Downloaded 79 times


![Example of GPU calculation – Reduction algorithm
●item[0]
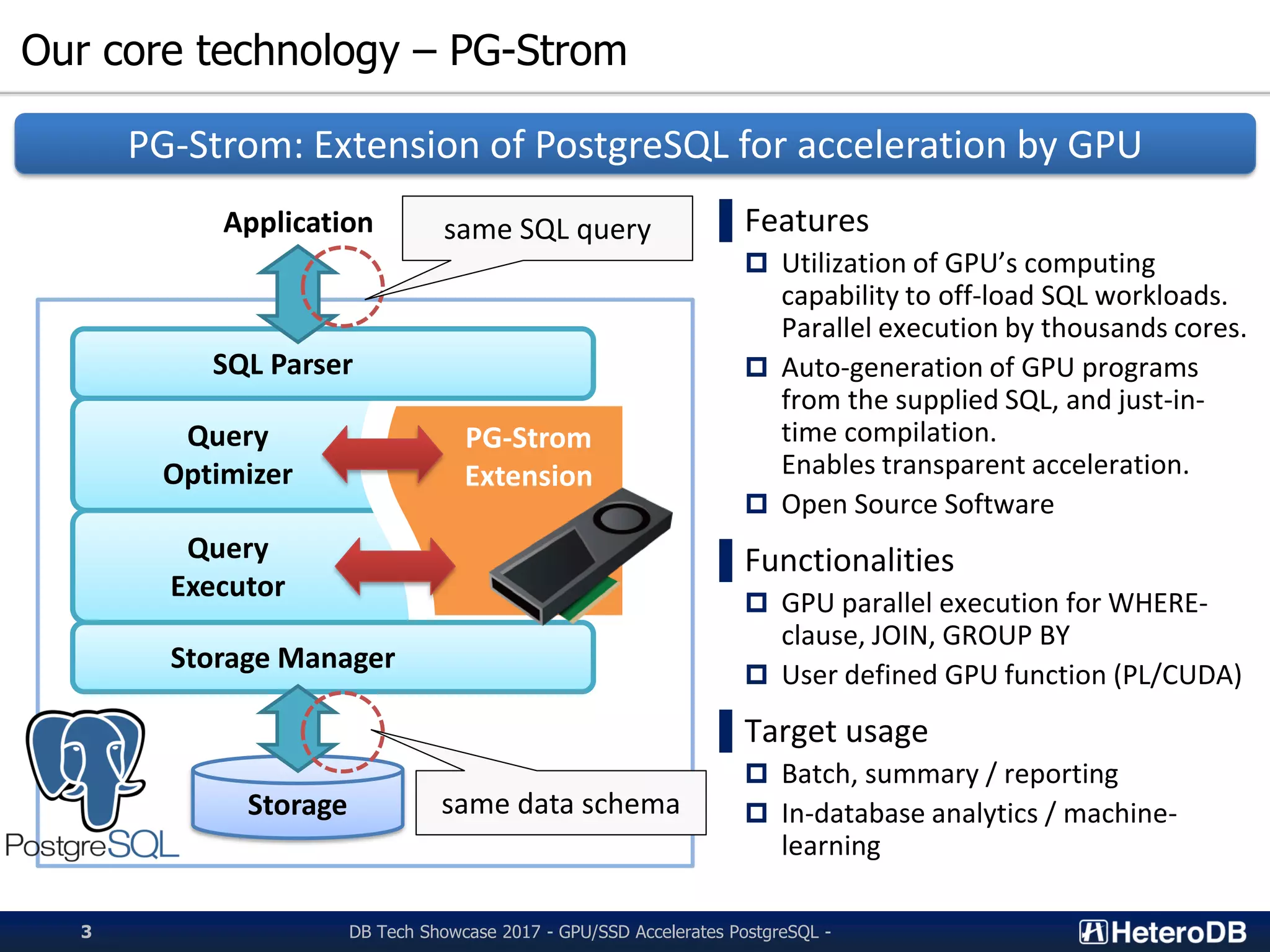
step.1 step.2 step.4step.3
Calculation of the total
sum of an array by GPU
Σi=0...N-1item[i]
◆
●
▲ ■ ★
● ◆
●
● ◆ ▲
●
● ◆
●
● ◆ ▲ ■
●
● ◆
●
● ◆ ▲
●
● ◆
●
item[1]
item[2]
item[3]
item[4]
item[5]
item[6]
item[7]
item[8]
item[9]
item[10]
item[11]
item[12]
item[13]
item[14]
item[15]
Total sum of items[]
with log2N steps
Inter-cores synchronization with hardware support
SELECT count(X),
sum(Y),
avg(Z)
FROM my_table;
Same logic is internally used to
implement aggregate function.
DB Tech Showcase 2017 - GPU/SSD Accelerates PostgreSQL -5](https://image.slidesharecdn.com/20170906dbtsgpussdacceleratespostgresqlen-170906080222/75/GPU-SSD-Accelerates-PostgreSQL-challenge-towards-query-processing-throughput-10GB-s-5-2048.jpg)
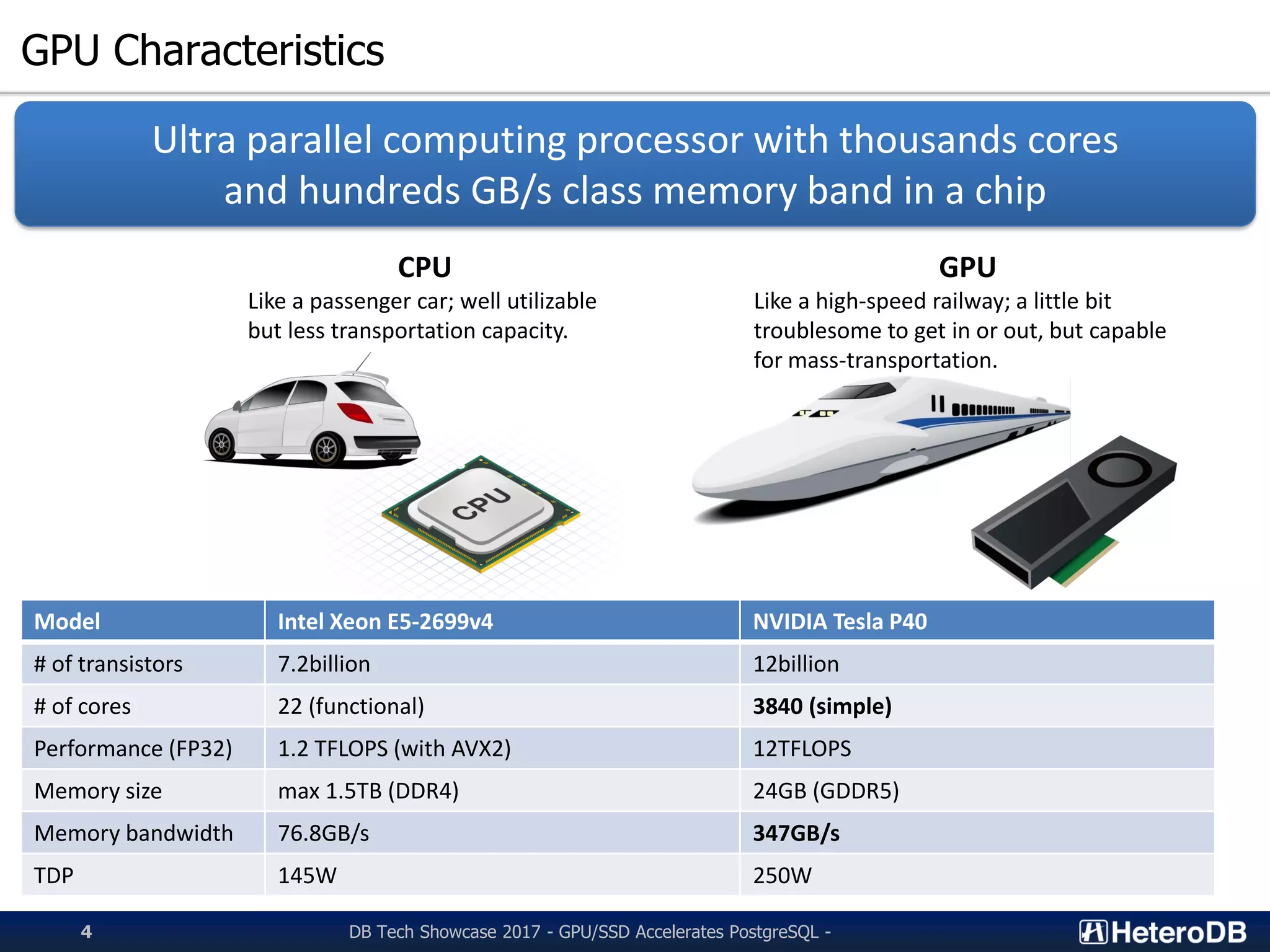
![Is SQL workload similar to image processing?
Image Data =
int/float[] array
Transposition
ID X Y Z
SELECT * FROM my_table
WHERE X BETWEEN 40 AND 60
Parallel Execution
GPU’s advantage: Same operations to massive amount of data.
DB Tech Showcase 2017 - GPU/SSD Accelerates PostgreSQL -6](https://image.slidesharecdn.com/20170906dbtsgpussdacceleratespostgresqlen-170906080222/75/GPU-SSD-Accelerates-PostgreSQL-challenge-towards-query-processing-throughput-10GB-s-6-2048.jpg)

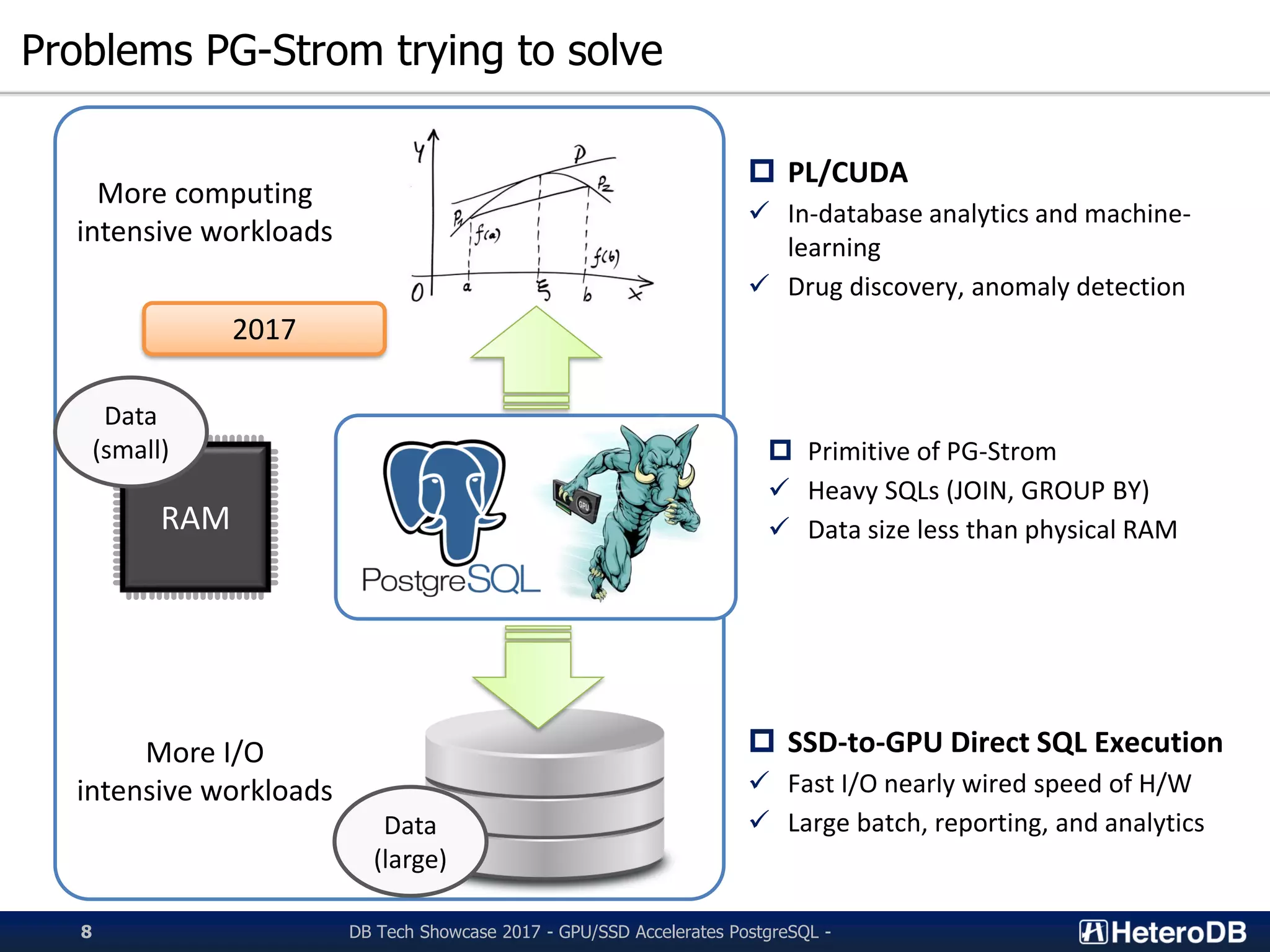


![A simple micro-benchmark
DB Tech Showcase 2017 - GPU/SSD Accelerates PostgreSQL -16
▌Test Query:
SELECT cat, count(*), avg(x)
FROM t0 NATURAL JOIN t1 [NATURAL JOIN t2 ...]
GROUP BY cat;
✓ t0 contains 100M rows, t1...t8 contains 100K rows (like a star schema)
8.48
13.23
18.28
23.42
28.88
34.50
40.77
47.16
5.00 5.46 5.91 6.45 7.17 8.07
9.22 10.21
0.0
5.0
10.0
15.0
20.0
25.0
30.0
35.0
40.0
45.0
50.0
2 3 4 5 6 7 8 9
QueryResponseTime[sec]
Number of tables joined
PG-Strom microbenchmark with JOIN/GROUP BY
PostgreSQL v9.6 PG-Strom 2.0devel
CPU: Xeon E5-2650v4
GPU: Tesla P40
RAM: 128GB
OS: CentOS 7.3
DB: PostgreSQL 9.6.2 +
PG-Strom 2.0devel](https://image.slidesharecdn.com/20170906dbtsgpussdacceleratespostgresqlen-170906080222/75/GPU-SSD-Accelerates-PostgreSQL-challenge-towards-query-processing-throughput-10GB-s-16-2048.jpg)


![Benchmark results (1/2)
We run the Q1-Q4 below towards lineorder table (351GB).
Definition of throughput is (351 * 1024) / (Query response time[sec])
Q1... SELECT count(*) FROM lineorder;
Q2... SELECT count(*),sum(lo_revenue),sum(lo_supplycost) FROM lineorder;
Q3... SELECT count(*) FROM lineorder GROUP BY lo_orderpriority;
Q4... SELECT count(*),sum(lo_revenue),sum(lo_supplycost)
FROM lineorder GROUP BY lo_shipmode;
※ max_parallel_workers_per_gather is 24 for PostgreSQL v9.6, 4 for PG-Strom.
889.05 859.31 875.69 842.04
5988.0 5989.9 5988.8 5979.6
0
1000
2000
3000
4000
5000
6000
Q1 Q2 Q3 Q4
QueryExecutionThroughput[MB/s]
PostgreSQL v9.6 + SN260 PG-Strom v2.0 + SN260
DB Tech Showcase 2017 - GPU/SSD Accelerates PostgreSQL -25](https://image.slidesharecdn.com/20170906dbtsgpussdacceleratespostgresqlen-170906080222/75/GPU-SSD-Accelerates-PostgreSQL-challenge-towards-query-processing-throughput-10GB-s-25-2048.jpg)
![Benchmark results (2/2)
Full scan on the 351G table by the 128GB RAM system, thus its storage system obviously
limits the query execution performance.
PG-Strom could pull out Seq-Read performance of the SSD close to the catalog spec.
PostgreSQL has unignorable overhead around I/O.
0
1000
2000
3000
4000
5000
6000
7000
0 100 200 300 400
StorageReadThroughput[MB/s]
Elapsed Time for Query Execution [sec]
Time Series Results (Q4) with iostat
PG-Strom v2.0devel + SN260 PostgreSQL v9.6 + SN260
[kaigai@saba ~]$ iostat -cdm 1
:
Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn
sda 6.00 0.19 0.00 0 0
sdb 0.00 0.00 0.00 0 0
sdc 0.00 0.00 0.00 0 0
nvme0n1 24059.00 5928.41 0.00 5928 0
:
DB Tech Showcase 2017 - GPU/SSD Accelerates PostgreSQL -26](https://image.slidesharecdn.com/20170906dbtsgpussdacceleratespostgresqlen-170906080222/75/GPU-SSD-Accelerates-PostgreSQL-challenge-towards-query-processing-throughput-10GB-s-26-2048.jpg)









![Example of GPU calculation – Reduction algorithm
●item[0]
step.1 step.2 step.4step.3
Calculation of the total
sum of an array by GPU
Σi=0...N-1item[i]
◆
●
▲ ■ ★
● ◆
●
● ◆ ▲
●
● ◆
●
● ◆ ▲ ■
●
● ◆
●
● ◆ ▲
●
● ◆
●
item[1]
item[2]
item[3]
item[4]
item[5]
item[6]
item[7]
item[8]
item[9]
item[10]
item[11]
item[12]
item[13]
item[14]
item[15]
Total sum of items[]
with log2N steps
Inter-cores synchronization with hardware support
SELECT count(X),
sum(Y),
avg(Z)
FROM my_table;
Same logic is internally used to
implement aggregate function.
DB Tech Showcase 2017 - GPU/SSD Accelerates PostgreSQL -5](https://crownmelresort.com/image.slidesharecdn.com/20170906dbtsgpussdacceleratespostgresqlen-170906080222/75/GPU-SSD-Accelerates-PostgreSQL-challenge-towards-query-processing-throughput-10GB-s-5-2048.jpg)
![Is SQL workload similar to image processing?
Image Data =
int/float[] array
Transposition
ID X Y Z
SELECT * FROM my_table
WHERE X BETWEEN 40 AND 60
Parallel Execution
GPU’s advantage: Same operations to massive amount of data.
DB Tech Showcase 2017 - GPU/SSD Accelerates PostgreSQL -6](https://crownmelresort.com/image.slidesharecdn.com/20170906dbtsgpussdacceleratespostgresqlen-170906080222/75/GPU-SSD-Accelerates-PostgreSQL-challenge-towards-query-processing-throughput-10GB-s-6-2048.jpg)









![A simple micro-benchmark
DB Tech Showcase 2017 - GPU/SSD Accelerates PostgreSQL -16
▌Test Query:
SELECT cat, count(*), avg(x)
FROM t0 NATURAL JOIN t1 [NATURAL JOIN t2 ...]
GROUP BY cat;
✓ t0 contains 100M rows, t1...t8 contains 100K rows (like a star schema)
8.48
13.23
18.28
23.42
28.88
34.50
40.77
47.16
5.00 5.46 5.91 6.45 7.17 8.07
9.22 10.21
0.0
5.0
10.0
15.0
20.0
25.0
30.0
35.0
40.0
45.0
50.0
2 3 4 5 6 7 8 9
QueryResponseTime[sec]
Number of tables joined
PG-Strom microbenchmark with JOIN/GROUP BY
PostgreSQL v9.6 PG-Strom 2.0devel
CPU: Xeon E5-2650v4
GPU: Tesla P40
RAM: 128GB
OS: CentOS 7.3
DB: PostgreSQL 9.6.2 +
PG-Strom 2.0devel](https://crownmelresort.com/image.slidesharecdn.com/20170906dbtsgpussdacceleratespostgresqlen-170906080222/75/GPU-SSD-Accelerates-PostgreSQL-challenge-towards-query-processing-throughput-10GB-s-16-2048.jpg)








![Benchmark results (1/2)
We run the Q1-Q4 below towards lineorder table (351GB).
Definition of throughput is (351 * 1024) / (Query response time[sec])
Q1... SELECT count(*) FROM lineorder;
Q2... SELECT count(*),sum(lo_revenue),sum(lo_supplycost) FROM lineorder;
Q3... SELECT count(*) FROM lineorder GROUP BY lo_orderpriority;
Q4... SELECT count(*),sum(lo_revenue),sum(lo_supplycost)
FROM lineorder GROUP BY lo_shipmode;
※ max_parallel_workers_per_gather is 24 for PostgreSQL v9.6, 4 for PG-Strom.
889.05 859.31 875.69 842.04
5988.0 5989.9 5988.8 5979.6
0
1000
2000
3000
4000
5000
6000
Q1 Q2 Q3 Q4
QueryExecutionThroughput[MB/s]
PostgreSQL v9.6 + SN260 PG-Strom v2.0 + SN260
DB Tech Showcase 2017 - GPU/SSD Accelerates PostgreSQL -25](https://crownmelresort.com/image.slidesharecdn.com/20170906dbtsgpussdacceleratespostgresqlen-170906080222/75/GPU-SSD-Accelerates-PostgreSQL-challenge-towards-query-processing-throughput-10GB-s-25-2048.jpg)
![Benchmark results (2/2)
Full scan on the 351G table by the 128GB RAM system, thus its storage system obviously
limits the query execution performance.
PG-Strom could pull out Seq-Read performance of the SSD close to the catalog spec.
PostgreSQL has unignorable overhead around I/O.
0
1000
2000
3000
4000
5000
6000
7000
0 100 200 300 400
StorageReadThroughput[MB/s]
Elapsed Time for Query Execution [sec]
Time Series Results (Q4) with iostat
PG-Strom v2.0devel + SN260 PostgreSQL v9.6 + SN260
[kaigai@saba ~]$ iostat -cdm 1
:
Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn
sda 6.00 0.19 0.00 0 0
sdb 0.00 0.00 0.00 0 0
sdc 0.00 0.00 0.00 0 0
nvme0n1 24059.00 5928.41 0.00 5928 0
:
DB Tech Showcase 2017 - GPU/SSD Accelerates PostgreSQL -26](https://crownmelresort.com/image.slidesharecdn.com/20170906dbtsgpussdacceleratespostgresqlen-170906080222/75/GPU-SSD-Accelerates-PostgreSQL-challenge-towards-query-processing-throughput-10GB-s-26-2048.jpg)


























HeteroDB, Inc. specializes in GPU- and SSD-accelerated SQL database products, primarily utilizing the pg-strom extension for PostgreSQL to enhance query processing speeds. Founded by experts in the database and GPU acceleration fields, the company provides solutions for heavy SQL workloads and in-database analytics, targeting enterprises needing efficient data processing. The technology includes auto-generation of GPU programs and direct execution from SSDs to GPUs, significantly improving throughput for complex queries and analytics workloads.
Introduction to GPU and SSD acceleration for PostgreSQL to enhance query processing throughput.
Description of PG-Strom, its utilization of GPU capabilities, and open-source functionalities.
Comparative analysis of CPU and GPU architectures highlighting performance and memory bandwidth.
Illustration of GPU's reduction algorithm in calculating total sums in arrays.
Comparison of SQL workloads to image processing, stressing on parallel execution advantages.
Challenges in SQL processing related to data size and computing intensity, including analytics.
Recap of previous DB tech showcase presentations and recent advancements.
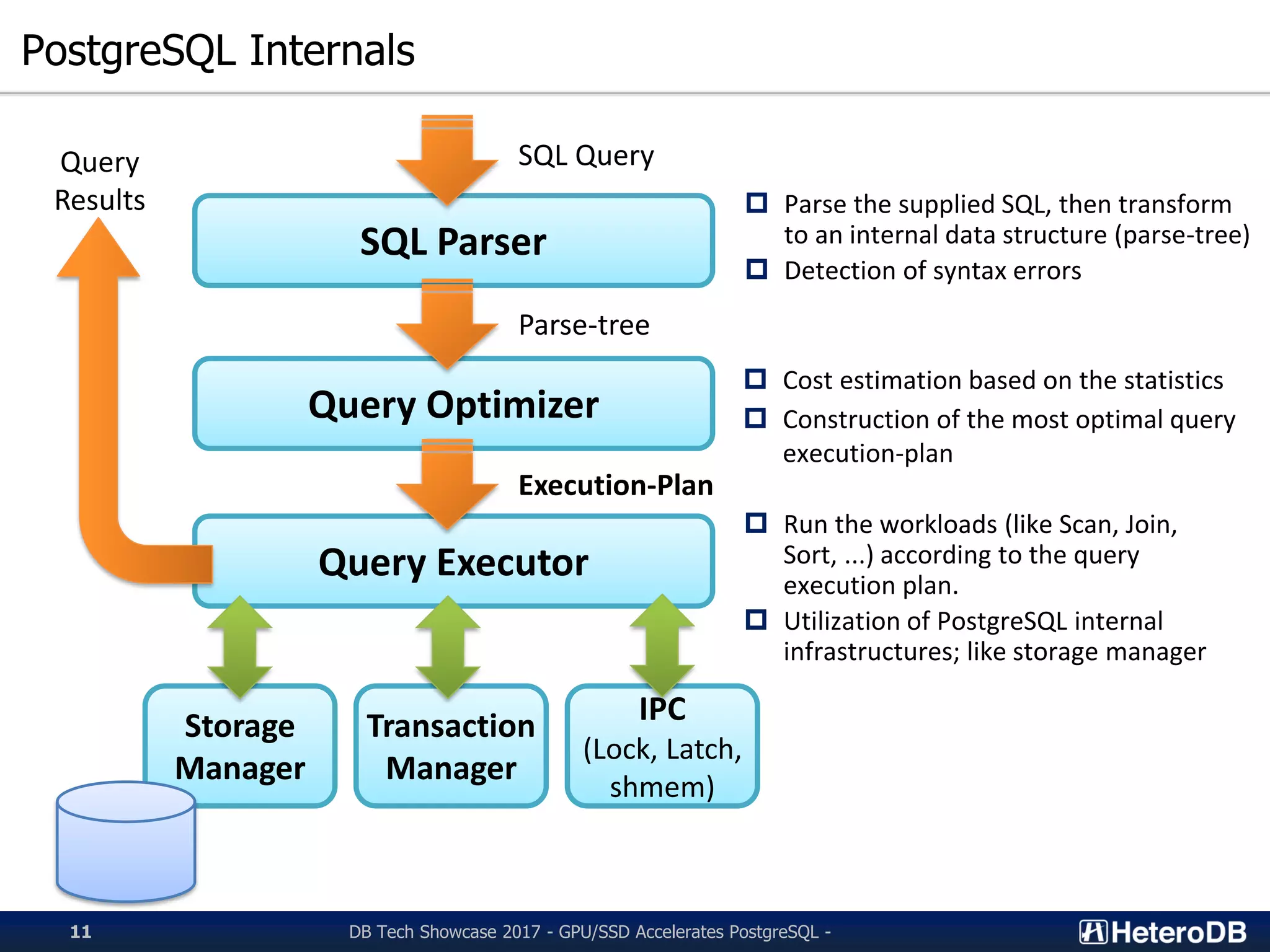
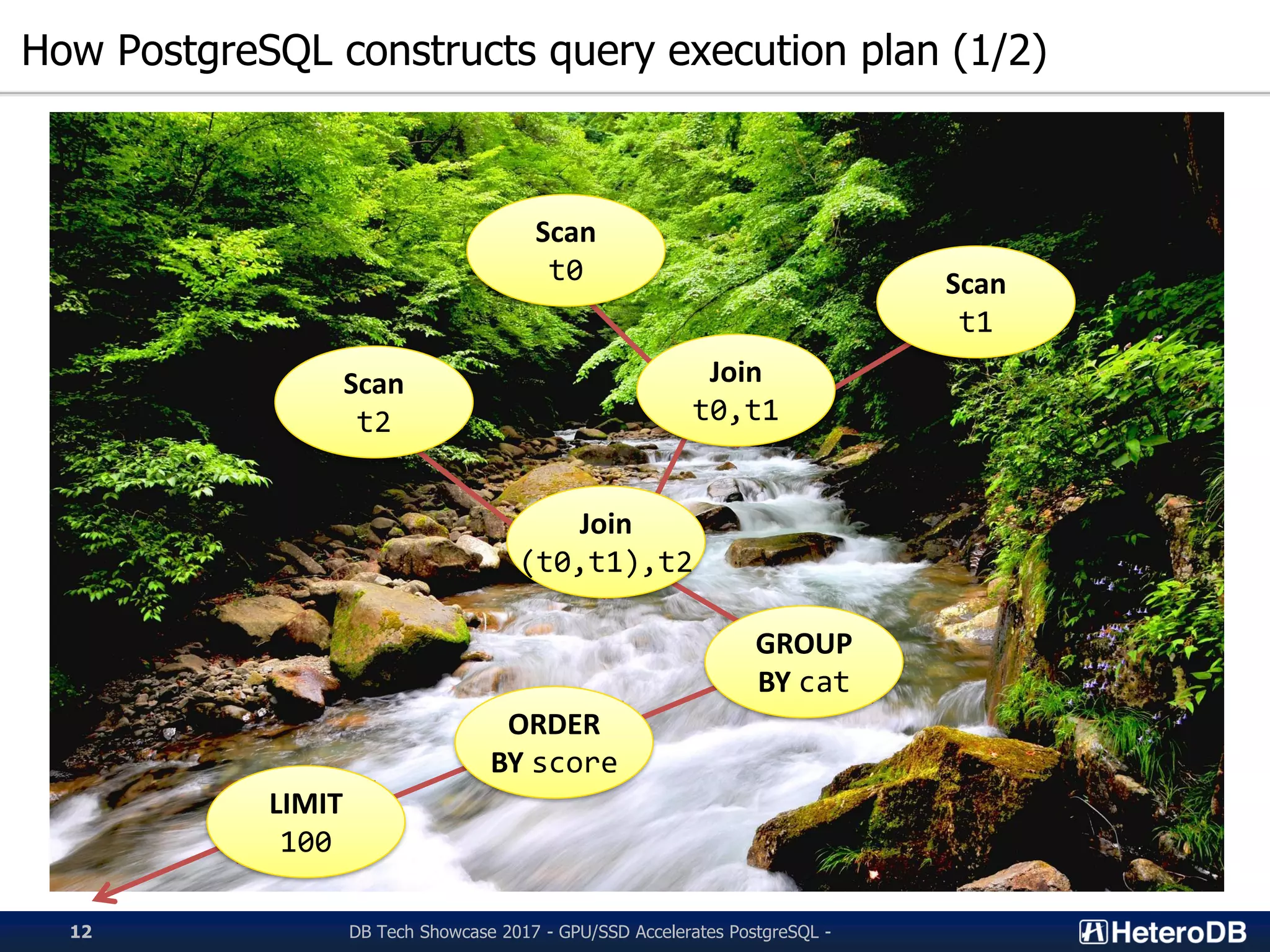
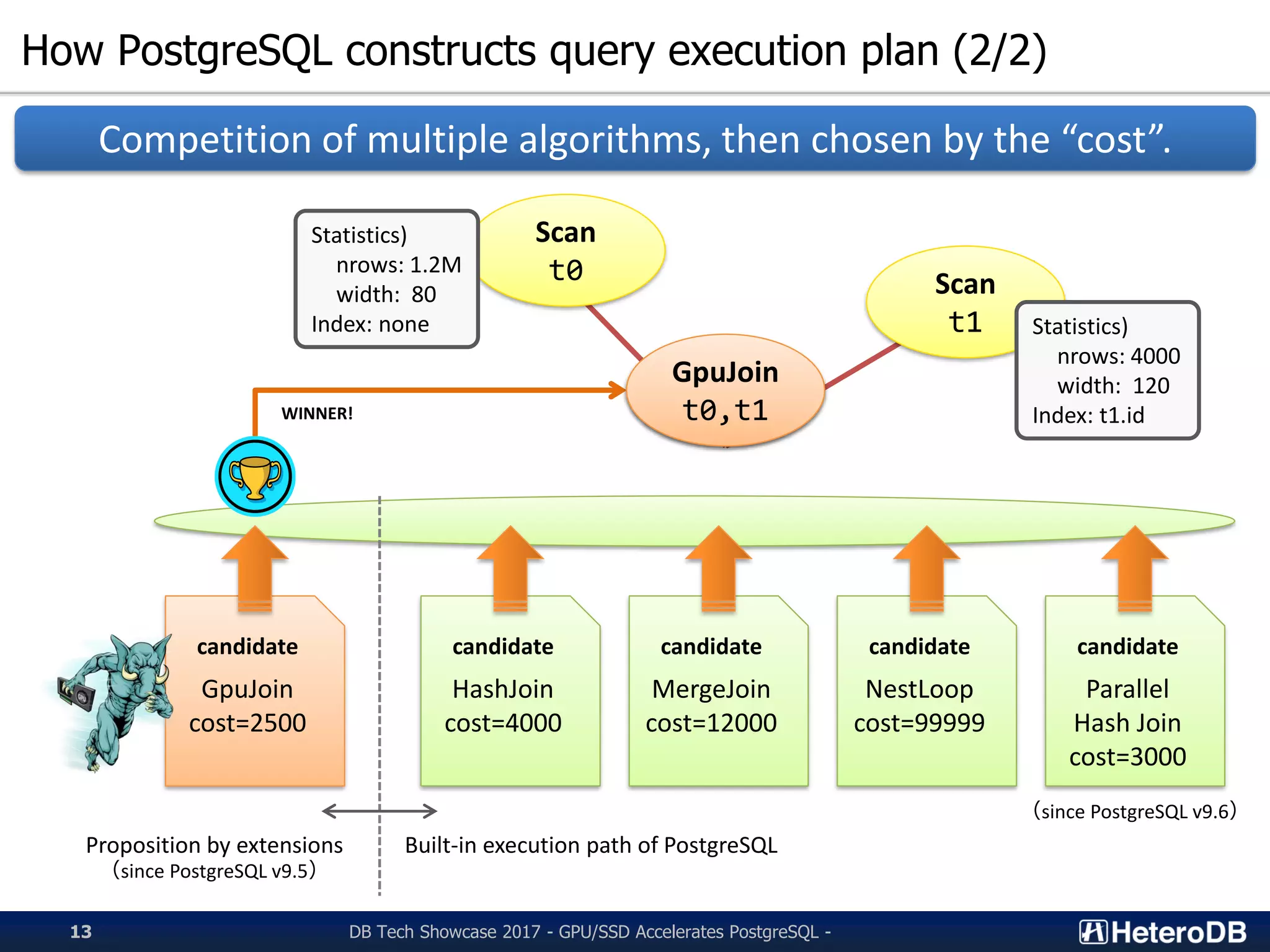
Insight into PostgreSQL architecture, its query execution planning, and optimizations used.
Detailed interaction of PG-Strom with PostgreSQL via CustomScan for optimized performance.
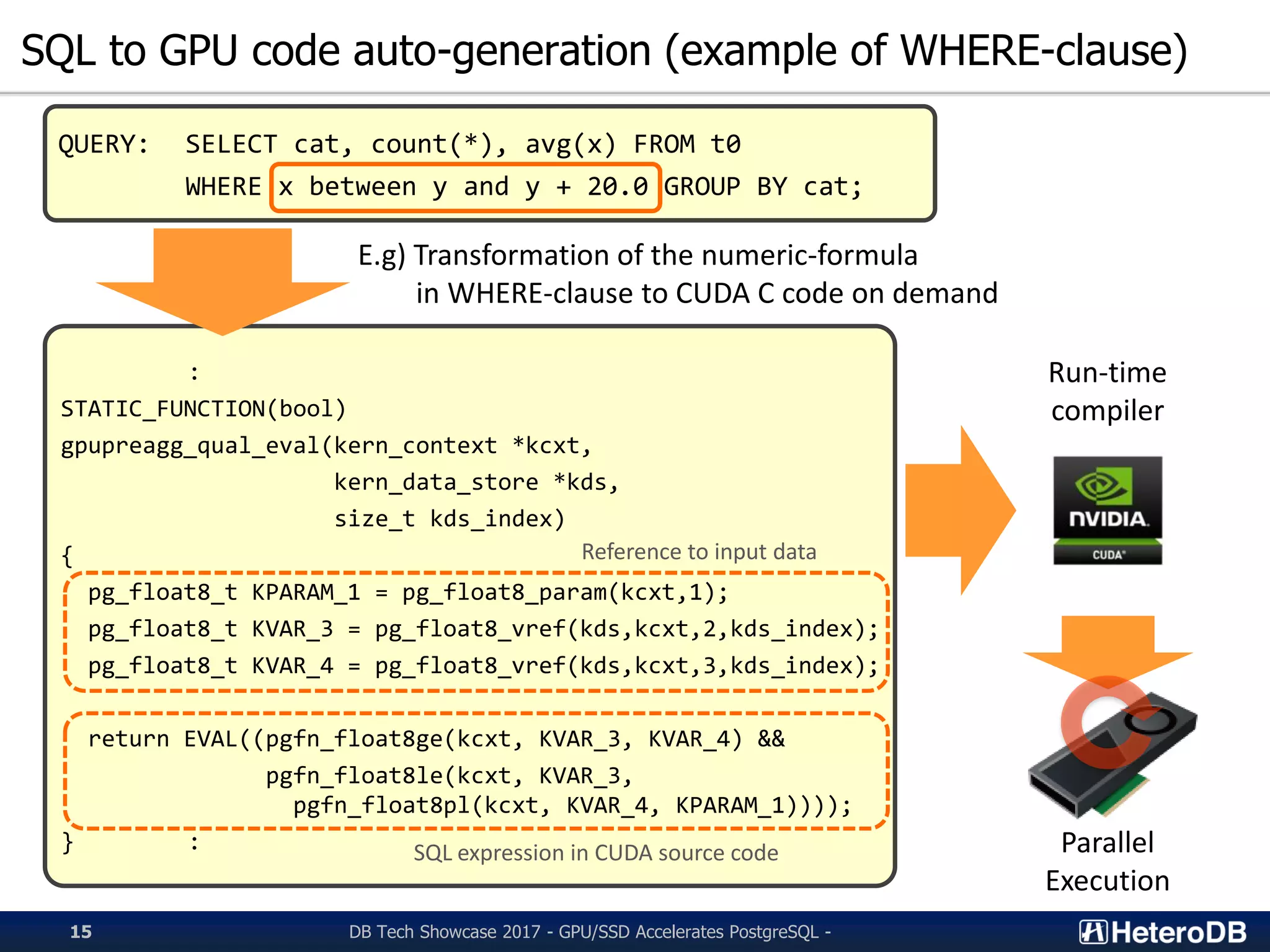
Auto-generation of GPU code from SQL queries, demonstrating transformation and execution.
Results of PG-Strom performance in micro-benchmarks showcasing response times in SQL execution.
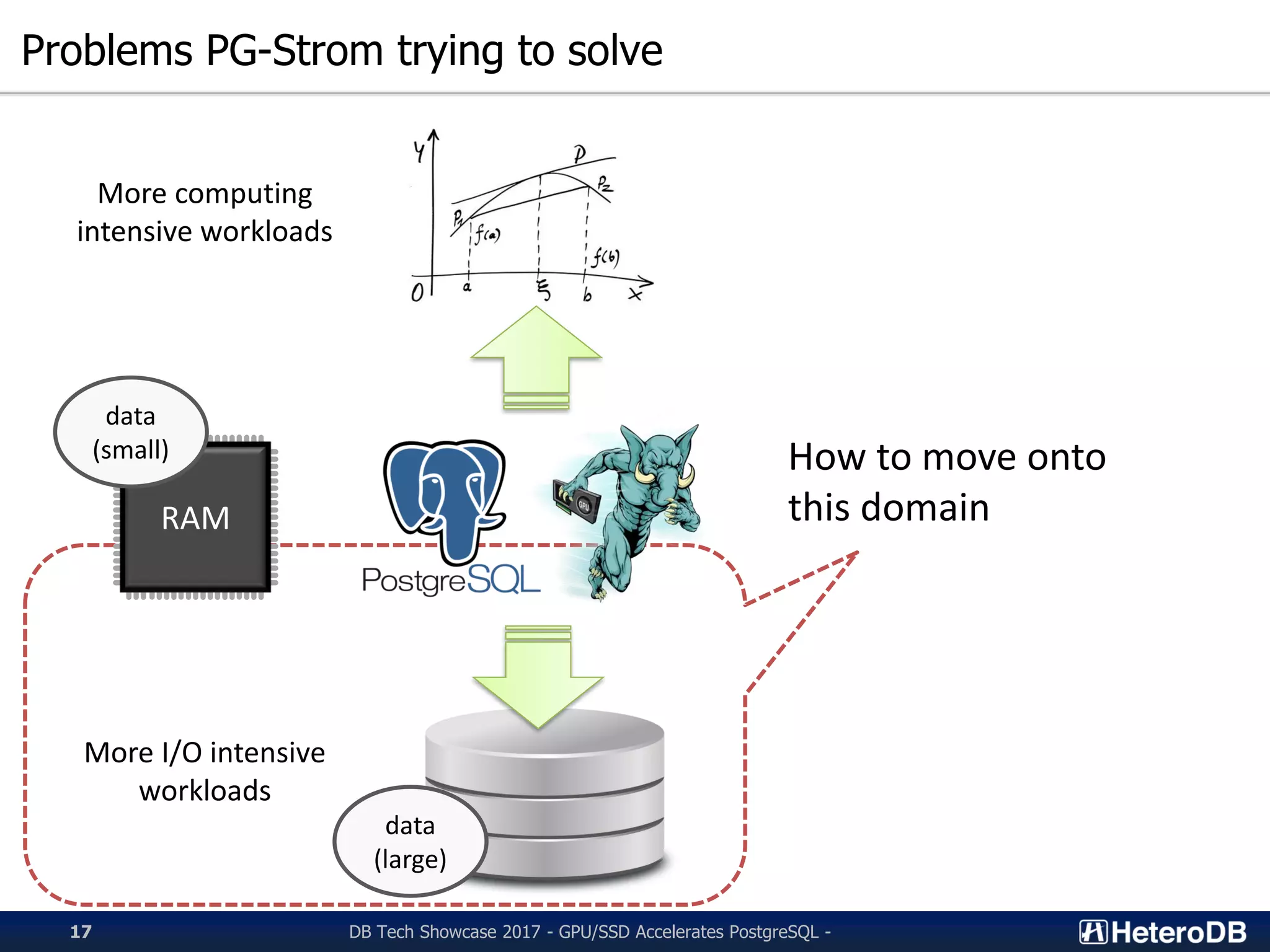
Discussing computational and I/O intensive workloads PG-Strom aims to solve.
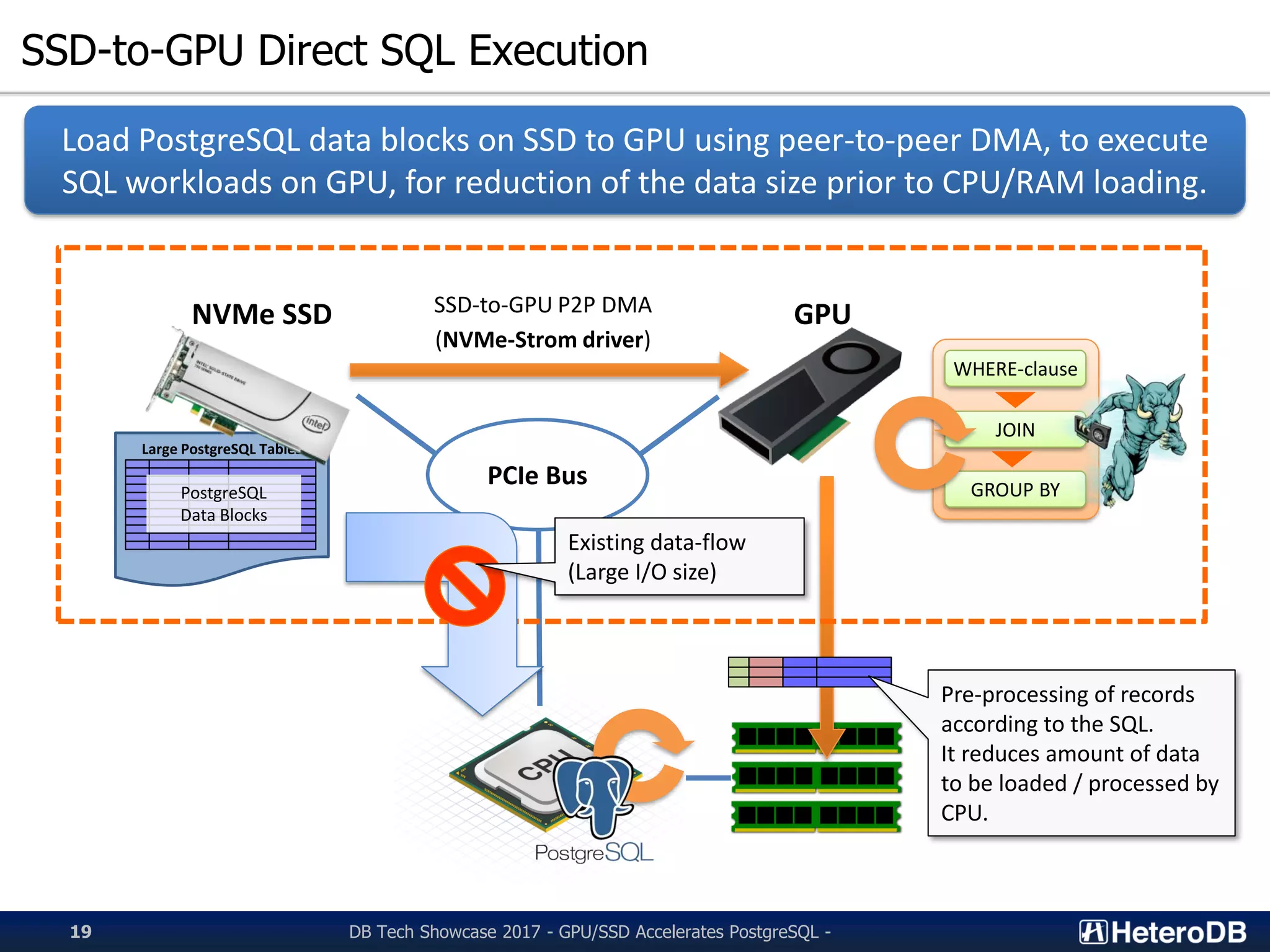
Introduction to SSD-to-GPU direct SQL execution to optimize data processing speed.
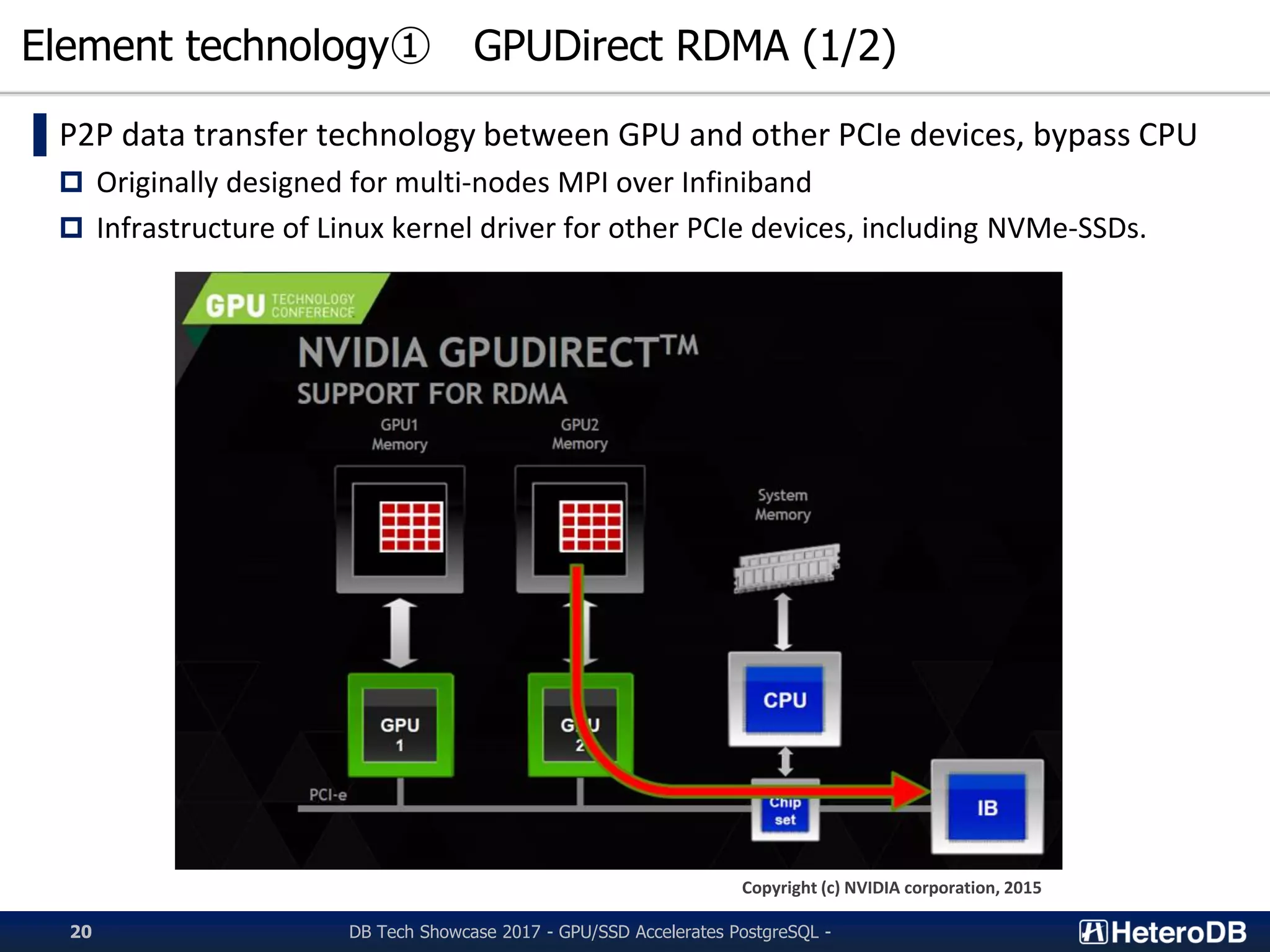
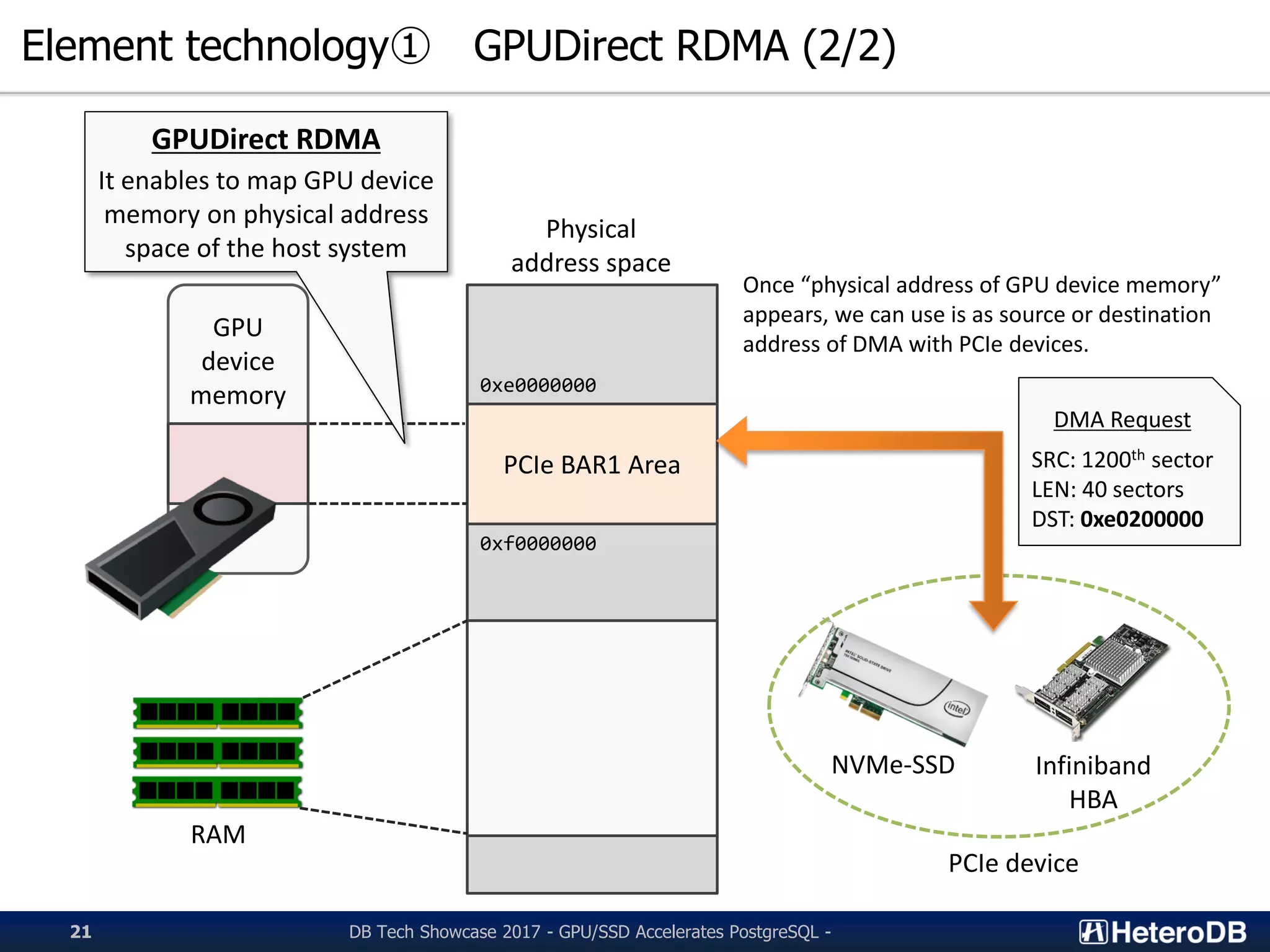
Overview of GPUDirect RDMA technology to enhance data transfer between GPUs and NVMe-SSDs.
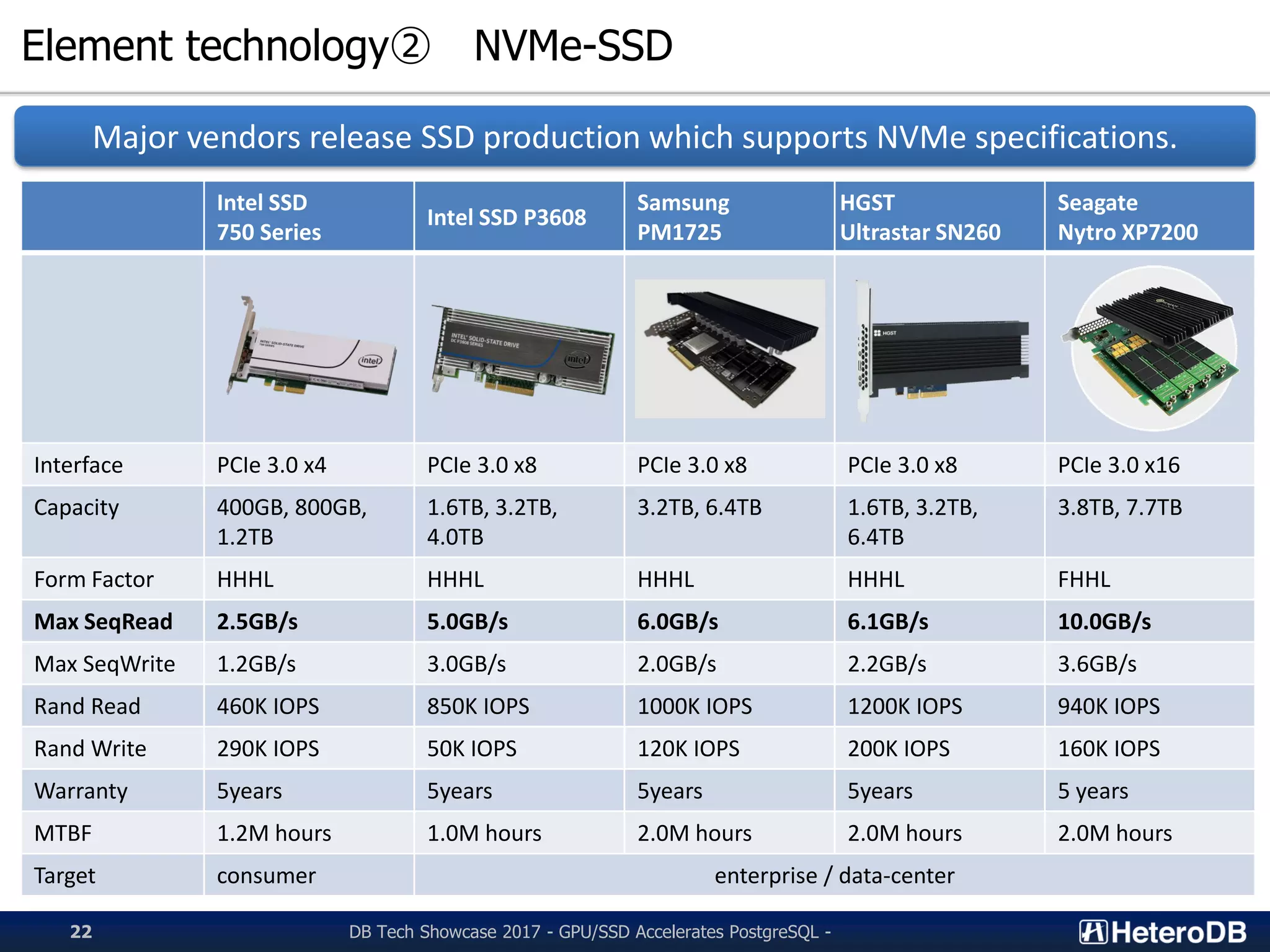
Analysis of NVMe SSD technologies and their specifications for optimal performance.
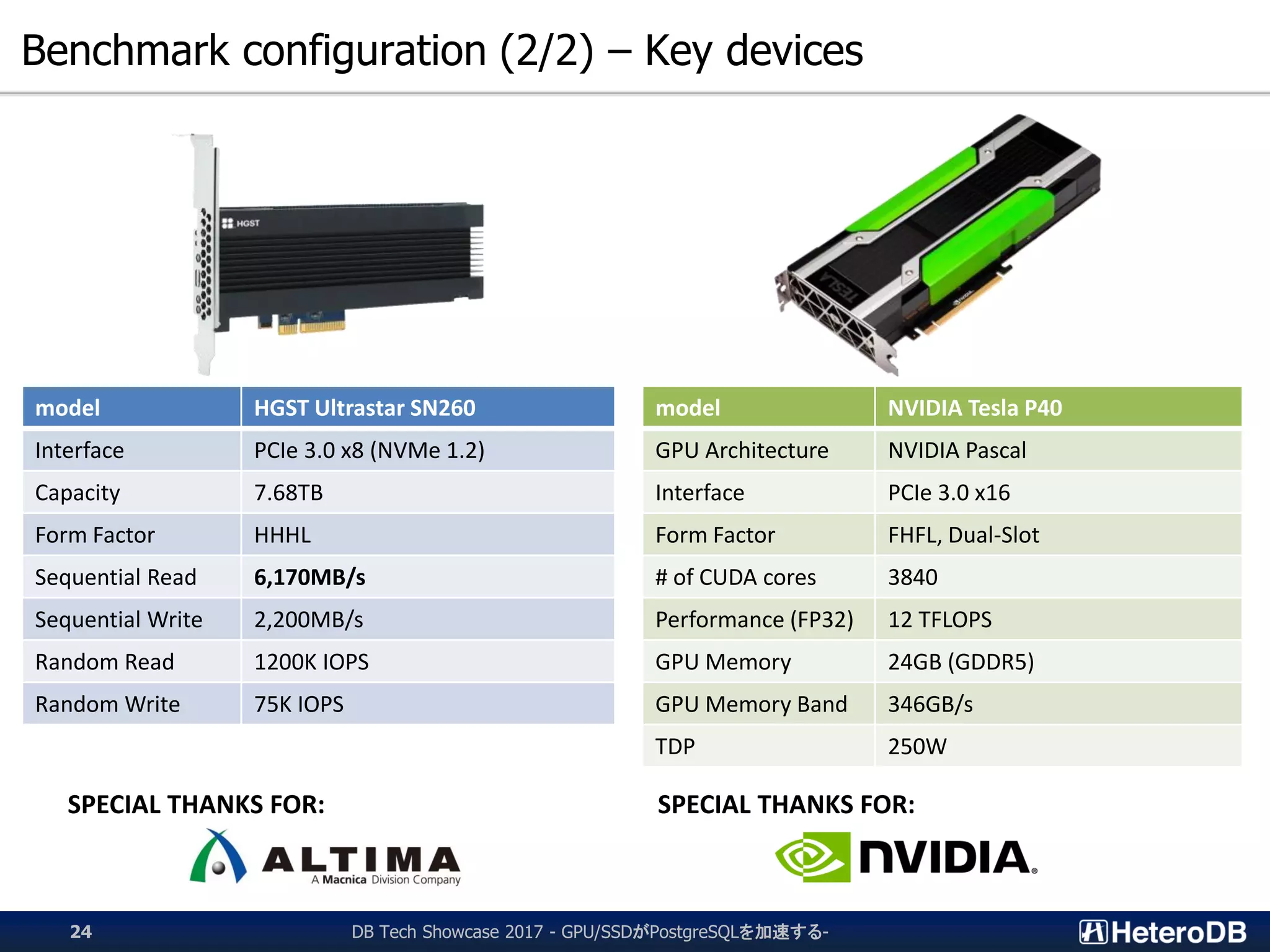
Details of benchmark configurations for testing PG-Strom's performance with various devices.
Benchmark results showing query execution throughput and performance differences between systems.
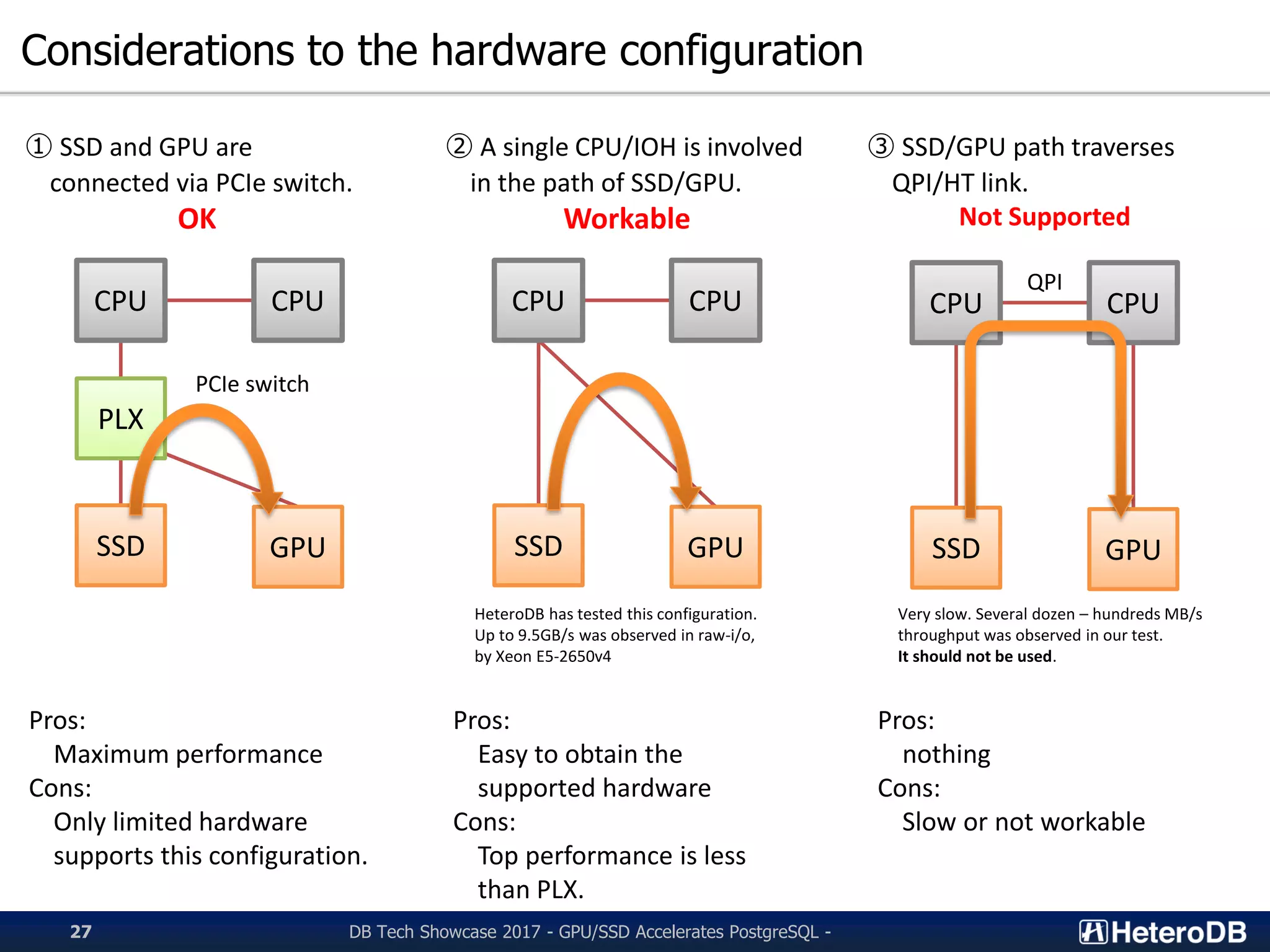
Recommendations and observations regarding SSD and GPU configurations for optimal performance.
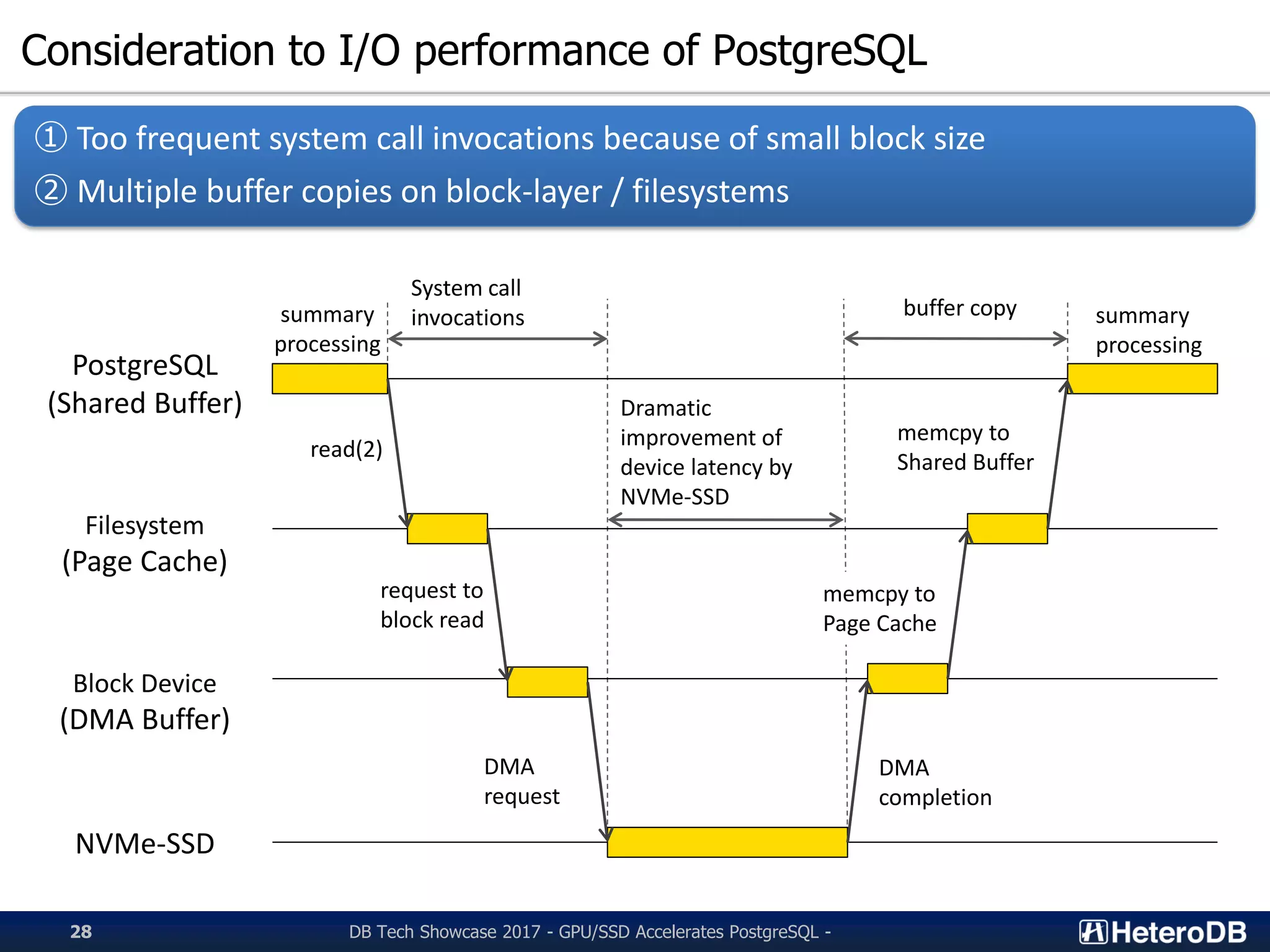
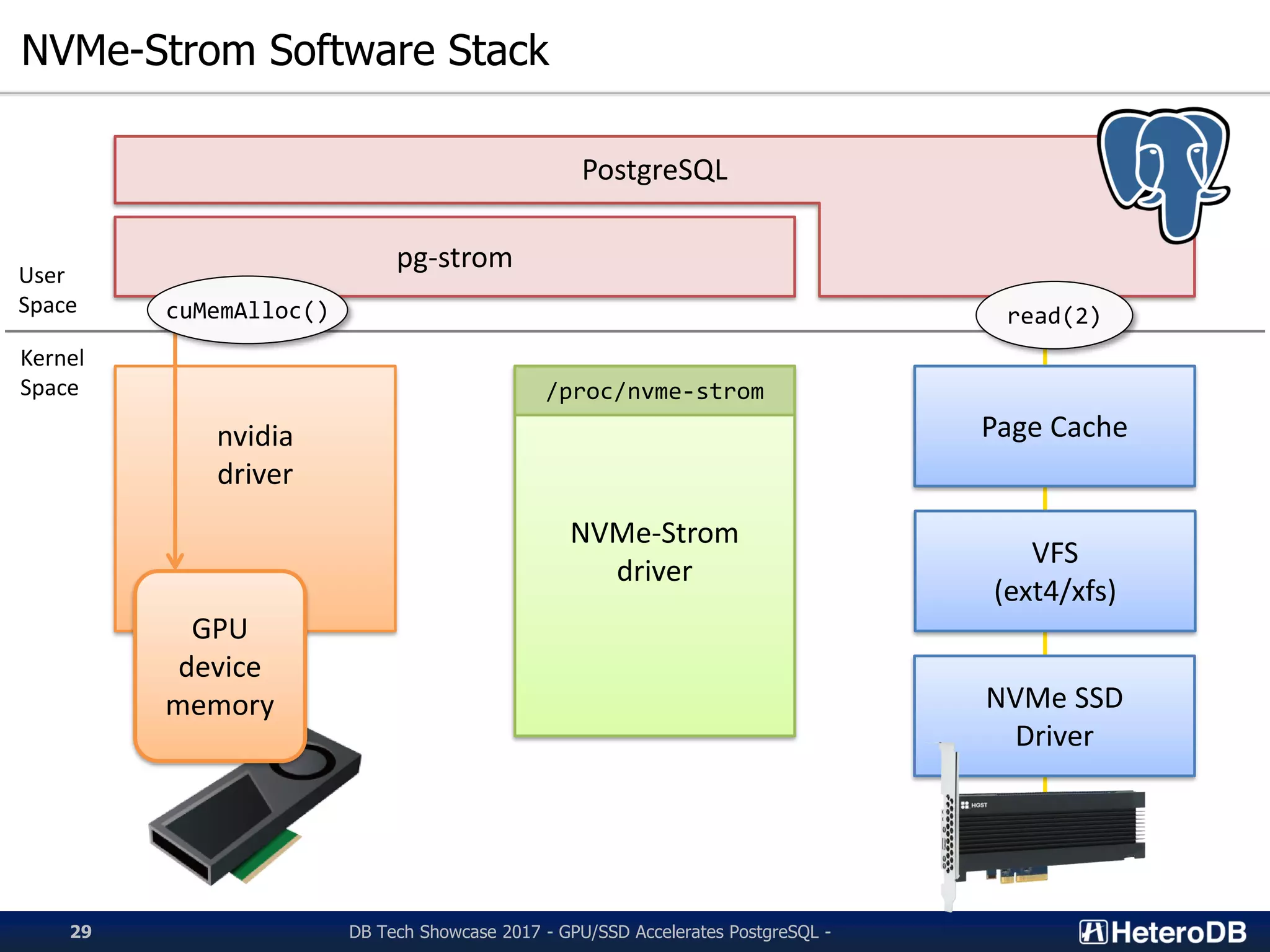
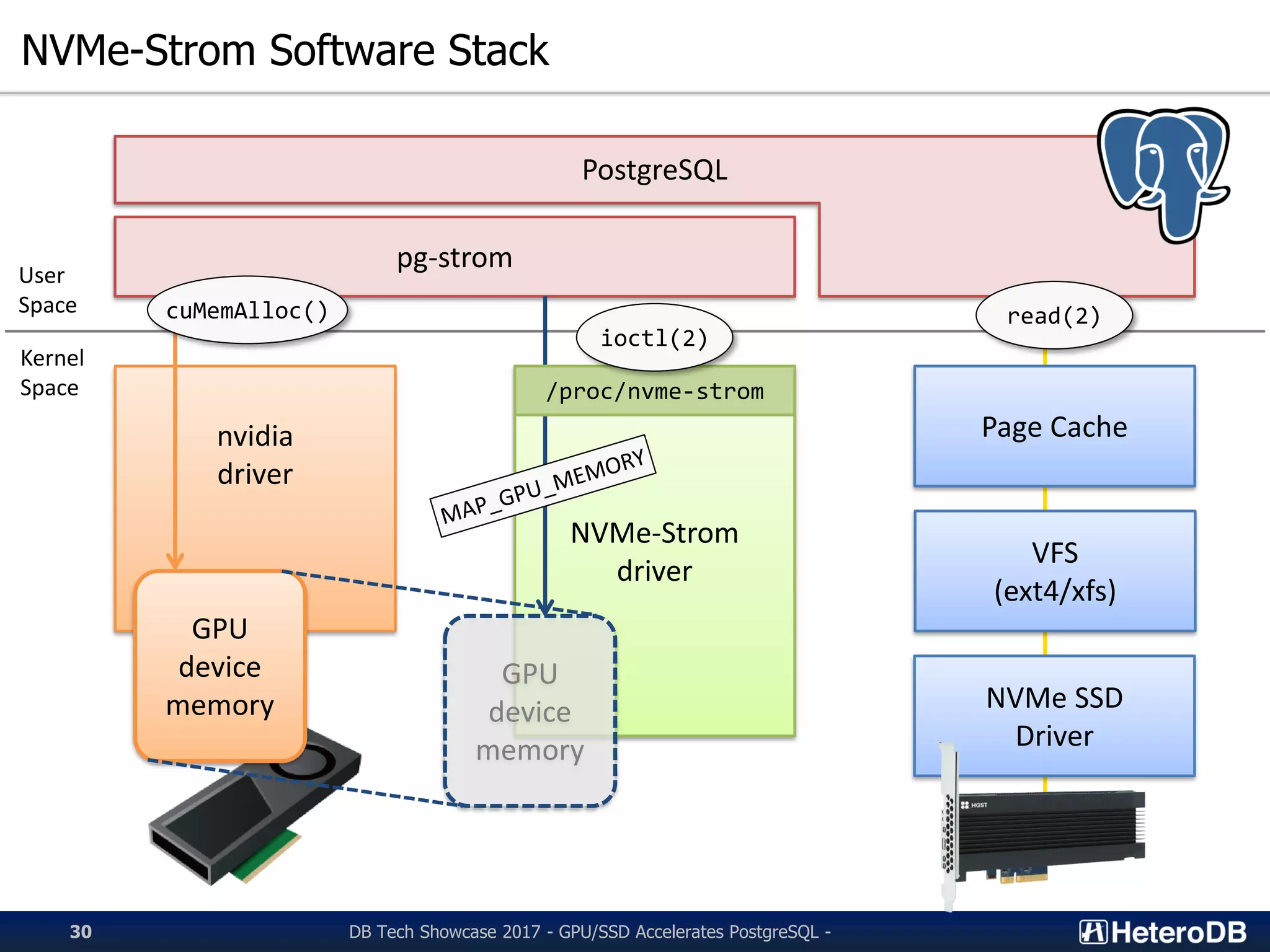
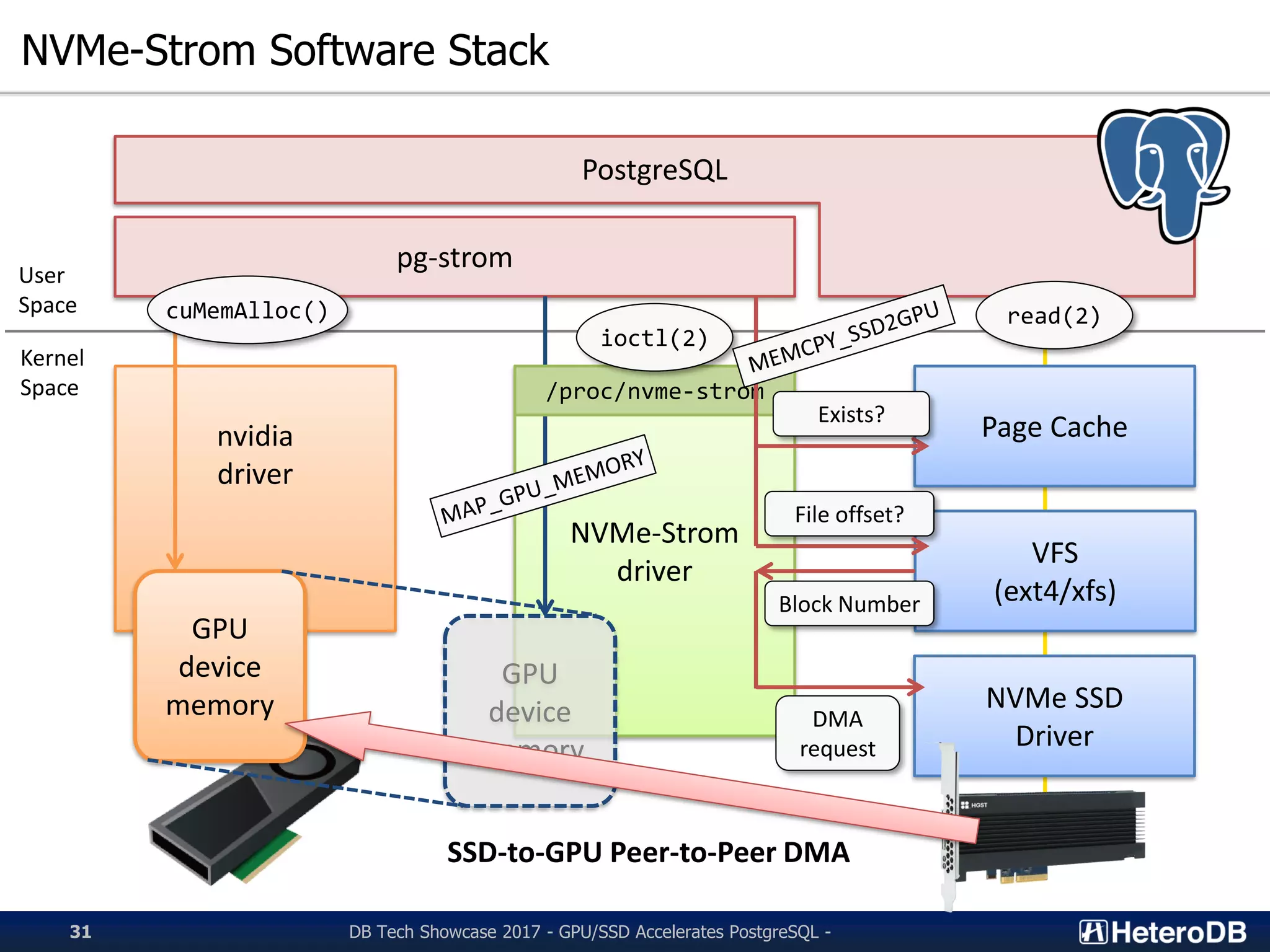
Discussion on the NVMe-Strom software stack and its interaction with PostgreSQL.
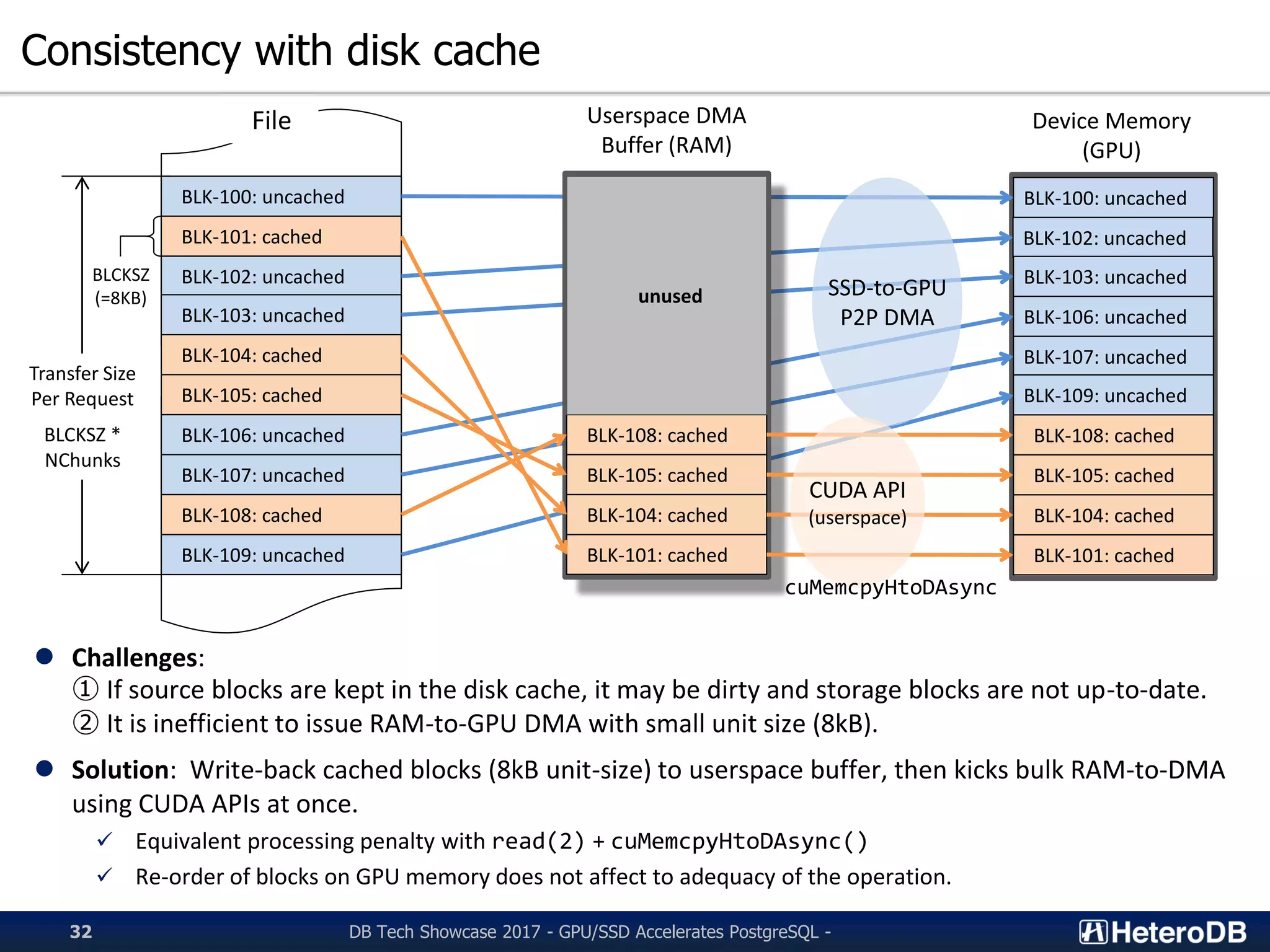
Challenges of maintaining consistency with disk cache and proposed solutions.
Objective to achieve 10GB/s in query execution throughput with various considerations.
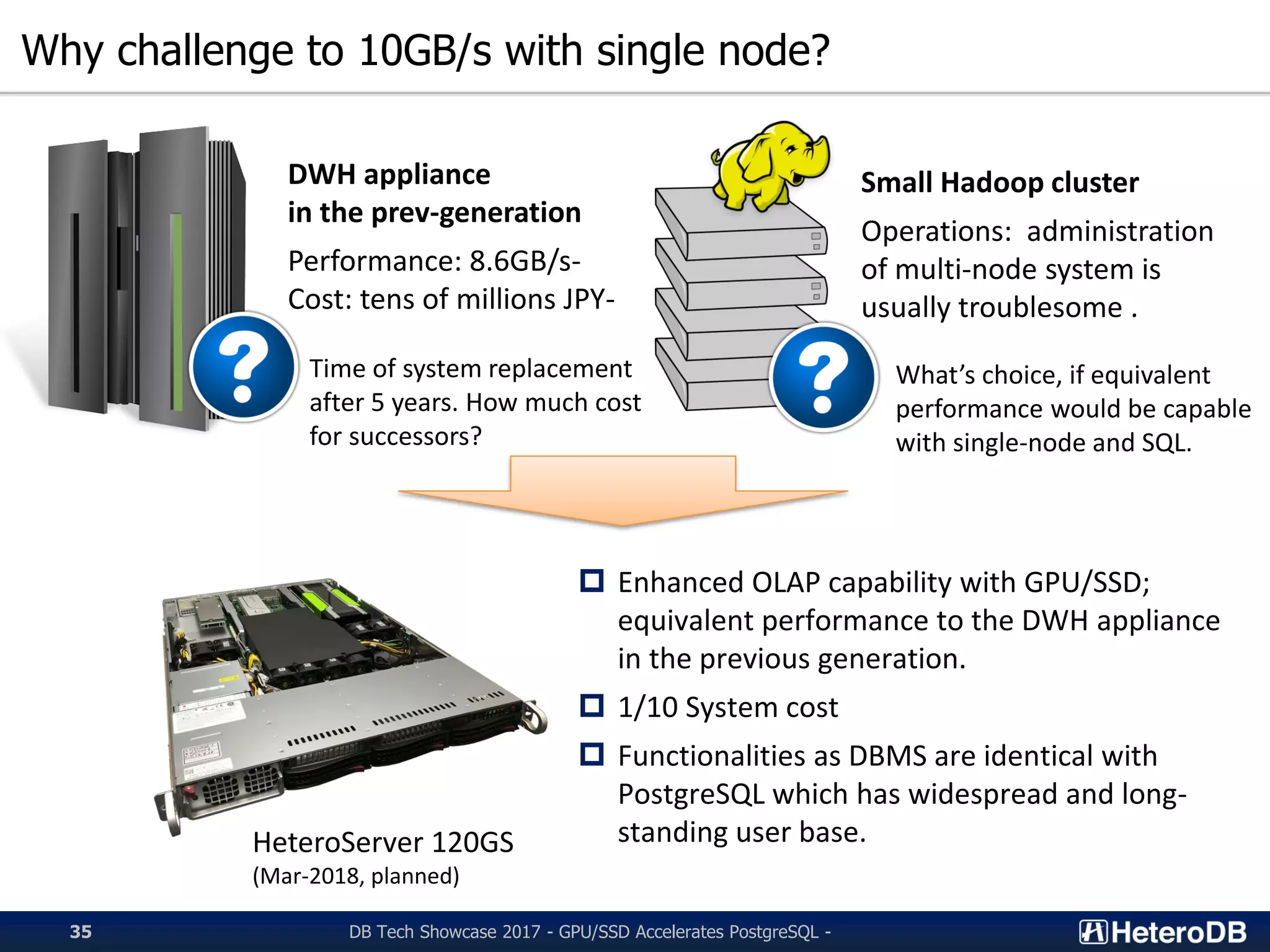
Discussion on the rationale for targeting 10GB/s throughput, comparing costs and performance.
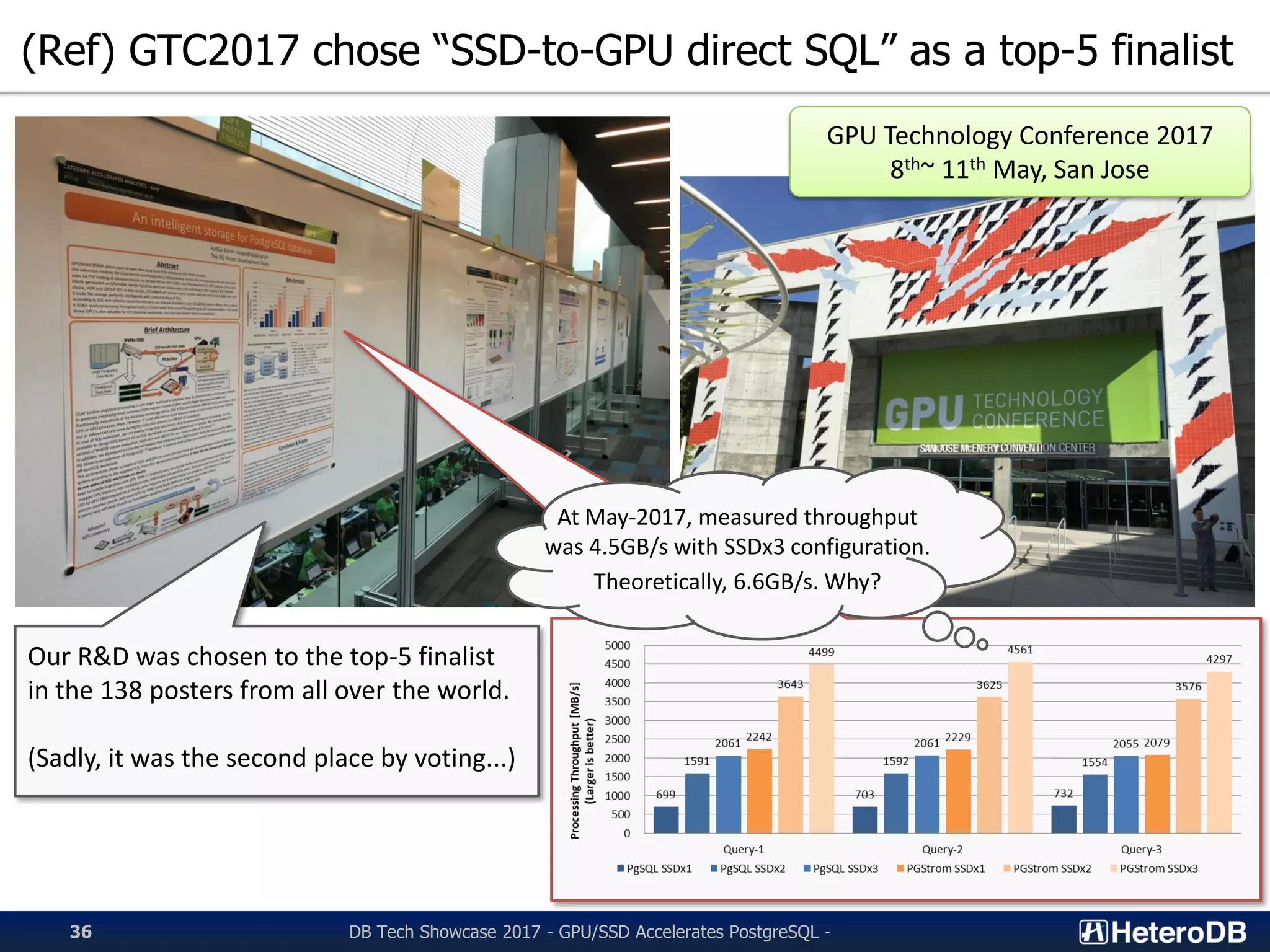
Recognition of PG-Strom R&D work at the GPU Technology Conference and performance statistics.
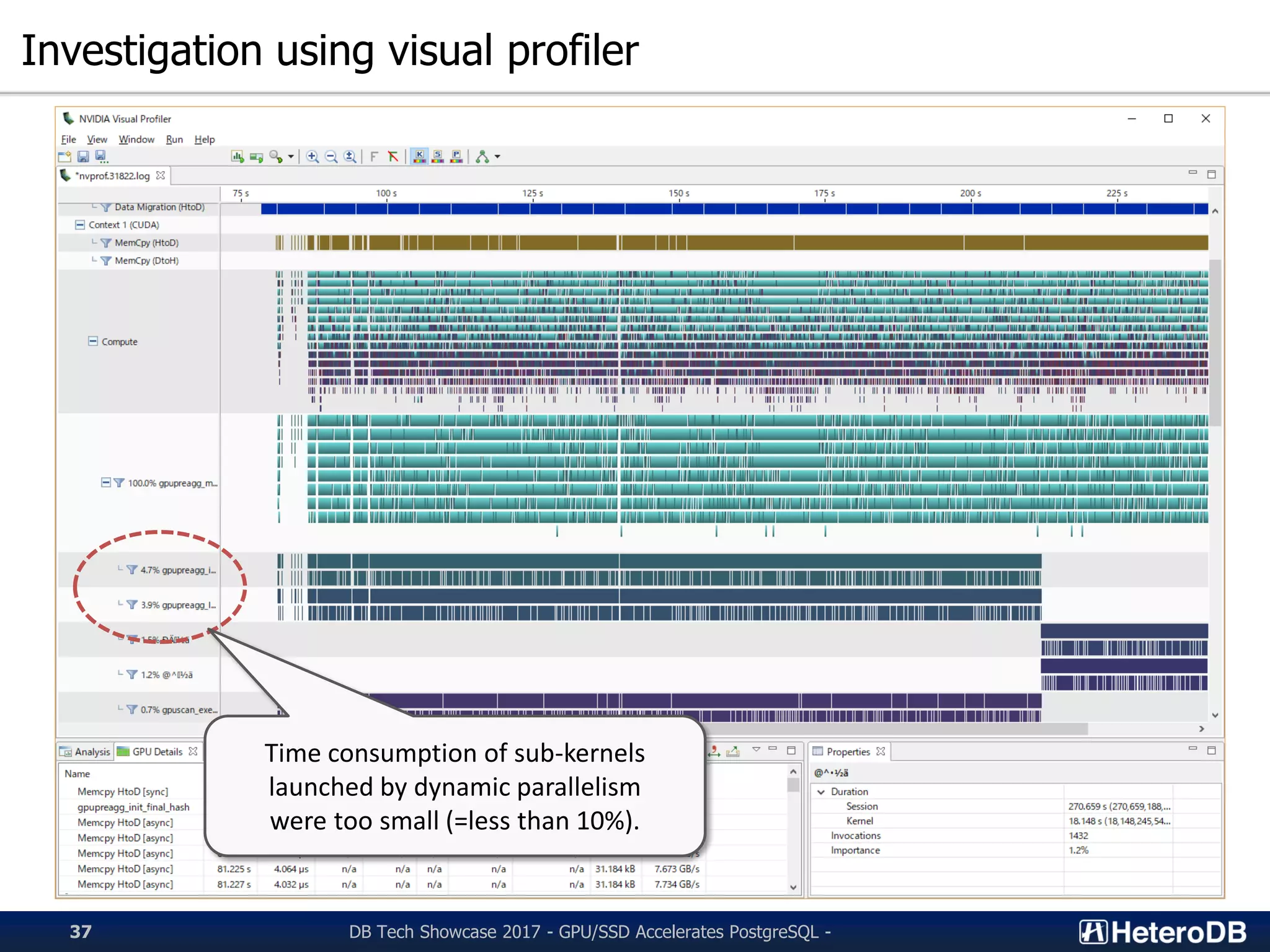
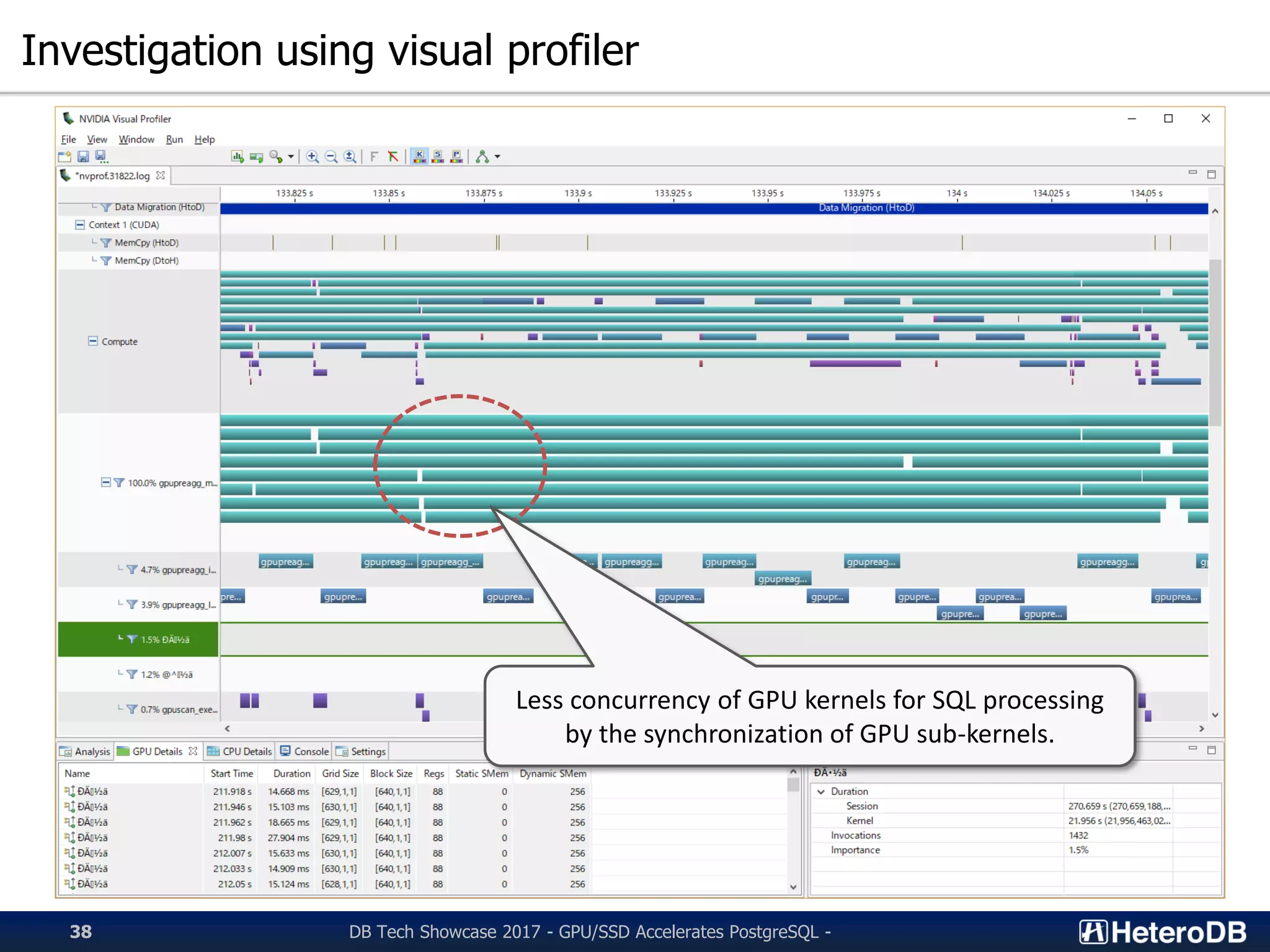
Investigation of performance bottlenecks in dynamic parallelism and sub-kernel concurrency.
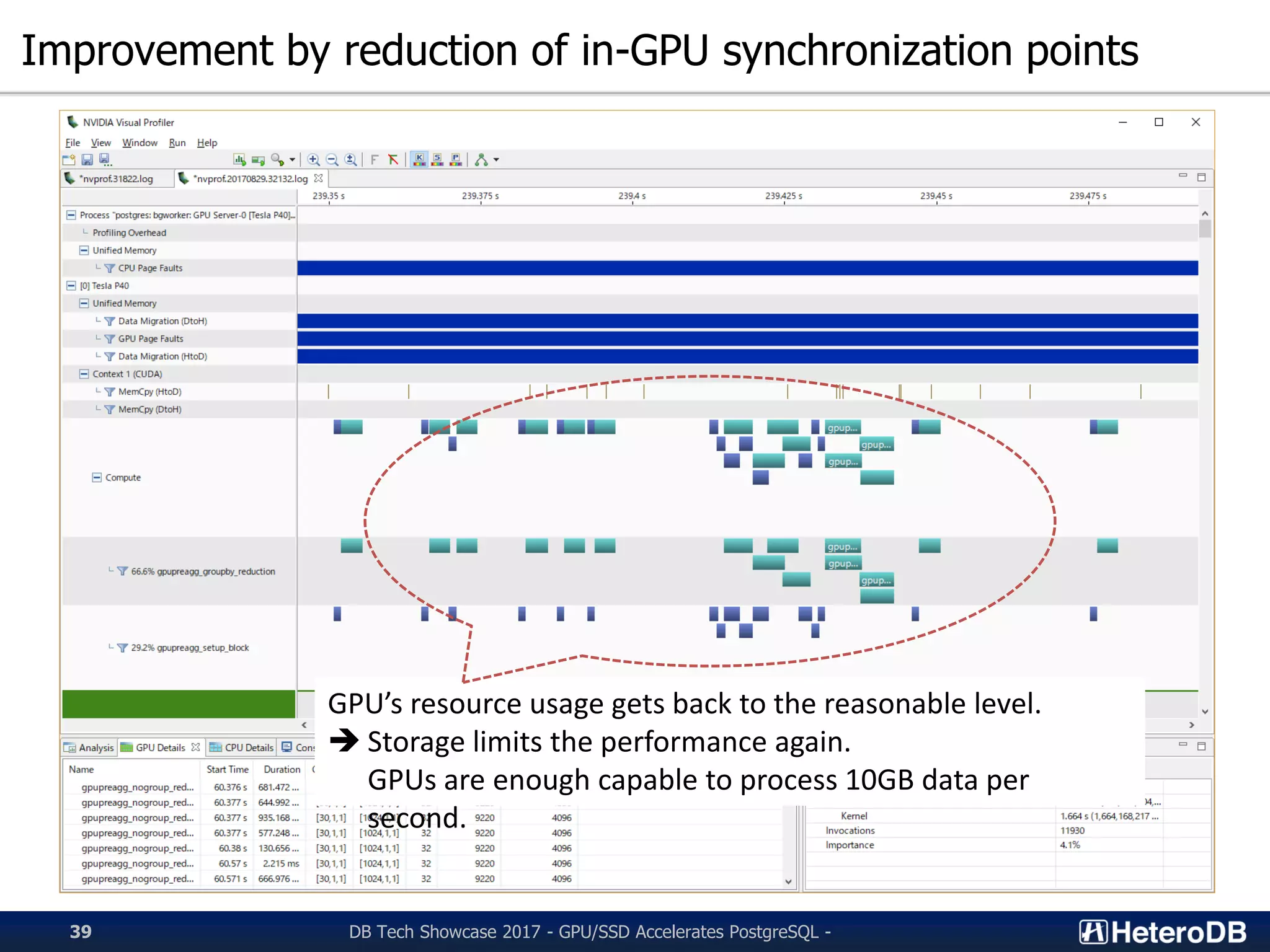
Plans for reducing synchronization points in GPU tasks to optimize performance.
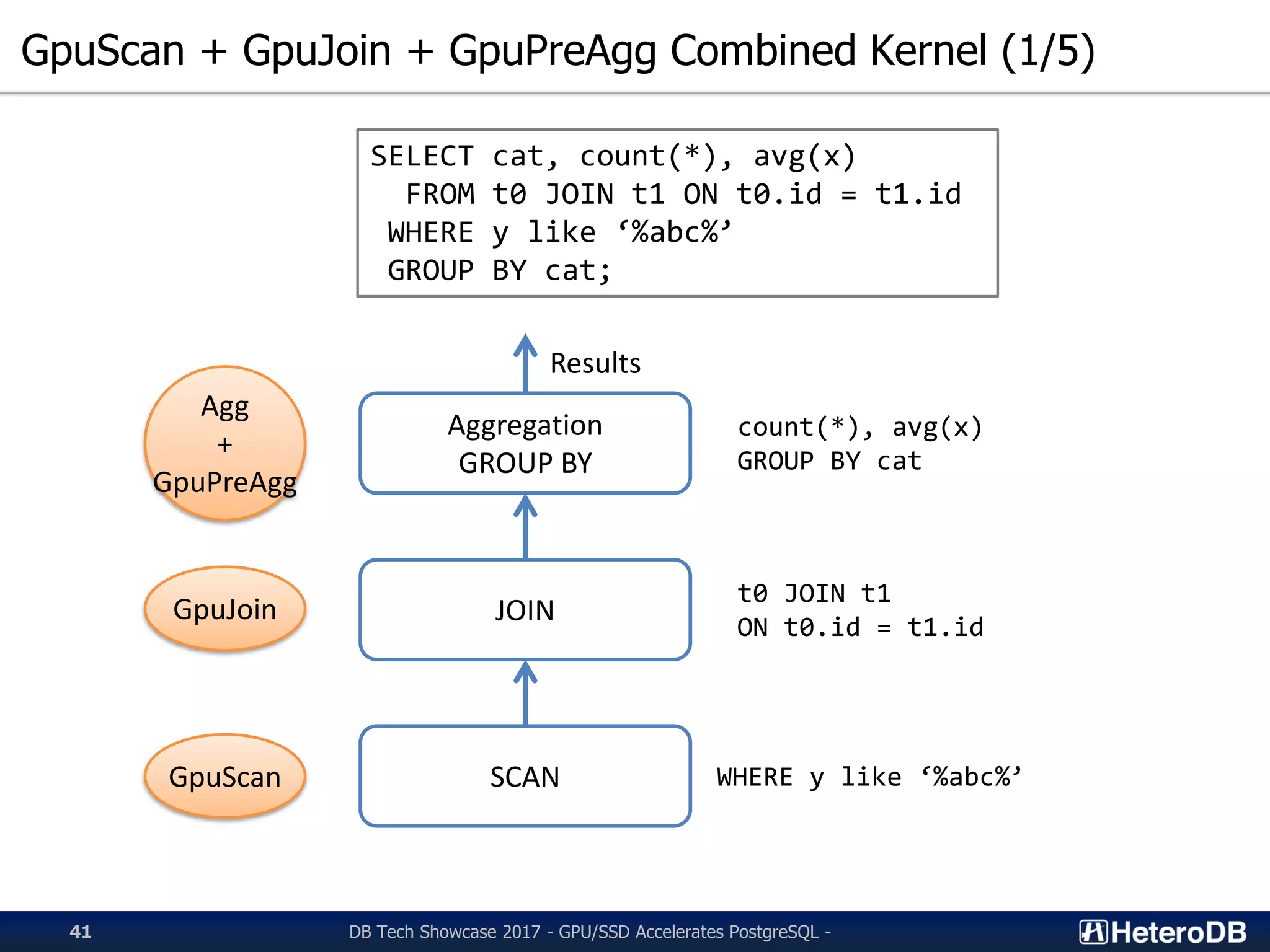
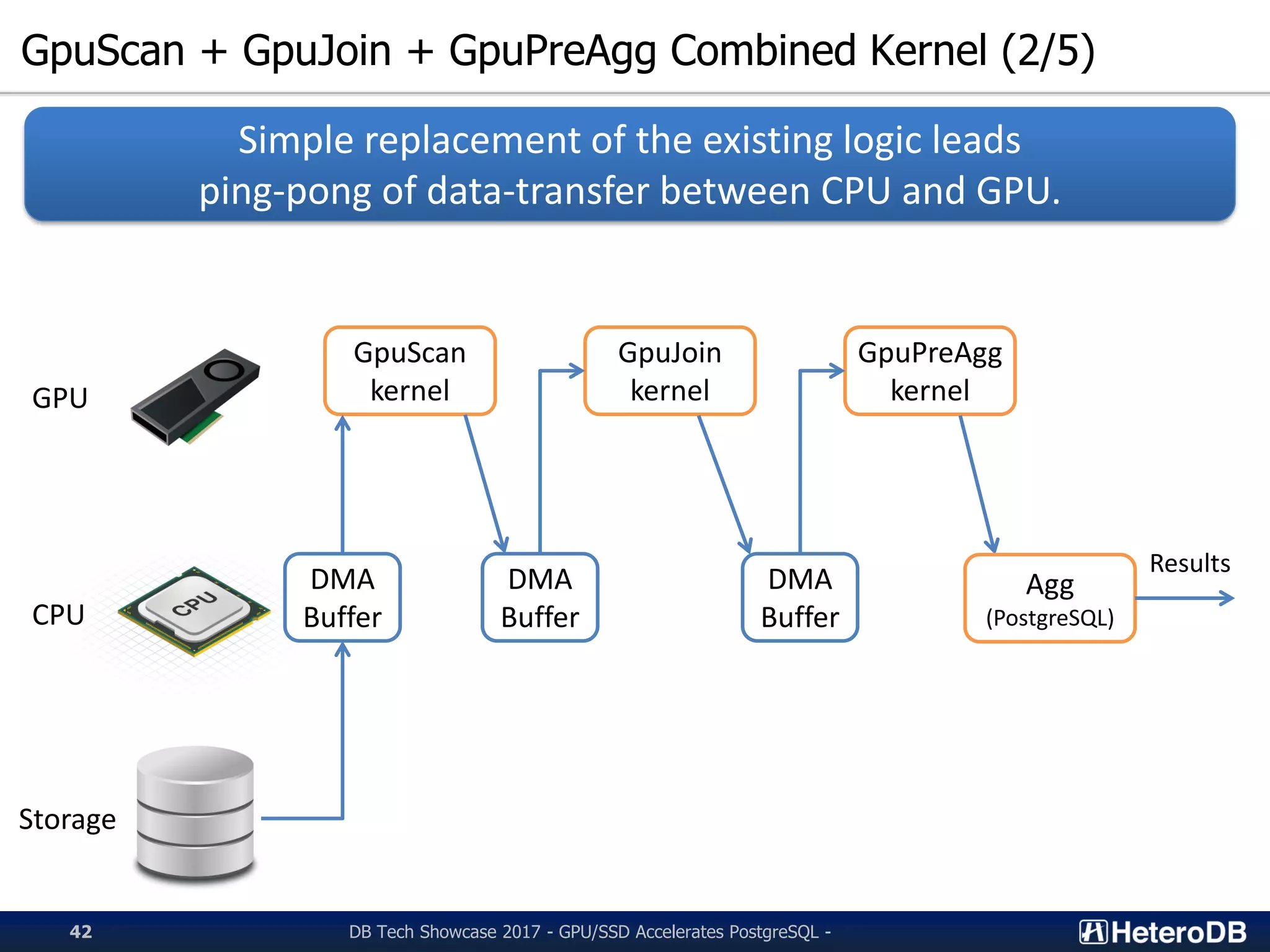
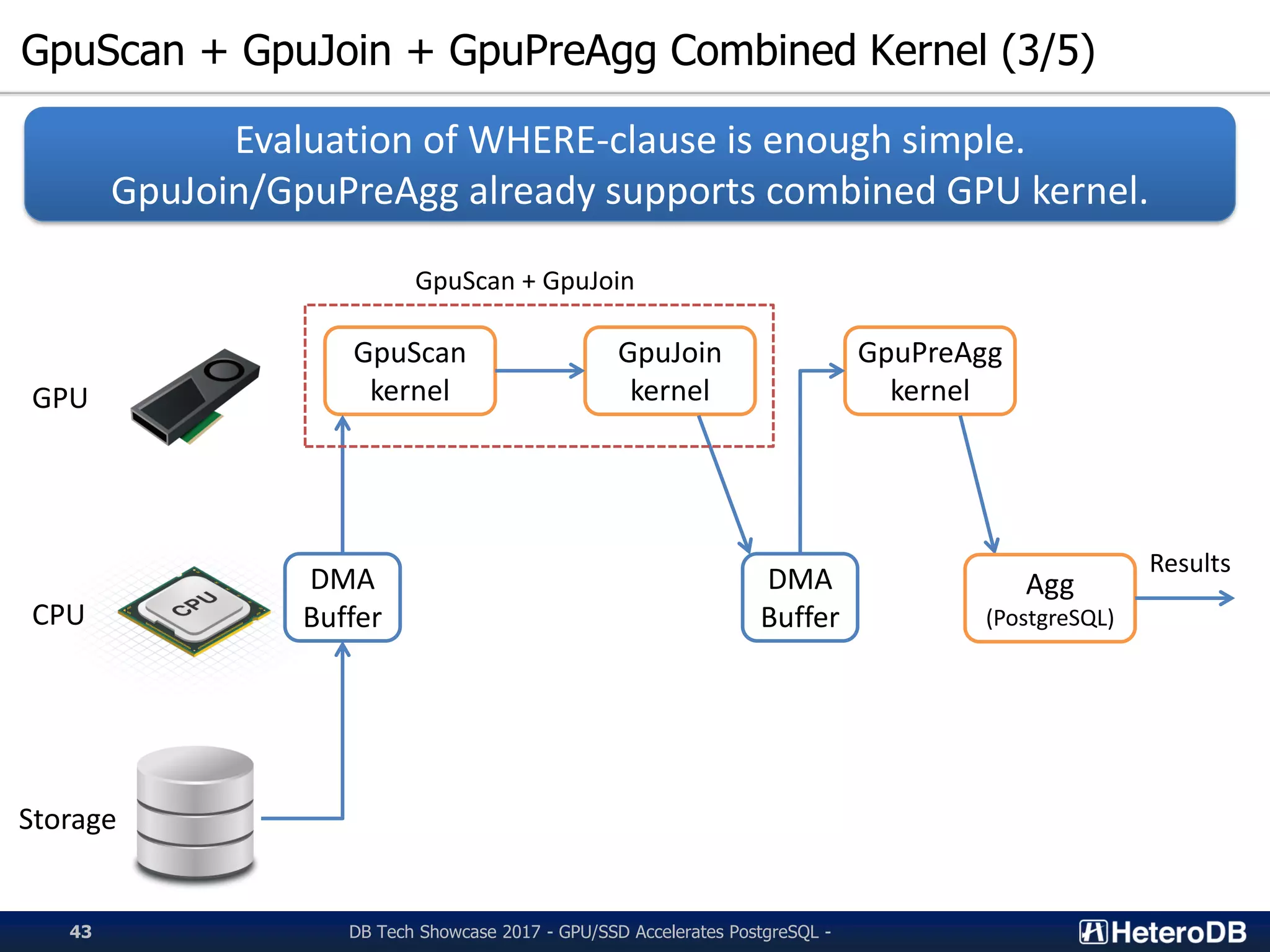
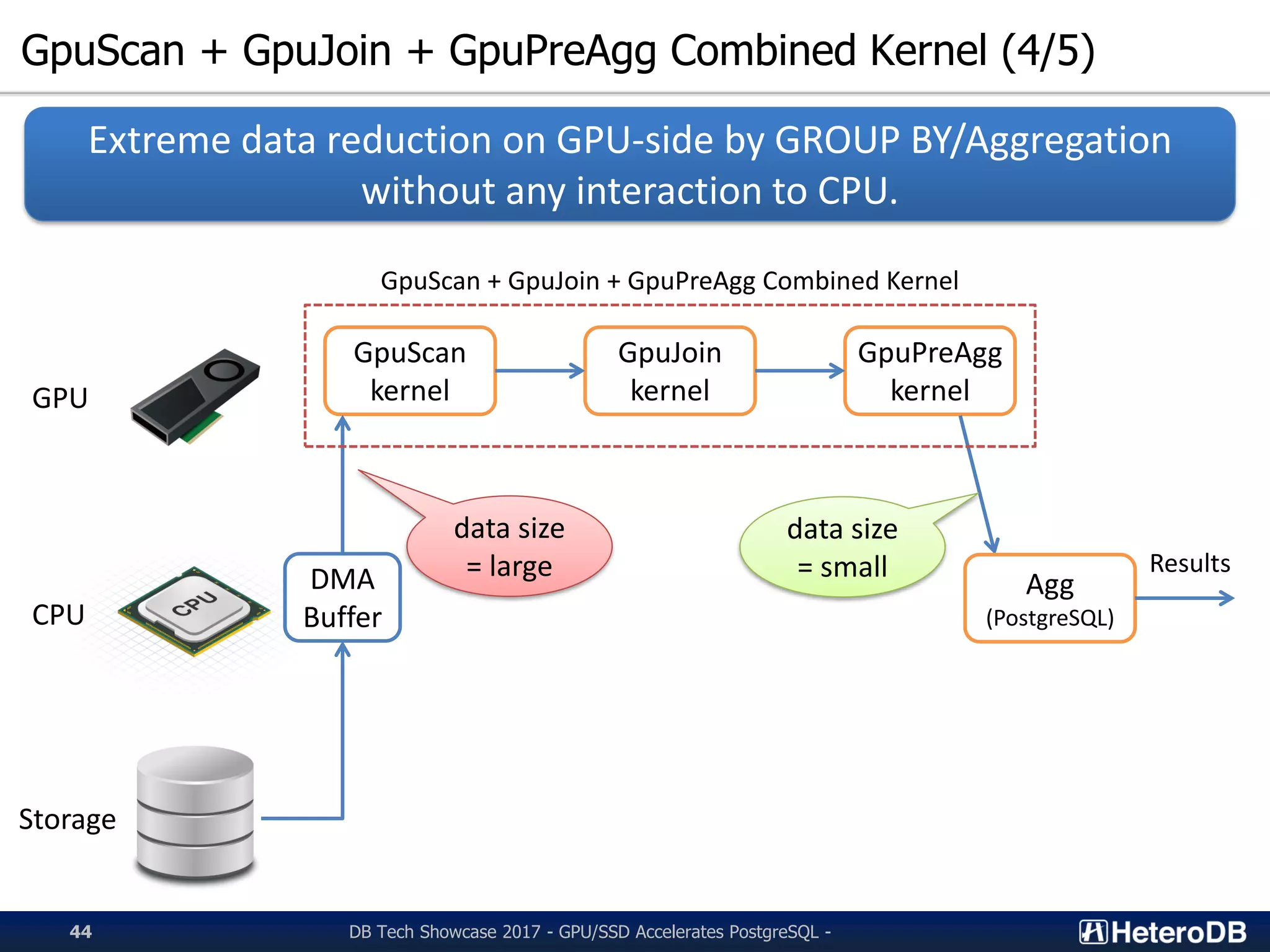
Details of combined GPU kernels (GpuScan, GpuJoin, GpuPreAgg) for efficient SQL execution.
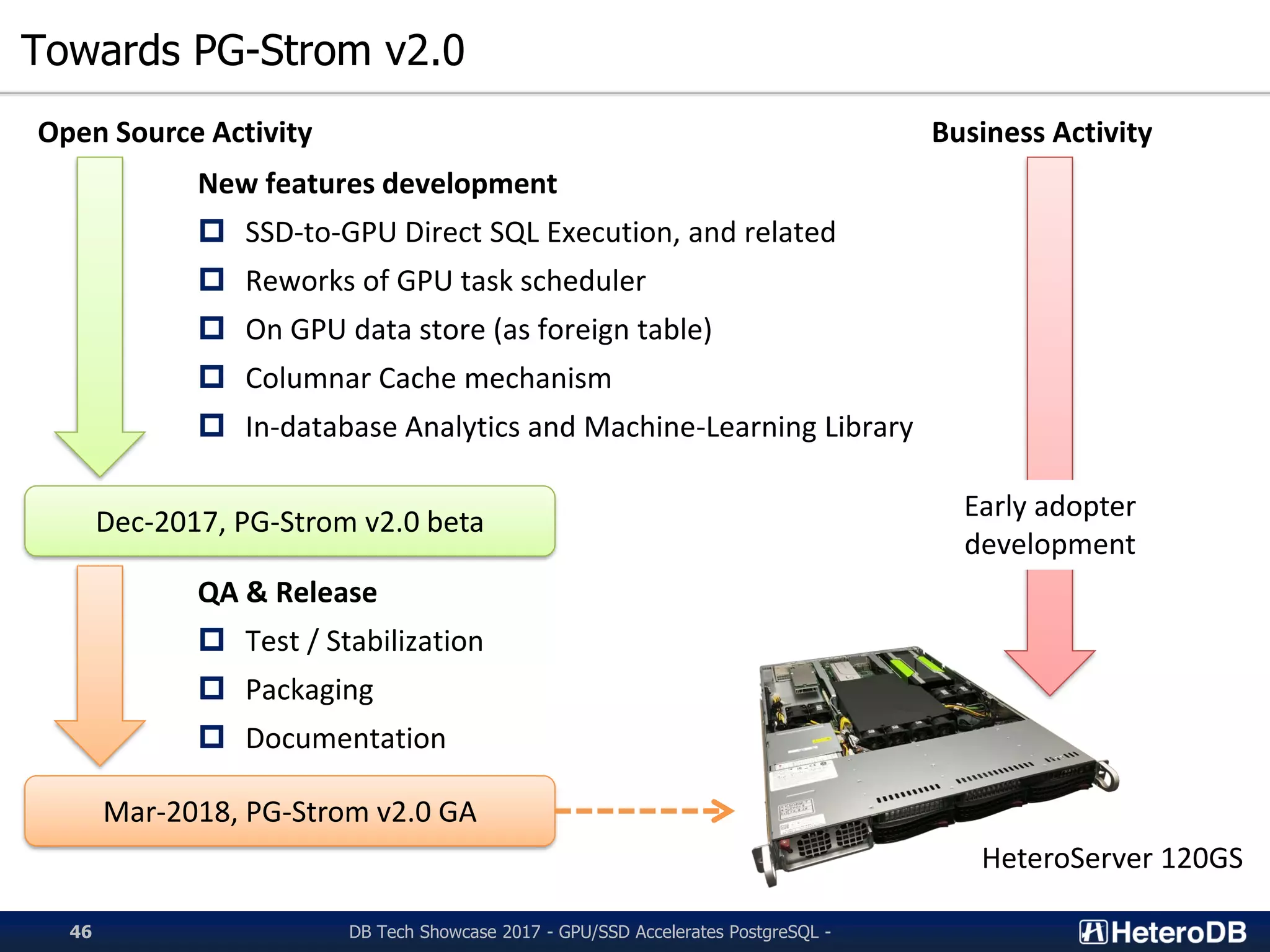
Future advancements in PG-Strom v2.0 and planned features for GPU/SSD integration.
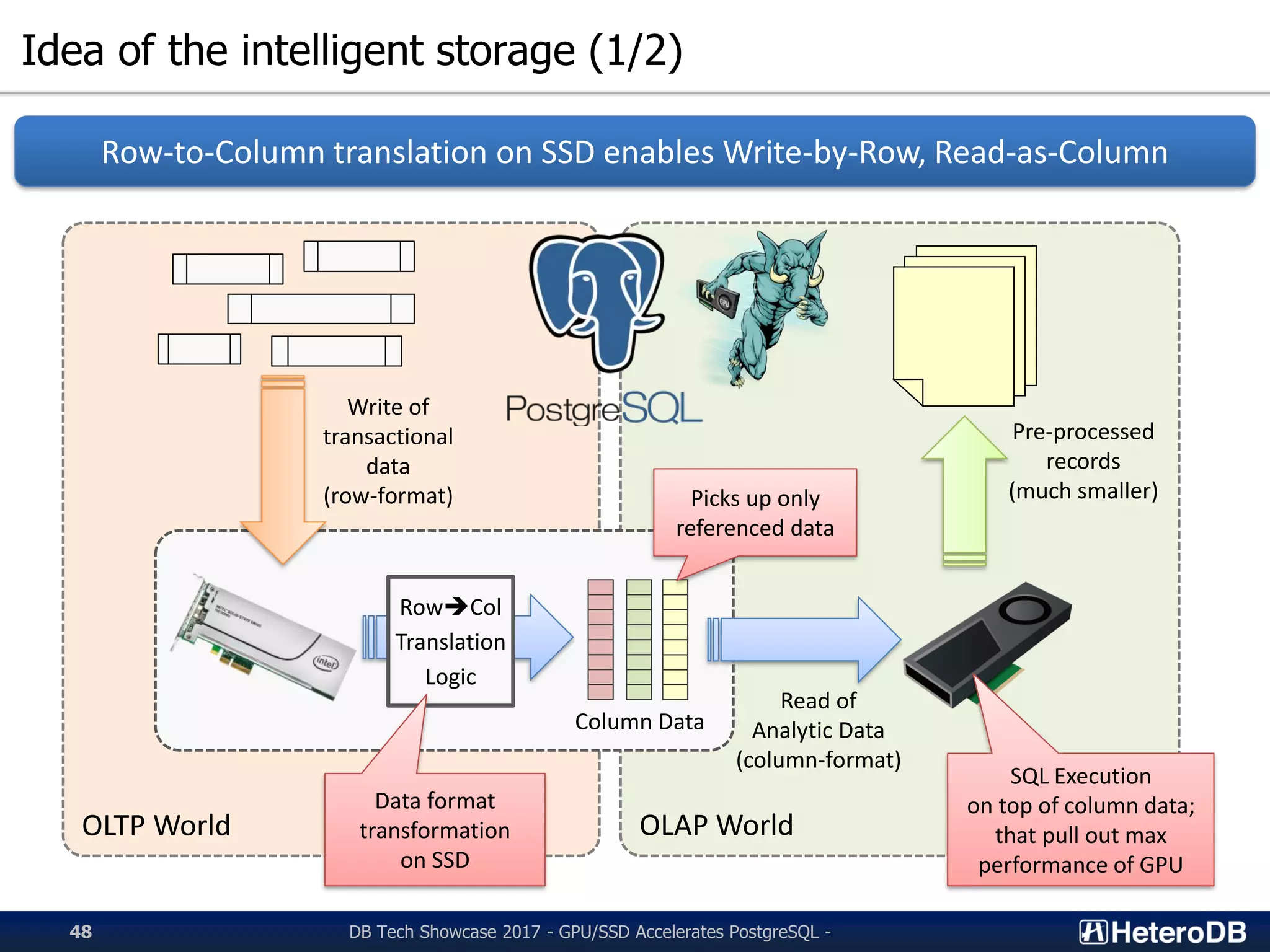
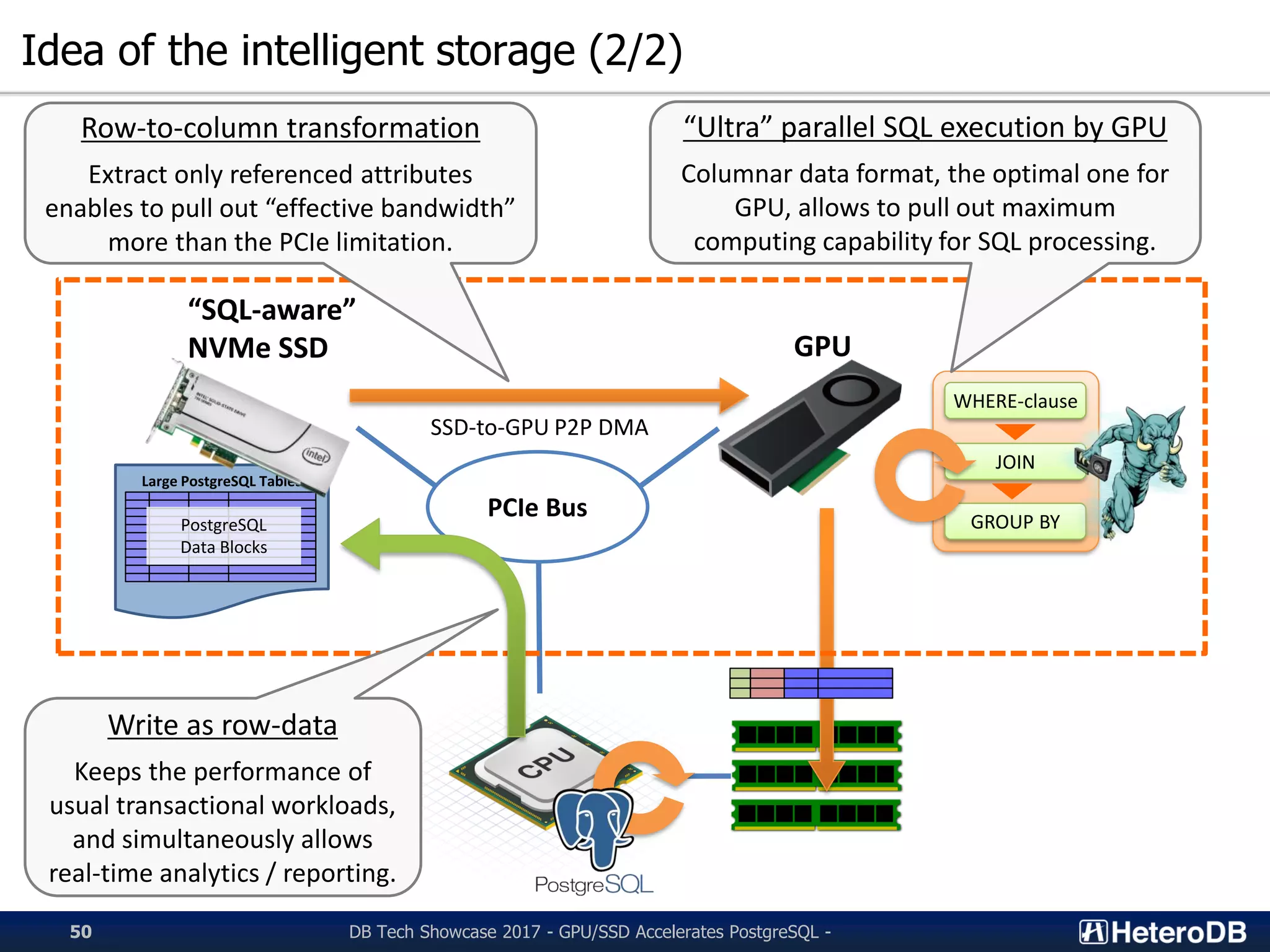
Idea of intelligent storage for improving database performance through optimized data formats.
Closing remarks with contact information for further inquiries.









![[Pgday.Seoul 2017] 2. PostgreSQL을 위한 리눅스 커널 최적화 - 김상욱](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-171106040432-thumbnail.jpg?width=640&height=640&fit=bounds)













































































