Download as PDF, PPTX










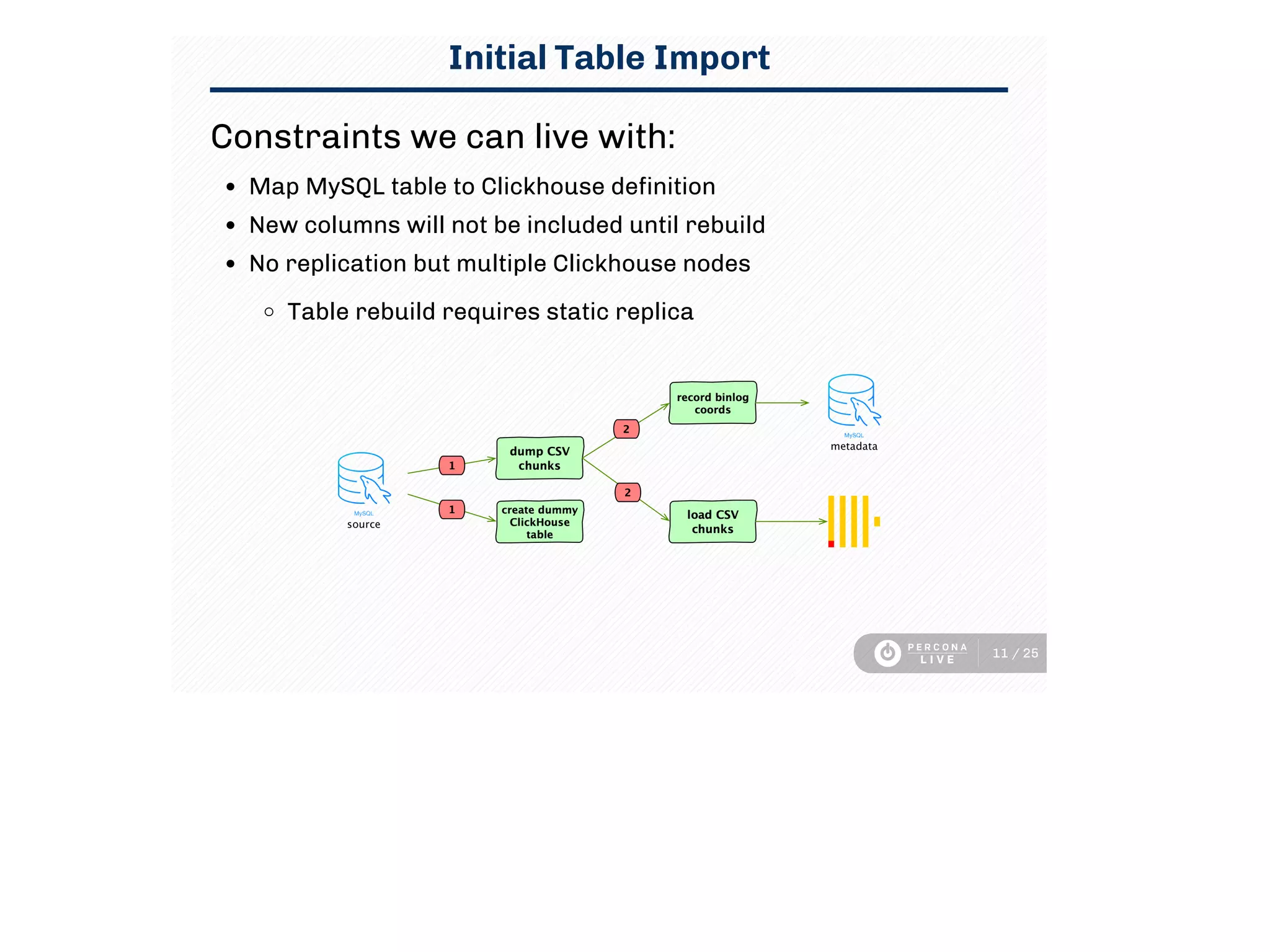
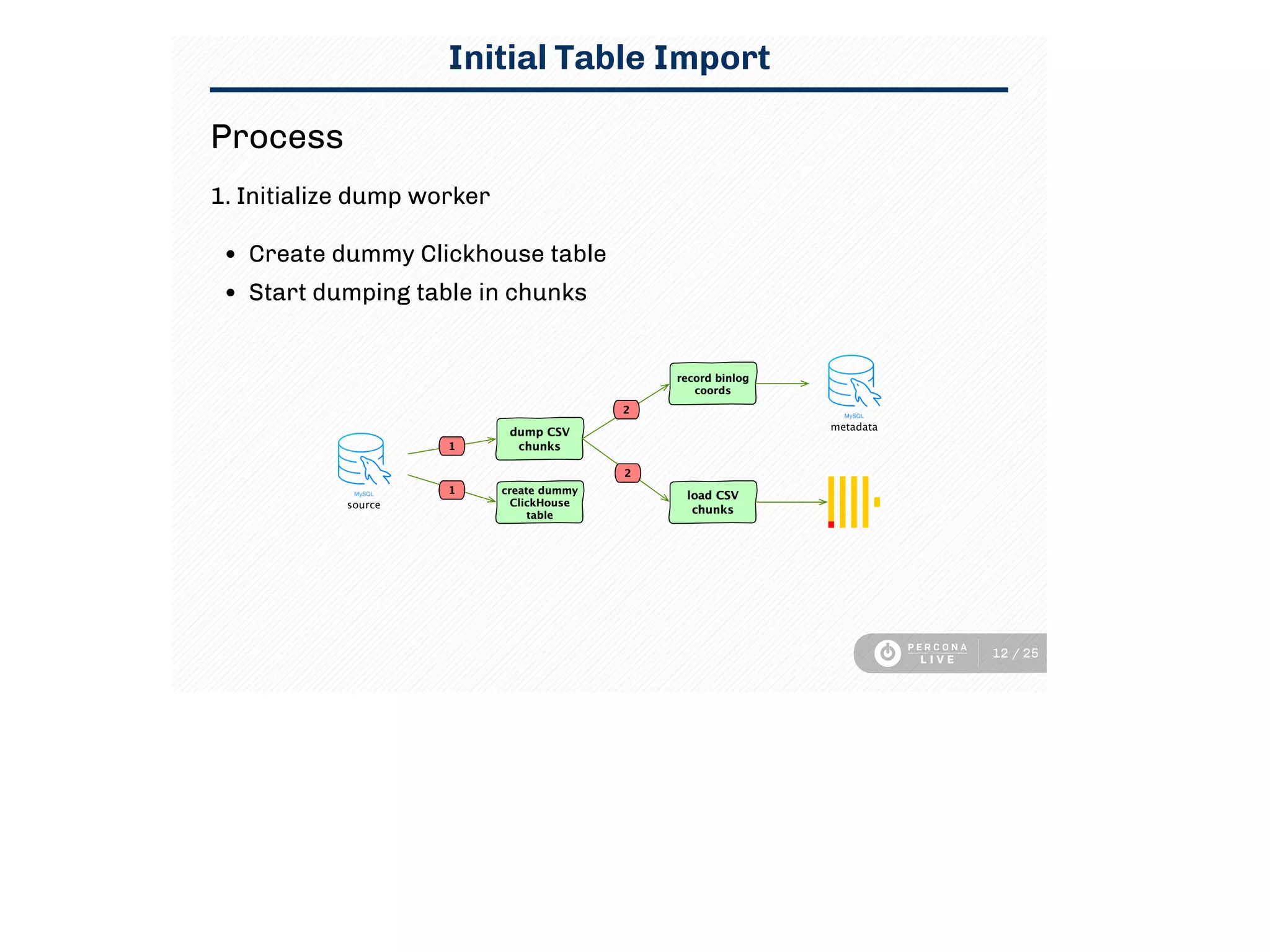
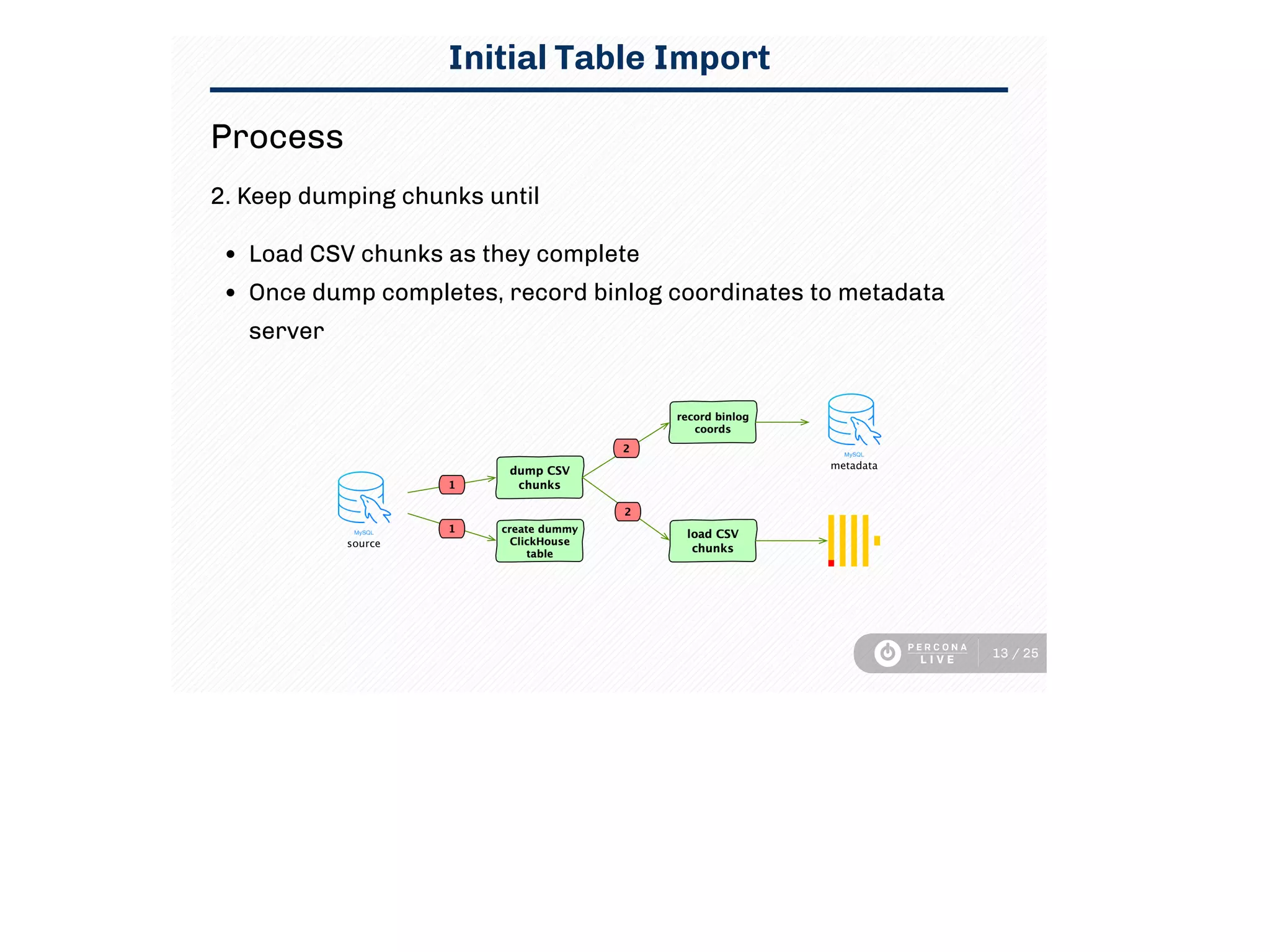
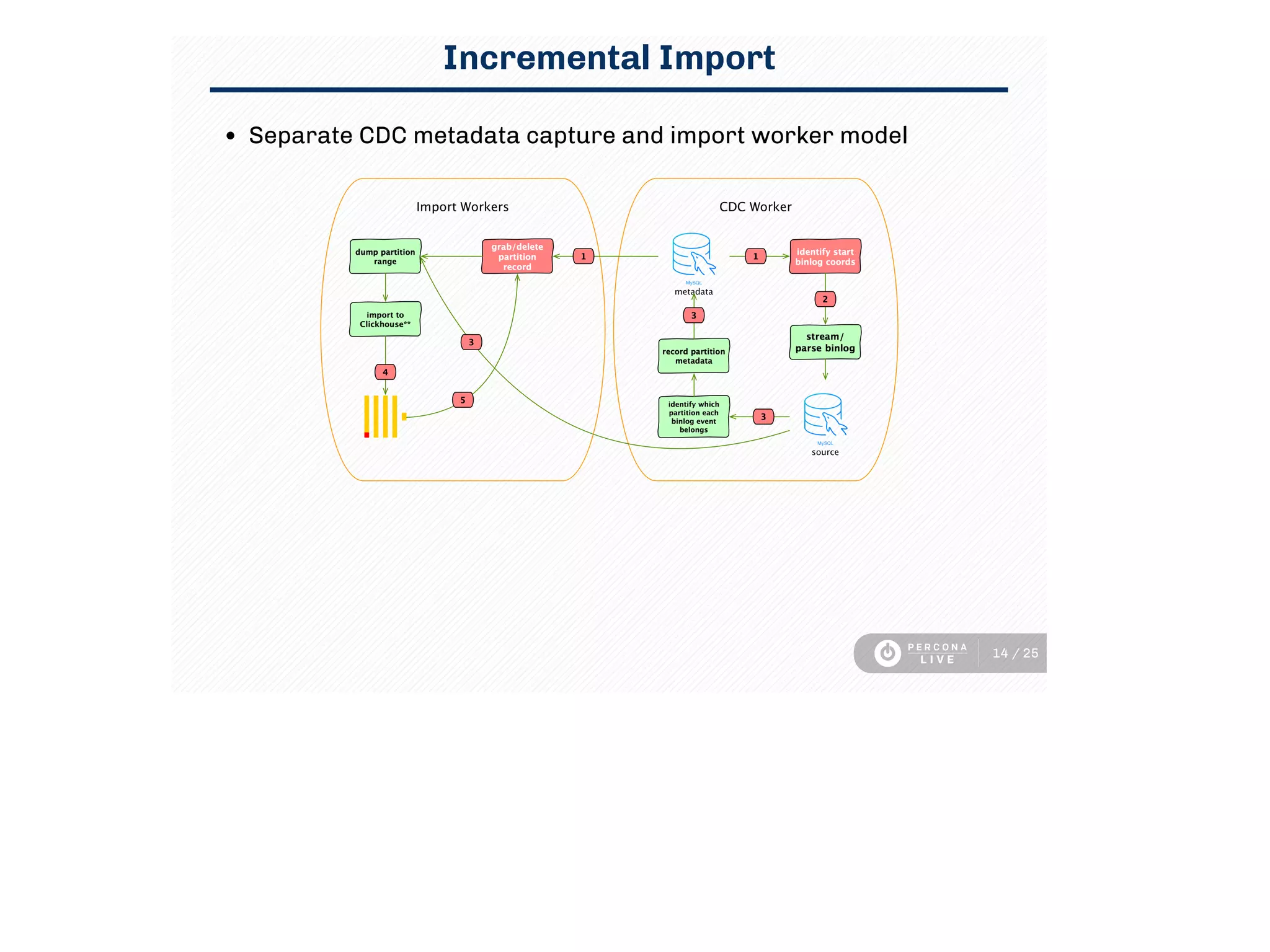
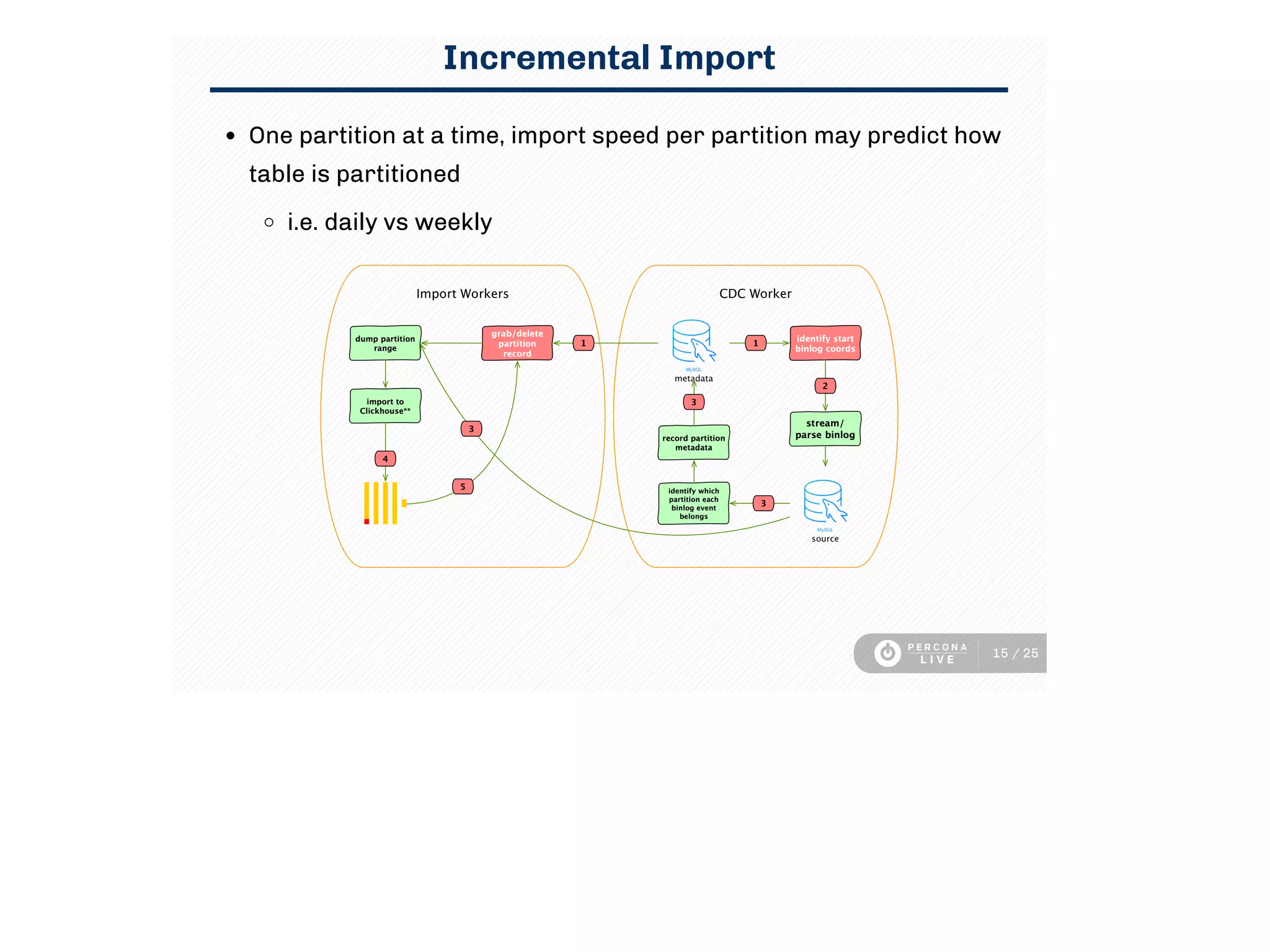
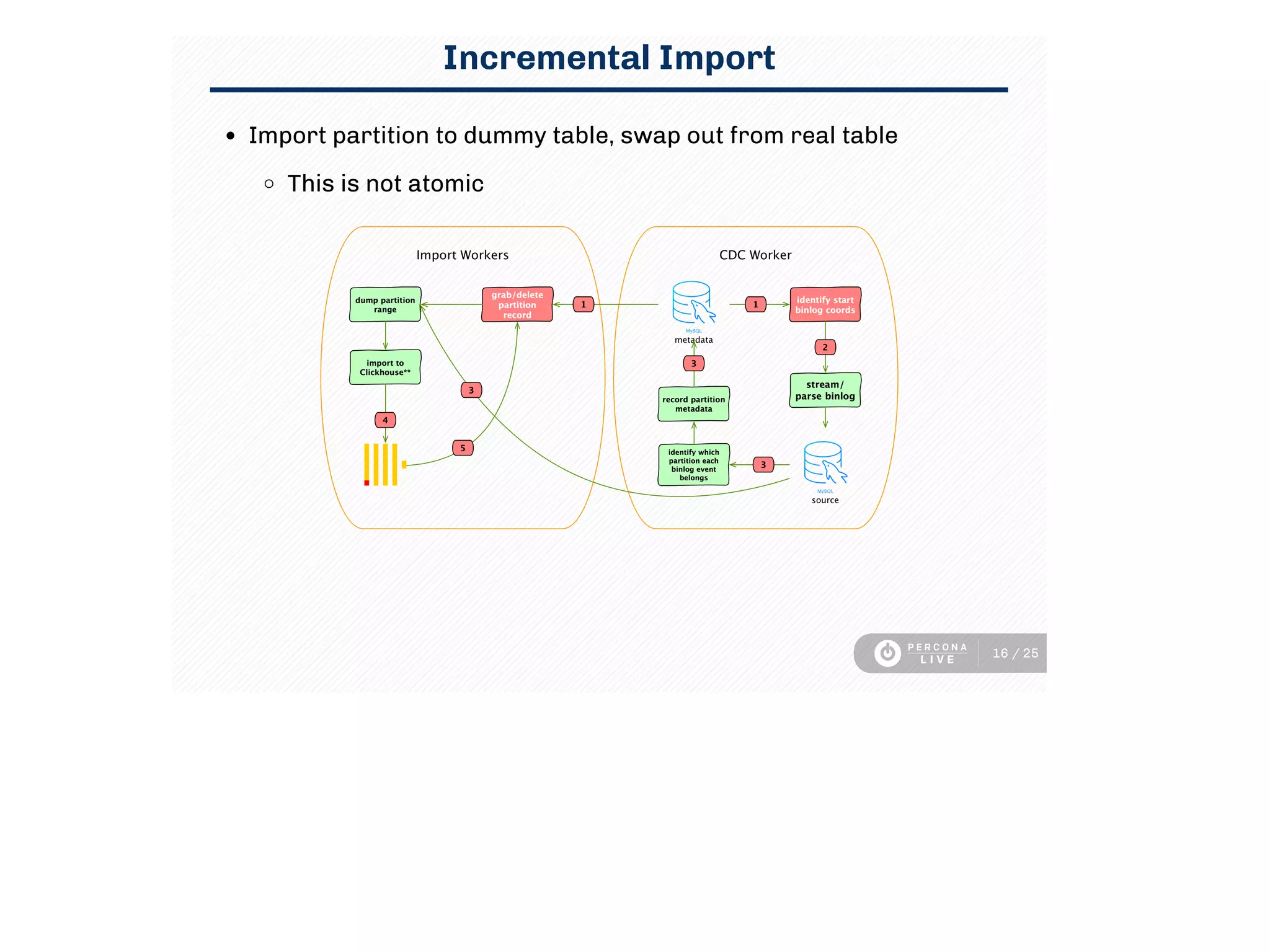



































This document discusses using Clickhouse to improve query performance for dashboards compared to using MySQL alone. It describes replicating data from MySQL to Clickhouse to enable faster analytics queries. Three methods for replication are outlined, and the process used is described, including initial full table imports and incremental changes. Limitations are noted around updates/deletes and resource usage. Sample dashboard queries are shown that demonstrate significant performance gains in Clickhouse. In summary, Clickhouse was able to meet the sub-15 minute latency requirement for dashboard queries, using a single instance, whereas MySQL required multiple instances and caching to achieve similar performance.











![[Meetup] a successful migration from elastic search to clickhouse](https://cdn.slidesharecdn.com/ss_thumbnails/meetupasuccessfulmigrationfromelasticsearchtoclickhouse-191004114403-thumbnail.jpg?width=640&height=640&fit=bounds)








































