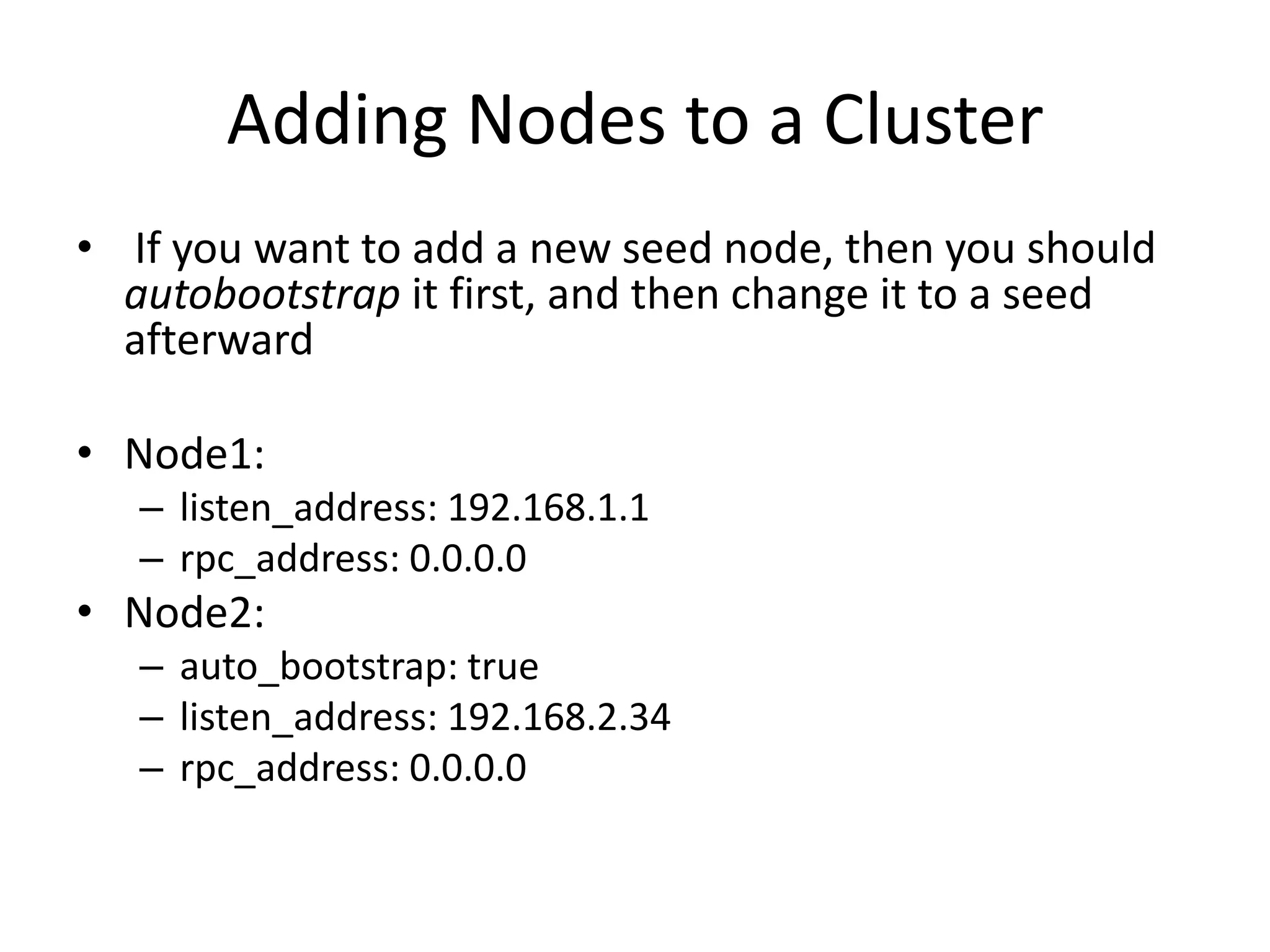
Downloaded 40 times









![• Set YYYYY[“XiaoMing”][“name”] = “小明”
• Get YYYYY[“XiaoMing”]](https://image.slidesharecdn.com/cassandra-111116102351-phpapp02/75/Cassandra-12-2048.jpg)

































![• Set YYYYY[“XiaoMing”][“name”] = “小明”
• Get YYYYY[“XiaoMing”]](https://crownmelresort.com/image.slidesharecdn.com/cassandra-111116102351-phpapp02/75/Cassandra-12-2048.jpg)


























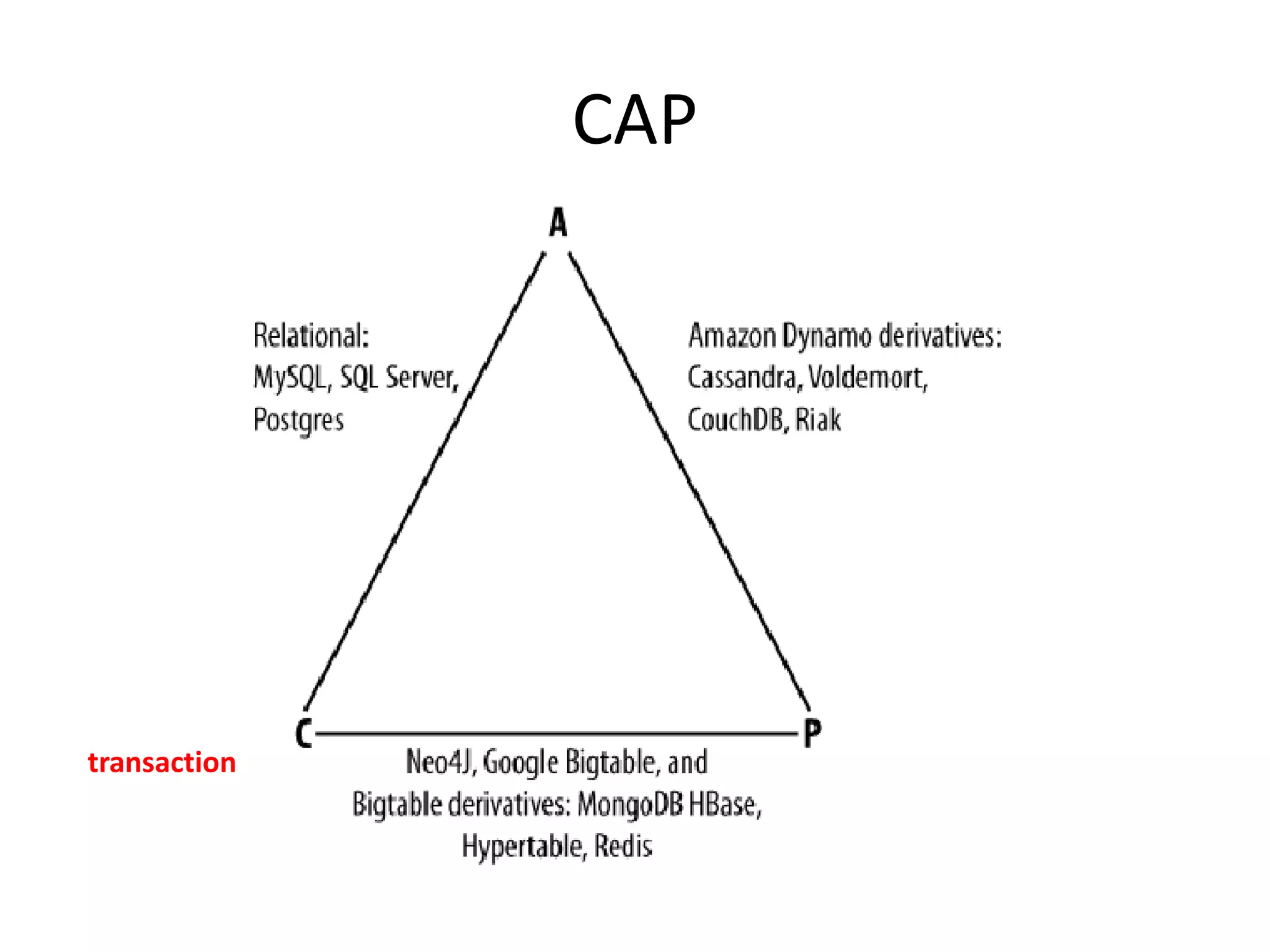
Cassandra is an open source, distributed, decentralized, elastically scalable, highly available, and fault-tolerant database. It originated at Facebook in 2007 to solve their inbox search problem. Some key companies using Cassandra include Twitter, Facebook, Digg, and Rackspace. Cassandra's data model is based on Google's Bigtable and its distribution design is based on Amazon's Dynamo.





















































































