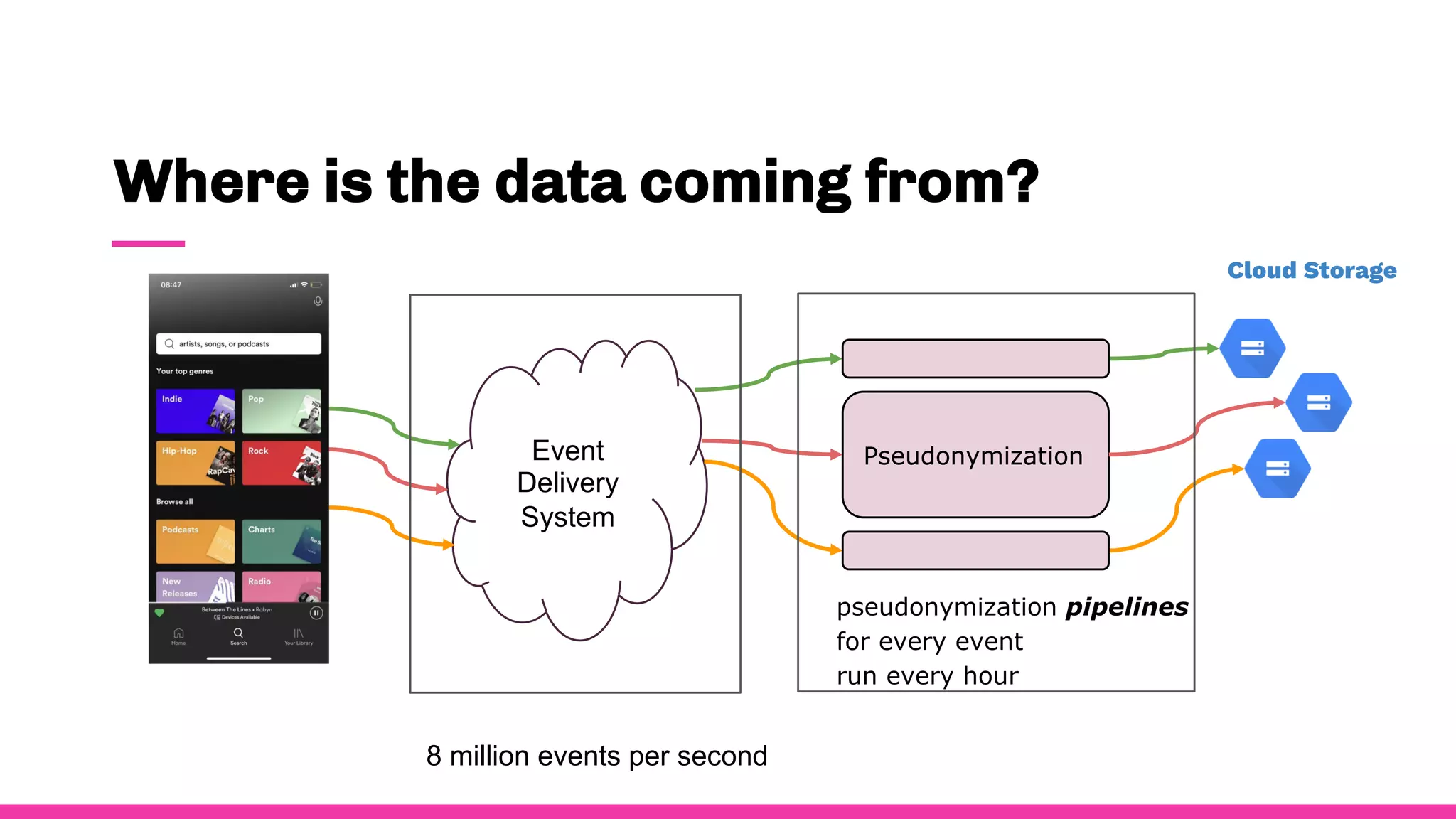
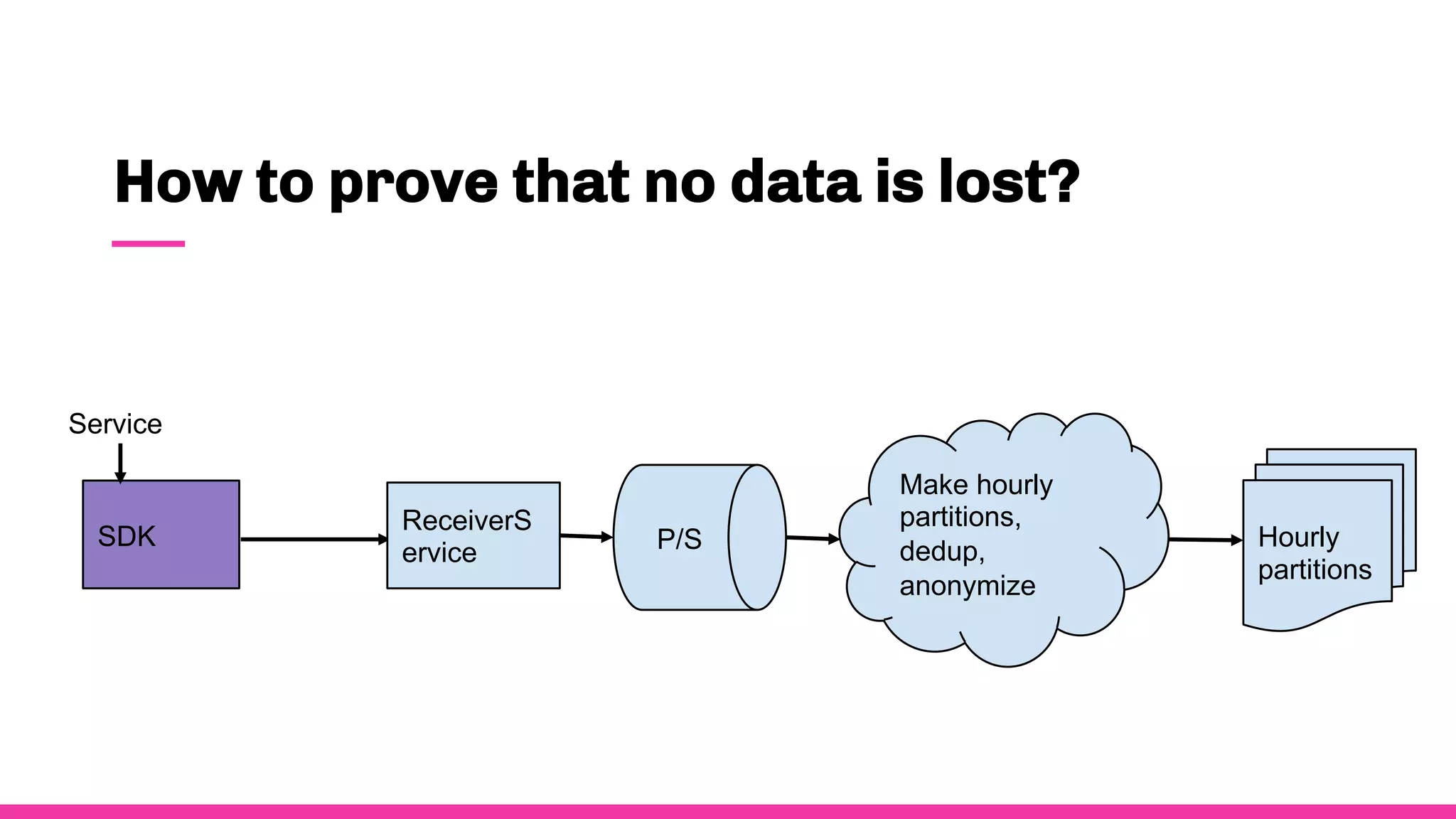
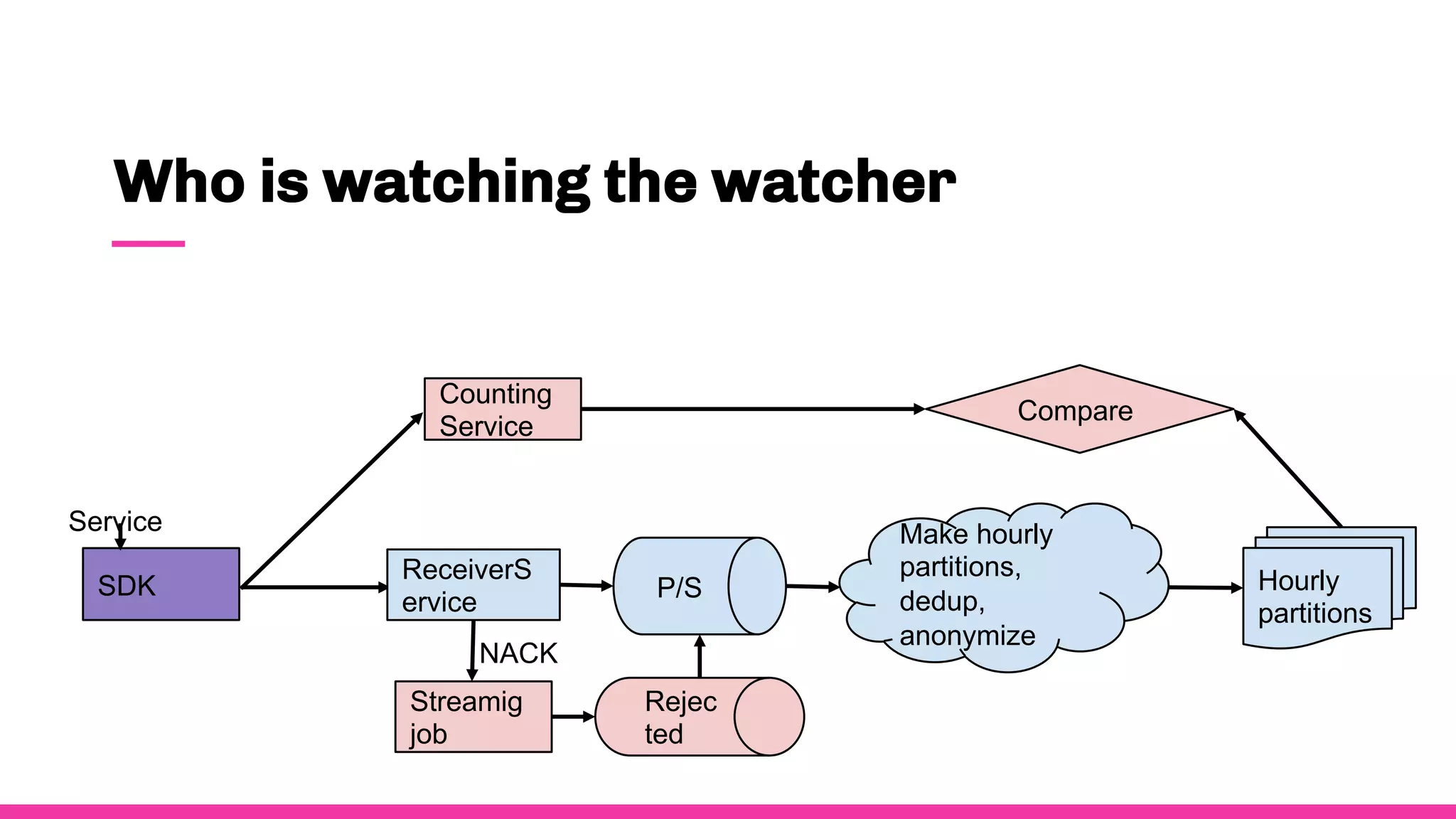
- Data observability is important for Spotify because they process massive amounts of data from 8 million events per second.
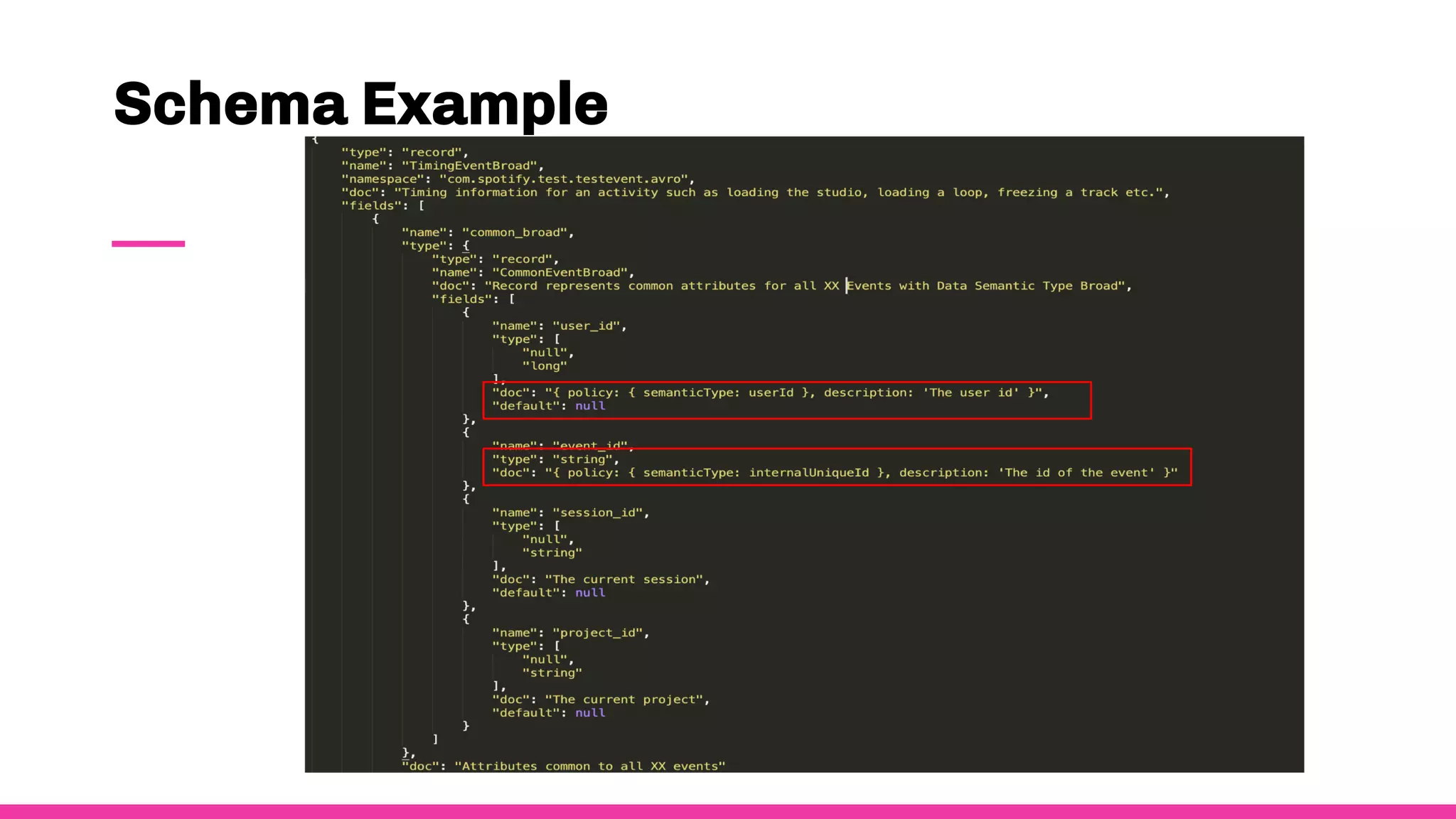
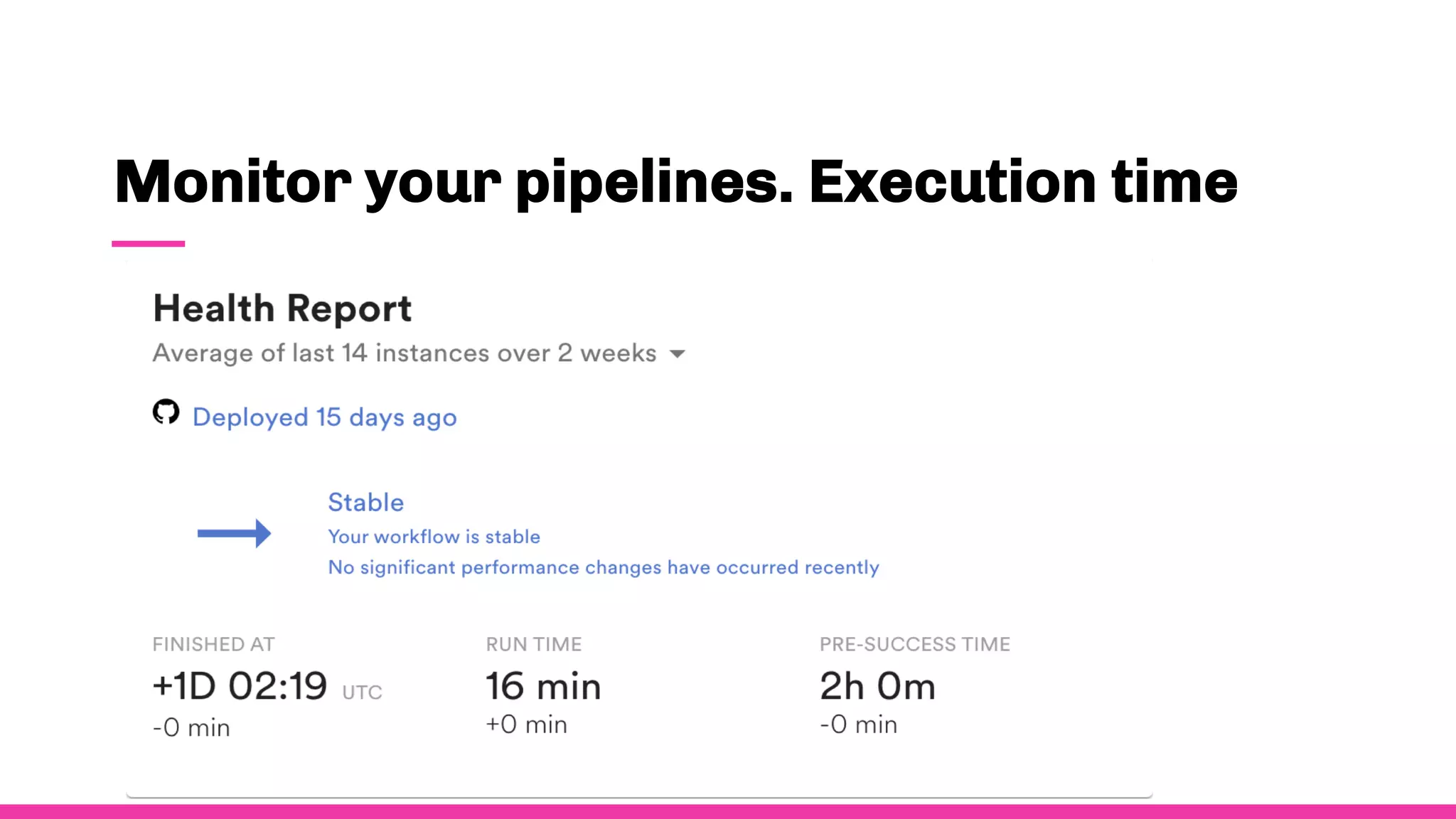
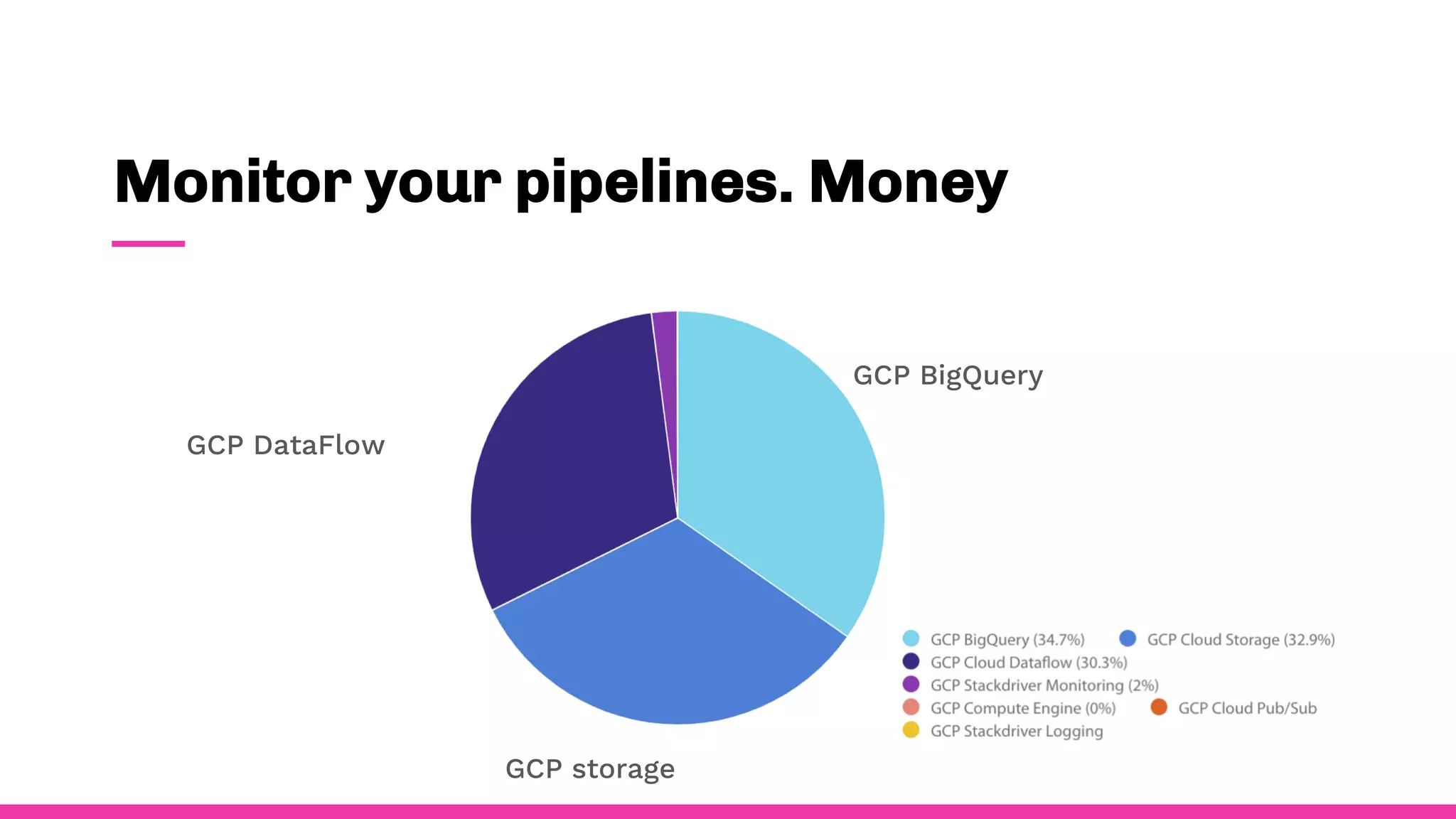
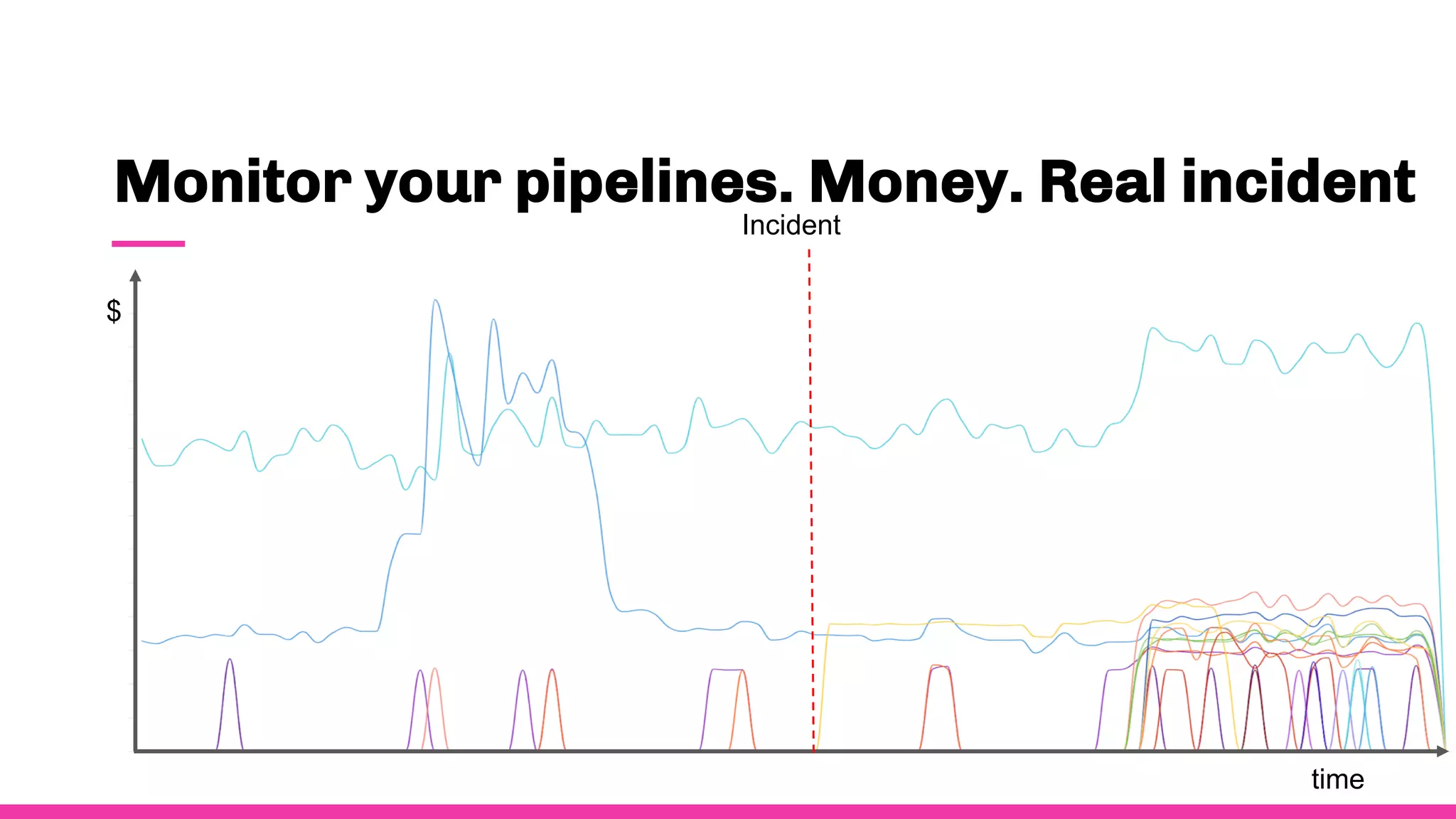
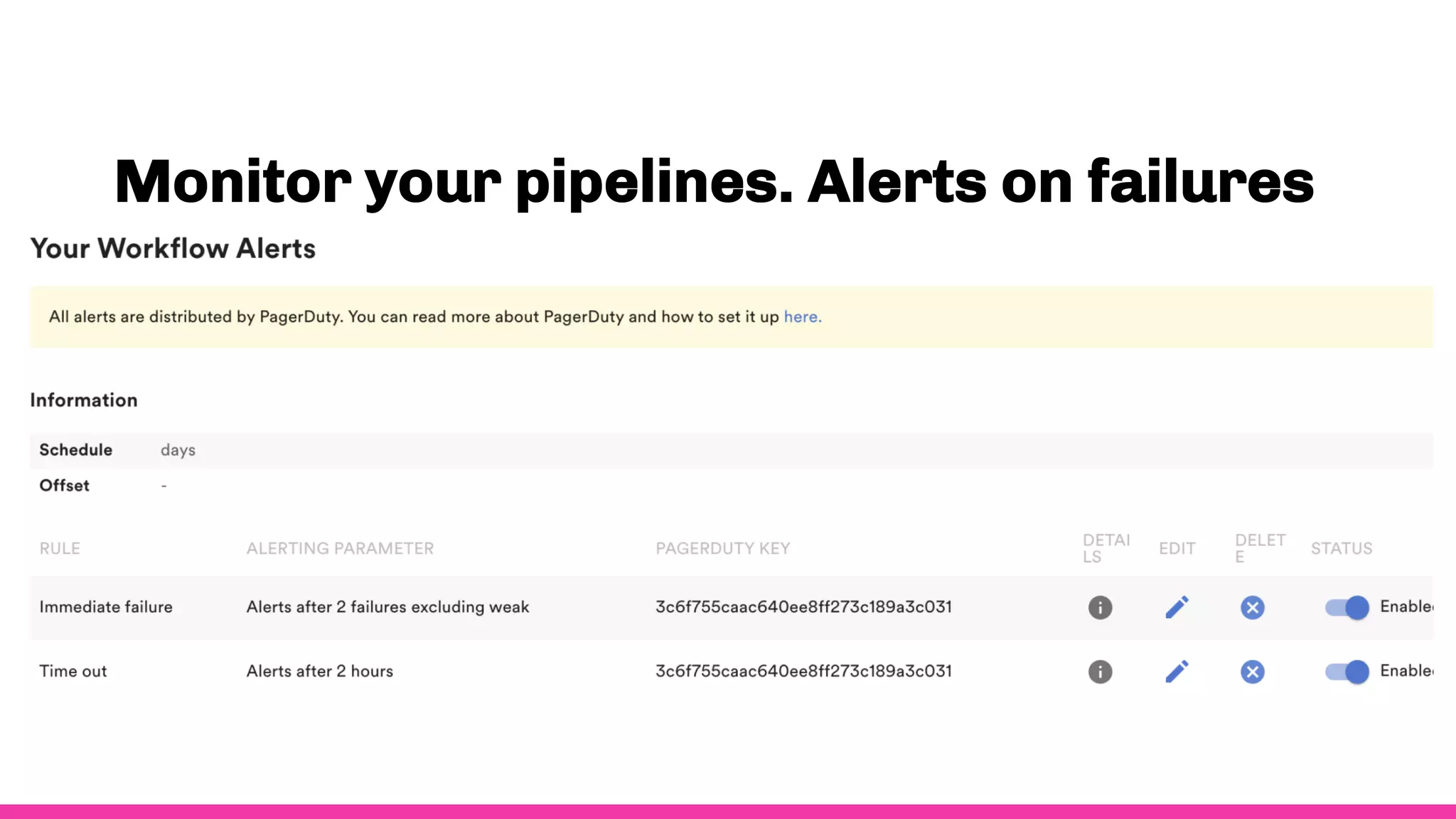
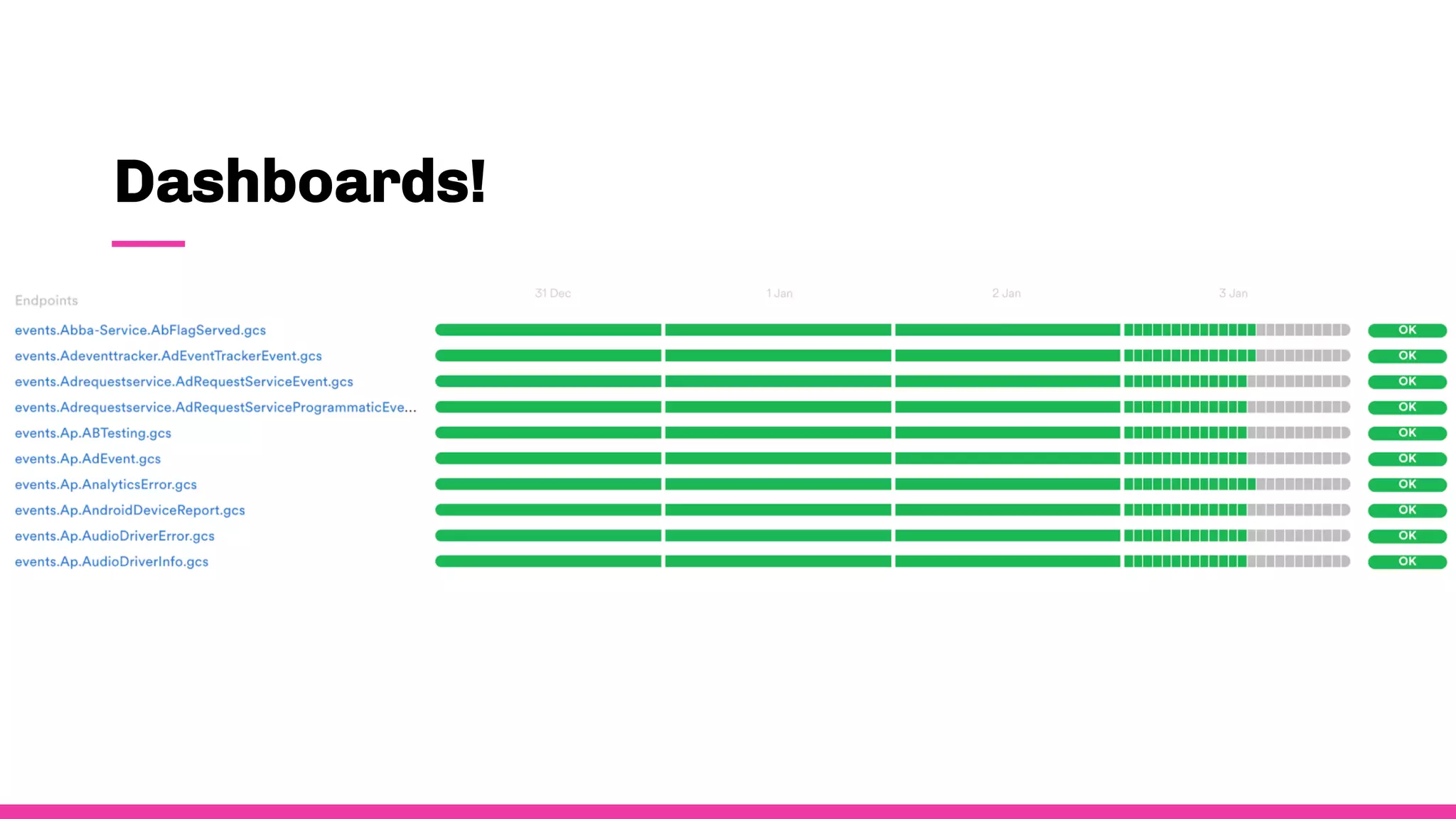
- To ensure observability, Spotify annotates and documents their data schemas, monitors pipeline execution times and counts to check for errors, monitors financial costs of pipelines and storage, and sets up alerts and dashboards to monitor for failures.
- Having good data observability helps Spotify understand where their data is coming from and going, troubleshoot issues quickly, and ensure royalty payments to artists are accurate since they rely on the data pipelines.