Downloaded 20 times

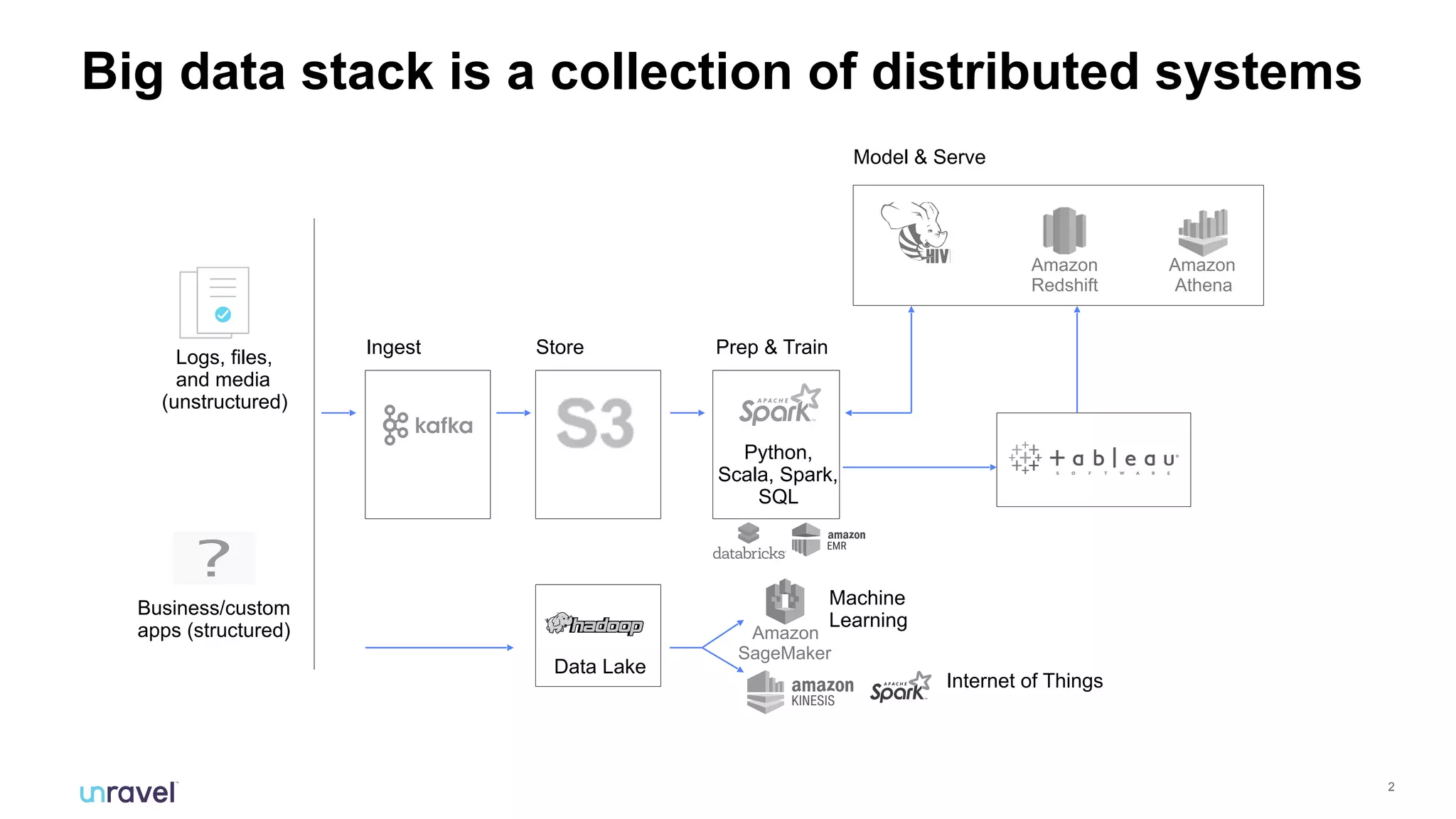




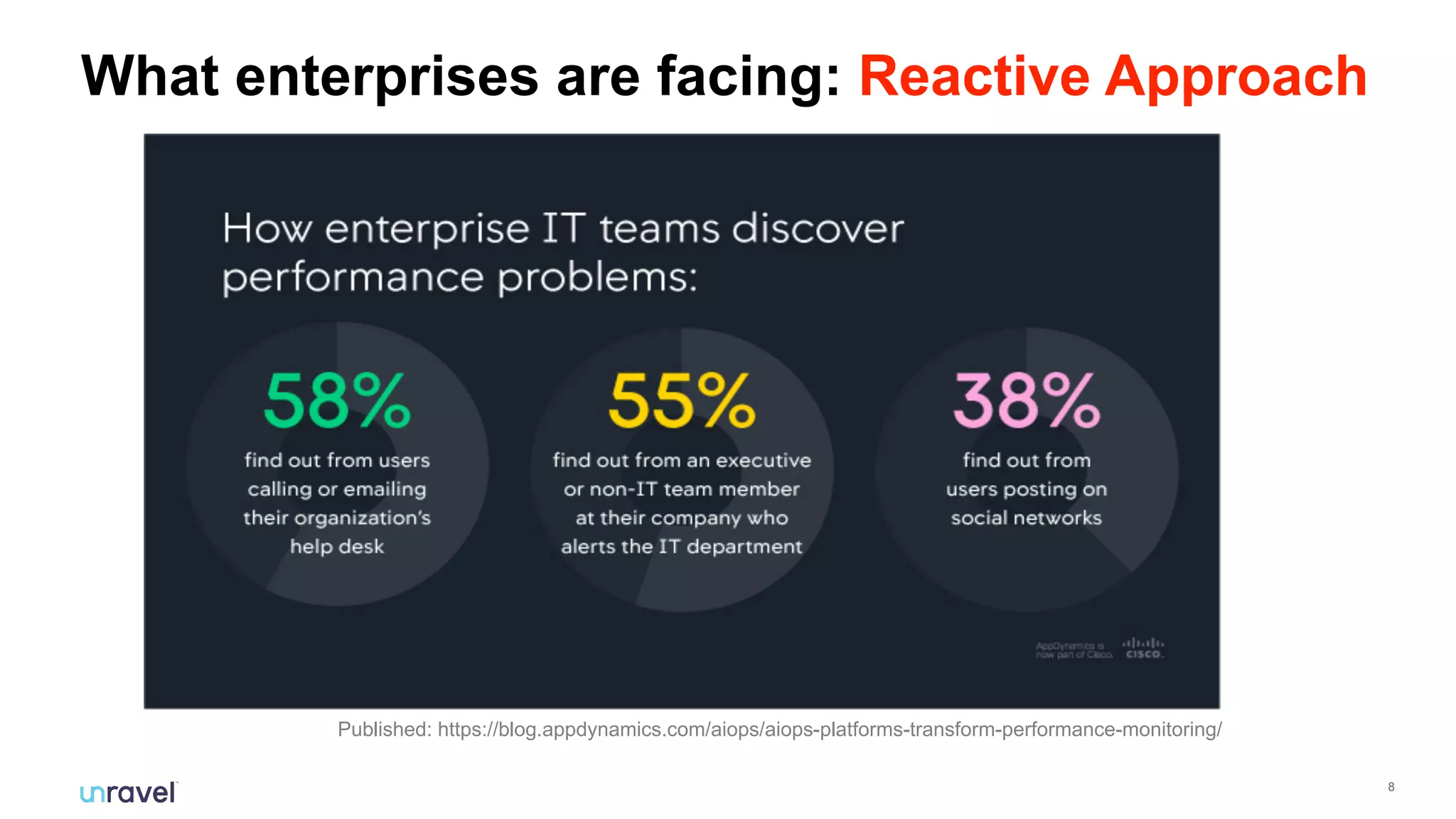




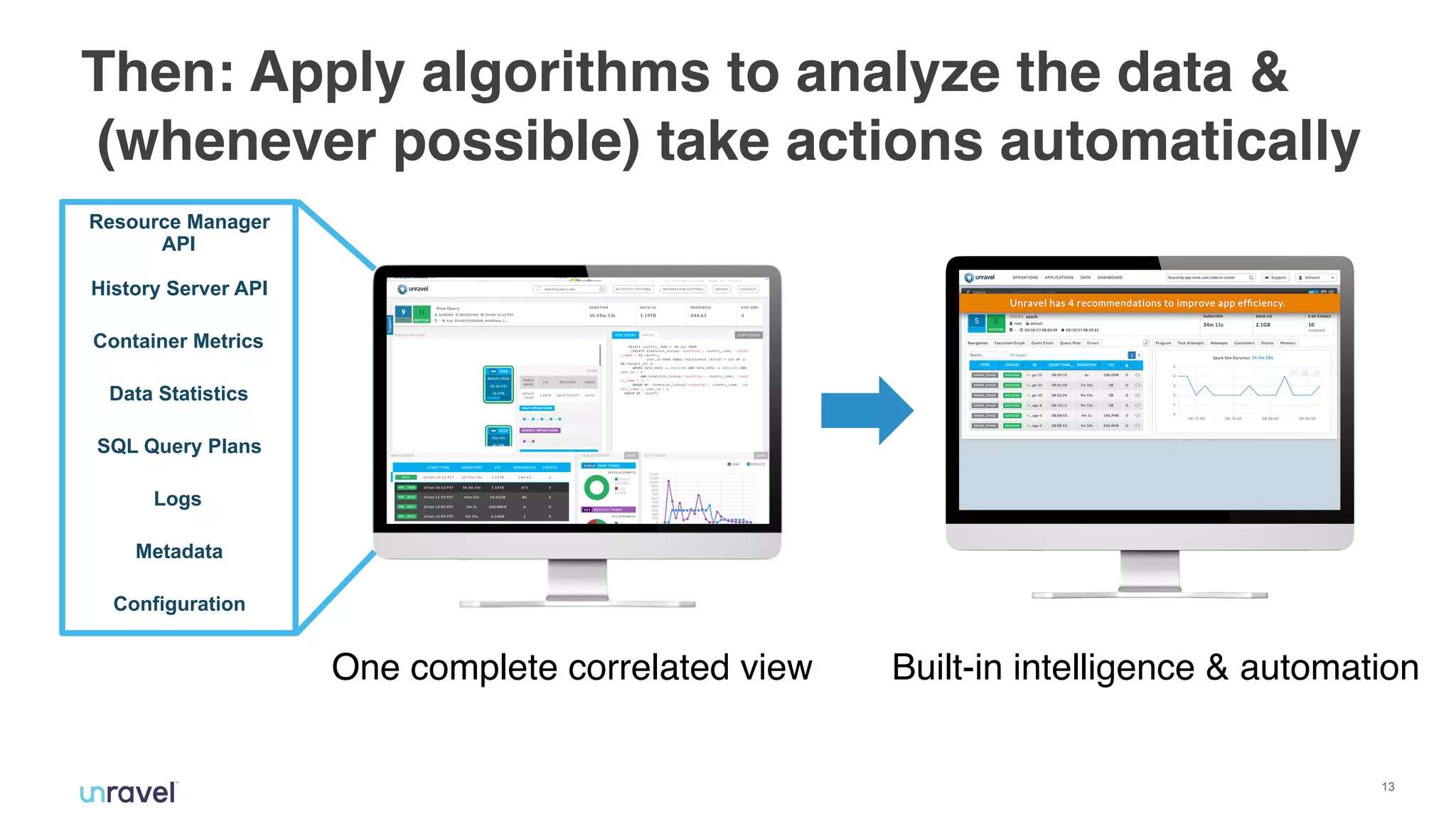
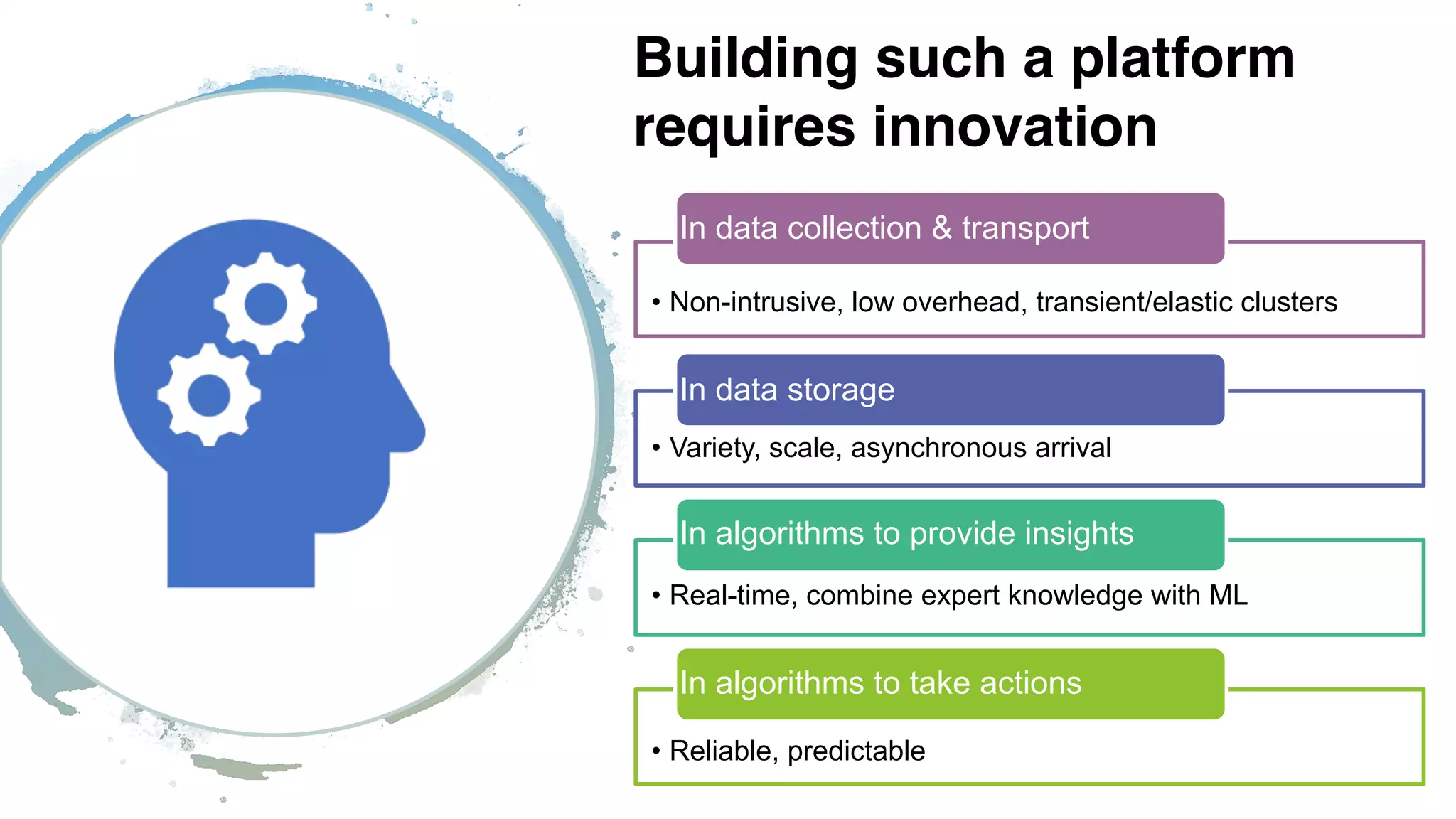

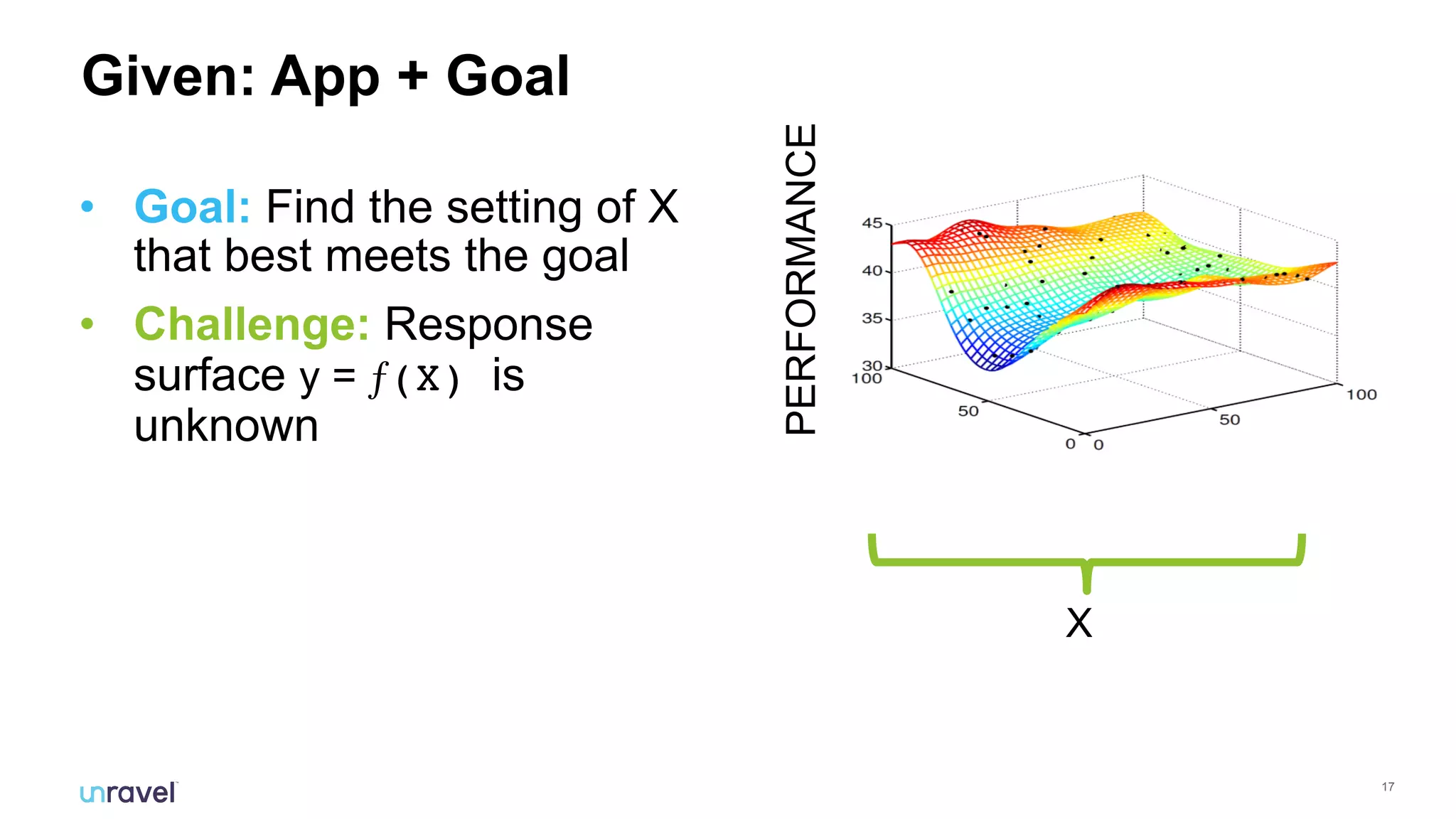
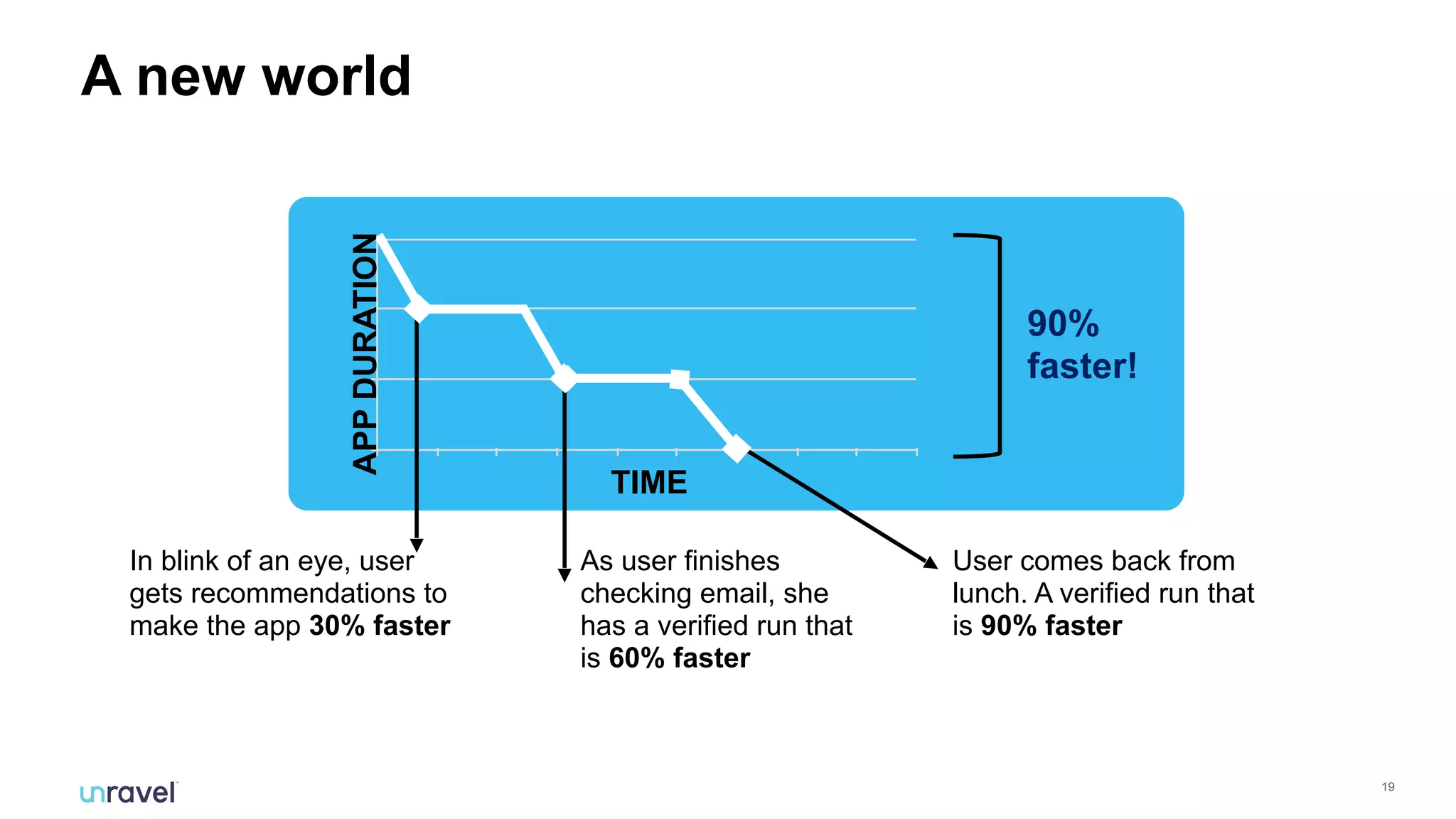
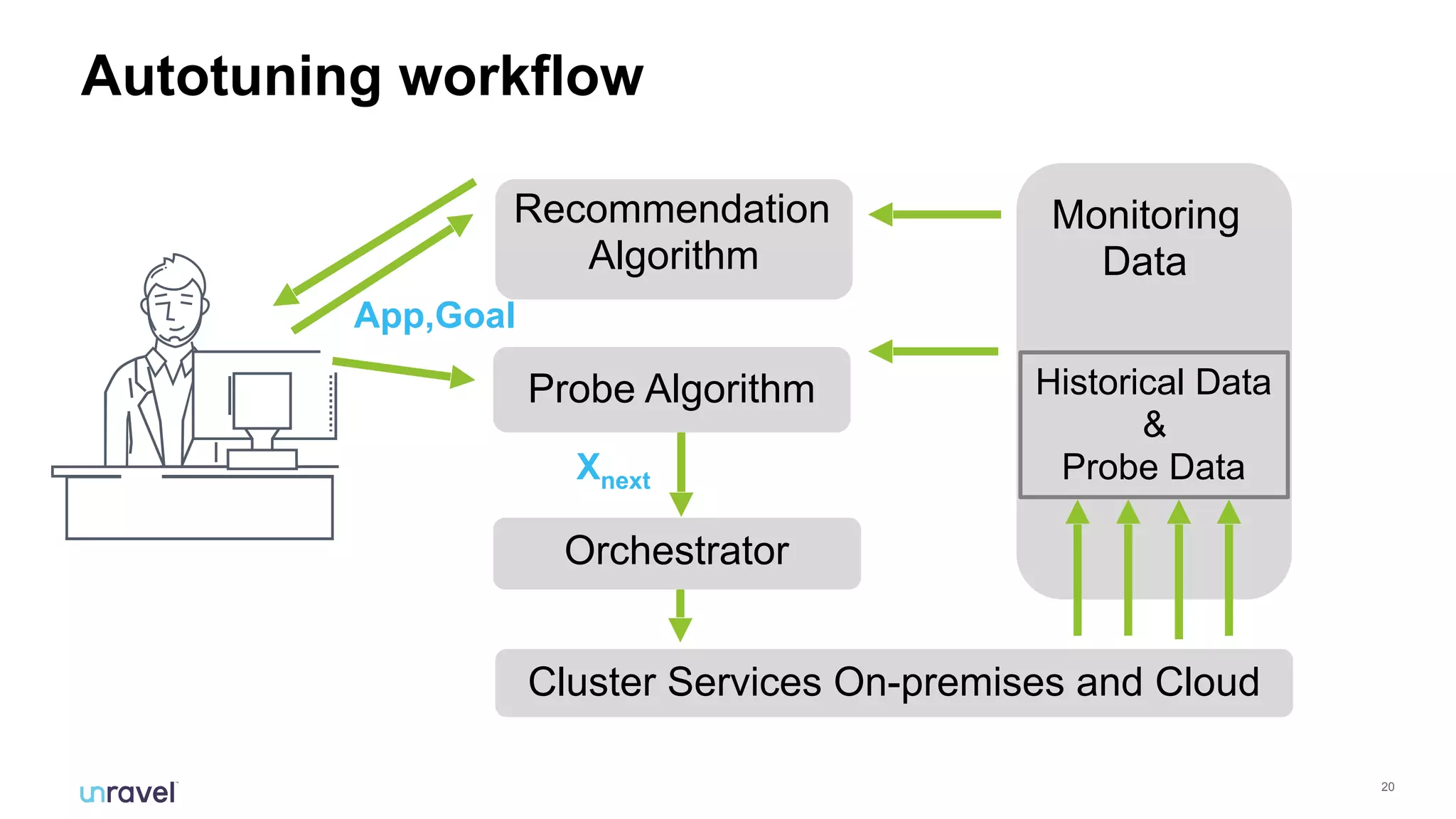
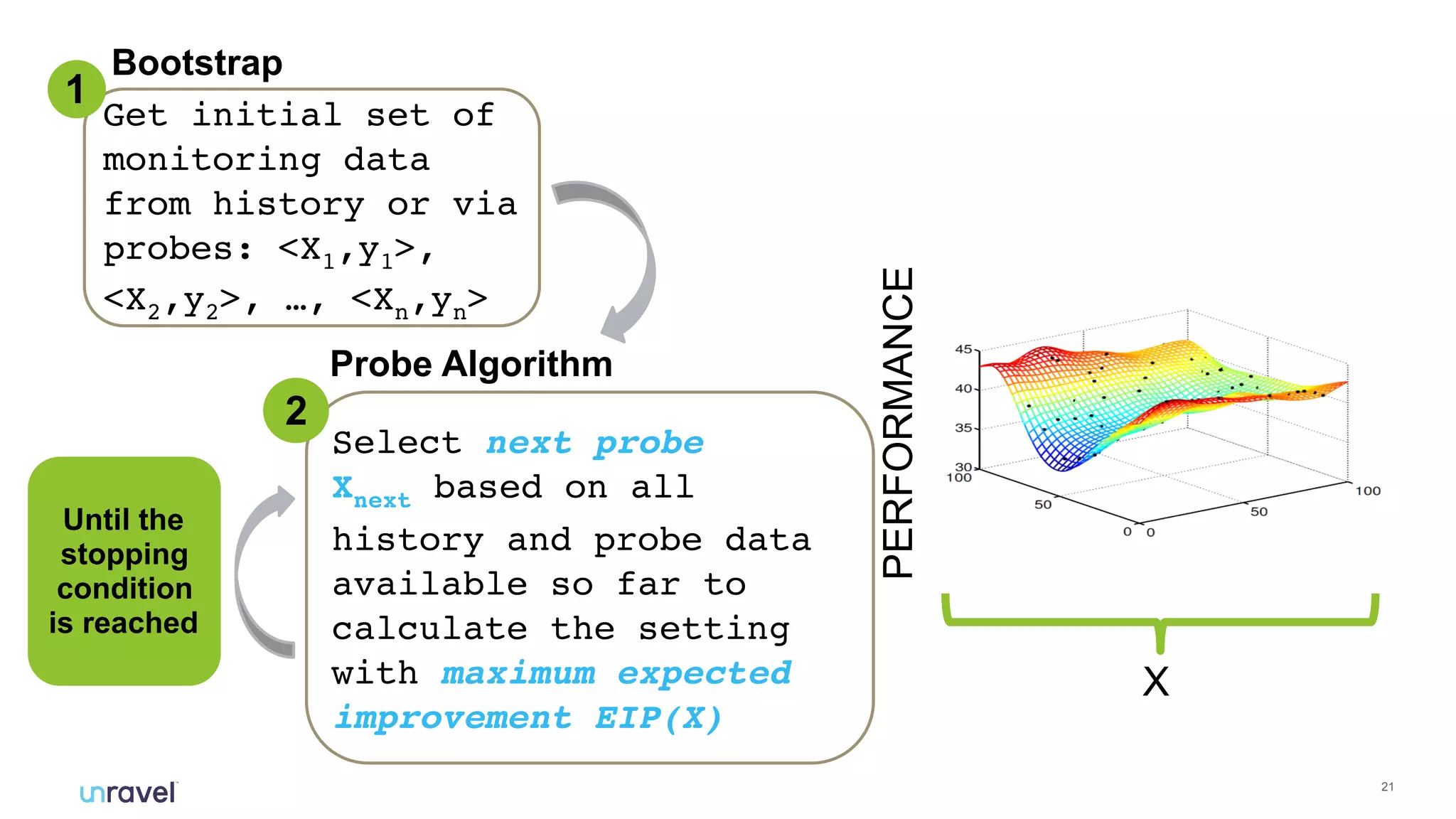
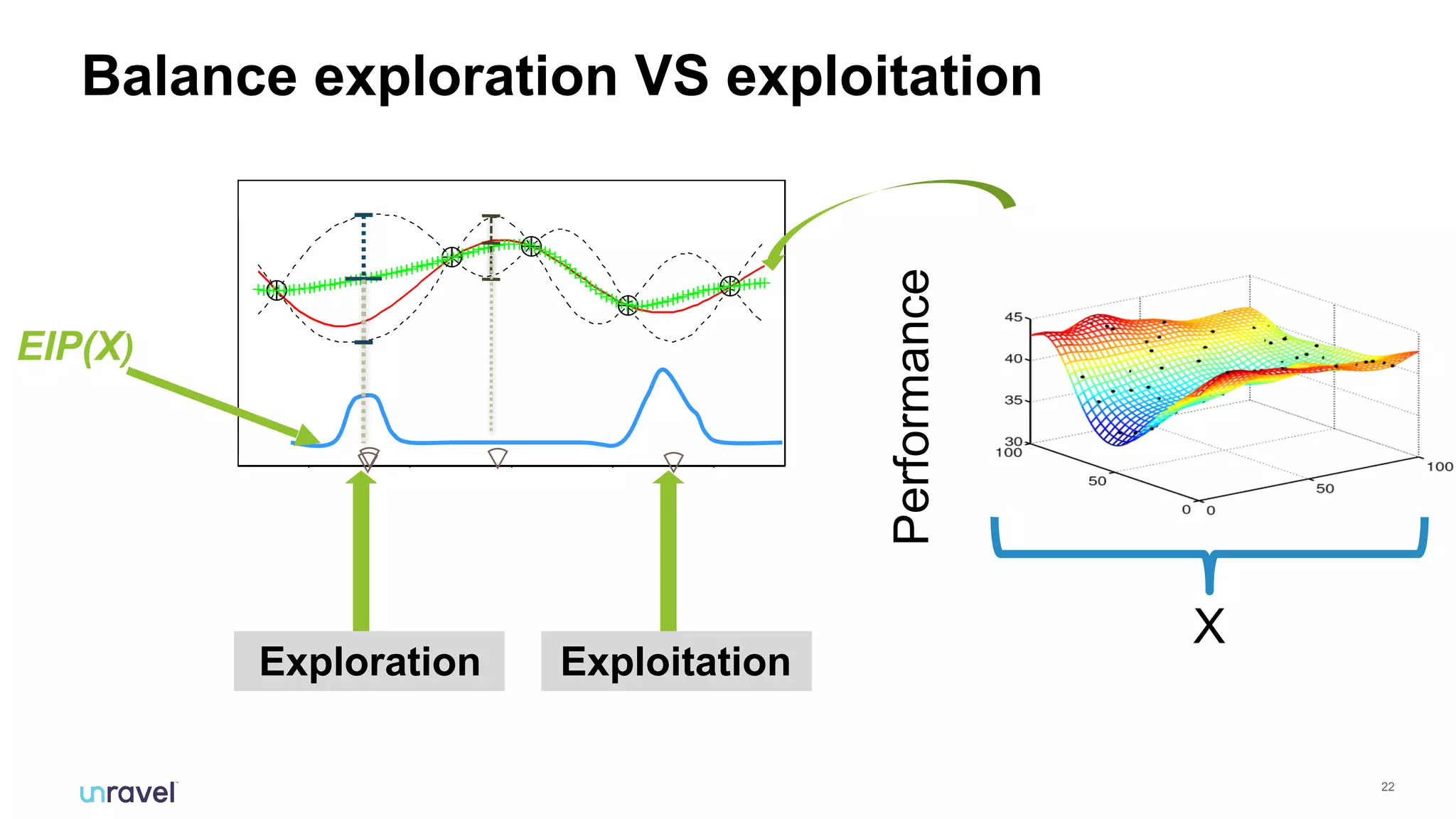















































The document discusses the challenges enterprises face with siloed monitoring data and reactive performance management in distributed applications, highlighting a survey indicating that 91% of IT professionals struggle with these issues. It proposes leveraging AI and machine learning for automated root cause analysis, performance optimization, and application tuning across clusters to enhance efficiency. The approach emphasizes collecting and analyzing monitoring data in a unified platform to derive actionable insights and optimize configurations based on workload characteristics.























































































