Downloaded 86 times






























![But wait, there’s even more!
● [Many] More use cases for views -- Any kind of transformation!
○ Reading from specialized table engines like KafkaEngine
○ Different sort orders
○ Using views as indexes
○ Down-sampling data for long-term storage
○ Creating build pipelines](https://image.slidesharecdn.com/clickhousematerializedviews-themagiccontinues-200226194257/75/ClickHouse-Materialized-Views-The-Magic-Continues-48-2048.jpg)
















































![But wait, there’s even more!
● [Many] More use cases for views -- Any kind of transformation!
○ Reading from specialized table engines like KafkaEngine
○ Different sort orders
○ Using views as indexes
○ Down-sampling data for long-term storage
○ Creating build pipelines](https://crownmelresort.com/image.slidesharecdn.com/clickhousematerializedviews-themagiccontinues-200226194257/75/ClickHouse-Materialized-Views-The-Magic-Continues-48-2048.jpg)


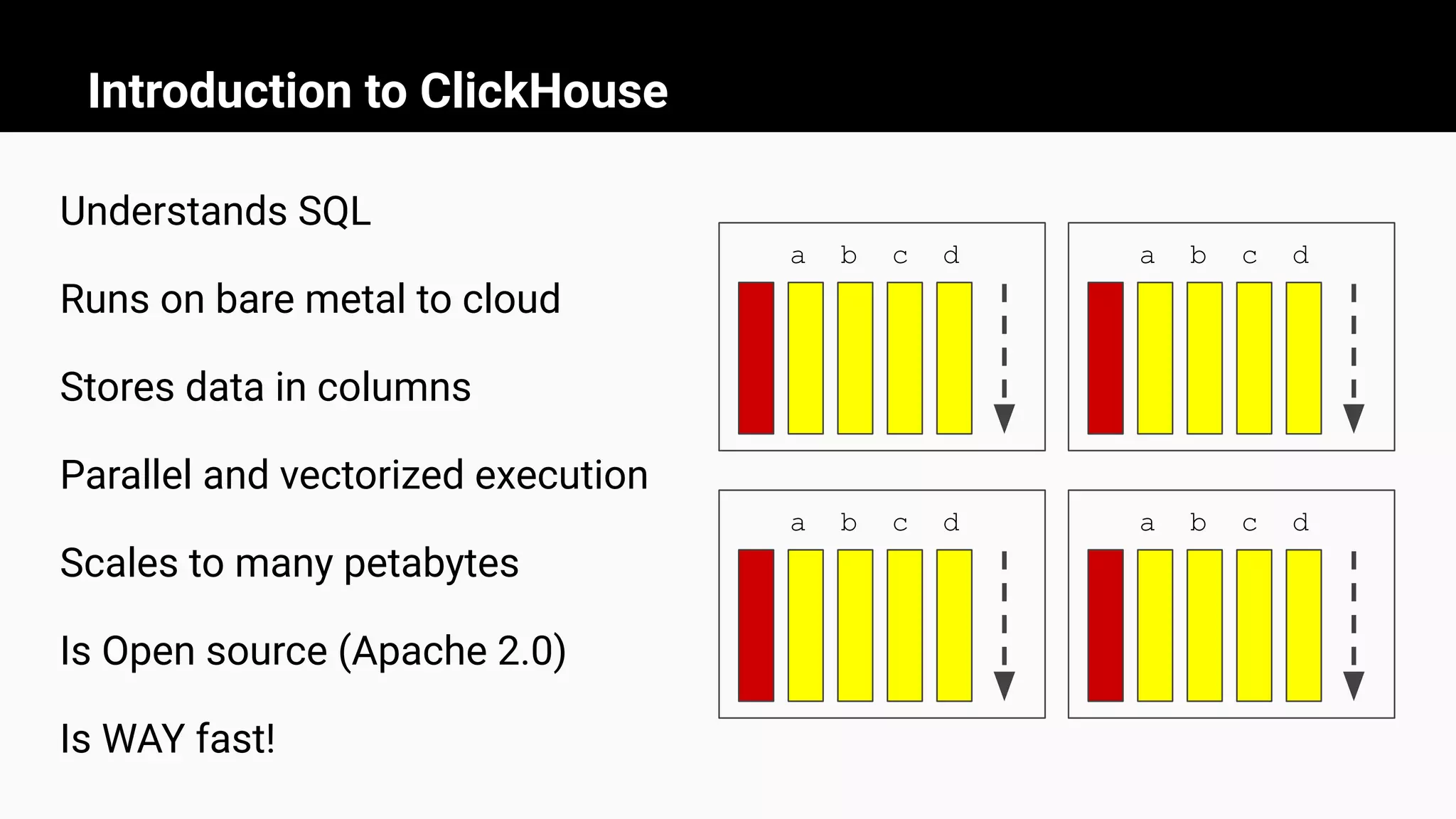
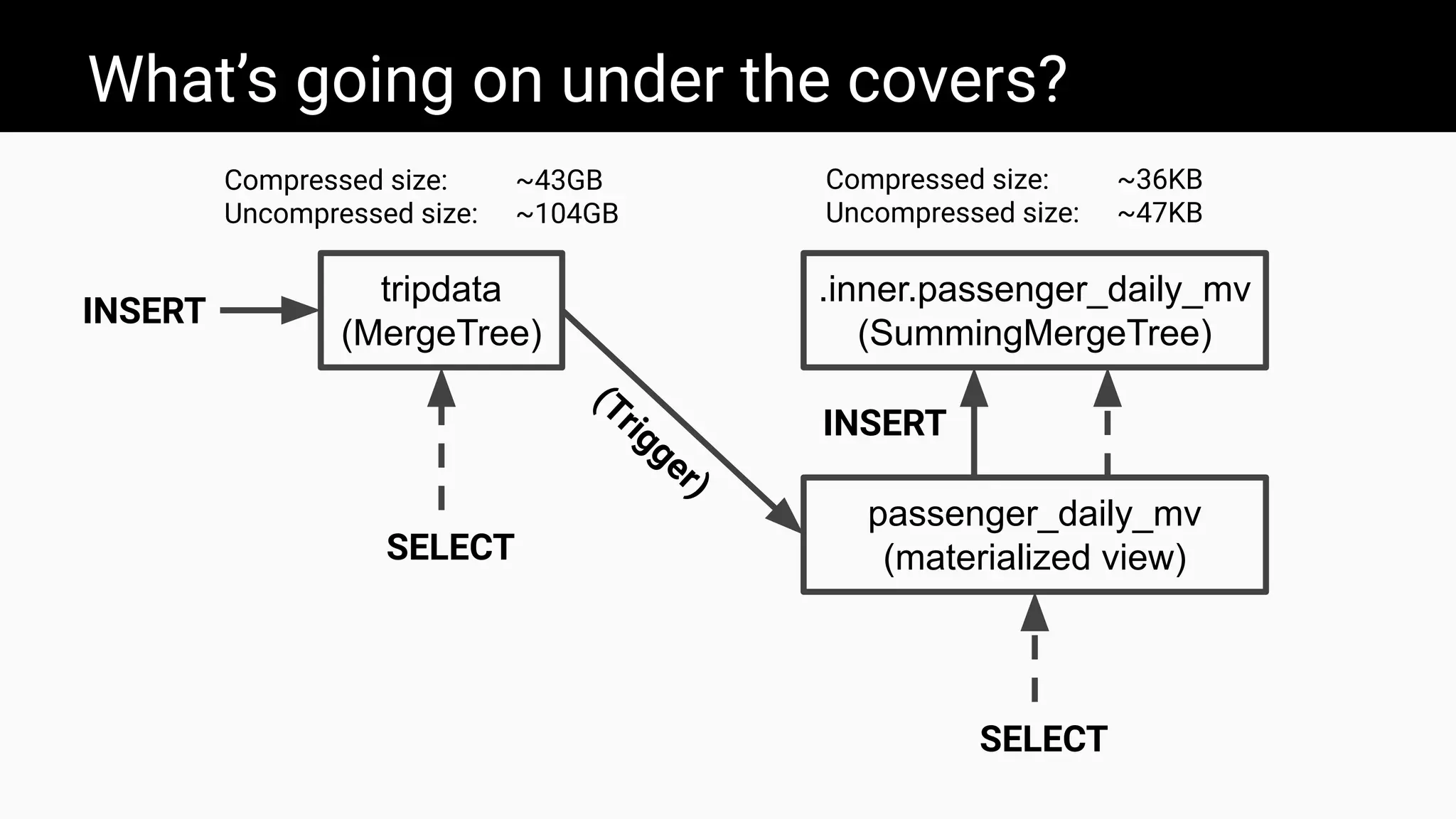
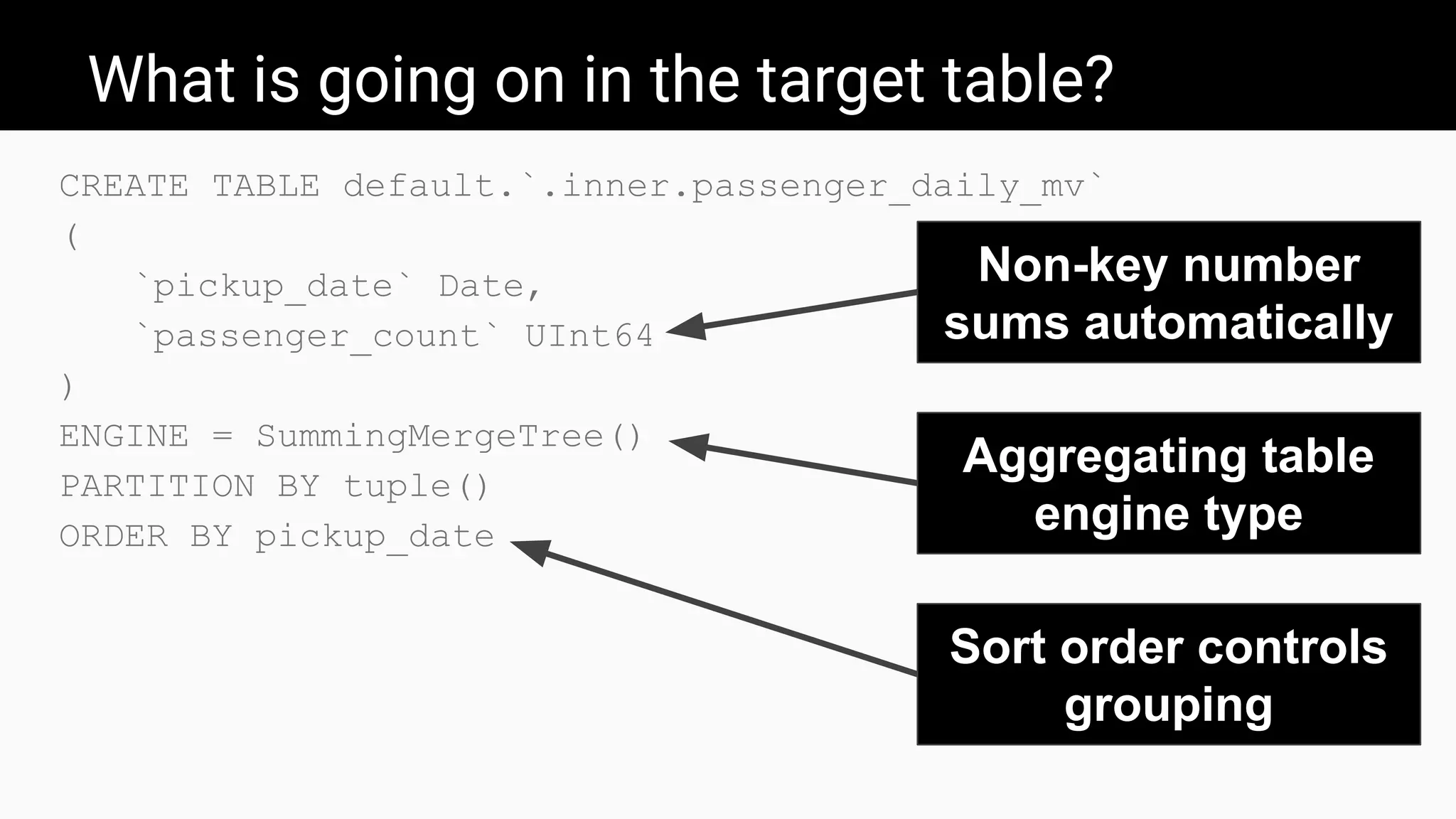
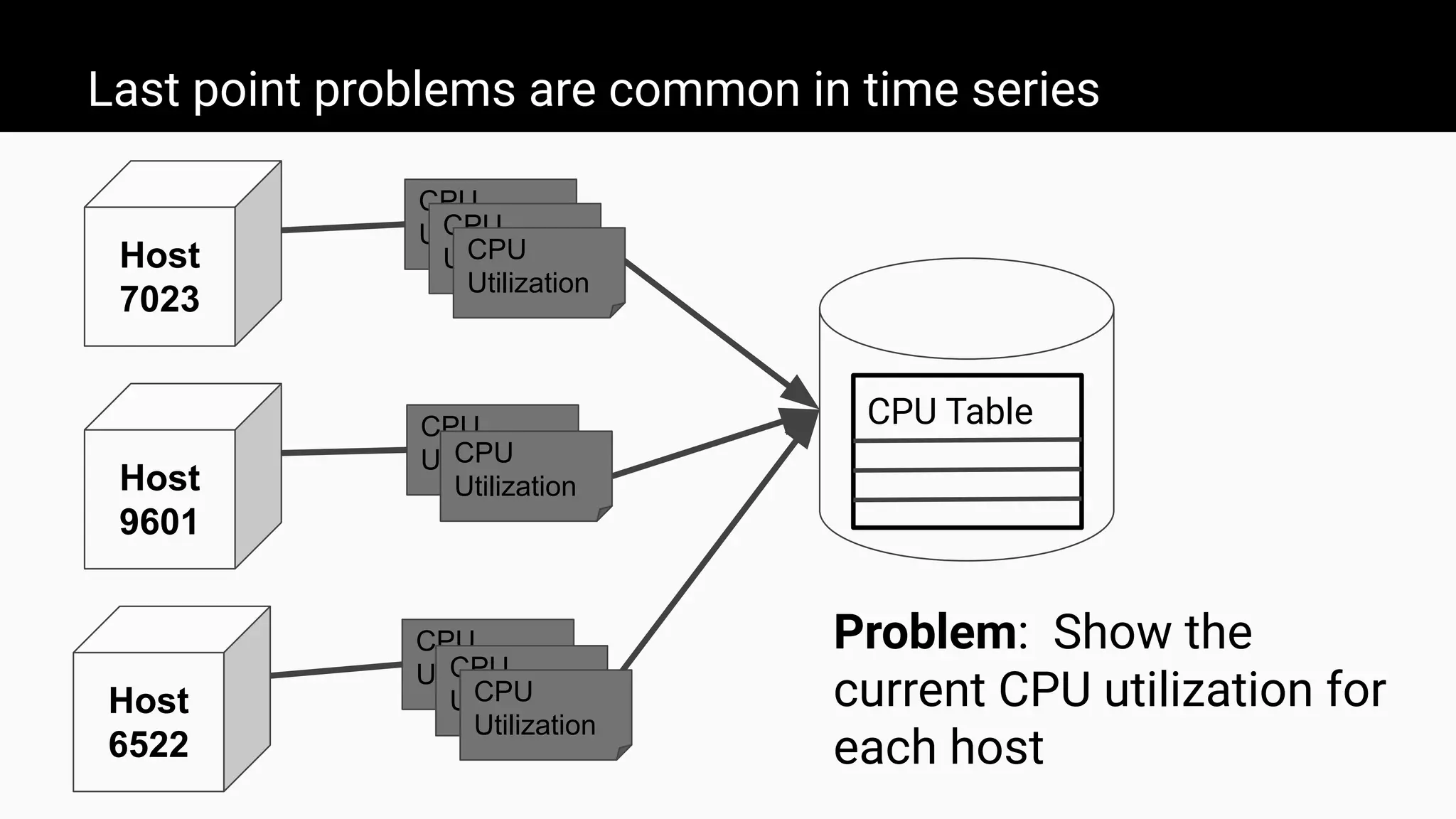
The document introduces ClickHouse, a high-performance columnar database management system, and details the use of materialized views to optimize query performance and data aggregation. It demonstrates through examples how materialized views can significantly enhance the speed of querying large datasets, such as calculating average taxi passengers in New York City and tracking CPU utilization. Additionally, it covers various techniques for creating and managing materialized views to automate data transformations and improve efficiency in real-time data scenarios.























































































