This document provides an overview of Cassandra, a decentralized structured storage model. Some key points:
- Cassandra is a distributed database designed to handle large amounts of data across commodity servers. It provides high availability with no single point of failure.
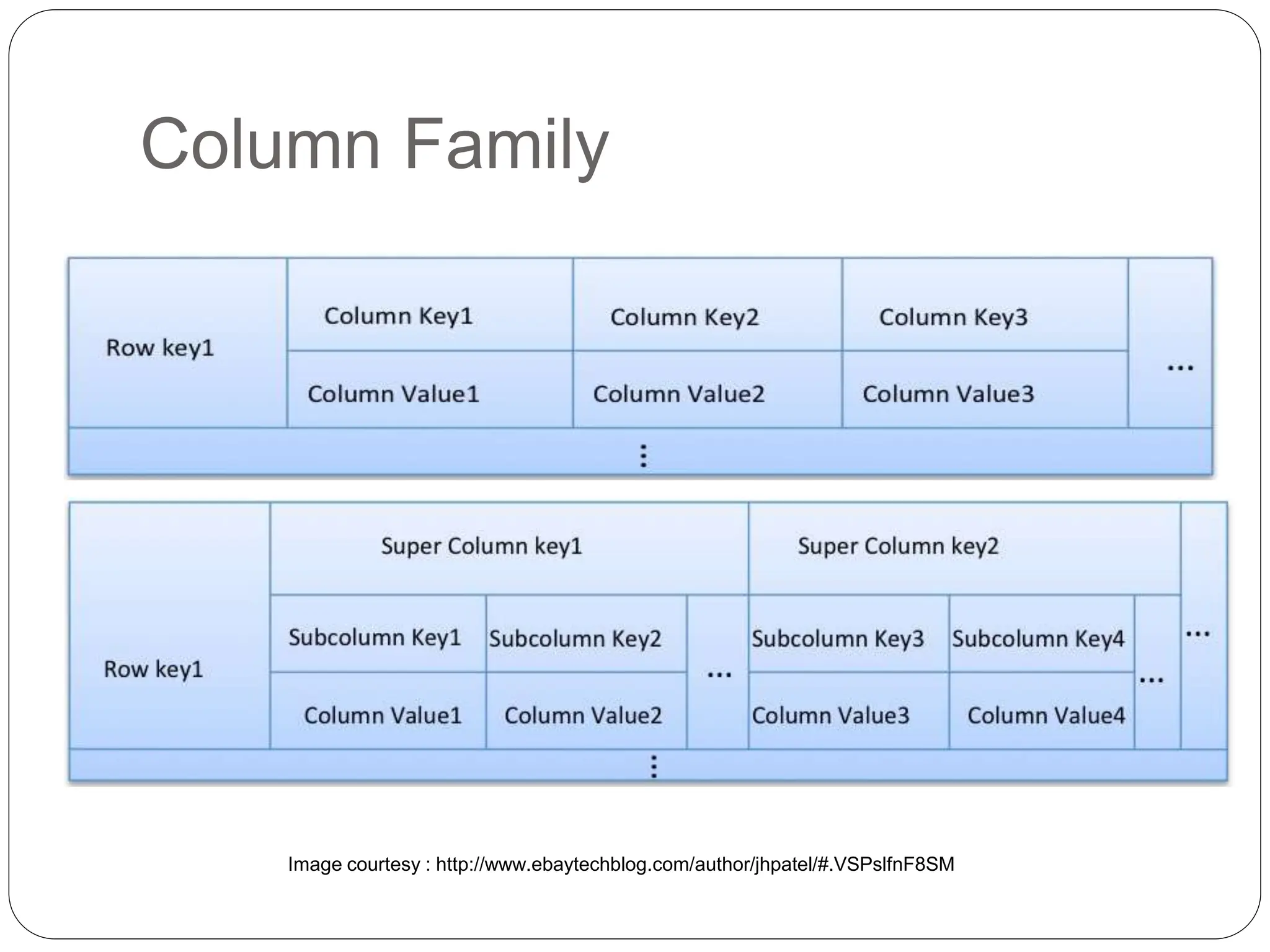
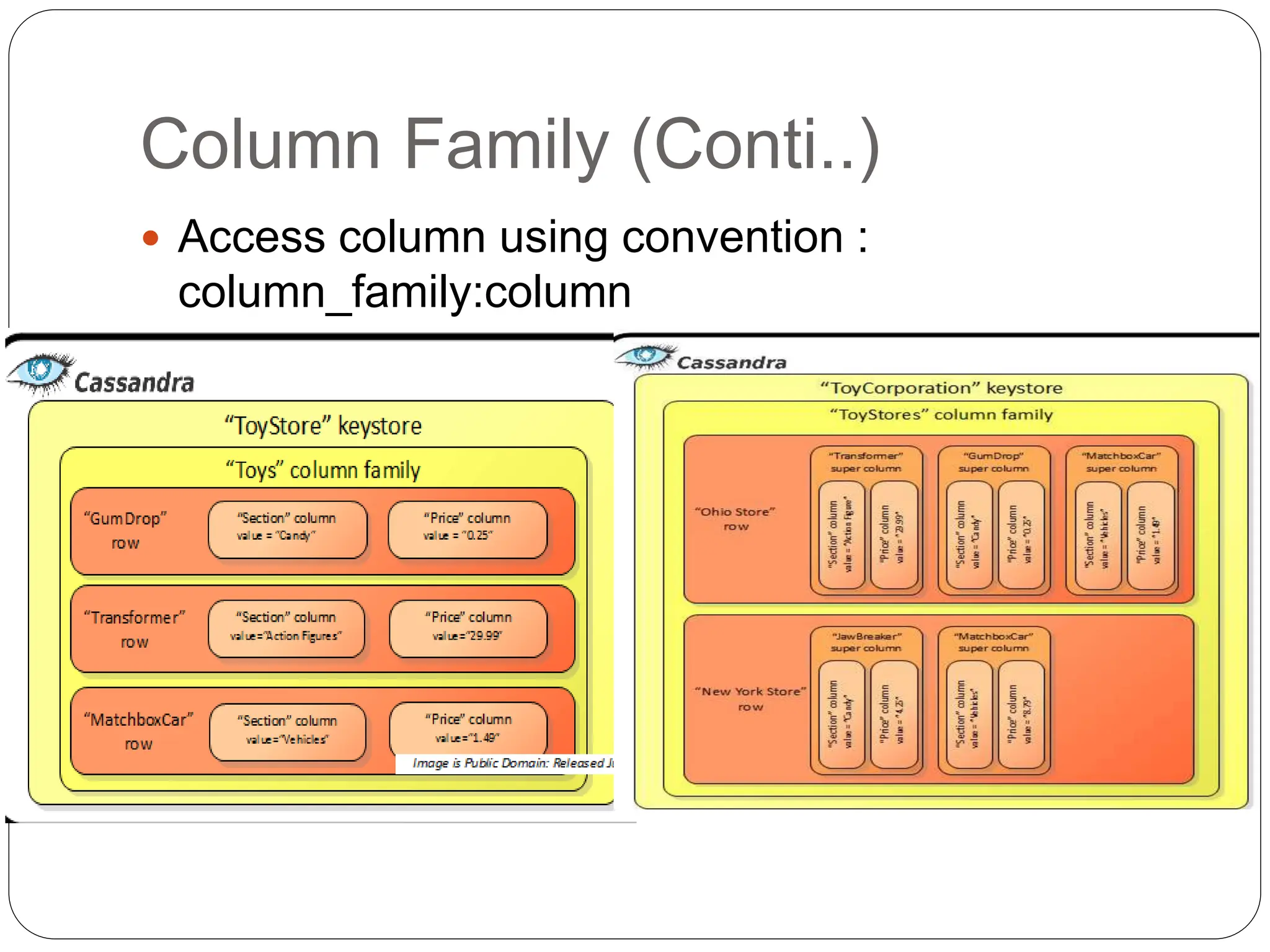
- Cassandra's data model is based on Dynamo and BigTable, with data distributed across nodes through consistent hashing. It uses a column-based data structure with rows, columns, column families and supercolumns.
- Cassandra was originally developed at Facebook to address issues of high write throughput and latency for their inbox search feature, which now stores over 50TB of data across 150 nodes.
- Other large companies using Cassandra include Netflix, eBay