This document provides an introduction and overview of Cassandra, including:
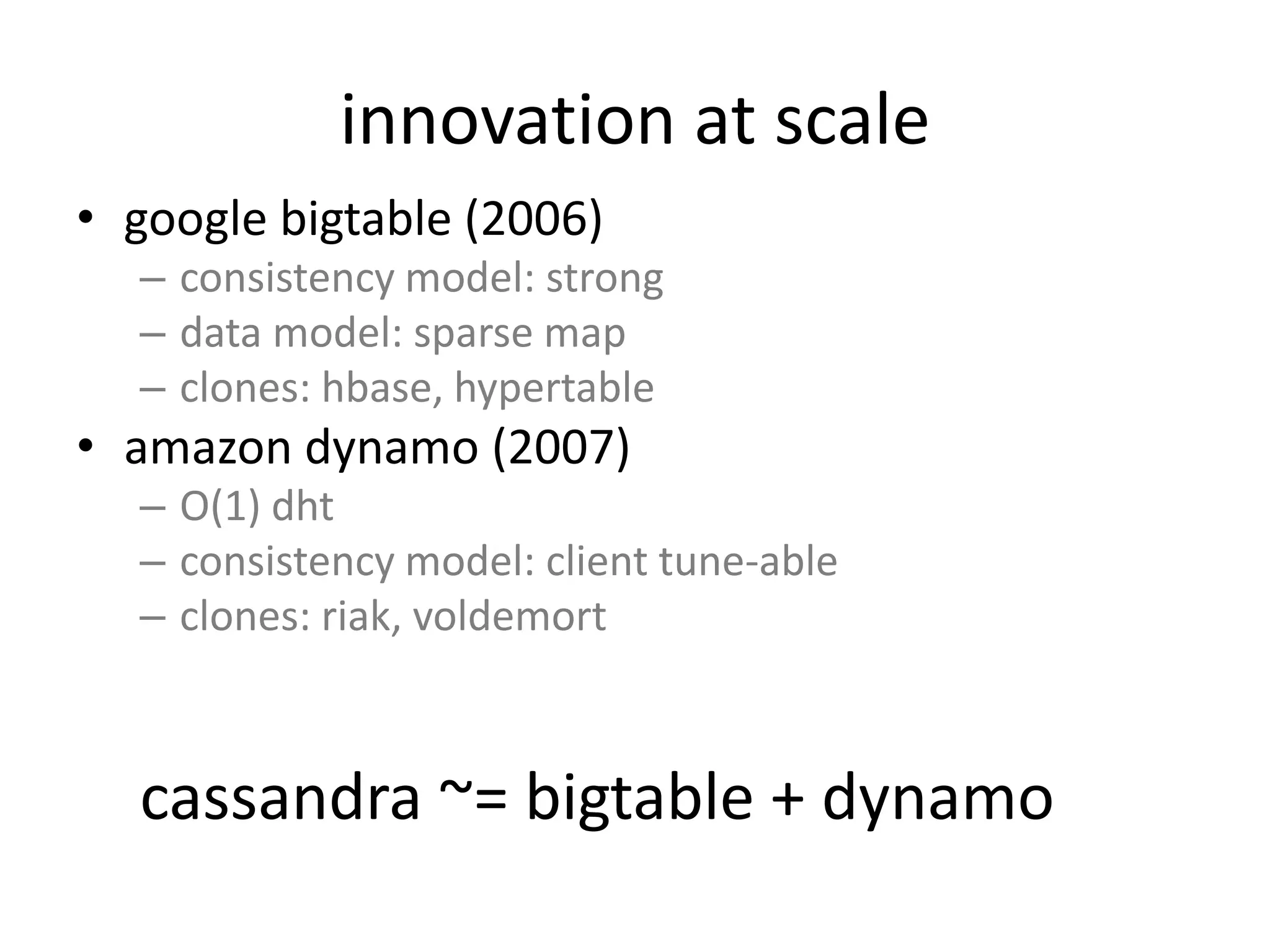
- Cassandra is a distributed database modeled after Google's Bigtable and Amazon's Dynamo, designed for massive scalability and high availability.
- It allows tuning of consistency levels, has very fast writes, linear scalability, and is fault tolerant.
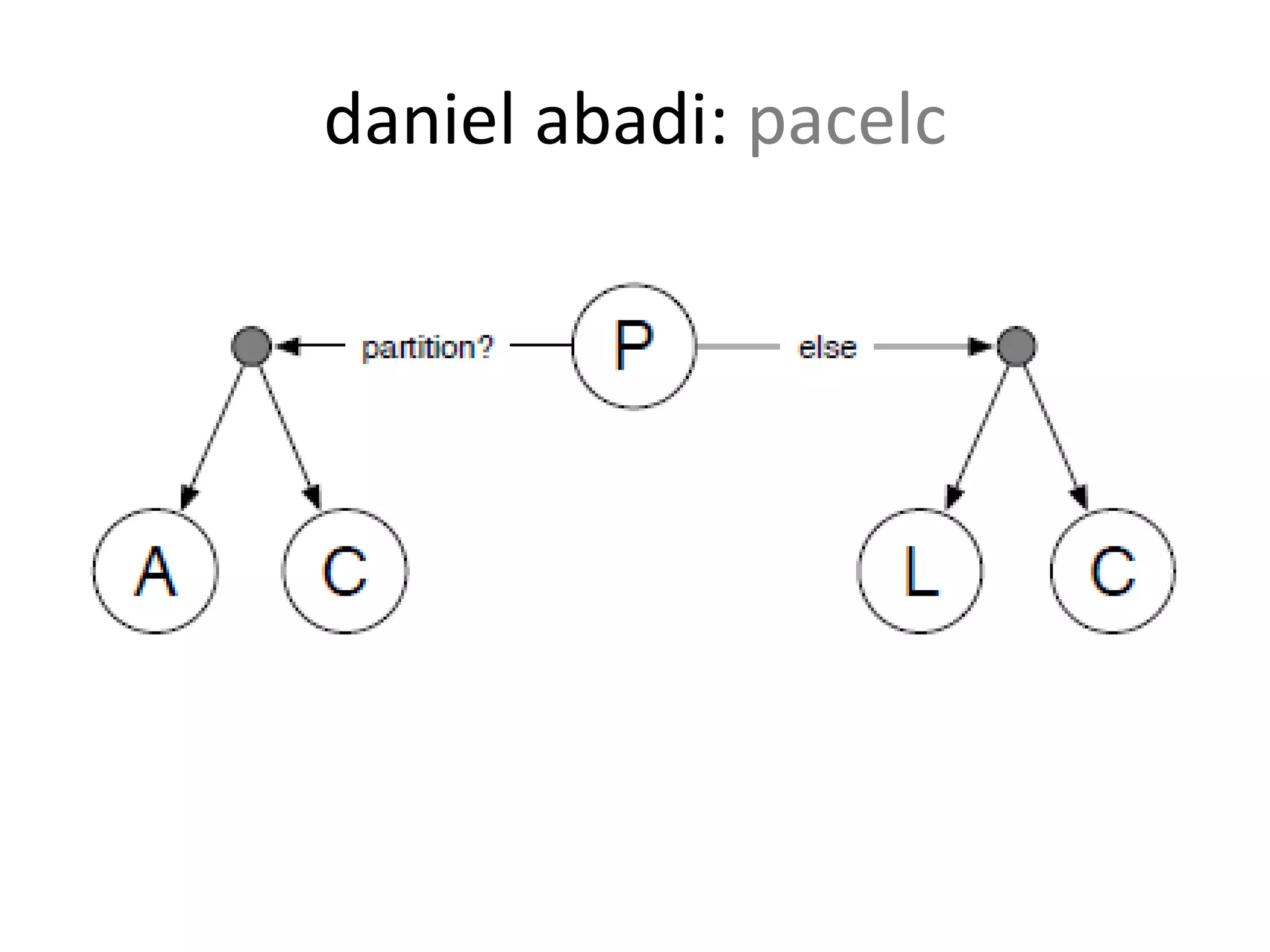
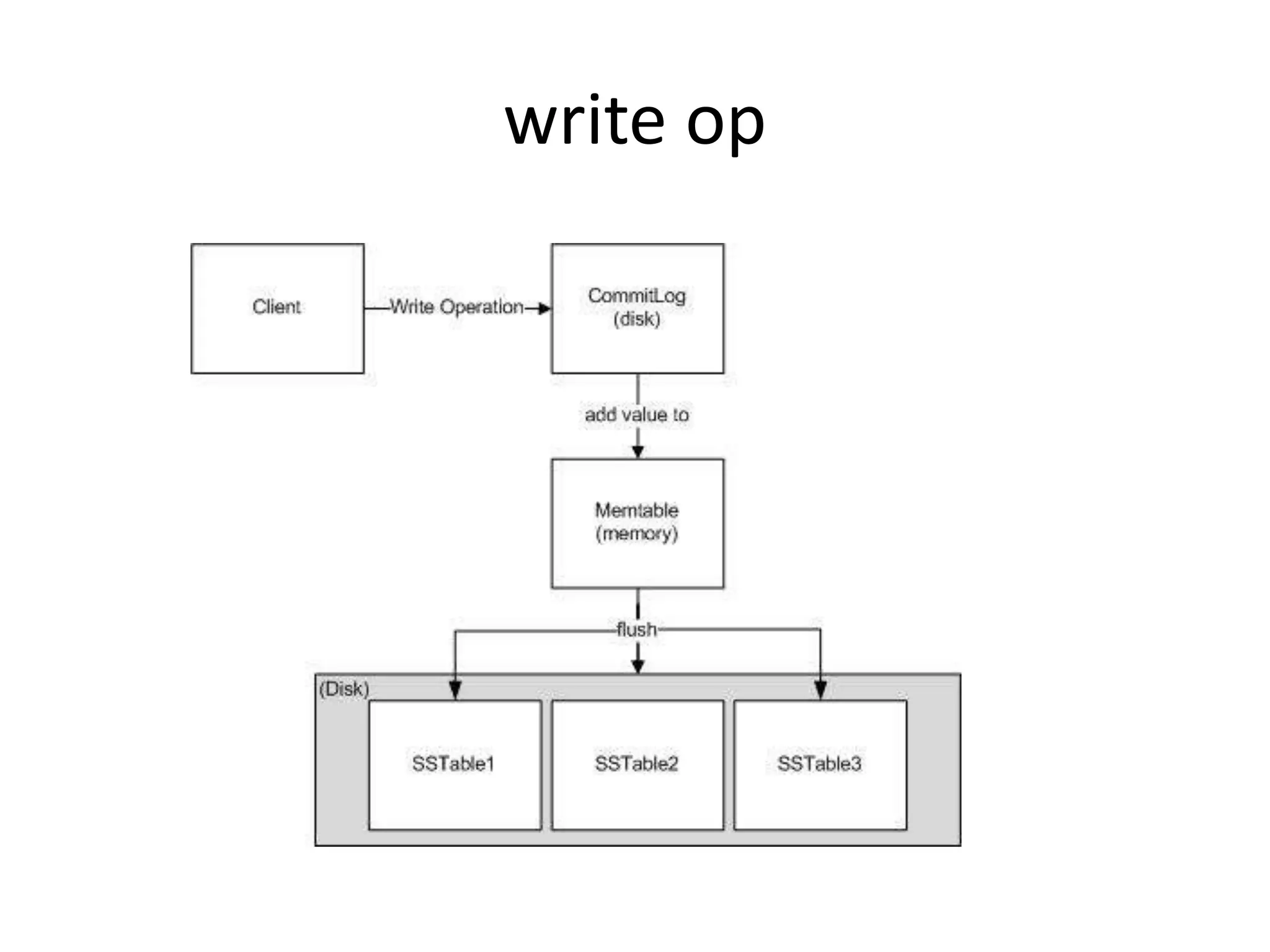
- Cassandra uses a column-oriented data model with tunable consistency levels and a decentralized architecture.
- It is well suited for applications with large datasets, evolving schemas, and loose domain modeling.













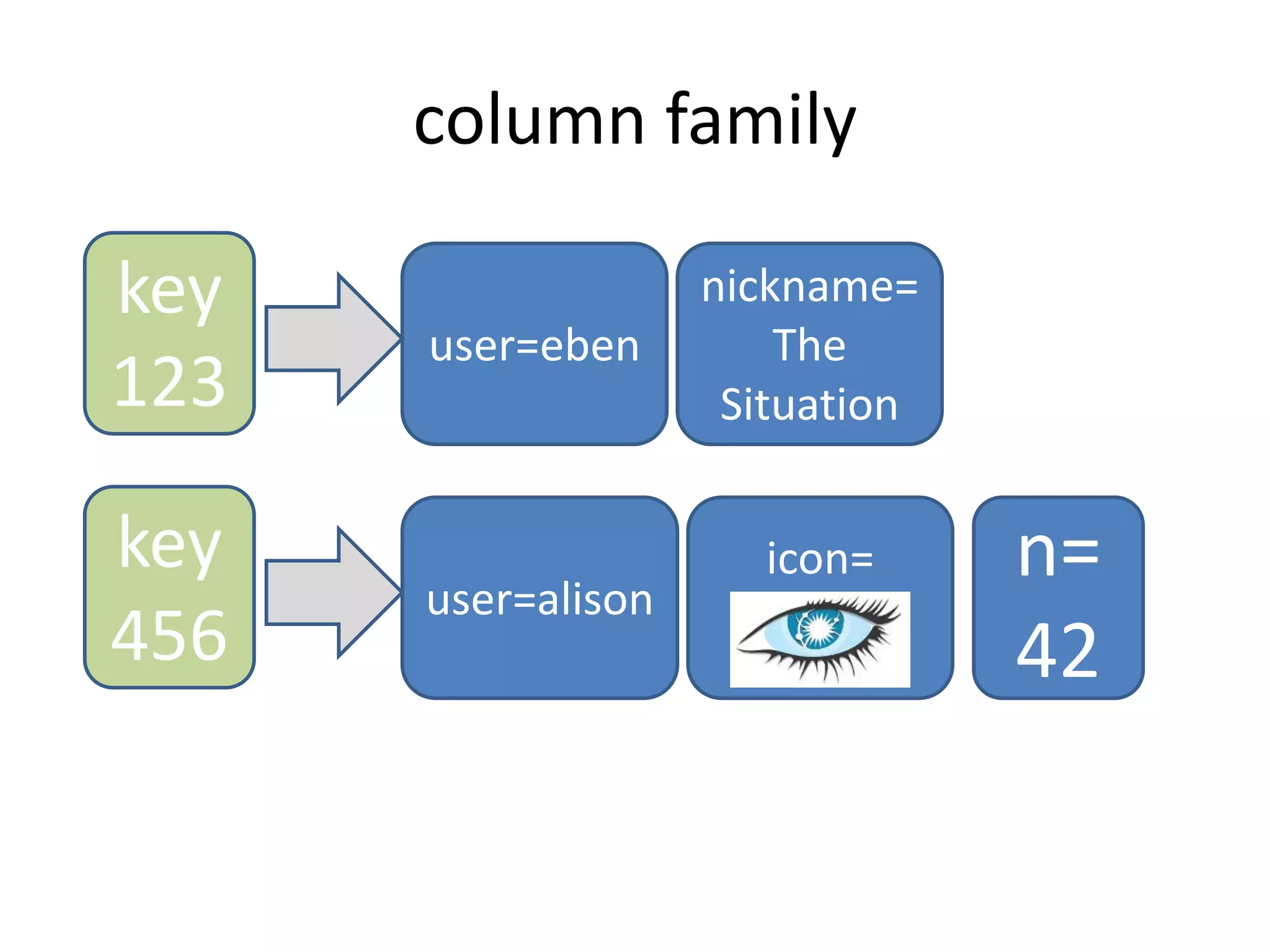
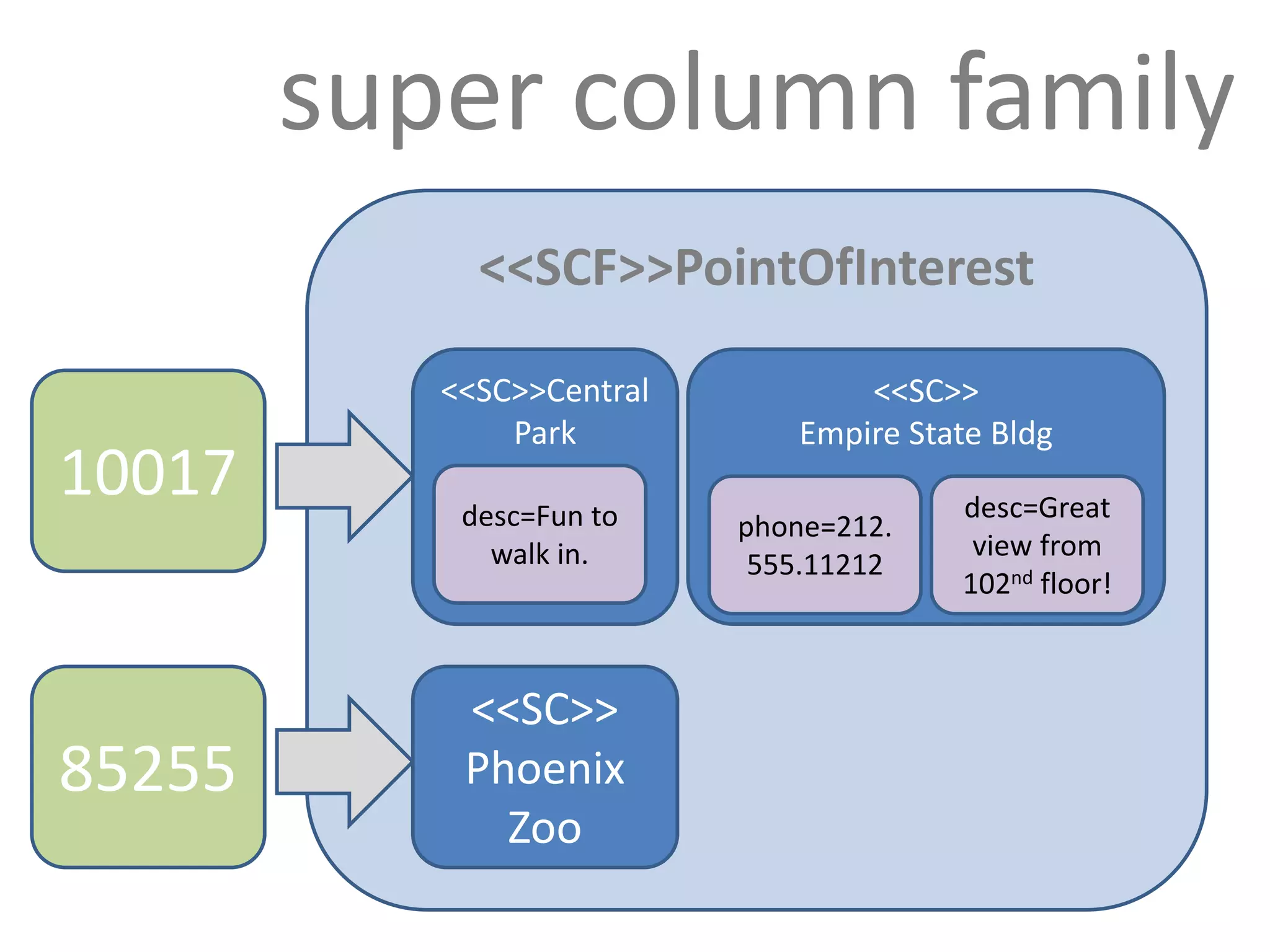
![structure
keyspace
settings
(eg,
partitioner)
column family
settings (eg,
comparator,
type [Std])
column
name value clock](https://image.slidesharecdn.com/scalingwebapplicationswithcassandrapresentation-230721155315-744a69d7/75/Scaling-Web-Applications-with-Cassandra-Presentation-ppt-18-2048.jpg)




![0.6 example
$cassandra –f
$bin/cassandra-cli
cassandra> connect localhost/9160
cassandra> set
Keyspace1.Standard1[‘eben’][‘age’]=‘29’
cassandra> set
Keyspace1.Standard1[‘eben’][‘email’]=‘e@e.com’
cassandra> get Keyspace1.Standard1[‘eben'][‘age']
=> (column=6e616d65, value=39,
timestamp=1282170655390000)](https://image.slidesharecdn.com/scalingwebapplicationswithcassandrapresentation-230721155315-744a69d7/75/Scaling-Web-Applications-with-Cassandra-Presentation-ppt-24-2048.jpg)
![a column has 3 parts
1. name
– byte[]
– determines sort order
– used in queries
– indexed
2. value
– byte[]
– you don’t query on column values
3. timestamp
– long (clock)
– last write wins conflict resolution](https://image.slidesharecdn.com/scalingwebapplicationswithcassandrapresentation-230721155315-744a69d7/75/Scaling-Web-Applications-with-Cassandra-Presentation-ppt-25-2048.jpg)






![read api
• get() : Column
– get the Col or SC at given ColPath
COSC cosc = client.get(key, path, CL);
• get_slice() : List<ColumnOrSuperColumn>
– get Cols in one row, specified by SlicePredicate:
List<ColumnOrSuperColumn> results =
client.get_slice(key, parent, predicate, CL);
• multiget_slice() : Map<key, List<CoSC>>
– get slices for list of keys, based on SlicePredicate
Map<byte[],List<ColumnOrSuperColumn>> results =
client.multiget_slice(rowKeys, parent, predicate, CL);
• get_range_slices() : List<KeySlice>
– returns multiple Cols according to a range
– range is startkey, endkey, starttoken, endtoken:
List<KeySlice> slices = client.get_range_slices(
parent, predicate, keyRange, CL);](https://image.slidesharecdn.com/scalingwebapplicationswithcassandrapresentation-230721155315-744a69d7/75/Scaling-Web-Applications-with-Cassandra-Presentation-ppt-33-2048.jpg)
![write api
client.insert(userKeyBytes, parent,
new Column(“band".getBytes(UTF8),
“Funkadelic".getBytes(), clock), CL);
batch_mutate
– void batch_mutate(
map<byte[], map<String, List<Mutation>>> , CL)
remove
– void remove(byte[],
ColumnPath column_path, Clock, CL)](https://image.slidesharecdn.com/scalingwebapplicationswithcassandrapresentation-230721155315-744a69d7/75/Scaling-Web-Applications-with-Cassandra-Presentation-ppt-34-2048.jpg)
![batch_mutate
//create param
Map<byte[], Map<String, List<Mutation>>> mutationMap =
new HashMap<byte[], Map<String, List<Mutation>>>();
//create Cols for Muts
Column nameCol = new Column("name".getBytes(UTF8),
“Funkadelic”.getBytes("UTF-8"), new Clock(System.nanoTime()););
Mutation nameMut = new Mutation();
nameMut.column_or_supercolumn = nameCosc; //also phone, etc
Map<String, List<Mutation>> muts = new HashMap<String, List<Mutation>>();
List<Mutation> cols = new ArrayList<Mutation>();
cols.add(nameMut);
cols.add(phoneMut);
muts.put(CF, cols);
//outer map key is a row key; inner map key is the CF name
mutationMap.put(rowKey.getBytes(), muts);
//send to server
client.batch_mutate(mutationMap, CL);](https://image.slidesharecdn.com/scalingwebapplicationswithcassandrapresentation-230721155315-744a69d7/75/Scaling-Web-Applications-with-Cassandra-Presentation-ppt-35-2048.jpg)

























![structure
keyspace
settings
(eg,
partitioner)
column family
settings (eg,
comparator,
type [Std])
column
name value clock](https://crownmelresort.com/image.slidesharecdn.com/scalingwebapplicationswithcassandrapresentation-230721155315-744a69d7/75/Scaling-Web-Applications-with-Cassandra-Presentation-ppt-18-2048.jpg)





![0.6 example
$cassandra –f
$bin/cassandra-cli
cassandra> connect localhost/9160
cassandra> set
Keyspace1.Standard1[‘eben’][‘age’]=‘29’
cassandra> set
Keyspace1.Standard1[‘eben’][‘email’]=‘e@e.com’
cassandra> get Keyspace1.Standard1[‘eben'][‘age']
=> (column=6e616d65, value=39,
timestamp=1282170655390000)](https://crownmelresort.com/image.slidesharecdn.com/scalingwebapplicationswithcassandrapresentation-230721155315-744a69d7/75/Scaling-Web-Applications-with-Cassandra-Presentation-ppt-24-2048.jpg)
![a column has 3 parts
1. name
– byte[]
– determines sort order
– used in queries
– indexed
2. value
– byte[]
– you don’t query on column values
3. timestamp
– long (clock)
– last write wins conflict resolution](https://crownmelresort.com/image.slidesharecdn.com/scalingwebapplicationswithcassandrapresentation-230721155315-744a69d7/75/Scaling-Web-Applications-with-Cassandra-Presentation-ppt-25-2048.jpg)







![read api
• get() : Column
– get the Col or SC at given ColPath
COSC cosc = client.get(key, path, CL);
• get_slice() : List<ColumnOrSuperColumn>
– get Cols in one row, specified by SlicePredicate:
List<ColumnOrSuperColumn> results =
client.get_slice(key, parent, predicate, CL);
• multiget_slice() : Map<key, List<CoSC>>
– get slices for list of keys, based on SlicePredicate
Map<byte[],List<ColumnOrSuperColumn>> results =
client.multiget_slice(rowKeys, parent, predicate, CL);
• get_range_slices() : List<KeySlice>
– returns multiple Cols according to a range
– range is startkey, endkey, starttoken, endtoken:
List<KeySlice> slices = client.get_range_slices(
parent, predicate, keyRange, CL);](https://crownmelresort.com/image.slidesharecdn.com/scalingwebapplicationswithcassandrapresentation-230721155315-744a69d7/75/Scaling-Web-Applications-with-Cassandra-Presentation-ppt-33-2048.jpg)
![write api
client.insert(userKeyBytes, parent,
new Column(“band".getBytes(UTF8),
“Funkadelic".getBytes(), clock), CL);
batch_mutate
– void batch_mutate(
map<byte[], map<String, List<Mutation>>> , CL)
remove
– void remove(byte[],
ColumnPath column_path, Clock, CL)](https://crownmelresort.com/image.slidesharecdn.com/scalingwebapplicationswithcassandrapresentation-230721155315-744a69d7/75/Scaling-Web-Applications-with-Cassandra-Presentation-ppt-34-2048.jpg)
![batch_mutate
//create param
Map<byte[], Map<String, List<Mutation>>> mutationMap =
new HashMap<byte[], Map<String, List<Mutation>>>();
//create Cols for Muts
Column nameCol = new Column("name".getBytes(UTF8),
“Funkadelic”.getBytes("UTF-8"), new Clock(System.nanoTime()););
Mutation nameMut = new Mutation();
nameMut.column_or_supercolumn = nameCosc; //also phone, etc
Map<String, List<Mutation>> muts = new HashMap<String, List<Mutation>>();
List<Mutation> cols = new ArrayList<Mutation>();
cols.add(nameMut);
cols.add(phoneMut);
muts.put(CF, cols);
//outer map key is a row key; inner map key is the CF name
mutationMap.put(rowKey.getBytes(), muts);
//send to server
client.batch_mutate(mutationMap, CL);](https://crownmelresort.com/image.slidesharecdn.com/scalingwebapplicationswithcassandrapresentation-230721155315-744a69d7/75/Scaling-Web-Applications-with-Cassandra-Presentation-ppt-35-2048.jpg)




































































