Download to read offline






![Counting: Bags of Words
from sklearn.feature_extraction.text import CountVectorizer
count_vect = CountVectorizer()
word_counts = count_vect.fit_transform([sipatext])
print('{}'.format(word_counts))
print('{}'.format(count_vect.vocabulary_))](https://image.slidesharecdn.com/session07textdata-160510160403/75/Session-07-text-data-pptx-7-2048.jpg)
![Counting sets of words: N-Grams
● Pairs (or triples, 4s etc) of words
● Also: pairs etc of characters, e.g. [‘mor’, ‘ore’, ‘re ‘,
‘e t’, ‘ th’, ‘tha’, ‘han’]
● Know your Ns:
○ ‘Unigram’ == 1-gram
○ ‘Bigram’ == 2-gram
○ ‘Trigram’ == 3-gram
count_vectn = CountVectorizer(ngram_range =(2, 2))](https://image.slidesharecdn.com/session07textdata-160510160403/75/Session-07-text-data-pptx-8-2048.jpg)
![Stopwords
count_vect2 =
CountVectorizer(stop_words='english')
word_counts2 =
count_vect2.fit_transform([sipatext])](https://image.slidesharecdn.com/session07textdata-160510160403/75/Session-07-text-data-pptx-9-2048.jpg)



![The 20newsgroups dataset
from sklearn.datasets import fetch_20newsgroups
cats = ['alt.atheism', 'soc.religion.christian', 'comp.graphics', 'sci.med']
twenty_train = fetch_20newsgroups( subset='train', categories=cats)
twenty_test = fetch_20newsgroups(subset='test', categories=cats)](https://image.slidesharecdn.com/session07textdata-160510160403/75/Session-07-text-data-pptx-13-2048.jpg)
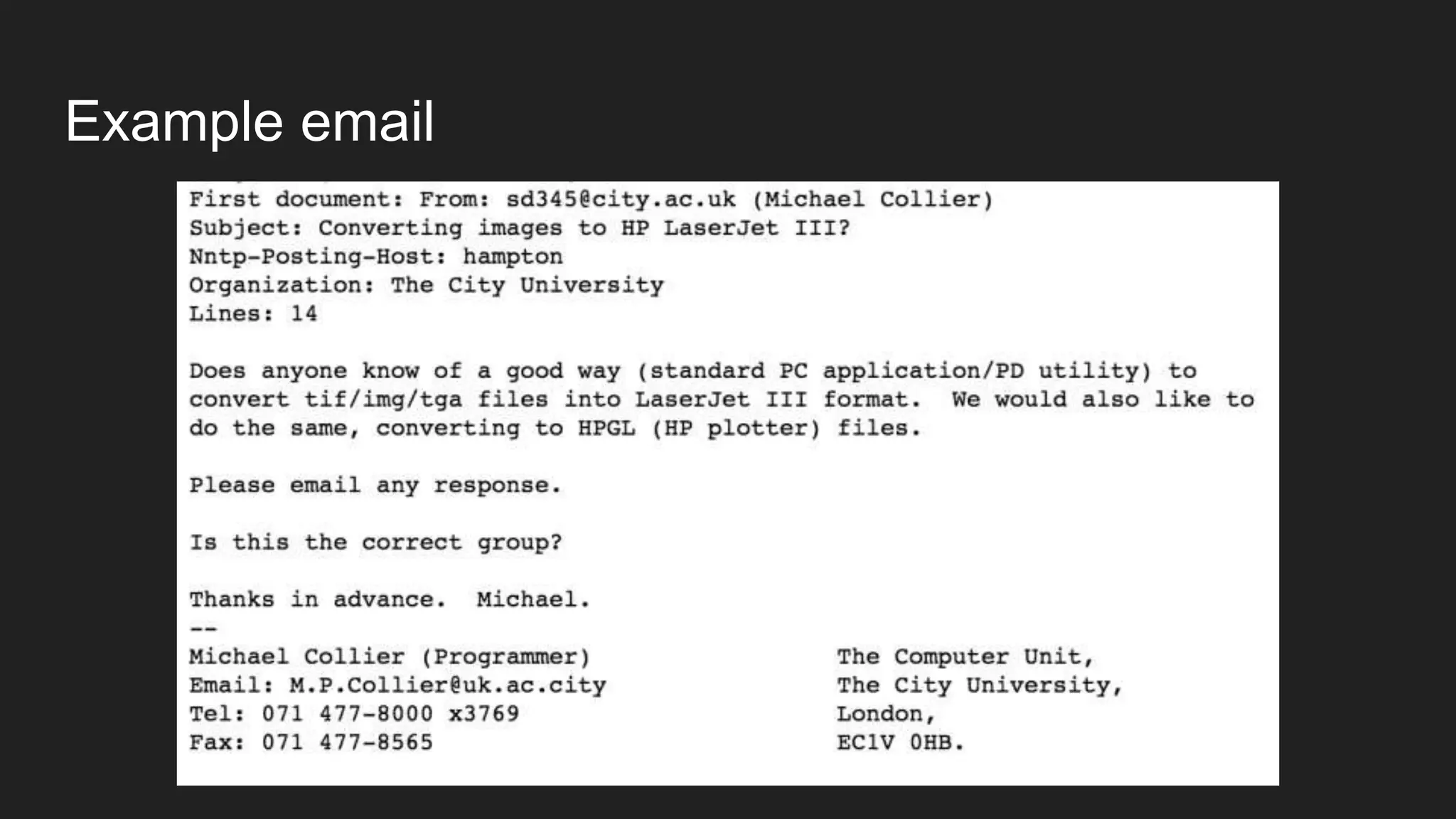


![Test your model
docs_test = ['God is love', 'OpenGL on the GPU is fast']
X_new_counts = count_vect.transform(docs_test)
X_new_tfidf = tfidf_transformer.transform(X_new_counts)
predicted = nb_classifier.predict(X_new_tfidf)
for doc, category in zip(docs_test, predicted):
print('{} => {}'.format(doc, twenty_train.target_names[category]))](https://image.slidesharecdn.com/session07textdata-160510160403/75/Session-07-text-data-pptx-17-2048.jpg)







![NLTK: concordance
textlist.concordance(‘school’)
textlist.similar('school')
textlist.common_contexts(['school', 'university'])](https://image.slidesharecdn.com/session07textdata-160510160403/75/Session-07-text-data-pptx-27-2048.jpg)
![NLTK: word dispersion plots
from nltk.book import *
text2.dispersion_plot(['Elinor', 'Willoughby', 'Sophia'])](https://image.slidesharecdn.com/session07textdata-160510160403/75/Session-07-text-data-pptx-28-2048.jpg)
![NLTK: Word Meanings
from nltk.corpus import wordnet as wn
word = 'class'
synset = wn.synsets(word)
print('Synset: {}n'.format(synset))
for i in range(len(synset)):
print('Meaning {}: {} {}'.format(i, synset[i].lemma_names(), synset[i].definition()))](https://image.slidesharecdn.com/session07textdata-160510160403/75/Session-07-text-data-pptx-29-2048.jpg)

![NLTK: converting words into logic
from nltk import load_parser
parser = load_parser('grammars/book_grammars/simple-sem.fcfg', trace=0)
sentence = 'Angus gives a bone to every dog'
tokens = sentence.split()
for tree in parser.parse(tokens):
print(tree.label()['SEM'])](https://image.slidesharecdn.com/session07textdata-160510160403/75/Session-07-text-data-pptx-31-2048.jpg)

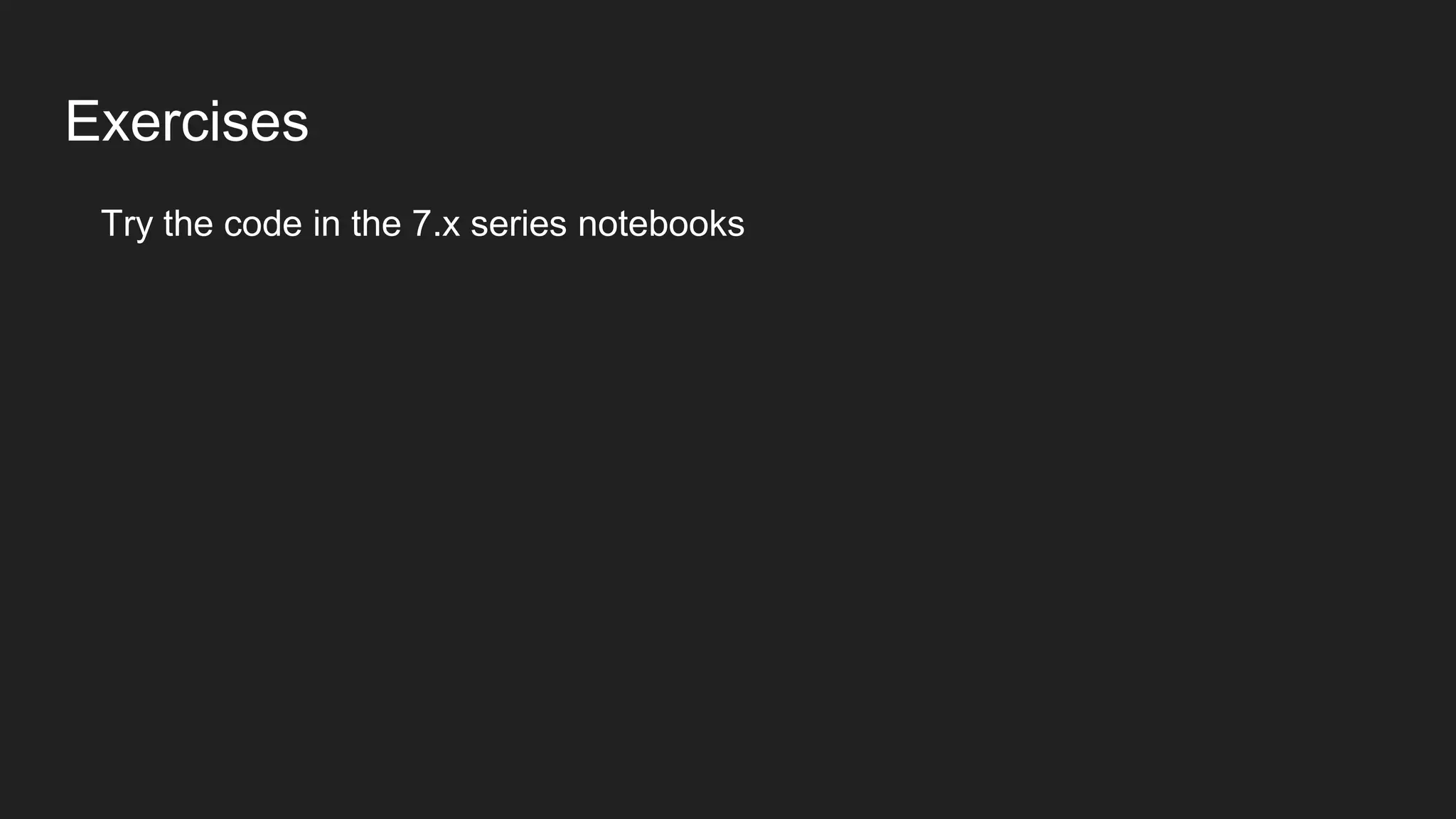






![Counting: Bags of Words
from sklearn.feature_extraction.text import CountVectorizer
count_vect = CountVectorizer()
word_counts = count_vect.fit_transform([sipatext])
print('{}'.format(word_counts))
print('{}'.format(count_vect.vocabulary_))](https://crownmelresort.com/image.slidesharecdn.com/session07textdata-160510160403/75/Session-07-text-data-pptx-7-2048.jpg)
![Counting sets of words: N-Grams
● Pairs (or triples, 4s etc) of words
● Also: pairs etc of characters, e.g. [‘mor’, ‘ore’, ‘re ‘,
‘e t’, ‘ th’, ‘tha’, ‘han’]
● Know your Ns:
○ ‘Unigram’ == 1-gram
○ ‘Bigram’ == 2-gram
○ ‘Trigram’ == 3-gram
count_vectn = CountVectorizer(ngram_range =(2, 2))](https://crownmelresort.com/image.slidesharecdn.com/session07textdata-160510160403/75/Session-07-text-data-pptx-8-2048.jpg)
![Stopwords
count_vect2 =
CountVectorizer(stop_words='english')
word_counts2 =
count_vect2.fit_transform([sipatext])](https://crownmelresort.com/image.slidesharecdn.com/session07textdata-160510160403/75/Session-07-text-data-pptx-9-2048.jpg)



![The 20newsgroups dataset
from sklearn.datasets import fetch_20newsgroups
cats = ['alt.atheism', 'soc.religion.christian', 'comp.graphics', 'sci.med']
twenty_train = fetch_20newsgroups( subset='train', categories=cats)
twenty_test = fetch_20newsgroups(subset='test', categories=cats)](https://crownmelresort.com/image.slidesharecdn.com/session07textdata-160510160403/75/Session-07-text-data-pptx-13-2048.jpg)



![Test your model
docs_test = ['God is love', 'OpenGL on the GPU is fast']
X_new_counts = count_vect.transform(docs_test)
X_new_tfidf = tfidf_transformer.transform(X_new_counts)
predicted = nb_classifier.predict(X_new_tfidf)
for doc, category in zip(docs_test, predicted):
print('{} => {}'.format(doc, twenty_train.target_names[category]))](https://crownmelresort.com/image.slidesharecdn.com/session07textdata-160510160403/75/Session-07-text-data-pptx-17-2048.jpg)









![NLTK: concordance
textlist.concordance(‘school’)
textlist.similar('school')
textlist.common_contexts(['school', 'university'])](https://crownmelresort.com/image.slidesharecdn.com/session07textdata-160510160403/75/Session-07-text-data-pptx-27-2048.jpg)
![NLTK: word dispersion plots
from nltk.book import *
text2.dispersion_plot(['Elinor', 'Willoughby', 'Sophia'])](https://crownmelresort.com/image.slidesharecdn.com/session07textdata-160510160403/75/Session-07-text-data-pptx-28-2048.jpg)
![NLTK: Word Meanings
from nltk.corpus import wordnet as wn
word = 'class'
synset = wn.synsets(word)
print('Synset: {}n'.format(synset))
for i in range(len(synset)):
print('Meaning {}: {} {}'.format(i, synset[i].lemma_names(), synset[i].definition()))](https://crownmelresort.com/image.slidesharecdn.com/session07textdata-160510160403/75/Session-07-text-data-pptx-29-2048.jpg)

![NLTK: converting words into logic
from nltk import load_parser
parser = load_parser('grammars/book_grammars/simple-sem.fcfg', trace=0)
sentence = 'Angus gives a bone to every dog'
tokens = sentence.split()
for tree in parser.parse(tokens):
print(tree.label()['SEM'])](https://crownmelresort.com/image.slidesharecdn.com/session07textdata-160510160403/75/Session-07-text-data-pptx-31-2048.jpg)



This document covers techniques for processing and analyzing text data, including classification, clustering, and sentiment analysis. It introduces various methods for reading and manipulating text data, such as term frequency-inverse document frequency (TF-IDF) and n-grams, as well as machine learning applications using the 20 Newsgroups dataset. Additionally, it discusses natural language processing using the NLTK library, providing examples of word tokenization, sentiment analysis, and named entity recognition.






































































































