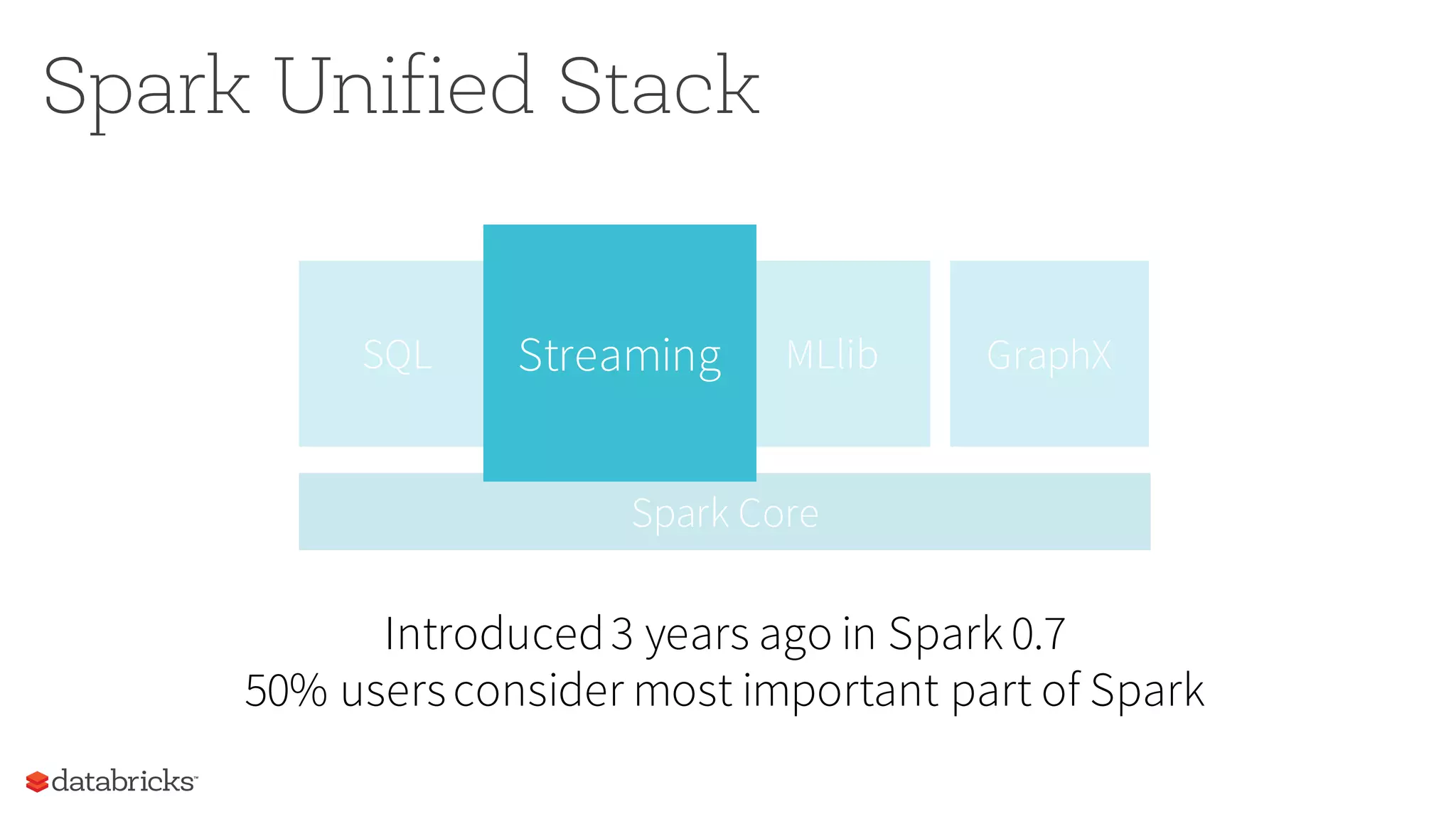
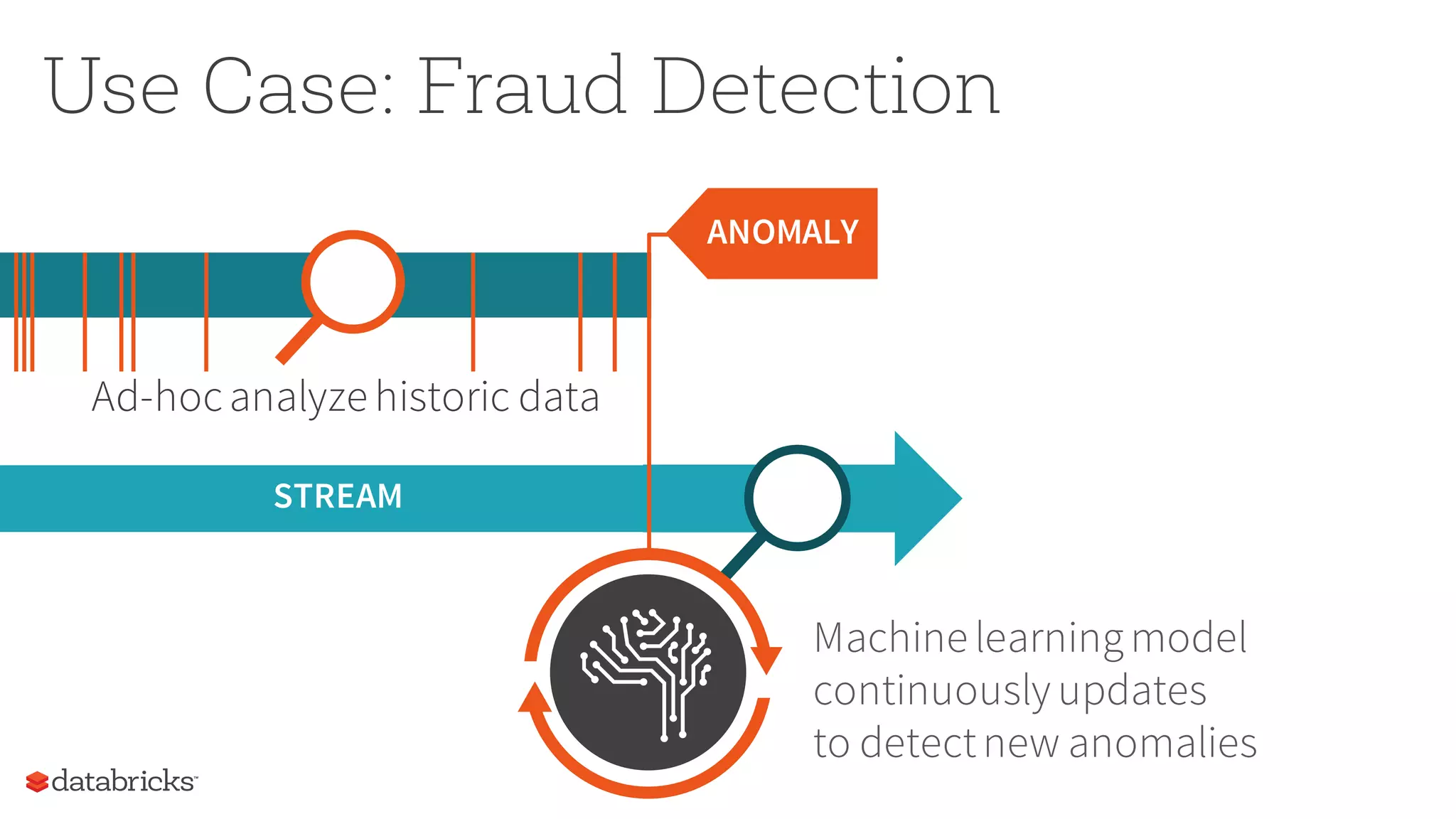
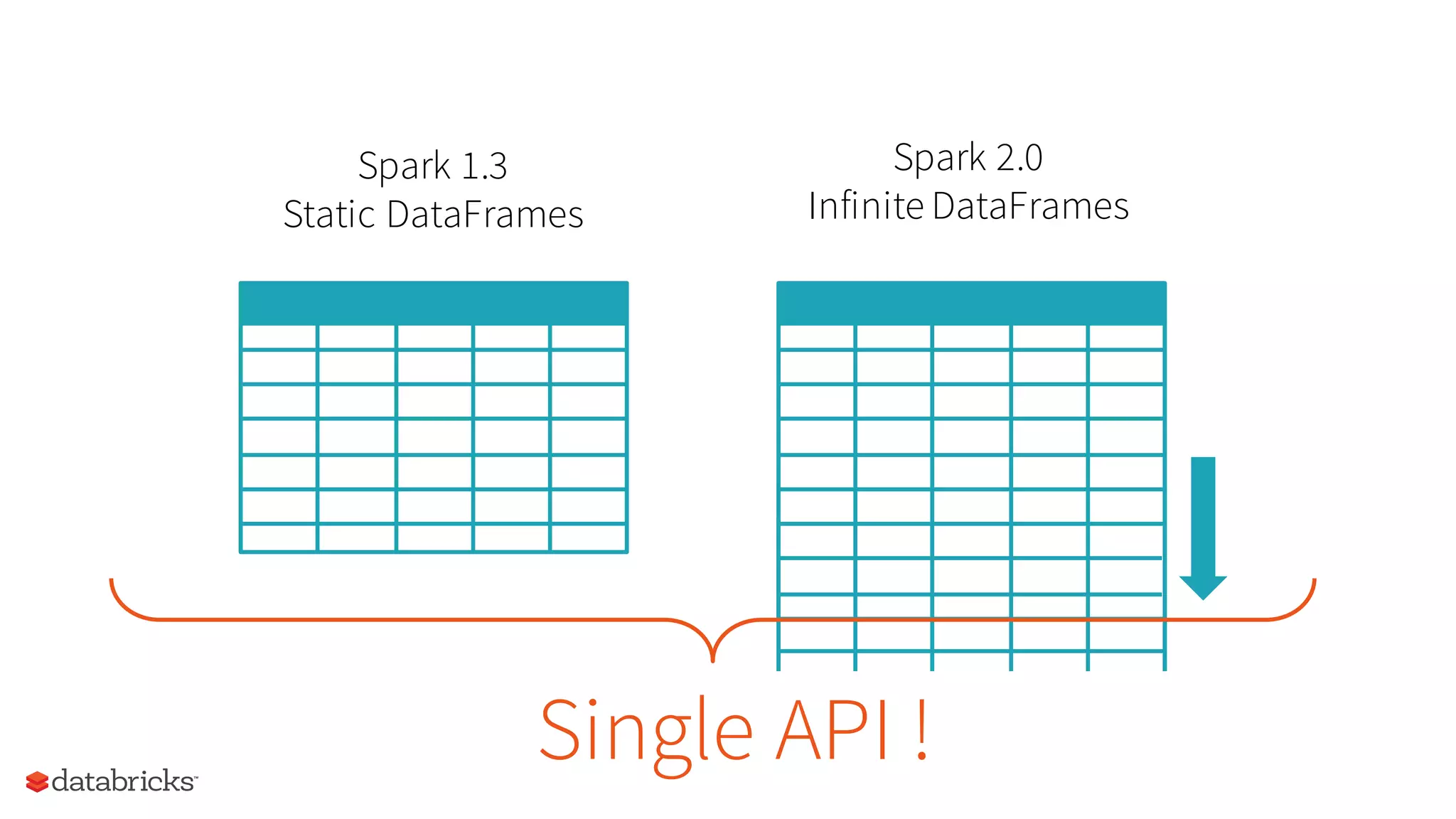
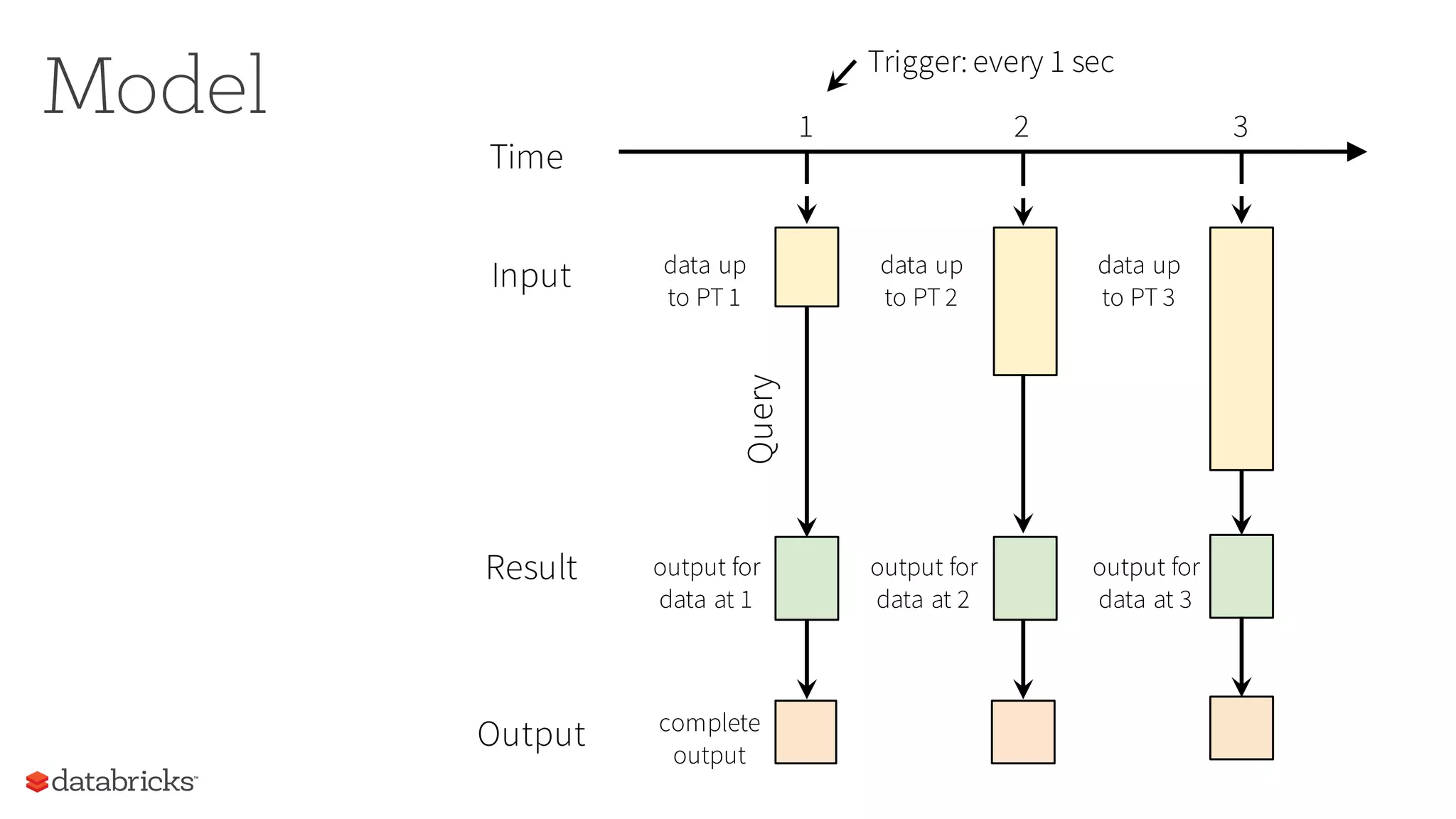
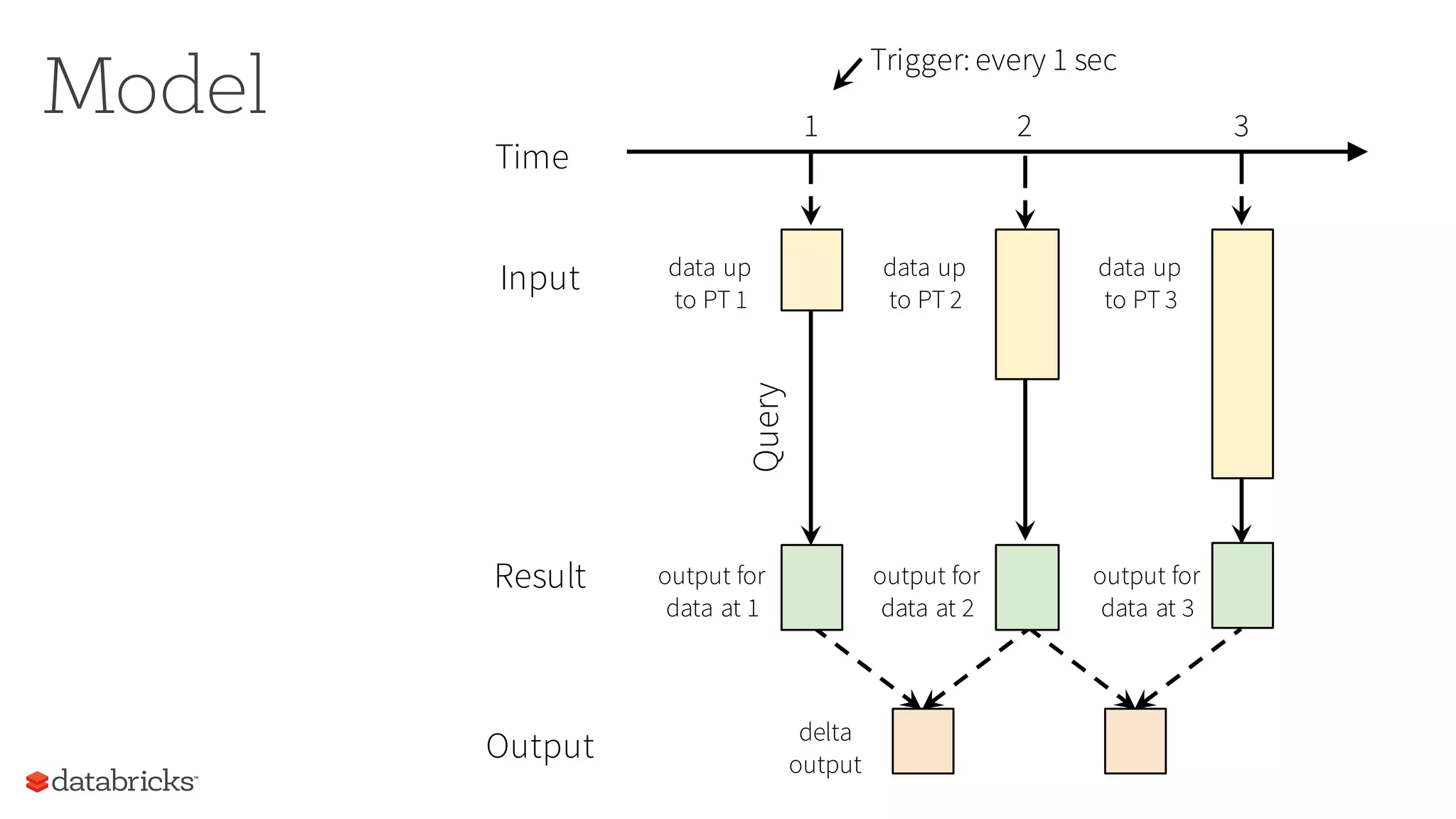
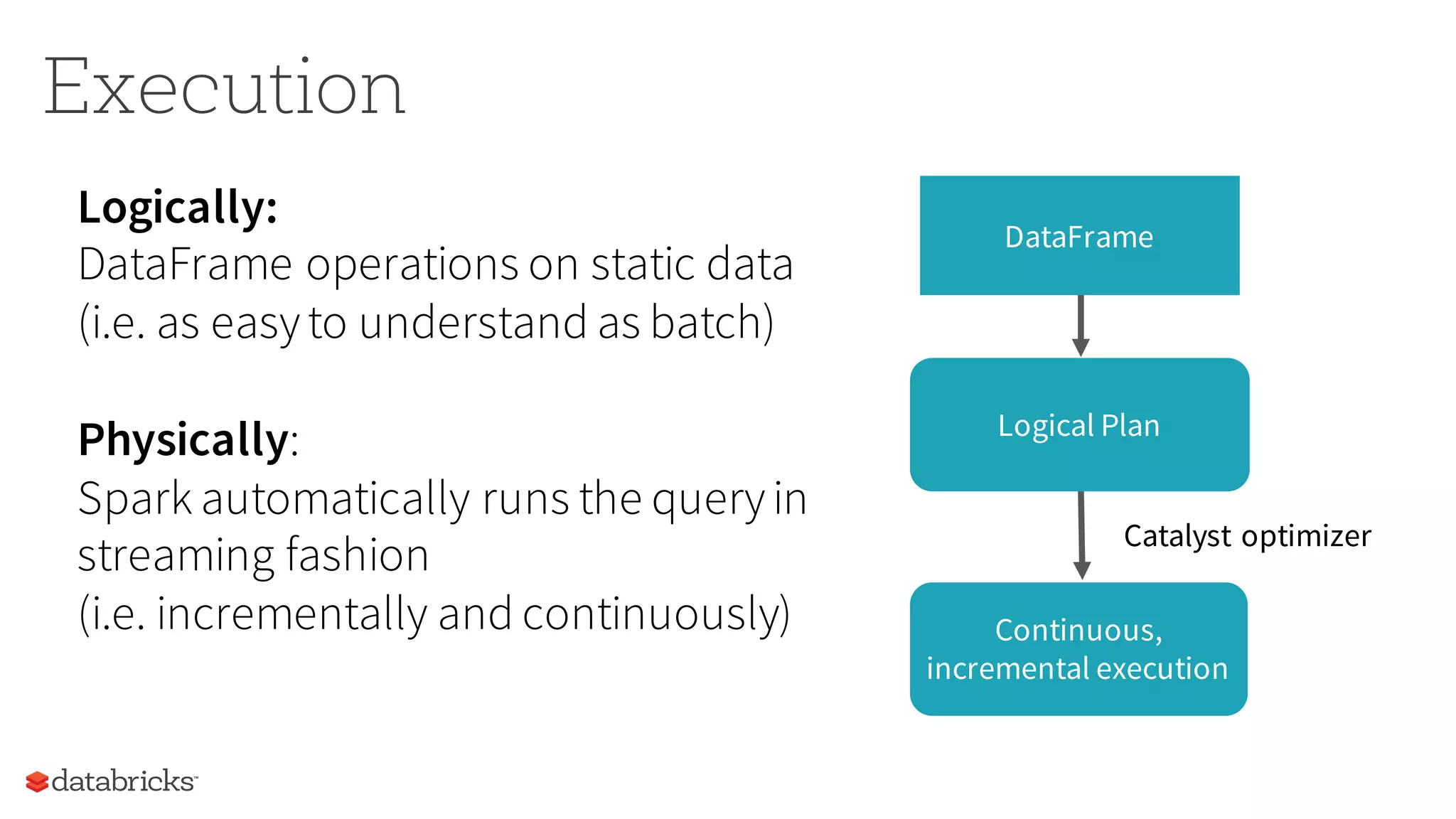
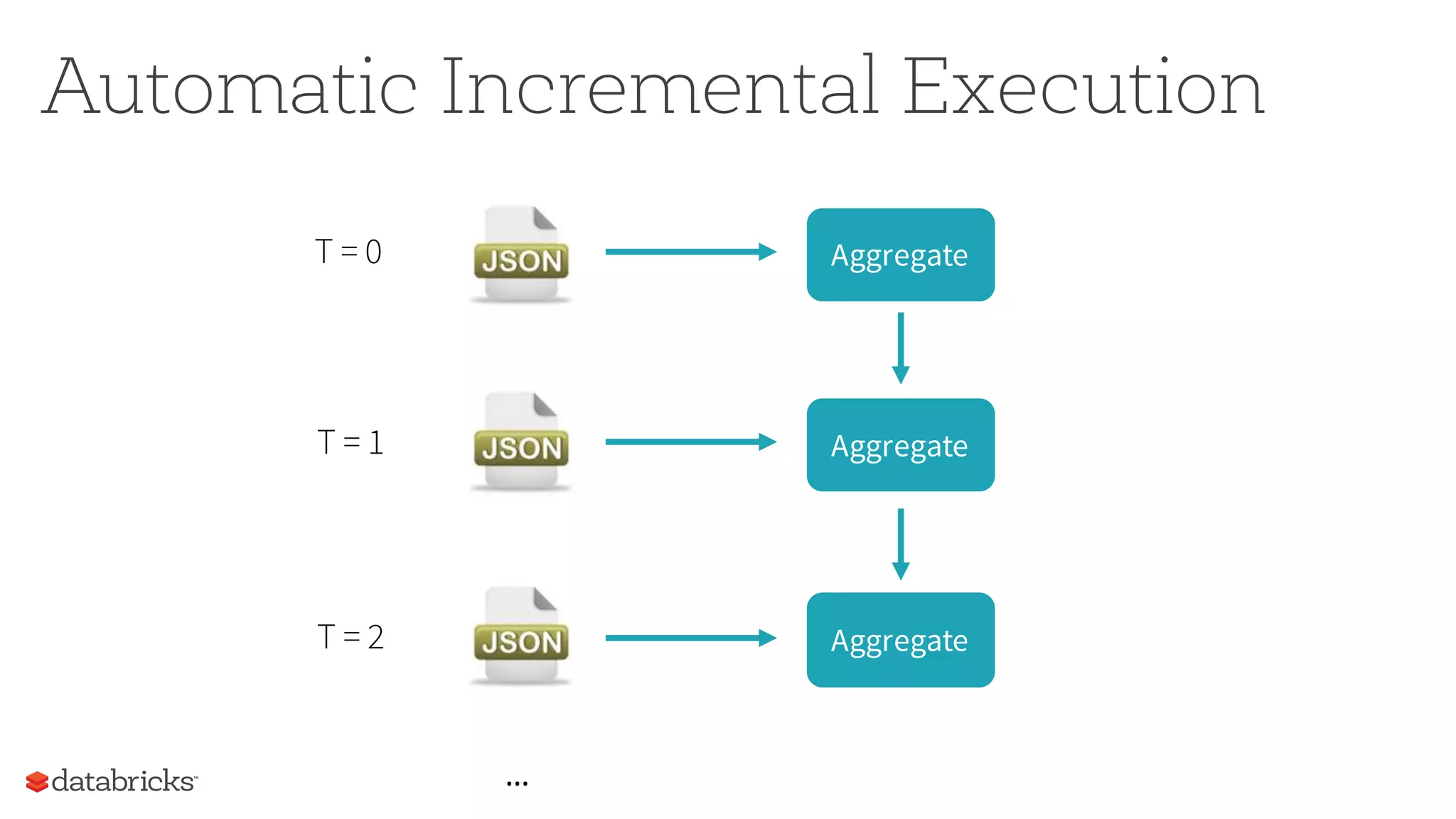
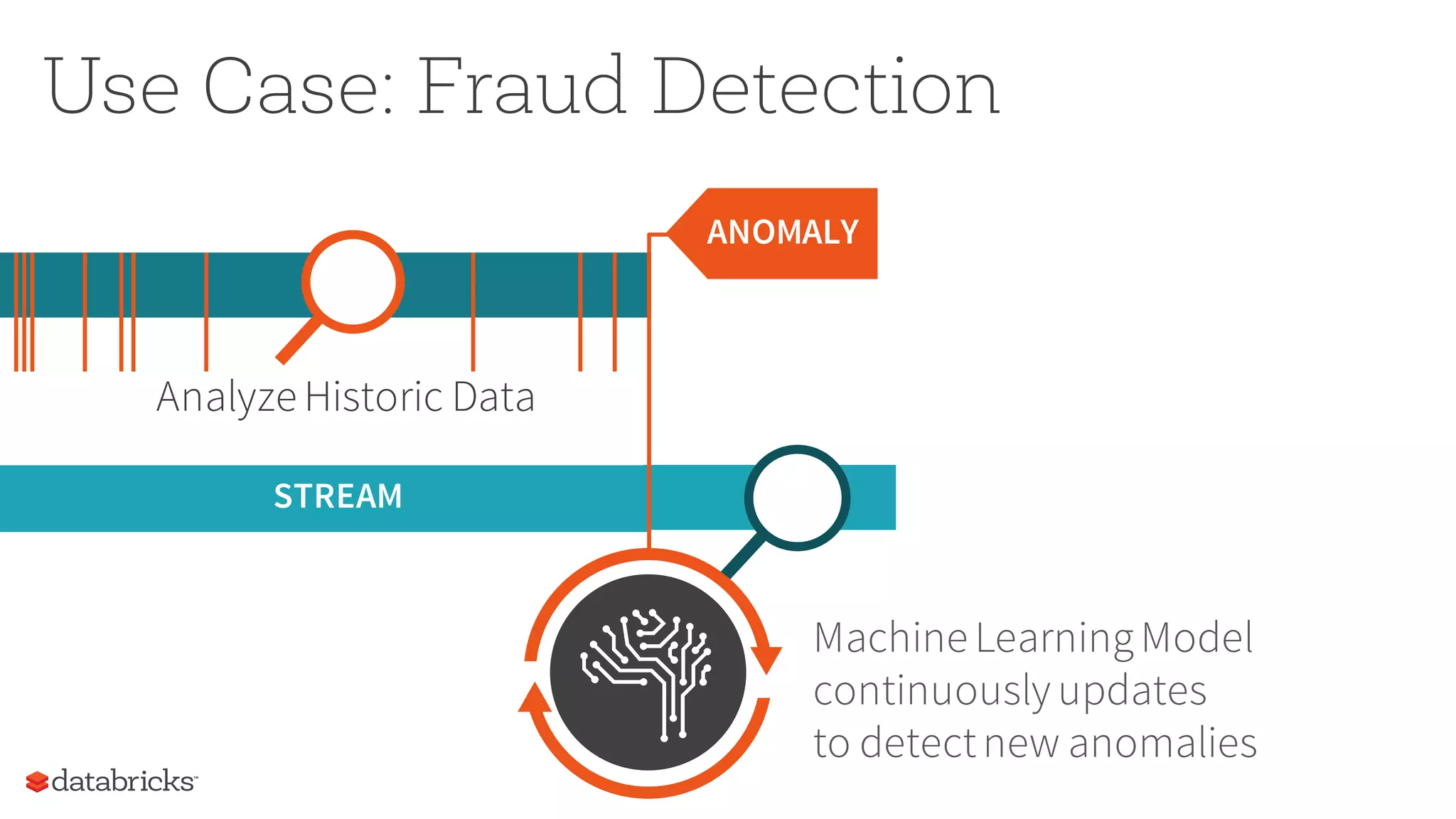
The document discusses the future of real-time data processing in Spark, highlighting its importance for faster decision-making in applications like fraud detection and industrial monitoring. It introduces Spark Streaming, which integrates streaming and batch processing with features like state management and exactly-once semantics, and outlines the challenges of building continuous applications. Additionally, it presents the structured streaming API in Spark 2.0, which simplifies streaming analytics by unifying various query types and ensuring seamless integration with existing systems.



























































































![[500DISTRO] Going for Global: 5 Guerrilla Tactics When the Slick Stuff Fails](https://cdn.slidesharecdn.com/ss_thumbnails/05rebeccarosenfeltairbnb-draft1-140806212908-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)















































