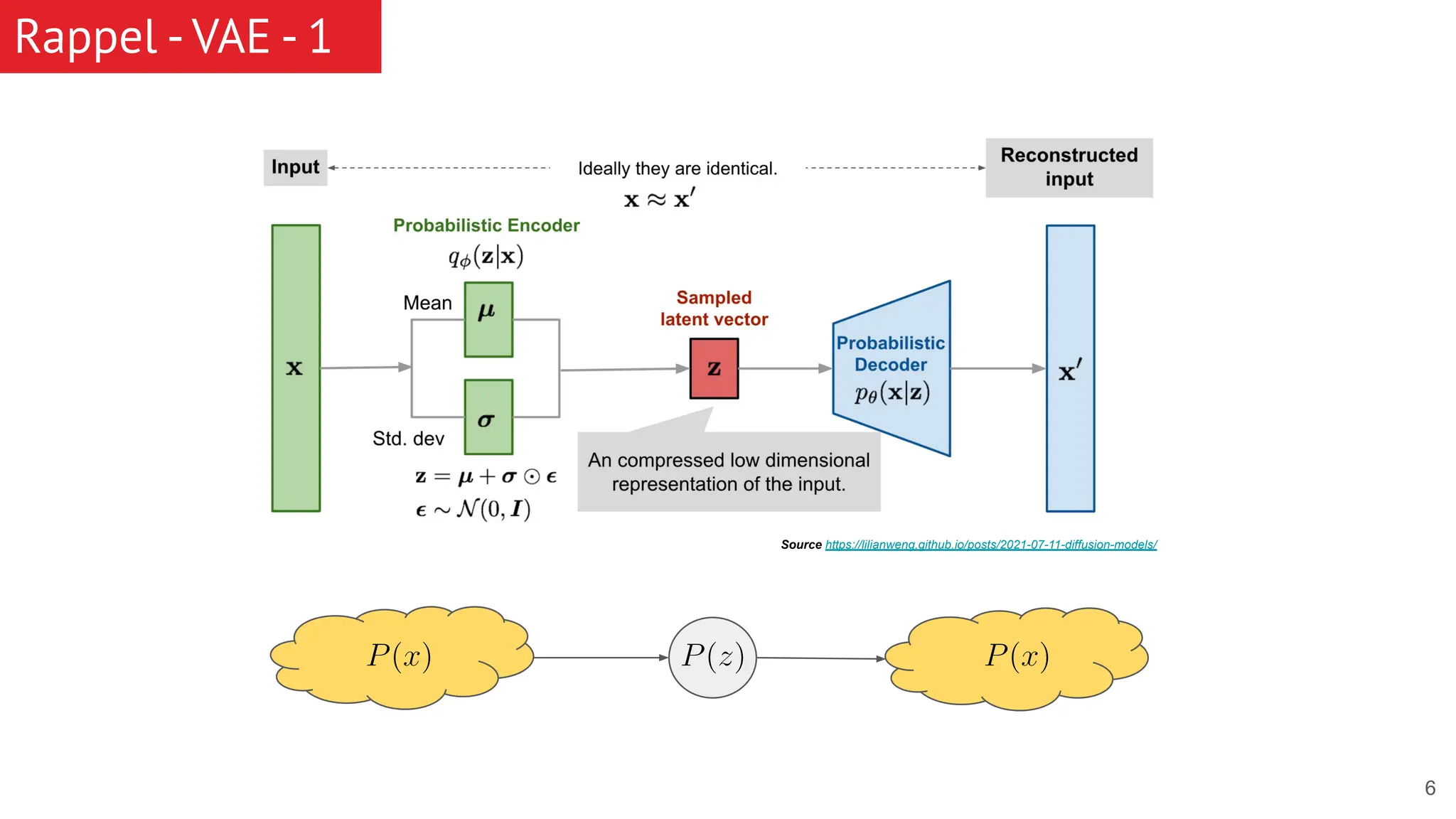
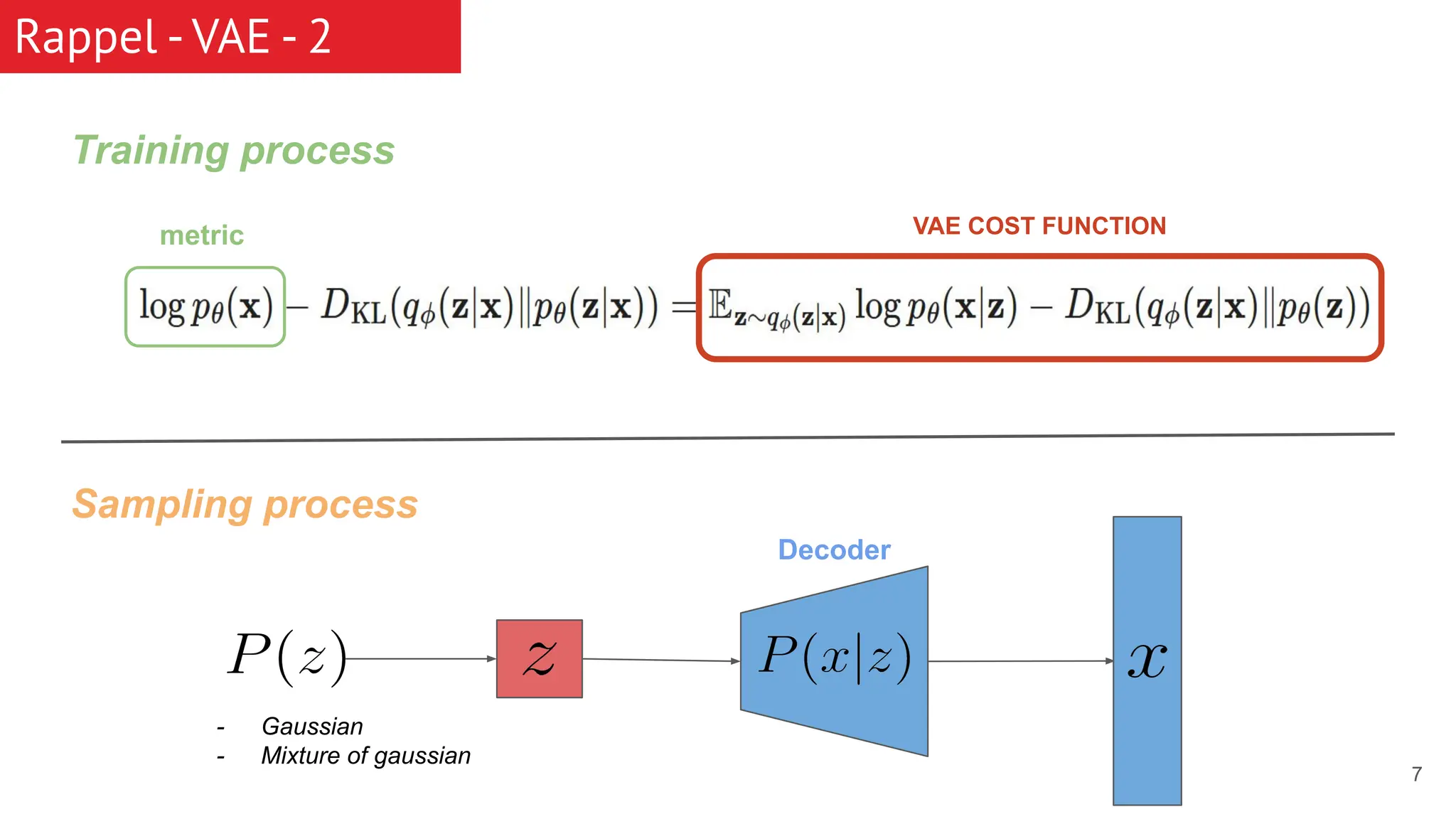
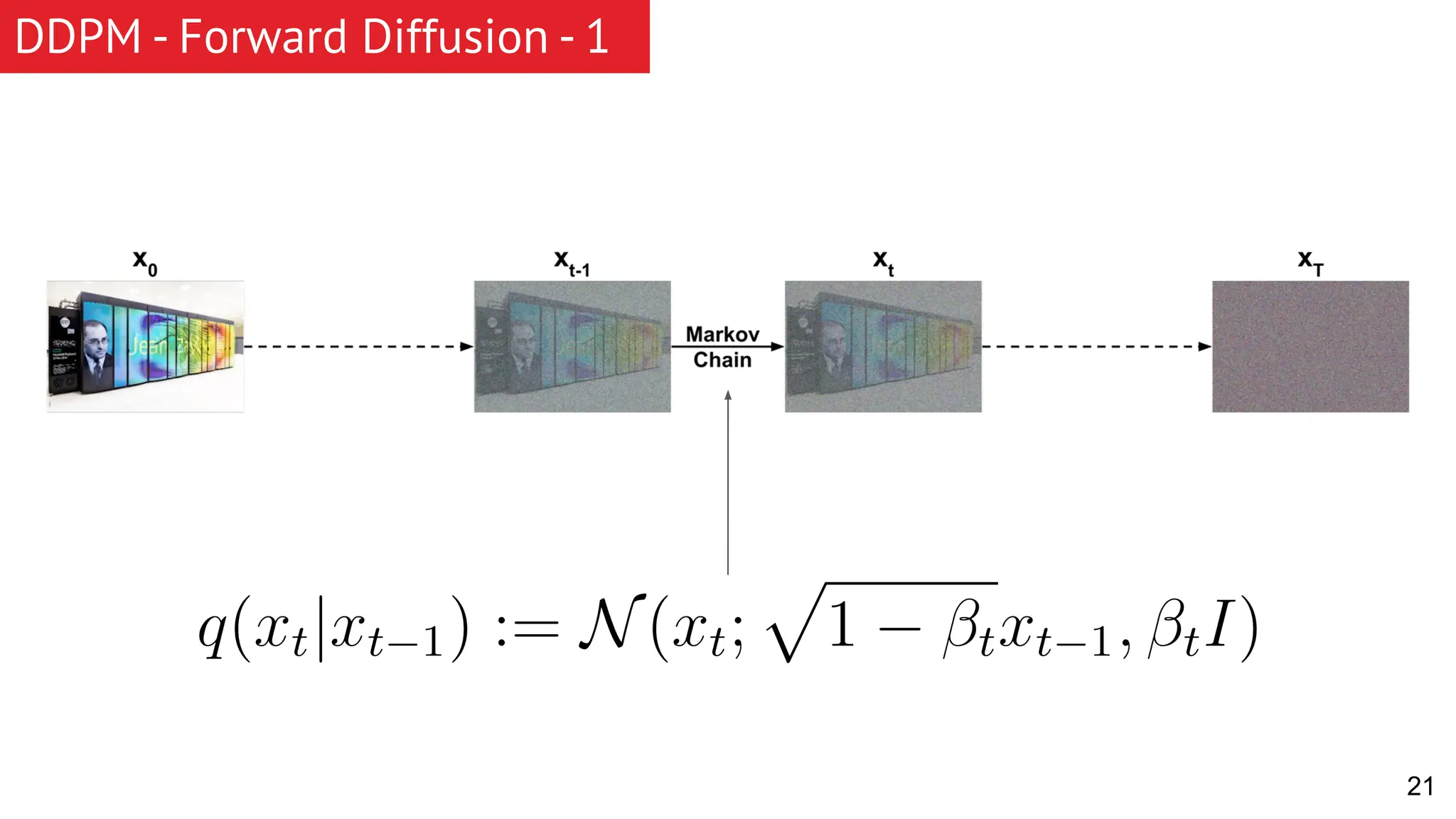
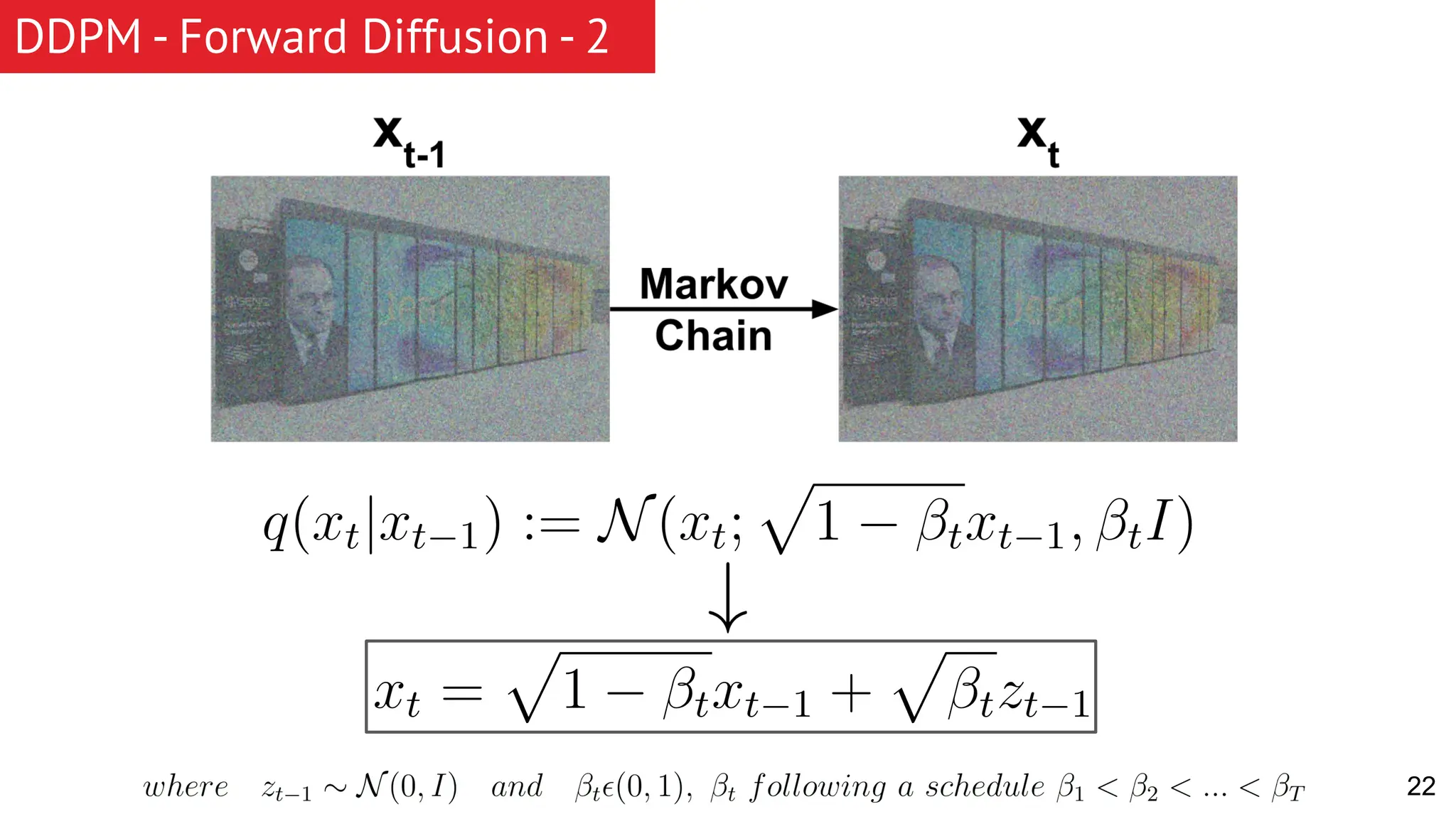
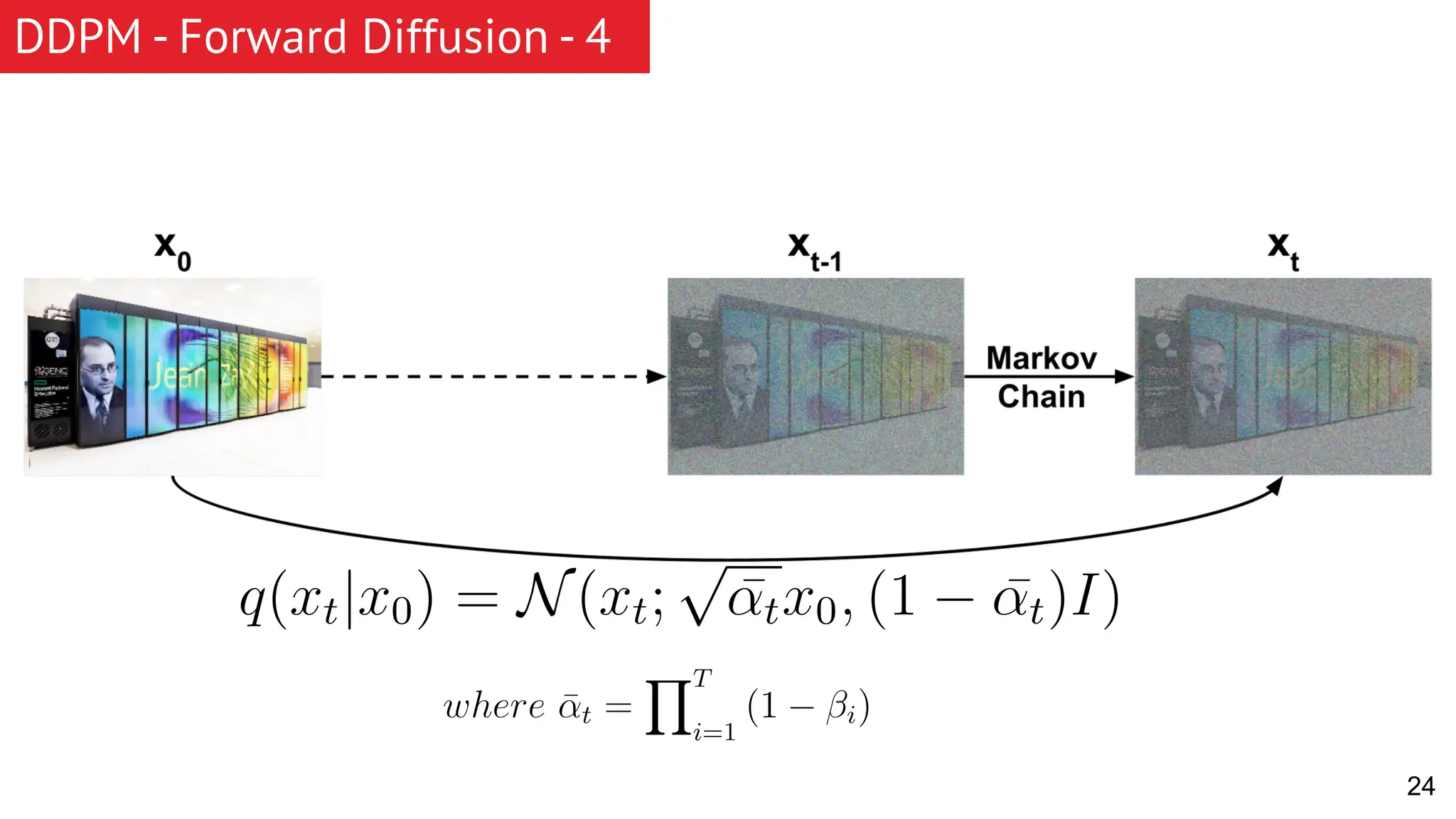
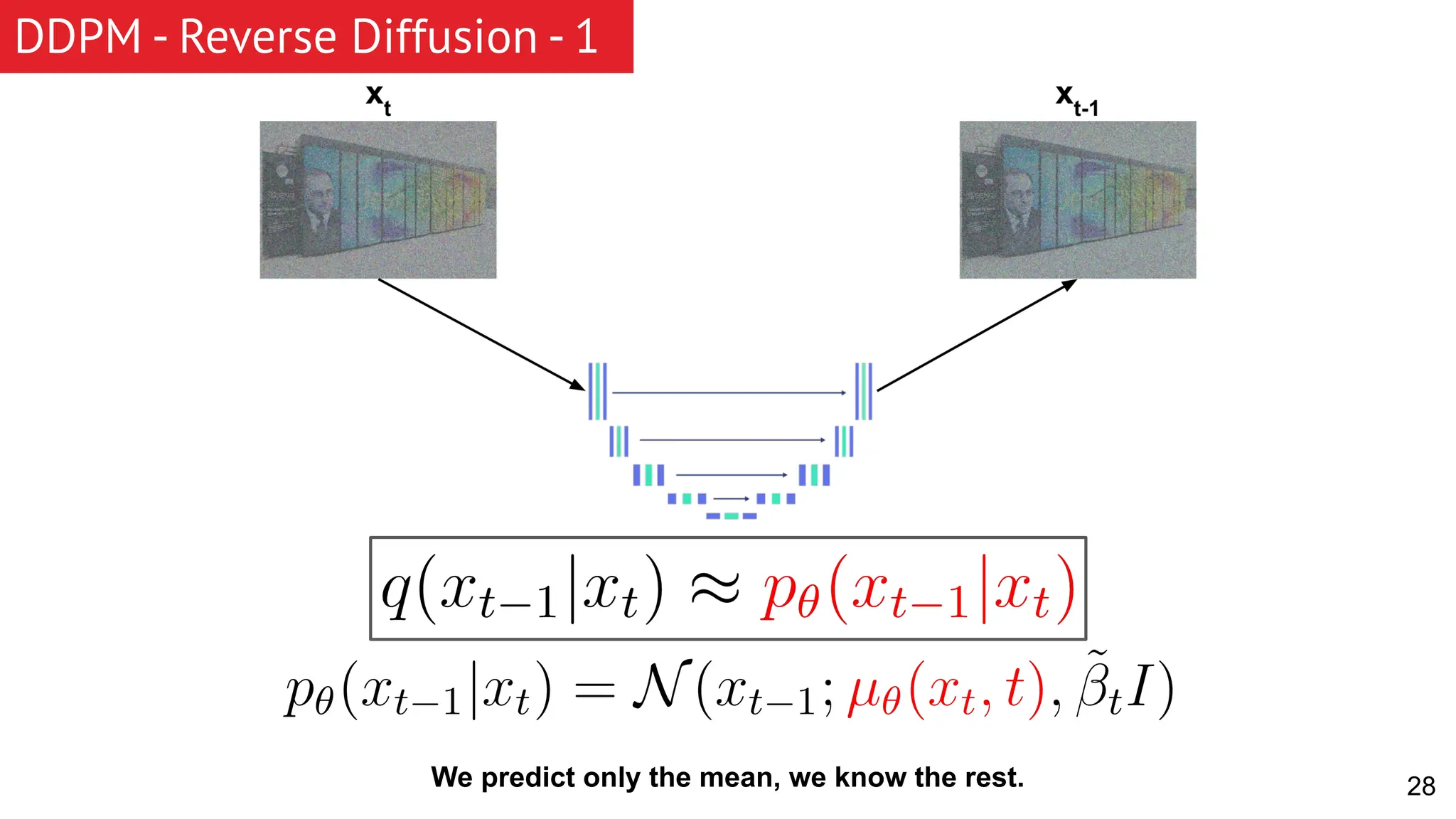
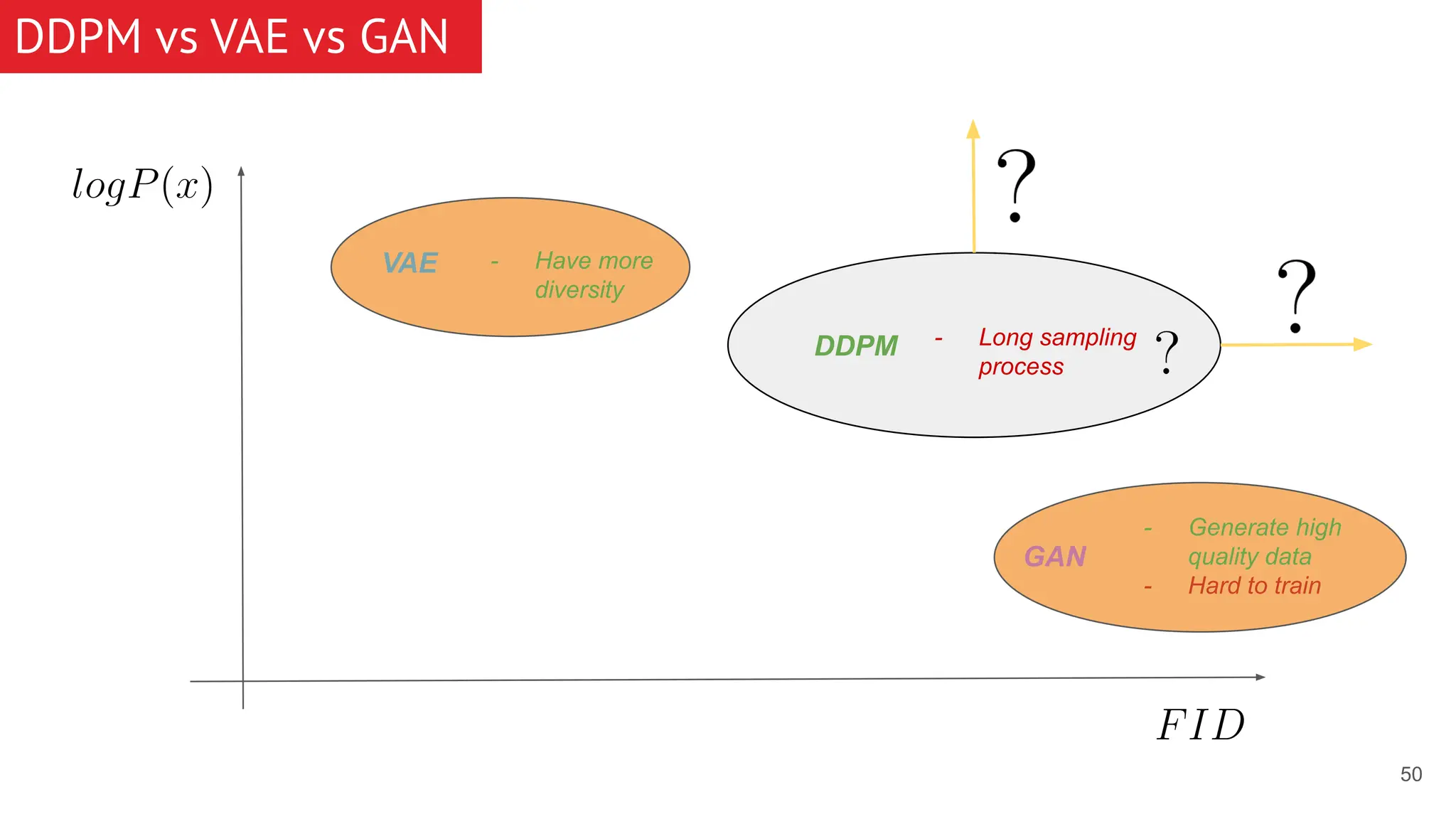
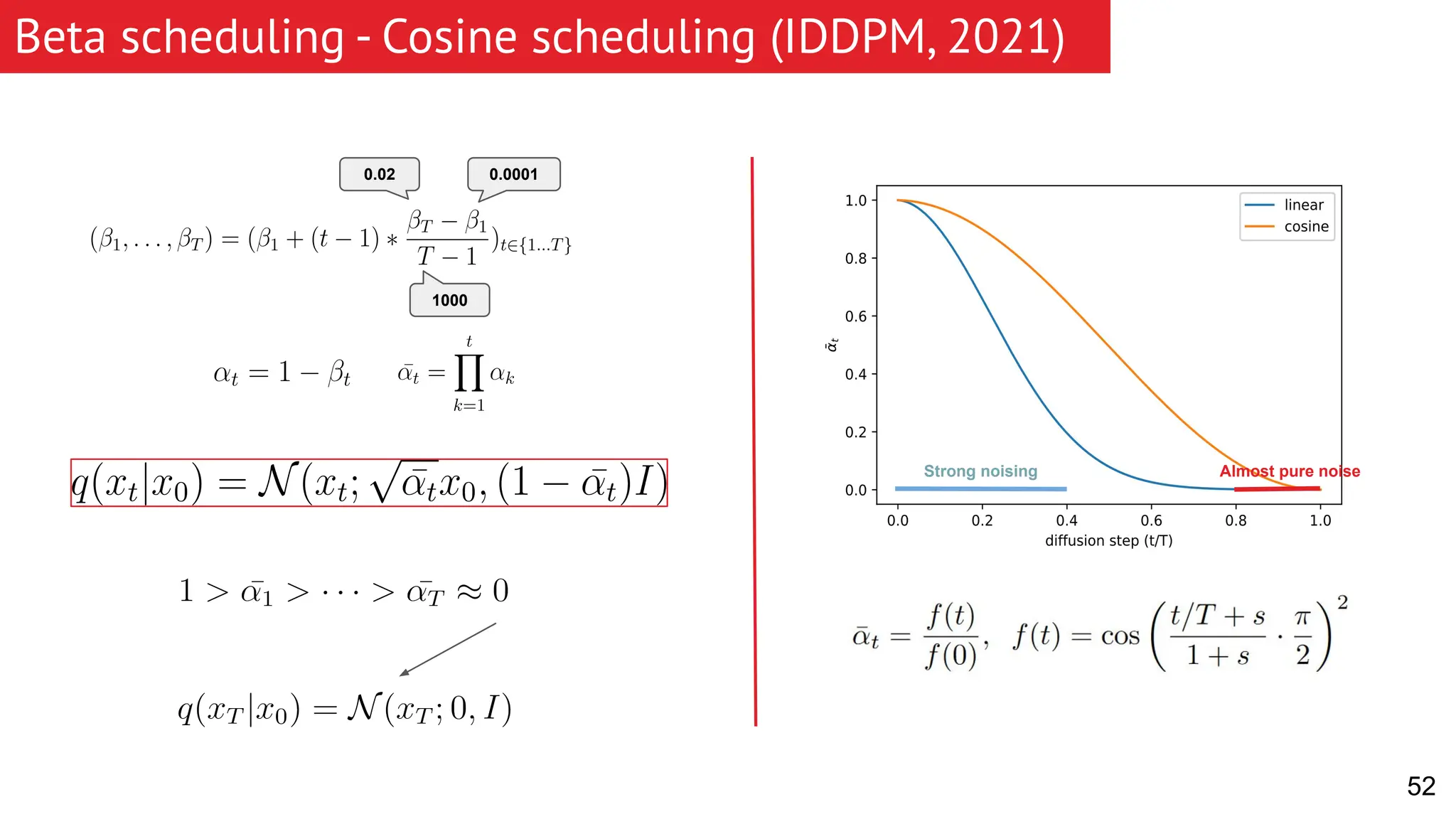
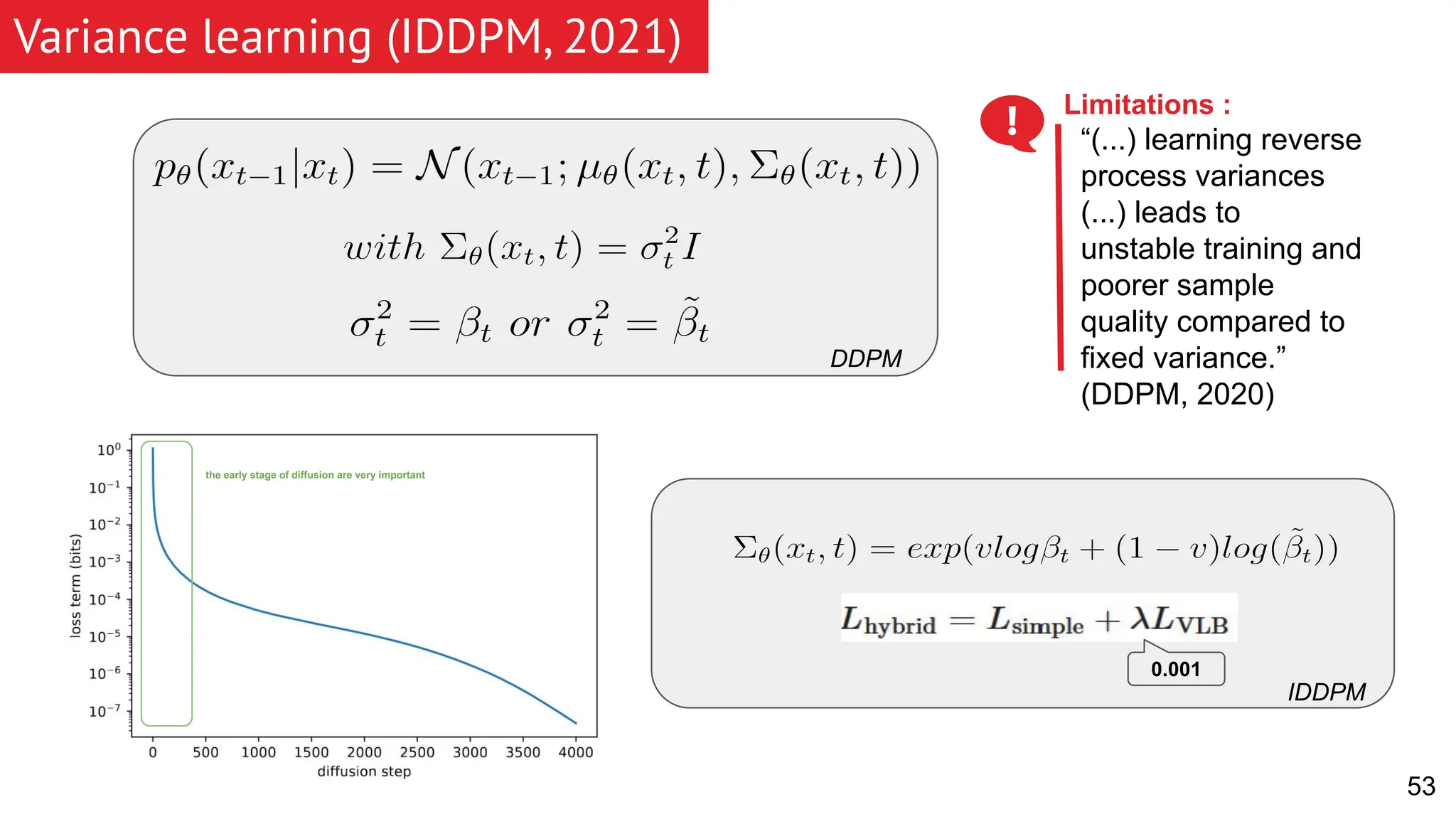
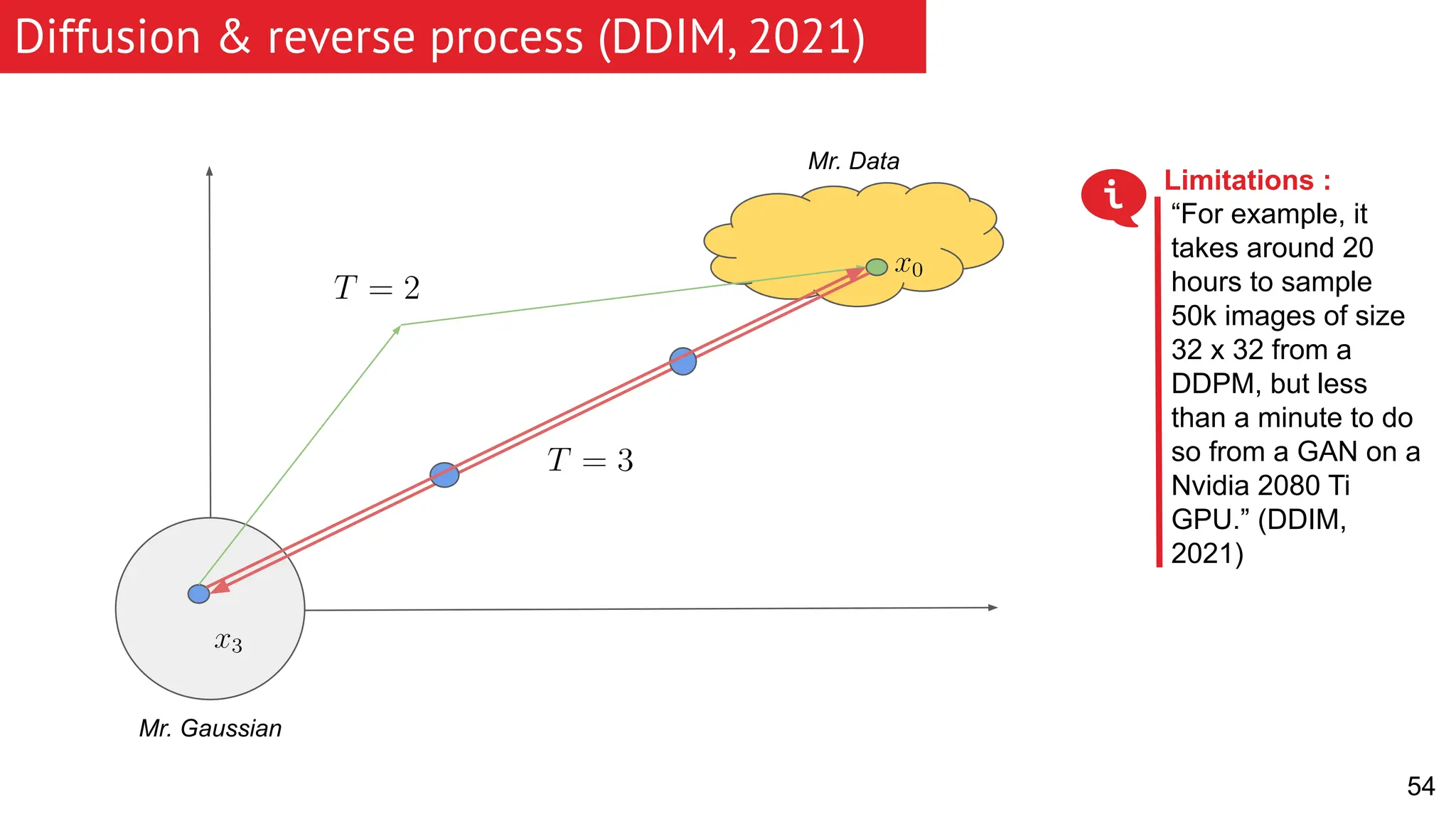
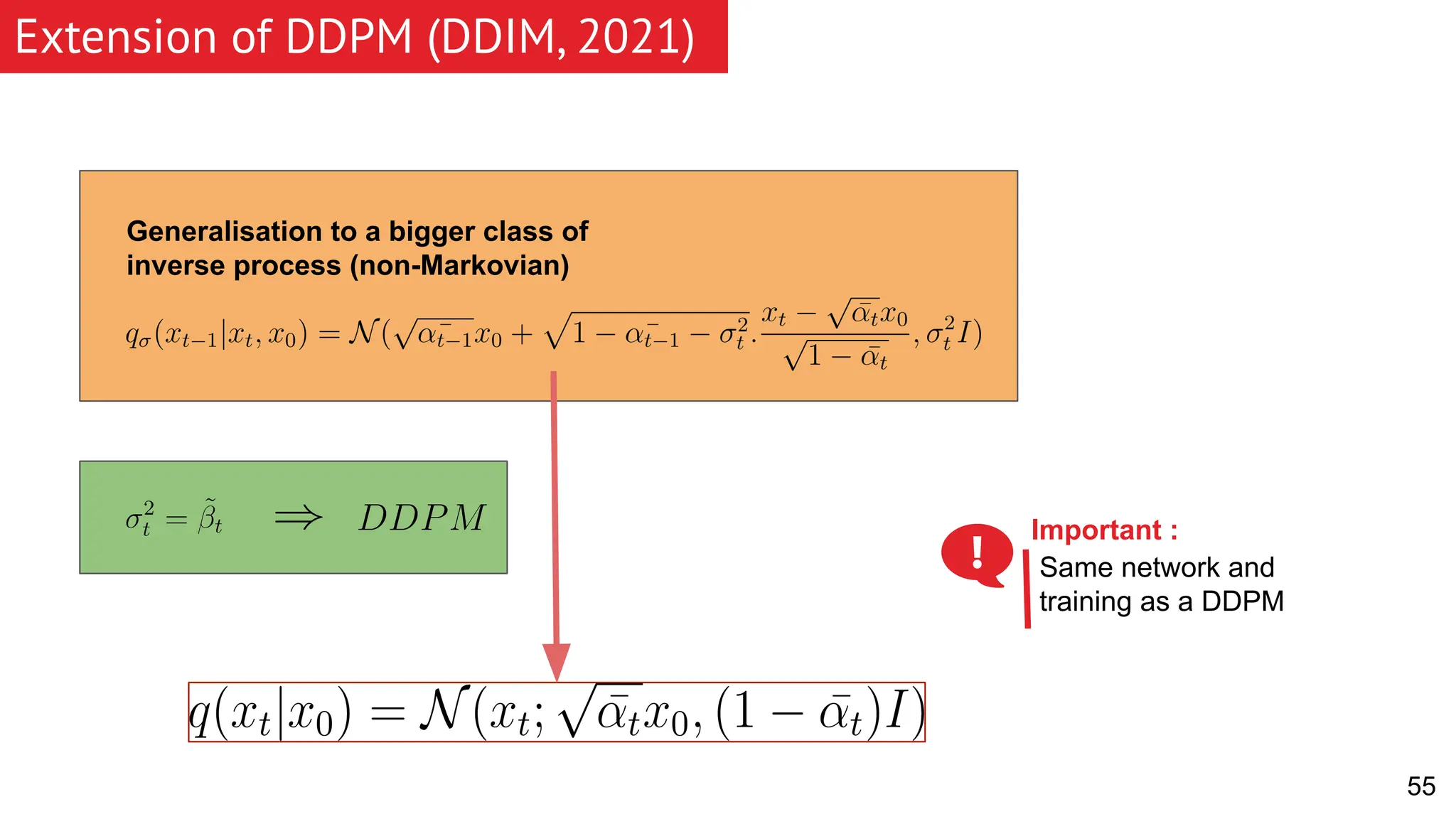
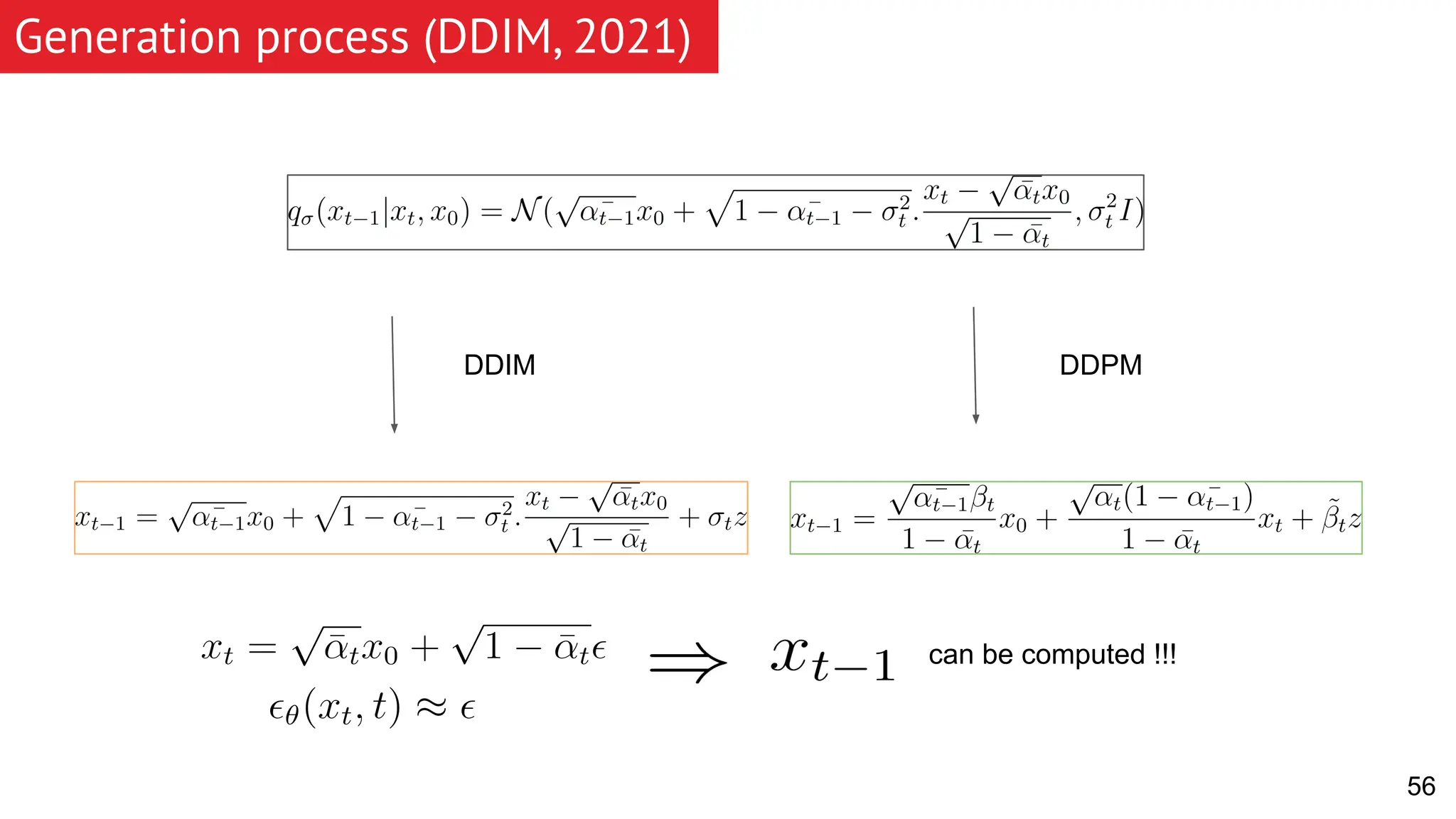
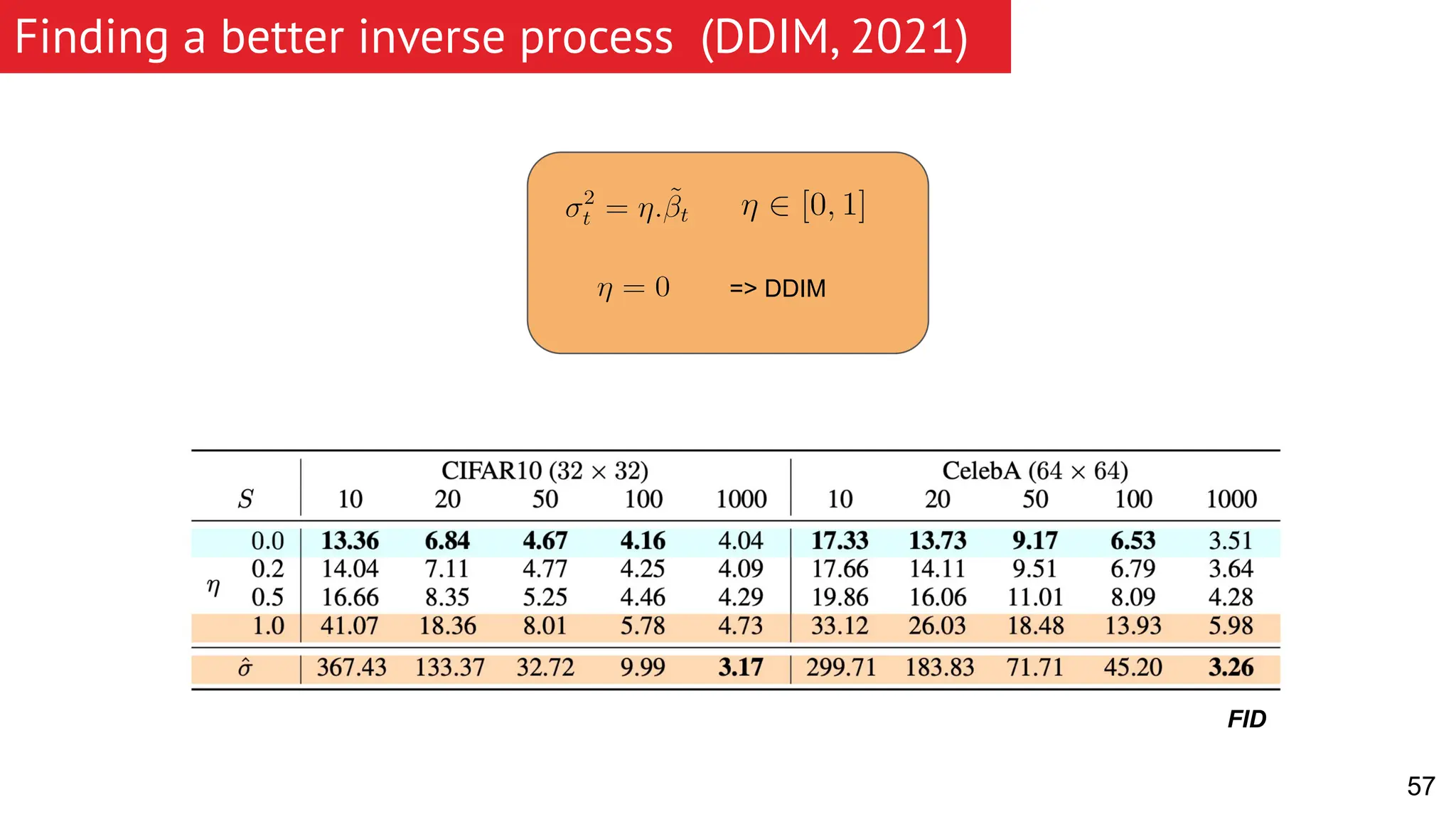
The document discusses generative models, focusing on diffusion models and their principles, including forward and reverse diffusion processes. It compares diffusion models, variational autoencoders (VAEs), and generative adversarial networks (GANs), highlighting the characteristics and applications of each. Additionally, it covers improvements in diffusion models, such as faster sampling and various tasks they can perform like inpainting and super-resolution.



























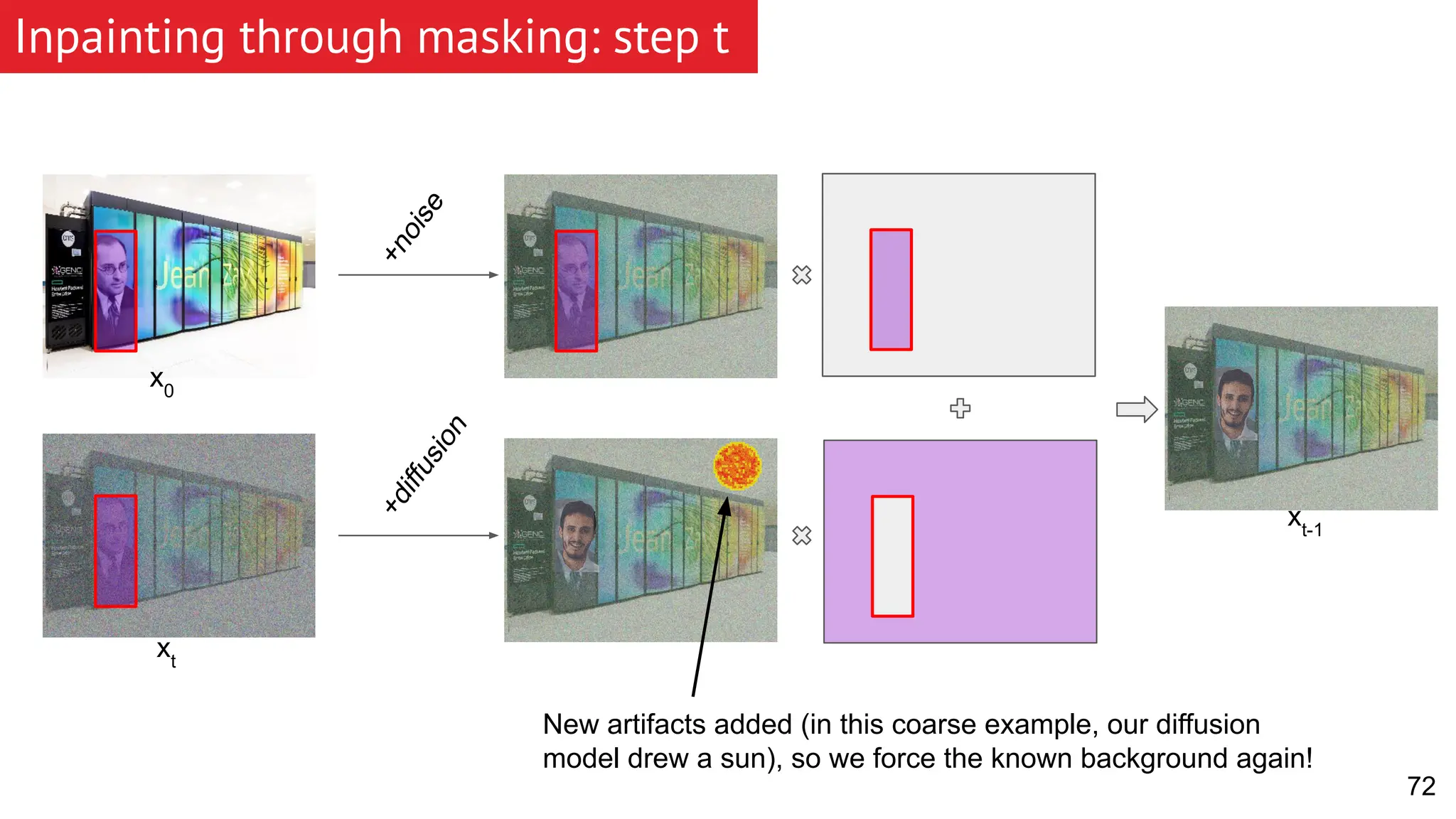
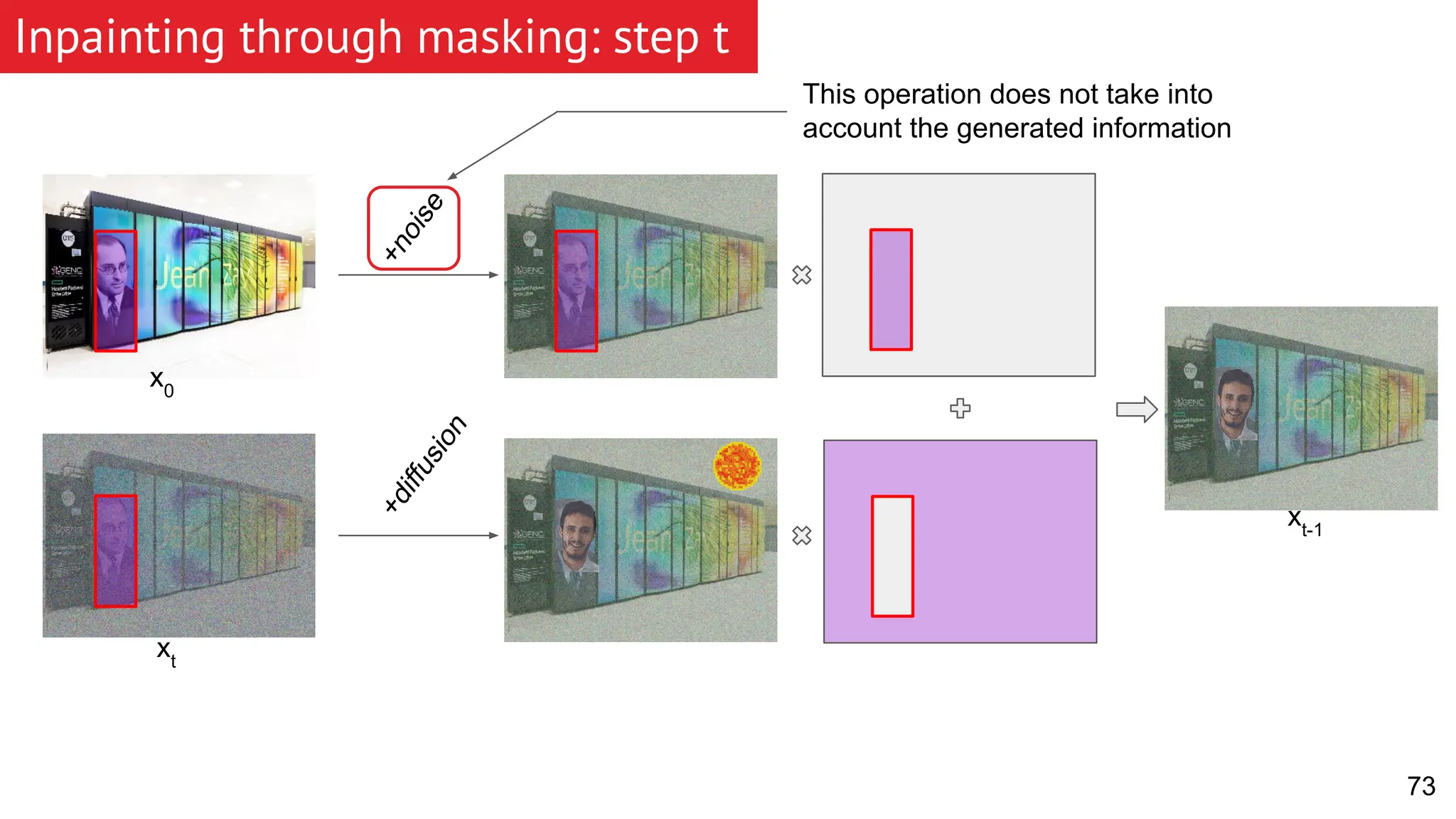

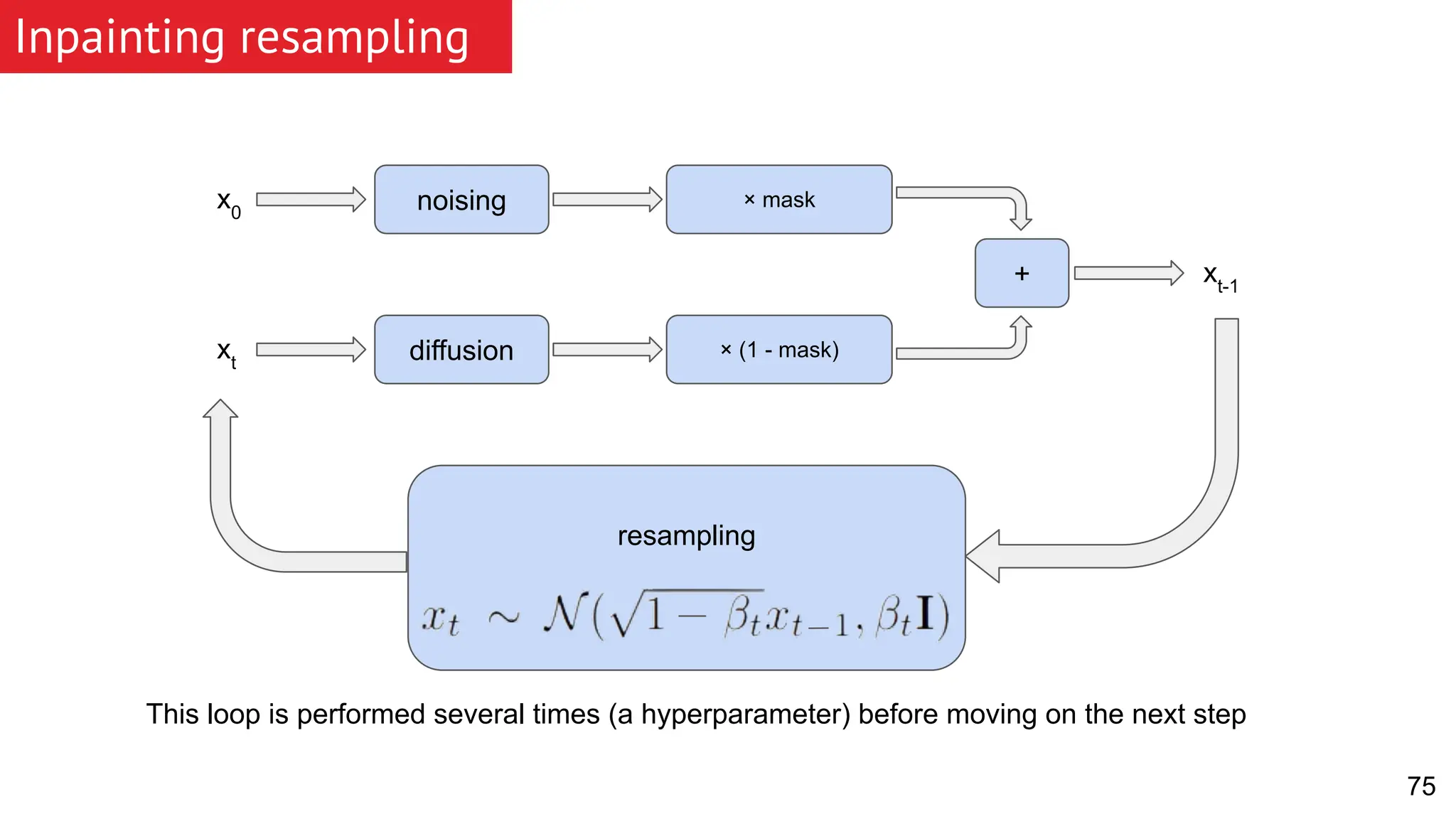




























































































![[BMVC 2022] DA-CIL: Towards Domain Adaptive Class-Incremental 3D Object Detec...](https://cdn.slidesharecdn.com/ss_thumbnails/0916slides-221108165348-620eaec7-thumbnail.jpg?width=640&height=640&fit=bounds)







































































