Downloaded 47 times




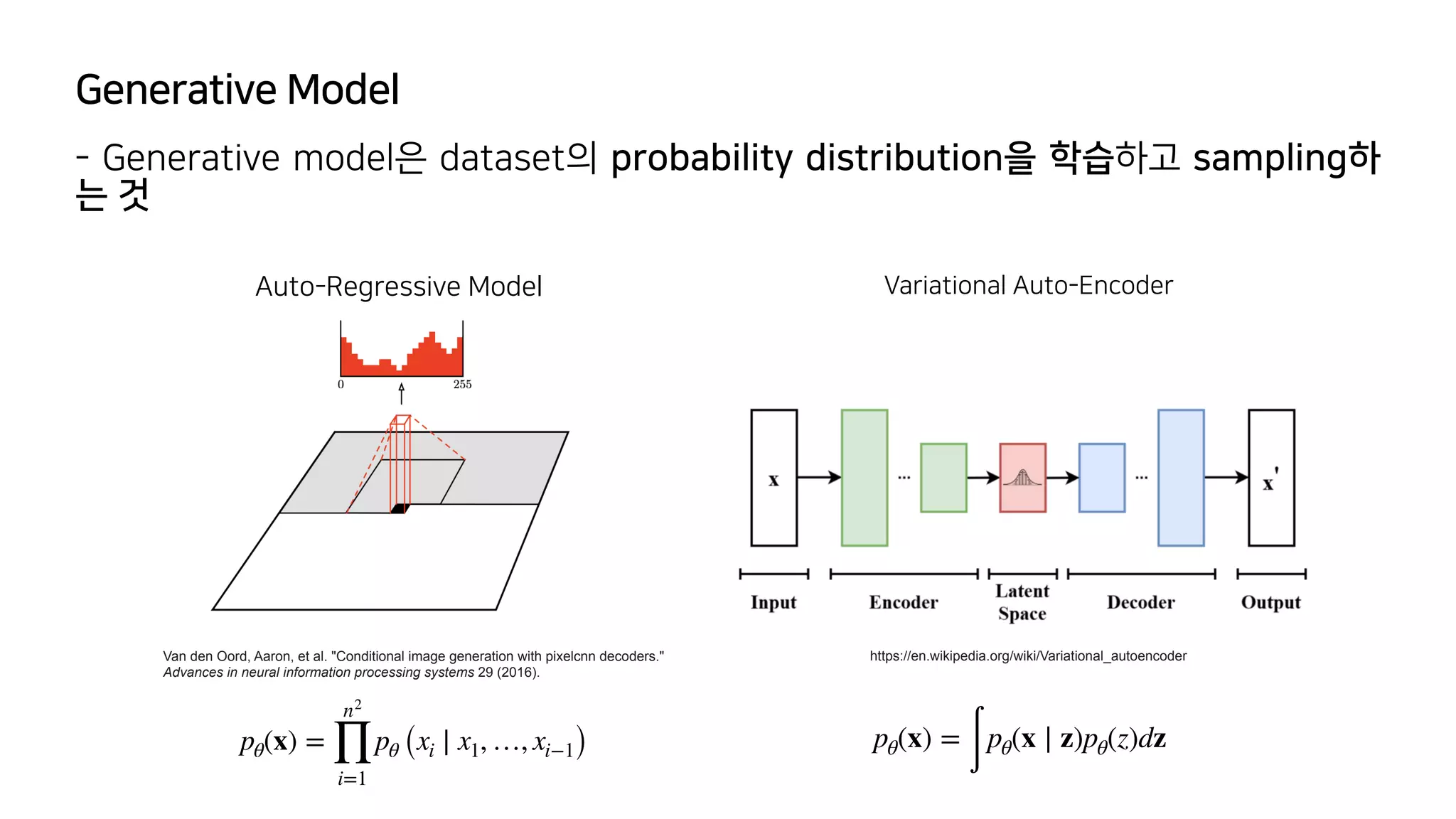
![Generative Model
Flow-based Model Generative Adversarial Networks
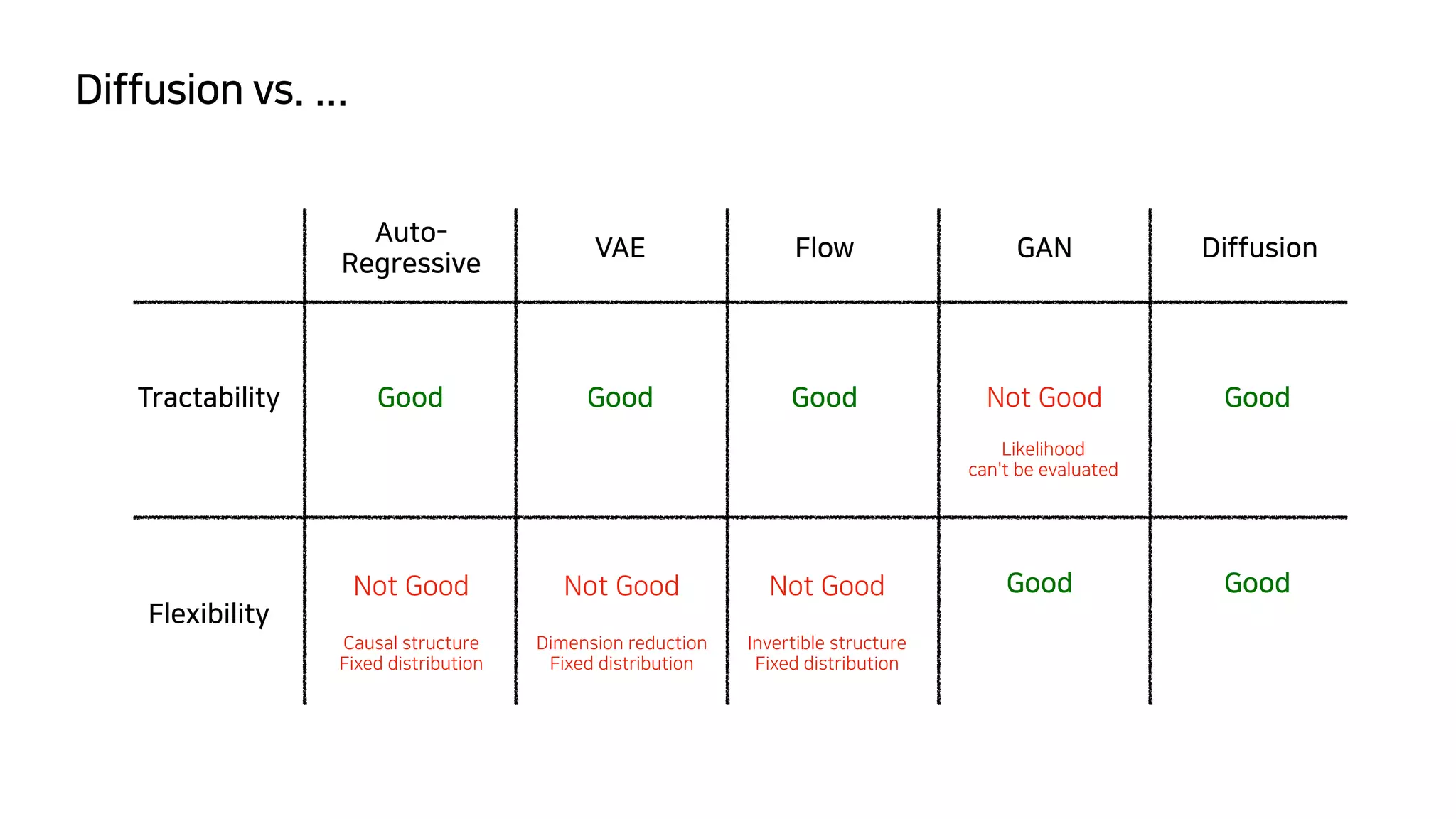
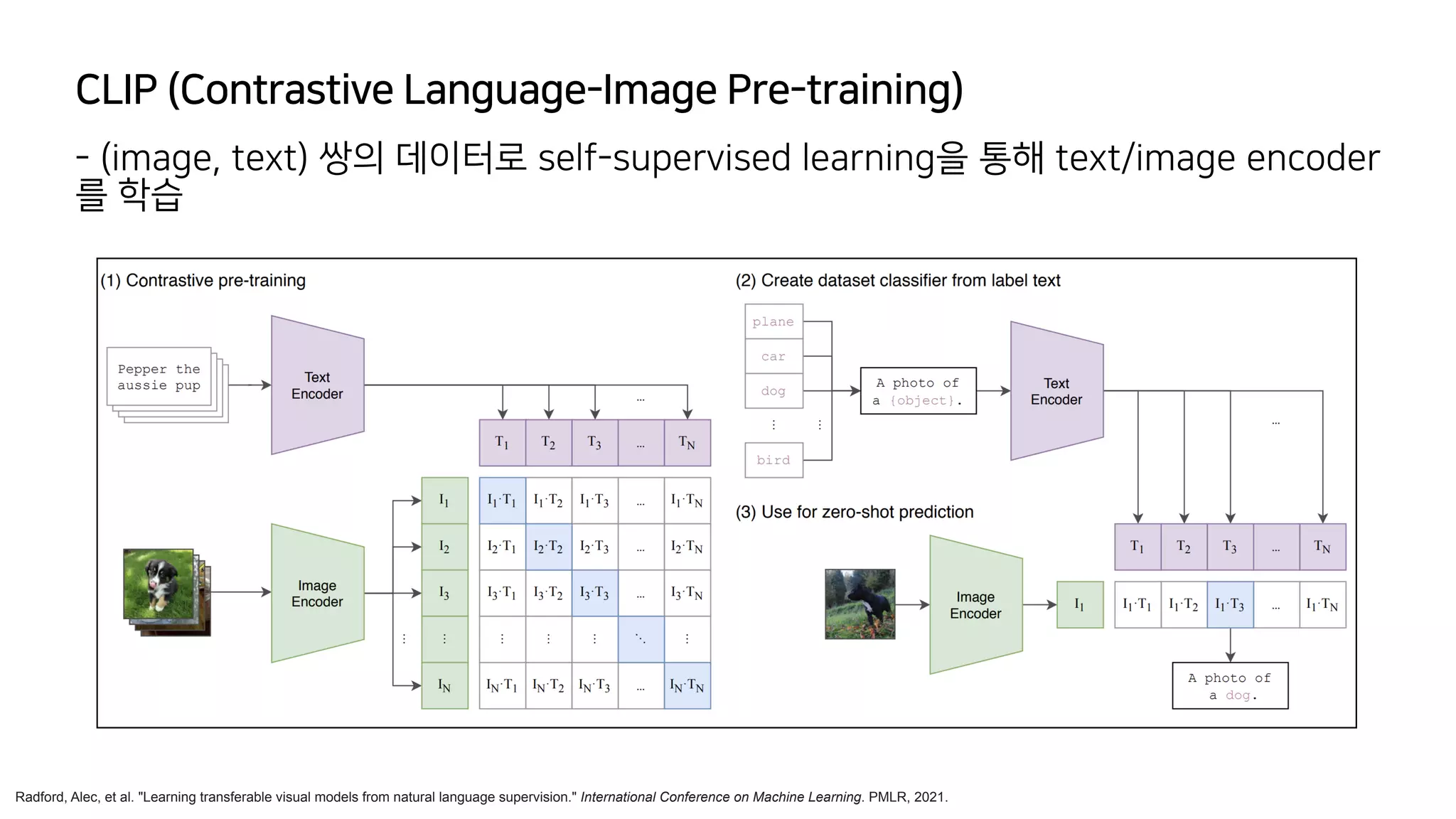
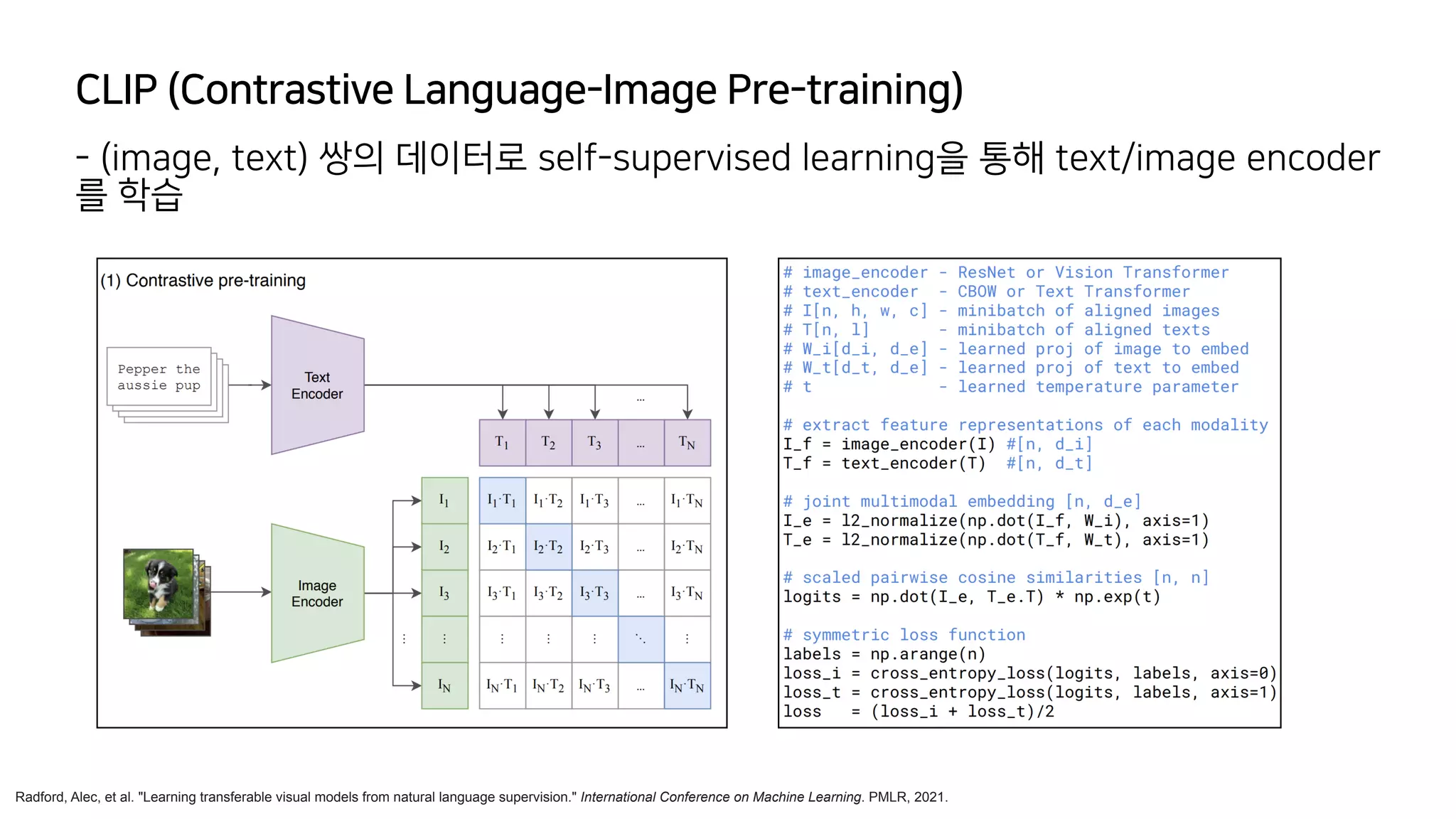
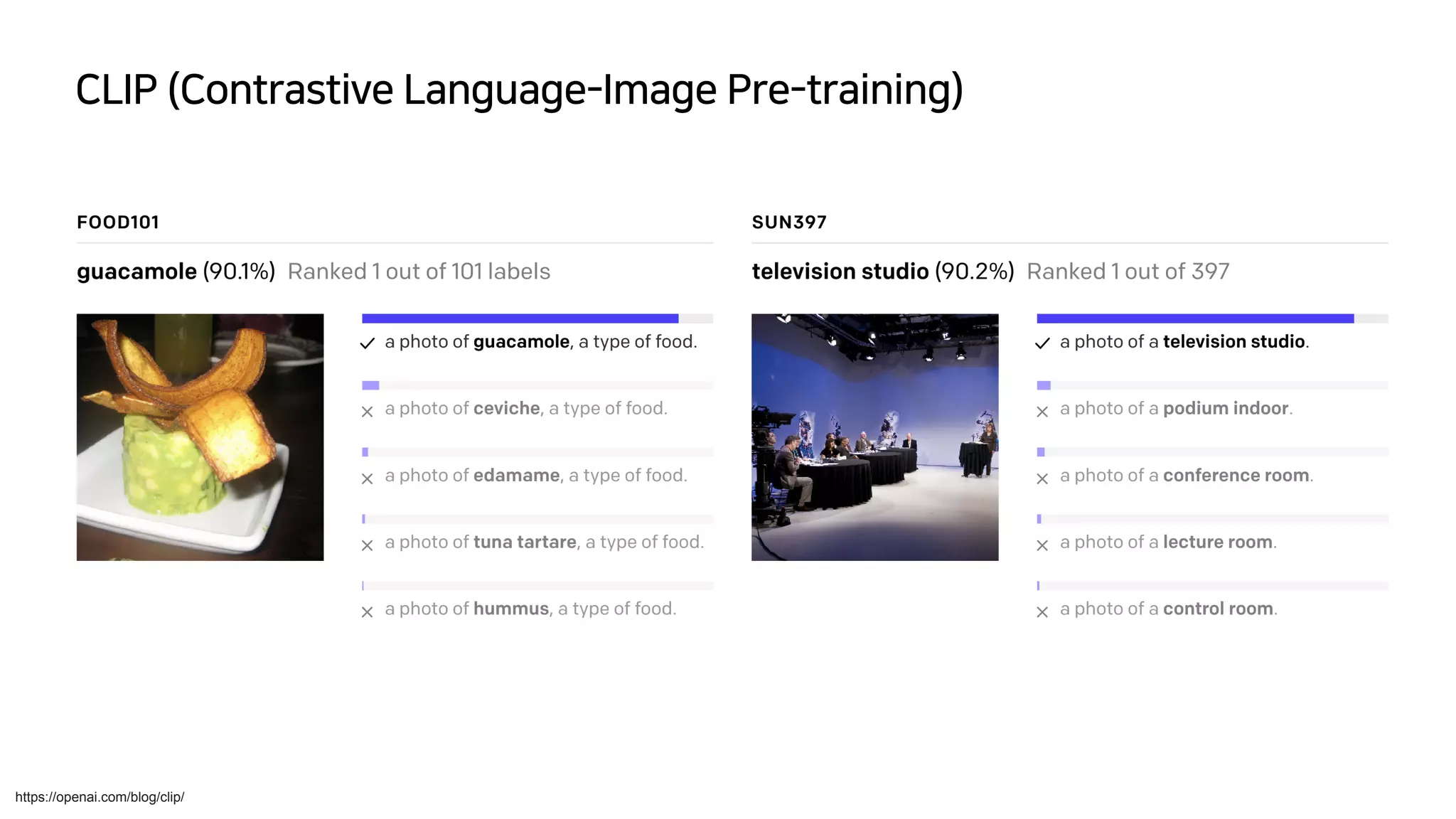
- Generative model은 dataset의 probability distribution을 학습하고 sampling하
는 것
Lil'Log, Flow-based Deep Generative Models
https://lilianweng.github.io/posts/2018-10-13-flow-models/
pθ(x) = pθ(z)|det(dz/dx)|
𝔼
x∼p
data (x)[log D(x)] +
𝔼
z∼pz(z)[log(1 − D(G(z)))]
Goodfellow, Ian, et al. "Generative adversarial nets."
Advances in neural information processing systems 27 (2014).](https://image.slidesharecdn.com/diffusiondalle2-220720062732-a5af0976/75/diffusion-DALLE2-pdf-6-2048.jpg)


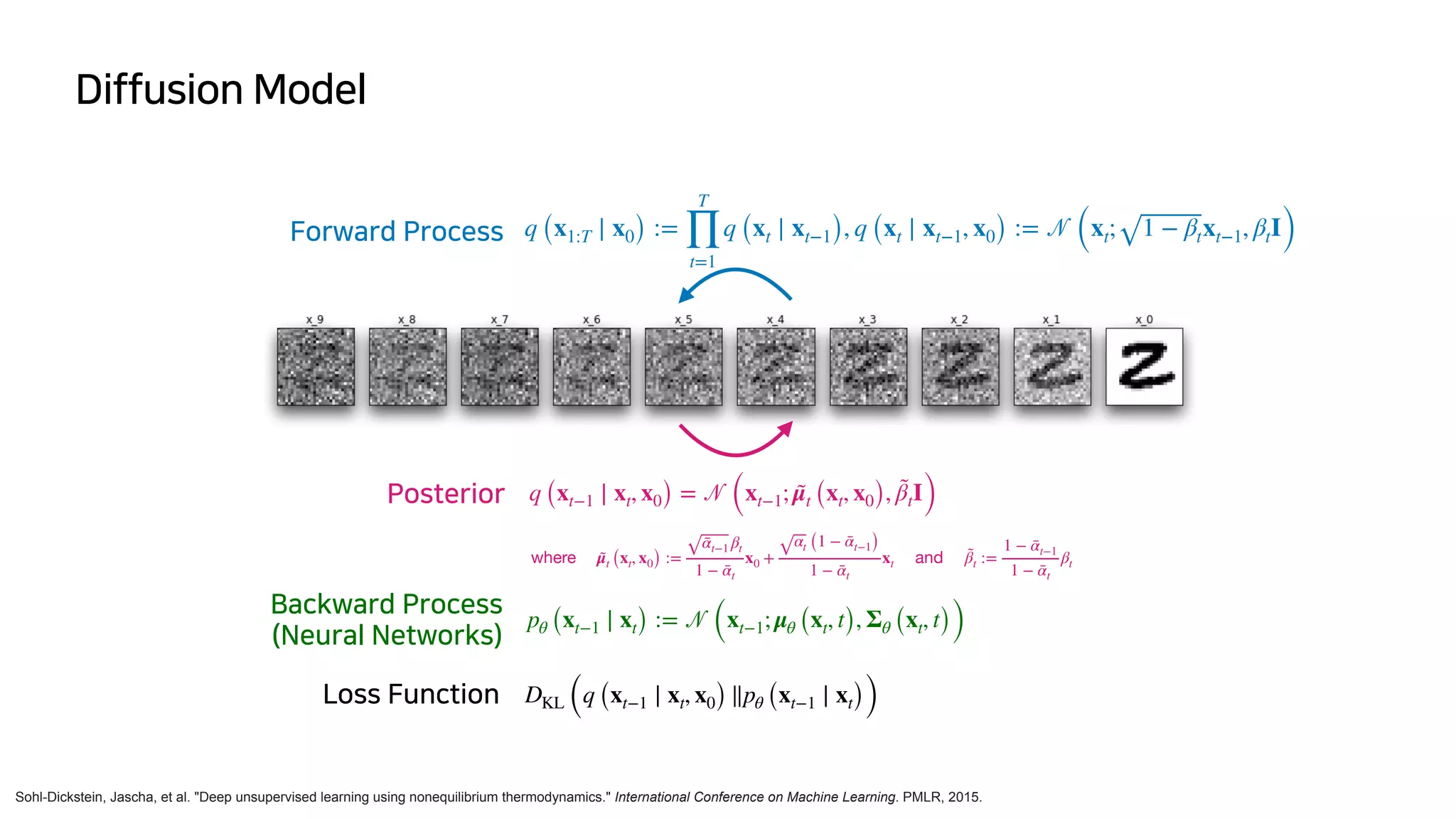
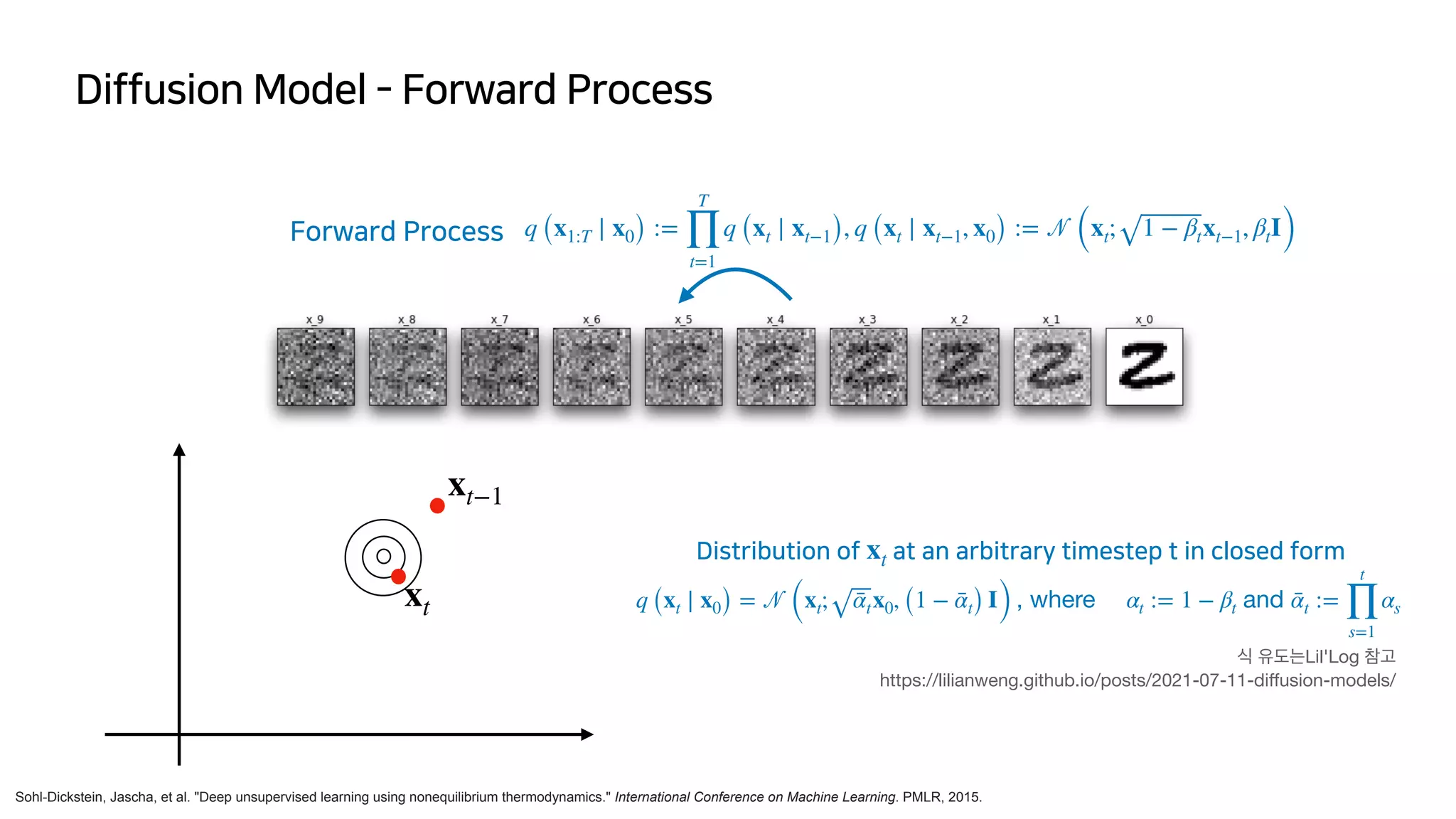
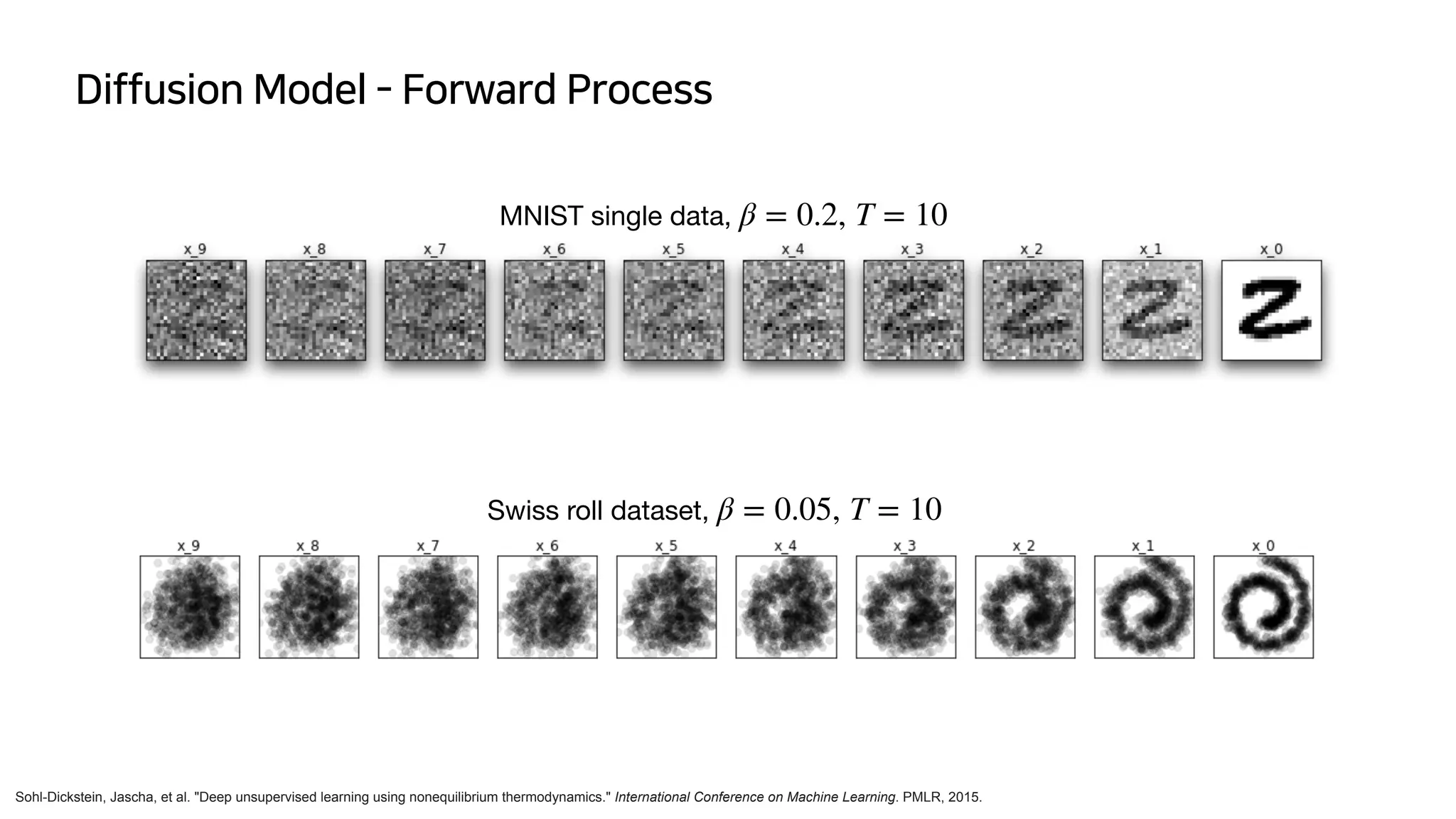


![DDPM (Denoising Diffusion Probabilistic Models)
Ho, Jonathan, Ajay Jain, and Pieter Abbeel. "Denoising diffusion probabilistic models." Advances in Neural Information Processing Systems 33 (2020): 6840-6851.
- Jonathan Ho의 논문 Denoising diffusion probabilistic models에서 제안
Distribution of at an arbitrary timestep t in closed form
xt
x0
ϵ ∼
𝒩
(0, I)
xt (x0, ϵ) = ᾱtx0 + 1 − ᾱtϵ
Lsimple (θ) :=
𝔼
t,x0,ϵ
[
ϵ − ϵθ ( ᾱtx0 + 1 − ᾱtϵ, t)
2
] is a linear combination of and
xt x0 ϵ
q (xt ∣ x0) =
𝒩
(xt; ᾱtx0, (1 − ᾱt) I) , where αt := 1 − βt and ᾱt :=
t
∏
s=1
αs
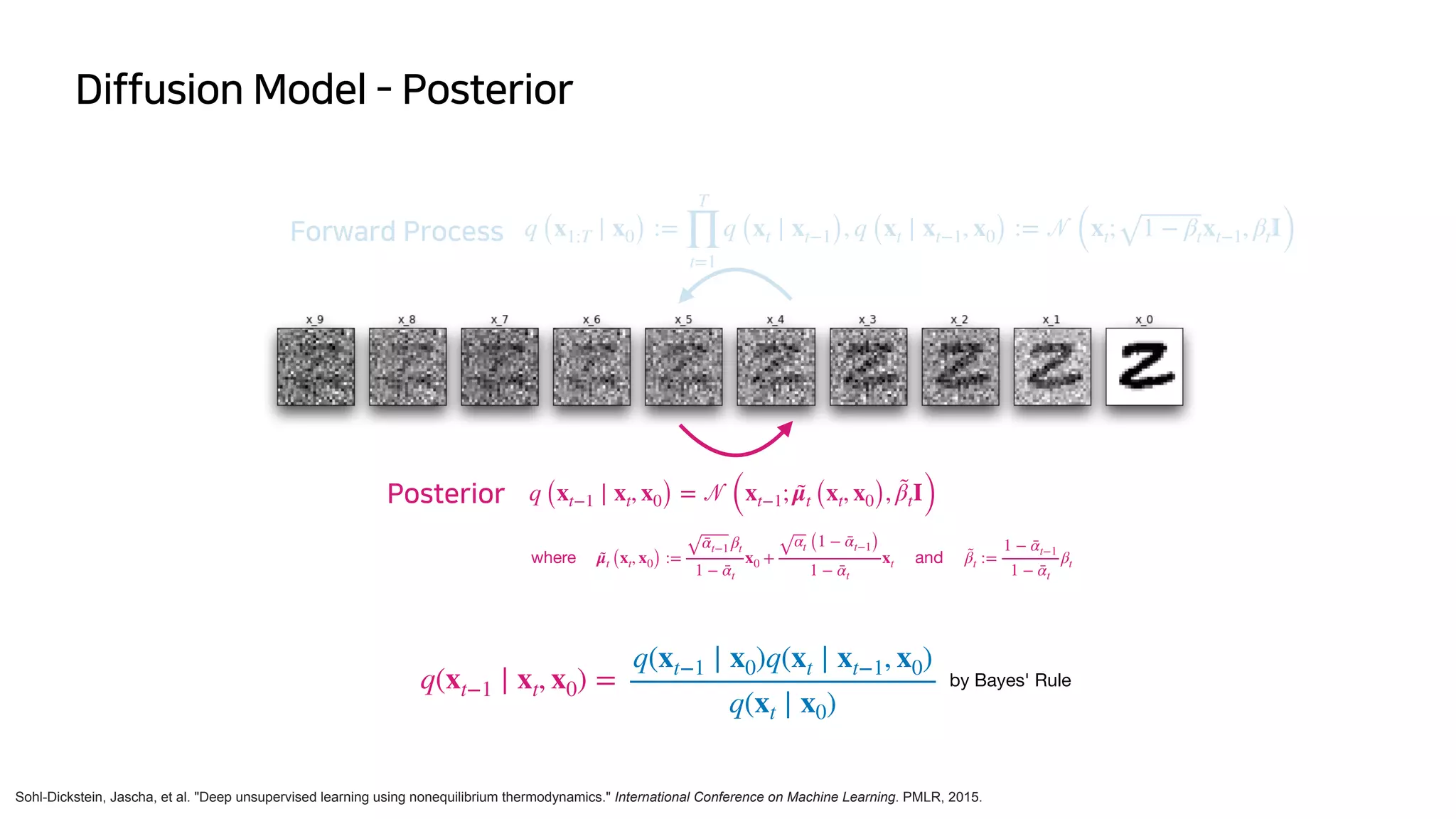
Posterior q (xt−1 ∣ xt, x0) =
𝒩
(xt−1; μ̃t (xt, x0), β̃tI)
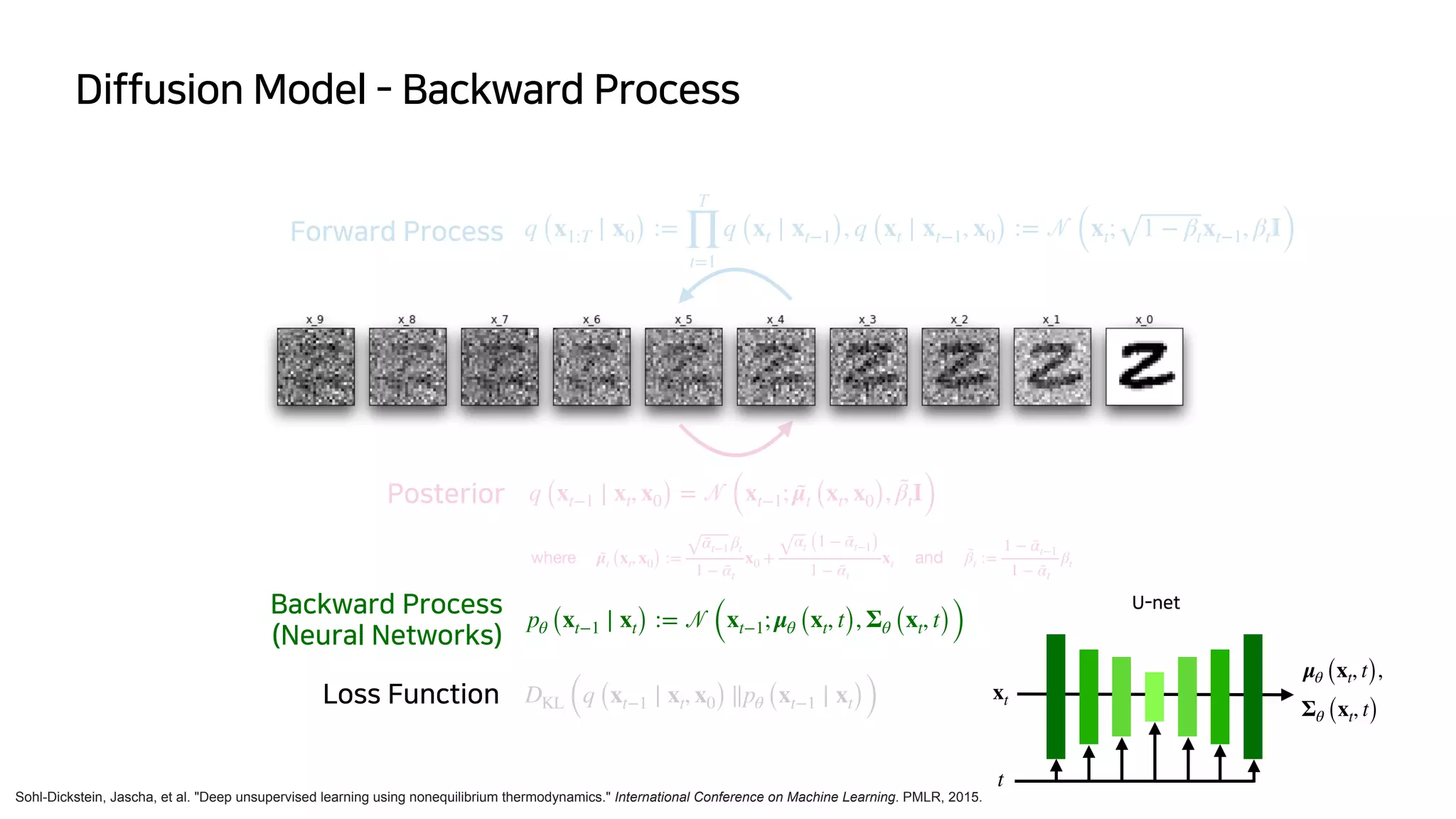
Loss Function
https://github.com/rosinality/denoising-di
ff
usion-pytorch/blob/master/
di
ff
usion.py
generate ϵ
sample xt
predict ϵ
Predict (or ) at each step
ϵ x0](https://image.slidesharecdn.com/diffusiondalle2-220720062732-a5af0976/75/diffusion-DALLE2-pdf-16-2048.jpg)
![DDPM (Denoising Diffusion Probabilistic Models)
Ho, Jonathan, Ajay Jain, and Pieter Abbeel. "Denoising diffusion probabilistic models." Advances in Neural Information Processing Systems 33 (2020): 6840-6851.
- Jonathan Ho의 논문 Denoising diffusion probabilistic models에서 제안
Distribution of at an arbitrary timestep t in closed form
xt
x0
ϵ ∼
𝒩
(0, I)
xt (x0, ϵ) = ᾱtx0 + 1 − ᾱtϵ
Lsimple (θ) :=
𝔼
t,x0,ϵ
[
ϵ − ϵθ ( ᾱtx0 + 1 − ᾱtϵ, t)
2
] is a linear combination of and
xt x0 ϵ
q (xt ∣ x0) =
𝒩
(xt; ᾱtx0, (1 − ᾱt) I) , where αt := 1 − βt and ᾱt :=
t
∏
s=1
αs
Posterior q (xt−1 ∣ xt, x0) =
𝒩
(xt−1; μ̃t (xt, x0), β̃tI)
Loss Function
https://github.com/rosinality/denoising-di
ff
usion-pytorch/blob/master/
di
ff
usion.py
generate ϵ
sample xt
predict ϵ
Predict (or ) at each step
ϵ x0](https://image.slidesharecdn.com/diffusiondalle2-220720062732-a5af0976/75/diffusion-DALLE2-pdf-17-2048.jpg)



















![Generative Model
Flow-based Model Generative Adversarial Networks
- Generative model은 dataset의 probability distribution을 학습하고 sampling하
는 것
Lil'Log, Flow-based Deep Generative Models
https://lilianweng.github.io/posts/2018-10-13-flow-models/
pθ(x) = pθ(z)|det(dz/dx)|
𝔼
x∼p
data (x)[log D(x)] +
𝔼
z∼pz(z)[log(1 − D(G(z)))]
Goodfellow, Ian, et al. "Generative adversarial nets."
Advances in neural information processing systems 27 (2014).](https://crownmelresort.com/image.slidesharecdn.com/diffusiondalle2-220720062732-a5af0976/75/diffusion-DALLE2-pdf-6-2048.jpg)









![DDPM (Denoising Diffusion Probabilistic Models)
Ho, Jonathan, Ajay Jain, and Pieter Abbeel. "Denoising diffusion probabilistic models." Advances in Neural Information Processing Systems 33 (2020): 6840-6851.
- Jonathan Ho의 논문 Denoising diffusion probabilistic models에서 제안
Distribution of at an arbitrary timestep t in closed form
xt
x0
ϵ ∼
𝒩
(0, I)
xt (x0, ϵ) = ᾱtx0 + 1 − ᾱtϵ
Lsimple (θ) :=
𝔼
t,x0,ϵ
[
ϵ − ϵθ ( ᾱtx0 + 1 − ᾱtϵ, t)
2
] is a linear combination of and
xt x0 ϵ
q (xt ∣ x0) =
𝒩
(xt; ᾱtx0, (1 − ᾱt) I) , where αt := 1 − βt and ᾱt :=
t
∏
s=1
αs
Posterior q (xt−1 ∣ xt, x0) =
𝒩
(xt−1; μ̃t (xt, x0), β̃tI)
Loss Function
https://github.com/rosinality/denoising-di
ff
usion-pytorch/blob/master/
di
ff
usion.py
generate ϵ
sample xt
predict ϵ
Predict (or ) at each step
ϵ x0](https://crownmelresort.com/image.slidesharecdn.com/diffusiondalle2-220720062732-a5af0976/75/diffusion-DALLE2-pdf-16-2048.jpg)
![DDPM (Denoising Diffusion Probabilistic Models)
Ho, Jonathan, Ajay Jain, and Pieter Abbeel. "Denoising diffusion probabilistic models." Advances in Neural Information Processing Systems 33 (2020): 6840-6851.
- Jonathan Ho의 논문 Denoising diffusion probabilistic models에서 제안
Distribution of at an arbitrary timestep t in closed form
xt
x0
ϵ ∼
𝒩
(0, I)
xt (x0, ϵ) = ᾱtx0 + 1 − ᾱtϵ
Lsimple (θ) :=
𝔼
t,x0,ϵ
[
ϵ − ϵθ ( ᾱtx0 + 1 − ᾱtϵ, t)
2
] is a linear combination of and
xt x0 ϵ
q (xt ∣ x0) =
𝒩
(xt; ᾱtx0, (1 − ᾱt) I) , where αt := 1 − βt and ᾱt :=
t
∏
s=1
αs
Posterior q (xt−1 ∣ xt, x0) =
𝒩
(xt−1; μ̃t (xt, x0), β̃tI)
Loss Function
https://github.com/rosinality/denoising-di
ff
usion-pytorch/blob/master/
di
ff
usion.py
generate ϵ
sample xt
predict ϵ
Predict (or ) at each step
ϵ x0](https://crownmelresort.com/image.slidesharecdn.com/diffusiondalle2-220720062732-a5af0976/75/diffusion-DALLE2-pdf-17-2048.jpg)






















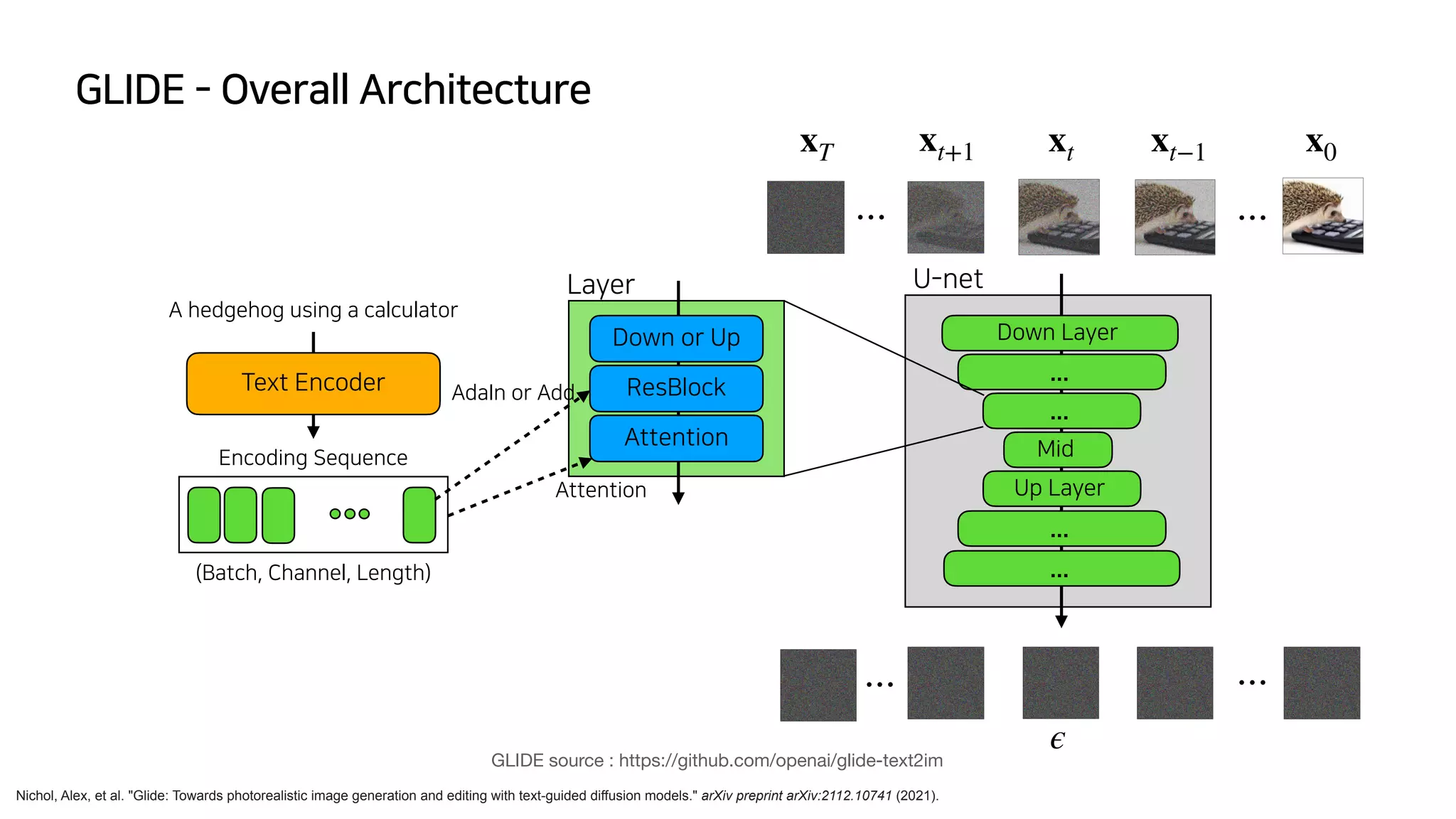
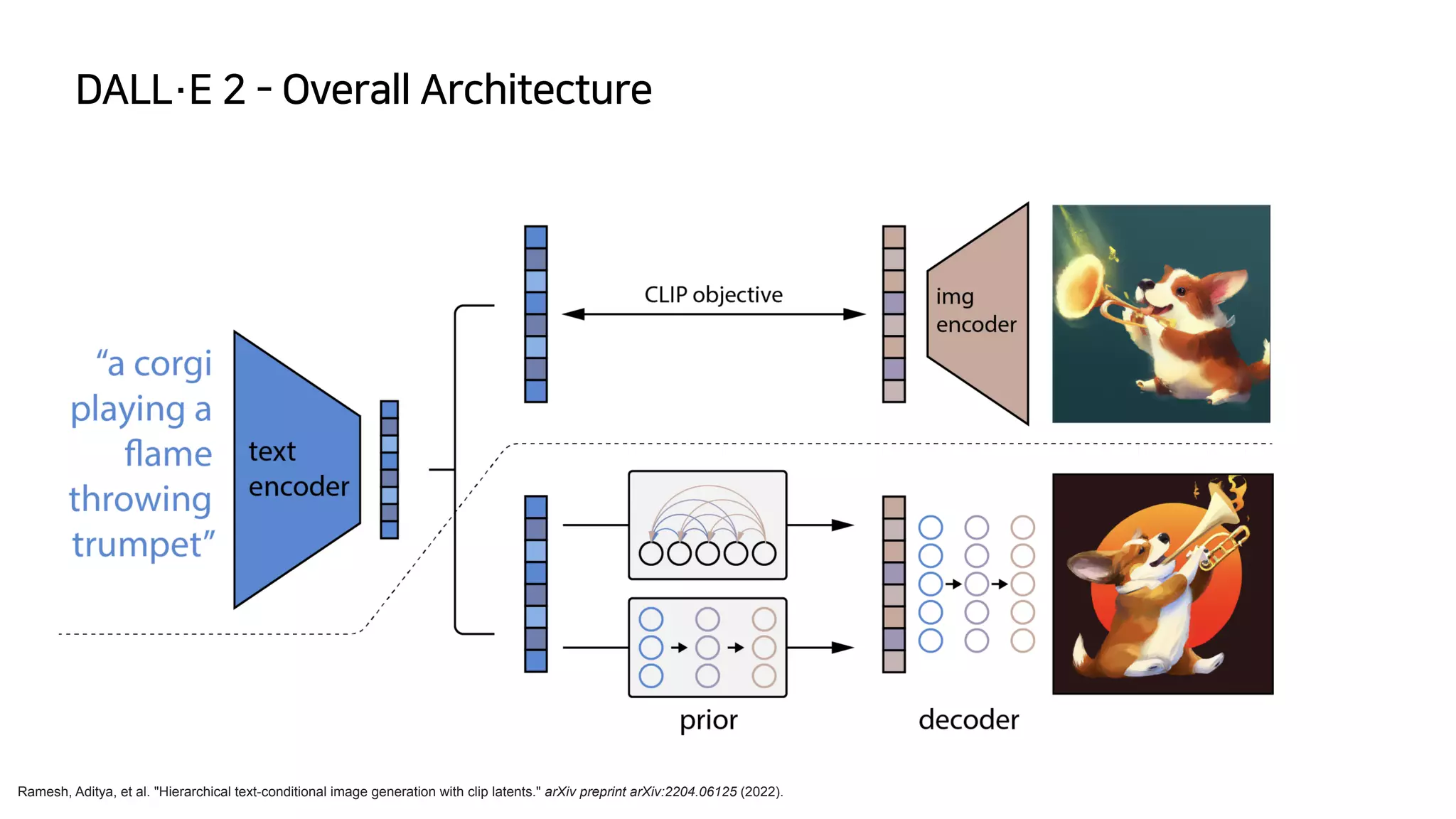
This document summarizes key concepts in diffusion models and their applications in generative AI systems. It discusses early diffusion models from Sohl-Dickstein and later improvements from DDPM. It also covers recent large diffusion models like GLIDE and DALL-E 2 that can generate images from text prompts. The document provides technical details on diffusion processes, loss functions, and model architectures.



![[PR12] understanding deep learning requires rethinking generalization](https://cdn.slidesharecdn.com/ss_thumbnails/pr12understandingdeeplearningrequiresrethinkinggeneralization-180121135850-thumbnail.jpg?width=640&height=640&fit=bounds)











![[Mmlab seminar 2016] deep learning for human pose estimation](https://cdn.slidesharecdn.com/ss_thumbnails/mucdgsomrcs8cgkh9gsp-signature-54f17826ed7e29e13653ed835b10fabd79d8e26ac84412798c7e96ef7d109006-poli-160811023645-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Generative Models of Visually Grounded Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20170602-170602005505-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会] GAN系の研究まとめ (NIPS2016とICLR2016が中心)](https://cdn.slidesharecdn.com/ss_thumbnails/dliwasawagansurvey-161220014753-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Wav2CLIP: Learning Robust Audio Representations From CLIP](https://cdn.slidesharecdn.com/ss_thumbnails/dlwav2clip1-211105022837-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-03] 自己教師あり学習における対照学習の基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/os2-04-210605061641-thumbnail.jpg?width=640&height=640&fit=bounds)











![[update] Introductory Parts of the Book "Dive into Deep Learning"](https://cdn.slidesharecdn.com/ss_thumbnails/d2lq1introbasicssimplemodels-190415080926-thumbnail.jpg?width=640&height=640&fit=bounds)

































