Downloaded 468 times








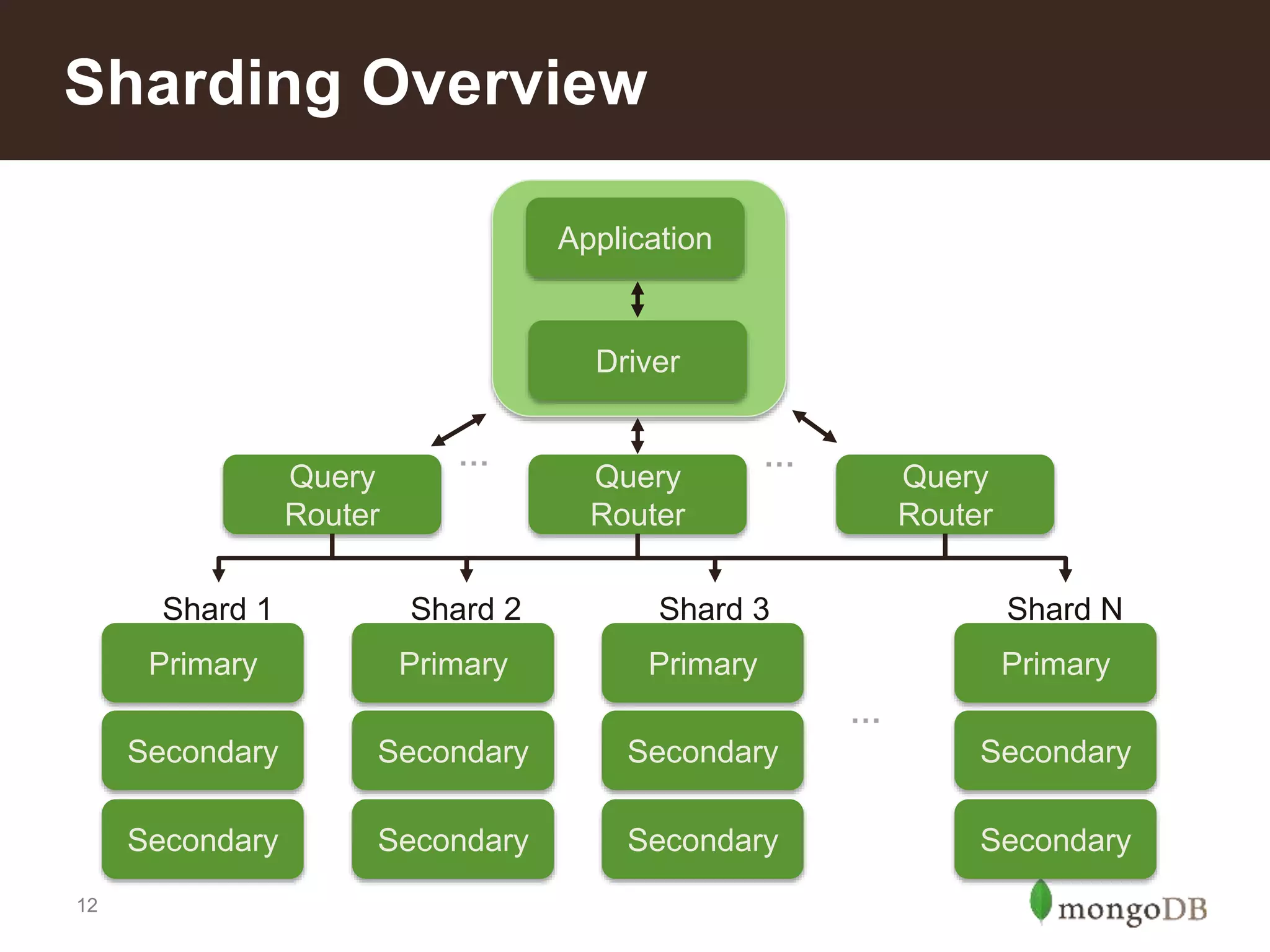


















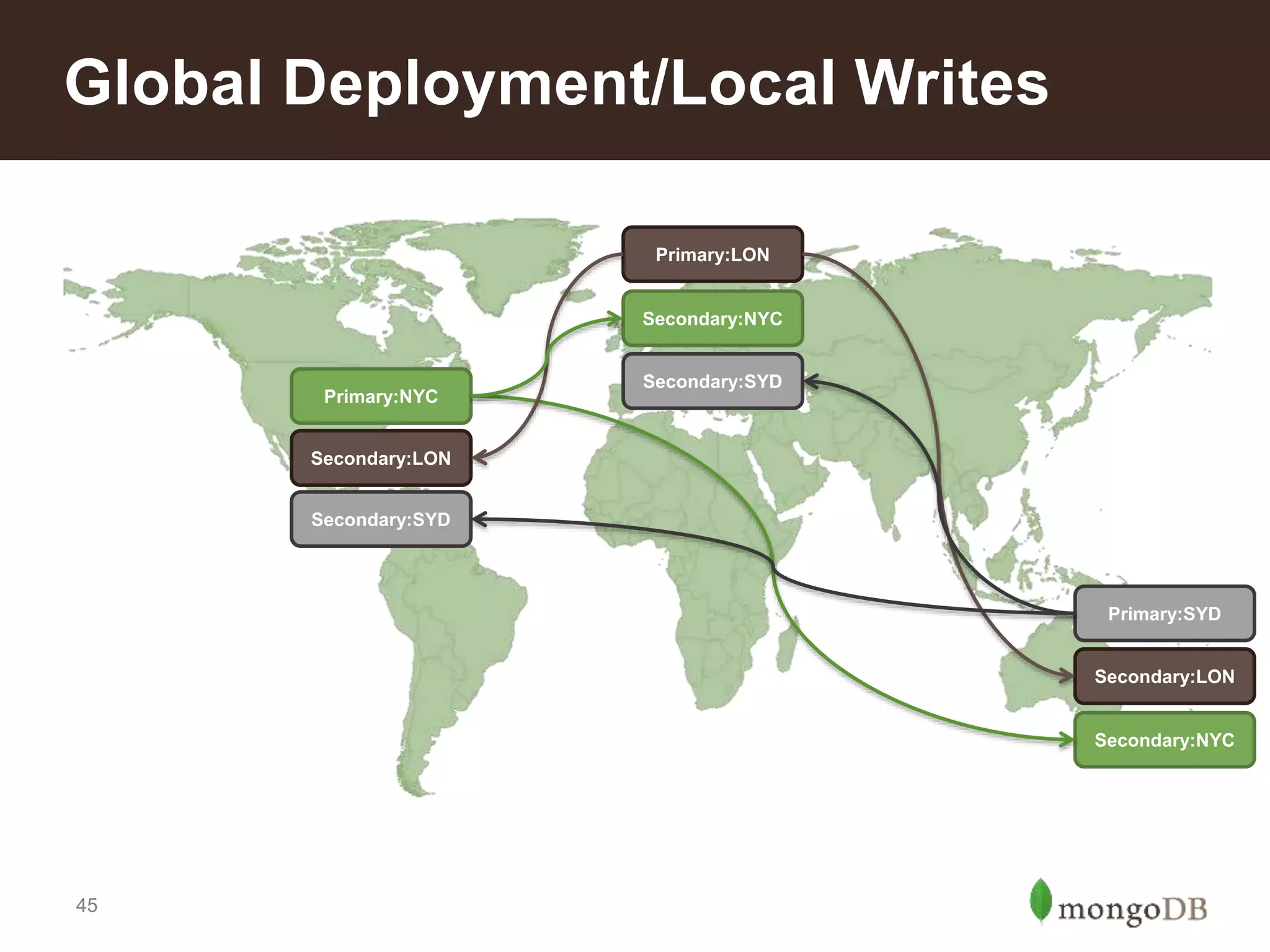































































Sharding in MongoDB allows for horizontal scaling of data and operations across multiple servers. When determining if sharding is needed, factors like available storage, query throughput, and response latency on a single server are considered. The number of shards can be calculated based on total required storage, working memory size, and input/output operations per second across servers. Different types of sharding include range, tag-aware, and hashed sharding. Choosing a high cardinality shard key that matches query patterns is important for performance. Reasons to shard include scaling to large data volumes and query loads, enabling local writes in a globally distributed deployment, and improving backup and restore times.
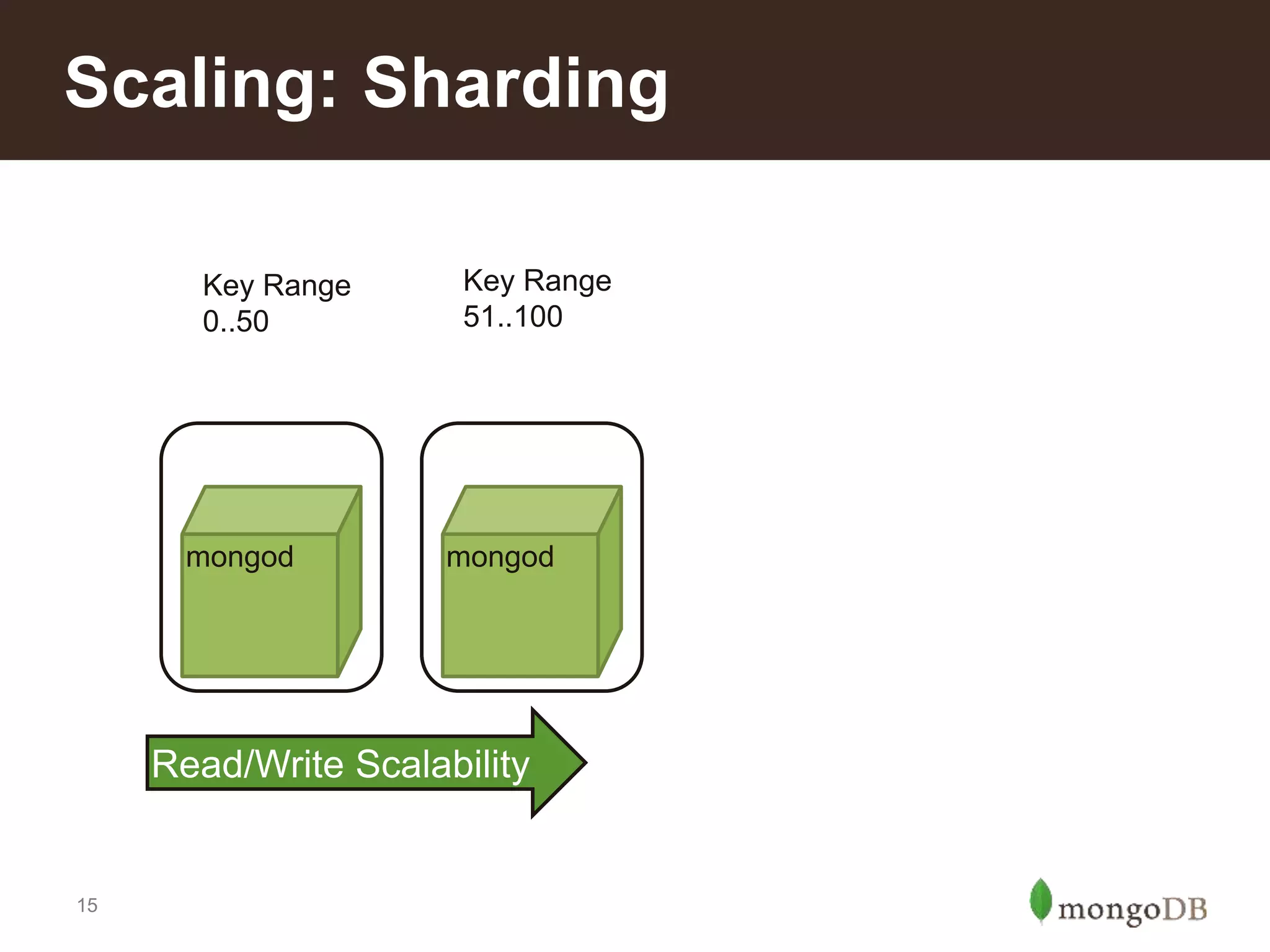
Introduction to sharding in MongoDB, agenda includes customer stories and various sharding methods.
Foursquare and CarFax examples illustrate usage of sharding: Foursquare with 50M users, 6B check-ins; CarFax with 13B+ documents, 12 shards.
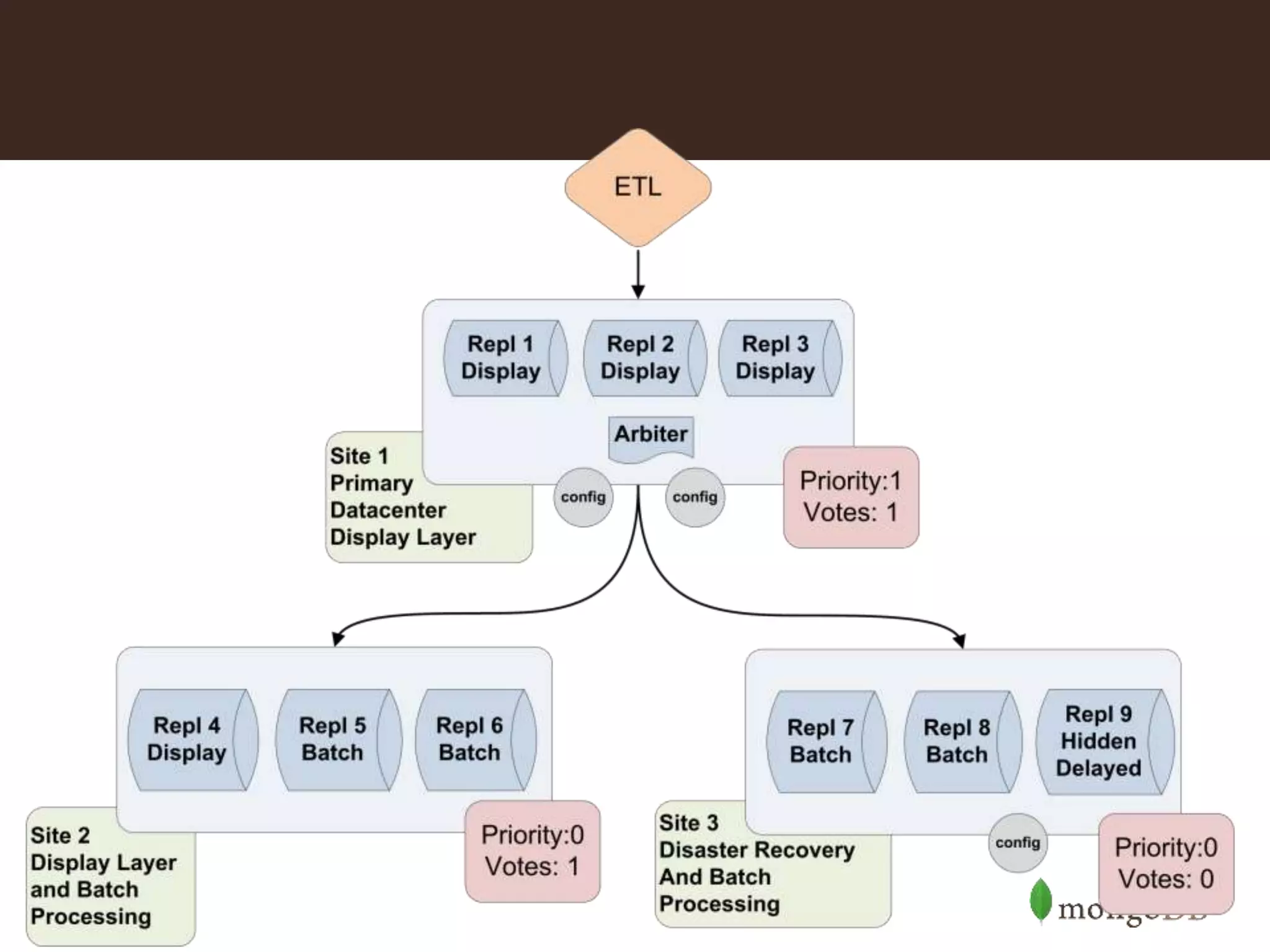
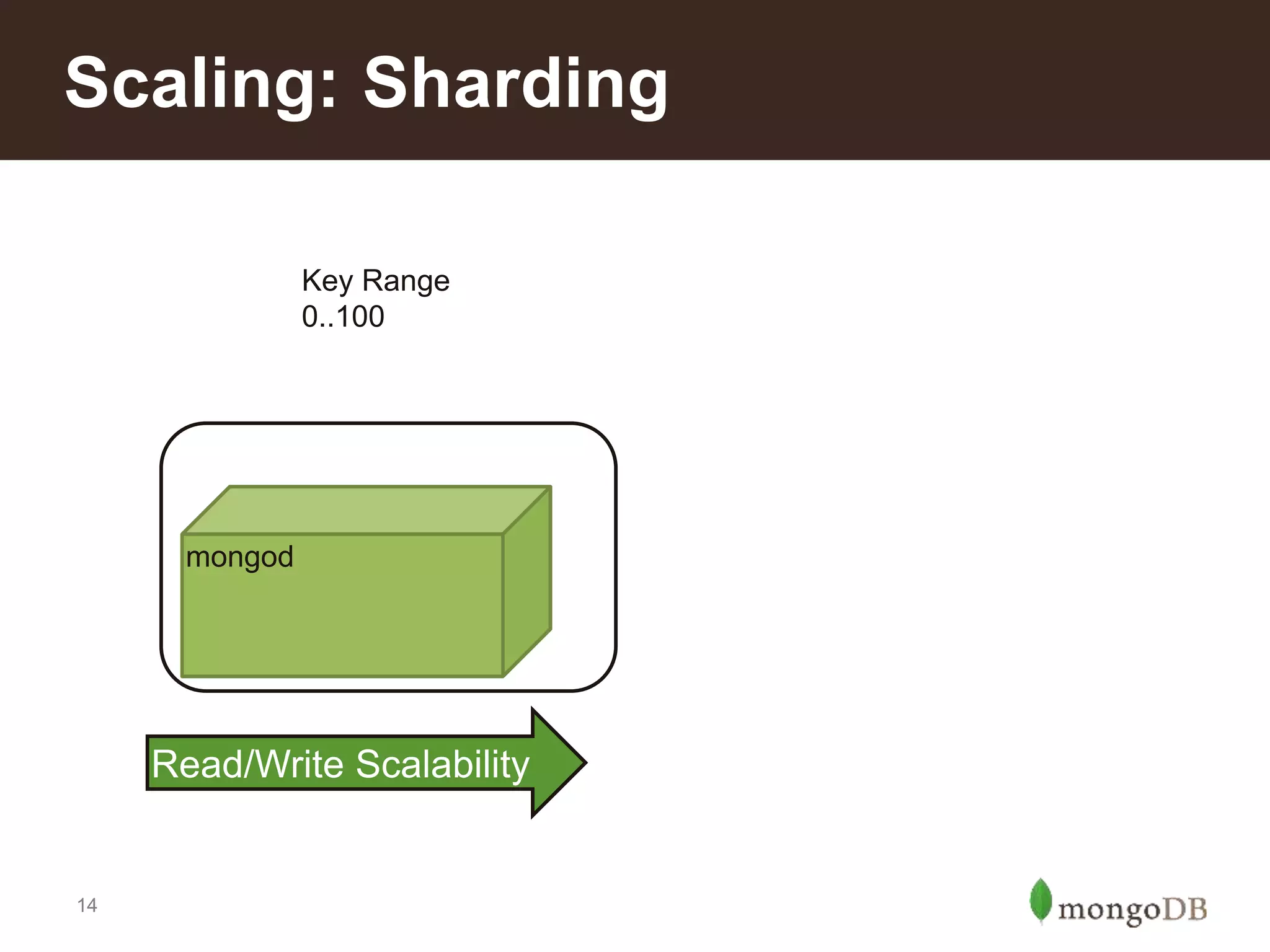
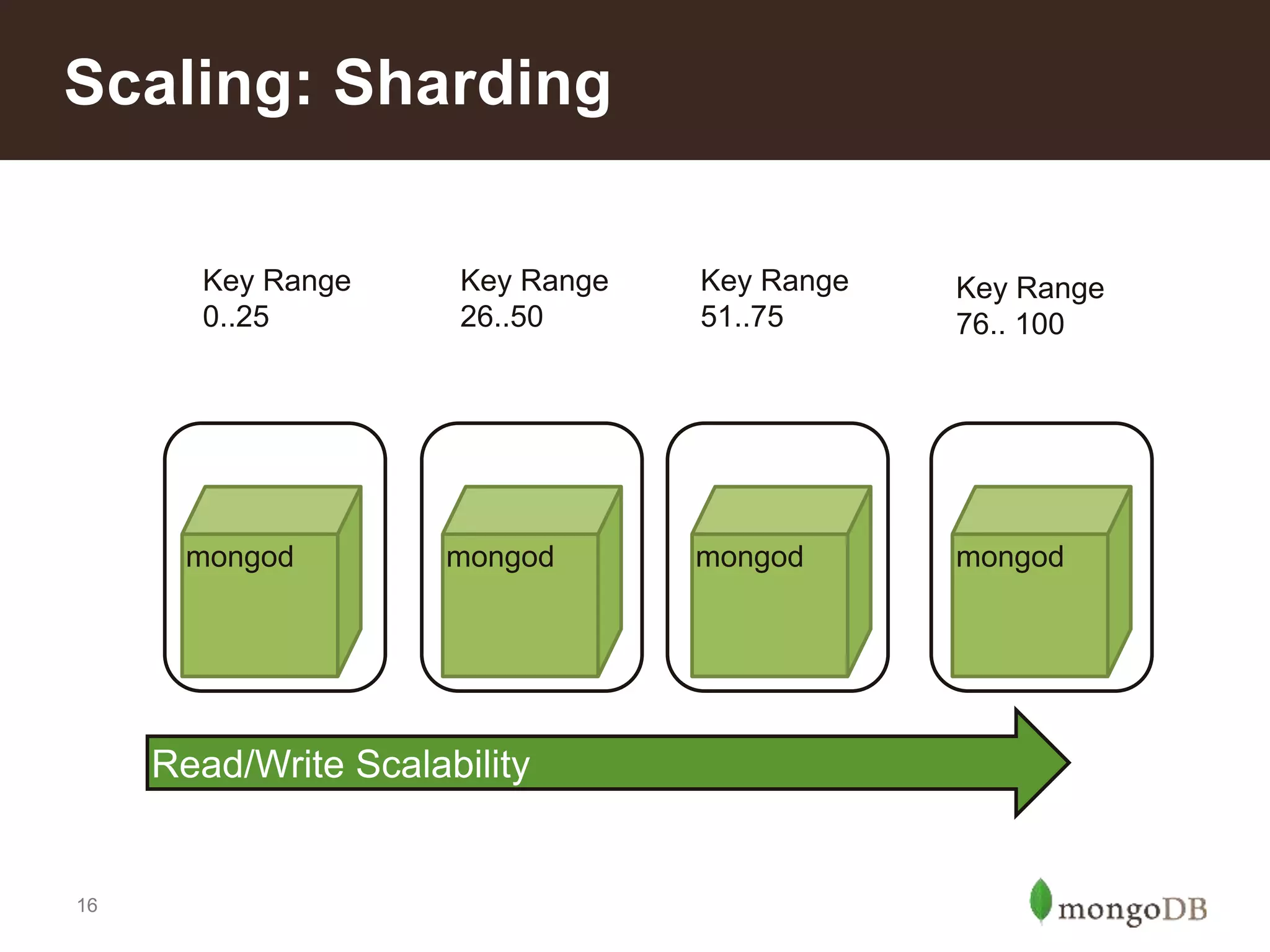
Defines sharding and illustrates scaling through examples of read/write scalability in MongoDB clusters.
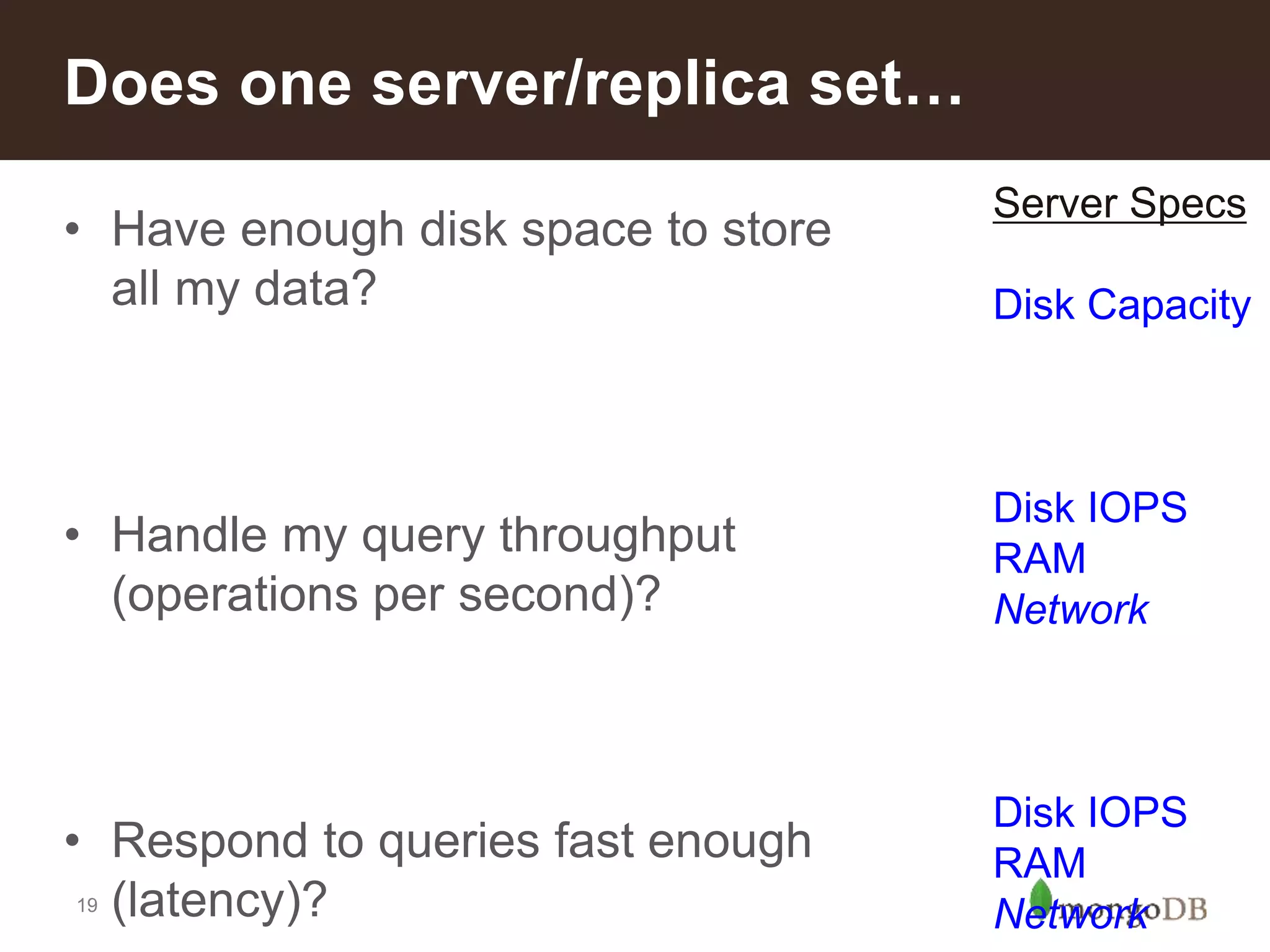
Criteria for when to shard: assessing disk space, query throughput, and IOPS; examples provided for estimating shard requirements.
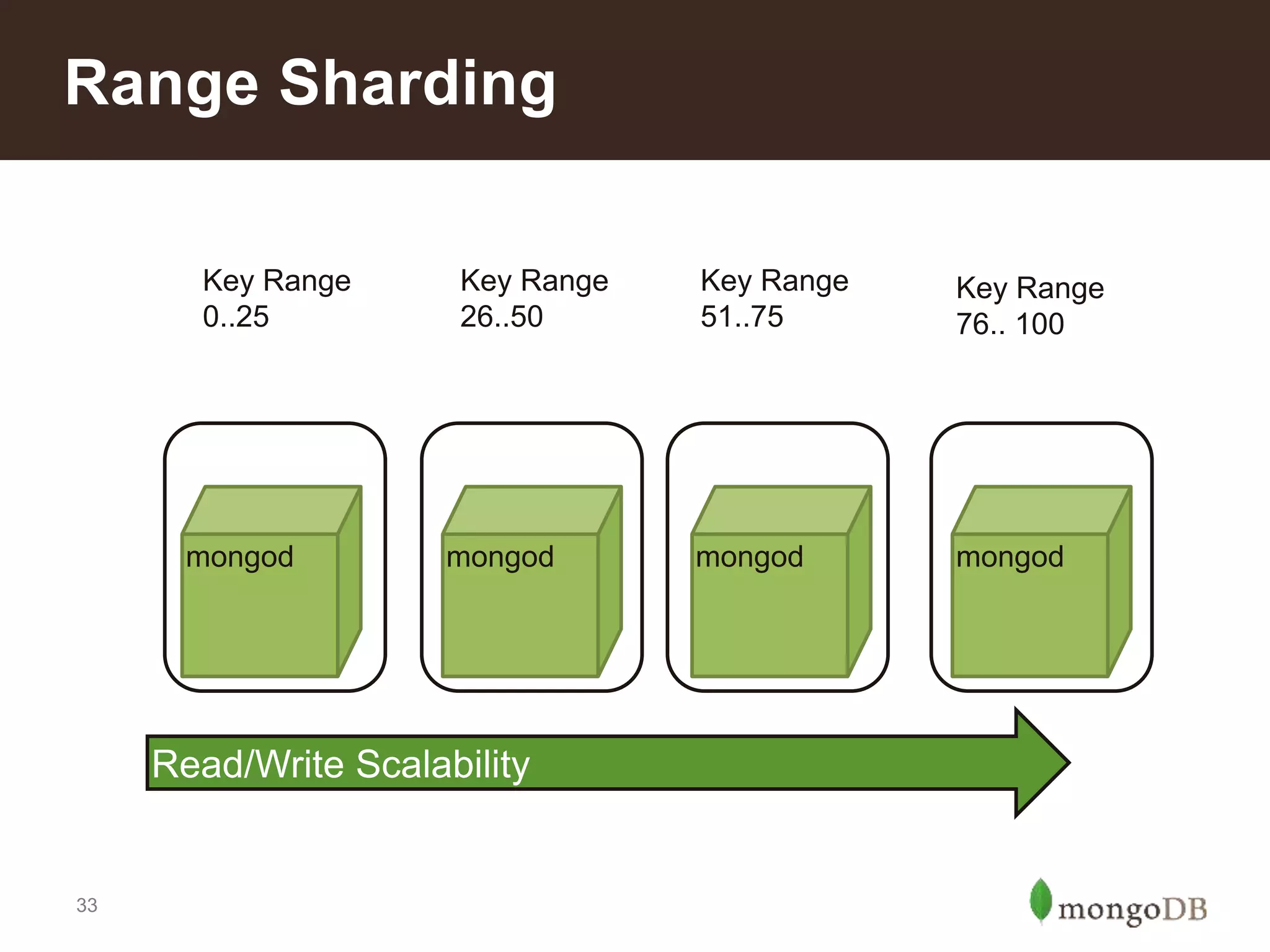
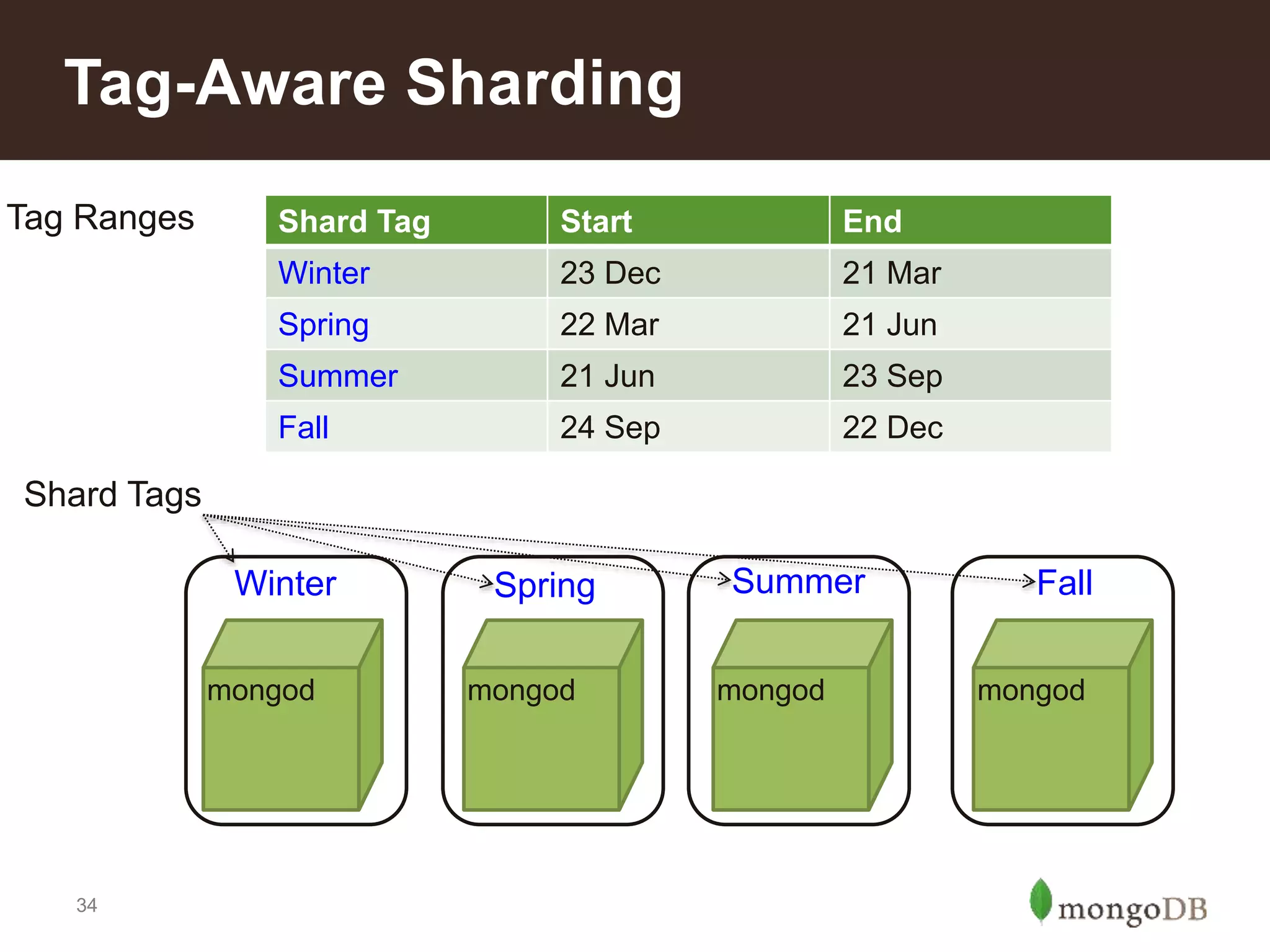
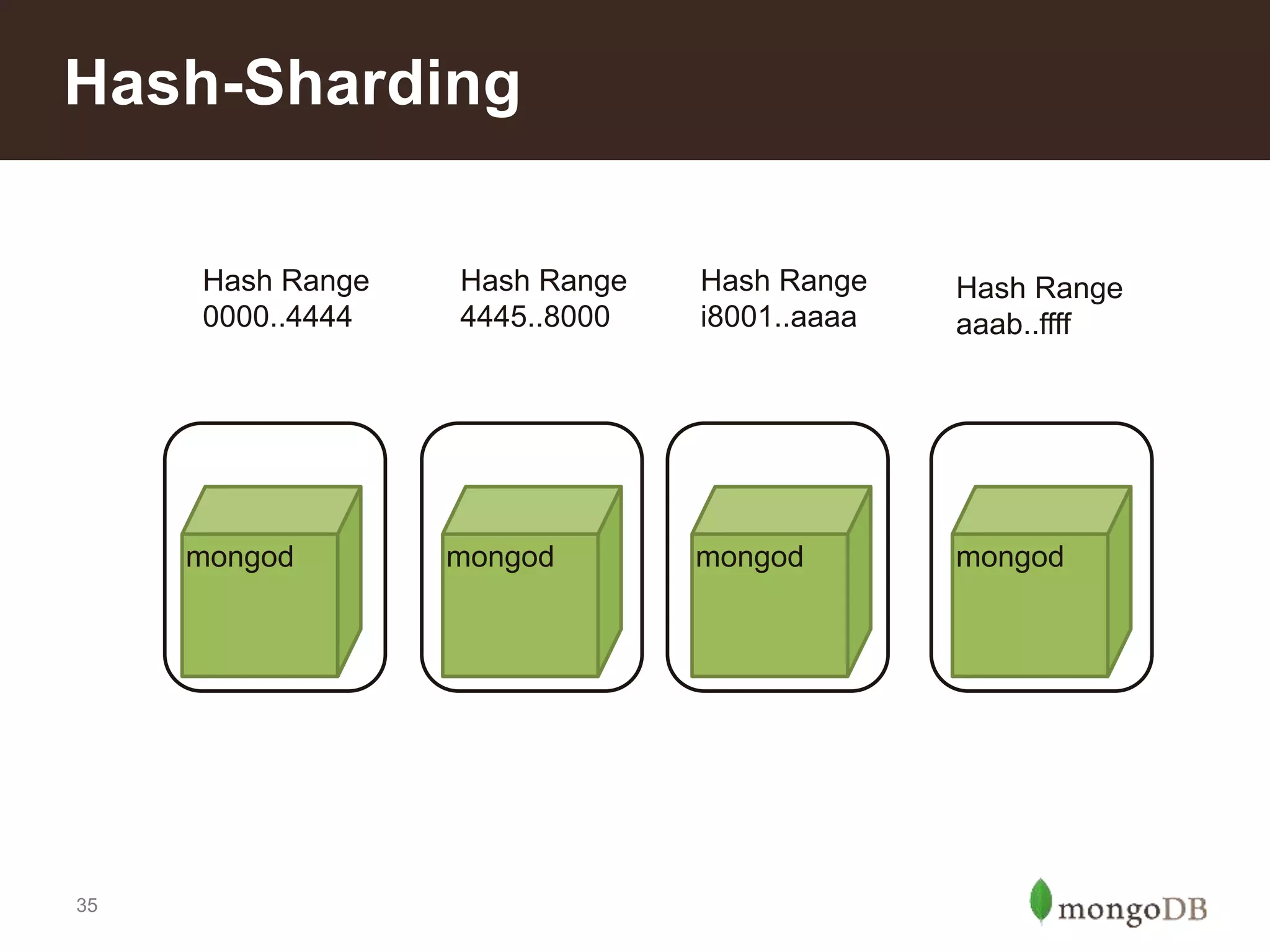
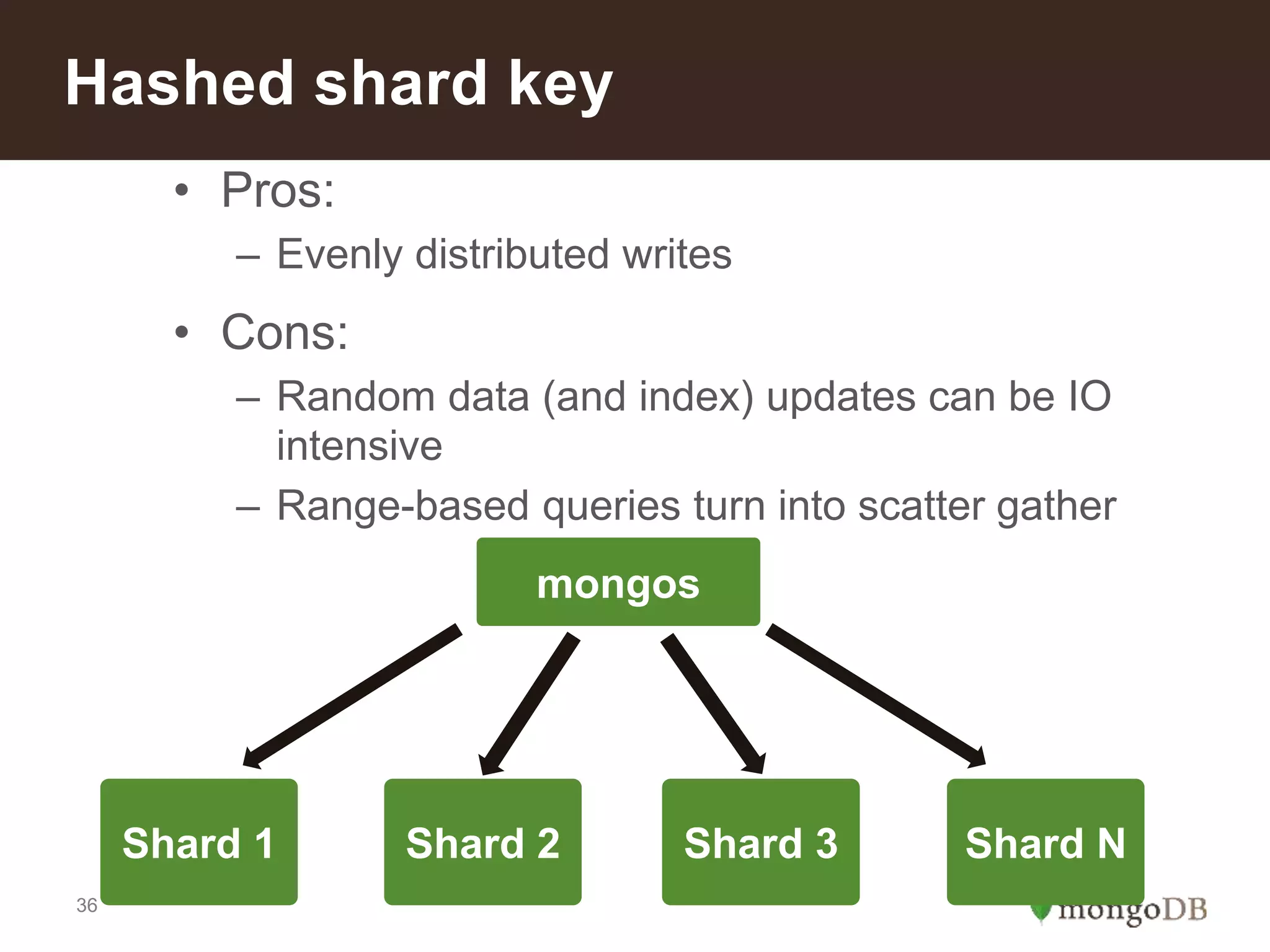
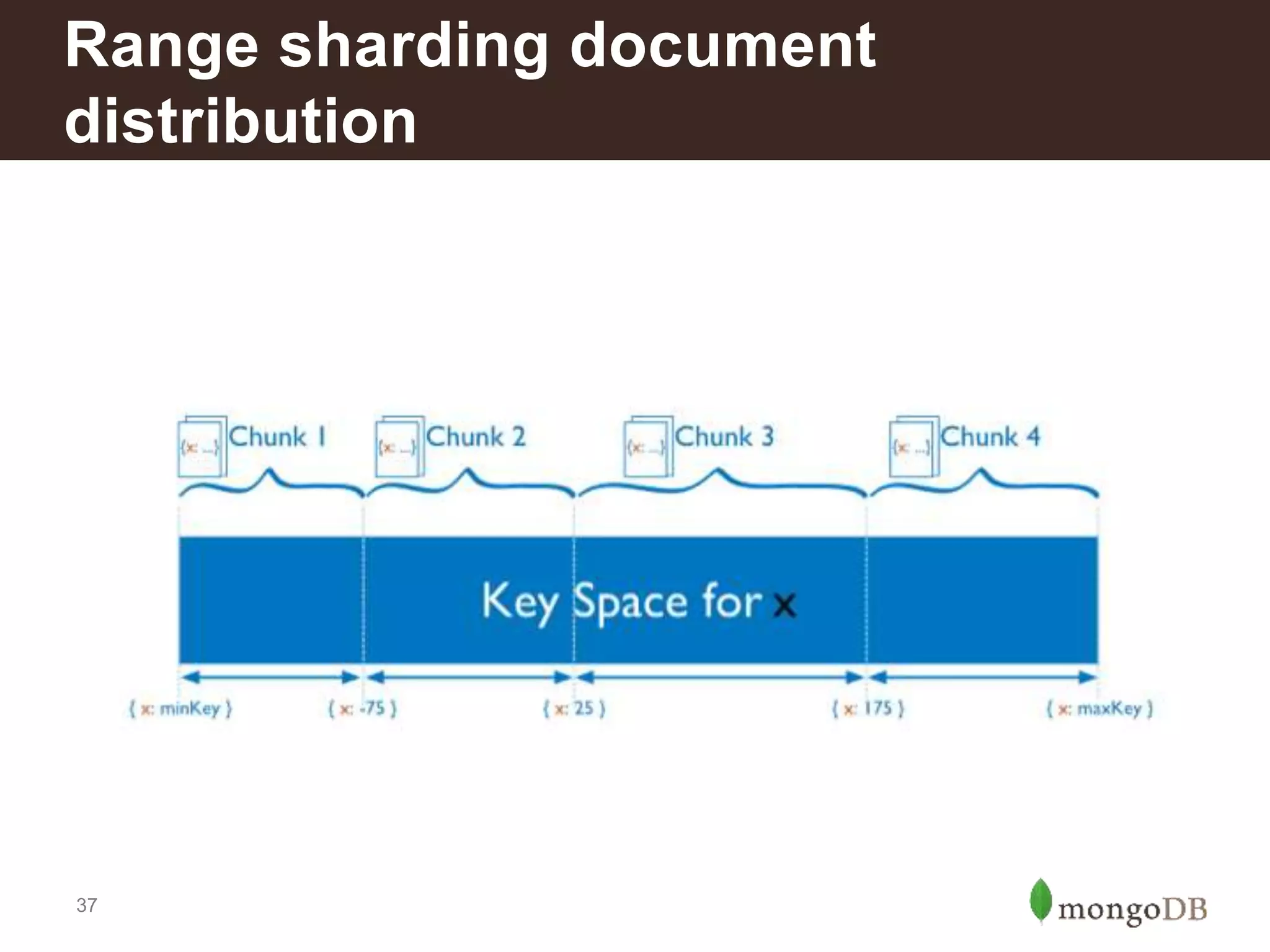
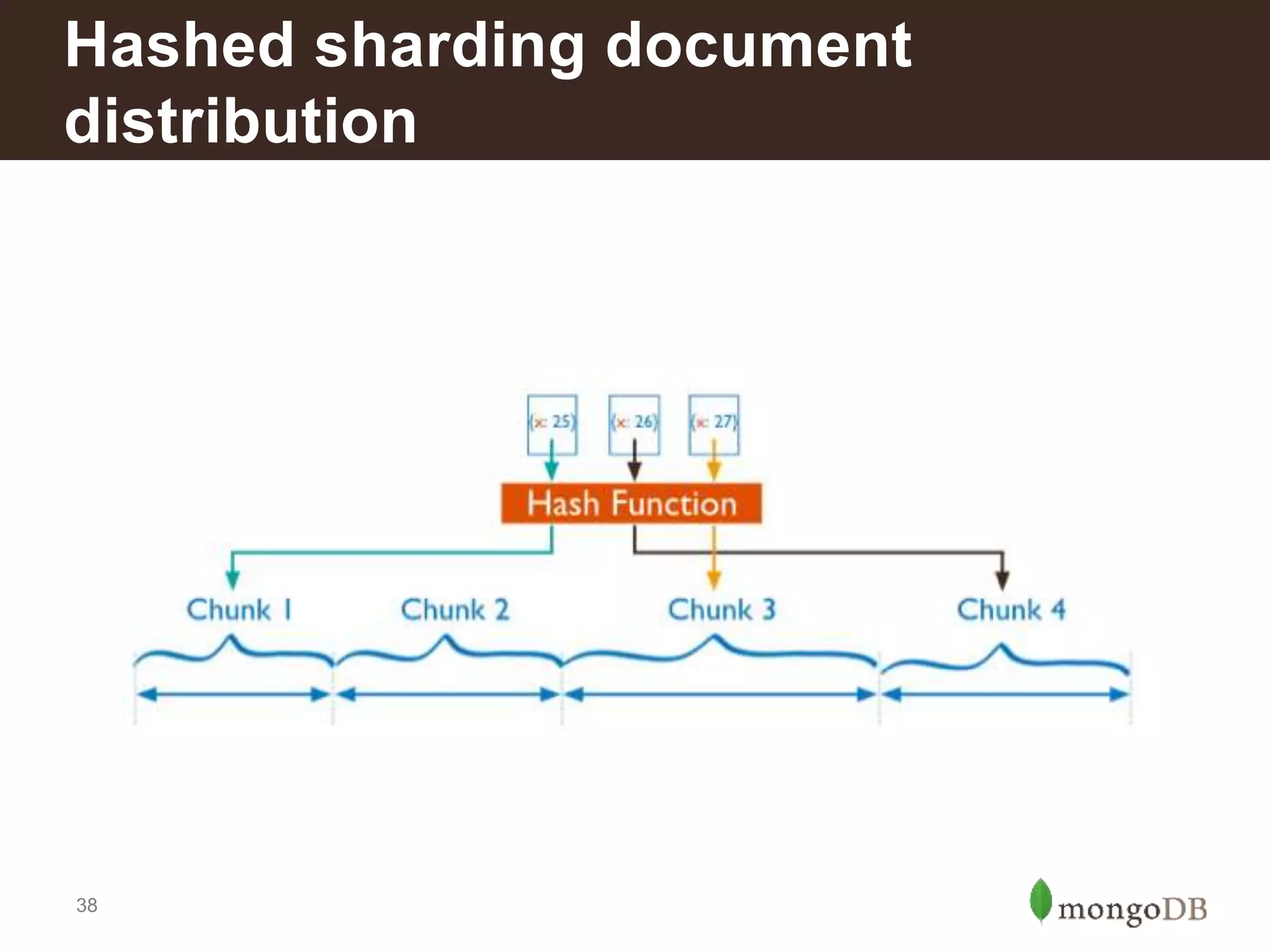
Introduction to different sharding types: range, tag-aware, and hashed sharding; pros and cons of each method.
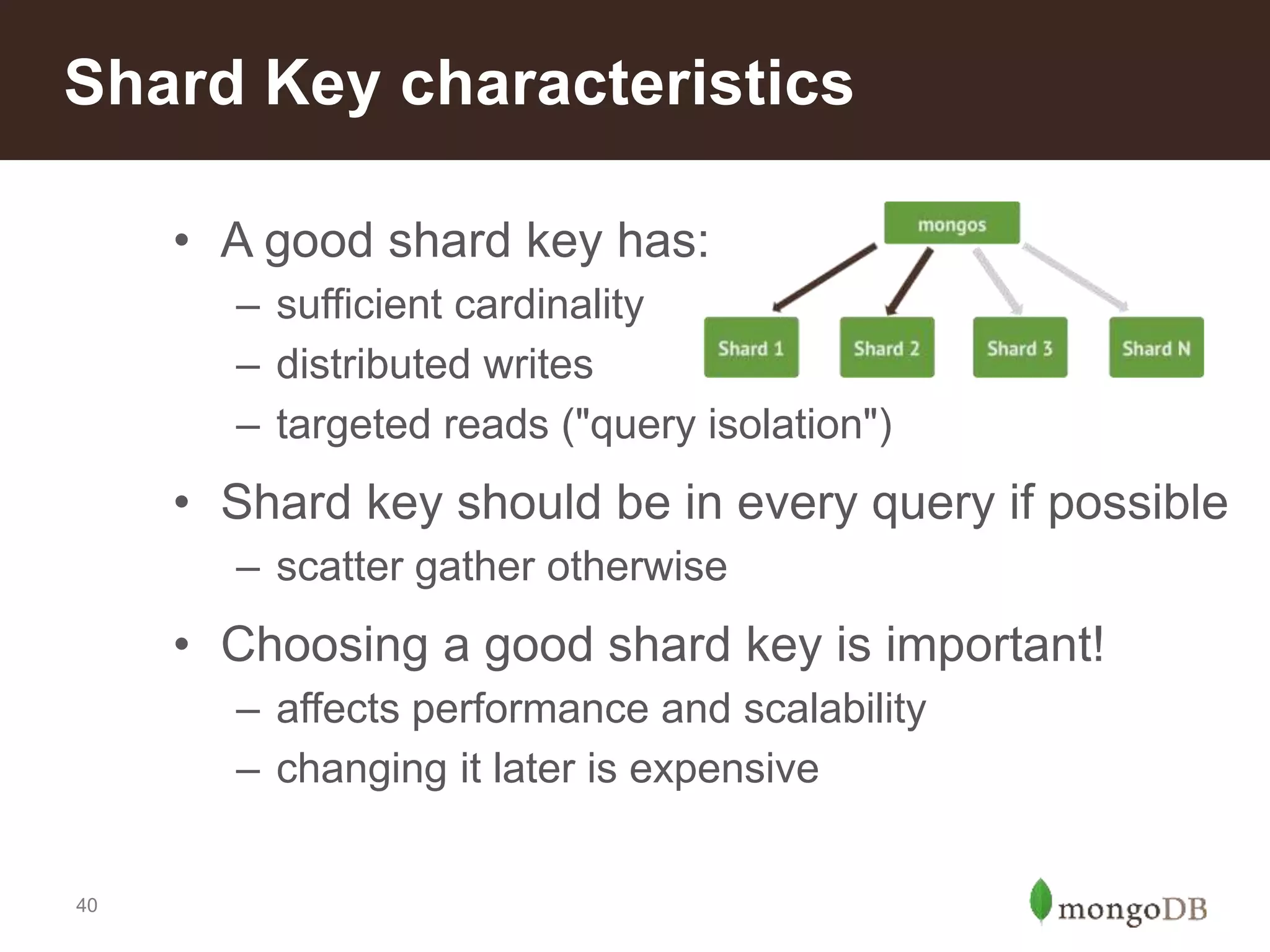
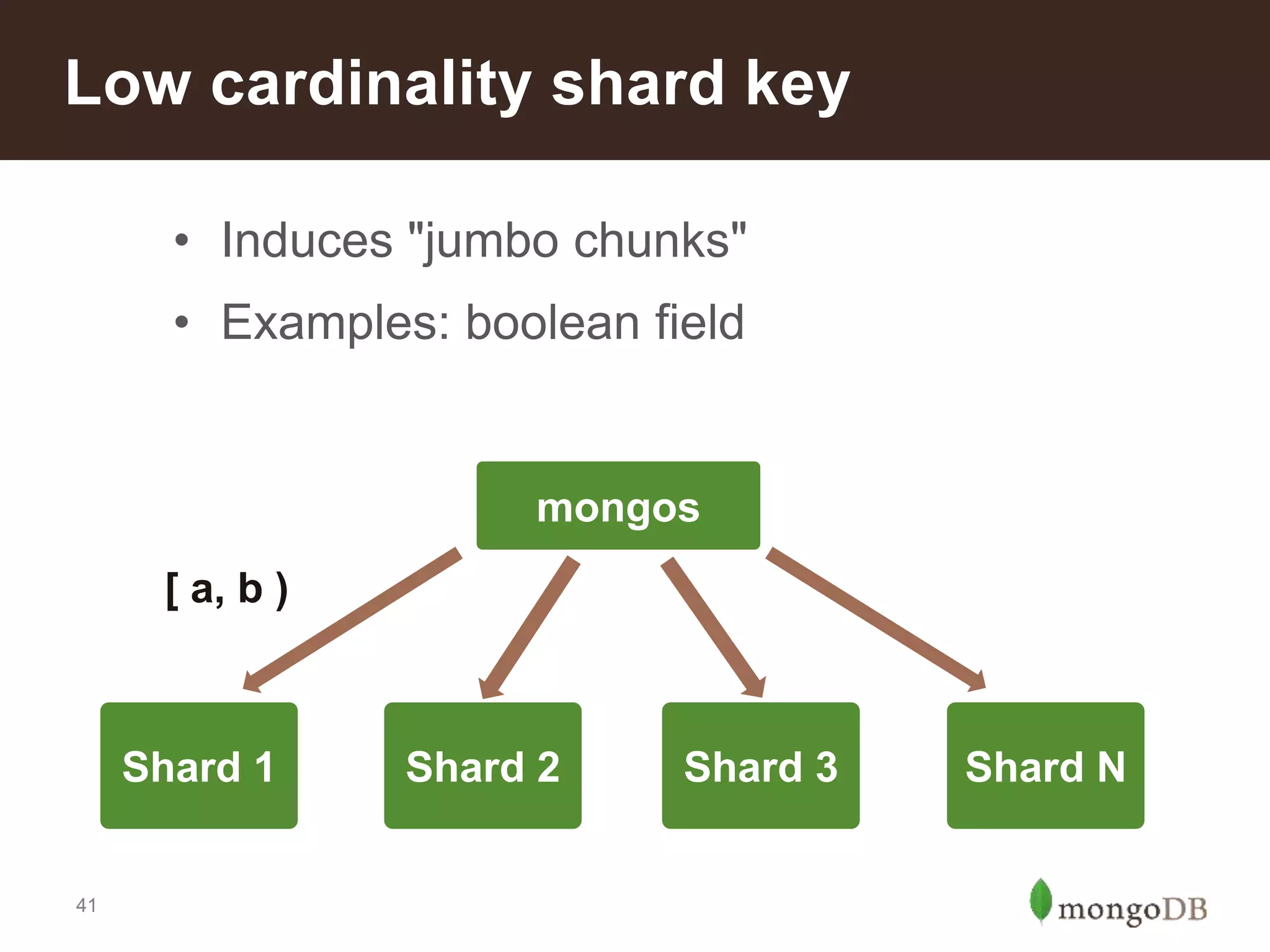
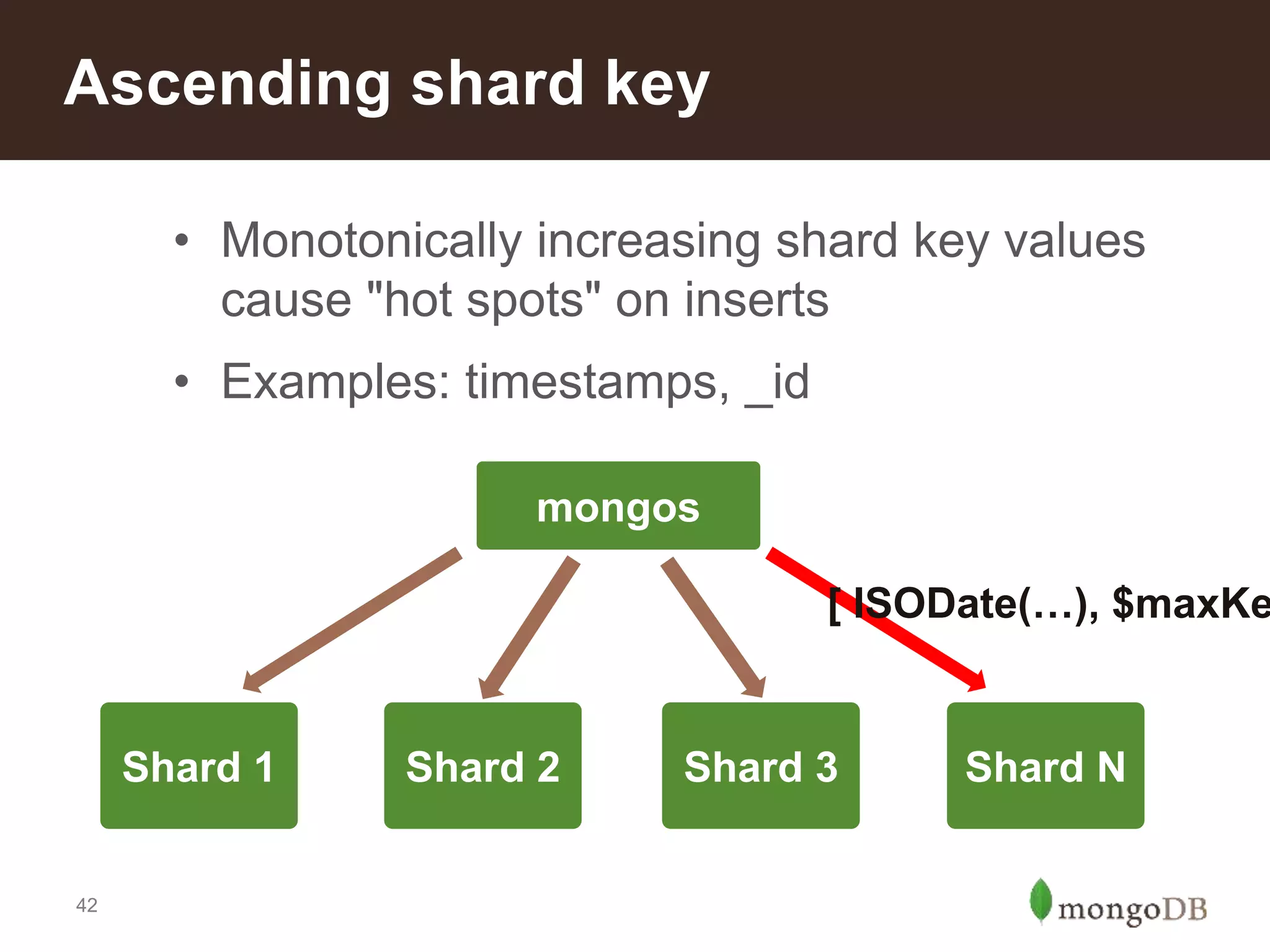
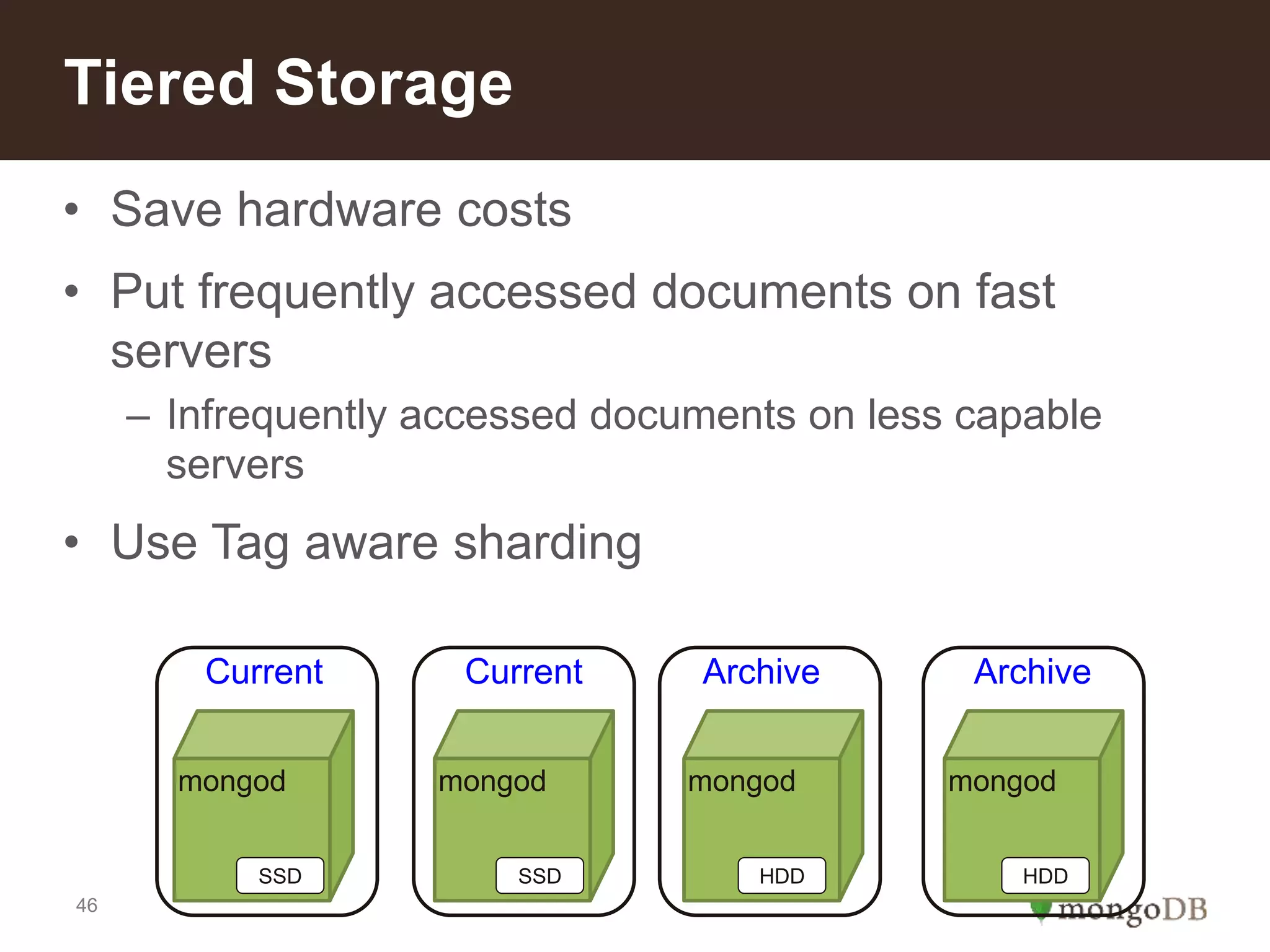
Characteristics of a good shard key for performance; importance of cardinality and distribution to avoid hotspots.Reasons to implement sharding: scale, local writes, tiered storage, and faster restore processes described.
Summary on determining number of shards based on storage, latency, throughput; scalability, and geo-aware considerations.
Resources for MongoDB sharding, webinars, and expert advice; invitation to a Q&A session.
Closing thanks and contact information for inquiries regarding MongoDB.

















![[2018] MySQL 이중화 진화기](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra03-190131073325-thumbnail.jpg?width=640&height=640&fit=bounds)



















































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)





























