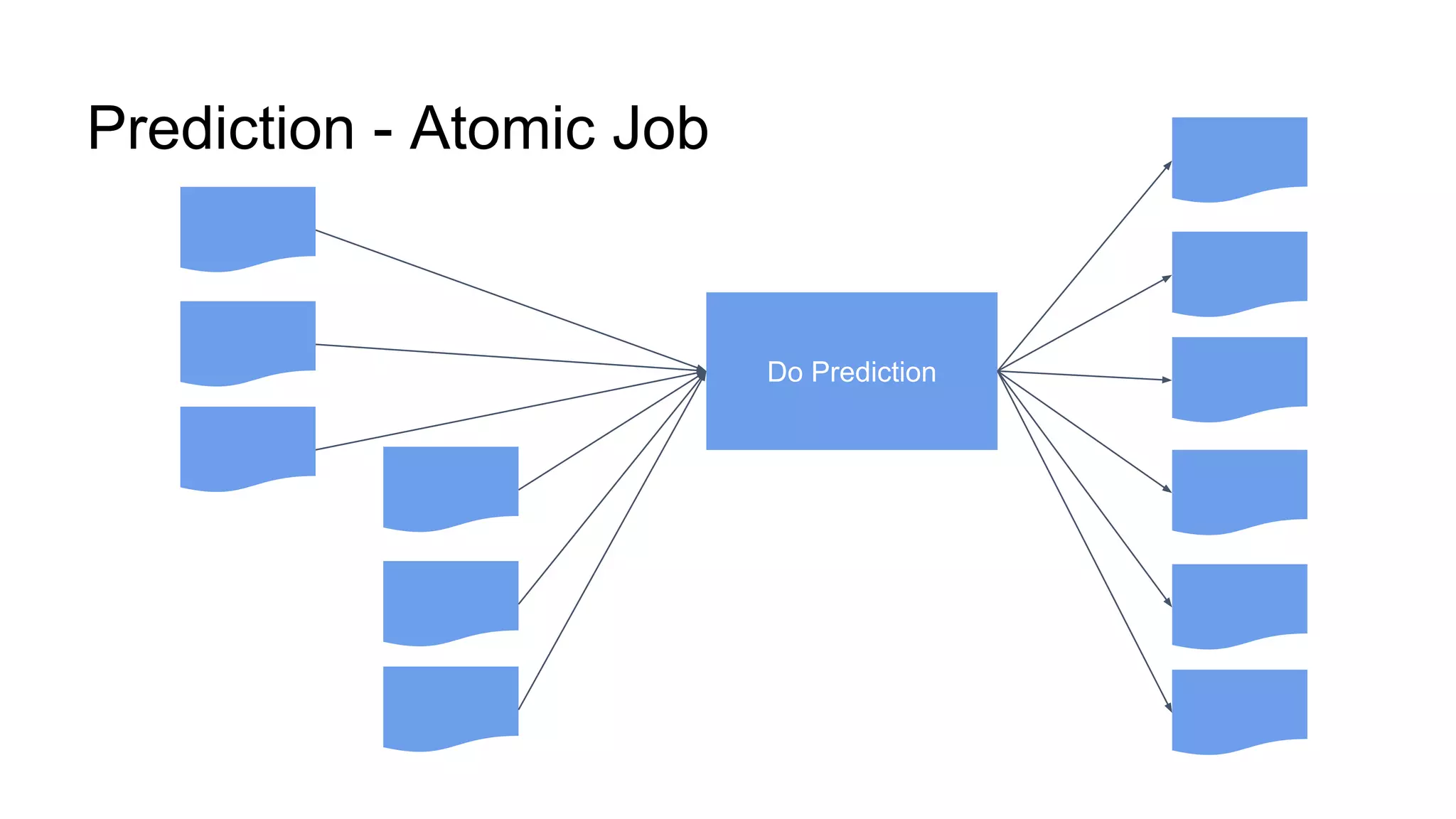
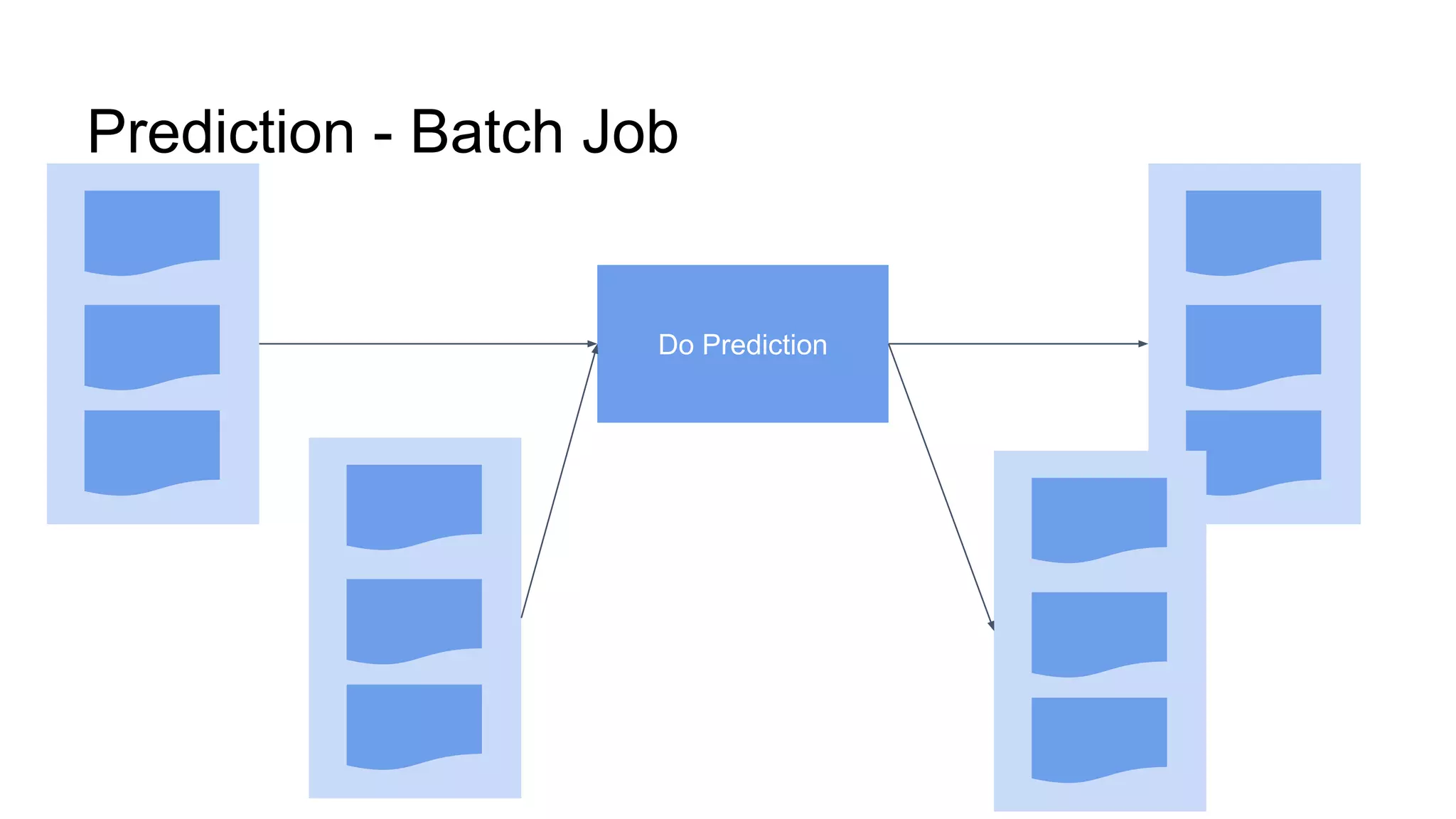


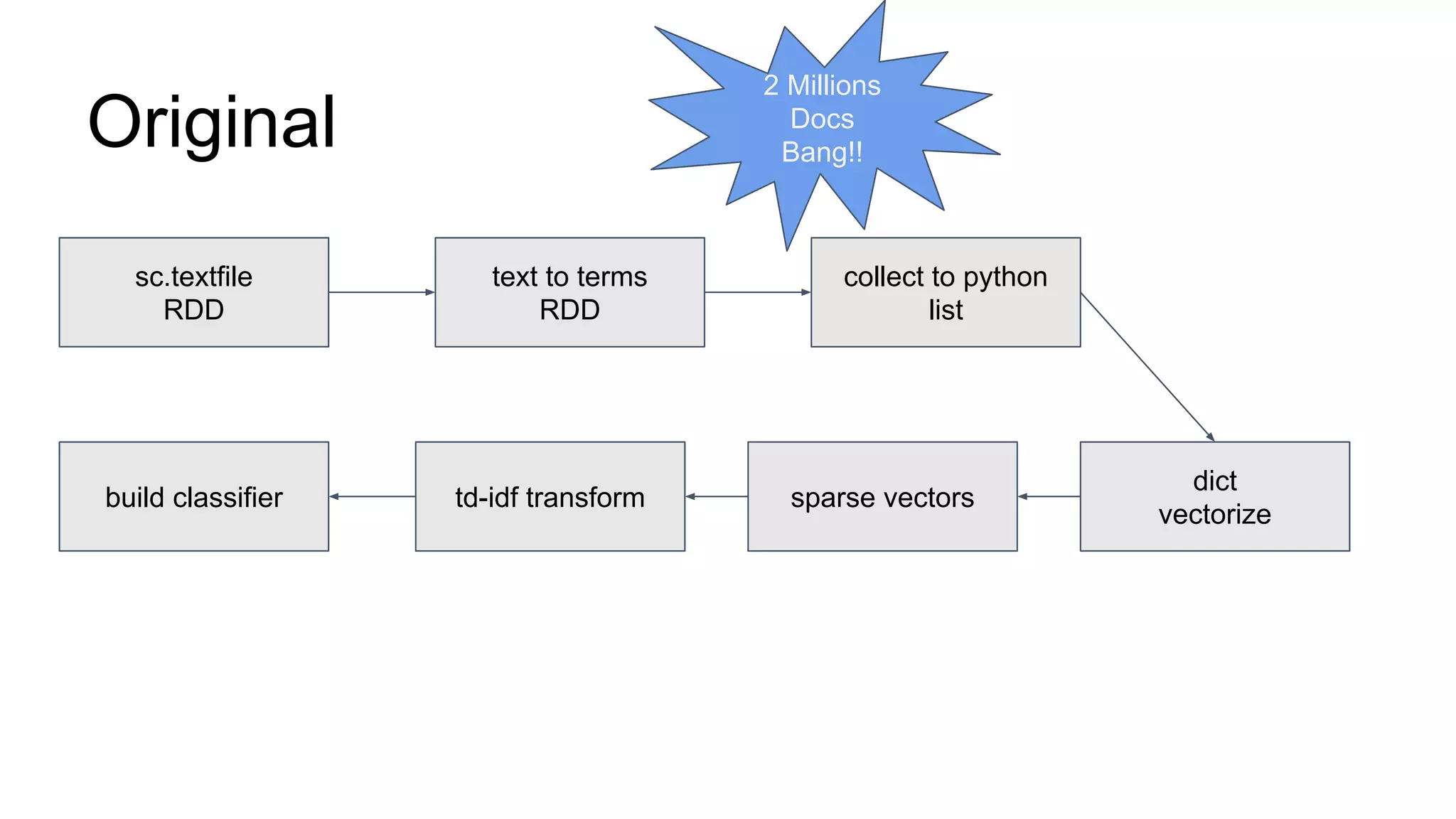
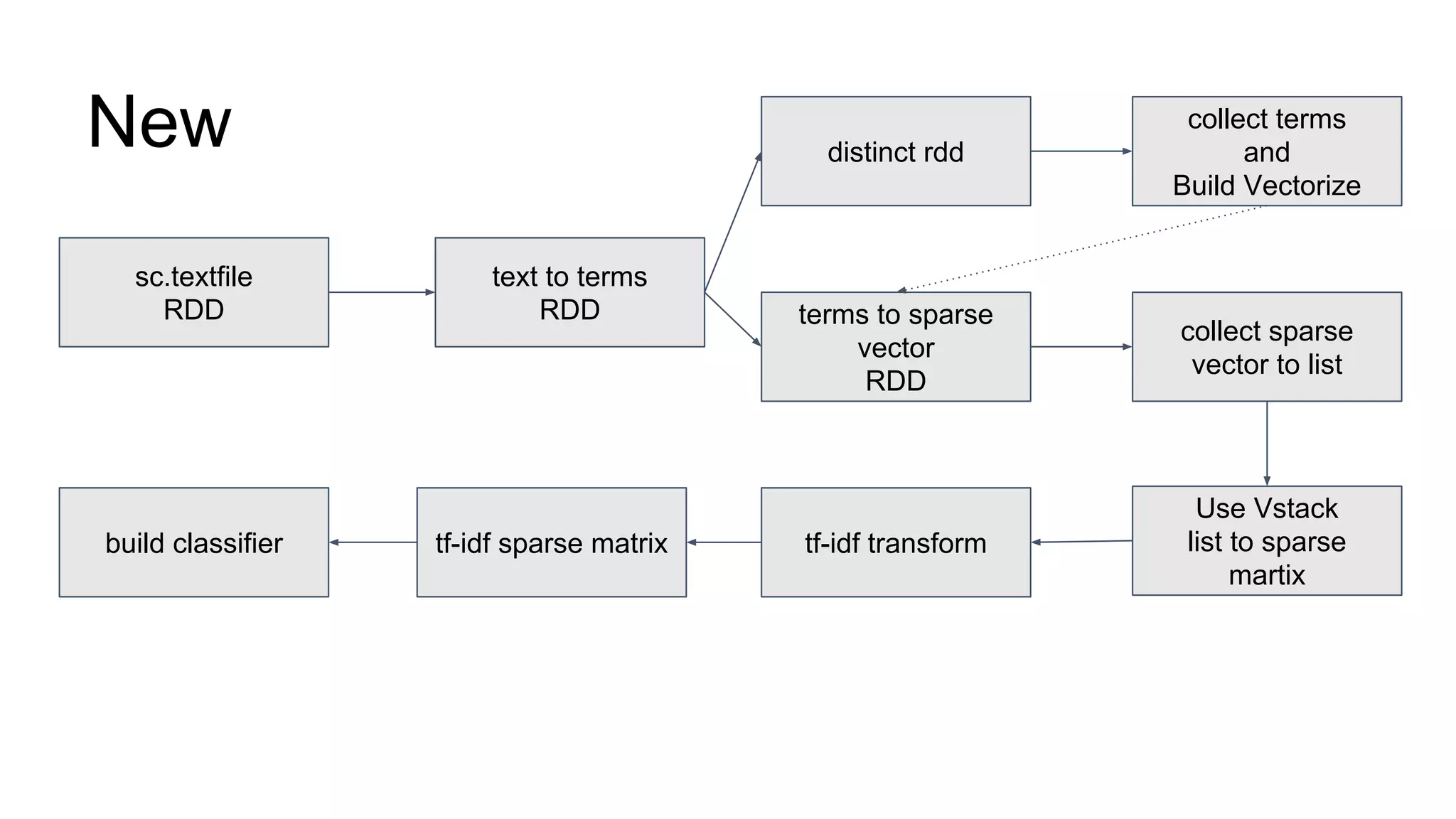


















The document discusses performance tuning for large-scale machine learning using Spark and Scikit-learn, focusing on the challenges of processing massive datasets. It outlines strategies for optimizing prediction tasks, emphasizing the use of pre-sorting data in databases and batch processing over atomic jobs. Additionally, it highlights a case study on spam article classification, detailing techniques for handling sparse datasets effectively.




































































