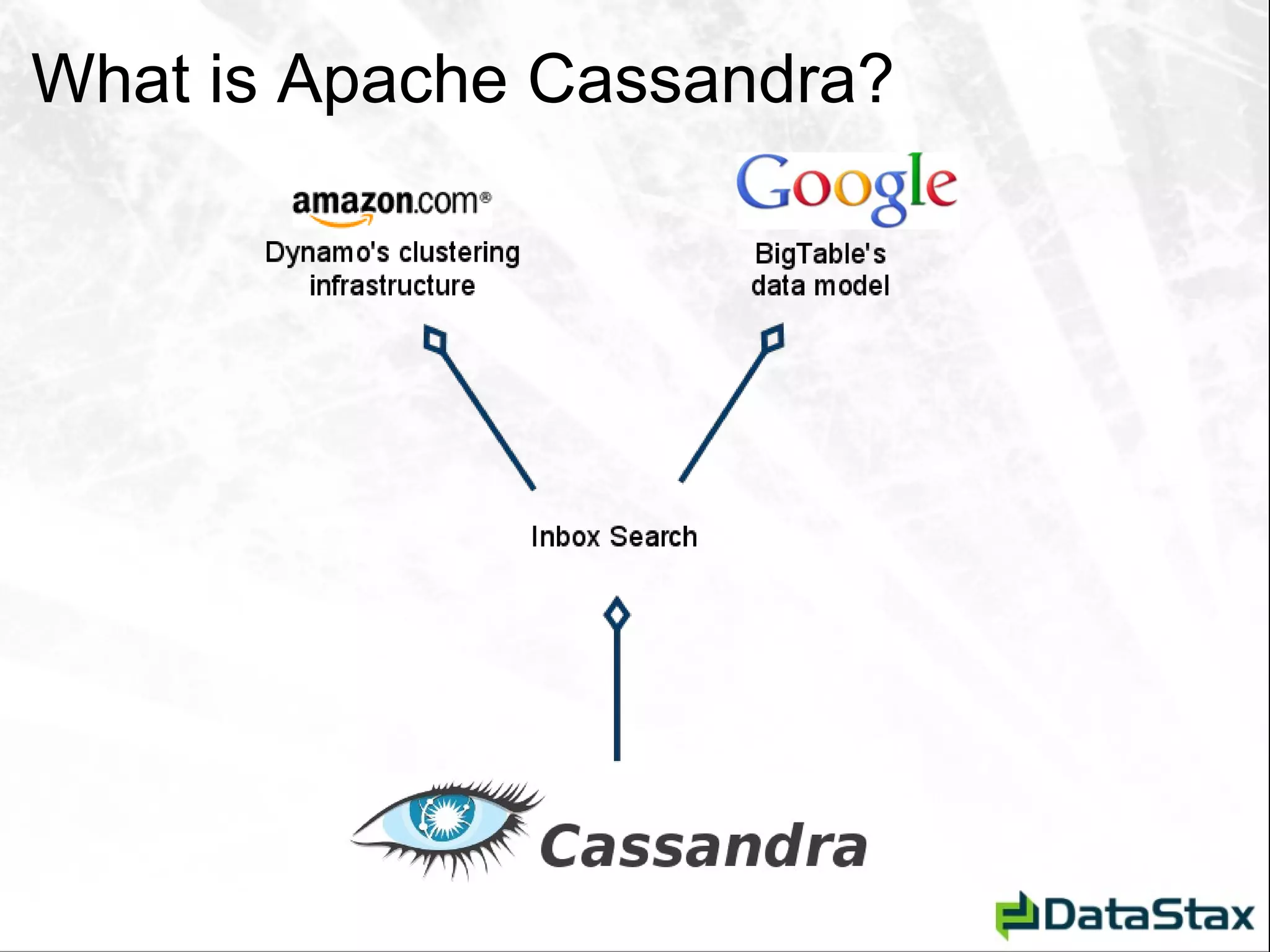
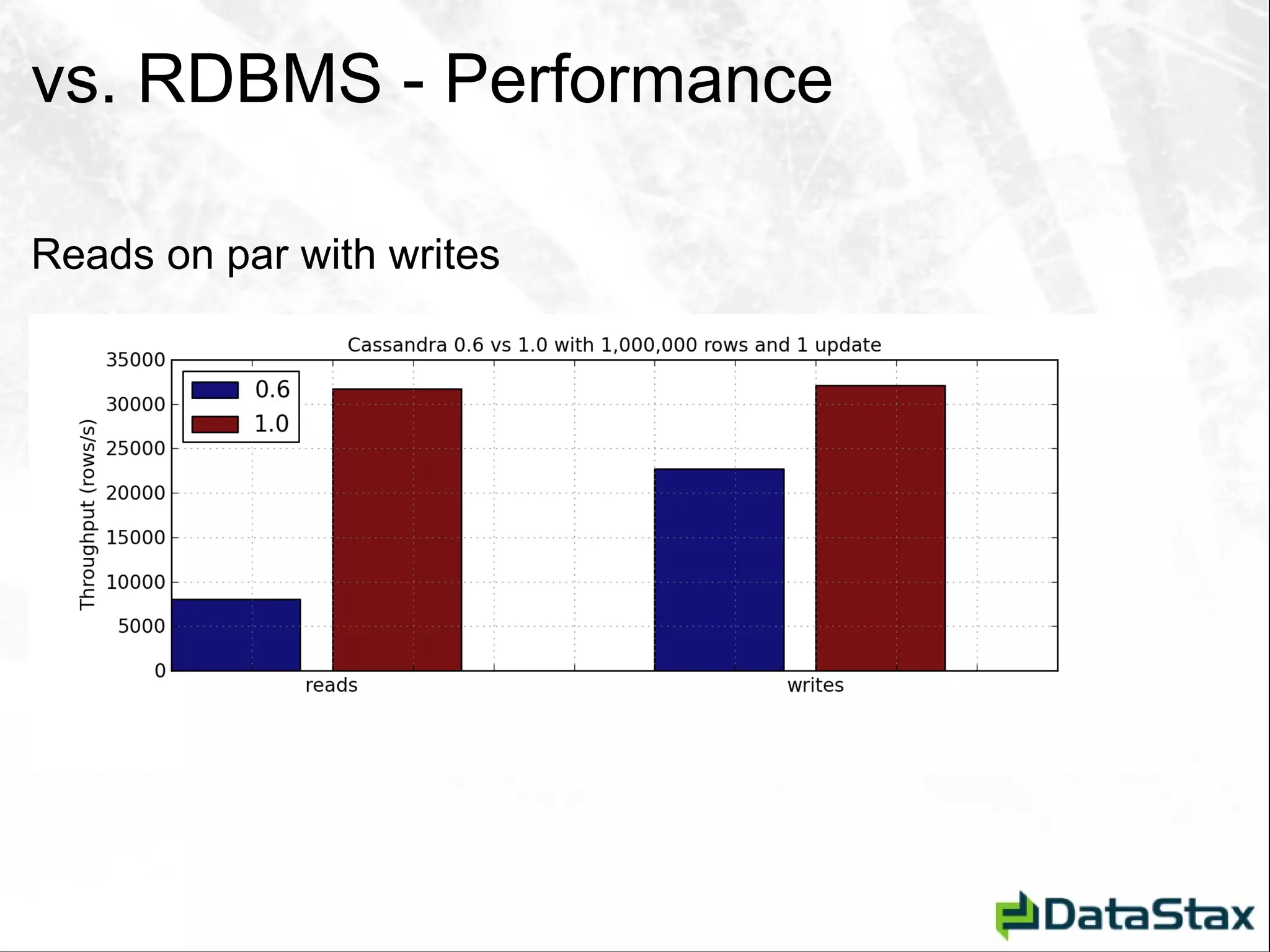
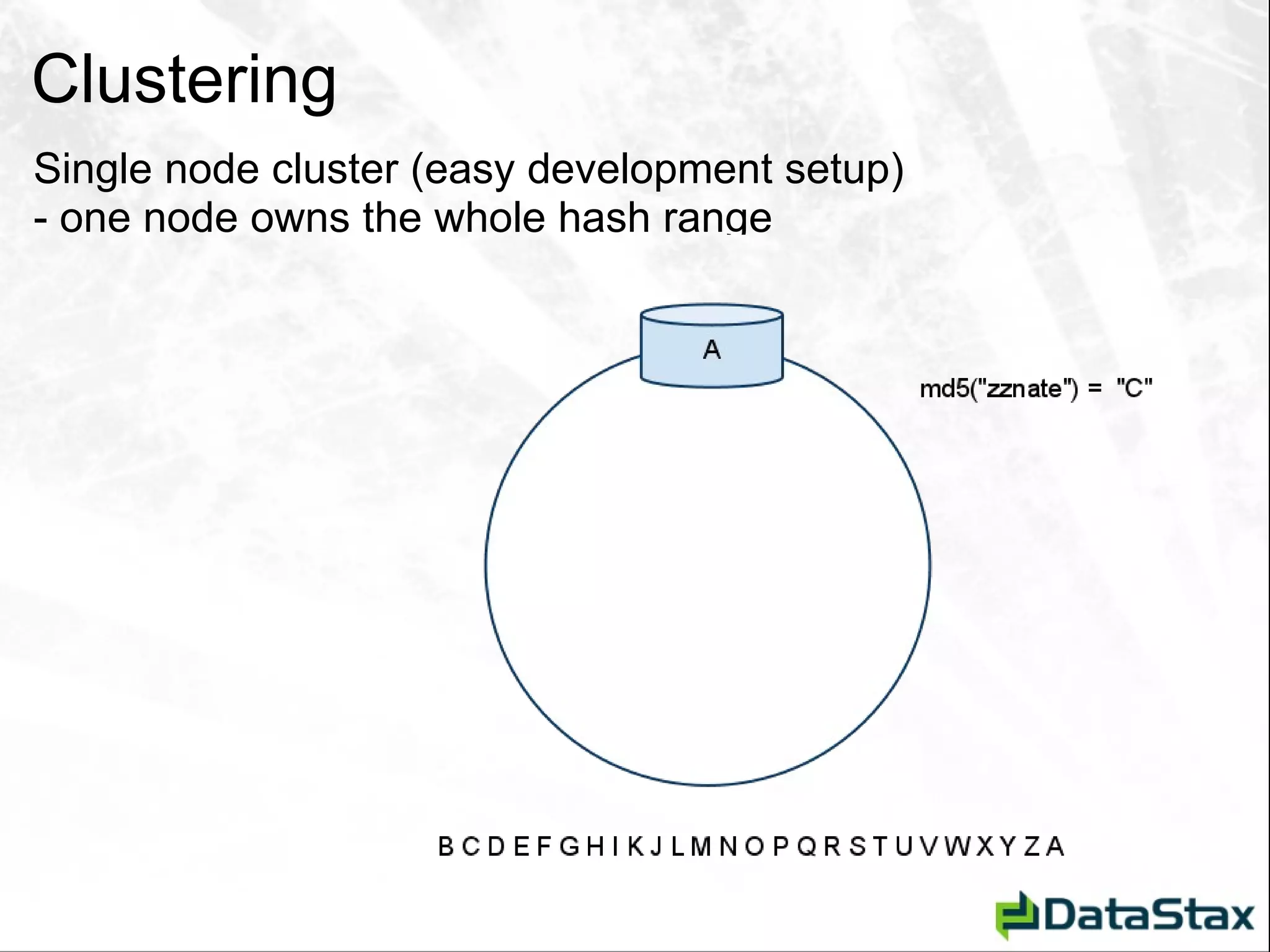
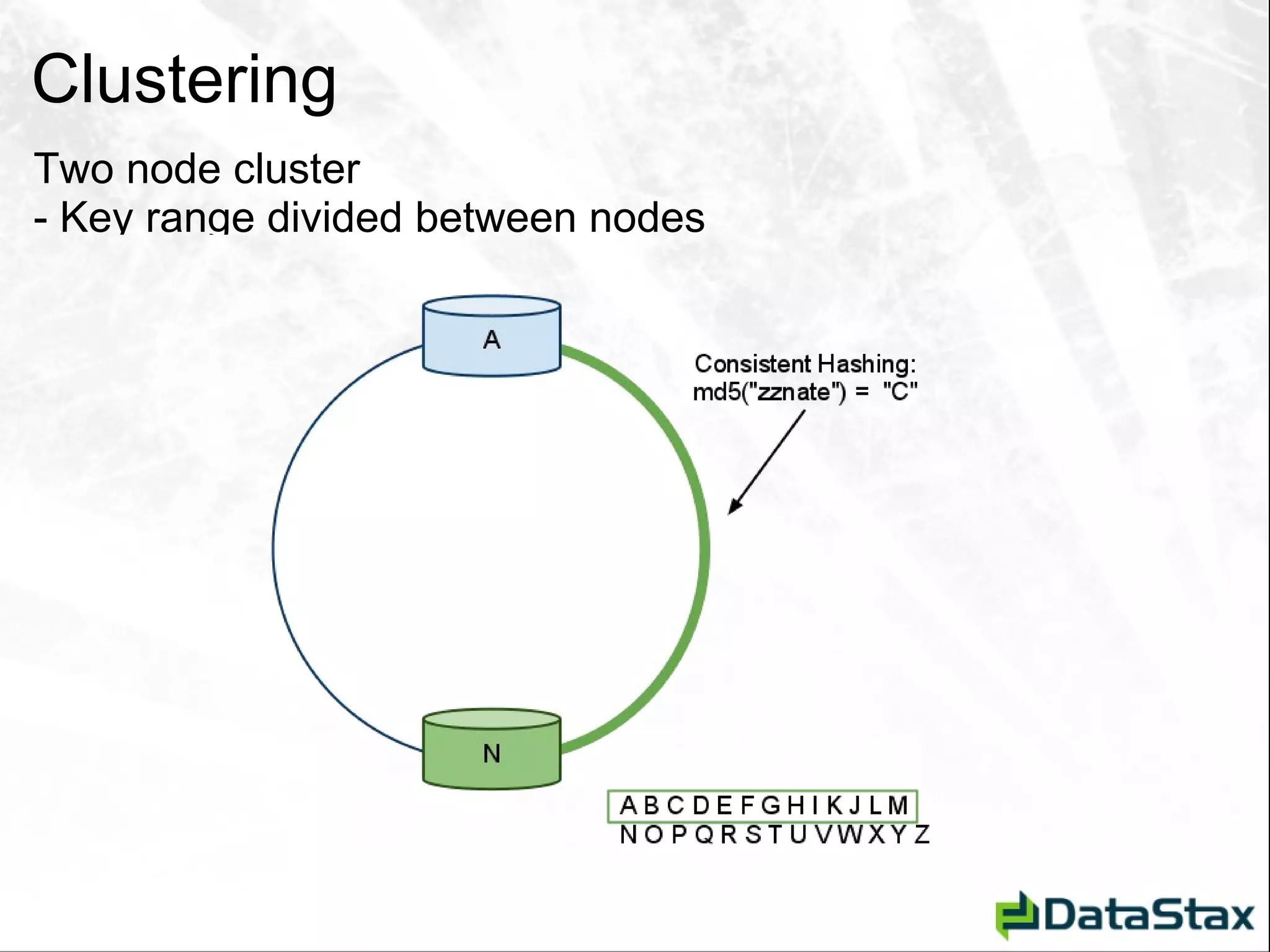
This document serves as an introductory guide to Apache Cassandra for Java developers, detailing its architecture, data model, and key concepts such as the CAP theorem, consistency, and partition tolerance. It contrasts Cassandra with traditional relational database management systems (RDBMS), emphasizing its non-relational, distributed nature and abilities like linear scalability and schema flexibility. The document also covers client interactions, data manipulation operations, and helpful resources for further learning.
![Apache Cassandra An Introduction for Java Developers Nate McCall [email_address] @zznate](https://image.slidesharecdn.com/javaonefinalzznate-111006180039-phpapp01/75/Introduciton-to-Apache-Cassandra-for-Java-Developers-JavaOne-1-2048.jpg)













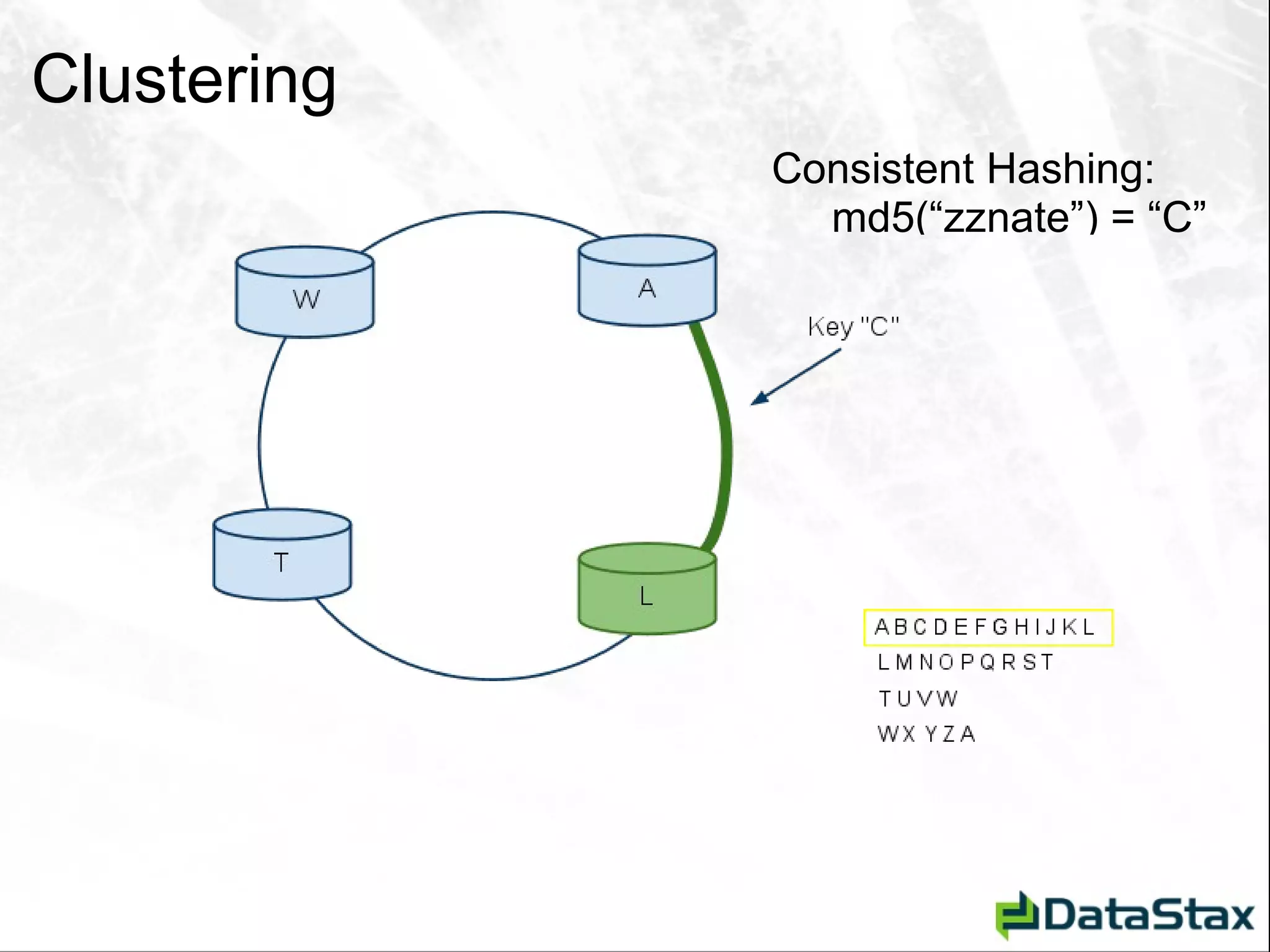

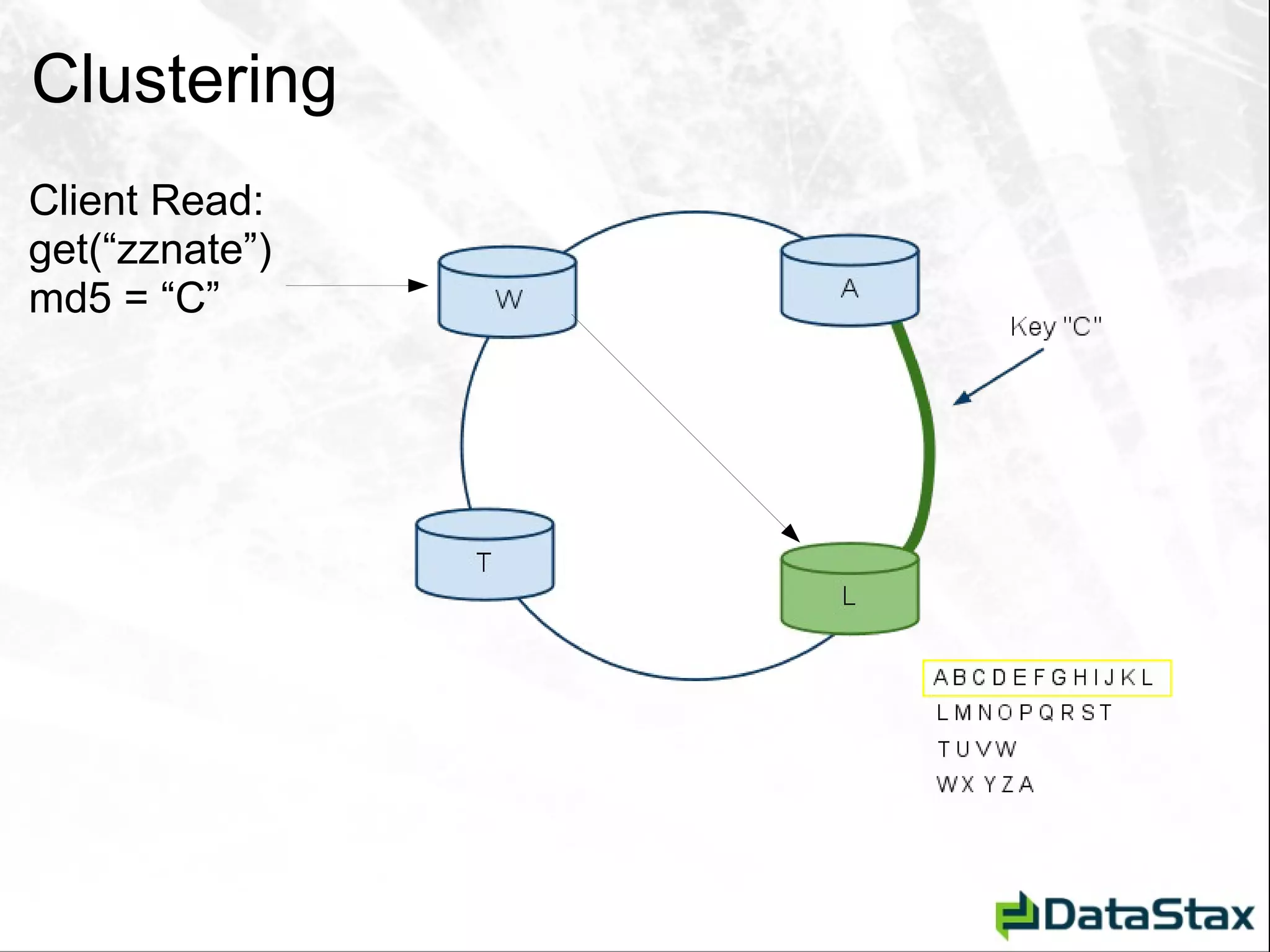
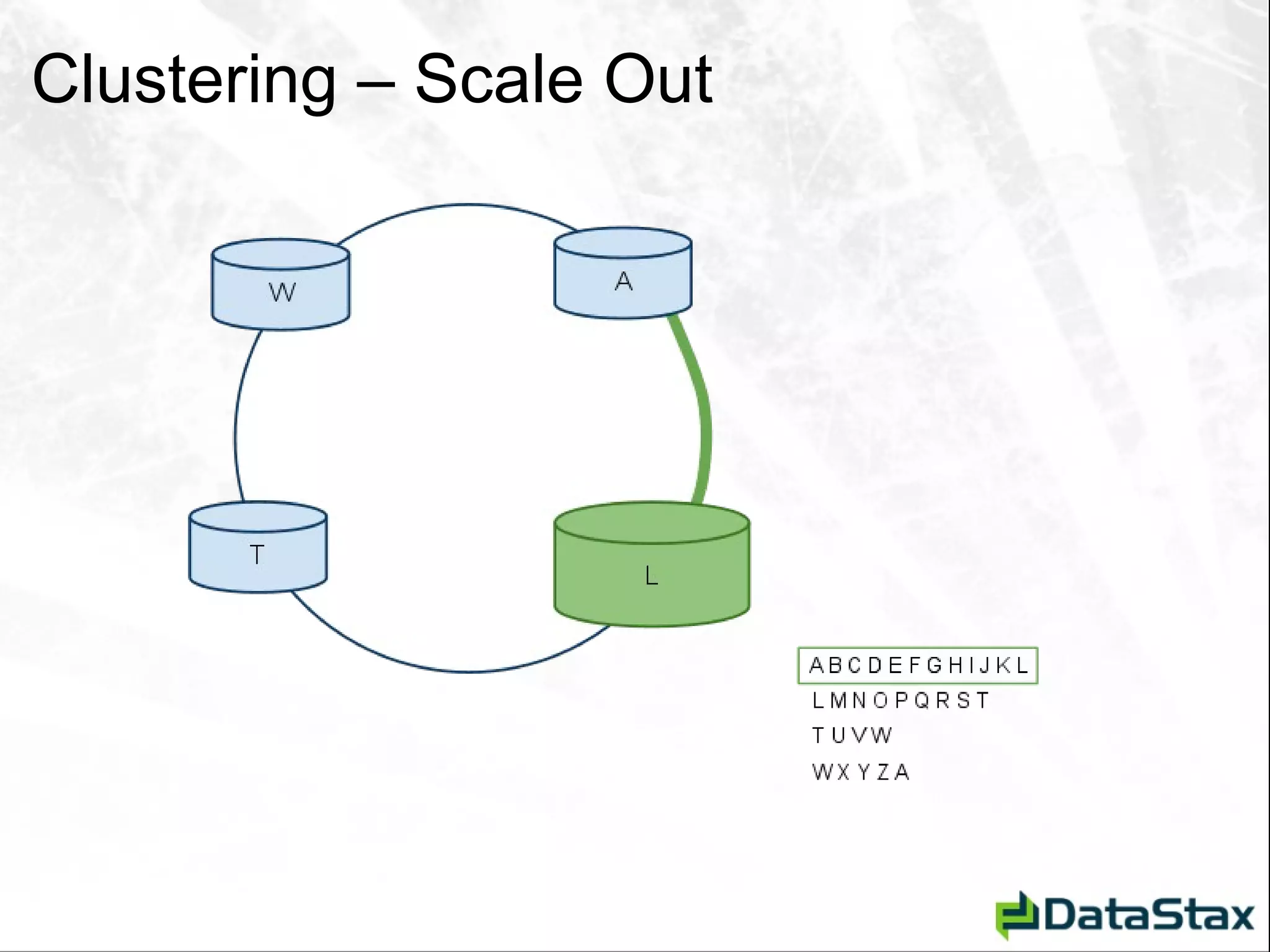
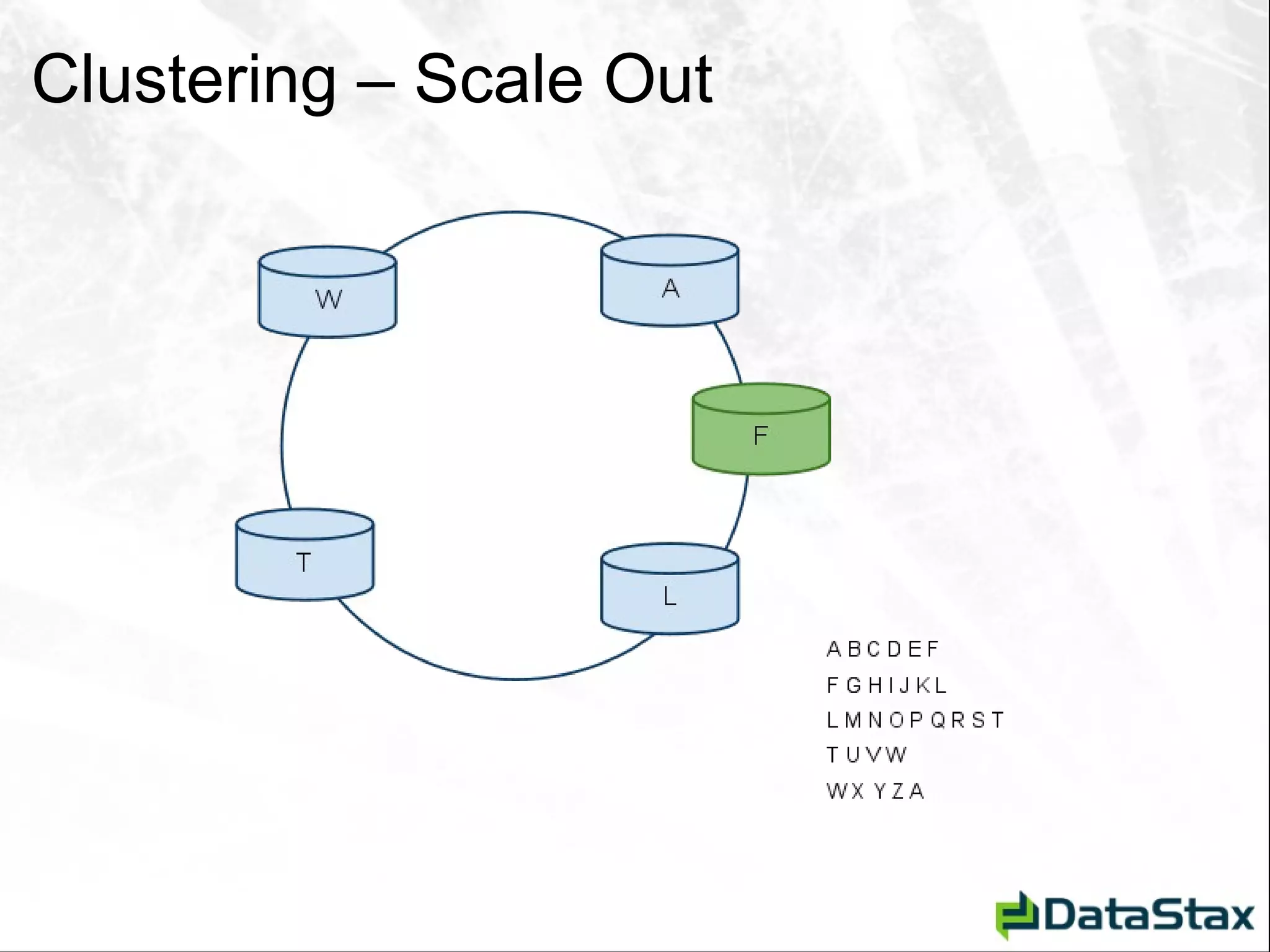


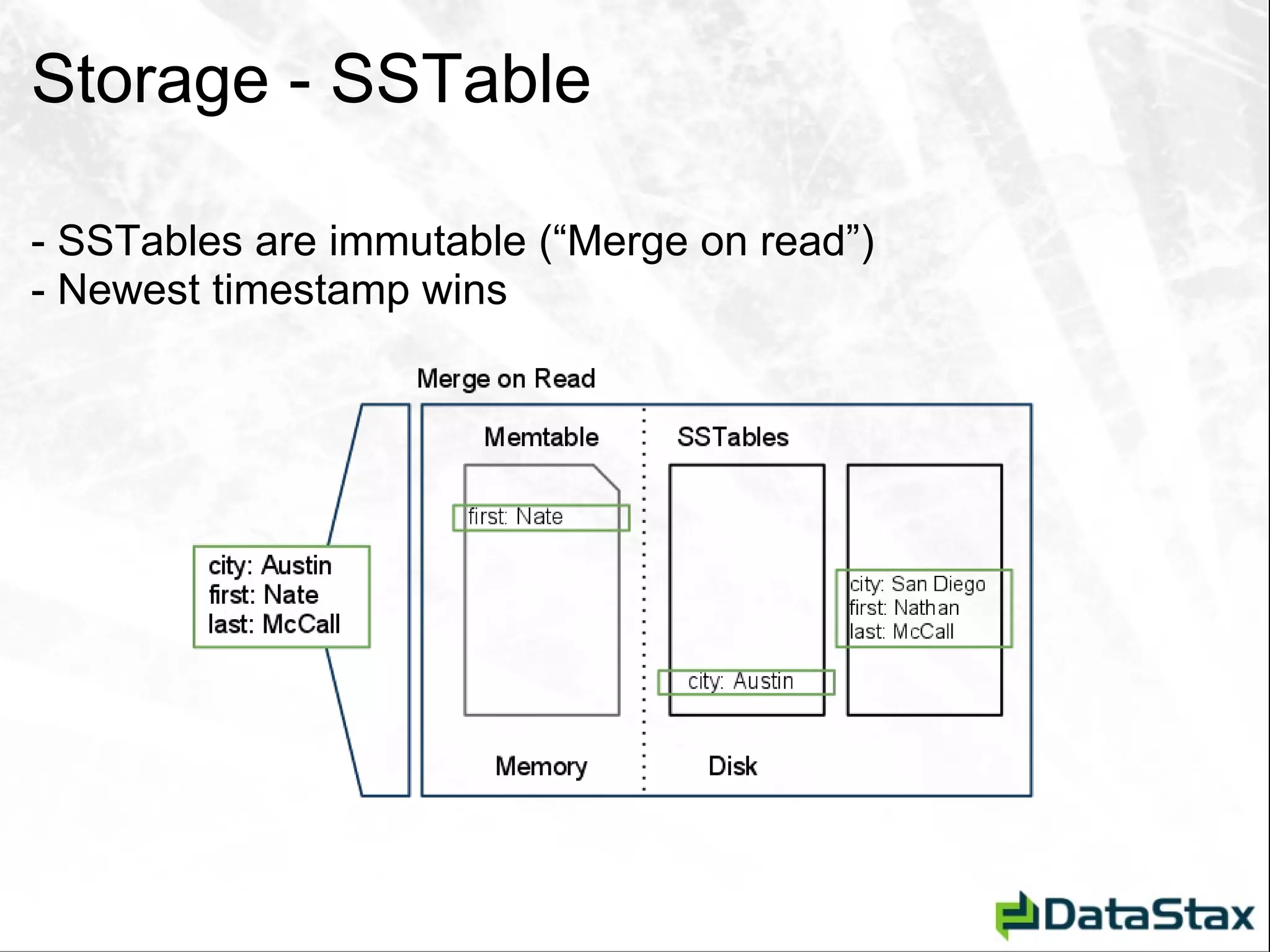
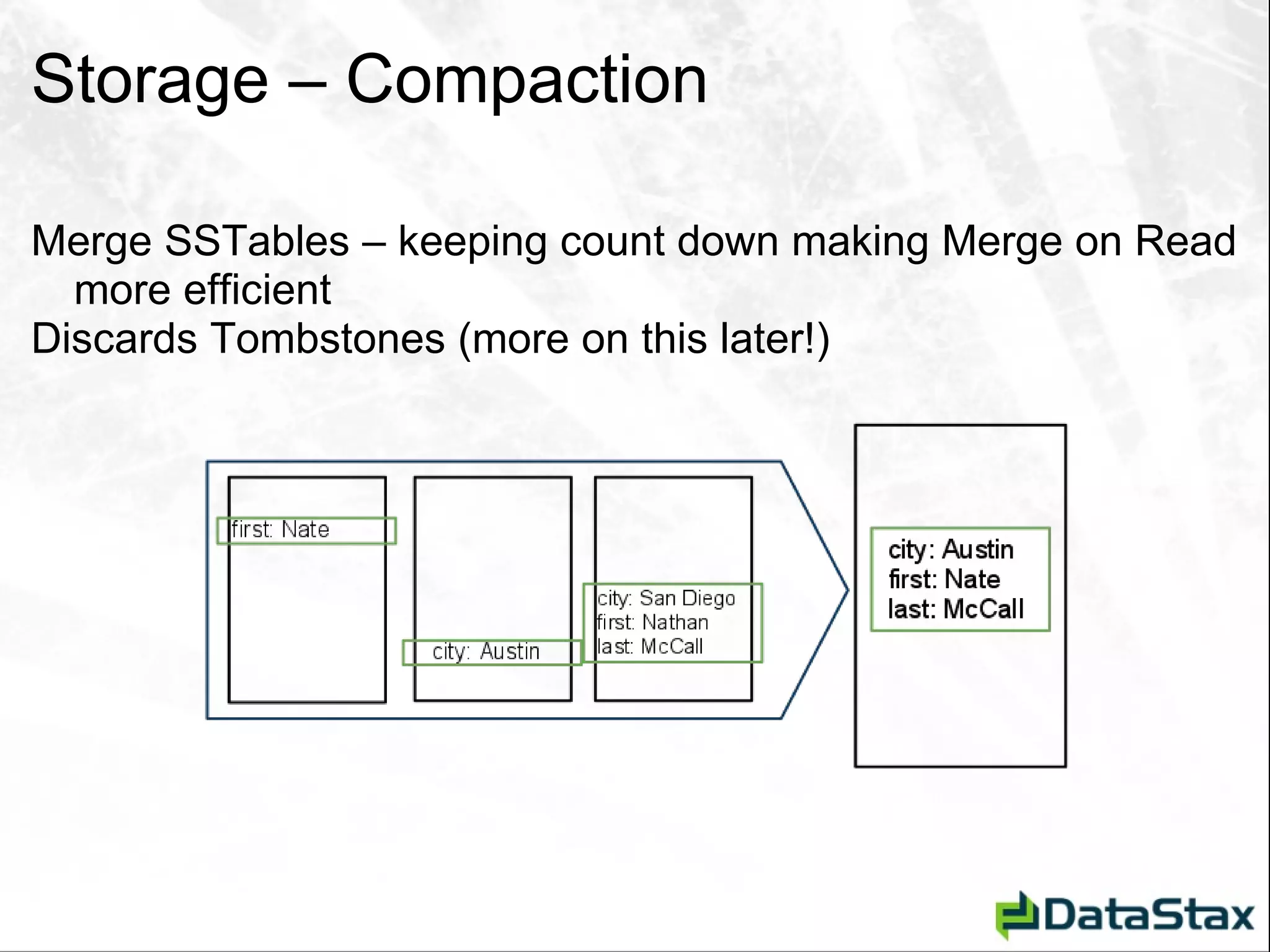




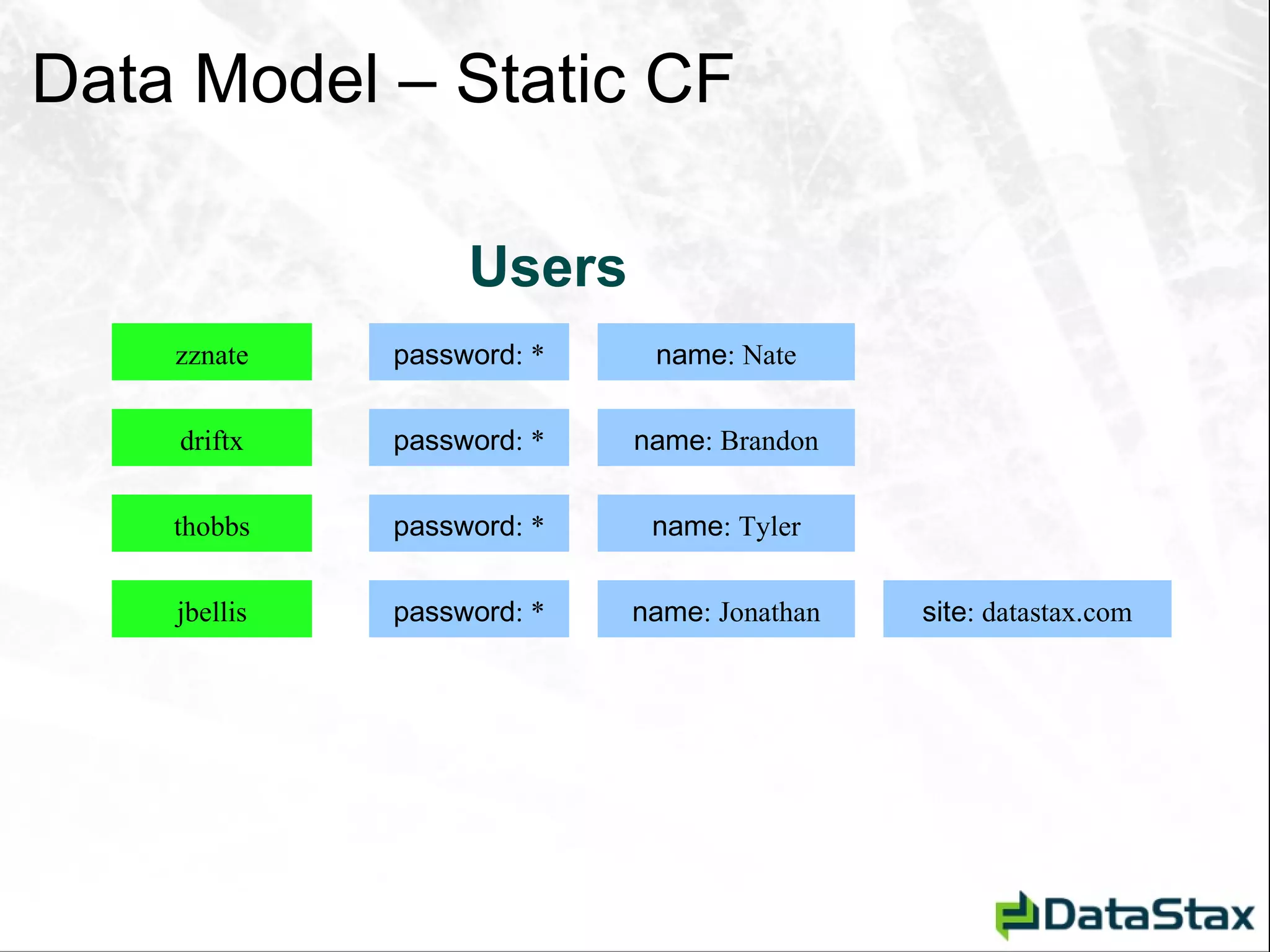
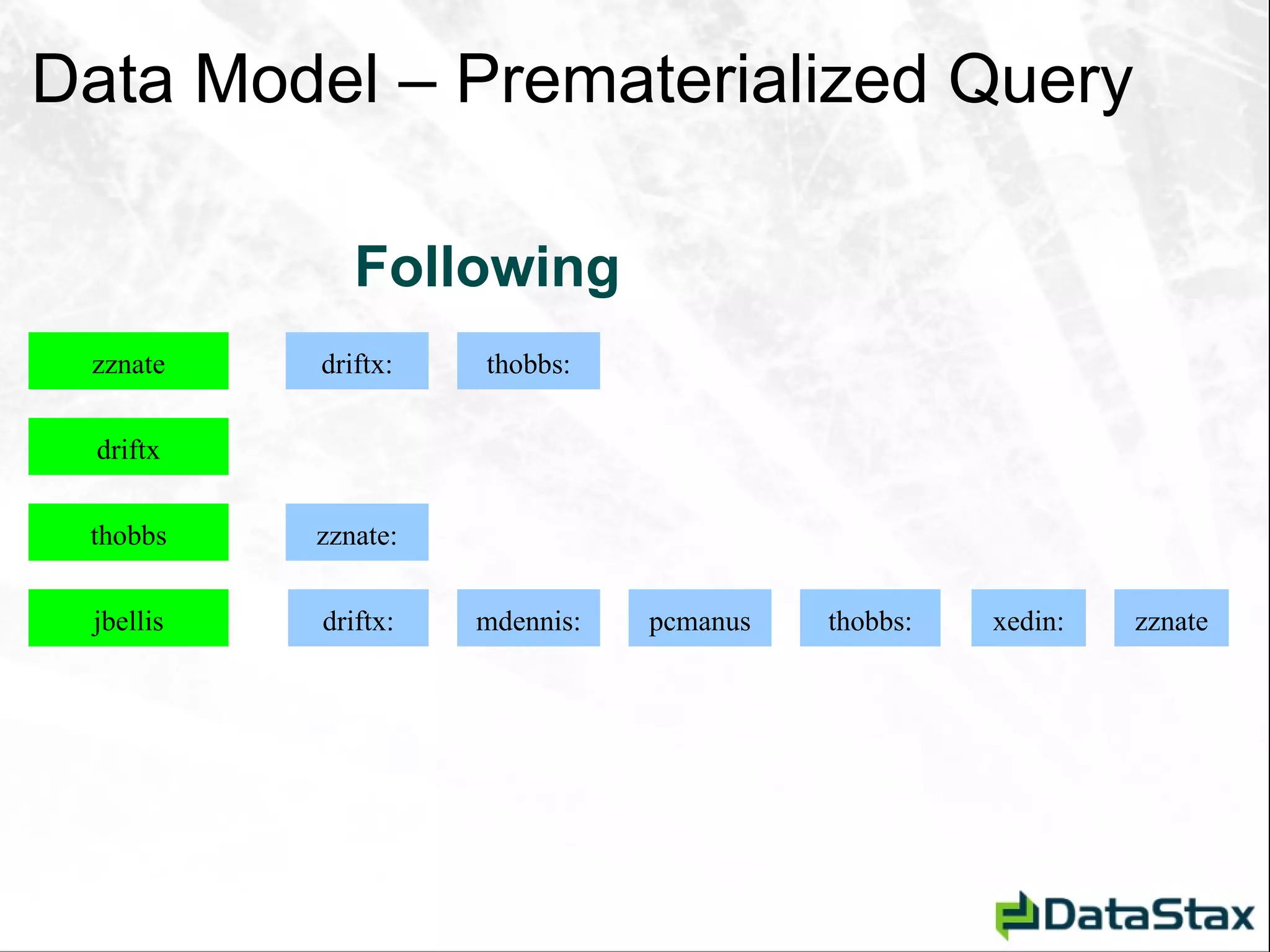






















![Deletion – As Seen by CLI [default@Tutorial] list StateCity; Using default limit of 100](https://image.slidesharecdn.com/javaonefinalzznate-111006180039-phpapp01/75/Introduciton-to-Apache-Cassandra-for-Java-Developers-JavaOne-65-2048.jpg)





![Apache Cassandra An Introduction for Java Developers Nate McCall [email_address] @zznate](https://crownmelresort.com/image.slidesharecdn.com/javaonefinalzznate-111006180039-phpapp01/75/Introduciton-to-Apache-Cassandra-for-Java-Developers-JavaOne-1-2048.jpg)































































![Deletion – As Seen by CLI [default@Tutorial] list StateCity; Using default limit of 100](https://crownmelresort.com/image.slidesharecdn.com/javaonefinalzznate-111006180039-phpapp01/75/Introduciton-to-Apache-Cassandra-for-Java-Developers-JavaOne-65-2048.jpg)


































































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)


