Download to read offline







.filter(a => broadcastListEventAll.value.map(r => a._2.matches(r)).foldLeft(false)(_ || _))
.map(a => (a._1, dateBucket, a._2))
.repartitionByCassandraReplica("instametrics", "events_raw_5m", 100)
.joinWithCassandraTable("instametrics", "events_raw_5m").cache()
• Write limiting (eg cassandra.output.throughput_mb_per_sec) not necessary as writes << reads
© DataStax, All Rights Reserved. 8](https://image.slidesharecdn.com/processing-160912022000/75/Processing-50-000-events-per-second-with-Cassandra-and-Spark-8-2048.jpg)












.filter(a => broadcastListEventAll.value.map(r => a._2.matches(r)).foldLeft(false)(_ || _))
.map(a => (a._1, dateBucket, a._2))
.repartitionByCassandraReplica("instametrics", "events_raw_5m", 100)
.joinWithCassandraTable("instametrics", "events_raw_5m").cache()
• Write limiting (eg cassandra.output.throughput_mb_per_sec) not necessary as writes << reads
© DataStax, All Rights Reserved. 8](https://crownmelresort.com/image.slidesharecdn.com/processing-160912022000/75/Processing-50-000-events-per-second-with-Cassandra-and-Spark-8-2048.jpg)





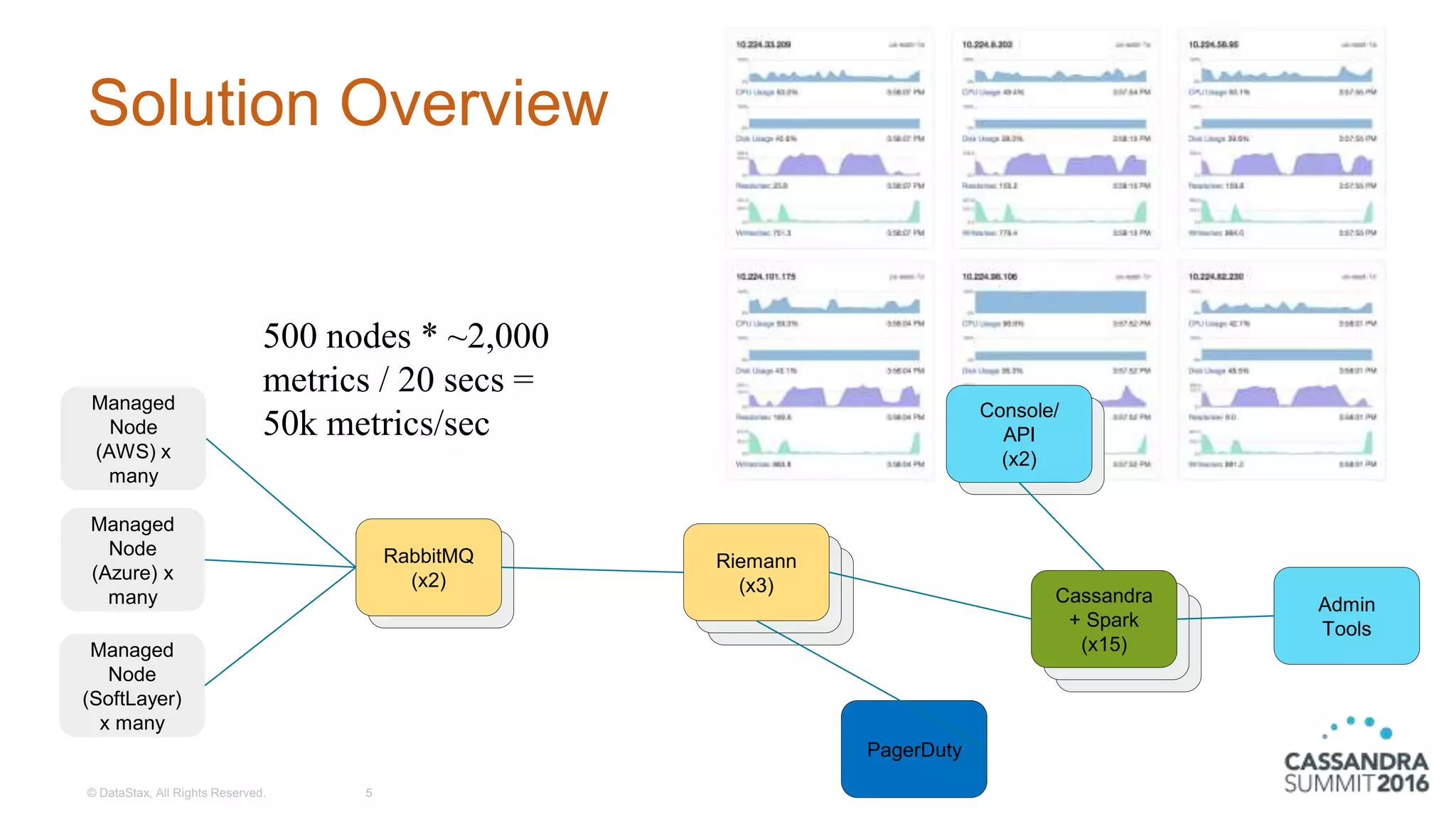
Ben Slater from Instaclustr discusses the challenges and solutions related to processing 50,000 events per second using Cassandra and Spark. The document outlines the architecture, implementation process, and lessons learned while integrating these technologies to monitor over 600 servers efficiently. It also emphasizes key performance strategies and future enhancements, including the use of Spark streaming and the addition of more complex analytics.