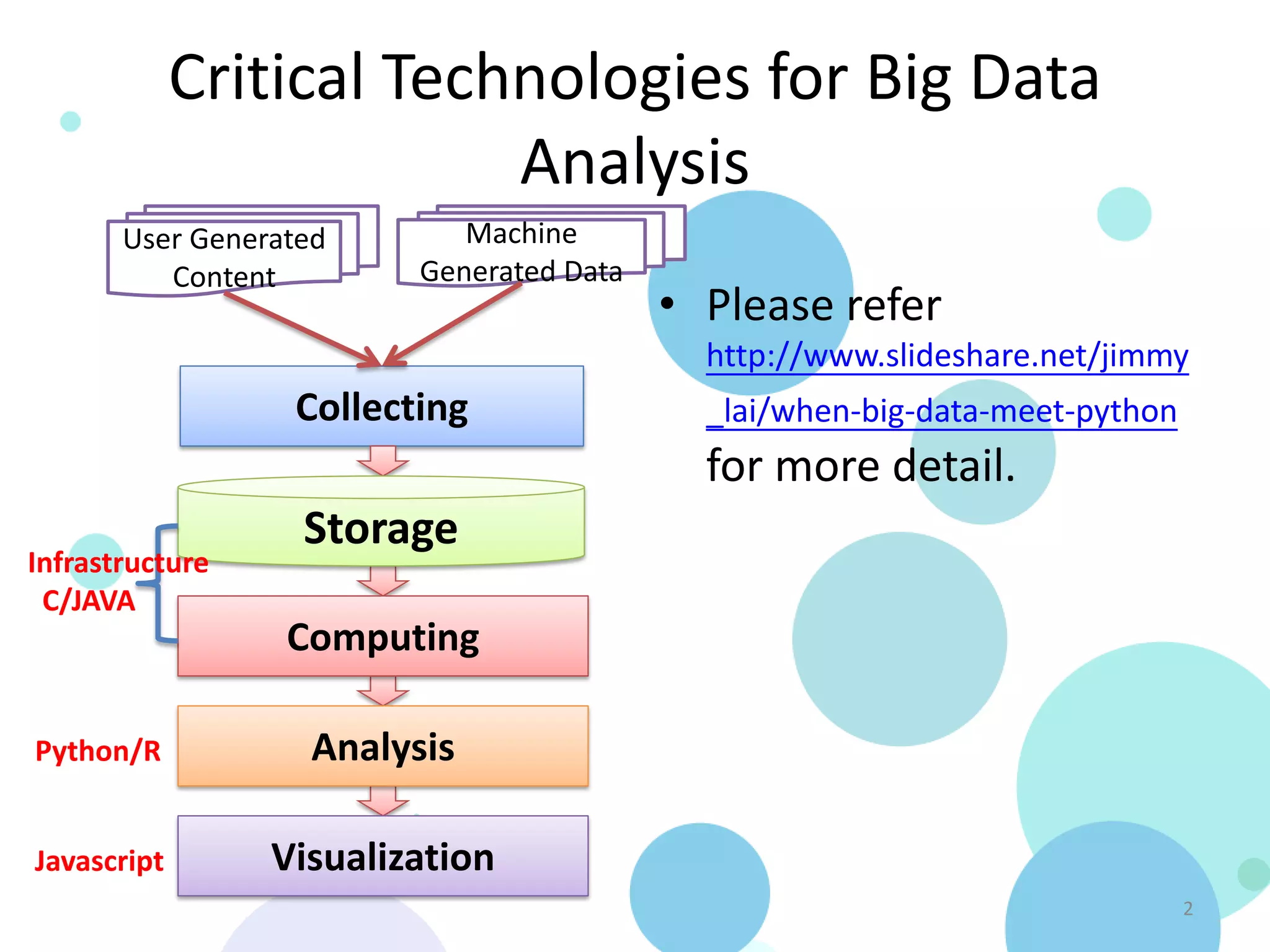
Download as PDF, PPTX
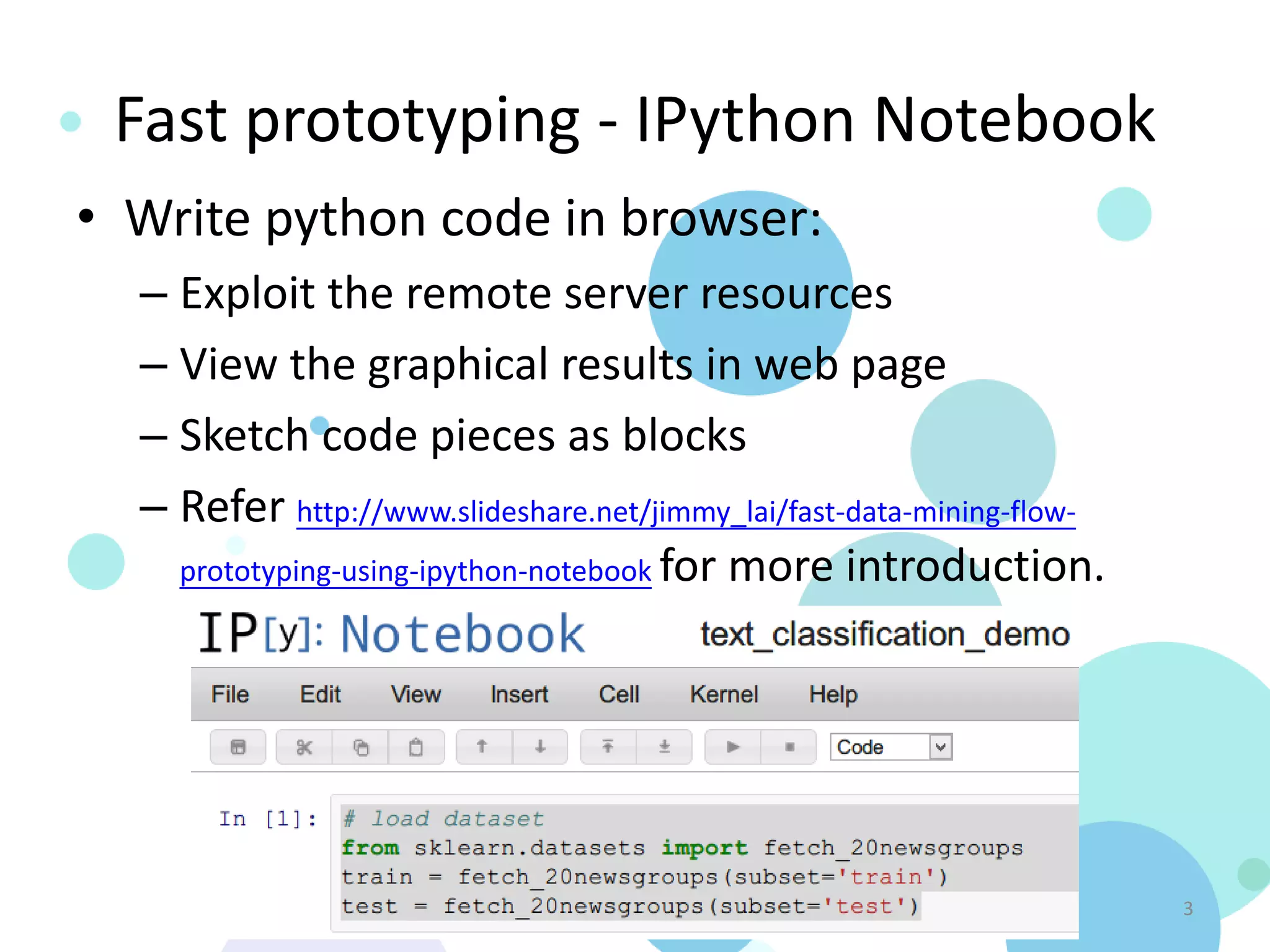
![Text Classification in Python – using
Pandas, scikit-learn, IPython
Notebook and matplotlib
Jimmy Lai
r97922028 [at] ntu.edu.tw
http://tw.linkedin.com/pub/jimmy-lai/27/4a/536
2013/02/17](https://image.slidesharecdn.com/textclassificationinpython-130218042632-phpapp01/75/Text-Classification-in-Python-using-Pandas-scikit-learn-IPython-Notebook-and-matplotlib-1-2048.jpg)

![Machine learning classification
• 𝑋 𝑖 = [𝑥1 , 𝑥2 , … , 𝑥 𝑛 ], 𝑥 𝑛 ∈ 𝑅
• 𝑦𝑖 ∈ 𝑁
• 𝑑𝑎𝑡𝑎𝑠𝑒𝑡 = 𝑋, 𝑌
• 𝑐𝑙𝑎𝑠𝑠𝑖𝑓𝑖𝑒𝑟 𝑓: 𝑦 𝑖 = 𝑓(𝑋 𝑖 )
Text Classification in Python 5](https://image.slidesharecdn.com/textclassificationinpython-130218042632-phpapp01/75/Text-Classification-in-Python-using-Pandas-scikit-learn-IPython-Notebook-and-matplotlib-5-2048.jpg)

![Dataset in sklearn
• sklearn.datasets
– Toy datasets
– Download data from http://mldata.org repository
• Data format of classification problem
– Dataset
• data: [raw_data or numerical]
• target: [int]
• target_names: [str]
Text Classification in Python 8](https://image.slidesharecdn.com/textclassificationinpython-130218042632-phpapp01/75/Text-Classification-in-Python-using-Pandas-scikit-learn-IPython-Notebook-and-matplotlib-8-2048.jpg)
![Feature extraction from structured
data (1/2)
• Count the frequency of
Keyword Count
keyword and select the Distribution 2549
keywords as features: Summary 397
['From', 'Subject', Disclaimer 125
File 257
'Organization', Expires 116
'Distribution', 'Lines'] Subject 11612
• E.g. From 11398
Keywords 943
From: lerxst@wam.umd.edu (where's my thing)
Subject: WHAT car is this!?
Originator 291
Organization: University of Maryland, College Organization 10872
Park Lines 11317
Distribution: None Internet 140
Lines: 15 To 106
Text Classification in Python 9](https://image.slidesharecdn.com/textclassificationinpython-130218042632-phpapp01/75/Text-Classification-in-Python-using-Pandas-scikit-learn-IPython-Notebook-and-matplotlib-9-2048.jpg)
![Feature extraction from structured
data (2/2)
• Separate structured • Transform token matrix
data and text data as numerical matrix by
– Text data start from sklearn.feature_extract
“Line:” ionDictVectorizer
• E.g.
[{‘a’: 1, ‘b’: 1}, {‘c’: 1}] =>
[[1, 1, 0], [0, 0, 1]]
Text Classification in Python 10](https://image.slidesharecdn.com/textclassificationinpython-130218042632-phpapp01/75/Text-Classification-in-Python-using-Pandas-scikit-learn-IPython-Notebook-and-matplotlib-10-2048.jpg)

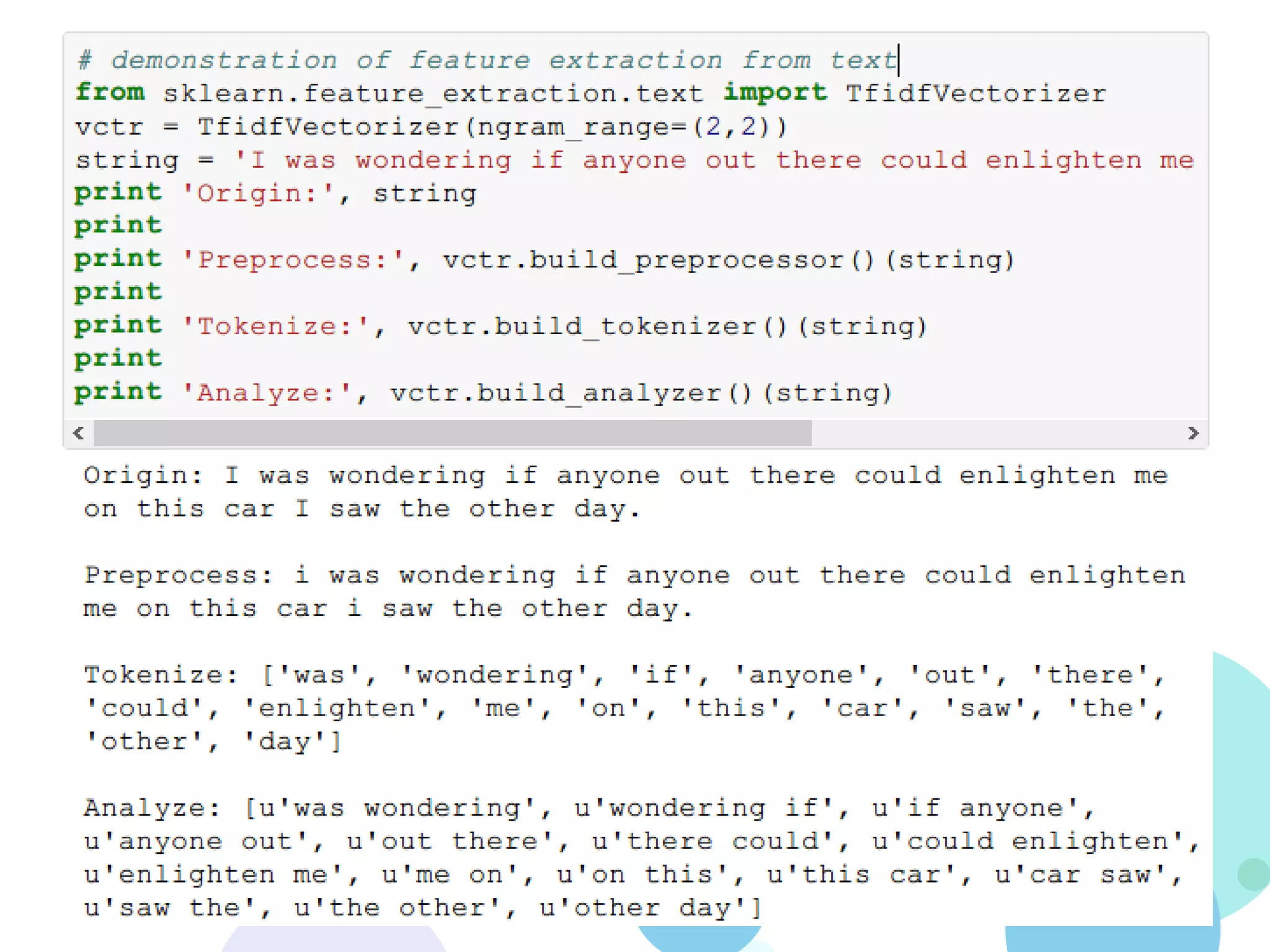
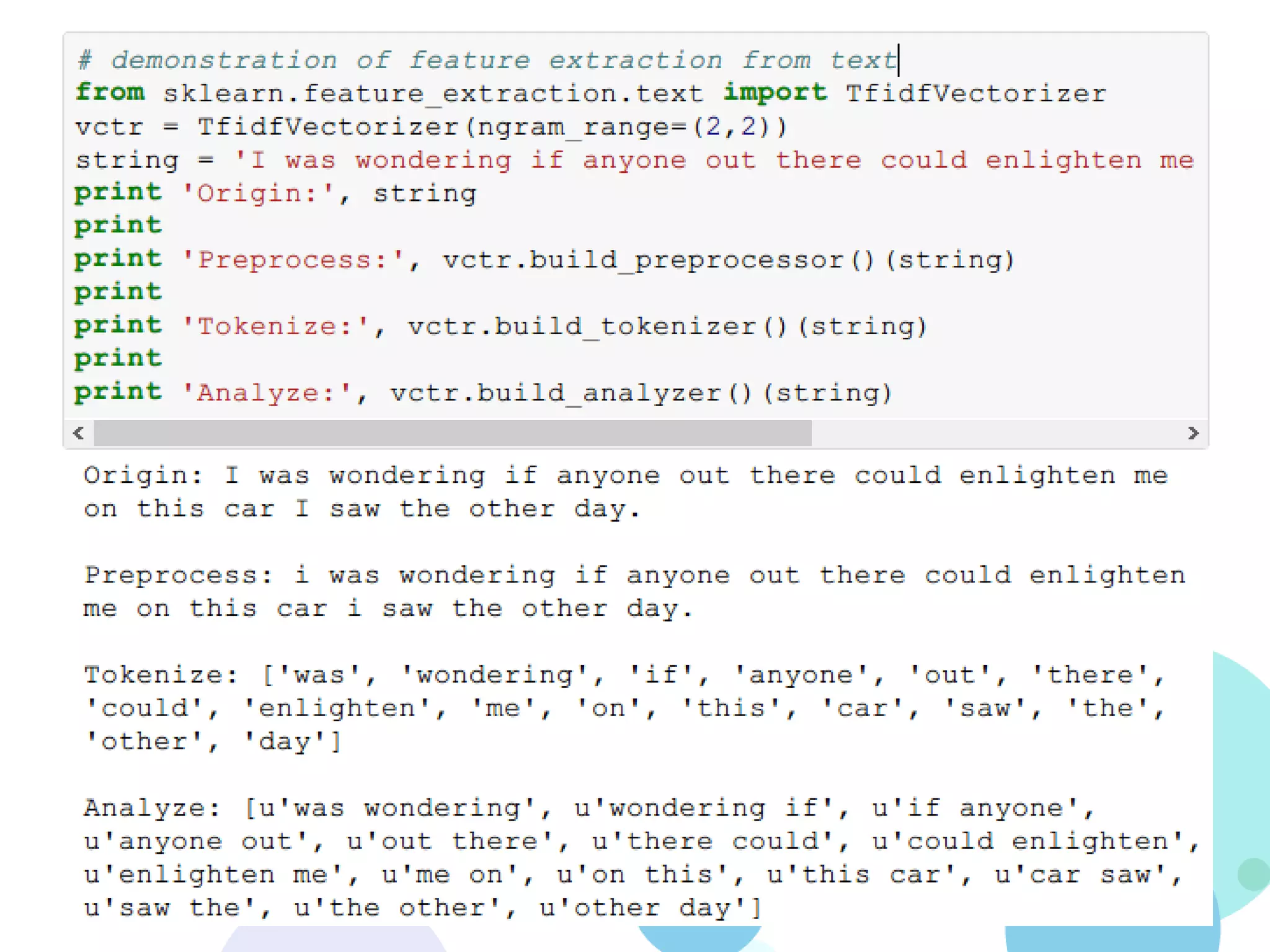
![Text Feature extraction
• Analyzer
– Preprocessor: str -> str
• Default: lowercase
• Extra: strip_accents – handle unicode chars
– Tokenizer: str -> [str]
• Default: re.findall(ur"(?u)bww+b“, string)
– Analyzer: str -> [str]
1. Call preprocessor and tokenizer
2. Filter stopwords
3. Generate n-gram tokens
Text Classification in Python 12](https://image.slidesharecdn.com/textclassificationinpython-130218042632-phpapp01/75/Text-Classification-in-Python-using-Pandas-scikit-learn-IPython-Notebook-and-matplotlib-12-2048.jpg)


![Cross Validation
• When tuning the parameters of model, let
each article as training and testing data
alternately to ensure the parameters are not
dedicated to some specific articles.
– from sklearn.cross_validation import KFold
– for train_index, test_index in KFold(10, 2):
• train_index = [5 6 7 8 9]
• test_index = [0 1 2 3 4]
Text Classification in Python 16](https://image.slidesharecdn.com/textclassificationinpython-130218042632-phpapp01/75/Text-Classification-in-Python-using-Pandas-scikit-learn-IPython-Notebook-and-matplotlib-16-2048.jpg)


![Text Classification in Python – using
Pandas, scikit-learn, IPython
Notebook and matplotlib
Jimmy Lai
r97922028 [at] ntu.edu.tw
http://tw.linkedin.com/pub/jimmy-lai/27/4a/536
2013/02/17](https://crownmelresort.com/image.slidesharecdn.com/textclassificationinpython-130218042632-phpapp01/75/Text-Classification-in-Python-using-Pandas-scikit-learn-IPython-Notebook-and-matplotlib-1-2048.jpg)

![Machine learning classification
• 𝑋 𝑖 = [𝑥1 , 𝑥2 , … , 𝑥 𝑛 ], 𝑥 𝑛 ∈ 𝑅
• 𝑦𝑖 ∈ 𝑁
• 𝑑𝑎𝑡𝑎𝑠𝑒𝑡 = 𝑋, 𝑌
• 𝑐𝑙𝑎𝑠𝑠𝑖𝑓𝑖𝑒𝑟 𝑓: 𝑦 𝑖 = 𝑓(𝑋 𝑖 )
Text Classification in Python 5](https://crownmelresort.com/image.slidesharecdn.com/textclassificationinpython-130218042632-phpapp01/75/Text-Classification-in-Python-using-Pandas-scikit-learn-IPython-Notebook-and-matplotlib-5-2048.jpg)


![Dataset in sklearn
• sklearn.datasets
– Toy datasets
– Download data from http://mldata.org repository
• Data format of classification problem
– Dataset
• data: [raw_data or numerical]
• target: [int]
• target_names: [str]
Text Classification in Python 8](https://crownmelresort.com/image.slidesharecdn.com/textclassificationinpython-130218042632-phpapp01/75/Text-Classification-in-Python-using-Pandas-scikit-learn-IPython-Notebook-and-matplotlib-8-2048.jpg)
![Feature extraction from structured
data (1/2)
• Count the frequency of
Keyword Count
keyword and select the Distribution 2549
keywords as features: Summary 397
['From', 'Subject', Disclaimer 125
File 257
'Organization', Expires 116
'Distribution', 'Lines'] Subject 11612
• E.g. From 11398
Keywords 943
From: lerxst@wam.umd.edu (where's my thing)
Subject: WHAT car is this!?
Originator 291
Organization: University of Maryland, College Organization 10872
Park Lines 11317
Distribution: None Internet 140
Lines: 15 To 106
Text Classification in Python 9](https://crownmelresort.com/image.slidesharecdn.com/textclassificationinpython-130218042632-phpapp01/75/Text-Classification-in-Python-using-Pandas-scikit-learn-IPython-Notebook-and-matplotlib-9-2048.jpg)
![Feature extraction from structured
data (2/2)
• Separate structured • Transform token matrix
data and text data as numerical matrix by
– Text data start from sklearn.feature_extract
“Line:” ionDictVectorizer
• E.g.
[{‘a’: 1, ‘b’: 1}, {‘c’: 1}] =>
[[1, 1, 0], [0, 0, 1]]
Text Classification in Python 10](https://crownmelresort.com/image.slidesharecdn.com/textclassificationinpython-130218042632-phpapp01/75/Text-Classification-in-Python-using-Pandas-scikit-learn-IPython-Notebook-and-matplotlib-10-2048.jpg)

![Text Feature extraction
• Analyzer
– Preprocessor: str -> str
• Default: lowercase
• Extra: strip_accents – handle unicode chars
– Tokenizer: str -> [str]
• Default: re.findall(ur"(?u)bww+b“, string)
– Analyzer: str -> [str]
1. Call preprocessor and tokenizer
2. Filter stopwords
3. Generate n-gram tokens
Text Classification in Python 12](https://crownmelresort.com/image.slidesharecdn.com/textclassificationinpython-130218042632-phpapp01/75/Text-Classification-in-Python-using-Pandas-scikit-learn-IPython-Notebook-and-matplotlib-12-2048.jpg)


![Cross Validation
• When tuning the parameters of model, let
each article as training and testing data
alternately to ensure the parameters are not
dedicated to some specific articles.
– from sklearn.cross_validation import KFold
– for train_index, test_index in KFold(10, 2):
• train_index = [5 6 7 8 9]
• test_index = [0 1 2 3 4]
Text Classification in Python 16](https://crownmelresort.com/image.slidesharecdn.com/textclassificationinpython-130218042632-phpapp01/75/Text-Classification-in-Python-using-Pandas-scikit-learn-IPython-Notebook-and-matplotlib-16-2048.jpg)




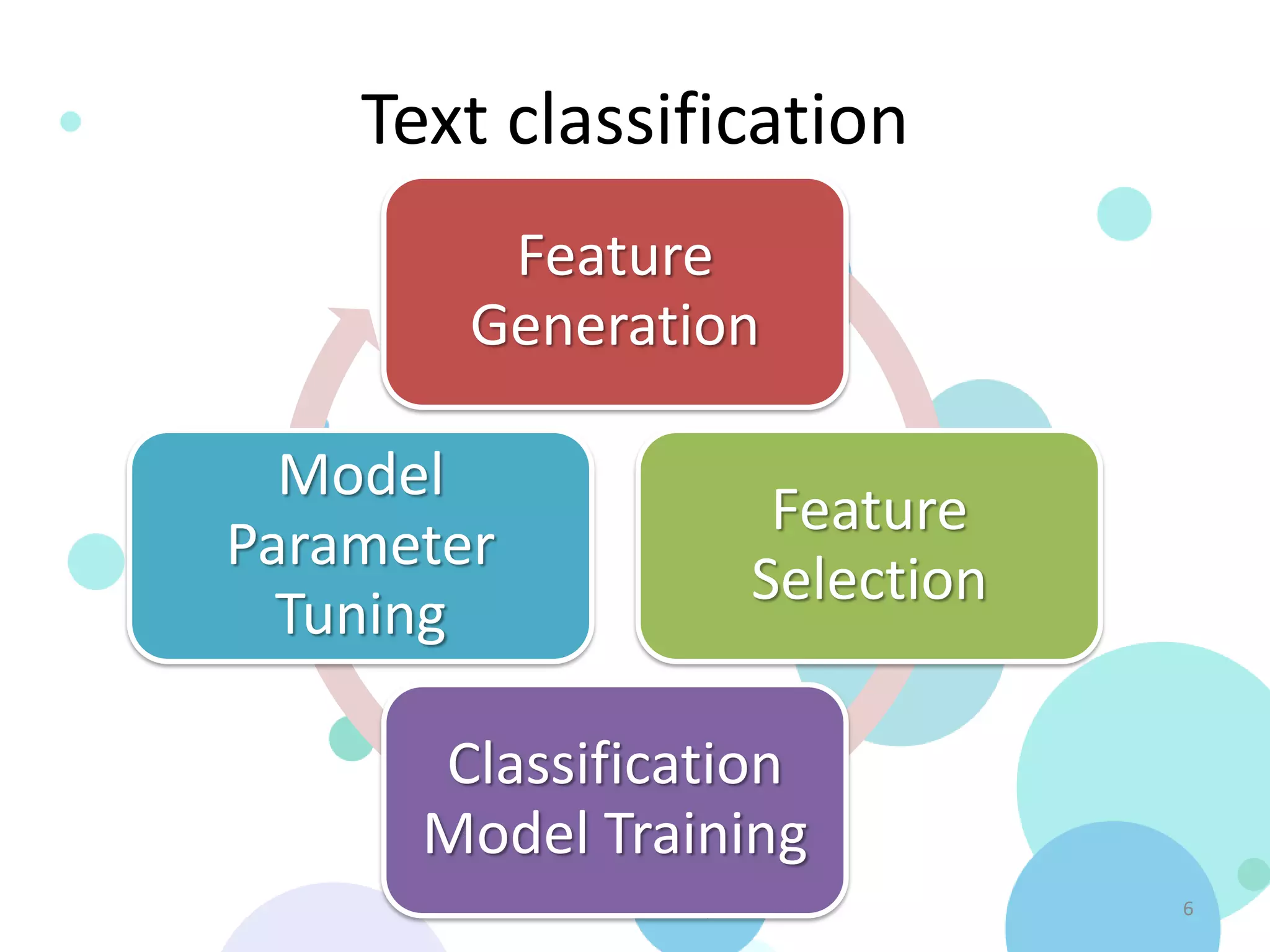
The document discusses text classification in Python utilizing libraries such as pandas, scikit-learn, and matplotlib. It covers the entire process from data collection and feature extraction to classification model training and performance evaluation using iPython notebooks for fast prototyping. Additionally, it includes practical examples, demo code, and references for further learning.



























![[DL輪読会]Understanding deep learning requires rethinking generalization](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170217-170217024917-thumbnail.jpg?width=640&height=640&fit=bounds)







































![[PyCon US 2025] Scaling the Mountain_ A Framework for Tackling Large-Scale Te...](https://cdn.slidesharecdn.com/ss_thumbnails/pyconus2025scalingthemountainaframeworkfortacklinglarge-scaletechdebt-250517122757-38c6df76-thumbnail.jpg?width=640&height=640&fit=bounds)










![[LDSP] Search Engine Back End API Solution for Fast Prototyping](https://cdn.slidesharecdn.com/ss_thumbnails/searchengineldsp-140126193834-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



![[LDSP] Solr Usage](https://cdn.slidesharecdn.com/ss_thumbnails/searchengineldspsolr-140127194826-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)























