Downloaded 429 times





























































This document provides a summary of best practices for high reliability data loading in ClickHouse. It discusses ClickHouse's ingestion pipeline and strategies for improving performance and reliability of inserts. Some key points include using larger block sizes for inserts, avoiding overly frequent or compressed inserts, optimizing partitioning and sharding, and techniques like buffer tables and compact parts. The document also covers ways to make inserts atomic and handle deduplication of records through block-level and logical approaches.
Overview of ClickHouse by Altinity, its capabilities, and presenter bios.
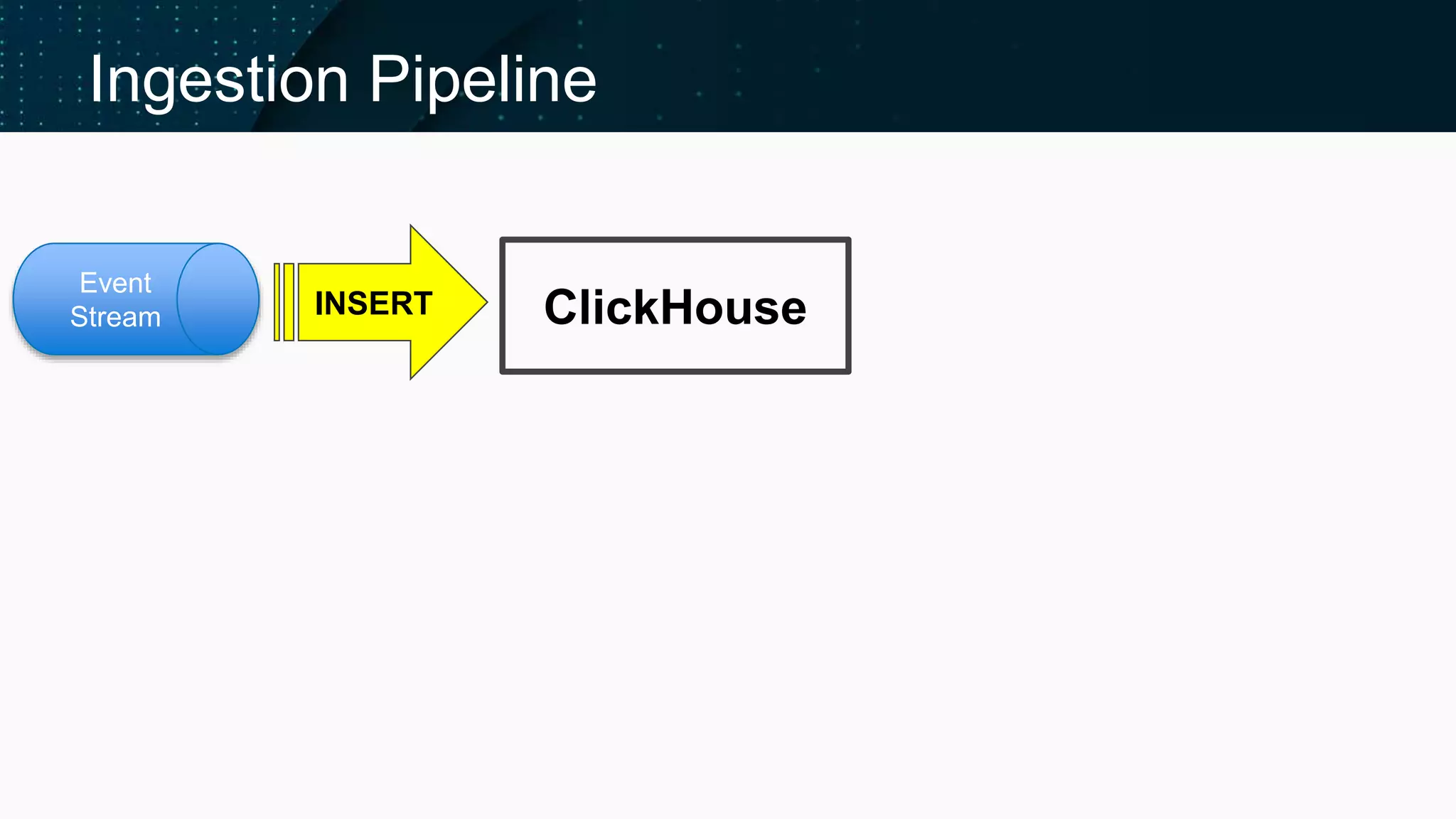
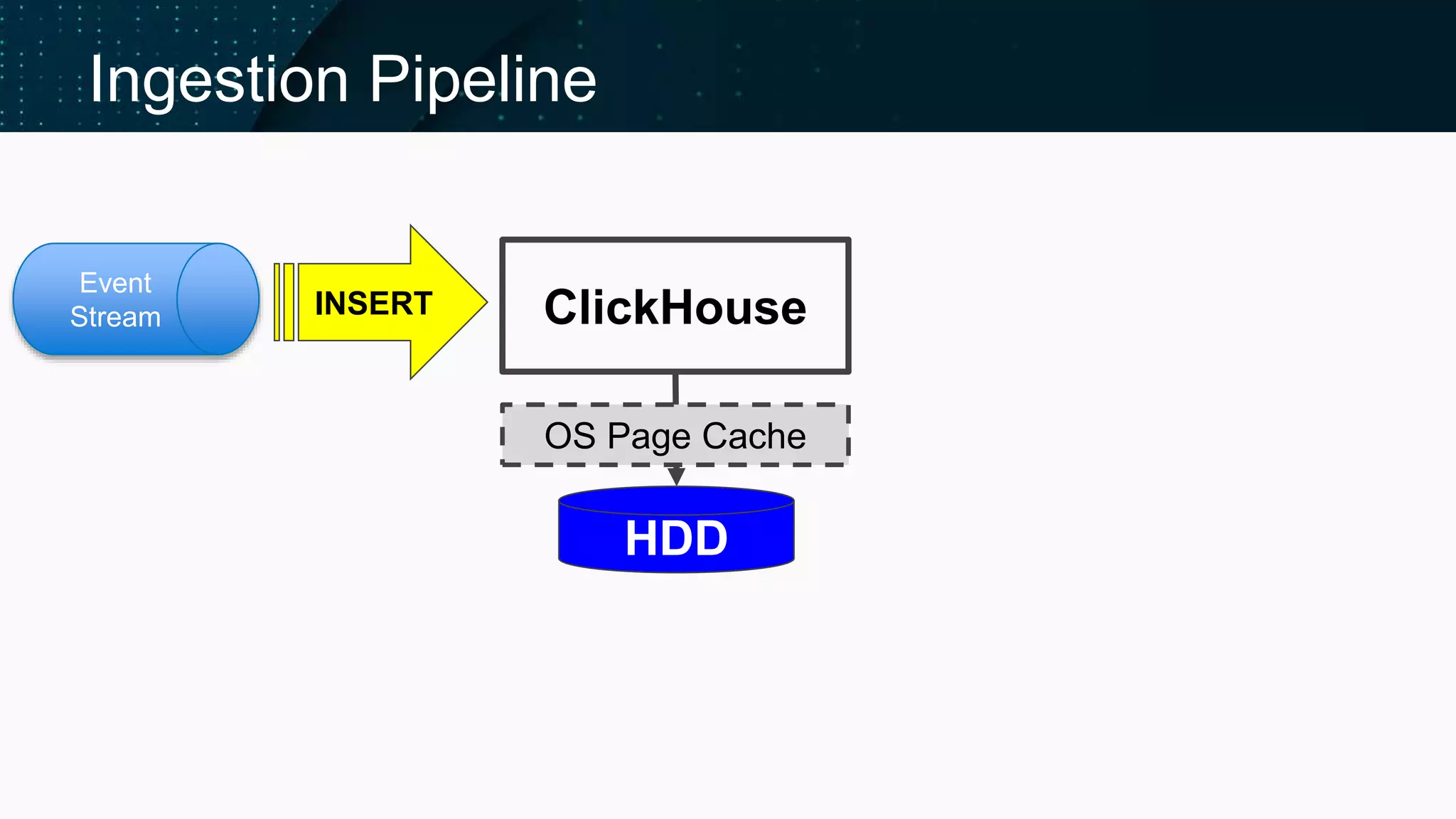
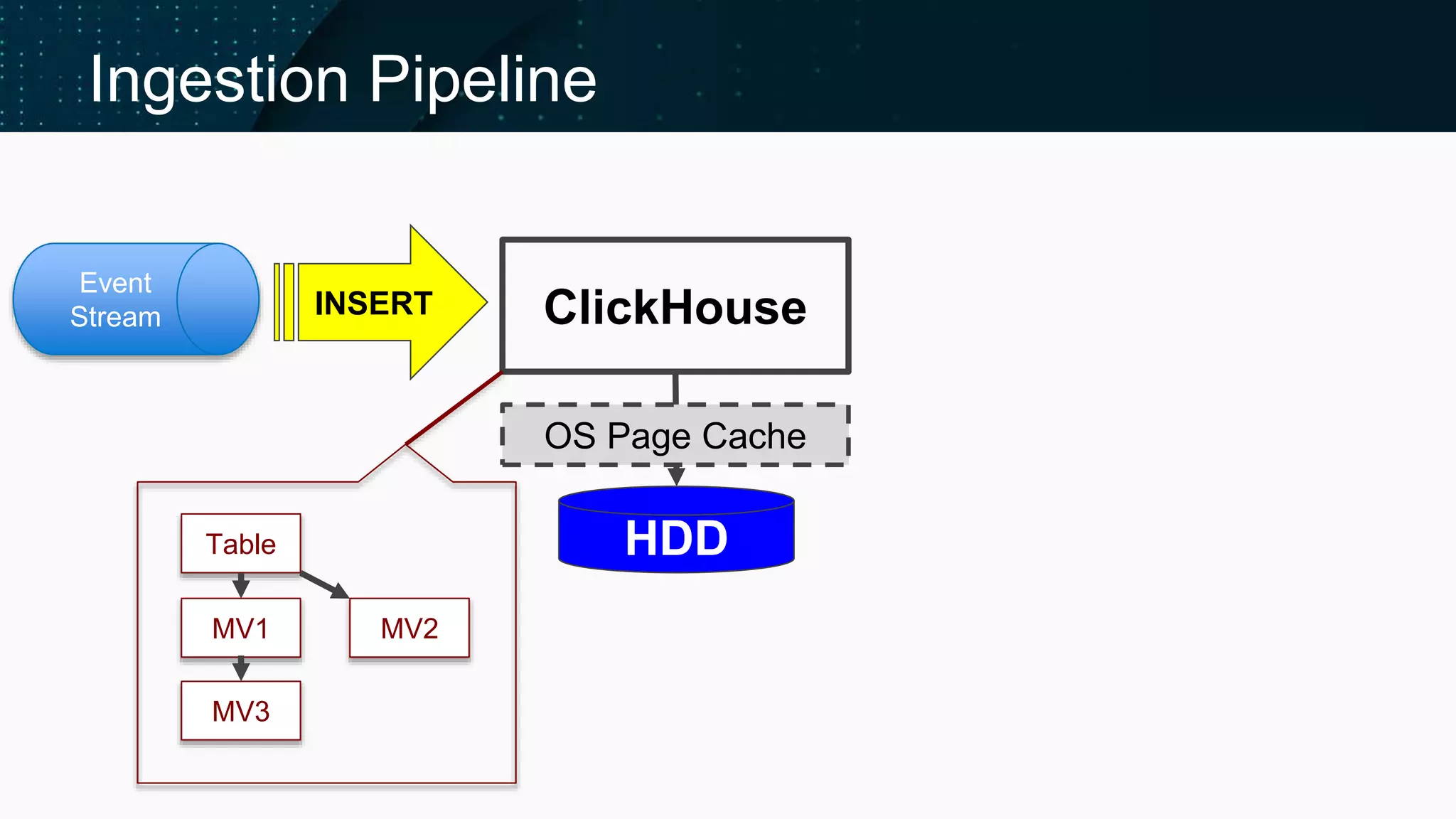
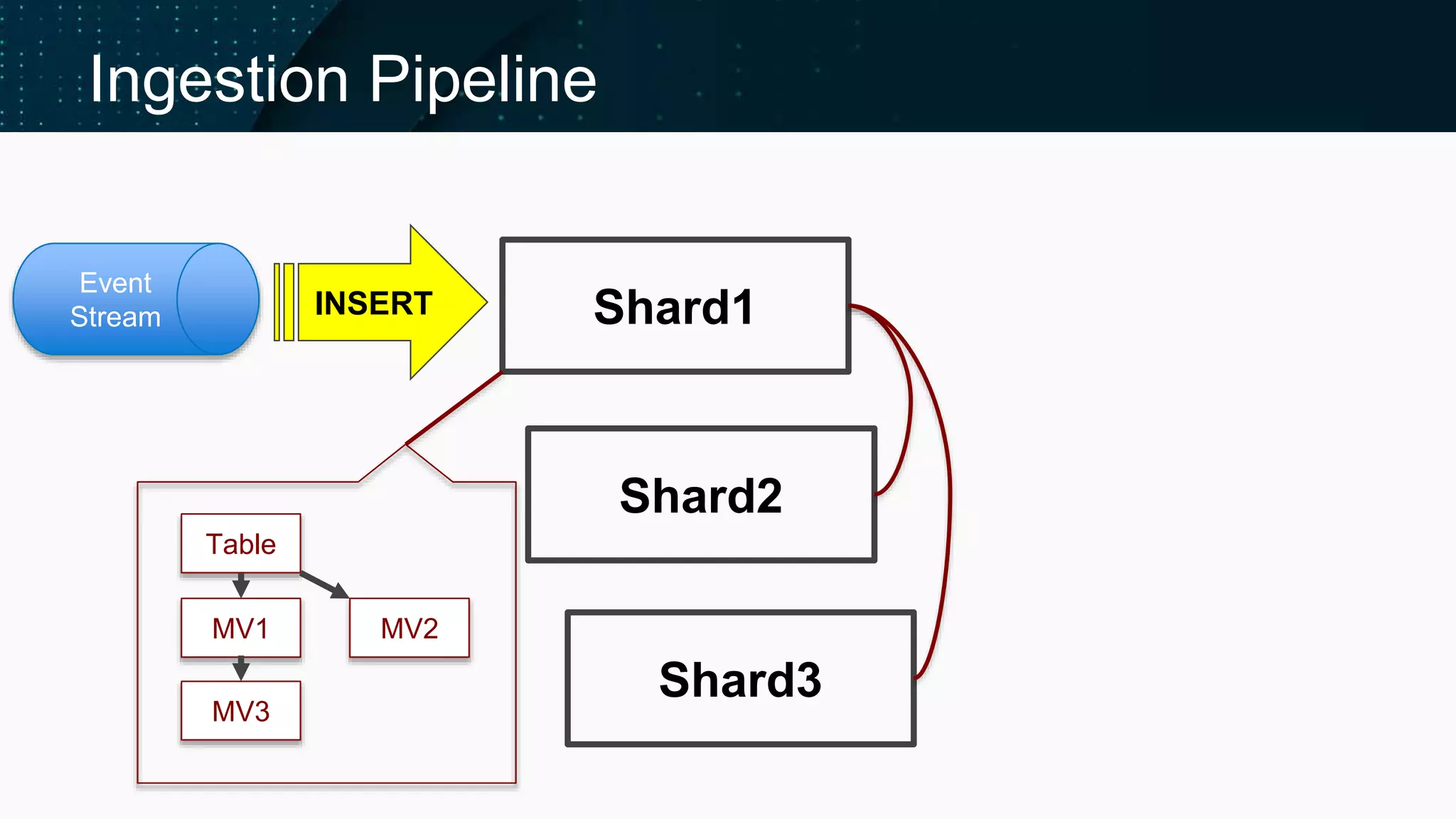
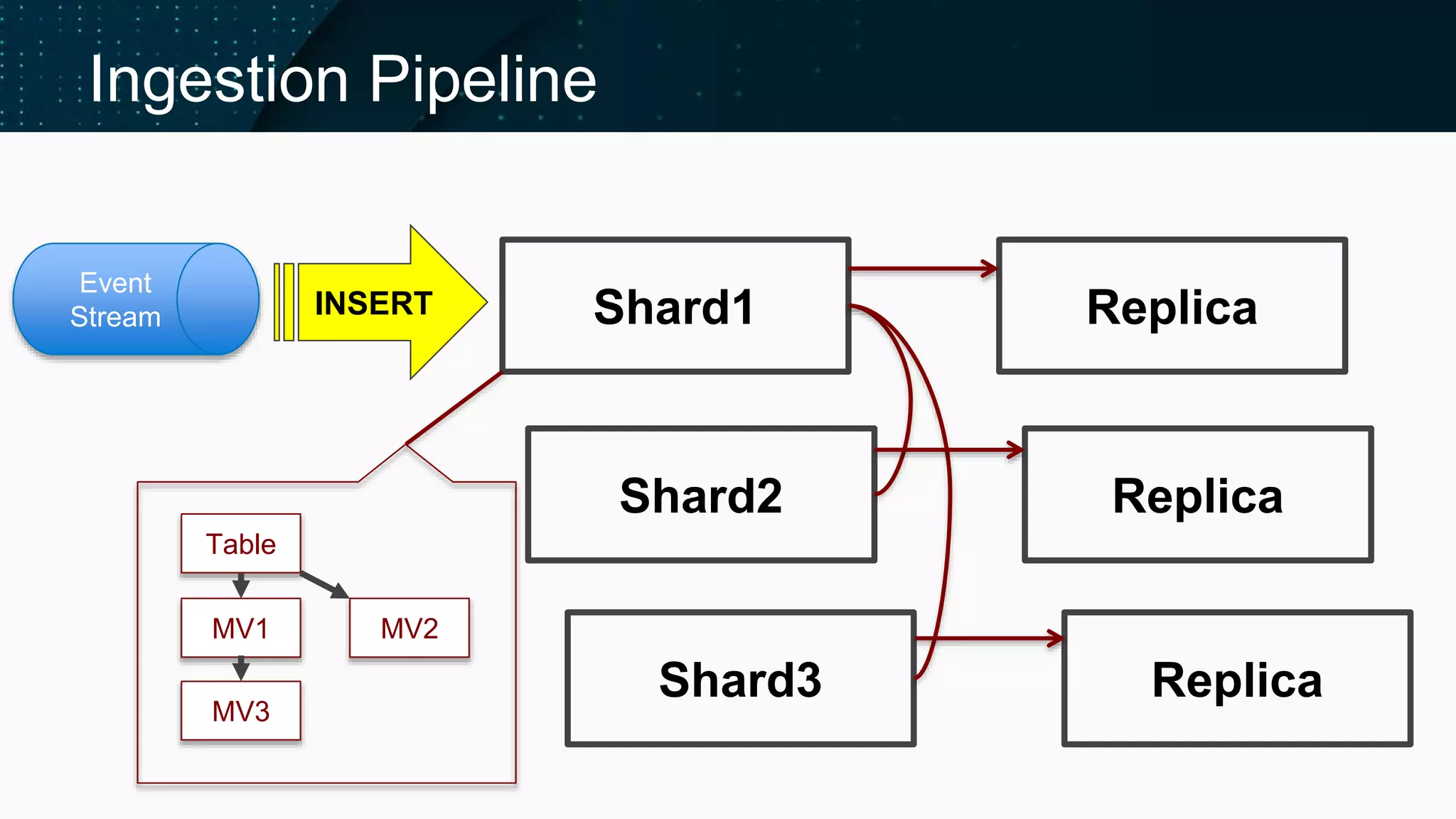
Illustrates the ClickHouse ingestion pipeline's components and architecture.
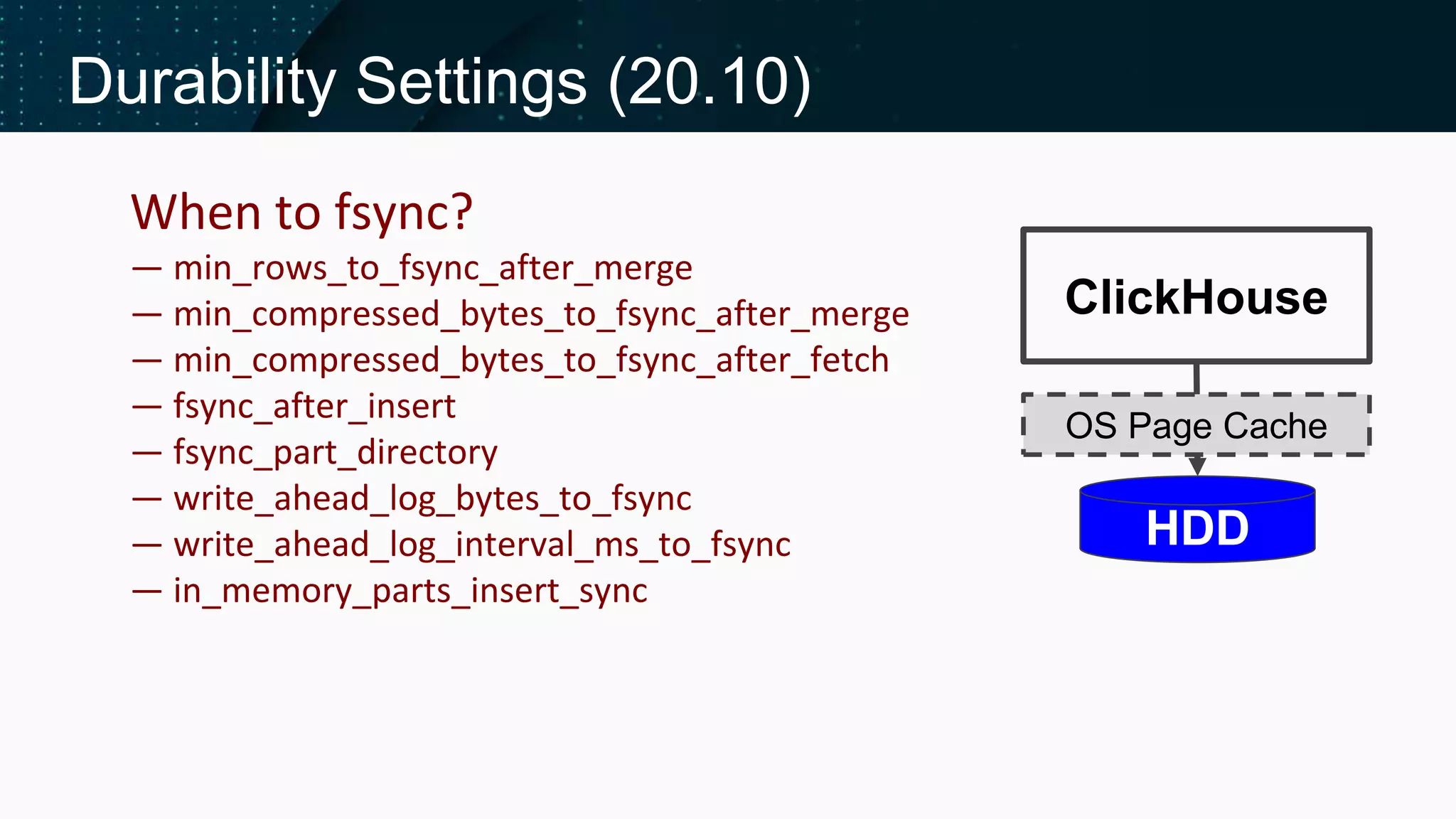
Discusses performance, reliability, and techniques to reduce overhead in data imsertion.
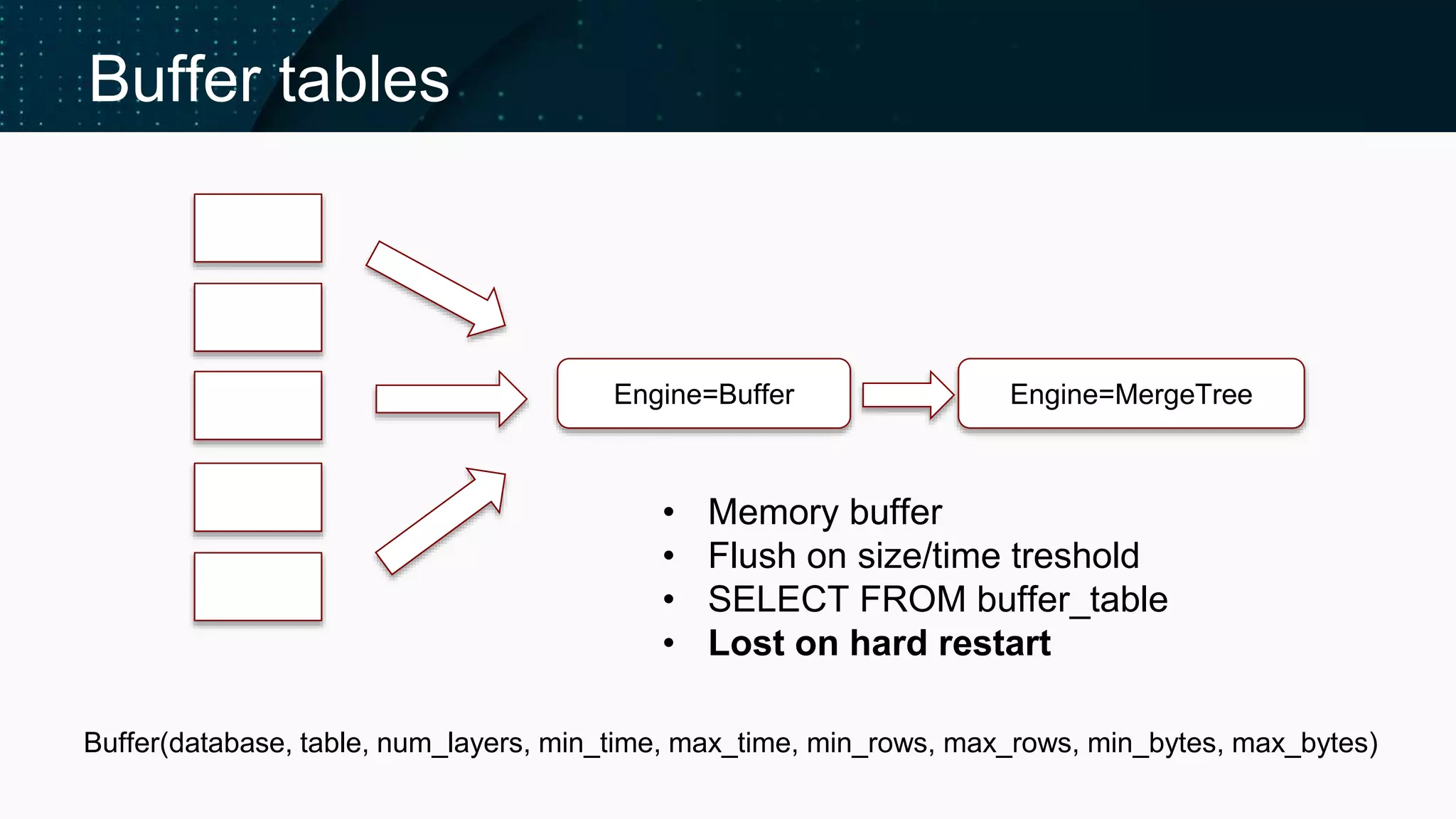
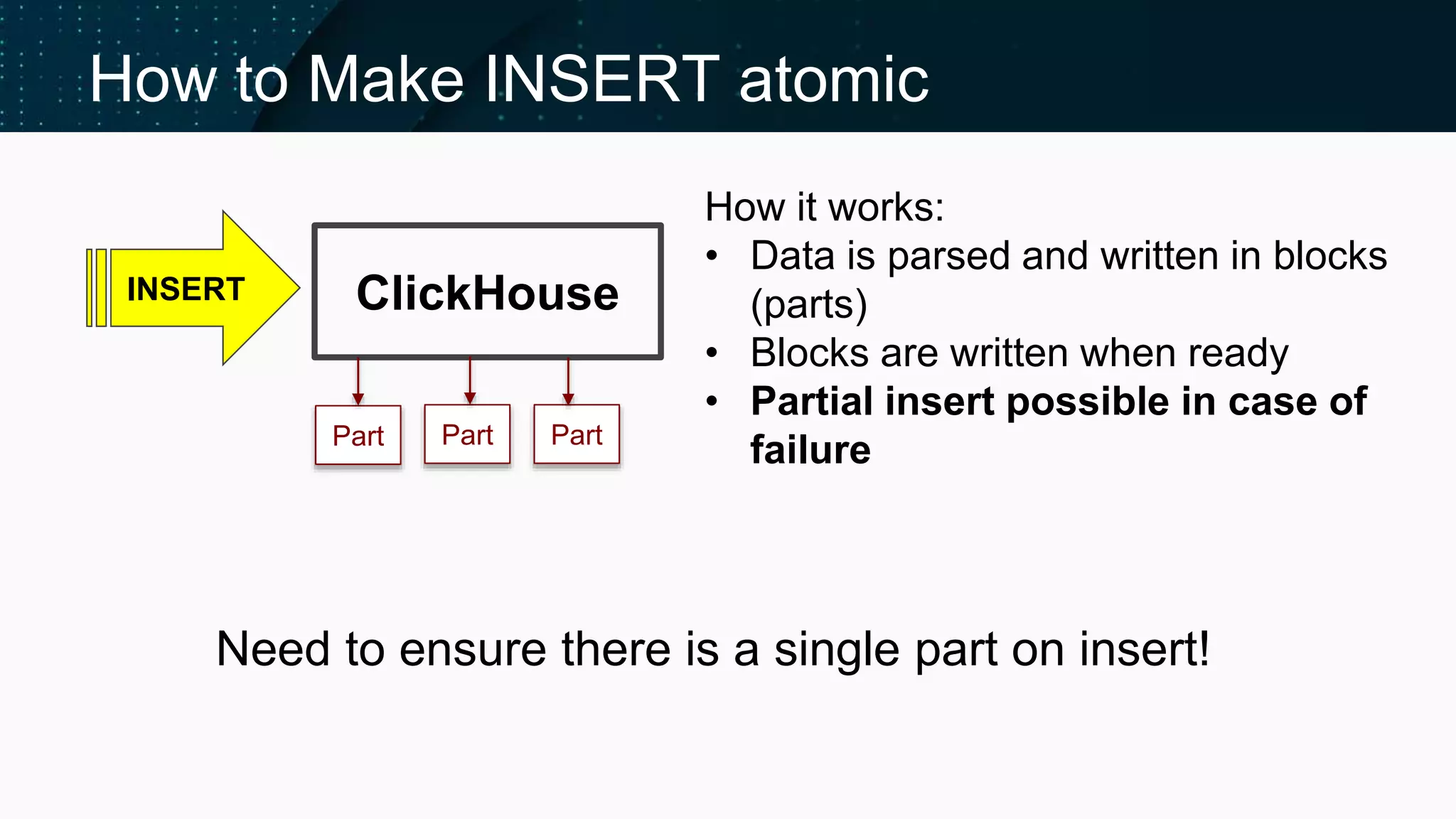
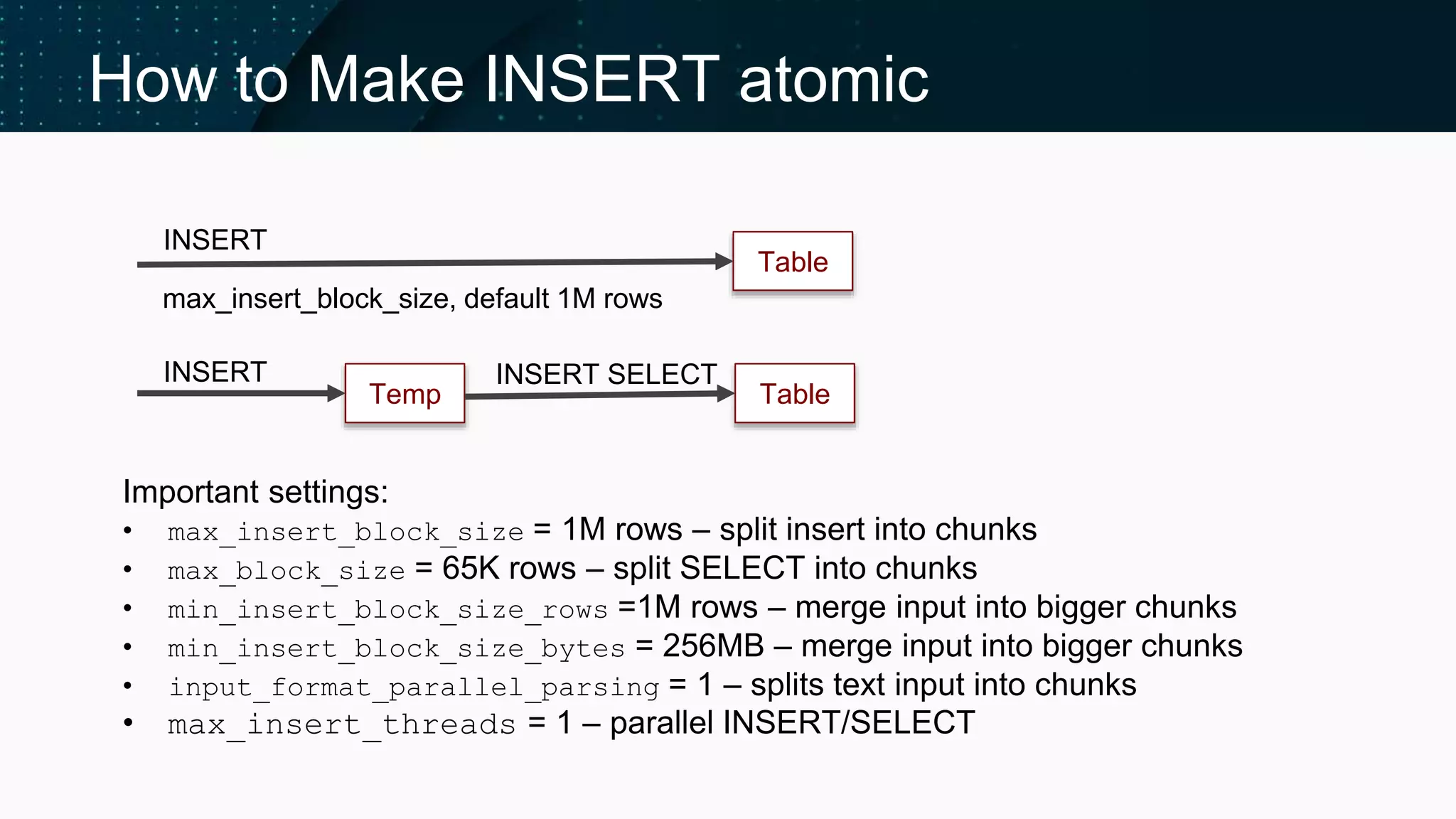
Insights on Buffer tables, Compact parts, and atomicity in INSERT operations.
Information on materialized views execution process and expected future features.
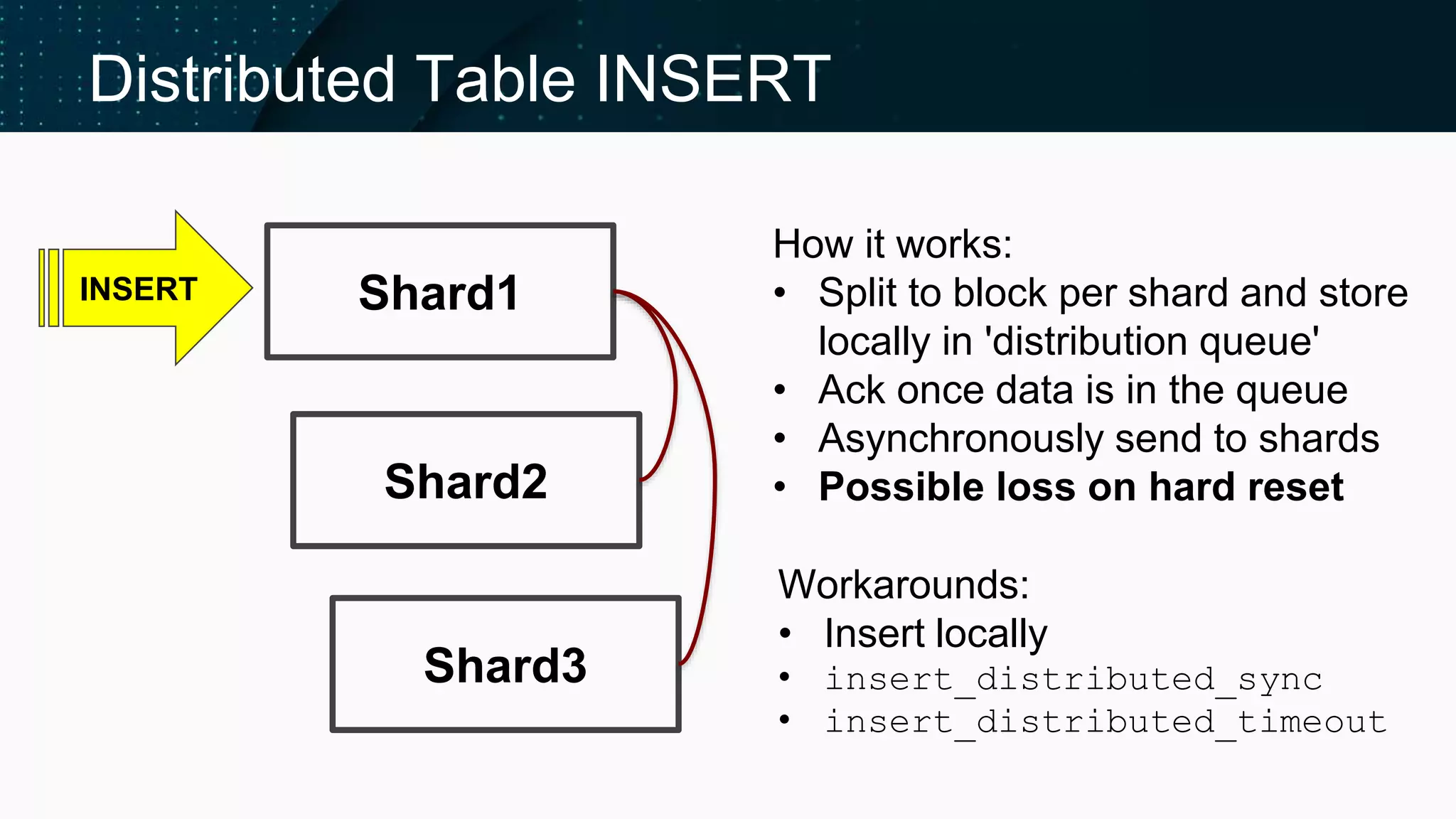
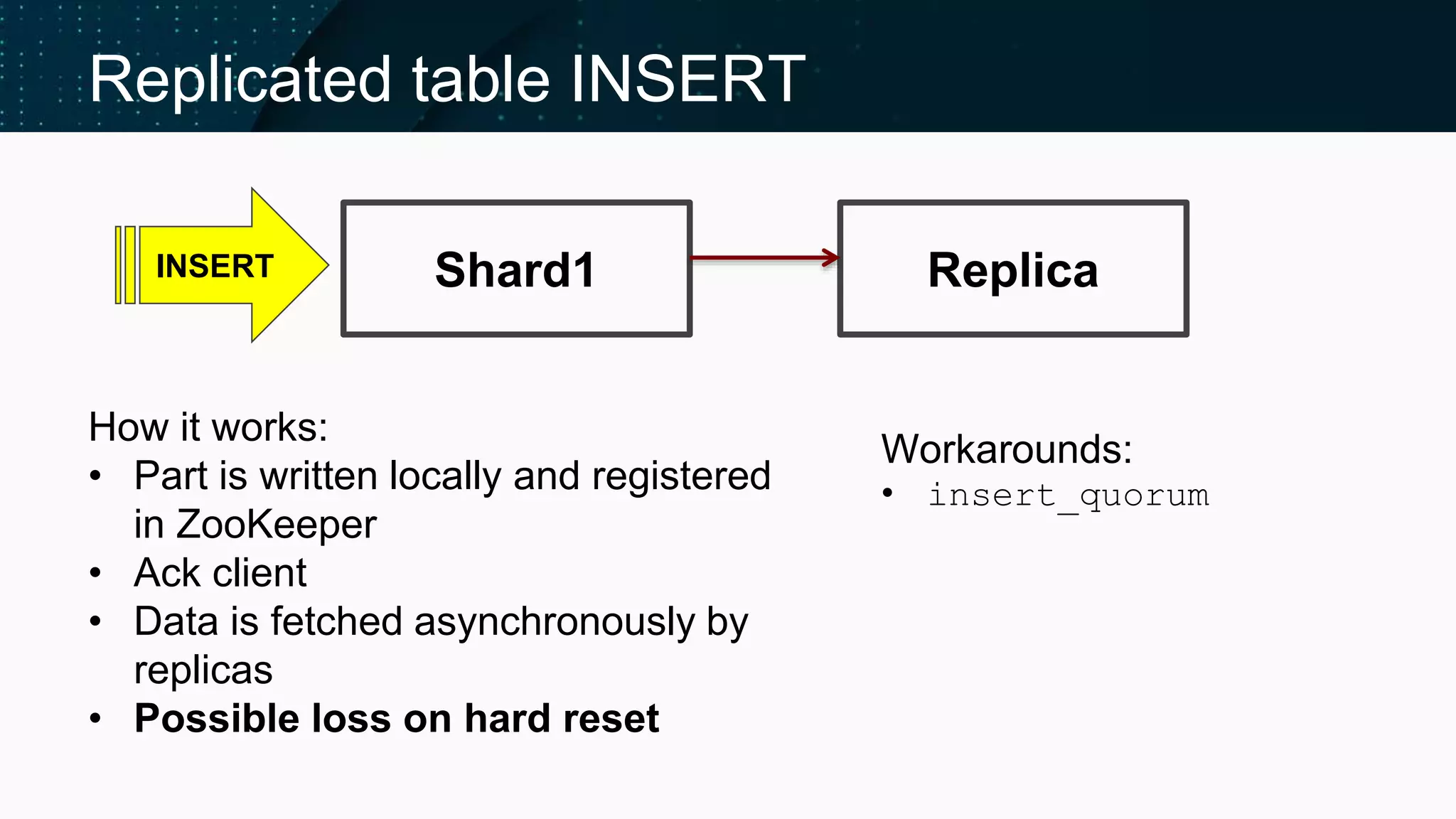
Details on distributed table inserts and ensuring data availability through replication.
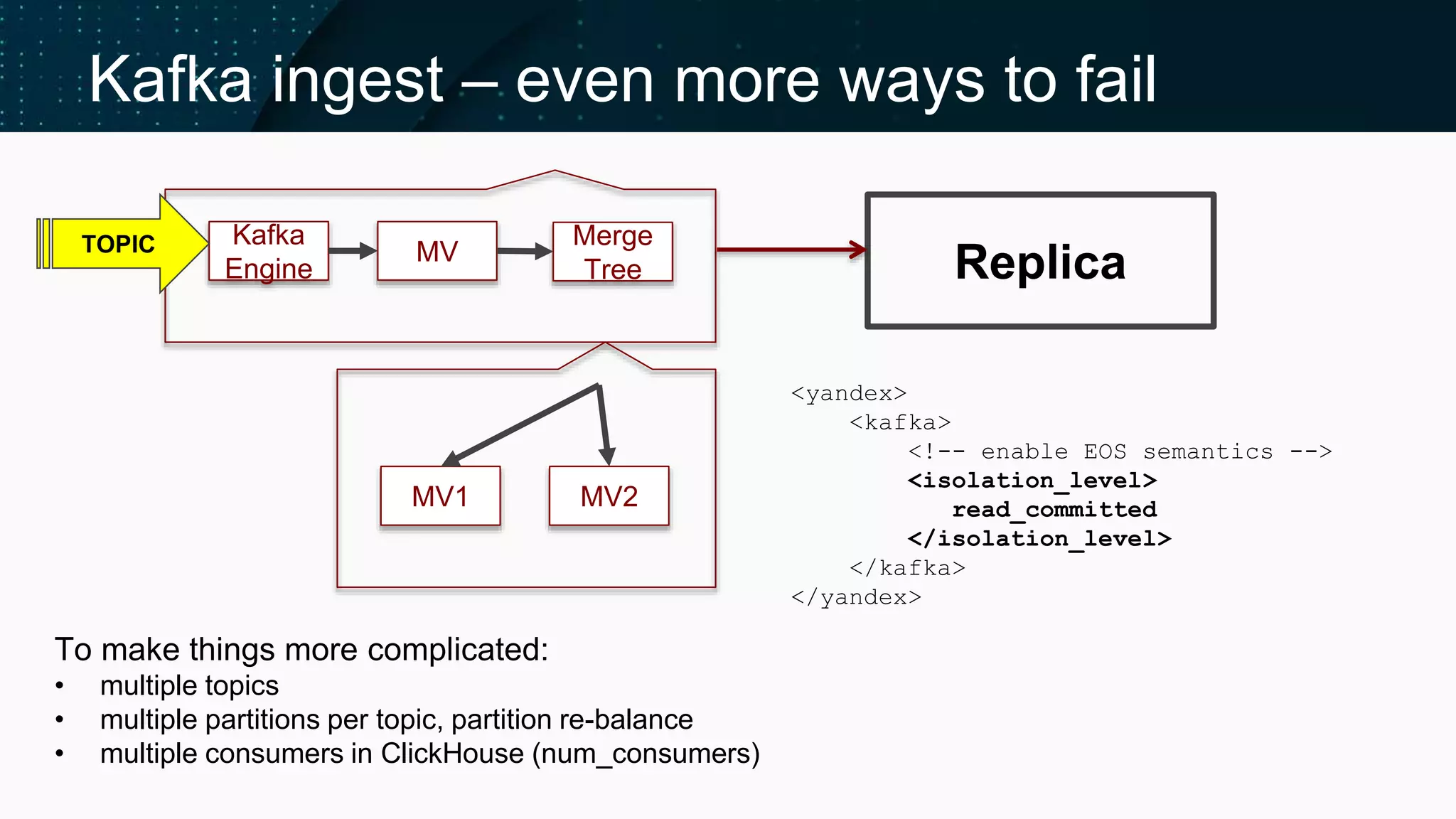
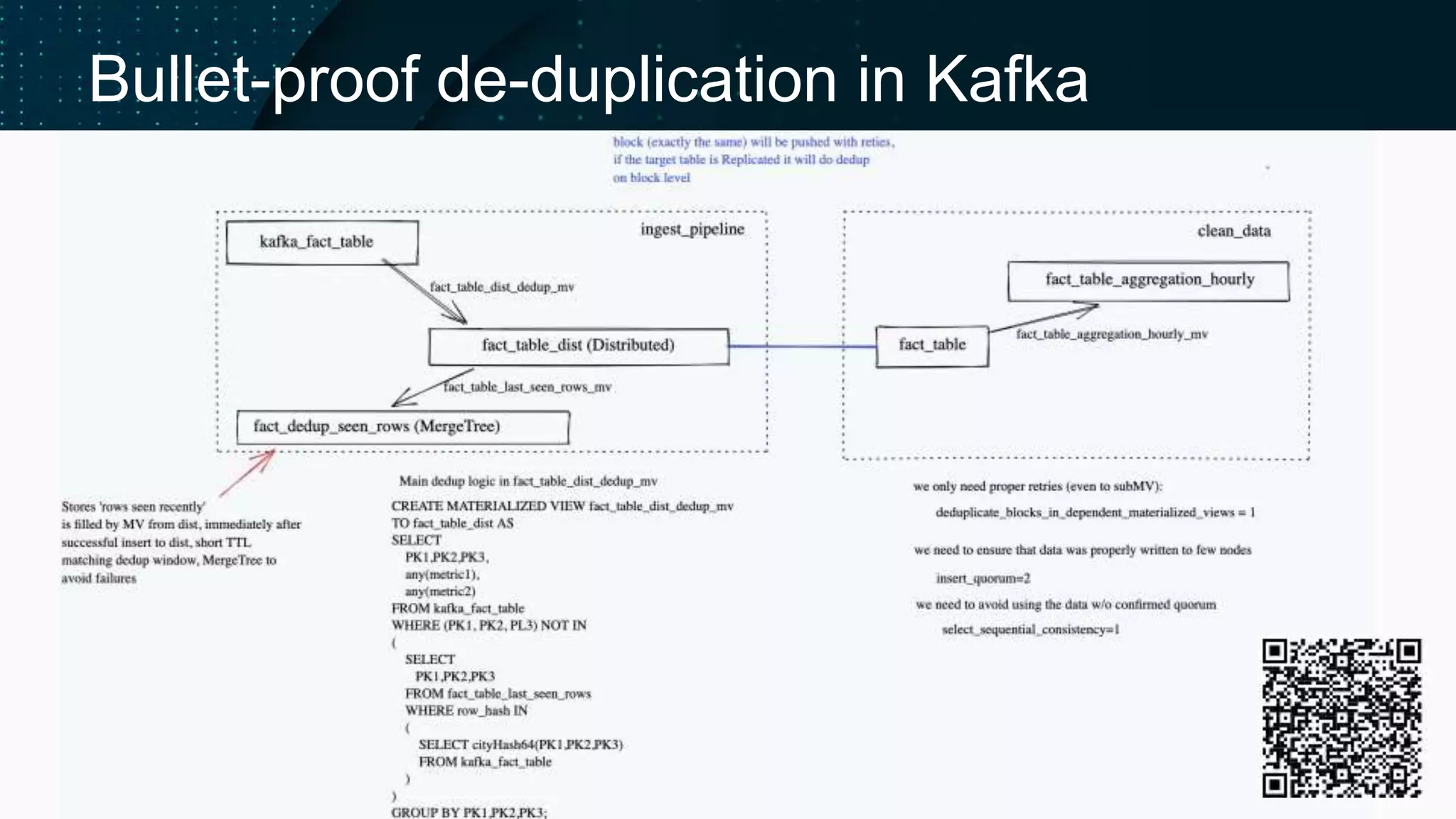
Challenges faced while ingesting data from Kafka, including maintenance of consistency.
Recommendations to ensure optimal insert operations and avoid known pitfalls.
Explores reasons for duplicates and methods for deduplication in ClickHouse.
Techniques for identifying and optimizing duplicate data in large tables.
Final remarks on ClickHouse performance, reliability, and upcoming features for 2021.

























![[Meetup] a successful migration from elastic search to clickhouse](https://cdn.slidesharecdn.com/ss_thumbnails/meetupasuccessfulmigrationfromelasticsearchtoclickhouse-191004114403-thumbnail.jpg?width=640&height=640&fit=bounds)

























































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)



