Download as PDF, PPTX















![Calcite Model
{
version: '1.0',
defaultSchema: 'TEST',
schemas: [ {
name: 'TEST',
type: 'custom',
factory: 'org.apache.calcite.adapter.geode.simple.GeodeSchemaFactory',
operand: {
locatorHost: 'localhost',
locatorPort: '10334',
regions: 'BookMaster',
pdxSerializablePackagePath: 'net.tzolov.geode.bookstore.domain.*'
}
}]
}
Reference to your adapter
schema factory implementation
class
Parameters to be passed to
your adapter schema factory
implementation
The path to <my-model>.json is passed as JDBC connection argument:
!connect jdbc:calcite:model=target/test-classes/<my-model-path>.json︎
Schema Name](https://image.slidesharecdn.com/apachecon2016christiantzolov-161115000837/75/Using-Apache-Calcite-for-Enabling-SQL-and-JDBC-Access-to-Apache-Geode-and-Other-NoSQL-Data-Systems-22-2048.jpg)
![Geode Calcite Schema and Schema Factory
public class GeodeSchemaFactory implements SchemaFactory {
public Schema create(SchemaPlus parentSchema, String schemaName, Map<String, Object> operand) {
String locatorHost = (String) operand.get(“locatorHost”);
int locatorPort = …
String[] regionNames = …
String pdxPackagePath = …
return new GeodeSchema(locatorHost, locatorPort, regionNames, pdxPackagePath);
}
}
public class GeodeSchema extends AbstractSchema {
private String regionName = ..
protected Map<String, Table> getTableMap() {
final ImmutableMap.Builder<String, Table> builder = ImmutableMap.builder();
Region region = … Get Geode Region by region name …
Class valueClass= … Find region’s value type …
builder.put(regionName, new GeodeScannableTable(regionName, valueClass, clientCache));
return tableMap;
}
Retrieves the parameters set in
the model.json
Create an Adapter Schema
instance with the provided
parameters.
Create GeodeScannableTable
instance for each Geode Region](https://image.slidesharecdn.com/apachecon2016christiantzolov-161115000837/75/Using-Apache-Calcite-for-Enabling-SQL-and-JDBC-Access-to-Apache-Geode-and-Other-NoSQL-Data-Systems-23-2048.jpg)
![Geode Scannable Table
public class GeodeScannableTable extends AbstractTable implements ScannableTable {
public RelDataType getRowType(RelDataTypeFactory typeFactory) {
return new JavaTypeFactoryImpl().createStructType(valueClass);
}
public Enumerable<Object[]> scan(DataContext root) {
return new AbstractEnumerable<Object[]>() {
public Enumerator<Object[]> enumerator() { return new GeodeEnumerator<Object[]>(clientCache, regionName); }
}
public class GeodeEnumerator<E> implements Enumerator<E> {
private E current;
private SelectResults geodeIterator;
public GeodeEnumerator(ClientCache clientCache, String regionName) {
geodeterator = clientCache.getQueryService().newQuery("select * from /" + regionName).execute().iterator();
}
public boolean moveNext() { current = convert(geodeIterator.next()); return true;}
public E current() {return current;}
public abstract E convert(Object geodeValue) {
Convert PDX value into RelDataType row
}
Defined in the Linq4j sub-project
Retrieves the entire Region!!
Converts Geode value response into Calcite row data
Uses reflection (or pdx-instance) to builds
RelDataType from value’s class type
Returns an Enumeration over the entire
target data store](https://image.slidesharecdn.com/apachecon2016christiantzolov-161115000837/75/Using-Apache-Calcite-for-Enabling-SQL-and-JDBC-Access-to-Apache-Geode-and-Other-NoSQL-Data-Systems-24-2048.jpg)
![Non-Relational Tables
26
Scanned without intermediate relational expression.
• ScannableTable - can be scanned
• FilterableTable - can be scanned, applying supplied filter expressions
• ProjectableFilterableTable - can be scanned, applying supplied filter expressions
and projecting a given list of columns
Enumerable<Object[]> scan(DataContext root, List<RexNode> filters, int[] projects);
Enumerable<Object[]> scan(DataContext root, List<RexNode> filters);
Enumerable<Object[]> scan(DataContext root);](https://image.slidesharecdn.com/apachecon2016christiantzolov-161115000837/75/Using-Apache-Calcite-for-Enabling-SQL-and-JDBC-Access-to-Apache-Geode-and-Other-NoSQL-Data-Systems-26-2048.jpg)


























![Calcite Model
{
version: '1.0',
defaultSchema: 'TEST',
schemas: [ {
name: 'TEST',
type: 'custom',
factory: 'org.apache.calcite.adapter.geode.simple.GeodeSchemaFactory',
operand: {
locatorHost: 'localhost',
locatorPort: '10334',
regions: 'BookMaster',
pdxSerializablePackagePath: 'net.tzolov.geode.bookstore.domain.*'
}
}]
}
Reference to your adapter
schema factory implementation
class
Parameters to be passed to
your adapter schema factory
implementation
The path to <my-model>.json is passed as JDBC connection argument:
!connect jdbc:calcite:model=target/test-classes/<my-model-path>.json︎
Schema Name](https://crownmelresort.com/image.slidesharecdn.com/apachecon2016christiantzolov-161115000837/75/Using-Apache-Calcite-for-Enabling-SQL-and-JDBC-Access-to-Apache-Geode-and-Other-NoSQL-Data-Systems-22-2048.jpg)
![Geode Calcite Schema and Schema Factory
public class GeodeSchemaFactory implements SchemaFactory {
public Schema create(SchemaPlus parentSchema, String schemaName, Map<String, Object> operand) {
String locatorHost = (String) operand.get(“locatorHost”);
int locatorPort = …
String[] regionNames = …
String pdxPackagePath = …
return new GeodeSchema(locatorHost, locatorPort, regionNames, pdxPackagePath);
}
}
public class GeodeSchema extends AbstractSchema {
private String regionName = ..
protected Map<String, Table> getTableMap() {
final ImmutableMap.Builder<String, Table> builder = ImmutableMap.builder();
Region region = … Get Geode Region by region name …
Class valueClass= … Find region’s value type …
builder.put(regionName, new GeodeScannableTable(regionName, valueClass, clientCache));
return tableMap;
}
Retrieves the parameters set in
the model.json
Create an Adapter Schema
instance with the provided
parameters.
Create GeodeScannableTable
instance for each Geode Region](https://crownmelresort.com/image.slidesharecdn.com/apachecon2016christiantzolov-161115000837/75/Using-Apache-Calcite-for-Enabling-SQL-and-JDBC-Access-to-Apache-Geode-and-Other-NoSQL-Data-Systems-23-2048.jpg)
![Geode Scannable Table
public class GeodeScannableTable extends AbstractTable implements ScannableTable {
public RelDataType getRowType(RelDataTypeFactory typeFactory) {
return new JavaTypeFactoryImpl().createStructType(valueClass);
}
public Enumerable<Object[]> scan(DataContext root) {
return new AbstractEnumerable<Object[]>() {
public Enumerator<Object[]> enumerator() { return new GeodeEnumerator<Object[]>(clientCache, regionName); }
}
public class GeodeEnumerator<E> implements Enumerator<E> {
private E current;
private SelectResults geodeIterator;
public GeodeEnumerator(ClientCache clientCache, String regionName) {
geodeterator = clientCache.getQueryService().newQuery("select * from /" + regionName).execute().iterator();
}
public boolean moveNext() { current = convert(geodeIterator.next()); return true;}
public E current() {return current;}
public abstract E convert(Object geodeValue) {
Convert PDX value into RelDataType row
}
Defined in the Linq4j sub-project
Retrieves the entire Region!!
Converts Geode value response into Calcite row data
Uses reflection (or pdx-instance) to builds
RelDataType from value’s class type
Returns an Enumeration over the entire
target data store](https://crownmelresort.com/image.slidesharecdn.com/apachecon2016christiantzolov-161115000837/75/Using-Apache-Calcite-for-Enabling-SQL-and-JDBC-Access-to-Apache-Geode-and-Other-NoSQL-Data-Systems-24-2048.jpg)

![Non-Relational Tables
26
Scanned without intermediate relational expression.
• ScannableTable - can be scanned
• FilterableTable - can be scanned, applying supplied filter expressions
• ProjectableFilterableTable - can be scanned, applying supplied filter expressions
and projecting a given list of columns
Enumerable<Object[]> scan(DataContext root, List<RexNode> filters, int[] projects);
Enumerable<Object[]> scan(DataContext root, List<RexNode> filters);
Enumerable<Object[]> scan(DataContext root);](https://crownmelresort.com/image.slidesharecdn.com/apachecon2016christiantzolov-161115000837/75/Using-Apache-Calcite-for-Enabling-SQL-and-JDBC-Access-to-Apache-Geode-and-Other-NoSQL-Data-Systems-26-2048.jpg)















The document presents an overview of using Apache Calcite to enable SQL access to NoSQL data systems, specifically focusing on Apache Geode. It discusses the architecture, key features, and components of Apache Geode and its integration with Calcite for processing SQL queries. Additionally, it highlights use cases, query optimizations, and future development directions for improved support and performance.
Introduction to utilizing Apache Calcite for SQL access to NoSQL systems like Apache Geode. Speaker's credentials and disclaimer noted.
Overview of Big Data landscape attributes such as Volume, Velocity, Variety, Scalability, Latency, and the CAP theorem concerning consistency vs. availability.
Exploration of data access methods including SQL and custom APIs like Key/Value, Fluid API, and REST API, while questioning the costs of unified access.
Listing various Apache tools and frameworks capable of SQL access, highlighting Apache Geode as a significant player in the SQL landscape.
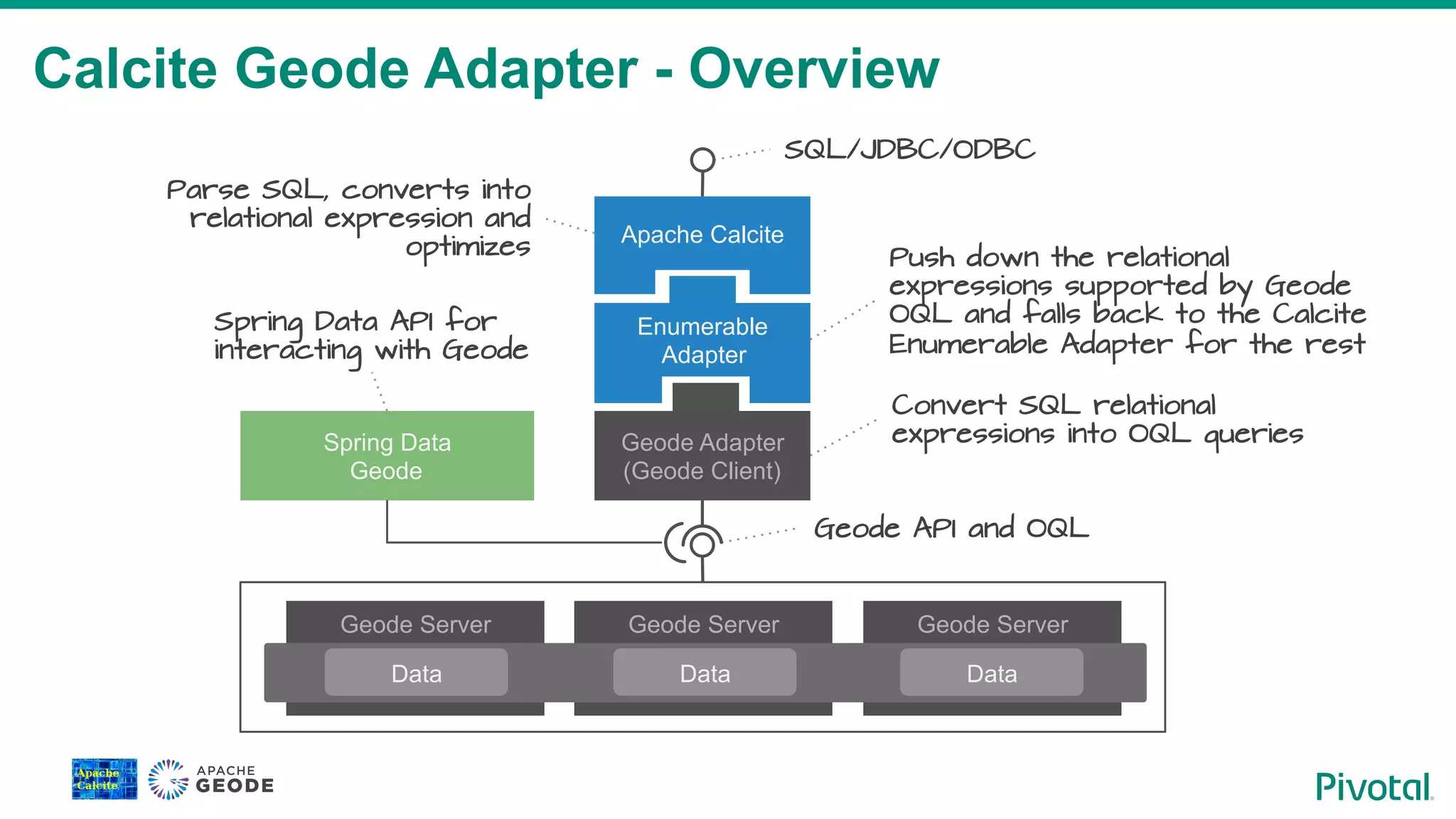
Introduction to the Geode adapter for Apache Calcite, detailing how SQL is converted into OQL queries for data interaction with Geode.
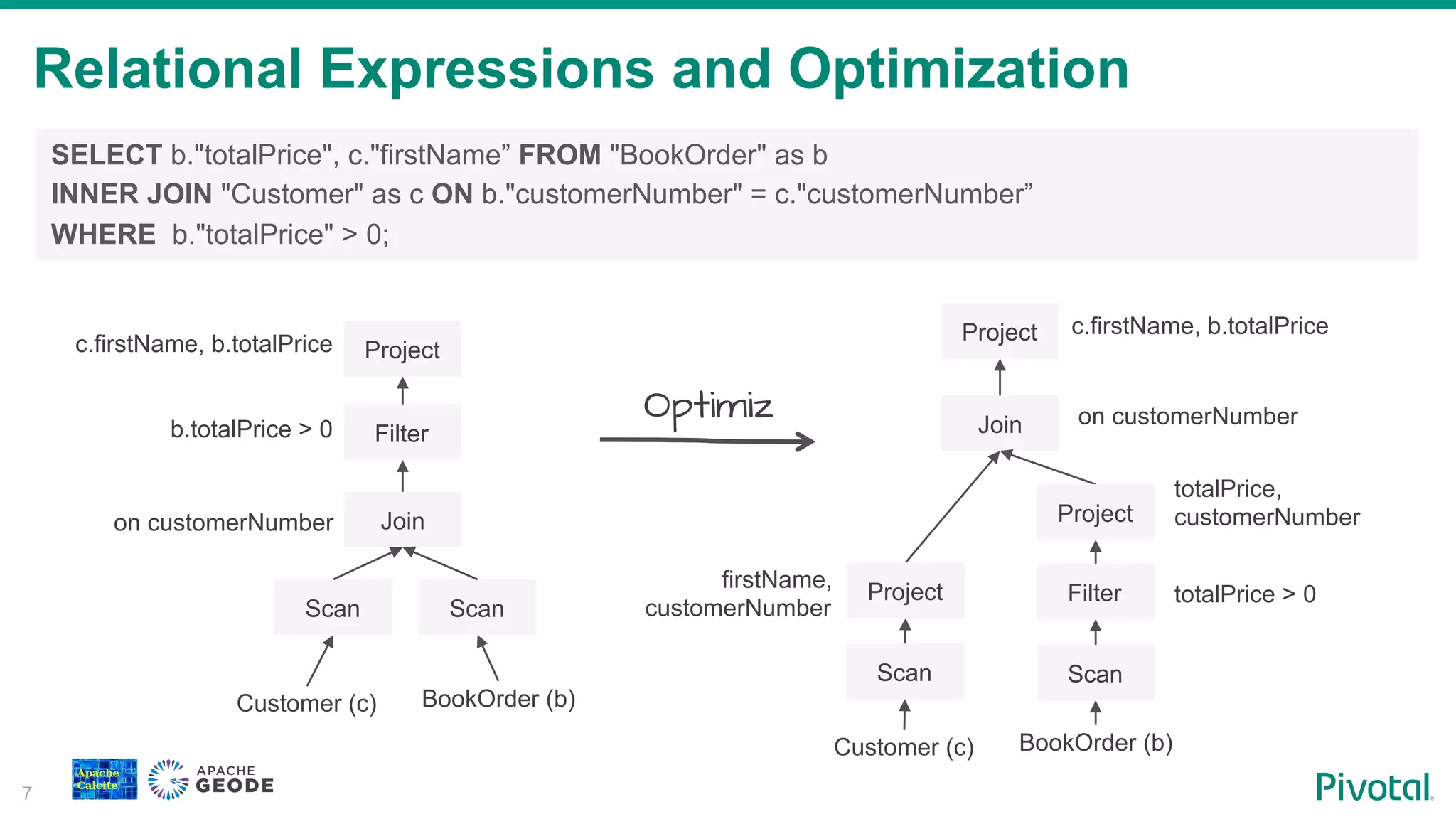
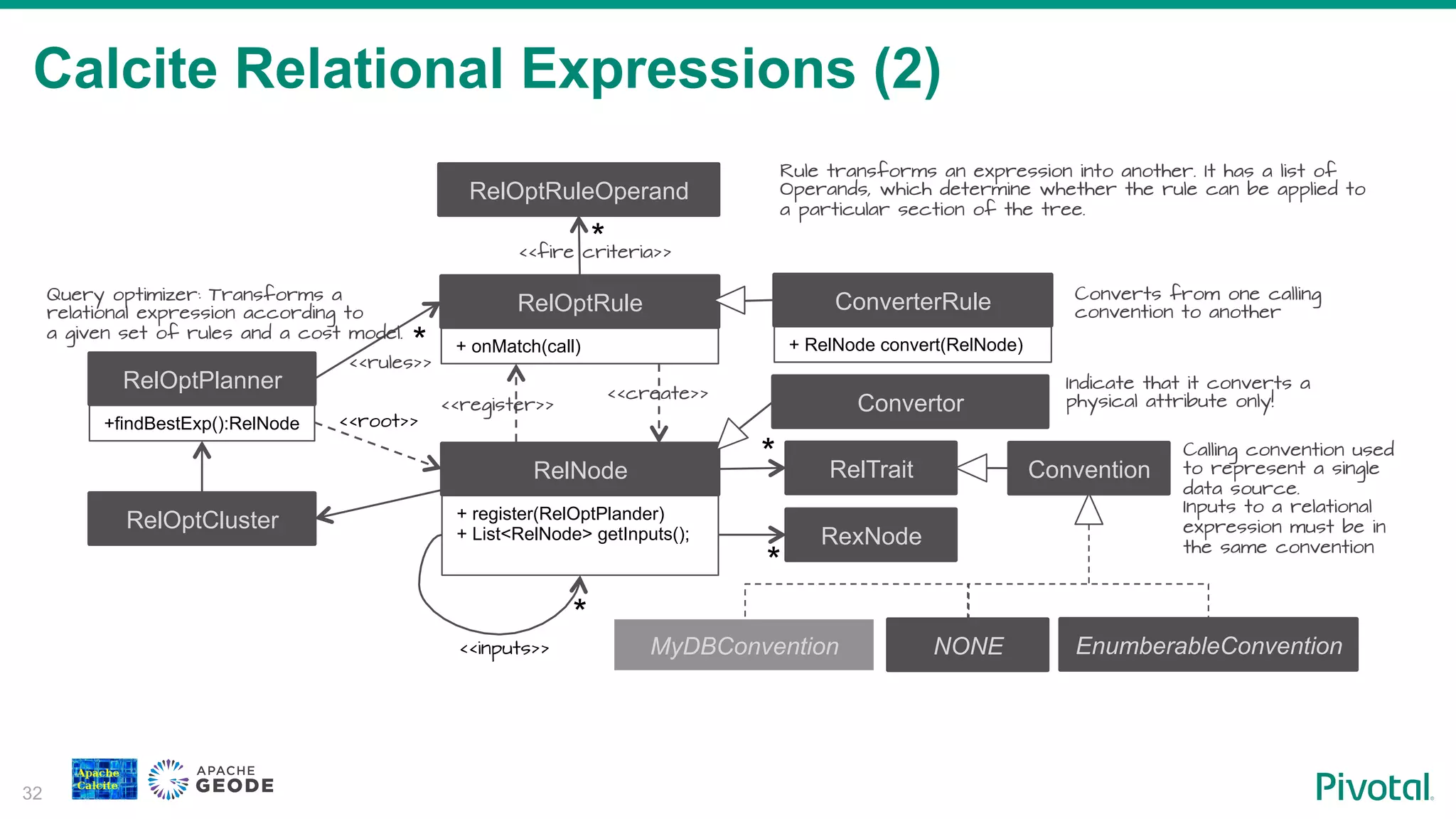
Explanation of relational expressions in SQL, their optimization, and Geode's support for various relational operators.
Description of Apache Geode as an in-memory database solution, showcasing its usage in large-scale applications with significant numerical data.
Detailed features of Apache Geode including in-memory data storage capabilities, ACID compliance, strong consistency, and scalability.
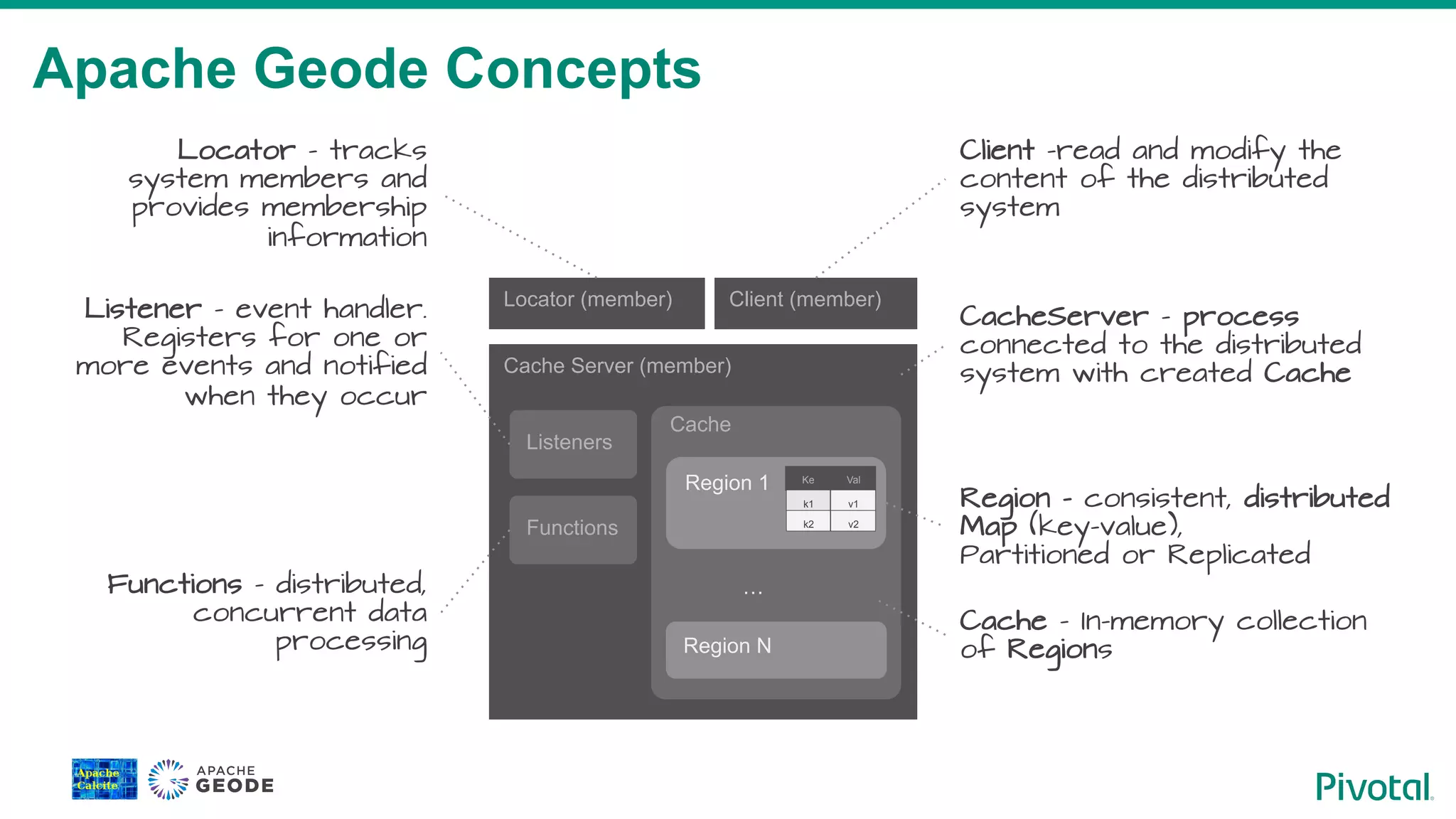
Introduction to key concepts within Apache Geode, including caches, regions, clients, and event listeners.
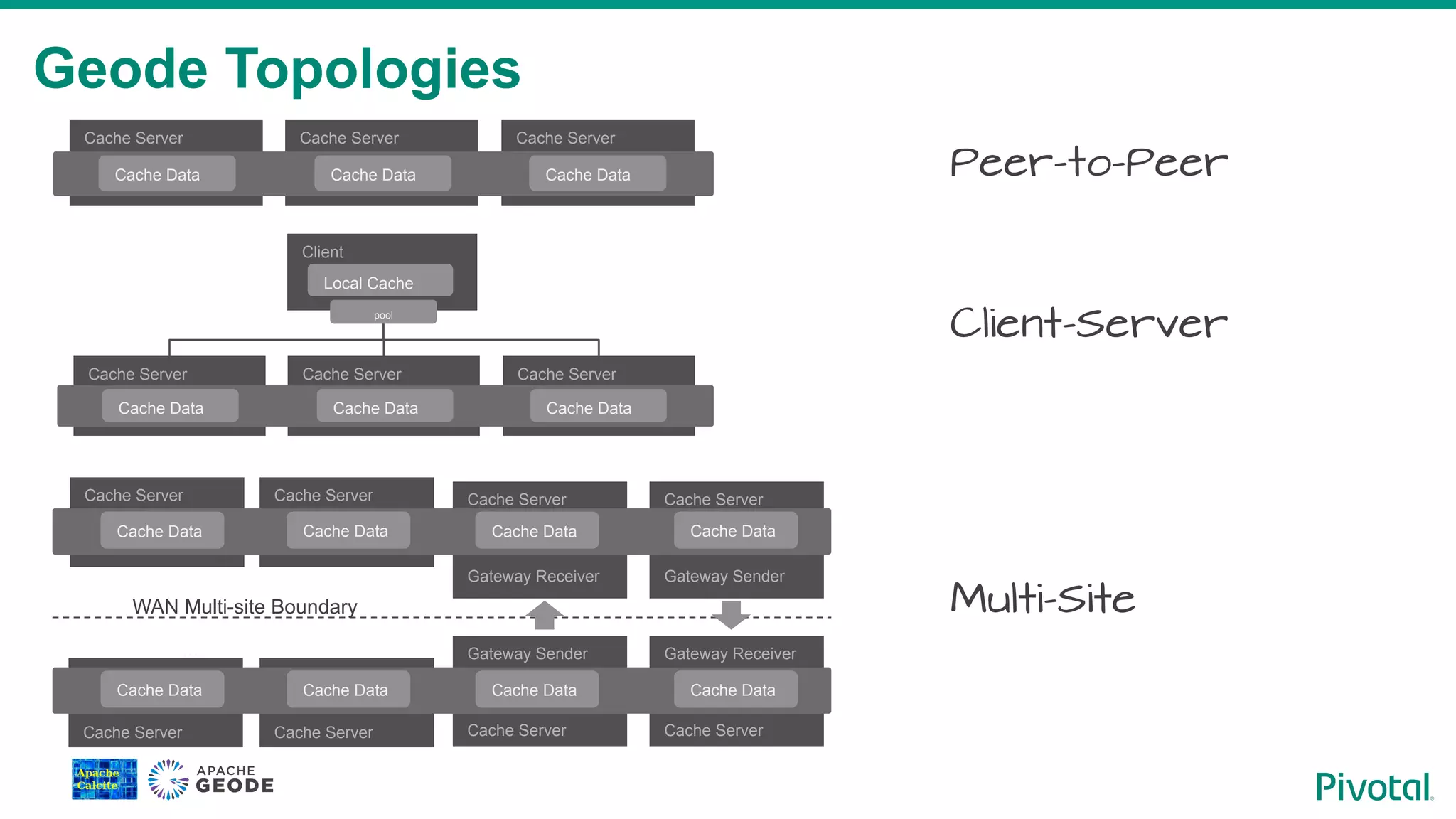
Overview of various Geode deployment topologies including peer-to-peer and client-server architectures.
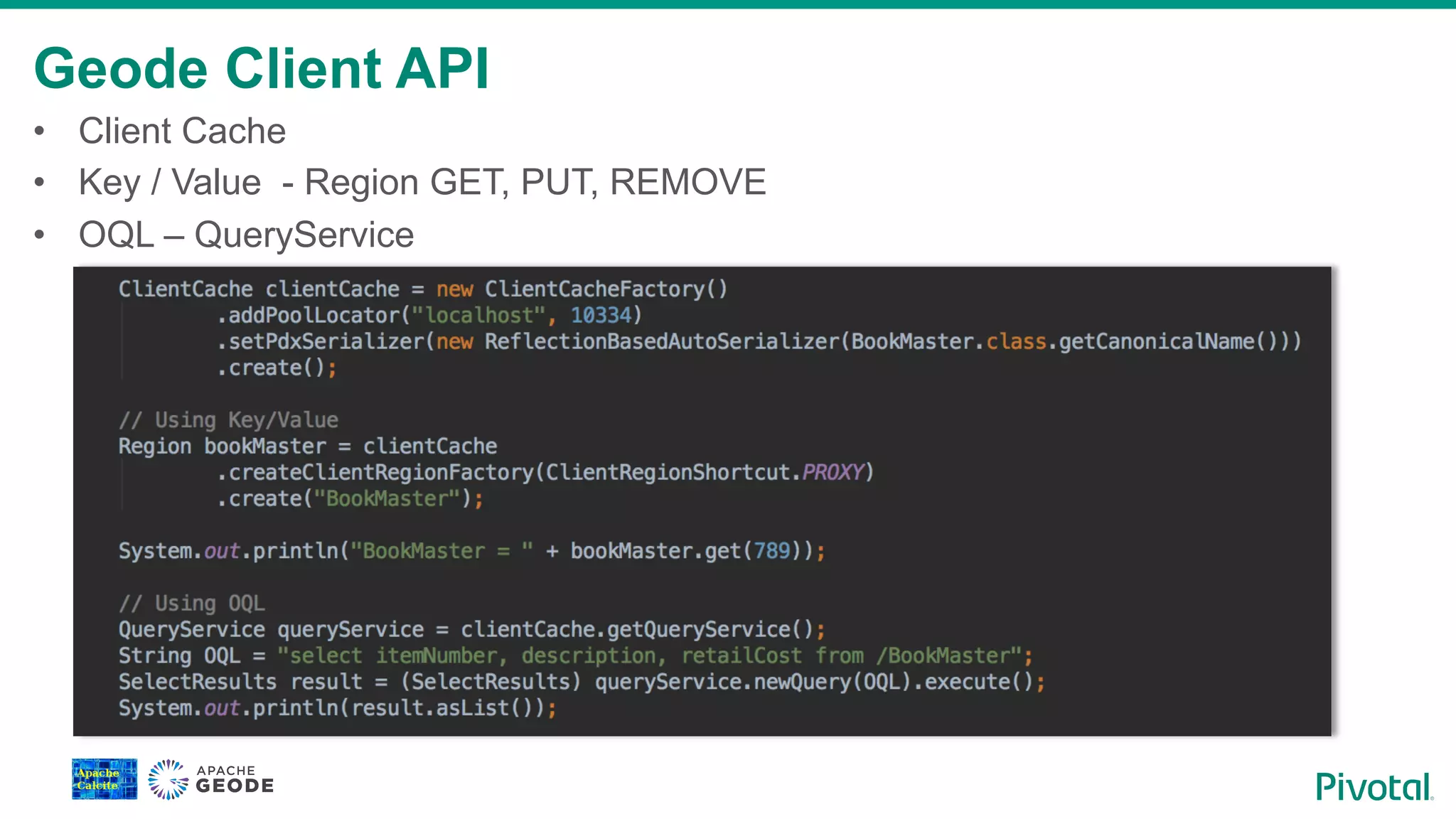
Description of Geode Client API, focusing on key-value operations and the OQL querying service.
Discussion on Geode's data types, including PDX serialization for efficient data handling and querying.
Live demo connecting to Geode cluster and executing OQL queries on available regions.
Introduction to Apache Calcite as a framework for SQL querying, highlighting its components and capabilities.
Exposition on Calcite's data types and structures including catalog, schemas, tables, and relational data types.
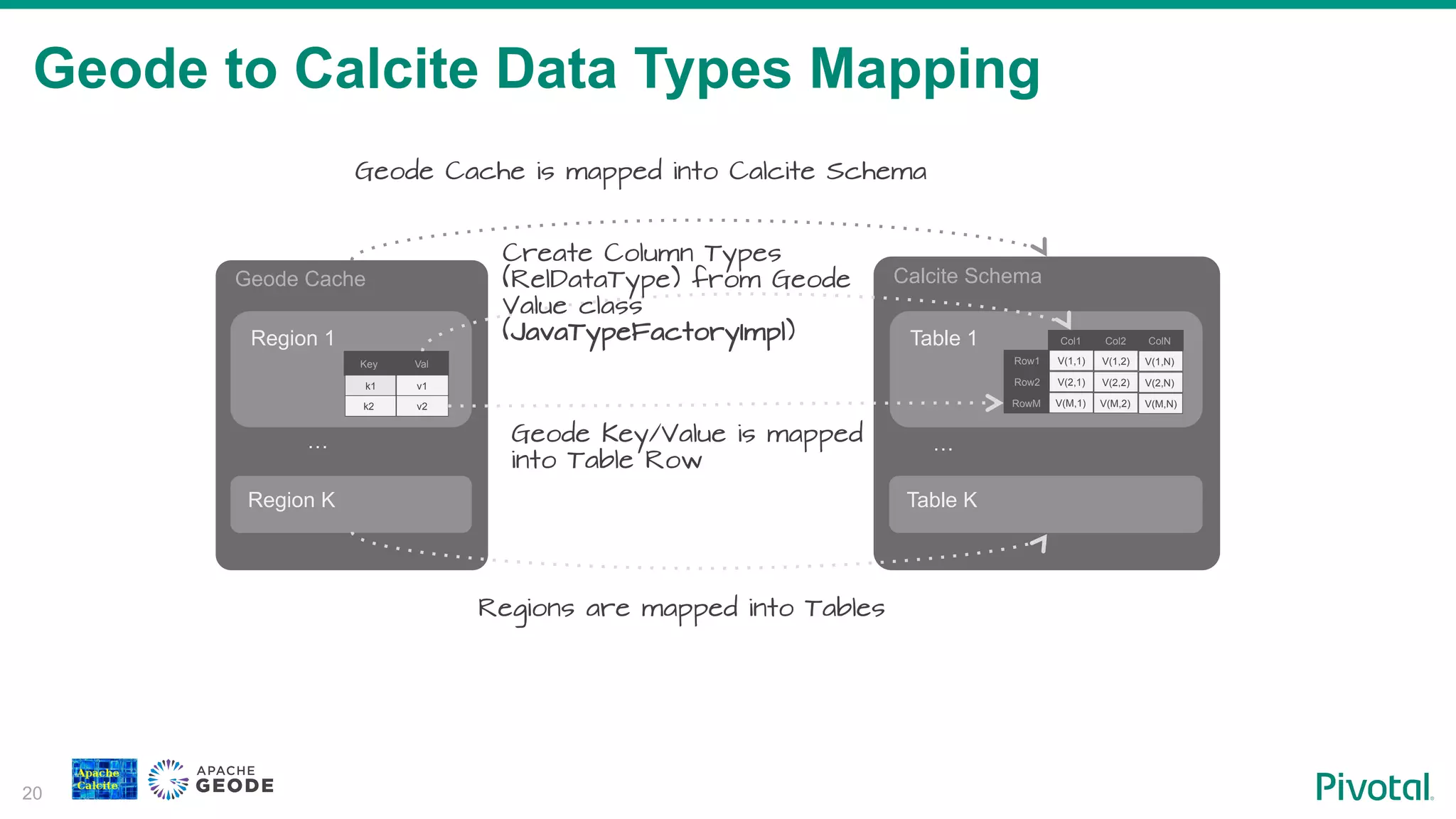
Details on how Geode cache regions map to Calcite schemas and tables, illustrating data integration.
Description of the initialization flow for Calcite model, from JSON configuration to schema creation.
Insight into implementation of schema factory for Geode within the Calcite framework, detailing schema creation.
Technical overview of the Geode Scannable Table and its integration with Calcite for row-type handling.
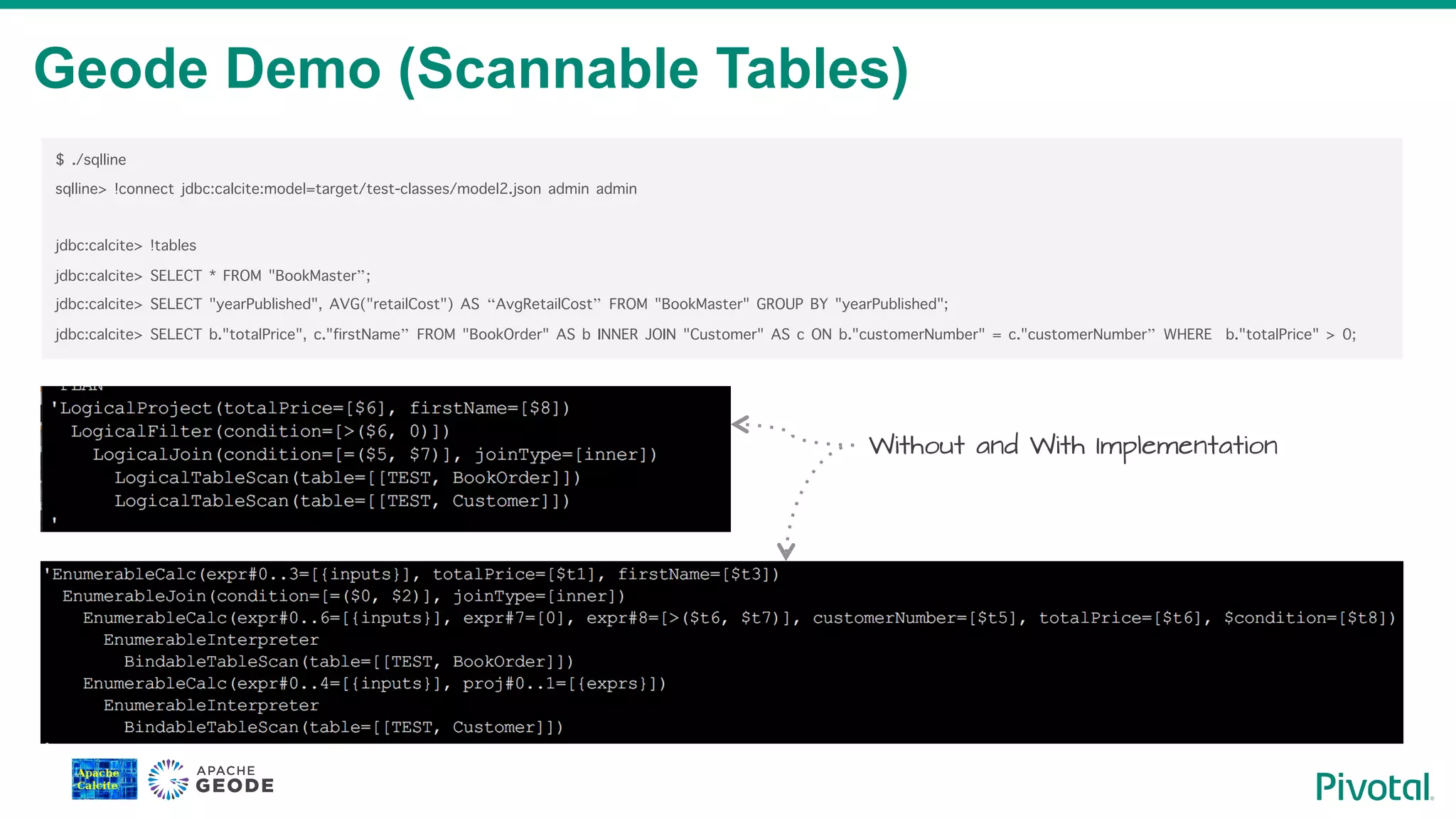
Live demonstration of executing SQL commands through the Geode implementation with scannable tables.
Introduction to non-relational tables in Calcite, emphasizing various table types and query capabilities.
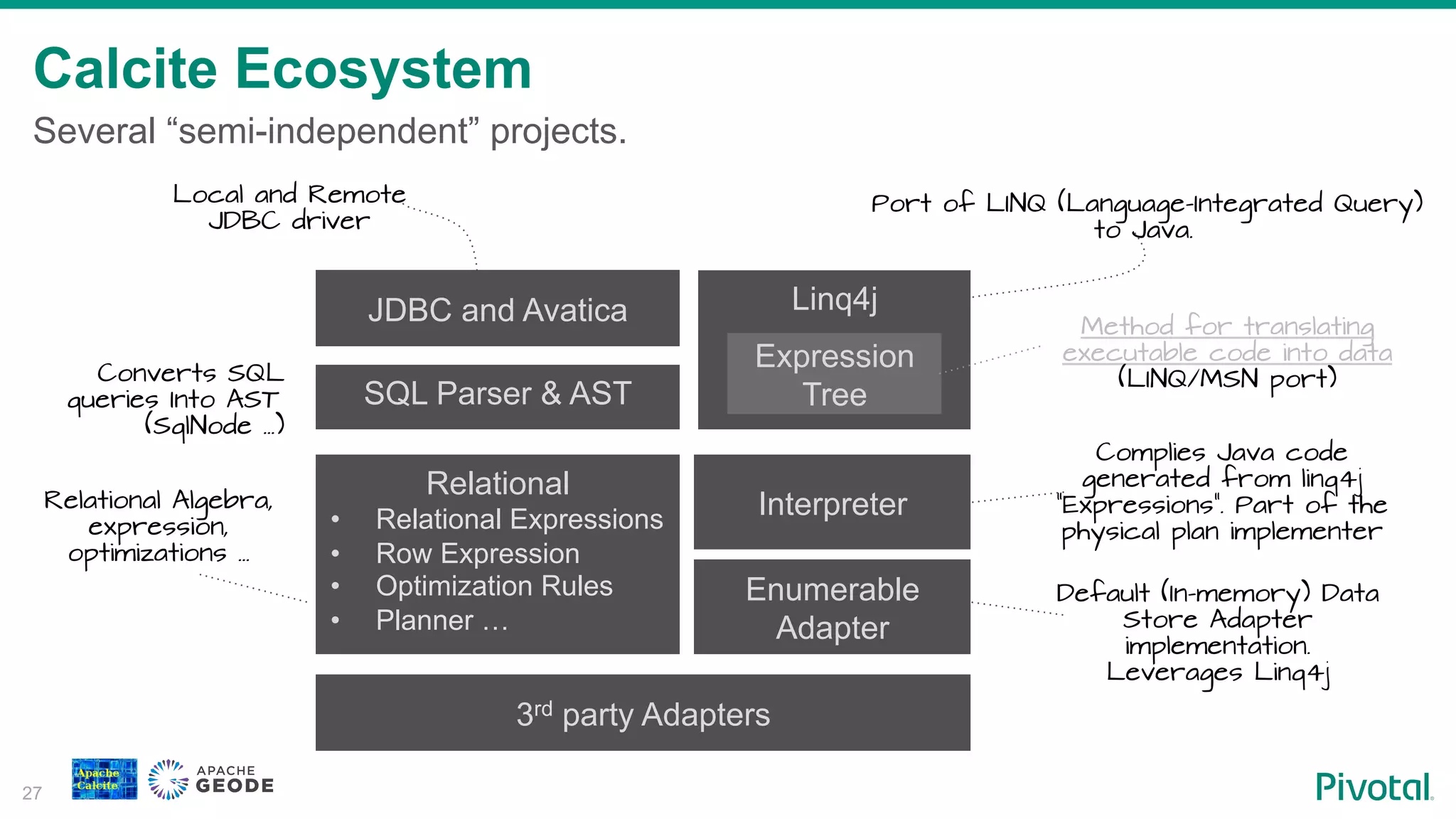
Discussion on the ecosystem surrounding Calcite, including its various components and interaction with different data stores.
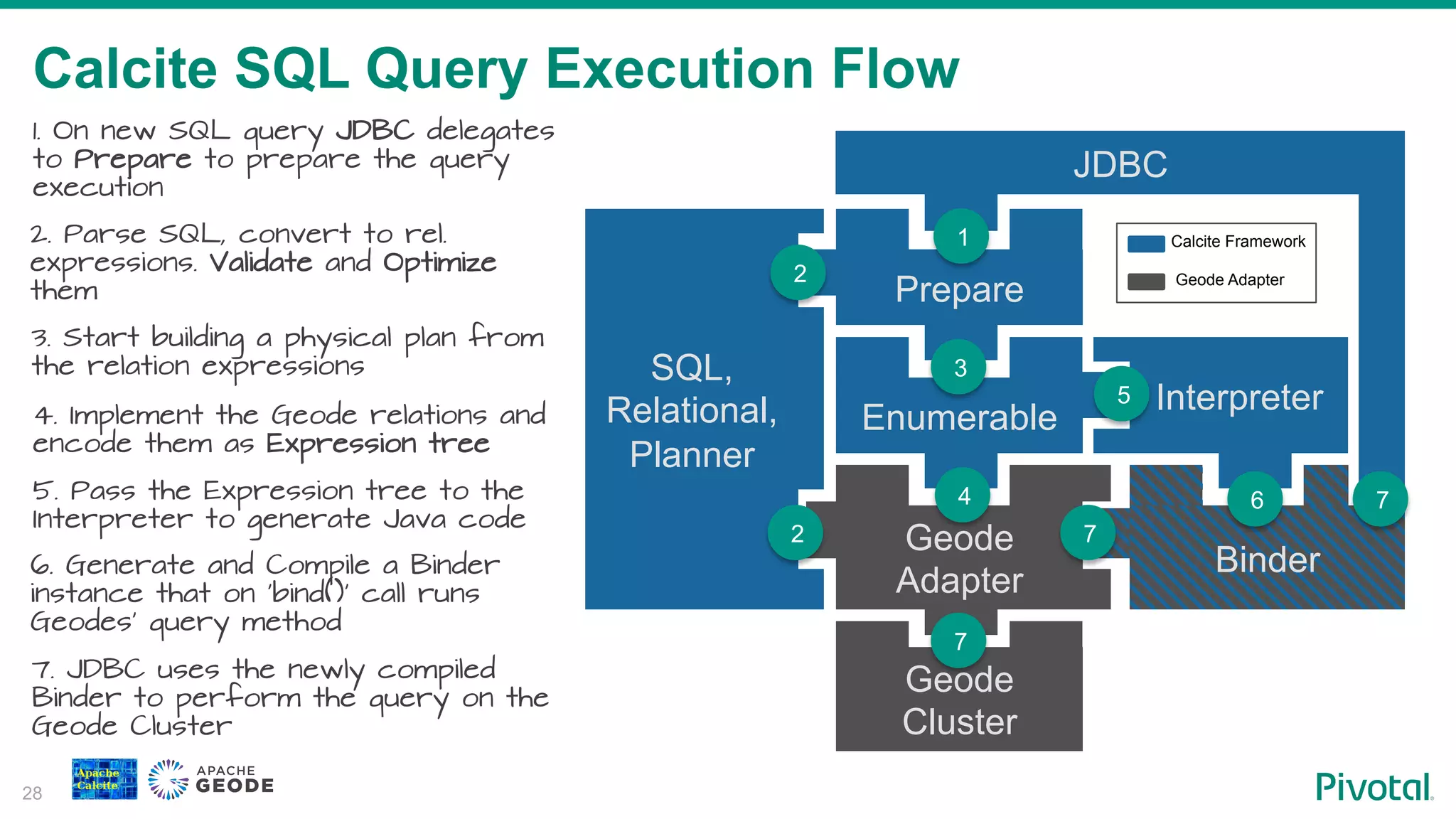
Exposition of the execution flow for SQL queries in Calcite, showing step-by-step processing from parsing to executing.
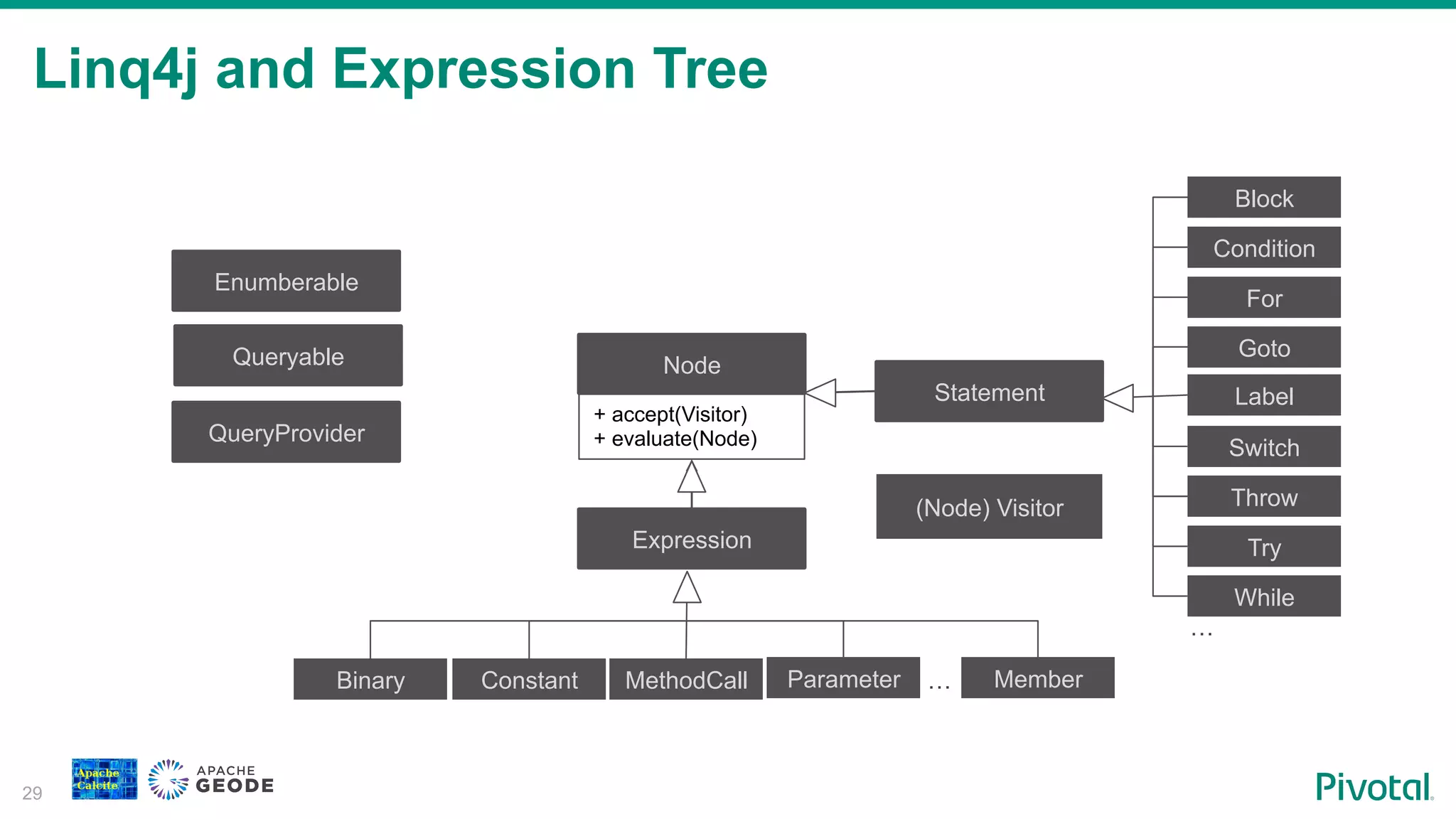
Introduction to Linq4j framework and its relationship with Expression Trees that facilitate query execution in Calcite.
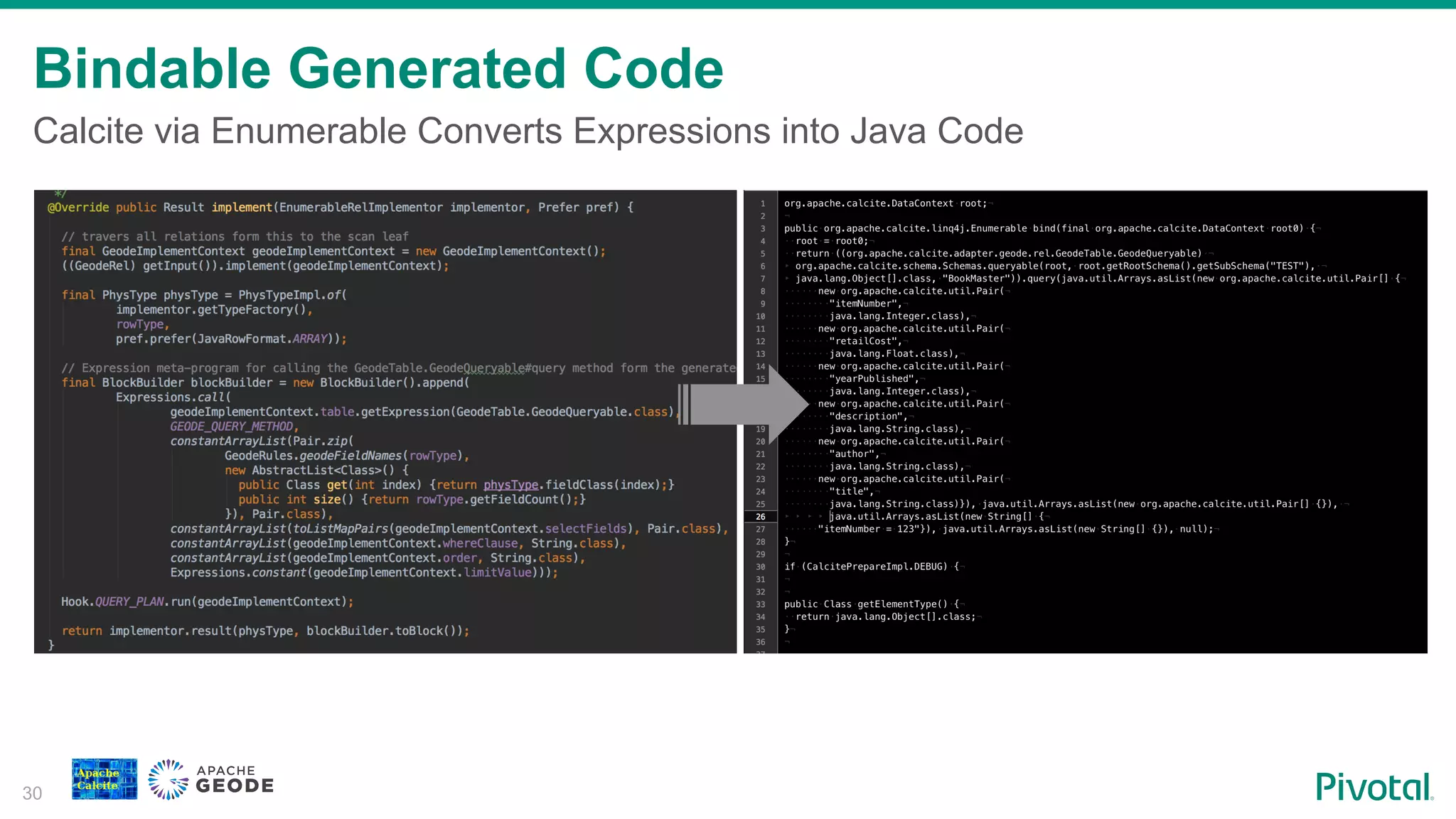
Overview of how Calcite converts expressions into Java code for bindable queries.
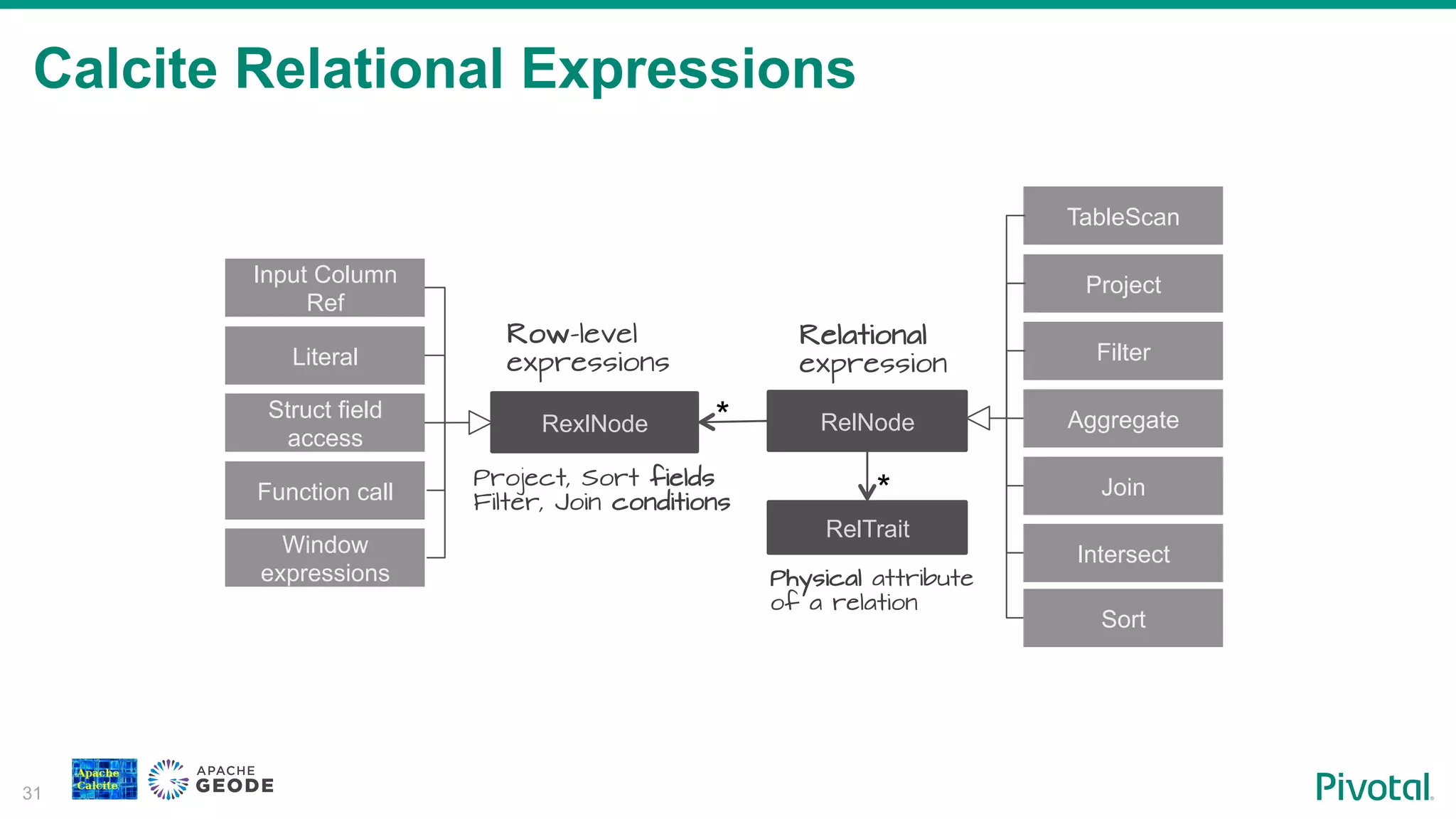
Description of relational expressions in Calcite, detailing how they are structured, optimized, and managed.
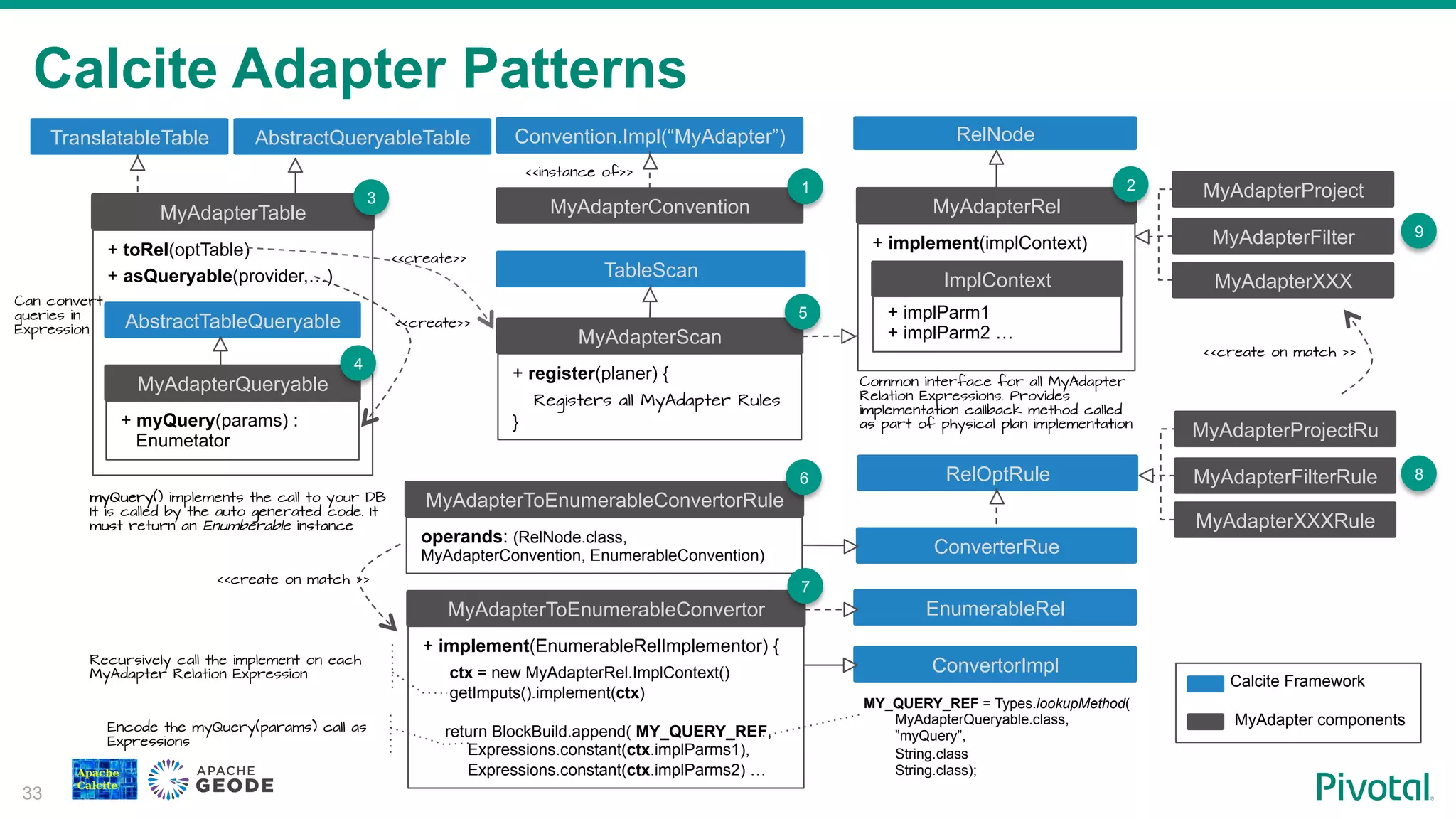
Exploration of adapter patterns within Calcite, outlining how custom implementations can be integrated.
Examples of SQL implementation with and without Calcite and Geode, showcasing their capabilities.
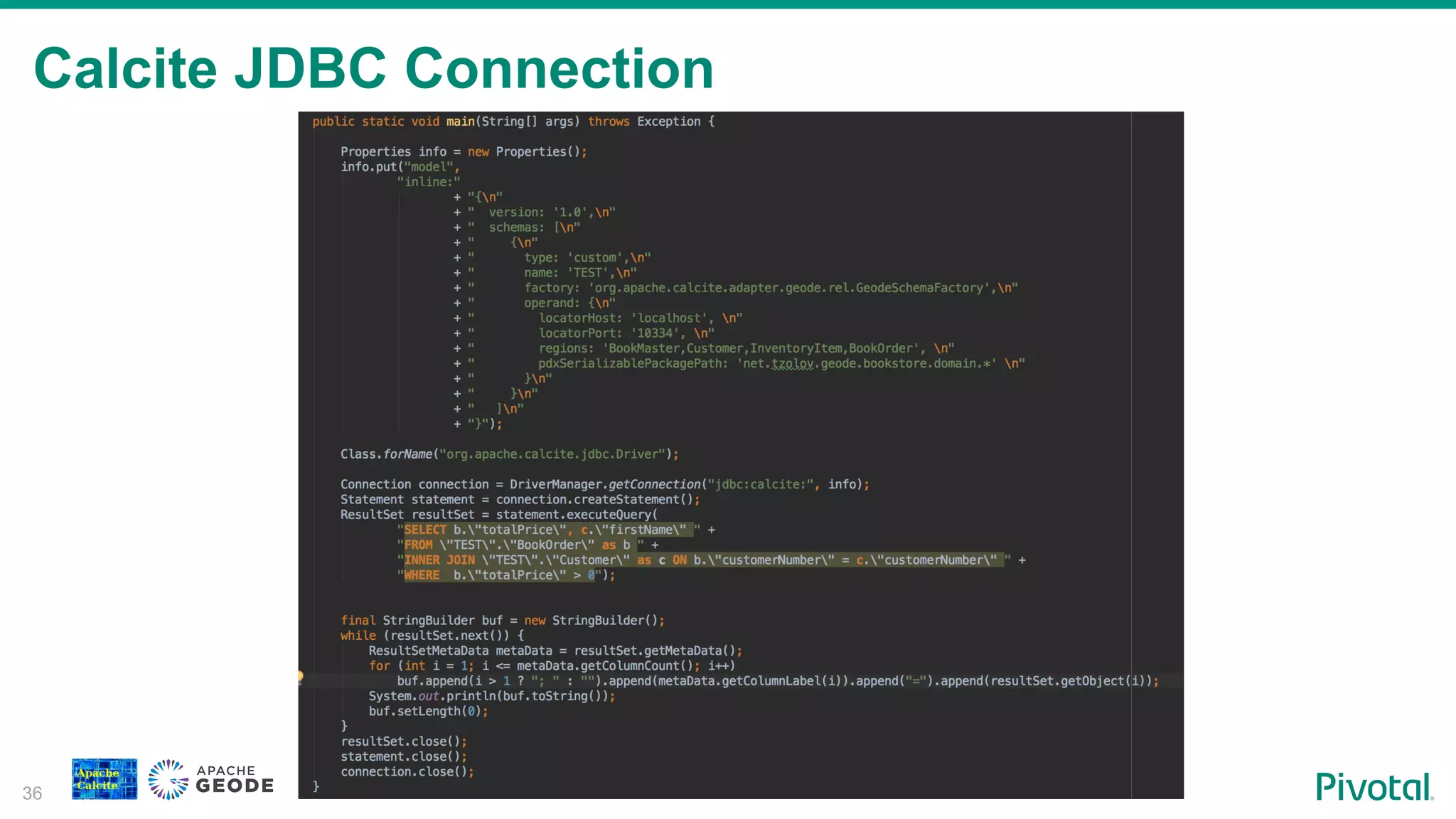
Steps to establish a JDBC connection for accessing Calcite services.
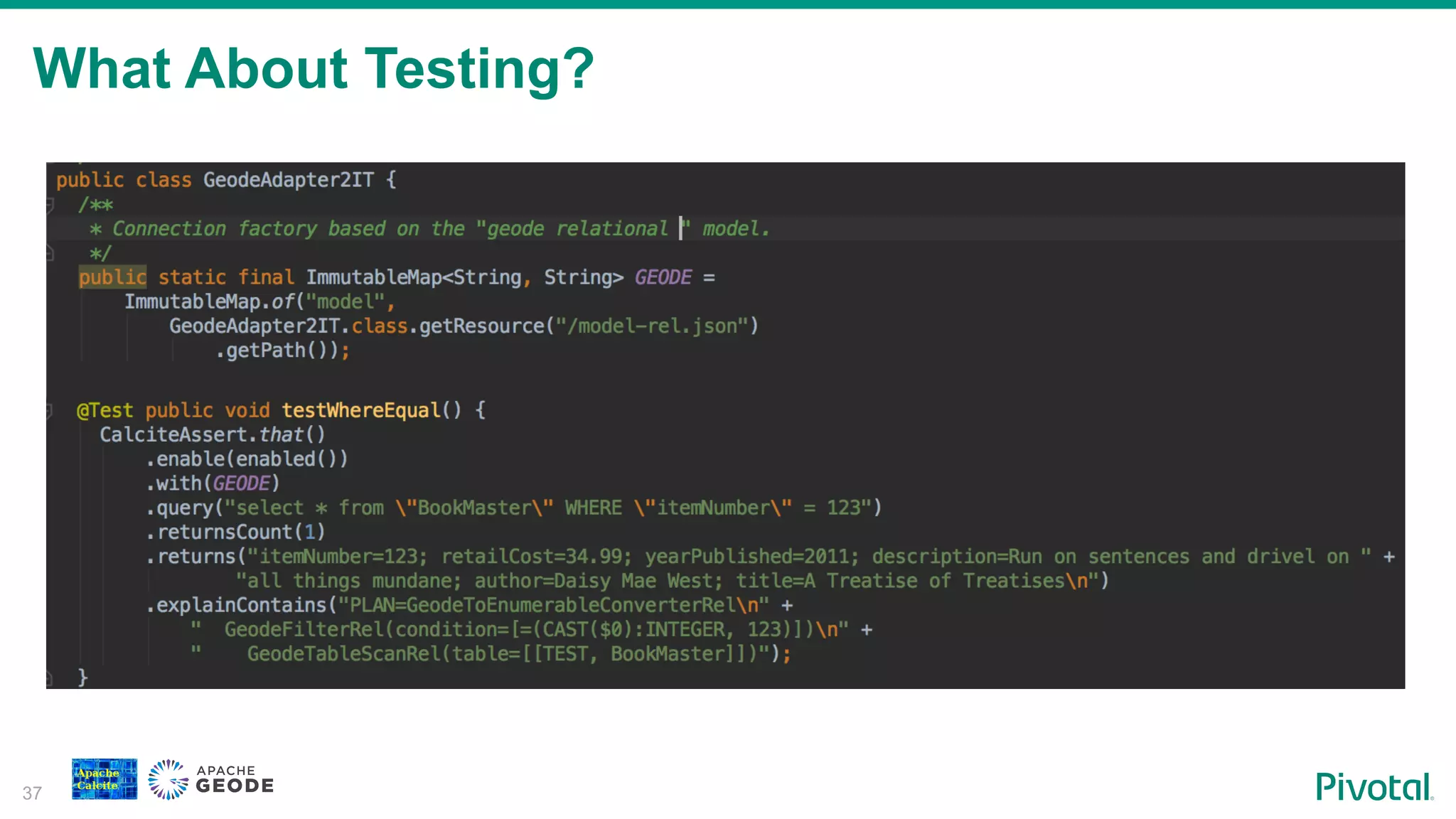
Discussion on testing strategies for integration with Calcite and Geode.
Outline of potential enhancements for Geode and Calcite integration, focusing on improved support and new features.
List of references and resources for further exploration of Apache Geode and Calcite implementation.























































































