Download to read offline








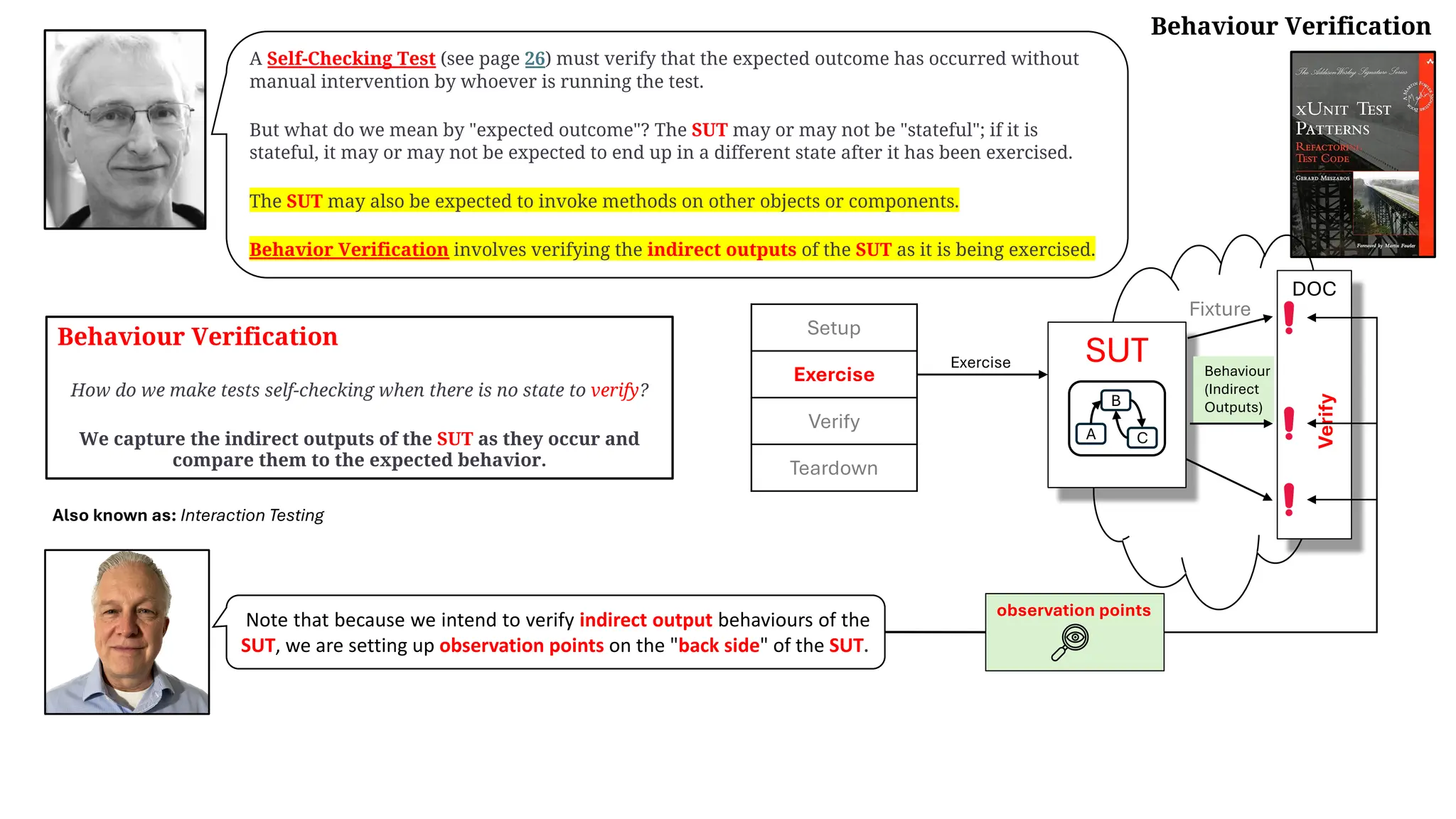


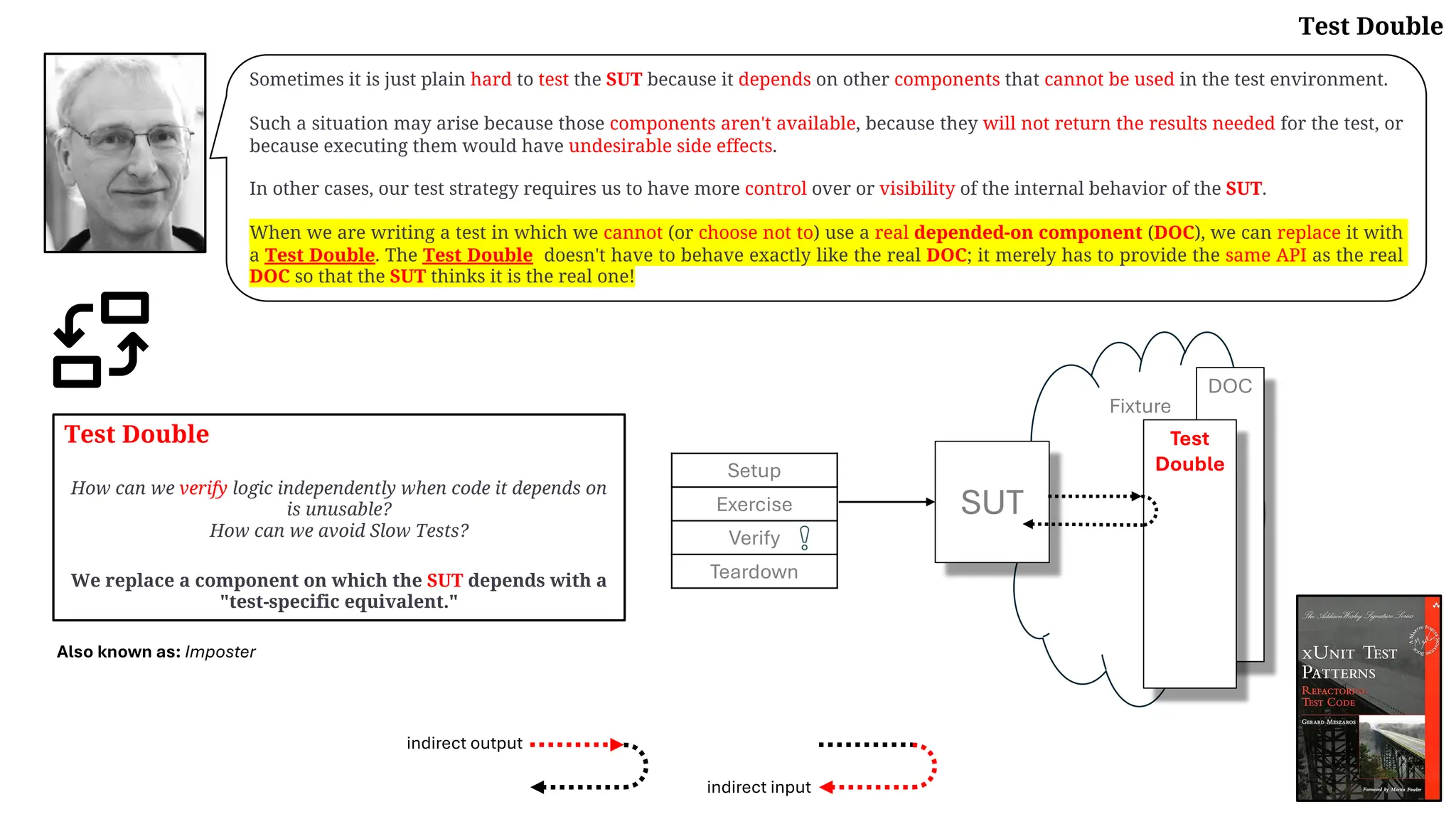




![Why Standardize Testing Patterns?
…I think it is important for us to standardize the names of the test automation patterns, especially those related
to Test Stubs (page 529) and Mock Objects (page 544). The key issue here relates to succinctness of
communication.
When someone tells you, "Put a mock in it" (pun intended!), what advice is that person giving you?
Depending on what the person means by a "mock," he or she could be suggesting that you control the indirect
inputs of your SUT using a Test Stub or that you replace your database with a Fake Database (see Fake
Object on page 551) that will reduce test interactions and speed up your tests by a factor of 50. …
Or perhaps the person is suggesting that you verify that your SUT calls the correct methods by installing
an Eager Mock Object (see Mock Object) preconfigured with the Expected Behavior (see Behavior
Verification on page 468).
If everyone used "mock" to mean a Mock Object—no more or less—then the advice would be pretty clear.
As I write this, the advice is very murky because we have taken to calling just about any Test Double (page 522)
a "mock object" (despite the objections of the authors of the original paper on Mock Objects [ET]).](https://image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-34-2048.jpg)

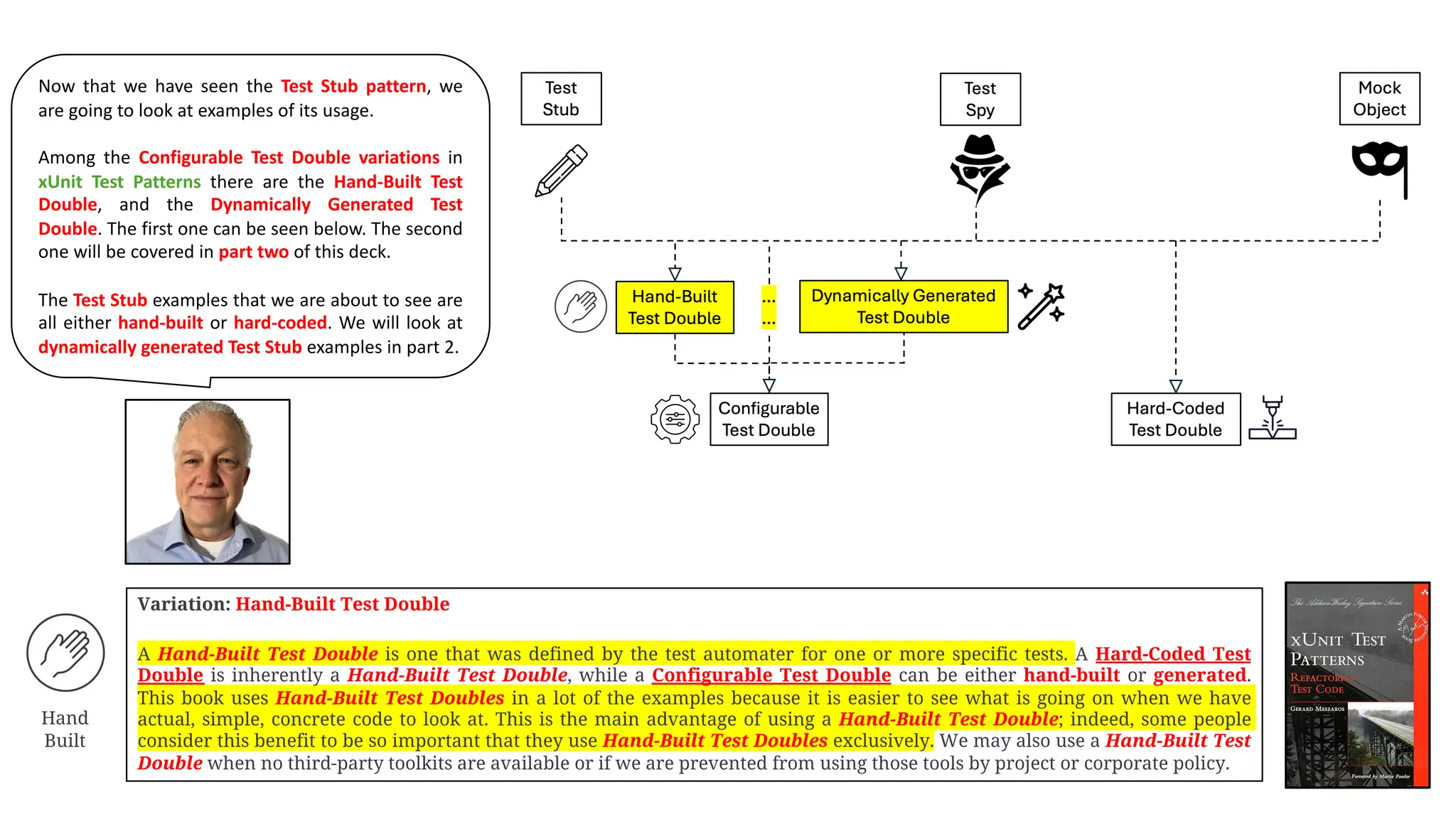

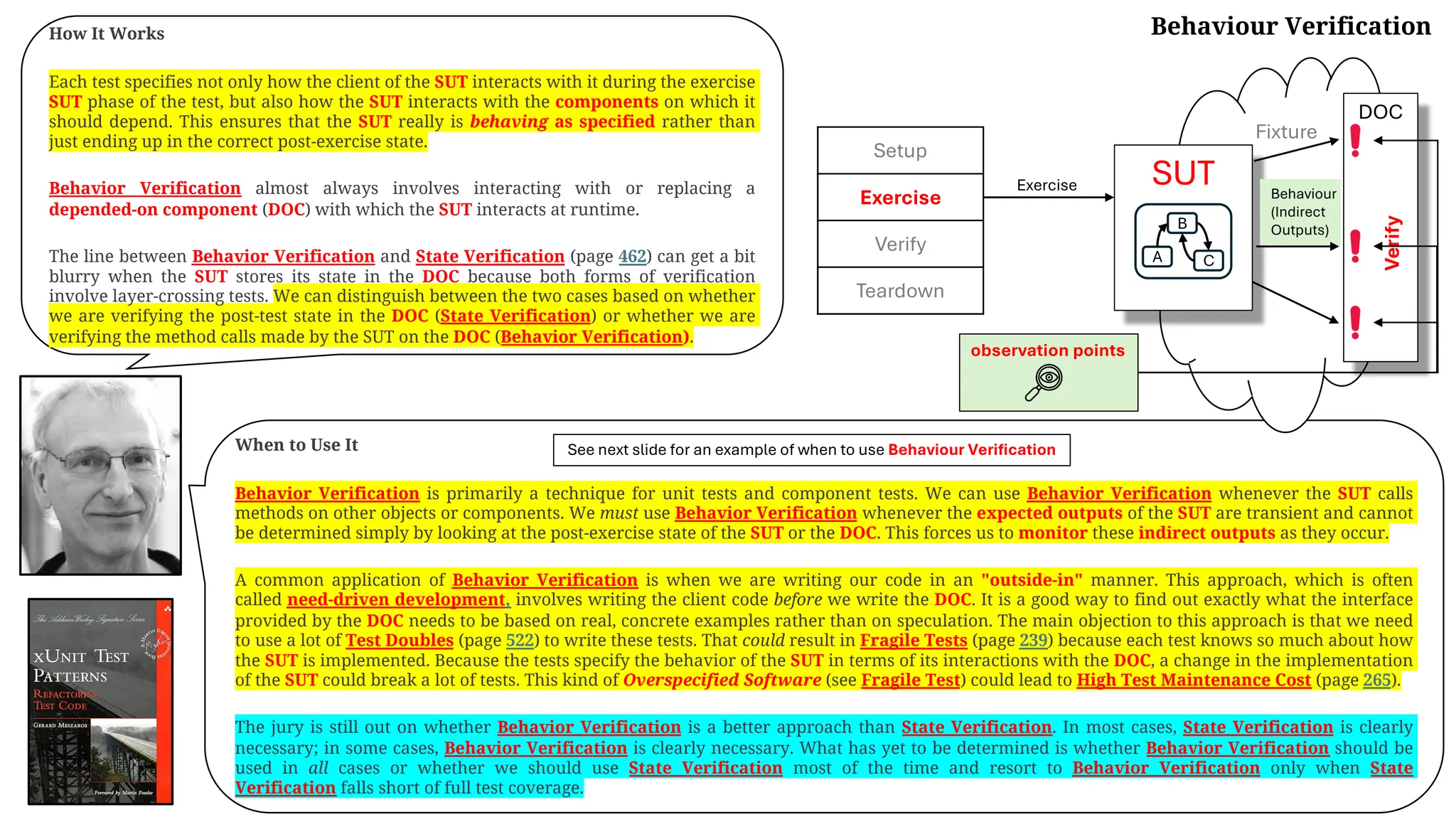
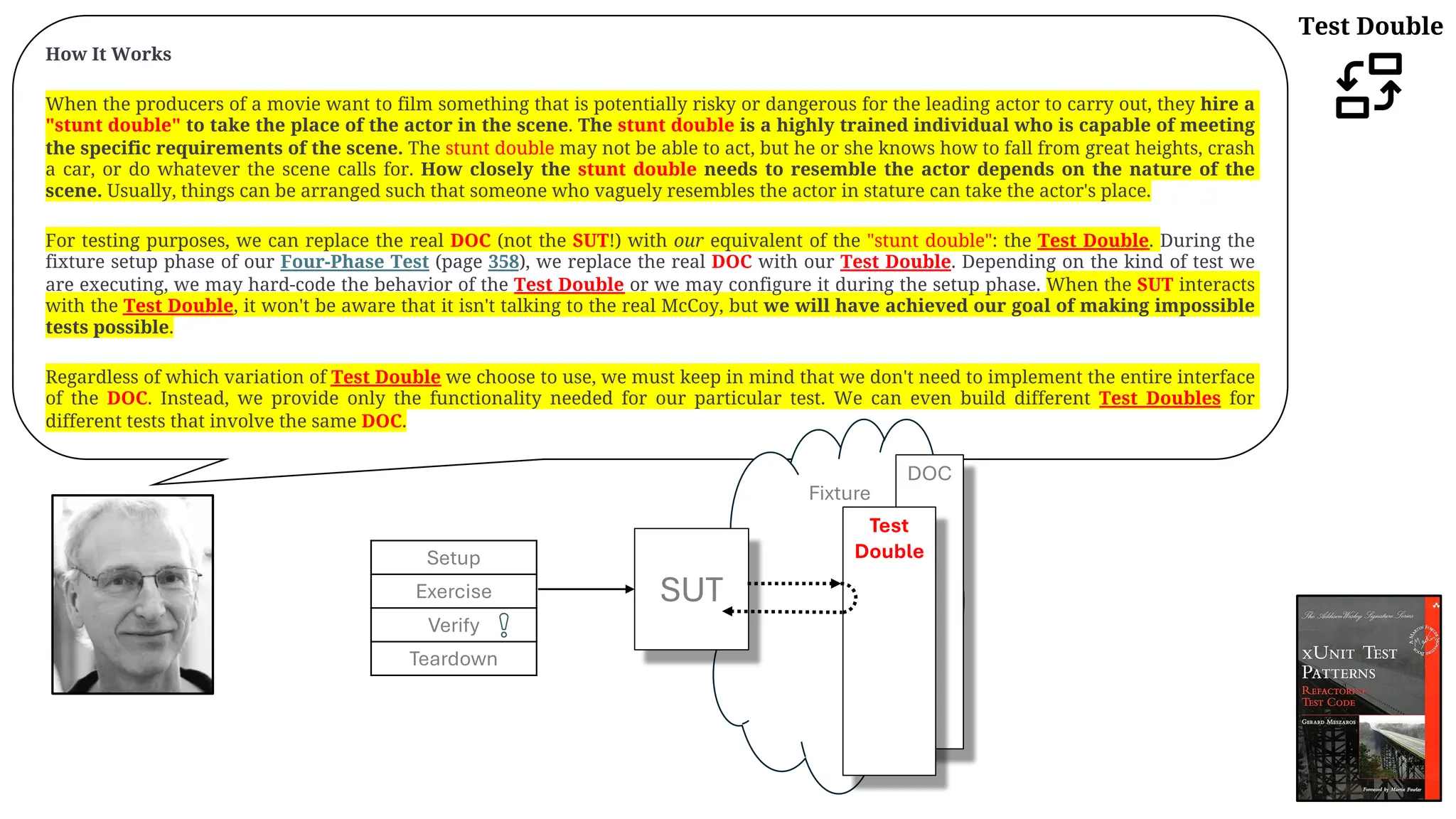
![Test Stub
…
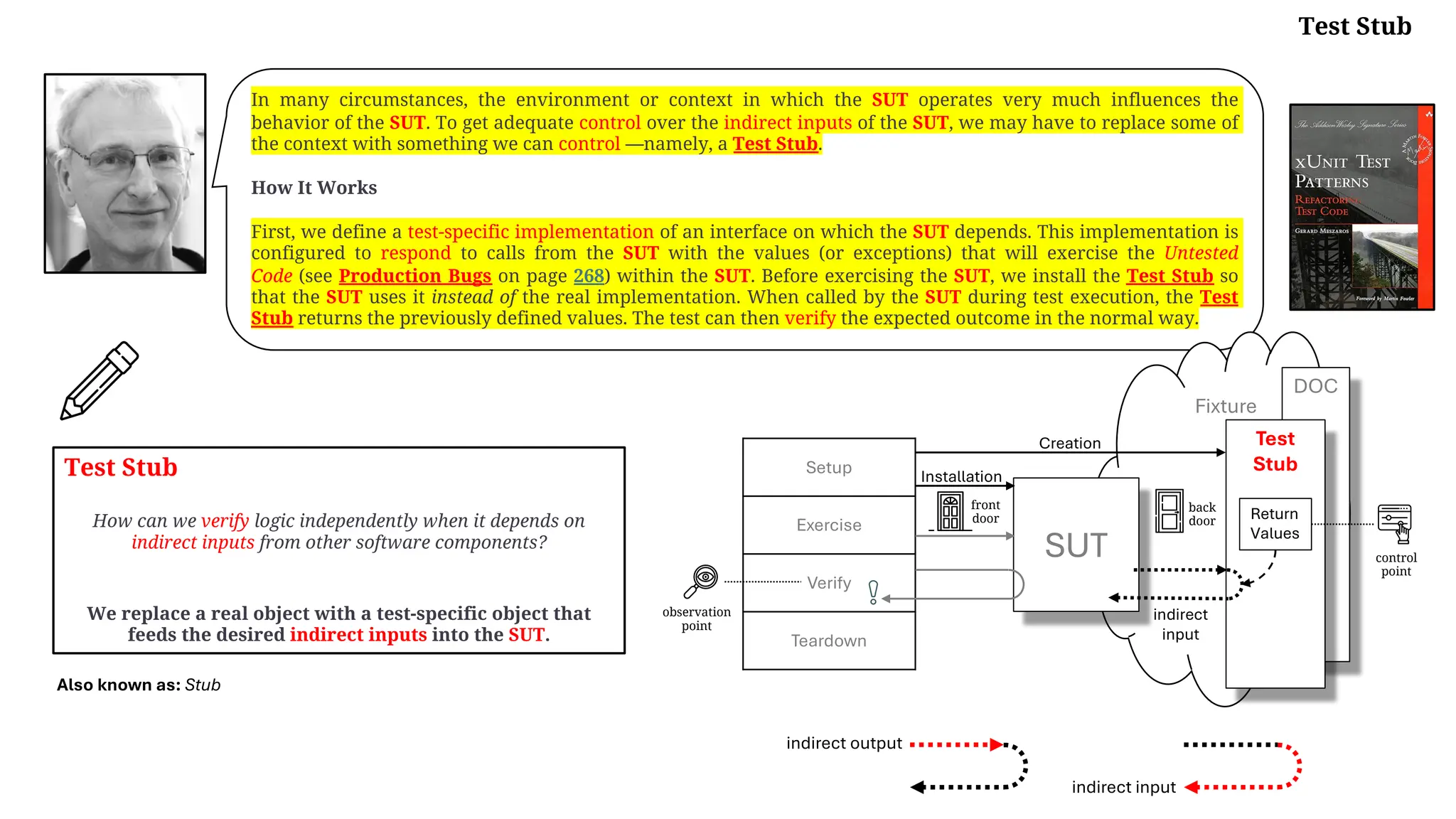
Motivating Example
The following test verifies the basic functionality of a component that formats an HTML string containing the current time. Unfortunately, it
depends on the real system clock so it rarely ever passes!
…
Refactoring Notes
We can achieve proper verification of the indirect inputs by getting control of the time. To do so, we use the Replace Dependency with Test Double
(page 522) refactoring to replace the real system clock (represented here by TimeProvider) with a Virtual Clock [VCTP]. We then implement it as
a Test Stub that is configured by the test with the time we want to use as the indirect input to the SUT.
[VCTP]
The Virtual Clock Test Pattern
http://www.nusco.org/docs/virtual_clock.pdf
By: Paolo Perrotta
This paper describes a common example of a Responder called Virtual Clock [VCTP]. The author uses the Virtual Clock Test Pattern as a Decorator
[GOF] for the real system clock, which allows the time to be "frozen" or resumed. One could use a Hard-Coded Test Stub or a Configurable Test
Stub just as easily for most tests. Paolo Perrotta summarizes the thrust of his article:
We can have a hard time unit-testing code that depends on the system clock. This paper describes both the problem and a common, reusable solution.](https://image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-44-2048.jpg)
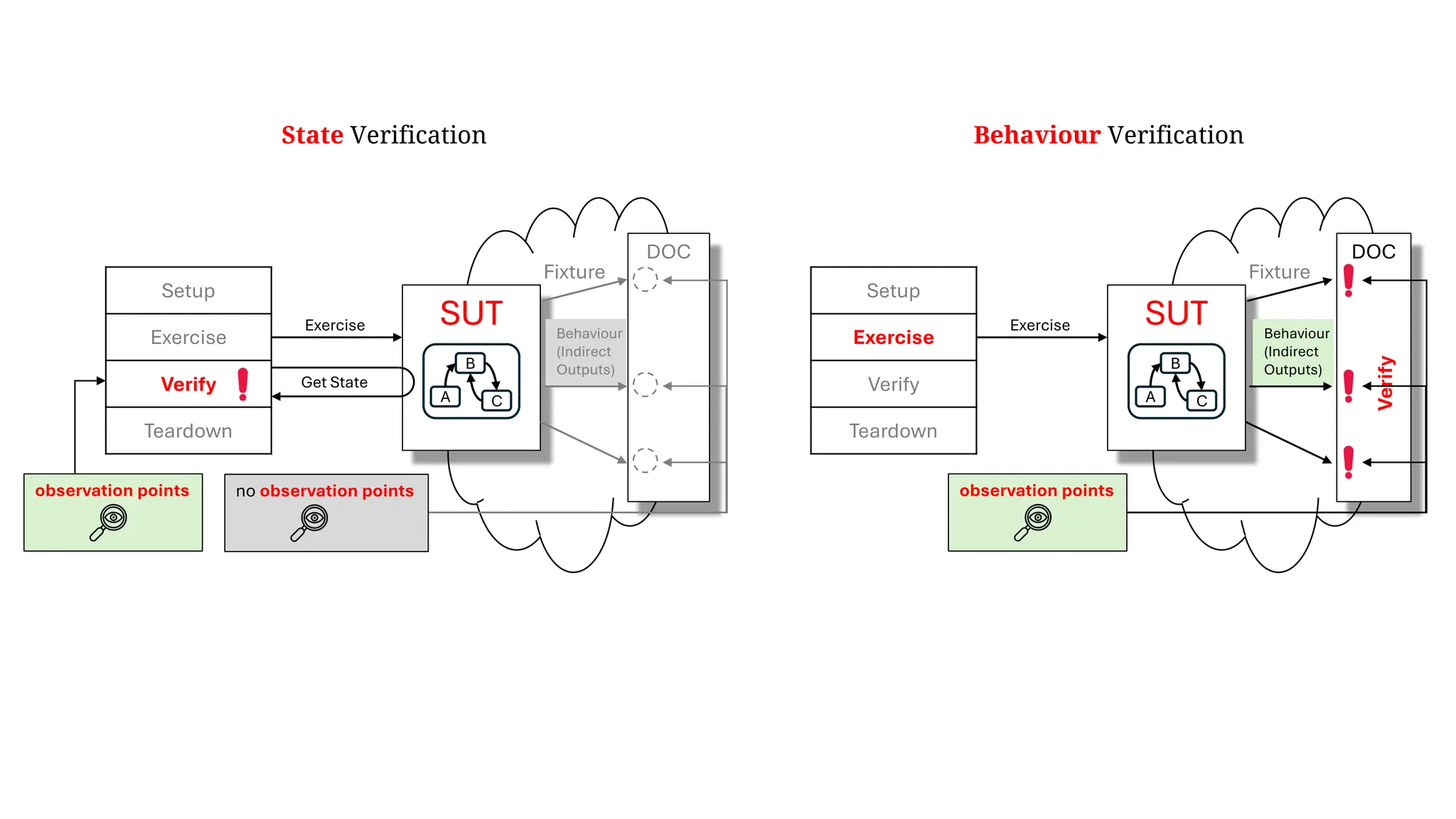
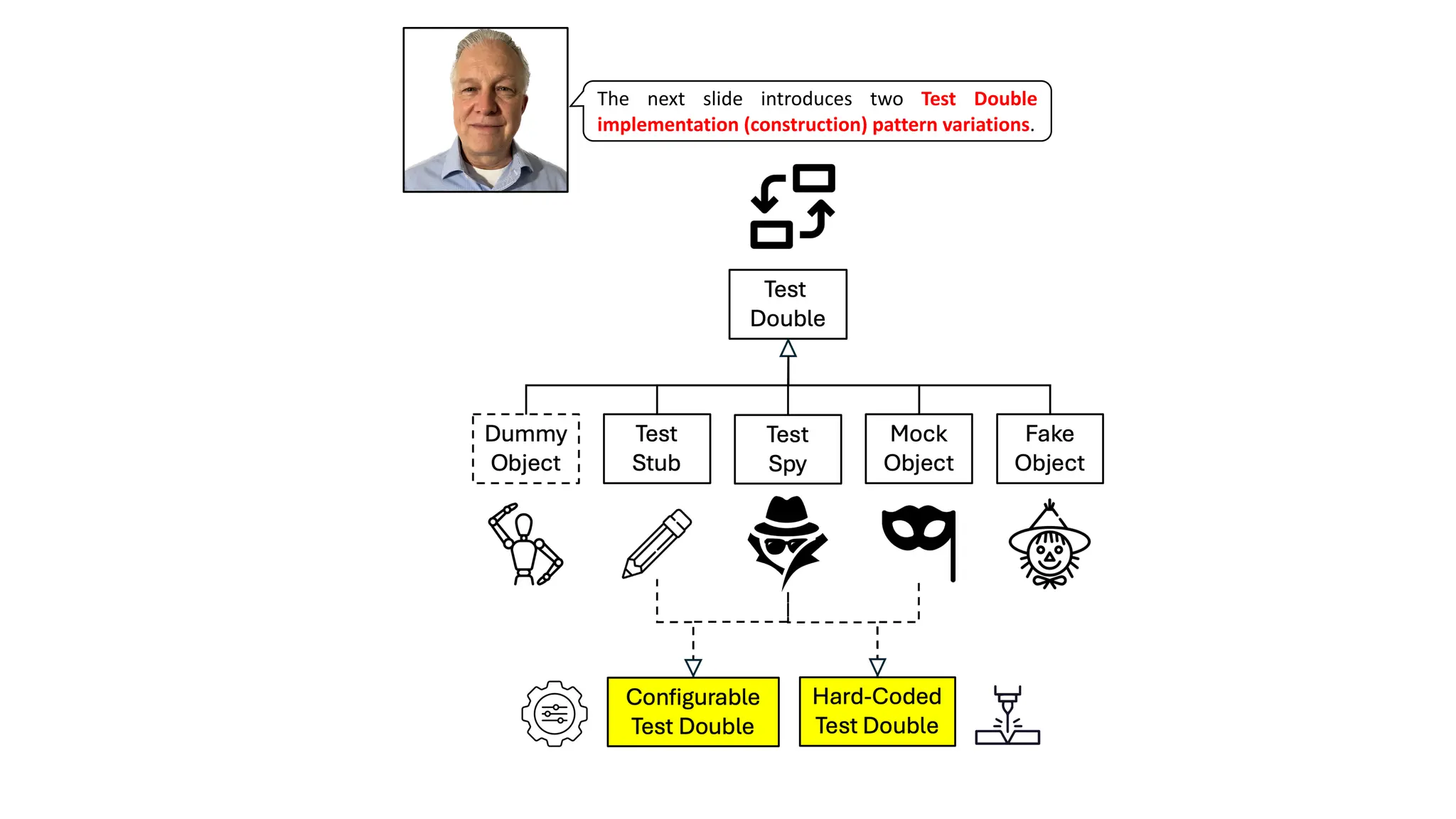
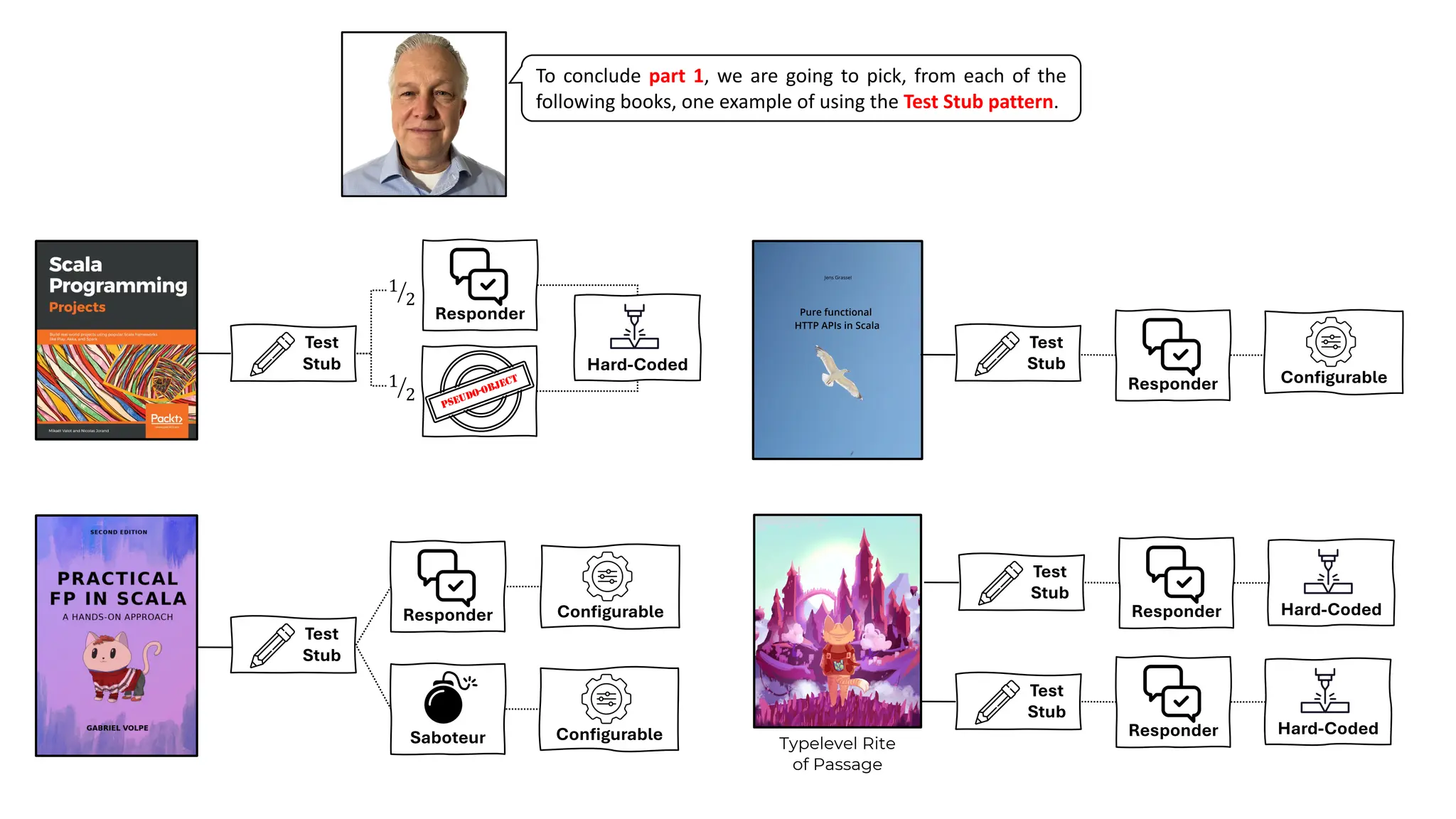
![Example #1
DOC
SparkSession
Timer[IO]
BatchProducer SUT
Timer[F]
DOC DOC
SparkSession
FakeTimer
BatchProducer SUT
Timer[F]
BatchProducerIT
Test
Stub
Production Integration Test
Responder
PSEUDO-OBJECT
!
1
2 !
1
2](https://image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-45-2048.jpg)
![class AppContext(val transactionStorePath: URI)
(implicit val spark: SparkSession,
implicit val timer: Timer[IO])
object BatchProducer {
val WaitTime: FiniteDuration = 59.minute
/** Number of seconds required by the API to make a transaction visible */
val ApiLag: FiniteDuration = 5.seconds
…
def processOneBatch(fetchNextTransactions: IO[Dataset[Transaction]],
transactions: Dataset[Transaction],
saveStart: Instant,
saveEnd: Instant)(implicit appCtx: AppContext)
: IO[(Dataset[Transaction], Instant, Instant)] = {
import appCtx._
val transactionsToSave = filterTxs(transactions, saveStart, saveEnd)
for {
_ <- BatchProducer.save(transactionsToSave, appCtx.transactionStorePath)
_ <- IO.sleep(WaitTime)
beforeRead <- currentInstant
// We are sure that lastTransactions contain all transactions until end
end = beforeRead.minusSeconds(ApiLag.toSeconds)
nextTransactions <- fetchNextTransactions
} yield (nextTransactions, saveEnd, end)
}
…
def currentInstant(implicit timer: Timer[IO]): IO[Instant] =
timer.clockRealTime(TimeUnit.SECONDS) map Instant.ofEpochSecond
DOC
SparkSession
FakeTimer
BatchProducer SUT
Timer[F]
BatchProducerIT
Test
Stub
Responder
PSEUDO-OBJECT
!
1
2 !
1
2
def sleep(duration: FiniteDuration)(implicit timer: Timer[IO]): IO[Unit] =
timer.sleep(duration)
cats.effect.IO
Example #1
Test Stub
• FakeTimer
Control Point
• clockRealTime function of FakeTimer
Indirect Input
• time returned by clockRealTime function](https://image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-46-2048.jpg)
![implicit object FakeTimer extends Timer[IO] {
private var clockRealTimeInMillis: Long =
Instant.parse("2018-08-02T01:00:00Z").toEpochMilli
def clockRealTime(unit: TimeUnit): IO[Long] =
IO(unit.convert(clockRealTimeInMillis, TimeUnit.MILLISECONDS))
def sleep(duration: FiniteDuration): IO[Unit] = IO {
clockRealTimeInMillis = clockRealTimeInMillis + duration.toMillis
}
def shift: IO[Unit] = ???
def clockMonotonic(unit: TimeUnit): IO[Long] = ???
}
DOC
SparkSession
FakeTimer
BatchProducer SUT
Timer[F]
BatchProducerIT
Test
Stub
Responder
PSEUDO-OBJECT
Hard-Coded
!
1
2
!
1
2
Example #1
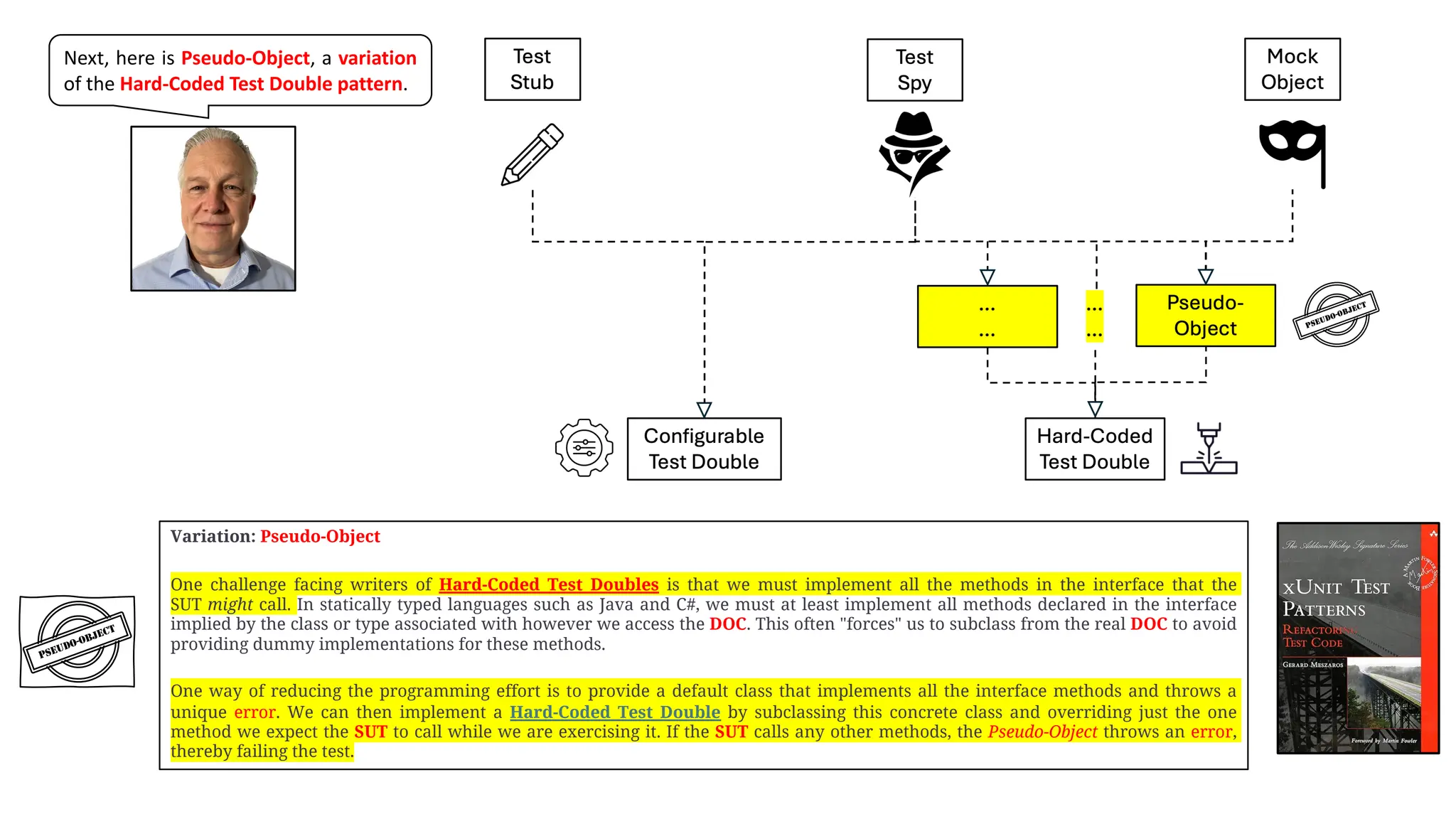
In the usual way of implementing the Pseudo-Object pattern, we would have (1) a base class providing undefined implementations (???
expressions) of all Timer’s functions, and (2) a concrete subclass that overrides only the functions we expect the SUT to call. Instead, here we
have a concrete Timer that provides (1) real implementations of the functions we expect the SUT to call, and (2) undefined implementations of
functions that the SUT is NOT expected to call.
By the way, note that while the term `fake` is included in the name of the timer implementation, it is not being used in a way that is consistent
with the terminology described in this deck series.
Test Stub
• FakeTimer
Control Point
• clockRealTime function of FakeTimer
Indirect Input
• time returned by clockRealTime function](https://image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-47-2048.jpg)
![class BatchProducerIT extends WordSpec with Matchers with SharedSparkSession {
…
"BatchProducer.processOneBatch" should {
"filter and save a batch of transaction, wait 59 mn, fetch the next batch" in withTempDir { tmpDir =>
implicit object FakeTimer extends Timer[IO] { … }
implicit val appContext: AppContext = new AppContext(transactionStorePath = tmpDir.toURI)
implicit def toTimestamp(str: String): Timestamp = Timestamp.from(Instant.parse(str))
val tx1 = Transaction("2018-08-01T23:00:00Z", 1, 7657.58, true, 0.021762)
val tx2 = Transaction("2018-08-02T01:00:00Z", 2, 7663.85, false, 0.01385517)
val tx3 = Transaction("2018-08-02T01:58:30Z", 3, 7663.85, false, 0.03782426)
val tx4 = Transaction("2018-08-02T01:58:59Z", 4, 7663.86, false, 0.15750809)
val tx5 = Transaction("2018-08-02T02:30:00Z", 5, 7661.49, true, 0.1)
// Start at 01:00, tx 2 ignored (too soon)
val txs0 = Seq(tx1)
// Fetch at 01:59, get nb 2 and 3, but will miss nb 4 because of Api lag
val txs1 = Seq(tx2, tx3)
// Fetch at 02:58, get nb 3, 4, 5
val txs2 = Seq(tx3, tx4, tx5)
// Fetch at 03:57, get nothing
val txs3 = Seq.empty[Transaction]
val start0 = Instant.parse("2018-08-02T00:00:00Z")
val end0 = Instant.parse("2018-08-02T00:59:55Z")
val threeBatchesIO = …
val (ds1, start1, end1, ds2, start2, end2) = threeBatchesIO.unsafeRunSync()
ds1.collect() should contain theSameElementsAs txs1
start1 should ===(end0)
// initialClock + 1mn - 15s - 5s
end1 should ===(Instant.parse("2018-08-02T01:58:55Z"))
ds2.collect() should contain theSameElementsAs txs2
start2 should ===(end1)
// initialClock + 1mn -15s + 1mn -15s -5s = end1 + 45s
end2 should ===(Instant.parse("2018-08-02T02:57:55Z"))
val lastClock = Instant.ofEpochMilli(FakeTimer.clockRealTime(TimeUnit.MILLISECONDS).unsafeRunSync())
lastClock should === (Instant.parse("2018-08-02T03:57:00Z"))
…
DOC
SparkSession
FakeTimer
BatchProducer SUT
Timer[F]
BatchProducerIT
Test
Stub
val threeBatchesIO =
for {
tuple1 <- BatchProducer.processOneBatch(IO(txs1.toDS()), txs0.toDS(), start0, end0) // end - Api lag
(ds1, start1, end1) = tuple1
tuple2 <- BatchProducer.processOneBatch(IO(txs2.toDS()), ds1, start1, end1)
(ds2, start2, end2) = tuple2
_ <- BatchProducer.processOneBatch(IO(txs3.toDS()), ds2, start2, end2)
} yield (ds1, start1, end1, ds2, start2, end2)
Example #1
Test Stub
• FakeTimer
Control Point
• clockRealTime function of FakeTimer
Indirect Input
• time returned by clockRealTime function](https://image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-48-2048.jpg)
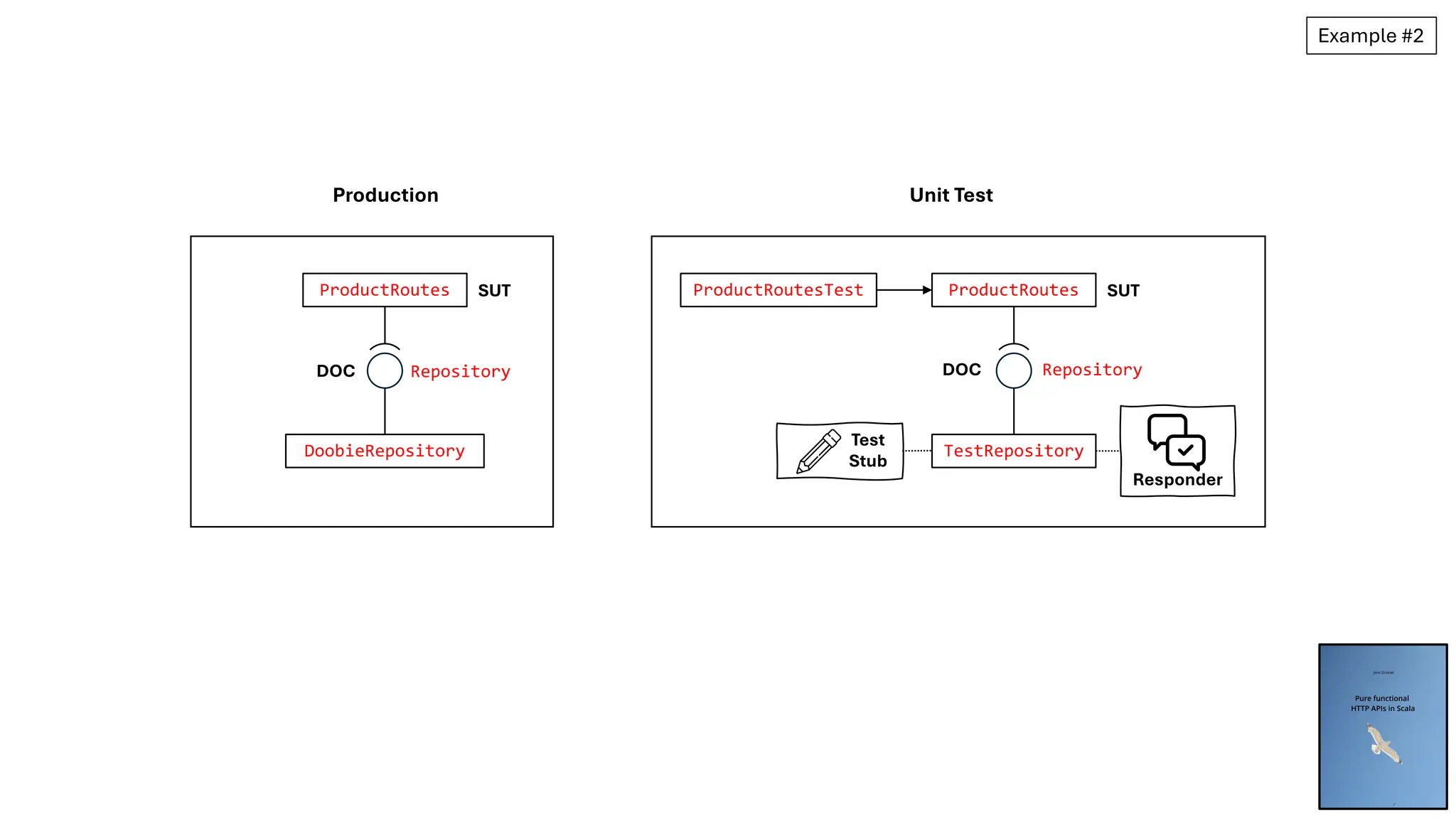
![final class ProductRoutes[F[_]: Sync](repo: Repository[F]) extends Http4sDsl[F] {
implicit def decodeProduct: EntityDecoder[F, Product] = jsonOf
implicit def encodeProduct[A[_]: Applicative]: EntityEncoder[A, Product] = jsonEncoderOf
val routes: HttpRoutes[F] = HttpRoutes.of[F] {
case GET -> Root / "product" / UUIDVar(id) =>
for {
rows <- repo.loadProduct(id)
resp <- Product.fromDatabase(rows).fold(NotFound())(p => Ok(p))
} yield resp
case req @ PUT -> Root / "product" / UUIDVar(id) =>
…
}
}
class TestRepository[F[_]: Effect](data: Seq[Product]) extends Repository[F] {
override def loadProduct(id: ProductId): F[Seq[(ProductId, LanguageCode, ProductName)]] =
data.find(_.id === id) match {
case None => Seq.empty.pure[F]
case Some(p) =>
val ns = p.names.toNonEmptyList.toList.to[Seq]
ns.map(n => (p.id, n.lang, n.name)).pure[F]
}
…
}
trait Repository[F[_]] {
/**
* Load a product from the database repository.
*
* @param id The unique ID of the product.
* @return A list of database rows for a single product which you'll need to combine.
*/
def loadProduct(id: ProductId): F[Seq[(ProductId, LanguageCode, ProductName)]]
…
}
TestRepository
ProductRoutes
Repository
ProductRoutesTest SUT
Test Stub
• TestRepository
Control Point
• loadProduct function of TestRepository
Indirect Input
• sequence of tuples returned by loadProduct function
Test
Stub
Responder
Configurable](https://image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-51-2048.jpg)
![final class ProductRoutesTest extends BaseSpec {
implicit def decodeProduct: EntityDecoder[IO, Product] = jsonOf
implicit def encodeProduct[A[_]: Applicative]: EntityEncoder[A, Product] = jsonEncoderOf
private val emptyRepository: Repository[IO] = new TestRepository[IO](Seq.empty)
"ProductRoutes" when {
"GET /product/ID" when {
"product does not exist" must {
val expectedStatusCode = Status.NotFound
s"return $expectedStatusCode" in {
forAll("id") { id: ProductId =>
Uri.fromString("/product/" + id.toString) match {
case Left(_) => fail("Could not generate valid URI!")
case Right(u) =>
def service: HttpRoutes[IO] =
Router("/" -> new ProductRoutes(emptyRepository).routes)
val response: IO[Response[IO]] = service.orNotFound.run(
Request(method = Method.GET, uri = u)
)
val result = response.unsafeRunSync
result.status must be(expectedStatusCode)
result.body.compile.toVector.unsafeRunSync must be(empty) }}}}
"product exists" must {
val expectedStatusCode = Status.Ok
s"return $expectedStatusCode and the product" in {
forAll("product") { p: Product =>
Uri.fromString("/product/" + p.id.toString) match {
case Left(_) => fail("Could not generate valid URI!")
case Right(u) =>
val repo: Repository[IO] = new TestRepository[IO](Seq(p))
def service: HttpRoutes[IO] =
Router("/" -> new ProductRoutes(repo).routes)
val response: IO[Response[IO]] = service.orNotFound.run(
Request(method = Method.GET, uri = u)
)
val result = response.unsafeRunSync
result.status must be(expectedStatusCode)
result.as[Product].unsafeRunSync must be(p)}}}}
}
TestRepository
ProductRoutes
Repository
ProductRoutesTest SUT
Test
Stub
Responder
Test Stub
• TestRepository
Control Point
• loadProduct function of TestRepository
Indirect Input
• sequence of tuples returned by loadProduct function](https://image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-52-2048.jpg)

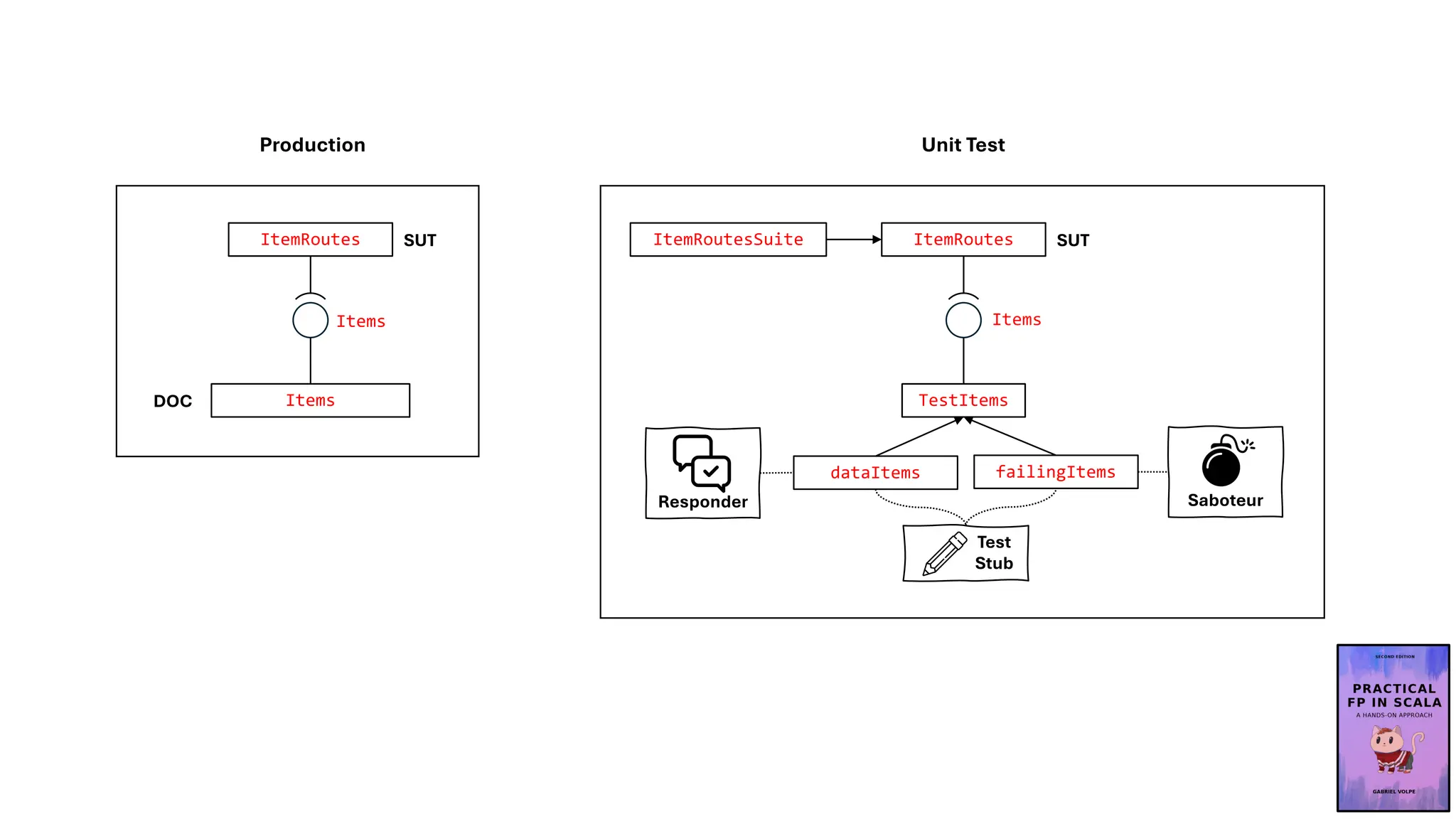
![def dataItems(items: List[Item]) = new TestItems {
override def findAll: IO[List[Item]] =
IO.pure(items)
override def findBy(brand: BrandName): IO[List[Item]] =
IO.pure(items.find(_.brand.name === brand).toList)
}
def failingItems(items: List[Item]) = new TestItems {
override def findAll: IO[List[Item]] =
IO.raiseError(DummyError) *> IO.pure(items)
override def findBy(brand: BrandName): IO[List[Item]] =
findAll
}
protected class TestItems extends Items[IO] {
def findAll: IO[List[Item]] = IO.pure(List.empty)
def findBy(brand: BrandName): IO[List[Item]] = IO.pure(List.empty)
def findById(itemId: ItemId): IO[Option[Item]] = IO.pure(none[Item])
def create(item: CreateItem): IO[ItemId] = ID.make[IO, ItemId]
def update(item: UpdateItem): IO[Unit] = IO.unit
}
final case class ItemRoutes[F[_]: Monad](
items: Items[F]
) extends Http4sDsl[F] {
private[routes] val prefixPath = "/items"
object BrandQueryParam extends OptionalQueryParamDecoderMatcher[BrandParam]("brand")
private val httpRoutes: HttpRoutes[F] = HttpRoutes.of[F] {
case GET -> Root :? BrandQueryParam(brand) =>
Ok(brand.fold(items.findAll)(b => items.findBy(b.toDomain)))
}
val routes: HttpRoutes[F] = Router(prefixPath -> httpRoutes)
}
trait Items[F[_]] {
def findAll: F[List[Item]]
def findBy(brand: BrandName): F[List[Item]]
def findById(itemId: ItemId): F[Option[Item]]
def create(item: CreateItem): F[ItemId]
def update(item: UpdateItem): F[Unit]
}
TestItems
ItemRoutes
Items
ItemRoutesSuite SUT
dataItems failingItems
Test
Stub
Responder Saboteur
Test Stubs
• dataItems, failingItems
Control Point
• findAll function of dataItems and failingItems
Indirect Input
• list of items
Configurable
Configurable](https://image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-55-2048.jpg)
).routes
expectHttpBodyAndStatus(routes, req)(it, Status.Ok)
}
}
…
test("GET items fails") {
forall(Gen.listOf(itemGen)) { it =>
val req = GET(uri"/items")
val routes = ItemRoutes[IO](failingItems(it)).routes
expectHttpFailure(routes, req)
}
…
}
Test Stubs
• dataItems, failingItems
Control Point
• findAll function of dataItems and failingItems
Indirect Input
• list of items
TestItems
ItemRoutes
Items
ItemRoutesSuite SUT
dataItems failingItems
Test
Stub
Responder Saboteur](https://image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-56-2048.jpg)
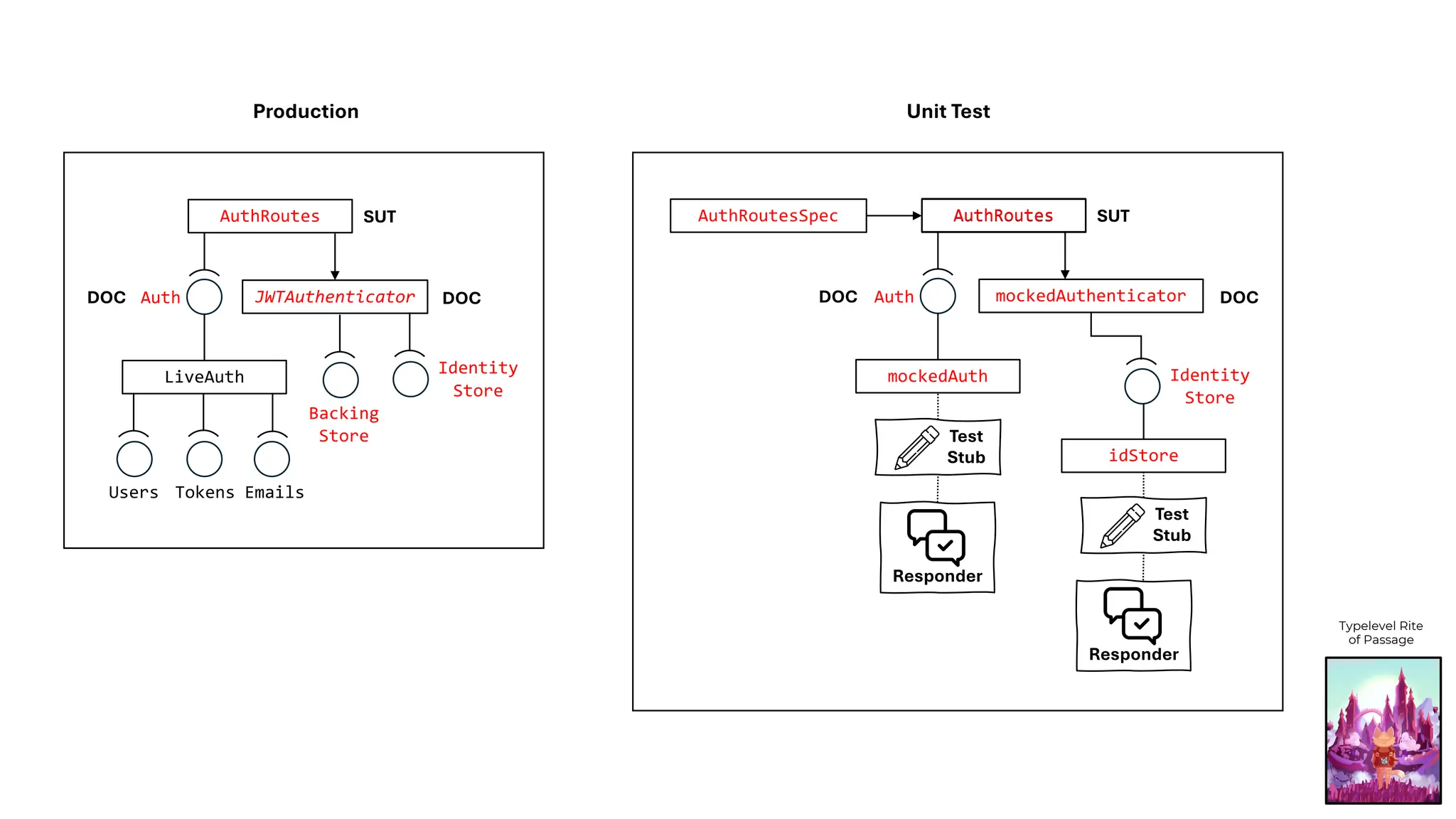
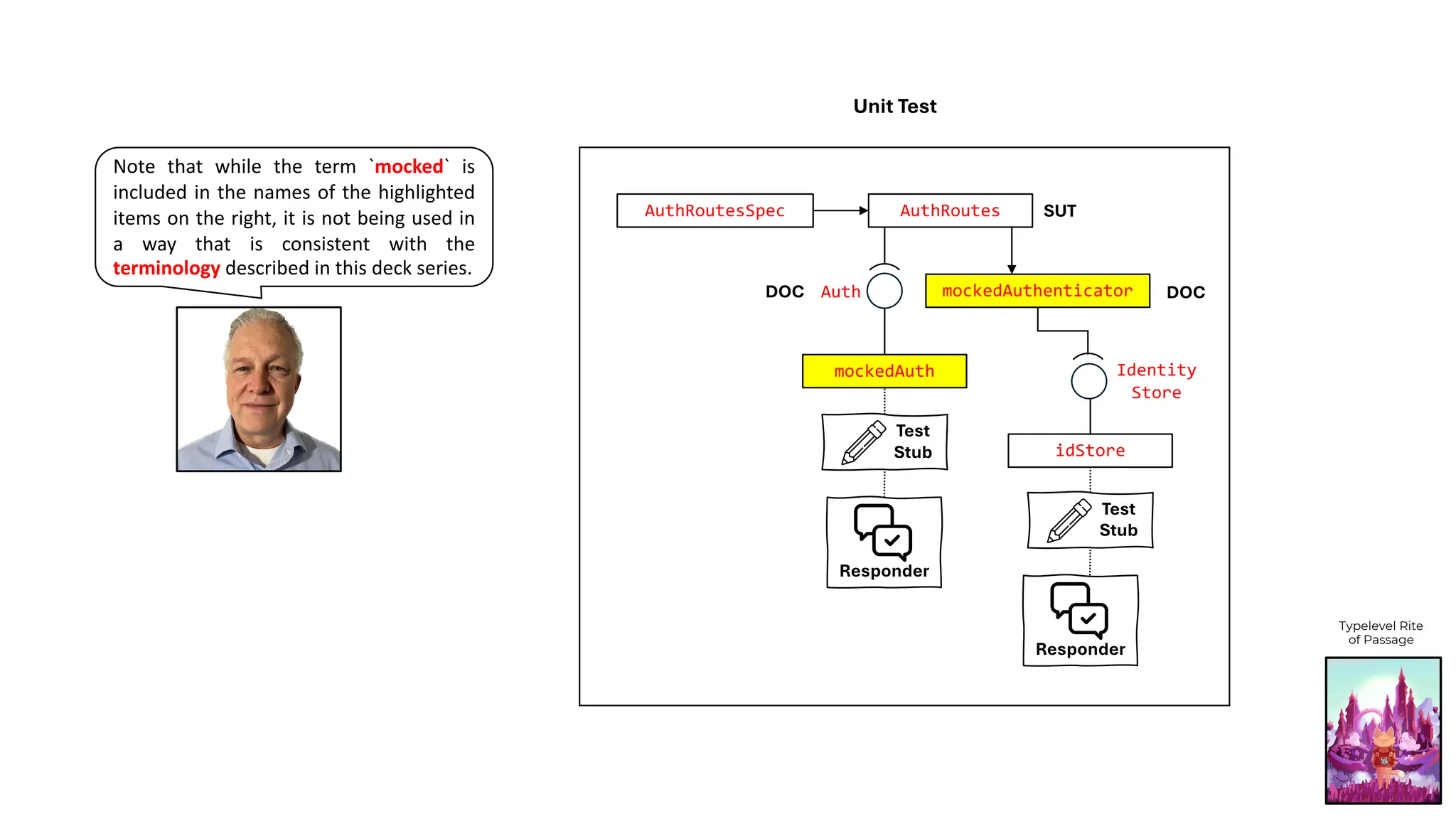
![type Authenticator[F[_]] = JWTAuthenticator[F, String, User, Crypto]
class AuthRoutes[F[_]: Concurrent: Logger: SecuredHandler] private (
auth: Auth[F],
authenticator: Authenticator[F]
) extends HttpValidationDsl[F] {
// POST /auth/login { LoginInfo } => 200 Ok with Authorization Bearer {jwt}
private val loginRoute: HttpRoutes[F] = HttpRoutes.of[F] {
case req@POST -> Root / "login" =>
req.validate[LoginInfo] { loginInfo =>
val maybeJwtToken =
for
maybeUser <- auth.login(loginInfo.email, loginInfo.password)
_ <- Logger[F].info(s"User logging in: ${loginInfo.email} ")
maybeToken <- maybeUser.traverse(user => authenticator.create(user.email))
yield maybeToken
maybeJwtToken.map {
case Some(token) => authenticator.embed(Response(Status.Ok), token)
case None => Response(Status.Unauthorized)
}
}
}
…
}
AuthRoutes
AuthRoutesSpec
mockedAuthenticator
mockedAuth
AuthRoutes SUT
Auth DOC
DOC
Test
Stub
Responder
idStore
Test
Stub
Responder
Typelevel Rite
of Passage](https://image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-60-2048.jpg)
![val mockedAuth: Auth[IO] = probedAuth(None)
def probedAuth(maybeRefEmailToTokenMap: Option[Ref[IO, Map[String, String]]]): Auth[IO] = new Auth[IO]:
override def login(email: String, password: String): IO[Option[User]] =
if email == danielEmail && password == danielPassword
then IO(Some(Daniel))
else IO.pure(None)
override def signup(newPasswordInfo: NewUserInfo): IO[Option[User]] = …
override def changePassword(email: String, newPasswordInfo: NewPasswordInfo): IO[Either[String, Option[User]]] = …
override def delete(email: String): IO[Boolean] = IO.pure(true)
override def sendPasswordRecoveryToken(email: String): IO[Unit] = …
override def recoverPasswordFromToken(email: String, token: String, newPassword: String): IO[Boolean] = …
type Authenticator[F[_]] = JWTAuthenticator[F, String, User, Crypto]
trait SecuredRouteFixture extends UserFixture:
val mockedAuthenticator: Authenticator[IO] = {
val key = HMACSHA256.unsafeGenerateKey
val idStore: IdentityStore[IO, String, User] = (email: String) =>
if email == danielEmail then OptionT.pure(Daniel)
else if email == riccardoEmail then OptionT.pure(Riccardo)
else OptionT.none[IO, User]
JWTAuthenticator.unbacked.inBearerToken(
expiryDuration = 1.day,
maxIdle = None,
identityStore = idStore,
signingKey = key
)
}
Test
Stub
Responder
Test
Stub
Responder Hard-Coded Typelevel Rite
of Passage
Hard-Coded](https://image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-61-2048.jpg)
![class AuthRoutesSpec extends AsyncFreeSpec with AsyncIOSpec with Matchers with Http4sDsl[IO] with SecuredRouteFixture {
…
val authRoutes: HttpRoutes[IO] =
AuthRoutes[IO](mockedAuth, mockedAuthenticator).routes
given Logger[IO] = Slf4jLogger.getLogger[IO]
"AuthRoutes" - {
"should return a 401 Unauthorised if login fails" in {
for
response <- authRoutes.orNotFound.run(
Request(method = Method.POST, uri"/auth/login")
.withEntity(
LoginInfo(email = danielEmail, password = "wrongpassword")))
yield response.status shouldBe Status.Unauthorized
}
"should return a 200 Ok + a JWT if login is successful" in {
for
response <- authRoutes.orNotFound.run(
Request(method = Method.POST, uri"/auth/login")
.withEntity(
LoginInfo(email = danielEmail, password = danielPassword)))
yield {
response.status shouldBe Status.Ok
response.headers.get(ci"Authorization") shouldBe defined
}
}
…
}
}
AuthRoutes
mockedAuthenticator
mockedAuth
AuthRoutes SUT
Auth
Test
Stub
Responder
idStore
Test
Stub
Responder
Typelevel Rite
of Passage
AuthRoutesSpec](https://image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-62-2048.jpg)


































![Why Standardize Testing Patterns?
…I think it is important for us to standardize the names of the test automation patterns, especially those related
to Test Stubs (page 529) and Mock Objects (page 544). The key issue here relates to succinctness of
communication.
When someone tells you, "Put a mock in it" (pun intended!), what advice is that person giving you?
Depending on what the person means by a "mock," he or she could be suggesting that you control the indirect
inputs of your SUT using a Test Stub or that you replace your database with a Fake Database (see Fake
Object on page 551) that will reduce test interactions and speed up your tests by a factor of 50. …
Or perhaps the person is suggesting that you verify that your SUT calls the correct methods by installing
an Eager Mock Object (see Mock Object) preconfigured with the Expected Behavior (see Behavior
Verification on page 468).
If everyone used "mock" to mean a Mock Object—no more or less—then the advice would be pretty clear.
As I write this, the advice is very murky because we have taken to calling just about any Test Double (page 522)
a "mock object" (despite the objections of the authors of the original paper on Mock Objects [ET]).](https://crownmelresort.com/image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-34-2048.jpg)









![Test Stub
…
Motivating Example
The following test verifies the basic functionality of a component that formats an HTML string containing the current time. Unfortunately, it
depends on the real system clock so it rarely ever passes!
…
Refactoring Notes
We can achieve proper verification of the indirect inputs by getting control of the time. To do so, we use the Replace Dependency with Test Double
(page 522) refactoring to replace the real system clock (represented here by TimeProvider) with a Virtual Clock [VCTP]. We then implement it as
a Test Stub that is configured by the test with the time we want to use as the indirect input to the SUT.
[VCTP]
The Virtual Clock Test Pattern
http://www.nusco.org/docs/virtual_clock.pdf
By: Paolo Perrotta
This paper describes a common example of a Responder called Virtual Clock [VCTP]. The author uses the Virtual Clock Test Pattern as a Decorator
[GOF] for the real system clock, which allows the time to be "frozen" or resumed. One could use a Hard-Coded Test Stub or a Configurable Test
Stub just as easily for most tests. Paolo Perrotta summarizes the thrust of his article:
We can have a hard time unit-testing code that depends on the system clock. This paper describes both the problem and a common, reusable solution.](https://crownmelresort.com/image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-44-2048.jpg)
![Example #1
DOC
SparkSession
Timer[IO]
BatchProducer SUT
Timer[F]
DOC DOC
SparkSession
FakeTimer
BatchProducer SUT
Timer[F]
BatchProducerIT
Test
Stub
Production Integration Test
Responder
PSEUDO-OBJECT
!
1
2 !
1
2](https://crownmelresort.com/image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-45-2048.jpg)
![class AppContext(val transactionStorePath: URI)
(implicit val spark: SparkSession,
implicit val timer: Timer[IO])
object BatchProducer {
val WaitTime: FiniteDuration = 59.minute
/** Number of seconds required by the API to make a transaction visible */
val ApiLag: FiniteDuration = 5.seconds
…
def processOneBatch(fetchNextTransactions: IO[Dataset[Transaction]],
transactions: Dataset[Transaction],
saveStart: Instant,
saveEnd: Instant)(implicit appCtx: AppContext)
: IO[(Dataset[Transaction], Instant, Instant)] = {
import appCtx._
val transactionsToSave = filterTxs(transactions, saveStart, saveEnd)
for {
_ <- BatchProducer.save(transactionsToSave, appCtx.transactionStorePath)
_ <- IO.sleep(WaitTime)
beforeRead <- currentInstant
// We are sure that lastTransactions contain all transactions until end
end = beforeRead.minusSeconds(ApiLag.toSeconds)
nextTransactions <- fetchNextTransactions
} yield (nextTransactions, saveEnd, end)
}
…
def currentInstant(implicit timer: Timer[IO]): IO[Instant] =
timer.clockRealTime(TimeUnit.SECONDS) map Instant.ofEpochSecond
DOC
SparkSession
FakeTimer
BatchProducer SUT
Timer[F]
BatchProducerIT
Test
Stub
Responder
PSEUDO-OBJECT
!
1
2 !
1
2
def sleep(duration: FiniteDuration)(implicit timer: Timer[IO]): IO[Unit] =
timer.sleep(duration)
cats.effect.IO
Example #1
Test Stub
• FakeTimer
Control Point
• clockRealTime function of FakeTimer
Indirect Input
• time returned by clockRealTime function](https://crownmelresort.com/image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-46-2048.jpg)
![implicit object FakeTimer extends Timer[IO] {
private var clockRealTimeInMillis: Long =
Instant.parse("2018-08-02T01:00:00Z").toEpochMilli
def clockRealTime(unit: TimeUnit): IO[Long] =
IO(unit.convert(clockRealTimeInMillis, TimeUnit.MILLISECONDS))
def sleep(duration: FiniteDuration): IO[Unit] = IO {
clockRealTimeInMillis = clockRealTimeInMillis + duration.toMillis
}
def shift: IO[Unit] = ???
def clockMonotonic(unit: TimeUnit): IO[Long] = ???
}
DOC
SparkSession
FakeTimer
BatchProducer SUT
Timer[F]
BatchProducerIT
Test
Stub
Responder
PSEUDO-OBJECT
Hard-Coded
!
1
2
!
1
2
Example #1
In the usual way of implementing the Pseudo-Object pattern, we would have (1) a base class providing undefined implementations (???
expressions) of all Timer’s functions, and (2) a concrete subclass that overrides only the functions we expect the SUT to call. Instead, here we
have a concrete Timer that provides (1) real implementations of the functions we expect the SUT to call, and (2) undefined implementations of
functions that the SUT is NOT expected to call.
By the way, note that while the term `fake` is included in the name of the timer implementation, it is not being used in a way that is consistent
with the terminology described in this deck series.
Test Stub
• FakeTimer
Control Point
• clockRealTime function of FakeTimer
Indirect Input
• time returned by clockRealTime function](https://crownmelresort.com/image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-47-2048.jpg)
![class BatchProducerIT extends WordSpec with Matchers with SharedSparkSession {
…
"BatchProducer.processOneBatch" should {
"filter and save a batch of transaction, wait 59 mn, fetch the next batch" in withTempDir { tmpDir =>
implicit object FakeTimer extends Timer[IO] { … }
implicit val appContext: AppContext = new AppContext(transactionStorePath = tmpDir.toURI)
implicit def toTimestamp(str: String): Timestamp = Timestamp.from(Instant.parse(str))
val tx1 = Transaction("2018-08-01T23:00:00Z", 1, 7657.58, true, 0.021762)
val tx2 = Transaction("2018-08-02T01:00:00Z", 2, 7663.85, false, 0.01385517)
val tx3 = Transaction("2018-08-02T01:58:30Z", 3, 7663.85, false, 0.03782426)
val tx4 = Transaction("2018-08-02T01:58:59Z", 4, 7663.86, false, 0.15750809)
val tx5 = Transaction("2018-08-02T02:30:00Z", 5, 7661.49, true, 0.1)
// Start at 01:00, tx 2 ignored (too soon)
val txs0 = Seq(tx1)
// Fetch at 01:59, get nb 2 and 3, but will miss nb 4 because of Api lag
val txs1 = Seq(tx2, tx3)
// Fetch at 02:58, get nb 3, 4, 5
val txs2 = Seq(tx3, tx4, tx5)
// Fetch at 03:57, get nothing
val txs3 = Seq.empty[Transaction]
val start0 = Instant.parse("2018-08-02T00:00:00Z")
val end0 = Instant.parse("2018-08-02T00:59:55Z")
val threeBatchesIO = …
val (ds1, start1, end1, ds2, start2, end2) = threeBatchesIO.unsafeRunSync()
ds1.collect() should contain theSameElementsAs txs1
start1 should ===(end0)
// initialClock + 1mn - 15s - 5s
end1 should ===(Instant.parse("2018-08-02T01:58:55Z"))
ds2.collect() should contain theSameElementsAs txs2
start2 should ===(end1)
// initialClock + 1mn -15s + 1mn -15s -5s = end1 + 45s
end2 should ===(Instant.parse("2018-08-02T02:57:55Z"))
val lastClock = Instant.ofEpochMilli(FakeTimer.clockRealTime(TimeUnit.MILLISECONDS).unsafeRunSync())
lastClock should === (Instant.parse("2018-08-02T03:57:00Z"))
…
DOC
SparkSession
FakeTimer
BatchProducer SUT
Timer[F]
BatchProducerIT
Test
Stub
val threeBatchesIO =
for {
tuple1 <- BatchProducer.processOneBatch(IO(txs1.toDS()), txs0.toDS(), start0, end0) // end - Api lag
(ds1, start1, end1) = tuple1
tuple2 <- BatchProducer.processOneBatch(IO(txs2.toDS()), ds1, start1, end1)
(ds2, start2, end2) = tuple2
_ <- BatchProducer.processOneBatch(IO(txs3.toDS()), ds2, start2, end2)
} yield (ds1, start1, end1, ds2, start2, end2)
Example #1
Test Stub
• FakeTimer
Control Point
• clockRealTime function of FakeTimer
Indirect Input
• time returned by clockRealTime function](https://crownmelresort.com/image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-48-2048.jpg)


![final class ProductRoutes[F[_]: Sync](repo: Repository[F]) extends Http4sDsl[F] {
implicit def decodeProduct: EntityDecoder[F, Product] = jsonOf
implicit def encodeProduct[A[_]: Applicative]: EntityEncoder[A, Product] = jsonEncoderOf
val routes: HttpRoutes[F] = HttpRoutes.of[F] {
case GET -> Root / "product" / UUIDVar(id) =>
for {
rows <- repo.loadProduct(id)
resp <- Product.fromDatabase(rows).fold(NotFound())(p => Ok(p))
} yield resp
case req @ PUT -> Root / "product" / UUIDVar(id) =>
…
}
}
class TestRepository[F[_]: Effect](data: Seq[Product]) extends Repository[F] {
override def loadProduct(id: ProductId): F[Seq[(ProductId, LanguageCode, ProductName)]] =
data.find(_.id === id) match {
case None => Seq.empty.pure[F]
case Some(p) =>
val ns = p.names.toNonEmptyList.toList.to[Seq]
ns.map(n => (p.id, n.lang, n.name)).pure[F]
}
…
}
trait Repository[F[_]] {
/**
* Load a product from the database repository.
*
* @param id The unique ID of the product.
* @return A list of database rows for a single product which you'll need to combine.
*/
def loadProduct(id: ProductId): F[Seq[(ProductId, LanguageCode, ProductName)]]
…
}
TestRepository
ProductRoutes
Repository
ProductRoutesTest SUT
Test Stub
• TestRepository
Control Point
• loadProduct function of TestRepository
Indirect Input
• sequence of tuples returned by loadProduct function
Test
Stub
Responder
Configurable](https://crownmelresort.com/image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-51-2048.jpg)
![final class ProductRoutesTest extends BaseSpec {
implicit def decodeProduct: EntityDecoder[IO, Product] = jsonOf
implicit def encodeProduct[A[_]: Applicative]: EntityEncoder[A, Product] = jsonEncoderOf
private val emptyRepository: Repository[IO] = new TestRepository[IO](Seq.empty)
"ProductRoutes" when {
"GET /product/ID" when {
"product does not exist" must {
val expectedStatusCode = Status.NotFound
s"return $expectedStatusCode" in {
forAll("id") { id: ProductId =>
Uri.fromString("/product/" + id.toString) match {
case Left(_) => fail("Could not generate valid URI!")
case Right(u) =>
def service: HttpRoutes[IO] =
Router("/" -> new ProductRoutes(emptyRepository).routes)
val response: IO[Response[IO]] = service.orNotFound.run(
Request(method = Method.GET, uri = u)
)
val result = response.unsafeRunSync
result.status must be(expectedStatusCode)
result.body.compile.toVector.unsafeRunSync must be(empty) }}}}
"product exists" must {
val expectedStatusCode = Status.Ok
s"return $expectedStatusCode and the product" in {
forAll("product") { p: Product =>
Uri.fromString("/product/" + p.id.toString) match {
case Left(_) => fail("Could not generate valid URI!")
case Right(u) =>
val repo: Repository[IO] = new TestRepository[IO](Seq(p))
def service: HttpRoutes[IO] =
Router("/" -> new ProductRoutes(repo).routes)
val response: IO[Response[IO]] = service.orNotFound.run(
Request(method = Method.GET, uri = u)
)
val result = response.unsafeRunSync
result.status must be(expectedStatusCode)
result.as[Product].unsafeRunSync must be(p)}}}}
}
TestRepository
ProductRoutes
Repository
ProductRoutesTest SUT
Test
Stub
Responder
Test Stub
• TestRepository
Control Point
• loadProduct function of TestRepository
Indirect Input
• sequence of tuples returned by loadProduct function](https://crownmelresort.com/image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-52-2048.jpg)


![def dataItems(items: List[Item]) = new TestItems {
override def findAll: IO[List[Item]] =
IO.pure(items)
override def findBy(brand: BrandName): IO[List[Item]] =
IO.pure(items.find(_.brand.name === brand).toList)
}
def failingItems(items: List[Item]) = new TestItems {
override def findAll: IO[List[Item]] =
IO.raiseError(DummyError) *> IO.pure(items)
override def findBy(brand: BrandName): IO[List[Item]] =
findAll
}
protected class TestItems extends Items[IO] {
def findAll: IO[List[Item]] = IO.pure(List.empty)
def findBy(brand: BrandName): IO[List[Item]] = IO.pure(List.empty)
def findById(itemId: ItemId): IO[Option[Item]] = IO.pure(none[Item])
def create(item: CreateItem): IO[ItemId] = ID.make[IO, ItemId]
def update(item: UpdateItem): IO[Unit] = IO.unit
}
final case class ItemRoutes[F[_]: Monad](
items: Items[F]
) extends Http4sDsl[F] {
private[routes] val prefixPath = "/items"
object BrandQueryParam extends OptionalQueryParamDecoderMatcher[BrandParam]("brand")
private val httpRoutes: HttpRoutes[F] = HttpRoutes.of[F] {
case GET -> Root :? BrandQueryParam(brand) =>
Ok(brand.fold(items.findAll)(b => items.findBy(b.toDomain)))
}
val routes: HttpRoutes[F] = Router(prefixPath -> httpRoutes)
}
trait Items[F[_]] {
def findAll: F[List[Item]]
def findBy(brand: BrandName): F[List[Item]]
def findById(itemId: ItemId): F[Option[Item]]
def create(item: CreateItem): F[ItemId]
def update(item: UpdateItem): F[Unit]
}
TestItems
ItemRoutes
Items
ItemRoutesSuite SUT
dataItems failingItems
Test
Stub
Responder Saboteur
Test Stubs
• dataItems, failingItems
Control Point
• findAll function of dataItems and failingItems
Indirect Input
• list of items
Configurable
Configurable](https://crownmelresort.com/image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-55-2048.jpg)
).routes
expectHttpBodyAndStatus(routes, req)(it, Status.Ok)
}
}
…
test("GET items fails") {
forall(Gen.listOf(itemGen)) { it =>
val req = GET(uri"/items")
val routes = ItemRoutes[IO](failingItems(it)).routes
expectHttpFailure(routes, req)
}
…
}
Test Stubs
• dataItems, failingItems
Control Point
• findAll function of dataItems and failingItems
Indirect Input
• list of items
TestItems
ItemRoutes
Items
ItemRoutesSuite SUT
dataItems failingItems
Test
Stub
Responder Saboteur](https://crownmelresort.com/image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-56-2048.jpg)



![type Authenticator[F[_]] = JWTAuthenticator[F, String, User, Crypto]
class AuthRoutes[F[_]: Concurrent: Logger: SecuredHandler] private (
auth: Auth[F],
authenticator: Authenticator[F]
) extends HttpValidationDsl[F] {
// POST /auth/login { LoginInfo } => 200 Ok with Authorization Bearer {jwt}
private val loginRoute: HttpRoutes[F] = HttpRoutes.of[F] {
case req@POST -> Root / "login" =>
req.validate[LoginInfo] { loginInfo =>
val maybeJwtToken =
for
maybeUser <- auth.login(loginInfo.email, loginInfo.password)
_ <- Logger[F].info(s"User logging in: ${loginInfo.email} ")
maybeToken <- maybeUser.traverse(user => authenticator.create(user.email))
yield maybeToken
maybeJwtToken.map {
case Some(token) => authenticator.embed(Response(Status.Ok), token)
case None => Response(Status.Unauthorized)
}
}
}
…
}
AuthRoutes
AuthRoutesSpec
mockedAuthenticator
mockedAuth
AuthRoutes SUT
Auth DOC
DOC
Test
Stub
Responder
idStore
Test
Stub
Responder
Typelevel Rite
of Passage](https://crownmelresort.com/image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-60-2048.jpg)
![val mockedAuth: Auth[IO] = probedAuth(None)
def probedAuth(maybeRefEmailToTokenMap: Option[Ref[IO, Map[String, String]]]): Auth[IO] = new Auth[IO]:
override def login(email: String, password: String): IO[Option[User]] =
if email == danielEmail && password == danielPassword
then IO(Some(Daniel))
else IO.pure(None)
override def signup(newPasswordInfo: NewUserInfo): IO[Option[User]] = …
override def changePassword(email: String, newPasswordInfo: NewPasswordInfo): IO[Either[String, Option[User]]] = …
override def delete(email: String): IO[Boolean] = IO.pure(true)
override def sendPasswordRecoveryToken(email: String): IO[Unit] = …
override def recoverPasswordFromToken(email: String, token: String, newPassword: String): IO[Boolean] = …
type Authenticator[F[_]] = JWTAuthenticator[F, String, User, Crypto]
trait SecuredRouteFixture extends UserFixture:
val mockedAuthenticator: Authenticator[IO] = {
val key = HMACSHA256.unsafeGenerateKey
val idStore: IdentityStore[IO, String, User] = (email: String) =>
if email == danielEmail then OptionT.pure(Daniel)
else if email == riccardoEmail then OptionT.pure(Riccardo)
else OptionT.none[IO, User]
JWTAuthenticator.unbacked.inBearerToken(
expiryDuration = 1.day,
maxIdle = None,
identityStore = idStore,
signingKey = key
)
}
Test
Stub
Responder
Test
Stub
Responder Hard-Coded Typelevel Rite
of Passage
Hard-Coded](https://crownmelresort.com/image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-61-2048.jpg)
![class AuthRoutesSpec extends AsyncFreeSpec with AsyncIOSpec with Matchers with Http4sDsl[IO] with SecuredRouteFixture {
…
val authRoutes: HttpRoutes[IO] =
AuthRoutes[IO](mockedAuth, mockedAuthenticator).routes
given Logger[IO] = Slf4jLogger.getLogger[IO]
"AuthRoutes" - {
"should return a 401 Unauthorised if login fails" in {
for
response <- authRoutes.orNotFound.run(
Request(method = Method.POST, uri"/auth/login")
.withEntity(
LoginInfo(email = danielEmail, password = "wrongpassword")))
yield response.status shouldBe Status.Unauthorized
}
"should return a 200 Ok + a JWT if login is successful" in {
for
response <- authRoutes.orNotFound.run(
Request(method = Method.POST, uri"/auth/login")
.withEntity(
LoginInfo(email = danielEmail, password = danielPassword)))
yield {
response.status shouldBe Status.Ok
response.headers.get(ci"Authorization") shouldBe defined
}
}
…
}
}
AuthRoutes
mockedAuthenticator
mockedAuth
AuthRoutes SUT
Auth
Test
Stub
Responder
idStore
Test
Stub
Responder
Typelevel Rite
of Passage
AuthRoutesSpec](https://crownmelresort.com/image.slidesharecdn.com/test-doubles-terminology-definitions-and-illustrations-with-examples-part-1-250914170828-909ab1ab/75/Test-Doubles-Terminology-Definitions-and-Illustrations-with-Examples-Part-1-62-2048.jpg)


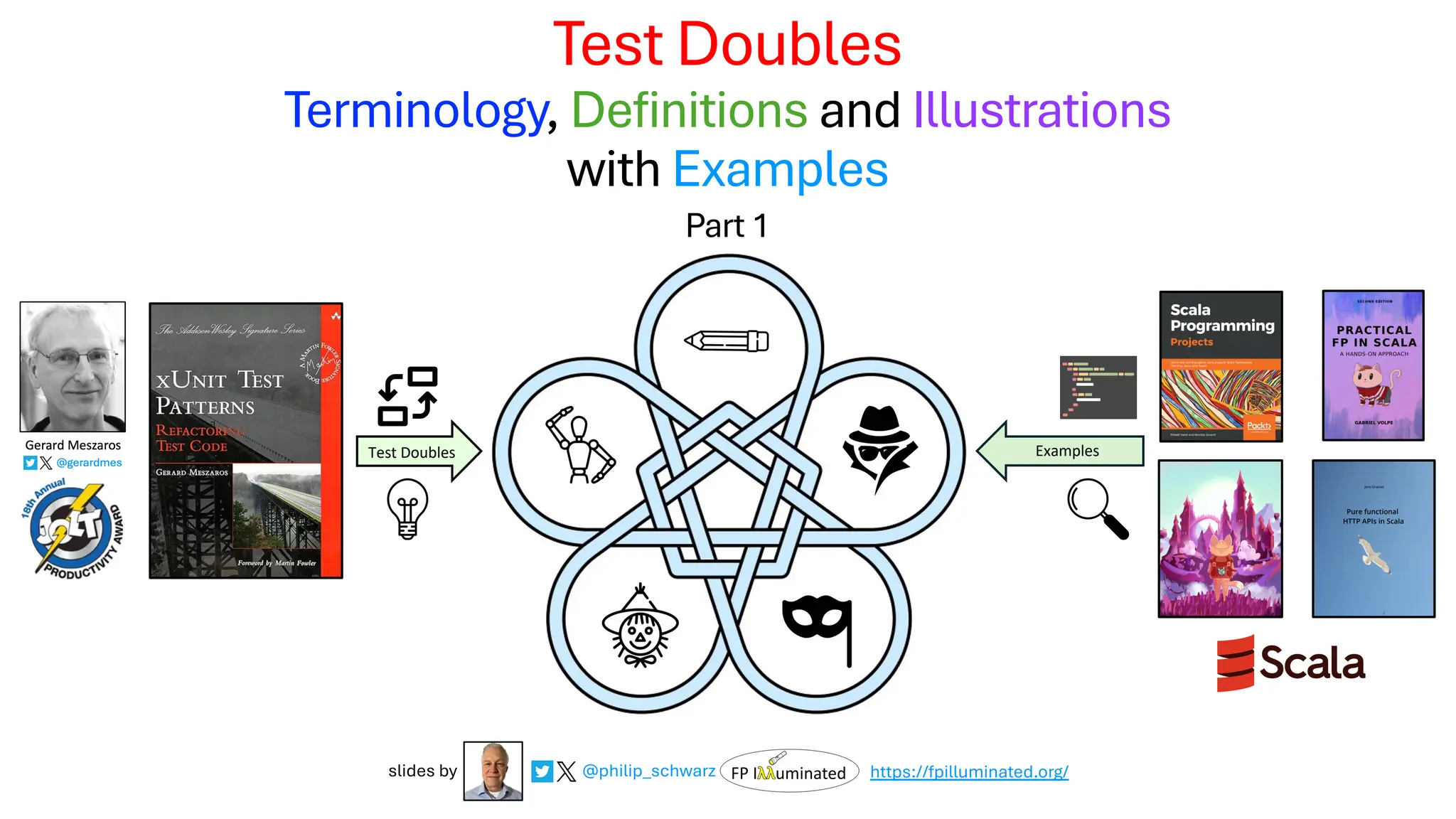
This deck is about a subset of the test automation patterns in Gerard Meszaros’ great book, xUnit Test Patterns – Refactoring Test Code. The subset in question consists of the patterns relating to the concept of Test Doubles. The deck is inspired by the patterns, and heavily reliant on extracts from the book. The motivation for the deck is my belief that it is quite beneficial, when using and discussing Test Doubles, to rely on standardised terminology and patterns.

![Unit testing [4] - Software Testing Techniques (CIS640)](https://cdn.slidesharecdn.com/ss_thumbnails/unit-testing-170926175035-thumbnail.jpg?width=640&height=640&fit=bounds)
































































